A lot of folks are using LLMs to help them write code these
days. David Chisnall, for one,
is unimpressed.
He has, however, found LLMs "vaguely useful" in one way while
programming, a way that made me smile:
The one place Copilot was vaguely useful was hinting at missing
abstractions (if it can autocomplete big chunks then my APIs
required too much boilerplate and needed better abstractions).
I love it! An LLM identifies a missing abstraction by
showing where it needs to be. It does
that by writing the sort of code that the abstraction
should hide away.
The book that taught me
about negative space
This makes me think about
the role of negative space
in software design, from one of the early posts on this blog.
LLMs generate the code we can see when we look head-on at a
problem we understand well. If we instead turn the problem
upside down, or inside out, we may have a better view of the
code we really need. The LLM's code points to that new view.
Following Chisnall's idea, we might set out to create
abstractions until the LLM can't auto-fill our code for us.
How is this for an LLM-driven design algorithm of sorts:
design a program
while (an LLM can fill in substantial boilerplate)
create a new abstraction
revise the program
Personally, I'm still not all that excited about using LLMs to
help me write code. I like to write code, and need more
opportunities to do so, not fewer. But if I decide to give them
more of a try, I might well use this approach. It tickles my
curiosity enough to make the outcome of real interest.
This is the time of year when many people in my world are gearing
up for
Advent of Code,
an annual communal celebration of daily programming challenges
that begins on December 1 and ends on Christmas. Many folks use
the event as an opportunity to learn or practice a new language.
If you are truly impressive, you solve each day's puzzle in a
different language, as
Matt Might did
in 2022.
Advent of Code looks like a lot of fun, but I have never fully
participated. Some years, I drop in for the first day or two,
solving the problems in a familiar language, like Racket or Python.
Those early problems sometimes make useful examples when teaching
functional programming in my spring course. I mentioned one such
case back
in 2016,
when I turned
Matthew Butterick's solution
to
one of the 2015 problems
into an extended homework assignment.
However, early December constitutes the last two weeks of semester
of our fall semester, which is followed by finals week, undergrad
research presentations, and grading. I don't want to have to carve
out an hour or more each day for three and a half weeks to work on
these problems, no matter how much fun they might be. That feels
like too much pressure, and just another kind of work.
Maybe that's why I was so pleased to read about
December Adventure,
a lower-key community programming event with a simple goal: to
write a little code every day of the month. Now, I write code most
every day for class or for work, so for me December Adventure is
about taking at least a few free minutes each day to program for my
own purposes.
Last week, before I read about December Adventure, I took an
unintentional test drive of the idea. I recently discovered
Alex Chan's blog
and read about
their adventure writing emptydir.
This is a script that deletes all directories that are essentially
empty: they contain only files we don't care about, such as stray
__pycache__ and .venv files or, on Macs,
the ubiquitous .DS_Store.
emptydir solves a problem I have all the time. Git
tracks files, not directories, and when I sync repos across my two
main machines, files sometimes get moved or deleted. The directory
that once contained them is now empty... except for
.DS_Store. So macOS keeps the directory, even though
for my purposes it is now empty.
This is the complement of a problem I mentioned
in September,
in which directories I create on one machine do not get synced by a
a git push or pull because they are empty. To solve that problem,
I wrote a script called touch-empty that leaves a
0-byte file git will track for me, keeping the folder alive.
Anyway, Chan's Rust program was the prompt I needed to write
rm-empty, my own version of emptydir. I
skimmed their Rust code and then put my own twist on the idea in
Python. It came together quickly, in programming bursts of a few
minutes each over three nights. The code itself wasn't too bad,
though I had to learn a bit more about the os.walk
function to make it work the way I wanted. However, as you might
imagine, testing a program that deletes folders and files calls for
extra attention!
I had fun writing rm-empty, and December Adventure
gives me a chance to extend of the mood. I'll cobble together a
few minutes each day to write code that I want to write, only
because I want to write it.
Rather than noodle around with no higher focus, I'm going to write
a little app I've been obsessed with since I read about it earlier
in the month
on Mastodon:
Recently I've started listening to my music library using an app
I call "an html file in the root directory of my music library,
which is regenerated using a shell script, consists of a js
searchable/sortable table of all the tracks, and switches the
content of an audio embed at the top". Honestly, it's better
than quite a few of the so-called apps out there.
Of course, I've been writing JavaScript this semester in my
client-side web development course, so this piques my interest in
two directions: learning a little more JS, and polishing my HTML
and CSS skills in an app where I myself care about the look and
feel. Who says the world doesn't need an in-browser replacement
for iTunes? And even if it doesn't, I might be happy to run my
own app in its stead.
The goal of my December Adventure is to keep expectations low and
have fun. I'm not going to place any demands on the exercise,
other than to spend at least a few minutes each day working on the
project. If all I can manage is a new test case one day, or a
quick bug fix, that's fine. If I can set aside more time for
design or implementation, that too will be fine.
If I end up creating an app that pleases me enough to use on a
daily basis, great. If instead I get to the end of the month and
don't have a functional page yet, that will be okay, too. I will
have had thirty-one days of fun working on it. I can decide then
whether I want to keep working on it. With any luck, the fun is
habit-forming and I stick with the daily recreational coding,
whatever the target.
I'm also using December Adventure as a blogging prompt. I've been
wanting to write a post or three all month... but instead I always
find myself writing code for class or working with students. This
was a break week, with extra free time, but I ended up using my
freest day doing some work on the next issue of
Transactions on Pattern Languages of Programming
(TPLoP), of which I am an editor. Maybe this blog post
and the programming challenge of December Adventure will keep me
moving, on both code and blogging.
According to the countdown on the Advent of Code home page, my
December Adventure begins in 2 hours, 15 minutes, and 9 seconds
— and counting. Tomorrow, I create the repo and make my
first commit.
Andrej Karpathy loves his calculator, and I like
his post
about how he loves his calculator. I was planning to quote the
beginning of one paragraph as a teaser, but I could not decide
where to clip the passage. Each sentence is worth seeing. I
hope he does not mind that I show you the entire paragraph with
encouragement to read the entire post:
Let's put this in perspective to the technology we increasingly
accept as normal. The calculator requires no internet
connection to set up. It won't ask for bluetooth permissions.
It doesn't want to know your precise location. You won't be
prompted to create an account and you don't need to log in. It
does not download updates every other week. You're not going
to be asked over and over to create and upgrade your
subscription to the Calculator+ version that also calculates
sine and cosine. It won't try to awkwardly become a platform.
It doesn't need your credit card on file. It doesn't ask to
track your usage to improve the product. It doesn't interrupt
you randomly asking you to review it or send feedback. It does
not harvest your information, for it be sold later on sketchy
data markets, or for it to be leaked on the dark web on the
next data breach. It does not automatically subscribe you to
the monthly newsletter. It does not notify you every time the
Terms of Service change. It won't break when the servers go
down. The computation you perform on this device is perfectly
private, secure, constrained fully to the device, and no
running record of it is maintained or logged anywhere. The
calculator is a fully self-contained arithmetic plugin for your
brain. It works today and it would work a thousand years ago.
You paid for it and now it is yours. It has no other master.
It just does the thing. It is perfect.
You paid for it, and now it's yours.
My favorite pieces of software and favorite creators of software
embody this ideal, at least as much of it as they can given the
constraints of the modern tech world.
Audio Hijack
from Rogue Amoeba comes to mind and
Acorn
from Flying Meat come to mind.
That said, I loved calculators long before the web existed at all.
Young Eugene had many hours of pleasure noodling on a calculator,
playing with numbers. I first learned about rounding errors and
limits by typing in a number and repeatedly hitting the square
root key until the display showed a 1. I computed batting
averages and winning percentages for my favorite teams and
players. Eventually I was computing chess ratings by hand, until
I sensed what a computer program could do for me. That would
become
the first program I ever wrote out of passion.
Even after learning to program, I never really lost the joy of
tinkering with an old handheld calculator. It just does its
thing. It is perfect.
Today I learned that HTML's <strike> tag has
been replaced by two tags, <del> and
<s>.
I knew that <strike> had been deprecated but
had never needed to learn its replacement, or that a replacement
even existed. I used it occasionally back in the days when
dinosaurs roamed the web, but only rarely since. When I used
it, browsers always displayed the text as expected, so I took
the easy route and kept on using it.
Two things have changed since the last time I used
<strike>. I taught web development for the
first time last fall and decided that I wanted to write modern,
compliant HTML and CSS whenever possible, both as a good example
for my students and as a way to up my web game to the 2020s.
The second change was more abrupt: I used
<strike> today and encountered a browser that
no longer supports it.
At first, I figured I'd just write a little CSS to simulate the
desire behavior with a class. That's the sort of thinking that
knowing CSS makes possible. But I also know that HTML includes
a remarkable set of elements and that we should prefer native
HTML whenever possible. So I looked <strike>
up in
the MDN documentation.
As they say, RTFM! The documentation enlightened me.
The two replacement elements have different semantics for the
act of striking through text:
<del> is for information that has been
deleted
<s> is for information that is no longer
correct
Now I have to think about which of these I mean when I decide to
strike text in a page. But I don't mind this at all. I'm a big
fan of HTML's
semantic elements.
What we write should express our intent, and these elements help
us encode meaning and structure directly into our documents.
Even better, browsers and screen readers can use the structure of
a document to present it more accurately, which means that using
semantic elements makes our web pages more accessible to
visually-impaired readers.
Further, using semantic elements also makes our pages more ready
for futures that don't exist yet. I love the story in
this blog post
about how pages written with semantic markup displayed properly on
the Apple Watch, even though they had been written well before the
product launched. (If you'd like to jump directly to that story in
the post, search for "NEW TYPES OF DEVICES".)
To bring my story to a close: I decided to use a
<del> tag in the page I was writing for my
students. The text in question was a bad idea, so I marked it as
deleted. Whenever I open up this page in the future, the markup
will include a hint as to why the text has been stricken.
Two Quotes That Aren't About Teaching But, No, They Really Are
First from French writer André Gide, in Le Traité
du Narcisse (1892):
Everything has been said before. But since nobody listens
we have to keep going back and beginning all over again.
Every teacher knows how Gide feels.
Then from Bruce Springsteen, in a New Yorker interview I've
lost track of:
This music has not been heard at this moment, in this place,
by these faces. That's why we go out there.
Springsteen said that when asked how he could still sing "Born
to Run" with so much energy after decades of performing. I
think something similar to myself on many teaching days. I
love the thing I am teaching and, even though it's old hat to
me, it's new to my students, and I want them to love it, too.
I've always been a sucker for quotes that aren't about teaching,
or programming, but could be. Making that sort of connection
can motivate me on those days when I need a little pick-up.
But I also realize that making connections to other disciplines
is a big part of how we teach or write programs at all. Metaphors
are everywhere in both. Consider this line from Zach Tellman in
a recent issue
of the newsletter about his book in progress, "Explaining Software
Design":
The queue is a useful metaphor because it makes us ask useful
questions.
We create analogies and metaphors because they help us ask useful
questions. They help us see our own objects of study, or own
activities, in a new way.
I guess this is my way of saying that I'm okay with my irrational
fondness for applying quotes out of context to my own world.
Doing so occasionally helps me ask better questions. Even when
they don't, I get to smile.
I decided to scratch an itch this afternoon with a trivial bit
of code.
My students use a homegrown system to submit their work in my
courses. After the assignment is due, I scp the
assignment's directory from the server to my machine and add
it to the course repository. This directory contains one
subdirectory for each student, holding their individual
submissions.
I use a few scripts and a couple of manual steps to review
student work, write up notes for them, and send them the
reviews. Most of the scripts iterate over the subdirectories.
For many tasks, it is simplest to assume one subdirectory for
each student in the class.
I do all this work on two machines, one at home and one in my
office. I use git to keep the repos in sync.
It's always been the case that, for any given assignment, one
student might not submit anything. That's not a problem when
I'm running my scripts on the same machine where I downloaded
the submissions. But on the other machine, which gets the
data via a git push or pull, the empty student subdirectories
— poof! — disappear. git tracks files,
not folders.
I'm sure there is a mechanism somewhere in git for handling
this sort of thing (isn't there a mechanism for
everything somewhere in git?), but in the past I've
done it by hand: I glanced at the subdirectory listing and,
when I saw an empty folder x, I typed
touch x/_nosubmit.
When there is only one empty student folder, this is quick
and easy. But as the number of empty student folders goes
up, it becomes tedious. Two developments over the last few
semesters have driven the tedium to an uncomfortable level.
First, I've noticed that the number of students who miss the
initial submission deadline rising. There are a variety of
reasons that this is happening. I am happy to work with
students who need to submit later, but this means more empty
directories when I make my first pass reviewing submissions.
Second, I am trying to give students many more low-stakes
opportunities to write code and get feedback. Instead of
grading one assignment per week, I may now be evaluating
submissions for three different tasks.
Put these two factors together, and I rapidly grew tired of
scanning subdirectory listings and touching
empty files.
Sounds like time for a new command. At first I tried to do
it in a single line of bash, using xargs, but
that didn't work. (My intuitions about xargs
often fail me.) So I wrote a simple for loop:
for entry in $(find "$1" -type d -empty)
do
touch "$entry"/_nosubmit
done
Stash that loop in a file, chmod +x, move it
to ~/bin, and the discomfort goes away.
It occurred to me almost immediately that I should have made
the name of the file to touch an optional second argument,
using _nosubmit, my placeholder of choice, as
a default. But you know what? YAGNI. If I ever find
myself in need of more flexibility, I'll add a fifth line
of code to initialize a FILENAME variable and use its value
in the touch line. For now, simpler is good
enough.
I sometimes half-jokingly tell my students that, whenever
they write a new piece of code, they should have at least
two alternatives in mind; that way, at least they know
they aren't doing the worst possible thing.
(They always laugh.) That's an old Kent Beck line, which
I memorialized in
a blog post
many years ago.
It's part joke because it's cold comfort even to
experienced programmers, and because students often don't
trust themselves to generate alternatives, let
alone evaluate their quality. But it's also quite serious,
because it can be the first step novices take on the path
to becoming a reflective practitioner.
That old story came to mind obliquely yesterday when I
saw
this Mastodon post
by Kent, which ends with:
Next time you hear, "But we have to make this decision
*now*!" ask yourself, "What skills would we need in
order to *not* have to make this decision until later?
How can we learn those skills?"
This seems to be an instance of a question useful to ask
oneself more generally. What data, knowledge,
tool, or skill would I need to be able to make this
decision later?
We shouldn't fetishize postponing decisions, of course.
Looking for a reason to wait to make every decision
could become a recipe for not making any decisions.
Further, this fetish can paralyze novices, who doubt
their own abilities to evaluate choices. They can find
themselves in a spiral of infinite postponement.
Fortunately, as long as we don't turn this mindset into
a pathology, waiting to make a decision is rarely going
to be a speed bump to writing programs. There are
always plenty of decisions to make, so being able to
delay some is a favorable option to have in hand.
In such a world, there is great value to be found in
viewing a seemingly forced decision as an opportunity to
learn.
It is almost never good to be in a position of having to
make a decision right now, to have no alternatives from
which to choose. We shouldn't settle for that condition
without doing a little work first.
~~~~
Kent has a knack for making me think more deeply with an
aphorism or a simple story. I've always admired that.
This post is yet another example.
We can sharpen our tools for other than practical reasons:
I also think that there is a place for sharpening one's tools just
for its own sake. Especially as we get older, and our responsibilities
increase, anything related to our work can start to feel like a burden.
Sometimes even a small amount of time invested in sharpening our tools
can bring a bit of joy and restore motivation.
-- Laurence Tratt
I wear my department head hat so many hours a week that sometimes an
opportunity to fiddle with my tools is a welcome break. It's not
always the most obviously productive use of my time -- with time
so precious, shouldn't I use these moments to work on my research
project or write Some Serious Code? -- but that bit of joy can
sustain me through a lot of dreary time later. That might even make
me more productive then. If not? That's okay, too.
~~~~~
Explanations, including documentation for software, really consist of
three parts:
Content, then, conveys more than itself. The prefix is reflected in
what our explanation takes for granted. The suffix is reflected in
what our explanation seems to value; whatever we have today, we'll
probably want more tomorrow.
-- Explaining Software Design
When people talk about critical thinking and critical reading, this
is what I imagine: As a reader, even of documentation for software,
it's worth thinking about what the doc takes for granted and what it
says about the values of the writer.
It's also worth thinking about as a writer. This is especially on
point as I prepare for the fall semester that looms around the
corner. What do my explanations for students take for granted? How
will they recognize and deal with what is not written down? What do
my explanations say about the things I value, and that I hope they
come to value through the course?
~~~~~
The beginning of a new academic year is exciting, and scary, and
a lot of work. It's the work we faculty choose to do.
The observation that computer programmers can build
executable abstractions that work but they then have
trouble understanding is not new and not surprising.
Lots of our code is smarter than we are.
I know this happens to me. I wonder how often something similar
happens to my students as they learn techniques and abstractions?
Imagine: They assemble several small pieces of code, each of
which they understand individually at least a little, into a
bigger program that mostly does what they want — but they
have trouble understanding the program as a whole. Further, the
size and complexity of the program as a whole makes them begin
to doubt their understanding of the individual pieces.
That seems a little far-fetched on its face, but it would
explain behavior I see in class all the time. It's a shame when
a student who seems to be doing fine begins to lose confidence
as the size and complexity of their programs grow. I try to
address these growing pains as best I can, but so much of their
learning happens away from me, back in their rooms writing code.
A few ask for help and stay on track. The ones who don't,
struggle and sometimes stop having fun.
If only I can help them see that this is, many ways, the natural
order for even the best programmers: We build abstractions that
work but which we have trouble understanding.
People like Tim Bray struggle with this, too. You'll be all right.
~~~~~
Wow. I let the entire month of July, and the last ten days of
June, pass without posting. That's the first calendar month with
a (0) next to it in the blog's archives. My long absence included
Knowing and Doing's 20th birthday,
July 9, 2004.
We should have had a party!
That means July 2024 was the first month of my twenty-first
year blogging. Putting up a bagel is not an auspicious start...
I have a few short posts in mind for the coming weeks. Let's see
if I can follow through. I like to write here.
One of the downsides of being department head is that much of the
daily work I have to do is less interesting to me than studying
computer science or writing programs. It's important work, sure,
at least most of it, but it's not why I became a computer scientist.
Today, I ended up not doing most of the administrative work I had
planned for the day. On the exercise bike this morning, I read
the recent Quanta article about
a new way to estimate the number of distinct items in a list.
My mind craved computing, so I spent some time implementing the
algorithm. I still have a bug somewhere, but I'm close.
Any day I get to write code for fun I call a good day. This is
important work, too, because it keeps me fresh. I can justify
the time practically, because the exercise also gives me raw
material for my courses and for research with my undergrads.
But the real value is in keeping me alive as a computer scientist.
The good feeling from writing code today is heightened knowing that
tomorrow's planned administrative work can't be postponed and is
not fun, for tomorrow I must finish up writing annual salary letters.
I am fortunate that writing these letters provokes as little stress
as possible, because the faculty in my department are all very good
and are doing good work. Even so... Salary letters? Ugh.
Thus I take extra pleasure in an absorbing programming process today.
I realized something about myself as a programmer while on a bike
ride with my wife this afternoon.
Even though I prefer to write code in small steps and to write tests
before (or in parallel with) the code, I have a weakness: If you
give me the algorithm for a task in full upfront, and I grok it, I
will occasionally implement the entire algorithm upfront, too. Then
I end up debugging the program one error at a time, like a caveman.
Today, I succumbed to this tendency without even thinking about it.
I am human.
Avdi Grimm
sent out an email to one of his lists this week. After describing
his daily domestic tasks, which are many, he segues to professional
life. I am not a software consultant, but this sounded familiar:
I telepresence into my client team, who I will sit with all day. My
title might as well be "mom" here as well; 20% of my contributions
leverage my software development career, and the rest of the time I
am a source of gentle direction, executive function, organization,
and little nudges to stay on target.
There are days when the biggest contribution I make to my students'
progress consist of gentle direction and little nudges that have
little to do with Racket, programming languages concepts, or
compilers. Often what they need most is help staying focused on a
given task. Error messages can distract them to the point that they
start working on a different problem, when all they really need to
do is to figure out what the message means in their specific context.
Or encountering an error makes them doubt that they are on the right
path, and they start looking for alternative paths, which will only
take them farther from a solution.
I don't sit virtually with any students all day, but I do have a few
who like to camp out in my office during office hours. They find
comfort in having someone there to help them make sense of the
feedback they get as they work on code. My function is one part
second brain for executive function and one part emotional support.
My goal as educator in these encounters is to help them build up
their confidence and their thinking habits to the point that they
are comfortable working on their own.
I have had colleagues in the past who thought that this kind of work
is outside of the role that profs should play. I think, though, that
playing this role is one way that we can reach a group of students
who might not otherwise succeed in CS at the university level.
Almost all of them can learn the material, and eventually they can
develop the confidence and thinking habits they need to succeed
independently.
So, if being dad or mom for a while helps, I am up for the attempt.
I'm glad to know that industry pros like Avdi also find themselves
playing this role and are willing to help their clients grow in this
way.
The Truths We Express To Children Are Really Our Hopes
In
her Conversation with Tyler,
scholar Katherine Rundell said something important about the
books we give our children:
Children's novels tend to teach the large, uncompromising truths
that we hope exist. Things like love will matter, kindness will
matter, equality is possible. I think that we express them as
truths to children when what they really are are hopes.
This passage immediately brought to mind Marick's Law: In
software, anything of the form "X's Law" is better understood
by replacing the word "Law" with "Fervent Desire".
(More on this law below.)
While comments on different worlds, these two ideas are very much
in sync. In software and so many other domains, we coin laws that
are really much more expressions of our aspiration. This no less
true in how we interact with young people.
We usually think that our job is to teach children the universal
truths we have discovered about the world, but what we really
teach them is our view of how the world can or should be. We can
do that by our example. We can also do that with good books.
But aren't the universal truths in our children's literature
true? Sometimes, perhaps, but not all of them are true all of
the time, or for all people. When we tell stories, we are
describing the world we want for our children, and giving them
the hope, and perhaps the gumption, to make our truths truer than
we ourselves have been able to.
I found myself reading lots of children's books and YA fiction
when my daughters were young: to them, and with them, and on their
recommendation. Some of them affected me enough that I
quoted them in blog posts.
There is so many good books for our youth in the library: honest,
relevant to their experiences, aspirational, exemplary. I concur
in Rundell's suggestion that adults should read children's fiction
occasionally, both for pleasure and "for the unabashed politics of
idealism that they have".
More on Marick's Law and Me
I remember posting Marick's Law on this blog
in October 2015,
when I wanted to share a link to it with Mike Feathers. Brian had
tweeted the law in 2009, but a link to a tweet didn't feel right,
not at a time when the idealism of the open web was still alive.
In my post, I said "This law is too important to be left vulnerable
to the vagaries of an internet service, so let's give it a permanent
home".
In 2015, the idea that Twitter would take a weird turn, change its
name to X, and become a place many of my colleagues don't want to
visit anymore seemed far-fetched. Fortunately, Brian's tweet is
still there and, at least for now,
publicly viewable
via redirect. Even so, given the events of the last couple of
years, I'm glad I trusted my instincts and gave the law a more
home on Knowing and Doing. (Will this blog outlive Twitter?)
The funny thing, though, is that that wasn't its first appearance
here. I found the 2015 URL for use in this post by searching for
the word "fervent" in my Software category. That search also
brought up
a Posts of the Day post
from April 2009 — the day after Brian tweeted the law. I
don't remember that post now, and I guess I didn't remember it
in 2015 either.
Sometimes, "Great minds think alike" doesn't require two different
people. With a little forgetfulness, they can be Past Me and
Current Me.
At some point last week, I found myself pointed to
this short YouTube video
of Jerry Seinfeld talking with Howard Stern about work habits.
Seinfeld told Stern that he was essentially always thinking
about making comedy. Whatever situation he found himself in,
even with family and friends, he was thinking about how he
could mine it for new material. Stern told him that sounded
like torture. Jerry said, yes, it was, but...
Your blessing in life is when you find the torture you're
comfortable with.
This is something I talk about with students a lot.
Sometimes it's a current student who is worried that CS isn't
for them because too often the work seems hard, or boring.
Shouldn't it be easy, or at least fun?
Sometimes it's a prospective student, maybe a HS student on a
university visit or a college student thinking about changing
their major. They worry that they haven't found an area of
study that makes them happy all the time. Other people tell
them, "If you love what you do, you'll never work a day in
your life." Why can't I find that?
I tell them all that I love what I do -- studying, teaching,
and writing about computer science -- and even so, some days
feel like work.
I don't use torture as analogy the way Seinfeld does, but I
certainly know what he means. Instead, I usually think of
this phenomenon in terms of drudgery: all the grunt work that
comes with setting up tools, and fiddling with test cases, and
formatting documentation, and ... the list goes on. Sometimes
we can automate one bit of drudgery, but around the corner
awaits another.
And yet we persist. We have found the drudgery we are comfortable
with, the grunt work we are willing to do so that we can be part
of the thing it serves: creating something new, or understanding
one little corner of the world better.
I experienced the disconnect between the torture I was comfortable
with and the torture that drove me away during my first year in
college. As I've mentioned here a few times, most recently in
my post on Niklaus Wirth,
from an early age I had wanted to become an architect (the kind who
design houses and other buildings, not software). I spent years
reading about architecture and learning about the profession. I
even took two drafting courses in high school, including one in
which we designed a house and did a full set of plans, with
cross-sections of walls and eaves.
Then I got to college and found two things. One, I still liked
architecture in the same way as I always had. Two, I most assuredly
did not enjoy the kind of grunt work that architecture students had
to do, nor did I relish the torture that came with not seeing a
path to a solution for a thorny design problem.
That was so different from the feeling I had writing BASIC programs.
I would gladly bang my head on the wall for hours to get the tiniest
detail just the way I wanted it, either in the code or in the output.
When the torture ended, the resulting program made all the pain
worth it. Then I'd tackle a new problem, and it started again.
Many of the students I talk with don't yet know this feeling. Even
so, it comforts some of them to know that they don't have to find
The One Perfect Major that makes all their boredom go away.
However, a few others understand immediately. They are often the
ones who learned to play a musical instrument or who ran cross
country. The pianists remember all the boring finger exercises
they had to do; the runners remember all the wind sprints and all
the long, boring miles they ran to build their base. These students
stuck with the boredom and worked through the pain because they
wanted to get to the other side, where satisfaction and joy are.
Like Seinfeld, I am lucky that I found the torture I am comfortable
with. It has made this life a good one. I hope everyone finds
theirs.
Today in "It's not the objects; it's the messages"
Alan Kay is fond of saying that object-oriented programming is
not about the objects; it's about the messages. He also looks
to the biological world for models of how to think about and
write computer programs.
This morning I read two things on the exercise bike that brought
these ideas to mind, one from the animal kingdom and one from
the human sphere.
First was
a surprising little article
on how an invasive ant species is making it harder for Kenyan
lions to hunt zebras, with elephants playing a pivotal role in
the story, too. One of the scientists behind the study said:
"We often talk about conservation in the context of species.
But it's the interactions which are the glue that holds the
entire system together."
And then I remembered: people are people through other people.
Meaning comes from between us, not within us.
It's not just the people. It's the interactions.
Both articles highlighted that we are usually better served by
thinking about interactions within systems, and not simply the
components of system. That way lies a more reliable approach to
build robust software. Alan Kay is probably somewhere nodding
his head.
The ideas in Jessitron's piece fit nicely into the software
analogy, but they mean even more in the world of people that
she is reflecting on. It's easy for each of us to fall into
the habit of walking around the world as an I and never quite
feeling whole. Wholeness comes from connection to others. I
occasionally have to remind myself to step back and see my day
in terms of the students and faculty I've interacted with, whom
I have helped and who have helped me.
It's not (just) the people. It's the interactions.
It's been a long time again between posts. That seems to be the new
normal. On top of that, though, teaching web development this fall
for the first time has been soaking up all of my free hours in the
evenings and over the weekends, which has left me little time to be
sad about not blogging. I've certainly been writing plenty of text
and a bit of code.
The course started off with a lot of positive energy. The students
were excited to learn HTML and CSS. I made a few mistakes in how I
organized and presented topics, but things went pretty well. By all
accounts, students seemed to enjoy what they were learning and doing.
And then came JavaScript.
Well, along came real computer programming. It could have been
Python or some other language, I think, but the transition to writing
programs, even short bits of code, took the wind out of the
students' excitement.
I was prepared for the possibility that the mood of the course would
change when we shifted from CSS to JavaScript. A previous offering
of the course had encountered a similar obstacle. Learning to program
is a challenge. I'm still not convinced that learning to program is
that much harder than a lot of things people learn to do, but it does
take time.
As I prepared for the course last summer, I saw so many different
approaches to teaching JavaScript for web development. Many assumed
a lot of HTML/CSS/DOM background, certainly more than my students had
picked up in six weeks. Others assumed programming experience most
of my students didn't have, even when the approach said
'no experience necessary!'. So I had to find a middle path.
My main source of inspiration in the first half of the course was
David Humphrey's
WEB 222 course, which was explicitly aimed at an audience of CS
students with programming experience. So I knew that I had to do
something different with my students, even as I used his wonderful
course materials whenever I could.
My department had offered this course once many years ago, aimed at
much the same kind of audience as mine, and the instructor —
a good friend — shared all of his materials. I used that
offering as a primary source of ideas for getting started with
JavaScript, and I occasionally adapted examples for use in my class.
The results were not ideal. Students don't seem to have enjoyed
this part of the course much at all. Some acknowledged that to me
directly. Even the most engaged students seemed to lose a bit of
their energy for the course. Performance also sagged. Based on
homework solutions and a short exam, I would say that only one
student has achieved the outcomes I had originally outlined for this
unit.
I either expected too much or did not do a good enough job helping
students get to where I wanted them to be.
I have to do better next time.
But how?
Programming isn't as hard as some people tell us, but most of us
can't learn to do it in five or six weeks, at least not enough to
become very productive. We don't expect students to master all of
CSS or even HTML in such a short time, so we can't expect them to
master JavaScript either. The difference is that there seems to be
a smooth on-ramp for learning HTML and CSS on the way to mastery,
while JavaScript (or any other programming language) presents a
steep climb, with occasional plateaus.
For now, I am thinking that the key to doing better is to focus on
an even narrower set of concepts and skills.
If people starting from scratch can't learn all of JavaScript in five
or six weeks, or even enough to be super-productive, what useful
skills can they learn in that time? For this course
I trimmed down the set of topics that we might cover in an intro CS
considerably, but I think I need to trim even more and — more
importantly — choose topics and examples that are even more
embedded in the act of web development.
Earlier this week, a sudden burst of thought outlined something like
this:
document.querySelector() to select an element in
a page
simple assignment statements to modify innerText,
innerHTML, and various style attributes
parameterizing changes to an element to create a function
document.querySelectorAll() to select collections of
elements in a page
forEach to process every element in a collection
guarded actions to select items in the collection using
if statements, without else clauses
That is a lot to learn in five weeks! Even so, it cuts way back on
several topics I tried cover this time, such as a more general
discussion of objects, arrays, and boolean values, and a deeper look
at the DOM. And it eliminates even mentioning several topics altogether:
if-else statements
while statements
counted for loops and, more generally, map-like
behavior
any fiddling with numbers and arithmetic, which are often used
to learn assignment statements, if statements,
and function
There are so many things a programmer can't do without these
concepts, such as writing an indefinite data validation loop or
really understanding what's going on in the DOM tree. But trying
to cover all of those topics too did not result in students being
able to do them either! I think it left them confused, with so many
new ideas jumbled in their minds, and a general dissatisfaction at
being unable to use JavaScript effectively.
Of course I would want to build hooks into the course for students
who want to go deeper and are ready to do so. There is so much good
material on the web for people who are ready for more. Providing
more enriched opportunities for advanced students is easier than
designing learning opportunities for beginners.
Can something like this work?
I won't know for a while. It will be at least a year before I teach
this course again. I wish I could teach it again sooner, so that I
could try some of my new ideas and get feedback on them sooner.
Such is the curse of a university calendar and once-yearly offerings.
It's too late to make any big changes in trajectory this semester.
We have only two weeks after the current one-week Thanksgiving break.
Next week, we will focus on input forms (HTML), styling (CSS), and a
little data validation (HTML+JavaScript). I hope that this return
to HTML+CSS helps us end the course on a positive note. I'd like for
students to finish with a good feeling about all they have learned
and now can do.
Last month, Gus Mueller
announced v7.4.3
of his image-editing tool
Acorn.
This release has a fun little extra built in:
One more super geeky thing I've added is a JavaScript Console:
...
This tool is really meant for folks developing plugins in Acorn,
and it is only accessible from the Command Bar, but a part of me
absolutely loves pointing out little things like this. I was
just chatting with
Brent Simmons
the other day at Xcoders how you can't really spelunk in apps
any more because of all the restrictions that are (justifiably)
put on recent MacOS releases. While a console isn't exactly a
spelunking tool, I still think it's kind of cool and fun and
maybe someone will discover it accidentally and that will inspire
them to do stupid and entertaining things like we used to do
back in the 10.x days.
I have had JavaScript consoles on my mind a lot in the last few
weeks. My students and I have used the developer tools in our
browsers as part of
my web development course for non-majors.
To be honest, I had never used a JavaScript console until this
summer, when I began preparing for the course in earnest. REPLs
are, of course, a big part of the programming background, from
Lisp to Racket to Ruby to Python, so I took to the console with
ease and joy. (My past experience with JavaScript was mostly in
Node.js, which has its own REPL.)
We just started our fourth week studying JavaScript in class, so
my students have started getting used to the console. At the
outset, it was new to most of them, who have never programmed
before. Our attention has now turned to interacting with the DOM
and manipulating the content of web page. It's been a lot of fun
for me. I'm not sure how it feels for all of my students, though.
Many came to the course for web design and really enjoy HTML and
CSS. JavaScript, on the other hand, is... programming: more
syntax, more semantics, and a lot of new details just to select,
say, the third h3 on the page.
Sometimes, you just gotta work over the initial hump to sense the
power and fun. Some of them are getting there.
Today I had great fun showing them how to add some simple search
functionality to a web page. It was our first big exercise using
document.querySelectorAll() and processing a collection
of HTML elements. Soon we'll learn about text fields and buttons
and events, at which point my
The Books of Bokonon
will become much more useful to the many readers who still find
pleasure in it. Just last night that page got its first modern
web styling in the form of a CSS style sheet. For its first
twenty-four years of existence, it was all 1990s-era HTML and
pseudo-layout using <center>, <hr>,
and <br> tags.
Anyway, I appreciate Gus's excitement at adding a console to Acorn,
making his tool a place to play as well as work. Spread the joy.
After a few months studying and using CSS, every once in a while I am
able to change a style sheet and cause something I want to happen.
It feels wonderful. Pretty soon, though, I'll make a typo somewhere,
or misunderstand a property, and not be able to make anything useful
happen. That makes me feel like I'm drowning in complexity.
Thankfully, the occasional wonderful feelings — and my strange
willingness to struggle with programming errors — pull me
forward.
I've been learning a lot while preparing to teach to our web
development course [
1
|
2
]. Occasionally, I feel incompetent, or not very bright. It's good
for me.
I haven't been blogging lately, but I've been writing lots of words.
I've also been re-purposing and adapting many other words that are
licensed to be reusable (thanks,
David Humphrey and John
Davis). Prepping a new course is usually prime blogging time for me,
with my mind in a constant state of churn, but this course has me
drowning in work to do. There is so much to learn, and so much new
material — readings, session plans and notes, examples, homework
assignments — to create.
I have made a few notes along the way, hoping to expand them into posts.
Today they become part of this post.
VS Code
This is my first time in a long time using an editor configured to
auto-complete and do all the modern things that developers expect these
days. I figured, new tool, why not try a new workflow...
After a short period of breaking in, I'm quite enjoying the experience.
One feature I didn't expect to use so much is the ability to collapse
an HTML element. In a large HTML file, this has been a game changer
for me. Yes, I know, this is old news to most of you. But as my brother
loves to say when he gets something used or watches a movie everyone
else has already seen, "But, hey, it's new to me!"
VS Code's auto-complete across HTML, CSS, and JavaScript, with built-in
documentation and links to MDN's more complete documentation, lets me
type code much faster than ever before. It made me think of one of my
favorite Kent Beck lines:
As the speed of development approaches infinity, reuse becomes irrelevant.
When programming, I often copy, paste, and adapt previous code. In VS
Code, I have found myself moving fast enough that copy, paste, and adapt
would slow me down. That sort of reuse has become irrelevant.
Examples > Prose
The class sessions for which I have written the longest and most
complete notes for my students (and me) tend to be the ones for which
I have the fewest, or least well-developed, code examples. The reverse
is also true: lots of good examples and code tends to mean smaller class
notes. Sometimes that is because I run out of time to write much prose
to accompany the session. Just as often, though, it's because the
examples give us plenty to do live in class, where the learning happens
in the flow of writing and examining code.
This confirms something I've observed over many years of teaching:
Examples First tends to work better for most students, even
people like me who fancy themselves as top-down thinkers. Good
examples and code exercises can create the conditions in which
abstract knowledge can be learned. This is a sturdy
pedagogical pattern.
Concepts and Patterns
There is so, so much to CSS! HTML itself has a lot of details for
new coders to master before they reach fluency. Many of the websites
aimed at teaching and presenting these topics quickly begin to feel
like a downpour of information, even when the authors try to organize
it all. It's too easy to fall into, "And then there's this other
property...".
After a few weeks, I've settled into trying to help students learn two
kinds of things for each topic:
a couple of basic concepts or principles
a few helpful patterns
My challenge is that I am still new enough to modern web design that
identifying either in advance is a challenge. My understanding is
constantly evolving, so my examples and notes are evolving, too.
I will be better next time, or so I hope.
~~~~~
We are only five weeks into a fifteen week semester, so take any
conclusions I draw with a grain of salt. We also haven't gotten to
JavaScript yet, the teaching and learning of which will present a
different sort of challenge than HTML and CSS with students who have
little or no experience programming. Maybe I will make time to write
up our experiences with JavaScript in a few weeks.
I ran across
this blog post
earlier this summer when browsing articles on CSS, as one does
while learning CSS for a fall course. Near the end, the writer
says:
This is thoroughly exciting to me, and I don't wanna whine about
improvements in CSS, but it's a bit concerning since I feel like
what the web is now capable of is slipping through my fingers.
And I guess that's what I'm worried about; I no longer have a
good idea of how these things interact with each other, or where
the frontier is now.
The map of CSS in my mind is real messy, confused, and teetering
with details that I can't keep straight in my head.
Imagine how someone feels as they learn CSS basically from the
beginning and tries to get a handle both on how to use it
effectively and how to teach it effectively. There is so much
there... The good news, of course, is that our course is for
folks with no experience, learning the basics of HTML, CSS, and
JavaScript from the beginning, so there is only so far we can
hope to go in fifteen weeks anyway.
My impressions of HTML and CSS at this point are quite similar:
very little syntax, at least for big chunks of the use cases,
and lots and lots of vocabulary. Having convenient access to
documentation such as that available at
developer.mozilla.org
via the web and inside VS Code makes exploring all of the options
more manageable in context.
I've been watching
Dave Humphrey's
videos for his
WEB 222 course
at Seneca College and learning tons. Special thanks to Dave for
showing me a neat technique to use when learning -- and teaching
-- web development: take a page you use all the time and try to
recreate it using HTML and CSS, without looking at the page's own
styles. He has done that a couple times now in his videos, and I
was able to integrate the ideas we covered about the two languages
in previous videos as Dave made the magic work. I have tried it
once on my own. It's good fun and a challenging exercise.
Learning layout by viewing page source used to be easier in the
old days, when pages were simpler and didn't include dozens of CSS
imports or thousands of scripts. Accepting the extra challenge of
not looking at a page's styles in 2023 is usually the simpler path.
Two re-creations I have on tap for myself in the coming days are a
simple Wikipedia-like page for myself (I'm not notable enough to
have an actual Wikipedia page, of course) and a page that acts like
my Mastodon home page, with anchored sidebars and a scrolling feed
in between. Wish me luck.
Last time
I posted this passage from Shop Class as Soulcraft, by
Matthew Crawford:
Countless times since that day, a more experienced mechanic has
pointed out to me something that was right in front of my face, but
which I lacked the knowledge to see. It is an uncanny experience;
the raw sensual data reaching my eye before and after are the same,
but without the pertinent framework of meaning, the features in
question are invisible. Once they have been pointed out, it seems
impossible that I should not have seen them before.
We perceive in part based on what we know. A lack of knowledge can
prevent us from seeing what is right in front of us. Our brains
and eyes work together, and without a perceptual frame, they don't
make sense of the pattern. Once we learn something, our eyes --
and brains -- can.
This reminds me of a line from the movie The Santa Clause,
which my family watched several times when my daughters were younger.
The new Santa Claus is at the North Pole, watching magical things
outside his window, and comments to the elf whose been helping him,
"I see it, but I don't believe it." She replies that adults don't
understand: "Seeing isn't believing; believing is seeing." As a
mechanic, Crawford came to understand that knowing is
seeing.
Later in the book, Crawford describes another way that knowing and
perceiving interact with one another, this time with negative results.
He had been struggling to figure out why there was no spark at the
spark plugs in his VW Bug, and his father -- an academic, not a
mechanic -- told him about Ohm's Law:
Ohm's law is something explicit and rulelike, and is true in the way
that propositions are true. Its utter simplicity makes it beautiful;
a mind in possession of this equation is charmed with a sense of its
own competence. We feel we have access to something universal, and
this affords a pleasure that is quasi-religious, perhaps. But this
charm of competence can get in the way of noticing things; it can
displace, or perhaps hamper the development of, a different kind of
knowledge that may be difficult to bring to explicit awareness, but
is superior as a practical matter. It superiority lies in the fact
that it begins with the typical rather than the universal, so it
goes more rapidly and directly to particular causes, the kind that
actually tend to cause ignition problems.
Rule-based, universal knowledge imposes a frame on the
scene. Unfortunately, its universal nature can impede perception
by blinding us to the particular details of the situation we are
actually in. Instead of seeing what is there, we see the scene as
our knowledge would have it.
This reminds me of a story and a technique from the book
Drawing on the Right Side of the Brain,
which I first
wrote about
in the earliest days of this blog. When asked to draw a chair, most
people barely even look at the chair in front of them. Instead, they
start drawing their idea of a chair, supplemented by a few
details of the actual chair they see. That works about as well as
diagnosing an engine by diagnosing your mind's eye of an engine,
rather than the mess of parts in front of you.
In that blog post, I reported my experience with one of Edwards's
techniques for seeing the chair, drawing the negative space:
One of her exercises asked the student to draw a chair. But, rather
than trying to draw the chair itself, the student is to draw the
space around the chair. You know, that little area hemmed in between
the legs of the chair and the floor; the space between the bottom of
the chair's back and its seat; and the space that is the rest of the
room around the chair. In focusing on these spaces, I had to actually
look at the space, because I don't have an image in my brain of an
idealized space between the bottom of the chair's back and its seat.
I had to look at the angles, and the shading, and that flaw in the
seat fabric that makes the space seem a little ragged.
Sometimes, we have to trick our eyes into seeing, because otherwise
our brains tell us what we see before we actually look at the scene.
Abstract universal knowledge helps us reason about what we see, but
it can also impede us from seeing in the first place.
What we know both enables and hampers what we perceive. This idea
has me thinking about how my students this fall, non-CS majors who
want to learn how to develop web sites, will encounter the course.
Most will be novice programmers who don't know what they see when
they are looking at code, or perhaps even at a page rendered in the
browser. Debugging code will be a big part of their experience this
semester. Are there exercises I can give them to help them see
accurately?
As I said in my previous post, there's lots of good stuff happening
in my brain as I read this book. Perhaps more posts will follow.
With the exception of
teaching our database course
during the COVID year, I have been teaching a stable pair of courses
for the last many semesters: Programming Languages in the spring and
our compilers course, Translation of Programming Languages, in the
fall. That will change this fall due to some issues with enrollments
and course demands. I'll be teaching a course in client-side web
development.
The official number and title of the course are
"CS 1100 Web Development: Client-Side Coding".
The catalog description for the course was written years ago by committee:
Client-side web development adhering to current Web standards. Includes
by-hand web page development involving basic HTML, CSS, data acquisition
using forms, and JavaScript for data validation and simple web-based
tools.
As you might guess from the 1000-level number, this is an introductory
course suitable for even first-year students. Learning to use HTML,
CSS, and Javascript effectively is the focal point. It was designed as
a service course for non-majors, with the primary audience these days
being students in
our Interactive Digital Studies program.
Students in that program learn some HTML and CSS in another course, but
that course is not a prerequisite to ours. A few students will come in
with a little HTML5+CSS3 experience, but not all.
So that's where I am. As I mentioned, this is one of my first courses
to design from scratch in a long time. Other than Database Systems, we
have to go back to
Software Engineering
in 2009. Starting from scratch is fun but can be daunting, especially
in a course outside my core competency of hard-core computer science.
The really big change, though, was mentioned two paragraphs ago:
non-majors. I don't think I've taught non-majors since teaching my
university's capstone 21 years ago -- so long ago that this blog did
not yet exist. I haven't taught a non-majors' programming course in
even longer, 25 years or more, when I last taught BASIC. That is so
long ago that their was no "Visual" in the language name!
So: new area, new content, new target audience. I have a lot of work
to do this summer.
I could use some advice from those of you who do web development for
a living, who know someone who does, or who are more up to date on
the field than I.
Generally, what should a course with this title and catalog description
be teaching to beginners in 2023?
Specifically, can you point me toward...
similar courses with material online that I could learn from?
resources for students to use as they learn: websites, videos,
even books?
For example, a former student and now friend mentioned that the
w3schools website includes a JavaScript tutorial which allows students
to type and test code within the web browser. That might simplify
practice greatly for non-CS students while they are learning other
development tools.
I have so many questions to answer about tools in particular right now:
Should we use an IDE or a simple text editor? Which one? Should we
learn raw JavaScript or a simple framework? If a framework, which one?
This isn't a job-training course, but to the extent that's reasonable
I would like for students to see a reasonable facsimile of what they
might encounter out in industry.
Thinking back, I guess I'm glad now that I
decided to play some around with JavaScript
in 2022... At least I now have more context for evaluatins the options
available for this course.
If you have any thoughts or suggestions, please do send them along.
Sending email
or replying on
Mastodon
or
Twitter
all work. I'll keep you posted on what I learn.
The last day of a conference is often a wildcard. If it ends early
enough, I can often drive or fly home afterward, which means that I
can attend all of the conference activities. If not, I have to
decide between departing the next day or cutting out early. When
possible, I stay all day. Sometimes, as with StrangeLoop, I can
stay all day, skip only the closing keynote, and drive home into
the night.
With virtual PyCon, I decided fairly early on that I would not be
able to attend most of the last day. This is Sunday, I have family
visiting, and work looms on the horizon for Monday. An afternoon
talk or two is all I will be able to manage.
Talk 1: A Pythonic Full-Text Search
The idea of this talk was to use common Python tools to implement
full-text search of a corpus. It turns out that the talk focused
on websites, and thus on tools common to Python web developers:
PostgreSQL and Django. It also turns out that
django.contrib.postgres provides lots of features for
doing search out of the box. This talk showed how to use them.
This was an interesting talk, but not immediately useful to me.
I don't work with Django, and I use SQLite more often then
PostgreSQL for my personal work. There may be some support for
search in django.contrib.sqlite, if it exists, but the
speaker said that I'd likely have to implement most of the
search functionality myself. Even so, I enjoyed seeing what was
possible with modules already available.
Talk 2: Using Python to Help the Unhoused
I thought I was done for the conference, but I decided I could
listen in one one more talk while making dinner. This
non-technical session sounded interesting:
How a group of volunteers from around the globe use Python to help
an NGO in Victoria, BC, Canada to help the unhoused. By building
a tool to find social media activity on unhoused in the Capitol
Region, the NGO can use a dashboard of results to know where to
move their limited resources.
With my attention focused on the Sri Lankan dal with coconut-lime
kale in my care, I didn't take detailed notes this time, but I did
learn about the existence of
Statistics Without Borders,
which sounds like a cool public service group that needs to exist
in 2023. Otherwise, the project involved scraping Twitter as a
source of data about the needs of the homeless in Victoria, and
using sentiment analysis to organize the data. Filtering the data
to zero in on relevant data was their biggest challenge, as
keyword filters passed through many false positives.
At this point, the developers have given their app to the NGO and
are looking forward to receiving feedback, so that they can make
any improvements that might be needed.
This is a nice project by folks giving back to their community, and
a nice way to end the conference.
~~~~~
I was a PyCon first-timer, attending virtually. The conference talks
were quite good. Thanks to everyone who organized the conference and
created such a complete online experience. I didn't use all of the
features available, but what I did use worked well, and the people
were great. I ended up with links to several Python projects to try
out, a few example scripts for PyScript and Mermaid that I cobbled
together after the talks, and lots of syntactic abstractions to
explore. Three days well spent.
Another way that attending a virtual conference is like the
in-person experience: you can oversleep, or lose track of time.
After a long morning of activity before the time-shifted start
of Day 2, I took a nap before the 11:45 talk, and...
Talk 1: Python's Syntactic Sugar
Grrr. I missed the first two-thirds of this talk, which I greatly
anticipated, but I slept longer than I planned. My body must have
needed more than I was giving it.
I saw enough of the talk, though, to know I want to watch the video on
YouTube when it shows up. This topic is one of my favorite topics
in programming languages: What is the smallest set of features we
need to implement the rest of the language?
The speaker spent a couple of years implementing various Python
features in terms of others, and arrived at a list of only ten
that he could not translate away. The rest are sugar. I missed the
list at the beginning of the talk, but I gathered a few of its
members in the ten minutes I watched: while, raise,
and try/except.
I love this kind of exercise: "How can you translate the statement
if X: Y into one that uses only core features?" Here's one
attempt the speaker gave:
try:
while X:
Y
raise _DONE
except _DONE:
None
I was today days old when I learned that Python's bool
subclasses int, that True == 1, and that
False == 0. That bit of knowledge was worth interrupting
my nap to catch the end of the talk.
Even better, this talk was based on
a series of blog posts.
Video is okay, but I love to read and play with ideas in written
form. This series vaults to the top of my reading list for the
coming days.
Talk 2: Subclassing, Composition, Python, and You
Okay, so this guy doesn't like subclasses much. Fair enough, but...
some of his concerns seem to be more about the way Python classes
work (open borders with their super- and subclasses) than with the
idea itself. He showed a lot of ways one can go wrong with arcane
uses of Python subclassing, things I've never thought to do with a
subclass in my many years doing OO programming. There are plenty
of simpler uses of inheritance that are useful and
understandable.
Still, I liked this talk, and the speaker. He was honest about his
biases, and he clearly cares about programs and programmers. His
excitement gave the talk energy.
The second half of the talk included a few good design examples,
using subclassing and composition together to achieve various ends.
It also recommended the book
Architecture Patterns with Python.
I haven't read a new software patterns book in a while, so I'll give
this one a look.
Toward the end, the speaker referenced the line "Software engineering
is programming integrated over time." Apparently, this is a Google
thing, but it was new to me. Clever. I'll think on it.
Talk 3: How We Are Making CPython Faster -- Past, Present and Future
I did not realize that, until Python 3.11, efforts to make the
interpreter had been rather limited. The speaker mentioned one
improvement made in 3.7 to optimize the typical method invocation,
obj.meth(arg), and one in 3.8 that sped up global variable
access by using a cache. There are others, but nothing systematic.
At this point, the talk became mutually recursive with the Friday
talk "Inside CPython 3.11's New Specializing, Adaptive Interpreter".
The speaker asked us to go watch that talk and return. If I were
more ambitious, I'd add a link to that talk now, but I'll let you
any of you are interested to visit
yesterday's post
and scroll down two paragraphs.
He then continued with improvements currently in the works, including:
efforts to optimize over larger regions, such as the different
elements of a function call
use of partial evaluation when possible
specialization of code
efforts to speed up memory management and garbage collection
He also mentions possible improvements related to C extension code,
but I didn't catch the substance of this one.
The speaker offered the audience a pithy takeaway from his talk:
Python is always getting faster. Do the planet a favor and
upgrade to the latest version as soon as you can. That's a
nice hook.
There was lots of good stuff here. Whenever I hear compiler talks
like this, I almost immediately start thinking about how I might
work some of the ideas into my compiler course. To do more with
optimization, we would have to move faster through construction of
a baseline compiler, skipping some or all of the classic material.
That's a trade-off I've been reluctant to make, given the course's
role in our curriculum as
a compilers-for-everyone experience.
I remain tempted, though, and open to a different treatment.
Talk 4:
The Lost Art of Diagrams: Making Complex Ideas Easy to See with Python
Early on, this talk contained a line that programmers sometimes need
to remember: Good documentation shows respect for users.
Good diagrams, said the speaker, can improve users' lives.
The talk was a nice general introduction to some of the design choices
available to us as we create diagrams, including the use of color,
shading, and shapes (Venn diagrams, concentric circles, etc.).
It then discussed a few tools one can use to generate better diagrams.
The one that appealed most to me was
Mermaid.js,
which uses a Markdown-like syntax that reminded me of GraphViz's
Dot language. My students and use GraphViz, so picking up Mermaid
might be a comfortable task.
~~~~~
My second day at virtual PyCon confirmed that attending was a good
choice. I've seen enough language-specific material to get me
thinking new thoughts about my courses, plus a few other topics to
broaden the experience. A nice break from the semester's grind.
One of great benefits of a virtual conference is accessibility. I
can hop from Iowa to Salt Lake City with the press of a button.
The competing cost to virtual conference is that I am accessible
... from elsewhere.
On the first day of PyCon, we had a transfer orientation session
that required my presence in virtual Iowa from 10:00 AM-12:00 noon
local time. That's 9:00-11:00 Mountain time, so I missed Ned
Batchelder's keynote and the opening set of talks. The rest of the
day, though, I was at the conference. Virtual giveth, and virtual
taketh away.
Talk 1: Inside CPython 3.11's New Specializing, Adaptive Interpreter
As I said yesterday, I don't know Python -- tools, community, or
implementation -- intimately. That means I have a lot to learn
in any talk. In this one, Brandt Bucher discussed the adaptive
interpreter that is part of Python 3.11, in particular how the
compiler uses specialization to improve its performance based on
run-time usage of the code.
Midway through the talk, he referred us to a talk on tomorrow's
schedule. "You'll find that the two talks are not only complementary,
they're also mutually recursive." I love the idea of mutually
recursive talks! Maybe I should try this with two sessions in
one of my courses. To make it fly, I will need to make some videos...
I wonder how students would respond?
This
online Python disassembler
by @pamelafox@fosstodon.org popped
up in the chat room. It looks like a neat tool I can use in my
compiler course. (Full disclosure: I have been following Pamela on
Twitter and Mastodon for a long time. Her posts are always
interesting!)
Talk 2: Build Yourself a PyScript
PyScript is
a Javascript module
that enables you to embed Python
in a web page, via WebAssembly. This talk described how PyScript
works and showed some of the technical issues in writing web apps.
Some of this talk was over my head. I also do not have deep
experience programming in the web. It looks like I will end up
teaching a beginning web development course this fall (more later),
so I'll definitely be learning more about HTML, CSS, and Javascript
soon. That will prepare me to be more productive using tools like
PyScript.
Talk 3: Kill All Mutants! (Intro to Mutation Testing)
Our test suites are often not strong enough to recognize changes
in our code. The talk introduced mutation testing, which modifies
code to test the suite. I didn't take a lot of notes on this one,
but I did make a note to try mutation testing out, maybe in
Racket.
Talk 4: Working with Time Zones: Everything You Wish You Didn't Need to Know
Dealing with time zones is one of those things that every software
engineer seems to complain about. It's a thorny problem with both
technical and social dimensions, which makes it really interesting
for someone who loves software design to think about.
This talk opened with example after example of how time zones
don't behave as straightforwardly as you might think, and
then discussed Python's newest time zone library, pytz.
My main takeaways from this talk: pytz looks useful, and I'm
glad I don't have to deal with time zones on a regular basis.
Talk 5: Pythonic Functional (iter)tools for your Data Challenges
This is, of course, a topic after my heart. Functional programming
is a big part of my programming languages course, and I like being
able to show students Python analogues to the Racket ideas they are
learning. There was not much new FP content for me here, but I did
learn some new Python functions from itertools that I can
use in class -- and in my own code.
I enjoyed the Advent of Code segment of the talk, in which the
speaker applied Python to some of the 2021 challenges. I use an
Advent of Code challenge or two each year in class, too. The early
days of the month usually feature fun little problems that my
students can understand quickly. They know how to solve them
imperatively in Python, but we tackle them functionally in Racket.
Most of the FP ideas needed to solve them in Python are similar, so
it was fun to see the speaker solve them using itertools.
Toward the end, the solutions got heavy quickly, which must be how
some of my students feel when we are solving these problems in class.
~~~~~
Between work in the morning and the conference afternoon and evening,
this was a long day. I have a lot of new tools to explore.
Heading off to #PyConUS in the morning, virtually. I just took my
first tour of Hubilo, the online platform. There's an awful lot
going on, but you need a lot of moving parts to produce the varied
experiences available in person. I'm glad that people have taken
up the challenge.
Why PyCon? I'm not an expert in the language, or as into the
language as I once was with Ruby. Long-time readers may recall
that I blogged about attending JRubyConf back in 2012. Here is a
link to
my first post
from that conference. You can scroll up from there to see several
more posts from the conference.
However, I do write and read a lot of Python code, because our
students learn it early and use it quite a bit. Besides, it's a
fun language and has a large, welcoming community. Like many
language-specific conferences, PyCon includes a decent number of
talks about interpreters, compilers, and tools, which are a big
part of my teaching portfolio these days. The conference offers
a solid virtual experience, too, which makes it attractive to
attend while the semester is still going on.
My goals for attending PyCon this year include:
learning some things that will help me improve my programming
languages and compiler courses,
learning some things that make me a better Python programmer,
and
simply enjoying computer science and programming for a few days,
after a long and occasionally tedious year. The work doesn't go
away while I am at a conference, but my mind gets to focus on
something else -- something I enjoy!
There are several revised approaches to "what's the deal with the ring?"
presented in "The History of The Lord of the Rings", and, as you read
through the drafts, the material just ... slowly gets better! Bit by
bit, the familiar angles emerge. There seems not to have been any
magic moment: no electric thought in the bathtub, circa 1931, that
sent Tolkien rushing to find a pen.
It was just revision.
Then:
... if Tolkien can find his way to the One Ring in the middle of the
fifth draft, so can I, and so can you.
In a recent blog post,
Why Grace Matters (for Software Development),
Avdi Grimm tells the story of how he came to name his training
site "Graceful.Dev". Check it out. This passage resolves into
the answer:
You know, the word "grace" is interesting, because it has two
different meanings. On the one hand, it means beauty in lines
or in motion. But if you were raised with a religious background
anything like mine, you know that grace is also something that
saves you.
And in that moment on the dance floor, I realized that these
two meanings of grace are really one and the same thing. Because
grace is something that makes space for you to screw up, and then
turns it into something beautiful.
I don't think I was raised in the same religious tradition as Avdi,
but I was raised in a tradition that valued deeply the notion of
grace. Grace manifest in sacrament was a powerful notion to me,
one of the religious ideas I found most compelling as I was
growing up.
That's probably why Avdi's realization strikes close to home for
me. I carry the idea of grace present in other parts of my life
as part of my cultural DNA. His connection of grace to software
feels right. "Grace makes space for you to screw up, and then
turns it into something beautiful." -- I imagine that many
programmers know this feeling, in an non-religious way, if only
vaguely.
As head of the Department of Computer Science at my university, I
often receive e-mail and phone calls from people with The Next
Great Idea. The phone calls can be quite entertaining! The
caller is an eager entrepreneur, drunk on their idea to
revolutionize the web, to replace Google, to top Facebook, or to
change the face of business as we know it. ...
They just need a programmer. ...
The opening of that piece sounds a little harsh more than a
decade later, but the basic premise holds. And, as Wendig
notes, it holds beyond the software world. I even once wrote
a short follow-up
when accomplished TV writer Ken Levine commented on his blog
about the same phenomenon in screenwriting.
Some misconceptions are evergreen.
Adding AI to the mix adds a new twist. I do think human
execution in telling stories will still matter, though. I'm
not yet convinced that the AI tools have the depth of network
to replace human creativity.
However, maybe tools such as ChatGPT can be the programmer people
need. A lot of folks are putting these tools to good use creating
prototypes, and people who know how to program are using them
effectively as accelerators. Execution will still matter, but
these programs may be useful contributors on the path to a product.
Robin Sloan speculates that language-learning models like ChatGPT
have gone through
a phase change
in what they can accomplish.
AI at this moment feels like a mash-up of programming and biology.
The programming part is obvious; the biology part becomes apparent
when you see AI engineers probing their own creations the way
scientists might probe a mouse in a lab.
Like so many people, I find my social media and blog feeds filled
with ChatGPT and LLMs and DALL-E and ... speculation about what
these tools mean for (1) the production of text and code, and (2)
learning to write and program. A lot of that speculation is
tinged with fear.
I admire Sloan's effort to be constructive in his approach to the
uncertainty:
I've found it helpful, these past few years, to frame my anxieties
and dissatisfactions as questions. For example, fed up with the
state of social media, I asked: what do I want from the internet,
anyway?
It turns out I had an answer to that question.
Where the GPT-alikes are concerned, a question that's emerging for
me is:
What could I do with a universal function — a tool for
turning just about any X into just about any Y with plain language
instructions?
I admit that I am reacting to these developments slowly compared
to many people. That's my style in most things: I am more likely
to under-react to a change than to over-react, especially at the
onset of the change. In this case, there is no chance of
immediate peril, so waiting to see what happens as people use
these tools seems like a reasonable reasonable. I haven't made
any effort to use these tools actively (or even been moved to),
so any speculating I do would be uninformed by personal experience.
Instead, I read as people whose work I respect experiment with
these tools and try to make sense of them. Occasionally, I draw
a small, tentative conclusion, such as that
prompting these generators is a lot like prompting students.
After a few months of reading and a little reflection, I still
think the biggest risk we face is probably that
we tend to change the world around us to accommodate our technologies.
If we put these tools to work for us in ways that enhance what we
do, then the accommodation will pay off. If not, then we may, as
Daniel Steinberg wrote in one of his newsletters, stop asking the
questions we want to ask and start asking only the questions these
tools can answer.
Professionally, I think most about the effect that ChatGPT and its
ilk will have on programming and CS education. In these regards,
I've been paying special attention to reports from David Humphrey,
such as
this blog post
on his university's attempt to grapple the widespread availability
of these tools. David has approached OpenAI with an open mind and
written thoughtfully about the promise and the risk. For example,
he has
written a lot of code
with an LLM assistant and found it improving his ability both to
write code and to think about problems. Advanced CS students can
benefit from this kind of assistance, too, but David wonders how
such tools might interfere
with students first learning to program.
What do we educators want from generative programming tools anyway?
What do I as a programmer and educator want from them?
So, at this point, my personal interaction with the phase change
that Sloan describes has been mostly passive: I read about what
others are doing and think about the results of their exploration.
Perhaps this post is a guilty conscience asserting that I should be
doing more. Really, though, I think of it more as an active form
of inaction: an effort to collect some of my thinking as I slowly
respond to the changes that are coming. Perhaps some day soon I
will feel moved to use of these tools as I write code of my own.
For now, though, I am content to watch from the sidelines. You can
learn a lot just by watching.
In
this episode of Conversations With Tyler,
Cowen asks economist Jeffrey Sachs if he agrees with several
other economists' bearish views on a particular issue. Sachs
says they "have been wrong ... for 20 years", laughs, and
goes on to say:
They just got it wrong time and again. They had failed to
understand, and the same with [another economist]. It's the
same story. It doesn't fit our model exactly, so it can't
happen. It's got to collapse. That's not right. It's
happening. That's the story of our time. It's happening.
"It doesn't fit our model, so it can't happen." But it is
happening.
When your model keeps saying that something can't happen,
but it keeps happening anyway, you may want to reconsider
your model. Otherwise, you may miss the dominant story of
the era -- not to mention being continually wrong.
Sachs spends much of his time with Cowen emphasizing the
importance of context in determining which model to
use and which actions to take. This is essential in
economics because the world it studies is simply too
complex for the models we have now, even the complex
models.
I think Sachs's insight applies to any discipline that works
with people, including education and software development.
The topic of education even comes up toward the end of the
conversation, when Cowen asks Sachs how to "fix graduate
education in economics". Sachs says that one of its problems
is that they teach econ as if there were "four underlying,
natural forces of the social universe" rather than studying
the specific context of particular problems.
He goes on to highlight an approach that is affecting every
discipline now touched by data analytics:
We have so much statistical machinery to ask the question,
"What can you learn from this dataset?" That's the wrong
question because the dataset is always a tiny, tiny fraction
of what you can know about the problem that you're studying.
Every interesting problem is bigger than any dataset we build
from it. The details of the problem matter. Again: context.
Sachs suggests that we shouldn't teach econ like physics,
with Maxwell's overarching equations, but like biology, with
the seemingly arbitrary details of DNA.
In my mind, I immediately began thinking about my discipline.
We shouldn't teach software development (or econ!) like pure
math. We should teach it as a mix of principles and context,
generalities and specific details.
There's almost always a tension in CS programs between timeless
knowledge and the details of specific languages, libraries,
and tools. Most of students don't go on to become theoretical
computer scientists; they go out to work in the world of messy
details, details that keep evolving and morphing into something
new.
That makes our job harder than teaching math or some sciences
because, like economics:
... we're not studying a stable environment. We're studying
a changing environment. Whatever we study in depth will be
out of date. We're looking at a moving target.
That dynamic environment creates a challenge for those of us
teaching software development or any computing as practiced
in the world. CS professors have to constantly be moving,
so as not to fall our of date. But they also have to try to
identify the enduring principles that their students can count
on as they go on to work in the world for several decades.
To be honest, that's part of the fun for many of us CS profs.
But it's also why so many CS profs can burn out after 15 or
20 years. A never-ending marathon can wear anyone out.
I finally read Rudolf Winestock's 2011 essay
The Lisp Curse,
which is summarized in one line:
Lisp is so powerful that problems which are technical issues
in other programming languages are social issues in Lisp.
It seems to me that Racket and Clojure have overcome the curse.
Racket was built by a small team that grew up in academia.
Clojure was designed and created by an individual. Yet they
are both 100% solutions, not the sort of one-off 80% personal
solutions that tend to plague the Lisp world.
But the creators went further: They also attracted and built
communities.
The Racket and Clojure communities consist of programmers who
care about the entire ecosystem. The Racket community welcomes
and helps newcomers. I don't move in Clojure circles, but I
see and hear good things from people who do.
Clojure has made a bigger impact commercially, of course.
Offering a high level of performance and running on the JVM
have their advantages. I doubt either will ever displace Java
or the other commercial behemoths, but they appear to have
staying power. They earned that status by solving both
technical issues and social issues.
Today I received an email message similar to this:
I didn't do very well in my first semester, so I'm looking for ways
to do better this time around. Do you have any ideas about study
resources or tips for succeeding in CS courses?
As an advisor, I'm occasionally asked by students for advice of this
sort. As department head, I receive even more queries, because early
on I am the faculty member students know best, from campus visits
and orientation advising.
When such students have already attempted a CS course or two, my
first step is always to learn more about their situation. That way,
I can offer suggestions suited to their specific needs.
Sometimes, though, the request comes from a high school student, or
a high school student's parent: What is the best way to succeed as
a CS student?
To be honest, most of the advice I give is not specific to a computer
science major. At a first approximation, what it takes to succeed as
a CS student is the same as what it takes to succeed as a student in
any major: show up and do the work. But there are a few things a CS
student does that are discipline-specific, most of which involve the
tools we use.
I've decided to put together a list of suggestions that I can point
our students to, and to which I can refer occasionally in order to
refresh my mind.
My advice usually includes one or all of these suggestions, with a
focus on students at the beginning of our program:
Go to every class and every lab session. This is #0 because
it should go without saying, but sometimes saying it helps.
Students don't always have to go to their other courses every
day in order to succeed.
Work steadily on a course. Do a little work on your course,
both programming and reading or study, frequently -- every day,
if possible. This gives your brain a chance to see patterns
more often and learn more effectively. Cramming may help you
pass a test, but it doesn't usually help you learn how to
program or make software.
Ask your professor questions sooner rather than later. Send
email. Visit office hours. This way, you get answers sooner
and don't end up spinning your wheels while doing homework.
Even worse, feeling confused can lead you to shying away from
doing the work, which gets in the way of #1.
Get to know your programming environment. When programming in
Python, simply feeling comfortable with IDLE, and with the
file system where you store your programs and data, can make
everything else seem easier. Your mind doesn't have to look
up basic actions or worry about details, which enables you to
make the most of your programming time: working on the assigned
task.
Spend some of your study time with IDLE open. Even when you
aren't writing a program, the REPL can help you! It lets you
try out snippets of code from your reading, to see them work.
You can run small experiments of your own, to see whether you
understand syntax and operators correctly. You can make up
your own examples to fill in the gaps in your understanding
of the problem.
Getting used to trying things out in the interactions window
can be a huge asset. This is one of the touchstones of being
a successful CS student.
That's what came to mind at the end of a Friday, at the end of a
long week, when I sat down to give advice to one student. I'd love
to hear your suggestions for improving the suggestions in my list,
or other bits of advice that would help our students.
Email me
your ideas, and I'll make my list better for anyone who cares to
read it.
Someone on Mastodon posted a link to
a 2021 survey
of how the parsers for major languages are implemented. Are they
written by hand, or automated by a parser generator? The answer
was mixed: a few are generated by yacc-like tools (some of which
were custom built), but many are written by hand, often for speed.
My two favorite notes:
Julia's parser is handwritten but not in Julia. It's in Scheme!
Good for the Julia team. Scheme is a fine language in which to
write -- and maintain -- a parser.
Not only [is Clang's parser] handwritten but the same file handles
parsing C, Objective-C and C++.
I haven't clicked through to the source code for Clang yet but,
wow, that must be some file.
Finally, this closing comment in the paper hit close to the heart:
Although parser generators are still used in major language
implementations, maybe it's time for universities to start
teaching handwritten parsing?
I have persisted in having my compiler students write table-driven
parsers by hand for over fifteen years. As I noted in
this post at the beginning of the 2021 semester,
my course is compilers for everyone in our major, or potentially
so. Most of our students will not write another compiler in their
careers, and traditional skills like implementing recursive descent
and building a table-driven program are valuable to them more
generally than knowing yacc or bison. Any of my compiler students
who do eventually want to use a parser generator are well prepared
to learn how, and they'll understand what's going on when they do,
to boot.
My course is so old school that it's back to the forefront. I just
had to be patient.
(I posted the seeds of this entry
on Mastodon.
Feel free to comment there!)
Thoughts on Software and Teaching from Last Week's Reading
I'm trying to get back into the habit of writing here more regularly.
In the early days of my blog, I posted quick snippets every so often.
Here's a set to start 2023.
Funnily enough, traditional arch bridges
were built by first having a wood framing
on which to lay all the stones in a solid arch
(YouTube). That wood framing is called
falsework,
and is necessary until the arch is complete and can stand on its
own. Only then is the falsework taken away. Without it, no such
bridge would be left standing. That temporary structure, even if
no trace is left of it at the end, is nevertheless critical to
getting a functional bridge.
Programmers sometimes write a function or an object that helps them
build something else that they couldn't easily have built otherwise,
then delete the bridge code after they have written the code they
really wanted. A big step in the development of a student programmer
is when they do this for the first time, and feel in their bones why
it was necessary and good.
that treats breakage and repair as part of the history of an object,
rather than something to disguise.
I have this pattern around my home, at least on occasion. I often
repair my backpack, satchel, or clothing and leave evidence of the
repair visible. My family thinks it's odd, but figure it's just me.
Do I do this in code? I don't think so. I tend to like clean code,
with no distractions for future readers. The closest thing to
Kintsugi I can think of now are comments that mention where some bit
of code came from, especially if the current code is not intuitive
to me at the time. Perhaps my memory is failing me, though. I'll
be on the watch for this practice as I program.
• "It is good to watch the master."
I've been reading a rundown of the top 128 tennis players of the last
hundred years, including
this one about Pancho Gonzalez,
one of the great players of the 1940s, '50s, and '60s. He was forty
years old when the Open Era of tennis began in 1968, well past his
prime. Even so, he could still compete with the best players in the
game.
Even his opponents could appreciate the legend in their midst.
Denmark's Torben Ulrich lost to him in five sets at the 1969 US Open.
"Pancho gives great happiness," he said. "It is good to watch the
master."
The old masters give me great happiness, too. With any luck, I can
give a little happiness to my students now and then.
Living with AI in a World Where We Change the World to Accommodate Our Technologies
My social media feeds are full of ChatGPT screenshots and speculation
these days, as they have been with LLMs and DALL-E and other machine
learning-based tools for many months. People wonder what these tools
will mean for writers, students, teachers, artists, and anyone who
produces ordinary text, programs, and art.
These are natural concerns, given their effect on real people right
now. But if you consider the history of human technology, they miss
a bigger picture. Technologies often eliminate the need for a certain
form of human labor, but they just as often create a new form of human
labor. And sometimes, they increase the demand for the old kind of
labor! If we come to rely on LLMs to generate text for us, where will
we get the text with which to train them? Maybe we'll need people to
write even more replacement-level prose and code!
As Robin Sloan reminds us in the latest edition of his newsletter,
A Year of New Avenues,
we redesign the world to fit the technologies we create and adopt.
Likewise, here's a lesson from
my work making olive oil.
In most places, the olive harvest is mechanized, but that's only
possible because olive groves have been replanted to fit the shape
of the harvesting machines. A grove planted for machine harvesting
looks nothing like
a grove planted for human harvesting.
Which means that our attention should be on how programs like GPT-2
might lead us to redesign the world we live and work in better to
accommodate these new tools:
For me, the interesting questions sound more like
What new or expanded kinds of human labor might AI systems
demand?
How will the world now be reshaped to fit their needs?
That last question will, on the timescale of decades, turn out to
be the most consequential, by far. Think of cars ... and of how
dutifully humans have engineered a world just for them, at our own
great expense. What will be the equivalent, for AI, of the gas
station, the six-lane highway, the parking lot?
Many professors worry that ChatGPT makes their homework assignments
and grading rubrics obsolete, which is a natural concern in the
short run. I'm old enough that I may not live to work in a world
with the AI equivalent of the gas station, so maybe that world
seems too far in the future to be my main concern. But the really
interesting questions for us to ask now revolve around how tools
such as these will lead us to redesign our worlds to accommodate
and even serve them.
Perhaps, with a little thought and a little collaboration, we can
avoid engineering a world for them at our own great expense. How
might we benefit from the good things that our new AI technologies
can provide us while sidestepping some of the highest costs of, say,
the auto-centric world we built? Trying to answer that question is
a better long-term use of our time and energy that fretting about
our "Hello, world!" assignments and advertising copy.
In the essay "On Societies as Organisms", Lewis Thomas says that
we "violate science" when we try to read human meaning into the
structures and behaviors of insects. But it's hard not to:
Ants are so much like human beings as to be an embarrassment. They
farm fungi, raise aphids as livestock, launch armies into wars, use
chemical sprays to alarm and confuse enemies, capture slaves. The
families of weaver ants engage in child labor, holding their larvae
like shuttles to spin out the thread that sews the leaves together
for their fungus gardens. They exchange information ceaselessly.
They do everything but watch television.
I'm not sure if humans should be embarrassed for still imitating
some of the less savory behaviors of insects, or if ants should be
embarrassed for reflecting some of the less savory behaviors of
humans.
Biology has never been my forte, so I've read and learned less
about it than many other sciences. Enjoying chemistry a bit at
least helped keep me within range of the life sciences. I was
fortunate to grow up in the Digital Age.
But with many people thinking the 21st century will the Age of
Biology, I feel like I should get more in tune with the times. I
picked up Thomas's now classic The Lives of a Cell, in
which the quoted essay appears, as a brief foray into biological
thinking about the world. I'm only a few pages in, but it is
striking a chord. I can imagine so many parallels with computing
and software. Perhaps I can be as at home in the 21st century as
I was in the 20th.
Like so many people, I have been checking out new social media
options in the face of Twitter's upheaval. None are ideal,
but for now I have focused most of my attention on Mastodon,
a federation of servers implemented using the ActivityPub
protocol. Mastodon has an open API, which makes it attractive
to programmers. I've had an account there for a few years (I
like to grab username wallingf whenever a new service
comes out) but, like so many people, hadn't really used it.
Now feels more like the time.
On Friday, I spent a few minutes writing a small script that
posts to my Mastodon account from the command line. I
occasionally find that sort of thing useful, so the script has
practical value. Really, though, I just wanted to play a bit
in code and take a look at Mastodon's API.
Several people in my feed posted, boosted, and retweeted a
link to
this DEV Community article,
which walks readers through the process of posting a status
update using curl or Python. Everything worked exactly as
advertised, with one small change: the Developers link that
used to be in the bottom left corner of one's Mastodon home
page is now a Development link on the Preferences page.
I've read a lot in the last few weeks about how the culture
of Mastodon is different from the culture of Twitter. I'm
trying to take seriously the different culture. One concrete
example is the use of content warnings or spoiler alerts to
hide content behind a brief phrase or tag. This seems like
a really valuable practice, useful in a number of different
contexts. At the very least, it feels like the Subject: line
on an email message or a Usenet News post. So I looked up
how to post content warnings with my command-line script. It
was dead simple, all done in a few minutes.
There may be efficiency problems under the hood with how
Mastodon requests work, or so I've read. The public
interface seems well done, though.
I went with Python for my script, rather than curl. That
fits better with most my coding these days. It also makes
it easier to grow the script later, if I want. bash is
great for a few lines, but I don't like to live inside bash
for very long. On any code longer than a few lines, I want
to use a programming language. At a couple of dozen lines,
my script was already long enough to merit a real language.
I went mostly YAGNI this time around. There are no classes,
just a sequence of statements to build the http request from
some constants (server name, authorization token) and
command-line args (the post, the content warning). I did
factor the server name and authorization token out of the
longer strings and include an option to write the post via
stdin. I want the flexibility of writing longer toots now,
and I don't like magic constants. If I ever need to change
servers or tokens, I never have to look past the few first
few lines of the file.
As I briefly imagined morphing the small but growing script
into a Toot class, I recalled a project I gave my Intermediate
Computing students back in 2009 or so: implement the barebones
framework of a Twitter-like application. That felt cutting
edge back then, and most of the students really liked putting
their new OO design and programming skills to use in a program
that seemed to matter. It was good fun, and a great playground
for so many of the ideas they had learned that semester.
All in all, this was a great way to spend a few minutes on a
free afternoon. The API was simple to use, and the result is
a usable new command. I probably should've been grading or
doing some admin work, but profs need a break, too. I'm
thankful to enjoy little programming projects so much.
This weekend, I learned that Kathleen Booth, a British mathematician
and computer scientist, invented assembly language.
An October 29 obituary
reported that Booth died on September 29 at the age of 100. By 1950,
when she received her PhD in applied mathematics from the University
of London, she had already collaborated on building at least two
early digital computers. But her contributions weren't limited to
hardware:
As well as building the hardware for the first machines, she
wrote all the software for the ARC2 and SEC machines, in the
process inventing what she called "Contracted Notation" and
would later be known as assembly language.
Her 1958
book,
Programming for an Automatic Digital Calculator, may
have been the first one on programming written by a woman.
I love the phrase "Contracted Notation".
Thanks to several people in my Twitter feed for sharing this link.
Here's hoping that Twitter doesn't become uninhabitable, or that a
viable alternative arises; otherwise, I'm going to miss out on a
whole lotta learning.
I've been meaning to write a post about my fall compilers course since
the beginning of the semester but never managed to set aside time to
do anything more than jot down a few notes. Now we are at the end of
Week 9 and I just must write. Long-time readers know what motivates
me most: a fun program to write in my student's source language!
Yesterday, it wasn't a puzzle so much as discovering a new kind of
number,
Carmichael numbers.
Of course, I didn't discover them (neither did Carmichael, though);
I learned of them from
a Quanta article about a recent proof
about these numbers that masquerade as primes. One way of defining
this set comes from Korselt:
A positive composite integer n is a Carmichael number if and
only if it has multiple prime divisors, no prime divisor repeats, and
for each prime divisor p, p-1 divides n-1.
This definition is relatively straightforward, and I quickly imagined
am imperative solution with a loop and a list. The challenge of
writing a program to verify a number is a Carmichael number in my
compiler course's source language is that it has neither of these
things. It has no data structures or even local variables; only
basic integer and boolean arithmetic, if expressions, and
function calls.
Challenge accepted.
I've written many times over the years about the languages I ask my
students to write compilers for and about my adventures programming
in them, from
Twine last year
through
Flair a few years ago
to a recurring favorite, Klein, which features prominently in popular
posts about
Farey sequences
and
excellent numbers.
This year, I created a new language, Graphene, for my students. It is
essentially a small functional subset of Google's new language Carbon.
But like it's predecessors, it is something of an integer assembly
language, fully capable of working with statements about integers and
primes. Korselt's description of Carmichael numbers is right in
Graphene's sweet spot.
As I wrote in the post about Klein and excellent numbers, my standard
procedure in cases like this is to first write a reference program in
Python using only features available in Graphene. I must do this if
I hope to debug and test my algorithm, because we do not have a working
Graphene compiler yet! (I'm writing my compiler in parallel with my
students, which is one of the key subjects in my phantom unwritten
post.)
I was proud this time to write my reference program in a Graphene-like
subset of Python from scratch. Usually I write a Pythonic solution,
using loops and variables, as a way to think through the problem, and
then massage that code down to a program using a limited set of
concepts. This time, I started with short procedural outline:
# walk up the primes to n
# - find a prime divisor p:
# - test if a repeat (yes: fail)
# - test if p-1 divides n-1 (no : fail)
# return # prime divisors > 1
and then implemented it in a single recursive function.
The first few tests were promising. My algorithm rejected many small
numbers not in the set, and it correctly found 561, the smallest
Carmichael number. But when I tested all the numbers up to 561, I
saw many false positives. A little print-driven debugging found the
main bug: I was stopping too soon in my search for prime divisors, at
sqrt(n), due to some careless thinking about factors. Once I fixed
that, boom, the program correctly handled all n up to 3000.
I don't have a proof of correctness, but I'm confident the code is
correct. (Famous last words, I know.)
As I tested the code, it occurred to me that my students have a chance
to one-up standard Python. Its rather short standard stack depth
prevented my program from reaching even n=1000. When I set
sys.setrecursionlimit(5000), my program found the first five
Carmichael numbers: 561, 1105, 1729, 2465, and 2821. Next come 6601
and 8911; I'll need a lot more stack frames to get there.
All those stack frames are unnecessary, though. My main "looping"
function is beautifully tail recursive: two failure cases, the final
answer case checking the number of prime divisors, and two
tail-recursive calls that move either to the next prime as potential
factor or to the next quotient when we find one. If my students
implement proper tail calls -- an optimization that is optional in the
course but encouraged by their instructor with gusto -- then their
compiler will enable us to solve for values up to the maximum integer
in the language, 231-1. We'll be
limited only by the speed of the target language's VM, and the speed
of the target code the compiler generates. I'm pretty excited.
Now I have to resist the urge to regale my students with this entire
story, and with more details about how I approach programming in a
language like Graphene. I love to talk shop with students about
design and programming, but our time is limited... My students are
already plenty busy writing the compiler that I need to run my
program!
This lark resulted in an hour or so writing code in Python, a few more
minutes porting to Graphene, and an enjoyable hour writing this blog
post. As the song says, it was a good day.
From the closing pages from The Orchid Thief, which I
mentioned in
my previous post:
"The thing about computers," Laroche said, "the thing that I like
is that I'm immersed in it but it's not a living thing that's
going to leave or die or something. I like having the minimum
number of living things to worry about in my life."
Actually, I have two comments.
If Laroche had gotten into open source software, he might have found
himself with the opposite problem: software that won't die.
Programmers sometimes think, "I know, I'll design and implement my own
programming language!" Veterans of the programming languages community
always seem to advise: think twice. If you put something out there,
other people will use it, and now you are stuck maintaining a package
forever. The same can be said for open source software more generally.
Oh, and did I mention it would be really great if you added this feature?
I like having plants in my home and office. They give me joy every day.
They also tend to live a lot longer than some of my code. The hardy
orchid featured above bloomed like clockwork twice a year for me for
five and a half years. Eventually it needed more space than the pot in
my office could give, so it's gone now. But I'm glad to have enjoyed
it for all those years.
The Difference Between Medicine and Being a Doctor Is Like ...
Morgan Housel's recent piece on
experts trying too hard
includes a sentence that made me think of what I teach:
A doctor once told me the biggest thing they don't teach in medical school
is the difference between medicine and being a doctor — medicine is
a biological science, while being a doctor is often a social skill of
managing expectations, understanding the insurance system, communicating
effectively, and so on.
Most of the grads from our CS program go on to be software developers or
to work in software-adjacent jobs like database administrator or web
developer. Most of the rest work in system administration or networks.
Few go on to be academic computer scientists. As Housel's doctor knows
about medicine, there is a difference between academic computer science
and being a software developer.
The good news is, I think the CS profs at many schools are aware of this,
and the schools have developed computer science programs that at least
nod at the difference in their coursework. The CS program at my school
has a course on software engineering that is more practical than
theoretical, and another short course that teaches practical tools such
as version control, automated testing, and build tools, and skills such
as writing documentation. All of our CS majors complete a large project
course in which students work in teams to create a piece of software or
a secure system, and the practical task of working as a team to deliver
a piece of working software is a focus of the course. On top of those
courses, I think most of our profs try to keep their courses real for
students they know will want to apply what they learn in Algorithms, say,
or Artificial Intelligence in their jobs as developers.
Even so, there is always a tension in classes between building foundational
knowledge and building practical skills. I encounter this tension in both
Programming Languages and Translation of Programming Languages. There are
a lot of cool things we could learn about type theory, some of which might
turn out to be quite useful in a forty-year career as a developer. But
any time we devote to going deeper on type theory is time we can't devote
to the concrete languages skills of a software developer, such as learning
and creating APIs or the usability of programming languages.
So, we CS profs have to make design trade-offs in our courses as we try to
balance the forces of students learning computer science and students
becoming software developers. Fortunately, we learn a little bit about
recognizing, assessing, and making trade-offs in our work both as computer
scientists and as programmers. That doesn't make it easy, but at least we
have some experience for thinking about the challenge.
The sentence quoted above reminds me that other disciplines face a similar
challenge. Knowing computer science is different from being a software
developer, or sysadmin. Knowing medicine is different from being a doctor.
And, as Housel explains so well in his own work, knowing finance is
different from being an investor, which is usually more about psychology
and self-awareness than it is about net present value or alpha ratios.
(The current stock market is a rather harsh reminder of that.)
Thanks to Housel for the prompt. The main theme of his piece — that
experts makes mistakes that novices can't make, which leads to occasional
unexpected outcomes — is the topic for another post.
This past weekend, it was supposed to rain Saturday evening into Sunday,
so I woke up with uncertainty about my usual Sunday morning bike ride.
My exercise bike broke down a few weeks back, so riding outdoors was
my only option. I decided before I went to bed on Saturday night that,
if it was dry when I woke up, I would ride a couple of miles to a small
lake in town and ride laps in whatever time I could squeeze in between
rain showers.
The rain in the forecast turned out to be a false alarm, so I had more
time to ride than I had planned. I ended up riding the 2.3 miles to the
fifteen 1.2-mile laps, and 2.30 miles back home. Fifteen mile-plus laps
may seem crazy to you, but it was the quickest and most predictable
adjustment I could make in the face of the suddenly available time. It
was like a speed workout on the track from my running days. Though
shorter than my usual Sunday ride, it was an unexpected gift of exercise
on what turned out to be a beautiful morning.
A couple of laps into the ride, the hill on the far end of the loop began
to look look foreboding. Thirteen laps to go... Thirteen more times up
an extended incline (well, at least what passes for one in east central
Iowa).
After a few more laps, my mindset had changed. Six down. This feels
good. Let's do nine more!
I had found the rhythm of doing repeats.
I used to do track repeats when training for marathons and always liked
them. (One of my earliest blog entries sang the praises of
short iterations and frequent feedback
on the track.) I felt again the hit of endorphins every time I completed
one loop around the lake. My body got into the rhythm. Another one,
another one. My mind doesn't switch off under these conditions, but it
does shift into a different mode. I'm thinking, but only in the moment
of the current lap. Then there's one more to do.
I wonder if this is one of the reasons some programmers like programming
with stories of a limited size, or under the constraints of test-driven
design. Both provide opportunities for frequent feedback and frequent
learning. They also provide a hit of endorphins every time you make a
new test pass, or see the light go green after a small refactoring.
My willingness to do laps, at least in service of a higher goal, may
border on the unfathomable. One Sunday many years ago, when I was still
running, we had huge thunderstorms all morning and all afternoon. I was
in the middle of marathon training and needed a 20-miler that day to stay
on my program. So I went to the university gym -- the one mentioned in
the blog post linked above, with 9.2 laps to a mile -- and ran 184 laps.
"Are you nuts?" I loved it! The short iterations and frequent feedback
dropped me in to a fugue-like rhythm. It was easy to track my pace,
never running too fast or too slow. It was easy to make adjustments
when I noticed something off-plan. In between moments checking my time,
I watched people, I breathed, I cleared my mind. I ran. All things
considered, it was a good day.
Sunday morning's fifteen laps were workaday in comparison. At the end,
I wished I had more time to ride. I felt strong enough. Another five
laps would have been fun. That hill wasn't going to get me. And I liked
the rhythm.
Last month, I picked up a copy of The Writing Life by Annie
Dillard at the library. It's one of those books that everyone seems to
quote, and I had never read it. I was pleased to find it is a slim
volume.
It didn't take long to see one of the often-quoted passages, on the page
before the first chapter:
No one expects the days to be gods. -- Emerson
Then, about a third of the way in, came the sentences for which everyone
knows Dillard:
How we spend our days is, of course, how we spend our lives.
What we do with this hour, and that one, is what we are doing.
Dillard's portrayal of the writing life describes some of the mystery
that we non-writers imagine, but mostly it depicts the ordinariness of
daily grind and the extended focus that looks like obsession to those
of us on the outside.
Occasionally, her stories touched on my experience as a writer of
programs. Consider this paragraph:
Every year the aspiring photographer brought a stack of his best prints
to an old, honored photographer, seeking his judgment. Every year the
old man studied the prints and painstakingly ordered them into two
piles, bad and good. Every year that man moved a certain landscape
print into the bad stack. At length he turned to the young man: "You
submit this same landscape every year, and every year I put it on the
bad stack. Why do you like it so much?" The young photographer said,
"Because I had to climb a mountain to get it."
I have written that code. I bang my head against some problem for days
or weeks. Eventually, I find a solution. Sometimes it's homely code
that gets the job; usually it seems more elegant than it is, in relief
against the work that went into discovering it. Over time, I realize
that I need to change it, or delete it altogether, in order to make
progress on the system in which it resides. But... the mountain.
It's a freeing moment when I get over the fixation and make the change
the code needs. I'll always have the mountain, but my program needs
to move in a different direction.
I recently ran across an old post by
@joepolitz,
Beginner REPL Stumbles,
that records some of the ways he has observed students struggle as they
learn to use IDEs with REPLs and files. As I mentioned
on Twitter,
it struck a chord with me even though I don't teach beginning programmers
much these days. My tweets led to a short conversation that I'd like
to record, and slightly expoand on, here.
I've noticed the first of the struggles in my junior-level Programming
Languages class: students not knowing, or not taking seriously enough,
the value of ctrl-up to replay and edit a previous interaction. If
students cannot work effectively in the REPL, they will resort to typing
all of their code in the definitions pane and repeatedly re-running it.
This programming style misses out on the immense value of the REPL as a
place to evolve code rapidly, with continual feedback, on the way to
becoming a program.
As recommended in the post, I now demonstrate ctrl-up early in the
course and note whenever I use it in a demo. If a student finds that
their keyboard maps ctrl-up to another behavior, I show them how to
define a shortcut in Preferences. This simple affordance can have an
inordinate effect on the student's programming experience.
The other observations that Politz describes may be true for my students,
too, and I just don't see them. My students are juniors and seniors who
already have a year of experience in Python and perhaps a semester using
Java. We aren't in the lab together regularly. I usually hear about
their struggles with content when they ask questions, and when they do,
they don't usually ask about process or tools. Sometimes, they will
demo some interaction for me and I'll get to see an unexpected behavior
in usage and help them, but that's rare.
(I do recall a student coming into my office once a few years ago and
opening up a source file -- in Word. They said they had never gotten
comfortable with Dr. Racket and that Word helped them make progress
typing and editing code faster. We talked about ways to learn and
practice Dr. Racket, but I don't think they ever switched.)
Having read about some of the usage patterns that Politz reports, I
think I need to find ways to detect misunderstandings and difficulties
with tools sooner. The REPL, and the ability to evolve code from
interactions in the REPL into programs in the definitions pane, are
powerful tools -- if one groks them and learns to use them
effectively. As Politz notes, direct instruction is a necessary
antidote to address these struggles. Direct instruction up front may
also help my students get off to a better start with the tools.
There is so much room for improvement hidden inside assumptions that
are baked into our current tools and languages. Observing learners
can expose things we never think about, if we pay attention. I wonder
what else I have been missing...
Fortunately, both Joe Politz and Shriram Krishnamurthi encountered my
tweets. Krishnamurthi provided
helpful context,
noting that the PLT Scheme team noticed many of these issues in the
early days of Dr. Scheme. They noticed others while running teacher
training sessions for
@Bootstrapworld.
In both cases, instructors were in the lab with learners while they used
the tools. In the crush to fix more pressing problems, the interaction
issues went unaddressed. In my experience, they are also subtle and
hard to appreciate fully without repeated exposure.
Politz provided a link to
a workshop paper
on Repartee, a tool that explicitly integrates interactive programming
and whole-program editing. Very cool. As Krishnamurthi
noted
to close the conversation, Repartee demonstrates that we may be able to
do better than simply teach students to use a REPL more effectively.
Perhaps we can make better tools.
I've been learning a lot about CS education research the last few years.
It is so much more than the sort of surface-level observations and
uncontrolled experiments I saw, and made, at the beginning of my career.
This kind of research demands a more serious commitment to science but
offers the potential of real improvement in return for the effort. I'm
glad to know CS ed researchers are making that commitment. I hope to
help where I can.
Knowing Context Gives You Power, Both To Choose And To Make
We are at the point in my programming languages course where my
students have learned a little Racket, a little functional
programming, and a little recursive programming over inductive
datatypes. Even though I've been able to connect many of the
ideas we've studied to programming tasks out in the world that
they care about themselves, a couple of students have asked,
"Why are we doing this again?"
This is a natural question, and one I'm asked every time I teach
this course. My students think that they will be heading out
into the world to build software in Java or Python or C, and
the ideas we've seen thus far seem pretty far removed from the
world they think they will live in.
These paragraphs from
near the end
of Chelsea Troy's 3-part essay on API design do a nice job of
capturing one part of the answer I give my students:
This is just one example to make a broader point: it is worthwhile
for us as technologists to cultivate knowledge of the context
surrounding our tools so we can make informed decisions about when
and how to use them. In this case, we've managed to break down
some web request protocols and build their pieces back up into a
hybrid version that suits our needs.
When we understand where technology comes from, we can more
effectively engage with its strengths, limitations, and use cases.
We can also pick and choose the elements from that technology that
we would like to carry into the solutions we build today.
The languages we use were designed and developed in a particular
context. Knowing that context gives us multiple powers. One
power is the ability to make informed decisions about the
languages -- and language features -- we choose in any given
situation. Another is the ability to make new languages, new
features, and new combinations of features that solve the problem
we face today in the way that works best in our current context.
Not knowing context limits us to our own experience. Troy does
a wonderful job of demonstrating this using the history of web
API practice. I hope my course can help students choose tools
and write code more effectively when they encounter new languages
and programming styles.
Computing changes. My students don't really know what world they
will be working in in five years, or ten, or thirty. Context is
a meta-tool that will serve them well.
It's been a while since I read a non-technical article and made as many
notes as I did this morning on
this Paris Review interview with Billy Collins.
Collins was poet laureate of the U.S. in the early 2000s. I recall
reading his collection, Sailing Alone Around the Room, at PLoP
in 2002 or 2003. Walking the grounds at Allerton with a poem in your
mind changes one's eyes and hears. Had I been blogging by then, I
probably would have commented on the experience, and maybe one or two
of the poems, in a post.
As I read this interview, I encountered a dozen or so passages that made
me think about things I do, things I've thought, and even things I've
never thought. Here are a few.
I'd like to get something straightened out at the beginning: I write
with a Uni-Ball Onyx Micropoint on nine-by-seven bound notebooks made
by a Canadian company called Blueline. After I do a few drafts, I type
up the poem on a Macintosh G3 and then send it out the door.
Uni-Ball Micropoint pens are my preferred writing implement as well,
though I don't write enough on paper any more to make buying a
particular pen much worth the effort. Unfortunately, just yesterday
my last Uni-Ball Micro wrote its last line. Will I order more? It's
a race between preference and sloth.
I type up most of the things I write these days on a 2015-era MacBook
Pro, often connected to a Magic Keyboard. With the advent of the M1
MacBook Pros, I'm tempted to buy a new laptop, but this one serves me
so well... I am nothing if not loyal.
The pen is an instrument of discovery rather than just a recording
implement. If you write a letter of resignation or something with
an agenda, you're simply using a pen to record what you have thought
out. In a poem, the pen is more like a flashlight, a Geiger counter,
or one of those metal detectors that people walk around beaches with.
You're trying to discover something that you don't know exists, maybe
something of value.
Programming may be like writing in many ways, but the search for
something to say isn't usually one of them. Most of us sit down to
write a program to do something, not to discover some
unexpected outcome. However, while I may know what my program will
do when I get done, I don't always know what that program will look
like, or how it will accomplish its task. This state of uncertainty
probably accounts for my preference in programming languages over the
years. Smalltalk, Ruby, and Racket have always felt more like
flashlights or Geiger counters than tape recorders. They help me find
the program I need more readily than Java or C or Python.
I love William Matthews's idea--he says that revision is not cleaning up
after the party; revision is the party!
Refactoring is not cleaning up after the party; refactoring is
the party! Yes.
... nothing precedes a poem but silence, and nothing follows a poem
but silence. A poem is an interruption of silence, whereas prose is
a continuation of noise.
I don't know why this passage grabbed me. Perhaps it's just the imagery
of the phrases "interruption of silence" and "continuation of noise". I
won't be surprised if my subconscious connects this to programming
somehow, but I ought to be suspicious of the imposition. Our brains love
to make connections.
She's this girl in high school who broke my heart, and I'm hoping
that she'll read my poems one day and feel bad about what she did.
This is the sort of sentence I'm a sucker for, but it has no real
connection to my life. Though high school was a weird and wonderful
time for me, as it was for so many, I don't think anything I've ever
done since has been motivated in this way. Collins actually goes on
to say the same thing about his own work. Readers are people with
no vested interest. We have to engage them.
Another example of that is my interest in bridge columns. I don't
play bridge. I have no idea how to play bridge, but I always read
Alan Truscott's bridge column in the Times. I advise
students to do the same unless, of course, they play bridge. You
find language like, South won with dummy's ace, cashed the club
ace and ruffed a diamond. There's always drama to it: Her thirteen
imps failed by a trick. There's obviously lots at stake, but I
have no idea what he's talking about. It's pure language. It's a
jargon I'm exterior to, and I love reading it because I don't know
what the context is, and I'm just enjoying the language and the
drama, almost like when you hear two people arguing through a wall,
and the wall is thick enough so you can't make out what they're
saying, though you can follow the tone.
I feel seen. Back when we took the local daily paper, I always read
the bridge column by Charles Goren, which ran on the page with the
crossword, crypto cipher, and other puzzles. I've never played
bridge; most of what I know about the game comes from reading Matthew
Ginsberg's papers about building AI programs to bid and play. Like
Collins, I think I was merely enjoying sound of the language, a jargon
that sounds serious and silly at the same time.
Yeats summarizes this whole thing in "Adam's Curse" when he writes:
"A line will take us hours maybe, / Yet if it does not seem a
moment's thought / Our stitching and unstitching has been naught."
I'm not a poet, and my unit of writing is rarely the line, but I know
a feeling something like this in writing lecture notes for my students.
Most of the worst writing consists of paragraphs and sections I have
not spent enough time on. Most of the best sounds natural, a clean
distillation of deep understanding. But those paragraphs and sections
are the result of years of evolution. That's the time scale on which
some of my courses grow, because no course ever gets my full attention
in any semester.
When I finish a set of notes, I usually feel like the stitching and
unstitching have not yet reached their desired end. Some of the text
"seems a moment's thought", but much is still uneven or awkward.
Whatever the state of the notes, though, I have move on to the next
task: grading a homework assignment, preparing the next class session,
or -- worst of all -- performing the administrivia that props up the
modern university. More evolution awaits.
~~~~
This was a good read for a Sunday morning on the exercise bike, well
recommended. The line on revision alone was worth the time; I expect
it will be a stock tool in my arsenal for years to come.
My recent post
on what language or tool I should dive into next got
some engagement on Twitter,
with many helpful suggestions. Thank you all! So I figure I should post
a quick update to report what I'm thinking at this point.
In that post, I mentioned JavaScript and Pharo by name, though I was open
to other ideas. Many folks pointed out the practical value of
JavaScript, especially in a context where many of my students know and
use it. Others offered lots of good ideas in the Smalltalk vein, both
Pharo and several lighter-weight Squeaks. A couple of folks recommended
Glamorous Toolkit (GToolkit), from
@feenkcom,
which I had not heard of before.
I took to mind several of the suggestions that commenters made about the
how to think about making the decision. For example, there is more
overhead to studying Pharo and GToolkit than JavaScript or one of the
lighter-weight Squeaks. Choosing one of the latter would make it
easier to tinker. I think some of these comments had students in mind,
but they are true even for my own study during the academic semester.
Once I get into a term (my course begins one week from today), my
attention gets pulled in many directions for fifteen or sixteen weeks.
Being able to quickly switch contexts when jumping into a coding session
means that I can jump more often and more productively.
Also, as
Glenn Vanderburg pointed out,
JavaScript and Pharo aren't likely to teach me much new. I have a lot
of background with Smalltalk and, in many ways, JavaScript is just
another language. The main benefit of working with either would be
practical, not educational.
GToolkit might teach me something, though. As I looked into GToolkit,
it became more tempting. The code is Smalltalk, because it is
implemented in Pharo. But the project has a more ambitious vision of
software that is "moldable": easier to understand, easier to figure out.
GToolkit builds on Smalltalk's image in the direction of a computational
notebook, which is an idea I've long wanted to explore. (I feel a
little guilty that I haven't look more into the work that
David Schmüdde
has done developing a notebook in Clojure.)
GToolkit sounds like a great way for me to open several doors at once
and learn something new. To do it justice, though, I need more time
and focus to get started.
So I have decided on a two-pronged approach. I will explore JavaScript
during the spring semester. This will teach me more about a language
and ecosystem that are central to many of my students' lives. There is
little overhead to picking it up and playing with it, even during the
busiest weeks of the term. I can have a little fun and maybe make some
connections to my programming languages course along the way. Then for
summer, I will turn my attention to GToolkit, and perhaps a bigger
research agenda.
I started playing with JavaScript on Tuesday. Having just read
a blog post
on scripting to compute letter frequencies in Perl, I implemented some
of the same ideas in JavaScript. For the most part, I worked just as
my students do: relying on vague memories of syntax and semantics and,
when that failed, searching about for examples online.
A couple of hours working like this refreshed my memory on the syntax I
knew from before and introduced me to some features that were new to me.
It took a few minutes to re-internalize the need for those pesky
semicolons at the end of every line...
The resulting code is not much more verbose than Perl. I drifted pretty
naturally to using functional programming style, as you might imagine,
and it felt reasonably comfortable. Pretty soon I was thinking more
about the tradeoff between clarity and efficiency in my code than about
syntax, which is a good sign. I did run into one of JavaScript's gotchas:
I used for...in twice instead of for...of and was
surprised by the resulting behavior. Like any programmer, I banged my
head on wall for a few minutes and then recovered. But I have to admit
that I had fun. I like to program.
I'm not sure what I will write next, or when I will move into the
browser and play with interface elements. Suggestions are welcome!
I am pretty sure, though, that I'll start writing unit tests soon.
I used SUnit briefly and have a lot of experience with JUnit. Is
JSUnit a thing?
I've never been one to write year-end retrospectives on my blog, or
prospective posts about my plans for the new year. That won't change
this year, this post notwithstanding.
I will say that 2021 was a weird year for me, as it was for many people.
One positive was purchasing a 29" ultra-wide monitor for work at home,
seen in
this post from my Strange Loop series.
Programming at home has been more fun since the purchase, as have been
lecture prep, data-focused online meetings, and just about everything.
The only downside is that it's in my basement office, which hides me
away. When I want to work upstairs to be with family, it's back to
the 15" laptop screen. First-world problems.
Looking forward, I'm feeling a little itchy. I'll be teaching
programming languages again this spring and plan to inject some new
ideas, but the real itch is: I am looking for a new project to work
on, and a new language to study. This doesn't have to be a new
language, just one that one I haven't gone deep on before. I have
considered a few, including Swift, but right now I am thinking of
Pharo and JavaScript.
Thinking about mastering JavaScript in 2022 feels like going backward.
It's old, as programming languages go, and has been a dominant force
in the computing world for well over a decade. But it's also the most
common language many of my students know that I have never gone deep
on. There is great value in studying languages for their novel ideas
and academic interest, but there is also value in having expertise
with a language and toolchain that my students already care about.
Besides, I've really enjoyed reading about work on JIT compilation of
JavaScript over the years, and it's been a long time since I wrote
code in a prototype-based OO language. Maybe it's time to build
something useful in JavaScript.
Studying
Pharo
would be going backward for me in a different way. Smalltalk always
beckons. Long-time followers of this blog have read many posts about
my formative experiences with Smalltalk. But it has been twenty years
since I lived in an image every day. Pharo is a modern Smalltalk with
a big class library and a goal of being suitable for mission-critical
systems. I don't need much of a tug; Smalltalk always beckons.
My current quandary brings to mind a dinner at a Dagstuhl seminar in
the summer of 2019 (*). It's been a while now, so I hope my memory
doesn't fail me too badly. Mark Guzdial was talking about a Pharo
MOOC he had recently completed and how he was thinking of using the
language to implement a piece of software for his new research group
at Michigan, or perhaps a class he was teaching in the fall. If I
recall correctly, he was torn between using Pharo and... JavaScript.
He laid out some of the pros and cons of each, with JavaScript winning
out on several pragmatic criteria, but his heart was clearly with
Pharo. Shriram Krishnamurthi gently encouraged Mark to follow his
heart: programming should be joyful, and programming languages allow
us to build in languages that give us enjoyment. I seconded the
(e)motion.
And here I sit mulling a similar choice.
Maybe I can make this a two-language year.
~~~~~
(*) Argh! I never properly blogged about about
this seminar,
on the interplay between notional machines and programming language
semantics, or the experience of visiting Europe for the first time.
I did write
one post
that mentioned Dagstuhl, Paris, and Montenegro, with an expressed
hope to write more. Anything I write now will be filtered through
two and a half years of fuzzy memory, but it may be worth the time
to get it down in writing before it's too late to remember anything
useful. In the meantime: both the seminar and the vacation were
wonderful! If you are ever invited to participate in a Dagstuhl
seminar, consider accepting.
An Experience Rewriting a Piece of Code as as Teaching Tool
Over the last four or five offerings of my compiler course, I have
been making progress in how I teach code generation, with teams
becoming increasingly successful at producing a working code
generator. In the 2019 offering, students asked a few new questions
about some low-level mechanical issues in the run-time system. So I
whipped up a simple one the night before class, both to refamiliarize
myself with the issues and to serve as a potential example. It was
not a great piece of software, but it was good enough for a quick
in-class demo and as a seed for discussion.
Jump ahead to 2021. As I mentioned in
my previous post,
this fall's group had a lot more questions about assembly language,
the run-time stack, activation records, and the like. When I pulled
out my demo run-time system from last time, I found that it didn't
help them as much as it had the previous group. The messiness of the
code got in the way. Students couldn't see the bigger picture from
the explanatory comments, and the code itself seemed opaque to them.
Working with a couple of students in particular, I began to refine the
code. First, I commented the higher-level structure of generator more
clearly. I then used those comments to reorganize the code bit, with
the goal of improving the instructional presentation rather than the
code's efficiency or compactness. I chose to leave some comments in
rather than to factor out functions, because the students found the
linear presentation easier to follow.
Finally, I refined some sections of the code and rewrote others
entirely, to make them clearer. At this point, I did extract a helper
function or two in an attempty not to obscure the story the program
was telling with low-level details.
I worked through two iterations of this process: comment, reorganize,
rewrite. At the end, I had a piece of code that is pretty good, and
one that is on the student's path to a full code generator.
Of course, I could have designed my software up front and proceeded
more carefully as I wrote this code. I mean, professionals and
academics understand compiler construction pretty well. The result
might well have been a better example of what the run-time generator
should look like when students are done.
But I don't think that would have been as helpful to most members of
my class. This process was much more like how my students program,
and how many of us program, frankly, when we are first learning a
new domain. Following this process, and working in direct response
to questions students had as we discussed the code, gave me insights
into some of the challenges they encounter in my course, including
tracking register usage and seeing how the calling and return sequences
interact. I teach these ideas in class, but my students were seeing
that material as too abstract. They couldn't make the leap to code
quite as easily as I had hoped; they were working concretely from the
start.
In the end, I ended up with both a piece of code I like and a better
handle on how my students approach the compiler project. In terms of
outcomes assessment, this experience gives me some concrete ideas for
improving the prerequisite courses students take before my course,
such as computer organization. More immediately, it helps me improve
the instruction in my own course. I have some ideas about how I can
reorganize my code generator units and how I might simplify some of
my pedagogical material. This may lead to a bigger redesign of the
course in a coming semester.
I must admit: I had a lot of fun writing this code -- and revising
and improving it! One bit of good news from the experience is that
the advice I give in class is pretty good. If they follow my practical
suggestions for writing their code, they can be successful. What
needs improvement now is finding ways for students to have the relevant
bits of advice at hand when they need them. Concrete advice that
gets separated from concrete practice tends to get lost in the wind.
Finally, this experience reminded me first hand that the compiler
project is indeed a challenge. It's fun, but it's a challenge,
especially for undergrads attempting to write their first large piece
of software as part of a team. There may be ways I can better help
them to succeed.
Well, fall semester really got away from me quickly. It seems not long
ago that I wrote of
launching the course
with a renewed mindset of "compilers for the masses, not compilers for
compiler people". I'm not sure how well that went this time, as many
students came into the course with less understanding of the underlying
machine model and assembly language than ever before. As a result, many
of them ended up stressing over low-level implementation details while
shoring up that knowledge than thinking about some of the higher-level
software engineering ideas. I spent more time this semester working
with more teams to help them understand parsing rules, semantic actions,
and activation records than in anytime I can remember.
I suspect that the students' programming maturity and state of knowledge
at the start of the course are in large part a result of experiencing
the previous two and a half semesters under the damper of the pandemic.
Some classes were online, others were hybrid, and all were affected by
mitigation efforts, doubt, and stress. Students and professors alike
faced these effects, me included, and while everyone has been doing
the best they could under the circumstances, sometimes the best we can
do comes up a little short.
At the beginning of the course, I wrote about
a particular uncertainty
raised by the preceding pandemic semesters: how isolation and the
interruption of regular life had reduced the chances for students to
make friends in the major and to build up personal and professional
connections with their classmates. I underestimated, I think, the
effect that the previous year and a half would have on learning outcomes
in our courses.
The effect on project teams themselves turned out to be a mixed bag.
Three of the five teams worked pretty well together, even if one of the
teammates was unable to contribute equally to the project. That's
pretty typical. Two other teams encountered more serious difficulties
working together effectively. Difficulties derailed one project that
got off to an outstanding start, and the second ended up being a
one-person show (a very impressive one-person show, in fact). In
retrospect, many of these challenges can be traced back to problems some
students had with content: they found themselves falling farther behind
their teammates and responded by withdrawing from group work. The result
is a bad experience for those still plugging along.
That's perhaps too many words about the difficulties. Several teams
seemed to have pretty typical experiences working one another, even
though they didn't really know each other before working together.
The combination of some students struggling with course content and
some struggling with collaboration led to mixed bag of results. Two
teams produced working compilers that handled essentially all language
features correctly, or nearly so. That's pretty typical for a five-team
semester. One team produced an incomplete system, but one they could be
proud of after working pretty hard the entire semester. That's typical,
too.
Two teams produced systems without code generators beyond a rudimentary
run-time system. That's a bit unusual. These teams were disappointed
because they had set much higher goals for themselves. Many of these
students were taking heavy course and research loads and, unfortunately,
all that work eventually overwhelmed them. I think I felt as bad for
them as they did, knowing what they might have accomplished with a more
forgiving schedule. I do hope they found some value in the course and
will be able to look back on the experience as worthwhile. They learned
a lot about working on a big project, and perhaps about themselves.
What about me? A few weeks into the course, I declared that I was
programming like a student again,
trying to implement the full compiler project I set before my students.
Like many of my students, I accomplished some of my goals and fell
short when outside obstacles got in the way. One the front end, my
scanner is in great shape, while my parser is correct but in need of
some refactoring. At that point in the semester, I got busy both with
department duties and with working one on one with the teams, and my
productivity dropped off.
I did implement a solid run-time system, one I am rather happy with. My
work on it came directly out of answering students' questions about code
generation and working with them to investigate and debug their programs.
I'll have more to say about my run-time system in the next post.
So, my latest compiler course is in the books. All in all, my students
and I did about as well as we could under the circumstances. There is
still great magic in watching a team's compiler generate an executable,
then running that executable on an input that produces tens of thousands
of activation records and executes several million lines of assembly.
The best we can do is often quite good enough.
In other words, the high level thinking is the difference between
a task being possible and impossible, but the microskills are the
difference between a task being 20 minutes and six hours. That's
why it can take us days to find the right one-liner.
Some students love to program and look for every opportunity to
write code. These students develop a satchelful of microskills,
usually far behind what we could every teach them or expose them
to in class. They tend to do fine on the programming assignments
we give in class.
Other students complain that a programming assignment I gave them,
intended as a one-hour practice session, took them eight or ten
hours. My first reaction is usually to encourage them never to
spin their wheels that long without asking me a question. I want
them to develop grit, but usually that kind of wheel spinning is a
sign that they may be missing a key idea or piece of information.
I'd like to help them get moving sooner.
There is another reason, though, that many of these students spin
their wheels. For a variety of reasons, they program only when
they are required by a class. They are ambivalent about programming,
either because they don't find it as interesting as their peers or
because they don't enjoy the grind of working in the trenches yet.
I say "yet" because one of the ways we all come to enjoy the grind
is... to grind away! That's how we develop the microskills Hillel
is talking about, which turn a six-hour task into a 20-minute task,
or a disappointing one-hour experience with a homework problem into
a five-minute joy.
Students who have yet to experience the power of microskills are
prone to underestimate their value. That makes it less enjoyable
to practice programming, which makes it hard to develop new skills.
It's a self-reinforcing loop, and not the kind we want to encourage
in our students.
Even after all these years in the classroom, I still struggle to find
ways to help my students practice programming skills in a steady,
reliable way. Designing engaging problems to work on helps. So does
letting students choose the problems they work on, which works better
in some courses than others. Ultimately, though, I think what works
best is to develop as much of a personal relationship with each
student as possible. This creates a condition in which they are more
inclined to ask for help when they need it and to trust suggestions
from that sound a little crazy to the beginner's mind.
I am teaching my compiler development course this semester, which
means that I am working with students near the end of their time with
us, whose habits are deeply ingrained from previous courses. The
ones who don't already possess a few of the microskills they need are
struggling as the task of writing a parser or semantic checker or
code generator stretches out like an endless desert before them.
Next semester, I teach my programming languages course and have the
joy of introducing my students to Racket and functional programming.
This essay me already thinking of how I can help my students
develop some of the microskills they will want and need in the
course and beyond. Perhaps a more explicit focus early on the use
Dr. Racket to create, run, test, and debug code can set them up for
a more enjoyable experience later in the course -- and help put them
on a virtuous self-reinforcing loop developing skills and using them
to enjoy the next bit of learning they do.
A couple of weeks back, I saw an article in which Malcom Gladwell noted
that he did not know The Triggering Town, a slim book of essays
by poet Richard Hugo. I was fortunate to hear about Hugo many years ago
from software guru Richard Gabriel, who is also a working poet. It had
been fifteen years or more since I'd read The Triggering Town,
so I stopped into the library on my way home one day and picked it up.
I enjoyed it the second time around as much as the first.
I frequently make notes of passages to save. Here are five from this
reading.
Actually, the hard work you do on one poem is put in on all poems.
The hard work on the first poem is responsible for the sudden ease
of the second. If you just sit around waiting for the easy ones,
nothing will come. Get to work.
That advice works for budding software developers, too.
Emotional honesty is a rare thing in the academic world or anywhere
else for that matter, and nothing is more prized by good students.
Emotion plays a much smaller role in programming than in writing
poetry. Teaching, though, is deeply personal, even in a technical
discipline. All students value emotional honesty, and profs who
struggle to be open usually struggle making connections to their
students.
Side note: Teachers, like policemen, firemen, and service personnel,
should be able to retire after twenty years with full pension. Our
risks may be different, but they are real. In twenty years most
teachers have given their best.
This is a teacher speaking, so take the recommendation with caution.
But more than twenty years into this game, I know exactly what Hugo
means.
Whatever, by now, I was old enough to know explanations are usually
wrong. We never quite understand and we can't quite explain.
Yet we keep trying. Humans are an optimistic animal, which is one
of the reasons we find them so endearing.
... at least for me, what does turn me on lies in a region of myself
that could not be changed by the nature of my employment. But it
seems important (to me even gratifying) that the same region lies
untouched and unchanged in a lot of people, and in my innocent way
I wonder if it is reason for hope. Hope for what? I don't know.
Maybe hope that humanity will always survive civilization.
This paragraph comes on the last page of the book and expresses
one of the core tenets of Hugo's view of poetry and poets. He
fought in World War 2 as a young man, then worked in a Boeing
factory for 15-20 years, and then became an English professor at
a university. No matter the day job, he was always a poet. I
have never been a poet, but I know quite well the region of which
he speaks.
Also: I love the sentence, "Maybe hope that humanity will always
survive civilization."
I am usually tired on the second day of a conference, and today was
no exception. But the day started and ended with talks that kept
my brain alive.
• "Poems in an Accidental Language" by Kate Compton -- Okay,
so that was a Strange Loop keynote. When the video goes
live on YouTube, watch it. I may blog more about the talk later,
but for now know only that it included:
"Evenings of Recreational Ontology" (I also learned about Google
Sheet parties)
"fitting an octopus into an ontology"
"Contemplate the universe, and write an API for it."
Like I said, go watch this talk!
• Quantum computing is one of those technical areas I know
very little about, maybe the equivalent of a 30-minute pitch talk.
I've never been super-interested, but some of my students are. So
I attended "Practical Quantum Computing Today" to see what's up
these days. I'm still not interested in putting much of my time
into quantum computing, but now I'm better informed.
• Before my lunch walk, I attended a non-technical talk on
"tech-enabled crisis response". Emma Ferguson and Colin Schimmelfing
reported on their experience doing something I'd like to be able to
do: spin up a short-lived project to meet a critical need, using
mostly free or open-source tools. For three months early in the
COVID pandemic, their project helped deliver ~950,000 protective
masks from 7,000 donors to 6,000 healthcare workers. They didn't
invent new tech; they used existing tools and occasionally wrote
some code to connect such tools.
My favorite quote from the talk came when Ferguson related the team's
realization that they had grown too big for the default limits on
Google Sheets and Gmail. "We thought, 'Let's just pay Google.' We
tried. We tried. But we couldn't figure it out." So they
built their own tool. It is good to be a programmer.
• After lunch, Will Crichton live-coded a simple API in Rust,
using traits (Rust's version of interfaces) and aggressive types.
He delivered almost his entire talk within emacs, including an
ASCII art opening slide. It almost felt like I was back in grad
school!
• In "Remote Workstations for Discerning Artists", Michelle
Brenner from Netflix described the company's cloud-based
infrastructure for the workstations used by the company's artists
and project managers. This is one of those areas that is simply
outside my experience, so I learned a bit. At the top level,
though, the story is familiar: the scale of Netflix's goals
requires enabling artists to work wherever they are, whenever they
are; the pandemic accelerated a process that was already underway.
• Eric Gade gave another talk in the long tradition of Alan
Kay and a bigger vision for computing. "Authorship Environments:
In Search of the 'Personal' in Personal Computing" started by
deconstructing Steve Jobs's "bicycle for the mind" metaphor (he's
not a fan of what most people take as the meaning) and then moved
onto the idea of personal computing as literacy: a new level at
which to interrogate ideas, including one's own.
This talk included several inspirational quotes. My favorite was
was from Adele Goldberg:
There's all these layers in everything we do...
We have to learn how to peel.
As with most talks in this genre, I left feeling like there is so
much more to be done, but frustrated at not knowing how to do it.
We still haven't found a way to reach a wide audience with the
empowering idea that there is more to computing than typing into
a Google doc or clicking in a web browser.
• The closing keynote was delivered by Will Byrd. "Strange
Dreams of Stranger Loops" took Douglas Hofstadter's Gödel,
Escher, Bach as its inspiration, fitting both for the conference
and for Byrd's longstanding explorations of relational programming.
His focus today: generating quines in
mini-Kanren,
and discussing how quines enable us to think about programs,
interpreters, and the strange loops at the heart of GEB.
As with the opening keynote I may blog more about this talk later.
For now I give you two fun items:
Byrd expressed his thanks to D((a(d|n))oug), a regular
expression that matches on Byrd (his father), Friedman (his
academic mentor), and Hofstadter (his intellectual inspiration).
While preparing his keynote, Byrd clains to have suffered from
UDIS: Unintended Doug Intimidation Syndrome. Hofstader is so
cultured, so well-read, and so deep a thinker, how can the rest
of us hope to contribute?
Rest assured: Byrd delivered. A great talk, as always.
Strange Loop 2021 has ended. I "hit the road" by walking upstairs
to make dinner with my wife.
For the first time in many years, I got the urge this fall to
implement the compiler project I set before my students.
I've written here about this course many times over the years.
It serves students interested in programming languages and
compilers as well as students looking for a big project course
and students looking for a major elective. Students implement
a compiler for a small language by hand in teams of 2-5,
depending on the source language and the particular group of
people in the course.
Having written small compilers like this many times, I don't
always implement the entire project each offering. That would
not be a wise use of my time most semesters. Instead, when
something comes up in class, I will whip up a quick scanner or
type checker or whatever so that we can explore an idea. In
recent years, the bits I've written have tended to be on the
backend, where I have more room to learn.
But this fall, I felt the tug to go all in.
I created a new source language for the class this summer, which
I call Twine. Much of its concrete syntax was inspired by
SISAL,
a general-purpose, single-assignment functional language with
implicit parallelism and efficient array handling. SISAL was
designed in the mid-1980s to be a high-level language for large
numerical programs, to be run on a variety of multiprocessors.
With advances in multiprocessors and parallel processors, SISAL
is well suited for modern computation. Of course, it contains
many features beyond what we can implement in a one-semester
compiler course where students implement all of their own
machinery. Twine is essentially a subset of SISAL, with a few
additions and modifications aimed at making the language more
suitable for our undergraduate course.
(Whence the name "Twine"? The name of SISAL comes from the
standard Unix word list. It was chosen because it contains
the phrase "sal", which is an acronym for "single assignment
language". The word "sisal" itself is the name of a flowering
plant native to southern Mexico but widely cultivated around
the world. Its leaves are crushed to extract a fiber that is
used to create rope and twine. So, just as the sisal plant is
used to create twine, the SISAL programming language was used
to create the Twine programming language.)
With new surface elements, the idea of implementing a new front
end appealed to me. Besides, the experience of implementing
a complete system feels different than implementing a one-off
component... That's one of the things we want our students to
experience in our project courses! After eighteen months of
weirdness and upheaval at school and in the world, I craved
that sort of connection to some code. So here I am.
Knocking out a scanner in my free time over the last week and
getting started on my parser has been fun. It has also reminded
me how the choice of programming language affects how I think
about the code I am writing.
I decided to implement in Python, the language most of my student
teams are using this fall, so that I might have recent experience
with specific issues they encounter. I'd forgotten just how
list-y Python is. Whenever I look at Python code on the web, it
seems that everything is a list or a dictionary. The path of
least resistance flows that way... If I walk that path, I soon
find myself with a list of lists of lists, and my brain is
swimming in indices. Using dictionaries replaces integer indices
with keys of other types, but the conceptual jumble remains.
It did not take me long to appreciate anew why I like to work
with objects. They give me the linguistic layers I need to
think about my code independent of languages primitives. I know,
I know, I can achieve the same thing with algebraic types and
layers of function definitions. However, my mind seems to work
on a wavelength where data encapsulation and abstract messages
go together. Blame Smalltalk for ruining me, or enlightening me,
whichever your stance.
Python provides a little extra friction to classes and objects
that seems to interrupt my flow occasionally. For a few minutes
this week, I felt myself missing Java and wondering if I ought
to have chosen it for the project instead of Python. I used to
program in Java every day, and this was the first time in a long
while that I felt the pull back. After programming so much in
Racket the last decade, though, the wordiness of Java keeps me
away. Alas, Python is not the answer. Maybe I'm ready to go
deep on a new language, but which one? OOP doesn't seem to be
in vogue these days. Maybe I need to return to Ruby or Smalltalk.
For now I will live with OOP in Python and see whether its other
charms can compensate. Living with Python's constraints shows up
as a feature of another choice I made for this project: to let
pycodestyle
tell me how to format my code. This is an obstacle for any
programmer who is as idiosyncratic as I am. After a few rounds
of reformatting my code, though, I am finding surrender easier
to accept. This has freed me to pay attention to more important
matters, which is one of the keys ideas behind coding and style
standards in the first place. But I am a slow learner.
It's been fun so far. I look forward to running Twine programs
translated by my compiler in a few weeks! As long as I've been
programming, I have never gotten over the thrill of watching my
compiler I've written -- or any big program I've written -- do
its thing. Great joy.
In the middle of
an old post
about computing an "impossible" integral, John Cook says:
In the artificial world of the calculus classroom, everything
works out nicely. And this is a shame.
When I was a student, I probably took comfort in the fact that
everything was supposed to work out nicely on the homework we
did. There *was* a solution; I just had to find the pattern,
or the key that turned the lock. I suspect that I was a good
student largely because I was good at finding the patterns,
the keys.
It wasn't until I got to grad school that things really changed,
and even then course work was typically organized pretty neatly.
Research in the lab was very different, of course, and that's
where my old skills no longer served me so well.
In university programs in computer science, where many people
first learn how to develop software, things tend to work out
nicely. That is a shame, too. But it's a tough problem to
solve.
In most courses, in particular introductory courses, we create
assignments with that have "closed form" solutions, because we
want students to practice a specific skill or learn a particular
concept. Having a fixed target can be useful in achieving the
desired outcomes, especially if we want to help students build
confidence in their abilities.
It's important, though, that we eventually take off the training
wheels and expose students to messier problems. That's where
they have an opportunity to build other important skills they
need for solving problems outside the classroom, which aren't
designed by a benevolent instructor to have follow a pattern.
As Cook says, neat problems can create a false impression that
every problem has a simple solution.
Students who go on to use calculus for anything more than
artificial homework problems may incorrectly assume they've
done something wrong when they encounter an integral in the
wild.
CS students need experience writing programs that solve messy
problems. In more advanced courses, my colleagues and I all
try to extend students' ability to solve less neatly-designed
problems, with mixed results.
It's possible to design a coherent curriculum that exposes students
to an increasingly messy set of problems, but I don't think many
universities do this. One big problem is that doing so requires
coordination across many courses, each of which has its own
specific content outcomes. There's never enough time, it seems,
to teach everything about, say, AI or databases, in the fifteen
weeks available. It's easier to be sure that we cover another
concept than it is to be sure students take a reliable step
along the path from being able to solve elementary problems to
being able to solve to the problems they'll find in the wild.
I face this set of competing forces every semester and do my best
to strike a balance. It's never easy.
Courses that involve large systems projects are one place where
students in my program have a chance to work on a real problem:
writing a compiler, an embedded real-time system, or an AI-based
system. These courses have closed form solutions of sorts, but
the scale and complexity of the problems require students to do
more than just apply formulas or find simple patterns.
Many students thrive in these settings. "Finally," they say,
"this is a problem worth working on." These students will be
fine when they graduate. Other students struggle when they have
to do battle for the first time with an unruly language grammar
or a set of fussy physical sensors. One of my challenges in my
project course is to help this group of students move further
along the path from "student doing homework" to "professional
solving problems".
That would be a lot easier to do if we more reliably helped
students take small steps along that path in their preceding
courses. But that, as I've said, is difficult.
This post describes a problem in curriculum design without
offering any solutions. I will think more about how I try to
balance the forces between neat and messy in my courses, and
then share some concrete ideas. If you have any approaches that
have worked for you, or suggestions based on your experiences as
a student, please
email me
or send me a message
on Twitter.
I'd love to learn how to do this better.
I've written a number of posts over the years that circle around
this problem in curriculum and instruction. Here are three:
On one of the tapes of studio chatter at Abbey Road you can
hear McCartney saying, of something they're working on,
"It's complicated now. If we can get it simpler, and then
complicate it where it needs to be complicated..."
People talk a lot about making software as simple as possible.
The truth is, software sometimes has to be complicated. Some
programs perform complex tasks. More importantly, programs
these days often interact in complex environments with a lot
of dissimilar, distributed components. We cannot avoid
complexity.
As McCartney knows about music, the key is to make things as
simple as can be and introduce complexity only where it is
essential. Programmers face three challenges in this regard:
learning how to simplify code,
learning how to add complexity in a minimal, contained
fashion, and
learning how to recognize the subtle boundary between
essential simplicity and essential complexity.
I almost said that new programmers face those challenges, but
after many years of programming, I feel like I'm still learning
how to do all three of these things. I suspect other experienced
programmers are still learning, too.
On an unrelated note, another passage in this article spoke to
me personally as a programmer. While discussing McCartney's
propensity to try new things and to release everything, good and
bad, it refers to some of the songs on his most recent album (at
that time) as enthusiastically executed misjudgments.
I empathize with McCartney. My hard drive is littered with
enthusiastically executed misjudgments. And I've never written
the software equivalent of "Hey Jude".
McCartney just released a new album this month at the age of 78.
The third album in a trilogy conceived and begun in 1970, it has
already gone to #1 in three countries. He continues to write,
record, and release, and collaborates frequently with today's
artists. I can only hope to be enthusiastically producing software,
and in tune with the modern tech world, when I am his age.
Was the time I spent writing my RSS scripts more than the time
I would now spend thinking about the "best" RSS aggregator and
reader? Doesn't matter. I enjoyed writing the scripts. I
learned new things and got satisfaction out of seeing them run
correctly. I get nothing like that out of comparing apps and
services.
I concur so strongly not only because he writes about RSS, which
I'm
on record
as supporting and using. I enjoy rolling my own simple software
in almost any domain. Simple has a lot of advantages. Under my
control has a lot of advantages. But the biggest advantage echoes
what Dr. Drang says: Programming is often more fun than the
alternative uses of my time.
If You Want to Create Greatness, Encourage Everyone
I read two passages in the last few days that echo one another.
First, I read this from Wallace Shawn, in
a Paris Review interview:
But my God, without writers, humanity might be trapped in a swamp
of idiotic, unchanging provincial clichés. Yes, there are
writers who merely reinforce people's complacency, but a writer
like Rachel Carson inspired the activism of millions, and writers
like Lady Murasaki, Milton, and Joyce have reordered people's
brains! And for any writers to exist at all, there must surely
be a tradition of writing. Maybe in order for one valuable
writer to exist, there must be a hundred others who aren't
valuable at all, but it isn't possible at any given moment for
anyone to be sure who the valuable one is.
Then, in
his response
to Marc Andreessen's "It's Time to Build", Tanner Greer writes:
To consistently create brilliant poets, you need a society awash
in mediocre, even tawdry poetry. Brilliant minds will find their
way towards poem writing when poem writing and poem reading is the
thing that people do.
I once
blogged briefly
about The Art of Fear tells the story of an artist
sketching hundreds of roosters, which laid the foundation for
creating a single sketch for his client. For us as individuals,
this means that "talent is rarely distinguishable, over the long
run, from perseverance and lots of hard work." As Richard Gabriel
often says, "Talent determines only how fast you get good, not how
good you get". Volume creates the conditions under which quality
can appear.
Shawn and Greer remind us that the same dynamic applies at the
scale of a culture. A community that produces many writers has a
better chance to produce great writers. When the community values
writers, it increases the chances that someone will do the work
necessary to becoming a writer. The best way to produce a lot of
writers is to have a tradition that welcomes, even encourages, all
members of the community to write, even if they aren't great.
The same applies to other forms of achievement, too. In particular,
I think it applies to programming.
Sandi Metz's
latest newsletter
is about the heuristic not to name a class after the design pattern
it implements. Actually, it's about a case in which Metz
wanted to name a class after the pattern it implements in
her code and then realized what she had done. She decided that she
either needed to have a better reason for doing it than "because it
just felt right" or she needed practice what she preaches to the rest
of us. What followed was some deep thinking about what makes the
rule a good one to follow and her efforts to put her conclusions in
writing for the benefit of her readers.
I recognize with Metz's sense of discomfort at breaking a rule when
it feels right and her need to step back and understand the rule at
a deeper level. Between her set up and her explanation, she writes:
I've built a newsletter around this rule not only because I believe
that it's useful, but also because my initial attempts to explain it
exposed deep holes in my understanding. This was a revelation. Had
I not been writing a book, I might have hand-waved around these gaps
in my knowledge forever.
People sometimes say, "If you you really want to understand something,
teach it to others." Metz's story is a great example of why this is
really true. I mean, sure, you can learn any new area and
then benefit from explaining it to someone else. Processing knowledge
and putting it in your own words helps to consolidate knowledge at the
surface. But the real learning comes when you find yourself in a
situation where you realize there's something you've taken for
granted for months or for years, something you thought you knew, but
suddenly you sense a deep hole lying under the surface of that supposed
understanding. "I just know breaking the rule is the right thing to
do here, but... but..."
I've been teaching long enough to have had this experience many times
in many courses, covering many areas of knowledge. It can be
terrifying, at least momentarily. The temptation to wave my hands
and hurry past a student's question is enormous. To learn from
teaching in these moments requires humility, self-awareness, and a
willingness to think and work until you break through to that deeper
understanding. Learning from these moments is what sets the best
teachers and writers apart from the rest of us.
As you might guess from Metz's reaction to her conundrum, she's a
pretty good teacher and writer. The story in the newsletter is from
the new edition of her book "99 Bottles of OOP", which is now
available. I enjoyed the first edition of "99 Bottles" and found it
useful in my own teaching. It sounds like the second edition will
be more than a cleanup; it will have a few twists that make it a
better book.
I'm teaching our database systems course for the first time ever this
fall. This is a brand new prep for me: I've never taught a database
course before, anywhere. There are so many holes in my understanding,
places where I've internalized good practices but don't grok them in
the way an expert does. I hope I have enough humility and
self-awareness this semester to do my students right.
I recently read
a Five Books interview
about the best books on philosophical wonder. One of the books
recommended by philosopher Eric Schwitzgebel was Diaspora,
a science fiction novel by Greg Egan I've never read. The story unfolds
in a world where people are able to destroy their physical bodies to
upload themselves into computers. Unsurprisingly, this leads to some
fascinating philosophical possibilities:
Well, for one thing you could duplicate yourself. You could back
yourself up. Multiple times.
And then have divergent lives, as it were, in parallel but
diverging.
Yes, and then there'd be the question, "do you want to merge back
together with the person you diverged from?"
Egan wrote Diaspora before the heyday of distributed version
control, before darcs and mercurial and git.
With distributed VCS, a person could checkout a new personality, or
change branches and be a different person every day. We could run
diffs to figure out what makes one version of a self so different from
another. If things start going too wrong, we could always revert to
an earlier version of ourselves and try again. And all of this could
happen with copies of the software -- ourselves -- running in parallel
somewhere in the world.
And then there's Git. Imagine writing such a story now, with Git's
complex model of versioning and prodigious set of commands and flags.
Not only could people branch and merge, checkout and diff... A person
could try something new without ever committing changes to the
repository. We'd have to figure out what it means to
push origin or reset --hard HEAD. We'd be able to
rewrite history by rebasing, amending, and squashing. A Git guru can
surely explain why we'd need to --force-with-lease or
--unset-upstream, but even I can imagine the delightful
possibilities of git stash in my personal improvement plan.
Perhaps the final complication in our novel would involve a merge so
complex that we need a third-party diff tool to help us put our desired
self back together. Alas, a Python library or Ruby gem required by the
tool has gone stale and breaks an upgrade. Our hero must find a solution
somewhere in her tree of blobs, or be doomed to live a forever splintered
life.
If you ever see a book named Dreaming in Git or Bug
Report on an airport bookstore's shelves, take a look. Perhaps
I will have written the first of my Git fantasies.
It's been a long time since I was excited by a new piece of software
the way I was excited by
Loglo,
Avi Bryant's new creation. Loglo is "LOGO for the Glowforge", an
experimental programming environment for creating SVG images. That's
not a problem I need to solve, but the way Loglo works drew me in
immediately. It consists of a stack programming language and a set of
primitives for describing vector graphics, integrated into a spreadsheet
interface. It's the use of a stack language to program a spreadsheet
that excites me so much.
Actually, it's the reverse relationship that really excites me: using
a spreadsheet to build and visualize a stack-based program. Long-time
readers know that I am interested in this style of programming (see
Summer of Joy
for a post from last year) and sometimes introduce it in my programming
languages course. Students understand small examples easily enough,
but they usually find it hard to grok larger programs and to fully
appreciate how typing in such a language can work. How might Loglo
help?
In Loglo, a cell can refer to the values produced by other cells in the
familiar spreadsheet way, with an absolute address such as "a1"
or "f2". But Loglo cells have two other ways to refer to other
cell's values. First, any cell can access the value produced by the cell
to its left implicitly, because Loglo leaves the result of a cell's
computation sitting on top of the stack. Second, a cell can access the
value produced by the cell above it by using the special variable
"^". These last two features strike me as a useful way for
programmers to see their computations grow over time, which can
be an even more powerful mode of interaction for beginners who are
learning this programming style.
Stack-oriented programming
of this sort is
concatenative:
programs are created by juxtaposing other programs, with a stack of
values implicitly available to every operator. Loglo uses the stack
as leverage to enable programmers to build images incrementally, cell
by cell and row by row, referring to values on the stack as well as to
predecessor cells. The programmer can see in a cell the value produced
by a cumulative bit of code that includes new code in the cell itself.
Reading Bryant's description of programming in Loglo, it's easy to see
how this can be helpful when building images. I think my students
might find it helpful when learning how to write concatenative programs
or learning how types and programs work in a concatenative language.
For example, here is a concatenative program that works in Loglo as
well as other stack-based languages such as Forth and Joy:
2 3 + 5 * 2 + 6 / 3 /
Loglo tells us that it computes the value 1.5:
This program consists of eleven tokens, each of which is a program in
its own right. More interestingly, we can partition this program into
smaller units by taking any subsequences of the program:
2 3 + 5 * 2 + 6 / 3 /
--------- ------- ---
These are the programs in cells A1, B1, and C1 of our spreadsheet. The
first computes 25, the second uses that value to compute 4.5, and the
third uses the 4.5 to compute 1.5. Notice that the programs in cells
B1 and C1 require an extra value to do their jobs. They are like
functions of one argument. Rather than pass an argument to the function,
Loglo allows it to read a value from the stack, produced by the cell to
its left.
By making the intermediate results visible to the programmer, this
interface might help programmers better see how pieces of a concatenative
program work and learn what the type of a program fragment such as
2 + 6 / (in cell B1 above) or 3 / is.
Allowing locally-relative references on a new row will, as Avi points out,
enable an incremental programming style in which the programmer uses a
transformation computed in one cell as the source for a parameterized
version of the transformation in the cell below. This can give the novice
concatenative programmer an interactive experience more supportive than
the usual REPL. And Loglo is a spreadsheet, so changes in one cell
percolate throughout the sheet on each update!
Am I the only one who thinks this could be a really cool environment
for programmers to learn and practice this style of programming?
Teaching concatenative programming isn't a primary task in my courses,
so I've never taken the time to focus on a pedagogical environment for
the style. I'm grateful to Avi for demonstrating a spreadsheet model
for stack programs and stimulating me to think more about it.
For now, I'll play with Loglo as much as time permits and think more
about its use, or use of a tool like it, in my courses. There are
couple of features I'll have to get used to. For one, it seems that a
cell can access only one item left on the stack by its left neighbor,
which limits the kind of partial functions we can write into cells.
Another is that named functions such as rotate push themselves
onto the stack by default and thus require a ! to apply them,
whereas operators such as + evaluate by default and thus
require quotation in a {} block to defer execution. (I have
an academic's fondness for overarching simplicity.) Fortunately,
these are the sorts of features one gets used to whenever learning a
new language. They are part of the fun.
Thinking beyond Loglo, I can imagine implementing an IDE like this for
my students that provides features that Loglo's use cases don't require.
For example, it would be cool to enable the programmer to ctrl-click on
a cell to see the type of the program it contains, as well as an option
to see the cumulative type along the row or built on a cell referenced
from above. There is much fun to be had here.
To me, one sign of a really interesting project is how many tangential
ideas flow out of it. For me, Loglo is teeming with ideas, and I'm not
even in its target demographic. So, kudos to Avi!
There's value to going into a field that you find difficult to
grasp, as long as you're willing to be persistent. Even better,
others can benefit from your persistence, too.
In
an old essay,
James Propp notes that working in a field where you lack intuition
can "impart a useful freedom from prejudice". Even better...
... there's value in going into a field that you find difficult to
grasp, as long as you're willing to be really persistent, because
if you find a different way to think about things, something that
works even for someone like you, chances are that other
people will find it useful too.
This reminded me of a passage in
Bob Nystroms's post
about his new book,
Crafting Interpreters.
Nystrom took a long time to finish the book in large part because
he wanted the interpreter at the end of each chapter to compile
and run, while at the same time growing into the interpreter
discussed in the next chapter. But that wasn't the only reason:
I made this problem harder for myself because of the meta-goal I
had. One reason I didn't get into languages until later in my
career was because I was intimidated by the reputation compilers
have as being only for hardcore computer science wizard types.
I'm a college dropout, so I felt I wasn't smart enough, or at
least wasn't educated enough to hack it. Eventually I discovered
that those barriers existed only in my mind and that anyone
can learn this.
Some students avoid my compilers course because they assume it must
be difficult, or because friends said they found it difficult. Even
though they are CS majors, they think of themselves as average
programmers, not "hardcore computer science wizard types". But
regardless of the caliber of the student at the time they start the
course, the best predictor of success in writing a working compiler
is persistence. The students who plug away, working regularly
throughout the two-week stages and across the entire project, are
usually the ones who finish successfully.
One of my great pleasures as a prof is seeing the pride in the faces
of students who demo a working compiler at the end of the semester,
especially in the faces of the students who began the course
concerned that they couldn't hack it.
As Propp points out in his essay, this sort of persistence can pay off
for others, too. When you have to work hard to grasp an idea or to
make something, you sometimes find a different way to think about
things, and this can help others who are struggling. One of my jobs
as a teacher is to help students understand new ideas and use new
techniques. That job is usually made easier when I've had to work
persistently to understand the idea myself, or to find a better way to
help the students who teach me the ways in which they struggle.
In Nystrom's case, his hard work to master a field he didn't grasp
immediately pays of for his readers. I've been following the growth
of
Crafting Interpreters
over time, reading chapters in depth whenever I was able. Those
chapters were uniformly easy to read, easy to follow, and entertaining.
They have me thinking about ways to teach my own course differently,
which is probably the highest praise I can give as a teacher. Now I
need to go back and read the entire book and learn some more.
Teaching well enough that students grasp what they thought was not
graspable and do what they thought was not doable is a constant goal,
rarely achieved. It's always
a work in progress.
I have to keep plugging away.
If you can just quickly whip something out and it's done, maybe
it's time, once in a while, to think and think and think, "Can
I make it better than it is, a little superior?" What that
does is not necessarily make the product better in the end, but
it brings you closer to the product, and your own head understands
it better. Your neurons have gone through the code you wrote,
or the circuits you designed, have gone through it more times,
and it's just a little more solidly in your head and once in a
while you'll wake up and say, "Oh my God, I just realized a bug
that's in there, something I hadn't thought of."
Or, if you have to modify something, or add something new, you
can do it very quickly when it's all in your head. You don't
have to pull out the listing and find out where and maybe make
a mistake. You don't make as many mistakes.
Many programmers know this feeling, of having a program in your
head and moving in sync with it. When programs are small, it's
easy for me to hold a program in my head. As it grows larger and
spreads out over many functions, classes, and files, I have to
live with it over an extended period of time. Taking one of Woz's
dives into the just to work on it is a powerful way to refresh the
feeling.
Beginning programmers have to learn this feeling, I think, and we
should help them. In the beginning, my students know what it's
like to have a program in their head all at once. The programs
are small, and the new programmer has to pay attention to every
detail. As programs grow, it becomes harder for them. They work
locally to make little bits of code work, and suddenly they have
a program that does fit naturally in their head. But they don't
have the luxury of time to do what Woz suggests, because they are
on to the next reading assignment, the next homework, the next
class across campus.
One of the many reasons I like project courses such as my compiler
course is that students live with the same code for an entire
semester. Sure, they finish the scanner and move on to the parser,
and then onto a type checker and a code generator, but they use
their initial stages every day and live with the decisions they
made. It's not uncommon for a student to tell me 1/2 or 3/4 of
the way through the course, "I was looking at our scanner (or
parser) the other day, and now I understand why we were having
that problem I told you about. I'm going to fix it over
Thanksgiving break."
In my programming languages course, we close with a three week
three assignment project building an interpreter. I love when a
student submitting on Part 3 says, "Hey, I just noticed that some
parts of Part 2 could be better. I hope you don't mind that I
improved that, too." Um, no. No, I don't mind at all. They get
it.
It's easy to shortchange our students with too many small projects.
I like most of my courses to have at least some code grow over the
course of the semester. Students may not have the luxury of a lot
of free time, but at least they work in proximity to their old
code for a while. Serendipity may strike if we create the right
conditions for it.
I have already begun to think about how I can foster this in
my new course
this fall. I hope to design it into the course upfront.
Software Can Make You Feel Alive, or It Can Make You Feel Dead
This week I read one of
Craig Mod's old essays
and found a great line, one that everyone who writes programs for
other people should keep front of mind:
When it comes to software that people live in all day long, a 3%
increase in fun should not be dismissed.
Working hard to squeeze a bit more speed out of a program, or to
create even a marginally better interaction experience, can make
a huge difference to someone who uses that program everyday. Some
people spend most of their professional days inside one or two
pieces of software, which accentuates further the human value of
Mod's three percent. With shelter-in-place and work-from-home the
norm for so many people these days, we face a secondary crisis of
software that is no fun.
I was probably more sensitive than usual to Mod's sentiment when
I read it... This week I used Blackboard for the first time, at
least my first extended usage. The problem is not Blackboard, of
course; I imagine that most commercial learning management
systems are little fun to use. (What a depressing phrase
"commercial learning management system" is.) And it's not just
LMSes. We use various PeopleSoft "campus solutions" to run the
academic, administrative, and financial operations on our campus.
I always feel a little of my life drain away whenever I spend an
hour or three clicking around and waiting inside this large and
mostly functional labyrinth.
It says a lot that my first thought after
downloading my final exams
on Friday morning was, "I don't have to login to Blackboard
again for a good long while. At least I have that going for me."
I had never used our LMS until this week, and then only to
create a final exam that I could reliably time after being
forced into remote teaching with little warning. If we are in
this situation again in the fall, I plan to have an alternative
solution in place. The programmer in me always feels an urge to
roll my own when I encounter substandard software. Writing an
entire LMS is not one of my life goals, so I'll just write the
piece I need. That's more my style anyway.
Later the same morning, I saw this spirit of writing a better
program in a context that made me even happier. The Friday of
finals week is my department's biennial undergrad research day,
when students present the results of their semester- or
year-long projects. Rather than give up the tradition because
we couldn't gather together in the usual way, we used Zoom.
One student talked about alternative techniques for doing
parallel programming in Python, and another presented empirical
analysis of using IR beacons for localization of FIRST Lego
League robots. Fun stuff.
The third presentation of the morning was by a CS major with a
history minor, who had observed how history profs' lectures are
limited by the tools they had available. The solution? Write
better presentation software!
As I watched this talk, I was proud of the student, whom I'd
had in class and gotten to know a bit. But I was also proud of
whatever influence our program had on his design skills,
programming skills, and thinking. This project,
I thought,
is a demonstration of one thing every CS student should learn:
We can make the tools we want to use.
This talk also taught me something non-technical: Every CS
research talk should include maps of Italy from the 1300s.
Don't dismiss 3% increases in fun wherever they can be made.
This passage from
Remembering the LAN
recalls an earlier time that feels familiar:
My father, a general practitioner, used this infrastructure of cheap
286s, 386s, and 486s (with three expensive laser printers) to write
the medical record software for the business. It was used by a dozen
doctors, a nurse, and receptionist. ...
The business story is even more astonishing. Here is a non-programming
professional, who was able to build the software to run their small
business in between shifts at their day job using skills learned from
a book.
I wonder how many hobbyist programmers and side-hustle programmers of
this sort there are today. Does programming attract people the way it
did in the '70s or '80s? Life is so much easier than typing programs
out of Byte or
designing your own BASIC interpreter from scratch.
So many great projects out on Github and the rest of the web to clone,
mimic, adapt. I occasionally hear a student talking about their own
projects in this way, but it's rare.
As Crawshaw points out toward the end of his post, the world in which
we program now is much more complex. It takes a lot more gumption to
get started with projects that feel modern:
So much of programming today is busywork, or playing defense against
a raging internet. You can do so much more, but the activation energy
required to start writing fun collaborative software is so much higher
you end up using some half-baked SaaS instead.
I am not a great example of this phenomenon -- Crawshaw and his dad
did much more -- but even today I like to roll my own, just for me. I
use a simple accounting system I've been slowly evolving for a decade,
and I've cobbled together bits and pieces of
my own tax software,
not an integrated system, just what I need to scratch an itch each
year. Then there are all the short programs and scripts I write for
work to make Spreadsheet City more habitable. But I have multiple CS
degrees and a lot of years of experience. I'm not a doctor who decides
to implement what his or her office needs.
I suspect there are more people today like Crawshaw's father than I
hear about. I wish it were more of a culture that we cultivated for
everyone. Not everyone
wants to bake their own bread,
but people who get the itch ought to feel like the world is theirs to
explore.
So, instead of merely changing the food, Bakker changed the
foodscape, ensuring that nearly every option at Google is
healthy -- or at least healthyish -- and that the options
that weren't stayed out of sight and out of mind.
This is how I've been thinking lately about teaching functional
programming to my students, who have experience in procedural
Python and object-oriented Java. As with deciding what we eat,
how we think about problems and programs is mostly unconscious,
a mixture of habit and culture. It is also something intimate
and individual, perhaps especially for relative beginners who
have only recently begun to know a language well enough to solve
problems with some facility. But even for us old hands, the
languages and mental tools we use to write programs can become
personal. That makes change, and growth, hard.
In my last few offerings of our programming languages course, in
which students learn Racket and functional style, I've been
trying to change the programming landscape my students see in
small ways whenever I can. Here are a few things I've done:
I've shrunk the set of primitive functions that we use in the
first few weeks. A larger set of tools offers more power and
reach, but it also can distract. I'm hoping that students can
more quickly master the small set of tools than the larger set
and thus begin to feel more accomplished sooner.
We work for the first few weeks on problems with less need for
the tools we've moved out of sight, such as local variables
and counter variables. If a program doesn't really benefit
from a local variable, students will be less likely to reach
for one. Instead, perhaps, they will reach for a function
that can help them get closer to their goal.
In a similar vein, I've tried to make explicit connections
between specific triggers ("We're processing a list of data,
so we'll need a loop.") with new responses ("map can
help us here."). We then follow up these connections with
immediate and frequent practice.
By keeping functional tools closer at hand, I'm trying to make it
easier for these tools to become the new habit. I've also noticed
how the way I speak about problems and problem solving can subtly
shape how students approach problems, so I'm trying to change a
few of my own habits, too.
It's hard for me to do all these things, but it's harder still
when I'm not thinking about them. This feels like progress.
So far students seem to be responding well, but it will be a while
before I feel confident that these changes in the course are
really helping students. I don't want to displace procedural or
object-oriented thinking from their minds, but rather to give them
a new tool set they can bring out when they need or want to.
I saw Robin Sloan's
An App Can Be a Home-Cooked Meal
floating around Twitter a few days back. It really is quite good;
give it a read if you haven't already. This passage captures a lot
of the essay's spirit in only a few words:
The exhortation "learn to code!" has its foundations in market
value. "Learn to code" is suggested as a way up, a way out.
"Learn to code" offers economic leverage, a squirt of power.
"Learn to code" goes on your resume.
But let's substitute a different phrase: "learn to cook." People
don't only learn to cook so they can become chefs. Some do! But
far more people learn to cook so they can eat better, or more
affordably, or in a specific way. Or because they want to carry
on a tradition. Sometimes they learn just because they're bored!
Or even because -- get this -- they love spending time with the
person who's teaching them.
Sloan expresses better than I ever have an idea that I blog about
every so often. Why should people learn to program? Certainly
it offers a path to economic gain, and that's why a lot of
students study computer science in college, whether as a major, a
minor, or a high-leverage class or two. There is nothing wrong
with that. It is for many a way up, a way out.
But for some of us, there is more than money in programming. It
gives you a certain power over the data and tools you use. I
write here occasionally about how a small script or a relatively
small program makes my life so much easier, and I feel bad for
colleagues who are stuck doing drudge work that I jump past.
Occasionally I'll try to share my code, to lighten someone else's
burden, but most of the time there is such a mismatch between the
worlds we live in that they are happier to keep plugging along.
I can't say that I blame them. Still, if only they could program
and used tools that enabled them to improve their work environments...
One of the things that students like about my classes is that I love
what I do, and they are welcome to join me on the journey. Just
today a student in my Programming Languages drifted back to my
office with me after class , where we ended up talking for half an
hour and sketching code on a whiteboard as we deconstructed a
vocabulary choice he made on our latest homework assignment. I
could sense this student's own love of programming, and it raised
my spirits. It makes me more excited for the rest of the semester.
I've had people come up to me at conferences to say that the reason
they read my blog is because they like to see someone enjoying
programming as much as they do. many of them share links with
their students as if to say, "See, we are not alone." I look
forward to days when I will be able to write in this vein more often.
Sloan reminds us that programming can be -- is -- more than a line
on a resume. It is something that everyone can do, and want to do,
for a lot of different reasons. It would be great if programming
"were marbled deeply into domesticity and comfort, nerdiness and
curiosity, health and love" in the way that cooking is. That is
what makes Computing for All really worth doing.
Practical campaign security is a wood chipper for your hopes
and dreams. It sits at the intersection of 19 kinds of status
quo, each more odious than the last. You have to accept the
fact that computers are broken, software is terrible, campaign
finance is evil, the political parties are inept, the DCCC
exists, politics is full of parasites, tech companies are run
by arrogant man-children, and so on.
This piece from last year has some good advice, plenty of
sarcastic humor from Maciej, and one remark that was especially
timely for the past week:
You will fare especially badly if you have written an app to
fix politics. Put the app away and never speak of it again.
In a conversation between Tom Waits and Elvis Costello from
the late 1980s, Waits talks about tinkering too long with a
song:
TOM: "You have to know the difference between neurosis and
actual process, 'cause if you're left with it in your hands
for too long, you may unravel everything. You may end up
with absolutely nothing."
In software, when we keep code in our hands for too long, we
usually end up with an over-engineered, over-abstracted boat
anchor. Let the tests tell you when you are done, then stop.
People say, "if you love what you do you'll never work a day
in your life." I think good work can be painful--I think
sometimes it feels exactly like work.
Some weeks more than others. Trust me. That's okay. You can
still love what you do.
In 1957,
Dan McCracken
published
Digital Computer Programming,
perhaps the first book on the new art of programming. His book
shows that the roots of extreme programming run deep. In this
passage, McCracken encourages both the writing of tests before
the writing of code and the involvement of the customer in the
software development process:
The first attack on the checkout problem may be made before coding
is begun. In order to fully ascertain the accuracy of the answers,
it is necessary to have a hand-calculated check case with which to
compare the answers which will later be calculated by the machine.
This means that stored program machines are never used for a true
one-shot problem. There must always be an element of iteration to
make it pay. The hand calculations can be done at any point during
programming. Frequently, however, computers are operated by
computing experts to prepare the problems as a service for
engineers or scientists. In these cases it is highly desirable
that the "customer" prepare the check case, largely because logical
errors and misunderstandings between the programmer and customer
may be pointed out by such procedure. If the customer is to
prepare the test solution is best for him to start well in advance
of actual checkout, since for any sizable problem it will take
several days or weeks to calculate the test.
I don't have a copy of this book, but I've read a couple of other
early books by McCracken, including one of his Fortran books for
engineers and scientists. He was a good writer and teacher.
I had the great fortune to meet Dan at an NSF workshop in Clemson,
South Carolina, back in the mid-1990s. We spent many hours in the
evening talking shop and watching basketball on TV. (Dan was
cheering his New York Knicks on in the NBA finals, and he was
happy to learn that I had been a Knicks and Walt Frazier fan in
the 1970s.) He was a pioneer of programming and programming
education who was willing to share his experience with a young CS
prof who was trying to figure out how to teach. We kept in touch
by email thereafter. It was honor to call him a friend.
I recently read
an interview
with documentary filmmaker Errol Morris, who has unorthodox
opinions about documentaries and how to make them. In
particular, he prefers to build his films out of extended
interviews with a single subject. These interviews give
him all the source material he needs, because they aren't
about questions and answers. They are about stories:
First of all, I think all questions are more or less rhetorical
questions. No one wants their questions answered. They just
want to state their question. And, in answering the question,
the person never wants to answer the question. They just want
to talk.
Morris isn't asking questions; he is stating them. His subjects
are not answering questions; they are simply talking.
(Think about this the next time your listening to an interview
with a politician or candidate for office...)
At first, I was attracted to the sentiment in this paragraph.
Then I became disillusioned with what I took to be its cynicism.
Now, though, after a week or so, I am again enamored with its
insight.
How many of the questions I ask of software clients and
professional colleagues are really statements of a position?
How many of their answers are disconnected from the essential
element of my questions? Even when these responses are
disconnected, they communicate a lot to me, if only I listen.
My clients and colleagues are often telling me exactly what
they want me to know.
This dynamic is present surprisingly often when I work with
students at the university, too. I need to listen carefully
when students don't seem to be answering my question.
Sometimes it's because they have misinterpreted the question,
and I need to ask differently. Sometimes it's because they
are telling me what they want me to know, irrespective of
the question.
And when my questions aren't really questions, but statements
or some other speech act... well, I know I have some work
to do.
In case you find Morris's view on interviews cynical and
would prefer to ponder the new year with greater hope, I'll
leave you with a more ambiguous quote about questions:
There are years that ask questions, and years that answer.
That's from Their Eyes Were Watching God, by Zora
Neale Hurston. In hindsight, it may be true or false for any
given year. As a way to frame the coming months, though, it
may be useful.
I hope that 2020 brings you the answers you seek, or the
questions.
More Adventures in Constrained Programming: Elo Predictions
I like tennis. The Tennis Abstract blog helps me keep up
with the game and indulge my love of sports stats at the
same time. An entry earlier this month gave
a gentle introduction to Elo ratings
as they are used for professional tennis:
One of the main purposes of any rating system is to predict
the outcome of matches--something that Elo does better than
most others, including the ATP and WTA rankings. The only
input necessary to make a prediction is the difference
between two players' ratings, which you can then plug into
the following formula:
1 - (1 / (1 + (10 ^ (difference / 400))))
This formula always makes me smile. The first computer
program I ever wrote
because I really wanted to
was a program to compute Elo ratings for my high school chess
club. Over the years I've come back to Elo ratings occasionally
whenever I had an itch to dabble in a new language or even an
old favorite. It's like a personal kata of variable scope.
I read the Tennis Abstract piece this week as my students were
finishing up their compilers for the semester and as I was
beginning to think of break. Playful me wondered how I might
implement the prediction formula in my students' source
language. It is a simple functional language with only two
data types, integers and booleans; it has no loops, no local
variables, no assignments statements, and no sequences. In
another old post,
I referred to this sort of language as akin to an integer
assembly language. And, heaven help me, I love to program in
integer assembly language.
To compute even this simple formula in Klein, I need to think
in terms of fractions. The only division operator performs
integer division, so 1/x for any x gives 0. I also need to
think carefully about how to implement the exponentiation
10 ^ (difference / 400). The difference between
two players' ratings is usually less than 400 and, in any
case, almost never divisible by 400. So My program will have
to take an arbitrary root of 10.
Which root? Well, I can use our gcd() function
(implemented using
Euclid's algorithm,
of course) to reduce diff/400 to its lowest terms,
n/d, and then compute the dth root of 10^n.
Now, how to take the dth root of an integer for an
arbitrary integer d?
Fortunately, my students and I have written code like this
in various integer assembly languages over the years. For
instance, we have a SQRT function that uses binary search to
hone in on the integer closest to the square of a given integer.
Even better, one semester a student implemented a square root
program that uses
Newton's method:
xn+1 = xn - f(xn)/f'(xn)
That's just what I need! I can create a more general version
of the function that uses Newton's method to compute an
arbitrary root of an arbitrary base. Rather than work with
floating-point numbers, I will implement the function to take
its guess as a fraction, represented as two integers: a numerator
and a denominator.
This may seem like a lot of work, but that's what working in
such a simple programming language is like. If I want my
students' compilers to produce assembly language that predicts
the result of a professional tennis match, I have to do the
work.
This morning, I read
a review
of Francis Su's new popular math book, Mathematics for Human
Flourishing. It reminds us that math isn't about rules and
formulas:
Real math is a quest driven by curiosity and wonder. It requires
creativity, aesthetic sensibilities, a penchant for mystery, and
courage in the face of the unknown.
Writing my Elo rating program in Klein doesn't involve much
mystery, and it requires no courage at all. It does, however,
require some creativity to program under the severe constraints
of a very simple language. And it's very much true that my
little programming diversion is driven by curiosity and wonder.
It's fun to explore ideas in a small space uses limited tools.
What will I find along the way? I'll surely make design choices
that reflect my personal aesthetic sensibilities as well as the
pragmatic sensibilities of a virtual machine that know only
integers and booleans.
I've been thinking a lot about technical debt this week. My student
teams are in Week 13 of their compiler project and getting ready to
submit their final systems. They've been living with their code
long enough now to appreciate
Ward Cunningham's original idea
of technical debt: the distance between their understanding and the
understanding embodied in their systems.
... it was important to me that we accumulate the learnings we did
about the application over time by modifying the program to look as
if we had known what we were doing all along and to look as if it
had been easy to do in Smalltalk.
Actually, I think they are experiencing two gulfs: one relates to
their understanding of the domain, compilers, and the other to
their understanding of how to build software. Obviously, they are
just learning about compilers and how to build one, so their content
knowledge has grown rapidly while they've been programming. But
they are also novice software engineers. They are really just
learning how to build a big software system of any kind. Their
knowledge of project management, communication, and their tools has
also grown rapidly in parallel with building their system.
They have learned a lot about both content and process this semester.
Several of them wish they had time to refactor -- to pay back the
debt they accumulated honestly along the way -- but university
courses have to end. Perhaps one or two of them will do what one or
two students in most past semesters have done: put some of their own
time into their compilers after the course ends, to see if they can
modify the program to look as if they had known what they were doing
all along, and to look as if it had been easy to do in Java or Python.
There's a lot of satisfaction to be found at the end of that path,
if they have the time and curiosity to take it.
One team leader tried to bridge the gulf in real time over the last
couple of weeks: He was so unhappy with the gap between his team's
code and their understanding that he did a complete rewrite of the
first five stages of their compiler. This team learned what every
team learns about rewrites and large-scale refactoring: they spend
time that could otherwise have been spent on new development. In a
time-boxed course, this doesn't always work well. That said, though,
they will likely end up with a solid compiler -- as well as a lot of
new knowledge about how to build software.
Being a prof is fun in many ways. One is getting to watch students
learn how to build something while they are building it, and coming
out on the other side with new code and new understanding.
This morning I read an old blog post by Michael Feathers,
The Flawed Theory Behind Unit Testing.
It discusses what makes TDD and Clean Room software development
so effective for writing code with fewer defects: they define
practices that encourage developers to work in a continuous
state of reflection about their code. The post holds up well
ten years on.
The line that lit my mind up, though, was this one:
John Nolan gave his developers a challenge: write OO code with no getters.
Twenty-plus years after the movement of object-oriented programming
into the mainstream, this still looks like a radical challenge to
many people. "Whenever possible, tell another object to do something
rather than ask for its data." This sort of behavioral abstraction
is the heart of OOP and the source of its design power. Yet it is
rare to find big Java or C++ systems where most classes don't provide
public accessors. When you open that door, client code will walk in
-- even if you are the person writing the client code.
Whenever I look at a textbook intended for teaching undergraduates
OOP, I look to see how it introduces encapsulation and the use of
"getters" and "setters". I'm usually disappointed. Most CS faculty
think doing otherwise would be too extreme for relative beginners.
Once we open the door , though, it's a short step to using (gulp)
instanceof to switch on kinds of objects. No wonder that
some students are unimpressed and that too many students don't see
any much value in OO programming, which as they learn it doesn't
feel much different from what they've done before but which puts
new limitations on them.
To be honest, though, it is hard to go Full Metal OOP. Nolan was
working with professional programmers, not second-year students,
and even so programming without getters was considered a challenge
for them. There are certainly circumstances in which the forces at
play may drive us toward cracking the door a bit and letting an
instance variable sneak out. Experienced programmers know how to
decide when the trade-off is worth it. But our understanding the
downside of the trade-off is improved after we know how to design
independent objects that collaborate to solve problems without
knowing anything about the other objects beyond the services they
provide.
Maybe we need to borrow an idea from the
TDD As If You Meant It
crowd and create workshops and books that teach and practice OOP as
if we really meant it. Nolan's challenge above would be one of the
central tenets of this approach, along with the
Polymorphism Challenge
and other practices that look odd to many programmers but which are,
in the end, the heart of OOP and the source of its design power.
~~~~~
If you like this post, you might enjoy
The Summer Smalltalk Taught Me OOP.
It's isn't about OOP itself so much as about me throwing away systems
until I got it right. But the reason I was throwing systems away was
that I was still figuring out how to build an object-oriented system
after years programming procedurally, and the reason I was learning
so much was that I was learning OOP by building inside of Smalltalk
and reading its standard code base. I'm guessing that code base
still has a lot to teach many of us.
You: Explain this code to me, please.
They: blah blah blah.
You: Show me where the code says that.
They: <silence>
You: Let's make it say that.
I find this strategy quite helpful when writing my own code. If
I can't explain any bit of code to myself clearly and succinctly,
then I can take a step back and work on fixing my understanding
before trying to fix the code. Once I understand, I'm a big fan
of creating functions or methods whose names convey their meaning.
This is also a really handy strategy for me in my teaching. As
a prof, I spend a fair amount of time explaining code I've written
to students. The act of explaining a piece of code, whether
written or spoken, often points me toward ways I can make the
program better. If I find myself explaining the same piece of
code to several students over time, I know the code can probably
be better. So I try to fix it.
I also use a gentler variation of Jeffries' approach when working
directly with students and their code. I try whenever I can to
help my students learn how to write better programs. It can be
tempting to start lecturing them on ways that their program could
be better, but unsolicited advice of this sort rarely finds a
happy place to land in their memory. Asking questions can be more
effective, because questions can lead to a conversation in which
students figure some things out on their own. Asking general
questions usually isn't helpful, though, because students may not
have enough experience to connect the general idea to the details
of their program.
So: I find it helpful to ask a student to explain their code to
me. Often they'll give me a beautiful answer, short and clear,
that stands in obvious contrast to the code we are looking at out.
This discrepancy leads to a natural follow-up question: How
might we change the code so that it says that? The student
can take the lead in improving their own programs, guided by me
with bits of experience they haven't had yet.
Of course, sometimes the student's answer is complex or rambles
off into silence. That's a cue to both of us that they don't
really understand yet what they are trying to do. We can take a
step back and help them fix their understanding -- of the problem
or of the programming technique -- before trying to fix the code
itself.
I recently read Anne-Laure Le Cunff's
Interleaving: Rethink The Way You Learn.
Le Cunff explains why interleaving -- "the process of mixing the
practice of several related skills together" -- is more effective
for long-term learning than blocked practice, in which students
practice a single skill until they learn it and then move on to
the next skill. Interleaving forces the brain to retrieve
different problem-solving strategies more frequently and under
different circumstances, which reinforces neural connections and
improves learning.
To illustrate the distinction between interleaving and blocked
practice, Le Cunff uses this image:
When I saw that diagram, I thought immediately of Extreme Programming.
In particular, I thought of a diagram I once saw that distinguished
XP from more traditional ways of building software in terms of how
quickly it moved through the steps of the development life cycle.
That image looked something like this:
If design is good, why not do it all the time? If testing is good,
why not do it all the time, too?
I don't think that the similarity between these two images is an
accident. It reflects one of XP's most important, if sometimes
underappreciated, benefits: By interleaving short spurts of analysis,
design, implementation, and testing, programmers strengthen their
understanding of both the problem and the evolving code base. They
develop stronger long-term memory associations with all phases of
the project. Improved learning enables them to perform even more
effectively deeper in the project, when these associations are more
firmly in place.
Le Cunff offers a caveat to interleaved learning that also applies
to XP: "Because the way it works benefits mostly our long-term
retention, interleaving doesn't have the best immediate results."
The benefits of XP, including more effective learning, accrue to
teams that persist. Teams new to XP are sometimes frustrated by
the small steps and seemingly narrow focus of their decisions.
With a bit more experience, they become comfortable with the
rhythm of development and see that their code base is more supple.
They also begin to benefit from the more effective learning that
interleaved practice provides.
~~~~
Image 1: This image comes from Le Cunff's article, linked above.
It is by Anne-Laure Le Cunff, copyright Ness Labs 2019, and
reproduced here with permission.
Image 2: I don't remember where I saw the image I hold in my memory,
and a quick search through Extreme Programming Explained
and Google's archives did not turn up anything like it. So I made
my own. It is licensed
CC BY-SA 4.0.
Earlier this week, I read this snippet about the benefits of
"enjoyment bias" in Morgan Housel's
latest blog post:
2. Enjoyment bias: An inefficient investing strategy that
you enjoy will outperform an efficient one that feels like
work because anything that feels like work will eventually
be abandoned.
Getting anything to work requires giving it an appropriate
amount of time. Giving it time requires not getting bored
or burning out. Not getting bored or burning out requires
that you love what you're doing, because that's when the
hard parts become acceptable.
The programmer in me immediately thought, "I have this pattern."
My guess is that this bias applies to a lot of things outside of
investing. In software development, the choices of development
methodology and programming language often benefit from enjoyment
bias.
In programming as in investing, we can take this too far and hurt
ourselves, our teams, and our users. Anything can be overdone.
But, in general, we are more likely to stick with the hard work of
building software when we enjoy the way we are building it and the
tools we are using. Don't let others shame you away from what
works for you.
This bias actually reminded me of a short bit from
one of Paul Graham's essays
on, of all things, procrastination:
I think the way to "solve" the problem of procrastination
is to let delight pull you instead of making a to-do list
push you. Work on an ambitious project you really enjoy,
and sail as close to the wind as you can, and you'll leave
the right things undone.
Delight can keep you happily working when the going gets rough,
and it can pull you toward work when a lack of delight would
leave you killing time on stuff that doesn't matter.
(By the way, I think that several other biases described by
Housel are also useful in programming. Consider the value of
reasonable ignorance, number three on his list....)
So the Sage Air Defense system, which never produced a single
usable line of software running on any piece of hardware -- we
spent more on the Sage Air Defense System than we did on the
entire Manhattan Project. And it was in one sense the ultimate
government Defense Department boondoggle. But on the other hand
it trained a whole generation of computer programmers at a time
when very little else was useful that computer programmers could
exercise their skills on.
And by the time the 1960s rolled around we not only ... the fact
that Sage had almost worked provided say American Airlines with
the idea that maybe they should do a computer-driven reservations
system for their air travel, which I think was the next big
Manhattan Project-scale computer programming project.
And as that moved on the computer programmers began finding more
and more things to do, especially after IBM developed its System
360.
And we were off and running.
As DeLong says earlier in the conversation, this development
upended IBM president Thomas Watson's alleged claim that there
was "a use for maybe five computers in the world". This famous
quote is almost certainly
an urban legend,
but Watson would not have been as off-base as people claim even
if he had said it. In the 1950s, there was not yet a widespread
need for what computers did, precisely because most people did
not yet understand how computing could change the landscape of
every activity. Training a slew of programmers for a project
that ultimately failed had the unexpected consequence of
creating the intellectual and creative capital necessary to
begin exploring the ubiquitous applications of computing. Money
unexpectedly well spent.
The line that merits its link in today's session is:
We wrote an ugly, fragile state machine for our typeahead,
which quickly became a source of pain and shame.
My students will soon likely experience those emotions about
the state machines; they are building for lexers for their
semester-long compiler project. I reassure them: These
emotions are normal for programmers.
Software grows until it exceeds our capacity to understand it.
In the case of Raganwald's tweet, languages that enable us to handle
accidental complexity well lead to more accidental complexity,
because the people who use them will be more be more ambitious -- until
they reach their saturation point. Both of these observations about
software resemble the original Peter Principle, in which people who
succeed are promoted until they reach a point at which they can't, or
don't, succeed.
I am happy to dub Raganwald's observation "The Peter Principle of
Accidental Complexity", but after three examples, I begin to recognize
a pattern... Is there a general name for this phenomenon, in which
successful actors advance or evolve naturally until they reach a point
at which the can't, or don't, succeed?
I wasn't getting any work done today on my to-do list, so I
decided to write some code.
One of my learning exercises to open
the Summer of Joy
is to solve the term frequency problem from Crista Lopes's
Exercises in Programming Style.
Joy is a little like Scheme: it has a lot of cool operations,
especially higher-order operators, but it doesn't have much in
the way of practical level tools for basic tasks like I/O. To
compute term frequencies on an arbitrary file, I need to read
the file onto Joy's stack.
I played around with Joy's low-level I/O operators for a while
and built a new operator called readfile, which
expects the pathname for an input file on top of the stack:
The first line leaves an empty list and an input stream object
on the stack. Line 2 reads lines from the file and conses them
onto the list until it reaches EOF, leaving a list of lines
under the input stream object on the stack. The last line
closes the stream and pops it from the stack.
This may not seem like a big deal, but I was beaming when I got
it working. First of all, this is my first while
in Joy, which requires two quoted programs. Second, and more
meaningful to me, the loop body not only works in terms of the
dip idiom I mentioned in my previous post, it even
uses the higher-order swonsd operator to implement
the idiom. This must be how I felt the first time I mapped an
anonymous lambda over a list in Scheme.
readfile leaves a list of lines on the stack.
Unfortunately, the list is in reverse order: the last line of the
file is the front of the list. Besides, given that Joy is a
stack-based language, I think I'd like to have the lines on the
stack itself. So I noodled around some more and implemented the
operator pushlist:
DEFINE pushlist ==
(* 1 *) [ null not ] [ uncons ] while
(* 2 *) pop.
Look at me... I get one loop working, so I write another. The
loop on Line 1 iterates over a list, repeatedly taking
(head . tail) and pushing head and tail onto the
stack in that order. Line 2 pops the empty list after the loop
terminates. The result is a stack with the lines from the file in
order, first line on top:
line-n ... line-3 line-2 line-1
Put readfile and pushlist together:
DEFINE fileToStack == readfile pushlist.
and you get fileToStack, something like Python's
readlines() function, but in the spirit of Joy: the
file's lines are on the stack ready to be processed.
I'll admit that I'm pleased with myself, but I suspect that this
code can be improved. Joy has a lot of dandy higher-order operators.
There is probably a better way to implement pushlist
and maybe even readfile. I won't be surprised if
there is a more idiomatic way to implement the two that makes the
two operations plug together with less rework. And I may find that
I don't want to leave bare lines of text on the stack after all and
would prefer having a list of lines. Learning whether I can improve
the code, and how, are tasks for another day.
My next job for solving the term frequency problem is to split the
lines into individual words, canonicalize them, and filter out stop
words. Right now, all I know is that I have two more functions in
my toolbox, I learned a little Joy, and writing some code made my
day better.
"Elementary" ideas are really hard & need to be revisited
& explored & re-revisited at all levels of mathematical
sophistication. Doing so actually moves math forward.
--
James Tanton
Three summers ago, I spent a couple of weeks re-familiarizing
myself with the concatenative programming language Joy and trying
to go a little deeper with the style. I even wrote a few blog
entries, including
a few quick lessons
I learned in my first week with the language. Several of those
lessons hold up, but please don't look at the code linked there;
it is the raw code of a beginner who doesn't yet get the idioms
of the style or the language. Then other duties at work and home
pulled me away, and I never made the time to get back to my studies.
I have dubbed this the Summer of Joy. I can't devote the entire
summer to concatenative programming, but I'm making a conscious
effort to spend a couple of days each week in real study and
practice. After only one week, I have created enough forward
momentum that I think about problems and solutions at random
times of the day, such as while walking home or making dinner. I
think that's a good sign.
An even better sign is that I'm starting to grok some of the
idioms of the style. Joy is different from other concatenative
languages like Forth and Factor, but it shares the mindset of
using stack operators effectively to shape the data a program
uses. I'm finally starting to think in terms of
dip, an operator that enables a program to
manipulate data just below the top of the stack. As a result,
a lot of my code is getting smaller and beginning to look like
idiomatic Joy. When I really master dip and
begin to think in terms of other "dipping" operators, I'll know
I'm really on my way.
One of my goals for the summer is to write a Joy compiler from
scratch that I can use as a demonstration in my fall compiler
course. Right now, though, I'm still in Joy user mode and am
getting the itch for a different sort of language tool... As my
Joy skills get better, I find myself refactoring short programs
I've written in the past. How can I be sure that I'm not breaking
the code? I need unit tests!
So my first bit of tool building is to implement a simple JoyUnit.
As a tentative step in this direction, I created the simplest
version of RackUnit's
check-equal?
function possible:
DEFINE check-equal == [i] dip i =.
This operator takes two quoted programs (a test expression and an
expected result), executes them, and compares the results. For
example, this test exercises a square function:
[ 2 square ] [ 4 ] check-equal.
This is, of course, only the beginning. Next I'll add a message to
display when a test fails, so that I can tell at a glance which
tests have failed. Eventually I'll want my JoyUnit to support tests
as objects that can be organized into suites, so that their results
can be tallied, inspected, and reported on. But for now, YAGNI.
With even a few simple functions like this one, I am able to run
tests and keep my code clean. That's a good feeling.
To top it all off, implementing JoyUnit will force me to practice
writing Joy and push me to extend my understanding while growing
the set of programming tools I have at my disposal. That's another
good feeling, and one that might help me keep my momentum as a busy
summer moves on.
Sometimes I believe that writing software, while great, will
never be huge like writing a book that will survive for
centuries. Not because software is not as great per se, but
because as a side effect it is also useful... and will be
replaced when something more useful is around.
We write most software with a particular use in mind, so it
is really only fair to compare it to non-fiction books,
which also have a relatively short shelf life. To be fair,
though, not many fiction books survive for centuries, either.
Language and fashion doom them almost as much as evolving
technology destines most software to fade away within a
generation, and a short generation at that.
Still, I won't be surprised if the DNA of Smalltalk-80 or
some early Lisp implementation lives on deep in a system
that developers use in the 22nd century.
There are several modern APL-like languages today -- such as J
and K -- but I would criticize them as being too much like the
classic APL. It is possible to extract what is really great
from APL and use it in new language designs without being so
tied to the past. This would be a great project for some grad
students of today: what does the APL perspective mean today,
and what kind of great programming language could be inspired
by it?
The APL perspective was more radical even twenty years ago,
before MapReduce became a thing and before functional
programming ascended. When I was an undergrad, though, it
seemed otherworldly: setting up a structure, passing it through
a sequence of operators that changed its shape, and then passing
it through a sequence of operators that folded up a result. We
knew we weren't programming in Fortran anymore.
I'm still fascinated by APL, but I haven't done a lot with it in
the intervening years. These days I'm still thinking about
concatenative programming in languages like Forth, Factor, and
Joy, a project I reinitiated (and last
blogged about)
three summers ago. Most concatenative languages work with an
implicit stack, which gives it a very different feel from APL's
dataflow style. I can imagine, though, that working in the
concision and abstraction of concatenative languages for a
while will spark my interest in diving back into APL-style
programming some day.
Kay's full answer is worth a read if only for the story in which
he connects Iverson's APL notation, and its effect on
how we understand computer systems, to the evolution of Maxwell's
equations. Over the years, I've heard Kay talk about
McCarthy's Lisp interpreter
as akin to Maxwell's equations, too. In some ways, the analogy
works even better with APL, though it seems that the lessons of
Lisp have had a larger historical effect to date.
Perhaps that will change? Alas, as Kay says in the paragraph
that precedes his challenge:
As always, time has moved on. Programming language ideas move
much slower, and programmers move almost not at all.
Kay often comes off as pessimistic, but after all the computing
history he has lived through (and created!), he has earned
whatever pessimism he feels. As usual, reading one of his
essays makes me want to buckle down and do something that would
make him proud.
Nevertheless, the spreadsheet was something never seen before.
A chart indicating the 64 greatest events in accounting and
business history contains VisiCalc.
This reminds me of a line from The Tao of Pooh:
Take the path to Nothing, and go Nowhere until you reach it.
A lot of research is like this, but even more so in computer
science, where the things we produce are generally made out
of nothing. Often, like VisiCalc, they aren't really like
anything we've ever seen or used before either.
In
one of his "Conversations with Tyler",
Tyler Cowen talks with Daniel Kahneman about intuition and its
relationship to thinking fast and slow. According to Kahneman,
evidence supports his position that most people have not had
the experience necessary to develop intuition that is good
enough for solving problems directly. So he thinks that most
people, including most so-called experts, should slow down.
So I think delaying intuition is a very good idea. Delaying
intuition until the facts are in, at hand, and looking at
dimensions of the problem separately and independently is a
better use of information.
The problem with intuition is that it forms very quickly, so
that you need to have special procedures in place to control
it except in those rare cases...
...
Break the decision up. It's not so much a matter of time because
you don't want people to get paralyzed by analysis. But it's a
matter of planning how you're going to make the decision, and
making it in stages, and not acting without an intuitive certainty
that you are doing the right thing. But just delay it until all
the information is available.
This is one of the things that I find most helpful about test-driven
design when I practice it faithfully. It's pretty easy for me to
think that I know everything I need to implement a program after
I've read the spec and thought about it for a few minutes. I mean,
I've written a lot of code over the years... If my intuition tells
me where to go, I can start right away and have the whole path ahead
of me in my mind.
But how often do I really have evidence that my intuitive plan is
the correct one? If I'm wrong, I'll spend a bunch of time and write
a bunch of code, only later to find out I'm wrong. What's worse,
all that code I've written usually ends up feeling like a constraint
within which I have to work as I try to dig myself out of the mess.
Writing one test at a time and implementing just the code I need to
pass it is a way to force my intuitive mind to slow down. It helps
me think about the actual problem I'm solving, rather than the
abstraction my expert brain infers from the spec. The program
grows slowly along side my understanding and points me in the
direction of the next small step to take.
TDD is a procedure I can put in place to help me control my
intuition until the facts are in, and it encourages me to look at
different dimensions of the problem independently as write the code
to solve them.
When I refactor my code, I most often think in terms of what
Martin Fowler calls
preparatory refactoring:
if it's difficult to add a new feature to my program, I refactor
the existing code into a state where the feature fits naturally
somewhere, then I add the feature. As is often the case, Kent
Beck captured this notion memorably in
a tweet-sized aphorism.
I was delighted to see that Martin's blog post, which I remember
fondly, cites the same tweet!
Ideas from programming are usually instances of more general
ideas from the broader world, specialized to a world of bits
and computation. Back when I taught our object-oriented
programming course every semester, I often referred my
students to a web site that offered real-life examples of the
various design patterns we were learning. I remember an
example of Decorator that showed how we can embellish a
painting with a matte or a frame, and its use of the U.S.
Constitution's specification of the President to illustrate
the idea of a Singleton. I can't find that site on the web
just now, but there's almost surely a local copy buried in
one of my course websites from way back.
The idea of refactoring is useful outside the world of software,
too. Just yesterday, my dean suggested what I consider to be
a preparatory refactoring.
A committee on campus is charged with proposing ways that the
university can restructure its colleges and departments. With
the exception of a merger of two colleges a few years ago, we
have had essentially the same academic structure for my entire
time here. In those years, disciplines have changed and
budgets have changed, so now the administration is thinking
that the university might be more efficient or more productive
with a different structure. Thinking about the process from
this perspective, restructuring is largely a reaction to change
that has already happened.
My dean suggested another way to approach the task. Think, he
said, of the new academic programs that you'd like to create in
the future. We may not have money available right now to create
a new major or to organize a new research center, but one day
we might. What university structure would make adding this
program go more smoothly and work better once in place? Which
departments would the new program want to work with? Which
administrative structures already in place would minimize
unnecessary overhead of the new program?
As much as possible, he suggested, let's try to create a new
academic structure that suits the future programs we'd like to
build. That will reduce friction later, which is good:
Administrative friction often grinds new academic ideas to a
halt before they get off the ground.
In programming terms, this is quite bit different than the sort
of refactoring I prefer. I try to practice
YAGNI
and refactor only for the specific feature that I want to add
right now, not taking into account imagined future features I
may never need. In terms of academic structure, though, this
sort of ip-front design makes a lot of sense. Academic
structures are much harder to change than software; getting a
few things right now may make future changes at the program
level much easier to implement later.
Thinking about academic restructuring this way has another
positive side effect: it might entice faculty to be more
engaged, because what we do now matters to the future we would
like to build. It's not merely a reaction to past changes.
My dean is suggesting that we build academic structures now
that make the changes we want to implement later (when the
resources and requisite will exist) easier to implement.
Building those structures now may take more work than simply
responding to past changes, but it will be worth the effort
when we are ready to create new programs. I think Kent and
Martin might be proud.
I ran across
an old interview with Douglas Crockford
recently. When asked what traits were common to the weak
programmers he'd seen over his career, Crockford said:
That's an easy one: lack of curiosity. They were so satisfied
with the work that they were doing was good enough (without an
understanding of what 'good' was) that they didn't push
themselves.
I notice a lack of curiosity in many CS students, too. It's
even easier for beginners than professional programmers to be
satisfied with meeting the minimal requirements of a project --
"I got the right answers!" or, much worse, "It compiles!" -- and
not realize that good code can be more. Part of our goal as
teachers is to help students develop higher standards and more
refined taste while they are in school.
There's another sense, though, in which holding students' lack
of curiosity against them is a dangerous trap for professors.
In moments of weakness, I occasionally look at my students and
think, "Why doesn't this excite them more? Why don't they want
to write code for fun?" I've come to realize over the years
that our school system doesn't always do much to help students
cultivate their curiosity. But with a little patience and a
little conversation, I often find that my students are
curious -- just not always about the things that intrigue me.
This shouldn't be a surprise. Even at the beginning of my
career as a prof, I was a different sort of person than most of
my students. Now that I'm a few years older, it's almost certain
that I will not be in close connection with my students and what
interests them most. Why would they necessarily care about the
things I care about?
Bridging this gap takes time and energy. I have to work to build
relationships both with individuals and with the group of
students taking my course each semester. This work requires
patience, which I've learned to appreciate more and more as I've
taught. We don't always have the time we need in one semester,
but that's okay. One of the advantages of teaching at a smaller
school is time: I can get to know students over several semesters
and multiple courses. We have a chance to build relationships
that enrich the students' learning experience -- and my
experience as a teacher.
Trying to connect with the curiosity of many different students
creates logistical challenges when designing courses, examples,
and assignments, of course. I'm often drawn back to Alan Kay's
paradigm, Frank Oppenheimer's Exploratorium, which Kay discussed
in
his Turing Award lecture.
The internet is, in many ways, a programmer's exploratorium, but
it's so big, so disorganized, and of such varying levels of
quality... Can we create collections of demos and problems that
will contain something to connect with just about every student?
Many of my posts on this blog, especially in the early years,
grappled with this idea. (Here are two that specifically mention
the Exploratorium:
Problems Are The Thing
and
Mathematics, Problems, and Teaching.)
Sometimes I think the real question isn't: "Why aren't students
more curious?" It is: "Are we instructors curious enough about
our students?"
I always have to warn my students before they attend SIGCSE that
it's not a place for deep and nuanced discussions about learning,
nor is it a place to get critical feedback about their ideas.
It is, however, a wonderful place to be immersed in the concerns
of CS teachers and their perceptions of evidence.
I'm not sure I agree that one can't have deep, nuanced discussions
about learning at SIGCSE, but it certainly is not a research
conference. It is a great place to talk to and learn from people
in the trenches teaching CS courses, with a strong emphasis on the
early courses. I have picked up a lot of effective, creative, and
inspiring ideas at SIGCSE over the years. Putting them onto sure
scientific footing is part of my job when I get back.
Unless we can understand the real reasons why programmers
continue to use C, we risk researchers continuing to solve
a set of problems that is incomplete and/or irrelevant, while
practitioners continue to use flawed tools.
For example,
... "faster safe languages" is seen as the Important Research
Problem, not better integration.
... whereas Kell believes that C's superiority in the realm of
integration is one of the main reasons that C remains a
dominant, essential systems language.
Even with the freedom granted by tenure, academic culture tends
to restrict what research gets done. One cause is a desire to
publish in the best venues, which encourages work that is valued
by certain communities. Another reason is that academic research
tends to attract people who are interested in a certain kind of
clean problem. CS isn't exactly "round, spherical chickens in a
vacuum" territory, but... Language support for system integration,
interop, and migration can seem like a grungier sort of work than
most researchers envisioned when they went to grad school.
"Some Were Meant for C" is an elegant paper, just the sort of work,
I imagine, that Richard Gabriel had when envisioned the essays
track at Onward. Well worth a read.
The thing I'm really frustrated by is that it doesn't matter whether
people are writing from a socialist or a libertarian perspective.
Too much of the discussion of political economy is normative. It's
about "what should the ideal state be?"
I'm much more concerned with the questions of "what good states are
possible?" And once good states are created that are possible, what
good states are sustainable? And that, in my view, is a still
understudied and very poorly understood issue.
For some reason, this made me think about software development.
Programming styles, static and dynamic typing, software development
methodologies, ... So much that is written about these topics tells
us what's the right the thing to do. "Do this, and you will be able
to reliably make good software."
I know I've been partisan on some of these issues over the course
of my time as a programmer, and I still have my personal preferences.
But these days especially I find myself more interested in "what
good states are sustainable?". What has worked for teams? What
conditions seem to make those practices work well or not so well?
How do teams adapt to changes in the domain or the business or the
team's make-up?
This isn't too say that we can't draw conclusions about forces and
context. For example, small teams seem to make it easier to adapt
to changing conditions; to make it work with bigger teams, we need
to design systems that encourage attention and feedback. But it
does mean that we can help others succeed without always telling
them what they must do. We can help them find a groove that syncs
with them and the conditions under which they work.
Standing back and surveying the big picture, it seems that a lot of
good states are sustainable, so long as we pay attention and adapt
to the world around us. And that should be good news to us all.
I have said that a book is a collection of components.
I have concrete evidence that some of my users
specifically excerpt sections that suit their purpose.
...
I forecast that one day, rich document formats like PDF
will recognize this reality and permit precisely such
specifications. Then, when a user selects a group of
desired chapters to generate a thinner volume, the
software will automatically evaluate constraints and
include all dependencies. To enable this we will even
need "program" analyses that help us find all the
dependencies, using textual concordances as a starting
point and the index as an auxiliary data structure.
I am one of the users Krishnamurthi speaks of, who has
excerpted sections from his
Programming Languages: Application and Interpretation
to suit the purposes of my course. Though I've not written
a book, I do post, use, adapt, and reuse detailed lecture
notes for my courses, and as a result I have seen both sides
of the divide he discusses. I occasionally change the order
of topics in a course, or add a unit, or drop a unit. An
unseen bit of work is to account for the dependencies among
concepts, examples, problems, and code in the affected
sections, but also in the new whole. My life is simpler
than book writers who have to deal at least in part with
rich document formats: I do everything in a small, old-style
subset of HTML, which means I can use simple text-based
tools for manipulating everything. But dependencies? Yeesh.
Maybe I need to write a big
makefile
for my course notes. Alas, that would not help me manage
dependencies in the way I'd like, or in the way Krishnamurthi
forecasts. As such, it would probably make things worse. I
suppose that I could create the tool I need.
Building reusable code is something that's easier to do in
hindsight with a couple of examples of use in the code base,
than foresight of ones you might want later. On the plus
side, you're probably re-using a lot of code already just
by using the file-system, why worry that much? A little
redundancy is healthy.
It's good to copy-paste code a couple of times, rather than
making a library function, just to get a handle on how it
will be used. Once you make something a shared API, you
make it harder to change.
There's not a great one-liner in there, but these paragraphs
point to a really important lesson, one that we programmers
sometimes have a hard time learning. We are told so often
"don't repeat yourself" that we come to think that all
repetition is the same. It's not.
One use of repetition is in avoiding what @tef calls, in
another 'programming is terrible' post,
"preemptive guessing". Consider the creation of a new framework.
Oftentimes, designing a framework upfront doesn't work very
well because we don't know the domain's abstractions yet. One
of the best ways to figure out what they are is to write
several applications first, and let framework fall out the
applications. While doing this, repetition is our friend: it's
most useful to know what things don't change from one
application to another. This repetition is a hint on how to
build the framework we need. I learned this technique from
Ralph Johnson.
I use and teach a similar technique for programming in smaller
settings, too. When we see two bits of code that resemble one
another, it often helps to
increase the duplication in order to eliminate it.
(I learned this idea from Kent Beck.) In this case, the goal
of the duplication is to find useful abstractions. Sometimes,
though, code duplication is really
a hint to think differently about a problem.
Factoring out a function or class -- finding a new abstraction
-- may be incidental to the learning that takes place.
For me, this line from from the second programming-is-terrible
post captures this idea perfectly:
... duplicate to find the right abstraction first, then
deduplicate to implement it.
My spell checker objects to the word "deduplicate", but I'll
allow it.
All of these ideas taken together are the reason that I think
copy-and-paste gets an undeservedly bad name. Used properly,
it is a valuable programming technique -- essential, really.
I've long wanted to write a
Big Ball of Mud-style
paper about copy-and-paste patterns. There are plenty of good
reasons why we write repetitive code and, as @tef says in the
two posts I link to above, sometimes leaving duplication in
your code is the right thing to do.
One final tribute to repetition for now. While researching
this blog post, I ran across
a blog entry of mine
from October 2016. Apparently, I had just read @tef's
Write code that is easy to delete...
post and felt an undeniable urge to quote and comment on it.
If you read that 2016 post, you'll see that my
Writing code that is easy to delete
post from last week duplicates it in spirit and, in a few
cases, even the details. I swear that I read @tef's post
again last week and wrote the new blog entry from scratch,
with no memory of the 2016 events.
I am perfectly happy with this second act. Sometimes, ideas
circle through our brains again, changing us in imperceptible
ways. As @tef says, a little redundancy is healthy.
Programming Never Feels Easier. You Just Solve Harder Problems.
Alex Honnold
is a rock climber who was the first person to "free solo"
Yosemite's El Capitan rock wall. In an interview for a
magazine, he was asked what it takes to reach ever higher
goals. One bit of advice was to "aim for joy, not euphoria".
When you prepare to achieve a goal, it may not feel like
a big surprise when you achieve it because you
prepared to succeed. Don't expect to be overwhelmed by
powerful emotions when you accomplish something new; doing
so sets too high a standard and can demotivate you.
This paragraph, though, is the one that spoke to me:
Someone recently said to me about running: "It never feels
easier--you just go faster." A lot of sports always feel
terrible. Climbing is always like that. You always feel
weak and like you suck, but you can do harder and harder
things.
As a one-time marathoner, never fast but always training
to run a PR in my next race, I know what Honnold means.
However, I also feel something similar as a programmer.
Writing software often seems like a slog that I'm not
very good at. I'm forever looking up language features
in order to get my code to work, and then I end up with
programs that are bulky and fight me at every turn. I
refactor and rewrite and... find myself back in the slog.
I don't feel terrible all that often, but I am usually a
little on edge.
Yet if I compare the programs I write today with ones I
wrote 5 or 10 or 30 years ago, I can see that I'm doing
more interesting work. This is the natural order. Once
I know how to do one thing, I seek tougher problems to
solve.
In the article, the passage quoted above is labeled
"Feeling awful is normal." I wonder if programming feels
more accessible to people who are comfortable with a
steady, low-grade intellectual discomfort punctuated by
occasional bouts of head banging. Honnold's observation
might reassure beginning programmers who don't already
know that feeling uneasy is a natural part of pushing
yourself to do more interesting work.
All that said, even when I was training for my next
marathon, I was always able to run for fun. There was
nothing quite like an easy run at sunrise to boost my
mood. Fortunately, I am still able to program that
way, too. Every once in a while, I like to write code
to solve some simple problem I run across on Twitter or
in a blog entry somewhere. I find that these interludes
recharge me before I battling the next big problem I
decide to tackle. I hope that my students can still
programming in this way as they advance on to bigger
challenges.
Last week someone tweeted a link to
Write code that is easy to delete, not easy to extend.
It contains a lot of great advice on how to create codebases
that are easy to maintain and easy to change, the latter
being an essential feature of almost any code that is the
former. I liked this article so much that I wanted to share
some of its advice here. What follows are a few of the many
one- and two-liners that serve as useful slogans for building
maintainable software, with light commentary.
... repeat yourself to avoid creating dependencies, but don't
repeat yourself to manage them.
This line from the first page of the paper hooked me. I'm
not sure I had ever had this thought, at least not so
succinctly, but it captures a bit of understanding that I
think I had. Reading this, I knew I wanted to read the rest
of the article.
Make a util directory and keep different utilities
in different files. A single util file will always
grow until it is too big and yet too hard to split apart.
Using a single util file is unhygienic.
This isn't the sort of witticism that I quote in the rest of
this post, but its solid advice that I've come to live by
over the years. I have this pattern.
Boiler plate is a lot like copy-pasting, but you change some
of the code in a different place each time, rather than the
same bit over and over.
I really like the author's distinction between boilerplate
and copy-and-paste. Copy-and-paste has valuable uses
(heresy, I know; more later), whereas boilerplate sucks the
joy out of almost every programmer's life.
You are writing more lines of code, but you are writing
those lines of code in the easy-to-delete parts.
Another neat distinction. Even when we understand that
lines of code are an expense as much as (or instead of) an
investment, we know that sometimes we have write more code.
Just do it in units that are easy to delete.
A lesson in separating concerns, from Python libraries:
requests is about popular http adventures,
urllib3 is about giving you the tools to choose
your own adventure.
Layers! I have had users of both of these libraries
suggest that the other should not exist, but they serve
different audiences. They meet different needs in a way
that that more than makes up for the cost of the supposed
duplication.
Building a pleasant to use API and building an extensible
API are often at odds with each other.
There's nothing earth-shattering in this observation, but I
like to highlight different kinds of trade-off whenever I
can. Every important decision we make writing programs is
a trade-off.
Good APIs are designed with empathy for the programmers who
will use it, and layering is realising we can't please
everyone at once.
This advice elaborates on the quote earlier to repeat code in
order not to create dependencies, but not to manage them.
Creating a separate API is one way to avoid dependencies to
code that are hard to delete.
Sometimes it's easier to delete one big mistake than try to
delete 18 smaller interleaved mistakes.
Sometimes it really is best to write a big chunk of code
precisely because it is easy to delete. An idea that is
distributed throughout a bunch of functions or modules has
to be disentangled before you can delete it.
Becoming a professional software developer is accumulating a
back-catalogue of regrets and mistakes.
I'm going to use this line in my spring Programming Languages
class. There are unforeseen advantages to all the practice
we profs ask students to do. That's where experience comes
from.
We are not building modules around being able to re-use them,
but being able to change them.
This is another good bit of advice for my students, though
I'll write this one more clearly. When students learn to
program, textbooks often teach them that the main reason to
write a function is that you can reuse it later, thus saving
the effort of writing similar code again. That's certainly
one benefit of writing a function, but experienced programmers
know that there are other big wins in creating functions,
classes, and modules, and that these wins are often even more
valuable than reuse. In my courses, I try to help students
appreciate the value of names in understanding and
modifying code. Modularity also makes it easier to
change and, yes, delete code. Unfortunately, students don't
always get the right kind of experience in their courses to
develop this deeper understanding.
Although the single responsibility principle suggests that
"each module should only handle one hard problem", it is more
important that "each hard problem is only handled by one
module".
Lovely. The single module that handles a hard problem is a
point of leverage. It can be deleted when the problem goes
away. It can be rewritten from scratch when you understand
the problem better or when the context around the problem
changes.
This line is the heart of the article:
The strategies I've talked about -- layering, isolation,
common interfaces, composition -- are not about writing good
software, but how to build software that can change over time.
Good software is software that can you can change. One way
to create software you can change is to write code that you
can easily replace.
Good code isn't about getting it right the first time. Good
code is just legacy code that doesn't get in the way.
A perfect aphorism to close to the article, and to perfect way
to close this post: Good code is legacy code that doesn't get
in the way.
So my proposal for Rust 2019 is not that big of a deal,
I guess: we just need to redesign our decision making
process, reorganize our governance structures, establish
new norms of communication, and find a way to redirect a
significant amount of capital toward Rust contributors.
A solid understatement usually makes me smile. Decision-making
processes, governance structure, norms of communication,
and compensation for open-source developers... no big
deal, indeed. We all await the results. If the results
come with advice that generalizes beyond a single project,
especially the open-source compensation thing, all the
better.
Communication is a big part of the recommendation for
2019. Changing how communication works is tough in any
organization, let alone an organization with distributed
membership and leadership. In every growing organization
there eventually comes the time for intentional systems
of communication:
But we've long since reached the point where coordinating
our design vision by osmosis is not working well. We
need an active and intentional circulatory system for
information, patterns, and frameworks of decision making
related to design.
I'm not a member of the Rust community, only an observer.
But I know that the language
inspires some programmers,
and I learned a bit about its tool chain and community
support a couple of years ago when an ambitious student
used it successfully to implement his compiler in my
course. It's the sort of language we need, being created
in what looks to be an admirable way. I wish the Rust
team well as they tackle their organizational debt and
tackle their growing pains.
If it matters enough to be careful, it matters enough to build a system.
In
Quality and Effort,
Seth Godin reminds us that being careful can take us only
so far toward the quality we seek. Humans make mistakes,
so we need processes and systems in place to help us
avoid them. Near the end of the post, he writes:
In school, we harangue kids to be more careful, and
spend approximately zero time teaching them to build
better systems instead. We ignore checklists and
processes because we've been taught that they're
beneath us.
This paragraph isolates one of the great powers we can
teach our students, but also a glaring weakness in how
most of us actually teach. I've been a professor for
many years now, and before that I was a student for many
years. I've seen a lot of students succeed and a few
not do as well as they or I had hoped. Students who are
methodical, patient, and disciplined in how they read,
study, and program are much more likely to be in the
successful group.
Rules and discipline sometimes get a bad rap these days.
Creativity and passion are our catchwords. But dull,
boring systems are often the keys that unlock the doors
to getting things done and moving on to learn and do
cooler things.
Students occasionally ask me why I slavishly follow the
processes I teach them, whether it's a system as big as
test-first development and refactoring or a process as
simple as the technique for creating NFAs and converting
them to DFAs. I tell them that I don't always trust
myself but that I do trust the system: it almost always
leads me to a working solution. Sure, in this moment or
that I might be fine going off script, but... Good
habits generate positive returns, while freewheeling it
too often lets an error sneak in. (When I go off script
in class, they too often get to see just that!)
We do our students a great favor when when we help them
learn systems that work. Following a
design recipe
or something like it may be boring, but students who
learn to follow it develop stronger programming skills,
enjoy the success of getting projects done successfully,
and graduate on to more interesting problems. As the
system becomes ingrained as habit, they usually begin to
appreciate it as an enabler of their success.
I agree with Godin: If it matters enough to be careful,
then it matters enough to build (or learn) a system.
This morning I read
Against Software Development,
which considers two tragedies of software development and a
moral exhortation. One of the tragedies:
Software grows until it exceeds our capacity to understand it.
This observation reminds me of
the Peter Principle
from business management, which points out that people in a
business are promoted until to they reach a level at which
they are incompetent. Success in the hierarchy ends when
people find that their skills no longer match the needs of
their job.
We see something similar in software. We write a program to
solve a problem. At this point, we understand the program
completely so, when we see an opportunity for a new feature,
we extend it. We still understand the system, so we add a
bit more complexity, either implementing a new subtask or
elaborating an existing feature with more detail. This
process keeps happening until... we don't understand the
program any more. Or, more likely, we understand it at a
macro level but no longer grok all of the interconnections
and dependencies among components.
The result is Peter-like: the program stops growing. The
root cause is not the incompetence of developers, but a fear
born out complexity.
Having a system under a comprehensive set of tests can help
stave off this fear. With careful attention, some time, and
energy, we can use refactoring can sometimes reverse the
entropy that sets in over time. But often the practicalities
of organizations leave us with a big piece of software that
we don't really understand, a system that can't grow or be
changed to fit the evolving context in which it operates.
Many companies then find themselves in an odd situation:
ossifying the organization's processes and procedures in order
to stay in conformance with a piece of software its developers
no long understand. Software rigidity becomes organizational
rigidity.
Stay vigilant! With good development practices, perhaps you
can push the point of no understanding farther into the future.
But be ready for the day. It will probably arrive, sooner or
later.
Beds are useful. I enjoyed my bed at the hotel last night. But
you won't find a pattern called bed in A Pattern Language,
and that's because we don't have a problem with beds. Beds are
solved. What we have a problem with is building with beds. And
that's why, if you look in A Pattern Language, you'll
find there are a number of patterns that involve beds.
Now, the analogy I want to make is, basically, the design patterns
in the book Design Patterns are at the same level as the
building blocks in the book A Pattern Language. So Bridge,
which is one of the design patterns, is the same kind of thing as
column. You can call it a pattern, but it's not really a pattern
that gets at the root problem we're trying to solve. And if
Alexander had written a book that had a pattern called Bed and
another one called Chair, I imagine that that book would have
failed and not inspired all of the people that the actual book
did inspire. So that, I claim, is why patterns failed.
Those two nearly-sequential paragraphs are from
Patterns Failed. Why? Should We Care?,
a talk Brian Marick gave at
Deconstruct 2017.
It's a good talk. Marick's provocative claim that, as an idea,
software patterns failed is various degrees of true and false
depending on how you define 'patterns' and 'failed'. It's hard
to declare the idea an absolute failure, because a lot of
software developers and UI designers use patterns to good effect
as a part of their work every day. But I agree with Brian that
software patterns failed to live up to their promise or to the
goals of the programmers who worked so hard to introduce
Christopher Alexander's work to the software community. I agree,
too, that the software pattern community's inability to document
and share patterns at the granularity that made Alexander's
patterns so irresistible is a big part of why.
I was a second- or third-generation member of the patterns
community, joining in after Design Patterns had been
published and, like Marick, I worked mostly on the periphery.
Early on I wrote patterns that related to my knowledge-based
systems work. Much of my pattern-writing, though, was at the
level of elementary patterns, the patterns that novice programmers
learn when they are first learning to program. Even at that
level, the most useful patterns often were ones that operated up
one level from the building blocks that novices knew.
Consider
Guarded Linear Search,
from the Loop Patterns paper that Owen Astrachan and I
workshopped at
PLoP 1998.
It helps beginners learn how to arrange a loop and an if
statement in a way that achieves a goal. Students in my beginning
courses often commented how patterns like this one helped them
write programs because, while they understood if
statements and for statements and while
statements, they didn't always know what to do with them
when facing a programming task. At that most elementary level,
the Guarded Linear Search pattern was a pleasing -- and useful --
whole.
That said, there aren't many "solved problems" for beginners, so
we often wrote patterns that dropped down to the level of building
blocks simply to help novices learn basic constructs. Some of the
Loop Patterns paper does that, as does Joe Bergin's
Patterns for Selection.
But work in the elementary patterns community would have been much
more valuable, and potentially had more effect, if we had thought
harder about how to find and document patterns at the level of
Alexander's patterns.
Perhaps the patterns sub-community in which I've worked in which
best achieved its goals was the
pedagogical patterns
community. These are not software patterns but rather patterns
of teaching techniques. They document solutions to problems that
teachers face every day. I think I'd be willing to argue that
the primary source of pedagogical patterns' effectiveness is that
these solutions combine more primitive building blocks (delivery
techniques, feedback techniques, interaction techniques) in a way
that make learning and instruction both more effective and more
fun. As a result, they captured a lot of teachers' interest.
I think that Marick's diagnosis also points out the error in a
common criticism of software patterns. Over the years, we often
heard folks say that software patterns existed only because people
used horrible languages like C++ and Java. In a more powerful
language, any purported pattern would be implemented as a language
primitive or could be made a primitive by writing a macro.
But this misses the point of Alexander's insight. The problem in
software development isn't with inheritance and message passing
and loops, just as the problem in architecture isn't with beds and
windows and space. It's with finding ways to arrange these
building blocks in a way that's comfortable and nice and, to use
Alexander's term, "life-giving". That challenge exists in all
programming languages.
Finally, you probably won't be surprised to learn that I agree with
Marick that we should all care that software patterns failed to
live up to their promise. Making software is fun, but it's also
challenging. Alexander's idea of a pattern language is one way
that we might help programmers do their jobs better, enjoy their
jobs more, and produce software that is both functional and habitable.
The first pass was a worthy effort, and a second pass, informed by
the lessons of the first, might get us closer to the goal.
Thanks to Brian for giving this talk and to the folks at Deconstruct
for posting it online. Go watch it.
Philip Wadler is a rockstar to the Strange Loop crowd.
His 2015 talk
on propositions as types introduced not a few developers to one of
computer science's great unities. This year, he returned to add a
third idea to what is really a triumvirate: categories. With a
little help from his audience, he showed that category theory has
elements which correspond directly to ...
logical 'and', which models the record (or tuple, or pair) data
type
logical 'or', which models the union (or variant record) data
type
a map, which models the function data type
What's more, the product/sum dual models
De Morgan's laws,
but with more structure, which enables it to model sets beyond the
booleans!
Wadler is an entertaining teacher; I recommend the video of his talk!
But he is also as quotable as any CS prof I've encountered in a long
while. Here is a smattering of his great lines from "Categories for
the Working Hacker":
If you can use math to do something, do it. It will make your life
better.
That's the great thing about math. It lets you see something obvious
after only thirty or forty years.
Pick your favorite algebra. If you don't have one, get one.
Let's do that in Java. That's what you should always do when you
learn a new idea: do it in Java.
That's what category theory is really about: avoiding traffic jams.
Sums are the secret origin of folds.
If you don't understand this, I don't mind, because it's Java.
While watching the presentation, I created a one-liner of my own:
Surprise! If you do something that matches exactly what Haskell
does, Haskell code will be much shorter than Java code.
This was a very good talk; I enjoyed it quite a bit. However, I
also left the room with a couple of nagging questions. The talk
was titled "Categories for the Working Hacker", and it did a nice
job of presenting some basic ideas from category theory in a way
that most any developer could understand, even one without much
background in math. But... How does this knowledge make one a
better hacker? Armed with this new, entertaining knowledge, what
are software developers able to do that they couldn't do before?
I have my own ideas for answers to these questions, but I would
love to hear Wadler's take.
I just read on the old Agile/XP mailing list that
Jerry Weinberg
passed away on Tuesday, August 7. The message hailed Weinberg
as "one of the finest thinkers on computer software development".
I, like many, was a big fan of work.
My first encounter with Weinberg came in the mid-1990s when
someone recommended The Psychology of Computer Programming
to me. It was already over twenty years old, but it captivated
me. It augmented years of experience in the trenches developing
computer software with a deep understanding of psychology and
anthropology and the firm but gentle mindset of a gifted teacher.
I still refer back to it after all these years. Whenever I open
it up to a random page, I learn something new again. If you've
never read it, check it out now. You can buy
the ebook
-- along with many of Weinberg's books -- online through LeanPub.
After the first book, I was hooked. I never had the opportunity
to attend one of Weinberg's workshops, but colleagues lavished
them with praise. I should have made more of an effort to attend
one. My memory is foggy now, but I do think I exchanged email
messages with him once back in the late 1990s. I'll have to see
if I can dig them up in one of my mail archives.
Fifteen years ago or so, I picked up a copy of Introduction
to General Systems Thinking tossed out by a retiring colleague,
and it became the first in a small collection of Weinberg books
now on my shelf. As older colleagues retire in the coming years,
I would be happy to salvage more titles and extend my collection.
It won't be worth much on the open market, but perhaps I'll be
able to share my love of Weinberg's work with students and younger
colleagues. Books make great gifts, and more so a book by Gerald
Weinberg.
Perhaps I'll share them with my non-CS friends and family, too.
A couple of summers back, my wife saw a copy of Are Your
Lights On?, a book Weinberg co-wrote with Donald Gause,
sitting on the floor of my study at home. She read it and liked
it a lot. "You get to read books like that for your work?" Yes.
I just read
Weinberg's final blog entry
earlier this week. He wasn't a prolific blogger, but he wrote
a post every week or ten days, usually about consulting, managing,
and career development. His final post touched on something that
we professors experience at least occasionally: students sometimes
solve the problems we et before them better than we expected, or
better than we ourselves can do. He reminded people not to be
defensive, even if it's hard, and to see the situation as an
opportunity to learn:
When I was a little boy, my father challenged me to learn
something new every day before allowing myself to go to
bed. Learning new things all the time is perhaps the
most important behavior in my life. It's certainly the
most important behavior in our profession.
Weinberg was teaching us to the end, with grace and gratitude.
I will miss him.
Oh, and one last personal note: I didn't know until after he
passed that we shared the same birthday, a few years apart. A
meaningless coincidence, of course, but it made me smile.
Software Projects, Potential Employers, and Memories
I spent a couple of hours this morning at a roundtable discussion
listening to area tech employers talk about their work and their
companies' needs. It was pretty enjoyable (well, except perhaps
for the CEO who too frequently prefaced his remarks with "What
the education system needs to understand is ..."). To a company,
they all place a lot of value on the projects that job candidates
have done. Their comments reminded me of
an old MAA blog post
in which a recent grad said:
During the fall of my junior year, I applied for an
internship at Red Ventures, a data analytics and
technology company just outside Charlotte. Throughout
the rigorous interview process, it wasn't my GPA that
stood out. I stood out among the applicants, in part,
because I was able to discuss multiple projects I had
taken ownership of and was extremely passionate about.
I encourage this mentality in my students, though I think
"passionate about" is too strong a condition (not to mention
cliché). Students should have a few projects that they
are interested in, or proud of, or maybe just completed.
Most of the students taking my compiler course this fall won't
be applying for a compiler job when they graduate, but they will
have written a compiler as part of a team. They will have met a
spec, collaborated on code, and delivered a working product.
That is evidence of skill, to be sure, but also of hard work and
persistence. It's a significant accomplishment.
The students who take our intelligent systems course or our
real-time embedded systems will be able to say the same thing.
Some students will also be able to point to code they wrote for
a club or personal projects. They key is to build things, care
about them, and "deliver", whatever that means in the context of
that particular project.
I made note of one new piece of advice to give our students,
offered by a former student I mentioned in
a blog post
many years ago who is now head of a local development team for
mobile game developer
Jam City:
Keep all the code you write. It can be a GitHub repo, as
many people now recommend, but it doesn't have to be. A simple
zip file organized by courses and projects can be enough. Such
a portfolio can show prospective employers what you've done, how
you've grown, and how much you care about the things you make.
It can say a lot.
You might even want to keep all that code for Future You. I'm old
enough that it was difficult to keep digital copies of all the
code I wrote in college. I have a few programs from my undergrad
days and a few more from grad school, which have migrated across
storage media as time passed, but I missing much of my class work
as a young undergrad and all of the code I wrote in high school.
I sometimes wish I could look back at some of that code...
I saw a lot of favorable links to this post a while back and
finally got around to it. Meh. I generally agree with the
author: GEB is verbose in places, there's a lot of
unnecessary name checking, and the dialogues that lead off each
chapter are often tedious. I even trust the author's assertion
that Hofstadter's forays beyond math, logic, and computers are
shallow.
So what? Things don't have to be perfect for me to like them, or
for them to make me think. GEB was a swirl of ideas
that caused me to think and helped me make a few connections.
I'm sure if I read the book now that I would feel differently
about it, but reading it when I did, as an undergrad CS major
thinking about AI and the future, it energized me.
I do thank the author for his pointer (in a footnote) to Vi Hart's
wonderful
Twelve Tones.
You should watch it. Zombie Schonberg!
This post wasn't quite what I expected, but even a few years old
it has something to say to web designers today.
Everything on the web ultimately needs to degrade down to plain
text (images require alt text; videos require transcripts), so
the text editor might just become the most powerful app in the
designer's toolbox.
People outside the XP community often don't realize how seriously
the popularizers of XP explored the limitations of their own ideas.
This page documents one of several challenges that push XP values
and practices to the limits: When do they break down? Can they
be adapted successfully to the task? What are the consequences of
applying them in such circumstances?
Re-reading this old wiki page was worth it if only for this great
line from Ron Jeffries:
In
Getting Critiqued,
Adam Morse reflects on his evolution from art student to web
designer, and how that changed his relationship with users and
critiques. Artists create things in which they are, at some
level, invested. Their process matters. As a result, critiques,
however well-intentioned, feel personal. The work isn't about
a user; it's about you. But...
... design is different. As a designer, I don't matter.
My work doesn't matter. Nothing I make matters in the
context of my process. It's all about the people you
are building for. You're just trying to solve problems
for people. Once you realize this, it's the most
liberating thing.
Now, criticism isn't really about you as artist. It's about how
well the design meets the needs of the user. With that in mind,
the artist can put some distance between himself or herself and
think about the users. That's probably what the users are paying
for anyway.
I've never been a designer, but I was fortunate to learn how
better to separate myself from my work by participating in
the software patterns community
and
its writers' workshop format.
From the workshops, I came to appreciate the value of providing
positive and constructive feedback in a supportive way. But I
also learned to let critiques from others be about my writing and
not about me. The ethos of writers' workshops is one of shared
commitment to growth and so creates as supportive framework as
possible in which to deliver suggestions. Now, even when I'm not
in such an conspicuously supportive environment, I am better able
to detach myself from my work. It's never easy, but it's easier.
This mindset can wear off a bit over time, so I find an occasional
inoculation via PLoP or another supportive setting to be useful.
Morse offers another source of reminder: the designs we create
for the web -- and for most software, too-- are not likely to
last forever. So...
Don't fall in love with borders, gradients, a shade of
blue, text on blurred photos, fancy animations, a
certain typeface, flash, or music that autoplays. Just
get attached to solving problems for people.
That last sentence is pretty good advice for programmers and
designers alike. If we detach ourselves from our specific work
output a bit and instead attach ourselves to solving problems
for other people, we'll be able to handle their critiques more
calmly. As a result, we are also likely to do better work.
In the last few days I have needed to make the transition
from writing a piece of software all on my own to bringing
in a collaborator. Which means I've needed to go into my
code and change a lot of things, in order to make everything
easier to understand and communicate.
There was a part of me that felt grumpy about this. After
all, I already knew exactly where everything was before this
other person ever came on board.
But then I looked at the changes I had made, and realized
that the entire system was now much cleaner, more robust,
and far easier to maintain. Clearly there is something
intrinsically better about code that is designed
for collaboration.
Knowing that our code must communicate with other people causes
us to write better code.
The above is an usually large quotation from another post for me.
Even so, Perlin makes a bigger point than this, so read the
entire post.
By the way, Perlin's blog has probably been the happiest addition
I've made to my blog reader over the past year. He writes short,
thoughtful posts everyday, on topics that include programming,
teaching, academic life, and virtual reality. I enjoy almost all
of them and always look forward to the next one.
YouTube, which is by far the largest streaming-music site in
the world (it wasn't designed that way--that's just what it
became)...
Companies starting in one line of business and evolving into
something else is nothing new. I mean, The Connecticut Leather
Company became
Coleco
and made video game consoles. But there's something about
software that make this sort of evolution seem so normal. We
build a computer system to solve one problem and find that our
users -- who have needs and desires that neither we nor they
fully comprehend -- use it to solve a different problem.
Interesting times. Don't hem yourself in, and don't hem your
software in, or the people who use it.
Software as Adaptation-Executer, Not Fitness-Maximizer
In
Adaptation-Executers, not Fitness-Maximizers,
Eliezer Yudkowsky talks about how evolution has led to human
traits that may no longer be ideal in the our current
environment. He also talks about tools, though, and this
summary sentence made me think of programs:
So the screwdriver's cause, and its shape, and
its consequence, and its various meanings, are
all different things; and only one of these things is
found within the screwdriver itself.
I often fall victim to thinking that the meaning of software
is at least somewhat inherent in its code, but that really
is what the designer intended as its use -- a mix of what
Yudkowsky calls its cause and its consequence. These are
things that exist only in the mind of the designer and the
user, not in the computational constructs that constitute
the code.
When approaching new software, especially a complex piece
of code with many parts, it's helpful to remember that it
doesn't really have objective meaning or consequences,
only those intended by its designers and those exercised
by its users. Over time, the users' conception tends to
drive the designers' conception as they put the software
to particular uses and even modify it to better suit these
new uses.
Perhaps software is best thought of as an adaptation-executer,
too, and not as a fitness-maximizer.
Arthur Miller's first, and I think, only novel, Focus,
was, in my opinion, every bit as good as his first produced
play, All My Sons. I once asked him why, if he was
equally talented in both forms, he chose to write plays. Why
would he give up the total control of the creative process
that a novel provides to write instead for communal control,
where a play would first go into the hands of a director and
then pass into the hands of a cast, set designer, producer,
and so forth? His answer was touching. He loved seeing what
his work evoked in others. The result could contain revelations,
feelings, and ideas that he never knew existed when he wrote
the play. That's what he hoped for.
Writing software for people to use is something quite different
from writing a play for audiences to watch, but this paragraph
brought to mind experiences I had as a grad student and new
faculty member. As a part of my doctoral work, I implemented
a expert system shells for a couple of problem-solving styles.
Experts and grad students in domains such as chemical
engineering, civil engineering, education, manufacturing, and
tax accounting used these shells to build expert systems in
their domains. I often found myself in the lab with these
folks as they used my tools. I learned a lot by watching them
and discussing with them the languages implemented in the tools.
Their comments and ideas sometimes changed how I thought about
the languages and tools, and I was able to fold some of these
changes back into the systems.
Software design can be communal, too. This is, of course, one
of the cornerstones of agile software development. Giving up
control can help us write better software, but it can also be
a source of the kind of pleasure I imagine Miller got from
working to bring his plays to life on stage.
In
an old blog post
promoting his book on timing, Daniel Pink writes:
... Connie Gersick's research has shown that group projects rarely
progress in a steady, linear way. Instead, at the beginning of a
project, groups do very little. Then at a certain moment, they
experience a sudden burst of activity and finally get going. When
is that moment? The temporal midpoint. Give a team 34 days, they
get started in earnest on day 17. Give a team 11 days, they get
really get going on day 6. In addition, there’s other research
showing that being behind at the midpoint--in NBA games and in
experimental settings--can boost performance in the second half.
So we need to recognize midpoints and try to use them as a spark
rather than a slump.
I wonder if this research suggests that we should favor shorter
projects over longer ones. If most of us start going full force
only at the middle of our projects, perhaps we should make the
middle of our projects come sooner.
I'll admit that I have a fondness for short over long: short
iterations over long iterations in software development, quarters
over semesters in educational settings, short books (especially
non-fiction) over long books. Shorter cycles seem to lead to
higher productivity, because I spend more time working and less
time ramping up and winding down. That seems to be true for my
students and faculty colleagues, too.
In the paragraph that follows the quoted passage, Pink points
inadvertently to another feature of short projects that I
appreciate: more frequent beginnings and endings. He talks about
the poignancy of endings, which adds meaning to the experience.
On the other end of the cycle are beginnings, which create a
sense of newness and energy. I always look forward to the
beginning of a new semester or a new project for the energy it
brings me.
Agile software developers know that, on top of these reasons,
short projects offer another potent advantage: more opportunities
to take stock of what we have learned and feed that learning back
into what we do.
The general lesson that I take away from this bug is humility:
It is hard to write even the smallest piece of code correctly,
and our whole world runs on big, complex pieces of code.
Having just written a small interpreter for my programming languages
course, I, too, am feeling humble. Even in code that couldn't
possibly go wrong, I had a small bug that bedeviled me for fifteen
minutes. (You have to dereference those bindings in order to get
the cells you want to mutate...) The experience is good preparation
for a couple of software projects I hope to do this summer and for
my compiler course this fall.
Oh, and Bloch's old post reminds me that it may be a good time to
work through "Programming Pearls" again. It's been a while.
For years now, I've been listening to many people -- smart,
accomplished people -- feverishly proclaim that functional
programming is here to right the wrongs of object-oriented
programming. For many years before that, I heard many people
-- smart, accomplished people -- feverishly proclaim that
object-oriented programming was superior to functional
programming, an academic toy, for building real software.
Alas, I don't have a home in the battle between OOP and FP.
I like and program in both styles. So it's nice whenever
I come across something like
Alan Kay's recent post
on Quora, in response to the question, "Why is functional
programming seen as the opposite of OOP rather than an
addition to it?" He closes with a paragraph I could take
on as my credo:
So: both OOP and functional computation can be completely
compatible (and should be!). There is no reason to munge
state in objects, and there is no reason to invent
"monads" in FP. We just have to realize that "computers
are simulators" and figure out what to simulate.
As in many things, Kay encourages to go beyond today's pop
culture of programming to create a computational medium that
incorporates big ideas from the beginning of our discipline.
While we work on those ideas, I'll continue to write programs
in both styles, and to enjoy them both. With any luck, I'll
bounce between mindsets long enough that I eventually attain
enlightenment, like
the venerable master Qc Na.
(See the koan at the bottom of that link.)
Oh: Kay really closes his post with
I will be giving a talk on these ideas in July in Amsterdam
(at the "CurryOn" conference).
If that's not a reason to go to Amsterdam for a few days, I
don't know what is.
Some of the other speakers
looks pretty good, too.
Greg Wilson wrote
a short blog post
recently about why JavaScript isn't suitable for teaching
Data Carpentry-style
workshops. In closing, he suggests an unusual way to design
programming languages:
What I do know is that the world would be a better place
if language designers adopted tutorial-driven design: write the
lessons that introduce newcomers to the language, then implement
the features those tutorials require.
That's a different sort of TDD than I'm used to...
This is the sort of idea that causes me to do a double or triple
take. At first, it has an appealing ring to it, when considering
how difficult it is to teach most programming languages to novices.
Then I think a bit and decide that it sounds crazy because, really,
are we going to hamstring our languages by focusing on the
struggles of beginners? But then it sits in my mind for a while
and I start to wonder if we couldn't grow a decent language this
way. It's almost like using the old TDD to implement new the TDD.
The PLT Scheme folks have designed a set of teaching languages
that enable beginners to grow into an industry-strength language.
That design project seems to have worked from the outsides in,
with a target language in mind while designing the teaching
languages. Maybe Wilson's idea of starting at the beginning
isn't so crazy after all.
Racket -- "A Programmable Programming Language" -- is the cover
story for next month's Communications of the ACM. The
new issue is already featured on
the magazine's home page,
including a short video in which Matthias Felleisen explains
the idea of code as more than a machine artifact.
My love of Racket is no surprise to readers of this blog.
Still one of my favorite old posts here is
The Racket Way,
a write-up of my notes from Matthew Flatt's talk of the same
name at StrangeLoop 2012. As I said in that post, this was
a deceptively impressive talk. I think that's especially
fitting, because Racket is a deceptively impressive language.
One last little bit of love from
a recent message
to the Racket users mailing list...
Stewart Mackenzie
describes his feelings about the seamless interweaving of
Racket and Typed Racket via a #lang directive:
So far my dive into Racket has positive. It's magical how
I can switch from untyped Racket to typed Racket simply by
changing #lang. Banging out my thoughts
in a beautiful lisp 1, wave a finger, then finger crack to
type check. Just sublime.
That's what you get when your programming language is as
programmable as your application.
I was reading a poet from the Tang dynasty... One of his lines
from, I don't know, page 812, was "No new feelings". When I
read that I laughed out loud. People have been writing about
the same things since the invention of the written word. The
only originality comes from the language itself.
After a week revising lecture notes and rewriting a recruiting
talk intended for high school students and their parents, I
know just what Offill and that Tang poet mean. I sometimes
feel the same way about code.
How Do We Choose The Programming Languages We Love?
In
Material as Metaphor,
the artist Anni Albers talks about how she came to choose
media in which she worked:
How do we choose our specific material, our means of
communication? "Accidentally". Something speaks to
us, a sound, a touch, hardness or softness, it
catches us and asks us to be formed. We are finding
our language, and as we go along we learn to obey
their rules and their limits. We have to obey, and
adjust to those demands. Ideas flow from it to us
and though we feel to be the creator we are involved
in a dialogue with our medium. The more subtly we
are tuned to our medium, the more inventive our
actions will become. Not listening to it ends in
failure.
This expresses much the way I feel about different programming
languages and styles. I can like them all, and sometimes do!
I go through phases when one style speaks to me more than
another, or when one language seems to be in sync with how I
am thinking. When that happens, I find myself wanting to
learn its rules, to conform so that I can reach a point where
I feel creative enough to solve interesting problems in the
language.
If I find myself not liking a language, it's usually because
I'm not listening to it; I'm fighting back. When I first
tried to learn Haskell, I refused to bend to its style of
functional programming. I had worked hard to grok FP in
Scheme, and I was so proud of my hard-won understanding that
I wanted to impose it on the new language. Eventually, I
retreated for a while, returned more humbly, and finally
came to appreciate Haskell, if not master it deeply.
My experience with Smalltalk went differently.
One summer
I listened to what it was telling me, slowly and patiently,
throwing code away and starting over several times on an
application I was trying to build. This didn't feel like a
struggle so much as a several-month tutoring session. By
the end, I felt ideas flowing through me. I think that's
the kind of dialogue Albers is referring to.
If I want to master a new programming language, I have to
be willing to obey its limits and to learn how to use its
strengths as leverage. This can be a conscious choice.
It's frustrating when that doesn't seem to be enough.
I wish I could always will myself into the right frame of
mind to learn a new way of thinking. Albers reminds us that
often a language speaks to us first. Sometimes, I just have
to walk away and wait until the time is right.
In In the Blink of an Eye, Walter Murch tells
the story of human and chimpanzee DNA, about how the DNA
itself is substantially the same and how the sequencing,
which we understand less well, creates different beings
during the development of the newborn. He concludes by
bringing the analogy back to film editing:
My point is that the information in the DNA can be seen as uncut
film and the mysterious sequencing as the editor. You could sit
in one room with a pile of dailies and another editor could sit
in the next room with exactly the same footage and both of you
could make different films out of the same material.
This struck me as quite the opposite of what programmers do.
When given a new problem and a large language in which to
solve it, two programmers can choose substantially different
source material and yet end up telling the same story.
Functional and OO programmers, say, may decompose the problem
in a different way and rely on different language features to
build their solutions, but in the end both programs will solve
the same problem and meet the same user need. Like the chimp
and the human, though, the resulting programs may be better
adapted for living in different environments.
While grading one last project for the semester, I ran across
this gem:
if checkInputParameters() == False:
[...]
This code was not written by a beginning programmer, but a senior
who likely will graduate in May. Sigh.
I inherited this course late in the semester, so it would be nice
if I could absolve myself of responsibility for allowing a student
to develop such a bad habit. But this isn't the first time I've
seen this programming pattern. I've seen it in my courses and in
other faculty's courses, in first-year courses and fourth-year
courses. In fact, I was so certain that I blogged about the
pattern before that I spent several minutes trolling the archive.
Alas, I never found the entry.
Don't let anyone tell you that Twitter can't be helpful. Within
minutes of tweeting
my dismay,
two colleagues suggested new strategies for dealing with this
anti-pattern.
James T. Kirk "Kobayashi Maru"-style solution: Hack CPython
to properly parse that new syntax:
unless checkInputParameters(): ...
Maybe I'll turn this into a programming exercise for the next
student in my compiler class who wanders down the path of
temptation. Deep in my heart, though, I know that enterprising
programmers will use the new type of statement to write this:
This might actually be a productive pedagogical tack to follow:
light-hearted and spot on, highlighting the anti-pattern's flaw
by applying it to its own output. ("Anti-pattern eats its own
dog food.") With any luck, some students will be enlightened,
Zen-like. Others will furrow their brow and say "What?"
... and even if we look past the boolean crime in our featured
code snippet, we really ought to take on that function name.
'Tis the season, though, and the semester is over. I'll save
that rant for another time.
After taking a look at the finished Turtle object, I
did wonder a little bit about whether the idea of a curried
object in Ruby is nothing more than an ordinary object making
use of object composition. However, because the name of the
pattern is helpful for describing the intent of this sort of
object in a succinct way, it may be a good label for us to
use when discussing the merits of different design options.
In the end it is, indeed, all just objects, or functions, or
whatever the primitives structures are in your programming
style du jour. The value of design patterns in any
styles lies in teaching us stereotypical patterns of usage,
the web of objects or functions we might not have thought of
in the course of design. Once we know about the patterns,
the names become a valuable part of the vocabulary we use to
talk about design.
I know that Brown's blog entry is six years old, that Noble's
paper is seventeen, and that talking about design patterns is
passé in many circles. But I still find the notion of
patterns and pattern languages to be immensely useful, and
even in 2017 I hear people express surprise at patterns are
just commonsense or bad design dressed up in fancy writing.
That makes me sad. We need more descriptions of experts'
implicit holistic design knowledge, not fewer.
In closing, though, please don't read my reaction here as a
diss of Brown's blog entry. His two entries on Noble's patterns
do a nice job showing how these patterns can improve a Ruby
program and exploring the trade-offs between the "before"
and "after" versions of the code. I hope that he bring his
Practicing Ruby project back to life.
I recently ran across
an old post from Spotify
about how the confluence of Spotify's generous policy for
usernames, the oddities of Unicode, and a change in standard
Python libraries led to a situation in which a person could
hijack an existing username. The post explains how Spotify
tracked down the problem and fixed it -- a good read.
The paragraph before the closing "Some Take-Aways" section
says:
So changes in the standard python library from one python
version to the next introduced a subtle bug in twisted's
nodepre.prepare() function which in turn introduced a
security issue in Spotify's account creation.
... which, to my mind, hints at a bonus takeaway not listed
in the closing. It would really have been nice to have had
a test that noticed when nodeprep's method for canonicalizing
(ugh) usernames was no longer idempotent.
Not having such a test is understandable. I don't write tests
for all or even many of the library functions I use. This
means trusting the creators of the libraries I use. (It also
means choosing libraries judiciously.) In this case, there
wasn't even a bug in twisted's original code; a change in
Python introduced one. It is hard to anticipate when a
language upgrade will create a bug in a library that I am
using.
However, when something like this occurs, I find that it is a
good time to add a test. This bug exposed just how
important it is for the code to ensure idempotence when
lower-casing a username. A new test or two can protect the
code base from unexpected errors from without without placing
an unreasonable burden on me as a developer. And those tests
give me peace of mind, which is usually more than worth an
extra millisecond when running my tests.
If you have read any of Chuck Moore's work, you know that he
is an extreme programmer in the literal sense of the word: a
unique philosophy that embraces small, fast, self-contained
programs in a spare language and an impressive development
environment. But as I read the opening sections of Moore's
book
Programming a Problem-Oriented Language,
I began to mistake him for an XP-style extreme programmer.
Do not put code in your program that might be used. Do
not leave hooks on which you can hang extensions. The things
you might want to do are infinite; that means that each one has
0 probability of realization. If you need an extension later,
you can code it later - and probably do a better job than if
you did it now. And if someone else adds the extension, will
they notice the hooks you left? Will you document that aspect
of your program?
Moore also has a corollary called Do It Yourself!, which
encourages you, in general, to write your own subroutines rather
than import one a canned subroutine from a library. That doesn't
sound like
Doing the Simplest Thing That Can Work,
but his intent is similar: an external routine is a dependency,
and it probably doesn't match the specific needs of the problem
you are solving. Indeed, Moore closes this section with:
Let me take a stand: I can't solve the problems of the world.
With luck, I can write a good program.
That could well be the manifesto of XP.
In the next section, a preview of the rest of the book, Moore
tells his readers that they won't find flowcharts in the pages
to come documenting the algorithms he describes:
I've never liked them, for they seem to include a useless amount
of information - either too little or too much. Besides they
imply a greater rigidity in program structure than usually
exists. I will be quite specific about what I think you should
do and how you should do it. But I will use words, and not
diagrams. I doubt that you would give a diagram the attention
it deserved, anyway. Or that I would in preparing it.
Other than using a few words, he lets the code stands for
itself. Documentation would not add enough value to outweigh
the cost of preparing it, or reading it. Usually, the best
thing to do with Moore's books is to
Listen To The Code:
settle into your Forth environment, type the code in, run it,
and learn from it.
There is no accounting for my weird fascination with stack-based
languages. Chuck Moore always give me more to think about than
I expected. I suspect that he would be at odds with some of the
practices encouraged by XP, but I often feel the spirit of XP in
his philosophy.
I learned about a couple of cool CLI tools from Nikita Sobolev's
Using Better CLIs.
hub and tig look like they may be worth a deeper
look. This article also reminded me of one of the examples in
the blog entry I rmed
the other day. It reflects a certain attitude about languages
and development.
One of the common complaints about OOP is that what would be a
single function in other programming styles usually ends up
distributed across multiple classes in an OO program. For example,
instead of:
void draw(Shape s) {
case s of
Circle : [code for circle]
Square : [code for square]
...
}
the code for the individual shapes ends up in the classes for
Circle, Square, and so on. If you have to change
the drawing code for all of the shapes, you have to track down all
of the classes and modify them individually.
This is true, and it is a serious issue. We can debate the relative
benefits and costs of the different designs, of course, but we might
also think about ways that our development tools can help us.
As a grad student in the early 1990s, I worked in a research group
that used VisualWorks Smalltalk to build all of its software. Even
within a single Smalltalk image, we faced this code-all-over-the-place
problem. We were adding methods to classes and modifying methods
all the time as part of our research. We spent a fair amount of time
navigating from class to class to work on the individual methods.
Eventually, one of my fellow students had an epiphany: we could
write a new code browser. We would open this browser on a
particular class, and the browser would provide a pane listing and
all of its subclasses, and all of their subclasses. When we
selected a method in the root class, the browser enabled us to
click on any of the subclasses, see the code for the subclass's
corresponding method, and edit it there. If the class didn't have
an overriding method, we could add one in the empty pane, with the
method signature supplied by the browser.
This browser didn't solve all of the problems we had learning to
manage a large code base spread out over many classes, but it was
a huge win for dealing with the specific issue of an algorithm
being distributed across several kinds of object. It also taught
me two things:
to appreciate the level of control that Smalltalk gave
developers to inspect code and shape the development
experience
to appreciate the mindset that creating new tools is the way
to mitigate many problems in software development, if not to
solve them completely
The tool-making mindset is one that I came to appreciate and
understand more and more as the years past. I'm disappointed
whenever I don't put it to good use, but oftentimes I wise up and
make the tools I need to help me do my work.
I'm Not Correcting Someone Who Was Wrong on the Internet
Yesterday, I wrote an entire blog entry that I rm'ed
before posting. I had read a decent article on a certain flavor
of primitive obsession and design alternatives, which ended with
what I thought was a misleading view of object-oriented
programming. My blog entry set out to right this wrong.
In a rare moment of self-restraint, I resisted the urge to
correct
someone who was wrong on the internet.
There is no sense in subjecting you to that. Instead, I'll just
say that I like both OOP and functional programming, and use
both regularly. I remain, in my soul, object-oriented.
On a more positive note, this morning I read an old article that
made me smile,
Why I'm Productive in Clojure.
I don't use Clojure, but this short piece brought to mind many
of the same feelings in me, but about Smalltalk. Interestingly,
the sources of my feelings are similar to the author's: the right
amount of syntax, facilities for meta-programming, interactive
development. The article gave me a feeling that is the opposite
of schadenfreude: pleasure from the pleasure of others. Some
Buddhists call this
mudita.
I felt mudita after reading this blog entry. Rock on, Clojure
dude.
Blaise Pascal believed that the key error of the school of
philosophy known as
Stoicism
lay in thinking that people can do always what they
can, in reality, only do sometimes.
Had Pascal lived in the time of software development, he would
probably have felt the same way about Extreme Programming and
test-driven design.
I was reminded of Pascal the philosopher (not the language)
earlier this week when I wrote code for several hours without
writing my unit tests. As a result, I found myself refactoring
blind for most of the project. The code was small enough that
this worked out fine, and I didn't even feel much fear while
moving along at a decent pace. Even so, I felt a little guilty.
Pascal made a good point about Stoicism, but I don't think that
this means I ought not be a Stoic -- or a practitioner of XP.
XP helps me to be a better programmer. I do have to be aware,
though, that it asks me to act against my natural tendencies,
just as Stoicism encourages us not to be controlled by desire
or fear.
One of the beauties of XP is that it intertwines a number of
practices that mutually support one another, which helps to
keep me in a groove. It helps me to reduce the size of my
fear, so that I don't as much to control. If I hadn't been
refactoring so often this week, I probably wouldn't have even
noticed that I hadn't written tests!
One need not live in fear of coming up short of the ideal.
No one is perfect. I'll get back to writing my tests on my
next program. There is no need to beat myself up about one
program. Everything worked out fine.
Yesterday, I
mentioned
rewriting the rules for computing FIRST and FOLLOW sets using
only "plain English". As I was refactoring my descriptions, I
realized that one of the reasons students have difficulty with
many textbook treatments of the algorithms is that the books give
complete and correct definitions of the sets upfront. The
presence of X := ε rules complicates the construction
of both sets, but they are unnecessary to understanding the
commonsense ideas that motivate the sets. Trying to deal with
ε too soon can interfere with the students learning what
they need to learn in order to eventually understand ε!
When I left the ε rules out of my descriptions, I ended up
with what I thought were an approachable set of rules:
The FIRST set of a terminal contains only the
terminal itself.
To compute FIRST for a non-terminal X, find all
of the grammar rules that have X on the lefthand side.
Add to FIRST(X) all of the items in the
FIRST set of the first symbol of each righthand
side.
The FOLLOW set of the start symbol contains the
end-of-stream marker.
To compute FOLLOW for a non-terminal X, find all
of the grammar rules that have X on the righthand side.
If X is followed by a symbol in the rule, add to
FOLLOW(X) all of the items in the FIRST
set of that symbol. If X is the last symbol in the rule,
add to FOLLOW(X) all of the items in the
FOLLOW set of the symbol on the rule's lefthand
side.
These rules are incomplete, but they have offsetting benefits.
Each of these cases is easy to grok with a simple example or
two. They also account for a big chunk of the work students
need to do in constructing the sets for a typical grammar.
As a result, they can get some practice building sets before
diving into the gnarlier details ε, which affects both
of the main rules above in a couple of ways.
These seems like a two-fold application of the Concrete, Then
Abstract pattern. The first is the standard form: we get to see
and work with accessible concrete examples before formalizing the
rules in mathematical notation. The second involves the nature
of the problem itself. The rules above are the concrete
manifestation of FIRST and FOLLOW sets; students can master them
before considering the more abstract ε cases. The abstract
cases are the ones that benefit most from using formal notation.
I think this is an example of another pattern that works well
when teaching. We might call it "Learn Exceptions Later",
"Handle Exceptions Later", "Save Exceptions For Later", or even
"Treat Exceptions as Exceptions". (Naming things is hard.) It
is often possible to learn a substantial portion of an idea
without considering exceptions at all, and doing so prepares
students for learning the exceptions anyway.
I guess I now have at least one idea for my next PLoP paper.
Ironically, writing this post brings to mind a programming pattern
that puts exceptions up top, which I learned during
the summer Smalltalk taught me OOP.
Instead of writing code like this:
if normal_case(x) then
// a bunch
// of lines
// of code
// processing x
else
throw_an_error
you can write:
if abnormal_case(x) then
throw_an_error
// a bunch
// of lines
// of code
// processing x
This idiom brings the exceptional case to the top of the function
and dispatches with it immediately. On the other hand, it also
makes the normal case the main focus of the function, unindented
and clear to the eye.
It may look like this idiom violates the "Save Exceptions For
Later" pattern, but code of this sort can be a natural outgrowth of
following the pattern. First, we implement the function to do its
normal business and makes sure that it handles all of the usual cases.
Only then do we concern ourselves with the exceptional case, and we
build it into the function with minimal disruption to the code.
This pattern has served me well over the years, far beyond Smalltalk.
I've been meaning to blog about my compilers course for more
than a month, but life -- including my compilers course --
have kept me busy. Here are three quick notes to prime the
pump.
I recently came across Lindsey Kuper's
My First Fifteen Compilers
and thought again about this unusual approach to a
compiler course: one compiler a week, growing last week's
compiler with a new feature or capability, until you have
a complete system. Long, long-time readers of this blog
may remember me
writing about this idea
once over a decade ago.
The approach still intrigues me. Kuper says that it was
"hugely motivating" to have a working compiler at the end
of each week. In the end I always shy away from the
approach because (1) I'm not yet willing to adopt for my
course the Scheme-enabled micro-transformation model for
building a compiler and (2) I haven't figured out how to
make it work for a more traditional compiler.
I'm sure I'll remain intrigued and consider it again in
the future. Your suggestions are welcome!
Last week, I
mentioned on Twitter
that I was trying to explain how to compute FIRST and
FOLLOW sets using only "plain English". It was hard.
Writing a textual description of the process made me
appreciate the value of using and understanding
mathematical notation. It is so expressive and so
concise. The problem for students is that it is also
quite imposing until they get it. Before then, the
notation can be a roadblock on the way to understanding
something at an intuitive level.
My usual approach in class to FIRST and FOLLOW sets, as
for most topics, is to start with an example, reason
about it in commonsense terms, and only then to formalize.
The commonsense reasoning often helps students understand
the formal expression, thus removing some of its bite.
It's a variant of
the "Concrete, Then Abstract" pattern.
Mathematical definitions such as these can motivate some
students to develop their formal reasoning skills. Many
people prefer to let students develop their "mathematical
maturity" in math courses, but this is really just an
avoidance mechanism. "Let the Math department fail them"
may solve a practical problem, sometimes we CS profs have
to bite the bullet and help our students get better when
they need it.
I have been trying to write more code for the course this
semester, both for my enjoyment (and sanity) and for use
in class. Earlier, I wrote a couple of toy programs such
as
a Fizzbuzz compiler.
This weekend I took a deeper dive and began to implement my
students' compiler project in full detail. It was a lot of
fun to be deep in the mire of a real program again. I have
already learned and re-learned a few things about Python,
git, and bash, and I'm only a quarter of the way in! Now
I just have to make time to do the rest as the semester
moves forward.
In her post, Kuper said that her first compiler course was "a
lot of hard work" but "the most fun I'd ever had writing code".
I always tell my students that this course will be just like
that for them. They are more likely to believe the first claim
than the second. Diving in, I'm remembering those feelings
firsthand. I think my students will be glad that I dove in.
I'm reliving some of the challenges of doing everything that
I ask them to do. This is already generating a new source of
empathy for my students, which will probably be good for them
come grading time.
As the host symbiont who lives and breathes the system:
strike the words "just", "easy", "obvious", "simple",
and "straightforward" from your vocabulary. These
words are contextual, and no other human shares your
context.
My first experience coming to grips with my use of these words
was not in software development, but in the classroom.
"Obvious" has never been a big part of my vocabulary, but I
started to notice a few years ago how often I said "just",
"easy", and "simple" in class and wrote them in my lecture
notes. Since then, I have worked hard to cut back sharply on
my uses of these minimizers in both spoken and written
interactions with my students. I am not always successful, of
course, but I am more aware now and frequently catch myself
before speaking, or in the act of writing.
I find that I still use "straightforward" quite often these days.
Often, I use it to express contrast explicitly, something to the
effect, "This won't necessarily be easy, but at least it's
straightforward." By this I mean that some problem or task may
require hard work, but at least the steps they need to perform
should be clear. I wonder now, though, whether students always
take it this way, even when expressed explicitly. Maybe they
hear me minimizing the task head, not putting the challenge they
face into context.
Used habitually, even with good intentions, a word like
"straightforward" can become a crutch, a substitute minimizer.
It lets me to be lazy when I try to summarize a process or to
encourage students when things get difficult. I'm going to try
this fall to be more sensitive to my use of "straightforward"
and see if I can't find a better way in most situations.
As for the blog post that prompted this reflection,
Hyperproductive Development
summarizes as effectively as anything I've read the truth behind
the idea that some programmers are so much more effective than
others: "it isn't the developers, so much as the situation".
It's a good piece, well worth a quick read.
The Need for Apprenticeship in Software Engineering Education
In
his conversation with Tyler Cowen,
Ben Sasse talks a bit about how students learn in our schools of
public policy, business, and law:
We haven't figured out in most professional schools how to
create apprenticeship models where you cycle through different
aspects of what doing this kind of work will actually look
like. There are ways that there are tighter feedback loops at
a med school than there are going to be at a policy school.
There are things that I don't think we've thought nearly
enough about ways that professional school models should
diverge from traditional, theoretical, academic disciplines or
humanities, for example.
We see a similar continuum in what works best, and what is needed,
for learning computer science and learning software engineering.
Computer science education can benefit from the tighter feedback
loops and such that apprenticeship provides, but it also has a
substantial theoretical component that is suitable for classroom
instruction. Learning to be a software engineer requires a shift
to the other end of the continuum: we can learn important things,
in the classroom, but much of the important the learning happens
in the trenches, making things and getting feedback.
A few universities have made big moves in how they structure
software engineering instruction, but most have taken only halting
steps. They are often held back by a institutional loyalty to the
traditional academic model, or out of sheer curricular habit.
The one place you see apprenticeship models in CS is, of course,
graduate school. Students who enter research work in the lab
under the mentorship of faculty advisors and more senior grad
students. It took me a year or so in graduate school to figure
out that I needed to begin to place more focus on my research
ideas than on my classes. (I hadn't committed to a lab or an
advisor yet.)
In lieu of a changed academic model, internships of the sort I
mentioned recently
can be really helpful for undergrad CS students looking to go
into software development. Internships create a weird tension
for faculty... Most students come back from the workplace with
a new appreciation for the academic knowledge they learn in the
classroom, which is good, but they also back to wonder why more
of their schoolwork can't have the character of learning in the
trenches. They know to want more!
Project-based courses
are a way for us to bring the value of apprenticeship to the
undergraduate classroom. I am looking forward to building
compilers with ten hardy students this fall.
Some Thoughts from a Corporate Visit: Agility and Curriculum
Last Thursday, I spent a day visiting a major IT employer in our
state. Their summer interns, at least three of whom are
students in my department, were presenting projects they had
developed during a three-day codejam. The company invited
educators from local universities to come in for the
presentations, preceded by a tour of the corporate campus, a
meeting with devs who had gone through the internship program in
recent years, and a conversation about how the schools and
company might collaborate more effectively. Here are a few of
my impressions from the visit.
I saw and heard the word "agile" everywhere. The biggest effects
of the agility company-wide seemed to be in setting priorities
and in providing transparency. The vocabulary consisted
mostly of terms from Scrum and kanban. I started to wonder how
much the programming practices of XP or other agile methodologies
had affected software development practices there. Eventually I
heard about the importance of pair programming and unit testing
and was happy to know that the developers hadn't been forgotten
in the move to agile methods.
Several ideas came to mind during the visit of things we might
incorporate into our programs or emphasize more. We do a
pretty good job right now, I think. We currently introduce
students to agile development extensively in our software
engineering course, and we have a dedicated course on software
verification and validation. I have even taught a dedicated
course on agile software development several times before, most
recently in
2014
and
2010.
Things we might do better include:
having students work on virtual teams. Our students
rarely, if ever, work on virtual teams in class, yet this is
standard operating procedure even within individual companies
these days.
having students connect their applications programs to
front and back ends. Our students often solve interesting
problems with programs, but they don't always have to connect
their solution to front ends that engage real users or to back
ends that ultimately provide source data. There is a lot to
learn in having to address these details.
encouraging students to be more comfortable with failure
on projects. Schools tends to produce graduates who are
risk-averse, because failure on a project in the context of a
semester-long course might mean failure in the course. But
the simple fact is that some projects fail. Graduates need to
be able to learn from failure and create successes out of it.
They also need to be willing to take risks; projects with
risk are also where big wins come from, not to mention new
knowledge.
Over the course of the day, I heard about many of the attributes
this company likes to see in candidates for internships and
full-time positions, among them:
comfort speaking in public
ability to handle, accept, and learn from failure
curiosity
initiative
a willingness to work in a wide variety of roles: development,
testing, management, etc.
Curiosity was easily the most-mentioned desirable attribute. On
the matter of working in a wide variety of roles, even the people
with "developer" in their job title reported spending only 30% of
their time writing code. One sharp programmer said, "If you're
spending 50% of your time writing code, you're doing something
wrong."
The codejam presentations themselves were quite impressive. Teams
of three to six college students can do some amazing things in
three days when they are engaged and when they have the right
tools available to them. One theme of the codejam was "platform
as a service", and students used a slew of platforms, tools, and
libraries to build their apps. Ones that stood out because they
were new to me included IBM BlueMix (a l´ AWS and Azure),
Twilio ("a cloud platform for building SMS, voice and messaging
apps"), and Flask ("a micro web framework written in Python").
I also saw a lot of node.js and lots and lots of NoSQL. There
was perhaps a bias toward NoSQL in the tools that the interns
wanted to learn, but I wonder if students are losing appreciation
for relational DBs and their value.
Each team gave itself a name. This was probably my favorite:
int erns;
I am a programmer.
All in tools, the interns used too many different tools for me to
take note of. That was an important reminder from the day for me.
There are so many technologies to learn and know how to use
effectively. Our courses can't possibly include them all. We need
to help students learn how to approach a new library or framework
and become effective users as quickly as possible. And we need to
have them using source control all the time, as ingrained habit.
One last note, if only because it made me smile. Our conversation
with some of the company's developers was really interesting. At
the end of the session, one of the devs handed out his business
card, in case we ever wanted to ask him questions after leaving.
I looked down at the card and saw...
... Alan Kay. Who knew that Alan was moonlighting as an application
developer for a major financial services company in the Midwest?
I'm not sure whether sharing a name with a titan of computer science
is a blessing or a curse, but for the first time in a long while I
enjoyed tucking a business card into my pocket.
Someone wrote on the Software Carpentry mailing list:
I'm using Python's unittest framework and everything
is already set up. The specific problem I need help
with is what tests to write...
That is, indeed, a problem. I have the tool. What now?
Rather than snark off-line, like me, Titus Brown wrote
a helpful answer
with generic advice for how to get started writing tests for code
that is already written, aimed at scientists relatively new to
software development. It boils down to four suggestions:
Write "smoke" tests that determine whether the program works
as intended.
Write a series of basic tests for edge cases.
As you add new code to the program, write tests for it at the
same time.
"Whenever you discover a bug, write a test against that bug
before fixing it."
Brown says that the smoke tests "should be as dumb and robust as
possible". They deliver a lot of value for the little effort.
I would add that they also get you in the rhythm of writing tests
without a huge amount of thought necessary. That rhythm is most
helpful as you start to tackle the tougher cases.
Brown calls his last bullet "stupidity driven testing", which is
a self-deprecating way to describe a locality phenomenon that many
of us have observed in our programs: code in which we've found
errors is often likely to contain other errors. Adding tests to
this part of the program helps the test suite to evolve to protect
a potentially weak part of the codebase.
He also recommends a simple practice for the third bullet that I
have found helpful for both bullets three and four: When you
write these tests, try to cover some of the existing, working
functionality, too. Whenever I add a new test to the growing
test base, I try to add one or two more tests not called for by
the new code or the bug I'm fixing. I realize that this may
distract a bit from the task at hand, but it's a low-cost way to
grow the test suite without setting aside dedicated time. I try
to keep these add-on tests reasonably close to the part of the
program I'm adding or fixing. This allows me to benefit from the
thinking I'm already doing about that part of the program.
At some point, it's good to take a look at code coverage to see
if there are parts of the code that con't yet have tests written
for them. Those parts of the program can be the focus of
dedicated test-writing sessions as time permits.
Brown also gives a piece of advice that seasoned developers should
already know: make the tests part of continuous integration. They
should run every time we update the application. This keeps us
honest and our code clean.
All in all, this is pretty good advice. That's not surprising.
I usually learn something from Brown's writing.
Over the last couple of weeks, I have spent a few minutes most
afternoons writing a little code. It's been the best part of
my work day. The project was a little compiler.
One of the first things we do in my compiler course is to study
a small compiler for a couple of the days. This is a nice way
to introduce the stages of a compiler and to raise some of the
questions that we'll be answering over the course of the
semester. It also gives students a chance to see the insides
of a working compiler before they write their own. I hope that
this demystifies the process a little: "Hey, a compiler really
is just a program. Maybe I can write one myself."
For the last decade or so, I have used a compiler called
acdc for this demo, based on Chapter 2 of
Crafting A Compiler
by Fischer, Cytron, and LeBlanc. ac is a small
arithmetic language with two types of numbers, sequences of
assignment statements, and print statements.
dc
is a stack-based desk calculator that comes as part of many
Unix installations. I whipped up a acdc compiler in
Java about a decade ago and have used it ever since. Both
languages have enough features to be useful as a demo but not
enough to overwhelm. My hacked-up compiler is also open to
improvements as we learn techniques throughout the course,
giving us a chance to use them in the small before students
applied them to their own project.
I've been growing dissatisfied with this demo for a while now.
My Java program feels heavy, with too many small pieces to be
simple enough for a quick read. It requires two full class
sessions to really understand it well, and I've been hoping to
shorten the intro to my course. ac is good, but it
doesn't have any flow control other than sequencing, which means
that it does not give us a way to look at assembly language
generation with jumps and backpatching. On top of all that, I
was bored with acdc; ten years is a long time to spend
with one program.
This spring I stumbled on a possible replacement in
The Fastest FizzBuzz in the West.
It defines a simple source language for writing
FizzBuzz
programs declaratively. For example:
1...150
fizz=3
buzz=5
woof=7
produces the output of a much larger program in other languages.
Imagine being able to pull this language during your next
interview for a software dev position!
This language is really simple, which means that a
compiler for it can be written in relatively few lines of code.
However, it also requires generating code with a loop and
if-statements, which requires thinking about branching
patterns in assembly language.
The "Fastest FizzBuzz" article uses a Python parser generator to
create its compiler. For my course, I want something that my
students can read with only their knowledge coming into the course,
and I want the program to be transparent enough so that they can
see directly how each stage works and how it interacts with other
parts of the compiler.
I was also itching to write a program, so I did.
I wrote my compiler in Python. It performs a simple scan of the
source program, taking as much advantage of the small set of simple
tokens as possible. The parser works by recursive descent, which
also takes advantage of the language's simple structure. The type
checker makes sure the numbers all make sense and that the words
are unique. Finally, to make things even simpler, the code
generator produces an executable Python 3.4 program.
I'm quite hopeful about this compiler's use as a class demo. It is
simple enough to read in one sitting, even by students who enter the
course with weaker programming skills. Even so, the language can
also be used to demonstrate the more sophisticated techniques we
learn throughout the course. Consider:
Adding comments to the source language overwhelms the
ad hoc approach I use in the scanner, motivating
the use of a state machine.
While the parser is easily handled by recursive descent,
the language is quite amenable to a simple table-driven
approach, too. The table-driven parser will be simple
enough that students can get the hang of the technique
with few unnecessary details.
The type checker demonstrates walking an abstract syntax
tree without worrying about too many type rules. We can
focus our attention on type systems when dealing with the
more interesting source language of their project.
The code generator has to deal with flow of control, which
enables us to learn assembly language generation on a
smaller scale without fully implementing code to handle
function calls.
So this compiler can be a demo in the first week of the course
and also serve as a running example throughout.
We'll see how well this plays in class in a couple of months. In
any case, I had great fun ending my days the last two weeks by
firing up emacs or IDLE and writing code. As a bonus, I used this
exercise to improve my git skills, taking them beyond the small
set of commands I have used on my academic projects in the past.
(git rebase -i is almost my friend now.) I also wrote
more pyunit tests than I have written in a long, long
time, which reminded me of some of the challenges students face
when trying to test their code. That should serve me well in the
fall, too.
The article
Why Aren't American Teenagers Working Anymore?
comments on a general trend I have observed locally over the
last few years: most high school students don't have summer
jobs any more. At first, you might think that rising college
tuition would provide an incentive to work, but the effect is
almost the opposite:
"Teen earnings are low and pay little toward the costs of
college," the BLS noted this year. The federal minimum wage
is $7.25 an hour. Elite private universities charge tuition
of more than $50,000.
Even in-state tuition at a public universities has grown large
enough to put it out of the reach of the typical summer jobs.
Eventually, there is almost no point in working a low-paying
job; you'll have to borrow significant amount anyway.
These days, students have another alternative that might pay
off better in the long run anyway. With a little gumption and
free resources available on the web, many students can learn
to program, build websites, and make mobile apps. Time spent
not working a job but developing skills that are in high
demand and which pay well might be time spent well.
Even as a computer scientist, though, I'm traditional enough to
be a little uneasy with this idea. Don't young people benefit
from summer jobs in ways other than a paycheck? The authors of
this article offer the conventional thinking:
A summer job can help teenagers grow up as it expands their
experience beyond school and home. Working teens learn how
to manage money, deal with bosses, and get along with
co-workers of all ages.
You know what, though... A student working on an open-source
project can learn also how to deal with people in positions
of relative authority and learn how to get along with
collaborators of all ages. They might even get to interact
with people from other cultures and make a lasting contribution
to something important.
Maybe instead of worrying about teenagers getting summer jobs
we should introduce them to programming and open-source
software.
Using Programs and Data Analysis to Improve Writing, World Bank Edition
Last week I read a tweet that linked to an article by Paul
Romer. He is an economist currently working at the World
Bank, on leave from his chair at NYU. Romer writes well,
so I found myself digging deeper and reading a couple of
his blog articles. One of them,
Writing,
struck a chord with me both as a writer and as a computer
scientist.
Consider:
The quality of written prose should be higher in
documents that will have many readers.
This is true of code, too. If a piece of code will be read
many times, whether by one person or several, then each
minute spent making it shorter and clearer improves reading
comprehension every single time. That's even more important
in code than in text, because so often we read code in order
to change it. We need to understand it at even deeper level
to ensure that our changes have the intended effect. Time
spent making code better repays itself many times over.
Romer caused a bit of a ruckus when he arrived at the World
Bank by insisting, to some of his colleagues' displeasure,
that everyone in his division writer clearer, more concise
reports. His goal was admirable: He wanted more people to
be able to read and understand these reports, because they
deal with policies that matter to the public.
He also wanted people to trust what the World Bank
was saying by being able more readily to see that a claim
was true or false. His article looks at two different
examples that make a claim about the relationship between
education spending and GDP per capita. He concludes his
analysis of the examples with:
In short, no one can say that the author of the
second claim wrote something that is false because
no one knows what the second claim means.
In science, writing clearly builds trust. This trust is
essential for communicating results to the public, of course,
because members of the public do not generally possess the
scientific knowledge they need to assess the truth of claim
directly. But it is also essential for communicating results
to other scientists, who must understand the claims at a
deeper level in order to support, falsify, and extend them.
In the second half of the article, Romer links to
a study of the language
used in World Bank's yearly reports. It looks at patterns
such as the frequency of the word "and" in the reports and
the ratio of nouns to verbs. (See
this Financial Times article
for a fun little counterargument on the use of "and".)
Romer wants this sort of analysis to be easier to do, so
that it can be used more easily to check and improve the
World Bank's reports. After looking at some other patterns
of possible interest, he closes with this:
To experiment with something like this, researchers in
the Bank should be able to spin up a server in the
cloud, download some open-source software and start
experimenting, all within minutes.
Wonderful: a call for storing data in easy-to-access forms
and a call for using (and writing) programs to analyze text,
all in the name not of advancing economics technically but
of improving its ability to communicate its results.
Computing becomes a tool integrated into the process of the
World Bank doing its designated job. We need more leaders
in more disciplines thinking this way. Fortunately, we hear
reports of such folks more often these days.
Alas, data and programs were not used in this way when Romer
arrived at the World Bank:
When I arrived, this was not possible because people
in ITS did not trust people from DEC and, reading
between the lines, were tired of dismissive arrogance
that people from DEC displayed.
One way to create more trust is to communicate better.
Not being dismissively arrogant is, too, though calling
that sort of behavior out may be what got Romer in so
much hot water with the administrators and economists at
the World Bank in the first place.
Porting Programs, Refactoring, and Language Translation
In his commonplace book A Certain World, W.H. Auden
quotes C.S. Lewis on the controversial nature of tramslation:
[T]ranslation, by its very nature, is a continuous implicit
commentary. It can become less tendentious only by becoming
less of a translation.
Lewis was merely acknowledging a truth about language: Translators
must have a point of view, and often that point of view will be
controversial.
I once saw Kurt Vonnegut speak with a foreign language class here
many years ago. One of the students asked him what he thought
about the quality of the translations done for his book. Vonnegut
laughed and said that his books were so peculiar and so steeped in
Americana that translating one was akin to writing a new book. He
said that his translators deserved all the royalties from the books
they created by translating him. They had to write brand new works.
These memories came to mind again recently while I was reading Tyler
Cowen's
conversation with Jhumpa Lahiri,
especially when Lahiri said this:
At one point I was talking about this idea, in antiquity: in
Latin, the word for "translator" is "interpreter". I teach
translation now, and I talk a lot to my students about
translation being the most intimate form of reading and how
there was the time when translating and interpreting and
analyzing were all one thing.
As my mind usually does, it began to think about computer programs.
Like many programmers, I often find myself porting a program from
one language to another. This is clearly translation but, as
Vonnegut and and Lahiri tell us, it is also a form of interpretation.
To port a piece of code, I have to understand its meaning and express
that meaning in a new language. That language has its own constructs,
idioms, patterns, and set of community practices and expectations.
To port a program, one must have a point of view, so the process can
be, to use Lewis's word, tendentious.
I often refactor code, too, both my own programs and programs written
by others. This, too, is a form of translation, even though it
leaves the new code written in the same language as the original.
Refactoring is necessarily an opinionated act, and thus tendentious.
Occasionally, I refactor a program in order to learn what it does and
how it does it. In those cases, I'm not judging the original code as
anything but ill-suited to my current state of knowledge. Even so,
when I get done, I usually like my version better, if only a little
bit. It expresses what I learned in the process of rewriting the code.
It has always been hard for me to port a program without refactoring
it, and now I understand why. Both activities are a kind of
translation, and translation is by its nature an activity that
requires a point of view.
This fall, I will again teach our "Translation of Programming Languages"
course. Writing a compiler requires one to become intimate not only
with specific programs, the behavior of which the compiler must
preserve, but also the language itself. At the end of the project, my
students know the grammar, syntax, and semantics of our source language
in a close, almost personal way. The target language, too. I don't
mind if my students develop a strong point of view, even a
controversial one, along the way. (I'm actually disappointed if the
stronger students do not!) That's a part of writing new software, too.
A few years ago, someone asked MathOverflow, "Why do so many
textbooks have so much technical detail and so little
enlightenment?" Some CS textbooks suffer from this problem,
too, though these days the more likely case is that the book
tries to provide too much context. They try to motivate so
much that they drown the reader in a lot of unhelpful words.
The top answer
on MathOverflow (via
Brian Marick)
points out that the real problem does not usually lie in the
lack of motivation or context provided by textbooks. The real
goal is to learn how to do math, not "know" it. That
is even more true of software developent. A textbook can't
really teach to write programs; most of that is learned through
doing itself. Perhaps the best purpose that the text can serve,
says the answer, is to show the reader what he or she needs to
learn. From there, the reader must go off and practice.
How does learning occur from there?
Based on my own experience as both a student and a teacher,
I have come to the conclusion that the best way to learn is
through "guided struggle". You have to do the work
yourself, but you need someone else there to either help
you over obstacles you can't get around despite a lot of
effort or provide you with some critical knowledge (usually
the right perspective but sometimes a clever trick) you are
missing. Without the prior effort by the student, the
knowledge supplied by a teacher has much less impact.
Some college CS students seem to understand this, or perhaps
they simply get lucky because they are motivated to program
for some other reason. They go off and try to do something
using the knowledge they have. Then they come to class, or
to the prof's office hours, to ask questions about what does
not go smoothly. Students who skip the practice and hope
that lectures will soak into them like a magic balm generally
find that they don't know much when they attempt problems
after class.
The MathOverflow answer matches up pretty well with my
experience. Teachers and written material can have strong
positive effect on learning, but they are most effective once
the student has engaged with the material by trying to solve
problems or write code. The teacher's job then has two parts:
First, create conditions in which students can work productively.
Second, pay close attention to what students are doing, diagnose
misconceptions and mistakes, and help students get back onto a
productive path by pointing out missing practices or bits of
knowledge.
All of this reminds me of some of mymore effective class
sessions teaching novice programmers, using design patterns.
A typical session looks something like this:
I give the students a problem to solve.
Students work on a solution, using techniques that have
worked in the past.
They encounter problems, because the context around the
problem has shifted in ways that they can't see given only
what they know.
We discuss the forces at play and tease out the underlying
problem.
I demonstrate the pattern's solution.
Ahhhh.
This is a guided struggle in the small. Students then go off
to write a larger program that lets them struggle a bit more,
and we discuss whatever gets in their way.
A final note... One of the comments on the answer points out
that a good lecture can "do" math (or CS), rather than "tell",
and that such lectures can be quite effective. I agree, but
in my experience this is one of the hardest skills for a
professor to develop. Once I have solved a problem, it is
quite difficult for me to make it look to my students as if I
am solving it anew in class. The more ingrained the skill, the
harder it is for me to lecture about it in a way that is more
helpful than telling a story. Such stories are an essential
tool in the teacher's toolbox, but their lies more in motivating
students than in teaching them how to write programs. Students
still have to go off and do the hard work themselves. The
teacher's job is to guide them through their struggles.
Screenwriter Ken Levine answers
one of his Friday Questions
about how he and writing partner David Isaacs worked:
We always worked on the same script. And we always worked
together in the room. Lots of teams will divide up scenes,
write separately, then return to either polish it together
or rewrite each other's scenes on their own. We wrote
head-to-head. To us the value of a partnership is to get
immediate feedback from someone you trust, and more
importantly, have someone to go to lunch with.
It sounds like Levine and Isaacs (MASH, Cheers, Frasier, ...)
discovered the benefits of pair programming in their own line
of work.
I liked the second part of his answer, too, about whether they
ever gave up on a script once they starting writing it:
Nothing gets done unless both team members are committed
to it. Once we began to write a spec there was never any
discussion of just junking or tabling it to work on
something else. We would struggle at times with the story
or certain jokes but we always fought our way through it.
Wrestling scripts to the ground is excellent training for
when you do go on staff.
Wrestling code to the ground is excellent training for what
you have to do as a developer, too. On those occasions when
what you thought was a good idea turns out to be a bad one,
it is wise to pitch it and move on. But it's too easy to
blame difficulty in the trenches on the idea. Often, the
difficulty is a hint that you need to work harder or
dig deeper. Pairing with another programmer often provides
the support you need to stick with it.
In
an essay
in The Guardian, writer George Saunders reflects on having
written his first novel after many years writing shorter fiction.
To a first approximation, he found the two experiences to be quite
similar. In particular,
What does an artist do, mostly? She tweaks that which she's
already done.
I read this on a day when I had just graded thirty-plus programming
assignments from my junior/senior-level Programming Languages
courses, and this made me think of student programmers. My first
thought was snarky, and only partly tongue-in-cheek: Students write
and then submit. Who has the time or interest to tweak?
My conscience quickly got the better of me, and I admitted that this
was unfair. In a weak moment at the end of a long day, it's easy to
be dismissive and not think about students as people who face all
sorts of pressures both in and out of the classroom. Never forget
Hanlon's Razor,
my favorite formulation of which is:
Never attribute to malice or stupidity that which can be
explained by moderately rational individuals following
incentives in a complex system of interactions.
Even allowing the snark, my first thought was inaccurate. The code
students submit is often the end result of laborious tweaking. The
thing is, most students tweak only while the code gives incorrect
answers. In the worst case, some students tweak and tweak,
employing an age-old but highly inefficient software development
methodology: Make another change and see if it works.
Most students are under time pressures that make artistry a luxury
good; they are happy to find time to make their code work at all.
If the code passes the tests, it's probably good enough for now.
But there is more to the student's willingness to stop tinkering so
soon than just external pressures. It takes a lot of programming
experience and a fair amount of time to come to even appreciate
Rules 2 through 4. Why does it matter if code reveals the
programmer's intention, in terms of either art or engineering?
What's the big deal about a little duplication? The fewest
elements? -- making that happen takes time that could be spent on
something much more interesting.
I am coming to think of Kent's rules as a sort of
Bloom's taxonomy
for the development of programming expertise. Students start
at Level 1, happy to write code that achieves its stated purpose.
As they grow, programmers move through the rules, mastering
deeper levels of understanding of design, simplicity, and, yes,
artistry. They don't move through the stages in a purely linear
fashion, but they do tend to master the rules in roughly the
order listed above.
Today is a day of empathy for my novice programmers. As I write
this, they are writing the final exam in my course. I hope that
in a few weeks, after the blur of a busy semester settles in their
minds, they reflect a bit and see that they have made progress as
programmers -- and that they can now ask better questions about the
programming languages they use than they could at the beginning of
the course.
Data Compression and the Complexity of Consciousness
Okay, so this is cool:
Neuroscientists stimulate the brain with brief pulses
of energy and then record the echoes that bounce back.
Dreamless sleep and general anaesthesia return simple
echoes; brains in conscious states produce more complex
patterns. Then comes a little inspiration from data
compression:
Excitingly, we can now quantify the complexity of these
echoes by working out how compressible they are, similar
to how simple algorithms compress digital photos into
JPEG files. The ability to do this represents a first
step towards a "consciousness-meter" that is both
practically useful and theoretically motivated.
This made me think of Chris Ford's StrangeLoop 2015 talk about
using compression to understand music.
Using compressibility as a proxy for complexity gives us
a first opportunity to understand all sorts of phenomena
about which we are collecting data. Kolmogorov complexity
is a fun tool for programmers to wield.
One common way to split problems is via the "generate and test"
pattern, where one component suggests results and the other one
discards invalid ones. (In my experience, undergrad programmers
are experts in this pattern, although they tend to use it as a
[software development] methodology--but that's another story.)
When some students learn to program for the first time, they
start out by producing code that looks like something they have
seen before, trying it out, and then tinkering with it until it
works or until they become exasperated. (I always hope that
they act on their exasperation by asking me for help, rather
than by giving up.) These students usually understand little
bits of the code locally, but they don't really understand the
program or function as a whole. Yet, somehow, they find a way
to make it work.
It's surprising how far some students can get in a course of
study by programming this way. (That's why Callaghan calling
the approach a methodology made me smile.) It's unfortunate,
too, because eventually the approach hits a wall when problems
and domains become more challenging. Or when they run into a
course where they program in Racket, in which one misplaced
parenthesis can cause an otherwise perfect piece of code to
implode. Lisp-like languages do not provide a supportive
environment for this kind of "programming by wandering around".
And then there's this, from Andy Hertzfeld's
fun little story
about the writing of the classic manual Inside Macintosh:
Pretty soon, I figured out that if Caroline had trouble
understanding something, it probably meant that the
design was flawed. On a number of occasions, I told
her to come back tomorrow after she asked a penetrating
question, and revised the API to fix the flaw that she
had pointed out. I began to imagine her questions when
I was coding something new, which made me work harder
to get things clearer before I went over them with her.
In this story, Caroline is not a student, but a young new
writer assigned to the Mac documentation team. Still, she
reminds me of students who are as delightful to work with
as generate-and-test programmers can be frustrating. These
students pay attention. They ask good questions, ones that
often challenge the unstated assumptions underlying what we
have explained before. At first, this can seem frustrating
to us teachers, because we have to formulate answers for
things that should be obvious. But that's the point: they
aren't obvious, at least not to everyone, and us thinking
they are obvious is inhibiting our teaching.
Last semester, I had one team of students in my compilers
class that embodied this attitude. They asked questions no
one had ever bothered to ask me before. At first, I thought,
"How can these guys not understand such basic material?"
Like Hertzfeld, though, pretty soon I figured out that their
questions were exposing holes or weaknesses in my lectures,
examples, and sample code. I began to anticipate their
questions as I prepared for class. Their questions helped me
see ways to make my course better.
As along
so many other dimensions,
part of the challenge in teaching CS is the wide variation in
the way students study, learn, and approach their courses. It
is also a part of the great fun of teaching, especially when
you encounter the Carolines and Averys who push me to get better.
That's a direct quote from this blog. Don't remember it? I don't
blame you; neither do I. I do remember blogging about McPhee
back when,
but as I read the same Paris Review piece again last Sunday
and this, I had no recollection of reading it before, no sense of
déjà vu at all.
Sometimes having a memory like mine is a blessing: I occasionally
get to read something for the first time again. If you read my
blog, then you get to read my first impressions for a second time.
I like this story that McPhee told about Bob Bingham, his editor
at The New Yorker:
Bingham had been a writer-reporter at The Reporter
magazine. So he comes to work at The New Yorker, to
be a fact editor. Within the first two years there, he goes
out to lunch with his old high-school friend Gore Vidal.
And Gore says, What are you doing as an editor, Bobby? What
happened to Bob Bingham the writer? And Bingham says, Well,
I decided that I would rather be a first-rate editor than a
second-rate writer. And Gore Vidal draws himself up and
says, And what is wrong with a second-rate writer?
I can just hear the faux indignation in Vidal's voice.
McPhee talked a bit about his struggle over several years to write
a series of books on geology, which had grown out of an idea for
a one-shot "Talk of the Town" entry. The interviewer asked him
if he ever thought about abandoning the topic and moving on to
something he might enjoy more. McPhee said:
The funny thing is that you get to a certain point and you
can't quit. Because I always worried: if you quit, you'll
quit again. The only way out was to go forward, to learn
your way and write your way out of it.
I know that feeling. Sometimes, I really do need to quit
something and move on, but I always wonder whether quitting this
time will make it easier to do next time. Because sometimes, I
need to stick it out and, as McPhee says, learn my way out of the
difficulty. I have no easy answers for knowing when quitting is
the right thing to do.
Toward the end of the interview, the conversation turned to the
course McPhee teaches at Princeton, once called "the literature
of fact". The university first asked him to teach on short
notice, over the Christmas break in 1974, and he accepted
immediately. Not everyone thought it was a good idea:
One of my dear friends, an English teacher at Deerfield,
told me: Do not do this. He said, Teachers are a dime a
dozen -- writers aren't. But my guess is that I've been
more productive as a writer since I started teaching than
I would have been if I hadn't taught. In the overall crop
rotation, it's a complementary job: I'm looking at other
people's writing, and the pressure's not on me to do it
myself. But then I go back quite fresh.
I know a lot of academics who feel this way. Then again, it's
a lot easier to stay fresh in one's creative work if one has
McPhee's teaching schedule, rather than a full load of courses:
My schedule is that I teach six months out of thirty-six,
and good Lord, that leaves a lot of time for writing,
right?
Indeed it does. Indeed it does.
On this reading of the interview, I marked only two passages that
I wrote about last time. One came soon after the above response,
on how interacting with students is its own reward. The other was
a great line about the difference between mastering technique and
having something to say: You demonstrated you know how to saddle
a horse. Now go find the horse.
That said, I unconsciously channeled this line from McPhee just
yesterday:
Writing teaches writing.
We had a recruitment event on campus, and I was meeting with a
dozen or so prospective students and their entourages. We were
talking about our curriculum, and I said a few words about our
senior project courses. Students generally like these courses,
even though they find them difficult. The students have never
had to write a big program over the course of several months,
and it's harder than it looks. The people who hire our graduates
like these courses, too, because they know that these courses are
places where students really begin to learn to program.
In the course of my remarks, I said something to the effect, "You
can learn a lot about programming in classes where you study
languages and techniques and theory, but ultimately you learn to
write software by writing software. That's what the project
courses are all about." There were a couple of experienced
programmers in the audience, and they were all nodding their heads.
They know McPhee is right.
As I got ready for class yesterday morning, I decided to refactor
a piece of code. No big deal, right? It turned out to be a
bigger deal than I expected. That's part of the fun of
programming.
The function in question is a lexical addresser for a little
language we use as a specimen in my Programming Languages course.
My students had been working on a design, and it was time for us
to build a solution as a group. Looking at my code from the
previous semester, I thought that changing the order of two cases
would make for a better story in class. The cases are independent,
so I swapped them and ran my tests.
The change broke my code. It turns out that the old "else" clause
had been serving as a convenient catch-all and was only working
correctly due to an error in another function. Swapping the cases
exposed the error.
Ordinarily, this wouldn't be a big deal, either. I would simply
fix the code and give my students a correct solution. Unfortunately,
I had less than an hour before class, so I now found myself in a
scramble to find the bug, fix it, and make the changes to my lecture
notes that had motivated the refactor in the first place. Making
changes like this under time pressure is rarely a good idea... I
was tempted to revert to the previous version, teach class, and make
the change after class. But I am a programmer, dogged and often
foolhardy, so I pressed on.
With a few minutes to spare, I closed the editor on my lecture notes
and synced the files to my teaching machine. I was tired and still
had a little nervous energy coursing through me, but I felt great.
That's part of the fun of programming.
I will say this: Boy, was I glad to have my test suite! It was
incomplete, of course, because I found an error in my program.
But the tests I did have helped me to know that my bug fix had
not broken something else unexpectedly. The error I found led to
several new tests that make the test suite stronger.
This experience was fresh in my mind this morning when I read
"Physics Was Paradise",
an interview with Melissa Franklin, a distinguished experimental
particle physicist at Harvard. At one point, Franklin mentioned
taking her first physics course in high school. The interviewer
asked if physics immediately stood out as something she would
dedicate her life to. Franklin responded:
Physics is interesting, but it didn't all of a sudden grab me
because introductory physics doesn't automatically grab
people. At that time, I was still interested in being a
writer or a philosopher.
I took my first programming class in high school and, while I
liked it very much, it did not cause me to change my longstanding
intention to major in architecture. After starting in the
architecture program, I began to sense that, while I liked
architecture and had much to learn from it, computer science was
where my future lay. Maybe somewhere deep in my mind was memory
of an experience like the one I had yesterday, battling a piece
of code and coming out with a sense of accomplishment and a
desire to do battle again. I didn't feel the same way when
working on problems in my architecture courses.
Intro CS, like intro physics, doesn't always snatch people away
from their goals and dreams. But if you enjoy the fun of
programming, eventually it sneaks up on you.
But then it hit me. Code is not literature and we are not
readers. Rather, interesting pieces of code are specimens
and we are naturalists. So instead of trying to pick out
a piece of code and reading it and then discussing it like
a bunch of Comp Lit. grad students, I think a better model
is for one of us to play the role of a 19th century naturalist
returning from a trip to some exotic island to present to
the local scientific society a discussion of the crazy beetles
they found: "Look at the antenna on this monster! They look
incredibly ungainly but the male of the species can use these
to kill small frogs in whose carcass the females lay their
eggs."
The point of such a presentation is to take a piece of code
that the presenter has understood deeply and for them to help
the audience understand the core ideas by pointing them out
amidst the layers of evolutionary detritus (a.k.a. kludges)
that are also part of almost all code. One reasonable approach
might be to show the real code and then to show a stripped down
reimplementation of just the key bits, kind of like a biologist
staining a specimen to make various features easier to discern.
My scientist friends often like to joke that CS isn't science, even
as they admire the work that computer scientists and programmers do.
I think Seibel's essay expresses nicely one way in which studying
software really is like what natural scientists do. True, programs
are created by people; they don't exist in the world as we find it.
(At least programs in the sense of code written by humans to run on
a computer.) But they are created under conditions that look a lot
more like biological evolution than, say, civil engineering.
As Hal Abelson says in the essay, most real programs end up
containing a lot of stuff just to make it work in the complex
environments in which they operate. The extraneous stuff enables
the program to connect to external APIs and plug into existing
frameworks and function properly in various settings. But the
extraneous stuff is not the core idea of the program.
When we study code, we have to slash our way through the brush to
find this core. When dealing with complex programs, this is not
easy. The evidence of adaptation and accretion obscures everything
we see.
Many people do what Seibel does when they approach a new, hairy
piece of code: they refactor it, decoding the meaning of the
program and re-coding it in a structure that communicates their
understanding in terms that express how they understand it. Who
knows; the original program may well have looked like this simple
core once, before it evolved strange appendages in order to adapt
to the condition in which it needed to live.
The folks who helped to build the software patterns community
recognized this. They accepted that every big program "in the
wild" is complex and full of cruft. But they also asserted that
we can study such programs and identify the recurring structures
that enable complex software both to function as intended and to
be open to change and growth at the hands of programmers.
One of the holy grails of software engineering is to find a way
to express the core of a system in a clear way, segregating the
extraneous stuff into modules that capture the key roles that
each piece of cruft plays. Alas, our programs usually end up
more like the human body: a mass of kludges that intertwine to
do some very cool stuff just well enough to succeed in a harsh
world.
And so: when we
read code,
we really do need to bring the mindset and skills of a scientist
to our task. It's not like reading People magazine.
"Flying by Instruments" and Learning a New Programming Style
Yesterday afternoon I listened to a story told by someone who had
recently been a passenger in a small plane flown by a colleague.
As they climbed to their cruising altitude, which was clear and
beautiful, the plane passed through a couple thousand feet of
heavy clouds. The pilot flew confidently, having both training
and experience in
instrument flight.
The passenger telling the story, however, was disoriented and a
little scared by being in the clouds and not knowing where they
were heading. The pilot kept him calm by explaining the process
of "flying by instruments" and how he had learned it. Sometimes,
learning something new can give us confidence. Other times, just
listening to a story can distract us enough to get us through a
period of fear.
This story reminded me of a session early in my programming
languages course, when students are learning Racket and functional
programming style. Racket is quite different from any other
language they have learned. "Don't dip your toes in the water,"
I tell them. "Get wet."
For students who prefer their learning analogies not to involve
potential drowning -- that is, after all, the sensation many of
them report feeling as they learn to cope with all of Racket's
parentheses for the first time -- I relate an Alan Kay story that
talks about learning to fly an airplanes after already knowing
how to drive a car. Imagine what the world be like if everyone
refused to learn how to fly a plane because driving was so much
more comfortable and didn't force them to bend their minds a bit?
Sure, cars are great and serve us well, but planes completely
change the world by bringing us all closer together.
I have lost track of where I had heard or read Kay telling that
story, so when I wrote up the class notes, I went looking for a
URL to cite. I never found one, but while searching I ran across
a different use of airplanes in an analogy that I have since worked
into my class. Here's the paragraph I use in my class notes, the
paragraph I thought of while listening to the flying-by-instruments
story yesterday:
The truth is that bicycles and motorcycles operate quite
differently than wheeled vehicles that keep three or more
wheels on the ground. For one thing, you steer by leaning,
not with the handlebars or steering wheel. Learning to fly
an airplane gives even stronger examples of having to learn
that your instincts are wrong, and that you have to train
yourself to "instinctively" know not only that you turn by
banking rather than with the rudder, but that you control
altitude primarily with the throttle, not the elevators,
speed primarily with the elevators not the throttle, and so
forth.
Learning to program in a new style, whether object-oriented,
functional, or concatenative, usually requires us to overcome
deeply-ingrained design instincts and to develop new instincts
that feel uncomfortable while we are learning. Developing new
instincts takes some getting used to, but it's worth the effort,
even if we choose not to program much in the new style after we
learn it.
Now I find myself thinking about what it means to "fly by
instruments" when we program. Is our unit testing framework one
of the instruments we come to rely on? What about a code smell
detector such as
Reek?
If you have thoughts on this idea, or pointers to what others
have already written, I would love to
hear from you.
Over the last couple of days, a thread on the SIGCSE mailing list
has been revisiting the well-tilled ground of comments in code.
As I told my students at the beginning of class this semester,
some of my colleagues consider me a heretic for not preaching the
Gospel of Comments in Code. Every context seems to have its own
need for, and expectations of, comments. Wherever students end
up working, both while in school and after graduation, their
employers will set a standard and expect them to follow. They
will figure it out.
In most of my courses, I define a few minimal standard, try to
set a good example in the code I give my students, and otherwise
don't worry much about comments. Part of my example is that
different files I give them are commented differently, depending
on the context. A demo of an idea, a library to be reused in the
course, and an application are different enough that they call
for different kinds of comments. In a course such as compiler
development, I require more documentation, both in and out of
the code. Students live with that code for a semester and come
to value some of their own comments many weeks later.
Anyway, the SIGCSE thread included two ideas that I liked, though
they came from competing sides of the argument. One asserted
that comments are harmful, because:
They're something the human reader can see but the computer can't,
and therefore are a source of misunderstanding.
I love the idea of thinking in terms of misunderstandings between
humans and the computer.
The other responded to another poster's suggestion that students
be encouraged to write comments with themselves in mind: What
would you like to know if you open this code six months from now?
The respondent pointed out that this is unreasonable: Answering
that question requires...
... a skill that is at least on par with good programming skills.
Certainly new CS students are unable to make this kind of decision.
The thread has been a lot of fun to read. I remain mostly of
the view that:
It's better to write code that says what it means and thus
needs as few comments as possible. This is a skill
students can and should work on all the time time.
If the code is likely to conflict with the expectations of
the people most likely to read your code, then add a comment.
This part depends a lot on context and experience. Students
are just now earning their experience, and the context in
which they work changes from course to course and job to
job.
Students who care about programming, or who come to care about
it over time, will care (or come to care) about comments, too.
I haven't found a way to generate these kinds of insights
about math without surrounding myself with people learning
math for the first time.
I've learned a lot about programming from teaching college
students. Insights can come at all levels, from working
with seniors who are writing compilers as their first big
project, through midstream students who are learning OOP
or functional programming as a second or third style,
right down to beginners who are seeing variables and loops
and functions for the first time.
Sometimes an insight comes when a student asks a new question,
or an old question at the right time. I had a couple of
students in my compiler course last fall who occasionally
asked the most basic questions, especially about code
generation. Listening to their questions and creating new
examples to illustrate my answers helped me think differently
about the run-time system.
Other times, they come while listening to students talk among
themselves. One student's answer to another student's
question can trigger an entirely new way for me to think about
a concept I think I understand pretty well. I don't have any
recent personal examples in mind, but this sort of experience
seems to be part of what triggered Meyer's post.
People are always telling us to "be the least experienced
person in the room", to surround ourselves with "smarter" or
more experienced people and learn from them. But there is a
lot to be learned from programmers who are just starting out.
College profs have that opportunity all the time, if they are
willing to listen and learn.
Howard Marks on Investing -- and Software Development
Howard Marks
is an investor and co-founder of Oaktree Capital Management. He
has a big following in the financial community for his views on
markets and investing, which often stray from orthodoxy, and for
his straightforward writing and speaking style. He's a lot like
Warren Buffett, with less public notoriety.
This week I read Marks's
latest memo
[
PDF
] to Oak Tree's investors, which focuses on expert opinion and
forecasting. This memo made me think a lot about software
development. Whenever Marks talks about experts predicting how
the market would change and how investors should act, I thought
of programming. His comments sound like the wisdom of an agile
software developer.
Consider what he learned from the events of 2016:
First, no one really knows what events are going to transpire.
And second, no one knows what the market's reaction to those
events will be.
Investors who got out of the market for the last couple of months
of 2016, based on predictions about what would happen, missed a
great run-up in value.
If a programmer cannot predict what will happen in the future, or
how stakeholders will respond to these changes, then planning in
too much detail is at best an inefficient use of time and energy.
At worst it is a way to lock yourself into code that you really
need to change but can't.
Or consider these thoughts on surprises (the emphasis in the
original):
It's the surprises no one can anticipate that would move markets
most if they were to happen. But (a) most people can't imagine
them and (b) most of the time they don't happen. That's why
they're called surprises.
To Marks, this means that investors should not try to get cute,
predict the future, and outsmart the market. The best they can
do is solid technical analysis of individual companies and invest
based on observable facts about value and value creation.
To me, this means that we programmers shouldn't try to prepare
for surprises by designing them into our software. Usually, the
best we can do is to implement simple, clean code that does just
what it does and no more. The only prediction we can make about
the future is that we may well have to change our code. Creating
clean interfaces and hiding implementation choices enable us to
write code that is as straightforward as possible to change when
the unimaginable happens, or even the imaginable.
Marks closes this memo with five quotes about forecasting from
a collection he has been building for forty years. I like this
line from former GE executive Ian Wilson, which expresses the
conundrum that every designer faces:
No amount of sophistication is going to allay the fact that
all of your knowledge is about the past and all your decisions
are about the future.
It isn't really all that strange that the wisdom of an investor
like Marks might be of great value to a programmer. Investors
and programmers both have to choose today how to use a finite
resource in a way that maximizes value now and in the future.
Both have to make these choices based on knowledge gleaned from
the past. Both are generally most successful when the future
looks like the past.
A big challenge for investors and programmers alike is to find
ways to use their experience of the past in a way that maximizes
value across a number of possible futures, both the ones we
can anticipate and the ones we can't.
As I settle into a new semester of teaching students functional
programming and programming languages, I find myself again in
the role of grader of, and commenter, on code. This passage
from Tobias Wolff in
Paris Review interview
serves as a guide for me:
Now, did [Pound] teach Eliot to write? No. But he did help
him see that there were more notes to be played he was playing.
That is the kind of thing I hope to do. And to counsel patience
-- the beauty of patience, which is not a virtue of the young.
Students often think that learning to program is all about the
correctness of their code. Correctness matters, but there's a
lot more. Knowing what is possible and learning to be patient
as they learn often matter more than mere correctness. For
some students, it seems, those lessons must begin before more
technical habits can take hold.
On
the racket-users mailing list
yesterday, Matthias Felleisen issued "a research challenge that
is common in the Racket world":
If you are here and you see the blueprints for paradise over
there, don't just build paradise. Also build the bridge
from here to there.
This is one of the things I love about Racket. And I don't use
even 1% of the goodness that is Racket and its ecosystem.
Over the last couple of years, I have been migrating my
Programming Languages course from a Scheme subset of Racket to
Racket itself. Sometimes, this is simply a matter of talking
about Racket, not Scheme. Others, it means using some of the
data structures, functions, and tools Racket provides rather
than doing without or building our own. Occasionally, this
shift requires changing something I do in class, because Racket
is fussier than Scheme in some regards. That's usually a good
thing, because the change makes Racket a better language for
engineering big programs. In general, though, the shift goes
smoothly.
Occasionally, the only challenge is a personal one. For
example, I decided to use first and rest
this semester when working with lists, instead of car
and cdr. This should make some students' lives better.
Learning a new language and a new style and new IDE all at once
can be tough for students with only a couple of semesters'
programming experience, and using words that mean what they say
eliminates one unnecessary barrier. But, as I
tweeted,
I don't feel whole or entirely clean when I do so. As my
college humanities prof taught me through Greek tragedies, old
habits die hard, if at all.
One of my goals for the course this semester is to have the
course serve as a better introduction to Racket for students
who might be inclined to take advantage of its utility and
power in later courses, or who simply want to enjoy working in
a beautiful language. I always seem to have a few who do, but
it might be nice if even more left the course thinking of
Racket as a real alternative for their project work. We'll
see how it goes.
Garbage collection is a hard problem, really hard, one that has
been studied by an army of computer scientists for decades. Be
very suspicious of supposed breakthroughs that everyone else
missed. They are more likely to just be strange or unusual
tradeoffs in disguise, avoided by others for reasons that may
only become apparent later.
It's wise always to be on the lookout for "strange or unusual
tradeoffs in disguise".
Wolff is willing, however, to share stories about what has worked
for him. He just doesn't think what works for him will necessarily
work for anyone else. He doesn't even think that what works for
him on one story will work for him on the next. Eventually, he
sums up his advice with this:
There's no right way to tell all stories, only the right way
to tell a particular story.
Wolff follows a few core practices that keep him moving forward
every day, but he isn't dogmatic about them. He does whatever he
needs to do to get the current story written -- even if it means
moving to Italy for several months.
Wolfe is taking about short stories and novels, but this sentiment
applies to more than writing. It captures what is, for me, the
fundamental attitude of agile software developers: There is no
right way to write all programs, only a good way to write each
particular program. We find that certain programming practices
-- taking small steps, writing tests early, refactoring mercilessly,
pairing -- apply to most tasks. These practices are so powerful
precisely because they give us feedback frequently and help us
adjust course quickly.
But when conditions change around us, we must be willing to adapt.
(Even if that means moving to Italy for several months.) This is
what it means to be agile.
The idea is not that you need language for thinking
but that when language comes along, it sure is useful. It
changes the way you think, it allows you to operate in
different ways because you can use the words as tools.
This is how I think about programming in general and about
new, and better, programming languages in particular. A
programmer can think quite well in just about any language.
Many of us cut our teeth in BASIC, and simply learning how
to think computationally allowed us to think differently
than we did before. But then we learn a radically
different or more powerful language, and suddenly we are
able to think new thoughts, thoughts we didn't even
conceive of in quite the same way before.
It's not that we need the new language in order to think,
but when it comes along, it allows us to operate in
different ways. New concepts become new tools.
I am looking forward to introducing Racket and functional
programming to a new group of students this spring semester.
First-class functions and higher-order functions can change
how students think about the most basic computations such
as loops and about higher-level techniques such as OOP. I
hope to do a better job this time around helping them see
the ways in which it really is different.
To echo the Running Conversation article again, when we
learn a new programming style or language, "Something
really special is created. And the thing that is created
might well be unique in the universe."
I'm reminded of a student I met with once who told me that
he planned to go to law school, and then a few minutes
later, when going over a draft of a lab report, said
"Yeah... Grammar isn't really my thing." Explaining why
I busted up laughing took a while.
When I ask prospective students why they decided not to pursue
a CS degree, they often say things to the effect of "Computer
science seemed cool, but I heard getting a degree in CS was a
lot of work." or "A buddy of mine told me that programming is
tedious." Sometimes, I meet these students as they return to
the university to get a second degree -- in computer science.
Their reasons for returning vary from the economic (a desire
for better career opportunities) to personal (a desire to do
something that they have always wanted to do, or to pursue a
newfound creative interest).
After you've been in the working world a while, a little hard
work and some occasional tedium don't seem like deal breakers
any more.
Such conversations were on my mind as I read physicist Chad
Orzel's recent
Science Is Not THAT Special.
In this article, Orzel responds to the conventional wisdom
that becoming a scientist and doing science involve a lot of
hard work that is unlike the exciting stuff that draws kids
to science in the first place. Then, when kids encounter
the drudgery and hard work, they turn away from science as a
potential career.
Orzel's takedown of this idea is spot on. (The quoted
passage above is one of the article's lighter moments in
confronting the stereotype.) Sure, doing science involves
a lot of tedium, but this problem is not unique to science.
Getting good at anything requires a lot of hard work and
tedious attention to detail. Every job, every area of
expertise, has its moments of drudgery. Even the rare few
who become professional athletes and artists, with careers
generally thought of as dreams that enable people to earn
a living doing the thing they love, spend endless hours
engaged in the drudgery of practicing technique and
automatizing physical actions that become their professional
vocabulary.
Why do we act as if science is any different, or should be?
Computer science gets this rap, too. What could be worse
than fighting with a compiler to accept a program while you
are learning to code? Or plowing threw reams of poorly
documented API descriptions to plug your code into someone's
e-commerce system?
Personally, I can think of lots of things that are worse. I
am under no illusion, however, that other professionals are
somehow shielded from such negative experiences. I just prefer
my pains to theirs.
Maybe some people don't like certain kinds of drudgery. That's
fair. Sometimes we gravitate toward the things whose drudgery
we don't mind, and sometimes we come to accept the drudgery of
the things we love to do. I'm not sure which explains my
fascination with programming. I certainly enjoy the drudgery
of computer science more than that of most other activities --
or at least I suffer it more gladly.
I'm with Orzel. Let's be honest with ourselves and our students
that getting good at anything takes a lot of hard work and, once
you master something, you'll occasionally face some tedium in
the trenches. Science, and computer science in particular, are
not that much different from anything else.
Khoi Vinh wrote a short blog entry called
The Underestimated Merits of Copying Someone Else's Work
that reminds us how valuable copying others' work, a standard
practice in the arts, can be. At the lowest level there is
copying at the textual level. Sometimes, the value is mental
or mechanical:
Hunter S. Thompson famously re-typed, word for word, F. Scott
Fitzgerald's "The Great Gatsby" just to learn how it was done.
This made me think back to the days when people typed up code
they found in Byte magazine and other periodicals. Of
course, typing a program gave you more than practice typing or a
sense of what it was like to type that much; it also gave you a
working program that you could use and tinker with. I don't know
if anyone would ever copy a short story or novel by hand so that
they could morph it into something new, but we can do that
meaningfully with code.
I missed the "copy code from Byte" phase of computing.
My family never had a home computer, and by the time I got to
college and changed my major to CS, I had plenty of new programs
to write. I pulled ideas about chess-playing programs and other
programs I wanted to write from books and magazines, but I never
typed up an entire program's source code. (I mention one of my
first personal projects in
an old OOPSLA workshop report.)
I don't hear much these days about people copying code keystroke
for keystroke.
Zed Shaw
has championed this idea in a series of introductory programming
books such as
Learn Python The Hard Way.
There is probably something to be learned by copying code Hunter
Thompson-style, feeling the rhythm of syntax and format by
repetition, and soaking up semantics along the way.
Vinh has a more interesting sort of copying in mind, though:
copying the interface of a software product:
It's odd then to realize that copying product interfaces is such
an uncommon learning technique in design. ... it's even easier
to re-create designs than it is to re-create other forms of art.
With a painting or sculpture, it's often difficult to get access
to the historically accurate tools and materials that were used
to create the original. With today's product design, the tools
are readily available; most of us already own the exact same
software employed to create any of the most prominent product
designs you could name.
This idea generalizes beyond interfaces to any program for which
we don't have source code. We often talk about reverse
engineering a program, but in my experience this usually refers
to creating a program that behaves "just like" the original.
Copying an interface pixel by pixel, like copying a program or
novel character by character, requires the artist to attend to
the smallest details -- to create an exact replica, not a similar
work.
We cannot reverse engineer a program and arrive at identical
source code, of course, but we can try to replicate behavior
and interface exactly. Doing so might help a person appreciate
the details of code more. Such a practice might even help a
programmer learn the craft of programming in a different way.
I am a regular reader of
John Regehr's blog,
which provides a steady diet of cool compiler conversation.
One of Regehr's frequent topics is undefined behavior in
programming languages, and what that means for implementing
and testing compilers. A lot of those blog entries involve
C and C++, which I don't use all that often any more, so
reading them is more spectator sport than contact sport.
This week, I got see how capricious C++ compilers can feel
up close.
My students are implementing a compiler for a simple subset
of a Pascal-like language. We call the simplest program in
this language print-one:
$ cat print-one.flr
program main();
begin
return 1
end.
One of the teams is writing their compiler in C++. The
team completed its most recent version, a parser that
validates its input or reports an error that renders its
input invalid. They were excited that it finally worked:
I sat down at my desktop computer to exercise their compiler.
$ g++ compiler.cpp -o compiler
In file included from compiler.cpp:7:
In file included from ./parser.cpp:3:
In file included from ./ast-utilities.cpp:4:
./ast-utilities.hpp:7:22: warning: in-class initialization of non-static data
member is a C++11 extension [-Wc++11-extensions]
std::string name = "Node";
^
[...]
24 warnings generated.
Oops, I forgot the -std=c++14 flag. Still, it compiled,
and all of the warnings come from a part of the code has no
effect on program validation. So I tried the executable:
$ compiler print-one.flr
ERROR at line #3 -- unexpected <invalid> 1
Invalid flair program
Hmm. The warnings are unrelated to part of the executable that
I am testing, but maybe they are creating a problem. So I
recompile with the flag:
$ g++ -std=c++14 compiler.cpp -o compiler
error: invalid value 'c++14' in '-std=c++14'
What? I check my OS and compiler specs:
$ sw_vers -productVersion
10.9.5
$ g++ --version
Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-dir=/usr/include/c++/4.2.1
Apple LLVM version 6.0 (clang-600.0.57) (based on LLVM 3.5svn)
[...]
Oh, right, Apple doesn't ship gcc any more; it ships clang and
link gcc to the clang exe. I know my OS is a bit old, but it
still seems odd that the -std=c++14 flag isn't
supported. I google for an answer (thanks, StackOverflow!)
and find that that I need to use -std=c++1y. Okay:
$ g++ -std=c++1y compiler.cpp -o compiler
$ compiler print-one.flr
ERROR at line #3 -- unexpected <invalid> 1
Invalid flair program
Now the student compiler compiles but gives incorrect, or at
least unintended, behavior. I'm surprised that both my clang
and the students' gcc compile their compiler yet produce
executables that give different answers. I know that gcc and
clang aren't 100% compatible, but my students are using a
relatively small part of C++. How can this be?
Maybe it has something to do with how clang processes the
c++1y standard flag. So I backed up to the previous
standard:
$ g++ -std=c++0x compiler.cpp -o compiler
$ compiler print-one.flr
ERROR at line #3 -- unexpected <invalid> 1
Invalid flair program
Yes, that's c++0x, not c++0y. The student
compiler still compiles and still gives incorrect or unintended
behavior. Maybe it is a clang problem? I upload their code
to our student server, which runs Linux and gcc:
Now, the c++14 flag works, and it produces a
compiler that produces the correct behavior -- or at least the
intended behavior.
I am curious about this anomaly, but not curious enough to
research the differences between clang and gcc, the differences
between the different versions of clang, or what Apple or Debian
are doing. I'm also not curious enough to figure out which nook
of C++ my students have stumbled into that could expose a rift in
the behavior of these various C++ compilers, all of which are
standard tools and pretty good.
At least now I remember what it's like to program in a language
with undefined behavior and can read Regehr's blog posts with
a knowing nod of the head.
Last week some tweeted a link to
Write code that is easy to delete, not easy to extend,
an old blog entry by @tef from last February. When I read it
yesterday, I was nodding my head so hard that I almost fell
off of the elliptical machine. I have done that before.
Trust me, you don't want to do it. You don't really fall;
the machine throws you. If you are moving fast, it throws
you hard.
I don't gush over articles in my blog as much these days as I
once did, but this one is worthy. If you write code, go read
this article. Nothing I write hear will replace reading the
entire piece. For my own joy and benefit, though, I record a
few of my favorite passages here -- along with comments, as I
am wont to do.
... if we wish to count lines of code, we should not regard
them as "lines produced" but as "lines spent".
This is actually a quote from
EWD 1036,
one of Dijkstra's famous notes. I don't always agree with
EWD, but this line is gold and a perfect tagline for @tef's
entry
Building reusable code is easier to do in hindsight with a
couple of examples of use in the code base, than foresight
of ones you might want later.
When OO frameworks first became popular, perhaps the biggest
mistake that developers made was to try to write a framework
up front. Refactoring from multiple programs is still the
best way for most of us mortals to create a framework. This
advice also applies to cohesive libraries of functions.
Aside: Make a util directory and keep different
utilities in different files. A single util
file will always grow until it is too big and yet too
hard to split apart. Using a single util file
is unhygienic.
Golf clap. I have this pattern. I am glad to know that
others do, too.
Boiler plate is a lot like copy-pasting, but you change
some of the code in a different place each time, rather
than the same bit over and over.
For some reason, reading this made me think of copy-and-paste
as a common outcome of programming language design, if not
its intended effect.
Boilerplate works best when libraries are expected to
cater to all tastes, but sometimes there is just too
much duplication. It's time to wrap your flexible
library with one that has opinions on policy, workflow,
and state. Building simple-to-use APIs is about turning
your boilerplate into a library.
Again, notice the role refactoring plays here. Build lots
of code that works, then factor out boilerplate or wrap it.
The API you design will be informed by real uses of the
functions you define.
It is not so much that we are hiding detail when we wrap
one library in another, but we are separating concerns:
requests is about popular http adventures;
urllib3 is about giving you the tools to choose
your own adventure.
One of the things I like about this blog entry is its theme
of separating concerns. Some libraries are perfect when you
are building a common application; others enable you to build
your own tools when you need something different.
A lot of programming is exploratory, and it's quicker to
get it wrong a few times and iterate than think to get
it right first time.
Agile Development 101. Even when I know a domain well, if the
domain affords me a lot of latitude when building apps, I like
explore and iterate as a way to help me choose the right path
for the current implementation.
[O]ne large mistake is easier to deploy than 20 tightly
coupled ones.
And even more, as @tef emphasizes throughout: It's easier to
delete, too.
Becoming a professional software developer is accumulating a
back-catalogue of regrets and mistakes.
When we teach students to design programs in their first couple
of years of CS, we often tell them that good design comes from
experience, and experience comes from bad design. An important
step in becoming a better programmer is to start writing code,
as much as you can. (That's how you build your catalog of
mistakes.) Then think about the results. (That's how you turn
mistakes into experience.)
We are not building modules around being able to re-use them,
but being able to change them.
This is one of the central lessons of software development.
One of the things I loved about OO programming was that it
gave me another way to create modules that isolated different
concerns from one another. So many folks make the mistake of
thinking that objects, classes, and even frameworks are about
reuse. But reuse is not the key; separation of concerns is.
Design your objects that create
shearing layers
within your program, which make it easier to change the code.
It isn't so much that you're iterating, but you have a
feedback loop.
As I
blogged recently,
competence is about creating conditions that minimize mistakes
but also help you to recognize mistakes quickly and correct
them. You don't iterate for the sake of iterating. You
iterate because that's how you feed learning back into the
work.
The strategies I've talked about [...] are not about writing
good software, but how to build software that can change
over time.
This blog entry isn't a recipe for writing good code. It's
a recipe for creating conditions in which you can write good
code. I do claim, though, that all other things being
reasonably equal, in most domains, code that you can change
is better code than code you can't change.
Good code isn't about getting it right the first time. Good
code is just legacy code that doesn't get in the way.
That is a Kent Beck-caliber witticism: Good code is just legacy
code that doesn't get in the way.
Competence and Creating Conditions that Minimize Mistakes
I enjoyed
this interview with Atul Gawande
by Ezra Klein. When talking about making mistakes, Gawande
notes that humans have enough knowledge to cut way down on
errors in many disciplines, but we do not always use that
knowledge effectively. Mistakes come naturally from the
environments in which we work:
We're all set up for failure under the conditions of complexity.
Mistakes are often more a matter of discipline and attention
to detail than a matter of knowledge or understanding. Klein
captures the essence of Gawande's lesson in one of his
questions:
We have this idea that competence is not making mistakes and
getting everything right. [But really...] Competence is
knowing you will make mistakes and setting up a context that
will help reduce the possibility of error but also help deal
with the aftermath of error.
In my experience, this is a hard lesson for computer science
students to grok. It's okay to make mistakes, but create
conditions where you make as few as possible and in which
you can recognize and deal with the mistakes as quickly as
possible. High-discipline practices such as test-first and
pair programming, version control, and automated builds make
a lot more sense when you see them from this perspective.
Shocking News: Design Technique Not Helpful When Design Is Already Done
Thanks to Greg Wilson for a pointer to
this paper,
which reports the result of an empirical evaluation of the effects
of test-driven development on software quality and programmer
productivity. In
a blog entry about the paper,
Wilson writes:
This painstaking study is the latest in a long line to find
that test-driven development (TDD) has little or no impact
on development time or code quality.
He is surprised, because he feels more productive when he writes
tests up-front.
I'd like to be able to say that these researchers and
others must be measuring the wrong things, or measuring
things the wrong way, but after so many years and so
many different studies, those of us who believe might
just have to accept that our self-assessment is wrong.
Never fear! Avdi Grimm
points the way
toward resolution. Section 3.3 of the research paper describes
the task that was given to the programmers in the experiment:
The task was divided into 13 user stories of incremental
difficulty, each building on the results of the previous
one. An example, in terms of input and expected output,
accompanied the description of each user story. An
Eclipse project, containing a stub of the expected API
signature, (51 Java SLOC); also an example JUnit test
(9 Java SLOC) was provided together with the task
description.
Notice what this says:
Test subjects were given the user stories.
The stories were sequenced to assist the subjects.
Each story was accompanied by an example.
Subjects were given code stubs with method signatures
already defined.
The paper reports that previous studies of this sort have also
set tasks before programmers with similar initial conditions.
Grimm identifies a key feature of all these experiments: The
problem given to the test subjects has already been defined in
great detail.
Shocking news: test-driven design is not helpful when the
design is already done!
As Grimm says, TDD helps the programmer think about how to start
writing code and when to stop. For me, the most greatest value
in doing TDD is that it helps me think about what I need to
build, and why. That is design. If the problem is already
defined to the point of implementation, most of the essential
design thinking has been done. In that context, the results
reported in this research paper are thoroughly unsurprising.
Like Grimm, I sympathize with the challenge of doing empirical
research on the practices of programmers. I am glad that people
such as the paper's authors are doing such research and that
people such as Wilson discuss the results. But when we wonder
why some research results conflict with the personal assessments
of real programmers and our assessments of our own experiences,
I think I know what one of the problems might be:
Evaluating the efficacy of a design methodology properly requires
that we observe people doing, um, design.
In the Paris Review's
The Art of Fiction No. 123,
Tom Wolfe tells how he learned about writer's block. Wolfe was
working at Esquire magazine, and his first editor, Byron
Dobell, had assigned him to write an article about car customizers.
After doing all his research, he was totally blocked.
I now know what writer's block is. It's the fear you cannot
do what you've announced to someone else you can do, or else
the fear that it isn't worth doing. That's a rarer form.
In this case I suddenly realized I'd never written a magazine
article before and I just felt I couldn't do it. Well, Dobell
somehow shamed me into writing down the notes that I had taken
in my reporting on the car customizers so that some competent
writer could convert them into a magazine piece. I sat down
one night and started writing a memorandum to him as fast as I
could, just to get the ordeal over with. It became very much
like a letter that you would write to a friend in which you're
not thinking about style, you're just pouring it all out, and
I churned it out all night long, forty typewritten,
triple-spaced pages. I turned it in in the morning to Byron
at Esquire, and then I went home to sleep.
Later that day, Dobell called him to say that they were deleting
the "Dear Byron" at the top of the memo and running the piece.
Most of us need more editing than that after we write anything,
but... No matter; first you have to write something. Even if
it's the product of a rushed all-nighter, just to get an
obligation off our table.
When I write, and especially when I program, my reluctance to start
usually grows out of a different sort of fear: the fear that I won't
be able to stop, or want to. Even simple programming tasks can
become deep holes into which we fall. I like that feeling, but I
don't have enough control of my work schedule most days to be able
to risk disappearing like that. What I could use is an extra dose
of audacity or impetuosity. Or maybe a boss like Byron Dobell.
Call me a crazy extreme programmer, but when I came across
the Tolkien passage quoted in my previous post on
commitment and ignorance
again recently after many years, my first thought was that
Elrond sounded like a wise old agile developer:
Look not too far ahead!
You aren't gonna need it, indeed.
This first thought cast Gimli in the role of a Big Design
Up Front developer. Unfortunately, that analogy sells his
contribution to the conversation short. Just as Gimli's
deep commitment to the mission is balanced by Elrond's
awareness, so, too, is Gimli's perspective applied to
software balanced by Elrond's YAGNI. Perhaps then Gimli
plays the role of Metaphor in this fantasy: the impulse
that drives the team forward to the ultimate goal.
Just another one of those agile moments I have every now
and then. I wonder if they will start happening with
more frequency, and less reality, as I get older. They
are a little like senior moments, only focused on
programming.
It took two years of hard work and late nights at the
whiteboard to build a prototype of something we knew we
could be proud of -- and what Silicon Valley investor
would agree to fund something that would take two years
to release? Not only that, but it would have cost us
roughly 6 times as much money to develop it in Silicon
Valley -- for no immediate benefit.
If moving to Beijing is not an option for you, fear not. You
do not have to travel that far to find patient investors, great
programmers, and low cost of living. Try Des Moines. Or St.
Louis. Or Indianapolis. Or, if you must live in a Major World
City, try Chicago. Even my small city can offer a good starting
point, though programmers are not as plentiful as we might like.
The US Midwest has a lot of advantages for founders, but none of
the smog you'll find in Beijing and much shorter commutes than
you will find in all the places people tell you you have to go.
Functional Programming, Inlined Code, and a Programming Challenge
I recently came across an old entry on Jonathan Blow's blog
called
John Carmack on Inlined Code.
The bulk of the entry consists an even older email message
that
Carmack,
lead programmer on video games such as Doom and Quake, sent
to a mailing list, encouraging developers to consider
inlining function calls
as a matter of style. This email message is the earliest
explanation I've seen of Carmack's drift toward functional
programming, seeking to as many of its benefits as possible
even in the harshly real-time environment of game programming.
The article is a great read, with much advice borne in the
trenches of writing and testing large programs whose run-time
performance is key to their success. Some of the ideas
involve programming language:
It would be kind of nice if C had a "functional" keyword to
enforce no global references.
... while others are more about design style:
The function that is least likely to cause a problem is one
that doesn't exist, which is the benefit of inlining it.
... and still others remind us to rely on good tools to help
avoid inevitable human error:
I now strongly encourage explicit loops for everything, and
hope the compiler unrolls it properly.
(This one may come in handy as I prepare to teach my compiler
course again this fall.)
This message-within-a-blog-entry itself quotes another email
message, by
Henry Spencer,
which contains the seeds of a programming challenge. Spencer
described a piece of flight software written in a particularly
limiting style:
It disallowed both subroutine calls and backward branches,
except for the one at the bottom of the main loop. Control
flow went forward only. Sometimes one piece of code had to
leave a note for a later piece telling it what to do, but
this worked out well for testing: all data was allocated
statically, and monitoring those variables gave a clear
picture of most everything the software was doing.
Wow: one big loop, within which all control flows forward.
To me, this sounds like a devilish challenge to take on when
writing even a moderately complex program like a scanner or
parser, which generally contain many loops within loops. In
this regard, it reminds me of
the Polymorphism Challenge's
prohibition of if-statements and other forms of
selection in code. The goal of that challenge was to help
programmers really grok how the use of substitutable objects
can lead to an entirely different style of program than we
tend to create with traditional procedural programming.
Even though Carmack knew that "a great deal of stuff that goes on
in the aerospace industry should not be emulated by anyone, and
is often self destructive", he thought that this idea might have
practical value, so he tried it out. The experience helped him
evolve his programming style in a promising direction. This is
a great example of the power of the pedagogical pattern known
as
Three Bears:
take an idea to its extreme in order to learn the boundaries of
its utility. Sometimes, you will find that those boundaries
lie beyond what you originally thought.
Carmack's whole article is worth a read. Thanks to Jonathan Blow
for preserving it for us.
~~~~
The image above is an example of the cover art for the "Commander
Keen" series of video games, courtesy of
Wikipedia.
John Carmack was also the lead programmer for this series. What
a remarkable oeuvre he has produced.
Like many people, I am fond of analogies between software
development and arts like writing and painting. It's
easy to be seduced by similarities even when the daily
experiences of programmers and artists are often so
different.
For that reason, I was glad that this statement by sculptor
Jacques Lipschutz stood out in such great relief from the
text around it:
Teaching is death. If he teaches, the sculptor has to open
up and reveal things that should be closed and sacred.
For me, teaching computer science has been just the opposite.
Teaching forces me to open up my thinking processes. It
encourages me to talk with professional developers about how
they do what they do and what they think about along the way.
Through these discussions, we do reveal things that sometimes
feel almost sacred, but I think we all benefit from the
examination. It not only helps me to teach novice developers
more effectively; it also helps me to be a better programmer
myself.
I recently wrote about some experiences
programming in Joy,
in which I use Joy to solve
five problems
that make up a typical homework assignment early in my Programming
Languages course. These problems introduce my students to writing
simple functions in a functional style, using Racket. Here is
my code,
if you care to check it out. I'm just getting back to stack
programming, so this code can surely be improved. Feel free to
email me
suggestions or tweet me at @wallingf!
What did these problems teach me about Joy?
The language's documentation is sparse. Like my
students, I had to find out which Joy primitives were
available to me. It has a lot of the basic arithmetic
operators you'd expect, but finding them meant searching
through a plain-text file. I should write Racket-caliber
documentation for the language to support my own work.
The number and order of the arguments to a function
matters a lot. A function that takes several arguments
can become more complicated than the corresponding Racket
function, especially if you need to use them multiple times.
I encountered this on
my first day back to the language.
In Racket, this problem requires a compound expression,
but it is relatively straightforward, because arguments
have names. With all its arguments on the stack, a Joy
function has to do more work simply to access values,
let alone replicate them for multiple uses.
A slight difference in task can lead to a large change
in the code. For Problem 4, I implemented operators
for modular addition, subtraction, and multiplication.
+mod and *mod were elegant
and straightforward. -mod was a different
story. Joy has a rem operator that operates
like Racket's remainder, but it has no
equivalent to modulo. The fact that
rem returns negative values means that I
need a boolean expression and quoted programs and a new
kind of thinking. This militates for a bigger shift in
programming style right away.
I miss the freedom of Racket naming style. This
isn't a knock on Joy, because most every programming
language restricts severely the set of characters you can
use in identifiers. But after being able to name functions
+mod, in-range?, and
int->char in Racket, the restrictions
feel even more onerous.
As in most programming styles, the right answer in Joy
is often to write the correct helpers. The
difference in level of detail between +mod
and *mod on the one hand and
-mod on the other indicates that I am
missing solution. A better approach is to implement a
modulo operator and use it to write all
three mod operators. This will hide lower-level details
in a general-purpose operator. modulo
would make a nice addition to a library of math operators.
Even simple problems can excite me about the next
step. Several of these solutions, especially the
mod operators, cry out for higher-order operators. In
Racket, we can factor out the duplication in these
operators and create a function that generates these
functions for us. In Joy, we can do it, too, using
quoted programs of the sort you see in the code
for -mod. I'll be moving on to quoted
programs in more detail soon, and I can't wait... I
know that they will push me farther along the transition
to the unique style of stack programming.
It's neat for me to be reminded that even the simplest little
functions raise interesting design questions. In Joy, use of
a stack for all data values means that identifying the most
natural order for the arguments we make available to an
operators can have a big effect on the ability to read and
write code. In what order will arguments generally appear
"in the wild"?
In the course of experimenting and trying to debug my code (or,
even more frustrating, trying to understand why the code I
wrote worked), I even wrote my first general utility operator:
DEFINE clear == [] unstack.
It clears the stack so that I can see exactly what the code I'm
about to run creates and consumes. It's the first entry in my
own little user library, named utilities.joy.
Fun, fun, fun. Have I ever said that I like to write programs?
Oberon is a software stack created by Niklaus Wirth and his
lab at ETH Zürich. Lukas Mathis describes some of
what makes Oberon unusual,
including the fact that its desktop is "an infinitely large
two-dimensional space on which windows ... can be arranged":
It's incredibly easy to move around on this plane and zoom
in and out of it. Instead of stacking windows, hiding them
behind each other (which is possible in modern versions of
Oberon), you simply arrange them next to each other and
zoom out and in again to switch between them. When people
held presentations using Oberon, they would arrange all
slides next to each other, zoom in on the first one, and
then simply slide the view one screen size to the right to
go to the next slide.
This sounds like interacting with Google Maps, or any other
modern map app. I wonder if anyone else is using this as a
model for user interaction on the desktop?
Check out Mathis's article for more. The section "Everything
is a Command Line" reminds me of workspaces in Smalltalk. I
used to have several workspaces open, with useful snippets of
code just waiting for me to do it. Each workspace
window was like a custom text-based menu.
I've always liked the idea of Oberon and even considered using
the programming language in my compilers course. (I ended up
using a variant.) A version of
Compiler Construction
is now available free online, so everyone can see how Wirth's
clear thinking lead to a sparse, complete, elegant whole.
I may have to build the latest installment of Oberon and see
what all they have working these days.
Yesterday, William Stein's
talk about the origins of SageMath
spread rapidly through certain neighborhoods of Twitter. It is
a thorough and somewhat depressing discussion of how hard it is
to develop open source software within an academic setting.
Writing code is not part of the tenure reward system or the
system for awarding grants. Stein has tenure at the University
of Washington but has decided that he has to start a company,
SageMath, work for it full-time in order to create a viable
open source alternative to the "four 'Ma's": Mathematica, Matlab,
Maple, and Magma.
Stein's talk reminded me of something I read earlier this year,
from
a talk
by Matthew Butterick:
"Information wants to be expensive, because it's so valuable
... On the other hand, information wants to be free, because
the cost of getting it out is getting lower ... So you have
these two fighting against each other."
This was said by a guy named Stewart Brand, way back in 1984.
So what's the message here? Information wants to be free?
No, that's not the message. The message is that there are
two forces in tension. And the challenge is how to balance
the forces.
Proponents of open source software -- and I count myself one
-- are often so glib with the mantra "information wants to be
free" that we forget about the opposing force. Wolfram et al.
have capitalized quite effectively on information's desire to
be expensive. This force has an economic power that can
overwhelm purely communitarian efforts in many contexts, to
the detriment of open work. The challenge is figuring out how
to balance the forces.
In my mind, Mozilla stands out as the modern paradigm of seeking
a way to balance the forces between free and expensive, creating
a non-profit shell on top of a commercial foundation. It also
seeks ways to involve academics in process. It will be
interesting to see whether this model is sustainable.
Oh, and Stewart Brand. He pointed out this tension thirty
years ago. I recently recommended How Buildings Learn
to my wife and thought I should look back at the copious notes
I took when I read it twenty years ago. But I should read the
book again myself; I hope I've changed enough since then that
reading it anew brings new ideas to mind.
Brilliance Is Better Than Magic, Because You Get To Learn It
Brent Simmons has recently suggested that Swift would be better
if it were more dynamic. Some readers have interpreted his
comments as an unwillingness to learn new things. In
Oldie Complains About the Old Old Ways,
Simmons explains that new things don't bother him; he simply
hopes that we don't lose access to what we learned in the
previous generation of improvements. The entry is short and
worth reading in its entirety, but the last sentence of this
particular paragraph deserves to be etched in stone:
It seemed like magic, then. I later came to understand how it
worked, and then it just seemed like brilliance. (Brilliance
is better than magic, because you get to learn it.)
This gets to close to the heart of why I love being a computer
scientist.
So many of the computer programs I use every day seem like magic.
This might seem odd coming from a computer scientist, who has
learned how to program and who knows many of the principles that
make complex software possible. Yet that complexity takes many
forms, and even a familiar program can seem like magic when I'm
not thinking about the details under its hood.
As a computer scientist, I get to study the techniques that make
these programs work. Sometimes, I even get to look inside the
new program I am using, to see the algorithms and data structures
that bring to life the experience that feels like magic.
Looking under the hood reminds me that it's not really magic. It
isn't always brilliance either, though. Sometimes, it's a very
cool idea I've never seen or thought about before. Other times,
it's merely a bunch of regular ideas, competently executed, woven
together in a way that give an illusion of magic. Regular ideas,
competently executed, have their own kind of beauty.
After I study a program, I know the ideas and techniques that make
it work. I can use them to make my own programs.
This fall, I will again teach a course in compiler construction.
I will tell a group of juniors and seniors, in complete honesty,
that every time I compile and execute a program, the compiler
feels like magic to me. But I know it's not. By the end of the
semester, they will know what I mean; it won't feel like magic to
them any more, either. They will have learned how their compilers
work. And that is even better than the magic, which will never go
away completely.
After the course, they will be able to use the ideas and techniques
they learn to write their own programs. Those programs will
probably feel like magic to the people who use them, too.
In her 1942 book Philosophy in a New Key, philosopher
Susanne Langer
wrote:
A question is really an ambiguous proposition; the answer is
its determination.
This sounds like something a Prolog programmer might say in a
philosophical moment. Langer even understood how tough it can
be to write effective Prolog queries:
The way a question is asked limits and disposes the ways in
which any answer to it -- right or wrong -- may be given.
Try sticking a
cut
somewhere and see what happens...
It wouldn't be too surprising if a logical philosopher reminded
me of Prolog, but Langer's specialties were consciousness and
aesthetics. Now that I think about it, though, this connection
makes sense, too.
Prolog can be a lot of fun, though logic programming always felt
more limiting to me than most other styles. I've been fiddling
again with Joy, a language created by a philosopher,
but every so often I think I should earmark some time to revisit
Prolog someday.
David Andersen offers a rather thorough list of ways that
academics might
adapt Google's coding practices
to their research. It's a good read; check it out! I did
want to comment on one small comment, because it relates
to a common belief about pair programming:
But, of course, effective pair programming requires a lot
of soft skills and compatible pairs. I'm not going to
pretend that this solution works everywhere.
I don't pretend that pair programming works everywhere, either,
or that everyone should adopt it, but I often wonder about
statements like this one. Andersen seems to think that pair
programming is a good thing and has helped him and members of
his team's to produce high-quality code in the past. Why
downplay the practice in a way he doesn't downplay other
practices he recommends?
Throughout, the article encourages the use of new tools and
techniques. These tools will alter the practice of his students.
Some are complex enough that they will need to be taught, and
practiced over some length of time, before they become an
effective part of the team's workflow. To me, pair programming
is another tool to be learned and practiced. It's certainly no
harder than learning git...
Pair programming is a big cultural change for many
programmers, and so it does require some coaching and extended
practice. This isn't much different than the sort of "onboarding"
that Andersen acknowledges will be necessary if he is to adopt
some of Google's practices successfully in his lab upon upon his
return. Pair programming takes practice and time, too, like most
new skills.
I have seen the benefit of pair programming in an academic setting
myself. Back when I used to teach our introductory course to
freshmen, I had students pair every week in the closed lab
sessions. We had thirty students in each section, but only
fifteen computers in our lab. I paired students in a rotating
fashion, so that over the course of fifteen weeks each student
programmed with fifteen different classmates. We didn't use a
full-on "pure" XP-style of pairing, but what we did was consistent
with the way XP encourages pair programming.
This was a good first step for students. They got to know each
other well and learned from one another. The better students
often helped their partners in the way senior developers can help
junior developers progress. In almost all cases, students helped
each other find and fix errors. Even though later courses in the
curriculum did not follow up with more pair programming, I saw
benefits in later courses, in the way students interacted in the
lab and in class.
I taught intro again
a couple of falls ago
after a long time away. Our lab has twenty-eight machines now,
so I was not forced to use pair programming in my labs. I got
lazy and let them work solo, with cross-talk. In the end, I
regretted it. The students relied on me a lot more to help them
find errors in their code, and they tended to work in the same
insulated cliques throughout the semester. I don't think the
group progressed as much as programmers, either, even though some
individuals turned out fine.
A first-year intro lab is a very different setting than a research
lab full of doctoral students. However, if freshmen can learn to
pair program, I think grad students can, too.
Pair programming is more of a social change than a technical
change, and that creates different issues than, say, automated
testing and style checking. But it's not so different from the
kind of change that capricious adherence to style guidelines
or other kinds of code review impose on our individuality.
Are we computer scientists so maladjusted socially that we can't
-- or can't be bothered -- to learn the new behaviors we need to
program successfully in pairs? In my experience, no.
Like Andersen, I'm not advocating that anyone require pair
programming in a lab. But: If you think that the benefits of
pair programming exceed the cost, then I encourage you to
consider having your research students or even your undergrads
use it. Don't shy away because someone else thinks it can't
work. Why deprive your students of the benefits?
The bottom line is this. Pair programming is a skill to be
learned, like many others we teach our students.
The book in question was Thinking Forth by Leo Brodie
(Brodie 1987) and upon reading it I immediately put it
into my own "personal pantheon" of influential programming
books (along with SICP, AMOP, Object-Oriented Software
Construction, Smalltalk Best Practice Patterns, and
Programmers Guide to the 1802).
The other five books, though, are in my own pantheon influential
programming books. Some readers may be unfamiliar with these
books or the acronyms, or aware that so many of them are
available free online. Here are a few links and details:
Thinking Forth
teaches us how to program in Forth, a concatenative language
in which programs run against a global stack. As Fogus
writes, though, Brodie teaches us so much more. He teaches
a way to think about programs.
AMOP is
The Art of the Metaobject Protocol,
a gem of a book that far too few programmers know about.
It presents a very different and more general kind of OOP
than most people learn, the kind possible in a language like
Common Lisp. I don't know of an authorized online version
of this book, but there is
an HTML copy
available.
Object-Oriented Software Construction
is Bertrand Meyer's opus on OOP. It did not affect me as
deeply as the other books on this list, but it presents the
most complete, internally consistent software engineering
philosophy of OOP that I know of. Again, there seems to be
an unauthorized version
online.
I love Smalltalk Best Practice Patterns and have
mentioned it a couple of times over the years [
1
|
2
]. Ounce for ounce, it contains more practical wisdom for
programming in the trenches than any book I've read. Don't
let "Smalltalk" in the title fool you; this book will help
you become a better programmer in almost any language and
any style. I have a PDF of a pre-production draft of SBPP,
and Stephane Ducasse has posted
a free online copy,
with Kent's blessing.
There is one book on my own list that Fogus did not mention:
Paradigms of Artificial Intelligence Programming,
by Peter Norvig. It holds perhaps the top position in my
personal pantheon. Subtitled "Case Studies in Common Lisp",
this book teaches Common Lisp, AI programming, software
engineering, and a host of other topics in a classical case
studies fashion. When you finish working through this book,
you are not only a better programmer; you also have working
versions of a dozen classic AI programs and a couple of
language interpreters.
Reading Fogus's paragraph of λove for Thinking
Forth brought to mind how I felt when I discovered
PAIP as a young assistant professor. I once wrote
a short blog entry
praising it. May these paragraphs stand as a greater testimony
of my affection.
I've learned a lot from other books over the years, both books
that would fit well on this list (in particular,
A Programming Language
by Kenneth Iverson) and others that belong on a different list
(say,
Gödel, Escher, Bach
-- an almost incomparable book). But I treasure certain
programming books in a very personal way.
I did my undergrad at Wisconsin, which is one of the 25 schools
that claims to be a top 10 cs/engineering school...
Even though he comes from one of the best CS schools, Luu recognizes
that grads of many other schools are well prepared for careers in
industry. Companies that bias their hiring toward the top schools
miss out on a lot of "talent". Then again, they miss out on a lot
of great talent in many other ways, too. For example:
A typical rejection reason was something like "we process millions
of transactions per day here and we really need someone with more
relevant experience who can handle these things without ramping up".
The people you don't hire won't have to ramp up. There is only one
problem: You didn't hire anyone, so there's no way they can help
you handle these things. Maybe you should hire people with strong
foundations, a little curiosity, and a little drive. Those people
can develop all the relevant experience you need.
As Luu says, "It's much easier to hire people who are underrated,
especially if you're not paying market rates." That's where the
Moneyball analogy comes in handy. I wonder if any company is
doing sabermetric-like analysis of software developers? If so,
they could develop a durable competitive advantage in hiring.
Software entrepreneurs and companies in my part of the world, the
American Midwest, have always faced stiff challenges when it comes
to hiring and retaining tech talent from the coasts. Luu reminds
them that they also have an opportunity: find underrated people
from non-elite schools who want to stay in the Midwest, and then
develop a team of professionals who rival in performance anything
you can find on the coasts.
In my town,
Banno
is a great example of a company that has accepted this challenge.
It's not easy, but with patience and strong leadership, it seems
to be working.
Somehow, I recently came across a link to
Stay on the Bus,
an excerpt from a commencement speech Arno Rafael Minkkinen
gave at the New England School of Photography in June 2004.
It is also titled "The Helsinki Bus Station Theory: Finding
Your Own Vision in Photography". I almost always enjoy reading
the thoughts of an artist on his or her own art, and this was
no exception. I also usually hear echoes of what I feel about
my own arts and avocations. Here are three.
What happens inside your mind can happen inside a camera.
This is one of the great things about any art. What happens
inside your mind can happen in a piano, on a canvas, or in a
poem. When people find the art that channels their mind best,
beautiful things -- and lives -- can happen.
One of the things I like about programming is that is really
a meta-art. Whatever happens in your mind can happen inside
a camera, inside a piano, on a canvas, or in a poem. Yet
whatever happens inside a camera, inside a piano, or on a
canvas can happen inside a computer, in the form of
a program. Computing is a new medium for experimenting,
simulating, and creating.
Teachers who say, "Oh, it's just student work," should maybe
think twice about teaching.
Amen. There is no such thing as student work. It's the work
our students are ready to make at a particular moment in time.
My students are thinking interesting thoughts and doing their
best to make something that reflects those thoughts. Each
program, each course in their study is a step along a path.
All work is student work. It's just that some of us
students are at a different point along our paths.
Georges Braque has said that out of limited means, new forms
emerge. I say, we find out what we will do by knowing what
we will not do.
This made me think of an entry I wrote many years ago,
Patterns as a Source of Freedom.
Artists understand better than programmers sometimes that
subordinating to a form does not limit creativity; it unleashes
it. I love Minkkinen's way of saying this: we find out what we
will do by knowing what we will not do. In programming as in
art, it is important to ask oneself, "What will I not
do?" This is how we discover we will do, what we can do, and
even what we must do.
Those are a few of the ideas that stood out to me as I read
Minkkinen's address. The Helsinki Bus Station Theory is a
useful story, too.
In
Sledgehammers vs Nut Crackers,
Thomas Guest talks about pulling awk of the shelf to solve a
fun little string-processing problem. He then shows a solution
in Python, one of his preferred general-purpose programming
languages. Why bother with languages like awk when you have
Python at the ready? Guest writes:
At the outset of this post I admitted I don't generally
bother with awk. Sometimes, though, I encounter the
language and need to read and possibly adapt an existing
script. So that's one reason to bother. Another reason
is that it's elegant and compact. Studying its operation
and motivation may help us compose and factor our own
programs -- programs far more substantial than the
scripts presented here, and in which there will surely
be places for mini-languages of our own.
As I watch some of my students struggle this semester to
master Racket, recursive programming, and functional style,
I offer them hope that learning a new language and a new
style will make them better Python and Java programmers,
even if they never write another Racket or Lisp program
again. The more different ways we know how to think about
problems and solutions, the more effective we can be as
solvers of problems. Of course, Racket isn't a special
purpose language, and a few students find they so like
the new style that they stick with the language as their
preferred tool.
Experienced programmers understand what Guest is saying,
but in the trenches of learning, it can be hard to
appreciate the value of knowing different languages and
being able to think in different ways. My sledgehammer
works fine, my students say; why am I learning to use a
nutcracker? I have felt that sensation myself.
I try to keep this feeling in mind as my students work
hard to master a new way of thinking. This helps me
empathize with their struggle, all the while knowing
that Racket will shape how some of them think about
every program they write in the future.
As computer scientists get older, we all find ourselves reminiscing
about the computers we knew in the past. I sometimes tell my
students about using 5.25" floppies with capacities listed in
kilobytes, a unit for which they have no frame of reference. It
always gets a laugh.
In
a recent blog entry,
Daniel Lemire reminisces about the Cray 2, "the most powerful
computer that money could buy" when he was in high school. It was
took up more space than an office desk (see some photos
here),
had 1 GB of memory, and provided a peak performance of 1.9 gigaflops.
In contrast, a modern iPhone fits in a pocket, has 1 GB of memory,
too, and contains a graphics processing unit that provides more
gigaflops than the Cray 2.
I saw Lemire's post a day after someone tweeted
this image
of a 64 GB memory card from 2016 next to a 2 GB Western Digital hard
drive from 1996:
The youngest students in my class this semester were born right
around 1996. Showing them a 1996 hard drive is like my college
professors showing me magnetic cores: ancient history.
This sort of story is old news, of course. Even so, I occasionally
remember to be amazed by how quickly our hardware gets smaller and
faster. I only wish I could improve my ability to make software
just as fast. Alas, we programmers must deal with the constraints
of human minds and human organizations. Hardware engineers do
battle only with the laws of the physical universe.
Lemire goes a step beyond reminiscing to close his entry:
And what if, today, I were to tell you that in 40 years, we will
be able to fit all the computational power of your phone into a
nanobot that can live in your blood stream?
Imagine the problems we can solve and the beauty we can make with
such hardware. The citizens of 2056 are counting on us.
I learned this
one summer
while writing and deleting the same program several times:
The instinct to discard is finally a kind of faith. It
tells me there's a better way to do this page even though
the evidence is not accessible at the present time.
The engineer in me always whispered that evidence supported the
desire to delete the program and start over: a recognition that
I understood encapsulation of behavior more clearly, or messages
as a means of decoupling subsystems. Yet in the end there is
also small bit of faith. "Surely some of the code I'm deleting
is good enough to survive to the next generation..." The
programmer, like the writer, must be willing to believe in such
situations that "nature will restore itself".
What Is The Best Way Promote a Programming Language?
A newcomer to the Racket users mailing list asked which was
the better way to promote the language: start a discussion on
the mailing list, or ask questions on Stack Overflow. After
explaining that neither was likely to promote Racket, Matthew
Butterick gave
some excellent advice:
Here's one good way to promote the language:
Make something impressive with Racket.
When someone asks "how did you make that?", give
Racket all the credit.
Don't cut corners in Step 1.
This technique applies to all programming languages.
Butterick has made something impressive with Racket:
Practical Typography,
an online book. He wrote the book using a publishing system named
Pollen, which he created in Racket. It's a great book and a joy
to read, even if typography is only a passing interest. Check it
out. And he gives Racket and the Racket team a lot of credit.
What a Tiny Language Can Teach Us About Gigantic Systems
StrangeLoop is
long in the books
for most people, but I'm still thinking about some of the things
I learned there. This is the first of what I hope to be a few
more posts on talks and ideas still on my mind.
The conference opened with a keynote address by
Peter Alvaro,
who does research at the intersection of distributed systems and
programming languages. The talk was titled "I See What You Mean",
but I was drawn in more by his alternate title: "What a Tiny
Language Can Teach Us About Gigantic Systems". Going in, I had
no idea what to expect from this talk and so, in an attitude whose
pessimism surprised me, I expected very little. Coming out, I had
been surprised in the most delightful way.
Alvaro opened with the confounding trade-off of all abstractions:
Hiding the distracting details of a system can illuminate the critical
details (yay!), but the boundaries of an abstraction lock out the
people who want to work with the system in a different way (boo!).
He illustrated the frustration felt by those who are locked out with
a tweet from
@pxlplz:
SELECT bs FROM table WHERE sql="arrgh" ORDER BY hate
From this base, Alvaro moved on to his personal interests: query
languages, semantics, and distributed systems. When modeling
distributed systems, we want a language that is resilient to failure
and tolerant of a loose ordering on the execution of operations. But
we also need a way to model what programs written in the language mean.
The common semantic models express a common split in computing:
operational semantics: a program means what it does
model-theoretic semantics: a program means the set of facts
that makes it true
With query languages, we usually think of programs in terms of the
databases of facts that makes them true. In many ways, the streaming
data of a distributed system is a dual to the database query model.
In the latter, program control flows down to fixed data. In
distributed systems, data flows down to fixed control units. If I
understood Alvaro correctly, his work seeks to find a sweet spot amid
the tension between these two models.
Alvaro walked through three approaches to applicative programming.
In the simplest form, we have three operators:
select (σ),
project (Π), and
join (⋈).
The database language SQL adds to this set negation (¬).
The Prolog subset
Datalog
makes computation of the least fixed point a basic operation. Datalog
is awesome, says Alvaro, but not if you add ¬! That
creates a language with too much power to allow the kind of reasoning
we want to do about a program.
Declarative programs don't have assignment statements, because they
introduce time into a model. An assignment statement
effectively partitions the past (in which an old value holds) from the
present (characterized by the current value). In a program with state,
there is an hidden clock inside the program.
We all know the difficulty of managing state in a standard system.
Distributed systems create a new challenge. They need to deal with
time, but a relativistic time in which different programs seem to
be working on their own timelines. Alvaro gave a couple of common
examples:
a sender crashes, then restarts and begins to replay a set of
transaction
a receiver enters garbage collection, then comes back to life
and begins to respond to queued messages
A language that helps us write better distributed systems must give
us a way to model relativistic time without a hidden universal clock.
The rest of the talk looked at some of Alvaro's experiments aimed at
finding such languages for distributed systems, building on the ideas
he had introduced earlier.
The first was
Dedalus,
billed as "Datalog in time and space". In Dedalus, knowledge is
local and ephemeral. It adds two temporal operators to the set found
in SQL: @next, for making assertions about the future, and
@async, for making assertions of independence between
operations. Computation in Dedalus is rendezvous between data and
control. Program state is a deduction.
But what of semantics? Alas, a Dedalus program has an infinite number
of models, each model itself infinite. The best we can do is to pull
at all of the various potential truths and hope for quiescence. That's
not comforting news if you want to know what your program will mean
while operating out in the world.
Dedalus as the set of operations {σ, Π,
⋈, ¬, @next, @async} takes us
back to the beginning of the story: too much power for effective
reasoning about programs.
However, Dedalus minus ¬ seems to be a sweet spot. As an
abstraction, it hides state representation and control flow and
illuminates data, change, and uncertainty. This is the direction
Alvaro and his team are moving in now. One result is
Bloom,
a small new language founded on the Dedalus experiment. Another is
Blazes,
a program analysis framework that identifies potential inconsistencies
in a distributed program and generates the code needed to ensure
coordination among the components in question. Very interesting stuff.
Alvaro closed by returning to the idea of abstraction and the role of
programming language. He is often asked why he creates new programming
languages rather than working in existing languages. In either approach,
he points out, he would be creating abstractions, whether with an API or
a new syntax. And he would have to address the same challenges:
Respect users. We are they.
Abstractions leak. Accept that and deal with it.
It is better to mean well than to feel good. Programs have
to do what we need them to do.
Creating a language is an act of abstraction. But then, so is all
of programming. Creating a language specific to distributed systems
is a way to make very clear what matters in the domain and to
provide both helpful syntax and clear, reliable semantics.
Alvaro admits that this answer hides the real reason that he creates
new languages:
Inventing languages is dope.
At the end of this talk, I understood its title, "I See What You
Mean", better than I did before it started. The unintended double
entendre made me smile. This talk showed how language interacts
with problems in all areas of computing, the power language gives us
as well as the limits it imposes. Alvaro delivered a most excellent
keynote address and opened StrangeLoop on a high note.
Check out
the full talk
to learn about all of this in much greater detail, with the many
flourishes of Alvaro's story-telling.
This morning, I wanted to send
Michael Feathers
a link to Marick's Law. The only link I could find to it
was
a tweet
of Brian's. This law is too important to be left vulnerable
to the vagaries of an internet service, so let's give it a
permanent home:
In software, anything of the form "X's Law" is better
understood by replacing the word "Law" with "Fervent
Desire".
This is a beautiful observation, lovingly and consciously
self-referential. I think of it almost daily. Use it well.
~~~~~
Historical note. When I searched for
Marick's Law, I did find reference to another law going by
the same name.
Uncle Bob
calls this Marick's Law: "When it comes to code, it never pays
to rush." This is a useful aphorism as well, and perhaps
Brian once called it Marick's Law, too. Uncle Bob's post is
dated November 2008. Brian's coining tweet is dated April 2009.
I'm going to stick with the first-person post as definitive and
observe that Brian, like Whitman, is large and contains multitudes.
I cannot help but notice that we can and should apply the
definitive Marick's Law to the secondhand quote given by Uncle
Bob. Many of us fervently desire it to be true that, when it
comes to code, it never pays to rush. If it's not, then many
of our best practices need an overhaul. Besides, we fear deep
in our hearts that sometimes it probably does pay to rush.
Mike Feathers draws an analogy I'd never thought of before in
The Universality of Postel's Law:
what we think of as "good character" can be thought of as an
application of
Postel's Law
to ordinary human relations.
Societies often have the notion of 'good character'.
We can attempt all sorts of definitions but at its
core, isn't good character just having tolerance for
the foibles of others and being a person people can
count on? Accepting wider variation at input and
producing less variation at output? In systems
terms that puts more work on the people who have
that quality -- they have to have enough control to
avoid 'going off' on people when others 'go off on
them', but they get the benefit of being someone
people want to connect with. I argue that those
same dynamics occur in physical systems and software
systems that have the Postel property.
These days, most people talk about Postel's Law as a social
law, and criticisms of it even in software design refer to it
as creating moral hazards for designers. But Postel coined
this "principle of robustness" as a way to talk about
implementing TCP, and most references I see to it now relate
to HTML and web browsers. I think it's pretty cool when a
software design principle applies more broadly in the design
world, or can even be useful for understanding human behavior
far removed from computing. That's the sign of a valuable
pattern -- or anti-pattern.
Software Gets Easier to Consume Faster Than It Gets Easier to Make
In
What Is the Business of Literature?,
Richard Nash tells a story about how the ideas underlying writing,
books, and publishing have evolved over the centuries, shaped by
the desires of both creators and merchants. One of the key points
is that technological innovation has generally had a far greater
effect on the ability to consume literature than on the ability to
create it.
But books are just one example of this phenomenon. It is, in fact,
a pattern:
For the most part, however, the technical and business-model
innovations in literature were one-sided, far better at
supplying the means to read a book than to write one. ...
... This was by no means unique to books. The world has
also become better at allowing people to buy a desk than to
make a desk. In fact, from medieval to modern times, it has
become easier to buy food than to make it; to buy clothes
than to make them; to obtain legal advice than to know the
law; to receive medical care than to actually stitch a wound.
One of the neat things about the last twenty years has been the
relatively rapid increase in the ability for ordinary people to
to write and disseminate creative works. But an imbalance remains.
Over a shorter time scale, this one-sidedness has been true of
software as well. The fifty or sixty years of the Software Era
have given us seismic changes in the availability, ubiquity, and
backgrounding of software. People often overuse the word
'revolution', but these changes really have had an immense effect
in how and when almost everyone uses software in their lives.
Yet creating software remains relatively difficult. The evolution
of our tools for writing programs hasn't kept pace with the
evolution in platforms for using them. Neither has the growth in
our knowledge of how make great software.
There is, of course, a movement these days to teach more people
how to program and to support other people who want to learn on
their own. I think it's wonderful to open doors so that more
people have the opportunity to make things. I'm curious to see
if the current momentum bears fruit or is merely a fad in a
world that goes through fashions faster than we can comprehend
them. It's easier still to toss out a fashion that turns out to
require a fair bit of work.
Writing software is still a challenge. Our technologies have
not changed that fact. But this is also true, as Nash reminds us,
of writing books, making furniture, and a host of other creative
activities. He also reminds us that there is hope:
What we see again and again in our society is that people do
not need to be encouraged to create, only that businesses
want methods by which they can minimize the risk of
investing in the creation.
The urge to make things is there. Give people the resources they
need -- tools, knowledge, and, most of all, time -- and they will
create. Maybe one of the new programmers can help us make better
tools for making software, or lead us to new knowledge.
Net Prophet, aka Scott Turner, is
porting the Pain Machine,
his college hoops prediction system, from Common Lisp to
Python. The new program is getting different values than
the old one in one portion of the code, though they don't
seem to affect model's overall performance. Which program
is right?
I suspect the Python version is probably "more correct"
than the Common Lisp version, because this is a
matrix-manipulation heavy part of the code, and it is
expressed much more succinctly and clearly in Python.
Scott's
a darn good programmer
and someone with a lot of Lisp experience, so don't go there.
This isn't a language testimonial. It's a testament to how
programmers' confidence in their code goes up when they can
see more clearly that it says what they intended to say. It
is easier to trust something we understand. (But don't
forget to run some tests, too!)
Among the reasons David Heinemeier Hansson gives in his
advice to
Fire the Workaholics
is that working too much is a sign of bad judgment:
If all you do is work, your value judgements are unlikely
to be sound. Making good calls on "is it worth it?" is
absolutely critical to great work. Missing out on life
in general to put more hours in at the office screams
"misguided values".
I agree, in two ways. First, as DHH says, working too much is
itself a general indicator that your judgment is out of whack.
Second is the more specific case:
For workaholics, doing more work always looks like a reasonable
option. As a result, when you are trying to decide, "Should I
make this or not?", you never have to choose not to make
the something in question -- even when not making it is the
right thing to do. That sort of indifferent decision making
can be death in any creative endeavor.
In the Paris Review's
Garrison Keillor, The Art of Humor No. 2,
Keillor thinks back to his decision to become a writer, which
left him feeling uncertain about himself:
Someone once asked John Berryman, How do you know if something
you've written is good? And John Berryman said, You don't.
You never know, and if you need to know then you don't want to
be a writer.
This doesn't mean that you don't care about getting better. It
means that you aren't doing it to please someone else, or at least
that your doing it is not predicated on what someone else thinks.
You are doing it because that's what you think about. It means
that you keep writing, whether it's good or not. That's how you
get better.
It's always fun to watch our students wrestle with this sort of
uncertainty and come out on the other side of the darkness. Last
fall, I taught first-semester freshmen who were just beginning to
find out if they wanted to be programmers or computer scientists,
asking questions and learning a lot about themselves. This fall,
I'm teaching our senior project course, with students who are
nearing the end of their time at the university. Many of them
think a lot about programming and programming languages, and they
will drive the course with their questions and intensity. As a
teacher, I enjoy both ends of the spectrum.
We all hear the common refrain these days that more people should
learn to program, not just CS majors. I agree. If you know how
to program, you can make things. Even if you don't write many
programs yourself, you are better prepared to talk to the
programmers who make things for you. And even if you don't need
to talk to programmers, you have expanded your mind a bit to a way
of thinking that is changing the world we live in.
Why is it that our entertainment software has such primitive
algorithms in it? The answer lies in the people creating
them. The majority are programmers. Programmers aren't
really idea people; they're technical people. Yes, they use
their brains a great deal in their jobs. But they don't
live in the world of ideas. Scan a programmer's bookshelf
and you'll find mostly technical manuals plus a handful of
science fiction novels. That's about the extent of their
reading habits. Ask a programmer about Rabelais, Vivaldi,
Boethius, Mendel, Voltaire, Churchill, or Van Gogh, and
you'll draw a blank. Gene pools? Grimm's Law? Gresham's
Law? Negentropy? Fluxions? The mind-body problem? Most
programmers cannot be troubled with such trivia. So how can
we expect them to have interesting ideas to put into their
algorithms? The result is unsurprising: the algorithms in
most entertainment products are boring, predictable,
uninformed, and pedestrian. They're about as interesting
in conversation as the programmers themselves.
We do have some idea people working on interactive entertainment;
more of them show up in multimedia than in games. Unfortunately,
most of the idea people can't program. They refuse to learn the
technology well enough to express themselves in the language of
the medium. I don't understand this cruel joke that Fate has
played upon the industry: programmers have no ideas and idea
people can't program. Arg!
My office bookshelf occasionally elicits a comment or two from
first-time visitors, because even here at work I have a complete
works of Shakespeare, a thin volume of William Blake (I love me
some Blake!), several philosophy books, and "The Brittanica Book
of Usage". I really should have some Voltaire here, too. I do
cover one of Crawford's bases: a recent blog entry made
a software analogy to Gresham's Law.
In general, I think you're more likely to find a computer scientist
who knows some literature than you are to find a literary
professional who knows much CS. That's partly an artifact of our
school system and partly a result of the wider range historically
of literature and the humanities. It's fun to run into a colleague
from across campus who has read deeply in some area of science or
math, but rare.
However, we are all prone to fall into the chasm of our own
specialties and miss out on the well-roundedness that makes us
better at whatever specialty we practice. That's one reason that,
when high school students and their parents ask me what students
should take to prepare for a CS major, I tell them: four years of
all the major subjects, including English, math, science, social
science, and the arts; plus whatever else interests them, because
that's often where they will learn the most. All of these topics
help students to become better computer scientists, and better
people.
And, not surprisingly, better game developers. I agree with
Crawford that more programmers should be learn enough other stuff
to be idea people, too. Even if they don't make games.
A conversation this morning with a student reminded me of a
story one of our alumni, a local entrepreneur, told me about
his usual practice whenever he has an idea for a new system
or a new feature for an existing system.
The alum starts by jotting the idea down in Java, Scala, or
some other programming language. He puts this sketch into a
git repository and uses the readme.md file to document
his thought process. He also records there links to related
systems, links to papers on implementation techniques, and any
other resources he thinks might be handy. The code itself can
be at varying levels of completeness. He allows himself to
work out some of the intermediate steps in enough detail to
make code work, while leaving other parts as skeletons.
This approach helps him talk to technical customers about the
idea. The sketch shows what the idea might look like at a high
level, perhaps with some of the intermediate steps running in
some useful way. The initial draft helps him identify key
development issues and maybe even a reasonable first estimate
for how long it would take to flesh out a complete implementation.
By writing code and making some of it work, the entrepreneur in
him begins to see where the opportunities for business value lie.
If he decides that the idea is worth a deeper look, he passes the
idea onto members of his team in the form of his git repo. The
readme.md file includes links to relevant reading and
his initial thoughts about the system and its design. The code
conveys ideas more clearly and compactly than a natural language
description would. Even if his team decides to use none of the
code -- and he expects they won't -- they start from something
more expressive than a plain text document.
This isn't quite a prototype or a spike, but it has the same
spirit. The code sketch is another variation on how programming
is a medium for expressing ideas in a way that other media can't
fully capture.
I recently found myself reading a few of Gregor Hohpe's blog
posts and came across
Design Patterns: More Than Meets The Eye.
In it, Hohpe repeats a message that needs to be repeated
every so often even now, twenty years after the publication
of the GoF book: software patterns are fundamentally about
human communication:
The primary purpose of patterns is to help humans understand
design problems. Solving design problems is generally much
more difficult than typing in some code, so patterns have
enormous value in themselves. Patterns owe their popularity
to this value. A better hammer can help speed up the
construction of a bed, but a pattern helps us place the bed
in a way that makes us feel comfortable.
The last sentence of that paragraph is marvelous.
Hohpe published that piece five and a half years ago. People who
write or teach software patterns will find themselves telling a
similar story and answering questions like the ones that
motivated his post all the time. Earlier this year, Avdi Grimm
wrote a like-minded piece,
Patterns are for People,
in which he took his shot at dispelling misunderstandings from
colleagues and friends:
There's a meme, originating from certain corners of the Functional
side of programming, that "patterns are a language smell". The
implication being that "good" languages either already encode the
patterns as language features, or they provide the tools to extend
the language such that modeling the pattern explicitly isn't
needed.
This misses the point on rather a lot of levels.
Design patterns that are akin to hammers for making better code
are plentiful and often quite helpful. But we need more software
patterns that help us place our beds in ways that increase human
comfort.
Well-designed components are easy to replace. Eventually, they
will be replaced by ones that are not so easy to replace.
This is a dandy observation of how software tends to get worse
over time, in a natural process of bad components replacing
good ones. It made me think of
Gresham's Law,
which I first encountered in my freshman macroeconomics course:
When a government overvalues one type of money and undervalues
another, the undervalued money will leave the country or
disappear from circulation into hoards, while the overvalued
money will flood into circulation.
A more compact form of this law is, "Bad money drives good money
out of circulation."
My memory of Gresham's Law focuses more on human behavior than
government behavior. If people value gold more than a paper
currency, even though the currency denominates a specific amount
of gold, then they will use the paper money in transactions and
hoard the gold. The government can redenominate the paper
currency at any time, but the gold will always be gold. Bad
money drives out the good.
In software, bad components drive good components out of a system
for different reasons. Programmers don't hoard good components;
they are of no particular value when not being using, even in the
future. It's simply pragmatic. If a component is hard to replace,
then we are less likely to replace it. It will remain a part of
the system over time precisely because it's hard to take out.
Conversely, a component that is easy to replace is one that we may
replace.
We can also think of this in evolutionary terms, as Brian Foote
and Joe Yoder did in
The Selfish Class:
A hard-to-replace component is better adapted for survival than
one that is easy to replace. Designing components to be better
for programmers may make them less likely to survive in the long
term. How is that for the bad driving out the good?
When we look at this from the perspective of the software system
itself, Sustrik's Law reminds us that software is subject to a
particular kind of entropy, in which well-designed systems with
clean interfaces devolve towards big balls of mud (another term
coined by Foote and Yoder). Programmers do not yet have a simple
formula to predict this entropy, such as
Gibbs entropy law
for thermodynamic systems, and may never. But then, computer
science is still young. There is a lot we don't know.
Ideas about software have so many connections to other disciplines.
I rely on many connections to help me think about them, too. Hat
tips to
Brian Rice
for retweeting
this tweet
about Sustrik's Law, to
Jeff Miller
for reminding me about "The Selfish Class", and to
Henrik Johansson
for suggesting the connection to Gibb's formula.
[Hemingway] keeps track of his daily progress -- "so as not to kid
myself" -- on a large chart made out of the side of a cardboard
packing case and set up against the wall under the nose of a
mounted gazelle head. The numbers on the chart showing the daily
output of words differ from 450, 575, 462, 1250, back to 512, the
higher figures on days [he] puts in extra work so he won't feel
guilty spending the following day fishing on the Gulf Stream.
He uses the chart to keep himself honest. Even our greatest writers
can delude themselves into thinking they are making enough progress
when they aren't. All the more so for those of us who are still
learning, whether how to run a marathon, how to write prose, or how
to make software. When a group of people are working together, a
chart can help the individuals maintain a common, and honest,
understanding of how the team is doing.
Oh, and notice Hemingway's technology: the side of a cardboard
packing case. No fancy dashboard for this writer who is known for
his direct, unadorned style. If you think you need a digital
dashboard with toggles, flashing lights, and subviews, you are doing
it wrong. The point of the chart is to keep you honest, not give you
another thing to do when you are not doing what you should be doing.
There is another lesson in this passage beyond the chart, about
sustainable pace. Most of the numbers are in the ballpark of 500
(average: 499 3/4!), except for one day when he put in a double day.
Perhaps 500 words a day is a pace that Hemingway finds productive
over time. Yet he allows himself an occasional bit of overtime --
for something important, like time away from his writing desk, out
on the water. Many of us programmers need to be reminded every so
often that getting away from our work is valuable, and worth an
occasional 0 on the big visible chart. It's also a more human
motivation for overtime than the mad rush to a release date.
A few pages later in the interview, we read Hemingway repeating a
common adage among writers that also echoes nicely against the
agile practices:
You read what you have written and, as you always stop when you
know what is going to happen next, you go on from there.
Hemingway stops each day at a point where the story will pull him
forward the next morning. In this, XP devotees can recognize the
habit of ending each day with a broken test. In the morning, or
whenever we next fire up our editors, the broken test tells us
exactly where to begin and gives us a concrete goal. By the time
the test passes, our minds are ready to move on to something new.
Agility is useful when fighting bulls. Apparently, it helps when
writing novels, too.
Yesterday, Sean Heber made
a suggestion
drawn, I imagine, from Apple's foray into the world of watchmaking:
I propose we adopt the watch term "complications" for all
software features.
It turns out that, in the world of horology,
complication
is a technical term:
In horology, the study of clocks and watches, a complication
refers to any feature in a timepiece beyond the simple display of
hours and minutes. A timepiece indicating only hours and minutes
is otherwise known as a simple movement.
I don't know if Heber was writing tongue in cheek, but "complication"
is certainly a term that programmers can appreciate. In software, we
value functions, classes, modules, and even whole systems that do only
one thing but do it well. This is sometimes referred to as the
single responsibility principle, which engenders a separation
of concerns and leads to software that is easier to modify and maintain.
Simple movement is one of the defining elements that make up of the
the Unix philosophy:
Write programs that do one thing and do it well. Write programs
to work together.
In Unix, there is even a standard interface for simple movements,
the text stream, which enables almost trivial little programs to be
combined to solve any problem.
Horology's use of "complication" also reminds me of Rich Hickey's
adoption of the word complect for talking about software
systems. See, for example, his RailsConf 2012 talk,
Simplicity Matters.
Tools that interleave multiple strands of functionality are
inherently less reliable, in addition to being harder to work with,
so we should seek to create tools with a single strand.
In order to talk about timekeeping devices that perform several
functions, watchmakers specialize their term. Informally, a
grand complication is a device that contains at least three
complications, with at least one timing complication, one
astronomical complication, and one striking complications. It might
be instructive to classify in a similar fashion the ways in which
programmers typically "complect" their code.
The Wikipedia page for "complication" states explicitly that adding
complications to a watch makes it more difficult to "design, create,
assemble, and repair". That sounds a lot like how programmers feel
about complexity. But the page also gives the sense that fine
watchmakers revel in complications and see them as a sign of great
achievement. Some watchmakers
even glory in the complexity
of their timepieces.
It seems that watchmakers have more in common with programmers than
you might think. Perhaps Heber is on to something here.
I would rather have too little architecture
than too much because that might interfere
with the truth of what I say.
-- Ivan Turgenev
How can agile approaches to software development create coherent
programs? Don't we need a plan, a well-thought-out design to follow
closely? Without one, won't we end up with a mess?
Let's turn
again
to Italo Calvino for some perspective. He is known for novels with
intricate structure and acknowledges that, for at least a decade,
the "architecture" of his books occupied more of his mind than it
should have. Yet his novels never seemed to follow closely any of
his advance plans:
I spend a lot of time constructing a book, making outlines
that eventually prove to be of no use to me whatsoever. I
throw them away. What determines the book is the writing,
the material that's actually on the page.
The ultimate architecture of a book comes to life alongside the book
itself, hand-in-hand with the writing.
And so it can be with software. Programmers can and should think
about what they are building but, in the end, what determines the
program is the programming, the material that's actually on the
page or in the browser.
Again, we must careful not to take the analogy too far. Programs
are often created for external clients with specific technical
requirements. Programmers are not usually free, as novelists are,
to change the product they are creating. Even so, design is how
we make the product, not what it does. Whether it evolves during
the course of programming or is specified up-front, the client
can receive the product they asked us to make.
Ward Cunningham once gave what is, for me, still the best definition
of design:
Design is the thinking you do when you make something.
The most important product of that thinking is not a design document
or an architecture. It is the mind that is prepared to make the
thing you need to make.
Lahey: You write, "One either absorbs the grammatical
principles of one's native language in conversation and in
reading or one does not." If this is true, why teach grammar
in school at all? Why bother to name the parts?
King: When we name the parts, we take away the mystery
and turn writing into a problem that can be solved. I used
to tell them that if you could put together a model car or
assemble a piece of furniture from directions, you could
write a sentence. Reading is the key, though. A kid who
grows up hearing "It don't matter to me" can only learn
doesn't if he/she reads it over and over again.
There are at least three nice ideas in King's answer.
It is helpful to beginners when we can turn writing into a
problem that can be solved. Making concrete things out of
ideas in our head is hard. When we giving students tools
and techniques that help them to create basic sentences,
paragraphs, and stories, we make the process of creating a
bit more concrete and a bit less scary.
A first step in this direction is to give names to the
things and ideas students need to think about when writing.
We don't want students to memorize the names for their own
sake; that's a step in the wrong direction. We simply need
to have words for talking about the things we need to talk
about -- and think about.
Reading is, as the old slogan tells us, fundamental. It
helps to build knowledge of vocabulary, grammar, usage, and
style in a way that the brain absorbs naturally. It creates
habits of thought that are hard to undo later.
All of these are true of teaching programmers, too, in their own
way.
We need ways to demystify the process and give students
concrete steps they can take when they encounter a new
problem. The
design recipe
used in the How to Design Programs approach is a great
example. Naming recipes and their steps makes them a part
of the vocabulary teachers and students can use to make
programming a repeatable, reliable process.
I've often had great success by giving names to design and
implementation patterns, and having those patterns become
part of the vocabulary we use to discuss problems and
solutions. I have a category for
posts about patterns,
and a fair number of those relate to teaching beginners.
I wish there were more.
Finally, while it may not be practical to have students read
a hundred programs before writing their first, we cannot
underestimate the importance of students reading code in
parallel with learning to write code. Reading lots of good
examples is a great way for students to absorb ideas about
how to write their own code. It also gives them the raw
material they need to ask questions. I've long thought that
Clancy's and Linn's work on
case studies of programming
deserves more attention.
Finding ways to integrate design recipes, patterns, and case
studies is an area I'd like to explore more in my own teaching.
And you don't have to be in software. In
Jonathan Ive and the Future of Apple,
Ian Parker describes how the process of developing products at
Apple has changed during Ive's tenure.
... design had been "a vertical stripe in the chain of events"
in a product's delivery; at Apple, it became "a long horizontal
stripe, where design is part of every conversation." This
cleared a path for other designers.
By the time the iPhone launched, Ive had become "the hub of the
wheel".
The vertical stripe/horizontal stripe image brought to mind Kent
Beck's reimagining of the software development cycle in XP. I
was thinking the image in my head came from Extreme Programming
Explained, but the closest thing to my memory I can find is
in his IEEE Computer article,
Embracing Change with Extreme Programming:
My mental image has time on the x-axis, though, which meshes
better with the vertical/horizontal metaphor of Robert Brunner,
the designer quoted in the passage above.
versus
If analysis is important, do it all the time. If design is
important, do it all the time. If implementation is important,
do it all the time. If testing is important, do it all the time.
Ive and his team have shown that there is value in making design
an ongoing part of the process for developing hardware products,
too, where "design is part of every conversation". This kind of
thinking is not just for software any more.
After a long break from playing chess, I recently
played a few games
at the local club. Playing a couple of games twice in the last
two weeks has reminded me that I am very rusty. I've only made
two horrible blunders in four games, but I have made many small
mistakes, the kind of errors that accumulate over time and make
a position hard to defend, even untenable. Having played better
in years past, these inaccuracies are irksome.
Still, I managed to win all four games. As I've watched games
at the club, I've noticed that most games are won by the player
who makes the second-to-last blunder. Most of the players are
novices, and they trade mistakes: one player leaves his queen
en prise; later, his opponent launches an underprepared
attack that loses a rook; then the first player trades pieces
and leaves himself with a terrible pawn structure -- and so on,
the players trading weak or bad moves until the position is lost
for one of them.
My secret thus far has been one part luck, one part simple
strategy: winning by not losing.
This experience reminded me of a paper called
The Loser's Game,
which in 1975 suggested that it was no longer possible for a
fund manager to beat market averages over time because most of
the information needed to do well was available to everyone. To
outperform the market average, a fund manager has to profit from
mistakes made by other managers, sufficiently often and by a
sufficient margin to sustain a long-term advantage. Charles
Ellis, the author, contrasts this with the bull markets of the
1960s. Then, managers made profits based on the specific winning
investments they made; in the future, though, the best a manager
could hope for was not to make the mistakes that other investors
would profit from. Fund management had transformed from being a
Winner's Game to a Loser's Game.
Ellis drew his inspiration from another world, too. Simon Ramo
had pointed out the differences between a Winner's Game and a
Loser's Game in
Extraordinary Tennis for the Ordinary Tennis Player.
Professional tennis players, Ramo said, win based on the positive
actions they take: unreturnable shots down the baseline, passing
shots out of the reach of a player at the net, service aces,
and so on. We duffers try to emulate our heroes and fail...
We hit our deep shots just beyond the baseline, our passing
shots just wide of the sideline, and our killer serves into
the net. It turns out that mediocre players win based on the
errors they don't make. They keep the ball in play,
and eventually their opponents make a mistake and lose the
point.
Ramo saw that tennis pros are playing a Winner's Game, and
average players are playing a Loser's Game. These are
fundamentally different games, which reward different mindsets
and different strategies. Ellis saw the same thing in the
investing world, but as part of a structural shift: what had
once been a Winner's Game was now a Loser's Game, to the
consternation of fund managers whose mindset is finding the
stocks that will earn them big returns. The safer play now,
Ellis says, is to minimize mistakes. (This is good news for us
amateurs investors!)
This is the same phenomenon I've been seeing at the chess club
recently. The novices there are still playing a Loser's Game,
where the greatest reward comes to those who make the fewest
and smallest mistakes. That's not very exciting, especially
for someone who fancies herself to be Adolf Anderssen or Mikhail
Tal in search of an
immortal game.
The best way to win is to stay alive, making moves that are as
sound as possible, and wait for the swashbuckler across the
board from you to lose the game.
What does this have to do with learning to program? I think
that, in many respects, learning to program is a Loser's Game.
Even a seemingly beginner-friendly programming language such
as Python has an exacting syntax compared to what beginners
are used to. The semantics seem foreign, even opaque. It is
easy to make a small mistake that chokes the compiler, which
then spews an error message that overwhelms the new programmer.
The student struggles to fix the error, only to find another
error waiting somewhere else in the code. Or he introduces a
new error while eliminating the old one, which makes even
debugging seem scary. Over time, this can dishearten even the
heartiest beginner.
What is the best way to succeed? As in all Loser's Games, the
key is to make fewer mistakes: follow examples closely, pay
careful attention to syntactic details, and otherwise not stray
too far from what you are reading about and using in class.
Another path to success is to make the mistakes smaller and
less intimidating: take small steps, test the code frequently,
and grow solutions rather than write them all at once. It is
no accident that the latter sounds like XP and other agile
methods; they help to guard us from the Loser's Game and enable
us to make better moves.
Just as playing the Loser's Game in tennis or investing calls
for a different mindset, so, too does learning to program.
Some beginners seem to grok programming quickly and move on to
designing and coding brilliantly, but most of us have to settle
in for a period of discipline and growth. It may not be
exciting to follow examples closely when we want to forge ahead
quickly to big ideas, but the alternative is to take big shots
and let the compiler win all the battles.
Unlike tennis and Ellis's view of stock investing, programming
offers us hope: Nearly all of us can make the transition from
the Loser's Game to the Winner's Game. We are not destined to
forever play it safe. With practice and time, we can develop
the discipline and skills necessary to making bold, winning
moves. We just have to be patient and put time and energy into
the process of becoming less mistake-prone. By adopting the
mindset needed to succeed in a Loser's Game, we can eventually
play the Winner's Game.
I'm not too sure about the phrases "Loser's Game" and "Winner's
Game", but I think that this analogy can help novice programmers.
I'm thinking of ways that I can use it to help my students
survive until they can succeed.
With an expressive type system for its teaching
languages,
HtDP
could avoid this problem to some
extent, but adding such rich types would also take
the fun out of programming.
As we approach the midpoint of the semester, Matthias Felleisen's
Turing Is Useless
strikes a chord in me. My students have spent the last two months
learning a little Racket, a little functional programming, and a
little about how to write data-driven recursive programs. Yet bad
habits learned in their previous courses, or at least unchecked by
what they learned there, have made the task harder for many of them
than it needed to be.
The essay's title plays off the Church-Turing thesis, which asserts
that all programming languages have the same expressive power.
This powerful claim is not good news for students who are learning
to program, though:
Pragmatically speaking, the thesis is completely useless at best
-- because it provides no guideline whatsoever as to how to
construct programs -- and misleading at worst -- because it
suggests any program is a good program.
With a Turing-universal language, a clever student can find a way
to solve any problem with some program. Even uninspired
but persistent students can tinker their way to a program that
produces the right answers. Unfortunately, they don't understand
that the right answers aren't the point; the right program is.
Trolling StackOverflow
will get them a program,
but too often the students don't understand whether it is a good
or bad program in their current situation. It just works.
I have not been as faithful to the HtDP approach this semester as
I probably should have been, but I share its desire to help
students to design programs systematically. We have looked at
design patterns that implement specific strategies, not language
features. Each strategy focuses on the definition of the data
being processed and the definition of the value being produced.
This has great value for me as the instructor, because I can
usually see right away why a function isn't working for the
student the way he or she intended: they have strayed from the
data as defined by the problem.
This is also of great value to some of my students. They want
to learn how to program in a reliable way, and having tools that
guide their thinking is more important than finding yet another
primitive Racket procedure to try. For others, though "garage
programming" is good enough; they just want get the job done
right now,
regardless of which muscles they use.
Design is not part of their attitude, and that's a hard habit
to break. How use doth breed a habit in a student!
Last semester, I taught intro CS from what Felleisen calls a
traditional text. Coupled that experience with my experience so
far this semester, I'm thinking a lot these days about how we can
help students develop a design-centered attitude at the outset of
their undergrad courses. I have several blog entries in draft
form about last semester, but one thing that stands out is the
extent to which every step in the instruction is driven by the
next cool programming construct. Put them all on the table,
fiddle around for a while, and you'll make something that works.
One conclusion we can draw from the Church-Turing thesis is that
this isn't surprising. Unfortunately, odds are any program created
this way is not a very good program.
~~~~~
(The sentence near the end that sounds like Shakespeare is. It's
from The Two Gentlemen of Verona, with a suitable change
in noun.)
The book emphasizes systematic design. You can solve this specific
problem with brute force regular-expression matching in a few lines
of code. The question is whether you want to learn to solve
problems or copy code from mailing lists and StackOverflow without
understanding what's really going on.
Students today aren't much different from the students in the good
old days. But the tools and information so readily available to
them make it a lot easier for them to indulge their baser urges.
In the good old days, we had to work hard to get good grades
and not understand what we were doing.
Anyone interested in thinking about how programmers can design
software without mapping its structure out in advance should
read Ted Gioia's
Jazz: The Aesthetics of Imperfection,
which appeared in the Winter 1987 issue of The Hudson
Review (Volume 39, Number 4, pages 585-600). It explores
in some depth the ways in which jazz, which relies heavily on
spur-of-the-moment improvisation and thus embraces imperfection,
can still produce musical structure worthy of the term "art".
Gioia's contrast of producing musical form via the blueprint
method and the retrospective method will resonate
with anyone who has grown a large software system via small
additions to, and refactorings of, an evolving code base. This
paragraph brings to mind the idea of selecting a first test to
pass at random:
Some may feel that the blueprint method is the only method
by which an artist can adhere to form. But I believe this
judgment to be quite wrong. We can imagine the artist
beginning his work with an almost random maneuver, and then
adapting his later moves to this initial gambit. For
example, the musical improviser may begin his solo with a
descending five-note phrase and then see, as he proceeds,
that he can use this same five-note phrase in other
contexts in the course of his improvisation.
Software is different from jazz performance in at least one
way that makes the notion of retrospective form even more
compelling. In jazz, the most valuable currency is live
performance, and each performance is a new creation. We see
something similar in the code kata, where each implementation
starts from scratch. But unlike jazz, software can evolve
over time. When we nurture the same code base over time, we
can both incorporate new features and eliminate imperfections
from previous iterations. In this way, software developers
can create retrospective designs that both benefit from
improvisation and reach stable architectures.
Another interesting connection crossed my mind as I read about
the role the recording technology played in the development of
jazz. With the invention of the phonograph:
... for the first time sounds could be recorded with the
same precision that books achieved in recording words. Few
realize how important the existence of the phonograph was to
the development of improvised music. Hitherto, the only
method of preserving musical ideas was through notation, and
here the cumbersome task of writing down parts made any
significant preservation of improvisations unfeasible. But
with the development of the phonograph, improvised music
could take root and develop; improvising musicians who lived
thousands of miles apart could keep track of each other's
development, and even influence each other without ever
having met.
Software has long been a written form, but in the last two
decades we have seen an explosion of ways in which programs
could be recorded and shared with others. The internet and
the web enabled tools such as SourceForge and GitHub, which
in turn enabled the growth of communities dedicated to the
creation and nurturing of open source software. The
software so nurtured has often been the product of many
people, created through thousands of improvisations by
programmers living in all corners of the world. New
programmers come to these repositories, the record stores of
our world, and are able to learn from masters by studying
their moves and their creations. They are then able to make
their own contributions to existing projects, and to create
new projects of their own.
As Gioia says of jazz, this is not to make the absurd claim
that agile software did not exist before it was recorded and
shared in this way, but the web and the public repository have
had profound impacts on the way software is created. The
retrospective form espoused by agile software design methods,
the jazz of our industry, has been one valuable result.
Check out Gioia's article. It repaid my investment with
worthy connections. If nothing else, it taught me a lot about
jazz and music criticism.
Exceptions signal something outside the expected bounds of behavior
of the code in question. But if you're running some checks on
outside input, this is because you expect some messages to fail --
and if a failure is expected behavior, then you shouldn't be using
exceptions.
That is a snippet from
Replacing Throwing Exceptions with Notification in Validations,
a refactoring Martin Fowler published earlier this month. The
refactoring is based on an extraordinarily useful piece of software
design advice: exceptions should be unexpected. If something is
expected, it's not exceptional. Make your software say so. A
notification mechanism can carry as much information about system
behavior as exceptions and generally provides superior cohesion and
division of labor.
Over the last few years, I've come to see that is really a tenet of
good system design more generally. A couple of examples from my
university experience:
If your curriculum depends on frequent student requests to
enable programs of study that faculty accept as reasonable,
then you should probably modify the curriculum to allow what is
reasonable. Not only are you gumming up the larger system with
unnecessary paperwork, you are likely disadvantaging students
who aren't savvy or cheeky enough to disregard the rules.
If the way you pay for instruction and equipment doesn't match
the stated budget, then you should change the budget to reflect
reality. If you don't control the writing of the budget, then
you should find ways to communicate reality to the budget
writers whenever possible. Sometimes, you can work around the
given budget to accomplish what you really need for a long
time. But over time the system will evolve in response to
other external forces, and you reach a point where the budget
in no way reflects reality. A sudden change in funding can put
you in a state of real crisis. Few people will be able to
understand why.
People sometimes tell me that I am naive to think complex systems
like a university or even a curriculum should reflect reality
closely. Programming has taught me that we almost always benefit
from keeping our design as clean, as understandable, and as truthful
as we can. I am pragmatic enough to understand that there are
exceptions even to this tenet, in life and in software. But
exceptions should be exceptional.
Perhaps amid the daily tribulations of a software project,
Steven Baker
writes
Oy. A moving goal line, with a skeleton crew, on a shoestring
budget. Technical problems are the easy ones.
And here we all sit complaining about monads and Java web
frameworks...
My big project this semester has not been developing software but
teaching beginners to develop software, in our intro course. There
is more to Intro than programming, but for many students the tasks
of learning a language and trying to write programs comes to
dominate most everything else. More on that soon.
Yet even with this different sort of project, I feel much as Baker
does. Freshmen have a lot of habits to learn and un-learn, habits
that go well beyond how they do Python. My course competes with
several others for the students' attention, not to mention with
their jobs and their lives outside of school. They come to class
with a lifetime of experience and knowledge, as well some surprising
gaps in what they know. A few are a little scared by college, and
many worry that CS won't be a good fit for them.
The Codist told
the story of DeltaGraph
last week. It must be quite a feeling to have code you wrote
twenty-five years ago still running in a commercial product
today. Of course, such longevity creates challenges for the
maintainers. The longer a program lives, the more likely
that a feature that you thought you'd never need becomes
desirable, even necessary.
Like a Windows version, circa 1989:
When I started the UI code I asked two questions of Deltapoint
(1) will this code ever be ported to Windows (2) do you want
to support multiple documents open at a time. The answer to
both was no. Windows was still too primitive to care about
and multiple open documents was fairly uncommon.
Within a few years, "You Aren't Gonna Need It" turned into "Now
We Need It":
With 3.0 they actually began to port it to Windows 3.1, and it
was an immense pain to do. I had spent no time trying to
worry about cross platform issues as I had asked up front and
been told no. Of course Windows was now becoming important.
The port was never very stable as a result and I think it
actually became a separate code base, making new features hard
to do.
This is one of the balancing essential acts of writing software.
Operating with a YAGNI mindset is generally a prudent way to
ensure we don't write code that is unnecessarily complex and hard
to work with. Yet we have to make our programs open to the
changes that will inevitably follow. And some changes are easier
to make if we have built hooks and fulcrums into the code.
So, we strive for ways not to build the things we don't need now,
but make it possible to accommodate them later. For me, this has
always been the great promise of object-oriented programming. I
try to think that way even when I'm working in languages that
don't support the style directly, but I'm not good enough yet.
That only helps me admire the accomplishments of teams like the
one that created DeltaGraph even more.
I procrastinated one day with my intro students in mind.
This is the bedtime story I told them as a result. Yes, I
know that I can write shorter Python code to do this. They
are intro students, after all.
~~~~~
Once upon a time, a buddy of mine, Chad, sent out a tweet. Chad
is a physics prof, and he was procrastinating. How many
people would I need to have in class, he wondered, to
have a 50-50 chance that my class roster will contain people
whose last names start with every letter of the alphabet?
Adams
Brown
Connor
...
Young
Zielinski
This is a lot like the old trivia about how we only need to
have 23 people in the room to have a 50-50 chance that two
people share a birthday. The math for calculating that is
straightforward enough, once you know it. But last names
are much more unevenly distributed across the alphabet than
birthdays are across the days of the year. To do this right,
we need to know rough percentages for each letter of the
alphabet.
I can procrastinate, too. So I surfed over to
the US Census Bureau,
rummaged around for a while, and finally found a page on
Frequently Occurring Surnames from the Census 2000.
It provides a little summary information and then links to a
couple of data files, including a spreadsheet of data on all
surnames that occurred at least 100 times in the 2000 census.
This should, I figure, cover enough of the US population to
give us a reasonable picture of how peoples' last names are
distributed across the alphabet. So I grabbed it.
(We live in a wonderful time. Between open government, open
research, and open source projects, we have access to so
much cool data!)
The first and third columns are what we want. After thirteen
weeks, we know how to do compute the percentages we need: Use
the running total pattern to count the number of people whose
name starts with 'a', 'b', ..., 'z', as well as how many people
there are altogether. Then loop through our collection of
letter counts and compute the percentages.
Now, how should we represent the data in our program? We need
twenty-six counters for the letter counts, and one more for the
overall total. We could make twenty-seven unique variables,
but then our program would be so-o-o-o-o-o long, and tedious to
write. We can do better.
For the letter counts, we might use a list, where slot 0 holds
a's count, slot 1 holds b's count, and so one, through slot 25,
which holds z's count. But then we would have to translate
letters into slots, and back, which would make our code harder
to write. It would also make our data harder to inspect directly.
---- ---- ---- ... ---- ---- ---- slots in the list
0 1 2 ... 23 24 25 indices into the list
The downside of this approach is that lists are indexed by
integer values, while we are working with letters. Python
has another kind of data structure that solves just this
problem, the dictionary. A dictionary maps keys
onto values. The keys and values can be of just about
any data type. What we want to do is map letters (characters)
onto numbers of people (integers):
---- ---- ---- ... ---- ---- ---- slots in the dictionary
'a' 'b' 'c' ... 'x' 'y' 'z' indices into the dictionary
With this new tool in hand, we are ready to solve our problem.
First, we build a dictionary of counters, initialized to 0.
count_all_names = 0
total_names = {}
for letter in 'abcdefghijklmnopqrstuvwxyz':
total_names[letter] = 0
(Note two bits of syntax here. We use {} for
dictionary literals, and we use the familiar []
for accessing entries in the dictionary.)
Next, we loop through the file and update the running total
for corresponding letter, as well as the counter of all names.
source = open('app_c.csv', 'r')
for entry in source:
field = entry.split(',') # split the line
name = field[0].lower() # pull out lowercase name
letter = name[0] # grab its first character
count = int( field[2] ) # pull out number of people
total_names[letter] += count # update letter counter
count_all_names += count # update global counter
source.close()
Finally, we print the letter → count pairs.
for (letter, count_for_letter) in total_names.items():
print(letter, '->', count_for_letter/count_all_names)
(Note the items method for dictionaries. It
returns a collection of key/value tuples. Recall that tuples
are simply immutable lists.)
We have converted the data file into the percentages we need.
q -> 0.002206197888442366
c -> 0.07694634659082318
h -> 0.0726864447688946
...
f -> 0.03450702533438715
x -> 0.0002412718532764804
k -> 0.03294646311104032
(The entries are not printed in alphabetical order. Can you
find out why?)
I dumped the output to a text file and used Unix's built-in
sort to create my final result. I tweet Chad,
Here are your percentages. You do the math.
Hey, I'm a programmer. When I procrastinate, I write code.
In the lab, Student 1 asks a question about the loop variable
on a Python for statement. My first thought is, "How
can you not know that? We are in Week 11." I answer, he asks
another question, and we talk some more. The conversation shows
me that he has understood some ideas at a deeper level, but a
little piece was missing. His question helped him build a more
complete and accurate model of how programs work.
Before class, Student 2 asks a question about our current
programming assignment. My first thought is, "Have you read the
assignment? It answers your question." I answer, he asks another
question, and we talk some more. The conversation shows me that
he is thinking carefully about details of the assignment, but
assignments at this level of detail are new to him. His question
helped him learn a bit more about how to read a specification.
After class, Student 3 asks a question about our previous
programming assignment. We had recently looked at my solution to
the assignment and discussed design issues. "Your program is so
clean and organized. My program is so ugly. How can I write
better-looking programs?" He is already one of the better
students in the course. We discuss the role of experience in
writing clearly, and I explain that the best programs are often
the result of revision and refactoring. They started out just
good enough, and the author worked to make them better. The
conversation shows me that he cares about the quality of his
code, that elegance matters as much to him as correctness. His
question keeps him moving along the path to becoming a good
programmer.
Three students, three questions: all three are signs of good things
to come. They also remind me that even questions which seem
backward at first can point forward.
Many people in and out of the software world think of design and
programming as separate activities, which is a natural result of
analogies that compare software development to engineering
disciplines. I've never been fond of separating these tasks in
my mind. When I build software with other people, there is too
much fluidity between designing software and writing code to
make separate roles productive.
In
The Myth of the Builder,
Soroush Khanlou objects to the analogy for a different reason:
designers and programmers are really doing the same sort of
thing, only at different levels of detail:
... We know that the designer is not doing the building; if
programmer is also not doing the building, how is software
turning from idea into reality?
What is happening is that the designer presents the software
as very high-level blueprints to the programmer. The
programmer then takes those and creates a lower-level set of
blueprints for the compiler.
Thinking in terms of blueprints at a higher or lower level helps
make sense of how it feels to be:
designing software, and thinking about how this will play
out code, and
writing code, and thinking about how this affects the
design of the system.
We can think of design and programming as different tasks, but
not really as different kinds of task.
Khanlou goes a step farther:
(Incidentally, the compiler is producing an even lower-level
blueprint, called the Intermediate Representation, which is
translated in to a final set of blueprints, the specific
instructions for different CPUs. It's blueprints all the
way down.)
That's a catchy phrase, with a nod to other parts of computing
culture. (I first saw the phrase
it's turtles all the way down
in Gödel, Escher, Bach, though I think its use in
computing goes back farther.) Fortunately for software
developers and compiler writers, we eventually hit the bottom
turtle. When we write most programs, we don't have to worry
about that, though.
Khanlou's blog ends with a useful reminder, echoing "Structure
and Interpretation of Computer Programs":
It's not valuable to think of software as a bridge; it's too
weird for that.
Analogies from software development to various engineering
disciplines can take us only so far. Software is different.
In The Wave in the Mind, a collection of talks and essays,
Ursula Le Guin describes Ernest Hemingway as "someone who did Man
right". She also gives us insight to Hemingway's preferences in
programming languages. Anyone who has read Hemingway knows that
he loved short sentences. Le Guin tells us more:
Ernest Hemingway would have died rather than have syntax.
Or semicolons.
So, Java and C are out. Python would fit. Or maybe Lisp. All
the greats know Lisp.
On the evolution of education in the Age of the Web.
Tyler Cowen, in Average Is Over, via
The Atlantic:
It will become increasingly apparent how much of current education
is driven by human weakness, namely the inability of most students
to simply sit down and try to learn something on their own.
I'm curious whether we'll ever see a significant change in the
number of students who can and do take the reins for themselves.
The web works as well as it does because we mostly agree on a
set of tools and practices. But it evolves when we disagree,
try different approaches, and test them against one another in
a marketplace of ideas. Citizens of a web-literate planet
should appreciate both the agreements and the disagreements.
Some disagreements are easier to appreciate after they fade into
history.
... when [the Old Guard] say, "It feels off..." what they are
poorly articulating is, "This process that you're building does
not support one (or more) of the key values of the company."
I suspect the presence of incompatible JSON libraries means that
our software no longer supports the key values of our company.
For Programmers, There Is No "Normal Person" Feeling
I see this in the lab every week. One minute, my students
sit peering at their monitors, their heads buried in their
hands. They can't do anything right. The next minute, I
hear shouts of exultation and turn to see them, arms thrust
in the air, celebrating their latest victory over the Gods
of Programming. Moments later I look up and see their heads
again in their hands. They are despondent. "When will this
madness end?"
Last week, I ran across
a tweet from Christina Cacioppo
that expresses nicely a feeling that has been vexing so many
of my intro CS students this semester:
I still find programming odd, in part, because I'm either
amazed by how brilliant or how idiotic I am. There's no
normal-person feeling.
Christina is no beginner, and neither am I. Yet we know this
feeling well. Most programmers do, because it's a natural part
of tackling problems that challenge us. If we didn't bounce
between feeling puzzlement and exultation, we wouldn't be
tackling hard-enough problems.
What seems strange to my students, and even to programmers with
years of experience, is that there doesn't seem to be a middle
ground. It's up or down. The only time we feel like normal
people is when we aren't programming at all. (Even then, I
don't have many normal-person feelings, but that's probably
just me.)
I've always been comfortable with this bipolarity, which is
part of why I have always felt comfortable as a programmer. I
don't know how much of this comfort is natural inclination --
a personality trait -- and how much of it is learned attitude.
I am sure it's a mixture of both. I've always liked solving
puzzles, which inspired me to struggle with them, which helped
me get better struggling with them.
Part of the job in teaching beginners to program is to convince
them that this is
a habit they can learn.
Whatever their natural inclination, persistence and practice
will help them develop the stamina they need to stick with
hard problems and the emotional balance they need to handle
the oscillations between exultation and despondency.
I try to help my students see that persistence and practice
are the answer to most questions involving missing skills or
bad habits. A big part of helping them this is coaching and
cheerleading, not teaching programming language syntax and
computational concepts. Coaching and cheerleading are not
always tasks that come naturally to computer science PhDs,
who are often most comfortable with syntax and abstractions.
As a result, many CS profs are uncomfortable performing them,
even when that's what our students need most. How do we get
better at performing them? Persistence and practice.
The "no normal-person feeling" feature of programming is an
instance of a more general feature of doing science. Martin
Schwartz, a microbiologist at the University of Virginia,
wrote a marvelous one-page article called
The importance of stupidity in scientific research
that discusses this element of being a scientist. Here's a
representative sentence:
One of the beautiful things about science is that it allows
us to bumble along, getting it wrong time after time, and
feel perfectly fine as long as we learn something each time.
Scientists get used to this feeling. My students can, too.
I already see the resilience growing in many of them. After
the moment of exultation passes following their latest
conquest, they dive into the next task. I see a gleam in
their eyes as they realize they have no idea what to do.
It's time to bury their heads in their hands and think.
In
A Fresh Look at Rust,
Armin Ronacher tells us that some of what inspires him about Rust:
For me programming in Rust is pure joy. Yes I still don't agree
with everything the language currently forces me to do but I
can't say I have enjoyed programming that much in a long time.
It gives me new ideas how to solve problems and I can't wait for
the language to get stable.
Rust is inspiring for many reasons. The biggest reason I like
it is because it's practical. I tried Haskell, I tried Erlang
and neither of those languages spoke "I am a practical language"
to me. I know there are many programmers that adore them, but
they are not for me. Even if I could love those languages,
other programmers would never do and that takes a lot of
enjoyment away.
I enjoy reading personal blog entries from people excited by a
new language, or newly excited by a language they are visiting
again after a while away. I've only read Rust code, not written
it, but I know just how Ronacher feels. These two paragraphs
touch on several truths about how languages excite us:
Programmers are often most inspired when a language shows
them new ideas how to solve problems.
Even if we love a language, we won't necessarily love
every feature of the language.
What inspires us is personal. Other people can be inspired
by languages that do not excite us.
Community matters.
Many programmers make a point of learning a new language
periodically. When we do, we are often most struck by a language
that teaches us new ways to think about problems and how to solve
them. These are usually the languages that have the most teach
us at the moment.
As
Kevin Kelly
says, progress sometimes demands that we let go of problems.
We occasionally have to seek new problems, in order to be excited
by new ways to answer them.
This all is very context-specific, other. How wonderful it is to
live in a time with so many languages available to learn from.
Let them all flourish, I say.
In a thread on motivating students on the SIGCSE mailing list,
a longtime CS prof and textbook author wrote:
Over the years, I have come to believe that those of us who
can become successful programmers have different internal
wiring than most in the population. We know you need
problem solving, mathematical, and intellectual skills but
beyond that you need to be persistent, diligent, patient,
and willing to deal with failure and learn from it.
These are necessary skills, indeed. Many of our students
come to us without these skills and struggle to learn how to
think like a computer scientist. And without persistence,
diligence, patience, and a willingness to deal with failure
and learn from it, anyone will likely have a difficult time
learning to program.
Over time, it's natural to begin to think that these attributes
are prerequisites -- things a person must have before he or she
can learn to write programs. But I think that's wrong.
As someone else pointed out in the thread, too many people
believe that to succeed in certain disciplines, one must be
gifted, to possess an inherent talent for doing that kind of
thing. Science, math, and computer science fit firmly in that
set of disciplines for most people. Carol Dweck has shown
that having such a "fixed" mindset of this sort prevents many
people from sticking with these disciplines when they hit
challenges, or even trying to learn them in the first place.
The attitude expressed in the quote above is counterproductive
for teachers, whose job it is to help students learn things even
when the students don't think they can.
When I talk to my students, I acknowledge that, to succeed in CS,
you need to be persistent, diligent, patient, and willing to
deal with failure and learn from it. But I approach these
attributes from a growth mindset:
Persistence, diligence, patience, and willingness to learn from
failure are habits anyone can develop with practice. Students
can develop these habits regardless of their natural gifts or
their previous education.
Aristotle said that excellence is not an act, but a habit. So
are most of the attributes we need to succeed in CS. They are
habits, not traits we are born with or actions we take.
Donald Knuth once said that only about 2 per cent of the
population "resonates" with programming the way he does. That
may be true. But even if most of us will never be part of
Knuth's 2%, we can all develop the habits we need to program at
a basic level. And a lot more than 2% are capable of building
successful careers in the discipline.
The more you produce and the more needs you meet, the more
freedom you earn.
As
Seth Godin says,
it's fun to be (only) a consumer, but in the long run, smart
producers win. Knowing how to produce solutions for yourself
and others is the first step to freedom. Actually making
things is the second.
Pretty sure I could build a git-based curriculum management
system in two weeks that would be miles better than anything
on the market now.
Yes, I know that it is easy to have ideas, and that carrying an
idea through to a product is the real challenge. At least I
don't
just need a programmer...
My tweet was the result of temporary madness provoked by yet
another round of listening to non-CS colleagues talk about one
of the pieces of software we use on campus. It is a commercial
product purchased for one task only, to help us manage the
cycle of updating the university catalog. Alas, in its current
state, it can handle only one catalog at a time. This is, of
course, inconvenient. There are always at least two catalogs:
the one in effect at this moment, and the one in progress of
being updated. That doesn't even take into account all of the
old catalogs still in effect for the students who entered the
university when they were The Catalog.
Yes, we need version control. Either the current software does
not provide it, or that feature is turned off.
The madness arises because of the deep internal conflict that
occurs within me when I'm drawn into such conversations.
Everyone assumes that programs "can't do this", or that the
programmers who wrote our product were mean or incompetent. I
could try to convince them otherwise by explaining the idea of
version control. But their experience with commercial software
is so uniformly bad that they have a hard time imagining I'm
telling the truth. Either I misunderstand the problem, or I am
telling them a white lie.
The alternative is to shake my head, agree with them implicitly,
and keep thinking about how to teach my intro students how to
design simple programs.
I'm convinced that a suitable web front-end to a git
back end could do 98% of what we need, which is about 53% more
than either of our last two commercial solutions has done for
us.
Maybe it's time for me to take a leave of absence, put
together a small team of programmers, and do this. Yes, I would
need a team. I know my limitations, and besides working with a
few friends would be a lot more fun. The current tools in this
space leave a lot of room for improvement. Built well and
marketed well, this product would make enough money from
satisfaction-starved universities to reward everyone on the team
well enough for all to retire comfortably.
Maybe not. But the idea is free the taking. All I ask is that
if you build it, give me a shout-out on your website. Oh, and
cut my university a good deal when we buy your software to
replace whatever product we are grumbling about when you reach
market.
Indeed, you should view the study of mathematics, history,
science, and mechanics as the study of
archetypes,
basic patterns that you will recognize over and over. But
this means that, when you study these disciplines, you should
be asking, "what is the pattern" (and not merely "what are
the facts"). And asking this question will actually make
these disciplines easier to learn.
Even in our intro course, I try to help students develop this
habit. Rather than spending all of our time looking at syntax
and a laundry list of language features, I am introducing them
to some of the most basic code patterns, structures they will
encounter repeatedly as they solve problems at this level.
In week one came Input-Process-Output. Then after learning
basic control structures, we encountered guarded actions,
range tests, running totals, sentinel loops, and "loop and a
half". We encounter these patterns in the process of solving
problems.
While they are quite low-level, they are not merely idioms.
They are patterns every bit as much as patterns at the level
of the Gang of Four or PoSA. They solve common problems,
recur in many forms, and are subject to trade-offs that
depend on the specific problem instance.
They compose nicely to create larger programs. One of my goals
for next week is to have students solve new problems that allow
them to assemble programs from ideas they have already seen.
No new syntax or language features, just new problems.
Our first reaction to any comrade, any other person passionate
about and interested in building things with computers, any human
crazy and masochistic enough to try to expand the capabilities of
these absurd machines, should be empathy and love.
You can scarcely compress the time it takes to do good design.
The best you can do is arrange the process so that progress is
conspicuous and the partially-completed result has its own
intrinsic value.
Taylor's piece is about an idea much bigger than simply software
methodology, but this passage leapt off the page at me. It seems
to embody two of the highest goals of the various agile approaches
to making software: progress that is conspicuous and partial
results that have intrinsic value to the user.
If you like ambition attempts to create a philosophy of design,
check out the whole essay. Taylor connects several disparate
sources:
Edwin Hutchins and Cognition in the Wild,
Donald Norman and Things That Make Us Smart, and
Douglas Hofstadter and Gödel, Escher, Bach
with the philosophy of Christopher Alexander, in particular
Notes on the Synthesis of Form and The Nature of
Order. Ambitious it is.
My Jacket Blurb for "Exercises in Programming Style"
On Monday, my copy of Crista Lopes's new book,
Exercises in Programming Style,
arrived. After blogging about the book
last year,
Crista asked me to review some early chapters. After I did
that, the publisher graciously offered me a courtesy copy.
I'm glad it did! The book goes well beyond Crista's
talk at StrangeLoop
last fall, with thirty three styles grouped loosely into
nine categories. Each chapter includes historical notes and
a reading list for going deeper. Readers of this blog know
that I often like to go deeper.
I haven't had a chance to study any of the chapters deeply
yet, so I don't have a detailed review. For now, let me
share the blurb I wrote for the back cover. It gives a sense
of why I was so excited by the chapters I reviewed last summer
and by Crista's talk last fall:
It is difficult to appreciate a programming style until you
see it in action. Cristina's book does something amazing:
it shows us dozens of styles in action on the same program.
The program itself is simple. The result, though, is a
deeper understanding of how thinking differently about a
problem gives rise to very different programs. This book
not only introduced me to several new styles of thinking;
it also taught me something new about the styles I already
know well and use every day.
The best way to appreciate a style is to use it yourself. I
think Crista's book opens the door for many programmers to
do just that with many styles most of us don't use very often.
As for the blurb itself: it sounds a little stilted as I read
it now, but I stand by the sentiment. It is very cool to see
my blurb and name along side blurbs from James Noble and Grady
Booch, two people whose work I respect so much. Very cool.
Leave it to James to sum up his thoughts in a sentence!
While you are waiting for your copy of Crista's book to arrive,
check out her recent blog entry on
the evolution of CS papers
in publication over the last 50+ years. It presents a lot of
great information, with some nice images of pages from a few
classics. It's worth a read.
Q: What do you call a company that has staff members
with "programmer" or "software developer" in their titles?
A: A company.
Back in 2012, Alex Payne wrote
What Is and Is Not A Technology Company
to address a variety of issues related to the confounding of
companies that sell technology with companies that
merely use technology to sell something else. Even
then, developing technology in house was a potential source
of competitive advantage for many businesses, whether that
involved modifying existing software or writing new.
The competitive value in being able to adapt and create
software is only larger and more significant in the last two
years. Not having someone on staff with "programmer"
in the title is almost a red flag even for non-tech companies
these days.
Those programmers aren't likely to have been CS majors in
college, though. We don't produce enough. So we need to find
a way to convince more non-majors to learn a little programming.
As I
mentioned recently,
design skills were a limiting factor for some of the students
in my May term course on agile software development. I saw
similar issues for many in my spring Algorithms course as well.
Implementing an algorithm from lecture or reading was
straightforward enough, but organizing the code of the larger
system in which the algorithm resided often created challenges
for students.
I've been thinking about ways to improve how I teach design in
the future, both in courses where design is a focus and in
courses where it lives in the background of other material.
Anything I come up with can be also part of conversation with
colleagues as we talk about design in their courses.
I read Kent Beck's
initial Responsive Design article
when it first came out a few years ago and
blogged about it
then, because it had so many useful ideas for me and my students.
I decided to re-read the article again last week, looking for a
booster shot of inspiration.
First off, it was nice to remember how many of the techniques
and ideas that Kent mentions already play a big role in my
courses. Ones that stood out on this reading included:
taking safe steps,
isolating changes within modules,
recognizing that design is a team sport, fundamentally a
social activity,
and
My recent experiences in the classroom made two other items
in Kent's list stand out as things I'll probably emphasize
more, or at least differently, in upcoming courses.
Exploit Symmetries. Divide similar elements into
identical parts and different parts.
As I noted in my first blog about this article, many
programmers find it counterintuitive to use duplication as a
tool in design. My students struggle with this, too. Soon
after that blog entry, I described an example of
increasing duplication in order to eliminate duplication
in a course. A few years later, in a fit of deja vu,
I wrote about another example, in which
code duplication is a hint to think differently
about a problem.
I am going to look for more opportunities to help students see
ways in which they can make design better by isolating code
into the identical and the different.
Inside or Outside. Change the interface or the
implementation but not both at the same time.
This is one of the fundamental tenets of design, something
students should learn as early as possible. I was surprised
to see how normal it was for students in my agile development
course not to follow this pattern, even when it quickly got
them into trouble. When you try to refactor interface and
implementation at the same time, things usually don't go
well. That's not a safe step to take...
My students and I discussed writing unit tests before writing
code a lot during the course. Only afterward did it occur to
me that Inside or Outside is the basic element of
test-first programming and TDD. First, we write the test;
this is where we design the interface of our system. Then,
we write code to pass the test; this is where we implement
the system.
Again, in upcoming courses, I am going to look for opportunities
to help students think more effectively about the distinction
between the inside and the outside of their code.
Thus, I have a couple of ideas for the future. Hurray! Even
so, I'm not sure how I feel about my blog entry of four years
ago. I had the good sense to read Kent's article back then,
draw some good ideas from it, and write a blog entry about
them. That's good. But here I am four years later, and I
still feel like I need to make the same sort of improvements
to how I teach.
In the end, I am glad I wrote that blog entry four years ago.
Reading it now reminds me of thoughts I forgot long ago, and
reminds me to aim higher. My opening reference to getting a
booster shot seems like a useful analogy for talking about
this situation in my teaching.
Last time, I thought about the
the role of forgiveness
in selecting programming languages for instruction. I mentioned
that BASIC had worked well for me as a first programming language,
as it had worked for so many others. Yet I would probably would
never choose it as a language for CS1, at least for more than a
few weeks of instruction. It is missing a lot of the features
that we want CS majors to learn about early. It's also a bit
too free.
In that post, I did say that I still consider Pascal a good
standard for first languages. It dominated CS1 for a couple of
decades. What made it work so well as a first instructional
language?
Pascal struck a nice balance for its time. It was small enough
that students could master it all, and also provided constructs
for structured programming. It had the sort of syntax that
enabled a compiler to provide students guidance about errors,
but its compilers did not seem overbearing. It had a few
"gothchas", such as the ; as a statement
separator, but not so many that students were constantly
perplexed. (Hey to C++.) Students were able try things out
and get programs to work without becoming demoralized by a
seemingly endless stream of complaints.
(Aside: I have to admit that I liked Pascal's ;
statement separator. I understood it conceptually and, in
a strange way, appreciated it aesthetically. Most others
seem to have disagreed with me...)
Python has attracted a lot of interest as a CS1 language in
recent years. It's the first popular language in a long
while that brings to mind Pascal's feel for me. However,
Pascal had two things that supported the teaching of CS
majors that Python does not: manifest types and pointers.
I love dynamically-typed languages with managed memory and
prefer them for my own work, but using that sort of language
in CS1 creates some new challenges when preparing students
for upper-division majors courses.
So, Pascal holds a special place for me as a CS1 language,
though it was not the language I learned there. We used it
to teach CS1 for many years and it served me and our students
well. I think it balances a good level of forgiveness with
a reasonable level of structure, all in a relatively small
package.
Programming Languages and the Right Level of Forgiveness
In the last session of my May term course on agile software
development, discussion eventually turned to tools and
programming languages. We talked about whether some
languages are more suited to agile development than others,
and whether some languages are better tools for a given
developer team at a given time. Students being students,
we also discussed the courses used in CS courses, including
the intro course.
Having recently thought some about
choosing the right languages for early CS instruction,
I was interested to hear what students thought. Haskell and
Scala came up; they are the current pet languages of students
in the course. So did Python, Java, and Ada, which are
languages our students have seen in their first-year courses.
I was the old guy in the room, so I mentioned Pascal, which
I still consider a good standard for comparing CS1 languages,
and classic Basic, which so many programmers of my generation
and earlier learned as their first exposure to the magic of
making computers do our bidding.
Somewhere in the conversation, an interesting idea came up
regarding the first language that people learn: good first
languages provide the right amount of forgiveness when
programmers make mistakes.
A language that is too forgiving will allow the learner to
be sloppy and fall into bad habits.
A language that is not forgiving enough can leave students
dispirited under a barrage of not good enough, a barrage of
type errors and syntax gotchas.
What we mean by 'forgiving' is hard to define. For this
and other reasons, not everyone agrees with this claim.
Even when people agree in principle with this idea, they
often have a hard time agreeing on where to draw the line
between too forgiving and not forgiving enough. As with so
many design decisions, the correct answer is likely a local
maximum that balances the forces at play among the teachers,
students, and desired applications involved.
I found Basic to be just right. It gave me freedom to play,
to quickly make interesting programs run, and to learn from
programs that didn't do what I expected. For many people's
taste, though Basic is too forgiving and leads to diseased
minds. (Hey to Edsger Dijkstra.) Maybe I was fortunate to
learn how to use GOSUBs early and well.
Haskell seems like a language that would be too unforgiving
for most learners. Then again, neither my students nor I
have experience with it as a first-year language, so maybe
we are wrong. We could imagine ways in which learning it
first would lead to useful habits of thought about types
and problem decomposition. We are aware of schools that use
Haskell in CS1; perhaps they have made it work for them.
Still, it feels a little too judgmental...
In the end, you can't overlook context and the value of
good tools. Maybe these things shift the line of "just
right" forgiveness for different audiences. In any case,
finding the right level seems to be a useful consideration
in choosing a language.
I suspect this is true when choosing languages to work in
professionally, too.
SS: Yeah, math is social. ... The fact that math
is social would come as a surprise to the people who think
of it as antisocial.
PH: It might also come as a surprise to some math
teachers!
SS: It's extremely social. Mathematicians constantly
spend time talking to each other about places where they're
stuck. They get insights from each other, new ways of
looking at things. Sometimes it's just to commiserate.
Programming is social, too. Most people think it's not. With
assistance from media portrayals of programmers and sloppy
stereotypes of our own, they think most of us would prefer to
work alone in the dark. Some do, of course, but even then most
programmers I know like to talk shop with other programmers all
the time. They like to talk about the places where they are
stuck, as well as the places they used to be stuck.
War stories are the currency of the programmer community.
I think a big chunk of the "programming solo" preference many
programmers profess is learned habit. Most programming
instruction and university course work encourages or requires
students to work alone. What if we started students off with
pair programming in their CS 1 course, and other courses
nurtured that habit throughout the rest of their studies?
Perhaps programmers would learn a different habit.
My agile software development students this semester are doing
all of their project work via pair programming. Class time is
full of discussion: about the problem they are solving, about
the program they are evolving, and about the intricacies of
Java. They've been learning something about all three, and a
large part of that learning has been social.
They've only been trying out XP for a couple of weeks, so
naturally the new style hasn't replaced their old habits. I
see them fall out of pairing occasionally. One partner will
switch off to another computer to look up the documentation
for a Java class, and pretty soon both partners are quietly
looking at their own screens. Out of deference to me or the
course, though, they return after a couple of minutes and
resume their conversation. (I'm trying to be a gentle coach,
not a ruthless tyrant, when it comes to the practices.)
I suspect a couple members of the class would prefer to
program on their own, even after noticing the benefits of
pairing. Others really enjoy pair programming but may well
fall back into solo programming after the class ends. Old
habits die hard, if at all. That's too bad, because most of
us are better programmers when pairing.
But even if they do choose, or fall back into, old habits,
I'm sure that programming will remain a social activity for
them, at some level. There are too many war stories to tell.
(An aside, because I use exceptions to indicate failures, I
almost always use the "fail" keyword rather than the "raise"
keyword in Ruby. Fail and raise are synonyms so there is no
difference except that "fail" more clearly communicates that
the method has failed. The only time I use "raise" is when
I am catching an exception and re-raising it, because here
I'm *not* failing, but explicitly and purposefully raising
an exception. This is a stylistic issue I follow, but I
doubt many other people do).
Words matter: the right words, used at the right times.
Weirich always cared about words, and it showed both in his
code and in his teaching and writing.
The students in my agile class got to see my obsession with
word choice and phrasing in class yesterday, when we worked
through the story cards they had written for their project.
I asked questions about many of their stories, trying to
help them express what they intended as clearly as possible.
Occasionally, I asked, "How will you write the test for
this?" In their proposed test we found what they really
meant and were able to rephrase the story.
Writing stories is hard, even for experienced programmers.
My students are doing this for the first time, and they
seemed to appreciate the need to spend time thinking about
their stories and looking for ways to make them better.
Of course, we've already discussed the importance of good
names, and they've already experienced that way in which
words matter in their own code.
Whenever I hear someone say that oral and verbal communication
skills aren't all that important for becoming a good
programmer, I try to help them see that they are, and why.
Almost always, I find that they are not programmers and are
just assuming that we techies spend all our time living inside
mathematical computer languages. If they had ever written
much software, they'd already know.
After spending a couple of days becoming familiar with
pair programming and unit tests,
for Day 4 we moved on to the next step: refactoring. I had
the students study the "before" code base from Martin Fowler's
book, Refactoring, to identify several ways they
thought we could improve it. Then they worked in pairs to
implement their ideas. The code itself is pretty simple -- a
small part of the information system for a movie rental store
-- and let the students focus on practice with tools, running
tests, and keeping the code base "green".
We all know Fowler's canonical definition of refactoring:
Refactoring is the process of changing a software system in
such a way that it does not alter the external behavior of
the code yet improves its internal structure.
... but it's easy to forget that refactoring really is
about design. Programmers with limited experience in
Java or OOP can bring only so much to the conversation about
improving an OO program written in Java. We can refactor
confidently and well only if we have a target in mind, one
we understand and can envision in our code. Further, creating
a good software design requires taste, and taste generally
comes from experience.
I noticed this lack of experience manifesting itself in the
way my students tried to decompose the work of a refactoring
into small, safe steps. When we struggle with decomposing a
refactoring, we naturally struggle with choosing the next
step to work on. Kent Beck calls this the challenge of
succession. Ordering the steps of a refactoring is
a more subtle challenge than many programmers realize at first.
This session reminded me why I like to teach design and
refactoring in parallel: coming to appreciate new code smells
and quickly learning how to refactor code into a better state.
This way, programming skill grows along side the design skill.
On Day 5, we tried to put the skills from the three previous
days all together, using an XP-style test-code-refactor-repeat
cycle to implement a bit of code. Students worked on either
the Checkout kata
from Dave Thomas or
a tic-tac-toe game
based on a write-up by Gojko Adzic. No, these are not the most
exciting programs to build, but as I told the class, this makes
it possible for them to focus on the XP practices and habits of
mind -- small steps, unit tests, and refactoring -- without
having to work too hard to grok the domain.
My initial impression as the students worked was that the
exercise wasn't going as well as I had hoped it would. The
step size was too big, and the tests were too intrusive, and
the refactoring was almost non-existent. Afterwards, though,
I realized that programmers learning such foreign new habits
must go through this phase. The best I can do is inject an
occasional suggestion or question, hoping that it helps
speed them along the curve.
This morning, I decided to have each student pair up with
someone who had worked on the other task last time, flip a
coin, and work on the one of the same two tasks. This way,
each pair had someone working on the same problem again and
someone working on a new problem. I instructed them to start
from scratch -- new code, new thoughts -- and have the person
new to the task write the first test.
The goal wass to create an asymmetry within each pair.
Working on the same piece again would be valuable for the
partner doing so, in the way playing finger exercises or
etudes is valuable for a musician. At the same time, the
other partner would see a new problem, bringing fresh eyes
and thoughts to the exercise. This approach seems like a
good one, as it varies the experience for both members of
the pair. I know how important varying the environment can
be for student learning, but I sometimes forget to do that
often enough in class.
The results seemed so much better today. Students commented
that they made better progress this time around, not because
one of them had worked on the same problem last time, but
because they were feeling more comfortable with the XP
practices. One students something to the effect,
Last time, we were trying to work on the simplest or
smallest piece of code we could write. This time, we were
trying to work on the smallest piece of functionality we
could add to the program.
That's a solid insight from an undergrad, even one with a
couple of years programming experience.
I also liked the conversation I was hearing among the pairs.
They asked each other, "Should we do this feature next, or
this other?" and said, "I'm not sure how we can test this."
-- and then talked it over before proceeding. One pair had
a wider disparity in OO experience, so the more experienced
programmer was thinking out loud as he drove, taking into
account comments from his partner as he coded.
This is a good sign. I'm under no illusion that they have
all suddenly mastered ordering features, writing unit tests,
or refactoring. We'll hit bumps over the next three weeks.
But they all seem to be pretty comfortable with working
together and collaborating on code. That's an essential
skill on an agile team.
Next up: the Planning Game for a project that we'll work on
for the rest of the class. They chose their own system to
build, a cool little Android game app. That will change the
dynamic a bit for customer collaboration and story writing,
but I think that the increased desire to see a finished
product will increase their motivation to master the skills
and practice. My job as part-time customer, part-time coach
will require extra vigilance to keep them on track.
Days 2 and 3 of my Agile Software Development May term
course are now in the books. This year, I decided to move as
quickly as we could in the lab. Yesterday, the students did
their first pair-programming session, working for a little
over an hour on one of the industry standard exercises,
Conway's Game of Life.
Today, they did their first pair programming with unit tests,
using Bill Wake's
Test-First Challenge
to implement the beginnings of a simple data model for
spreadsheets.
I always enjoy watching students write code and interacting
with them while they do it. The thing that jumped out to me
yesterday was just how much code some students write before
they ever think about compiling it, let alone testing it.
Another was how some students manage to get through a year
of programming-heavy CS courses without mastering their
basic tools: text editor, compiler, and language. It's hard
to work confidently when your tools feel uncomfortable in
your hands.
There's not much I can do to help students develop greater
facility with their tools than give them lots of practice,
and we will do that. However, writing too much code before
testing even its syntactic correctness is a matter of
mindset and habit. So I opened today's session with a brief
discussion, and then showed them what I meant in the form of
a short bit of code I wrote yesterday while watching them.
Then I turned them loose with Wake's spreadsheet tests and
encouragement to help each other write simple code, compile
frequently even with short snippets, and run the tests as
often as their code compiles.
Today, we had an odd number of students in class, something
that's likely to be our standard condition this term, so
paired with one of the students on a spreadsheet. He wanted
to work in Haskell, and I was game. I refreshed my Haskell
memories a bit and even contributed some helpful bits of
code, in addition to meta-contributions on XP style.
The student is relatively new to the language, so he's still
developing the Haskell in his in his mind. There were times
we struggled because we were thinking of the problem in a
stateful way. As you surely know, that's not the best way
to work in Haskell. Our solutions were not always elegant,
but we did our best to get in the rhythm of writing tests,
writing code, and running.
As the period was coming to an end, our code had just passed
a test that had been challenging us. Almost simultaneously,
a student in another thrust his arms in the air as his pair's
code passed a challenging test, too, much deeper in the suite.
We all decided to declare victory and move on. We'll all
get better with practice.
Next up: refactoring, and tools to support it and automated
testing.
May term started today, so my agile course is off the ground.
We will meet for 130 minutes every morning through June 6,
excepting only Memorial Day. That's a lot of time spent
together in a short period of time.
As I told the students today, each class is almost a week's
worth of class in a regular semester. This means committing
a fair amount of time out of class every day, on the order
of 5-7 hours. There isn't a lot of time for our brains to
percolate on the course content. We'll be moving steadily
for four weeks.
This makes May term unsuitable, in my mind at least, for a
number of courses. I would never teach CS 1 in May term.
Students are brand new to the discipline, to programming,
and usually to their first programming language. They
need time for the brains to percolate. I don't
think I'd want to teach upper-division CS courses in May
term if they have a lot of content, either. Our brains
don't always absorb a lot of information quickly in a short
amount of time, so letting it sink in more slowly, helped
by practice and repetition, seems best.
My agile course is, on the other hand, almost custom made
for a compressed semester. There isn't a lot of essential
"content". The idea is straightforward. I don't expect
students to memorize lists of practices, or the rules of
tools. I expect them to do the practices. Doing
them daily, in extended chunks of time, with immediate
feedback, is much better than taking a day off between
practice sessions.
Our goal is, in part, to learn new habits and then reflect
on how well they fit, on where they might help us most and
where they might get in the way. We'll have better success
learning new habits in the compressed term than we would
with breaks. And, as much as I want students to work daily
during a fifteen-week semester to build habits, it usually
just doesn't happen. Even when the students buy in and
intend to work that way, life's other demands get in the
way. Failing with good intentions is still failing, and
sometimes feels worse than failing without them.
So we begin. Tomorrow we start working on our first
practice, a new way of working with skills to be learned
through repetition every day the rest of the semester. Wish
us luck.
Spring semester ends today. May term begins Monday. I haven't
taught during the summer since 2010, when I offered a course on
agile software development.
I'm reprising that course this month, with nine hardy souls
signed on for the mission. That means no break for now, just
a new start. I like those.
I'm sure I could blog for hours on the thoughts running through
my head for the course. They go beyond
the readings
we did last time and the project we built, though all that is
in the mix, too.
For now, though, three passages that made the highlights of my
recent reading. All fit nicely with the theme of college days
and transition.
Adam invented all the different ways in which a young man can
make a fool of himself, and the college yell at the end of
them is just a frill that doesn't change essentials.
College is a place all its own, but it's just a place. In many
ways, it's just the place where young people spend a few years
while they are young.
If I've done my job, you won't be happy with anything you write
for the next 10 years. It's not because you won't be writing
well, but because I've raised your standards for yourself.
Whatever we "content" teach our students, raising their standards
and goals is sometimes the most important thing we do. "Don't
compare yourselves to each other", she says. Compare yourselves
to the best writers. "Shoot there." This advice works just as
well for our students, whether they are becoming software
developers or computer scientists. (Most of our students end up
being a little bit of both.)
It's better to aim at the standard set by Ward Cunningham or Alan
Kay than at the best we can imagine ourselves doing right now.
~~~~
Now that I think about it, this last one has nothing to do with
college or transitions. But it made me laugh, and after a long
academic year, with no break imminent, a good laugh is worth
something.
What do you call a rigorous demonstration that a statement
is true?
If "proof", then you're a mathematician.
If "experiment", then you're a physicist.
If you have no word for this concept, then
you're an economist.
This is the first of several items in
The Mathematical Dialect Quiz
at Math with Bad Drawings. It adds a couple of new twists to
the tongue-in-cheek differences among mathematicians, computer
scientists, and engineers. With bad drawings.
Several people have recommended Pat Brisbin's
Thinking in Types
for programmers with experience in dynamically-typed languages
who are looking to grok Haskell-style typing. He wrote it
after helping one of his colleagues of mine was get unstuck
with a program that "seemed conceptually simple but resulted
in a type error" in Haskell when implemented in a way similar
to a solution in a language such as Python or Ruby.
This topic is of current interest to me at a somewhat higher
level. Few of our undergrads have a chance to program in
Haskell as a part of their coursework, though a good number
of them learn Scala while working at a local financial tech
company. However, about two-thirds of undergrads now start
with a one or two semesters of Python, and types are something
of a mystery to them. This affects their learning of Java and
colors how they think about types if they take my course on
programming languages.
So I read this paper. I have two comments.
First, let me say that I agree with my friends and colleagues
who are recommending this paper. It is a clear, concise, and
well-written description of how to use Haskell's types to
think about a problem. It uses examples that are concrete
enough that even our undergrads could implement with a little
help. I may use this as a reading in my languages course
next spring.
Second, I think think this paper does more than simply teach
people about types in a Haskell-like language. It also gives
a great example of how thinking about types can help
programmers create better designs for their programs, even if
they are working in an object-oriented language! Further, it
hits right at the heart of the problem we face these days,
with students who are used to working in scripting languages
that provide high-level but very generic data structures.
The problem that Brisbin addresses happens after he helps his
buddy create type classes and two instance classes, and they
reach this code:
renderAll [ball, playerOne, playerTwo]
renderAll takes a list of values that are
Render-able. Unfortunately, in this case, the
arguments come from two different classes... and Haskell does
not allow heterogeneous lists. We could try to work around
this feature of Haskell and "make it fit", but as Brisbin
points out, doing so would cause you to lose the advantages
of using Haskell in the first place. The compiler wouldn't
be able to find errors in the code.
The Haskell way to solve the problem is to replace the generic
list of stuff we pass to renderAll with a new type.
With a new Game type that composes a ball with two
players, we are able to achieve several advantages at once:
create a polymorphic render method for
Game that passes muster with the type checker
allow the type checker to ensure that this element of
our program is correct
make the program easier to extend in a type-safe way
our program is correct
and, perhaps most importantly, express the intent of
the program more clearly
It's this last win that jumped off the page for me. Creating
a Game class would give us a better object-oriented
design in his colleague's native language, too!
Students who become accustomed to programming in languages like
Python and Ruby often become accustomed to using untyped lists,
arrays, hashes, and tuples as their go-to collections. They
are oh, so, handy, often the quickest route to a program that
works on the small examples at hand. But those very handy
data structures promote sloppy design, or at least enable it;
they make it easy not to see very basic objects living in the
code.
Who needs a Game class when a Python list or Ruby array
works out of the box? I'll tell you: you do, as soon as you
try to almost anything else in your program. Otherwise, you
begin working around the generality of the list or array,
writing code to handle special cases really aren't special
cases at all. They are simply unbundled objects running wild
in the program.
Good design is good design. Most of the features of a good
design transcend any particular programming style or language.
So: This paper is a great read! You can use it to learn
better how to think like a Haskell programmer. And you can
use it to learn even if thinking like a Haskell programmer
is not your goal. I'm going to use it, or something like it,
to help my students become better OO programmers.
As Corey Haines
tells us,
it really can be this simple:
def assert_equal(expected, actual, message)
if expected != actual
raise "Expected #{expected}, got #{actual}\n#{message}"
end
end
Don't let the overhead of learning or using a test harness
prevent you from starting. Write a test, then write some
code. Or, if you prefer: Write some code, then write a
test.
The Special Case Object Pattern in "Confident Ruby"
I haven't had a chance to pick up a copy of
Avdi Grimm's
new book,
Confident Ruby,
yet. I did buzz by the book's
Pragmatic Programmers page,
where I was able to pick up a sample chapter or two for
elliptical reading.
The chapter "Represent special cases as objects" was my first
look. This chapter and the "Represent do-nothing cases as
null objects" chapter that follows deal with situations in
which our program is missing a kind of object. The result is
code that has too many responsibilities because there is no
object charged with handling them.
The chapter on do-nothing cases is @avdi's re-telling of the
Null Object pattern. Bobby Woolf workshopped
his seminal write-up
of this pattern at
PLoP 1996
(the first patterns conference I attended) and later published
an improved version in
the fourth Pattern Languages of Program Design book.
I had the great pleasure to correspond with Bobby as he
wrote his original paper and to share a few ideas about
the pattern.
@avdi's special cases chapter is a great addition to the
literature. It shows several different ways in which our
code can call out for a special case object in place of a
null reference. It then shows how creating a new
kind of object can make our code better in each case,
giving concrete examples written in Ruby, in the context
of processing input to a web app.
I was discussing the pattern and the chapter with a student,
who asked a question about this example:
if current_user
render_logout_button
else
render_login_button
end
This is the only example in which the if
check is not eliminated after introducing the special case
object, an instance of the new class, GuestUser.
Instead, @avdi adds an authenticated? to the
User and GuestUser classes, has them
return true and false respectively, and
then changes the original expression to:
if current_user.authenticated?
render_logout_button
else
render_login_button
end
As the chapter tells us, using the authenticated?
predicate makes the conditional statement express the
programmer's intent more clearly. But it also says that "we
can't get rid of the conditional". My student asked, "Why
not?"
Of course we can. The question is whether we want to. (I
have a hard time using words like "cannot", "never", and
"always", because I can usually imagine an exception to the
absolute...)
In this case, there is a lingering smell in the code that
uses the special case object: authenticated? is a
surrogate for type check. Indeed, it behaves just like a
query to find the object's class so that we can tailor our
behavior to receiver's type. That's just the sort of thing
we don't have to do in an OO program.
The standard remedy for this code smell is to push the
behavior into the classes and send the object, whatever its
type, a message. Rather ask a user if it is authenticated
so that we can render the correct button, we might ask it
to render the correct button itself:
current_user.render_button
...
class User
def render_button
render_logout_button
end
end
class GuestUser
def render_button
render_login_button
end
end
Unfortunately, it's not quite this simple. The
render_logXXX_button methods don't live in the
user classes, so the render_button methods need
to send those messages to some other object. If the user
object already knows to whom to send it, great. If not,
then the send of the render_button message will
need to send itself as an argument along with the message,
so that the receiver can send the appropriate message back.
Either of these approaches requires us to let some knowledge
from the original context leak into our User and
GuestUser classes, and that creates a new form of
coupling. Ideally, there will be a way to mitigate this
coupling in the form of some other shared association. Ruby
web developers know the answer to this better than I.
In any case, this may be what @avdi means when he says that
we can't get rid of the if check.
Doing so may create more downside than upside.
This turned into a great opportunity to discuss design with
my student. Design is about trade-offs. Things never seem
quite as simple in the trenches as they do when we learn
the rules and heuristics of design. There is no perfect
solution. Our goal as programmers should be to develop the
ability to make informed decisions in these situations,
taking into account the context in which we are working.
Patterns document design solutions and so must be used with
care. One of the thing I love about the pattern form is
that it encourages the writer to make as explicit as
possible the context in which the solution applies and the
forces that make its use more or less applicable. This
helps the reader to face the possible trade-offs with his
or her eyes wide open.
So, one minor improvement @avdi might make in this chapter
is to elaborate on the reason underlying the assertion that
we can't eliminate this particular if check.
Otherwise, students of OOP are likely to ask the same
question my student asked.
Of course, the answer may be obvious to Ruby web developers.
In the end, working with patterns is like all other design:
the more experience we have, the better.
This is a relatively minor issue, though. From what I've
seen, "Confident Ruby" will be a valuable addition to most
Ruby programmers' bookshelves.
A few weeks ago, Reginald Braithwaite wrote
a short piece
discouraging us from creating class hierarchies. His
article uses Javascript examples, but I think he intends
his advice to apply everywhere:
So if someone asks you to explain how to write a class
hierarchy? Go ahead and tell them: "Don't do that!"
If you have done much object-oriented programming in a
class-based language, you will recognize his concern
with class hierarchies: A change to the implementation
of a class high up in the hierarchy could break every
class beneath it. This is often called the "fragile
base class" problem. Fragile code can't be changed
without a lot of pain, fixing all the code broken by
the change.
I'm going to violate the premise of Braithwaite's advice
and suggest a way that you can make your base classes
less fragile and thus make small class hierarchies more
attractive. If you would like to follow his advice,
feel free to tell me "Don't do that!" and stop reading
now.
The technique I suggest follows directly from a practice
that OO programmers use to create good objects, one that
Braithwaite advocates in his article: encapsulating data
tightly within an object.
JavaScript does not enforce private state, but it's
easy to write well-encapsulated programs: simply avoid
having one object directly manipulate another object's
properties. Forty years after Smalltalk was invented,
this is a well-understood principle.
The article then shows a standard example of a bank
account object written in this style, in which client
code uses the object without depending on its
implementation. So far, so good.
What about classes?
It turns out, the relationship between classes in a
hierarchy is not encapsulated. This is because
classes do not relate to each other through a
well-defined interface of methods while "hiding" their
internal state from each other.
Braithwaite then shows an example of a subclass method
that illustrates the problem:
The ChequingAccount directly accesses its
_currentBalance member, which it inherits from
the Account prototype. If we now change the
internal implementation of Account so that it
does not provide a _currentBalance member, we
will break ChequingAccount.
The problem, we are told, is that objects are encapsulated,
but classes are not.
... this dependency is not limited in scope to a carefully
curated interface of methods and behaviour. We have no
encapsulation.
However, as the article pointed out earlier, JavaScript
does not enforce private state for objects! Even so, it's
easy to write well-encapsulated programs -- by not letting
one object directly manipulate another object's properties.
This is a design pattern that makes it possible to write
OO programs even when the language does not enforce
encapsulation.
The problem isn't that objects are encapsulated and classes
are not. It's that we tend treat superclasses differently
than we treat other classes.
When we write code for two independent objects, we think
of their classes as black boxes, sealed off from external
inspection. The data and methods defined in the one class
belong to it and its objects. Objects of one class must
interact with objects of another via a carefully
curated interface of methods and behavior.
But when we write code for a subclass, we tend to think of
the data and methods defined in the superclass as somehow
"belonging to" instances of the subclass. We take the
notion of inheritance too literally.
My suggestion is that you treat your classes like you treat
objects: Don't let one class look into another class and
access its state directly. Adopt this practice even when
the other class is a superclass, and the state is an
inherited member.
Many OO programs have this pattern. I usually call it the
"Subclass as Client" pattern. Instances of a subclass act
as clients of their superclass, treating it -- as much as
possible -- as an independent object providing a set of
well-defined behaviors.
When code follows this pattern, it takes Braithwaite's
advice for designing objects up a level and follows it
more faithfully. Even instance variables inherited
from the superclass are encapsulated, accessible only
through the behaviors of the superclass.
I don't program in Javascript, but I've written a lot
of Java over the years, and I think the lessons are
compatible. Here's my story.
~~~~~
When I teach OOP, one of the first things my students
learn about creating objects is this:
All instance variables are private.
Like Javascript, Java doesn't require this. We can tell
the compiler to enforce it, though, through use of the
private modifier. Now, only methods
defined in the same class can access the variable.
For the most part, students are fine with this idea --
until we learn about subclasses. If one class
extends another, it cannot access the
inherited data members. The natural thing to do is what
they see in too many Java examples in their texts and on
the web: change private variables in the
superclass to protected. Now, all is
right with the world again.
Except that they have stepped directly into the path of
the fragile base class problem. Almost any change to
the superclass risks breaking all of its subclasses.
Even in a sophomore OO course, we quickly encounter the
problem of fragile base classes in our programs. But
other choice do we have?
Make each class a server to its subclasses. Keep the
instance variables private, and (in
Braithwaite's words) carefully curate an interface of
methods for subclasses to use. The class may be willing
to expose more of its identity to its subclasses than to
arbitrary objects, so define protected
methods that are accessible only to its subclasses.
This is an intentional extension of the class's interface
for explicit interaction with subclasses. (Yes, I know
that protected members in Java are
accessible to every class in the package. Grrr.)
This is the same discipline we follow when we write
well-behaved objects in any language: encapsulate data
and define an interface for interaction. When applied
to the class-subclass relationship, it helps us to avoid
the dangers of fragile base classes.
Forty years after Smalltalk was invented, this principle
should be better understood by more programmers. In
Smalltalk, variables are encapsulated within their
classes, which forces subclasses to access them through
methods defined in the superclass. This language feature
encourages the writer of the class to think explicitly
about how instances of a subclass will interact with the
class. (Unfortunately, those methods are public to the
world, so programmers have to enforce their scope by
convention.)
Of course, a lazy programmer can throw away this advantage.
When I first learned OO in Smalltalk, I quickly figured out
that I could simply define accessors with the same names as
the instance variables. Hurray! My elation did not last
long, though. Like my Java students, I quickly found
myself with a maze of class-subclass entanglements that
made programming unbearable. I had re-invented the Fragile
Base Class problem.
Fortunately, I had the Smalltalk class library to study,
as well as programs written by better programmers than I.
Those programs taught me the Subclass as Client pattern,
I learned that it was possible to use subclasses well, when
classes were designed carefully. This is just one of the
many ways that
Smalltalk taught me OOP.
~~~~~
Yes, you should prefer composition to inheritance, and, yes,
you should strive to keep your class hierarchies as small
and shallow as possible. But if you apply basic principles
of object design to your superclasses, you don't need to
live in absolute fear of fragile base classes. You can "do
that" if you are willing to carefully curate an interface of
methods that define the behavior of a class as a superclass.
This advice works well only for the class hierarchies you
build for yourself. If you need to work with a class from
an external package you don't control, then you can't be
control the quality of those class's interfaces. Think
carefully before you subclass an external class and depend
on its implementation.
One technique I find helpful in this regard is to build a
wrapper class around the external class, carefully define
an interface for subclasses, and then extend the wrapper
class. This at least isolates the risk of changes in the
library class to a single class in my program.
Of course, if you are programming in Javascript, you might
want to look to the Self community for more suitable OO
advice than to Smalltalk!
Programming is our way of encoding thought such that the
computer can help us with it.
Read the whole piece, which recounts Granger's reflection after
the Light Table project left him unsatisfied and he sought
answers. He concludes that we need to re-center our idea of
what programming is and how we can make it accessible to more
people. Our current idea of programming doesn't scale because,
well,
It turns out masochism is a hard sell.
Every teacher knows this. You can sell masochism to a few
proud souls, but not to anyone else.
That is the advice I find myself giving to students again
and again this semester: Sooner.
Review the material we cover in class sooner.
Ask questions sooner.
Think about the homework problems sooner.
Clarify the requirements sooner.
Write code sooner.
Test your code sooner.
Submit a working version of your homework sooner. You can
submit a more complete version later.
A lot of this advice boils down to the more general Get
feedback sooner. In many ways, it is a dual of the
advice,
Take small steps.
If you take small steps, you can ask, clarify, write, and
test sooner. One of the most reliable ways to do those
things sooner is to take small steps.
If you are struggling to get things done, give sooner
a try. Rather than fail in a familiar way, you might succeed
in an unfamiliar way. When you do, you probably won't want
to go back to the old way again.
In
this interview
prior to Monday's debut of FiveThirtyEight, Joe Coscarelli asked
Nate Silver if the venture was ready to launch. Silver said
that they they were probably 75-80% ready and that it was time
to go live.
You're going to make some mistakes once you launch that you
can't really deal with until you actually have a real product.
If they waited another month, they'd probably feel like they were
... 75-80% ready. There are some things you can't learn "unless
your neck is on the line".
It ought not be surprising that Silver feels this way. His
calling card is using data to make better decisions. Before you
can have big data, or good data, you have to have data. It is
usually better to start collecting it now than to start collecting
it later.
Sass, Flexbox, Git, Grunt? Frank Chimero
whispers:
(Look at that list, programmers. You need to get better at
naming things. No wonder why people are skittish about
development. It's like we're in a Dr. Seuss book.)
For new names, it's time to hunt.
I will not Git!
I will not Grunt!
Nevermore shall we let these pass.
No more Flexbox!
No more Sass!
In his recent article on
the future of the news business,
Marc Andreessen has a great passage in his section on
ways for the journalism industry to move forward:
Experimentation: You may not have all the right
answers up front, but running many experiments changes
the battle for the right way forward from arguments to
tests. You get data, which leads to correctness and
ultimately finding the right answers.
I love that clause: "running many experiments changes the
battle for the right way forward from arguments to tests".
While programming, it's easy to get caught up in what we
know about the code we have just written and assume that
this somehow empowers us to declare sweeping truths about
what to do next.
When students are first learning to program, they often
fall into this trap -- despite the fact that they don't
know much at all. From other courses, though, they are
used to thinking for a bit, drawing some conclusions, and
then expressing strongly-held opinions. Why not do it
with their code, too?
No matter who we are, whenever we do this, sometimes we
are right, and sometimes, we are wrong. Why leave it to
chance? Run a simple little experiment. Write a snippet
of code that implements our idea, and run it. See what
happens.
Programs let us test our ideas, even the ideas we have
about the program we are writing. Why settle for
abstract assertions when we can do better? In the end,
even well-reasoned assertions are so much hot air. I
learned this from Ward Cunningham: It's all talk until
the tests run.
This week I saw a link to
The Turing School of Software & Design,
"a seven-month, full-time program for people who want to become
professional developers". It reminded me of Neumont University,
a ten-year-old school that offers a B.S. degree program in
Computer science that students can complete in two and a half
years.
While riding the bike, I occasionally fantasize about doing
something like this. With the economics of universities
changing so quickly [
1
|
2
], there is an opportunity for a new kind of higher education.
And there's something appealing about being able to work
closely with a cadre of motivated students on the full
spectrum of computer science and software development.
This could be an accelerated form of traditional CS instruction,
without the distractions of other things, or it could be
something different. Traditional university courses are pretty
confining. "This course is about algorithms.
That one is about programming languages." It would be
fun to run a studio in which students serve as apprentices
making real stuff, all of us learning as we go along.
A few years ago, one of our ChiliPLoP hot topic groups
conducted a greenfield thought experiment
to design an undergrad CS program outside of the constraints of
any existing university structure. Student advancement was
based on demonstrating professional competencies, not completing
packaged courses. It was such an appealing idea! Of course,
there was a lot of hard work to be done working out the details.
My view of university is still romantic, though. I like the
idea of students engaging the great ideas of humanity that lie
outside their major. These days, I think it's conceivable to
include the humanities and other disciplines in a new kind of CS
education. In a recent blog entry, Hollis Robbins floats the
idea of
Home College
for the first year of a liberal arts education. The premise is
that there are "thousands of qualified, trained, energetic, and
underemployed Ph.D.s [...] struggling to find stable teaching
jobs". Hiring a well-rounded tutor could be a lot less
expensive than a year at a private college, and more lucrative
for the tutor than adjuncting.
Maybe a new educational venture could offer more than targeted
professional development in computing or software. Include a
couple of humanities profs, maybe some a social scientist, and
it could offer a more complete undergraduate education --
one that is economical both in time and money.
But the core of my dream is going broad and deep in CS without
the baggage of a university. Sometimes a fantasy is all you
need. Other times...
If a CS major learns only one habit of professional practice
in four years, it should be:
Take small steps.
A corollary:
If things aren't working, take smaller steps.
I once heard Kent Beck say something similar, in the context
of TDD and XP. When my colleague
Mark Jacobson
works with students who are struggling, he uses a similar
mantra: Solve a simpler problem. As
Dr. Nick notes,
students and professionals alike should scale the step size
according to their level of knowledge or their confidence
about the problem.
When I tweeted these thoughts yesterday, two pieces of related
advice came in:
Slow down.
-- Big steps are usually a sign of trying to hurry.
Beginners are especially prone to this.
Lemma: Keep moving.
-- Small steps keep us moving more reliably. We can
always fool ourselves into believing that the next big
step is all we need...
I was looking over a couple of files of old notes and found
several quotes that I still like, usually from articles I
enjoyed as well. They haven't found their way into a blog
entry yet, but they deserve to see the light of day.
Evidence, Please!
From
a short note
on the tendency even among scientists to believe unsubstantiated
claims, both in and out of the professional context:
It's hard work, but I suspect the real challenge will lie
in persuading working programmers to say "evidence, please"
more often.
More programmers and computer scientists are trying to collect
and understand data these days, but I'm not sure we've made
much headway in getting programmers to ask for evidence.
The code is a lot simpler to understand than the math,
I think.
I often understand the language of code more quickly than the
language of math. Reading, or even writing, a program sometimes
helps me understand a new idea better than reading the math.
Theory is, however, great for helping me to pin down what I
have learned more formally.
Right now, the Rubyists are grinning, the Smalltalkers are
furiously waving their hands in the air to get the teacher's
attention, and the Lispers are just nodding smugly in the
back row (all as usual).
As a Big Fan of all three languages, I am occasionally conflicted.
Grin? Wave? Nod? Look like the court jester by doing all three
simultaneously?
You know what they say about good design coming from experience,
and experience coming from bad design? That phenomenon is true
of most things non-trivial. Here's
an example from men's college basketball.
The University of Florida has a veteran team. The University of
Kentucky has a young team. Florida's players are very good, but
not generally considered to be in the same class as Kentucky's
highly-regarded players. Yesterday, the two teams played a
close game on Kentucky's home floor.
Once they fell behind by five with less than two minutes
remaining, Kentucky players panicked. Florida players didn't.
Why not? "Well, we have a veteran group here that's panicked
before -- that's been in this situation and not handled it
well," [Patric] Young said.
How did Florida's players maintain their composure at the end
of a tight game on the road against another good team?
They had been in that same situation three times before,
and failed. They didn't panic this time in large part
because they had panicked before and learned from those
experiences.
Kentucky's starters have played a total of 124 college games.
Florida's four seniors have combined to play 491. That's a
lot of experience -- a lot of opportunities to panic, to guess
wrong, to underestimate a situation, or otherwise to come up
short. And a lot of opportunities to learn.
The young players at Kentucky hurt today. As the author of the
linked game report notes, Florida's players have hurt like that
before, for coming up short in much the same way, "and they used
that pain to get better".
It turns out that composure comes from experience, and experience
comes from lack of composure.
As a teacher, I try to convince students not to shy away from the
error messages their compiler gives them, or from the convoluted
code they eventually sneak past it. Those are the experiences
they'll eventually look back to when they are capable, confident
programmers. They just need the opportunity to learn.
My students and I debriefed a programming assignment in class
yesterday. In the middle of class, I said, "Now for a big
question: How do you know your code is correct?
There were a lot of knowing smiles and a lot of nervous
laughter. Most of them don't.
Sure, they ran a few test cases, but after making additions
and changes to the code, some were just happy that it still
ran. The output looked reasonable, so it must be done. I
suggested that they might want to think more about testing.
This morning I read a great quote from
Nathan Marz
that I will share with my students:
Feedback is everything. Most of the time you're wrong, and
feedback is the only way to realize your mistakes and help
you become less wrong. This applies to everything.
Most of the time you're wrong. Do things that help you become
less wrong. Getting feedback, early and often, is one of the
best ways to do this.
A comment by a student earlier in the period foreshadowed our
discussion of testing, which made me feel even better. In
response to the retrospective question, "What design or
programming choices went well for you?", he answered unit
tests.
That set me up quite nicely to segue from manual testing into
automated testing. If you aren't testing your code early and
often, then manual testing is a huge improvement. But you can
do even better by pushing those test cases into a form that
can be executed quickly and easily, with the code doing the
tedious work of verifying the output.
My students are writing code in many different languages, so I
showed them testing frameworks in Ruby, Java, and Python. The
code looks simple, even with the boilerplate imposed by the
frameworks.
The big challenges in getting students to write unit tests are
the same as for getting professionals to write them: lack of
time, and misplaced confidence. I hope that a few of my
students will see that the real time sink is debugging bad code
and that a fear of changing code is a lack of confidence. The
best way to be confident is to have evidence.
The student who extolled unit tests works in Racket and so has
test cases in
RackUnit.
He set me up nicely for a future discussion, too, when he
admitted out loud that he wrote his tests first. This time,
it was I who smiled knowingly.
When asked to design and implement a program, beginning programmers
often aren't sure what data type or data structure to use for a
particular value. Should they use an array or a list? Or they've
decided to use a record but can't decide exactly what fields to
include, or names to give them.
"What should it be?", they ask.
I often have a particular implementation in mind, based on what
we've been studying or on my own experience as a programmer, but I
prefer not to tell them what to do. This is a great opportunity
for them to learn to think about design.
Instead, I ask questions. "What have you considered?" "Do you
think one or the other is better?" "Why?"
We discuss how so often there is no "right" answer. There are
merely trade-offs. They have to choose. This is a design
decision.
But, in making this decision, there's another opportunity to learn
something about design. They don't have to commit now and forever
to an implementation before proceeding with the rest of their
program. Because the rest of the program shouldn't know about
their decision anyway!
They should make an object that encapsulates the choice.
They are then able to start building the rest of the program
without fear that it depends on the details of their design choice.
The rest of the program will interact with the object in terms of
what the object means in the program, not in terms of how
it is implemented. Later, if they change their minds, they will be
able to change the implementation details without disturbing the
rest of the code.
Yes this is basic stuff, but beginners often struggle with basic
stuff. They've learned about ADTs or OOP, and they can talk
abstractly about abstraction. But when it comes time to write code,
indecision descends upon them. They are afraid of messing up.
If I can help allay their fears of proceeding, then I've contributed
something to their work that day. I even suggest that writing the
rest of the program might even help them figure out which alternative
is better. I like to listen to my code, even if that idea seems
strange or absurd to them. Some day soon, it may not.
In any case, they have the beginnings of a program, and perhaps a
better idea of what design is all about.
A well-known programmer got collared by a university student
who asked, "Do you think I could be a programmer?"
"Well," the programmer said, "I don't know... Do you like
function calls?"
The programmer could see the student's amazement. Function
calls? Do I like function calls? I am twenty years old and
do I like function calls?
If the student had liked function calls, of course, he could
begin, like a joyful painter I knew. I asked him how he
came to be a painter. He said, "I liked the smell of paint."
I've never really cared about source code before. I don't really
consider myself a 'programmer'.
Then he says this:
Dyad has 193k lines of code, all C++.
193,000 lines of C++? Um, dude, you're a programmer.
Even so, the point is worth thinking about. For most people,
programming is a means to an end: a way to create something.
Many CS students start with a dream program in mind and only
later, like McGrath, come to appreciate code for its own
sake. Some of our graduates never really get there, and
appreciate programming mostly for what they can do with it.
If the message we send from academic CS is "come to us only
if you already care about code for its own sake", then we
may want to fix our message.
Sometimes I see other people [screw] up a project over and
over, and I say "I could do that better", and then I get a
chance to try, and I discover it was a lot harder than I
thought, I realize that those people who tried before are
not as stupid as as I believed.
That did not happen this time.
Sometimes, good design is pretty simple. Separate interface
from implementation. Create simple abstraction layers to
separate different levels of functionality. Encapsulate
data and behavior in objects that circumscribe potential
change.
I liked a few of the specific tactics described, too:
Don't use raw primitives from the language, even standard
classes. "Instead of using raw DateTime [a
standard Perl class], we wrapped it in a derived class called
Moonpig::DateTime."
Define convenience functions that hide underlying data
implementations. Moonpig does this in several places,
most notably money and time.
Use mutable data sparingly, and never for values.
One way Moonpig does this is to implement "values with
history", an idea I first learned from Ralph Johnson in
Smalltalk. Each new value for an entity is pushed onto an
array. When a piece of code asks for the current value, it
receives the top of the array.
Object-oriented programming is centered around objects.
That means encapsulated behavior. Other concepts, such as
classes and inheritance, are add-ons. Dominus is especially
hard on inheritance, based on past experience. I agree that
it must be used carefully and sparingly. I like how Moonpig
uses roles to eliminate the need for classes entirely in the
application.
Whenever I write a new piece of code, I like to have
at least two alternatives in mind. That way, I know
I am not doing the worst thing possible.
I heard Kent say something like this at OOPSLA in the
late 1990s. This is advice I give often to students
and colleagues, but I've never had a URL that I could
point them to.
It's tempting for programmers to start implementing the
first good idea that comes to mind. It's especially
tempting for novices, who sometimes seem surprised that
they have even one good idea. Where would a second one
come from?
More experienced students and programmers sometimes
trust their skill and experience a little too easily.
That first idea seems so good, and I'm a good programmer...
Famous last words. Reality eventually catches up with
us and helps us become more humble.
Some students are afraid: afraid they won't get done if
they waste time considering alternatives, or afraid that
they will choose wrong anyway. Such students need more
confidence, the kind born out of small successes.
I think the most likely explanation for why beginners
don't already seek alternatives is quite simple. They
have not developed the design habit. Kent's advice can
be a good start.
One pithy statement is often enough of a reminder for
more experienced programmers. By itself, though, it
probably isn't enough for beginners. But it can be an
important first step for students -- and others -- who
are in the habit of doing the first thing that pops into
their heads.
Do note that this advice is consistent with XP's counsel
to
do the simplest thing that could possibly work.
"Simplest" is a superlative. Grammatically, that suggests
having at least three options from which to choose!
Your Programming Language is Your Raw Material, Too
Recently someone I know retweeted this familiar sentiment:
If carpenters were hired like programmers:
"Must have at least 5 years experience with the
Dewalt 18V 165mm Circular Saw"
This meme travels around the world in various forms all
the time, and every so often it shows up in one of my
inboxes. And every time I think, "There is more to the
story."
In one sense, the meme reflects a real problem in the
software world. Job ads often use lists of programming
languages and technologies as requirements, when
what the company presumably really wants is a competent
developer. I may not know the particular technologies
on your list, or be expert in them, but if I am an
experienced developer I will be able to learn them and
become an expert.
Understanding and skill run deeper than a surface list
of tools.
But. A programming language is not just a tool.
It is a building material, too.
Suppose that a carpenter uses a Dewalt 18V 165mm circular
saw to add a room to your house. When he finishes the
project and leaves your employ, you won't have any trace
of the Dewalt in his work product. You will have a new
room.
He might have used another brand of circular saw. He may
not have used a power tool at all, preferring the fine
craftsmanship of a handsaw. Maybe he used no saw of any
kind. (What a magician!) You will still have the same
new room regardless, and your life will proceed in the
very same way.
Now suppose that a programmer uses the Java programming
language to add a software module to your accounting
system. When she finishes the project and leaves your
employ, you will have the results of running her code,
for sure. But you will have a trace of Java in her work
product. You will have a new Java program.
If you intend to use the program again, to generate a
new report from new input data, you will need an
instance of the JVM to run it. If want to modify the
program to work differently, then you will also need a
Java compiler to create the byte codes that run in the
JVM. If you want to extend the program to do more, then
you again will need a Java compiler and interpreter.
Programs are themselves tools, and we use programming
languages to build them. So, while the language itself
is surely a tool at one level, at another level it is
the raw material out of which we create other things.
To use a particular language is to introduce a slew of
other dependencies to the overall process: compilers,
interpreters, libraries, and sometimes even machine
architectures. In the general case, to use a
particular language is to commit at least some part of
the company's future attention to both the language and
its attendant tooling.
So, while I am sympathetic to sentiment behind our
recurring meme, I think it's important to remember that
a programming language is more than just a particular
brand of power tool. It is the stuff programs are made
of.
I finally got around to reading Atul Gawande's
Slow Ideas
this morning. It's a New Yorker piece from last summer
about how some good ideas seem to resist widespread adoption,
despite ample evidence in their favor, and ways that one might
help accelerate their spread.
As I read, I couldn't help but think of parallels to teaching
students to write programs and helping professionals develop
software more reliably. We know that development practices such
as version control, short iterations, and pervasive testing lead
to better software and more reliable process. Yet they are hard
habits for many programmers to develop, especially when they have
conflicting habits in place.
Other development practices seem counterintuitive. "Pair
programming can't work, right?" In these cases, we have to help
people overcome both habits of practice and habits of thought.
That's a tall order.
Gawande's article is about medical practice, from surgeons to
home practitioners, but his conclusions apply to software
development as well. For instance: People have an easier
time changing habits when the benefit is personal, immediate,
and visceral. When the benefit is not so obvious, a whole new
way of thinking is needed. That requires time and education.
The key message to teach surgeons, it turned out, was not how
to stop germs but how to think like a laboratory scientist.
This is certainly true for software developers. (If you replace
"germs" with "bugs", it's an even better fit!) Much of the time,
developers have to think about evidence the ways scientists do.
This lesson is true not just for surgeons and software developers.
It is true for most people, in most ways of life. Sometimes,
we all have to be able to think and act like a scientist. I
can think of no better argument for treating science as important
for all students, just as we do reading and writing.
Other lessons from Gawande's article are more down-to-earth:
Many of the changes took practice for her, she said. She had
to learn, for instance, how to have all the critical supplies
-- blood-pressure cuff, thermometer, soap, clean gloves, baby
respiratory mask, medications -- lined up and ready for when
she needed them; how to fit the use of them into her routine;
how to convince mothers and their relatives that the best thing
for a child was to be bundled against the mother's skin. ...
So many good ideas in one paragraph! Many software development
teams could improve by putting them in action:
Construct a work environment with essential tools ready
at hand.
Adjust routine to include new tools.
Help collaborators see and understand the benefit of new
habits.
Finally, the human touch is essential. People who understand
must help others to see and understand. But when we order,
judge, or hector people, they tend to close down the paths of
communication, precisely when we need them to be most open.
Gawande's colleagues have been most successful when they built
personal relationships:
"It wasn't like talking to someone who was trying to find
mistakes," she said. "It was like talking to a friend."
Good teachers know this. Some have to learn it the hard way,
in the trenches with their students. But then, that is how
Gawande's colleagues learned it, too.
"Slow Hands" is good news for teachers all around. It teaches
ways to do our job better. But also, in many ways, it tells us
that teaching will continue to matter in an age dominated by
technological success:
People talking to people is still how the world's standards
change.
This blog entry
tells the sad story of a computational biologist who had to retract
six published articles. Why? Their conclusions depended on the
output of a computer program, and that program contained a critical
error. The writer of the entry, who is not the researcher in
question, concludes:
What this should flag is the necessity to aggressively test all the
software that you write.
Actually, you should have tests for any program you use to
draw important conclusions, whether you wrote it or not. The same
blog entry mentions that a grad student in the author's previous
lab had found several bugs a molecular dynamics program used by
many computational biologists. How many published results were
affected before they were found?
Case 2: Small Scripts.
Titus Brown reports
finding bugs every time he reused one of his Python scripts. Yet:
Did I start doing any kind of automated testing of my scripts?
Hell no! Anyone who wants to write automated tests for all their
little scriptlets is, frankly, insane. But this was one of the
two catalysts that made me personally own up to the idea that
most of my code was probably somewhat wrong.
Most of my code has bugs but, hey, why write tests?
Didn't a famous scientist define insanity as doing the same thing
over and over but expecting different results?
I consider myself insane, too, but mostly because I don't
write tests often enough for my small scripts. We say to
ourselves that we'll never reuse them, so we don't need tests.
But we don't throw them away, and then we do reuse them,
perhaps with a tweak here or there.
We all face time constraints. When we run a script the first
time, we may well pay enough attention to the output that we are
confident it is correct. But perhaps we can all agree that the
second time we use a script, we should write tests for it if we
don't already have them.
There are only three numbers in computing, 0, 1, and many. The
second time we use a program is a sign from the universe that we
need the added confidence provided by tests.
To be fair, Brown goes on to offer some good advice, such as
writing tests for code after you find a bug in it. His article
is an interesting read, as is almost everything he writes about
computation and science.
I hope I don't sound like I'm saying, "Testing is for chumps."
It's not. It's a matter of priorities. Are you trying to
write good software or are you trying to be done by next week?
You can't do both.
Sigh. If you you don't have good software by next week, maybe you
aren't done yet.
I understand that the real world imposes constraints on us, and
that sometimes worse is better. Good enough is good enough, and
we rarely need a perfect program. I also understand that
Zawinski was trying to be fair to the idea of testing, and that
he was surely producing good enough code before releasing.
Even still, the pervasive attitude that we can either write good
programs or get done on time, but not both, makes me sad. I hope
that we can do better.
And I'm betting that the computational biologist referred to in
Case 1 wishes he had had some tests to catch the simple error
that undermined five years worth of research.
The benefits go beyond the plainly obvious. You need good R&D
for the same reason you need a good space program. It doesn't just
get you to the Moon. It gives you things like
memory foam, scratch-resistant lenses, and Dustbusters.
It gets you the workaday byproducts of striving for higher goals.
I showed that last sentence
a little Twitter love,
because it's something people often forget to consider, both when
they are working in the trenches and when they are selecting
projects to work on. An ambitious project may have a higher risk
of failure than something more mundane, but it also has a higher
chance of producing unexpected value in the form of new tools and
improved process.
This is also something that university curricula don't do well.
We tend to design learning experiences that fit neatly into a
fifteen-week semester, with predictable gains for our students.
That sort of progress is important, of course, but it misses out
on opportunities for students to produce their own workaday
byproducts. And that's an important experience for students to
have.
It also gives a bad example of what learning should feel like, and
what it should do for us. Students generally learn what we teach
them, or what we make easiest for them to learn. If we always set
before them tasks of known, easily-understood dimensions, then
they will have to learn after leaving us that the world doesn't
usually work like that.
This is one of the reasons I am such a fan of
project-based computer science education,
as in the traditional compiler course. A compiler is an audacious
enough goal for most students that they get to discover their own
personal memory foam.
Even when we plan ahead a bit, the design of a program
tends to evolve. Gary Bernhardt gives an example in
his essay on abstraction:
If I feel the need to violate the abstraction, I need to
reconsider how to modify the boundaries to match that need,
rather than violating the boundaries by crossing them.
This is the moment when design happens...
This is a hard design lesson to give students, because it
is likely to click with them only after living with the
consequences of violating the abstraction. This requires
working with the same large program over time, preferably
one they are building along the way.
This is one of the reasons I so like our senior project
courses. My students are building a compiler this term,
which gives them a chance to experience a moment when
design happens. Their abstract syntax trees and symbol
tables are just the sort of abstractions that invite
violation -- and reward a little re-design.
Clay Shirky explains the cultural attitudes that underlie
Healthcare.gov's problems in his recent essay on
the gulf between planning and reality.
The danger of this gulf exists in any organization, whether
business or government, but especially in large organizations.
As the number of levels grows between the most powerful decision
makers and the workers in the trenches, there is an increasing
risk of developing "a culture that prefers deluding the boss
over delivering bad news".
But this is also a story of the danger inherent in so-called
Big Design Up Front, especially for a new kind of product.
Shirky oversimplifies this as the waterfall method, but the
basic idea is the same:
By putting the most serious planning at the beginning, with
subsequent work derived from the plan, the waterfall method
amounts to a pledge by all parties not to learn anything
while doing the actual work.
You may learn something, of course; you just aren't allowed
to let it change what you build, or how.
Instead, waterfall insists that the participants will
understand best how things should work before accumulating
any real-world experience, and that planners will always
know more than workers.
If the planners believe this, or they allow the workers to
think they believe this, then workers will naturally
avoid telling their managers what they have learned. In the
best case, they don't want to waste anyone's time if sharing
the information will have no effect. In the worst case, they
might fear the results of sharing what they have learned. No
one likes to admit that they can't get the assigned task done,
however unrealistic it is.
As Shirky notes, many people believe that a difficult launch
of Healthcare.gov was unavoidable, because political and
practical factors prevented developers from testing parts of
the project as they went along and adjusting their actions
in response. Shirky hits this one out of the park:
That observation illustrates the gulf between planning and
reality in political circles. It is hard for policy people
to imagine that Healthcare.gov could have had a phased
rollout, even while it is having one.
You can learn from feedback earlier, or you can learn from
feedback later. Pretending that you can avoid problems you
already know exist never works.
One of the things I like about agile approaches to software
development is they encourage us not to delude ourselves, or
our clients. Or our bosses.
Not long ago, I read
Unhappy Truckers and Other Algorithmic Problems,
an article by Tom Vanderbilt that looks at efforts to optimize
delivery schedules at UPS and similar companies. At the heart
of the challenge lies
the traveling salesman problem.
However, in practice, the challenge brings companies face-to-face
with a bevy of human issues, from personal to social, psychological
to economic. As a result, solving this TSP is more complex than
what we see in the algorithms courses we take in our CS programs.
Yet, in the face of challenges both computational and human, the
human planners working at these companies do
a pretty good job.
How? Over the course of time, researchers figured out that
finding optimal routes shouldn't be their main goal:
"Our objective wasn't to get the best solution," says Ted Gifford,
a longtime operations research specialist at Schneider. "Our
objective was to try to simulate what the real world planners were
really doing."
This is a lesson I learned the hard way, too, back in graduate
school, when my advisor's lab was trying to build knowledge-based
systems for real clients, in chemical engineering, aeronautics,
business, and other domains. We were working with real people
who were solving hard problems under serious constraints.
At the beginning I was a typically naive programmer, armed with
fancy AI techniques and unbounded enthusiasm. I soon learned
that, if you walk into a workplace and propose to solve all the
peoples' problems with a program, things don't go as smoothly as
the programmer might hope.
First of all, this impolitic approach generally creates immediate
pushback. These are people, with personal investment in the way
things work now. They tend to bristle when a 20-something grad
student walks in the door promoting the wonder drug for all their
ills. Some might even fear that you are right, and success for
your program will mean negative consequences for them personally.
We see this dynamic in Vanderbilt's article.
There's a deeper reason that things don't go so smoothly, though,
and it's the real lesson of Vanderbilt's piece. Until you
implement the existing solution to the problem, you don't really
understand the problem yet.
These problems are complex, often with many more constraints than
typical theoretical solutions have dealt with. The humans solving
the problem often have many years of experience contributing to
their approach. They have deep knowledge of the domain, but also
repeated exposure to the exceptions and edge cases that sometimes
confound theoretical solutions. They use heuristics that are hard
to tease apart or articulate.
I learned that it's easy to solve a problem if you are solving the
wrong one.
A better way to approach these challenges is: First, model the
existing system, including the extant solution. Then, look for
ways to improve on the solution.
This approach often gives everyone involved greater confidence that
the programmers understand -- and so are solving -- the right
problem. It also enables the team to make small, incremental
changes to the system, with a correspondingly higher probability of
success. Together, these two outcomes greatly increase the chance
of human buy-in from the current workers. This makes it easier
for the whole team to recognize the need for larger-scale changes
to the process, and to support and contribute to an improved
solution.
Vanderbilt tells a similarly pragmatic story. He writes:
When I suggest to Gifford that he's trying to understand the real
world, mathematically, he concurs, but adds: "The word 'understand'
is too strong--we are happy to get positive outcomes."
Positive outcomes are what the company wants. Fortunately for
the academics who work on such problems in industry, achieving
good outcomes is often an effective way to test theories, encounter
their shortcomings, and work on improvements. That, too, is
something I learned in grad school. It was a valuable lesson.
This was yet another time when I felt slightly foolish as
I wrote the automated tests, assuming that the time and
effort I spent on testing this trivial function would be
time and effort thrown away on nothing -- and then they
detected a real fault. Someday perhaps I'll stop feeling
foolish writing tests for functions like this one; until
then, many cases just like this one will help me remember
that I must write the tests even though I feel foolish
doing it.
Even excellent programmers feel silly writing tests sometimes.
But they also benefit from writing them. Dominus was saved
here by his test-writing habit, or by his sense of right and
wrong.
Helping students develop that habit or that moral sense is a
challenge. Even so, I rarely come across a situation where my
students or I write or run too many tests. I regular encounter
cases where we write or run too few.
Dominus's blog entry also a great passage on a larger lesson
from that coding experience. In the end, his clever solution
to a tricky problem results not from "just thinking" but from
deeper thought: from "applying carefully-learned and practiced
technique". That's an important form of thinking, too.
There is a great insight in an old post by Brian Marick,
Discipline and Skill,
which I re-read this week. The topic sentence asserts:
Discipline can be a personal virtue, but it must also be structural.
Extreme Programming illustrates this claim. It draws its greatest
power from the structural discipline it creates for developers.
Marick goes on:
For example, one of the reasons to program in pairs is that two
people are less likely to skip a test than one is. Removing code
ownership makes it more likely someone within glaring distance
will see that you didn't leave code as clean as you should have.
The business's absolute insistence on getting working -- really
working -- software at frequent intervals makes the pain of
sloppiness strike home next month instead of next year,
stiffening the resolve to do the right thing today.
P consists of a lot of relatively simple actions, but simple
actions can be hard to perform, especially consistently and
especially in opposition to deeply ingrained habits. XP
practices work together to create structural discipline that
helps developers "do the right thing".
We see the use of social media playing a similar role these
days. Consider diet. People who are trying to lose weight
or exercise more have to do some pretty simple things.
Unfortunately, those things are not easy to do consistently,
and they are opposed by deep personal and cultural habits.
In order to address this, digital tool providers like FitBit
make it easy for users to sync their data to a social media
account and share with others.
This is a form of social discipline, supported by tools and
practices that give structure to the actions people want to
take. Just like XP. Many behaviors in life work this way.
I was reading Roger Hui's
Remembering Ken Iverson
this morning on the elliptical, and it reminded me of this passage
from
A Conversation with Arthur Whitney.
Whitney is a long-time APL guru and the creator of the A, K, and Q
programming languages. The interviewer is Bryan Cantrill.
BC: Software has often been compared with civil engineering,
but I'm really sick of people describing software as being like a
bridge. What do you think the analog for software is?
AW: Poetry.
BC: Poetry captures the aesthetics, but not the precision.
AW: I don't know, maybe it does.
A poet's use of language is quite precise. It must balance forces
in many dimensions, including sound, shape, denotation, and
connotation. Whitney seems to understand this.
Richard Gabriel
must be proud.
Brevity is a value in the APL world. Whitney must have a similar
preference for short language names. I don't know the source of
his names A, K, and Q, but I like Hui's explanation of where J's
name came from:
... on Sunday, August 27, 1989, at about four o'clock in the
afternoon, [I] wrote the first line of code that became the
implementation described in this document.
The name "J" was chosen a few minutes later, when it became
necessary to save the interpreter source file for the first
time.
Beautiful. No messing around with branding. Gotta save my file.
Software design is the act of making bets about the future. A
well-designed program is a bet on what will change in the future,
and what will not change. And a well-designed program communicates
the nature of that bet by being relatively flexible about things
that the designers think are most likely to change, and being
relatively inflexible about the things the designers think are
least likely to change.
That's what refactoring is all about, of course. Sometimes, a
particular guess turns out to be wrong. We have the wrong factors,
the wrong components, for adding a new feature. So we change the
shape of the code -- we factor it into different components -- to
reflect our new best understanding of the future. Then we move on.
Sometimes, though, there are forces that make more desirable a
relatively monolithic piece of code (or, as Braithwaite points out,
a system decomposed into relatively less flexible components). In
these cases, we need to defactor, to use Braithwaite's term: we
recombine some or all of the parts to create a new design.
Predicting the future is hard, even for experienced programmers.
One of the goals of agile design is to not think too far ahead,
because that means committing to a future too far removed from
what we already know to be true about our program.
I had been looking forward to Crista Lopes's StrangeLoop talk
since May,
so I made sure I was in the room well before the scheduled
time. I even had a copy of the trigger book in my bag.
Crista opened with something that CS instructors have learned
the hard way: Teaching programming style is difficult and
takes a lot of time. As a result, it's often not done at all
in our courses. But so many of our graduates go into software
development for the careers, where they come into contact with
many different styles. How can they understand them -- well,
quickly, or at all?
To many people, style is merely the appearance of code on the
screen or printed. But it's not. It's more, and something
entirely different. Style is a constraint. Lopes
used images of a few stylistic paintings to illustrate the
idea. If an artist limits herself to
pointillism
or
cubism,
how can she express important ideas? How does the style limit
the message, or enhance it?
Lopes pointed to a more universal example, though: the
canonical
The Elements of Programming Style.
Drawing on this book and other work in software, she said that
programming style ...
is a way to express tasks
exists at all scales
recurs at multiple scales
is codified in programming language
For me, the last bullet ties back most directly to idea of style
as constraint. A language makes some things easier to express
than others. It can also make some things harder to express.
There is a spectrum, of course. For example, some OO languages
make it easy to create and use objects; others make it hard to
do anything else! But the language is an enabler and enforcer
of style. It is a proxy for style as a constraint on the
programmer.
Back to the talk. Lopes asked, Why is it so important that we
understand programming style? First, a style provides the
reader with a frame of reference and a vocabulary. Knowing
different styles makes us a more effective consumers of
code. Second, one style can be more appropriate for a given
problem or context than another style. So, knowing different
styles makes us a more effective producers of code.
(Lopes did not use the producer-consumer distinction in the
talk, but it seems to me a nice way to crystallize her idea.)
The, Lopes said, I came across Raymond Queneau's playful little
book, "Exercises in Style". Queneau constrains himself in
many interesting ways while telling essentially the same story.
Hmm... We could apply the same idea to programming! Let's do
it.
Lopes picked a well-known problem, the common word problem
famously solved in
a Programming Pearls column
more than twenty-five years. This is a fitting choice, because
Jon Bentley included in that column a critique of Knuth's
program by Doug McIlroy, who considered both engineering
concerns and program style in his critique.
The problem is straightforward: identify and print the k
most common terms that occur in a given text document, in
decreasing order. For the rest of the talk, Lopes presented
several programs that solve the problem, each written in a
different style, showing code and highlighting its shape and
boundaries.
Python was her language of choice for the examples. She was
looking for a language that many readers would be able to
follow and understand, and Python has the feel of pseudo-code
about it. (I tell my students that it is the Pascal of their
time, though I may as well be speaking of hieroglyphics.) Of
course, Python has strengths and weaknesses that affect its
fit for some styles. This is an unavoidable complication for
all communication...
Also, Lopes did not give formal names to the styles she
demonstrated. Apparently, at previous versions of this talk,
audience members had wanted to argue over the names more than
the styles themselves! Vowing not to make that mistake again,
she numbered her examples for this talk.
That's what programmers do when they don't have good names.
In lieu of names, she asked the crowd to live-tweet to her
what they thought each style is or should be called. She
eventually did give each style a fun, informal name. (CS
textbooks might be more evocative if we used her names instead
of the formal ones.)
I noted eight examples shown by Lopes in the talk, though
there may have been more:
monolithic procedural code -- "brain dump"
a Unix-style pipeline -- "code golf"
procedural decomposition with a sequential main -- "cook
book"
the same, only with functions and composition -- "Willy
Wonka"
functional decomposition, with a continuation parameter
-- "crochet"
modules containing multiple functions -- "the kingdom of
nouns"
relational style -- (didn't catch this one)
functional with decomposition and reduction -- "multiplexer"
Lopes said that she hopes to produce solutions using a total
of thirty or so styles. She asked the audience for help with
one in particular: logic programming. She said that
she is not a native speaker of that style, and Python does not
come with a logic engine built-in to make writing a solution
straightforward.
Someone from the audience suggested she consider yet another
style: using a domain-specific language. That would
be fun, though perhaps tough to roll from scratch in Python.
By that time, my own brain was spinning away, thinking about
writing a solution to the problem in
Joy,
using a concatenative style.
Sometimes, it's surprising just how many programming styles
and meaningful variations people have created. The human mind
is an amazing thing.
The talk was, I think, a fun one for the audience. Lopes is
writing a book based on the idea. I had a chance to review an
early draft, and now I'm looking forward to the finished product.
I'm sure I'll learn something new from it.
Rich Hickey spoke at one of the previous StrangeLoops I attended,
but this was my first time to attend one of his talks in person.
I took the shaky photo seen at the right as proof. I must say,
he gives a good talk.
The title slide read "Clojure core.async Channels", but
Hickey made a disclaimer upfront: this talk would be about what
channels are and why Clojure has them, not the details of how
they are implemented. Given that there were
plenty of good compiler talks
elsewhere at the conference, this was a welcome change of pace.
It was also a valuable one, because many more people will
benefit from what Hickey taught about program design than would
have benefited from staring at screens full of Clojure macros.
The issues here are important ones, and ones that few programmers
understand very well.
The fundamental problem is this: Reactive programs need to be
machines, but functions make bad machines. Even sequences of
functions.
The typical solution to this problem these days is to decompose
the system logic into a set of response handlers. Alas, this
leads to callback hell, a modern form of spaghetti code. Why?
Even though the logic has been decomposed into pieces, it is
still "of a piece", essentially a single logical entity. When
this whole is implemented across multiple handlers, we can't see
it as a unit, or talk about it easily. We need to, though,
because we need to design the state machine that it comprises.
Clojure's solution to the problem, in the form of
core.async, is the channel. This is an implementation
of Tony Hoare's
communicating sequential process.
One of the reasons that Hickey likes this approach is that it
lets a program work equally well in fully threaded apps and in
apps with macro-generated inversion of control.
Hickey then gave some examples of code using channels and
talked a bit about the implications of the implementation for
system design. For instance, the language provides handy
put! and take! operators for integrating
channels with code at the edge of non-core.async
systems. I don't have much experience with Clojure, so I'll
have to study a few examples in detail to really appreciate
this.
For me, the most powerful part of the talk was an extended
discussion of communication styles in program. Hickey focused
on the trade-offs between direct communication via shared
state and indirect communication via channels. He highlighted
six or seven key distinctions between the two and how these
affect the way a system works. I can't do this part of the
talk justice, so I suggest you watch the video of the talk. I
plan to watch it again myself.
I had always heard that Hickey was eminently quotable, and he
did not disappoint. Here are three lines that made me smile:
"Friends don't let friends put logic in handlers."
"Promises and futures are the one-night stands" of
asynchronous architecture.
"Unbounded buffers are a recipe for a bad program. 'I
don't want to think about this bug yet, so I'll leave
the buffer unbounded.'"
That last one captures the indefatigable optimism -- and
self-delusion -- that characterizes so many programmers. We
can fix that problem later. Or not.
In the end, this talk demonstrates how a good engineer
approaches a problem. Clojure and its culture reside firmly
in the functional programming camp. However, Hickey recognizes
that, for the problem at hand, a sequence of functional calls
is not the best solution. So he designs a solution that allows
programmers to do FP where it fits best and to do something else
where FP doesn't. That's a pragmatic way to approach problems.
Still, this solution is consistent with Clojure's overall design
philosophy. The channel is a first-class object in the language.
It converts a sequence of functional calls into data,
whereas callbacks implement the sequence in code. As
code, we see the sequence only at run-time. As data, we see it
in our program and can use it in all the ways we can use any data.
This consistent focus on making things into data is an attractive
part of the Clojure language and the ecosystem that has been
cultivated around it.
I took a refreshing walk in the rain over the lunch hour
on Friday. I managed to return late and, as a result,
missed the start of Avi Bryant's talk on algebra and
analytics. Only a few minutes, though, which is good.
I enjoyed this presentation.
Bryant didn't talk about the algebra we study in eighth
or ninth grade, but
the mathematical structure
math students encounter in a course called "abstract" or
"modern" algebra. A big chunk of the talk focused on an
even narrower topic: why +, and operators
like it, are cool.
One reason is that grouping doesn't matter. You can add
1 to 2, and then add 4 to the result, and have the same
answer as if you added 4 to 1, and then added 2 to the
result. This is, of course, the associative
property.
Another is that order doesn't matter. 1 + 2 is
the same as 2 + 1. That's the commutative
property.
Yet another is that, if you have nothing to add, you can
add nothing and have the same value you started with.
4 + 0 = 4. 0 is the identity element
for addition.
Finally, when you add two numbers, you get a number back.
This is not quite as true in computers as in math, because
an operation can cause an overflow or underflow and create
an error. But looked at through fuzzy lenses, this is
true in our computers, too. This is the closure
property for addition of integers and real numbers.
Addition isn't the only operation on numbers that has these
properties. Finding the maximum value in a set of numbers,
does, too. The maximum of two numbers is a number.
max(x,y) = max(y,x), and if we have three or
more numbers, it doesn't how matter how we group them;
max will find the maximum among them. The identity
value is tricky -- there is no smallest number... -- but in
practice we can finesse this by using the smallest number of
a given data type, or even allowing max to take
"nothing" as a value and return its other argument.
When we see a pattern like this, Bryant said, we should
generalize:
We have a function f that takes two
values from a set and produces another member of the
same set.
The order of f's arguments doesn't
matter.
The grouping of f's arguments doesn't
matter.
There is some identity value, a conceptual "zero", that
doesn't matter, in the sense that f(i,zero)
for any i is simply i.
There is a name for this pattern. When we have such as set
and operation, we have a commutative monoid.
S ⊕ S → S
x ⊕ y = y ⊕ x
x ⊕ (y ⊕ z) = (x ⊕ y) ⊕ z
x ⊕ 0 = x
I learned about this and other such patterns in grad school
when I took an abstract algebra course for kicks. No one
told me at the time that I'd being seeing them again as soon
as someone created the Internet and it unleashed a torrent of
data on everyone.
Just why we are seeing the idea of a commutative monoid again
was the heart of Bryant's talk. When we have data coming
into our company from multiple network sources, at varying
rates of usage and data flow, and we want to extract meaning
from the data, it can be incredibly handy if the meaning
we hope to extract -- the sum of all the values, or the
largest -- can be computed using a commutative monoid.
You can run multiple copies of your function at the entry
point of each source, and combine the partial results later,
in any order.
Bryant showed this much more attractively than that, using
cute little pictures with boxes. But then, there should be
an advantage to going to the actual talk... With pictures and
fairly straightforward examples, he was able to demystify the
abstract math and deliver on his talk's abstract:
A mathematician friend of mine tweeted that anyone who doesn't
understand abelian groups shouldn't build analytics systems.
I'd turn that around and say that anyone who builds analytics
systems ends up understanding abelian groups, whether they
know it or not.
That's an important point. Just because you haven't studied
group theory or abstract algebra doesn't mean you shouldn't
do analytics. You just need to be prepared to learn some new
math when it's helpful. As programmers, we are all looking
for opportunities to capitalize on patterns and to generalize
code for use in a wider set of circumstances. When we do,
we may re-invent the wheel a bit. That's okay. But also
look for opportunities to capitalize on patterns recognized
and codified by others already.
Unfortunately, not all data analysis is as simple as summing
or maximizing. What if I need to find an average? The
average operator doesn't form a commutative monoid with
numbers. It falls short in almost every way. But, if you
switch from the set of numbers to the set of pairs [n,
c], where n is a number and c is a count
of how many times you've seen n, then you are back in
business. Counting is addition.
So, we save the average operation itself as a post-processing
step on a set of number/count pairs. This turns out to be a
useful lesson, as finding the average of a set is a lossy
operation: it loses track of how many numbers you've seen.
Lossy operations are often best saved for presenting data,
rather than building them directly into the system's computation.
Likewise, finding the top k values in a set of numbers
(a generalized form of maximum) can be handled just fine as
long as we work on lists of numbers, rather than numbers
themselves.
This is actually one of the Big Ideas of computer science.
Sometimes, we can use a tool or technique to solve a problem
if only we transform the problem into an equivalent
one in a different space. CS theory courses hammer this
home, with oodles of exercises in which students are asked to
convert every problem under the sun into
3-SAT
or
the clique problem.
I look for chances to introduce my students to this Big Idea
when I teach AI or any programming course, but the lesson
probably gets lost in the noise of regular classwork. Some
students seem to figure it out by the time they graduate,
though, and the ones who do are better at solving all kinds
of problems (and not by converting them all 3-SAT!).
Sorry for the digression. Bryant didn't talk about 3-SAT,
but he did demonstrate several useful problem transformations.
His goal was more practical: how can we use this idea of a
commutative monoid to extract as many interesting results
from the stream of data as possible.
This isn't just an academic exercise, either. When we can
frame several problems in this way, we are able to use a
common body of code for the processing. He called this body
of code an aggregator, comprising three steps:
prepare the data by transforming it into the space of
a commutative monoid
reduce the data to a single value in that space,
using the appropriate operator
present the result by transforming it back into its
original space
In practice, transforming the problem into the space of a monoid
presents challenges in the implementation. For example, it is
straightforward to compute the number of unique values in a
collection of streams by transforming each item into a set of
size one and then using set union as the operator. But union
requires unbounded space, and this can be inconvenient when
dealing with very large data sets.
One approach is to compute an estimated number of uniques using
a hash function and some fancy arithmetic. We can make the
expected error in estimate smaller and smaller by using more
and more hash functions. (I hope to write this up in simple
code and blog about it soon.)
Bryant looked at one more problem, computing frequencies, and
then closed with a few more terms from group theory: semigroup,
group, and abelian group. Knowing these terms -- actually,
simply knowing that they exist -- can be useful even for the
most practical of practitioners. They let us know that there
is more out there, should our problems become harder or our
needs become larger.
That's a valuable lesson to learn, too. You can learn all
about abelian groups in the trenches, but sometimes it's good
to know that there may be some help out there in the form of
theory. Reinventing wheels can be cool, but solving the
problems you need solved is even cooler.
The conference opened with a talk by
Jenny Finkel
on the role machine learning play at Prismatic, the customized
newsfeed service. It was a good way to start the conference, as it
introduced a few themes that would recur throughout, had a little
technical detail but not too much, and reported a few lessons from
the trenches.
Prismatic is trying to solve the discovery problem: finding content
that users would like to read but otherwise would not see. This is
more than simply a customized newsfeed from a singular journalistic
source, because it draws from many sources, including other reader's
links, and because it tries to surprise readers with articles that
may not be explicitly indicated by their profiles.
The scale of the problem is large, but different from the scale of
the raw data facing Twitter, Facebook, and the like. Finkel said
that Prismatic is processing only about one million timely docs at
a time, with the set of articles turning over roughly weekly. The
company currently uses 5,000 categories to classify the articles,
though that number will soon go up to the order of 250,000.
The complexity here comes from the cross product of readers,
articles, and categories, along with all of the features used to
try to tease out why readers like the things they do and don't
like the others. On top of this are machine learning algorithms
that are themselves exponentially expensive to run. And with
articles turning over roughly weekly, they have to be amassing
data, learning from it, and moving on constantly.
The main problem at the heart of a service like this is: What
is relevant? Everywhere one turns in AI, one sees this
question, or its more general cousin, Is this similar?
In many ways, this is the problem at the heart of all intelligence,
natural and artificial.
Prismatic's approach is straight from AI, too. They construct a
feature vector for each user/article pair and then try to learn
weights that, when applied to the values in a given vector, will
rank desired articles high and undesired articles low. One of
the key challenges when doing this kind of working is to choose
the right features to use in the vector. Finkel mentioned a few
used by Prismatic, including "Does the user follow this topic?",
"How many times has the reader read an article from this publisher?",
and "Does the article include a picture?"
With a complex algorithm, lots of data, and a need to constantly
re-learn, Prismatic has to make adjustments and take shortcuts
wherever possible in order to speed up the process. This is a
common theme at a conference where many speakers are from industry.
First, learn your theory and foundations; learn the pragmatics
and heuristics need to turn basic techniques into the backbone
of practical applications.
Finkel shared one pragmatic idea of this sort that Prismatic uses.
They look for opportunities to fold user-specific feature weights
into user-neutral features. This enables their program to compute
many user-specific dot products using a static vector.
She closed the talk with five challenges that Prismatic has faced
that other teams might be on the look out for:
Bugs in the data. In one case, one program was updating
a data set before another program could take a snapshot of the
original. With the old data replaced by the new, they thought
their ranker was doing better than it actually was. As Finkel
said, this is pretty typical for an error in machine learning.
The program doesn't crash; it just gives the wrong answer.
Worse, you don't even have reason to suspect something is wrong
in the offending code.
Presentation bias. Readers tend to look at more of the
articles at the top of a list of suggestions, even if they would
have enjoyed something further down the list. This is a feature
of the human brain, not of computer programs. Any time we write
programs that interact with people, we have to be aware of human
psychology and its effects.
Non-representative subsets. When you are creating a
program that ranks things, its whole purpose is to skew a set of
user/article data points toward the subset of articles that the
reader most wants to read. But this subset probably doesn't have
the same distribution as the full set, which hampers your ability
to use statistical analysis to draw valid conclusions.
Statistical bleeding. Sometimes, one algorithm looks
better than it is because it benefits from the performance of
the other. Consider two ranking algorithms, one an "explorer"
that seeks out new content and one an "exploiter" that recommend
articles that have already been found to be popular. If we
in comparing their performances, the exploiter will tend to look
better than it is because it benefits from the successes of the
explorer without being penalized for its failures. It is crucial
to recognize that one feature you measure is not dependent on
another. (Thanks to Christian Murphy for the prompt!)
Simpson's Paradox. The iPhone and the web have different
clickthrough rates. They once found them in a situation where one
recommendation algorithm performed worse than another on both
platforms, yet better overall. This can really disorient teams
who follow up experiments by assessing the results. The issue
here is usually a hidden variable that is confounding the results.
(I remember discussing
this classic statistical illusion
with a student in my early years of teaching, when we encountered
a similar illusion in his grade. I am pretty sure that I enjoyed
our discussion of the paradox more than he did...)
This part of a talk is of great value to me. Hearing about another
team's difficulties rarely helps me avoid the same problems in my
own projects, but it often does help me recognize those
problems when they occur and begin thinking about ways to work
around them. This was a good way for me to start the conference.
This morning presented a short cautionary tale for me and my
students, from a silly mistake I made in a procmail filter.
Back story: I found out recently that I am still subscribed
to a Billy Joel fan discussion list from the 1990s. The list
has been inactive for years, or I would have been filtering
its messages to a separate mailbox. Someone has apparently
hacked the list, as a few days ago it started spewing hundreds
of spam messages a day.
I was on the road for a few days after the deluge began and
was checking mail through a shell connection to the mail
server. Because I was busy with my trip and checking mail
infrequently, I just deleted the messages by hand. When I
got back, Mail.app soon learned they were junk and filtered
them away for me. But the spam was still hitting my inbox
on the mail server, where I read my mail occasionally even
on campus.
After a session on the server early this morning, I took a
few minutes to procmail them away. Every message from the
list has a common pattern in the Subject: line,
so I copied it and pasted it into a new procmail recipe to
send all list traffic to /dev/null :
:0
* ^Subject.*[billyjoel]
/dev/null
Do you see the problem? Of course you do.
I didn't at the time. My blindness probably resulted from a
combination of the early hour, a rush to get over to the gym,
and the tunnel vision that comes from focusing on a single
case. It all looked obvious.
This mistake offers programming lessons at several different
levels.
The first is at the detailed level of the regular expression.
Pay attention to the characters in your regex -- all of them.
Those brackets really are in the Subject: line, but
by themselves mean something else in the regex. I need to
escape them:
* ^Subject.*\[billyjoel\]
This relates to a more general piece of problem-solving advice.
Step back from individual case you are solving and think about
the code you are writing more generally. Focused on the
annoying messages from the list, the brackets are just
characters in a stream. Looked at from the perspective of the
file of procmail recipes, they are control characters.
The second is at the level of programming practice. Don't
/dev/null something until you know it's junk. Much
better to send the offending messages to a junk mbox first:
* ^Subject.*\[billyjoel\]
in.tmp.junk
Once I see that all and only the messages from the list are
being matched by the pattern, I can change that line send
list traffic where it belongs. That's a specific example
of the sort of
defensive programming
that we all should practice. Don't commit to solutions too
soon.
This, too, relates to more general programming advice about
software validation and verification. I should have exercised
a few test cases to validate my recipe before turning it loose
unsupervised on my live mail stream.
I teach my students this mindset and program that way myself,
at least most of the time. Of course, the time you most need
test cases will be the time you don't write them.
The day provided a bit of irony to make the story even better.
The topic of today's session in my compilers course? Writing
regular expressions to describe the tokens in a language. So,
after my mail admin colleague and I had a good laugh at my
expense, I got to tell the story to my students, and they did,
too.
Matt Welsh recently posted
a blog entry
on experiences rewriting a large system in Go and some of his
thoughts about the language afterwards. One of the few
shortcomings in his mind had to do with how Go's type
inference made it hard for him to know the type of a variable.
Sure, an IDE or other tool could help, but Welsh says:
I staunchly refuse to edit code with any tool that requires
using a mouse.
That's mostly how I feel, too, though I'm more an emacs man.
I use IDEs and appreciate what they can give. I used Eclipse
a fair amount back when it was young, but it's gotten so big
and complex these days that I shudder at the thought of
starting it up. RubyMine gave me many pleasant moments when
I used it for a while a couple of years ago.
When I use IDEs, I prefer simpler IDEs, such as Dr. Racket or
even Dr. Java, to complex ones anyway. They don't generally
provide as much support, but they do help. When not helping,
they mostly staying out of the way while I am writing code.
For me, the key word in Welsh's refusal is require'.
If I *need* a mouse or a lot of IDE support just to use a
language, that's a sign that the code either isn't telling
me everything it should, or there's too much to think about.
Code should speak for itself, and it only say things that
the programmer needs to know.
Game programmer Jeff Wofford wrote
a nice piece
on some of the lessons he learned by programming a game in forty-eight
hours. One of the recurring themes of his article is the value of a
high-powered scripting language for moving fast. That's not too
surprising, but I found his ruminations on this phenomenon to be
interesting. In particular:
A programmer's chief resource is the energy of his or her mind.
Everything that expends or depletes that energy makes him or her less
effective, more tired, and less happy.
A powerful scripting language sitting atop the game engine is one of
the best ways to conserve programmer energy. Sometimes, though, a
game programmer must work hard to achieve the performance required by
users. For this reason, Wofford goes out of his way not to diss C++,
the tool of choice for many game programmers. But C++ is an energy
drain on the programmer's mind, because the programmer has to be in
a constant state of awareness of machine cycles and memory consumption.
This is where the trade-off with a scripting language comes in:
When performance is of the essence, this state of alertness is an
appropriate price to pay. But when you don't have to pay that price
-- and in every game there are systems that have no serious
likelihood of bottlenecking -- you will gain mental energy back by
essentially ignoring performance. You cannot do this in C++: it
requires an awareness of execution and memory costs at every step.
This is another argument in favor of never building a game without a
good scripting language for the highest-level code.
I think this is true of almost every large system. I sure wish that
the massive database systems at the foundation of my university's
operations had scripting languages sitting on top. I even want to
script against the small databases that are the lingua franca
of most businesses these days -- spreadsheets. The languages
available inside the tools I use are too clunky or not powerful, so
I turn to Ruby.
Unfortunately, most systems don't come with a good scripting language.
Maybe the developers aren't allowed to provide one. Too many CS
grads don't even think of "create a mini-language" as a possible
solution to their own pain.
Fortunately for Wofford, he both has the skills and inclination. One
of his to-dos after the forty-eight hour experience is all about
language:
Building a SWF importer for my engine could work. Adding script
support to my engine and greatly refining my tools would go some of
the distance. Gotta do something.
Gotta do something.
I'm teaching our compiler course again this term. I hope that the
dozen or so students in the course leave the university knowing
that creating a language is often the right next action and having
the skills to do it when they feel compelled to do something.
I recently stumbled across an old
How We Will Read interview
with Clive Thompson and was intrigued by his idea for a new kind
of annotated book:
I've had this idea to write a provocative piece, or hire someone
to write it, and print it on-demand it with huge margins, and
then send it around to four people with four different pens --
red, blue, green and black. It comes back with four sets of
comments all on top of the text. Then I rip it all apart and
make it into an e-book.
This is an interesting mash-up of ideas from different eras.
People have been writing in the margins of books for hundreds
of years. These days, we comment on blog entries and other
on-line writing in plain view of everyone. We even comment on
other people's comments. Sites such as Findings.com, home of
the Thompson interview, aim to bring this cultural practice to
everything digital.
Even so, it would be pretty cool to see the margin notes of
three or four insightful, educated people, written independently
of one another, overlaid in a single document. Presentation as
an e-book offers another dimension of possibilities.
Ever the computer scientist, I immediately began to think of
programs. A book such as
Beautiful Code
gives us essays from master programmers talking about their
programs. Reading it, I came to appreciate design decisions
that are usually hidden from readers of finished code. I also
came to appreciate the code itself as a product of careful
thought and many iterations.
My thought is: Why not bring Thompson's mash-up of ideas to
code, too? Choose a cool program, perhaps one that changed
how we work or think, or one that unified several ideas into
a standard solution. Print it out with huge margins, and send
it to three of four insightful, thoughtful programmers who read
it, again or for the first time, and mark it up with their own
thoughts and ideas. It comes back with four sets of comments
all on top of the text. Rip it apart and create an e-book that
overlays them all in a single document.
Maybe we can skip the paper step. Programming tools and Web 2.0
make it so easy to annotate documents, including code, in ways
that replace handwritten comments. That's how most people
operate these days. I'm probably showing my age in harboring a
fondness for the written page.
In any case, the idea stands apart from the implementation.
Wouldn't it be cool to read a book that interleaves and
overlays the annotations made by programmers such as Ward
Cunningham and Grady Booch as they read John McCarthy's
first Lisp interpreter, the first Fortran compiler from
John Backus's team, QuickDraw, or Qmail? I'd stand in line
for a copy.
Writing this blog entry only makes the idea sound more worth
doing. If you agree, I'd love to
hear from you
-- especially if you'd like to help. (And especially
if you are Ward Cunningham and Grady Booch!)
I think revision is hugely underrated. It is very seldom
recognized as a place where the higher creativity can
live, or where it can manifest. I think it was Yeats who
said that literary revision was the only place in life
where a man could truly improve himself.
I find it a lot easier to come up with clean, simple designs
when I have code in my hands to work with, rather than
requirements. Even detailed requirements are abstract with
respect to our programs. Code is the raw material.
She could feel her own lungs suspended as she worked, and
she forced herself to inhale, suddenly frustrated by the
insurmountable inability to make the paint correspond
exactly and precisely to what was in her head. It was
always doomed from the outset, but here she was, making
another goddamned painting.
Why did I want to do something different? In part, because I
wanted something that felt more tangible. But mostly because
the story of the internet continues to be the story of our time.
I'm pretty sure that if you truly want to follow -- or, better
still, bend -- that story's arc, you should know how to write
code.
So, rather than settle for her lot as a non-programmer, beyond
the accepted school age for learning these things -- technology
is a young person's game, you know -- Cacioppo decided to learn
how to build web apps. And build one.
When did we decide our time's most important form of creation
is off-limits? How many people haven't learned to write
software because they didn't attend schools that offered those
classes, or the classes were too intimidating, and then they
were "too late"? How much better would the world be if those
people had been able to build their ideas?
Yes, indeed.
These days, she is enjoying the experience of making stuff:
trying ideas out in code, discarding the ones that don't work,
and learning new things every day. Sounds like a programmer
to me.
Earlier this summer, my daughter was talking about something
one of her friends had done with Instagram. As a smug
computer weenie, I casually mentioned that she could do
that, too.
She replied, "Don't taunt me, Dad."
You see, no one in our family has a cell phone, smart or
otherwise, so none of us use Instagram. That's not a big deal
for dear old dad, even though (or perhaps because) he's a
computer scientist. But she is a teenager growing up in an
entirely different world, filled with technology and social
interaction, and not having a smart phone must surely seem
like a form of child abuse. Occasionally, she reminds us so.
This gave me a chance to explain that Instagram filters are,
at their core, relatively simple little programs, and that she
could learn to write them. And if she did, she could run them
on almost any computer, and make them do things that even
Instagram doesn't do.
I had her attention.
So, this summer I am going to help her learn a little Python,
using some of the ideas from media computation. At the end
of our first pass, I hope that she will be able to manipulate
images in a few basic ways: changing colors, replacing colors,
copying pixels, and so on. Along the way, we can convert
color images to grayscale or sepia tones, posterize images,
embed images, and make simple collages.
That will make her happy. Even if she never feels the urge
to write code again, she will know that it's possible. And
that can be
empowering.
I have let my daughter know that we probably will not write code
that does as good a job as what she can see in Instagram or
Photoshop. Those programs are written by pros, and they have
evolved over time. I hope, though, that she will appreciate
how simple the core ideas are. As James Hague said in
a recent post,
then key idea in most apps require relatively few lines of
code, with lots and lots of lines wrapped around them to
handle edge cases and plumbing. We probably won't write much
code for plumbing... unless she wants to.
Desire and boredom often lead to creation. They also lead to
the best kind of learning.
This sentence in Reid Draper's
Data Traceability
made me laugh recently:
I previously worked in the data ingestion team at a music data company.
Nice turn of phrase. I suppose that another group digests the data,
and yet another expels it.
Draper's sentence came to mind again yesterday while I was banging
my head on a relatively simple problem, transforming a CSV file
generated by my university's information system, replete with
embedded quotes and commas, into something more manageable. As
data ingestion goes, this isn't much of a problem at all. There
are plenty of libraries that do the heavy lifting for you, in most
any language you choose, Ruby included.
Of course, I was just writing a quick-and-dirty script, so I was
rolling my own CSV-handling code. As usual, "quick and dirty" is
often dirty, but rarely quick. I tweeted a bit of my frustration,
in response to which @geoffwozniak wrote:
Welcome to the world of enterprise data ingress.
If I had to deal with these files everyday, I might head for the
egress. ... or master a good library, so that I could bang my head
on more challenging data ingestion problems.
Agile Moments: Stories, Tests, and Refactoring in Visual Design
In
A Place for Sharing Ideas and Stories,
designers Teehan+Lax tell the story of their role in creating
Medium,
"a better place to read and write things that matter". The
section "Forging ahead", about features added to the platform
after its launch, made me think of some of the ideas we use
when designing code test-first, only at a much higher level.
We reset by breaking the team up into new feature teams. Each
feature team would have at least one designer, one front-end
developer and a back-end developer. Some teams would take on
multiple features depending on their complexity. We used one
page briefs that were easy to write, easy to understand and
helped guide the teams when working through their feature(s).
They consisted of questions like:
Who is this page for?
What problem does this page solve for the user?
How do we know they need it?
What is the primary action we want users to take on this page?
What might prompt a user to take this action?
How will we know that this page is doing what we want it to do?
This bullet list embodies several elements of agile development.
For each feature, the brief acts like a story card that boils
the feature down to a clear need of the user, a clear action,
and, most important in my mind, a test: How will we know
that this page is doing what we want it to do? In a lot
of my work, this is a crucial element. As Kent Beck says, "How
will I know I'm done?"
The paragraph preceding the list highlights a couple of other
attributes common to agile development. One, teams are working
on stories in parallel on a common artifact. Two, the teams
include a designer, a front-end developer, and a back-end
developer. The team doesn't include a user, which can be a
huge advantage for developers, but the author mentions elsewhere
that nearly everyone on the team was a user:
As the internal product progressed and its features and
capabilities became clearer, we would reduce the amount of ad
hoc meetings and focus on getting stuff built into the product
so we could actually use it. Talking about work is great at
first, but usage is what breathes life into the product.
The author also stresses the value of physical co-location of
the designers and developers over even well-supported electronic
communication, which echoes for me the value of having a user in
the room with the developers.
What happens as features were enhanced or added by separate teams?
"... maintaining some sort of design integrity across the entire
product."
This thing was about to get full of user choices (read:
complexity) in a hurry -- The product was now at a critical
point in its life.
Of course, complexity and incoherence can creep into products even
when they are designed and built by one team, when it works on
multiple features in rapid succession.
The solution for Medium sounded familiar:
We took a week off current fixes and features and focused on
redesigning three pages from scratch: Home, Collection and
Post. Some of it went live, some of it went away.
And:
We hated to see some of the stuff we'd designed (and even
built) not go live, but it needed to die so the product could
grow through simplification.
This reminded me a lot like refactoring, even with differences
from the way we refactor at the code level. As teams added
features without considering the effect of the changes on the
global structure of the product, they accumulated something
akin to "design debt". So after a while they dedicated time
to paying off the debt and bringing back to the product the
sense of wholeness that had been lost. I am curious to know
whether the teams ever looked back at the page briefs to verify
that the redesigned pages still did what they wanted them to do.
That would be the equivalent of "running the tests".
We programmers really do have it nice. Lines and units of code
are a bit more separable than the visual design elements of a
product. This allows us to refactor all the time, if we are so
inclined, not just in batch after a large set of changes. The
presence of concrete tests, written as code, allows us to test
the efficacy of our changes relatively easily before we move
forward. While down in the trenches writing code, it's easy to
forget just how liberating -- and empowering -- this combination
of separability and testability are for design and redesign.
It's also easy to forget sometimes that similar challenges face
designers and creators across domains and disciplines. Many of
the same themes run through stories the things we create,
whether software in the small, software in the large, or
physical artifacts. Reading Teahan+Lax's story reminded me of
that, too.
I find I'm more ready to discard pages than I used to be.
I used to look for things to keep. I used to find ways
to save a paragraph or a sentence, maybe by relocating it.
Now I look for ways to discard things. If I discard a
sentence I like, it's almost as satisfying as keeping a
sentence I like. I don't think I've become ruthless or
perverse--just a bit more willing to believe that nature
will restore itself. The instinct to discard is finally
a kind of faith. It tells me there's a better way to do
this page even though the evidence is not accessible at
the present time.
Says Don DeLillo, in
The Art of Fiction No. 135.
Even in programming, the willingness to cut a chunk of working
code, or to rm -f a file, generally follows from a
deep-seated belief that nature will restore itself. We are
often happy to find that nature does a better job the second
time around.
And I use it as an example of how not to make a class.
If you have ever seen
the Point class,
you might understand why. Two public instance variables,
seven methods for reading and writing the instance variables,
and only one method (translate) that could conceivably
be considered a behavior. But it's not; it's just a relative
writer.
When this is the first class we show our students and ask them
to use, we immediately handicap them with an image of objects
as buckets of data and programs as manipulation of values. We
may as well teach them C or Pascal.
This has long been a challenger for teaching OOP in CS1. If
a class has simple enough syntax for the novice programmer to
understand, it is generally a bad example of an object. If a
class has interesting behavior, it is generally too complex
for the novice programmer to understand.
This is one of the primary motivations for authors to create
frameworks for their OOP/CS1 textbooks. One of the earliest
such frameworks I remember was the Graphics Package (GP)
library in
Object-Oriented Programming in Pascal,
by Connor, Niguidula, and van Dam. Similar approaches have
been used in more recent books, but the common thread is an
existing set of classes that allow users to use and create
meaningful objects right away, even as they learn syntax.
A lot of these frameworks have a point objects as egregious as
Java's GP included. But with these frameworks, the misleading
Point class need not be the first thing students see, and when
seen they are used in a context that consist of rich objects
interacting as objects should.
These frameworks create a new challenge for the legacy CS
profs among us. We like to "begin with the fundamentals"
and have students write programs "from scratch", so that they
"understand the entire program" from the beginning. Because,
you know, that's the way we learned to program.
I just registered for
Strange Loop 2013,
which doesn't happen until this fall. This has become a popular
conference, deservedly so, and it didn't seem like a good idea
to wait to register and risk being shut out.
One of the talks I'm looking forward to is by
Crista Lopes.
I mentioned Crista in
a blog entry from last year's Strange Loop,
for a talk she gave at OOPSLA 2003 that made an analogy between
programming language and natural language. This year, she will
give a talk called
Exercises in Style
that draws inspiration from a literary exercise:
Back in the 1940s, a French writer called Raymond Queneau wrote
an interesting book with the title Exercises in Style featuring
99 renditions of the exact same short story, each written in a
different style. This talk will shamelessly do the same for a
simple program. From monolithic to object-oriented to
continuations to relational to publish/subscribe to monadic to
aspect-oriented to map-reduce, and much more, you will get a
tour through the richness of human computational thought by
means of implementing one simple program in many different ways.
If you've been reading this blog for long, you can image how
much I like this idea. I even checked
Queneau's book
out of the library and announced on Twitter my plan to read it
before the conference. From the response I received, I gather
a lot of conferences attendees plan to do the same. You gotta
love the audience Strange Loop cultivates.
I actually have a little experience with this idea of writing
the same program in multiple styles, only on a much smaller
scale. For most of the last twenty years, our students have
learned traditional procedural programming in their first-year
sequence and object-oriented programming in the third course.
I taught the third course twice a year for many years. One
of things I often did early in the course was to look at the
same program in two forms, one written in a procedural style
and one written in OOP. I hoped that the contrast between the
programs would help them see the contrast between how we think
about programs in the two styles.
I've been teaching functional programming regularly for the
last decade, after our students have seen procedural and OO
styles in previous courses, but I've rarely done the "exercises
in style" demo in this course. For one thing, it is a course
on languages and interpreters, not a course on functional
programming per se, so the focus is on getting to
interpreters as soon as possible. We do talk about differences
in the styles in terms of their concepts and the underlying
differences (and similarities!) in their implementation. But
I think about doing so every time I prep the next offering of
the course.
Not doing "exercises in style" can be attractive, too. Small
examples can mislead beginning students about what is important,
or distract them with concepts they'd won't understand for a
while. The wrong examples can damage their motivation to learn.
In the procedural/object-oriented comparison, I have had
reasonable success in our OOP course with a program for simple
bank accounts and a small set of users. But I don't know how
well this exercise would work for a larger and more diverse set
of styles, at least not at a scale I could use in our courses.
I thought of this when
@kaleidic
tweeted, "I hope @cristalopes includes an array language among
her variations." I do, too, but my next thought was, "Well,
now Crista needs to use an example problem for which an array
language is reasonably well-suited." If the problem is not well
suited to array languages, the solution might look awkward, or
verbose, or convoluted. A newcomer to array languages is left
to wonder, "Is this a problem with array languages, or with the
example?" Human nature as it is, too many of us are prone to
protect our own knowledge and assume that something is wrong
with the new style.
An alternative approach is to get learners to suspend their
disbelief for a while, learn some nuts and bolts, and then
help them to solve bigger problems using the new style. My
students usually struggle with this at first, but many of them
eventually reach a point where they "get" the style. Solving
a larger problem gives them a chance to learn the advantages
and disadvantages of their new style, and retroactively learn
more about the advantages and disadvantages of the styles they
already know well. These trade-offs are the foundation of a
really solid understanding of style.
I'm really intrigued by Queneau's idea. It seems that he uses
a small example not to teach about each style in depth but
rather to give us a taste. What does each style feel
like in isolation? It is up to the aspiring writer to use this
taste as a starting point, to figure out where each style might
take you when used for a story of the writer's choosing.
That's a promising approach for programming styles, too, which
is one of the reasons I am so looking forward to Crista's talk.
As a teacher, I am
a shameless thief of good ideas,
so I am looking forward to seeing the example she uses, the way
she solves it in the different styles, and the way she presents
them to the crowd.
Another reason I'm looking forward to the talk is that I love
programs, and this should be just plain fun.
A student stopped in for a chat late last week to discuss the
code he was writing for a Programming Languages assignment.
This was the sort of visit a professor enjoys most. The
student had clearly put in plenty of time on his interpreter
and had studied the code we had built in class. His code
already worked. He wanted to talk about ways to make his
code better.
Some students never reach this point before graduation. In
Coders at Work,
Bernie Cosell
tells a story about leading teams of new hires at BBN:
I would get people -- bright, really good people, right out of
college, tops of their classes -- on one of my projects. And
they would know all about programming and I would give them
some piece of the project to work on. And we would start
crossing swords at our project-review meetings. They would
say, "Why are you complaining about the fact that I have my
global variables here, that I'm not doing this, that you don't
like the way the subroutines are laid out? The program works."
They'd be stunned when I tell them, "I don't care that the
program works. The fact that you're working here at all means
that I expect you to be able to write programs that work.
Writing programs that work is a skilled craft and you're good
at it. Now, you have to learn how to program.
I always feel that we have done our students well if we can get
them to the point of caring about their craft before they leave
us. Some students come to us already having this mindset,
which makes for a very different undergraduate experience.
Professors enjoy working these students, too.
But what stood out to me most from this particular conversation
was something the student said, something to this effect:
When we built the lexical addresser in class a few weeks ago,
I didn't understand the idea and I couldn't write it. So I
studied it over and over until I could write it myself and
understand exactly why it worked. We haven't looked at
lexical addressing since then, but the work I did has paid off
every time we've written code to process programs in our little
languages, including this assignment. And I write code more
quickly on the exams now, too.
When he finished speaking, I could hardly contain myself. I
wish I could bottle this attitude and give to every student who
ever thinks that easy material is an opportunity to take it easy
in a course for a while. Or who thinks that the best response
to difficult material is to wait for something easier to come
along next chapter.
Both situations are opportunities to invest energy in
the course. The returns on investment are deeper understanding
of the material, sharper programming skills, and the ability to
get stuff done.
This student is reaping now the benefits of an investment he made
five weeks ago. It's a gift that will keep on giving long after
this course is over.
I encourage students to approach their courses and jobs in this
way, but the message doesn't always stick. As Clay Stone from
City Slickers
might say, I'm happy as a puppy with two peters whenever it does.
While walking this morning, I coined a word for this effect:
exceleration. It's a portmanteau combining "excellence"
and "acceleration", which fits this phenomenon well. As with
compound interest and reinvested dividends, this sort of
investment builds on its self over time. It accelerates learners
on their path to mastering their craft.
Whatever you call it, that conversation made my week.
It would be cool to teach a course called "Reading Code".
Reading code has been on mind for a few months now, as I've
watched my students read relatively small pieces of code in
my Programming Languages course and as I've read a couple
of small libraries while reading the exercise bike. Then I
ran across
John Regehr's short brainstorm
on the topic, and something clicked. So I tweeted.
Reading code, or learning to do it, must be on the minds of
a lot people, because my tweet elicited quite a few
questions and suggestions. It is an under-appreciated
skill. Computer science programs rarely teach students how
to do it, and then usually only implicitly, by hearing a
prof or other students talk about code they've read.
Several readers wanted to know what the course outline would
be. I don't know. That's one of the things about Twitter
or even a blog: it is easy to think out loud absent-mindedly
without having much content in mind yet. It's also easier
to express an interest in teaching a course than to design a
good one.
Right now, I have only a few ideas about how I'd start.
Several readers suggested
Code Reading
by Spinellis, which is the only textbook I know on then topic.
It may be getting a little old these days, but many of the
core techniques are still sound.
I was especially pleased that someone recommended Richard
Gabriel's idea for
an MFA in Software,
in which reading plays a big role. I've used some of Dick's
ideas in my courses before. Ironically, the last time I
mentioned the MFA in Software idea in my blog was in the
context of
a "writing code" course,
at the beginning of a previous iteration of Programming
Languages!
That's particularly funny to me because someone replied to
my tweet about teaching a course called "Reading Code" with:
... followed by a course "Writing Readable Code".
Anyone who has tried to grade thirty evolving language
interpreters each week appreciates this under-appreciated
skill.
Chris Demwell
responded to my initial tweet with direct encouragement:
Write the course, or at least an outline, and post it. I
begged indulgence for lack of time as the school year ends
and said that maybe I can take a stab this summer. Chris's
next tweet attempted to pull me into the 2010s:
1. Write an outline. 2. Post on github. 3. Accept pull requests.
Congrats, you're an editor!
The world has indeed changed. This I will do. Watch for more
soon. In the meantime, feel free to
e-mail me your suggestions.
(That's an Old School pull request.)
I've always liked this quote from the preface of Pragmatic
Ajax, by Gehtland, Galbraith, and Almaer:
Writing a book is a lot like (we imagine) flying a spaceship
too close to a black hole. One second you're thinking "Hey,
there's something interesting over there," and a picosecond
later, everything you know and love has been sucked inside
and crushed.
Programming can be like that, too, in a good way. Just be sure
to exit the black hole on the other side.
Global state is the zombie in the closet of every Clojure program.
This essay explains the difference between scope and extent, a
distinction that affects how easy it is to some of what happens
in a program with closures and first-order functions with free
variables. Sierra also shows the tension between variables of
different kinds, using examples from Clojure. An informative
read.
The motto [of the Go language] is, "Don't communicate by sharing
memory, share memory by communicating."
Imperative programmers who internalize this simple idea are on
their way to understanding and using functional programming
style effectively. The inversion of sharing and communication
turns a lot of design and programming patterns inside out.
Pike's notes provide a comprehensive example of how a new language
can grow out of the needs of a particular set of applications,
rather than out of programming language theory. The result can
look a little hodgepodge, but using such a language often feels
just fine. (This reminds me of
a different classification
of languages with similar practical implications.)
~~~~
(These papers weren't published April Fool's Day, so I don't
think I've been punked.)
We are deep in the semester now, using Racket in our programming
languages course. I was thinking recently about how little of
Racket's goodness we use in this course. We use it primarily as
a souped-up R5RS Scheme and handy IDE. Tomorrow we'll see some
of Racket's tools for creating new syntax, which will explore one
of the rich niches of the system my students haven't seen yet.
I'm thinking about ways to introduce a deeper understanding of
The Racket Way,
in which domain concepts are programming language constructs and
programming languages are extensible and composable. But it goes
deeper. Racket isn't just a language, or a set of languages. It
is an integrated family of tools to support language creation and
use. To provide all these services, Racket acts like an operating
system -- and gives you full programmatic access to the system.
(You can watch the video of Flatt's StrangeLoop talk "The Racket
Way"
at InfoQ
-- and you should.)
Operating System: An operating system is a collection of
things that don't fit into a language. There shouldn't be one.
Alan Kay talks often about this philosophy. The divide between
programming language and operating system makes some things
more difficult for programmers, and complicates the languages
and tools we use. It also creates a divide in the minds of
programmers and imposes unnecessary limitations on what
programmers think is possible. One of things that appealed to
me in Flatt's StrangeLoop talk is that presented a vision of
programming without those limits.
There are implications of this philosophy, and costs. Smalltalk
isn't just a language, with compilers and tools that you use at
your Unix prompt. It's an image, and a virtual machine, and an
environment. You don't use Smalltalk; you live inside it.
After you live in Smalltalk for a while, it feels strange to
step outside and use other languages. More important, when you
live outside Smalltalk and use traditional languages and tools,
Smalltalk feels uncomfortable at best and foreboding at worst.
You don't learn Smalltalk; you assimilate. -- At least that's
what it feels like to many programmers.
But the upside of the "programming language as operating system"
mindset you find in Smalltalk and Racket can be huge.
This philosophy generalizes beyond programming languages. emacs
is a text editor that subsumes most everything else you do, if
you let it. (Before I discovered Smalltalk in grad school, I
lived inside emacs for a couple of years.)
You can even take this down to the level of the programs we
write. In a blog entry on
delimited continuations,
Andy Wingo talks about the control this construct gives the
programmer over how their programs work, saying:
It's as if you were implementing a shell in your program, as
if your program were an operating system for other programs.
When I keep seeing the same idea pop up in different places,
with a form that fits the niche, I'm inclined to think I am
seeing one of the Big Ideas of computer science.
After eighteen printed pages showing the wonders of APL in
A Glimpse of Heaven,
Bernard Legrand encourages programmers to give the language a
serious look. But he cautions APL enthusiasts not to oversell
the ease of learning the language:
Beyond knowledge of the basic elements, correct APL usage assumes
knowledge of methods for organising data, and ways specific to
APL, of solving problems. That cannot be learnt in a hurry, in
APL or any other language.
Legrand is generous in saying that learning APL takes the same
amount of time as learning any other language. In my experience,
both as a learning of language and as a teacher of programmers,
languages and programming styles that are quite different from
one's experience take longer than more familiar topics. APL is
one of those languages that requires us to develop entirely new
ways of thinking about data and process, so it will take most
people longer to learn than yet another C-style imperative
language or OO knock-off.
But don't be impatient. Wanting to move too quickly is
a barrier to learning
and performing at all scales, and too often leads us to give up
too soon. If you give up on APL too soon, or on functional
programming, or OOP, you will never get to glimpse the heaven
that experienced programmers see.
Does Readability Give a False Sense of Understandability?
In
Good for Whom?,
Daniel Lyons writes about the readability of code. He starts
with Dan Ingall's classic
Design Principles Behind Smalltalk,
which places a high value on a system being comprehensible
by a single person, and then riffs on readability in J and
Smalltalk.
Early on, Lyons made me smile when he noted that, while J
is object-oriented, it's not likely to be used that way by
many people:
... [because] to use advanced features of J one must first
use J, and there isn't a lot of that going on either.
As a former Smalltalker, I know how he feels.
Ultimately, Lyons is skeptical about claims that readability
increases the chances that a language will attract a large
audience. For one thing, there are too many counterexamples
in both directions. Languages like C, which "combines the
power of assembly language with the readability of assembly
language" [
link
], are often widely used. Languages such as Smalltalk, Self,
and Lisp, which put a premium on features such as
purity
and
factorability,
which in turn enhance readability, never seem to grow beyond
a niche audience.
Lyons's insight is that readability can mislead. He
uses as an example the source code of the J compiler, which
is written in C but in a style mimicking J itself:
So looking at the J source code, it's easy for me to hold my
nose and say, that's totally unreadable garbage; how can that
be maintained? But at the same time, it's not my place to
maintain it. Imagine if it were written in the most clean,
beautiful C code possible. I might be able to dupe myself
into thinking I could maintain it, but it would be a
lie! Is it so bad that complex projects like J have
complex code? If it were a complex Java program instead, I'd
still need substantial time to learn it before I would stand
a chance at modifying it. Making it J-like means I am required
to understand J to change the source code. Wouldn't I have
to understand J to change it anyway?
There is no point in misleading readers who have trouble
understanding J-like code into thinking they understand the
compiler, because they don't. A veneer of readability cannot
change that.
I know how Lyons feels. I sometimes felt the same way as I
learned Smalltalk by studying the Smalltalk system itself. I
understood how things worked locally, within a method and then
within a class, but I didn't the full network of classes that
made up the system. And I had the scars -- and trashed images
-- to prove it. Fortunately, Smalltalk was able to teach me
many things, including
object-oriented programming,
along the way. Eventually I came to understand better, if
not perfectly, how Smalltalk worked down its guts, but that
took a lot of time and work. Smalltalk's readability made the
code accessible to me early, but understanding still took time.
Lyons's article brought to mind another insight about code's
understandability that I blogged about many years ago in
an entry on comments in code.
This insight came from Brian Marick, himself no stranger to
Lisp or Smalltalk:
[C]ode can only ever be self-explanatory with respect
to an expected reader.
Sometimes, perhaps it's just as well that a language or a
program not pretend to be more understandable than it really
is. Maybe a barrier to entry is good, by keeping readers
out until they are ready to wield the power it affords.
If nothing else, Lyons's stance can be useful as a
counterweight to an almost unthinking admiration of readable
syntax and programming style.
Somehow, at some point in every serious programming project,
it always comes down to the last option: stare at the code
until you figure it out. I wish I had a better answer, but
I don't. Anyway, it builds character.
This is, of course, the last resort. We need to teach students
better ways to debug before they have to fall back on what
looks a lot like wishful thinking. Fortunately, John Regehr
lists this approach as the last resort in his lecture on
How to Debug.
Before he tells students to fall back to the place we all have
to fall back to occasionally, he outlines an explicit,
evidence-driven process for finding errors in a program.
I like that Regehr includes this advice for what to do after
you find a bug: step back and figure out what error in
thinking led to the bug.
An important part of learning from a mistake is diagnosing why
you made it, and then taking steps wherever possible to make it
difficult or impossible to make the same mistake again. This
may involve changing your development process, creating a new
tool, modifying an existing tool, learning a new technique, or
some other act. But it requires an act. Learning rarely just
happens.
Student: "I didn't have time to write 150 lines of code for
the homework."
Master: "That's fine. It requires only 50."
Student: "Which 50?"
I have lived this story several times recently, as the homework
in my Programming Languages has become more challenging. A few
students do not complete the assignment because they do not spend
enough time on the course, either in practice or performance.
But most students do spend enough time, both in practice
and on the assignment. Indeed, they spend much more time on the
assignment than I intend.
When I see their code, I know why. They have written long
solutions: code with unnecessary cases, unnecessary special cases,
and unnecessary helper functions. And duplication -- lots and
lots of duplication. They run out of time to write the ten lines
they need to solve the last problem on the set because they spent
all their time writing thirty lines on each of the preceding
problems, where ten would have done quite nicely.
Don't let anyone fool you. Students are creative. The trick is
o help them harness their creativity for good. The opposite of
good here is not evil, but bad code -- and too much code.
This Fortune Management article
describes a technique Jeff Bezos uses in meetings of his executive
team: everyone begins by "quietly absorbing ... six-page printed
memos in total silence for as long as 30 minutes".
There is a good reason, Bezos knows, for an emphasis on reading and
the written word:
There is no way to write a six-page, narratively structured memo
and not have clear thinking.
This is certainly true for programming, that unique form of writing
that drives the digital world. To write a well-structured, six-page
computer program to perform a task, you have to be able to think
clearly about your topic.
Alas, the converse is not true, at least not without learning some
specific skills and practicing a lot. But then again, that makes
it just like writing narratives.
My Programming Languages students this semester are learning that,
for functional programming in Scheme, the size limit is somewhat
south of six pages. More along the lines of six lines.
That's a good thing if your goal is clear thinking. Work hard,
clarify your thoughts, and produce a small function that moves
you closer to your goal. It's a bad thing if your goal is to get
done quickly.
Thelonious Monk was a cool cat on the piano, but I think
he could feel at home as a programmer. For example:
The _inside_ of the tune is the part that makes the _outside_
sound good.
Monk would understand that the design of your code matters
as much as the design of your program's user interface. That is
certainly true for developers who will have to maintain and modify
the code over time. But it is also true for your program's users.
It's hard for a program to be well designed on the outside,
however pretty, when it is poorly designed on the inside.
Don't play _everything_ (or every time); let some things go by.
Some music is just _imagined_. What you _don't_ play can be more
important than what you _do_ play.
Some of the most effective software design happens in
the negative space
around software components. Alan Kay's original notions for
designing objects stressed the messages that pass between objects
more than the objects themselves. When we unfocus our eyes a bit
and look at our system as a whole, the parts you don't design can
come into focus.
And like Monk's missing notes, the code you don't write
can be as important as the code you do, or more. The
You Aren't Gonna Need It
mindset tells us not to solve problems that don't exist yet.
Live in the current spec. The result will be a minimal system,
in terms of code size, with maximal effect.
You've got to dig it to _dig_ it, you dig?
A lot of people don't dig XP. But that's because they don't
_dig_ it, you dig? Sometimes it takes surrendering old habits
and thought processes all the way, pulling on a whole new way
of approaching music or software, and letting it seep into your
being for a while before you can really dig it. Some people
begin skeptical but come to dig it after immersion.
This is true for a lot of practices that seem unusual or awkward,
not just XP. As Alan Kay is also fond of saying, "Don't dip your
toe in the water. Get wet."
"[S]oftware engineering" ... was introduced to suggest a
professionalism beyond the craft discipline that went before
it, only to become a symbol of lumbering lethargy among
adherents of the craft discipline that came after it.
It's funny how terms evolve and communities develop sometimes.
There are a lot of valuable lessons to be learned from the
discipline of software engineering. As a mindset, it can
shape how we build systems with good results. Taken too far,
it can be a mindset can stifles and overloads the process of
making software.
As a university professor, I have to walk a fine line, exposing
students to the valuable lessons without turning the creation
of software into a lethargic, lumbering process. My courses
tend to look different from similar courses taught by software
engineering profs. I presume that they feel different to
students.
As a programmer, I walk a fine line, too, trying to learn
valuable lessons from wherever I can. Often that's from the
software engineering community. But I don't want to fall into
a mindset where the process becomes more important than the
result.
Last week, one of my Programming Languages students sent me
a note saying that his homework solution worked correctly
but that he was bothered by some duplicated code.
I was so happy.
Any student who has me for class for very long hears a lot
about the dangers of duplication for maintaining code, and
also that duplication is often a sign of poor design.
Whenever I teach OOP or functional programming, we learn
ways to design code that satisfy
the DRY principle
and ways to eliminate it via refactoring when it does sneak in.
I sent the student an answer, along with hearty congratulations
for recognizing the duplication and wanting to eliminate it.
My advice
When I sat down to blog the solution, I had a sense of deja
vu... Hadn't I written this up before? Indeed I had, a couple
of years ago:
Increasing Duplication to Eliminate Duplication.
Even in the small world of my own teaching, it seems there is
nothing new under the sun.
Still, there was a slightly different feel to the way I talked
about this in class later that day. The question had come
earlier in the semester this time, so the code involved was
even simpler. Instead of processing a vector or a nested list
of symbols, we were processing with a flat list of symbols.
And, instead of applying an arbitrary test to the list items,
we were simply counting occurrences of a particular symbol,
s.
The duplication occurred in the recursive case, where the
procedure handles a pair:
(if (eq? s (car los))
(+ 1 (count s (cdr los))) ; <---
(count s (cdr los))) ; <---
Then we make the two sub-cases more parallel:
(if (eq? s (car los))
(+ 1 (count s (cdr los))) ; <---
(+ 0 (count s (cdr los)))) ; <---
And then use distributivity to push the choice down a level:
(+ (if (eq? s (car los)) 1 0)
(count s (cdr los))) ; <--- just once!
This time, I made a point of showing the students that not
only does this solution eliminate the duplication, it more
closely follows the command to
follow the shape of the data:
When defining a program to process an inductively-defined
data type, the structure of the program should follow the
structure of the data.
This guideline helps many programmers begin to write
recursive programs in a functional style, rather than an
imperative style.
Note that in the first code snippet above, the if
expression is choosing among two different solutions,
depending on whether we see the symbol s in the
first part of the pair or not. That's imperative thinking.
How many occurrences of s are in a pair? Obviously,
the number of s's found in the car of the list
plus the number of s's found in the cdr of the
list. If we design our solution to match the code to the data
type, then the addition operation should be at the top to
begin:
(+ ; number of s's found in the car
; number of s's found in the cdr )
If we define the answer for the problem in terms of the data
type, we never create the duplication-by-if in the
first place. We think about solving the subproblems for the
car and the cdr, fill in the blanks, and arrive immediately
at the refactored code snippet above.
I have been trying to help my students begin to "think
functionally" sooner this semester. There is a lot or room
for improvement yet in my approach. I'm glad this student
asked his question so early in the semester, as it gave me
another chance to model "follow the data" thinking. In any
case, his thinking was on the right track.
Interest in VoodooPad 5 far surpassed my expectations for it.
I know that VoodooPad has a lot of fans out there, but I guess
I just hadn't heard from them in a while.
People really seem to like the Markdown syntax support and the
new JavaScript events system I've built in for customization.
I also added ePub export to VP5 which I expected more interest
in -- but that hasn't seem to materialized. I'm never very
good at predicting which features people will like the most.
Gus is a Mac developer with a solid following and a couple of
very popular titles, the wiki editor VoodooPad and the image
editor
Acorn.
I am a
long-time user of VoodooPad
and an occasional user of Acorn's progenitor,
FlySketch,
and so have experienced firsthand Gus's open relationship with
the users of his products.
If even he can't predict which features his users will like
most and least, there isn't a lot of hope for the rest of us.
Our best strategy is to follow the agile advice: release
often, get feedback soon and frequently, and learn from what
our the users of our software tell us.
My students spent the last three weeks of the semester
implementing some of the infrastructure for a Twitter-like
messaging app. They grew the app in three iterations, with
new and changed features at each step. In the readme file
for one of the versions, a student commented:
I smiled and remembered again that even students who would
never write such code in a smaller, more focused setting can
be lulled into writing it in the process of growing a big,
complicated program. I made a mental note to pay a little
extra attention the next time I teach the course to the Law
of Demeter.
I actually don't talk much about the Law of Demeter in this
sophomore-level course, because it's a name we don't need.
But occasionally I'd like to point a student to a discussion
of it, and there don't seem to be a lot of resources at the
right level for these students. So I decided to draft the
beginnings of a simple reference. I welcome
your suggestions
on how to make it better.
The Law of Demeter isn't a law so much as a general principle
for software design. It is often referred to in the context
of object-oriented programming, so you may see it phrased in
terms of objects:
Objects should have short reach.
Or:
An object should not try to know too much, or need to.
If those are too squishy for you, the Wikipedia entry also as
a more formal summary:
The fundamental notion is that a given object should assume as
little as possible about the structure or properties of anything
else (including its subcomponents).
Framed this way, the Law of Demeter is just a restatement of
OOP 101. Objects are independent. They encapsulate their state
and behavior. Instance variables are private, and we should be
suspicious of getter methods.
As a matter of programming style, I often introduce this principle
in a pragmatic way:
An operation should live with the data it uses.
Those are all general statements of the Law of Demeter. You will
sometimes see a much more specific, formal statement of this sort:
A method m of an object obj may send messages only
to these objects:
obj itself
obj's instance variables
m's formal parameters
any objects created within m
This version of the Law is actually an enumeration of specific
ways that we can obey the more general principle. In the case
of existing code, this version can help us recognize that the
general principle has been violated.
Why is the Law of Demeter important?
This principle is often pitched as being about loose coupling:
we should minimize the amount of knowledge that any component
has about the implementation of any other component.
Another way to think about this principle from the perspective
of the receiver. Some object wants access to its parts in
order to do its job. From this angle, the Law of Demeter is
fundamentally about encapsulation. The receiver's
implementation should be private, and chained messages tend to
leak implementation detail. When we hide those details from
the object's collaborators, we shield other parts of the
system from changes to the implementation.
The simplest way to eliminate the sender's need to know about
thisInsideCollection and thisAttribute is to
add a method to thisCollection's class that
accomplishes
thisInsideCollection.thisAttribute.thisMethod(),
and
send the new message to thisCollection:
thisCollection.doSomething()
Coming up with a good name for the new message doSomething
forces us to think about what this behavior means in our program.
Many times, finding a good name helps us to clarify how we think
about the objects that make up our program.
Notice that the new method in thisCollection might still
violate our design principle, because thisCollection
needs to know that thisInsideCollection is implemented
in terms of thisAttribute and that thisAttribute
responds to thisMethod(). That's okay. You can apply
the same process again, looking for a way to push the behavior
that operates on thisAttribute into the object that
knows about it.
More generally, when you notice yourself violating the Law of
Demeter, think of the violation as an opportunity to rethink the
objects in your program and how they relate to one another. Why
is this object performing this task? Why doesn't its collaborator
provide that service? Perhaps we can give this responsibility to
another object. Who knows how to help this object with this task?
Sometimes, we even find that we can move thisMethod()
into thisCollection and take our object out the loop
entirely, letting the object that sent us the message communicate
directly with thisCollection. That is a great way to
make our code less tightly coupled.
A Potential Wrinkle
There is a potential problem when we program in a language like
Java, though. What if thisCollection is a primitive Java
class, say, a Vector or a HashMap? If so, you
cannot add a new method to the class. This is sign of another
problem looking in your program. This object depends on your
choice of data structure for thisCollection. What role
does thisCollection play in your domain? Maybe it's a
catalog of users, or the set of users that follow another user.
Make a new class that represents this domain object, and make
your data structure an instance variable in that class. Now you
can write your program in terms of the domain object, not the Java
primitive. This makes solves several problems for you:
Your code reflects the problem domain more faithfully.
Your code is easier to modify. You can now change the data
structure used to implement the domain object without
affecting the rest of the program.
Now you can solve the Law of Demeter violation by adding a
method to the new class.
This new wrinkle is sometimes called
Primitive Obsession.
OO masters know
to beware its temptations.
I sometimes like to
play a little game
in which every base type and every primitive class has been pushed
down to the bottom layer of my program and wrapped in a domain
object. This is often overkill -- taking a good thing too far --
but such an exercise can help you see just how often it really is
a good thing to hide implementation detail and program in terms
of the objects in your domain.
The programmers and teachers among you surely know this
feeling well:
As I drift back to sleep, I can't help thinking that it's
a wonderful thing to be right about the world. To weigh
the evidence, always incomplete, and correctly intuit the
whole, to see the world in a grain of sand, to recognize
its beauty, its simplicity, its truth. It's as close as
we get to God in this life, and we reside in the glow of
such brief flashes of understanding, fully awake,
sometimes, for two or three seconds, at peace with our
existence. And then we go back to sleep.
Or tackle the next requirement.
(The passage is from Richard Russo's Straight Man,
an enjoyable send-up of modern man in an academic life.)
Alan Kay talks about programming languages quite a bit in
this wide-ranging interview.
(Aren't all interviews with Kay wide-ranging?) I liked
this fuzzy bifurcation of the language world:
... a lot of them are either the agglutination of features
or ... a crystallization of style.
My initial reaction was that I'm a crystallization-of-style
guy. I have always had a deep fondness for style languages,
with Smalltalk at the head of the list and Joy and Scheme
not far behind.
But I'm not a purist when it comes to
neat and scruffy.
As an undergrad, I really liked programming in PL/I. Java
never bothered me as much as it bothered some of my purist
friends, and I admit unashamedly that I enjoy programming
in it.
These days, I like Ruby as much as I like any language. It
is a language that lies in the fuzz between Kay's categories.
It has an "everything is an object" ethos but, man alive,
is it an amalgamation of syntactic and semantic desiderata.
I attribute linguistic split personality to this: I prefer
languages with a "real center", but I don't mind imposing
a stylistic filter on an agglutinated language. PL/I always
felt comfortable because I programmed with a pure structured
programming vibe. When I program in Java or Ruby now,
somewhere in the center of my mind is a Smalltalk programmer
seeing the language through a Smalltalk lens. I have to
make a few pragmatic concessions to the realities of my tool,
and everything seems to work out fine.
This semester, I have been teaching with Java. Next semester,
I will be teaching with Scheme. I guess I can turn off the
filter.
When learning a new principle, try to apply it everywhere. That way,
you'll learn more quickly where it does and doesn't work well, even
if your initial intuitions about it are wrong.
Actually, you don't learn in spite of your initial intuitions
being wrong. You learn because your initial intuitions were
wrong. That's when learning happens best.
In
an interview
I linked to in
my previous entry,
Brian Eno and Ha-Joon Chang talk about the illusion of freedom.
Whenever you talk about freedom, as in a "free market" or "free
jazz",
... what you really mean is "constrained by rules that we've stopped
thinking about".
Free jazz isn't entirely free, because you are constrained by what
your muscles can do. Free markets aren't entirely free, because
there are limits we simply choose not to talk about. Perhaps we
once did talk about them and have chosen not to any more. Perhaps
we never talked about them and don't even recognize that they are
present.
I can't help but think of computer science faculty who claim we
shouldn't be teaching OO programming in the first course, or any
other "paradigm"; we should just teach basic programming first.
They may be right about not teaching OOP first, but not because
their approach is paradigm-free. It isn't.
I firmly believe that a time traveling debugger is worth more than
a boatload of language features[.]
This passage comes as part of a discussion of what it would take
to make
Bret Victor's
vision of programming a reality. Victor demonstrates powerful ideas
using "hand crafted illustrations of how such a tool might behave".
Bracha, whose work on Smalltalk and
Newspeak
have long inspired me -- reflects on what it would take to offer
Victor's powerful ideas in a general purpose programming environment.
Smalltalk as a language and environment works at a level where we
conceive of providing the support Victor and Bracha envision, but
most of the language tools people use today are too far removed
from the dynamic behavior of the programs being written. The
debugger is the most notable example.
Bracha suggests that we free the debugger from the constraints of
time and make it a tool for guiding the evolution of the program.
He acknowledges that he is not the first person to propose such an
idea, pointing specifically to Bill Lewis's proposal for
an omniscient debugger.
What remains is the hard work needed to take the idea farther and
provide programmers more transparent support for understanding
dynamic behavior while still writing the code.
Let's look at an example closer to home for us software
folks. You're an agile coach, arriving in a new environment
with a mission from management to "make this team more agile".
If you, like so many consultants in most every field, favor an
etic approach, you will begin by doing a gap analysis between
the behaviors and artifacts that you see and those with which
you are most familiar. That's useful, and practically
inevitable. The next natural step, however, may be less
helpful. That is to judge the gaps between what this team is
doing and what you consider to be normal as wrong.... By
deciding, as a consultant or coach, to now attempt to prepare
an emic description of the team's behaviors, you force yourself
to set aside your preconceptions and engage in meaningful
conversations with the team in order to understand how they
see themselves. Now you have two tools in your kit, where you
might before have had one, and more tools prepares you for more
situations.
When I speak to HS students and their parents, and when I advise
freshmen, I suggest that the consider picking up a minor or a
second major. I tell them that it almost doesn't matter which
other discipline they choose. College is a good time to broaden
oneself, to enjoy learning for its own sake. Some minors and
second majors may seem more directly relevant to a CS grad's
career interests, but you never know what domain or company you
will end up working in. You never know when having studied a
seemingly unrelated discipline will turn out to be useful.
Many students are surprised when I recommend social sciences such
as psychology, sociology, and anthropology as great partners for
CS. Their parents are, too. Understanding people, both
individually and in groups, is important in any profession, but
it is perhaps more important for CS grads than many. We build
software -- for people. We teach new languages and techniques
-- to people. We contract out our services to organizations --
of people. We introduce new practices and methodologies to
organizations -- of people. Ethnography may be a more important
to a software consultant's success than any set of business
classes.
I had my first experience with this when I was a graduate student
working in the area of knowledge-based systems. We built systems
that aimed to capture the knowledge of human experts, often teams
of experts. We found that they relied a lot on tacit knowledge,
both in their individual expertise and in the fabric of their
teams. It wasn't until I read some papers from John McDermott's
research group at Carnegie Mellon that I realized we were all
engaged in ethnographic studies. It would have been so useful
to have had some background in anthropology!
Bryan Helmkamp
recently posted
Why Ruby Class Methods Resist Refactoring
on the Code Climate blog. It explains nicely example how
using class methods makes it harder to refactor in a way
that makes you feel like you have actually improved the
code.
This is a hard lesson for beginners to learn, but even
experienced Ruby and Java programmers sometimes succumb to
the urge for simplicity that "just" writing a method offers.
It doesn't take long for a simple class method to grow into
something more complex, which gets in the way of growing the
program.
As Helmkamp points out, class methods have the insidious
feature of coupling your code to a particular class. Even
when we program with instances rather than classes, we like
to avoid that sort of coupling. Thus was born
the factory method.
Deep in the process of teaching OO to undergraduates, I was
drawn to an important truth found deep in the post, just
after mention of the class-name coupling:
You can't easily swap in new a class, but you can easily swap
in a new instance.
One of the great advantages of OOP is being able to plug a
different object into a program and thus change or extend the
program's behavior without modifying its code. Dynamic
polymorphism via substitutable objects is in many ways the
first principle of object-oriented programming.
That's why the first refactoring I usually apply whenever I
encounter a class method is Introduce Object.
[Naming functions is] an unforgiving and humbling activity. And the
issue is almost always the same. The reason you can't find a good
name is because you don't really understand with complete and
ultimate clarity what the function does.
Sometimes we can't come up with the perfect name for a function or
a variable until after we have written code that uses it. The act
of writing the program helps us to learn about the program's
content.
But in a computer language, each function name ultimately refers
to a particular piece of functionality that is defined in an
absolute way, and can be implemented by a specific precise program.
When we write OO programs, a name doesn't always refer to a specific
function. With polymorphic variables, we don't usually know which
method will be executed when we use a name. Any object that provides
the protocol required by the variable's type, or implements the
interface so named, may be stored in the variable. It may even be
an instance of a class I know nothing about.
For this reason, when I teach OO programming, I am careful to talk
about sending a message rather than "invoking a method" or
"calling a function". The receiver of the message interprets the
message, not the sender.
This doesn't invalidate what Wolfram says, though it does point to
a way in which we might rephrase it more generally. The name of a
good method isn't about specific functionality so much as about
expectation. It's about the core idea associated with an
interaction, not any particular implementation of that idea.
John Cook wrote about times in mathematics when
maybe you don't need to
do what you were asked to do. As one example, he used remainder
from division. In many cases, you don't need to do division,
because you can find the answer using a different, often simpler,
method.
We see a variation of John's theme in programming, too. Sometimes,
a client will ask for a result in a way that presupposes the
method that will be used to produce it. For example, "Use a stack
to evaluate these nested expressions." We professors do this to
students a lot, because they want the students to learn the
particular technique specified. But you see subtle versions of
this kind of request more often than you might expect outside the
classroom.
An important part of learning to design software is learning to
tease apart the subtle conflation of interface and
implementation in the code we write. Students who learn
OO programming after a traditional data structures course usually
"get" the idea of data abstraction, yet still approach large
problems in ways that let implementations leak out of their
abstractions in the form of method names and return values. Kent
Beck talked about how this problem afflicts even experienced
programmers in his blog entry
Naming From the Outside In.
Primitive Obsession
is another symptom of conflating what we need with how we produce
it. For beginners, it's natural to use base types to implement
almost any behavior. Hey, the extreme programming principle
You Ain't Gonna Need It
encourages even us more experienced developers not to create
abstractions too soon, until we know we need them and in what
form. The convenience offered by hashes, featured so prominently
in the scripting languages that many of us use these days, makes
it easy to program for a long time without having to code a
collection of any sort.
But learning to model domain objects as objects -- interfaces
that do not presuppose implementation -- is one of the powerful
stepping stones on the way to writing supple code, extendible
and adaptable in the face of reasonable changes in the spec.
Mathematical Formulas, The Great Gatsby, and Small Programs
... or: Why Less Code is Better
In
Don't Kill Math,
Evan Miller defends analytic methods in the sciences against Bret
Victor's "visions for computer-assisted creativity and scientific
understanding". (You can see
some of my reactions
to Victor's vision in a piece I wrote about his StrangeLoop talk.)
Miller writes:
For the practicing scientist, the chief virtue of analytic methods
can be summed up in a single word: clarity. An equation
describing a quantity of interest conveys what is important in
determining that quantity and what is not at all important.
He goes on to look at examples such as the universal law of gravitation
and shows that a single formula gives even a person with "minimal
education in physics" an economical distillation of what matters.
The clarity provided by a good analytic solution affords the reader
two more crucial benefits: confident understanding and
memorable insights.
Poet Peter Turchi describes a related phenomenon in fiction writing,
in his essay
You and I Know, Order is Everything.
A story can pull us forward by omitting details and thus creating
in the reader a desire to learn more. Referring to a particularly
strategic paragraph, he writes:
That first sentence created a desire to know certain information:
What is this significant event? ... We still don't have an answer,
but the context for the question is becoming increasingly clear --
so while we're eager to have those initial questions answered, we're
content to wait a little longer, because we're getting what seems to
be important information. By the third paragraph, ... we think we've
got a clue; but by that time the focus of the narrative is no longer
the simple fact of what's going on, but the [larger setting of the
story]. The story has shifted our attention from a minor mystery to
a more significant one. On some level or another nearly every
successful story works this way, leading us from one mystery to
another, like stepping stones across a river.
In a good story, eventually...
... we recognize that the narrator was telling us more than we could
understand, withholding information but also drawing our attention to
the very thing we should be looking at.
In two very different contexts, we see the same forces at play. The
quality of a description follows from the balance it strikes between
what is in the description and what is left out.
To me, this is another example of how a liberal education can
benefit students majoring in both the sciences and the humanities
[
1
|
2
].
We can learn about many common themes and patterns of life from
both traditions. Neither is primary. A student can encounter the
idea first in the sciences, or first in the humanities, whichever
interests the student more. But apprehending a beautiful pattern
in multiple domains of discourse can reinforce the idea and make
it more salient in the preferred domain. This also broadens our
imaginations, allowing us to see more patterns and more subtlety
in the patterns we already know.
So: a good description, a good story, depends in some part on the
clarity attendant in how it conveys what is important and what is
not important. What are the implications of this pattern for
programming? A computer program is, after all a description: an
executable description of a domain or phenomenon.
I think this pattern gives us insight into why less code is usually
better than more code. Given two functionally equivalent programs
of different lengths, we generally prefer the shorter program because
it contains only what matters. The excess code found in the longer
program obscures from the reader what is essential. Furthermore,
as with Miller's concise formulas, a short program offers its reader
the gift of more confident understanding and the opportunity for
memorable insights.
What is not in a program can tell us a lot, too. One of
the hallmarks of expert programmers is their ability to see the
negative space
in a design and program and learn from it. My students, who are
generally novice programmers, struggle with this. They are still
learning what matters and how to write descriptions at all, let
alone concise one. They are still learning how to focus their
programming tools, and on what.
As The Master was setting out on a journey, a young man ran
up, knelt down before him, and asked him, "Good teacher,
what must I do to inherit the eternal bliss of OO?"
The Master answered him, "Why do you call me good? No OO
programmer is good but
The Creator
alone.
"You know the commandments:
"'An object should have only a single responsibility.'
"'Software entities should be open for extension, but closed
for modification.'
"'Objects should be replaceable with instances of their subtypes
without altering the correctness of that program.'
"'Tell, don't ask.'
"'You shall not indulge in primitive obsession.'
"'All state is private.'"
The young man replied and said to Him, "Teacher, all of these
I have observed from my youth when first I learned to program."
The Master, looking at him, loved him and said to him, "You
are lacking in one thing. Go, surrender all primitive types,
and renounce all control structures. Write all code as
messages passed between encapsulated objects, with extreme
late-binding of all things. Then will you have treasure in
Heaven; then come, follow me."
At that statement the young man's face fell, and he went away
sad, for he possessed many data structures and algorithms.
The Master looked around and said to his disciples, "How hard
it is for those who have a wealth of procedural programming
experience to enter the kingdom of OO."
After talking about the advantages of making the changeable
aspects of the system as declarative as possible,
William Payne writes:
Having done a bit of Prolog programming in the dim and
distant past, my intuition is that trying to make
everything declarative is a mistake; one ends up tying
oneself into knots. The mental gymnastics simply are
not worth it. However, splitting the program into
declarative-and-non-declarative parts seems reasonable.
This is an application of
the Pareto Principle
to programming, in the form of the purity of style. The
Pareto Principle says that, "for many events, roughly 80%
of the effects come from 20% of the causes".
When I was first learning functional programming in Lisp
as an AI researcher, a more experienced researcher told me
that about 90% of a big system could be purely functional.
The remaining 10% should include all side-effecting operations,
cordoned off from the rest of the app into its own abstraction
layer. Since that time, I've heard 85-15 used as a reasonable
split for big Scheme programs.
The lesson is: don't kill yourself trying to be 100%. As
Payne says, the mental gymnastics simply are not worth it.
You'll end up with code that easier to understand, maintain,
and modify if you allow yourself a little impurity, in small,
controlled doses.
StrangeLoop 8: Reactions to Brett Victor's Visible Programming
The last talk I attended at StrangeLoop 2012 was Bret Victor's
Visible Programming. He has since posted an extended
version of his presentation, as a multimedia essay titled
Learnable Programming.
You really should read his essay and play the video in which
he demonstrates the implementation of his ideas. It is quite
impressive, and worthy of the discussion his ideas have
engendered over the last few months.
In this entry, I give only a high-level summary of the idea,
react to only one of his claims, and discuss only one of his
design principles in ay detail. This entry grew much longer
than I originally intended. If you would like to skip most of
my reaction, jump to the mini-essay that is the heart of this
entry,
Programing By Reacting, in the REPL.
~~~~
Programmers often discuss their productivity as at least a
partial result of the programming environments they use.
Victor thinks this is dangerously wrong. It implies, he says,
that the difficulty with programming is that we aren't doing
it fast enough.
But speed is not the problem. The problem is that our
programming environments don't help us to think. We do all of
our programming in our minds, then we dump our ideas into code
via the editor.
Our environments should do more. They should be our external
imagination. They should help us see how our programs work
as we are writing them.
This is an attractive guiding principle for designing tools to
help programmers. Victor elaborates this principle into a set
of five design principles for an environment:
read the vocabulary
-- what do these words mean?
follow the flow
-- what happens when?
see the state
-- what is the computer thinking?
create by reacting
-- start somewhere, then sculpt
create by abstracting
-- start concrete, then generalize
Victor's talk then discussed each design principle in detail
and showed how one might implement the idea using JavaScript
and Processing.js in a web browser. The demo was cool
enough that the StrangeLoop crowd broke into applause at
leas twice during the talk. Read
the essay.
~~~~
As I watched the talk, I found myself reacting in a way I had
not expected. So many people have spoken so highly of this
work. The crowd was applauding! Why was I not as enamored?
I was impressed, for sure, and I was thinking about ways to
use these ideas to improve my teaching. But I wasn't falling
head over heels in love.
A Strong Claim
First, I was taken aback by a particular claim that Victor made
at the beginning of his talk as one of the justifications for
this work:
If a programmer cannot see what a program is doing, she can't
understand it.
Unless he means this metaphorically, seeing "in the mind's eye",
then it is simply wrong. We do understand things we don't see
in physical form. We learn many things without seeing them in
physical form. During my doctoral study, I took several courses
in philosophy, and only rarely did we have recourse to images
of the ideas we were studying. We held ideas in our head,
expressed in words, and manipulated them there.
We did externalize ideas, both as a way to learn them and think
about them. But we tended to use stories, not pictures. By
speaking an idea, or writing it down, and sharing it with
others, we could work with them.
So, my discomfort with one of Victor's axioms accounted for
some of my unexpected reaction. Professional programmers can
and do manipulate ideas abstractly. Visualization can help,
but when is it necessary, or even most helpful?
Learning, Versus Doing
This leads to a second element of my concern. I think I had a
misconception about Victor's work. His talk and its title,
"Visible Programming", led me to think his ideas are aimed
primarily at working programmers, that we need to make programs
visible for all programmers.
The title of his essay, "Learnable Programming", puts his claims
into a different context. We need to make programs visible for
people who are learning to program. This seems a much
more reasonable position on its face. It also lets me see the
axiom that bothered me so much in a more sympathetic light: If
a novice programmer cannot see what a program is doing,
then she may not be able to understand it.
Seeing how a program works is a big part of learning to program.
A few years ago,
I wrote
about "biction" and the power of drawing a picture of what code
does. I often find that if I require a student to draw a
picture of what his code is doing before he can ask me for
debugging help, he will answer his own question before getting
to me.
The first time a student experiences this can be a powerful
experience. Many students begin to think of programming in a
different way when they realize the power of thinking about
their programs using tools other than code. Visible programming
environments can play a role in helping students think about
their programs, outside their code and outside their heads.
I am left puzzling over two thoughts:
How much of the value my students see in pictures comes from
not from seeing the program work but from drawing the picture
themselves -- the act of reflecting about the program? If
our tools visualizes the code for them, will we see the same
learning effect that we see in drawing their own pictures?
Certainly Victor's visible programming tools can help learners.
How much will they help programmers once they become experts?
Ben Shneiderman's
Designing the User Interface taught me that novices
and experts have different needs, and that it's often
difficult to know what works well for experts until we run
experiments.
My favorite parts of this talk were the sections on creating
by reacting and abstracting. Programmers, Victor says, don't
work like other creators. Painters don't stare at a blank
canvas, think hard, create a painting in their minds, and then
start painting the picture they know they want to create.
Sculptors don't stare at a block of stone, envision in their
mind's eye the statue they intend to make, and then reproduce
that vision in stone. They start creating, and react,
both to the work of art they are creating and to the materials
they are using.
Programmers, Victor says, should be able to do the same thing --
if only our programming environments helped us.
As a teacher, I think this is an area ripe for improvement in
how we help students learn to program. Students open up their
text editor or IDE, stare at that blank screen, and are
terrified. What do I do now? A lot of my work over the last
fifteen to twenty years has been in trying to find ways to help
students get started, to help them to overcome the fear of the
blank screen.
My approaches haven't been through visualization, but through
other ways to think about programs and how we grow them.
Elementary patterns
can give students tools for thinking about problems and growing
their code at a scale larger than characters or language keywords.
An agile approach can help them start small, add one feature at a
time, proceed in confidence with working tests, and refactor to
make their code better as they go along. Adding Victor-style
environment support for the code students write in CS1 and CS2
would surely help as well.
However, as I listened to Victor describe support for creating
by reacting, and then abstracting variables and functions out
of concrete examples, I realized something. Programmers don't
typically write code in an environment with data visualizations
of the sort Victor proposes, but we do program in the style that
such visualizations enable.
A simple, interactive computer programming environment enables
programmers to create by reacting.
They write short snippets of code that describe how a new
feature will work.
They test the code immediately, seeing concrete results from
concrete examples.
They react to the results, shaping their code in response to
what the code and its output tell them.
They then abstract working behaviors into functions that can
be used to implement another level of functionality.
Programmers from the Lisp and Smalltalk communities, and from the
rest of the dynamic programming world, will recognize this style
of programming. It's what we do, a form of creating by reacting,
from concrete examples in the interaction pane to code in the
definitions pane.
In the agile software development world, test-first development
encourages a similar style of programming, from concrete examples
in the test case to minimal code in the application class.
Test-driven design
stimulates an even more consciously reactive style of programming,
in which the programmer reacts both to the evolving program and to
the programmer's evolving understanding of it.
The result is something similar to Victor's goal for programmers
as they create abstractions:
The learner always gets the experience of interactively controlling
the lower-level details, understanding them, developing trust in
them, before handing off that control to an abstraction and moving
to a higher level of control.
It seems that Victor would like to perform even more support for
novices than these tools can provide, down to visualizing what the
program does as they type each line of code. IDEs with autocomplete
is perhaps the closest analog in our current arsenal. Perhaps we
can do more, not only for novices but also professionals.
~~~~
I love the idea that our environments could do more for us, to be
our external imaginations.
Like many programmers, though, as I watched this talk, I occasionally
wondered, "Sure, this works great if you creating art in Processing.
What about when I'm writing a compiler? What should my editor do
then?"
Victor anticipated this question and pre-emptively answered it.
Rather than asking, How does this scale to what I do?,
we should turn the question inside out and ask, These are the
design requirements for a good environment. How do we change
programming to fit?
I doubt such a dogmatic turn will convince skeptics with serious
doubts about this approach.
I do think, though, that we can reformulate the original question
in a way that focuses on helping "real" programmers. What does a
non-graphical programmer need in an external imagination? What
kind of feedback -- frequent, even in-the-moment -- would be most
helpful to, say, a compiler writer? How could our REPLs provide
even more support for creating, reacting, and abstracting?
These questions are worth asking, whatever one thinks of Victor's
particular proposal. Programmers should be grateful for his
causing us to ask them.
I have been using Racket since before it was Racket, back when it
was "just another implementation of Scheme". Even then, though, it
wasn't just another implementation of Scheme, because it had such
great libraries, a devoted educational community around it, and an
increasingly powerful facility for creating and packaging languages.
I've never been a deep user of Racket, though, so I was eager to see
this talk by one of its creators and learn from him.
Depending on your perspective, Racket is either a programming
language (that looks a lot like Scheme), a language plus a set of
libraries, or a platform for creating programs. This talk set out
to show us that Racket is more.
Flatt opened with a cute animated fairy tale, about three princesses
who come upon a wishing well. The first asks for stuff. The second
asks for more wishes. The third asks for a kingdom full of wishing
wells. Smart girl, that third one. Why settle for stuff when you
can have the source of all stuff?
This is, Flatt said, something like computer science. There is a
similar progression of power from:
a document, to
a language for documents, to
a language for languages.
Computer scientists wish for a way to write programs that do...
whatever.
This is the Racket way:
Everything is a program.
Concepts are programming language constructs.
Programming languages are extensible and composable.
The rest of the talk was a series of impressive mini-demos that
illustrated each part of the Racket way.
To show what it means to say that everything is a program, Flatt
demoed Scribble, a language for producing documents -- even the one
he was using to give his talk. Scribble allows writers to abstract
over every action.
To show what it means to say that concepts are programming language
constructs, Flatt talked about the implementation of Dr. Racket,
the flexible IDE that comes with the system. Dr. Racket needs to
be able to create, control, and terminate processes. Relying on
the OS to do this for it means deferring to what that OS offers.
In the end, that means no control.
Dr. Racket needs to control everything, so the language provides
constructs for these concepts. Flatt showed as examples threads and
custodians. He then showed this idea at work in an incisive way:
he wrote a mini-Dr. Racket, called Racket, Esq. -- live using
Racket. To illustrate its completeness, he then ran his talk inside
racket-esq. Talk about a strange loop. Very nice.
To show what it means to say that programming languages are extensible
and composable, Flatt showed a graph of the full panoply of Racket's
built-in languages and demoed several languages. He then used some
of the basic language-building tools in Racket -- #lang,
require, define-syntax, syntax-rules, and
define-syntax-rule -- to build the old text-based game
Adventure, which needs a natural language-like scripting language
for defining worlds. Again, very nice -- so much power in so many
tools.
This kind of power comes from taking seriously a particular way of
thinking about the world. It starts with "Everything is a program."
That is the Racket way.
Flatt is a relaxed and confident presenter. As a result, this was a
deceptively impressive talk. It reinforced its own message by the
medium in which it was delivered: using documents -- programs
-- written and processed in Racket. I am not sure how anyone could
see a slideshow with "hot" code, a console for output, and a REPL
within reach, all written in the environment being demoed, and not
be moved to rethink how they write programs. And everything else
they create.
As Flatt intimated briefly early on, The Racket Way of thinking is
not -- or should not be -- limited to Racket. It is, at its core,
the essence of of computer science. The
duality of code and data
makes what we do so much more powerful than most people realize,
and makes what we can do so much more powerful than most
us actually do with the tools we accept. I hope that Flatt's talk
inspires a few more of us not to settle for less than we have to.
I don't know if it was coincidence or by design of the conference
organizers, but Wednesday morning was a topical repeat of Tuesday
morning for me: two highly engaging talks on functional programming.
I had originally intended to write them up in a single entry, but
that write-up grew so long that I decided to give them their own
entries.
Y Not?
Watching talks and reading papers about the Y combinator are
something of a spectator
code kata
for me. I love to see new treatments, and enjoy seeing even
standard treatments every now and then. Jim Weirich presented it
at StrangeLoop with a twist I hadn't seen before.
Weirich opened, as speakers often do, with him. This is a
motivational talk, so it should be...
non-technical. But it's not. It is highly technical.
relevant. But it's not. It is extremely pointless.
good code. But it's not. It shows the worst Clojure
code ever.
But it will be, he promises, fun!
Before diving in, he had one more joke, or at least the first half
of one. He asked for audience participation, then asked his
volunteer to calculate cos(n) for some value of n I
missed. Then he asked the person to keep hitting the cosine
button repeatedly until he told him to stop.
At the dawn of computing, to different approaches were taken in an
effort to answer the question, What is effectively computable?
Alan Turing devised what we now call
a universal Turing machine
to embody the idea. Weirich showed
a video demonstration
of a physical Turing machine to give his audience a sense of what a
TM is like.
(If you'd like to read more about Turing and the implication of his
universal machine, check out
this reflection
I wrote earlier this year after a visit by Doug Hofstadter to my
campus. Let's just say that the universal TM means more than just
an answer to what functions are effectively computable.)
A bit ahead of Turing, Alonzo Church devised an answer to the same
question in the form of
the lambda calculus,
a formal logical system. As with the universal TM, the lambda
calculus can be used to compute everything, for a particular value
of eveything. These days, nearly every programming language has
lambdas of some form
... now came the second half of the joke running in the background.
Weirich asked his audience collaborator what was in his calculator's
display. The assistant called out some number, 0.7... Then
Weirich showed his next slide -- the same number, taken out many
more digits. How was he able to do this? There is a number
n such that cos(n) = n. By repeatedly
pressing his cosine button, Weirich's assistant eventually reached
it. That number n is called
the fixed point
of the cosine function. Other functions have fixed points to, and
they can be a source of great fun.
Then Weirich opened up his letter and wrote some code from the
ground up to teach some important concepts of functional programming,
using the innocuous function 3(n+1). With this short demo,
Weirich demonstrated the idea of a higher-order function, including
function factories, a set of useful functional refactorings that
included
Introduce Binding
-- where the new binding is unused in the body
Inline Definition
-- where a call to a function is replaced by the function
body, suitably parameterized
Wrap Function
-- where an expression is replaced by a function call that
computes the expression
Tennent Correspondence Principle
-- where an expression is turned into
a think
At the end of his exercise, Weirich had created a big function call
that contained no named function definitions yet computed the same
answer.
He asks the crowd for applause, then demurs. This is 80-year-old
technology. Now you know, he says, what a "chief scientist" at
New Context
does. (Looks a lot like what an academic might do...)
Weirich began a second coding exercise, the point behind all his
exposition to this point: He wrote the factorial function, and
began to factor and refactor it just as he had the simpler
3(n+1). But now inlining the function breaks the code!
There is a recursive call, and the name is now out of scope.
What to do?
He refactors, and refactors some more, until the body of factorial
is an argument to a big melange of lambdas and applications
of lambdas. The result is a function that computes the
fixed point of any function passed it.
That is Y. The Y combinator.
Weirich talked a bit about Y and related ideas, and why it matters.
He closed with a quote from Wittgenstein, from Philosophical
Investigations:
The aspects of things that are most important for us are hidden
because of their simplicity and familiarity. (One is unable to
notice something -- because it is always before one's eyes.)
The real foundations of his enquiry do not strike a man at all.
Unless that fact has at some time struck him. -- And this means:
we fail to be struck by what, once seen, is most striking and
most powerful.
The thing that sets Weirich's presentation of Y apart from the many
others I've seen is its explicit use of refactoring to derive Y.
He created Y from a sequence of working pieces of code, each the
result of a refactoring we can all understand. I love to do this
sort of thing when teaching programming ideas, and I was pleased
to see it used to such good effect on such a challenging idea.
The title of this talk -- Y Not? -- plays on Y's interrogative
homonym.
Another classic in this genre
echos the homonym in its title, then goes on to explain Y in four
pages of English and Scheme. I suggest that you study
@rpg's
essay while waiting for Weirich's talk to hit InfoQ. Then watch
Weirich's talk. You'll like it.
Most of the Tuesday afternoon talks engaged me less deeply than
the ones that came before. Part of that was the content, part
was the style of delivery, and part was surely that my brain
was swimming in so many percolating ideas that there wasn't
room for much more.
Lazy Guesses
Oleg Kiselyov, a co-author of the work behind
yesterday's talk on miniKanren,
gave a talk on how to implement guessing in computer code.
That may sound silly, for a couple of reasons. But it's not.
First, why would we want to guess at all? Don't we want to
follow principles that guarantee we find the right answer?
Certainly, but those principles aren't always available, and
even when they are the algorithms that implement them may be
computationally intractable. So we choose to implement
solutions that restrict the search space, for which we pay a
price along some other dimension, often expressiveness.
Kiselyov mentioned scheduling tasks early in his talk, and
any student of AI can list many other problems for which
"generate and test" is a surprisingly viable strategy. Later
in the talk, he mentioned parsing, which is also a useful
example. Most interesting grammars have nondeterministic
choices in them. Rather than allow our parsers to make
choices and fail, we usually adopt rules that make the
process predictable. The result is an efficient parser, but
a loss in what we can reasonably say in the language.
So, perhaps the ability to make good guesses is valuable.
What is so hard about implementing them? The real problem is
that there are so many bad guesses. We'd like to
use knowledge to guide the process of guessing again, to
favor some guesses over others.
The abstract for the talk promises a general principle on
which to build guessing systems. I must admit that I did
not see it. Kiselyov moved fast at times through his code,
and I lost sight of the big picture. I did see discussions
of forking a process at the OS level, a fair amount of OCaml
code, parser combinators, and lazy evaluation. Perhaps my
attention drifted elsewhere at a key moment.
The speaker closed his talk by showing a dense slide and
saying, "Here is a list of buzzwords, some of which I said
in my talk and some of which I didn't say in my talk." That
made me laugh: a summary of a talk he may or may not have
given. That seemed like a great way to end a talk about
guessing.
Akka
I don't know much about the details of Akka. Many of my
Scala-hacking former students talk about it every so often,
so I figured I'd listen to this quick tour and pick up a
little more. The underlying idea, of course, is
Hewitt's
Actor model.
This is something I'm familiar with from my days in AI and my
interest in Smalltalk.
The presenter, Akka creator Jonas Boner, reminded the audience
that Actors were a strong influence on the original Smalltalk.
In many ways, it is truer to Kay's vision of OOP than the
languages we use today.
This talk was a decent introduction to Hewitt's idea and its
implementation in Akka. My two favorite things from the talk
weren't technical details, but word play:
The name "Akka" has many inspirations, including
a mountain in northern Sweden,
a goddess
of the indigenous people of northern Scandinavia, and
a palindrome of Actor Kernel / Kernel Actor.
Out of context, this quote made the talk for me:
We have made some optimizations to random.
Ah, aren't we all looking for those?
Expressiveness and Abstraction
This talk by Ola Bini was a personal meditation on the
expressiveness of language. Bini, whose first slide
listed him as a "computational metalinguist", started from
the idea that, informally, the expressiveness of a language
is inversely proportional to the distance between our
thoughts and the code we have to write in that language.
In the middle part of the talk, he considered a number of
aspects of expressiveness and abstraction. In the latter
part, he listed ideas from natural language and wondered
aloud what their equivalents would be in programming
languages, among them similes, metaphors, repetition,
elaboration, and multiple equivalent expressions with
different connotations.
During this part of the talk, my mind wandered, too, to a
blog entry I wrote about
parts of speech in programming languages
back in 2003, and
a talk by Crista Lopes
at OOPSLA that year. Nouns, verbs, pronouns, adjectives,
and adverbs -- these are terms I use metaphorically when
teaching students about new languages. Then I thought
about different kinds of sentence -- declarative,
interrogative, imperative, and exclamatory -- and began
to think about their metaphorical appearances in our
programming languages.
Another fitting way for a talk to end: my mind wondering
at the end of a wondering talk.
StrangeLoop 3: Functional Programming 1 -- Monads and Patterns
The StrangeLoop program had a fair amount of functional
programming talks, and I availed myself of two to complete
the first morning of the conference.
Monad Examples for Normal People
The web is full of tutorials claiming to explain monads in a
way that anyone can understand. If any of them had succeeded,
we wouldn't need another. How could I not attend a talk
claiming to slay this dragon?
Getz started out with a traditional starting point: a sequence
of operations that can be viewed as composition of functions.
That works great for standard business logic. But consider a
common exceptional case: given a name, looking up an account
number fails. This requires us to break the symmetry of the
code with guards. These break composition, because now the
return type of the function doesn't fit.
The Maybe monad factors these guards out of the business logic.
If we further need to record and capture error coded, we can
use the Error monad, which factors the same sort of plumbing
out of the business logic and also serves as a facade for a
tuple of value and error code.
After these simple examples, the speaker dove into the sort of
exercise that tends to lose the interest of programmers in the
trenches building apps: building a Lisp interpreter in Python,
using monads to compose the elements of the interpreter. The
environment consists of a combination of the reader monad and
the writer monad; the interpreter consists of a combination of
the environment and the error monad. Several other monads
play a role in representing values, built-in procedures, state,
and non-standard control operators. An interpreter is, he said,
"monad heaven".
The best part of this talks message was in viewing a monad as
a design pattern that abstracts repetitive plumbing out of
applications in such a way that preserves function
composition.
After the talk, someone asked a question to the effect, "I get
by fine with macros and higher-order functions. When do I need
monads?" Getz answered from his personal experience: monads
enable him to write more elegant code, by factoring repetition
that other tools could not reach as nicely.
This wasn't the monad explanation to end the need for new monad
explanations, but it was a decent effort. With the Getz's focus
on factoring code and the question mentioning macros, I could
not help but think of
this essay
that presents monads in the light of code transformation, and
Brian Marick's approach treating a monad as a macro. Perhaps
we are getting near a metaphor for monads that will help "normal
people" grok them without resorting to abstract abstract math.
Functional Design Patterns
From the moment I saw the StrangeLoop line-up, I was excited to
see
Stuart Sierra
speak on functional design patterns. Sierra is one of the few
prominent people in the Lisp and Clojure worlds to acknowledge
the value of design patterns in functional style -- heck, even
to acknowledge they exist.
He opened his talk in a way that confronted the view commonly
held among Lispers, He conceded that, for many, "design
pattern" is a loaded term, bringing to mind an OO cult and the
ominous voice of the Gang of Four. The thing is, Sierra said,
Design Patterns
is a pretty good book, given the time it was written and the
programming language community to which it. speaks. However,
in the functional language community, the design patterns in
that book are best known for being debunked by Peter Norvig in
a 1998 tutorial.
Sierra reminded this audience that patterns can occur at all
levels of a program. He pointed to a lower-profile patterns
book of the mid-1990s,
Pattern-Oriented Software Architecture
(now a five-volume series), which organized patterns at
multiple levels:
architectural -- across components
design -- within components
idiom -- within a particular language
Sierra then went on to list, and describe briefly, several
common patterns he has noticed in functional programs and
used himself in Clojure. Like POSA, he organized
them into categories. Before proceeding, he admitted to
any Haskell programmers in the room that, yes, many of these
patterns are monadic in nature.
I'd very much like to write about some of Sierra's patterns
in greater detail than a single entry permits, including
providing links to blog entries he and others have written
about them. For now, let me list the ones I jotted down,
in Sierra's categories:
state patterns
State/Event, aka Event Sourcing
Consequences
data-building patterns
Accumulator
Reduce/Combine
Recursive Expansion
control flow patterns
Pipeline
Wrapper
Token
Observer
Strategy
Before describing Reduce/Combine, Sierra took a short digression
to talk about MapReduce, a pattern accepted by many in the world
of big data. He reminded us that this pattern is predicated on
the spinning disk becoming the bottleneck of our system. In the
future, this pattern will become less useful as other forces
come to dominate our system architecture.
Two of the control flow patterns, Observer and Strategy, are
held in common with the GoF catalog, though in the context of
functional programming a few new variations become more obvious.
It also seemed to me that Sierra's Wrapper is a lot like the
GoF's Decorator, though he did not make an explicit connection.
As I wrote a couple of years ago,
the time is right
for functional design patterns. I'm so glad that Sierra has
been documented patterns of this sort and articulating the
value of thinking in terms of patterns. The key is not
to look to OO programs for patterns of value to functional
programmers, but to look at functional programs for recurring
choices among design alternatives. (It's not too surprising
that many OO design patterns don't mean much to functional
programmers, just as it's not surprising that FP patterns
dealing with, say, state are afterthoughts in the OO world.)
For my lunch break, I walked a bit outside, to see the sun and
bend my knee a bit. I came back for a set of talks without an
obvious common thread. After seeing the talks, I saw a theme:
ideas for writing programs more conveniently or more concisely.
ClojureScript
David Nolen
talked about
ClojureScript,
a Clojure-like language that compiles to Javascript. As he
noted, there is a lot of work in this space, both older and
newer. The goal of all that work is to write Javascript more
conveniently, or generate it from something else. The goal of
ClojureScript is to bring the expressibility and flexible
programming style of the Lisp world to JS world. Nolen's talk
gave us some insights into the work being done to make the
compiler produce efficient Javascript, as well as into why you
might use ClojureScript in the first place.
Data Structures and Hidden Code
The message of
this talk
by Scott Vokes is that your choice in data structures plays a
big role in determining how much code you have to write. You
can make a lot of code disappear by using more powerful data
structures. We can, of course, generalize this claim from data
structures to data. This is the theme of functional
and object-oriented programming, too. This talk highlights how
often we forget the lowly data structure when we think of writing
less code.
As Vokes said, your choice in data structures sets the "path of
least resistance" for what your program will do and also for the
code you will write. When you start writing code, you often
don't know what the best data structure for your application is.
As long as you don't paint yourself into a corner, you should be
able to swap a new structure in for the old. The key to this is
something novice programmers learn early, writing code not in
terms of a data structure but in terms of higher-level behaviors.
Primitive obsession can become implementation obsession if you
aren't careful.
The meat of this talk was a quick review of four data structures
that most programmers don't learn in school:
skip lists,
difference list,
rolling hashes,
and jumpropes, a structure Vokes claims to invented.
This talk was a source of several good quote, including
"A data structure is just a stupid programming language."
-- Bill Gosper
"A data structure is just a virtual machine." -- Vokes
himself, responding to Gosper
"The cheapest, fastest, and most reliable components are
those that aren't there." -- Gordon Bell
The first two quotes there would make nice mottos for a debate
between functional and OO programming. They also are two sides
of the same coin, which destroys the premise of the debate.
miniKanren
As a Scheme programmer and a teacher of programming languages,
I have developed great respect and fondness for the work of
Dan Friedman
over the last fifteen years. As a computer programmer who
began his studies deeply interested in AI, I have long had a
fondness for
Prolog.
How could I not go to the talk on miniKanren? This is a small
implementation (~600 lines written in a subset of Scheme) of
Kanren,
a declarative logic programming system described in
The Reasoned Schemer.
This talk was like a tag-team vaudeville act featuring Friedman
and co-author
William Byrd.
I can't so this talk justice in a blog entry. Friedman and Byrd
interleaved code demo with exposition as they
showed miniKanren at its simplest, built from three operators
(fresh, conde, and run)
extended the language with a few convenient operators for
specifying constraints, types, and exclusions, and
illustrated how to program in miniKanren by building a
language interpreter, EOPL style.
The cool endpoint of using logic programming to build the
interpreter is that, by using variables in a specification,
the interpreter produces legal programs that meet a given
specification. It generates code via constraint resolution.
If that weren't enough, they also demo'ed how their system can,
given a language grammar, produce
quines
-- programs p such that
(equal p (eval p))
-- and twines, pairs of programs p and q
such that
(and (equal p (eval q))
(equal q (eval p)))
Then they live-coded an implementation of typed lambda calculus.
Yes, all in fifty minutes. Like I said, you really need to watch
the talk at InfoQ as soon as it's posted.
In the course of giving the talk, Friedman stated a rule that my
students can use:
Will's law:
If your function has a recursion, do the recursion last.
Will followed up with cautionary advice:
Will's second law:
If your function has two recursions, call Will.
We'll see how serious he was when I put a link to his e-mail
address in my Programming Languages class notes next spring.
This week I have the pleasure of spending a couple of days
expanding my mind at
StrangeLoop
2012. I like StrangeLoop because it's a conference for programmers.
The program is filled with hot programming topics and languages,
plus a few keynotes to punctuate our mental equilibria. The 2010
conference gave me
plenty to think about,
but I had to skip 2011 while
teaching and recovering.
This year was a must-see.
I'll be posting the following entries from the conference as
time permits me to write them.
Over the summer, I gave a talk as part of a one-day conference
on the STEM disciplines for area K-12, community college, and
university advisors. They were interested in, among other
things, the kind of classes that CS students take at the
university and the kind of jobs they get when they graduate.
In the course of talking about how some of the courses our
students take (say, algorithms and the theory of computing)
seem rather disconnected from many of the jobs they get (say,
web programmer and business analyst), I claimed that the more
abstract courses prepare students to understand the parts of
the computing world that never change, and the ones that do.
The specific programming languages or development stack they
use after they graduate to build financial reporting software
may change occasionally, but the foundation they get as a CS
major prepares them to understand what comes next and to adapt
quickly.
In this respect, I said, a university CS education is not job
training. Computer Science is a liberal art.
This is certainly true when you compare university CS education
with what students get at a community college. Students who
come out of a community college networking program often possess
specific marketable skills at a level we are hard-pressed to
meet in a university program. We bank our program's value on
how well it prepares students for a career, in which networking
infrastructure changes multiple times and our grads are asked to
work at the intersection of networks and other areas of computing,
some of which may not exist yet.
It is also true relative to the industries they enter after
graduation. A CS education provides a set of basic skills and,
more important, several ways to think about problems and
formulate solutions. Again, students who come out of a targeted
industry or 2-year college training program in, say, web dev,
often have "shovel ready" skills that are valuable in industry
and thus highly marketable. We bank our program's value on how
well it prepares students for a career in which ASP turns to JSP
turns PHP turns to JavaScript. Our students should be prepared
to ramp up quickly and have a shovel in the hands producing value
soon.
And, yes, students in a CS program must learn to write code.
That's a basic skill. I often hear people comment that computer
science programs do not prepare students well for careers in
software development. I'm not sure that's true, at least at
schools like mine. We can't get away with teaching all theory
and abstraction; our students have to get jobs. We don't try
to teach them everything they need to know to be good software
developers, or even many particular somethings. That should
and will come on the job. I want my students to be prepared
for whatever they encounter. If their company decides to go
deep with Scala, I'd like my former students to be ready to go
with them.
In
a comment
on John Cook's timely blog entry
How long will there be computer science departments?,
Daniel Lemire suggests that we emulate the model of medical
education, in which doctors serve several years in residency,
working closely with experienced doctors and learning the
profession deeply. I agree. Remember, though, that aspiring
doctors go to school for many years before they start residency.
In school, they study biology, chemistry, anatomy, and physiology
-- the basic science at the foundation of their profession. That
study prepares them to understand medicine at a much deeper level
than they otherwise might. That's the role CS should play for
software developers.
(Lemire also smartly points out that programmers have the ability
to do residency almost any time they like, by joining an open
source project. I love to read about how
Dave Humphrey
and people like him bring open-source apprenticeship directly into
the undergrad CS experience and wonder how we might do something
similar here.)
So, my claim that Computer Science is a liberal arts program for
software developers may be crazy, but it's not entirely crazy.
I am willing to go even further. I think it's reasonable to
consider Computer Science as part of the liberal arts for
everyone.
I'm certainly not the first person to say this. In 2010,
Doug Baldwin
and
Alyce Brady
wrote a guest editors' introduction to a special issue of the
ACM Transactions on Computing Education called
Computer Science in the Liberal Arts.
In it, they say:
In late Roman and early medieval times, seven fields of study,
rooted in classical Greek learning, became canonized as the
"artes liberales" [Wagner 1983], a phrase denoting the
knowledge and intellectual skills appropriate for citizens
free from the need to labor at the behest of others. Such
citizens had ample leisure time in which to pursue their own
interests, but were also (ideally) civic, economic, or moral
leaders of society.
...
[Today] people ... are increasingly thinking in terms of the
processes by which things happen and the information that
describes those processes and their results -- as a computer
scientist would put it, in terms of algorithms and data.
This transformation is evident in the explosion of activity
in computational branches of the natural and social sciences,
in recent attention to "business processes," in emerging
interest in "digital humanities," etc. As the transformation
proceeds, an adequate education for any aspect of life demands
some acquaintance with such fundamental computer science
concepts as algorithms, information, and the capabilities and
limitations of both.
The real value in a traditional Liberal Arts education is in
helping us find better ways to live, to expose us to the best
thoughts of men and women in hopes that we choose a way to
live, rather than have history or accident choose a way to
live for us. Computer science, like mathematics, can play a
valuable role in helping students connect with their best
aspirations. In this sense, I am comfortable at least
entertaining the idea that CS is one of the modern liberal
arts.
Last month I was teaching my wife to drive [a manual transmission
car], and it's amazing how easy stick shifting is if the car is
already moving.... However, when the car is stopped and you need
to get into 1st gear, it's extremely difficult. [So many things
can go wrong:] too little gas, too much clutch, etc. ...
The same is true with the work day. Once you get going, you want
to avoid coming to a standstill and having to get yourself moving
again.
As I make the move from runner to cyclist, I have learned how
much easier to keep moving on a bike than it is to
start moving on a bike.
This is true of programming, too. Test-driven development helps
us get started by encouraging us to focus on one new piece of
functionality to implement. Keep it small, make it work, and
move on to another small step. Pretty soon you are moving, and
you are on your way.
Another technique many programs use to get started is to code
a failing test before you stop the day before. This failing
test focuses you even more quickly and recruits your own memory
for help in recreating the feeling of motion more quickly.
It's like a way to leave the car running in second gear.
I'm trying to help my students, who are mostly still learning
how to write code, learn how to get started when they program.
Many of them seem repeatedly to find themselves sitting still,
grinding their gears and trying to figure out how to write the
next bit of code and get it running. Ultimately, the answer
may come down to the same thing we learn when we learn to
drive a stick: practice, practice, practice, and eventually
you get the feel of how the gearshift works.
I sometimes feel guilty that most of what I write here describes
connections between teaching or software development and what I
see in other parts of the world. These connections are valuable
to me, though, and writing them down is valuable in another way.
I'm certainly not alone. In Why Read, Mark Edmondson
argues for the value of reading great literature and trying on
the authors' view of the world. Doing so enables us to better
understand our own view of the world, It also gives us the raw
material out of which to change our worldview, or build a new
one, when we encounter better ideas. In the chapter "Discipline",
Edmondson writes:
The kind of reading that I have been describing here -- the
individual quest for what truth a work reveals -- is fit for
virtually all significant forms of creation. We can seek vital
options in any number of places. They may be found for this or
that individual in painting, in music, in sculpture, in the arts
of furniture making or gardening.
Thoreau
felt he could derive a substantial wisdom by tending his bean
field. He aspired to
"know beans".
He hoed for sustenance, as he tells us, but he also hoed in
search of
tropes,
comparisons between what happened in the garden and what happened
elsewhere in the world. In his bean field, Thoreau sought ways
to turn language -- and life -- away from old stabilities.
I hope that some of my tropes are valuable to you.
The way Edmondson writes of literature and the liberal arts
applies to the world of software in a much more direct ways too.
First, there is the research literature of computing and software
development. One can seek truth in the work of Alan Kay, David
Ungar, Ward Cunningham, or Kent Beck. One can find vital options
in the life's work of Robert Floyd, Peter Landin, or Alan Turing;
Herbert Simon, Marvin Minsky, or John McCarthy. I spent much of
my time in grad school immersed in the writings and work of
B. Chandrasekaran,
which affected my view of intelligence in both humans and
machines.
Each of these people offers a particular view into a particular
part of the computing world. Trying out their worldviews can
help us articulate our own worldviews better, and in the process
of living their truths we sometimes find important new truths
for ourselves.
We in computing need not limit ourselves to the study of research
papers and books. As Edmondson says the individual quest for the
truth revealed in a work "is fit for virtually all significant
forms of creation". Software is a significant form of creation,
one not available to our ancestors even sixty years ago. Live
inside any non-trivial piece of software for a while, especially
one that has withstood the buffets of human desire over a period
of time, and you will encounter truth -- truths you find there,
and truths you create for yourself. A few months trying on
Smalltalk and its peculiar view of the world
taught me OOP
and a whole lot more.
Patrick Honner has been writing a series of blog posts reviewing
problems from the June 2012 New York State Math Regents exams.
A recent entry
considered a problem in which students were asked to compute the
probability that a dart hits the bull's eye on a dartboard. This
question requires the student to make a specific assumption: "that
every point on the target is equally likely to be hit".
Honner writes:
... It's not necessarily bad that we make such assumptions:
refining and simplifying problems so they can be more easily
analyzed is a crucial part of mathematical modeling and
problem solving.
What's unfortunate is that, in practice, students are kept
outside this decision-making process: how and why we make
such assumptions isn't emphasized, which is a shame, because
exploring such assumptions is a fundamental mathematical
process.
The same kinds of assumptions are built into even the most realistic
problems that we set before our students. But discussing assumptions
is an essential part of doing math. Which assumptions are reasonable?
Which are necessary? What is the effect of a particular assumption on
the meaning of the problem, on the value of the answer we will obtain?
This kind of reasoning is, in many ways, the real math in a problem.
Once we have a formula or two, we are down to crunching numbers.
That's arithmetic.
Computer science teachers face the risks when we pose problems to our
students, including programming problems. Discovering the boundaries
of a problem and dealing with the messy details that live on the
fringe are an essential part of making software. When we create
assignments that can be neatly solved in a week or two, we hide "a
fundamental computing process" from our students. We also rob them of
a lot of fun.
As Honner says, though, making assumptions is not necessarily bad. In
the context of teaching a course, they are necessary. Sometimes, we
need to focus our students' attention on a specific new skill to be
learned or honed. Tidying up the boundaries of a problem bring that
skill into greater relief and eliminate what are at the moment
unnecessary distractions.
It is important, though, for a computing curriculum to offer students
increasing opportunities to confront the assumptions we make and begin
to make assumptions for themselves. That level of modeling is also a
specific skill to be learned and honed. It also can make class more
fun for the professor, if a lot messier when it comes time to
evaluating student work and assigning grades.
Even when we have to make assumptions prior to assigning a problem,
discussing them explicitly with students can open their eyes to the
rest of the complexity in making software. Besides, some students
already sense or know that we are hiding details from them, and having
the discussion is a way to honor their knowledge -- and earn their
respect.
So, the next time you assign a problem, ask yourself: What assumptions
have I made in simplifying this problem? Are they necessary? If not,
can I loosen them? If yes, can my students benefit from discussing
them?
And be prepared... If you leave a few messy assumptions lying around
a problem for your students to confront and make on their own, some
students will be unhappy with you. As Honner says, we teachers spend a
lot of time training students to make implicit assumptions unthinkingly.
In some ways, we are too successful for our own good.
The month has flown by, preparing for and now teaching our
"intermediate computing" course. Add to that a strange
and unusual set of administrative issues, and I've found
no time to blog. I did, however manage to post what has
become
my most-retweeted tweet
ever:
I wish I had enough money to run Oracle instead of Postgres.
I'd still run Postgres, but I'd have a lot of cash.
That's an adaptation of tweet originated by
@petdance
and retweeted my way by
@logosity.
I polished it up, sent it off, and -- it took off for the
sky. It's been fun watching its ebb and flow, as it
reaches new sub-networks of people. From this experience
I must learn at least one lesson: a lot of people are tired
of sending money to Oracle.
The first two weeks of my course have led the students a
few small steps toward object-oriented programming. I am
letting the course evolve, with a few guiding ideas but no
hard-and-fast plan. I'll write about the course's structure
after I have a better view of it. For now, I can summarize
the first four class sessions:
Run a simple "memo pad" app, trying to identify behavior
(functions) and state (persistent data). Discuss how
different groupings of the functions and data might
help us to localize change.
Look at the code for the app. Discuss the organization
of the functions and data. See a couple of basic design
patterns, in particular the separation of model and view.
Study the code in greater detail, with a focus on the
high-level structure of an OO program in Java.
Study the code in greater detail, with a focus on the
lower-level structure of classes and methods in Java.
The reason we can spend so much time talking about a simple
program is that students come to the course without (necessarily)
knowing any Java. Most come with knowledge of Python or Ada,
and their experiences with such different languages creates
an interesting space in which to encounter Java. Our goal
this semester is for students to learn their second language
as much as possible, rather than having me "teach" it to them.
I'm trying to expose them to a little more of the language
each day, as we learn about design in parallel. This approach
works reasonably well with Scheme and functional programming
in a programming languages course. I'll have to see how well
it works for Java and OOP, and adjust accordingly.
Next week we will begin to create things: classes, then small
systems of classes. Homework 1 has them implementing a simple
array-based class to an interface. It will be our first
experience with polymorphic objects, though I plan to save
that jargon for later in the course.
Finally, this is the new world of education: my students are
sending me links to on-line sites and videos that have helped
them learn programming. They want me to check them and and
share with the other students. Today I received a link to
The New Boston,
which has among its 2500+ videos eighty-seven beginning Java
and fifty-nine intermediate Java titles. Perhaps we'll come
to a time when I can out-source all instruction on specific
languages and focus class time on higher-level issues of
design and programming...
... providing the function in a separate program makes convenient
options ... easier to invent, because it isolates the problem as
well as the solution.
In OO, objects are the packages that create possibilities for us.
The beauty of this lesson is the justification: because a class
isolates the problem as well as the solution.
This solution affects no other programs, but can be used with all
of them.
This is one of the great advantages of polymorphic objects.
The key to problem-solving on the UNIX system is to identify the
right primitive operations and to put them at the right place.
Methods should live in the objects whose data they manipulate.
One of the hard lessons for novice OO programmers coming from a
procedural background is putting methods
with the thing, not a faux actor.
UNIX programs tend to solve general problems rather than special
cases.
Objects that are too specific should be rare, at least for
beginning programmers. Specificity in interface often indicates
that implementation detail is leaking out.
Merely adding features does not make it easier for users to do
things -- it just makes the manual thicker.
Keep objects small and focused. A big interface is often evidence
of an object waiting to be born.
~~~~
In many ways, The Unix Way is contrary to object-oriented programming.
Or so many of Linux friends tell me. But I'm quite comfortable with
the parallels found in these quotes, because they are more about
good design in general than about Unix or OOP themselves.
A lot of people think that you can't be old and be good, and that's
not true. You just have to be willing to let go of the strengths
that you had a year ago and get some new strengths this year.
Because it does change fast, and if you're not willing to do that,
then you're not really able to be a programmer.""
There is a lot of stuff I don't know. I won't run out of things
to read and learn and do for a long, long, time.
This is an ongoing theme in the life of a programmer, in the life
of a teacher, and the life of an academic: the choice we make
each day between
keeping up and settling down.
Keeping up is a lot more fun, but it's work. If you aren't
comfortable giving up what you were awesome at yesterday, it's
even more painful. I've been lucky mostly to enjoy learning new
stuff more than I've enjoyed knowing the old stuff. May you be
so lucky.
Charlie Stross is a sci-fi writer. Some of my friends have
recommended his fiction, but I've not read any. In
Writing a novel in Scrivener: lessons learned,
he, well, describes what he has learned writing novels using
Scrivener,
an app for writers well known in the Mac OS X world.
I've used it before on several novels, notably ones where the
plot got so gnarly and tangled up that I badly needed a tool
for refactoring plot strands, but the novel I've finished,
"Neptune's Brood", is the first one that was written from
start to finish in Scrivener...
... It doesn't completely replace the word processor in my
workflow, but it relegates it to a markup and proofing tool
rather than being a central element of the process of creating
a book. And that's about as major a change as the author's
job has undergone since WYSIWYG word processing came along in
the late 80s....
My suspicion is that if this sort of tool spreads, the long-term
result may be better structured novels with fewer dangling plot
threads and internal inconsistencies. But time will tell.
Stross's lessons don't all revolve around refactoring, but
being able to manage and manipulate the structure of the
evolving novel seems central to his satisfaction.
I've read a lot of novels that seemed like they could have used
a little refactoring. I always figured it was just me.
The experience of writing anything in long form can probably be
improved by a good refactoring tool. I know I find myself
doing some pretty large refactorings when I'm working on the
set of lecture notes for a course.
Programmers and computer scientists have the advantage of being
more comfortable writing text in code, using tools such as
LaTex
and
Scribble,
or homegrown systems. My sense, though, is that fewer programmers
use tools like this, at least at full power, than might benefit
from doing so.
Like Stross, I have a predisposition against using tools with
proprietary data formats. I've never lost data stored in
plaintext to version creep or application obsolescence. I do use
apps such as
VoodooPad
for specific tasks, though I am keenly aware of the exit strategy
(export to text or RTFD ) and the pain trade-off at exit (the more
VoodooPad docs I create, the more docs I have to remember to export
before losing access to the app). One of the things I like most
about
MacJournal
is that it's nothing but a veneer over a set of Unix directories
and RTF documents. The flip side is that it can't do for me
nearly what Scrivener can do.
Thinking about a prose writing tool that supports refactoring
raises an obvious question: what sort of refactoring operations
might it provide automatically? Some of
the standard code refactorings
might have natural analogues in writing, such as Extract
Chapter or Inline Digression.
Thinking about automated support for refactoring raises another
obvious question, the importance of which is surely as clear to
novelists as to software developers: Where are the unit tests?
How will we know we haven't broken the story?
I'm not being facetious. The biggest fear I have when I refactor
a module of a course I teach is that I will break something
somewhere down the line in the course. Your advice is welcome!
A Few Comments on the Alan Kay Interview, and Especially Patterns
Many of my friends and colleagues on Twitter today are
discussing the
Interview with Alan Kay
posted by Dr. Dobb's yesterday. I read the piece this morning
while riding the exercise bike and could not contain my desire
to underline passages, star paragraphs, and mark it up with my
own comments. That's hard to do while riding hard, hurting a
little, and perspiring a lot. My desire propelled me forward
in the face of all these obstacles.
Kay is always provocative, and in this interview
he leaves no oxen ungored.
Like most people do when whenever they read outrageous and
provocative claims, I cheered when Kay said something I agreed
with and hissed -- or blushed -- when he said something that
gored me or one of my pet oxen. Twitter is a natural place to
share one's cheers and boos for an artyicle with or by Alan
Kay, given the
amazing density of soundbites
one finds in his comments about the world of computing.
(One might say the same thing about Brian Foote, the source
of both soundbites in that paragraph.)
I won't air all my cheers and hisses here. Read the article,
if you haven't already, and enjoy your own. I will comment on
one paragraph that didn't quite make me blush:
The most disastrous thing about programming -- to pick one of
the 10 most disastrous things about programming -- there's a
very popular movement based on pattern languages. When
Christopher Alexander first did that in architecture, he was
looking at 2,000 years of ways that humans have made themselves
comfortable. So there was actually something to it, because he
was dealing with a genome that hasn't changed that much. I
think he got a few hundred valuable patterns out of it. But
the bug in trying to do that in computing is the assumption
that we know anything at all about programming. So extracting
patterns from today's programming practices ennobles them in a
way they don't deserve. It actually gives them more cachet.
Long-time Knowing and Doing readers know that
patterns
are one of my pet oxen, so it would have been natural for me
to react somewhat as
Keith Ray did
and chide Kay for what appears to be a typical "Hey, kids, get
off my lawn!" attitude. But that's not my style, and I'm such
a big fan of
Kay's larger vision for computing
that my first reaction was to feel a little sheepish. Have I
been wasting my time on a bad idea, distracting myself from
something more important? I puzzled over this all morning, and
especially as I read other people's reactions to the interview.
Ultimately, I think that Kay is too pessimistic when he says
we hardly know anything at all about programming. We may well
be closer to the level of the Egyptians who built the pyramids
than we are to the engineers who built the Empire State Building.
But I simply don't believe that people such as Ward Cunningham,
Ralph Johnson, and Martin Fowler don't have a lot to teach most
of us about how to make better software.
Wherever we are, I think it's useful to identify, describe, and
catalog the patterns we see in our software. Doing so enables
us to talk about our code at a level higher than
parentheses and semicolons.
It helps us bring other programmers up to speed more quickly, so
that we don't all have to struggle through all the same detours
and tar pits our forebears struggled through. It also makes it
possible for us to talk about the strengths and weaknesses of our
current patterns and to seek out better ideas and to adopt -- or
design -- more powerful languages. These are themes Kay himself
expresses in this very same interview: the importance of knowing
our history, of making more powerful languages, and of education.
Kay says something about education in this interview that is
relevant to the conversation on patterns:
Education is a double-edged sword. You have to start where
people are, but if you stay there, you're not educating.
The real bug in what he says about patterns lies at one edge
of the sword. We may not know very much about how to make
software yet, but if we want to remedy that, we need to start
where people are. Most software patterns are an effort to
reach programmers who work in the trenches, to teach them a
little of what we do know about how to make software. I can
yammer on all I want about functional programming. If a
Java practitioner doesn't appreciate the idea of
a Value Object
yet, then my words are likely wasted.
Ironically, many argue that the biggest disappointment of the
software patterns effort lies at the other edge of
education's sword: an inability to move the programming world
quickly enough from where it was in the mid-1990s to a better
place. In
his own Dr. Dobb's interview,
Ward Cunningham observed with a hint of sadness that an
unexpected effect of the Gang of Four
Design Patterns
book was to extend the life of C++ by a decade, rather than
reinvigorating Smalltalk (or turning people on to Lisp).
Changing the mindset of a large community takes time. Many in
the software patterns community tried to move people past a
static view of OO design embodied in the GoF book, but the
vocabulary calcified more quickly than they could respond.
Perhaps that is all Kay meant by his criticism that patterns
"ennoble" practices in a way they don't deserve. But if so,
it hardly qualifies in my mind as "one of the 10 most
disastrous things about programming". I can think of a lot
worse.
To all this, I can only echo the
Bokononists
in Kurt Vonnegut's novel Cat's Cradle: "Busy, busy,
busy." The machinery of life is usually more complicated and
unpredictable than we expect or prefer. As a result, reasonable
efforts don't always turn out as we intend them to. So it goes.
I don't think that means we should stop trying.
Don't let my hissing about one paragraph in the interview
dissuade you from reading the Dr. Dobb's interview. As usual,
Kay stimulates our minds and encourages us to do better.
Greg Robbins and Ron Avitzur, the authors of MacOS's original
Graphing Calculator, offer nine tips for
Designing Applications for the Power Macintosh.
All of them are useful whatever your target machine. One of
my favorites is:
5. Avoid programming cleverness. Instead, assume a good
compiler and write readable code.
This is good programming advice in nearly every situation, for
all the software engineering reasons we know. Perhaps
surprisingly, it is good advice even when you are writing code
that has to be fast and small, as Robbins and Avitzur were:
Cycle-counting and compiler-specific optimizations are favorite
pastimes of hackers, and sometimes they're important. But we
could never have completed the Graphing Calculator in under six
months had we worried about optimizing each routine. Rather,
we dealt with speed problems only when they were perceptible to
users.
We made no attempt to look at performance bottlenecks or at the
compiled code of the Calculator until after running execution
profiles. We were surprised where the time was being spent.
Most of the time that the Calculator is compute-bound it's
either in the math libraries or in QuickDraw. So little time
is spent in our code that even compiling it unoptimized didn't
slow it down perceptibly. Improving our code's performance
meant calling the math libraries less often.
This has been my experience with every large program or set of
programs I've written, too. I know where the code is
spending its time. Then I run the profiler, and it shows me
I'm wrong. Donald Knuth famously warned us against
small efficiencies and premature optimization.
Robbins and Avitzur's advice also has a user-centered dimension.
Programmers are often tempted to spend time saving a few bytes
or cycles or to fine-tune an algorithm. If the change isn't
visible to users, however, the benefits may not extend beyond
the programmer's satisfaction. When most of the code in an
application is straightforward and readable, maintenance and
improvements are easier to make. Those are changes that users
will notice.
We write code for our users. Programmer satisfaction comes
second. This passage reminds me of a lesson I internalized
from the early days extreme programming: At the end of the day,
if you haven't added value for your customer, you haven't earned
your day's pay.
I listened to about 3/4 of Zen and the Art of Motorcycle
Maintenance on a long-ish drive recently. It's been a
while since I've read the whole book, but I listen to it on
tape once a year or so. It always gets my mind in the mood
to think about learning to read, write, and debug programs.
This fall, I will be teaching our third course for first time
since became head seven years ago. In that time, we changed
the name of the course from "Object-Oriented Programming" to
"Intermediate Computing". In many ways, the new name is an
improvement. We want students in this course to learn a
number of skills and tools in the service of writing larger
programs. At a fundamental level, though OOP remains the
centerpiece of everything we do in the course.
As I listened to Pirsig make his way across the Great Plains,
a few ideas stood out as prepare to teach one of my favorite
courses:
• The importance of making your own thing, not
just imitating others. This is always a challenge
in programming courses, but for most people it is essential
if we hope for students to maximize their learning. It
underlies several other parts of Pirsig's zen and art, such
as caring about our artifacts, and the desire to go beyond
what something is to what it means.
• The value of reading code, both good and
bad. Even after only one year of programming,
most students have begun to develop a nose for which is
which, and nearly all have enough experience that they can
figure out the difference with minimal interference from the
instructor. If we can get them thinking about what features
of a program make it good or bad, we can move on to the more
important question: How can we write good programs? If we
can get students to think about this, then they can see the
"rules" we teach them for what they really are: guidelines,
heuristics that point us in the direction of good code.
They can learn the rules with an end in mind, and not as an
end in themselves.
• The value of grounding abstractions in everyday
life. When we can ground our classwork in their own
experiences, they are better prepared to learn from it. Note
that this may well involve undermining their naive ideas about
how something works, or turning a conventional wisdom from
their first year on its head. The key is to make what they
see and do matter to them.
One idea remains fuzzy in my head but won't let me go. While
defining the analytic method, Pirsig talks briefly about the
difference between analysis by composition and
analysis by function. Given that this course is
teaches object-oriented programming in Java, there are so many
ways in which this distinction could matter: composition and
inheritance, instance variables and methods, state and behavior.
I'm not sure whether there is anything particular useful in
Pirsig's philosophical discussion of this, so I'll think some
more about it.
I'm also thinking a bit about a non-Zen idea for the
course: Mark Guzdial's method of
worked examples and self-explanation.
My courses usually include a few worked examples, but Mark has
taken the idea to another level. More important, he pairs it
with an explicit step in which students explain examples to
themselves and others. This draws on results from research in
CS education showing that learning and retention are improved
when students explain something in their own words. I think
this could be especially valuable in a course that asks students
to learn a new style of writing code.
One final problem is on my mind right now, a more practical
matter: a textbook for the course. When I last taught this
course, I used Tim Budd's
Understanding Object-Oriented Programming with Java.
I have written in the past that
I don't like textbooks much,
but I always liked this book. I liked the previous
multi-language incarnation of the book
even more.
Unfortunately, one of the purposes of this course is to have
students learn Java reasonably well.
Also unfortunate is that Budd's OOP/Java book is now twelve
years old. A lot has happened in the Java world in the
meantime. Besides, as I found while
looking for a compiler textbook last fall,
the current asking price of over $120 seems steep --
especially for a CS textbook published in 2000!
So I persist in my quest. I'd love to find something that
looks like it is from this century, perhaps even reflecting
the impending evolution of the textbook
we've all been anticipating. Short of that, I'm looking for
a modern treatment of both OO principles and Java.
Of course, I'm a guy who still listens to books on tape, so
take my sense of what's modern with a grain of salt.
Every step of every research project we do is written in code,
from raw data to final paper. Doing research is therefore
writing software.
The authors are economists at the University of Chicago. I
have only skimmed the beginning of the paper, but I like
what little I've seen. They take seriously the writing
of computer programs.
"This document lays out some broad principles we should
all follow."
"We encourage you to invest in reading more broadly
about software craftsmanship, looking critically at your
own code and that of your colleagues, and suggesting
improvements or additions to the principles below."
"Apply these principles to every piece of code you check
in without exception."
"You should also take the time to improve code you are
modifying or extending even if you did not write the code
yourself."
...every piece of code you check in... Source code
management and version control? They are a couple of steps up
on many CS professors and students.
Unix guru
Rob Pike,
on "programming in the large":
There's this idea about "programming in the large" and
somehow C++ and Java own that domain. I believe that's
just a historical accident, or perhaps an industrial
accident. But the widely held belief is that it has
something to do with object-oriented design.
Big software needs methodology to be sure, but not
nearly as much as it needs strong dependency management
and clean interface abstraction and superb documentation
tools, none of which is served well by C++ (although
Java does noticeably better).
That is as succinct a summary as I've seen of what people
need from a language in order to write and maintain large
programs: strong dependency management, clean interface
abstraction, and superb documentation tools. I think
that individuals and small teams need them as much as
large teams, but that you experience the pain of not
having them much sooner when you work on larger teams.
The quoted passage is from
Less is exponentially more,
the text of a talk he gave this month about the biggest
surprise he experienced from the rolling out of
Go,
the programming language he and several colleagues created
at Google. He had expected Go to attract C and C++
programmers, because Go was designed to do the things that
C++ is used for. Instead, it attracts programmers from
Python and Ruby. I'm tempted to quote Pike's conclusion,
because it's so succinct, but instead I'll let you read
his blog post yourself.
It was interesting to read this paper the day after seeing
Leo Meyerovich's blog post
on the sociology of programming languages. After reading
Pike's thoughts on the spread of Go, I'm more motivated to
read
the paper
Meyerovich introduces, on the principles for programming
language adoption.
Irrespective of the adoption question: Pike's talk has no
code in it, yet it conveys the spirit of Go better than
anything I had read before.
Test-First Development and Implementation of Processing.js
While describing the lessons learned by the team that wrote
Processing.js,
Mike Kamermans talks about one of the benefits of writing
tests before writing code:
The usual process, in which code is written and then test
cases are written for that code, actually creates biased
tests. Rather than testing whether or not your code does
what it should do, according to the specification, you are
only testing whether your code is bug-free. In Processing.js,
we instead start by creating test cases based on what the
functional requirements for some function or set of functions
is, based on the documentation for it. With these unbiased
tests, we can then write code that is functionally complete,
rather than simply bug-free but possibly deficient.
When you implement a language processor, you can use the
language specification as a primary guide. Testing your code
efficiently, though, means translating the features of the
spec into test cases -- code. When you port a language from
one platform to another, you can usually use the documentation
of the original implementation as a guide, too. The Processing.js
team had the benefit that the original implementation also
came with a large set of test cases. This allowed them to
write code against tests from the beginning, and then write
their own tests before writing code that went beyond the scope
of the original.
The next time I teach our compiler course, I hope to do a
better job getting students to write tests sooner, if not first,
as a matter of habit. Perhaps I will seed the teams with a few
tests to help them get started.
~~~~
The passage above comes from
the chapter on Processing.js
in Volume 2 of
The Architecture of Open Source Applications.
This was a good read that taught me a bit about Javascript,
HTML 5, and the web browser as a platform. But most of all
it explained the thought process that went into porting a
powerful Java package to an architecture with considerably
different strengths and weakness. Language theory is all
fine and good, but language implementors have to make
pragmatic choices in the service of users. It's essential
to remember that, in the end, what matters is that the
compiler or interpreter produce correct results -- and not,
in the case of a port, that the resulting code resemble the
original (another lesson the Processing.js team learned).
Another lesson this chapter teaches is to acknowledge when
when program doesn't meet everyone's expectations. This
was a serious challenge for Processing.js, because Java
makes possible behaviors that a web browser does not. When
you can't make something work the way people expect, tell
them. Processing.js provides documentation for people
who come to it with a Processing background, and documentation
for people who come to it with a JavaScript background.
Basic Arithmetic, APL-Style, and Confident Problem Solvers
After writing last week about
a cool array manipulation idiom,
motivated by APL, I ran across another reference to "APL style"
computation yesterday while catching up with weekend traffic on
the
Fundamentals of New Computing
mailing list. And it was cool, too.
Consider the sort of multi-digit addition problem that we
all spend a lot of time practicing as children:
365
+ 366
------
The technique requires converting two-digit sums, such as
6 + 5 = 11 in the rightmost column, into a units digit and
carrying the tens digit into the next column to the left.
The process is straightforward but creates problems for
many students. That's not too surprising, because there is
a lot going on in a small space.
David Leibs described a technique, which he says he learned
from something Kenneth Iverson wrote, that approaches the task
of carrying somewhat differently. It takes advantage of the
fact that a multi-digit number is a vector of digits times
another vector of powers.
First, we "spread the digits out" and add them, with no concern
for overflow:
3 6 5
+ 3 6 6
------------
6 12 11
Then we normalize the result by shifting carries from right to
left, "in fine APL style".
6 12 11
6 13 1
7 3 1
According to Leibs, Iverson believed that this two-step approach
was easier for people to get right. I don't know if he had any
empirical evidence for the claim, but I can imagine why it might
be true. The two-step approach separates into independent
operations the tasks of addition and carrying, which are
conflated in the conventional approach. Programmers call this
separation of concerns, and it makes software easier to
get right, too.
Multiplication can be handled in a conceptually similar way.
First, we compute an outer product by building a digit-by-digit
times table for the digits:
This is straightforward, simply an application of the basic facts
that students memorize when they first learn multiplication.
Then we sum the diagonals running southwest to northeast, again
with no concern for carrying:
(9) (18+18) (18+36+15) (36+30) (30)
9 36 69 66 30
In the traditional column-based approach, we do this implicitly
when we add staggered columns of digits, only we have to worry
about the carries at the same time -- and now the carry digit
may be something other than one!
Finally, we normalize the resulting vector right to left, just
as we did for addition:
Again, the three components of the solution are separated into
independent tasks, enabling the student to focus on one task at a
time, using for each a single, relatively straightforward operator.
(Does this approach remind some of you of
Cannon's algorithm
for matrix multiplication in a two-dimensional mesh architecture?)
Of course, Iverson's
APL
was designed around vector operations such as these, so it includes
operators that make implementing such algorithms as straightforward
as the calculate-by-hand technique. Three or four Greek symbols
and, voilá, you have a working program. If you are
Dave Ungar,
you are well on your way to a compiler!
I have a great fondness for alternative ways to do arithmetic.
One of the favorite things I ever got from my dad was a worn
copy of Lester Meyers's
High-Speed Math Self-Taught.
I don't know how many hours I spent studying that book, practicing
its techniques, and developing my own shortcuts. Many of these
techniques have the same feel as the vector-based approaches to
addition and multiplication: they seem to involve more steps, but
the steps are simpler and easier to get right.
A good example of this I remember learning from High-Speed Math
Self-Taught is a shortcut for finding 12.5% of a number: first
multiply by 100, then divide by 8. How can a multiplication and a
division be faster than a single multiplication? Well, multiplying
by 100 is trivial: just add two zeros to the number, or shift the
decimal point two places to the right. The division that remains
involves a single-digit divisor, which is much easier than
multiplying by a three-digit number in the conventional way. The
three-digit number even has its own decimal point, which complicates
matters further!
To this day, I use shortcuts that Meyers taught me whenever I'm
making updating the balance in my checkbook register, calculating
a tip in a restaurant, or doing any arithmetic that comes my way.
Many people avoid such problems, but I seek them out, because I
have fun playing with the numbers.
I am able to have fun in part because I don't have to worry too
much about getting a wrong answer. The alternative technique
allows me to work not only faster but also more accurately. Being
able to work quickly and accurately is a great source of confidence.
That's one reason I like the idea of teaching students alternative
techniques that separate concerns and thus offer hope for making
fewer mistakes. Confident students tend to learn and work faster,
and they tend to enjoy learning more than students who are
handcuffed by fear.
I don't know if anyone was tried teaching Iverson's APL-style
basic arithmetic to children to see if it helps them learn faster
or solve problems more accurately. Even if not, it is both a great
demonstration of separation of concerns and a solid example of how
thinking about a problem differently opens the door to a new kind
of solution. That's a useful thing for programmers to learn.
~~~~
Postscript. If anyone has a pointer to a paper or book in which
Iverson talks about this approach to arithmetic, I would love to
hear from you.
IMAGE: the cover of Meyers's High-Speed Math Self-Taught,
1960. Source:
OpenLibrary.org.
When I was thinking about implementing the cool programming
idiom I
blogged about yesterday,
I forgot the first rule of programming in Ruby:
It's already in there.
It didn't take long after my post went live that readers began
to point out that Ruby already offers the functionality of my
sub and R's { operator, via
Array#values_at:
I'm not surprised. I should probably spend a few minutes every
day browsing the documentation for a randomly-chosen Ruby class.
There's so much to find! There's also too much to remember out
of context, but I never know when I'll come across a need and
have a vague recollection that Ruby already does what I need.
Reader Gary Wright pointed out that I can get closer to R's
syntax by aliasing values_at with an unused
array operator, say:
class Array
def %(*args)
values_at(*args.first)
end
end
Now my use of % is as idiomatic in Ruby as
{ is in R:
I am happy to learn that Ruby already has my method and am just
as happy to have spent time thinking about and implementing it
on my own. I like to play with the ideas as much as I like
knowing the vast class library of a modern scripting language.
(If I were writing Ruby code for a living, my boss might not
look upon my sense of exploration so favorably... There are
advantages to being an academic!)
Fetching the values at indices 0, 1, 3, and 6, gives:
10 5 6 1
You can do this directly in APL-style languages such as
J
and
R.
In J, for example, you use the { operator:
0 1 3 6 { 10 5 9 6 20 17 1
Such an operator enables you to do some crazy things, like
producing a sorted array by accessing it with a permuted
set of indices. This:
6 1 3 2 0 5 4 { 10 5 9 6 20 17 1
produces this:
1 5 6 9 10 17 20
When I saw this, my first thought was, "Very cool!" It's been
a long time since I programmed in APL, and if this is even
possible in APL, I'd forgotten.
One of my next thoughts was, "I bet I can fake that in Ruby...".
I just need a way to pass multiple indices to the array, invoking
a method that fetches one value at a time and returns them all.
So I created an Array method named sub that takes
the indices as an array.
class Array
def sub slots
slots.map {|i| self[i] }
end
end
The J solution is a little cleaner, because my method requires
extra syntax to create an array of indices. We can do better by
using Ruby's
splat operator,
*. splat gathers up loose arguments into a single
collection.
class Array
def sub(*slots) # splat the parameter
slots.map {|i| self[i] }
end
end
This definition allows us to send sub any number
of integer arguments, all of which will be captured into the
parameter slots.
Now I can produce the sorted array by saying:
[10, 5, 9, 6, 20, 17, 1].sub(6, 1, 3, 2, 0, 5, 4)
Of course, Ruby allows us to omit the parentheses when we send
a message as long as the result is unambiguous. So we can go
one step further:
[10, 5, 9, 6, 20, 17, 1].sub 6, 1, 3, 2, 0, 5, 4
Not bad. We are pretty close to the APL-style solution now.
Instead of {, we have .sub.
And Ruby requires comma-separated argument lists, so we have
to use commas when we invoke the method. These are syntactic
limitations placed on us by Ruby.
Still, with relative simple code we are able to fake Hague's
idiom quite nicely. With a touch more complexity, we could write
sub to allow either the unbundled indices or
a single array containing all the indices. This would make the
code fit nicely with other Ruby idioms that produce array values.
If you have stronger Ruby-fu than I and can suggest a more
elegant implementation,
please share.
I'd love to learn something new!
An interviewer once asked writer Stephen King about extensive
rewrites, and
King responded:
One of the ways the computer has changed the way I work is that
I have a much greater tendency to edit "in the camera" -- to
make changes on the screen. With 'Cell' that's what I did. I
read it over, I had editorial corrections, I was able to make
my own corrections, and to me that's like ice skating. It's an
OK way to do the work, but it isn't optimal. With 'Lisey' I
had the copy beside the computer and I created blank documents
and retyped the whole thing. To me that's like swimming, and
that's preferable. It's like you're writing the book over again.
It is literally a rewriting.
The idea of typing an existing text made me think of Zed Shaw's
approach to teaching programming,
which has grown into
Learn Code the Hard Way.
You can learn a lot about a body of words or code by reading it
just enough to type it, and letting your brain do the rest.
I'm not sure how well this approach would work for a group of
complete novices. I suspect that a few would like it and that
many would not. I like having it around, though, because I
like having as diverse a set of tools as possible for reaching
students.
For someone who already knows how to write -- or, in King's case,
who actually wrote the text he is retyping -- the act offers a
different set of trade-offs than rewriting or refactoring in
place. It also offers a very different experience from
(re)writing from scratch,
or
deleting text so you won't be tempted to keep it.
You are probably tired of hearing me go on about JRubyConf,
so I'll try to wrap up with one more post. After the first
few talks, the main result of the rest of conference was to
introduced me to several cool projects and a few interesting
quotes.
Sarah Allen
gave a talk on agile business development. Wow, she has been
part of creating several influential pieces of software,
including AfterEffects, ShockWave, and FlashPlayer. She
talked a bit about her recent work to increase diversity among
programmers and reminded us that diversity is about more than
the categories we usually define:
I may be female and a minority here, but I'm way more
like everybody in here than everybody out there.
Increasing diversity means making programming accessible to
people who wouldn't otherwise program.
Regarding agile development, Sarah reminded us that agile's
preference for working code over documentation is about more
than just code:
Working code means not only "passes the tests" but also
"works for the customer".
... which is more about being the software they need than simply
getting right answers to some tests written in JUnit.
Nate Schutta
opened day two with a talk on leading technical change. Like
Venkat Subramaniam on day one,
Schutta suggested that tech leaders consider management's point
of view when trying to introduce new technology, in particular
the risks that managers face. If you can tie new technology to
the organization's strategic goals and plans, then managers can
integrate it better into other actions. Schutta attributed his
best line to
David Hussman:
Change must happen with people, not to them.
The award for the conference's most entertaining session goes to
Randall Thomas
and
Tammer Saleh
for "RUBY Y U NO GFX?", their tag-team exegesis of the history
of computer graphics and where Ruby fits into that picture today.
They echoed several other speakers in saying that JRuby is the
bridge to the rest of the programming world that Ruby programmers
need, because the Java community offers so many tools. For
example, it had never occurred to me to use JRuby to connect my
Ruby code to
Processing,
the wonderful open-source language for programming images and
animations. (I first mentioned Processing here over four years
ago in
its original Java form,
and most recently was thinking of
its JavaScript implementation.)
Finally, a few quickies:
Jim Remsik suggested Simon Sinek's TED talk,
How great leaders inspire action,
with the teaser line, It's not what you do; it's why
you do it.
Yoko Harada introduced me to
Nokogiri,
a parser for HTML, XML, and the like.
Andreas Ronge
gave a talk on graph databases as a kind of NoSQL database and
specifically about
Neo4j.rb,
his Ruby wrapper on the Java library Neo4J.
I learned about
Square,
which operates in the
#fintech
space being explored by the Cedar Valley's own
T8 Webware
and by Iowa start-up darling
Dwolla.
I mentioned David Wood in
yesterday's entry.
He also told a great story involving rapper Jay-Z, illegal music
downloads, multi-million-listener audiences, Coca Cola, logos,
and video releases that encapsulated in a nutshell the new media
world in which we live. It also gives a very nice example of
why Jay-Z will soon be a billionaire, if he isn't already. He
gets it.
The last talk I attended before hitting the road was by Tony
Arcieri, on concurrent programming in Ruby, and in particular his
concurrency framework
Celluloid.
It is based on
the Actor model
of concurrency, much like Erlang and Scala's
Akka framework.
Regarding these two, Arcieri said that Celluloid stays truer the
original model's roots than Akka by having objects at its core
and that he currently views any differences in behavior between
Celluloid and Erlang as bugs in Celluloid.
One overarching theme for me of my time at JRubyConf: There is a lot
of stuff I don't know. I won't run out of things to read and learn
and do for a long, long, time.
JRubyConf was my first Ruby-specific conference, and one of the
things I most enjoyed was seeing how the spirit of the language
permeates the projects created by its community of users. It's
one thing to read books, papers, and blog posts. It's another
to see the eyes and mannerisms of the people using the language
to make things they care about. Being a variant, JRuby has its
own spirit. Usually it is in sync with Ruby's, but occasionally
it diverges.
The first talk after lunch was by Ian Dees, talking about his
toy programming language project
Thnad.
(He took the name from one of the new letters of the alphabet in
Dr. Seuss's On Beyond Zebra.)
Thnad looks a lot like Klein, a language I created for my compiler
course a few years ago, a sort of
functional integer assembly language.
The Thnad project is a great example of how easy it is to roll
little DSLs using Ruby and other DSLs created in it. To implement
Thnad, Dees uses
Parslet,
a small library for generating scanners and parsers
PEG-style,
and
BiteScript,
a Ruby DSL for generating Java bytecode and classes. This talk
demonstrated the process of porting Thnad from JRuby to
Rubinius,
a Ruby implementation written in Ruby. (One of the cool things
I learned about the Rubinius compiler is that it can produce
s-expressions as output, using the switch -S.)
Two other talks exposed basic tenets of the Ruby philosophy and
the ways in which implementations such as JRuby and Rubinius
create new value in the ecosystem.
On Wednesday afternoon,
David Wood
described how his company, the Jun Group, used JRuby to achieve
the level of performance its on-line application requires. He
told some neat stories about the evolution of on-line media
over the last 15-20 years and how our technical understanding
for implementing such systems has evolved in tandem. Perhaps
his most effective line was this lesson learned along the way,
which recalled an idea from
the keynote address
the previous morning:
Languages don't scale. Architectures do. But language and
platform affect architecture.
In particular, after years of chafing, he had finally reached
peace with one of the overarching themes of Ruby: optimize for
developer ease and enjoyment, rather than performance or
scalability. This is true of the language and of most of the
tools built around, such as Rails. As a result, Ruby makes it
easy to write many apps quickly. Wood stopped fighting the lack
of emphasis on performance and scalability when he realized that
most apps don't succeed anyway. If one does, you have
to rewrite it anyway, so suck it up and do it. You will have
benefited from Ruby's speed of delivery.
This is the story Twitter, apparently, and what Wood's team did.
They spent three person-months to port their app from MRI to
JRuby, and are now quite happy.
Where does some of that performance bump come from? Concurrency.
Joe Kutner
gave a talk after Thnad on Tuesday afternoon about using JRuby
to deploy efficient Ruby web apps on the JVM, in which he also
exposed a strand of Ruby philosophy and place where JRuby
diverges.
The canonical implementations of Ruby and Python use a
Global Interpreter Lock
to ensure that non-thread-safe code does not interfere with the
code in other threads. In effect, the interpreter maps all
threads onto a single thread in the kernel. This may seem like
an unnecessary limitation, but it is consistent with Matz's
philosophy for Ruby: Programming should be fun and easy.
Concurrency is hard, so don't do allow it to interfere with the
programmer's experience.
Again, this works just fine for many applications, so it's a
reasonable default position for the language. But it does not
work so well for web apps, which can't scale if they can't spawn
new, independent threads. This is a place where JRuby offers a big
win by running atop the JVM, with its support for multithreading.
It's also a reason why the Kilim fibers GSoC project mentioned by
Charles Nutter in
the State of JRuby session
is so valuable.
In this talk, I learned about three different approaches to
delivering Ruby apps on the JVM:
Warbler,
a light and simple tool for packaging .war files,
Trinidad,
which is a JRuby wrapper for a Tomcat server, and
TorqueBox,
an all-in-one app server that appears to be the hot new
thing.
Links, links, and more links!
Talks such as these reminded me of the feeling of ease and power
that Ruby gives developers, and the power that language implementors
have to shape the landscape in which programmers work. They also
gave me a much better appreciation for why projects like Rubinius
and JRuby are essential to the Ruby world because -- not despite
-- deviating from a core principle of the language.
Immediately after
the keynote address,
the conference really began for me. As a newcomer to JRuby,
this was my first chance to hear lead developers
Charles Nutter
and
Tom Enebo
talk about the language and community. The program listed this
session as "JRuby: Full of Surprises", and Nutter opened with a
slide titled "Something About JRuby", but I just thought of the
session as a "state of the language" report.
Nutter opened with some news. First,
JRuby 1.7.0.preview1 is available.
The most important part of this for me is that Ruby 1.9.3 is
now the default language mode for the interpreter. I still
run Ruby 1.8.7 on my Macs, because I have never really needed
more and that kept my installations simple. It will be nice
to have a 1.9.3 interpreter running, too, for cases where I
want to try out some of the new goodness that 1.9 offers.
Second, JRuby has been awarded eight
Google Summer of Code
placements for 2012. This was noteworthy because there were
no Ruby projects at all in 2010 or 2011, for different reasons.
Several of the 2012 projects are worth paying attention to:
creating a code generator for
Dalvik byte code,
which will give native support for JRuby on Android
more work on
Ruboto,
the current way to run Ruby on Android, via Java
implementing JRuby fibers using
Kilim fibers,
for lighterweight and faster concurrency than Java threads
can provide
work on
krypt,
"SSL done right" for Ruby, which will eliminate the existing
dependence on OpenSSL
filling in some of the gaps in the graphics framework
Shoes,
both Swing and SWT versions
Enebo then described several projects going on with JRuby. Some
are smaller, including closing gaps in the API for embedding Ruby
code in Java, and
Noridoc,
a tool for generating integrated Ruby documentation for Ruby and
Java APIs that work together. Clever -- "No
ri
doc".
One project is major: work on the JRuby compiler itself. This
includes improving to the intermediate representation used by
JRuby, separating more cleanly the stages of the compiler, and
writing a new, better run-time system. I didn't realize until
this talk just how much overlap there is in the existing scanner,
parser, analyzer, and code generator of JRuby. I plan to study
the JRuby compiler in some detail this summer, so this talk whet
my appetite. One of the big challenges facing the JRuby team is
to identify execution hot spots that will allow the compiler to
do a better job of caching, inlining, and optimizing byte codes.
This led naturally into Nutter's discussion of the other major
project going on:
JRuby support
for the JVM's new invokedynamic instruction. He hailed
invokedynamic as "the most important change to the JVM
-- ever". Without it, JRuby's method invocation logic is opaque
to the JVM optimizer, including caching and inlining. With it,
the JRuby compiler will be able not only to generate optimizable
function calls but also more efficient treatment of instance
variables and constants.
Nutter showed some performance data comparing JRuby to MRI Ruby
1.9.3 on some standard benchmarks. Running on Java 6, JRuby is
between 1.3 and 1.9 times faster than the C-based compiler on
the benchmark suites. When they run it on Java 7, performance
jumps to speed-ups of between 2.6 and 4.3. That kind of speed
is enough to make JRuby attractive for many compute-intensive
applications.
Just as Nutter opened with news, he closed with news. He and
Enebo are
moving to RedHat.
They will work with various RedHat and JBoss teams, including
TorqueBox,
which I'll mention in an upcoming JRubyConf post. Nutter and
Enebo have been at
EngineYard
for three years, following a three-year stint at Sun. It is
good to know that, as the corporate climate around Java and
Ruby evolves, there is usually a company willing to support
open-source JRuby development.
JRubyConf 2012: Keynote Address on Polyglot Programming
JRubyConf opened with a keynote address on polyglot programming by
Venkat Subramaniam.
JRuby is itself a polyglot platform, serving as a nexus between a
highly dynamic scripting language and a popular enterprise
language. Java is not simply a language but an ecosphere
consisting of language, virtual machine, libraries, and tools. For
many programmers, the Java language is the weakest link in its own
ecosphere, which is one reason we see so many people porting their
favorite languages run on the JVM, or creating new languages with
the JVM as a native backend.
Subramaniam began his talk by extolling the overarching benefits of
being able to program in many languages. Knowing multiple
programming languages changes how we design software in any language.
It changes how we think about solutions. Most important, it changes
how we perceive the world. This is something that
monolingual programmers often do not appreciate. When we know
several languages well, we see problems -- and solutions --
differently.
Why learn a new language now, even if you don't need to? So that
you can learn a new language more quickly later, when you do need to.
Subramaniam claimed that the amount of time required to learn a new
language is inversely proportional to the number of languages a
person has learned in last ten years. I'm not sure whether there is
any empirical evidence to support this claim, but I agree with the
sentiment. I'd offer one small refinement: The greatest benefits
come from learning different kinds of language. A new
language that doesn't stretch your mind won't stretch your mind.
Not everything is heaven for the polyglot programmer. Subramaniam
also offered some advice for dealing with the inevitable downsides.
Most notable among these was the need to "contend with the enterprise".
Many companies like to standardize on a familiar and well-established
technology stack. Introducing a new language into the mix raises
questions and creates resistance. Subramaniam suggested that we back
up one step before trying to convince our managers to support a
polyglot environment and make sure that we have convinced ourselves.
If you were really convinced of a language's value, you would find a
way to do it. Then, when it comes time to convince your manager, be
sure to think about the issue from her perspective. Make sure that
your argument speaks to management's concerns. Identify the problem.
Explain the proposed solution. Outline the costs of the solution.
Outline its benefits. Show how the move can be a net win for the
organization.
The nouveau JVM languages begin with a head start over other new
technologies because of their interoperability with the rest of the
Java ecosphere. They enable you to write programs in a new language
or style without having to move anyone else in the organization.
You can experiment with new technology while continuing to use the
rest of the organization's toolset. If the experiments succeed,
managers can have hard evidence about what works well and what
doesn't before making larger changes to the development environment.
I can see why Subramaniam is a popular conference speaker. He uses
fun language and coins fun terms. When talking about people who are
skeptical of unit testing, he referred to some processes as
Jesus-driven development. He admonished programmers who
are trying to do concurrency in JRuby without knowing the Java
memory model, because "If you don't understand the Java memory
model, you can't get concurrency right." But he followed that
immediately with, Of course, even if you do know the Java
memory model, you can't get concurrency right. Finally, my
favorite: At one point, he talked about how some Java developers
are convinced that they can do anything they need to do in Java,
with no other languages. He smiled and said, I admire Java
programmers. They share an unrelenting hope.
There were times, though, when I found myself wanting to defend
Java. That happens to me a lot when I hear talks like this one,
because so many complaints about it are really about OOP practiced
poorly; Java is almost an innocent bystander. For example, the
speaker chided Java programmers for suffering from
primitive obsession.
This made me laugh, because most Ruby programmers seem to have an
unhealthy predilection for strings, hashes, and integers.
In other cases, Subramaniam demonstrated the virtues of Ruby by
showing a program that required a gem and then solved a thorny
problem with three lines of code. Um, I could do that in Java, too,
if I used the right library. And Ruby programmers probably don't
want to draw to much attention to gems and the problems many Ruby
devs have with dependency management.
But those are small issues. Over the next two days, I repeatedly
heard echoes of Subramaniam's address in the conference's other
talks. This is the sign of a successful keynote.
After an award-winning author had criticized popular literature,
Stephen King responded with advice that is a useful reminder to
us all:
Get busy. You have a short life span. You need to stop this
crap about sitting there and talking about what we do, and
actually do it. Because God gave you some talent, but he
also gave you a certain number of years.
You don't have to be an award-winning author to waste precious
time commenting on other people's work. Anyone with a web
browser can fill his or her day talking about stuff, and not
actually making stuff. For academics, it is a professional
hazard. We need to balance the analytic and the creative. We
learn by studying others' work and writing about it, but we
also need to make time to make.
I wonder if McCarthy had to deal with complaints of
parentheses count in the earliest Lisps?
For me, this tweet immediately brought to mind Ward Cunningham's
experiment with
file signatures
as an aid in browsing unfamiliar code, which he presented at
a workshop on "software archeology" at OOPSLA 2001. In his
experiment, Ward collapsed each file in the Java 1.3 source
code distribution into a single line consisting of only
braces, quotes, and semicolons. For example, the AWT class
java.awt.peer.ComponentPeer looked like this:
As Ward said, it takes some time to get use to the "radical
summarization" of files into such punctuation signatures.
He was curious about how such a high-level view of a code
base might help a programmer understand the regularities
and irregularities in the code, via an interactive process
of inspection and projection.
Perhaps this came to mind as a result of experiences I had
when I was first learning to program in Scheme. Coming
from other languages with more syntax, I developed a bad
habit of writing code like this:
(define factorial
(lambda (n)
(if (zero? n)
1
(* n (factorial (- n 1)))
)))
When real Scheme and Lisp programmers saw my code, they
suggested that I put those closing parens at the end of the
multiplication line. They were even more insistent when I
dropped closing parens onto separate lines in the middle of
a larger piece of code, say, with a let
expression of several complex values. I objected that the
line breaks helped me to see the structure of my code better.
They told me to trust them; after I had more experience, I
wouldn't need the help, and my code would be cleaner and
more idiomatic.
They were right. Eventually, I learned to read Scheme code
more like real Schemers do. I found myself drawn to the
densest parts of the code, in which those closing parens
often played a role, and learned to see that that's where
the action usually was.
I think it was the connection between counting parentheses
and the structure of code that brought to mind Ward's work.
And then I wondered what it would be like to take the
signature of Lisp or Scheme code in terms of its maligned
primary punctuation, the parentheses?
In a few spare minutes, I fiddled with the I idea. As an
example, consider the following Lisp function, which is
part of an implementation of CLOS written by Patrick Henry
Winston and Berthold Horn to support their AI and Lisp
textbooks:
Collapsing this function into a single line of parentheses
results in:
(()((())((()(())(()))(((())())(()(())(()))))))
The semicolons in Java code give the reader a sense of the
code's length; collapsing Lisp in this way loses the line
breaks. So I wrote another function to insert a
| where the line breaks had been, which
results in:
This gives a better idea of how the code plays out on the
page, but it loses all sense of the code's structure, which
is so important when reading Lisp. So I implemented a third
signature, one that surrenders the benefit of a single line
in exchange for a better sense of structure. This signature
preserves leading white space and line breaks but otherwise
gives us just the parentheses:
I think there is a lot of room left to explore here in terms
of punctuation. To capture the nature of Scheme and Lisp
programs, we would probably want to include other characters,
such as the hash, the comma, quotes, and backquotes. These
would expose macro-related expressions to the human reader.
To expand the experiment to include Clojure, we would of
course want to include [] and
{} in the signatures.
I'm not an every-day Schemer, so I am not sure how much
either the flat signatures or the structured signatures would
help seasoned Lisp or Scheme programmers develop an intuitive
sense of a function's size, complexity, and patterns. As
Ward's experiment showed, the real value comes when signing
entire files, and for that task flat signatures may have more
appeal. It would be neat to apply this idea to a Lisp
distribution of non-trivial size -- say, the full distribution
of Racket or Clojure -- and see what might be learned.
In recent years, it is becoming even more common for
people to think of students as "paying customers" at
the university. People inside of universities,
especially the teachers, have long tried to discourage
this way of thinking, but it is becoming much harder
to make the case. Students and parents are being
required to shoulder an ever larger share of the bill
for higher education, and with that comes a sense of
ownership. Still, educators can't help but worry.
The customer isn't always right.
You can join a gym to get fit, but just joining doesn't
make you fit. It simply gives you access to machinery
and expertise that you can use to get fit. If you fail
to listen to the trainer or make use of the equipment
then you don't get a better body, you just get poorer.
You can buy all the running shoes you like, but if you
never lace them up and hit the road, you won't become
a runner.
I like this analogy. It also puts into perspective a
relatively recent phenomenon, the assertion that
software developers may not need a university
education. Think about such an assertion in the
context of physical fitness:
A lot of people manage to get in shape physically
without joining a gym. To do so, all you need is the
gumption (1) to learn what they need to do and (2) to
develop and stick to a plan. For example, there is a
lot of community support among runners, who are willing
to help beginners get started. As runners become part
of the community, they find opportunities to train in
groups, share experiences, and run races together. The
result is an informal education as good as most people
could get by paying a trainer at a gym.
The internet and the web have provided the technology
to support the same sort of informal education in
software development. Blogs, user groups, codeathons,
and GitHub all offer the novice opportunities to get
started, "train" in groups, share experiences, and work
together. With some gumption and hard work, a person
can become a pretty good developer on his or her own.
But it takes a lot of initiative. Not all people who
want to get in shape are ready or able to take control
of their own training. A gym serves the useful purpose
of getting them started. But each person has to do his
or her own hard work.
Likewise, not all learners are ready to manage their own
educations and professional development -- especially at
age 18, when they come out of a K-12 system that can't
always prepare them to be completely independent
learners. Like a gym, a university serves the useful
purpose of helping such people get started. And just as
important, as at the gym, students have to do their own
hard work to learn, and to prepare to learn on their own
for the rest of their careers.
Of course, other benefits may get lost when students
bypass the university. I am still idealistic enough to
think that a liberal education, even a liberal arts
education, has great value for all people. [
1
|
2
|
3
]. We are more than workers in an economic engine. We
are human beings with a purpose larger than our earning
potentials.
But the economic realities of education these days and
the concurrent unbundling of education made possible by
technology mean that we will have to deal with issues
such as these more and more in the coming years. In any
case, perhaps a new analogy might help us help people
outside the university understand better the kind of
"customer" our students need to be.
I'm beginning to look at the compilers my students produced
this semester. I teach a relatively traditional compiler
course; we want students to experience as many different
important ideas as possible within the time constraints of
a semester. As you might expect, my students' programs
read in a text file and produce a text file. These files
contain a high-level program and an assembly language
program, respectively.
I love seeing all the buzz floating around non-textual
languages and new kinds of programming environments such
as
Bret Victor's reactive documents
and
Light Table.
Languages and environments like these make my traditional
compiler course seem positively archaic. I still think
the traditional course adds a lot of value to students'
experience. Before you can think outside of the box,
you have to
start with a box.
These new programming ideas really are outside the confines
of how we think about programs. Jonathan Edwards
reminds us
how tightly related languages and tools are:
As long as we are programming in descendants of assembly
language, we will continue to program in descendants of
text editors.
Edwards has been exploring this pool of ideas for a few
years now. I first mentioned his work in this blog
back in 2004.
As he has learned, the challenge we face in trying to
re-think how we program is complicated by the network of
ideas in which we work. It isn't just syntax or language
or IDE or support tools that we have to change. To change
one in a fundamental way requires changing them all.
On top of that, once researchers create something new, we
will have to find a way to migrate there. That involves
education and lots of existing practitioners. Here's
hoping that the small steps people are taking with Tangle
and Light Table can help us bridge the gap.
Thinking Out Loud about the Compiler in a Pure OO World
John Cook
pokes fun at OO practice
in his blog post today. The "Obviously a vast improvement."
comment deftly ignores the potential source of OOP's benefits,
but then that's the key to the joke.
A commenter points to a blog entry by Smalltalk veteran Travis
Griggs. I agree with Griggs's recommendation to
avoid using verbs-turned-into-nouns as objects,
especially lame placeholder words such as "manager" and
"loader". As he says, they usually denote objects that
fiddle with the private parts of other objects. Those other
objects should be providing the services we need.
Griggs allows reasonable linguistic exceptions to the advice.
But he also acknowledges the pull of pop culture which, given
my teaching assignment this semester, jumped out at me:
There are many 'er' words that despite their focus on what
they do, have become so commonplace, that we're best to
just stick with them, at least in part. Parser. Compiler.
Browser.
I've thought about this break in my own OO discipline before,
and now I'm thinking about it again. What would it be like
to write compiles without creating parsers and code generators
-- and compilers themselves -- as objects?
We could ask a program to compile itself:
program.compileTo( targetMachine )
But is the program a program, or does it start life as a text
file? If the program starts as a text file, perhaps we say
program.parse()
to create an abstract syntax tree, which we then could ask
ast.compileTo( targetMachine )
(Instead of sending a parse() message, we might send
an asAbstractSyntax() message. There may be no
functional difference, but I think the two names indicate
subtle differences in mindset.)
When my students write their compilers in Java or another OO
language, we discuss in class whether abstract syntax trees
ought to be able to generate target code for themselves. The
danger lies in binding the AST class to the details of a
specific target machine. We can separate the details of the
target machine for the AST by passing an argument with the
compileTo() message, but what?
Given all the other things we have to learn in the course, my
students usually end up following Griggs's advice and doing
the traditional thing: pass the AST as an argument to a
CodeGenerator object. If we had more time, or a
more intensive OO design course prior to the compilers course,
we could look at techniques that enable a more OO approach
without making things worse in the process.
Looking back farther to the parse behavior, would it ever make
sense to send an argument with the parse() message?
Perhaps a parse table for an LL(1) or LR(1) algorithm? Or
the parsing algorithm itself, as a strategy object? We quickly
run the risk of taking steps in the direction that Cook joshes
about in his post.
Or perhaps parsing is a natural result of creating a
Program object from a piece of text. In that approach,
when we say
Program source = new Program( textfile );
the internal state of sourceis an abstract
syntax tree. This may sound strange at first, but a program
isn't really a piece of text. It's just that we are conditioned
to think that way by the languages and tools most of us learn
first and use most heavily. Smalltalk taught us long ago that
this viewpoint is not necessary. (Lisp, too, though in a
different way.)
These are just some disconnected thoughts on a Sunday afternoon.
There is plenty more to say, and plenty of prior art. I think
I'll fire up a Squeak image sometime soon and spend some time
reacquainting myself with its take on parsing and code
generation, in particular the way it compiles its core out to C.
I like doing this kind of "what if?" thinking. It's fun to
explore along the boundary between the land where OOP works
naturally and the murky territory where it doesn't seem to fit
so well. That's a great place to learn new stuff.
The first ties directly into the theme from the entry
on my summer of Smalltalk. As Wallace became more adept
at making the extensive cuts to his wide-ranging stories
suggested by his editor, he adopted a familiar habit:
Eventually, he learned to erase passages that he liked
from his hard drive, in order to keep himself from
putting them back in.
It's one thing to kill your darlings. It's another
altogether to keep them from sneaking back in. In
writing as in programming, sometimes
rm -r *.* is your friend.
A major theme in Wallace's work -- and life -- was the
struggle not to fall into the comfortable patterns of
thought engendered by the culture around us. The
danger is, those comfortable ruts separate us from what
is real:
Most 'familiarity' is mediated and delusive.
Programmers need to keep this in mind when they set out
to learn a new programming language and or a new style
of programming. We tend to prefer the familiar, whether
it is syntax or programming model. Yet familiarity is
conditioned by so many things, most prominently recent
experience. It deludes us into thinking some things
are easier or better than others, often for no other
reason than the accident of history that brought us to
a particular language or style first. When we look
past the experience that gets in the way of seeing the
new thing as it is, we enable ourselves to appreciate
the new thing as it is, and not as the lens of our
experience distorts it.
Of course, that's easier said than done. This struggle
consumed Wallace the writer his entire life.
Even so, we don't want to make the mistake of floating
along the surface of language and style. Sometimes, we
think that makes us free to explore all ideas unencumbered
by commitment to any particular syntax, programming model,
or development methodology. But it is in focusing our
energies and thinking to use specific tools, to write in
a specific cadre of languages, and to use a particular
styles that we enable ourselves to create, to do something
useful:
If I wanted to matter -- even just to myself -- I would
have to be less free, by deciding to choose in some kind
of definite way.
This line is a climactic revelation of the protagonist in
Wallace's posthumously published unfinished novel, The
Pale King. It reminds us that
freedom is not always so free.
It is much more important for a programmer to be a serial
monogamist than a confirmed bachelor. Digging deep into
language and style is what makes us stronger, whatever
language or style we happen to work in at any point in time.
Letting comfortable familiarity mediate our future
experiences is simply a way of enslaving ourselves to the
past.
In the end, reading Wallace's work and the interviews he
gave shows us again that writers and programmers have a
lot in common. Even after we throw away all the analogies
between our practices, processes, and goals, we are left
with an essential identity that we programmers share with
our fellow writers:
Writing fiction takes me out of time. That's probably as
close to immortal as we'll ever get.
Wallace said this in the first interview he gave after the
publication of his first novel. It is a feeling I know
well, and one I never want to live without.
Back at SIGCSE 2005,
Joe Bergin
and ran a workshop called The Polymorphism
Challenge that
I mentioned at the time
but never elaborated on. It's been on my mind again for the
last week. First I saw a link to
an OOP challenge
aimed at helping programmers move toward OO's ideal of small
classes and short methods. Then
Kent Beck
tweeted about
the Anti-IF Campaign,
which, as its name suggests, wants to help programmers "avoid
dangerous ifs and use objects to build a code that
is flexible, changeable, and easily testable".
That was the goal of The Polymorphism Challenge. I decided it
was time to write up the challenge and make our workshop
materials available to everyone.
Background
Beginning in the mid-1990s, Joe and I have been part of a cabal
of CS educators trying to teach object-oriented programming
style better. We saw dynamic polymorphism as one of the key
advantages to be found in OOP. Getting procedural programmers
to embrace it, including many university instructors, was a big
challenge.
At ChiliPLoP 2003, our group was riffing on the idea of extreme
refactoring, during which Joe and I created a couple of contrived
examples eliminating if statements
from a specific part of Karel the Robot
that seemed to require them.
This led Joe to propose a programming exercise he called an
étude, similar to what these days are called katas,
which I summarized in
Practice for Practice's Sake:
Write a particular program with a budget of nif-statements or fewer, for some small value of n.
Forcing oneself to not use an if statement wherever it
feels comfortable forces the programmer to confront how choices
can be made at run-time, and how polymorphism in the program can
do the job. The goal isn't necessarily to create an application
to keep and use. Indeed, if n is small enough and the
task challenging enough, the resulting program may well be stilted
beyond all maintainability. But in writing it the programmer may
learn something about polymorphism and when it should be used.
Motivated by
the Three Bears pattern,
Joe and I went a step further. Perhaps the best way to know that
you don't need if-statements everywhere is not to use
them anywhere. Turn the dials to 11 and make 'em all go away!
Thus was born the challenge, as a workshop for CS educators at
SIGCSE 2005. We think it is useful for all programmers. Below
are the materials we used to run the workshop, with only light
editing.
Task
Working in pairs, you will write (or re-write) simple but complete
programs that normally use if statements, to completely
remove all selection structures in favor of polymorphism.
Objective
The purpose of this exercise is not to demonstrate that if
statements are bad, but that they aren't necessary. Once you can
program effectively this way, you have a better perspective from
which to choose the right tool. It is directed at skilled
procedural programmers, not at novices.
Rules
You should attempt to build the solutions to one of the challenge
problems without using if statements or the equivalent.
You may use the libraries arbitrarily, even when you are pretty
sure that they are implemented with if statements.
You may use exceptions only when really needed and not as a
substitute for if statements. Similarly, while
loops are not to be used to simulate if statements.
Your problems should be solved with polymorphism: dynamic and
parameterized.
Note that if you use (for example) a hash map and the program
cannot control what is used as a key in a get (user
input, for example). then it might return null. You are
allowed to use an exception to handle this situation, or even an
if. If you can't get all if statements out of
your code, then see how few you really need to live with.
Challenges
Participants worked in pairs. They had a choice of programming
scenarios, some of which were adapted from work by others:
This pdf file
contains the full descriptions given to participants, including
some we did not try with workshop participants. If you come up
with a good scenario for this challenge, or variations on ours,
please
let me know.
Hints
When participants hit a block and asked for pointers, we offered
hints of various kinds, such as:
• When you have two behaviors, put them into different
objects. The objects can be created from the same class or from
related classes. If they are from the same class, you may want
to use parameterized polymorphism. When the classes are different,
you can use dynamic polymorphism. This is the easy step. Java
interfaces are your friend here.
• When you have the behaviors in different objects,
find a way to bring the right object into play at the right time.
That way, you don't need to use ad hoc methods to
distinguish among them. This is the hard part. Sometimes you can
develop a state change diagram that makes it easier. Then you can
replace one object with another at the well-defined state change
points.
• Note that you can eliminate a lot of if
statements by capturing early decisions -- perhaps made using
if statements -- in different objects. These objects can
then act as "flags with behavior" when they are passed around the
program. The flag object then encapsulates the earlier decision.
Now try to capture those decisions without if
statements.
(Note that this technique alone is a big win in improving the
maintainability of code. You replace many if statements
spread throughout a program with one, giving you a single point of
change in future.)
• Delegation from one object to another is a real help
in this exercise. This leads you to the Strategy design pattern.
An object M can carry with it another, S, that
encapsulates the strategy M has for solving a problem.
To perform the associated behavior, M delegates to S.
By changing the strategy object, you can change the behavior of the
object that carries it. M seems to behave polymorphically,
but it is really S that does the work.
• You can modify or enhance strategies using the
Decorator design pattern. A decorator D implements the same
interface as the thing it decorates, M. When sent a message,
the decorator performs some action and also sends the same message
to the object it decorates. Thus the behavior of M is
executed, but also more. Note that D can provide additional
functionality both before and after sending the message to M.
A functional method can return quite a different result when sent
through a decorated object.
• You can often choose strategies or other objects that
encapsulate decisions using the Factory design pattern. A hash map
can be a simple factory.
• You can sometimes use max and min
to map a range of values onto a smaller set and then use an index
into a collection to choose an object. max and min
are library functions so we don't care here how they might be
implemented.
At the end of the workshop, we gave one piece of general advice:
Doing this exercise once is not enough. Like an
étude, it can be practiced often, in order to develop and
internalize the necessary skills and thought patterns.
Conclusion
I'll not give any answers or examples here, so that readers can
take the challenge themselves and try their hand at writing code.
In future posts, I'll write up examples of the techniques
described in the hints, and perhaps a few others.
If you like the Polymorphism Challenge, you might want to try
some other challenges that ask you to do without features of
your preferred language or programming style that you consider
essential. Check out these
Programming Challenges.
I'll close with the same advice we gave at the end of the workshop:
Doing this exercise once is not enough, especially for OO novices.
Practice it often, like an étude or kata. Repetition can
help you develop the thought patterns of an OO programmer,
internalize them, and build the skills you need to write good OO
programs.
David Byrne's
essay on collective-creation
introduced me to a dandy little picture book by Bernard
Rudofsky called
Architecture Without Architects.
I love a slim book, and I love architecture, so I didn't
need much of a push to pick it up at the library.
For an agile software developer, the book's title evokes
something visceral. I think software architecture often
happens best when it happens organically, emerging as the
programmer grows the program piecemeal, feature by feature.
This is a
pragmatic view,
as expressed succinctly by Brian Marick in his recent
The Aim of Architecture:
Architecture isn't true, it's useful.
In software, as Marick says, knowing a program's architecture
helps us to navigate our way around the program and add new
code. An agile developer is willing to let architecture
describe the existing program, rather than prescribe its
shape. A descriptive, emergent architecture will be more
helpful in what we need it for than a prescribed, often
inaccurate architecture created ahead of time.
That's the mindset I brought to Architecture Without
Architects. I found, though, that it is about more than
piecemeal growth and emergence; it talks about buildings and
spaces created by regular people. Some people call this
"vernacular" architecture, but Rudofsky uses a number of
terms aimed at elevating the idea beyond the vulgar, among
them "indigenous", "spontaneous", and "non-pedigreed". I
think Rudofsky likes "non-pedigreed" best because it most
accurately expresses the distinction between the creations
he studies and "real" architecture: the only difference is
the credential held by the builder.
He lays responsibility for this harmful distinction at the
feat of historians, who emphasize "the parts played by
architects and their patrons" at the expense of "the
communal enterprise" of the built environment. But all of
us share in the blame:
Part of our trouble results from the tendency to ascribe to
architects -- or, for that matter, to all specialists --
exceptional insights into problems of living when, in truth,
most of them are concerned with problems of business and
prestige.
One of the goals of this book is to encourage the study of
non-pedigreed architecture, to describe a typology and to
document important examples. "There is much to learn,"
says Rudofsky, "from architecture before it became an
expert's art".
So, it turns out that Architecture Without Architects
is not about the same sense of "without architect" that we
in the software world usually mean. Agile developers are,
for the most part, professionals, not hobbyists or regular
Joes cobbling together programs on the side. Part of that
is cultural. People who would never think of writing a
program for themselves think nothing about diddling around
their houses. Part of it is technological. It's pretty
easy to go to the nearest home improvement center and buy
modular components that non-professionals can use to change
the shape and decoration of their houses. Programming,
not so much.
There are, of course, a few hobbyists tinkering around with
programs in their spare time. More important, there are
plenty of people with few or no credentials in computing or
software engineering making a living by writing programs.
Sometimes, they have switched careers out of necessity or
choice. Other times, they have slowly drifted into
software development over the course of a career.
In yet other cases, they retain their professional identity
in another discipline and write code to help them do their
jobs. Greg Wilson's
Software Carpentry
project is aimed at one such group of people: professional
scientists who find themselves writing and maintaining
software as an essential part of doing their science.
Rudofsky may be right when he chides us for attributing
exceptional insight to professional architects, and if
so we are certainly right not to attribute exceptional
insight to pedigreed software developers. But Wilson is
building a brand by reminding us that, while it may not
take exceptional insight to write programs, doing it well
does require some skill and knowledge.
I think that Rudofsky's interest in vernacular architecture
has other parallels in the software world. For example,
technologies such as SourceForge and now GitHub have
enabled developers to showcase, celebrate, and benefit from
the communal enterprise of writing programs. Programmers
may be sitting home working on their own, but they aren't
really alone. They are sharing what they write, sharing
in what others write, and otherwise participating in
vibrant communities of developers.
Then there is the idea of credentials. While many programmers
do have degrees in computer science or engineering, most
professionals don't have advanced academic degrees or an
academic bent. They write code in a world shaped by forces
beyond those usually talked about in algorithms and data
structures textbooks. The software patterns movement that
grew up in the 1990s aimed to document valuable lessons
learned programming "in the wild". Like Rudofsky's typology
of indigenous architecture, catalogs of design patterns
collected vernacular wisdom. As Rudofsky said about the
creations of the anonymous builders of most of the world
we actually live in,
The beauty of this architecture has long been dismissed
as accidental, but today we should be able to recognize
it as the result of rare good sense in the handling of
practical problems.
Say whatever else you want about
the Gang of Four book,
it captured a lot of OO wisdom learned in the trenches,
often from working with unforgiving building materials
like C++.
I enjoyed Architecture Without Architects greatly.
After an eight-page preface in which Rudofsky lays down
most of the ideas I've summarized here, the book consists
of 150 or so pages of pictures accompanied by explanatory
paragraphs. There was a lot of interesting detail and
even a little wisdom in those paragraphs. If you like
architecture, whether housing or programming, you might
enjoy spending a couple of hours with this book.
Nathan Marz has written a nice article on what he calls
suffering-oriented programming,
a development style that places great value on "You Aren't Gonna
Need It". It also has a guideline for when you should build
something: you feel the pain of not having it. If it
doesn't hurt yet, then you don't need it.
As you might imagine, Marz reports that the most important
characteristic of this style is a relentless focus on
refactoring. In refactoring, we often speak of code smells.
Suffering-oriented programmers operate within a different metaphor.
They are waiting for their code to make their lives difficult,
such as when the queues and workers in Marz's stream processing
system became unworkable at a larger scale. We need someone
like Kent Beck to coin a catchy phrase for this -- code owies,
perhaps.
I enjoyed the analogy Marz uses between refactoring and curve
fitting:
"Making it beautiful" is where you use your design and abstraction
skills to distill the problem space into simple abstractions that
can be composed together. I view the development of beautiful
abstractions as similar to statistical regression: you have a set
of points on a graph (your use cases) and you're looking for the
simplest curve that fits those points (a set of abstractions).
Do the simplest thing that would possibly work.
Marz presents a very practical instantiation of agile development
without the hype that accompanies some usages of the term. It is
worth a read.
You've got to learn your instrument.
Then, you practice, practice, practice.
And then, when you finally get up there on the bandstand,
forget all that and just wail.
-- Charlie Parker
I signed up for an opportunity to read early releases of
a book in progress,
Bootstrapping Design.
Chapter 4 contain a short passage that applies to beginning
programmers, too:
Getting good at design means cultivating your taste.
Right now, you don't have it. Eventually you will,
but until then you cannot trust your creativity.
Instead, focus on simplicity, clarity, and the cold,
hard science of what works.
This is hard advice for people to follow. We like to
use our brains, to create, to try out what we know. I
see this desire in many beginning programming students.
The danger grows as our skills grow. One of my greatest
frustrations comes in my Programming Languages course.
Many students in the course are reluctant to use
straightforward design patterns such as
mutual recursion.
At one level, I understand their mindset. They have
started to become accomplished programmers in other
languages, and they want to think, design, and program
for themselves. Oftentimes, their ill-formed approaches
work okay in the small, even if the code makes the prof
cringe. As our programs grow, though, the disorder
snowballs. Pretty soon, the code is out of the
student's control. The prof's, too.
A good example of this phenomenon, in both its positive
and negative forms, happened toward the end of
last semester's course.
A series of homework assignments had the students growing
an interpreter for a small, Scheme-like language. It
eventually became the largest functional program they had
ever written. In the end. there was a big difference
between code written by students who relied on "the cold,
hard science" we covered in class and code written by
students who had wondered off into the wilderness of their
own creativity. Filled with common patterns, the former
was relatively easy to read, search, and grade. The
latter... not so much. Even some very strong students
began to struggle with their own code. They had relied
too much on their own approaches for decomposing the
problem and organizing their programs, but those ideas
weren't scaling well.
I think what happens is that, over time, small errors,
missteps, and complexities accumulate. It's almost like
the effect of rounding error when working with floating
point numbers. I vividly remember experiencing that in
mu undergrad Numerical Analysis courses. Sadly, few of
our CS students these days take Numerical Analysis, so
their understanding of the danger is mostly theoretical.
Perhaps the most interesting embodiment of trusting one's
own creativity too much occurred on the final assignment
of the term. After several weeks and several assignments,
we had a decent sized program. Before assigning the
last set of requirements, I gave everyone in the class a
working solution that I had written, for reference. One
student was having so much trouble getting his own program
to work correctly, even with reference to my code, that he
decided to use my code as the basis for his assignment.
Imagine my surprise when I saw his submission. He used
my code, but he did not follow the example. The code he
added to handle the new requirements didn't look anything
like mine, or like what we had studied in class. It
repeated many of the choices that had gotten him into hot
water over the course of the earlier assignments. I could
not help but chuckle. At least he is persistent.
It can be hard to trust new ideas, especially when we don't
understand them fully yet. I know that. I do the same
thing sometimes. We feel constrained by someone else's
programming patterns and want to find our own way. But
those patterns aren't just constraints; they are also
a source of freedom.
I try to let my students grow in freedom as they progress
through the curriculum, but sometimes we encounter something
new like functional programming and have to step back into
the role of uncultivated programmer and grow again.
There is great value in learning the rules first and letting
our tastes and design skill evolve slowly. Seniors taking
project courses
are ready, so we turn them loose to apply their own taste
and creativity on Big Problems. Freshmen usually are not
yet able to trust their own creativity. They need to take
it slow.
To "think outside the box", you you have to
start with a box.
That is true of taste and creativity as much as it is of
knowledge and skill.
Last week, I found myself reading
The Most Entertaining Philosopher,
about William James. It was good fun. I have always liked James.
I liked the work of his colleagues in
pragmatism,
C.S. Peirce and John Dewey, too, but I always liked James more.
For all the weaknesses of his formulation of pragmatism, he always
seemed so much more human to me than Peirce, who did the heavy
theoretical lifting to create pragmatism as a formal philosophy.
And he always seemed a lot more fun than Dewey.
I wrote an entry a few years ago called
The Academic Future of Agile Methods,
which described the connection between pragmatism and my earlier
AI, as well as agile software development. I still consider
myself a pragmatist, though it's tough to explain just what that
means. The pragmatic stance is too often confounded with a
self-serving view of the world, a "whatever works is true"
philosophy. Whatever works... for me. James's references to
the "cash value" of truth didn't help. (James himself tried to
undo the phrase's ill effects, but it has stuck. Even in the
1800s, it seems, a good sound bite was better than the truth.)
As John Banville, the author NY Times book review piece says,
"It is far easier to act in the spirit of pragmatism than to
describe what it is." He then gives "perhaps the most concise
and elegant definition" of pragmatism, by philosopher C. I.
Lewis. It is a definition that captures the spirit of
pragmatism as well as any few lines can:
Pragmatism could be characterized as the doctrine that all
problems are at bottom problems of conduct, that all judgments
are, implicitly, judgments of value, and that, as there can be
ultimately no valid distinction of theoretical and practical,
so there can be no final separation of questions of truth of
any kind from questions of the justifiable ends of action.
This is what drew me to pragmatism while doing work in
knowledge-based systems, as a reaction to the prevailing view
of logical AI that seemed based in idealist and realist
epistemologies. It is also what seems to me to distinguish
agile approaches to software development from the more common
views of software engineering. I applaud people who are
trying to create an overarching model for software development,
a capital-t Theory, but I'm skeptical. The agile mindset is,
or at least can be, pragmatic. I view software development in
much the way James viewed consciousness: "not a thing or a
place, but a process".
As I read again about James and his approach, I remember my
first encounters with pragmatism and thinking: Pragmatism is
science; other forms of epistemology are mathematics.
An Adventure in Knowing Too Much ... Or Thinking Too Little
To be honest, it is a little of both.
I gave the students in my
compilers course
a small homework assignment. It's a relatively simple
translation problem whose primary goals are to help
students refresh their programming skills in their
language of choice and to think about the issues we
will be studying in depth in coming weeks: scanning,
parsing, validating, and generating.
I sat down the other day to write a solution ... and
promptly made a mess.
In retrospect, my problem was that I was somewhere in
between "do it 'simple'" and "do it 'right'". Unlike
most of the students in the class, already know a lot
about building compilers. I could use all that
knowledge and build a multi-stage processor that
converts a string in the source language (a simple
template language) into a string in the target
language (ASCII text). But writing a scanner, a
parser, a static analyzer, and a text generator seems
like overkill for such a simple problem. Besides, my
students aren't likely to write such a solution, which
would make my experience less valuable helping them to
solve the problem, and my program less valuable as an
example of a reasonable solution.
So I decided to keep things simple. Unfortunately,
though, I didn't follow my own agile advice and do
the simplest thing that could possibly work. As if
with the full-compiler option, I don't really want the
simplest program that could possibly work. This problem
is simple enough to solve with a single pass algorithm,
processing the input stream at the level of individual
characters. That approach would work but would obscure
the issues we are exploring in the course in a lot of
low-level code managing states and conditions. Our goal
for the assignment is understanding, not efficiency or
language hackery.
Later in the day, I was diddling around the house and
occasionally mulling over my situation. Suddenly I saw
a solution in mind. It embodied a simple understanding
of my the problem, in the middle ground between too
simple and too complex that was just right.
I had written my original code in a test-first way, but
that didn't help me avoid my mess. I know that pair
programming would have. My partner would surely have
seen through the complexity I was spewing to the fact
that I was off track and said, "Huh? Cut that out."
Pair programming is an unsung hero in cases like this.
I wonder if this pitfall is a particular risk for CS
academics. We teach courses that are full of details,
with the goal of helping students understand the full
depth of a domain. We often write quick and dirty code
for our own purposes. These are at opposite ends of
the software development spectrum. In the end, we have
to help students learn to think somewhere in the middle.
So, we try to show students well-designed solutions that
are simple enough, but no simpler. That's a much more
challenging task that writing a program at either
extreme. Not being full-time developers, perhaps our
instincts for finding the happy medium aren't as sharp
as they might be.
I occasionally read and hear people give advice about
how to find a career, vocation, or avocation that
someone will enjoy and succeed in. There is a lot of
talk about passion, which is understandable. Surely,
we will enjoy things we are passionate about, and
perhaps then we want to put in the hours required to
succeed. Still, "finding your passion" seems a little
abstract, especially for someone who is struggling to
find one.
I can say this about teaching. I love the hours spent
creating examples, writing sample code, improving it,
writing and rewriting lecture notes, and creating and
solving homework assignments. When a course doesn't go
as I had planned, I like figuring out why and trying to
fix it. Students see the finished product, not the hours
spent creating it. I enjoy both.
I don't necessarily enjoy all of the behind-the-scenes
work. I don't really enjoy grading. But my enjoyment of
the preparation and my enjoyment of the class itself --
the teaching equivalent of "the performance" -- carries
me through.
I can also say the same thing about programming. I love
to fiddle with source code, organizing and rewriting it
until it's all just so. I love to factor out repetition
and discover abstractions. I enjoy tweaking interfaces,
both the interfaces inside my code and the interfaces my
code's users see. I love that sudden moment of pleasure
when a program runs for the first time. Users see the
finished product, not the hours spent creating it. I
enjoy both.
Again, I don't necessarily enjoy everything that I have
to do the behind the scenes. I don't enjoy twiddling
with configuration files, especially at the interface to
the OS. Unlike many of my friends, I don't always enjoy
installing and uninstalling, all the libraries I need to
make everything work in the current version of the OS and
interpreter. But that time seems small compared the time
I spend living inside the code, and that carries me through.
In many ways, I think that Teller's simple declaration is
a much better predictor of what you will enjoy in a career
or avocation than other, fancier advice you'll receive.
If you love the stuff other folks never see, you are
probably doing the right thing for you.
Stanley Fish
wrote this week
about the end of a course he taught this semester, on "law,
liberalism and religion". In this course, his students a
number of essays and articles outside the usual legal
literature, including works by Locke, Rawls, Hobbes, Kant,
and Rorty. Fish uses this essay to respond to recent
criticisms that law schools teach too many courses like
this, which are not helpful to most students, who will, by
and large, graduate to practice the law.
Most anyone who teaches in a university hears criticisms
of this sort now and then. When you teach computer science,
you hear them frequently. Most of our students graduate
and enter practice the software development. How useful
are the theory of computation and the principles of
programming languages? Teach 'em Java Enterprise Edition
and Eclipse and XSLT and Rails.
My recent entry
Impractical Programming, With Benefits
starts from the same basic premise that Fish starts from:
There is more to know about the tools and methodologies
we use in practice than meets the eye. Understanding why
something is as it is, and knowing that something could
be better, are valuable parts of a professional's
preparation for the world.
Fish talks about these values in terms of the "purposive"
nature of the enterprise in which we practice. You want
to be able to thing about the bigger picture, because that
determines where you are going and why you are going there.
I like his connection to Searle's speech acts and how they
help us to see how the story we tell gives rise to the
meaning of the details in the story. He uses football as
his example, but he could have used computer science.
He sums up his argument in this way
That understanding is what law schools offer (among other
things). Law schools ask and answer the question, "What's
the game here?"; the ins and outs of the game you learn
later, as in any profession. The complaint ... is that
law firms must teach their new hires tricks of the trade
they never learned in their contracts, torts and (God
forbid) jurisprudence classes. But learning the tricks
would not amount to much and might well be impossible for
someone who did not know -- in a deep sense of know --
what the trade is and why it is important to practice it.
Such a deep understanding is even more important in a
discipline like computing, because our practices evolve
at a much faster rate than legal practices. Our tools
change even more frequently. When we taught functional
programming ten or fifteen years ago, many of our
students simply humored me. This wasn't going to help
them with Windows programming, but, hey, they'd learn
it for our sake. Now they live in a world where Scala,
Clojure, and F# are in the vanguard. I hope what they
learned in our Programming Languages course has helped
them cope with the change. Some of them are even
leading the charge.
The practical test of whether my Programming Languages
students learned anything useful this semester will
come not next year, but ten or fifteen years down the
road. And, as I said in the
Impractical Programming piece,
a little whimsy can be fun in its own right, easy while
it stretches your brain.
I've been reading a lot about Daniel Kahneman's new book,
Thinking, Fast and Slow. One of the themes of
the book is how our brains include two independent
systems for organizing and accessing knowledge. System
One is incredibly fast but occasionally (perhaps often)
wrong. It likely developed early in our biological
history and provided humans with an adaptive advantage
in a dangerous world. System Two developed later, after
humans had survived to create more protective surroundings.
It is slow -- conscious, deliberative -- and more often
right.
One reviewer summarized the adaptive value of System One
in this way:
In the world of the jungle, it is safer to be wrong and
quick than to be right and slow.
This phrase reminded me of
an old post by Allan Kelly,
on the topic of gathering requirements for software. The
entry's title is also its punch line:
You are better off being generally right than precisely
wrong.
These two quotes are quite different in important ways.
Yet they are related in some interesting ways, too.
It is easier to be fast and generally right
than to be fast and precisely right. The
pattern-matching mechanism in our brains and the
heuristics we use consciously are fast, but they are
often imprecise. If generally right is good enough,
then fast is possible.
Attempts to be slow and precisely right often
end up being slow and precisely wrong. Sometimes,
the world changes while we are thinking. Other times,
we end up solving the wrong problem because we didn't
understand our goals or the conditions of the world as
well we thought we did at the outset.
Evolution has given us two mechanisms with radically
different trade-offs and, it turns out, a biological
bias toward quick and wrong.
When I talk with friends who dislike or don't understand
agile approaches, I find that they often think that
agile folks overemphasize the use of System One in
software development. Why react, be wrong, and learn
from the mistake, when we could just think ahead and
do it right the first time?
In one way, they are right. Some proponents of agile
approaches speak rather loosely about Big Design Up
Front and about You Aren't Gonna Need It. They leave
the impression that one can program without thinking,
so long as one takes small enough steps and learns
from feedback. They also leave the impression that
everyone should work this way, in all contexts.
Neither of these impressions is accurate.
I try to help my skeptical friends to understand how
a "quick and (sometimes) wrong" mindset can be useful
for me even in contexts where I could conceivably plan
ahead well and farther. I try to help them understand
that I really am thinking all the time I'm working,
but that I treat any products of thought that are
not yet in code as contingent, awaiting the support of
evidence gained through running code.
And then I let them work in whatever way makes them
successful and comfortable.
I think that being aware of the presence of Systems
One and Two, and the fundamental trade-off between
them, can help agile developers work better. Making
conscious, well-founded decisions about how far to
think ahead, about what and how much to test, and
about when and how often to refactor are, in the end,
choices about which part of our brain to use at any
given moment. Context matters. Experience matters.
Blindly working in a quick-and-generally-right
way is no more productive approach for most of us
than working in a slow-and-sometimes-precisely-wrong
way.
I linked to Jacob Harris's recent
In Praise of Impractical Programming
in my previous entry, in the context of programming's
integral role in the modern newsroom. But as the title
of his article indicates, it's not really about the
gritty details of publishing a modern web site. Harris
rhapsodizes about wizards and the magic of programming,
and about a language that is for many of my colleagues
the poster child for impractical programming languages,
Scheme.
If you clicked through to the article but stopped reading
when you ran into MIT 6.001, you might want to go back
and finish reading. It is a story of how one programmer
looks back on college courses that seemed impractical at
the time but that, in hindsight, made him a better
programmer.
There is a tension in any undergraduate CS program between
the skills and languages of today and big ideas that will
last. Students naturally tend to prefer the former, as
they are relevant now. Many professors -- though not all
-- prefer academic concepts and historical languages. I
encounter this tension every time I teach Programming
Languages and think, should I continue to use Scheme as
the course's primary language?
As recently as the 1990s, this question didn't amount to
much. There weren't any functional programming languages
at the forefront of industry, and languages such as C++,
Java, and Ada didn't offer the course much.
But now there are Scala and Clojure and F#, all languages
in play in industry, not too mention several
"pretty good Lisps".
Wouldn't my students benefit from the extensive libraries
of these languages? Their web-readiness? The communities
connecting the languages to Hadoop and databases and data
analytics?
I seriously consider these questions each time I prep the
course, but I keep returning to Scheme. Ironically, one
reason is precisely that it doesn't have all
those things. As Harris learned,
Because Scheme's core syntax is remarkably impoverished,
the student is constantly pulling herself up by her
bootstraps, building more advanced structures off simpler
constructs.
In a course on the principles of programming
languages, small is a virtue. We have to build most of
what we want to talk about. And there is nothing quite
so stark as looking at half a page of code and realizing,
"OMG, that's what object-oriented programming is!", or
"You mean that's all a variable reference is?" Strange
as it may sound, the best way to learn deeply the big
concepts of language may be to look at the smallest atoms
you can find -- or build them yourself.
Harris "won't argue that "journalism schools should squander
... dearly-won computer-science credits on whimsical
introductions to programming" such as this. I won't even
argue that we in CS spend too many of our limited credits
on whimsy. But we shouldn't renounce our magic altogether,
either, for perfectly practical reasons of learning.
And let's not downplay too much the joy of whimsy itself.
Students have their entire careers to muck around in a
swamp of XML and REST and Linux device drivers, if that's
what they desire. There's something pretty cool about
watching Dr. Racket spew, in a matter of a second or two,
twenty-five lines of digits as the value of a trivial
computation.
As Harris says,
... if you want to advance as a programmer, you need to
take some impractical detours.
He closes with a few suggestions, none of which lapse into
the sort of navel-gazing and academic irrelevance that
articles like this one sometimes do. They all come down
to having fun and growing along the way. I second his
advice.
Our council of department heads meets in the dean's conference
room, in the same building that houses the Departments of Theater
and Art, among others. Before this morning's meeting, I noticed
an Edward Tufte poster on the wall and went out to take a look.
It turns out that the graphic design students were exhibiting
posters they had made in one of their classes, while studying
accomplished designers such as
Tufte
and
Paul Rand,
the creator of
the NeXT logo
for Steve Jobs.
As I browsed the gallery, I came across a couple of posters on
the work of
Charles and Ray Eames.
One of them prominently featured this quote from Charles:
Design is a plan for arranging elements in such a way
as best to accomplish a particular purpose.
This definition works just as well for software design as it
does for graphic design. It is good to be reminded occasionally
how universal the idea of design is to the human condition.
Dave Rooney wrote a recent entry on
what he does when coaching
in the realm of agile software development. He summarizes
his five main tasks as:
Listen
Ask boatloads of questions
Challenge assumptions
Teach/coach Agile practices
Work myself out of a job
All but the fourth is a part of my job every day. Listening,
asking questions, and challenging assumptions are essential
parts of helping people to learn, whatever one's discipline
or level of instruction. As a CS prof, I teach a lot of
courses that instruct or require programming, and I look for
opportunities to inject pragmatic programming skills and
agile development practices.
What of working myself out of a job? For consultants like
Rooney, this is indeed the goal: help an organization get
on a track where they don't need his advice, where they
can provide coaching from inside, and where they become
sufficient in their own practices.
In a literal sense, this is not part of my job. If I do my
job well, I will remain employed by the same organization,
or at least have that option available to me.
But in another sense, my goals with respect to working
myself out of a job are the same as as a consultant's,
only at the level of individual students. I want
to help students reach a point where they can learn
effectively on their own. As much as possible, I hope for
them to become more self-sufficient, able to learn as an
equal member of the larger community of programmers and
computer scientists.
A teacher's goal is, in part, to prepare students to move
on to a new kind of learning, where they don't need us to
structure the learning environment or organize the stream
of ideas and information they learn from. Many students
come to us pretty well able to do this already; they need
only to realize that they don't me!
With most universities structured more around courses than
one-on-one tutorials, I don't get to see the process through
with every student I teach. One of the great joys is to
have the chance to work with the same student many times
over the years, through multiple courses and one-on-one
through projects and research.
In any case, I think it's healthy for teachers to approach
their jobs from the perspective of working themselves out
of a job. Not to worry; there is always another class of
students coming along.
Of course, universities as we know them
may be disappearing.
But the teachers among us will always find people who want
to learn.
Last Friday afternoon, the CS faculty met with the
department's advisory board. The most recent addition to
the board is an alumnus who graduated a decade ago or so.
At one point in the meeting, he said that a particular
programming project from his undergraduate days stands
out in his mind after all these years. It was a series
of assignments from my Object-Oriented Programming course
called Cat and Mouse.
I can't take credit for the basic assignment. I got the
idea from
Mike Clancy
in the mid 1990s. (He later presented
his version of the assignment
on the original
Nifty Assignments
panel at SIGCSE 1999.) The problem includes so many cool
features, from coordinate systems to stopping conditions.
Whatever one's programming style or language, it is a
fun challenge. When done OO in Java, with great support
for graphics, it is even more fun.
But those properties aren't what he remembers best about
the project. He recalls that the project took place over
several weeks and that each week, I changed the requirements
of assignment. Sometimes, I added a new feature. Other
times, I generalized an existing feature.
What stands out in his mind after all these years is
getting the new assignment each week, going home,
reading it, and thinking,
@#$%#^. I have to rewrite my entire program.
You, see he had hard-coded assumptions throughout his
code. Concerns were commingled, not separated. Objects
were buried inside larger pieces of code. Model was
tangled up with view.
So, he started from scratch. Over the course of several
weeks, he built an object-oriented system. He
came to understand dynamic polymorphism and patterns
such as MVC and decorator, and found ways to use them
effectively in his code.
He remembers the dread, but also that this experience
helped him learn how to write software.
I never know exactly what part of what I'm doing in class
will stick most with students. From semester to semester
and student to student, it probably varies quite a bit.
But the experience of growing a piece of software over
time in the face of growing and changing requirements is
almost always a powerful teacher.
Avdi Grimm recently posted
a short but thorough introduction
to a common problem encountered by Ruby programmers:
nullifying an action when the required object is not present.
In a mixed-paradigm language, this becomes an issue when we
use if-statements to guard the action. Ruby, like
many languages, treats a distinguished value as false and
all other values as true. Thus, unless an object is "falsey",
it will be seen as true by the if-statement. This
requires us to do extra tests or wrap our objects to ensure
that tests pass and fail at the appropriate times. Grimm
explains the problem and walks us through several approaches
to solving this problem in Ruby. I recommend you read it.
Some of my functional programming friends teased me about
this article, along the lines of a pithy tweet:
Rubyists have discovered Maybe/Option.
Maybe
is a wrapper type in Haskell that allows programmers to
indicate that an expected value may not be available;
Option
is the Scala analog. Wrapper types are the natural way to
handle the problem of falsey-ness in functional programming,
especially in statically-typed languages. (Clojure, a
popular dynamically-typed functional language in the Lisp
tradition, doesn't make use of this idea.)
When I write Haskell code, as rare as that is, I use Maybe
as a natural part of typing my programs. As a functional
programmer more generally, I see its great value in writing
compact code. The alternative in Scheme is to us if
expressions to switch on value, separating null (usually)
base cases from inductive cases.
However, when I work as an OO programmer, I don't miss Maybe
or even falsey objects more generally. Indeed, I think the
best advice in Grimm's article comes in his conclusion:
If we're trying to coerce a homemade object into acting
falsey, we may be chasing a vain ideal. With a little
thought, it is almost always possible to transform code from
typecasing conditionals to duck-typed polymorphic method
calls. All we have to do is remember to represent the
special cases as objects in their own right, whether that
be a Null Object or something else.
My pithy tweet-like conclusion is this: If you are
checking for truthiness, you're doing OO wrong.
To do it right, use the Null Object pattern.
Ruby is an OO language, but it gives us great freedom to
write code in other styles as well. Many programmers in the
Ruby community, mostly those without prior OO experience,
miss out on the beauty and compactness one can achieve
using standard OO patterns.
I see a lot of articles on the web about the Null Object
pattern, but most of them involve extending the class
NilClass or its lone instance, nil. That
is fine if you are trying to add generic null object behavior
to a system, often in service of truthiness and falsey-ness.
A better approach in most contexts is to implement an object
that behaves like a "nothing" in your application. If you
are writing a program that consist of users, create an
unassigned user.
If you are creating a logging facility and need the ability
for a service not to use a log, create a null log. If you
are creating an MVC application and need a read-only
controller, create a null controller.
In some applications, the idea of the null object disappears
into another primitive object. When we implement a binary
tree, we create an object that has references to two other
tree objects. If all tree nodes behave similarly except
that some do not have children, then we can create a
NullTree object to serve as the values of the
instance variables in the actual leaves. If leaf nodes
behave differently than interior nodes, then we can create
a Leaf object to serve as the values of the
interior nodes' instance variables. Leaf subsumes
any need for a null object.
One of the consequences of using the Null Object pattern is
the elimination of if statements that switch on the
type of object present. Such if statements are a
form of ad hoc polymorphism. Programmers using
if statements while trying to write OO code should
not be surprised that their lives are more difficult than
they need be. The problem isn't with OOP; it's with not
taking advantage of dynamic polymorphism, one of the essential
benefits of OOP.
If you would like to learn more about the Null Object pattern,
I suggest you read its two canonical write-ups:
If you are struggling with making the jump to OOP, away from
typecasing switch statements and explicit loops over data
structures, take up the
programming challenge
writing increasingly larger programs with no if
statements and no for statements. Sometimes, you
have to
go to extremes
before you feel comfortable in the middle.
Last week, Bret Victor published a provocative essay on
the future of interaction design
that reminds us we should be more ambitious in our vision of
human-computer interaction. I think it also reminds us that
we can and should be more ambitious in our vision of most of
our pursuits.
I couldn't help but think of how Victor's particular argument
applies to software development. First he defines "tool":
Before we think about how we should interact with our Tools
Of The Future, let's consider what a tool is in the first place.
I like this definition: A tool addresses human needs by
amplifying human capabilities.
That is, a tool converts what we can do into what we want to do.
A great tool is designed to fit both sides.
The key point of the essay is that our hands have much more
consequential capabilities than our current interfaces use.
They feel. They participate with our brains in
numerous tactile assessments of the objects we hold and
manipulate: "texture, pliability, temperature; their
distribution of weight; their edges, curves, and ridges; how
they respond in your hand as you use them". Indeed, this
tactile sense is more powerful than the touch-and-slide
interfaces we have now and, in many ways, is more powerful than
even sight. These tactile senses are real, not metaphorical.
As I read the essay, I thought of the software tools we use,
from language to text editors to development processes. When I
am working on a program, especially a big one, I feel much more
than I see. At various times, I experience discomfort, dread,
relief, and joy.
Some of my colleagues tell me that these "feelings" are
metaphorical, but I don't think so. A big part of my affinity
for so-called agile approaches is how these sensations come into
play. When I am afraid to change the code, it often means that
I need to write more or better unit tests. When I am reluctant
to add a new feature, it often means that I need to refactor the
code to be more hospitable. When I come across a "code smell",
I need to clean up, even if I only have time for a small fix.
YAGNI and doing the simplest thing that can possibly work are
ways that I feel my way along the path to a more complete
program, staying in tune with the code as I go. Pair
programming is a social practice that engages more of my mind
than programming alone.
Victor closes with some inspiration for inspiration:
In 1968 -- three years before the invention of the microprocessor
-- Alan Kay stumbled across Don Bitzer's early flat-panel display.
Its resolution was 16 pixels by 16 pixels -- an impressive
improvement over their earlier 4 pixel by 4 pixel display.
Alan saw those 256 glowing orange squares, and he went home, and
he picked up a pen, and he drew a picture of a goddamn iPad.
We can
think bigger
about so much of what we do. The challenge I take from Victor's
essay is to think about the tools I to teach: what needs do they
fulfill, and how well do they amplify my own capabilities? Just
as important are the tools we give our students as they learn:
what needs do they fulfill, and how well do they amplify our
students' capabilities?
And I urge you to please notice when you are happy,
and exclaim or murmur or think at some point,
"If this isn't nice, I don't know what is."
-- Kurt Vonnegut, Jr.
I spent the entire day teaching and preparing to teach,
including writing some very satisfying code. It was a way
to spend a birthday.
With so much attention devoted to watching my students learn,
I found myself thinking consciously about my teaching and
also about some learning I have been doing lately, including
remembering how to write idiomatic Ruby. Many of my students
really want to be able to write solid, idiomatic Scheme
programs to process little languages. I see them struggle
with the gap between their desire and their ability. It
brought to mind something poet Mary Jo Bang said in
recent interview
about her long effort to become a good writer:
For a long time the desire to write and knowing how to write
well remained two separate things. I recognized good writing
when I saw it but I didn't know how to create it.
I do all I can to give students examples of good programs from
which they can learn, and also to help them with the process
of good programming. In the end, the only way to close the
gap is to write a lot of code. Writing deliberately and
reflectively can shorten the path.
Bang sees the same in her students:
Industriousness can compensate for a lot. And industry plus
imagination is a very promising combination.
Hard work is the one variable we all control while learning
something new. Some of us are blessed with more natural
capacity to imagine, but I think we can stretch our
imaginations with practice. Some CS students think that they
are learning to "engineer" software, a cold, calculating
process. But imagination plays a huge role in understanding
difficult problems, abstract problems.
Together, industry and time eventually close the gap between
desire and ability:
And I saw how, if you steadily worked at something, what you
don't know gradually erodes and what you do know slowly grows
and at some point you've gained a degree of mastery. What you
know becomes what you are. You know photography and you are a
photographer. You know writing and you are a writer.
... You know programming, and you are a programmer.
Erosion and growth can be slow processes. As time passes, we
sometimes find our learning accelerates, a sort of
negative splits
for mental exercise.
We work hardest when we are passionate about what we do.
It's hard for homework assigned in school to arouse passion,
but many of us professors do what we can. The best way to
have passion is to pick the thing you want to do.
Many of my best students have had a passion for something
and then found ways to focus their energies on assigned
work in the interest of learning the skills and gaining the
experience they need to fulfill their passion.
One last passage from Bang captures perfectly for me what
educators should strive to make "school":
It was the perfect place to cultivate an obsession that has
lasted until the present.
As a teacher, I see a large gap between my desire to create
the perfect place to cultivate an obsession and my ability
to deliver. For, now the desire and the ability remain two
separate things. I recognize good learning experiences when
I see them, and occasionally I stumble into creating one,
but I don't yet know how to create them reliably.
A few years ago, I heard a deacon give a rather compelling talk
to a group of college students on campus. When confronted with
a recommended way to live or act, students will often say that
living or acting that way is hard. These same students are
frustrated with the people who recommend that way of living or
acting, because the recommenders -- often their parents or
teachers -- act as if it is easy to live or act that way. The
deacon told the students that their parents and teachers don't
think it is easy, but they might well think it is simple.
How can this be? The students were confounding "simple" and
"easy". A lot of times, life is simple, because we know what
we should do. But that does not make life easy, because doing
a simple thing may be quite difficult.
This made an impression on me, because I recognized that
conflict in my own life. Often, I know just what to do. That
part is simple. Yet I don't really want to do it. To do it
requires sacrifice or pain, at least in the short term. To do
it means not doing something else, and I am not ready or willing
to forego that something. That part is difficult.
Switch the verb from "do" to "be", and the conflict becomes
even harder to reconcile. I may know what I want to be.
However, the gap between who I am and who I want to be may be
quite large. Do I really want to do what it takes to get
there? There may be a lot of steps to take which individually
are difficult. The knowing is simple, but the doing is hard.
This gap surely faces college students, too, whether it means
wanting to get better grades, wanting to live a healthier life,
or wanting to reach a specific ambitious goal.
When I heard the deacon's story, I immediately thought of some
of my friends, who like very much the idea of being a "writer"
or a "programmer", but they don't really want to do the hard
work that is writing or programming. Too much work, too much
disappointment. I thought of myself, too. We all face this
conflict in all aspects of life, not just as it relates to
personal choices and values. I see it in my teaching and
learning. I see it in building software.
I thought of this old story today when I watched Rich Hickey's
talk from StrangeLoop 2011,
Simple Made Easy.
I had put off watching this for a few days, after tiring of a
big fuss that blew up a few weeks ago over Hickey's purported
views about agile software development techniques. I knew,
though, that the dust-up was about more than just Hickey's
talk, and several of my friends recommended it strongly. So
today I watched. I'm glad I did; it is a good talk. I
recommend it to you!
Based only on what I heard in this talk, I would guess that
Hickey misunderstands the key ideas behind XP's practices of
test-driven development and refactoring. But this could well
be a product of how some agilistas talk about them. Proponents
of agile and XP need to be careful not to imply that tests and
refactoring make change or any other part of software development
easy. They don't. The programmer still has to understand the
domain and be able to think deeply about the code.
Fortunately, I don't base what I think about XP practices on
what other people think, even if they are people I admire for
other reasons. And if you can skip or ignore any references
Hickey makes to "tests as guard rails" or to statements that
imply refactoring is debugging, I think you will find this
really is a very good talk.
Hickey's important point is that simple/complex and easy/hard
are different dimensions. Simplicity should be our
goal when writing code, not complexity. Doing something that
is hard should be our goal when it makes us better, especially
when it makes us better able to create simplicity.
Simplicity and complexity are about the interconnectedness of
a system. In this dimension, we can imagine objective measures.
Ease and difficulty are about what is most readily at hand,
what is most familiar. Defined as they are in terms of a
person's experience or environment, this dimension is almost
entirely subjective.
And that is good because, as Hickey says a couple of times in
the talk, "You can solve the familiarity problem for yourself."
We are not limited to our previous experience or our current
environment; we can take on a difficult challenge and grow.
Alan Kay often talks about how it is worth learning to play
a musical instrument, even though playing is difficult, at
least at the start. Without that skill, we are limited in
our ability to "make music" to turning on the radio or
firing up YouTube. With it, you are able make
music. Likewise riding a bicycle versus walking, or
learning to fly an airplane versus learning to drive a car.
None of these skills is necessarily difficult once we learn
them, and they enable new kinds of behaviors that can be
simple or complex in their own right.
One of the things I try to help my students see is the value
in learning a new, seemingly more difficult language: it
empowers us to think new and different thoughts. Likewise
making the move from imperative procedural style to OOP or to
functional programming. Doing so stretches us. We think and
program differently afterward. A bonus is that something that
seemed difficult before is now less daunting. We are able to
work more effectively in a bigger world.
In retrospect, what Hickey says about simplicity and
complexity is actually quite compatible with the key
principles of XP and other agile methods. Writing tests is a
part of how we create systems that are as simple as we can in
the local neighborhood of a new feature. Tests can also help
us to recognize complexity as it seeps into our program, though
they are not enough by themselves to help us see complexity.
Refactoring is an essential part of how we eliminate complexity
by improving design globally. Refactoring in the presence of
unit tests does not make programming easy. It doesn't replace
thinking about design; indeed, it is thinking about
design. Unit tests and refactoring do help us to grapple with
complexity in our code.
Also in retrospect, I gotta make sure I get down to St. Louis
for StrangeLoop 2012. I missed the energy this year.
A few weeks ago I wrote a few entries that made connections
to Roger Rosenblatt's Unless It Moves the Human Heart:
The Craft and Art of Writing. As I am prone to doing,
I found a lot of connections between writing, as described
by Rosenblatt, and programming. I also saw connections
between teaching of writers and teaching of programmers.
The most recent entry in that series highlighted how
teachers want their students to
learn how to think the same way,
not how to write the same way.
Rosenblatt also occasionally explores similarities between
writing and teaching. Toward the end of the book, he points
out a very important difference between the two:
Wouldn't it be nice if you knew that your teaching had shape
and unity, and that when a semester came to an end, you could
see that every individual thing you said had coalesced into
one overarching statement? But who knows? I liken teaching
to writing, but the two enterprises diverge here, because any
perception of a grand scheme depends on what the students
pick up. You may intend a lovely consistency in what you're
tossing them, but they still have to catch it. In fact, I do
see unity to my teaching. What they see, I have no
clue. It probably doesn't matter if they accept the parts
without the whole. A few things are learned, and my wish for
more may be plain vanity.
Novelists, poets, and essayists can achieve closure and create
a particular whole. Their raw material are words and ideas,
which the writer can make to dance. The writer can have an
overarching statement in mind, and making it real is just a
matter of hard work and time.
Programmers have that sort of control over their raw material,
too. As a programmer, I relish taken on the challenge of a
hard problem and creating a solution that meets the needs of
a person. If I have a goal for a program, I can almost
always make it happen. I like that.
Teachers may have a grand scheme in mind, too, but they have
no reliable way of making sure that their scheme comes true.
Their raw material consists not only of words and ideas.
Indeed, their most important raw material, their most
unpredictable raw material, are students. Try as they might,
teachers don't control what students do, learn, or think.
I am acutely aware of this thought as we wrap up the first
half of our programming languages course. I have introduced
students to functional programming and recursive programming
techniques. I have a pretty good idea what I hope they know
and can do now, but that scheme remains in my head.
Rosenblatt is right. It is vanity for us teachers to expect
students to learn exactly what we want for them. It's okay
if they don't. Our job is to do what we can to help them
grow. After that, we have to step aside and let them run.
Students will create their own wholes. They will assemble
their wholes from the parts they catch from us, but also
from parts they catch everywhere else. This is a good
thing, because the world has a lot more to teach than I
can teach them on my own. Recognizing this makes it a lot
easier for me as a teacher to do the best I can to help them
grow and then get out of their way.
Update: This entry originally appeared on September 29.
I bungled my blog directory and lost two posts, and the simplest
way to get the content back on-line is to repost.
I remember back in the late 1990s and early 2000s when patterns
were still a hot topic in the software world, and many pattern
writers trying to make the conceptual move to pattern languages.
It was a fun time to talk about software design. At some point,
there was a long and illuminating discussion on the patterns
mailing list about whether patterns should describe what
to build or how to build.
Richard Gabriel
and Ron Goldman -- creators of the marvelous essay-as-performance-art
Mob Software
-- patiently taught the community that the ultimate goal is
what. Of course, if we move to a higher level of abstraction,
a what-pattern becomes a how-pattern. But the most
valuable pattern languages teach us what to build and when, with
some freedom in the how.
This is the real challenge that novice programmers face, in courses
like CS1 or in self-education: figuring out what to build. It is
easy enough for many students to "get" the syntax of the programming
language they are learning. Knowing when to use a loop, or a
procedure, or a class -- that's the bigger challenge.
Our CS students are usually in the same situation even later in
their studies. They are still learning what to build, even as we
teach them new libraries, new languages, and new styles.
I see this a lot when students who are learning to program in a
functional style. Mentally, many think they are focused on the how
(e.g., How do I write this in Scheme?). But when we probe
deeper, we usually find that they are really struggling with what to
say. We spend some time talking about the problem, and they begin
to see more clearly what they are trying to accomplish. Suddenly,
writing the code becomes a lot easier, if not downright easy.
This is one of the things I really respect in the
How to Design Programs
curriculum. Its
design recipes
give beginning students a detailed, complete, repeatable process
for thinking about problems and what they need to solve a new
problem. Data, contracts, and examples are essential elements
in understanding what to build. Template solutions help bridge
the what and the how, but even they are, at the student's current
level of abstraction, more about what than how.
The
structural recursion patterns
I use in my course are an attempt to help students think about
what to build. The how usually follows directly from that. As
students become fluent in their functional programming language,
the how is almost incidental.
Update: This entry originally appeared on September 28.
I bungled my blog directory and lost two posts, and the simplest
way to get the content back on-line is to repost.
John Cook
recently reported
that he has bundled up some of his earlier writings about the
soft maximum as
a tech report.
The soft maximum is "a smooth approximation to the maximum of
two real variables":
softmax(x, y) = log(exp(x) + exp(y))
When John posted his first blog entry about the softmax, I
grabbed the idea and made it a homework problem for my students,
who were writing their first Scheme procedures. I gave them a
link to John's page, so they had access to this basic formula as
well as a Python implementation of it. That was fine with me,
because I was simply trying to help students become more
comfortable using Scheme's unusual syntax:
On the next assignment, I asked students to generalize the
definition of softmax to more than two variables. This gave
them an opportunity to write a variable arity procedure
in Scheme. At that point, they had seen only a couple simple
examples of variable arity, such as this implementation of
addition using a binary + operator:
(define plus ;; notice: no parentheses around
(lambda args ;; the args parameter in lambda
(if (null? args)
0
(+ (car args) (apply plus (cdr args))) )))
Many students followed this pattern directly for softmax:
Some of their friends tried a different approach. They saw
that they could use higher-order procedures to solve
the problem -- without explicitly using recursion:
Not many students had looked back for that formula, I think,
but we can see that it matches the higher-order softmax
almost perfectly. (map exp args) constructs
a list of the exp(xi) values.
(apply + ...) adds them up.
(log ...) produces the final answer.
What about the recursive solution? If we look at how its
recursive calls unfold, we see that this procedure computes:
This is an interesting take on the idea of a soft maximum,
but it is not what John's generalized definition says, nor
is it particularly faithful to the original 2-argument function.
How might we roll our own recursive solution that computes the
generalized function faithfully? The key is to realize that
the function needs to iterate not over the maximizing behavior
but the summing behavior. So we might write:
This solution turns softmax-var into
interface procedure
and then uses
structural recursion
over a flat list of arguments. One advantage of using an
interface procedure is that the recursive procedure
accumulate-exps no longer has to deal with
variable arity, as it receives a list of arguments.
It was remarkable to me and some of my students just how
close the answers produced by the two student implementations
of softmax were, given how different the underlying behaviors
are. Often, the answers were identical. When different, they
differed only in the 12th or 15th decimal digit. As several
blog readers pointed out, softmax is associative, so the two
solutions are identical mathematically. The differences in the
values of the functions result from the vagaries of
floating-point precision.
The programmer in me left the exercise impressed by the
smoothness of the soft maximum. The idea is resilient across
multiple implementations, which makes it seem all the more
useful to me.
More important, though, this programming exercise led to
several interesting discussions with students about programming
techniques, higher-order procedures, and the importance of
implementing solutions that are faithful to the problem domain.
The teacher in me left the exercise pleased.
I mentioned
last time
that I've been spending some time with Norvig's work on Strachey's
checkers program in CPL. This is fun stuff that can be used in my
programming languages course. But it isn't the only new stuff I've
been learning. When you work with students on research projects
and independent studies, opportunities to learn await at every turn.
A grad student is taking the undergrad programming languages course
and so has to do some extra projects to earn his grad credit. He
is a lover of Ruby and has been looking at a couple of Scheme
interpreters implemented in Ruby,
Heist
and
Bus-Scheme.
I'm not sure where this will lead yet, but that is part of the
exercise.
The undergrad who
faced the "refactor or rewrite?" decision
a few weeks ago teaches me something new every week, not only through
his experiences writing a language processor but also about his
program's source and target languages, Photoshop and HTML/CSS.
Another grad student is working on a web application and teaching
me other things about Javascript. Now we are expanding into one
tool I've long wanted to study in greater detail,
Processing.js
and perhaps into another I only just learned of from
Dave Humphrey,
a beautiful little data presentation library called
D3.
All of these projects are good news. One of the great advantages
of working at a university is working with students and learning
along with him. Right now, I have a lot on my plate. It's
daunting but fun.
We have begun to write code in
my programming languages course.
The last couple of sessions we have been writing higher-order
procedures, and next time we begin a three-week unit learning
to write recursive programs following the structural recursion
patterns in my small pattern language
Roundabout.
One of the challenges for students is to learn how to use the
patterns without feeling a need to mimic my style perfectly.
Some students, especially the better ones, will chafe if I
try to make them write code exactly as I do. They are already
good programmers in other styles, and they can become good
functional programmers without aping me. Many will see the
patterns as a restriction on how they think, though in fact
the patterns are
source of great freedom.
They force you to write code in a particular way; they give
you tools for thinking about problems as you program.
Again, there is something for us to learn from our writing
brethren. Consider a writing course like the one Roger
Rosenblatt describes in his book, Unless It Moves the
Human Heart: The Craft and Art of Writing, which I have
referred to several times, most recently in
The Summer Smalltalk Taught Me OOP.
No student in Rosenblatt's course wants him to expect them
to leave the course writing just like he does. They are in
the course to learn elements of craft, to share and critique
work, and to get advice from someone with extensive experience
as a writer. Rosenblatt is aware of this, too:
Wordsworth quoted Coleridge as saying that every poet must
create the taste by which he is relished. The same is true
of teachers. I really don't want my students to write as I
do, but I want them to think about writing as I do. In them
I am consciously creating a certain taste for what I believe
constitutes skillful and effective writing.
The course is more about learning how to think about
writing as much as it is about learning how to write itself.
That's what a good pattern language can do for us: help us
learn to think about a class of problems or a class of
solutions.
I think this happens whether a teacher intends it consciously
or not. Students learn how to think and do by observing
their teachers thinking and doing. A programming course is
usually better if the teacher designs the course deliberately,
with careful consideration of the patterns to demonstrate and
the order in which students experience them in problems and
solutions.
In the end, I want my students to think about writing
recursive programs as I do, because experience as both a
programmer and as a teacher tells me that this way of thinking
will help them become good functional programmers as soon as
possible. But I do not want them to write exactly as I so;
they need to find their own style, their own taste.
This is yet another example of the tremendous power teachers
wield every time they step foot in a classroom. As a student,
I was always most fond of the teachers wielded it carefully
and deliberately. So many of them live on in me in how I
think. As a teacher, I have come to respect this power in my
own hands and try to wield it respectfully with my students.
P.S. For what it's worth, Coleridge is one of my favorite poets!
Elisabeth Hendrickson recently posted a good short piece about
Testing is a Whole Team Activity.
She gives examples of some of the comments she hears frequently
which indicate a misunderstanding about the relationship between
coding and testing. My favorite example was the first:
"We're implementing stories up to the last minute, so we
can never finish testing within the sprint."
Maybe I like this one so much because I hear it from students so
often, especially on code that they find challenging and are
having a hard time finishing.
"If we took the time to test our code, we would not get done on
time."
"What evidence do you have that your code works for the example
cases?"
"Well, none, really, but..."
"Then how do you know you are done?"
"'done'?" You keep using that word. I do not think it means
what you think it means.
Just before classes started, one of my undergrad research students
stopped by to talk about a choice he was weighing. He is writing
a tool that takes as input a Photoshop document and produces as
output a faithful, understandable HTML rendition of the design and
content. He has written a lot of code in Python over the last few
months, using an existing library of tools for working with
Photoshop docs. Now that he understands the problem well and has
figured out what a good solution looks like, he is dissatisfied
with his existing code. He thinks he can create a better, simpler
solution by writing his own Photoshop-processing tools.
The choice is: refactor the code incrementally until he has
replaced all the library code, or start from scratch?
My student's dilemma took me back over twenty years, to a time
when I faced the same choice, when I too was first learning my
craft.
I was one of my doctoral advisor's first graduate students. In
AI, this means that we had a lot of infrastructure to build in
support of the research we all wanted to do. We worked in
knowledge-based systems, and in addition to doing research in
the lab we also wanted to deliver working systems to our
collaborators on and off campus. Building tools for regular
people meant having reasonable interfaces, preferably with
GUI capabilities. This created an extra problem, because our
collaborators used PCs, Macs, and Unix workstations. My advisor
was a Mac guy. At the time, I was a Unix man in the process of
coming to love Macs. In that era, there was no Java and precious
few tools for writing cross-platform GUIs.
Our lab spent a couple of years chasing the ideal solution: a
way to write a program and run it on any platform, giving users
the same experience on all three. The lab had settled more or
less on PCL, a portable Common Lisp. It wasn't ideal, but we
grad students -- who were spending a lot of time implementing
libraries and frameworks -- were ready to stop building
infrastructure and start working full-time on our own code.
Then my advisor discovered Smalltalk.
The language included graphics classes in its base image, which
offered the promise of write-once-run-anywhere apps for clients.
And it was object-oriented, which matched the conceptual model
of the software we wanted to build to a T. I had just spent
several months trying to master CLOS, Common Lisp's powerful
object system, but Smalltalk looked like just what we wanted.
So we made the move -- and told advisor that this would be the
last move. Smalltalk would be our home.
I learned the basics of the language by working through every
tutorial I could my hands on, first Digitalk Smalltalk then
ObjectWorks. They were pretty good. Then I wrote some toy
programs of my own, to show I was ready to create on my own.
So I started writing my first Smalltalk system: a parser and
interpreter for a domain-specific AI language with a built-in
inference engine, a simple graphical and table-driven tool for
writing programs in these languages, and graphical front end
for running systems.
There was a lot going on there, at least for a green graduate
student only recently called up to the big leagues. But I
had done my homework. I was ready. I was sure of it. I was
cocky.
I crashed.
It turn out that I didn't really understand the role that data
should play in an OO program. My program soon became a tangle
of data dependencies design before I understood my solution all
that well, and the tangle made the code increasing turgid.
So I threw it away, rm -r'ed it into nothingness.
I started from scratch, sure that Version 2 would be perfect.
I crashed again.
The program was better this time around, but it turns out that
I didn't really understand how objects should interact in a
large OO program. My program soon became a tangle of objects
and wrappers and adapters, whose behavior I could not follow in
even the simplest scenarios. The tangle made the code increasing
murky.
So I threw it away -- rm -r again -- and started
from scratch. Surely Version 3, based on several weeks
of coding and learning, would be just what we wanted.
I crashed yet again. This time, the landing was more gentle,
because I really was making progress. But as I coded my third
system, I began to see ways to structure the program that would
make the code easier to grow as I added features, and easier to
change as I got better at design. I was just beginning to glimpse
the Land of Design Patterns. But I always seemed to learn each
lesson one day too late to use it.
My program was moving forward, creakily, but I just knew it could
be better. I did not like the idea of maintaining this code for
several years, as we modified apps fielded with our collaborators
and as we used it as part of the foundation for the lab's vision.
So I threw it away and wrote my system from scratch one last time.
The result was not a perfect program, but one that I could live
with and be proud of. It only took me four major iterations and
several months of programming.
Looking back, I faced the same decision my student faced recently
with his system. Refactor or start over? He has the advantage
of having written a better first program than I had, yet he made
the sound decision to rewrite.
Sometimes, refactoring really is the better approach. You can
keep system running while slowly corralling data dependencies,
spurious object interactions, and suboptimal design. Had I been
a more experienced programmer, I may well have chosen to refactor
from Version 3 to Version 4 of my program. But I wasn't.
Besides, I had neither a suite of unit tests nor access to
automated refactoring tools. Refactoring without either of these
makes the process scarier and more dangerous than it needs to be.
Maybe refactoring is the better approach most or all of the time.
I've read all about how the Great Rewrite is one of those
Things You Should Never Do.
But then, there is an axiom from Turing Award winner
Fred Brooks
that applies better to my circumstance of writing the initial
implementation of a program: "... plan to throw one away;
you will, anyhow". I find Brooks's advice most useful when
I am learning a lot while I am programmer. For me, that is one
context, at least, in which starting from scratch is a big win:
when my understanding is changing rapidly, whether of domain,
problem, or tools. In those cases, I am usually incapable of
refactoring fast enough to keep up with my learning. Starting over
offers a faster path to a better program than refactoring.
On that first big Smalltalk project of mine, I was learning so
much, so fast. Smalltalk was teaching me object-oriented
programming, through my trial and error and through my experience
with the rest of the Smalltalk class hierarchy. I had never written
a language interpreter or other system of such scale before, and
I was learning lessons about modularity and language processing. I
was eager to build a new and improved system as quickly as I could.
In such cases, there is nothing like the sound of OS X's shredder.
Freedom. No artificial constraints from what has suddenly become
legacy code. No limits from my past ignorance. A fresh start.
New energy!
This is something we programmers can learn from the experience
of other writers, if we are willing. In Unless It Moves the
Human Heart: The Craft and Art of Writing, Roger Rosenblatt
tells us that Edgar Doctorow ...
... had written 150 pages of The Book of Daniel before
he'd realized he had chosen the wrong way to tell the story.
... So one morning Edgar tossed out the 150 pages and started
all over.... I wanted the class to understand that Edgar was
happy to start from scratch, because he had picked the wrong
door the first time.
Sometimes, the best thing a programmer can admit is that he
or she has picked the wrong door and walked down the wrong
path.
But Brooks warns of a danger programmer's face on second efforts:
the Second System Effect. As Scott Rosenberg writes in
Code Reads #1: The Mythical Man-Month:
Brooks noted that an engineer or team will often make all the
compromises necessary to ship their first product, then founder
on the second. Throughout project number one, they stored up
pet features and extras that they couldn't squeeze into the
original product, and told themselves, "We'll do it right next
time." This "second system" is "the most dangerous a man ever
designs."
I never shipped the first version of my program, so perhaps I
eluded this pitfall out of luck. Still, I was cocky when I wrote
Version 1, and then I was cocky when I wrote Version 2. But both
versions humbled me, humbled me hard. I was a good programmer,
maybe, but I wasn't good enough. I had a lot to learn,
and I wanted to learn it all.
So it was relatively easy to start over on #3 and #4. I was
learning, and I had the luxury of time. Ah, to be a grad
student again!
In the end, I wrote a program that I could release to users
and colleagues with pride. Along the way, Smalltalk taught
me a lot about OOP, and writing the program taught me a lot
about expert system shells. It was time well spent.
In two recent entries [
1
|
2
], I mentioned that I had been recently reading Roger Rosenblatt's
Unless It Moves the Human Heart: The Craft and Art of Writing.
Many of you indulge me my fascination with writers talking about
writing, and I often see parallels between what writers of code
and writers of prose and poetry do. That Rosenblatt also connects
writing to teaching, another significant theme of my blog, only
makes this book more stimulating to me.
"Unless it moves the human heart" is the sort of thing writers say
about their calling, but not something many programmers say. (The
book title quotes Aussie poet A. D. Hope.) It is clearly at the
heart of Rosenblatt's views of writing and teaching. But in his
closing chapter, Rosenblatt includes a letter written to his
students as a postscript on his course that speaks to a desire
most programmers have for the lives' work: usefulness. To be
great, he says, your writing must be useful to the world. The
fiction writer's sense of utility may differ from the programmer's,
but at one level the two share an honorable motive.
This paragraph grabbed me as advice as important for us programmers
as it is for creative programmers. (Which software people do you
think of as you read it?)
How can you know what is useful to the world? The world will not
tell you. The world will merely let you know what it wants, which
changes from moment to moment, and is nearly always cockeyed. You
cannot allow yourself to be directed by its tastes. When a writer
wonders, "Will it sell?" he is lost, not because he is looking to
make an extra buck or two, but rather because, by dint of asking
the question in the first place, he has oriented himself to the
expectations of others. The world is not a focus group. The
world is an appetite waiting to be defined. The greatest love you
can show it is to create what it needs, which means you must know
that yourself.
What a brilliant sentence: The world is an appetite waiting to
be defined. I don't think Ward Cunningham went around asking
people if they needed wiki. He built it and gave it to them, and
when they saw it, their appetite took form. It is indeed a great
form of love to create what the world needs,
whether the people know it yet or not.
(I imagine that at least a few of you were thinking of Steve Jobs
and the vision that gave us the Mac, iTunes, and the iPad. I was
too, though Ward has always been my hero when it comes to making
useful things I had not anticipated.)
Rosenblatt tells his students that, to write great stories and
poems and essays, they need to know the world well and deeply.
This is also sound advice to programmers, especially those who
want to start the next great company or revolutionize their
current employers from the inside out. This is another good
reason to
read, study, and think broadly.
To know the world outside of one's Ruby interpreter, outside the
Javascript spec and the HTML 5.0, one must live in it and think
about it.
It seems fitting on this Labor Day weekend for us to think about
all the people who make the world we live in and keep it running.
Increasingly, those people are using -- and writing -- software
to give us useful things.
One of the students in my just-started Programming
Languages course recently mentioned that he has started
a company, Glass Cannon Games, to write games for the
Box and Android platforms. He is working out of my
university's student incubator.
Last summer,
I wrote
a bit about entrepreneurship and a recent student of mine,
Nick Cash, who has started
Book Hatchery
to "help authors publish their works digitally".
Over the last decade, Wade has taken a few big ideas and
worked hard to make them real. That's what Nick and,
presumably, Ian are doing, too.
Most entrepreneurs start with big thoughts. I try to
encourage students to think big thoughts, to consider an
entrepreneurial career. The more ideas they have, the more
options they have in careers and in life. Going to work for
a big company is the right path for some, but some want more
and can do their own thing -- if only they have the courage
to start.
This is a more important idea than just for starting
start-ups. We can "think big and write small" even for the
more ordinary programs we write. Sometimes we need a big
idea to get us started writing code. Sometimes, we even
need hubris. Every problem a novice faces can appear
bigger than it is. Students who are able to think big
often have more confidence. That is the confidence they
need to start, and to persevere.
It is fun as a teacher to be able to encourage students to
think big. As writer Roger Rosenblatt says,
One of the pleasures of teaching writing courses is that
you can encourage extravagant thoughts like this in your
students. These are the thoughts that will be concealed
in plain and modest sentences when they write. But
before that artistic reduction occurs, you want your
students to think big and write small.
Many students come into our programming courses unsure,
even a little afraid. Helping them free themselves to have
extravagant ideas is one of the best things a teacher can
do for them. Then they will be motivated to do the work
they need to master syntax and idioms, patterns and styles.
A select few of them will go a step further and believe
something even more audacious, that
... there's no purpose to writing programs unless you
believe in significant ideas.
Those will be the students who start the Glass Cannons,
the Book Hatcheries, and the T8s. We are all better off
when they do.
We have survived Week 1. This semester, I again get to
teach Programming Languages, a course I love and about
which I blog for a while every eighteen months of so.
I had thought I might blog as I prepped for the course,
but between
my knee
and department duties, time was tight. I've also been slow
to settle on new ideas for the course. In my blog ideas
folder, I found notes for an entry debriefing the last
offering of the course, from Spring 2010, and thought that
might crystallize some ideas for me. Alas, the notes held
nothing useful. They were just a reminder to write, which
went unheeded during
a May term
teaching
agile software development.
Yesterday I started reading a new book -- not a book related
to my course, but Roger Rosenblatt's Unless It Moves the
Human Heart: The Craft and Art of Writing. I love to
read writers talking about writing, and this book has an
even better premise: it is a writer talking about writing as
he teaches writing to novices! So there is plenty of
inspiration in it for me, even though it contains not a single
line of Scheme or Ruby.
Rosenblatt recounts teaching a course a course called
"Writing Everything". Most the students in the course want
to learn how to write fiction, especially short stories.
Rosenblatt has them also read write poems, in which they can
concentrate on language and sounds, and essays, in which they
can learn to develop ideas.
This is not the sort of course you find in CS departments.
The first analogy that came to mind was a course in which
students wrote, say, a process scheduler for an OS, a CRUD
database app for a business, and an AI program. The breadth
and diversity of apps might get the students to think about
commonalities and differences in their programming practice.
But a more parallel course would ask students to write a few
procedural programs, object-oriented programs, and functional
programs. Each programming style would let the student focus
on different programming concepts and distinct elements of
their craft.
I'd have a great time teaching such a "writing" course.
Writing programs is fun and hard to learn, and we don't have
many opportunities in a CS program to talk about the process
of writing and revising code. Software engineering courses
have a lot of their own content, and even courses on software
design and development often deal more with new content than
with programming practice. In most people's minds, there is
not room for a new course like this one in the curriculum.
In CS programs, we have theory and applications courses to
teach. In Software Engineering programs, they seem far too
serious about imitating other engineering disciplines to
have room for something this soft. If only more schools
would implement Richard Gabriel's idea of
an MFA in software...
Despite all these impediments, I think a course in which
students simply practiced programming in the large(r) and
focused on their craft could be of great value to most CS
grads.
I will let Rosenblatt's book inspire me and leak into my
Programming Languages course where helpful. But I will
keep our focus on the content and skills that our curriculum
specifies for the course. By learning the functional style
of programming and a lot about how programming languages
work, students will get a chance to develop a few practical
skills, which we hope will pay off in helping them to be
better programmers all around, whether in Java, Python,
Ruby, Scala, Clojure, or Ada.
One meta-message I hope to communicate both explicitly and
implicitly is that programmers never stop learning,
including their professor. Rosenblatt has the same goal in
his writing course:
I never fail to say "we" to my students, because I do
not want them to get the idea that you ever learn how
to write, no matter how long you've done it.
Beyond that, perhaps the best I can do is let my students
that I am still mesmerized by the cool things we are
learning. As Rosenblatt says,
Observing a teacher who is lost in the mystery of the
material can be oddly seductive.
Once students are seduced, they will take care of their
own motivation and their own learning. They won't be
able to help themselves.
Before reading interviews with
Hemingway
and
Jobs,
I read a report of
Ansel Adams's last interview.
Adams was one of America's greatest photographers of the 20th
century, of course, and several of his experiences seem to me
to apply to important issues in software development.
It turns out that both photography and software development
share a disconnect between teaching and doing:
One of the problems is the teaching of photography. In
England, I was told, there's an institute in which nobody can
teach photography until they've had five years' experience in
the field, until they've had to make a go of it professionally.
Would you recommend that?
I think that teachers should certainly have far more experience
than most of the ones I know of have had. I think very few of
them have had practical experience in the world. Maybe it's an
impossibility. But most of the teachers work pretty much the
same way. The students differ more from each other than the
teachers do.
Academics often teach without having experience making a living
from the material they teach. In computer science, that may
make sense for topics like discrete structures. There is a
bigger burden in most of the topics we teach, which are done
in industry and which evolve at a more rapid rate. New CS
profs usually come out of grad school on the cutting edge of
their specialties, though not necessarily on top of all the
trends in industry. Those who take research-oriented positions
stay on the cutting edge of their areas, but the academic
pressure is often to become narrower in focus and thus farther
from contemporary practice. Those who take positions at
teaching schools have to work really hard to stay on top of
changes out in the world. Teaching a broad variety of courses
makes it difficult to stay on top of everything.
Adams's comment does not address the long-term issue, but
it takes a position on the beginning of careers. If every new
faculty member had five years or professional programming
experience, I dare say most undergrad CS courses would be
different. Some of the changes might be tied too closely to
those experiences (someone who spent five years at Rockwell
Collins writing SRSs and coding in Ada would learn different
things from someone who spent five years writing e-commerce
sites in Rails), but I think would usually be some common
experiences that would improve their courses.
When I first read Adams's comment, I was thinking about how
the practitioner would learn and hone elements of craft that
the inexperienced teacher didn't know. But the most important
thing that most practitioners would learn is humility.
It's easy to lecture rhapsodically about some abstract approach
to software development when you haven't felt the pain it causes,
or faced the challenges left even when it succeeds. Humility
can be a useful personal characteristic in a teacher. It helps
us see the student's experience more accurately and to respond
by changing how and what we teach.
Short of having five years of professional experience, teachers
of programming and software development need to read and study
all the time -- and not just theoretical tomes, but also the
work of professional developers. Our industry is blessed with
great books by accomplished developers and writes, such as
Design Patterns and Refactoring. The web and
practitioners' conferences such as
StrangeLoop
are an incredible resource, too. As
Fogus tweeted
recently, "We've reached an exciting time in our industry:
colleges professors influenced by Steve Yegge are holding
lectures."
Other passages in the Adams interview stood out to me. When he
shared his intention to become a professional photographer,
instead of a concert pianist:
Some friends said, "Oh, don't give up music. ... A camera
cannot express the human soul." The only argument I had for
that was that maybe the camera couldn't, but I might try
through the camera.
What a wonderful response. Many programmers feel this way
about their code. CS attracts a lot of music students, either
during their undergrad studies or after they have spent a few
years in the music world. I think this is one reason: they
see another way to create beauty. Good news for them: their
music experience often gives them an advantage over those who
don't have it. Adams believed that studying music was valuable
to him as a photographer:
How has music affected your life?
Well, in music you have this absolutely necessary discipline
from the very beginning. And you are constructing various
shapes and controlling values. Your notes have to be accurate
or else there's no use playing. There's no casual approximation.
Discipline. Creation and control. Accuracy and precision.
Being close isn't good enough. That sounds a lot like
programming to me!
Another of
the interviews I've read recently
was The Rolling Stone's
1994 interview with Steve Jobs,
when he was still at NeXT. This interview starts slowly
but gets better as it goes on. The best parts are about
people, not about technology. Consider this, on the source
Jobs' optimism:
Do you still have as much faith in technology today as
you did when you started out 20 years ago?
Oh, sure. It's not a faith in technology. It's faith in
people.
Explain that.
Technology is nothing. What's important is that you have
a faith in people, that they're basically good and smart,
and if you give them tools, they'll do wonderful things
with them. It's not the tools that you have faith in --
tools are just tools. They work, or they don't work. It's
people you have faith in or not.
I think this is a basic attitude held by many CS teachers,
about both technology and about the most important set of
people we work with: students. Give them tools, and they
will do wonderful things with them. Expose them to ideas
-- intellectual tools -- and they will do wonderful things.
This mentality drives me forward in much the same way as
Jobs's optimism does about the people he wants to use
Apple's tools.
I also think that this is an essential attitude when you
work as part of a software development team. You can have
all the cool build, test, development, and debugging tools
money can buy, but in the end you are trusting people,
not technology.
Then, on people from a different angle:
Are you uncomfortable with your status as a celebrity
in Silicon Valley?
I think of it as my well-known twin brother. It's not me.
Because otherwise, you go crazy. You read some negative
article some idiot writes about you -- you just can't take
it too personally. But then that teaches you not to take
the really great ones too personally either. People like
symbols, and they write about symbols.
I don't have to deal with celebrity status in Silicon Valley
or anywhere else. I do get to read reviews of my work,
though. Every three years, the faculty of my department
evaluate my performance as part of the dean's review of my
work and his decision to consider for me another term. I
went through my second such review last winter. And, of
course, frequent readers here have seen my comments on
student assessments, which we do at the end of each semester.
I wrote about assessments of my spring Intelligent Systems
course
back in May.
Despite my twice annual therapy sessions in the form of
blog entries, I have a pretty good handle on these reviews,
both intellectually and emotionally. Yet there is something
visceral about reading even one negative comment that never
quite goes away. Guys like Jobs probably do there best not
to read newspaper articles and unsolicited third-party evals.
I'll have to try the twin brother gambit next semester. My
favorite lesson from Jobs's answer, though, is the second
part: While you learn to steel yourself against bad reviews,
you learn not to take the really great ones too personally,
either. Outliers is outliers. As Kipling said, all people
should count with you, but none too much. The key in these
evaluations to gather information and use it to improve your
performance. And that most always comes out of the middle
of the curve. Treating raves and rants alike with equanimity
keeps you humble and sane.
Ultimately, I think one's stance toward what others say comes
back to the critical element in the first passage from Jobs:
trust. If you trust people, then you can train yourself to
accept reviews as a source of valuable information. If you
don't, then the best you can do is ignore the feedback you
receive; the worst is that you'll damage your psyche every
time you read them. I'm fortunate to work in a department
where I can trust. And, like Jobs, I have a surprising faith
in my students' fairness and honesty. It took a few years to
develop that trust and, once I did, teaching came to feel much
safer.
"Always Stop When You Know What Is Going To Happen Next"
A few weeks ago, I ran across
an article
that quoted from published interviews with nine creative
people. Over the last couple of days, I have been reading
the original interviews that most interested me. Three in
particular jogged my mind about creativity, art, and the
making of things -- all of which are a part of how I view
craft as a programmer and teacher.
Who would have thought that an interview with author Ernest
Hemingway in
The Paris Review's "The Art of Fiction No. 21"
would make me think about computer programming and
test-driven development? But it did. When asked about his
writing schedule, Hemingway described a morning habit that
I myself enjoy:
When I am working on a book or a story I write every morning
as soon after first light as possible. There is no one to
disturb you and it is cool or cold and you come to your work
and warm as you write. You read what you have written and,
as you always stop when you know what is going to happen next,
you go on from there. You write until you come to a place
where you still have your juice and know what will happen
next and you stop and try to live through until the next day
when you hit it again. You have started at six in the morning,
say, and may go on until noon or be through before that. When
you stop you are as empty, and at the same time never empty
but filling, as when you have made love to someone you love.
Nothing can hurt you, nothing can happen, nothing means
anything until the next day when you do it again. It is the
wait until the next day that is hard to get through.
I love this paragraph. While discussing mundane details of
how he starts his writing day, Hemingway seamlessly shifts
into a simile comparing writing -- and stopping -- to making
love. Writers and other artists can say such things and
simply be viewed for what they are: artists. I dare say
many computer programmers feel exactly the same about
writing programs. Many times I have experienced the strange
coincident feelings of emptiness and fullness after a long
day or night coding, and the longing to begin again tomorrow.
Yet I knew, as Hemingway did, that the breaks were a
necessary part of the discipline one needed to write well
and consistently over the long haul. (Think
sustainable pace,
my friends.)
Yet, if one of us programmers were to say what Hemingway
said above, to compare the feeling we have when we stop
programming to the the feeling we have after making love
to a person we love, most people would have to fight back a
smirk and suppress an urge to joke about nerds never having
sex and not being able to get girls (or guys). The impolite
among them would say it out loud. If you are careful in
choosing your friends and perhaps a bit lucky, you will
surround yourself with friends who react to you saying this
with a sympathetic nod, because they know that you, too, are
a writer, and something of an artist.
On a more practical note, the writing habit Hemingway
describes resembles a habit many of us programmers have. In
the world of TDD, you will often hear people say, "Stop at
the end of the day with a failing test." My friend, poet and
programmer Richard Gabriel, has spoken of ending the day in
the middle of a line of code. Both ideas echo Hemingway's
advice, because they leave us in the same great position the
next morning: ready to start the day by doing something
obvious, something concrete.
But why is that so important?
But are there times when the inspiration isn't there at
all?
Naturally. But if you stopped when you knew what would happen
next, you can go on. As long as you can start, you are all
right. The juice will come.
Writing is hard. Starting is hard. But if you are a writer,
you must write, you must start. Likewise a programmer. As
many people will tell you, inspiration is a fickle and
overrated gift. Hemingway speaks elsewhere in the interview
of days filled with inspiration, but they are rare. The
writer writes regardless of inspiration. In writing, one
often creates the very inspiration he seeks.
As long as you can start, you are all right.
Later in the piece, Hemingway has something to interesting
to say about a different sort of starting: starting a career.
When asked if financial security can be a detriment to good
writing, he says:
If it came early enough and you loved life as much as you loved
your work it would take much character to resist the temptations.
Once writing has become your major vice and greatest pleasure
only death can stop it. Financial security then is a great help
as it keeps you from worrying. Worry destroys the ability to
write. [Worry] attacks your subconscious and destroys your
reserves.
This made me think of young CS grads in start-up companies,
working to get by on a minimal budget while fulfilling a
passion to make something. Being poor may not be as good for
our souls as some would have us think, but it does inoculate
us from temptations available to us only if we have resources.
Once programming is your habit -- "your major vice and greatest
pleasure" -- then you are on the path for a productive life as
a programmer. If financial success comes too early, or if you
are born with resources, you can still become a programmer,
but you may have too battle the attraction of things that will
get in the way of the work necessary to develop your craft.
This is one of the motives behind the grueling 6-year trial to
which we subject new profs to in our universities: to instill
habits of work and thought before they receive the
temptation-heavy mantle of tenure. Unlike Hemingway's
prescription, though, at most research schools the tenure-track
phase usually includes an unhealthy dose of uncertainty and
worry. But then again, maybe being a poor, struggling young
writer or artist does, too.
That's one reason I like Hemingway's answer so much. He does
not romanticize being poor. He acknowledges that, once one
has the habit of writing, financial security can be a great
benefit, because it relieves the writer of the stress that can
kill her productivity.
Despite enjoying these insightful passages so much, I cannot
say that this a great interview. Hemingway is too often
unwilling to talk about elements of the the craft of writing,
and he expends too many words telling interviewer George
Plimpton -- an intelligent man and accomplished journalist
himself -- that his questions are cliche, worn, or stupid.
Still, I was driven to read through to the end, and I enjoyed
it.
Methods, Names, and Assumptions in Adding New Code to a Program
Since the mid-1990s, there has been a healthy conversation
around refactoring, the restructuring of code to improve
its internal structure without changing its external
behavior. Thanks to Martin Fowler, we have a catalog of
techniques for refactoring that help us restructure code
safely and reliably. It is a wonderful tool for learners
and practitioners alike.
When it comes to writing new code, we are not so lucky.
Most of us learn to program by learning to write new code,
yet we rarely learn techniques for adding code to a program
in a way that is as safe and reliable as effective as the
refactorings we know and love.
You might think that adding code would be relatively simple,
at least compared to restructuring a large, interconnected
web of components. But how can we move with the same
confidence when adding code as we do when we follow a
meticulous refactoring recipe under the protection of good
unit tests permits? Test-driven design is a help, but I
have never felt like I had the same sort of support writing
new code as when I refactor.
So I was quite happy a couple of months ago to run across
J.B. Rainsberger's
Adding Behavior with Confidence.
Very, very nice! I only wish I had read it a couple of
months ago when I first saw the link. Don't make the same
mistake; read it now.
Rainsberger gives a four-step process that works well for
him:
Identify an assumption that the new behavior needs to
break.
Find the code that implements that assumption.
Extract that code into a method whose name represents
the generalisation you're about to make.
Enhance the extracted method to include the generalisation.
I was first drawn to the idea that a key step in adding new
behavior is to make a new method, procedure, or function.
This is one of the basic skills of computer programming.
It is one of the earliest topics covered in many CS1 courses,
and it should be taught sooner in many others.
Even still, most beginners seem to fear creating new methods.
Even more advanced students will regress a bit when learning
a new language, especially one that works differently than
the languages they know well. A function call introduces a
new point of failure: parameter passing. When worried about
succeeding, students generally try to minimize the number of
potential points of failure.
Notice, though, that Rainsberger starts not with a brand new
method, empty except for the new code to be written. This
technique asks us first to factor out existing code into a
new method. This breaks the job of writing the new code into
two, smaller steps: First refactor, relying on a
well-known technique
and the existing tests to provide safety. Second, add the new
code. (These are Steps 3 and 4 in Rainsberger's technique.)
That isn't what really grabbed my attention first, however.
The real beauty for me is that extracting a method forces us
to give it us a name. I think that naming gives us
great power, and
not just in programming.
A lot of times, CS textbooks make a deal about procedures as
a form of abstraction, and they are. But that often feels so
abstract... For programmers, especially beginners, we might
better focus on the fact that help us to name things in our
programs. Names, we get.
By naming a procedure that contains a few lines of code, we get
to say what the code does. Even the best factored code
that uses good variable names tends to say how something
is done, not what it is doing. Creating and calling a method
separates the two: the client does what the method does, and
the server implements how it is done. This separation gives
us new power: to refactor the code in other ways, certainly.
Rainsberger reminds us that it also gives us power to add
code more reliably!
"How can I add code to a program? Write a new function."
This is an unsurprising, unhelpful answer most of the time,
especially for novices who just see this as begging the question.
"Okay, but what do I do then?" Rainsberger makes it a helpful
answer, if a bit surprising. But he also puts it in a context
with more support, what to do before we start writing the new
code.
Creating and naming procedures was the strongest take-home
point for me when I first read this article. As the ideas
steeped in my mind for a few days, I began to have a greater
appreciation for Rainsberger's focus on assumptions. Novice
thinkers have trouble with assumptions. This is true whether
they are learning to program, learning to read and analyze
literature, or learning to understand and argue public
policy issues. They have a hard time seeing assumptions,
both the ones they make and the ones made by other writers.
When the assumptions are pointed out, they are often unsure
what to do with them, and are tempted to skip right over
them. Assumptions are easy to ignore sometimes, because they
are implicit and thus easy to lose track of when deep in a
argument.
Learning to understand and reason about assumptions is another
important step on the way to mature thinking. In CS courses,
we often introduce the idea of preconditions and
postconditions in Data Structures. (Students also
see them in a discrete structures course, but there they tend
to be presented as mathematical tools. Many students dismiss
their value out of hand). Writing pre- and postconditions for
a method is a way to make assumptions in your program explicit.
Unfortunately, most beginning don't yet see the value in
writing them. They feel like an extra, unnecessary step in
a process dominated by the uncertainty they feel about their
code. Assuring them that these invariants help is
usually like pushing a rock up a hill. Tomorrow, you get to
do it again.
One thing I like about Rainsberger's article is that it puts
assumptions into the context of a larger process aimed at
helping us write code more safely. Mathematical reasoning
about code does that, too, but again, students often see it
as something apart from the task of programming. Rainsberger's
approach is undeniably about code. This technique may
encourage programmers to begin thinking about assumptions sooner,
more often, and more seriously.
As I said, I haven't seen many articles or books talk about
adding code to a program in quite this way. Back in January,
"Uncle Bob" Martin wrote an article in the same spirit as this,
called
The Transformation Priority Premise.
It offers a grander vision, a speculative framework for all
additions to code. If you know Uncle Bob's teachings about
TDD, this article will seem familiar; it fits quite nicely
with the mentality he encourages when using tests to drive the
growth of a program. While his article is more speculative,
it seems worthy or more thought. It encourages the tiniest
of steps as each new test provokes new code in our program.
Unfortunately, it takes such small steps that I fear I'd have
trouble getting my students, especially the novices, to give
it a fair try. I have a hard enough time getting most students
to grok the value of TDD, even my seniors!
I have similar concerns about Rainsberger's technique, but his
pragmatism and unabashed focus on code gibes me hope that it
may be useful teaching students how to add functionality to
their programs.
If a code base is more complicated than a car, shouldn't it have
a maintenance plan too?
I asked him, "Refactoring every 3K miles?", and he joked back,
"Well, maybe every 3K lines." I had thought about using LOC in
my tweet decided to stick with the auto analogy. Whatever its
weaknesses, LOC seems to be the first place programmers' minds
go when we talk about the volume of code. (Though, as much
traveling as Feathers and other big-time consultants and
speakers do in a year, maybe 3000 miles is the right magnitude
after all.)
Feathers makes a serious point, even if he didn't mean it too
seriously. When we buy a car, we implicitly accept the notion
of scheduled maintenance: change the oil every so often; have
the engine tuned up every so often; replace the battery and
rotate the tires every so often. We accept it because we know
that it makes our car run better and last longer.
When we buy software, we want it to run forever, as is. Or
the company who sells it to us wants us to run it as-is forever
-- or buy a new version. Imagine having to buy a new car as
soon as your current car started coughing, wheezing, or seizing
up on dirty oil.
I mentioned refactoring in my joke because it is part of the
maintenance plan built in to XP and used in so many agile
approaches to software development. XP discourages long-form
maintenance in the form of refactoring every few months or
even weeks. Instead, it encourages a sort of continuous
maintenance, in a tight test-code-refactor cycle. It's kind
of like checking your car's oil, fluids, tires, etc., after
every use.
When we do that to a car, it's usually because the car is in
bad shape, breaking down as we try to extend its life. But
continuous refactoring of a code base is usually a sign of
robust health. It means that we know our code is in good
shape and ready for use -- and extension. Teams that maintain
their code on automobile-like time scales are usually sitting
on a time bomb. Users may be able to use the code, but the
programmers dare not touch its internals.
My other thought as I tweeted was about our inability, or
perhaps unwillingness, to make this idea come alive for the
students in our university CS programs.
It is an inability because it is so hard to create ways for
students to live with any body of code longer than a semester
or two, and time is a necessary ingredient facing the need for
maintenance. Of all my project courses, compilers seems the
most frequent teacher of this lesson. A semester may not be
long, but a compiler is complex enough, and a non-trivial
language spec hard enough to understand, to accelerate the
sense of age and deterioration.
It is perhaps an unwillingness because most every CS faculty
I know makes very little effort to change courses and degree
programs to make this lesson approachable. The good news is
that making changes to bring this idea within our students'
learning horizons also brings a lot of other important
software development lessons within their horizons.
I've been off-line a lot lately, doing physical therapy for
my knee and traveling a bit. That means I have a lot of
fun reading to catch up on! One page that made the rounds
recently is
Advice From An Old Programmer,
from Zed Shaw's intro book,
Learn Python The Hard Way.
Shaw has always been a thoughtful developer and an
entertaining writer with a unique take on programming. Now
he has put his money where his mouth is with a book that
aims to teach programming in a style he thinks most effective
for learners.
I look forward to digging into the book soon, but for now
his advice page has piqued a lot of interest. For
example:
Programming as a profession is only moderately interesting.
It can be a good job, but you could make about the same money
and be happier running a fast food joint. You're much better
off using code as your secret weapon in another profession.
As a matter of personal opinion, I disagree with the first
sentence, and could never make the switch discussed in the
second. But I do think that the idea of programming as a
secret weapon in other professions has a lot to offer people
who would never want to be computer scientists or full-time
software developers. It's a
powerful tool
that frees you from
wishing you have a programmer around.
It changes how you can think about problems in your discipline
and lets you
ask new questions.
Finally, Shaw tells his readers not too worry when non-programmers
treat them badly because they are now nerds who can program. He
gives good reasons why you shouldn't care about such taunts, and
then sums it up in a Zed Shaw-like killer closing line:
You can code. They cannot. That is pretty damn cool.
For the last year or so, there seems to have been something
of a backlash against agile software development. A lot of
conference speakers and bloggers have been telling us about
the failures of the move to agile approaches, both the
misconceptions at its base and the misdirections in its
evolution. I have been especially uncomfortable watching
writers and consultants who have teaching the world the
ways of agile development join the bandwagon.
Don't get me wrong. I am aware that agile development has
its weaknesses; all things do. I'm also aware that the
social and technical movement leading to its adoption across
our industry has had its problems; all movements do. I do
believe that we should understand the weaknesses in our
practices and our methods for teaching the world about them,
so that we can learn how to do those things better. Still,
it's been a little disconcerting to watch the backlash
proceed.
Then again, in my short career, I've seen something similar
happen to design patterns, object-oriented programming, and
structured programming. It seems the natural order of
history in our business. I've long wondered why.
Then I came across
The Return of the Barbarian,
which tells the story of humans history as a cycle between
barbarian culture and civilization. If we think of the
software world in similar terms, our own history makes
sense. Agile software development was once the barbarian.
Now its the civilized culture, ripe to be conquered by a
new, hungry barbarian.
How so? Think back to before the days of agile. The
software world, broadly speaking, had an entrenched
culture that we all recognize. Developers and clients
were different breeds. Developers and users, too. We
documented stable requirements, designed up front a
software system to deliver them, and passed the design onto
programmers, wrote code. When the process didn't go as
well as planned, programmers worked longer and harder to
meet their deadlines. This was an idealized world, to be
sure, but we strove hard to meet the ideal. People who had
made this style of development work -- smart people,
energetic people -- codified their knowledge in textbooks
and training courses, so that the rest of us could learn
how to duplicate their successes. Anyone willing to study
could learn the techniques and become part of civilized
society.
Collectively, we were wise, but individually, we were weak,
really, going through the motions.
Along came agile. It turns out that there were world-class
developers -- smart people, energetic people -- who did
things differently. They worked closely with their clients
and users. They collaborated heavily among themselves.
They took small steps, refactored their code, and grew their
software, rather than erecting it. To many in the industry,
this was a romantic way to live and work, and they wanted
to join in the fun.
The dominant software culture didn't see it that way, though.
Agile looked, well, barbaric. What happens when a cowboy
programmer does something to break the system? How can we
write programs if we don't know everything about what it
should do? Where are the systematic controls on the process?
Those entrenched in civilized software development culture
saw agile methods as a step backward, to a less advanced
time. But they were wrong, as we read in "The Return of the
Barbarian":
The reason this seems like a strange phenomenon is that we
confuse refinement with advancement. Finely-crafted jewelry
is not more advanced than roughly-hewn jewelry. A Boeing 747
is about a million times more capable than the Wright Flyer I,
but it does not contain a million times as much intelligence.
It is merely more refined.... The difference between
advancement and refinement is clearest in disruption. A
beautifully-crafted sword is not more advanced than a crude
gun. It is merely more refined.
The problem was, the software civilization built around
structured programming was more than refined than
the agile approaches, but not necessarily more advanced. The
system itself was quite intelligent, with much wisdom and
knowledge encoded in its practices, its textbooks, and its
other literature. But individually, developers did not need
to be as sharp, because the system guided them to success
(as much as it could).
The above passage is soon followed by a stark distinction:
The intelligence manifest in an artifact is simply the amount
of human thought that has been externalized into it.
Refinement on the other hand, is a measure of the amount of
work that has gone into it. In Hegelian terms,
intelligence in design is fundamentally a predatory quality
put in by barbarian-Masters. Refinement in design is a
non-predatory quality put in by civilized-Slaves.
It was in this context that agile -- a new barbarian culture
-- swooped in and made inroads. The existing culture derided
it as a fad, but it was in fact a set of advanced values,
principles, and practices, less polished than the refined
extant culture but full of deep thought and human experience.
Over time, we saw the inevitable cultural evolution. In order
to teach agile values, principles, and practices to a wider
audience, barbarian-masters wrote down their wisdom in the
form of books and conference talks and podcasts and index
cards. In order to reach the managerial class of the
corporations that build and buy software, first- and second-
generation agilista created management seminars and
certification programs and the trappings of institutional
respectability. The practices were packaged, adjusted...
refined. Soon everyone could "do" agile, or at least pretend
to, by following the rules. Some folks got it, though not
everyone, but most everyone tried to do it.
The agile barbarian has become the civilized
Organization Man.
Where is the romance in that?
Now new barbarians are at the gate, ready to shove the
once-romantic revolutionaries of OO and patterns and agile
development out into the streets. It is the natural order.
Here's the thing. Agile approaches still work as well as they
did back when they were the knowledge in the minds of great
programmers, who were unhindered by the rules that they follow
instinctively and break when necessary in the pursuit of a
great program. That knowledge was born out of experience and
embodied wisdom gained from living in the civilization that
came before.
If we want to become like the agile masters, we need to do
more than imitate them. We need to live the values, principles,
and practices -- to make them our own, not something written
in a book or a blog.
Perhaps this is just a fanciful retelling of our history to
explain away the agile movement's shortcomings and failures.
But I think it carries a grain of truth. A new barbarian
knocks down the door as soon as we become too civilized,
when we convert our deep, compiled, pragmatic, contextual
knowledge into handbooks and notecards and consultants'
packaged talks and on-site training courses.
To the extent that my tale is true, I think it offers us a
path forward: a reminder to embrace our barbarian past.
Each of us can develop his or her own individual intelligence,
rather than relying on the external trappings of a civilized
movement. Don't let the next revolution cause you to abandon
what works well. Look for useful knowledge and practice in
the ways of the next wave of barbarians, and use it to get
better.
Instead of arguing with others about test-first design, pair
programming and refactoring, about collaboration with users,
collective code ownership, and sustainable pace, we should
simply do them, in the way that fits best our context.
This leads by example. It may not scale as fast as the
civilized approach, but as we have seen, that approach is
fraught with its own dangers.
Besides, the goal isn't to scale or to create a movement.
It's to write great programs.
"The most successful people are those who are good at Plan B."
-- James Yorke
This is one of my personal challenges. I am a pretty good
Plan A person. Historically, though, I am a mediocre Plan B
person. This is true of creating Plan B, but more importantly
of recognizing and accepting the need for Plan B.
Great athletes are good at Plan B. My favorite Plan B from
the sporting world was executed by Muhammad Ali in the
Rumble in the Jungle,
his heavyweight title fight against George Foreman in
October 1974. Ali was regarded by most at that time as
the best boxer in the world, but in Foreman he encountered
a puncher of immense power. At the end of Round 1, Ali
realized that his initial plan of attacking Foreman was
unlikely to succeed, because Foreman was also a quick
fighter who had begun to figure out Ali's moves. So Ali
changed plans, taking on greater short-term risk by allowing
Foreman to hit him as much as he wanted, so long as the blows
were not the kind likely to end the fight immediately. Over
the next few rounds, Foreman began to wear down, unaccustomed
to throwing so many punches for so many rounds against an
opponent who did not weaken. Eventually, Ali found his
opening, attacked, and ended the fight in Round 8.
This fight is burned in my mind for the all-time great Plan
B moment: Ali sitting on his stool between the first and
second rounds, eyes as wide and white as platters. I do
not ever recall seeing fear in Muhammad Ali's eyes at any
other time in his career, before or after this fight. He
believed that Foreman could knock him out. But rather than
succumb to the fear, he gathered himself, recalculated, and
fought a different fight. Plan B. The Greatest indeed.
Crazy software developer that I am, I see seeds of Plan B
thinking in agile approaches. Keep Plan A simple, so that
you don't overcommit. Accept Plan B as a matter of course,
refactoring in each cycle to build what you learn from
writing the code back into the program. React to your
pair's ideas and to changes in the requirements with aplomb.
There is good news: We can learn how to be better at Plan B.
It takes effort and discipline, just as changing any of our
habits does. For me, it is worth the effort.
~~~~
If you would like to learn more about the Rumble in the
Jungle, I strongly recommend the documentary film
When We Were Kings,
which tells the story of this fight and how it came to
be. Excellent sport. excellent art, and you can see Ali's
Plan B moment with your own eyes.
I've been reading through some of the back entries in
Vivek Haldar's blog
and came across the entry
Coding Blind.
Haldar notes that most professionals and craftsmen learn
their trade at least in part by watching others work,
but that's not how programmers learn. He says that if
carpenters learned the way programmers do, they'd learn
the theory of how to hammer nails in a classroom and
then do it for the rest of their careers, with every
other carpenter working in a different room.
Programmers these days have a web full of open-source
code to study, but that's not the same. Reading a novel
doesn't give you any feel at all for what writing a
novel is like, and the same is true for programming.
Most CS instructors realize this early in their careers:
showing students a good program shows them what a
finished program looks like, but it doesn't give them
any feel at all for what writing a program is like. In
particular, most students are not ready for the false
starts and the rewriting that even simple problems will
cause them.
Many programming instructors try to bridge this gap by
writing code live in class, perhaps with student
participation, so that students can experience some of
the trials of programming in a less intimidating setting.
This is, of course, not a perfect model; instructors
tend not to make the same kind of errors as beginners,
or as many, but it does have some value.
Haldar points out one way that other kinds of writers
learn from their compatriots:
Great artists and writers often leave behind a large
amount of work exhaust other than their finished
masterpieces: notebooks, sketches, letters and journals.
These auxiliary work products are as important as the
finished item in understanding them and their work.
He then says, "But in programming, all that is shunned."
This made me chuckle, because I recently wrote a bit
about my experience having students maintain
engineering notebooks
for our Intelligent Systems course. I do this so that
they have a record of their thoughts, a place to dump
ideas and think out loud. It's an exercise in "writing
to learn", but Haldar's essay makes me think of another
potential use of the notebooks: for other
students to read and learn from. Given how reluctant
my students were to write at all, I suspect that they
would be even more reluctant to share their imperfect
thoughts with others in the course. Still, perhaps I
can find a way to marry these ideas.
This makes me think of another way that writers learn from
each other, writers' workshops. Code reviews are a standard
practice in software, and
PLoP,
the Pattern Languages of Programs conference, has adapted
the writers' workshop form for technical writers. One of
the reasons I like to teach certain project courses in a
studio format is that it gives all then teams an opportunity
to see each other's work and to talk about design, coding,
and anything else that challenges or excites them. Some
semesters, it works better than others.
Of course, a software team itself has the ability to help
its members learn from one another. One thing I noticed
more this semester than in the past was students commenting
that they had learned from their teammates by watching them
work. Some of the students who said this viewed themselves
as the weakest links on their teams and so saw this as a
chance to approach their more accomplished teammates' level.
Others thought of themselves as equals to their teammates
yet still found themselves learning from how others tackled
problems or approached learning a new API. This is a team
project succeeding as we faculty hope it might.
Distilling experience with techniques in more than just a
finished example or two is one of the motivations for the
software patterns community. It's one of the reasons I
felt so comfortable with both the literary form and the
community: its investment in and commitment to learning
from others' practice. That doesn't operate at quite the
fundamental level of watching another carpenter drive a
nail, but it does strike close to the heart of the matter.
J.B. Rainsberger's
short entry
grabbed my attention immediately. I think that Rainsberger
is talking about a pair of complementary patterns that all
developers learn at some point or other as they write more
and bigger programs. He elegantly captures the key ideas
in only a few words.
These patterns balance common forces between giving things
long names and giving things short names. A long name can
convey more information, but a short name is easier to
type, format, and read. A long name can be a code smell
that indicates a missing abstraction, but a short name can
be a code smell that indicates premature generalization,
a strange kind of YAGNI violation.
The patterns differ in the contexts in which they appear
successfully. Long names are most useful the first time
or two you implement an idea. At that point, there are
few or no other examples of the idea in our code, so there
is not yet a need for an abstraction. A long name can
convey valuable information about the idea. As an idea
appears more often, two or more long names will begin to
overlap, which is a form of duplication. We are now ready
to factor out the abstraction common to them. Now the
abstraction conveys some or all of the information and
short names become more valuable.
I need to incorporate these into any elementary pattern
language I document, as well as in the foundation patterns
layer of any professional pattern language. One thing I
would like to think more about is how these patterns
relate to Kent Beck's patterns Intention-Revealing
Name and Type-Revealing Name.
On the last day of my
Intelligent Systems course,
I asked my students three retrospective questions. Each
question asked them to identify one thing...
one thing you learned about AI by doing this
project
one thing you learned about writing software
by doing this project
one thing that makes your program
"intelligent"
Question 3 is a topic for another day, when I will
talk a bit about AI. Today I am thinking more about
what students learned about writing software. As
one of our curriculum's designated "project courses",
Intelligent Systems has the goal of giving students
an experience building a significant piece of
software, as part of a team. What do the students
themselves think they learned?
A couple of answers to the first question were of
more general software development interest:
I learned that some concepts are easy to understand
conceptually but difficult to implement or actually
use.
I learned to be open-minded about several approaches
to solving a problem. ... be prepared to accept
that an approach might take a lot of time to
understand and end up being [unsuitable].
There is nothing like trying to solve a real problem
to teach you how hard some solutions are to implement.
Neural networks were the most frequently mentioned
concept that is easy to understand but hard to make
work in practice. Many students come out their AI
course thinking neural nets are magic; it turns out
magic can be hard to serve up. I suspect this is
true of many algorithms and techniques students learn
over the course of their studies.
I don't recall talking about agile software development
much during this course, though no doubt it leaks out
in how I typically talk about writing software. Still,
I was surprised at the theme running through student
responses to the second question.
For example:
Design takes time. Multiple iterations, revise and test.
A couple of teams discovered spike solutions, sorta:
You may write a lot of worthless or bad code to help
with the final solution. We produced a lot of bad code
that was never used in the end product, but it helped
us get to that point.
These weren't true spikes, because the teams didn't set
out with the intention of using the code to learn. But
most didn't realize that they could or should do this.
Now that they know, they might behave differently in
the future. Most important, they learned that it's
okay to "code to learn".
Many students came to appreciate collective code
ownership and tools that support it:
When writing software in a group, it is important
to make your code readable: descriptive [names] and
comments that describe what is going on.
I learned how to maintain a project with a
repository so that each team member can keep his copy
up-to-date. ... I also learned how to use testing
suites.
Tests also showed up in one of my favorite student
comments, about refactoring:
I learned that when refactoring even small code you
need unit tests to make sure you are doing things
correctly. Brute forcing only gets you into trouble
and hours of debugging bad code.
Large, semester-long projects usually given students
their first opportunity to experience refactoring.
Living inside a code base for a while teaches them a
lot about what software development is really like,
especially code they themselves have written. Many
are willing to accept that living with someone else's
code can be difficult but believe that their own code
will be fine. Turns out it's not. Most students then
come to appreciate the value of refactoring techniques
I need to help them learn refactoring tools better.
Finally, this comment from the first student retrospective
I read captures a theme I saw throughout:
It is best to start off simple and make something work,
rather than trying to solve the entire problem at once
and get lost in its complexity.
This is in many ways the heart of agile software development
and the source for all the other practices we find so
useful. Whatever practices my own students adopt in
the coming years, I hope they are guided by this idea.
~~~~
Some of you will recognize the character in the image
above as Curly, the philosopher-cowboy from
City Slickers.
One of the great passages of that 1991 film has Curly
teaching protagonist Mitch about the secret of life,
"One thing. Just one thing."
I am not the first software person to use Curly as
inspiration. Check out, for example,
Curly's Law: Do One Thing.
Atwood shows how "do one thing" is central to "several
core principles of modern software development.
I'm pretty much done with my grading for the semester. All
that's left is freezing the grades and submitting them.
Intelligent Systems
is a project course, and I have students evaluate their and
their teammates' contributions to the project. One part of
the evaluation is to allocate the points their team earns
on the project to the team members according to the quality
and quantity of their respective contributions. As I
mentioned to the class earlier in the semester, point
allocations from semester to semester tend to exhibit
certain features. With few exceptions:
Students are remarkably generous to one another, as
long as the teammate makes a reasonable effort under
the circumstances.
If anything, students tend to undervalue their own
contribution.
The allocations are remarkably consistent across
teammates on the same team.
The allocations are remarkably consistent with what
I would assign, based on my interactions with the
team over the course of the project.
All that adds up to me being rather satisfied with the
grades that fall out of the grinder at the end of the
semester.
One thing that has not changed since I last taught this
course ten years ago or so is that most students don't
like the idea of an engineer's notebook. I ask each
student to maintain a record their of their notes while
working on the project along with a weekly log intended
to be a periodic retrospective of their work and progress,
their team's work and progress, and the problems they
encounter and solve along the way. Students have never
liked keeping notebooks. Writing doesn't seem to be a
habit we develop in our majors, and by the time they
reach their last ultimate or penultimate semester, the
habit of not writing is deeply ingrained.
One thing that may have changed in the last decade:
students seem more surly at being asked to keep a
notebook. In the past, students either did write or
didn't write. This year, for the most part, students
either didn't write or didn't write much except to say
how much they didn't like being asked to write. I have
to admire their honesty at the risk of being graded
more harshly for having spoken up. (Actually, I am
proud they trust me enough to still grade them fairly!)
I can't draw a sound conclusion from one semester's
worth of data, but I will watch for a trend in future
semesters.
One thing that did change this semester: I allowed
students to blog instead of maintaining a paper notebook.
I was surprised that only two students took me up on
the offer. Both ended up with records well above the
average for the class. One of the students treated his
blog a bit more formally than I think of an engineer's
notebook, but the other seemed to treat much as he would
have a paper journal. This was a win, one I hope to
replicate in the future.
The Greeks long ago recorded that old habits die hard,
if at all. In the future, I will have to approach the
notebook differently, including more and perhaps more
persuasive arguments for it up front and more frequent
evaluation and feedback during the term. I might even
encourage or require students to blog. This is 2011,
after all.
Reaching for Too Much, in Life and Software Development
I just read this passage from The Rhythm of Life,
by Matthew Kelly:
You never can get enough of what you don't really need.
Fulfillment comes not from having more and more of
everything forever into oblivion. Fulfillment comes
from having what you need.
Kelly is talking about how we live our lives. However,
I could not help but think of
You Aren't Gonna Need It
and agile software development.
From there, Kelly takes a moral turn, but even then
I hear the agile voice within:
The whole world is chasing illegitimate wants with
reckless abandon. We use all of our time, effort,
and energy in the pursuit of our illegitimate wants,
hypnotized by the lie that our illegitimate wants are
the key to our happiness.
At the same time, the gentle voice within us is
constantly calling out to us, trying to encourage us
not to ignore the wisdom we already possess.
There is a lot to be said for learning to be content
with implementing the features we are working on right
now, not features we think are coming in the future.
Perhaps if we can learn to be content in life we can
also learn to be content in code.
Part of what made
diagnosing my knee injury
challenging is that the injury has not presented normally.
Normally, this condition follows an obvious trauma. I did
not suffer one. Normally, the symptoms include occasional
locking of the joint and occasionally feeling as if the
joint is going to give out. I have not experienced either.
Normally, there is more pain than I seem to be having.
The doctors were surprised by this unusual presentation,
but it didn't worry them much. They are used to the fact
that there is no normal.
The human body is a complex machine, and people subject
their bodies to a complex set of stimuli and conditions.
As a result, the body responds in an unbelievable number
of ways. What we think of as the "normal" path of most
diseases, injuries, and processes is a composite of many
examples. Each symptom or observation has some likelihood
of occurring, but it is common for a particular case to
look quite unusual.
This is something we learn when we study statistical
methods. It's possible that no number in a set is equal
to the average of all the numbers in a set. It's possible
that no member in a set is normal in the sense of sharing
all the features that are common to most members.
A large software system is a complex machine, and people
subject software to a complex set of stimuli and
conditions. As a result, the software responds in a
surprising number of ways. When we think of this from
the perspective people as users, we realize just how
important designing for usability, reliability, and
robustness are.
Programmers are people who interact with software, too,
and we subject our programs to a wide-ranging set of
demands. When we think about "there is no normal" from
this perspective, we better understand why it is so
challenging to debug, extend, and maintain programs.
Our programs may not be as complex as the human body,
and we try to design them rather than let them evolve
unguided. But I think it's still useful to program
with a mindset that there is no normal. That way,
like my doctor, we can handle cases that seem unusual
with aplomb.
Last week, someone I follow tweeted
this link
in order to share this passage:
You will be newbie forever. Get good at the beginner
mode, learning new programs, asking dumb questions,
making stupid mistakes, soliciting help, and helping
others with what you learn (the best way to learn
yourself).
That blog entry is about inexorable change of technology
in then modern world and how, if we want to succeed in
this world, we need a mindset that accommodates change.
We might even argue that we need a mindset that welcomes
or seeks out change. To me, this is one of the more
compelling reasons for us to broaden the common
definition of the liberal arts to include computing and
other digital forms of communication.
As much as I like the quoted passage, I liked a couple
of others as much or more. Consider:
Understanding how a technology works is not necessary to
use it well. We don't understand how biology works, but
we still use wood well.
As we introduce computing and other digital media to more
people, we need to balance teaching how to use new ideas
and techniques and teaching underlying implementations.
Some tools change how we work without us knowing how
they work, or needing to know. It's easy for
people like me to get so excited about, say, programming
that we exaggerate its importance. Not everyone needs to
program all the time.
Then again, consider this:
The proper response to a stupid technology is to make a
better one yourself, just as the proper response to a
stupid idea is not to outlaw it but to replace it with
a better idea.
In the digital world as in the physical world, we are
not limited by our tools. We can change how our tools
work, through configuration files and scripts. We can
make our own tools.
Finally, an aphorism that captures differences between
how today's youth think about technology and how people
my age often think (emphasis added):
Nobody has any idea of what a new invention will really
be good for. To evaluate, don't think; try.
This has always been true of inventions. I doubt many
people appreciated just how different the world would be
after the creation of the automobile or the transistor.
But with digital tools, the cost of trying things out has
been driven so low, relative to the cost of trying things
in the physical world, that the cost is effectively zero.
In so many situations now, the net value of trying things
exceeds the net value of thinking.
I know that sounds strange, and I certainly don't mean to
say that we should all just stop thinking. That's the
sort of misinterpretation too many people made of the
tenets of extreme programming. But the simple fact is,
thinking too much means waiting too long. While you are
thinking -- waiting to start -- someone else is trying,
learning faster, and doing things that matter.
The scientific method has been teaching us the value of
empiricism over pure thought for a long time. In the
digital world, the value is even more pronounced.
I think we embraced scale as a goal when the economies
of that scale were so obvious that we didn't even need
to mention them. Now that it's so much easier to
produce a product in the small and market a product in
the small, and now that it's so beneficial to offer a
service to just a few, with focus and attention,
perhaps we need to rethink the very goal of scale.
Agile approaches to software development exploit the
economies of small:
small promises
short cycles
small teams
small steps
small changes
continuous integration
Traditional software engineering, based as it is on an
engineering metaphor, seems invested in traditional
economies of scale. That was a natural result of the
metaphor bust also the tools of the time. Back when
hardware and software made it more difficult to write
software rapidly over short iterations, scale in the
traditional sense -- large -- helped to make processes
and maybe even people more efficient.
(... or, as my brother likes to say about re-runs, "Hey,
it's new to me.")
I was excited this week to find, via my Twitter feed, a
new blog
on functional programming patterns by Jeremy Gibbons,
especially an entry on
recursion patterns.
I've
written about recursion patterns,
too, though in a different context and for a different
audience. Still, the two pieces are about a common
phenomenon that occurs in functional programs.
I poked around the blog a bit and soon ran across
articles such as
Lenses are the Coalgebras for the Costate Comonad.
I began to fear that the patterns on this blog would
not be able to help the world come to functional
programming in the way that the
Gang of Four book
helped the world come to object-oriented programming.
As difficult as the GoF book was for every-day
programmers to grok, it eventually taught them much
about OO design and helped to make OO programming
mainstream. Articles about coalgebras and the
costate comonad are certainly of value, but I suspect
they will be most valuable to an audience that is
already savvy about functional programming. They
aren't likely to reach every-day programmers in a
deep way or help them learn The Functional Way.
Of course, I admit that "capturing the code parts of
a pattern" is not the same as capturing the pattern
itself. There is more to the pattern than just the
code; the "prose, pictures, and prototypes" form an
important part of the story, and are not captured in
a HODGP representation of the pattern. So the HODGP
isn't a replacement for the pattern.
This is one of the few times that I've seen an FP
expert speak favorably about the idea that a design
pattern is more than just the code that can be
abstracted away via a macro or a type class. My
hope rebounds!
There is
work to be done
in the space of design patterns of functional
programming. I look forward to reading Gibbons's
blog as he reports on his work in that space.
Al Aho, Teaching Compiler Construction, and Computational Thinking
Last year I blogged about
Al Aho's talk at SIGCSE 2010.
Today he gave a major annual address sponsored by
the CS department at Iowa State University, one
of our sister schools. When
former student
and current ISU lecturer
Chris Johnson
encouraged me to attend, I decided to drive over
for the day to hear the lecture and to visit with
Chris.
Aho delivered a lecture substantially the same as
his SIGCSE talk. One major difference was that
he repackaged it in the context of computational
thinking. First, he defined computational thinking
as the thought processes involved in formulating
problems so that their solutions can be expressed
as algorithms and computational steps. Then he
suggested that designing and implementing a
programming language is a good way to learn
computational thinking.
With the talk so similar to the one I heard last
year, I listened most closely for additions and
changes. Here are some of the points that stood
out for me this time around, including some
repeated points:
One of the key elements for students when
designing a domain-specific language is to
exploit domain regularities in a
way that delivers expressiveness and
performance.
Aho estimates that humans today rely on
somewhere between 0.5 and 1.0 trillion
lines of software. If we assume that the
total cost associated with producing each
line is $100, then we are talking about a
most serious investment. I'm not sure where
he found the $100/LOC number, but...
Awk contains a fast, efficient regular
expression matcher. He showed a figure from
the widely read
Regular Expression Matching Can Be Simple And Fast,
with a curve showing Awk's performance --
quite close to Thompson NFA curve from the
paper. Algorithms and theory do
matter.
It is so easy to generate compiler front ends
these days using good tools in nearly every
implementation language. This frees up time
in his course for language design and documentation.
This is a choice I struggle with every time I
teach compilers. Our students don't have as
strong a theory background as Aho's do when they
take the course, and I think they benefit from
rolling their own lexers and parsers by hand.
But I'm tempted by what we could with the extra
time, including processing a more compelling
source language and better coverage of optimization
and code generation.
An automated build system and a complete
regression test suite are essential tools for
compiler teams. As Aho emphasized in both talks,
building a compiler is a serious exercise in
software engineering. I still think it's one
of the best SE exercises that undergrads can
do.
The language for quantum looks cool, but I still
don't understand it.
After the talk, someone asked Aho why he thought
functional programming languages were becoming so
popular. Aho's answer revealed that he, like any
other person, has biases that cloud his views.
Rather than answering the question, he talked about
why most people don't use functional languages.
Some brains are wired to understand FP, but most of
us are wired for, and so prefer, imperative languages.
I got the impression that he isn't a fan of FP and
that he's glad to see it lose out in the social
darwinian competition among languages.
I'm glad I took most of my day for this visit. The
ISU CS department and chair Dr. Carl Chang graciously
invited me to attend a dinner this evening in honor
of Dr. Aho and the department's external advisory
board. This gave me a chance to meet many ISU CS
profs and to talk shop with a different group of
colleagues. A nice treat.
The most important topic in my Intelligent Systems class
today was the comma. Over the last week or so, I had
grading their essays on communicating the structure and
intent of programs. I was not all that surprised to
find that their thoughts on communicating the structure
and intent of programs were not always reflected in
their essays. Writing well takes practice, and these
essays are for practice. But the thing that stood out
most glaringly from most of the papers was the overuse,
misuse, and occasional underuse of the comma. So after
I gave a short lecture on case-based reasoning, we
talked about commas. Fun was had by all, I think.
On a more general note, I closed our conversation with
a suggestion that perhaps they could draw on
lessons they learn writing, documenting, and explaining
programs to help them write prose. Take small steps
when writing new content, not worrying as much about
form as about the idea. Then refactor: spend time
reworking the prose, rewriting, condensing, and
clarifying. In this phase, we can focus on how well
our text communicates the ideas it contains. And,
yes, good structure can help, whether at the level of
sentences, paragraphs, or then whole essay.
I enjoyed the coincidence of later reading
this passage
in Roy Behrens's blog, The Poetry of Sight:
Fine advice from poet Richard Hugo in The Triggering
Town: Lectures and Essays on Poetry and Writing (New
York: W.W. Norton, 1979)--
Lucky accidents seldom happen to writers who don't
work. You will find that you may rewrite and rewrite
a poem and it never seems quite right. Then a much
better poem may come rather fast and you wonder why
you bothered with all that work on the earlier poem.
Actually, the hard work you do on one poem is put in
on all poems. The hard work on the first poem is
responsible for the sudden ease of the second. If
you just sit around waiting for the easy ones,
nothing will come. Get to work.
This is an important lesson for programmers, especially
relative beginners, to learn. The hard work you
do on one program is put in on all programs. Get
to work. Write code. Refactor.
Writing teaches writing.
~~~~
Long-time readers of this blog may recall that I once
recommended The Triggering Town in an entry
called
Reading to Write.
It is still one of my favorites -- and due for another
reading soon!
John McPhee is one of my favorite non-fiction writers. He
is a long-form journalist who combines equal measures of
detailed fact gathering and a literary style that I enjoy
as a reader and aspire to as a writer. For years, I have
used selections from the The John McPhee Reader
in advice to students on how to do gather requirements for
software, including knowledge acquisition for AI systems.
This weekend I enjoyed Peter Hessler's interview of McPhee
in The Paris Review,
John McPhee, The Art of Nonfiction No. 3.
I have been thinking about several bits of McPhee's wisdom
in the context of both writing and programming, which is
itself a form of writing. I also connected with a couple
of his remarks about teaching young writers -- and
programmers.
One theme that runs through the interview serves as a
universal truth connecting writing and programming:
Writing teaches writing.
In order to write or to program, one must first learn the
basics, low-level skills such as grammar, syntax, and
vocabulary. Both writers and programmers typically go on
to learn higher-level skills that deal with the structure
of larger works and the patterns that help creators create
and readers understand. In the programming world, we call
these "design" skills, though I imagine that's too much an
engineering term to appeal to writes.
Once you have these skills under your belt, there isn't
much more to teach, but there is plenty to learn. We help
newbies learn by sharing what we create, by reading and
critiquing each others work, and by talking about our craft.
But doing it -- writing, whether it's stories, non-fiction,
or computer programs -- that's the thing.
McPhee learned this in many ways, not the least of which
was one of the responses he received to his first novel,
which he wrote in lieu of a dissertation (much to the
consternation of many Princeton English professors!).
McPhee said
It had a really good structure and was technically fine.
But it had no life in it at all. One person wrote a note on
it that said, You demonstrated you know how to saddle a
horse. Now go find the horse.
He still had a lot to learn. This is a challenge for many
young programmers whom I teach. As they learn the skills
they need to become competent programmers, even excellent
ones, they begin to realize they also need a purpose.
At a miniconference on campus last week, a successful former
student encouraged today's students to find and nurture their
own passions. In those passions they will also find the
energy and desire to write, write, write, which is the only
he knew of to master the craft of programming.
Finding passion is hard, especially for students who come
through an educational system that sometimes seems more
focused on checking off boxes than on growing a person.
Luckily, though, finding problems to work on (or stories to
write) can be much less difficult. It requires only that
we are observant, that we open our eyes and pay attention.
As McPhee says:
There are zillions of ideas out there--they stream by like
neutrons.
For McPhee, most of the ideas he was willing to write about,
spending as much as three years researching and writing,
relate to things he did when I was a kid. That's not too
far from the advice we give young software developers: write
the programs you need or want to use. It's okay to start
with what you like and know even if no one else wants those
things. First of all, maybe they do. And second, even if
they really don't, those are the problems on which you will
be willing to work. Programming teaches programming.
If you have already found your passion, then finding cool
things to do gets even easier. Passion and obsession seem
to heighten our senses, making it easier to spot potential
new ideas and solution. I just saw a great example of this
in the movie The Social Network, when an exhausted
Mark Zuckerberg found the insight for adding Relationship
Status to Facebook from a friend's plaintive request for
help finding out whether a girl in his Art History class
was available.
So, you have an idea. How long does it take to write?
... It takes as long as it takes. A great line, and it's
so true of writing. It takes as long as it takes.
Despite what we learn in skill, this is true of most things.
They take however long they take. This was a hard lesson
for me to learn. I was a pretty good student in school,
and I learned early on how to prosper in the rhythm of the
quarter, semester, and school year. Doing research in grad
school helped me to see that real problems are much
messier, much less predictable than the previous sixteen
years of school had led me to believe.
As a CS major, though, I began to learn this lesson in my
last year as an undergrad, writing the
program at the core of my senior project.
It takes as long as it takes, whatever the university's
semester calendar says. Get to work.
As a teacher, I found most touching an answer McPhee gave
when asked why he still teaches writing courses at Princeton.
He is well past the usual retirement age and might be
expected to slow down, or at least spend all of his time on
his own writing. Every teacher who reads the answer will
feel its truth:
But above all, interacting with my students--it's a tonic thing.
Now I'm in my seventies and these kids really keep me alive.
To talk to a nineteen-year-old who's really a good writer, and
he's sitting in here interested in talking to me about the
subject--that's a marvelous thing, and that's why I don't want
to stop.
As I read this, my mind began to recount so many students who
have changed me as a programmer and teacher. The programmer,
artist, and musician who wanted to write a
program that could express artistic style,
who is now a filmmaker inflamed with understanding man and his
relationship to the world. The high school kid with big ideas
about fonts, AI, and design whose undergrad research qualified
for a national ACM competition and who is now a research
scientist at Apple. The brash PR student who wanted to become
a programmer and did, writing a
computer science thesis
and an even more important
communications studies thesis,
who is now set on changing how we study and understand human
communication in the age of the web. The precocious CS
student whose ideas were bigger than my courses before he set
foot in my classroom, who worked hard learning things beyond
what we were teaching and eventually doubling back to learn
what he had missed, an entrepreneur with a successful tech
start-up who is now helping a new generation of students
learn and dream.
The list could go on. Teaching keeps us alive. Students
learn, we hope, and so do we. They keep us in the present,
where the excitement of new ideas is fresh. And, as McPhee
admits with no sense of shame or embarrassment, it is
flattering, too.
Last week, a student stopped in to ask a question.
He had written a program for one of his courses
of which he was especially proud. It consisted in
large part of two local functions, and used
recursion in a way that created an elegant, clear
solution.
Yet his professor dinged his grade severely. The
student had used a global variable.
That's when the question for me arrived.
But why are we taught not to use global variables?
First, let me say that this a strong student. He
is not the sort to beg for points, and he wasn't
asking me this question as a snark or a complaint.
He really wanted to know the answer.
My first response was cynical and at least partly
tongue-in-cheek. We teach you not to use global
variables because we were taught to use
global variables.
My second response was to point out that "global"
is a relative term, not an absolute one. In OO
languages, we write classes that contain instance
variables and methods that operate on them. The
instance variables are global to class's
methods and local to class's clients.
The programming world seems to like such "globals"
just fine.
That is the beginning of my trouble trying to
create an argument that supports the way in which
his program was graded. In his program, written
in a traditional procedural language, the offending
variable was local to one procedure but
global to two nested procedures. That
sounds awfully similar to an ordinary Java class's
instance variables!
On the extreme end of the global/local continuum
we have a language like Cobol. All data is declared
at the top of a program in an elaborate Data
Division, and the "paragraphs" of the
Procedure Division refer back to it.
Not many computer scientists spend much time defending
Cobol, but its design and organization make perfectly
good sense in context, and programmers are able to
write understandable, large programs.
As the student and I talked, I explained two primary
reasons for the historical bias against globals:
Readability. When a variable lives outside
the code that manipulates it, there is a chance that
it can become separated in space from that code. As
a large program evolves over time, it seems that the
chance the variable will become separated from the
related code approaches 1. That makes the code hard
to understand. When the reader encounters a variable,
she may have a hard time knowing what it means without
seeing the code that uses it. When she encounters a
procedure with a reference to a faraway variable, she
may have a hard time knowing what the code does without
easy reference to the variable and any other code that
uses it.
This force is counteracted effectively in some
circumstances. In OOP, we try not to write classes
that are too long, which means that the instance vars
and the methods will be relatively close to one another
in the file or on the printed page. Furthermore, there
is a convention that the vars will be declared at the
top or bottom of the class, so the reader can always
find them easily enough. That's part of what makes
Cobol's layout work: readers study the Data
Division first and then read the
Procedure Division with an eye to the
top of the file.
My student's programming had a structure that mirrored
a small class: a procedure with a variable and two
local procedures of reasonable size. I can imagine
endorsing the relatively global variable because it
was part of a understandable, elegant program.
Not-Obvious Dependencies. When two or more
procedures operate on the same variable that lives
outside all of them, there is a risk of that lack of
readability rises to something worse: an inability to
divine how the program works. The two procedures
exert influence over each other's behavior through the
values stored in the shared variable. In OO programs,
this interaction is an expected part of how objects
behave, and we try to keep methods and the class as
a whole small enough to counteract the problem.
In the general case, though, we can end up with
variables and procedures scattered throughout a
program and interacting in non-obvious ways. A change
to one procedure might affect another. Adding another
procedure that refers to or changes the variable
complicates matters for all existing procedures in the
co-dependent relationship. Hidden dependencies are
the worst kind of all.
This is what really makes global variables bad for us.
Unless we can counteract this force effectively, we
really don't want to use them.
These are two simple technical reasons that programmers
prefer not to use global variables. CS professors
tend to simplify them into the dictum, "no global
variables allowed", and make it a hard and fast rule
for beginners. Unfortunately, sometimes we forget to
take the blinders off after our students -- or we
ourselves! -- become more accomplished programmers.
The dictum becomes dogma, and a substitute for
professional judgment.
I have what I regard as a healthy attitude about
global variables. But I admitted to my student that
I have my own weakness in the dictum-turned-dogma
arena. When I teach OOP to beginners, we follow the
rule All instance variables are private. I'm
a reasonable guy and so am willing to talk to students
who want to violate the rule, but it's pretty much
non-negotiable. I've never had a first- or second-
year OOP student convince me that one of his IVs
should protected or -- heaven forbid!
-- public. But even in my own code,
after a couple of decades of doing OOP, I rarely violate
this rule. I say "rarely" only in the interest of
being conservative in my assessment. I can't remember
the last time I wrote a class with a public instance
variable.
Not all teachers are good at giving up their dogma.
Some professors don't even realize that what they
believe is best thought of as an oversimplification for
the purposes of helping novices develop good habits of
thought.
Ironically, last semester I ran across the paper
Global Variable Considered Harmful,
by Bill Wulf and Mary Shaw. (If you can't get through
the ACM paywall, you can also find the paper
here.)
This is, I think, the first published attempt to explain
why the global variable is a bad idea. Read it -- it's
a nice treatment of the issues as they existed back in
1973. Forty years later, I am comfortable using
variables that are relatively global to one or more
procedures under controlled conditions. At this point
in my programming career, I willing to use my professional
judgment to help me make good programs, not just programs
that follow the rules.
I shared the Wulf and Shaw paper with my student. I hope
he got a kick out of it, and I hope he used it to inform
his already reliable professional judgment. The paper
might even launch him ahead of the profs who teach the
prohibition on global variables as if it were revealed
truth.
Ralph Johnson
reports
that "the conference on aspect oriented software development
is renaming itself to 'Modularity'", much as
OOPSLA has become SPLASH.
For the last couple of decades, computer science research
has been focusing on more and more specific domains. The
area of artificial intelligence, for example, soon spawned
journals and conferences devoted specifically to sub-areas
such as machine learning, expert systems, computer vision,
and many others. It's interesting for me to see
conferences such as AOSD and OOPSLA going the other
direction, moving from the technology that spawned the
conference in the first place to the more general idea or
goal that motivates its community.
Of course, these conferences aren't purely academic; they
have always had a strong alliance between industry and
academia. Perhaps that is one of the reasons they are
willing to rebrand themselves. Certainly, the changing
economic model that drives this sort of conference is
playing a big role.
By the way, Ralph's entry isn't really about the changing
conference name. He merely uses that as a launching point
for something more interesting: a first cut at cataloging
different types of modularity. That is the best reason
to read it!
I have been meaning to write about
SPLASH 2011
and especially the Educators' Symposium for
months, and now I find that Mark Guzdial
has beaten me to the punch
-- with my own words, no less! Thanks to Mark
for spreading the news. Go ahead and read his
post if you'd like to see the message I sent
to the SIGCSE membership calling for their
submissions. Or visit the
call for participation
straightaway and see what the program committee
has in mind. Proposals are due on April 8,
only a few weeks hence. Dream big -- we are.
For now, though, I will write the entry I've
been intending all these months:
The Next Ten Years of Software Education
By the early 2000s, I had become an annual attendee of
OOPSLA and had served on a few Educators' Symposium
program committees. Out of the blue,
John Vlissides
asked me to chair the 2004 symposium. I was honored
and excited. I eventually got all crazy and
cold called Alan Kay
and asked him to deliver our keynote address. He
inspired us with a
vision and ambitious charge,
which we haven't been able to live up to yet.
When I was asked to chair again in
2005,
we asked Ward Cunningham to
deliver our keynote address.
He inspired us with his suggestions for nurturing
simple ideas and practices. It was a very good
talk. The symposium as whole, though, was less
successful at shaking things than in 2004. That
was likely my fault.
I have been less involved in the Educators' Symposium
since 2006 or 2007, and even less involved in OOPSLA
more broadly. Being department head keeps me busy.
I have missed the conference.
Fast-forward to 2010. OOPSLA has become SPLASH, or
perhaps more accurately been moved under the umbrella
of SPLASH. This is something that we had
talked about for years.
2011 conference chair Crista Lopes was looking for a
Educators' Symposium chair and asked me for any names
I might suggest. I admitted to her that I would love
to get involved again, and she asked me to chair. I'm
back!
OOPSLA was OO, or at least that what its name said.
It had always been about more, but the name brand was
of little value in a corporate world in which OOP is
mainstream and perhaps even passe. Teaching OOP in
the university and in industry has changed a lot over
the last ten years, too. Some think it's a solved
problem. I think that's not true at all, but certainly
many people have stopped thinking very hard about it.
In any case, conference organizers have taken the
plunge. SPLASH != OOPSLA and is now explicitly not
just about OO. The new conference acknowledges itself
to be about programming more generally. That makes the
Educators' Symposium something new, too, something more
general. This creates new opportunities for the program
committee, and new challenges.
We have decided to build the symposium around a theme
of "The Next Ten Years". What ideas, problems, and
technologies should university educators and industry
trainers be thinking about? The list of possibilities
is long and daunting: big data, concurrency, functional
programming, software at Internet scale... and even our
original focus, object-oriented programming. Our goal
for the end of the symposium is to be able to write a
report outlining a vision for software development
education over the next ten years. I don't expect that
we will have many answers, if any, but I do expect that
we can at least begin to ask the right questions.
And now here's your chance to help us
chart a course into the future, whether you plan to
submit a paper or proposal to the symposium:
Who would be a killer keynote speaker?
What person could inspire us with a vision for computer
science and software, or could ask us the questions we
need to be asking ourselves?
Finding the right keynote speaker is one of the big
questions I'm thinking about these days. Do you have
any ideas?
Let me know.
(And yes, I realize that Alan Kay may well still be one
of the right answers!)
In closing, let me say that whenever I say "we" above,
I am not speaking royally. I mean the symposium
committee that has graciously offered their time and
energy to designing implementing this challenge: Curt
Clifton, Danny Dig, Joe Bergin, Owen Astrachan, and
Rick Mercer. There are also a handful of people who
have been helping informally. I welcome you to join
us.
Now we have
Turbulence,
a package for pulling useful metrics about our code
out of a git repository. The package began its life
when Feathers and Corey Haines wrote a script to
plot code churn versus its complexity. Haines has
written a bit about the Turbulence project.
It doesn't end there. Developers are using Turbulence
and adding to its code base. Feathers's has called
for a
renewed focus on design in the wild
using the data we have at our fingertips. The
physicians have begun to heal themselves, and they
are leading the way for the rest of us.
One nice side effect of this trend is making available
to a wider audience some of the academic research that
has been done in this vein, such as Nagappan and Ball's
paper on
code churn and defect density.
(I had the pleasure of meeting Ball when we served on
a panel at OOPSLA several years ago.)
As many people are saying,
we swim in data.
We just have to find ways to use it well. I remain
ever amazed at what our tools enable us to do.
All this talk about git has me resolved to go all the
way and make a full switch to it. I've dabbled with
git a bit and consumed a lot of software off GitHub,
but now it's time to do all my development in it.
Fortunately, there are a few excellent resources to
help me, including the often-lauded
Git Immersion
guided tour by Jim Weirich and crew. and Scott
Chacon's visually engaging
Getting Git
slidedeck. My trip to to SIGCSE and the spring break
that follows immediately after can't come to soon!
Over the weekend, I enjoyed re-reading Brian Foote's
The Craftsmen vs. the Scavengers,
which is subtitled "The Ruminations of a Foot Soldier on
the Reuse Revolution". Foote expressed an idea that has
been visited and re-visited every so often in recent years:
In a world dominated by code reuse, all programming,
will, in one sense, be maintenance programming.
Foote was a student of Ralph Johnson, who has written and
spoken occasionally about the idea that software development
is program transformation. I
blogged about
Ralph's idea and what it meant for me nearly five years ago,
just before teaching an intro CS course that emphasized the
modification and extension of existing code.
Some people worry that if we don't start students off with
writing their own code from scratch they won't really
learn to program. Most of the students in that CS1 course
have turned out to be pretty good programmers; that's just
anecdote, of course, and not evidence that the approach is
write or wrong. But at least I don't seem to have done
them irreparable harm.
This idea is comfortable to me as an old Smalltalk programmer.
As Foote elaborates, the Smalltalk toolset supports this
style of programming and, more importantly, the Smalltalk
culture encouraged code reuse, sharing, and a
sense of collective code ownership. We all felt we were
in the same boat -- the same image -- together.
The commingling of Foote's assertion and my recollection
of that CS1 course caused my mind to wander down another
path. What about those times when we do start with a
blank slate on a new project? If we approach the task
as programming from scratch, we might well design a
complete solution and try to implement it as a single
piece. When I do maintenance programming, I don't usually
think that way, even when I have a major change to make
to the program. I'm usually too scared to change too
many things at once! Instead, I make a series of small
changes to the code, coaxing and pruning the system
toward the goal state. This is, I think, just what XP
and TDD encourage us to do even when we code on a blank
slate. It's an effective way to think about writing new
programs.
The very next section of Foote's paper also caused echoes
in my mind. It suggest that, in a culture of reuse, bad
design might drive out good design simply by being there
first and attracting an audience. Good design takes a
while to evolve, and by the time it matures a mediocre
library or framework might already control the niche.
This may have happened in some parts of the Smalltalk
world, but I was lucky not to encounter it very often.
Foote's idea comes across as another form
Gresham's Law for software design,
so long as we are willing to mangle the original sense of
that term. The effect is similar: the world ends up
trafficking in a substandard currency.
It sobers me to note that Foote wrote this paper in the
summer of 1989. These ideas aren't new and have been on
the software world's mind since at least the shift to OOP
began twenty-five years ago or so. There truly is
nothing new for me to say.
As a community, though, we revisit these ideas from
different vantage points as we evolve. Perhaps we can
come away with new understanding as a result.
Several articles caught my eye this week which are worth
commenting on, but at this point none has triggered a
full entry of its own. Some of my favorite bloggers
do what they call "tab sweeps", but I don't store
cool articles in browser tabs. I cache URLs and short
notes to myself. So I'll sweep up three of my notes as
a single entry, related to programming.
... the craftsperson, someone who takes real care and
produces work for the ages. Everyone else might be a
hack, or a factory guy or a suit or a drone, but a
craftsperson was someone we could respect.
There's a lot of talk in the software development world
these days about craftsmanship. All the conversation
and all the hand-waving boil down to this. A craftsman
is the programmer we all respect and the programmer we
all want to be.
Real Problems...
Dan Meyer is an erstwhile K-12 math teacher who rails
against the phony problems we give kids when we ask
them to learn math. Textbooks do so in the name of
"context". Meyer calls it "pseudocontext". He gives
an example in his entry
Connect These Two Dots,
and then explains concisely what is wrong with
pseudocontext:
Pseudocontext sends two signals to our students,
both false:
Math is only interesting in its applications
to the world, and
By the way, we don't have any of those.
Are we really surprised that students aren't motivated
to practice and develop their craft on such nonsense?
Then we do the same things to CS students in our
programming courses...
... Are Everywhere These Days
Finally, Greg Wilson summarizes what he thinks
"computational science" means in one of his
Software Carpentry lessons.
It mostly comes down to data and how we understand it:
It's all just data.
Data doesn't mean anything on its own -- it has to be
interpreted.
Programming is about creating and composing abstractions.
In a
pair
of
tweets
today, Brian Marick offered an interesting idea for designing
instruction for programmers:
A useful educational service: examine a person's codebase.
Devise a new feature request that would be hard, given
existing code and skill...
... Keep repeating as the codebase and skill improve.
Would accelerate a programmer's skill at dealing with
normal unexpected change.
This could also be a great way to help each programmer
develop competencies that are missing from his or her
skill set. I like how this technique would create an
individualized learning for each student. The cost,
of course, is in the work needed by the instructor to
study the codebases and devise the feature requests.
With a common set of problems to work on, over time
an instructor might be able to develop a checklist of
(codebase characteristic, feature request) pairs that
covered a lot of the instructional space. This idea
definitely deserves some more thought!
Of course, we can sometimes analyze valuable features
of a codebase with relatively simple programs. Last
month, Michael Feathers blogged about
measuring the closure of code,
in which he showed how we can examine the Open/Closed
Principle in a codebase by extracting and plotting
the per-file commit frequencies of source files in a
project's version control repository. Feathers
discussed how developers could use this information
intentionally to improve the quality of their code.
I think this sort of analysis could be used to great
effect in the classroom. Students could see the OCP
graphically for a number of projects and, combined
with their programming knowledge of the projects,
begin to appreciate what the OCP means to a programmer.
A serendipitous side effect would be for students to
experience CS as an empirical discipline. This would
help us prepare developers more readily in sync with
Feathers's use of analytical data in their practice
and CS grads who understand the ways in which CS can
and should be an empirical endeavor.
I actually blogged a bit about
studying program repositories
last semester, for the purpose of understanding how
to design better programming languages. That work
used program repositories for research purposes.
What I like about Marick's and Feathers's recent
ideas is that they bring to mind how studying a
program repository can aid instruction, too. This
didn't occur to me so much back when one of my grad
students
studied relationships
among open-source software packages
with automated analysis of a large codebase. I'm
glad to have received a push in that direction now.
A long discussion on the SIGCSE members listserv about
math requirements for CS degrees has drifted, as most
curricular discussions seem to do, to "What is computer
science?" Somewhere along the way, someone said,
"Computer Science *is* a science, by name, and should
therefore be one by definition".
Brian Harvey
responded:
The first thing I tell my intro CS students is "Computer
Science isn't a science, and it isn't about computers."
(It should be called "information engineering.")
I think that this assertion is wrong, at least without
a couple of "only"s thrown in, but it is a great way to
start a conversation with students.
I've been seeing the dichotomy between CS as science and
CS as system-building again this semester in my
Intelligent course. The textbook my students used in
their AI course last semester is, like nearly every
undergrad AI text, primarily an introduction to the
science of AI: a taxonomy of concepts, results of
research that help to define and delimit the important
ideas. It contains essentially no pragmatic results for
building intelligent systems. Sure, students learn about
state-space search, logic as a knowledge representation,
planning, and learning, along with algorithms for the
basic methods of the field. But they are not prepared
for the fact that, when they try to implement search or
logical inference for a given problem, they still have a
huge amount of work to do, with little guidance from the
text.
In class today, we discussed this gap in two contexts:
the gap one sees between low-level programming and
high-level programming languages, and the difference
between general-purpose languages and domain-specific
languages.
My students seemed to understand my point of view, but I
am not sure they really grok it. That happens best after
they gain experience writing code and feel the gap while
making real systems run. This is one of the reasons I'm
such a believer in
projects,
real problems,
and
writing code.
We don't always understand ideas until we see them in a
concrete.
I don't imagine that intro CS students have any of the
experience they need to understand the subtleties academics
debate about what computer science is or what computer
scientists. We are almost surely better off asking them to
do something that matters them, whether a small problem or
a larger project. In these problems and projects, students
can learn from us and from their own work what CS is and
how computer scientists think.
Eventually, I hope that the students writing large-ish AI
programs in my course this semester learn just how much
more there is to writing an intelligent system than just
implementing a general-purpose algorithm from their text.
The teams that are using pre-existing packages as part of
they system might even learn that integrating software
systems is "more like performing a heart transplant than
snapping together LEGO blocks". (Thanks to John Cook for
that analogy.)
Turning Up the Knob on Functional OOP and Imperative OOP
One of my students has been learning Haskell as a prelude
to exploring purely functional data structures. Recently,
he wrote a short blog entry describing some of the ideas
he has found most exciting. It ended with a couple of
code snippets showing the elegance and brevity of list
comprehensions compared to what he was used to in
imperative languages. The student apologized for his
imperative example, because he wrote it in Java using
objects. In his mind, that made it object-oriented,
not imperative.
This is a common misconception. Most OOP is imperative.
Objects have state that changes.
Of course, one can write object-oriented code in a
functional style by emphasizing return values and by
creating new objects instead of changing existing objects.
Certain kinds of objects, such as money, should probably
be implemented as
value objects
without modifiable state. But most OO practice and intent
is stateful, hence imperative.
I've read many a blog entry over the last few years in
which OO gurus extol functional OO as a way to write better
code. I think we can overdo it, though. Whenever I take
this idea too far, though, I soon find myself contorting
the code in a way that seems to serve the idea but not the
program I am writing. Still, sometimes it can be fun to
turn the knob on the functional OO dial up to 10 and try
to write purely functional OO code, with no side effects
of any sort. This kind of
programming challenge
has always appealed to me. It can teach you a lot about
the strengths and limits of the tools you use.
It occurs to me that one way to enforce the rules of the
functional OO challenge would be to turn off the imperative
features in my language. That can be tough to do in a
language with libraries full of stateful objects. But
simply turning off the assignment operator in a language
such as Java would make many of us struggle to write even
simple programs.
Actually, I had the idea of turning off assignment
statements late in a long conversation I had with myself
while thinking about my student's comment and my response
to him. If most OO is imperative, I wonder what it would
be like to write "purely imperative" OO code. This would
mean creating objects that never returned a value in
response to a message. In a sense, these objects would
be pure state and action, at least from the perspective
of other objects in the system.
At first, this idea seemed absurd. What value could come
from it?
This stylistic challenge is quite easy to enforce, either
in practice or in tools: simply require all methods to be
void. Voilé! No return
statements are allowed. No values can be passed from one
object to another in response to a message. An object
would affect the state of the program either by modifying
its own state or by sending a state-changing message to
another object, perhaps an argument that it received along
with a message.
Talk about
Tell, Don't Ask!
In this style of programming, I can only tell
objects to do things. I can't ask for any data in return.
So, perhaps some value could come from this little
challenge after all. I would have to take Tell, Don't
Ask -- and encapsulation -- seriously. Programming in
this way can help us see just how much we can accomplish
with truly independent objects, providers of services
who encapsulate their state and take full responsibility
for its management. I think that, in many respects,
this idea is faithful to the original idea of objects
and OOP -- perhaps more faithful than our current
incarnation of them in languages with functions.
I think that this could also help us in another way.
Functional programming offers us one path to increased
parallelism by eliminating state changes and thus making
each computation independent of global context. Purely
imperative programming offers another path, one that
fits the early OO vision of encapsulated agents
interacting via message passing. This is similar to
the
actor model
that we see these days in languages such as Scala and
Erlang. Of course, this model goes back to the work
of Carl Hewitt, which inspired the evolution of both
Scheme and Smalltalk!
I have not thought through all the implications of my
thought experiment yet. Maybe it's nonsense; maybe
it's a solved problem. Still, I think it might be fun
to turn the dial up to 10 on stateful programming and
try to implement a non-trivial program with no
return statements. How far could I go
before things got uncomfortable? How far could I go
before I found myself contorting the code in a way that
serves the idea more than the program I was writing?
Sometimes I am surprised just how many interesting
thoughts can fall out of the simplest conversations.
Too bad time to play with them doesn't fall out, too.
Steve Martin's memoir, "Born Standing Up", tells the
story of how Martin's career as a stand-up comedian,
from working shops at Disneyland to being the
biggest-selling concert comic ever at his peak. I
like hearing people who have achieved some level of
success talk about the process.
This was my favorite passage in the book:
The consistent work enhanced my act. I Learned a
lesson: It was easy to be great. Every entertainer
has a night when everything is clicking. These
nights are accidental and statistical: Like the
lucky cards in poker, you can count on them
occurring over time. What was hard was to be
good, consistently good, night after night,
no matter what the abominable circumstances.
"Accidental greatness" -- I love that phrase. We
all like to talk about excellence and greatness,
but Martin found that occasional greatness was
inevitable -- a statistical certainty, even. If
you play long enough, you are bound to win every
now and then. Those wines are not achievement of
performance so much as achievements of being there.
It's like players and coaches in athletics who break
records for the most X in their sport. "That just
means I've been around a long time," they say.
The way to stick around a long time, as Martin was
able to do, is to be consistently good. That's
how Martin was able to be present when lightning
struck and he became the hottest comic in the
world for a few years. It's how guys like Don
Sutton won 300+ games in the major leagues: by
being good enough for a long time.
Notice the key ingredients that Martin discovered to
becoming consistently good: consistent work;
practice, practice, practice,
and more practice;
continuous feedback
from audiences into his material and his act.
We can't control the lightning strikes of unexpected,
extended celebrity or even those nights when
everything clicks and we achieve a fleeting moment
of greatness. As good as those feel, they won't
sustain us. Consistent work, reflective practice,
and small, continuous improvements are things we
can control. They are all things that any of us can
do, whether we are comics, programmers, runners, or
teachers.
The Toyota Production System encourages workers to solve every
problem two ways. First, you fix the issue at hand. Second,
you work back through the system to determine the systemic
reason that the issue arose. In this way, you eliminate this
as a problem in the future, or at least make it less likely.
As I
wrote recently,
I don't think of writing software as a production process.
But I do think that software developers can benefit from
the "solve it twice" mentality. When we encounter a bug
in our program or a design problem in our system or a
delivery problem on a project, we should address the
specific issue at hand. Then we should consider how we
might prevent this sort of problem from recurring. There
are several ways that we might improve:
We may need better or different tools.
We may be able to streamline or augment our process.
We may need to think about different things while working.
We may need to know something more deeply, or something new.
This approach would benefit us as university students and
university professors, too. If students and professors
thought more often in terms of continuous improvement and
committed to fixing problems the second time, too, we
might all have lower
mean times to competence.
To be a moral human being is to pay, be obliged to pay,
certain kinds of attention.
-- Susan Sontag, "The Novelist and Moral Reasoning"
For some reason, this struck me yesterday as important,
not just as a human being, but also as a programmer.
I am reminded that many of my friends and colleagues
in the software world speak passionately of our moral
obligations when writing code. The software patterns
community, especially, harkens to Christopher Alexander's
call regarding the moral responsibility of creators.
(If you want to read more from Sontag without tracking
down her essay, check out
this transcript
excerpted from a speech she gave in 2004.)
As head of the Department of Computer Science at my
university, I often receive e-mail and phone calls
from people with The Next Great Idea. The phone calls
can be quite entertaining! The caller is an eager
entrepreneur, drunk on their idea to revolutionize
the web, to replace Google, to top Facebook, or to
change the face of business as we know it. Sometimes
the caller is a person out in the community; other
times the caller is a university student in our
entrepreneurship program, often a business major.
The young callers project an enthusiasm that is
almost infectious. They want to change the world,
and they want me to help them!
They just need a programmer.
Someone has to take their idea and turn it into
PHP, SQL, HTML, CSS, Java, and Javascript. The
entrepreneur knows just what he or she needs.
Would I please find a CS major or two to join the
project and do that?
Most of these projects never find CS students to
work on them. There are lots of reasons. Students
are busy with classes and life. Most CS students
have jobs they like. Those jobs pay hard cash, if
not a lot of it, which is more attractive to most
students than the promise of uncertain wealth in
the future. The idea does not excite other people
as much as the entrepreneur, who created the idea
and is on fire with its possibilities.
A few of the idea people who don't make connections
with a CS student or other programmer contact me a
second and third time, hoping to hear good news.
The younger entrepreneurs can become disheartened.
They seem to expect everyone to be as excited by
their ideas as they are. (The optimism of youth!)
I always hope they find someone to help them turn
their ideas into reality. Doing that is exciting.
It also can teach them a lot.
Of course, it never occurs to them that they
themselves could learn how to program.
A while back, I tweeted something about receiving
these calls. Andrei Savu responded with a
pithy summary
of the phenomenon I was seeing:
@wallingf it's sad that they see software developers
as commodities. product = execution != original idea
As I wrote about at greater length in a
recent entry,
the value of a product comes from the combination of
having an idea and executing the
idea. Doing the former or having the ability to do
the latter aren't worth much by themselves. You
have to put the two together.
Many "idea people" tend to think most or all of the
value inheres to having the idea. Programmers are
a commodity, pulled off the shelf to clean up the
details. It's just a
small matter of programming,
right?
On the other side, some programmers tend to think
that most or all of the value inheres to executing
the idea. But you can't execute what you don't have.
That's what makes it possible for me and my buddy to
sit around over General Tsao's chicken and commiserate
about lost wealth. It's not really lost; we were
never in its neighborhood. We were missing a vital
ingredient. And there is no time machine or
other mechanism
for turning back the clock.
I still wish that some of the idea people had
learned how to program, or were willing to learn,
so that they could implement their ideas. Then
they, too, could know the
superhuman strength
of watching ideas become tangible. Learning to
program used to be an
inevitable consequence
of using computers. Sadly, that's no longer true.
The inevitable consequence of using computers these
days seems to be interacting with people we may or
may not know well and
watching videos.
Oh, and imagining that you have discovered The Next
Great Thing, which will topple Google or Facebook.
Occasionally, I have an urge to tell the entrepreneurs
who call me that their ideas almost certainly won't
change the world. But I don't, for at least two
reasons. First, they didn't call to ask my opinion.
Second, every once in a while a Microsoft or Google
or Facebook comes along and does change the
world. How am I to know which idea is that one in a
gazillion that will? If my buddy and I could
go back to 2000 and tell our younger and better-looking
selves about Facebook, would those guys be foresightful
enough to sit down and write it? I suspect not.
How can we know which idea is that one that will
change the world? Write the program, work hard to
turn it into what people need and want, and cross our
fingers. Writing the program is the ingredient the
idea people are missing. They are doing the right
thing to seek it out. I wonder what it would be like
if more people could implement their own ideas.
At a fulfillment center recently, one of our Kaizen
experts asked me, "I'm in favor of a clean fulfillment
center, but why are you cleaning? Why don't you
eliminate the source of dirt?" I felt like the Karate
Kid.
When I first read this in a blog entry, I immediately
thought of refactoring. I favor a style of
programming in which "cleaning up" is a fundamental
step: pick a small bit of new functionality, do the
simplest thing I can to make it work, and then clean
up the program's design and implementation. Should
I instead eliminate the source of dirt, and think
far enough ahead that the program is always clean?
It didn't take me long to realize that I'm neither
smart enough nor well enough informed about most
problems to do that. I will have to clean up every
so often, no matter how far I think ahead. Besides,
I find so much value in taking small steps and doing
simple things that I am willing to clean up.
Why is that? Why am I willing to clean up, rather
than keep things clean from the start? Why does
refactoring work for software developers?
If things are too clean, you probably are not creating
new things.
Kaizen notions are attractive to many in the "lean"
world of software development, and it is important --
in context. Production and creation are different
kinds of task. Keeping things clean and efficient
has great value in production environments, including
factories and perhaps in certain kinds of software
development. But when you are making new things,
there is great value in exploration, and exploration
is messy.
Bezos wrote that footnote on this passage:
Everywhere we look (and we all look), we find what
experienced Japanese manufacturers would call "muda"
or waste. I find this incredibly energizing. I see
it as potential -- years and years of variable and
fixed productivity gains and more efficient, higher
velocity, more flexible capital expenditures.
Amazon is a company that makes most of its profit
by delivering product to customers more efficiently
and less expensively than its competitors. If it
can eliminate a source of muda, it becomes a better
company. That's why the Kaizen expert's advice gave
Bezos a Karate Kid moment.
For me, the Karate Kid moment was just the opposite:
when I learned that programmers had vocabulary for
talking about refactoring and that some experts had
made it a deliberate part of their development process.
Wax on, wax off.
Recently, Kevin Carey's
Decoding the Value of Computer Science
got a lot of play among CS faculty I know. Carey talks
about how taking a couple of computer programming
courses way back at the beginning of his academic
career has served him well all these years, though he
ended up majoring in the humanities and working in the
public affairs sector. Some of my colleagues suggested
that this article gives great testimony about the value
of
computational thinking.
But note that Carey didn't study abstractions about
computation or theory or design or abstraction. He
studied BASIC and Pascal. He learned computer
programming.
Indeed, programming plays a central role in the key
story within the story. In his first job out of grad
school, Carey encountered a convoluted school financing
law in my home state of Indiana. He wrote code to
simulate the law in SAS and, between improving his
program and studying the law, he came to understand the
convolution so well that he felt confident writing a
simpler formula "from first principles". His formula
became the basis of an improved state law.
That's right. His code was so complicated and hard to
maintain, he through the system away and wrote a new
one. Every programmer has lived this experience with
computer code. Carey tried to debug a legal code and
found its architecture to be so bad that he was better
off creating a new one.
CS professors should use this story every time they try
to sell the idea of universal computer programming
experience to the rest of the university!
The idea of refactoring legal code via a program that
implements it is not really new. When I studied logic
programming and Prolog in grad school, I read about the
idea of expressing law as a Prolog programming and
using the program to explore its implications. Later,
I read examples where Prolog was used to do just that.
The
AI and law community
still works on problems of this sort. I should dig
into some of the recent work to see what progress, if
any, has been made since I moved away from that kind
of work.
My doctoral work involved modeling and reasoning about
legal arguments, which are very much like computer
programs. I managed to think in terms of argumentation
patterns, based on the work of Stephen Toulmin (whose
work I have
mentioned here before).
I wish I had been smart or insightful enough to make
the deeper connection from argumentation to software
development ideas such as architecture and refactoring.
It seems like there is room for some interesting
cross-fertilization.
(As always, if you know about work in this domain,
please
let me know!)
If a team wasn't productive, he'd come every couple
of weeks and say "let me help you out." What did he
do? He took away another person until the team started
shipping and stopped having unproductive meetings.
This turns mythical man-month on its head. I wonder
if I should try this in my project courses?
Smaller Scope
In the same blog entry, Scoble says:
[Instagram] actually started out as a service that did
a lot more than just photographs. But, they learned
they couldn't complete such a grand vision and do it
well. So they kept throwing out features.
If you can't do all that you dreamed of doing, do less
-- and do it well. Articles like this one imply that,
as organizations get larger and more visible, they lose
the ability to reduce scope and focus quality on a
smaller project. I'm not sure they lose their ability
so much as their will.
Smaller Promises
Paul Dyson
tells a familiar story
about the conflict between what a name comes to connote
and the actions that are what it should denote:
I recently sat in front of a customer's project manager
-- a very smart and reasonable person -- and accidentally
used the A-word ["agile"] when describing how we were
going to deliver our product and required customisations
to them, and they sneered.
They actually snorted in disgust.
When I then explained we would get them live and using
the base product quickly, followed by weekly incremental
improvements with regular reviews and plenty of
opportunity for rework they were very happy.
But they didn't see any connection between the two
things.
The hype that seems inevitably to smother so many great
ideas in the software world has, for many parts of our
world, made "agile" meaningless at best and
risible
at worst. That's too bad, because when we ruin good
words we lose a useful avenue for communication.
Later in the same piece, Dyson offers his solution:
... it's not about being agile/Agile or achieving agility,
or being lean/Lean and efficient. It's about delivering
software. And I figure the best way to champion that is
actually just to get better at doing it.
I love those last two sentences. The best way to show
people the value of patterns or TDD or refactoring or
almost any practice is to do it. It's about
delivering software.
cleaning up junit in preparation for 4.9 release with
@dsaff. why do bad design decisions spread faster than
good ones?
I immediately thought of
Gresham's Law
from economics, which is commonly expressed as "bad money
drives good money out of circulation". That sounds like
what Kent is saying: bad design decisions drive good ones
out of our code.
In reality, the two ideas are not alike. Gresham's Law
refers to a human behavior we can all understand.
Suppose we have two coins denominated as a worth one
dollar. The first coin is made of gold, a rare metal
of enduring social and economic value. The second is
made of nickel, a common metal not valued by the people
using the coins. Under these conditions, people will
tend to hoard the gold coins and use the nickel coins
in trade. The result is that, eventually, there will
be few or no gold coins in circulation. Hence the
aphorism: "bad money drives good money out of
circulation".
(Sir Thomas Gresham, a financial agent at the time of
Queen Elizabeth I, was not the first person to note
this behavior. According to
Wikipedia,
Aristophanes remarked on the phenomenon in his play
"The Frogs", at the end of the 5th century BC.)
That's not what is happening in JUnit or other
software systems. Kent and his partners aren't
hoarding good design decisions and using bad ones in
their place, in order to benefit later from having the
good decisions at hand. Good design decisions have
value only when they are deployed. They are good only
in a context where they balance forces in a pleasing
or supportive way. "Spending" bad design decisions
in code doesn't get rid of them; it requires that we
live with them every time we touch the code!
So, equating the phenomenon that Kent described with
Gresham's Law would be to misuse the law. If I did
so, I wouldn't be alone. Robert Mundell discusses
faulty renderings of the principle in an
academic paper.
It wouldn't even be the first time I made the mistake.
I remember vividly the night I took a midterm exam in
my undergrad macroeconomics class. I misstated
Gresham's Law in one of my responses. My instructor
was wondering around the room. He saw my answer,
leaned over, and whispered into my ear that I should
think about that question again. I did and was able
to correct my answer. (That guy was a way cool teacher,
and not just for helping me out on the exam.)
When I saw Kent's tweet, I did not make that mistake
again. I answered his question with "a perverse
malformation of Gresham's Law?" John Mitchell
offered
his own colorful phrase:
viral toxicity. That is almost certainly a
better reflection of the phenomenon than mine, yet
the ring of "the bad drives out the good" still
appeals to me.
I think Kent's question is worth thinking about some
more. Bad design does seem to infect other parts of
the system and spread, by requiring us to deform other
code to make it work well with the bad code, to fit
with the bad structures we've already created.
Perhaps Viral Toxicity is a sort of Gresham's Law for
software, a phenomenon that developers need to be
aware of and guard against. Maybe if we talk about
the viral toxicity of bad design, other people will
understand better the value and even necessity of
regular refactoring!
A few recent entries have given rise to interesting
responses from readers. Here are two.
Fat Arrows
Relationships, Not Characters
talked about how the most important part of design often
lies in the space between the modules we create, whether
objects or functions, not the modules themselves. After
reading this,
John Cook
reminded me about an article by Thomas Guest,
Distorted Software.
Near the end of that piece, which talks about design
diagrams, Guest suggests that the arrows in application
diagrams should be larger, so that they would be
proportional to the time their components take to
develop. Cook says:
We typically draw big boxes and little arrows in software
diagrams. But most of the work is in the arrows! We
should draw fat arrows and little boxes.
I'm not sure that would make our OO class diagrams better,
but it might help us to think more accurately!
My Kid Could Do That
Ideas, Execution, and Technical Achievement
wistfully admitted that knowing how to build Facebook or
Twitter isn't enough to become a billionaire. You have to
think to do it. David Schmüdde mentioned this entry
in his recent
My Kid Could Do That,
which starts:
One of my favorite artists is Mark Rothko. Many reject
his work thinking that they're missing some genius, or
offended that others see something in his work that they
don't. I don't look for genius because genuine genius
is a rare commodity that is only understood in hindsight
and reflection. The beauty of Rothko's work is, of
course, its simplicity.
That paragraph connects with one of the key points of my
entry: Genius is rare, and in most ways irrelevant to
what really matters. Many people have ideas; many people
have skills. Great things happen when someone brings
these ingredients together and does something.
Later, he writes:
The real story with Rothko is not the painting. It's what
happens with the painting when it is placed in a museum,
in front of people at a specific place in the world, at a
specific time.
In a comment on this post, I thanked Dave, and not just
because he discusses my personal reminiscence. I love art
but am a novice when it comes to understanding much of it.
My family and I saw an elaborate Rothko exhibit
at the Smithsonian this summer.
It was my first trip to the Smithsonian complex -- a
wonderful two days -- and my first extended exposure to
Rothko's work. I didn't reject his art, but I did leave
the exhibit puzzled. What's the big deal?, I wondered.
Now I have a new context in which to think about that
question and Rothko's art. I didn't expect the new context
to come from a connection a reader made to my post on tech
start-up ideas that change the world!
I am glad to know that thinkers like Schmüdde are able
to make connections like these. I should note that he is
a professional artist (both visual and aural), a teacher,
and a recovering computer scientist -- and a former student
of mine. Opportunities to make connections arise when
worlds collide.
Drama is is about relationships, not about characters.
This immediately brought to mind Alan Kay's insistence
that object-oriented programmers too often focus so much
on the objects in their programmers that they lose sight
of something more important: the space between the objects.
A few years ago, I wrote about this idea in an entry called
Software in Negative Space.
It remains one of my most-read articles.
The secret to good OO design is in the ma, the web
of relationships that make up a complex system, not in the
objects themselves.
I think this is probably true of good design in any style,
because it is really about how complex systems can manage
and use encapsulation. The very best OO design patterns
show us how multiple objects interact via message passing
to resolve a thorny set of forces. The individual objects
don't solve the problem; the solution lies in their
interfaces and delegation of responsibility. We need to
think about our designs at that level, too.
Now that functional programming is
receiving so much mainstream attention,
this is a good time to think about when and how good
functional design is about relationships, not (just)
functions. A combinator is an example: the particular
functions are not as important as they way they hook
together to solve a bigger problem. Designing functions
in this style requires thinking more about the interfaces
that expose abstractions to the world, and how other
modules use them as service, and less about their
implementation. Relationships.
Back in 1998, I documented some of the ideas that I used
to teach functional programming in Scheme. The result
was the beginnings of a small pattern language I called
Roundabout.
When I workshopped this paper at PLoP, I had a lot of
fun, but it was a challenge. My workshop consisted of
professional developers, most working in Java, with
little or no experience in Scheme. Worse, many had been
exposed to Lisp as undergraduates and had had negative
experiences. Even though they all seemed open to my
paper, subconsciously their eyes and ears were closed.
We gathered over lunch so that I could teach a quick
primer on how to read Scheme. The workshop went well,
and I received much useful feedback.
Still, that wasn't the audience for Roundabout. They
were are OO programmers. To the extent they were looking
for patterns to use, they were looking for GoF-style
OO patterns, C++, Java, and enterprise patterns. I had
a hard time finding an audience for Roundabout. Most
folks in the OO world weren't ready yet; they were still
trying to learn how to do OOD and OOP really well. I
gave a short talk on how I use Roundabout in class at
an ICFP workshop, but the folks there already knew these
patterns well, and most were beyond the novice level at
which they live. Besides, the functional programming
world
wasn't all that keen
on the idea of patterns at all, not patterns in the style
of Christopher Alexander.
Fast forward to 2010. We now have Scala and Clojure on
the JVM. A local developer I know is working hard to
wrap his head around FP. Last week, he sent me a link
to an InfoQ talk by Aino Corry on
Functional Design Patterns.
The talk is about patterns more generally, what they are
and how GoF patterns fit in the functional programming
world. At about the 19:00 mark, she mentions...
Roundabout! My colleague is surprised to hear my name
and tweets his excitement.
My work on functional design patterns is resurfacing.
Why? The world is changing. With Scala and Clojure
poised to make noise in the Java enterprise world,
functional programming is here. People are talking
about Scheme and especially Haskell again. Functional
programming is trendy now, with famous OO consultants
talking it up and making the rounds at conferences and
workshops giving talks about how important it is.
(Some folks have been saying that for a while...)
The software patterns "movement" grew out of a need
felt by many programmers around the world to learn how
to do OO design and programming. Most had been weaned
on traditional procedural programming and built up
years of experience programming in that style, only
to find that their experience didn't transfer smoothly
into the OO world. Patterns were an ideal vehicle for
documenting OO expertise and communicating it to
programmers as they learned the new style.
We now face a similar transition in industry and even
academia, as languages like Scala and Clojure begin to
change how professionals build their systems. They are
again finding that their experience -- now with OO --
does not transfer into the functional world without a
few hitches. What we need now are papers that document
functional design and programming patterns, both at the
most basic level (like Roundabout) and at a higher
level (like GoF). We have some starting points from
which to begin the journey. There has been some good
work done on
refactoring functional-style programs,
and refactoring is a complement to patterns.
This is a great opportunity for experienced functional
programmers to teach their style to a large new
audience that now has incentive to learn it. This is
also a great opportunity to demonstrate again the value
of the software pattern as a form for documenting and
teaching how to build things. The question is, what
to do next.
If I were more honest with myself, I would probably
have to say something like this more often:
He also gave me the white book, XP Explained,
which I dismissed outright as rubbish. The ideas did
not fit my mental model and therefore they were crap.
Like many people, I am too prone to impose my way of
thinking and working on everything. Learning requires
changing how I think and do, and that can only happen
when I don't dismiss new ideas as wrong.
I found that passage in
Corey's Code Retreat,
a review of a code retreat conducted by
Corey Haines.
The article closes with the author's assessment of
what he had learned over the course of the day,
including this gem:
... faith is a necessary component of design ...
This is one of the hardest things for beginning
programmers to understand, and that gets in the way
of their learning. Without much experience writing
code, they often are overwhelmed by the uncertainty
that comes with making anything that is just beyond
their experience. And that is where the most interesting
work lies: just beyond our experience.
Runners training for their first marathon often feel
the same way. But experience is no antidote for this
affliction. Despair and anger are common emotions,
and they sometimes
strike us hardest
when we know how to solve problems in one way and are
asked to learn a new way to think and do.
Some people are naturally optimistic and open to
learning. Others have cultivated an attitude of
openness. Either way, a person is better prepared to
have faith that they will eventually get it. Once
we have experience, our faith is buttressed by our
knowledge that we probably will reach a good design
-- and that, if we don't, we will know how to respond.
This article testifies to the power of a reflective code
retreat led by a master. After reading it, I want to
attend one! I think this would be a great thing for our
local software community to try. For example, a code
retreat could help professional programmers grok
functional programming better than just reading books
about FP or about the latest programming language.
~~~~
The article also opens with a definition of engineering
I had not seen before:
... the strategy for causing the best change in a poorly
understood situation within the available resources ...
I will think about it some more, but on first and
second readings, I like this.
I am back home from St. Louis and Des Moines, up to my
next in regular life. I recorded some of my thoughts
and experiences from
Strange Loop
in a set of entries here:
Unlike most of the academic conferences I attend, Strange
Loop was not held in a convention center or in a massive
conference hotel. The primary venue for the conference
was the
Pageant Theater,
a concert nightclub in the
Delmar Loop:
This setting gave the conference's keynotes something of
an edgy feel. The main conference lodging was the
boutique
Moonrise Hotel
a couple of doors down:
Conference session were also held in the Moonrise and
in the Regional Arts Commission building across the
street. The meeting rooms in the Moonrise and the
RAC were ordinary, but I liked being in human-scale
buildings that had some life to them. It was a
refreshing change from my usual conference venues.
It's hard to summarize the conference in only a few
words, other than perhaps to say, "Two thumbs up!"
I do think, though, that one of the subliminal
messages in Guy Steele's keynote is also a subliminal
message of the conference. Steele talked for half an
hour about a couple of his old programs and all of
his machinations twenty-five or forty years to make
them run in the limited computing environments of
those days. As he went to all the effort to
reconstruct the laborious effort that went into those
programs in the first place, the viewer can't help
but feel that the joke's on him. He was programming
in the Stone Age!
But then he gets to the meat of his talk and shows us
that how we program now is the relic of a passing age.
For all the advances we have made, we still write code
that transitions from state to state to state, one
command at a time, just like our cave-dwelling ancestors
in the 1950s.
It turns out that the joke is on us.
The talks and conversations at Strange Loop were
evidence that one relatively small group of programmers
in the midwestern US are ready to move into the
future.
After eating some dandy deep-dish BBQ chicken at
Pi Pizzeria
with the guys from
T8 Webware
(thanks,
Wade!),
I returned for a last big run of sessions. I'll
save the first session for last, because my report
of it is the longest.
Android Squared
I went to this session because so many of my
students want me to get down in the trenches with
phone programming. I saw a few cool tools,
especially
RetroFit,
a new open-source framework for Android. There are
not enough hours in a day for me to explore every
tool out there. Maybe I can have a student do an
Android project.
Java Puzzlers
And I went to this session because I am weak.
I am a sucker for silly programming puzzles, especially
ones that take advantage of the dark corners of our
programming languages. This session did not disappoint
in this regard. Oh, the tortured code they showed us!
I draw from this experience a two-part moral:
Bad programmers can write really bad code,
especially in a complex language.
A language that is too complex makes bad
programmers of us all.
Brian Marick on Outside-In TDD
Marick demoed a top-down | outside-in style of TDD
in Clojure using
Midje,
his homebrew test package. This package and style
make heavy use of mock objects. Though I've dinked
around a bit in Scala, I've done almost nothing in
Clojure, so I'll have to try this out. The best
quote of the session echoed a truth about all
programming: You should have no words in your
test that are not specifically about the test.
Douglas Crockford, Open-Source Heretic
Maybe my brain was fried by the end of the two days,
or perhaps I'm simply not clever enough. While I
able to chuckle several times through this closing
keynote, I never saw the big picture or the point
of the talk. There were plenty of interesting, if
disconnected, stories and anecdotes. I enjoyed
Crockford's coverage of several historical mark-up
languages, including Runoff and Scribe. (Runoff
was the forebear of troff, a Unix utility
I used throughout grad school -- I even produced
my wedding invitations using it! Fans of Scribe
should take a look at
Scribble,
a mark-up tool built-on top of Racket.) He also
told an absolutely wonderful story about Grace
Murray Hopper's A-0, the first compiler-like
tool and likely the first open-source software
project.
Panel on the Future of Languages
Panels like this often don't have a coherent summary.
About all I can do is provide a couple of one-liners
and short answers to a couple of particularly salient
questions.
Joshua Bloch: Today's patterns are tomorrow's
language features. Today's bugs are tomorrow's type
system features.
Douglas Crockford: Javascript has become what
Java was meant to be, the language that runs
everywhere, the assembly language of the web.
Someone in the audience asked, "Are changes in
programming languages driven by academic discovery
or by practitioner pain?" Guy Steele gave the
best answer: The evolution of ideas is driven
by academics. Uptake is driven by practitioner
needs.
So, what is the next big thing in programming
languages? Some panelists gave answers grounded in
today's problems: concurrency, a language that could
provide and end-to-end solution for the web, and
security. One panelists offered
laziness.
I think that laziness will change how many programmers
think -- but only after functional programming has
blanketed the mainstream. Collectively, several
panelists offered variations of sloppy
programming, citing as early examples Erlang's
approach to error recovery, NoSQL's not-quite-data
consistency, and Martin Rinard's work on
acceptability-oriented computing.
The last question from the audience elicited some
suggestions you might be able to use. What
language, obscure or otherwise, should people learn
in order to learn the language you really want
them to learn? For this one, I'll give you a
complete list of the answers:
Io. (Bruce Tate)
Rebol. (Douglas Crockford)
Forth. Factor. (Alex Payne)
Scheme. Assembly. (Josh Bloch)
Clojure. Haskell. (Guy Steele)
I second all of these suggestions. I also second
Steele's more complete answer: Learn any three
languages you do not know. The comparisons and
contrasts among them will teach you more than any
one language can.
Panel moderator Ted Neward closed the session with
a follow-up question: "But what should the Perl
guys learn while they are waiting for Perl 6?"
We are still waiting for the answer.
Perhaps my brain is becoming overloaded, or I have
been less disciplined in picking talks to attend,
or the slate of sessions for Day 2 is less coherent
than Day 1's. But today has felt scattered, and so
far less satisfying than yesterday. Still, I have
had some interesting thoughts.
Billy Newport on Enterprise NoSQL
This was yet another NoSQL talk, but not, because
it was different than the preceding ones at the
conference. This talk was not about any particular
technologies. It was about mindsets.
Newport explained that NoSQL means not only
SQL. These two general approaches to data storage
offer complementary strengths and weaknesses. This
means that they are best used in different contexts.
I don't do enough programming for big data apps to
appreciate all the details of this talk. Actually,
I understood most of the basic concepts, but they
soon starting blurring in my mind, because I don't
have personal experience on which to hang them. A
few critical points stood out:
In the SQL world, the database is the "system
of record" for all data, so consistency is a
given. In the NoSQL world, having multiple
systems of record is normal. In order to
ensure consistency, the application uses
business rules to bring data back into sync.
This requires a big mind shift for SQL guys.
In the SQL world, the row is a bottleneck.
In the NoSQL world, any node can handle the
request. So there is not a bottleneck, which
means the NoSQL approach scales transparently.
J But see the first
bullet.
These two issues are enough to see one of Newport's
key points. The differences between the two worlds
is not only technical but also cultural. SQL and
NoSQL programmers use different vocabulary and have
different goals. Consider that "in NoSQL, 'query'
is a dirty word". NoSQL programmers do everything
they can to turn queries into look-ups. For the
SQL programmer, the query is a fundamental concept.
The really big idea I took away from this talk is
that SQL and NoSQL solve different problems.
The latter optimizes for one dominant question, while
the former seeks to support an infinite number of
questions. Most of the database challenges facing
NoSQL shops boil down to this: "What happens
if you ask a different question?"
Dean Wampler on Scala
The slot in which this tutorial ran was longer than
the other sessions at the conference. This allowed
Wampler to cover a lot of details about Scala. I
didn't realize how much of an "all but the kitchen
sink" language Scala is. It seems to include just
about every programming language feature I know
about, drawn from just about every programming
language I know about.
I left the talk a bit sad. Scala contains so much.
It performs so much syntactic magic, with so many
implicit conversions and so many shortcuts. On the
one hand, I fear that large Scala programs will
overload programmers' minds the way C++ does. On
the other, I worry that its emphasis on functional
style will overload programmers' minds the way
Haskell does.
The last talk of the
afternoon of Day 1
was a keynote by Guy Steele. My notes for his talk
are not all that long, or at least weren't when I
started writing. However, as I expected, Steele
presented a powerful talk, and I want to be able
to link directly to it later.
Steele opened with a story about a program he wrote
forty years ago, which he called the ugliest program
he ever wrote. It fit on a single punch card. To
help us understand this program, he described in
some detail the IBM hardware on which it ran. One
problem he faced as a programmer is that the dumps
were undifferentiated streams of bytes. Steele
wanted line breaks, so he wrote an assembly language
program to do that -- his ugliest program.
Forty years later, all he has is the punch card --
no source. Steele's story then turned into CSI:
Mainframe. He painstakingly reverse-engineered
his code from punches on the card. We learned about
instruction format, data words, register codes...
everything we needed to know how this program
managed to dump memory with newlines and fit on a
single card. The number of hacks he used, playing
on puns between op codes and data and addresses, was
stunning. That he could resurrect these memories
forty years later was just as impressive.
I am just old enough to have programmed assembly
for a couple of terms on punch cards. This talk
brought back memories, even how you can recognize
data tables on a card by the unused rows where
there are no op codes. What a wonderful
forensics story.
The young guys in the room liked the story, but
I think some were ready for the meet of the talk.
But Steele told another, about a program for
computing sin 3x on a PDP-11. To write
this program, Steele took advantage of changes in
the assembly languages between the IBM mainframe
and the PDP-11 to create more readable code.
Still, he had to use several idioms to make it
run quickly in the space available.
These stories are all about automating resource
management, from octal code to assemblers on up
to virtual memory and garbage collection. These
techniques let the programmer release concerns
about managing memory resources to tools.
Steele's two stories demonstrate the kind of
thinking that programmers had to do back in the
days when managing memory was the programmer's
job. It turns out that the best way to think
about memory management is not to think about
it at all.
At this point, Steele closed his own strange
loop back to the title of his talk. His thesis
is this: the best way to think about parallel
programming is not to have to.
If we program using a new set of idioms, then
parallelism can be automated in our tools. The
idioms aren't about parallelism; they
are more like functional programming patterns
that commit the program less to underlying
implementation.
There are several implications of Steele's thesis.
Here are two:
Accumulators are bad. Divide and conquer
is good.
Certain algebraic properties of our code are
important. Programmers need to know and
preserve them in then code they write.
Steele illustrated both of these implications by
solving an example problem that would fit nicely
in a CS1 course: finding all the words in a
string. With such a simple problem, everyone in
the room has an immediate intuition about how to
solve it. And nearly everyone's intuition produces
a program using accumulators that violates several
important algebraic properties that our code might
have.
One thing I love about Steele's talks: he grounds
ideas in real code. He developed a complete
solution to the problem in
Fortress,
the language Steele and his team have been creating
at Sun/Oracle for the last few years. I won't try
to reproduce the program or the process. I will
say this much. One, the process demonstrated a
wonderful interplay between functions and objects.
Two, in the end, I felt like we had just used a
process very similar to the one I use when
teaching students to create this functional merge
sort function:
(define mergesort
(lambda (lst)
(merge-all (map list lst))))
Steele closed his talk with the big ideas that his
programs and stories embody. Among the important
algebraic properties that programs should have
whenever possible are ones we all learned in grade
school, explicitly or implicitly. Though they may
still sound scary, they all have intuitive common
meanings:
associative -- grouping don't matter
commutative -- order doesn't matter
idempotent -- duplicates don't matter
identity -- this value doesn't matter
zero -- other values don't matter
Steele said that "wiggle room" was the key buzzword
to take away from his talk. Preserving invariants
of these algebraic properties give the compiler
wiggle room to choose among alternative ways to
implement the solution. In particulars, associativity
and commutativity give the compiler wiggle room to
parallelize the implementation.
(Note that the merge-all operation in my
mergesort program satisfies all five properties.)
One way to convert an imperative loop to a parallel
solution is to think in terms of grouping and
functions:
Bunch mutable state together as a state
"value".
Look at the loop as an application of one or
more state transformation functions.
Look for an efficient way to compose these
transformation functions into a single
function.
The first two steps are relatively straightforward.
The third step is the part that requires ingenuity!
In this style of programming, associative combining
operators are a big deal. Creating new, more
diverse associative combining operators is the
future of programming. Creating new idioms -- the
patterns of programs written in this style -- is
one of our challenges. Good programming languages
of the future will provide, encourage, and enforce
invariants that give compilers wiggle room.
In closing, Steele summarized our task as this:
We need to do for processor allocation what garbage
collection did for memory allocation. This is
essential in a world in which we have parallel
computers of wildly different sizes. (Multicore
processors, anyone?)
I told some of the guys at the conference that I go
to hear Guy Steele irrespective of his topic. I've
been fortunate enough to be in a
small OOPSLA workshop on creativity
with Steele, gang-writing poetry and Sudoku
generators, and I have seen him speak a few times
over the years. Like his past talks, this talk
makes me think differently about programs. It
also crystallizes several existing ideas in a
way that clarifies important questions.
As busy as things are here with class and department duties,
I am excited to be heading to
StrangeLoop 2010
next week. The conference description sounds like it
is right up my alley:
Strange Loop is a developer-run software conference.
Innovation, creativity, and the future happen in the magical
nexus "between" established areas. Strange Loop eagerly
promotes a mix of languages and technologies in this nexus,
bringing together the worlds of bleeding edge technology,
enterprise systems, and academic research.
Of particular interest are new directions in data storage,
alternative languages, concurrent and distributed systems,
front-end web, semantic web, and mobile apps.
One of the reasons I've always liked OOPSLA is that it is
about programming. It also mixes hard-core developers
with academics, tools with theory. Unfortunately, I'll
be missing OOPSLA (now called SPLASH) again this year. I
hope that StrangeLoop will inspire me in a similar way.
The range of technologies and speakers on the program
tells me it probably will.
The day after I return from St. Louis, I hit the road
again for the
Des Moines Marathon,
where I'll run strange loops of a different sort. My
training has gone pretty well since the end of July,
with mileage and speed work hitting targets I set back
in June. Before my taper, I managed three weeks of
50 miles or more, including three 20+ mile long runs.
Will that translate into a good race day? We never
know. But I'm looking forward to the race, as well
as the Saturday expo and dinner with a good buddy the
night before.
If nothing else, the marathon will give me a few hours
to reflect on what I learn at StrangeLoop and to think
about what I will do with it!
Traffic on the XP mailing list has been heavy for the
last few weeks, with a lot of "meta" discussion spawned
by messages from questioners seeking a firmer
understanding of this thing we call "agile software
development". I haven't had time to read even a small
fraction of the messages, but I do check in occasionally.
Often, I'll target in on comments from specific writers
whose expertise and experience I value. Other times,
I'll follow a sub-sub-plot to see a broader spectrum of
ideas.
Two recent messages really stood out to me as important
signposts in the long-term conversation about agile
software development. First, Charlie Poole reminded
everyone that
Agile Isn't a "Thing".
The ongoing thread about whether is
always/sometimes/not always/never/ whatever "right" for
a given environment seems to me to be missing something
rather important. It seems to be based on the assumption
that "agile" is some particular thing that we can talk
about unambiguously.
It isn't.
If you come to the "agile" community looking for one
answer to any question, or agreement on specific
practices, or a dictum that developers or managers can
use to change minds, you'll be disappointed. It's much
more nebulous than that:
Agile is a set of values. They fit anywhere that those
values are respected, including places where folks are
trying to move the company culture away from antithetical
values and towards those of agile.
If you are working with a group of people who share these
values, or who are open to them, then you can "do agile"
by looking for ways to bring your group's practices
more in alignment with your values. You can accomplish
this in almost any environment. But to get specific
about agile, Charlie reminds us, you probably have to
shift the conversation to specific approaches to agile
development, and even specific practices.
When I use the term "agile", I try not to use it solo.
I like to say "agile software development" or simply
"agile development".
Software configuration management
guru
Brad Appleton
wrote the second post to catch my eye and goes a step
beyond "Agile Isn't a 'Thing'" to the root of the
issue: "agile" is an adjective!
"Agile" is something that you are (or are not),
not something that you "do".
So simple. Thanks, Brad.
I can talk about "agility" as a noun, where it is the
quality attained by "being agile". I can talk about
"agile" a modifier of a noun/thing, even if the "thing"
it is modifying is a set of values, principles, beliefs,
behaviors, etc.
He doesn't stop there, though, for which I'm glad. You
can try to develop software in an agile way -- with an
openness to change, typically using
short iterations and continuous feedback
-- and thus try to be more agile. You can adopt a set
of values, but if you don't change what you do
then you probably won't be any more agile.
I also liked that Brad points out it's not reasonable
to expect to realize the promise developing
software in an agile way if one ignores the
premise of the agile approaches. For example,
executing a certain method or set of practices won't
enable you to respond to change with facility unless
you also take actions that keep the cost of change low
and pay attention to whether or not these actions are
succeeding. Most importantly, "agile" is not a synonym
for happiness or success. "Being agile" may be a way
to be happier as a developer or person, but we should
not confuse the goal of "being agile" with the goal of
being happy or successful or happy.
The title of this entry, "What Agile Isn't", ought to
sound funny, because it isn't entirely grammatically
correct. If we quote the "Agile", at least then we
could be honest in indicating that we are talking
about a word.
Don't worry too much about whether you fit someone
else's narrow definition of "agile". Just keep trying
to get better by choosing -- deliberately and with care
-- actions and practices that will move you in the
direction of your goal. The rest will take care of
itself.
In Alan Kay's latest
comment-turned-blog entry,
he offers thoughts in response to Moti Ben-Ari's CACM
piece about object-oriented programming. Throughout, he
distinguishes "real oop" from what passes under the term
these days. His original idea of object-oriented software
is really quite simple to express: encapsulated modules
all the way down, with pure messaging. This statement
boils down to its essence many of the things he has written
and talked about over the years, such as in his
OOPSLA 2004 talks.
This is a way to think about and design systems, not a set
of language features grafted onto existing languages or
onto existing ways of programming. He laments what he
calls "simulated data structure programming", which is,
sadly, the dominant style one sees in OOP books these days.
I see this style in nearly every OOP textbook -- especially
those aimed at beginners, because those books generally
start with "the fundamentals" of the old style. I see it
in courses at my university, and even dribbling into my
own courses.
One of the best examples of an object-oriented system is
one most people don't think of as a system at all: the
Internet:
It has billions of completely encapsulated objects (the
computers themselves) and uses a pure messaging system of
"requests, not commands", etc.
Distributed client-server apps make good examples and
problems in courses on OO design precisely because they
separate control of the client and the server. When we
write OO software in which we control both sides of the
message, it's often too tempting to take advantage of how
we control both objects and to violate encapsulation.
These violations can be quite subtle, even when we take
into account idioms such as access methods and the Law
of Demeter. To what extent does one component depend on
how another component does its job? The larger the answer,
the more coupled the components.
Encapsulation isn't an end unto itself, of course. Nor
are other features of our implementation:
The key to safety lies in the encapsulation. The key to
scalability lies in how messaging is actually done (e.g.,
maybe it is better to only receive messages via "postings
of needs"). The key to abstraction and compactness lies
in a felicitous combination of design and mathematics.
I'd love to hear Kay elaborate on this "felicitous
combination of design and mathematics"... I'm not sure
just what he means!
As an old AI guy, I am happy to see Kay make reference to
the
Actor model
proposed by
Carl Hewitt
back in the 1970s. Hewitt's ideas drew some of their
motivation from the earliest Smalltalk and gave rise
not only to Hewitt's later work on concurrent programming
but also Scheme. Kay even says that many of Hewitt's
ideas "were more in the spirit of OOP than the subsequent
Smalltalks."
Another old AI idea that came to my mind as I read the
article was
blackboard architecture.
Kay doesn't mention blackboards explicitly but does talk
about how messaging might better be if instead of an
object sent messages to specific targets they might
"post their needs". In a blackboard system, objects
capable of satisfying needs monitor the blackboard and
offer to respond to a request as they are able. The
blackboard metaphor
maintains some currency in the software world, especially
in the distributed computing world; it even shows up as
an architectural pattern in
Pattern-Oriented Software Architecture.
This is a rich metaphor with much room for exploration
as a mechanism for OOP.
Finally, as a CS educator, I could help but notice Kay
repeating a common theme of his from the last decade,
if not longer:
The key to resolving many of these issues lies in carrying
out education in computing in a vastly different way than
is done today.
That is a tall order all its own, much harder in some ways
than carrying out software development in a vastly different
way than is done today.
Recently, one of the software developers I follow
on Twitter posted a link to
10 Things Non-Technical Users Don't Understand About Your Software.
It documents the gap the author has noticed between
himself as a software developer and the people who
use the software he creates. A couple, such as
copy and paste and data storage, are so basic that
they might surprise new developers. Others, such
concurrency and the technical jargon of software,
aren't all that surprising, but developers need
to keep them in mind when building and documenting
their systems. One, the need for back-ups, eludes
even for technical users. Unfortunately,
You can mention the need for back-ups in your
documentation and/or in the software, but it is
unlikely to make much difference. History shows
that this is a lesson most people have to learn
the hard way (techies included).
As I read this article, I began to think that it
would be fun and enlightening to write a series
of blog entries on the things that CS majors don't
understand about our courses. I could start with
ten as a target length, but I'm pretty sure that
I can identify even more. As the author of the
non-technical users paper points out, the value
in such a list is most definitely not
to demean the students or users. Rather, it is
exceedingly useful for professors to remember
that
their students are not like them
and to keep these differences in mind as they
design their courses, create assignments, and
talk with the students. Like almost everyone
who interacts with people, we can do a better
job if we understand our audience!
So, I'll be on the look-out for topics specific
to CS students. If you have any suggestions,
you know
how to reach me.
After I finished reading the article, I looked
back at the list and realized that many of
these things are themselves things that CS majors
don't understand about their courses. Consider
especially these:
the jargon you use
It took me several years to understand just how
often the jargon I used in class sounded like
white noise to my students. I'm under no illusion
that I now speak in the clearest vocabulary and
that all my students understand what I'm saying
as I say it. But I think about this often as I
prepare and deliver my lectures, and I think I'm
better than I used to be.
they should read the documentation
I'm used to be surprised when, on our student
assessments, a student responds to the question
"What could I have done better to improve my
learning in this course?" with "Read the book".
(Even worse, some students say "Buy
the book"!) Now, I'm just saddened. I can say
only so much in class. Our work in class can
only introduce students to the concepts we are
learning, not cover them in their entirety.
Students simply must read the textbook. In
upper-division courses, they may well need
to read secondary sources and software
documentation, too. But they don't always
know that, and we need to help them know it as
soon as possible.
Finally, my favorite:
the problem exists between keyboard and chair
Let me sample from the article and substitute
students for users:
Unskilled students often don't realize how unskilled
they are. Consequently they may blame your course
(and lectures and projects and tests) for problems
that are of their own making.
For many students, it's just a matter of learning
that they need to take responsibility for their
own learning. Our K-12 schools often do not
prepare them very well for this part of the college
experience. Sometimes, professors have to be
sensitive in raising this topic with students who
don't seem to be getting it on their own. A soft
touch can do wonders with some students; with
others, polite but direct statements are essential.
The author of this article closes his discussion
of this topic with advice that applies quite well
in the academic setting:
However, if several people have the same problem
then you need to change your product to be a better
fit for your users (changing your users to be a
better fit to your software unfortunately not being
an option for most of us).
You see, sometimes the professor's problem exists
between his keyboard and his chair, too!
Recursion, Trampolines, and Software Development Process
Yesterday I read an old article on
tail calls and trampolining in Scala
by Rich Dougherty, which summarizes nicely the problem
of recursive programming on the JVM. Scala is a
functional language, which lends itself to recursive
and mutually recursive programs. Compiling those
programs to run on the JVM presents problems because
(1) the JVM's control stack is shallow and (2) the JVM
doesn't support tail-call optimization. Fortunately,
Scala supports first-class functions, which enables
the programmer to implement a "trampoline" that avoids
the growing the stack. The resulting code is harder
to understand and so to maintain, but it runs without
growing the control stack. This is a nice little
essay.
Dougherty's conclusion about trampoline code being
harder to understand reminded me of a response by
reader Edward Coffin to my July entry on
CS faculty sending bad signals about recursion.
He agreed that recursion usually is not a problem from
a technical standpoint but pointed out a social
problem (paraphrased):
I have one comment about the use of recursion in
safety-critical code, though: it is potentially
brittle with respect to changes made by someone
not familiar with that piece of code, and brittle
in a way that makes breaking the code difficult to
detect. I'm thinking of two cases here: (1) a
maintainer unwittingly modifies the code in a way
that prevents the compiler from making the formerly
possible tail-call optimization and (2) the
organization moves to a compiler that doesn't
support tail-call optimization from one that did.
Edward then explained how hard it is to warn the
programmers that they have just made changes to the
code that invalidate essential preconditions. This
seems like a good place to comment the code, but we
can't rely on programmers paying attention to such
comments, even that the comments will accompany the
code forever. The compiler may not warn us, and it
may be hard to write test cases that reliably fail
when the optimization is missed. Scala's
@tailrec annotation
is a great tool to have in this situation!
"Ideally," he writes, "these problems would be things
a good organization could deal with." Unfortunately,
I'm guessing that most enterprise computing shops are
probably not well equipped to handle them gracefully,
either by personnel or process. Coffin closes with
a pragmatic insight (again, paraphrased):
... it is quite possible that [such organizations] are
making the right judgement by forbidding it, considering
their own skill levels. However, they may be using the
wrong rationale -- "We won't do this because it is
generally a bad idea." -- instead of the more
accurate "We won't do this because we aren't
capable of doing it properly."
Good point. I don't suppose it's reasonable for me or
anyone to expect people in software shops to say that.
Maybe the rise of languages such and Scala and Clojure
will help both industry and academia improve the level
of developers' ability to work with functional
programming issues. That might allow more organizations
to use a good technical solution when it is suitable.
That's one of the reasons I still believe that CS
educators should take care to give students a balanced
view of recursive programming. Industry is beginning
to demand it. Besides, you never know when a young
person will
get excited about a problem
whose solution feels so right as a recursion and set
off to write a program to grow his excitement. We
also want our graduates to be able to create solutions
to hard problems that leverage the power of recursion.
We need for students to grok the Big Idea of recursion
as a means for decomposing problems and composing
systems. The founding of Google offers an instructive
example of using inductive definition recursion, as
discussed in this
Scientific American article on web science:
[Page and Brin's] big insight was that the importance
of a page -- how relevant it is -- was best understood
in terms of the number and importance of the pages
linking to it. The difficulty was that part of this
definition is recursive: the importance of a page is
determined by the importance of the pages linking to
it, whose importance is determined by the importance
of the pages linking to them. [They] figured out an
elegant mathematical way to represent that property
and developed an algorithm they called PageRank to
exploit the recursiveness, thus returning pages ranked
from most relevant to least.
Much like my Elo ratings program that used successive
approximation, PageRank may be implemented in some
other way, but it began as a recursive idea. Students
aren't likely to have big recursive ideas if we spend
years giving them the impression it is an esoteric
technique best reserved for their theory courses.
So, yea! for Scala, Clojure, and all the other languages
that are making recursion respectable in practice.
This morning,
Mike Feathers tweeted
a link to an old article by Donald Norman,
Simplicity Is Highly Overrated
and mentioned that he disagrees with Norman. Many
software folks disagreed with Norman when he first
wrote the piece, too. We in software, often being
both designers and users, have learned to appreciate
simplicity, both functionally and aesthetically.
And, as
Kent Beck suggested,
products such as the iPod are evidence contrary
to the claim that people prefer the appearance of
complexity. Norman offered examples in support
of his position, too, of course, and claimed that
he has observed them over many years and in many
cultures.
This seems like a really interesting area for
study. Do people really prefer the appearance of
complexity as a proxy for functionality? Is the
iPod an exception, and if so why? Are software
developers different from the more general
population when it comes to matters of function,
simplicity, and use?
When answering these questions, I am leery of
relying on self-inspection and anecdote. Norman
said it nicely in the addendum to his article:
Logic and reason, I have to keep explaining, are
wonderful virtues, but they are irrelevant in
describing human behavior.
He calls this the Engineer's Fallacy. I'm glad
Norman also mentions economists, because much of
the economic theory that drives our world was
creating from deep analytic thought, often
well-intentioned but usually without much
evidence to support it, if any at all. Many
economists themselves recognize this problem,
as in this
familiar quote:
If economists wished to study the horse, they
wouldn't go and look at horses. They'd sit
in their studies and say to themselves, "What
would I do if I were a horse?"
This is a human affliction, not just a weakness
of engineers and economists. Many academics
accepted the
Sapir-Whorf Hypothesis,
which conjectures that our language restricts
how we think, despite little empirical support
for a claim so strong. The hypothesis affected
in disciplines such as psychology, anthropology,
and education, as well as linguistics itself.
Fortunately, others subjected the hypothesis to
study and found it lacking.
For a while, it was fashionable to dismiss
Sapir-Whorf. Now, as a
recent New York Times article
reports, researchers have begun to demonstrate
subtler and more interesting ways in which the
language we speaks shapes how we think. The new
theories follow from empirical data. I feel a
lot more confident in believing the new theories,
because we have derived them from more reliable
data than we ever had for the older, stronger
claim.
(If you read the Times article, you will see that
Whorf was an engineer, so maybe the tendency to
develop theories from logical analysis and sparse
data really is more prominent in those of us
trained in the creation of artifacts to solve
problems...)
We see the same tendencies in software design. One
of the things I find attractive about the agile
world is its predisposition toward empiricism.
Just yesterday Jason Gorman posted a great example,
Reused Abstractions Principle.
For me, software abstractions that we discover
empirically have a head-start toward confident
believability on the ones we design aforethought.
We have seen them instantiated in actual code.
Even more, we have seen them twice, so they have
already been reused -- in advance of creating the
abstraction.
Given how frequently even domain experts are wrong
in their forecasts of the future and their theorizing
about the world, how frequently we are all betrayed
by our biases and other subconscious tendencies, I
prefer when we have reliable data to support claims
about human preferences and human behavior. A flip
but too often true way to say "design aforethought"
is "make up".
Someone tweeted recently about a
recent interview with Fred Brooks
in Wired magazine. Brooks is one of
the giants of our field, so I went straight to
the page. I knew that I wanted to write something
about the interview as soon as I saw this exchange,
which followed up questions about how a 1940s
North Carolina schoolboy ended up working with
computers:
Wired: When you finally got your hands on a
computer in the 1950s, what did you do with it?
Brooks: In our first year of graduate school,
a friend and I wrote a program to compose tunes.
The only large sample of tunes we had access to was
hymns, so we started generating common-meter hymns.
They were good enough that we could have palmed them
off to any choir.
It never surprises me when I learn that programmers
and computer scientists are first drawn to software
by a desire to implement creative and intelligent
tasks. Brooks was first drawn to computers by a
desire to automatic data retrieval, which at the
time must have seemed almost as fantastic as
composing music. In an Communications of the
ACM interview printed sometime last year, Ed
Feigenbaum called AI the "manifest destiny" of
computer science. I often think he is right. (I
hope to write about that interview soon, too.)
But that's not the only great passage in Brooks's
short interview. Consider:
Wired: You say that the Job Control Language
you developed for the IBM 360 OS was "the worst
computer programming language ever devised by
anybody, anywhere." Have you always been so frank
with yourself?
Brooks: You can learn more from failure than
success. In failure you're forced to find out what
part did not work. But in success you can believe
everything you did was great, when in fact some
parts may not have worked at all. Failure forces
you to face reality.
As an undergrad, I took a two-course sequence in
assembly language programming and JCL on an old
IBM 370 system. I don't know how much the
JCL
on that machine had advanced beyond Brooks's worst
computer programming language ever devised, if it
had at all. But I do know that the JCL course
gave me a
negative-split learning experience
unlike any I had ever had before or have had since.
As difficult as that was, I will be forever grateful
for Dr. William Brown, a veteran of the IBM 360/370
world, and what he taught me that year.
There are at least two more quotables from Brooks
that are worth hanging on my door some day:
Great design does not come from great processes;
it comes from great designers.
Hey to Steve Jobs.
The insight most likely to improve my own work
came next:
The critical thing about the design process is
to identify your scarcest resource.
This one line will keep me on my toes for many
projects to come.
If great design comes from great designers, then
how can the rest of us work toward the goal of
becoming a great designer, or at least a better
one?
Design, design, and design; and seek knowledgeable
criticism.
Practice, practice, practice.
But that probably won't be enough. Seek out
criticism from thoughtful programmers, designers,
and users. Listen to what they have to say, and
use it to improve your practice.
A good start might be to read this interview and
Brooks's books.
Thinking about Software Development and My Compilers Course
Our semester is underway. I've had the pleasure of
meeting my compilers course twice and am looking
forward to diving into some code next week. As I
read these days, I am keenly watching for things I
can bring into our project, both the content of
defining and interpreting language and the process
of student teams writing a compiler. Of course, I
end up imposing this viewpoint on whatever I read!
Lately, I've been seeing a lot that makes me think
about the development process for the semester.
Greg Wilson recently posted three rules for
for supervising student programming projects.
I think these rules are just as useful for the
students as they work on their projects. In a
big project course, students need to think
about time, technology, and team interaction
realistically in a way they. I especially like
the rule, "Steady beats smart every time". It
gives students hope when things get tough, even
if they are smart. More importantly, it encourages
them to start and to keep moving. That's
the best way to make progress, no matter smart
you are. (I
gave similar advice
during my last offering of compilers.) My most
successful project teams in both the compilers
course and in our Intelligent Systems course
were the once who humbly kept working, one shovel
of dirt at a time.
I'd love to help my compiler students develop in
an agile way, to the extent they are comfortable.
Of course, we don't have time for a
full agile development course
while learning the intricacies of language
translation. In most of our project courses,
we teach some project management along side the
course content. This means devoting a relatively
small amount of time to team and management
functions. So I will have to stick to the
essential core of agile: short iterations
plus continuous feedback. As
Hugh Beyer writes:
Everything else is there to make that core work
better, faster, or in a more organized way. Throw
away everything else if you must but don't trade
off this core.
For the last couple of weeks, I have been thinking
about ways to decompose the traditional stages of
the compiler project (scanning, parsing, semantic
analysis, and code generation) into shorter
iterations. We can certainly implement the parser
in two steps, first writing code to recognize legal
programs and then adding code to produce abstract
syntax. The students in my most recent offering
of the compilers course also suggested splitting
the code generation phase of the project into two
parts, one for implementing the run-time system
and one for producing target code. I like this
idea, but we will have to come up with ways to
test the separate pieces and get feedback from
the earlier piece of our code.
Another way we can increase feedback is to do more
in-class code reviews of the students' compilers
as they write them. A student from the same
previous course offering wrote to me only yesterday,
in response to my article on
learning from projects in industry,
suggesting that reviews of student code would have
enhanced his project courses. Too often professors
show students only their own code, which has been
designed and implemented to be clean and easy to
understand. A lot of the most important learning
happens in working at the rough edges, encountering
problems that make things messy and solving them.
Other students' code has to confront and solve the
same problems, and reading that code and sharing
experiences is a great way to learn.
I'm a big fan of this idea, of course, and have
taught several of my courses using a studio style
in the past. Now I just need to find a way to
bring more of that style into my compilers course.
In the category
programming for all,
Paul Graham's latest essay explains his ideas
about
What Happened to Yahoo.
(Like the
classic Marvin Gaye album and song,
there is no question mark.) Most people may
not care about programming, but they ought to
care about programs. More and more, the success
of an organization depends on software.
Which companies are "in the software business"
in this respect? ... The answer is: any
company that needs to have good software.
If this was such a blind spot for an Internet
juggernaut like Yahoo, imagine how big a
surprise it must be for everyone else.
If you employ programmers, you may be tempted
to stay within your comfort zone and treat
your tech group just like the rest of the
organization. That may not work very well.
Programmers are a different breed, especially
great programmers. And if you are in the
software business, you want good programmers.
Hacker culture often seems kind of irresponsible.
... But there are worse things than seeming
irresponsible. Losing, for example.
Again: If this was such a blind spot for an
Internet juggernaut like Yahoo, imagine how
big an adjustment it would be for everyone
else.
I'm in a day-long retreat with my fellow
department heads in the arts and sciences, and
it's surprising how often software has come up
in our discussions. This is especially true
in recruitment and external engagement, where
consistent communication is so important. It
turns out the university is in the software
business. Unfortunately, the university
doesn't quite get that.
"Write a test first." But unit tests are low priority.
The business wants high priority items first.
When I asked, "Is correct code a high priority?", he
rephrased my question as, "Is proof of correct code a
high priority?"
I knew what he meant and so dropped the exchange, sad
that companies still settle for code without tests in
the name of expediency. I try not to be dogmatic
about writing tests with code, let alone driving the
design with tests, and know there are times when not
writing tests, at least now, feels okay.
But then it occurred to me. When I write tests, the
tests aren't really for "them", whoever "them" might
be: my bosses, my colleagues, or my users. My best
test suites are the ones I write for myself. They
are a part of how I write code.
When I'm not doing TDD and not writings tests in
parallel with my code -- when not writing tests feels
okay -- I am almost always not writing interesting
code. Perhaps I know the domain so well that I can
write the code with my eyes closed. Perhaps the
domain does not engage me enough that I care to get
into the deep flow that comes with testing, growing,
and refactoring my program. If the task is dull or
routine, then tests seem unnecessary, a drag.
(Perhaps, though, I especially need to write tests
in these situations, to guard against producing bad
code as a result of complacency and boredom!)
When I am writing code I enjoy, the tests are
for me. Saying to me, "Don't
take time to write tests" is like telling me not to
use version control. It's like saying to me,
"Don't take time to format your code
properly" or "Don't bother naming your
variables properly". Not writing tests seems
foreign. Not writing tests is an impediment to
writing code at all.
It's really not a matter of "taking time to write
a test first". I write tests because that's how
I write code.
Agile Moments: Metaphor as Practice, Metaphors for Practices
In the last few weeks, I've seen a few interesting metaphors
related to agile development. Surprisingly, one of them
was actually a metaphor, XP-style.
The Mute Button
Like many newcomers to XP, my students tend not to get the
reason that "metaphor" was one of the original XP practices.
I try to give examples that I've seen, but my set of examples
is too small. That's one reason I was excited when some
agile practitioners in industry created a
new discussion list on metaphor in software.
Joshua Kerievsky posted a link to a blog entry he had
written about
two metaphors that have helped him recently.
In one case, his company has started using the idea of a
playlist for the products it sells, instead a book. In the
other, which is the main theme of his entry, he extrapolates
from the presence of a "mute" feature in the Twitter client
Twittelator to a riff on thinking about Twitter as if it
were television. There are some interesting similarities,
as well as interesting differences. But it's a good example
of how a salient metaphor can be a source of common experience
for guiding the design of a software system.
Refactoring "Technical Debt"
A few months back, I wrote an
entry on technical debt,
suggesting that some technical debt might be okay to carry,
so long as we incur it for investment, not consumption.
Not everyone believes this, of course. I've been heartened
by Kent Beck's writing over the last couple of years about
his own questioning of when we might break our own rules,
at least the rules as they have been calcified over time
or hardened against the challenges of skeptical audiences.
Last month, Steve Freeman proposed a new picture of bad
code:
it isn't technical debt; it's an unhedged call option.
This metaphor highlights the risk we run when we allow
bad code to remain in the build. My metaphor's willingness
to carry debt for investment implies a risk, too, because
some investments fail deliver as hoped. Freeman's metaphor
raises this risk to a more dangerous level. I like his
story and think it applies quite nicely in many contexts.
Still, I'm willing to accept lower quality code in trade
for something of greater value now -- as long as I keep my
eye on the balance sheet and remain vigilant about the debt
load I carry. If the load begins to creep higher, or if I
begin to spend too many resources servicing the debt, then
I want to clean the code up right now. The cost of the debt
has risen above the value of the investment it bought me.
One of the nice things about software is that we can make
changes to improve its structure, if we are willing to
spend the time doing so.
What is Refactoring?
Finally, here is a metaphor you can use to explain
refactoring to people who don't get it yet:
refactoring is a time machine.
I'll be smarter tomorrow, more experienced, better informed
about what the system I am building today should look like.
That is when I should hop in the time machine and make my
code look the way it ought, given what I know then.
Boy, that take's a lot of pressure off trying to fake the
perfect design today, when I don't know yet what it is.
(If I could travel in a blogging time machine, I might go
back to
last Friday,
unmention the Kent Beck failing today, and find a way to use
for the first time here!)
Agile Moments: Values and Integrity Come Before Practices
As important as the technical practices of the agile
software developer are, it is good to keep in mind
that they are a means to an end. Jeff Langr and Tim
Ottinger do a great job of summarizing the
characteristics of agile development teams
and reminding us that they are not specific practices.
Ottinger boiled it down to a simple phrase in a recent
discussion of this piece on the XP mailing list: "...
start with the values."
Later in the same thread, Langr commented on what made
teaching XP practices so frustrating:
... I am very happy now to be developing in a team doing
TDD, and to not be debating daily with apathetic and/or
duplicitous people who want to make excuses. You're
right, you can reach the lazier folks, given enough
time.... It's the sly ones who spent more time crafting
excuses, instead of earnestly trying to learn, who drove
me nuts.
Few people can learn something entirely new to them
without making a good-faith effort. When someone
pretends to make a good-faith effort but then schemes
not to learn, everyone's time is wasted -- and a lot
of the coach's or teacher's limited energy, too. I have
been fortunate in my years teaching CS to encounter
very few students who behave this way. Most do make
an effort to learn, and their struggles are signs that
I need to try something different. And every once in
a while I run into into is honest and says outright,
"I'm not going to do that." This lets us both move
straight on to more productive uses of our time.
If the smart thing to do doesn't scale, maybe we
shouldn't scale.
His entry is in part about values. When someone says
that we can't treat people well "because that doesn't
scale", they are doing what many managerial strategies
and software development processes do to people. It
also reminds me of why many in the agile development
community favor small teams. Not everything that we
value scales, and we value those things enough that
we are willing to look for ways to work "small".
I just learned that the
Computer History Museum
has worked with Apple Computer to make
source code for MacPaint and QuickDraw
available to the public. Both were written by Bill
Atkinson for the original Mac, drawing on his earlier
work for the Lisa. MacPaint was the iconic drawing
program of the 1980s. The utility and quality of
this one program played a big role in the success of
the Mac. Andy Hertzfeld, another Apple pioneer,
credited QuickDraw for the success of the Mac for
its speed at producing the novel interface that
defined the machine to the public. These programs
were engineering accomplishments of a different time:
MacPaint was finished in October 1983. It coexisted in
only 128K of memory with QuickDraw and portions of the
operating system, and ran on an 8 Mhz processor that
didn't have floating-point operations. Even with those
meager resources, MacPaint provided a level of performance
and function that established a new standard for personal
computers.
Though I came to Macs in 1988 or so, I was never much of
a MacPaint user, but I was aware of the program through
friends who showed me works they created using it. Now
we can look under the hood to see how the program did
what it did. Atkinson implemented MacPaint in one
5,822-line Pascal program and four assembly language
files for the Motorola 6800 totaling 3,583 lines.
QuickDraw consists of 17,101 lines of Motorola 6800
assembly in thirty-seven modules.
I speak Pascal fluently and am eager to dig into the main
MacPaint program. What patterns will I recognize? What
design features will surprise me, and teach me something
new? Atkinson is a master programmer, and I'm sure to
learn plenty from him. He was working in an environment
that so constrained his code's size that he had to do
things differently than I ever think about programming.
This passage from the Computer History Museum piece
shares a humorous story that highlights how Atkinson
spent much of his time tightening up his code:
When the Lisa team was pushing to finalize their software
in 1982, project managers started requiring programmers
to submit weekly forms reporting on the number of lines
of code they had written. Bill Atkinson thought that was
silly. For the week in which he had rewritten QuickDraw's
region calculation routines to be six times faster and
2000 lines shorter, he put "-2000" on the form. After a
few more weeks the managers stopped asking him to fill
out the form, and he gladly complied.
I don't know assembly language nearly as well as I know
Pascal, let alone Motorola 6800 assembly, but I am
intrigued by the idea of being able to study more than
20,000 lines of assembly language that work together on
a common task and which also exposes a library API for
other graphics programs. Sounds like great material for
a student research project, or five...
I am a programmer, and I love to study code. Some
people ask why anyone would want to read listings of
any program, let alone a dated graphics program from
more than twenty-five years ago. If you use software
but don't write it, then you probably have no reason
to look under this hood. But keep in mind that I
study how computation works and how it solves problems
in a given context, especially when it has limited
access to time, space, or both.
But... People write programs. Don't we already know
how they work? Isn't that what we teach CS students,
at least ones in practical undergrad departments? Well,
yes and no. Scientists from other disciplines often
ask this question, not as a question but as an
implication that CS is not science. I have written on
this topic before, including
this entry about computation in nature.
But studying even human-made computation is a valuable
activity. Building large systems and building tightly
resource-constrained programs are still black arts.
Many programmers could write a program with the
functionality of MacPaint these days, but only a few
could write a program that offers such functionality
under similar resource limitations. That's true even
today, more than two decades after Atkinson and others
of his era wrote programs like this one. Knowledge and
expertise matter, and most of it is hidden away in code
that most of us never get to see. Many of the techniques
used by masters are documented either not well or not at
all. One of the goals of the software patterns community
is to document techniques and the design knowledge needed
to use them effectively. And one of the great services
of the free and open-source software communities is to
make programs and their source code accessible to everyone,
so that great ideas are available to anyone willing to
work to find them -- by reading code.
Historically, engineering has almost always run ahead
of science. Software scientists study source code in
order to understand how and why a program works, in a
qualitatively different way than is possible by
studying a program from the outside. By doing so, we
learn about both engineering (how to make software)
and science (the abstractions that explain how software
works). Whether CS is a "natural" science or not, it
is science, and source code embodies what it studies.
For me, encountering the release of source code for
programs such as MacPaint feels something like a
biologist discovering a new species. It is exciting,
and an invitation to do new work.
Update: This is worth an update: a portrait
of Bill Atkinson
created in MacPaint.
Well done.
While reading the July/August 2010 issue of
Running Times,
I ran across an article called "Why Form Matters"
that struck me as just as useful for programmers as
runners. Unfortunately, the new issue has not been
posted on-line yet, so I can't link to the article.
Perhaps I can make some of the connections for you.
For runners, form is the way our body works when we
run: the way we hold our heads and arms; the way our
feet strike the ground; the length and timing of our
strides. For programmers, I am thinking of what we
often call 'process', but also the smaller habitual
practices we follow when we code, from how we engage
a new feature to how and when we test our code, to
how we manage our code repository. Like running,
the act of programming is full of little features
that just happen when we work. That is form.
The article opened with a story about a coach trying
to fix Bill Rodgers' running form at a time when he
was the best marathoner in the world. The result
was surprising: textbook form, but lower efficiency.
Rodgers changed his form to something better and
became a worse runner.
Some runners take this to mean, "Don't fix what works.
My form works for me, however bad it is." I always
chuckle when I hear this and think, "When you are the
best marathoner in the world, let's talk. Until then,
you might want to consider ways that you can get
better." And you can be sure that Bill Rodgers was
always looking for ways that you can get better.
There are a lot of programmers who resist changing
style or form because, hey, what I do works for me.
But just as all top running coaches ask their pupils
-- even the best runners -- work on their form, all
programmers should work on their form, the practices
they use in the moment-to-moment activity of writing
code. Running form is sub-conscious, but so is the
part of our programming practice that has the biggest
effect on our productivity. These are the habits and
the
default answers
that pop into our head as we work.
If you buy this connection between running form and
programming practice, then there is a lot for
programmers to learn from this article. First, what
of that experiment with Bill Rodgers?
No reputable source claims that, at any one instant,
significantly altering your form from what your body
is used to will make you faster.
If you decide to try out a new set of practices, say,
to go agile and practice XP, you probably won't be
faster at the end of the day. New habits
take time.
The body and mind require practice and acclimation.
When we work in teams to build software, we have to
go through a process of acculturation. Time.
But that doesn't mean ... that the form your body
naturally gravitates toward is what will make you
fastest.
There are many reasons that you may have fallen into
the practices you use now. The courses and instructors
you had in school, the language(s) you learned first,
and the programming culture cut your professional teeth
in all lead you in a particular direction. You will
naturally try to get better within the context of
these influences.
Even when you have been working to get better, you may
(in AI terms) reach a local max biased by the initial
conditions on the search. So:
"... there is a difference between doing something
reasonably well and maximizing performance."
Sometimes, we need a change in kind rather than yet
another change in degree.
Nor does it mean that your "natural" form is in your
best long-term interest.
Initial conditions really do have a huge effect on how
we develop as runners. When we start running, our
muscles are weak and we have little stamina. This
affects our initial running form, which we then rehearse
slowly over many months as we become better runners.
The result is often that we now have stronger muscles,
more stamina, and bad form!
The same is true for programmers, both solo and in teams.
If we are bad at testing and refactoring when we start,
we develop our programming skills and get better while
not testing and refactoring. What we practice is what
we become.
Now, consider this cruel irony faced by runners:
"This belief system that just doing it over and over
is somehow going to make us better is really crazy.
Longtime runners actually suffer from the body's
ability to become efficient. You become so efficient
that you start recruiting fewer muscle fibers to do
the same exercise, and as you begin using [fewer]
muscle fibers you start to get a little bit weaker.
Over time, that can become significant. Once you've
stopped recruiting as many fibers you start exerting
too much pressure on the fibers you are recruiting to
perform the same action. And then you start getting
muscle imbalance injuries...."
We programmers may not have to worry about muscle
imbalance injuries, but we can find ourselves putting
all of our emphasis on our mastery of a small set of
coding skills, which then become responsible for all
facets of quality in the software we produce. There
may be no checks and balances, no practices that help
reinforce the quality we are trying to wring out of
our coding skills.
How do runners break out of this rut, which is the
result of locally maximizing performance? They do
something wildly different. Elites might start racing
at a different distance or even move to the mountains,
where they can run on hills and at altitude. We
duffers can also try a race at a new distances, which
will encourage us to train differently. Or we might
simply change our training regimen: add a track workout
once a week, or join a running group that will challenge
us in new ways.
Sometimes we just need a change, something new that will
jolt us out our equilibrium and stress our system in new
way. Programmers can do this, too, whether it's by
learning a new language every year or by giving a whole
new style a try.
"Running is the one sport where people think, 'I don't
have to worry about my technique. ...' We also have a
sport where people don't listen to what the top people
are doing. ..."
... I can't think of one top runner in the last two
decades who hasn't worked on form, either directly
through technique drills, indirectly through strength
work or simply by being mindful of it while running.
The best runners work on their form. So do the best
programmers. You and I should, too. Of course,
It's important when discussing running form to
remember that there's no "perfect" form that we
should all aspire to.
Even though I'm a big fan of XP and other approaches,
I know that there are almost as many reliable ways to
deliver great software as there are programmers. The
key for all of us is to keep getting better -- not just
strengthening our strengths, which can lead to the irony
of overtraining, but also finding our weaknesses and
building up those muscles. If you tend toward domains
and practices where up-front plans work best for you,
great. Just don't forget to work on practices that can
make you better. And, every once in a while, try
something crazy new. You never know where that might
lead you.
"... if I went out and said we're going to do
functional testing on a set of people, you're going to
find weaknesses in every single one of them. The body
has adapted to who you are, but has the body adapted to
the best possible thing you can offer it? No."
Runners owe it to their bodies to try to offer them the
best form possible. Programmers owe it to themselves,
their employers, and their customers to try to find the
best techniques and process for writing code. Sometimes,
that requires a little hill climbing in the search,
jumping off into some foreign territory and seeing how
much better we can get form there. For runners, this may
literally be hill climbing!
After the opening of the Running Times article,
it turned to discussion of problems and techniques very
specific to running. Even I didn't want to overburden my
analogy by trying to connect those passages to software
development. But then the article ended with a last bit
of motivation for skeptical runners, and I think it's
perfect for skeptical programmers, too:
If you're thinking, "That's all well and good for
college runners and pros who have all day for their
running, but I have only an hour a day total for my
running, so I'm better off spending that time just
getting in the miles," [Pete] Magill has an answer for
you.
"... if you have only an hour a day to devote to your
running, the first thing you've got to do is learn to
run. If you bring bad form into your running, all
you're going to be doing for that hour a day is
reinforcing bad form. ..."
"A lot of people waste far more time being injured from
running with muscle imbalances and poorly developed form
than they do spending time doing drills or exercises or
short hills or setting aside a short period each week to
work on form itself."
Sure, practicing and working to get better is hard and
takes time. But what is the alternative? Think about
all, the years, days, and minutes you spend making
software. If you do it poorly -- or even well, but
less efficiently than you might -- how much time are you
wasting? Practice is an investment, not a consumable.
We programmers are not limited to improving our form by
practicing off-line. We can also change what we do
on-line: we can write a test, take a short step, and
refactor. We can speed up the cycle between requirement
and running code, learn from the feedback we get -- and
get better at the same time.
The next time you are writing code, think about your
form. Surprise yourself.
Learning to do test-driven design requires a big
shift in mindset for many developers. I was
impressed with how well the students in my recent
agile development course took to the idea of
writing tests first. Even the most skeptical
students seemed willing to go along with the
group in using tests to specify the code they
needed to write. Other agile practices, such as
pair programming and communal development,
helped to support all of the students, willing
or skeptical, to move in the right direction.
Rather than frame the testing challenge with the
default being the old way of not testing:
Write a test when it makes sense.
Change your perspective to the default being to test:
Write a test unless you can explain
why you did not.
I like how Steve shifts the focus onto default
actions. The actions we take by default arise
when our mental habits come into contact with
the world. Some of my students prefer to talk
about their "instincts", but the principle is the
same: When things get hard -- or easy -- what
will you do?
We can change our habits. We can
develop our instincts.
Yes, it is hard to do. However we make the
change, we have to change the individual actions
we take at each moment of choice.
The way to turn running into a habit is to run.
When I have a run planned for a morning but wake
up feeling rotten, my default has to be to run.
I need to have a really good reason not
to run, a reason I am willing to tell my family
and running friends without shame. This is
another example of using positive peer pressure
to help myself act in a desired way.
There are good reasons not to run some days.
However, when I am creating a new habit, I have
to place the burden of proof on the old habit:
Why not?
When I follow this discipline, there is a risk
of overusing the technique I am learning. If
my default answer is to
just keep running,
I will run on some mornings when I really should
take a break. I may find out during the run,
in which case I need to
listen to my body
immediately and adapt. Or I may find out later,
when I see that my times from the workout were
substandard or when I am sore or fatigued beyond
reason later in the day. Whenever I recognize
the problem, I can examine the outcome and try
to learn the reason why I should not have run.
This will allow me to make a sound exception to
my default in the future.
The same risk comes when we try this technique
while learning test-driven design or any new
programming practice. I may write a test I
don't have to write. I may write code that is
too simple. I may
need it after all.
This risk is an integral part of learning. I
must learn when not to do something just as much
as I need to learn when to do it. The risk of
running when I ought not run carries a greater
potential cost than writing a test when I need
not write, because physical injury may result.
The only real cost of writing an unnecessary test
or taking too small a step forward in my code is
the time lost.
As a runner, the way I minimize the risk of
injury or other significant cost I have to
listen to my body. As a programmer, I still
also have to
listen to my code,
and keep it clean through refactoring. Done
steadily and faithfully, the side effect is a
new habit, better instincts.
The key to Steve's suggestion is that changing
practice isn't just about habit and instinct,
as important as they are. It's also about
attitude. There are times when my
surface attitude is compliant with
a picking up a new practice, but my
ingrained attitude gets in the way.
My conscious mind may say, "I want to learn
how to do TDD", while subconsciously I react
as if "I don't need to write a test here".
Taking the initiative to change my default
action consciously helps me to bridge the
gap. I think that's why I find Steve's idea
so helpful.
The conventional wisdom has it that when a program
intended for multiple users is to be written,
specifications should be designed in advance. It this
is not done, the result will be inferior. The place
to try anything new is in a research project which
users will not see.
Some people know better than this, but they have been
silenced.
If only it were so. The section explains why
incremental design was essential to the creation of
Emacs:
EMACS could not have been reached by a process of
careful design, because such processes arrive only
at goals which are visible at the outset, and whose
desirability is established on the bottom line at
the outset. Neither I nor anyone else visualized
an extensible editor until I had made one, nor
appreciated its value until he had experienced it.
EMACS exists because I felt free to make individually
useful small improvements on a path whose end was
not in sight.
Agile development teams also like to learn from
the act of creating software, allowing goals for
the software to emerge as the software grows and
allowing the value of features to be assessed in
the context of the overall system.
Of course, design still mattered to Stallman and
the other developers of Emacs:
While there was no overall goal, each small change
had a specific purpose in terms of improving the
text editor in general use, and each step had to be
individually well designed and reliable.
The resulting design was, according to Hal Ableson
(quoted
here),
good enough to support a new kind of software
development community: "Its structure was robust
enough that you'd have people all over the world
who were loosely collaborating [and] contributing
to it. I don't know if that had been done before."
Agile teams use test-driven design, refactoring,
and metaphor to keep the quality of their designs
on track. Like the Emacs project, agile projects
take advantage of real users to keep the usability
of their systems on track.
Raymond talks about the value of experimentation
in writing new software, relegating upfront design
to implementing new versions of existing features.
These new implementations can take "advantage of
hindsight". I'm often pleasantly reminded just
how often an experimental mindset can benefit me
as a software developer, even when implementing
systems in domains where I have some experience.
YAGNI and "scratch your own itch" don't just keep
code clean, elegant, and succinct, they also keep
it honest. The worst code you will ever
encounter in your career will contain program
logic which does something completely different
than it claims to, either in its comments or its
method, variable, and object names. Programmers
spend more time talking about good and evil than
priests or preachers do. The reason is simple:
bad code is nothing but lies.
I think beginning programmers don't often realize
how many different ways that code can lie to us.
Moreover, their lack of experience building large
programs and living with programs over time
usually means that they have no clue at all why
this matters, or how important it is.
I am also surprised that so many experienced
programmers seem not to grok this yet, especially
the role played by doing the simplest thing you
can to implement a feature. YAGNI helps us to
write more honest code because it helps us to be
more honest to ourselves.
Last time
I mentioned that students in my agile software
development course found several of the reading
assignments to be valuable. For what it's worth,
here is at least a relatively complete list of
the readings I assigned in the course of four
weeks, in no particular order.
Chapters 1-2 from Robert Martin's "Agile Software
Development", given as a handout
Chapter 3 from Fowler's "Refactoring", which is
a short example of refactoring a piece of Java
code, also given as a handout
When I still thought we might use a distributed version
control system, I asked students to read
Hg Init
and then a few items on git, including
Git for the Lazy,
the official
git tutorial man page,
and
Everyday Git.
Then, when I decided to show discretion in at least
one part of the project and use centralized version
control, I asked the class to read several items on
Subversion
I'm under no illusion that every student read every page
of every reading. This is an ambitious list for agile
beginners to tackle in four weeks while also working on
a big project. Still, it's clear from discussion that
many students read a lot of this material, had questions,
and even had comments for me.
As always, I'd love to
hear from you
any comments you have about this list, or any additions
you can suggest for future offerings.
Today I finished reviewing materials from my
agile software development course
so that I could assign final grades. The last thing
that students wrote for me was a short evaluation of
the course and some of the things we did. Their
comments are definitely valuable to me as I think
about offering the course again.
What worked best this semester? I was surprised
that the class was nearly unanimous in saying pair
programming. Their reasons were varied but
consistent. By pairing, they faced less down time
because one of the two developers usually had an idea
for how to proceed. Talking about the roadblock helped
them get around it. Several students commented that
programming was more fun when working with someone.
One student said that he "learned how to explain things
better". I imagine that part of this was that, as the
team came to build up trust and respect for each other,
he wanted to be more patient and helpful when responding
to questions. Another part was probably simply practice;
pair programming increases communication bandwidth.
The students who did not answer "pair programming" said
"learning Ruby". I was hopeful that students would
enjoy Ruby and pick it up quickly. But my hope was
not grounded in much empirical evidence, so I was a
little worried. The language was no worse than a
break even proposition for some students, and it was
a big win for most. And as a result I
had more fun!
I asked students, Who were the best partners you
worked with? The best part of these answers is
that they were not dominated by a few names, as I
thought they might be. There was a pretty good
spread of names listed, with only a couple of
students mentioned repeatedly. I take this to mean
that many students contributed relatively well to
the experience of their teammates, which is the sort
of horizontal distribution of knowledge that is
desired for XP teams. I did note an interesting
distinction made by one student between the
partner I learned the most from and the
partner with whom I felt the most productive.
Which of the assigned readings was most valuable?
I include a list of most of the readings I assigned
over the course of the four weeks. Of those, two
were identified most frequently by students as being
valuable: Bill Wake's
The Test-First Stoplight,
which was assigned early in the semester to give
students a sense of the rhythm of test-driven design
before diving in as a team, and
What is Software Design?
by Jack Reeves, which was assigned late in the
semester after the team had worked collaboratively
for a couple of weeks on a system that had no upfront
design and very little documentation. In class
discussion, a couple of students disagreed with a
few of Reeves's points, but even in those cases
the paper engaged and challenged the reader. That's
about all I can ask from a paper.
When asked, What did you learn best in the
courses?, the answers fell into roughly two
groups: TDD and the value of tests and
Ruby and OOP. The flip side is that many
students also said, "I wish I could have learned
more!" Again, that's about all I can ask from any
course, that it leave students both happy to have
learned something and eager to learn more.
I don't mind that Ruby and object-oriented programming
were the prized learning outcomes of a course on agile
software development. A couple of times during the
course I noted that a good project course is by its
nature about everything. We can design courses in
neat little bundles, but the work of making anything
-- and perhaps especially software -- is a tangled
weave of knowledge and discipline and habit that comes
together in the act of creating something real. If
Ruby and OOP were what some students most needed to
learn in May, I'm glad that's what they learned. I
will trust that the agile ideas will take root when
they are most Needed.
How could I improve the course? This is
always a tough question to ask students in an named
setting, because no matter how much they might trust
me I know that some will be reluctant to say what
they really think. Still, I received some answers
that will help me design the next iteration of this
course. Several times expressed a desire for more
time -- to write tests, to pair program, to work
on the system outside of class, to practice
refactoring, .... It seems that desire for more
time is a constant in human experience. (At least
they weren't so tired of the course that they all
said, "Good riddance!"!) Clearly, there is a trade-off
between a four-week semester focused on one course
and a fifteen-week semester given over to four or
five courses. The loss of absolute number of hours
available is a cost of the former. I'll have to
think about whether that cost is outweighed by its
benefits.
One of the more mature and experienced team members
offered an interesting comment: Having an instructor
who is a programmer act as client and explain the
project requirements to the developers affected a
lot of things. He wondered what it would be like
to have a non-technical client with the CS instructor
acting solely as agile coach. An insightful observation
and question!
All in all, this was valuable feedback. The students
came through again, as they did throughout the course.
Teaching a 3-credit semester course in one month feels
like running on a treadmill that speeds up every
morning but never stops. Then the course is over,
almost without warning. It reminds me a little bit of
how the Christmas season felt to me when I was a child.
(I should be honest with myself. That's still how the
Christmas season feels to me, because I am still a kid.)
I've blogged about the course only twice since we dove
head-long into software development, on
TDD and incremental design
and on the
rare pleasure of pair programming
with students. Today, we wrapped up the second of two
week-long iterations. Here are the numbers, after we
originally estimated 60 units of work for the ideal
week:
Iteration 1
Budgeted work for week: 30 units.
Actual work for week: 29.5 units.
Story points delivered: 24 units.
Iteration 2 (holiday-shortened)
Budgeted work: 16 units.
Actual work: 18 units.
Story points delivered: 11 units.
I was reasonably happy with the amount of software the
team was able to deliver, given all the factors at play,
among them never having done XP beyond single practices
in small exercises, never having worked together before,
learning a new programming language, work schedules
that hampered the developers' ability to pair program
outside our scheduled class time, and working a domain
far beyond most of their experiences.
And that doesn't even mention what was perhaps the team's
biggest obstacle: me. I had never coached an undergrad
team in such an intense, focused setting before. In
three weeks, I learned a lot about how to write better
stories for a student team and how to coach students
better when they ran into problems in the trenches. I
hope that I would do a much better job as coach if we
were to start working on a second release on Monday.
As my good friend
Joe Bergin
told me in e-mail today, "Just being agile."
We did short retrospectives at the end of both iterations,
with the second melting into a retrospective on the
project as a whole. In general, the students seemed
satisfied with the progress they made in each iteration,
even when they still felt uncomfortable with some of the
P practices (or remained downright skeptical). Most
thought that the foundation practices -- story selection,
pair programming, test-first programming, and continuous
integration -- worked well in both iterations.
When asked, "What could we improve?", many students gave
the same answers, because they recognized we were all
still learning. After the first iteration, several team
members were still uncomfortable with no
Big Design Up Front
(BDUF), and a couple thought that we might have avoided
needing to devote a day to refactoring if only we had
done more design at the beginning. I was skeptical,
though, and said so. If we had tried to design the system
at the beginning of the project, knowing what we knew
then, would we have had as good and as complete a
system as we had at the end of the iteration? No way.
We learned a lot building our first week's system, and
it prepared us for the design we did while refactoring.
I could be wrong, but I don't think so.
Most of the developers agreed that the team could be more
productive if they were not required to do all of their
programming in pairs. With a little guidance from me as
the coach, the team decided to loosen the restriction on
pairing as follows:
If a pair completes a story together, one member of
the pair was permitted to work alone to refactor the
code they worked on. Honor code: the solo programmer
would not create new code, only refactor, and the
solo programmer would not make changes to the code
that stayed very far from what the pair understood
while working together.
If a pair is nearly finished with a story, one member
of the pair was permitted to work alone to quickly
wrap up the story. Honor system: the programmer
would work for only 15-30 minutes alone; if it became
clear that the work remaining was more involved than
a quick wrap-up, the solo programmer stop immediately
and resume working with a partner at the next
opportunity.
A team member may experiment alone, doing a quick
spike in an effort to understand some part of the
system. Honor system: the solo programmer would
commit none of the spike's code; upon returning to
the studio, the developer would collaborate on an
equal basis within the pair, sharing what was learned
via the spike but not ramming it through to the
mainline system without agreement and understanding
from the partner.
At the next daily stand-up, any developer who had
worked solo since the previous class session would
explain all work done solo to the entire team.
After the second iteration, the team was happy with this
adaptation. Only three of the ten developers had worked
alone during the iteration, all doing work well within
the letter of the new rules and, even more important,
well within the spirit of the new rules, too. The rest
of the team was happy with the story wrap-up, the
refactoring, and the experimentation that had been done.
This seemed like a nice win for the group, as it was the
one chance to adapt the XP practices to its own needs,
and the modification worked well for them. Just being
agile!
As part of the course retrospective, I asked the students
whether they would have preferred working in a domain
they understood better, perhaps allowing them to focus
better on the new practices and new programming language.
Here are the notes I had made for myself before class,
to be shared after they had a chance to answer:
My thoughts on the domain:
I think it was essential that we work in a domain that
pushed you out of your comfort zone.
It is hard enough to break habits at all, let alone
working on problem you already understand well --
or think you do.
The benefits of agile approaches come in helping
the team to learn and to incorporate that learning
into the system.
Not knowing the domain forced you to ask lots of
questions. That's how real projects work. That's
also the best way to work on any system, even ones
you think you already understand.
There is a realness to reality. Choices matter.
When the user is a real person and is passionate
about the product, choices matter.
I was so impressed with the answers the students
gave. They covered nearly all of my points, sometimes
better than I did. One student identified the trade-off
between working in familiar and unfamiliar domains.
Another student pointed out that not knowing the domain
made the team slow down and think, which helped them
design better tests and code. Yet another remarked
that there probably was no domain that they all knew
equally well anyway. The comment that struck me as most
insightful was, roughly, "If we worked in a domain we
all understand, then we would probably all understand it
differently." That captures the problem of requirements
analysis as well as anything I've ever read in a software
engineering textbook.
It occurred to me while writing this that I should share
the list of readings I asked students to study. It's
nothing special, papers most people know about about,
but it might be a subset of all possible readings that
others might find useful. Sharing the list will also
make it possible for you to help me make the it better
for the next time I offer the course! I'll gather up
all of my links and post the list soon.
Sad to see May graduates in Computer Science applying
to do website design and updates. Seriously where did
the art of programming go?
The small and largely disconnected programming problems
that we assign students in most courses may engage some
students in the joy of programming, but I suspect that
these problems do not engage enough students deeply
enough. I remain convinced that courses like this one,
with a
real problem
explored more deeply and more broadly, with the student
developers more in control of what they do and how, is
one of the few things we can do in a traditional
university setting to help students grok what software
development is all about -- and why it can satisfy in
ways that other activities often cannot.
Next up on the teaching front: the compilers course.
But first, I turn my thoughts to sustainable pace and
look forward to breathing free for a few days.
When my student team began the second iteration of our
project this morning, one member had no partner. So
I jumped in to fill the void for half an hour or so.
When the missing student arrived, he joined us and
we worked as a trio.
What a treat! Most of the time, I code alone, and far
too often the only code I work closely with is code
I have written. Working with another programmer was
a lot of fun. We talked as we studied and tried our
ideas about how the code worked out on one another.
Studying someone's code added a second dimension to
the fun, because neither of us brought much experience
with this part of the system to our pairing session.
That meant real study, and real learning.
Our programming session reminded me just how valuable
tests can be. We bounced back and forth between the
class we needed to extend and its tests. We would
study the code, come up with an idea of how it
worked, and then inspected the tests to confirm or
disconfirm our idea. At one point, we were studying
a particularly confusing method. We finally figured
out what it was doing and went to the tests to check
our understanding. But there was no test to help us...
and there should have been. So we wrote a test that
embodied what we thought should happen, ran it, and
-- voilé -- it passed. That felt good.
The story my partner and I picked out turned out to
be effectively solved by the existing code. Rather
than taking the easy way out, mark the story as done,
and grab another story card, we decided to clean up
the code a bit. We were a bit disturbed at having to
study that confusing method so long and generally at
having to work so hard to understand the class as a
whole. So we refactored the class to express the
code's intent more clearly. The biggest product of
our clean-up was a helper class to structure the
parts of a journal entry and name them. This meant
taking a horizontal slice of data that was originally
sliced vertically. This clarified several of the
internal interfaces and even simplified one hairy
loop with an if statement that selected on value type
into two simpler loops. Ahh.
Is the new code better than the previous version? We
think so, but we won't know until the next developers
to touch it, whether others our ourselves, bump into
it again. I will say that it is at least more explicit.
The intention of the code shows up in the names of local
variables and formal parameters; it shows up in blocks
that send messages to objects of the same kind. It
shows up in tests that make finer-grained assertions
about the behavior of the system. That feels like an
improvement to me and, hopefully, my partners. We'll
know more soon enough.
I would love to have more chances like the one I had
today.
Today in the lab while developing code, we encountered
another example of
stories colliding.
We are early in the project, and most parts of the
system are still inchoate. So collisions are to be
expected.
Today, two pairs were working on stories involving
Account objects, which at the start of
the day knew only their account number, account name,
and current balance. In both stories, the code would
have to presume a more knowledgable object, one that
knows something about the date of on which the balance
is in effect and the various entries that have modified
the balance over time.
One team asked, "How can we proceed without knowing
the result of the other story?" More importantly, how
can either team proceed without knowing how journal
transactions will be recorded as entries to the
accounts? Implicit in the question, sometimes, is
a suggestion disguised as a question: Isn't this
an example of where we should do a little up-front
design?
In a professional setting, a little up-front design
might be the right answer. But with newcomers to XP
and TDD, I am trying to have us all think in as pure
an XP way as possible. Finding the right point on the
continuum between too little up-front design and too
much is something better done once the developer has
more experience with both ways of working.
This situation is actually a perfect place for us to
reinforce the idea behind TDD and why it can help us
write better software. Whatever the two pairs do
right now, there will likely be some conflicts that
need to be merged. Taking that as a given, how can
the pairs proceed best? As they write their tests,
each should ask itself,
What is the simplest interface we can possibly
use to implement this story?
When we write a test, we design a little part of our
system's internal interface. Students are used to
knowing everything about an already-designed object
when they write code to use the object. Programming
test-first forces us to think about the interface
first, without being privy to implementation. This
is good, as it will encourage us to design components
that are as loosely coupled as possible. Stories we
implement later will impose more specific details on
how the object behaves, and we can handle more
detailed implementation issues then. This is
good, as it encourages us (1) to write simple tests
that do not presume any more about the object than
is required, and (2) to do the simplest thing that
could possibly work to implement the new behavior,
because those later stories may well cause our
implementation to be extended or changed altogether.
Our story collision is both an obstacle of sorts and
an opportunity to let our tests drive us forward in
small steps!
This collision also has another lesson in store for
us. The whole team has been avoiding a couple of
stories about closing journals at the end of the
month. Implementing these stories will teach us
a lot about what accounts know and look like. By
avoiding them, the team has made implementing some
of our simplest stories more contingent than they
need to be.
i get stuck trying to write all the logic at once. feels
great to deliberately ignore cases that had me stumped.
"that's another test"
This is a skill I hope my students can develop this
month. In order for that to happen, I need to watch for
opportunities to point them in the right direction.
When a pair is at an impasse, unsure of what to do next,
I need to suggest that they step back and try to take a
smaller step. Write a test for that something smaller,
and see where that leads them. The Account
saga is a useful example for me to keep in mind.
If nothing else, teaching this course in real time --
in a lab with students testing, designing, and coding
all the time -- makes clear something we all know. It
is one thing to be able to do something, to
react and act in response to the world. It is another
thing all together to teach or coach others
to do the same thing. I have to have ready at hand
questions to ask and suggestions to make as students
encounter situations that I handle subconsciously
through ingrained experience. Teaching this course is
fun on a lot of levels.
Man, I having fun teaching my agile course. Writing code is
fun, and talking design and technique with students in real
time is fun. Other than being so intense as to tire me out
every day, I think I could get used to this course-in-a-month
model.
I had expected that this week would be our first iteration,
but it became clear early on that the student team did not
understand the domain of our project -- a simple home
accounting system
I might use
-- well enough to begin a development iteration. Progress
would have been too slow, and integration too halting, to
make the time well-spent.
So, in agile fashion, we adapted. We began our time together
yesterday by discussing the problem a bit more at the
one-page story
level. The team was having difficulty with idea of special
journals and different kinds of transactions. We collectively
decided to focus on the general journal for recording all
transactions, and so adjusted our thinking and our stories.
Then we took inspiration from XP's practice of a
spike solution.
In XP, a spike is a simple program that helps a team to
explore a thorny technical or design problem and learn enough
to begin working on live code. As
Ward Cunningham relates,
a spike is the answer to the question, "What is the simplest
thing we can program that will convince us we are on the
right track?" For our team, the problem wasn't technical or
design-related; it was a purely a matter of insufficient
domain understanding.
We paired up, took a simple story, wrote a test, and wrote
code. The story was:
Record a check written on May 15 for cash, in the amount
of $100.
By writing even one test for this story, the team began
to learn new things about the system to be built. For
example,
A transaction is atomic. You can't add a debit to a
journal independent of its balancing credit.
Recording a transaction does not update any
account. That happens when the journal is closed at
the end of the period.
There is a difference between the model, the
core computation and data of a program, and the
view, the way users see or experience the
program's behavior. We can and usually should think
about these parts of our program as independent.
The first two of these lessons are about the domain. The
third is about software design. Both kinds of lesson are
essential ones for a young team to to learn, or be reminded
of, before building the system.
Some pairs explored this story and its implications for an
hour or more. Others tried to forge ahead further, with a
second story:
Record receipt of a $200 paycheck, with $100 going to my
checking account, $20 to my prepaid medical expense account,
and $80 to income tax withholding.
Again, these teams learned something: A transaction may
consist of multiple debits or credits. This also means
that a transaction must be able to record multiple amounts,
unlike in the first story, because several debits may total
up to the value of single credit. Finally, if there are
multiple debits, the sum of their values must
total exactly to the value of the single credit.
Each little bit of learning will help the team to begin
to code productively and to be prepared to grow the design
of the system.
The development team was not the only party who learned
a lot with this spike. By watching the pairs implement
a story or two, offering advice and answering questions,
I did, too. I play two roles on this project, both as
a teacher of sorts. I am the customer for the product
and fully intend to use it when the course ends. This
makes me a teacher of the domain, both specifically this
program and generally Accounting 101. I am also the
coach, which finds me helping to guide the XP process
as well as teaching students a bit about Ruby, software
design, and OO.
By collaborating with the development team as they
wrote spike-like code, I learned a lot about how to
write better stories. This is true of me as customer,
who realized that my original stories lacked the
concrete focus the team needed to be able to focus
on essential features of the program. It is also true
of me as coach, who realized that certain stories would
be especially useful in helping the team arrive at a
more valuable design more quickly.
It is more than okay for the coach and the customer to
learn as much from working with the team as the team
members themselves; it is expected. That's one of the
great attractions and one of the great assets of agile
software development. My students are getting to see
that early in their experience with XP.
Tomorrow, I think we will shake of our experimental
mindset and begin to write our program. I don't have
a lot of experience with a team starting a brand-new
system from Code Zero in XP; most of my greenfield
development has been on projects where I am the only
programmer or the only one writing the initial code
base. I am considering trying out advice that
@jamesshore tweeted
last week:
When starting brand-new product, codebase too small
for 8 programmers to work separately. Instead, use
projector. 1 driver, 7 nav
This seems like a great way to build an initial code
base around a set of commonly-understood objects and
interfaces. If I try it out, I will need to avoid
one temptation. I will surely want to drive, but I
should let a student -- a member of the development
team -- control the keyboard!
Teaching a course two hours a day , especially a course that
is essentially new in this incarnation, feels like running
on ice. I'm enjoying every day, but tomorrow becomes today
way too fast!
At the end of last week, I began to feel the effects of
compressing a 3-credit course into four weeks. At the end
of Week 1, we are a quarter of the way through the course.
But one week is not really enough time for all these new
ideas to soak into a student's brain or fingertips. TDD,
refactoring, pairing, .... Ruby, an IDE, a VCS, ... Our
brains take time to adjust. The students are doing
remarkably well under the conditions, but some of them are
feeling the rush of days, too.
I most noticed the compression in my conflicting desires to
do stuff and to talk more about stuff before doing anything
big. Most professors tend to err on the side of talking
more, but that isn't the best way to learn most disciplines.
I decided that we had seen enough background on XP and that
students had practiced enough on small exercises such as
the spreadsheet TDD challenge
and
refactoring Fowler's code,
Ruby style.
It was time to start building software, and learn as we go.
So today we played the Planning Game and put ourselves in
position to write Line 1 of code tomorrow.
It's been interesting talking to students about XP's
practices. Pairing seemed odd to many of them at first, but
they seem to have taken to it quickly. They are social
beings. Refactoring seems like the Right Thing To Do to
many of them, but in practice it is hard. Using a tool
like Reek to identify some smells and an IDE like RubyMine
to perform some of the refactoring will help, but RubyMine
does not yet implement enough different refactorings to
really dampen their fear of breaking code.
TDD is causing a couple of programmers fits, because it
inverts how they think about coding. When it comes time
to write tests for the app they are building -- no longer
a small exercise in their minds -- I expect us to struggle
as we think about simple design steps. I hope, though,
that this practice will get them over the hump to see how
writing tests early or first can really affect how we
think about our code.
I am still surprised when developers bemoan their inability
to deliver working code and then balk so mightily at a
practice that could help them in a major way. But, as we
all know,
old habits die hard.
When the mind is ready, change can happen. All we can
hope for in a course is to try to be in position for
change to occur whenever the mind becomes ready.
It's been a long week teaching and doing end-of-year
reports for the department, not to mention
putting out daily fires.
I have a few things to say about the agile development
course at the 1/4 mark, but another day.
While writing reports this evening, I listened to
several talks and interviews. One was
Giles Bowkett's talk on meta-programming
at the 2008 Mountain West Ruby Conference. Actually,
Bowkett objects to the the idea of meta-programming,
as
I discussed a few months ago.
At one level, I agree with him; it's all just programming.
In this talk, he elaborates on this position and does
a little just-programming in Ruby to generate code.
The part of this talk that stood out for me this evening
was the part of his conclusion in which he discusses
Paul Graham's recent work. Bowkett summarizes most of
Graham's writing about Lisp, programming, and
meta-programming as:
Great programmers can write better programmers than
they can hire.
He disagrees with this sentiment in only one word:
'great'. After comically mocking an undue focus on
greatness that he attributes to most Harvard grads,
he explains that he prefers the more straightforward
'skilled': Skilled programmers can write
better programmers than they can hire.
I prefer 'skilled' to 'great' too, because 'great'
intimidates too many people. They think other
people are or can be great, but that they themselves
can be merely ordinary. Maybe so, but ordinary
programmers can improve their skills and learn new
things. Most ordinary programmers can become skilled
programmers, even in the dark art of metaprogramming.
They, too, can learn to write better programmers
than they can hire, or be.
Of course, this implies that we can help most of the
programmers we want to hire be better programmers,
by helping them to develop the skills that they need
to be good.
If you watch the talk, watch out for a his egregious
botching of Lisp syntax in the course of demeaning
all those evil parentheses that Lisp foists on us.
I would tell him the same thing I tell my students:
the parentheses aren't nearly as bad -- or as
numerous -- once you learn how to use them properly!
All developers know that bad code slows them down;
yet nearly all insist that writing bad code is faster.
This struck me as one of the themes I'd like for my
agile software developments students to pick up on
this month. It's tempting to write code quick and
dirty so that you can feel as if you are ready to
move on to the next task. But I as I
mentioned here recently,
"dirty remains long after quick has been forgotten".
The feeling of completion is an illusion, one that
we end up paying for later.
A
recent student
commented that this is the traditional trade-off
between "pay now" versus "pay later":
I'd compare it to buying a car today using a loan
versus paying outright next year. It's cheaper if
you're willing to wait, but can you?
This is an apt analogy, because it allows us to
peel off a layer and consider the decision at a
deeper level. For example, if I can borrow money
at a lower net interest rate than I can earn
investing my money elsewhere, then it makes sense
for me to borrow. This is a facet of financial
borrowing that I think we can learn from in the
context of software development. If we can borrow,
in the form of technical debt, at a lower net cost
than the value of the benefit we can accrue by
putting our efforts elsewhere, then it makes sense
for us to incur the technical debt.
Seth Godin wrote recently that
consumer debt is not your friend.
Thinking in this way about software development,
we can contrast borrowing for consumption
and borrowing for investment. Taking on
"consumer" technical debt is a sucker's bet, a
losing proposition. This is the sort of debt that
agile developers rightly warn us about. Rushing
through a story with inadequate testing or with
inattention to the shape of the system after we
add our code -- just so that we can make a tick on
the burndown chart and get more stories done --
this is a habit that eventually buries a team in
an avalanche of debt. Pretty soon, we can barely
keep up with the minimum monthly payment, and we
watch our total debt grow faster than we can add
new value to the system. The result is inevitable:
bankruptcy.
However, this analogy tells us that there may be a
kind of debt that we should be willing to take on.
As I described my own thinking above, if I can
borrow money at a lower net cost than I can earn
investing elsewhere, then it makes sense for me to
borrow. Godin writes of borrowing in order to
improve your productivity or to buy things that go
up in value. In the software development world,
this is what I call investment technical
debt. If a team makes a thoughtful, conscious
decision to let a part of the system fall out of
compliance with its usual standards for coding,
testing or design because doing so lets them
create greater value in another way, then
they will be better off in the future for taking
on the debt. This is investment, and done well it
can pay.
This is the sort of debt that Kent Beck has written
about in recent months when he dared to say that
it might be okay
not to write a test.
He has taken a lot of grief from some XP folks,
who seem to fear that talking about not following
agile practices to the letter will give other
developers license to do the wrong thing under the
mantle of Beck's advice. I feel for those folks.
Investment can be dangerous. People lose money in
the stock market all the time, and developers drown
in technical debt all the time. It is important for
beginners to learn solid fiscal habits, and good
development practices, before venturing too far into
the world of investing.
But Kent is speaking truth, the same truth my student
alluded to when raising the pay-now versus pay-later
trade-off. With experience and expertise, developers
can begin to take on technical debt for the
purpose of investment -- and not only survive, but
thrive as a result.
Of course, it is essential that the investor be
as honest as possible with herself about being able
to repay the debt later. The team must be able to
brings its test coverage back up to safe levels for
the long term, and it must be able to refactor the
system to bring its living design back up to a level
that it supports ongoing development. Some teams like
to pay down their debt in one or a few large focused
episodes. This is akin selling a stock to paying off
a note in whole, and I have done this in my own
programming more than once.
When I can, though, I prefer to amortize the work of
paying off technical debt over a more extended set
of development tasks. I still think of this in terms
of a relatively quick repayment, maybe a few iterations,
because I don't want to the burden of the debt to
affect the rhythm of development any longer than it
must. (Similarly, I would never take out a 5-year loan
to buy a car.) But I prefer the amortized approach
because it fits better with how I want to think about
my work: always conscious of the state of the system,
always taking small steps to make my programs better.
As a creature of habit, I like to work within a set of
practices that keep me focused on continuous improvement.
That sort of development is not easy to do, or to learn.
It's one of the challenges that newcomers to agile
software development must overcome. I think back
to another part of my student's comment: "It's cheaper
if you're willing to wait, but can you?" I think
this points out another common choice people face
all the time: want versus need. The consumer debt
situation in the U.S. is founded in large part on
the fact that many consumers confuse wanting
something with needing it. I imagine that some of
the so-called software crisis has its roots in the
same confusion. "We have to write subpar
code in order to meet our goal..." -- only to find
the team unable to meet its goal in party precisely
because it cut corners earlier.
Godin's article closes with an exhortation to resist
consumer debt in the face of temptation:
Stuff now is rarely better than stuff later, because
stuff now costs you forever if you go into debt to
purchase it. ... It takes discipline to forego
pleasure now to avoid a lifetime of pain and fees.
Software developers are wise when they take this
advice to heart, too. Investment debt is a good
idea in certain circumstances, once you have the
experience and expertise to take it on wisely,
manage it, and pay it off promptly. Consumer debt
is always a loser.
My summer agile course is less than 24 hours away.
My mind is turning on all cylinders...
Thanks to all of you who have written in response
to my
previous entry
with suggestions for my May term course on agile
software development. Most everyone recommended
what I knew to be true: source control, automated
builds, automated testing, and refactoring are
the foundation of agile teams. Keep those
suggestions coming!
Over the last semester I have been reading the XP
mailing list a little more closely in an effort
to discern the pulse of the community these days.
Every so often an interesting thread pops up. For
example, a few months back, the group talked about
its general aversion for software done "quick and
dirty". One poster quoted Steve McConnell as saying,
"The trouble with quick and dirty is that dirty remains
long after quick has been forgotten."
This thread stood out starkly against comments from
a couple of my colleagues who view agile ideas as a
poison, not just a bad idea but a set of temptations
that prevent developers from learning The Right Way
to make software. They often rail against XP and
its ilk as encouraging quick-and-dirty development,
producing bad code with no documentation before
moving on willy-nilly to the next "story".
That sounded quite funny as I read professionals who
use agile practices every day promote unit testing
and especially test-driven development as ways to
guard against a quick-and-dirty process.
Similarly, building refactoring into your weekly,
daily, or hourly development cycle is hardly a recipe
for reckless development; it is a practice that shows
deep care for the code base and for the quality of
the software we deliver to our clients.
One of the most active threads on the list over the
last few weeks has been a discussion of the
"characteristics of a great XP team". This thread
has been full of enlightening capsules from people
who have been doing XP in the trenches for many years.
Some of the discussion offered advice that applies to
great teams of any sort, such as a desire to know the
truth and adapt to it. Others took a stab at
highlighting what XP itself brings to the table. In
one especially insightful message,
Bill Caputo
suggested that, among other attributes, a great
P team...
can deliver well-tested software at a regular
pace indefinitely, because it has "successfully
flattened [the] cost-of-change curve".
"has mastered the art of adapting [its]
process to the needs of [its] environment."
"have such a distribution of knowledge ...
that any one person could leave [the] team, and
[its] velocity would not be negatively impacted
any more than any other person leaving."
Steve Gordon decomposed the question that launched the
thread into two parts:
What are the characteristics of a great software
team?
How does XP achieve -- or not achieve -- these
characteristics?
I think Gordon's decomposition serves as a nice way for
me and my students to approach our course, and I think
Caputo's list is a good start on what we mean when we
talk about agile teams.
April came and went in a flurry. Now begins a busy time
of transition. Today was the last session of my
programming languages course. This semester taught me
a few new things, which I hope to catalog and consider
soon.
Ordinarily the next teaching I do after programming
languages is the compiler course that follows. I will
be teaching that course, in the fall, as we seem to
have attracted a healthy enrollment. But my next
teaching assignments will be novelty and part-novelty
all in one. I am teaching Agile Software Development
in our May term, which runs May 10-June 4. This is
a novelty for me in several ways. In all my years on
the faculty, I have never taught summer school (!),
and I have certainly never taught a 3-credit course
in only four weeks. I expect the compressed schedule
to create an intensity and focus unlike a regular
course, but I fear that it will be hard to reflect
much as we keep peddling every day for two hours.
Full speed ahead!
The course is only part novelty because I have taught
Agile Software Development twice before, in regular
semesters. I'm also quite in tune with the agile
values, principles, and practices. Still, seven years
is an eon in the software world, so much has changed
since my last offerings in 2003 and prior. Tools
such as testing frameworks have evolved, changed
outright, or sprung up new. Scrum, lean, and kanban
have become major topics of discussion even as the
original practices of XP remain the foundation of
most agile teams. Languages have faded and surged.
There is a lot of new for me in this old course.
The compressed schedule offers opportunities I have
not had before when teaching a development course.
Class will meet two hours every business day for
four weeks. Students will be immersed in this course.
Most will be working in the afternoons, but few will
be taking a second course. This allows us to engage
the material and our projects with an intensity we
can't often muster. (I'll also have to be careful
to pace the course so that we don't wear ourselves
out, which seems a danger. This is a chance for me
and the class to practice one of XP's bedrock
practices, sustainable pace!)
The class will be small, only a dozen or so, which
also offers interesting possibilities for our project.
The best way to learn new practices is to use them,
and with the class meeting for nearly eleven hours
a week we have a chance to dig in and use tools and
practice the practices for extended periods, as a
group. The chance to pair program and work with
a story board has never been so vivid for one of
my classes.
I hope that we are able to craft a course and
project that help us bypass
some of the flaws
with typical course projects. Certainly, we will
be collocated more frequently and for longer stretches
than in my department's usual project course, and we
will be together enough to learn to work as a team.
There shouldn't be the constant context switching
between courses that students face during the academic
year. Whether we can manage close interaction with
a customer depends a lot on the availability of others
and on the project we end up pursuing.
We do face many of the same challenges as my
software engineering course last fall.
Our curriculum creates a Babel of several programming
languages. Students will come to the course with a
cavernous range of experience, skills, and maturity.
That gap offers a good test of how pair programming
collective code ownership, and apprenticeship can
help build and share culture and values. The lack of
a common tongue is simply a challenge, though, if we
hope to deliver software of value in four short weeks.
The next eleven days will find me busy, busy, busy,
thinking about my course, organizing readings, and
preparing a project and tools.
A couple of days ago, someone tweeted a link to
Are you one of the 10% of programmers who can write a binary search?,
which revisits a passage by Jon Bentley from twenty-five
years ago. Bentley observed back than that 90% of
professional programmers were unable to produce a
correct version of binary search, even with a couple of
hours to work. I'm guessing that most people who read
Bentley's article put themselves in the elite 10%.
Mike Taylor, the blogger behind The Reinvigorated
Programmer, challenged his readers. Write your best
version of binary search and report the results: is
it correct or not? One of his conditions was that
you were not allowed to run tests and fix your code.
You had to make it run correctly the first time.
Writing a binary search is a great little exercise,
one I solve every time I teach a data structures
course and occasionally in courses like CS1,
algorithms, and any programming language- or
style-specific course. So I picked up the gauntlet.
You can see my solution in a
comment on the entry,
along with a sheepish admission: I inadvertently
cheated, because I didn't read the rules ahead of
time! (My students are surely snickering.) I
wrote my procedure in five minutes. The first
test case I ran pointed out a bug in my stop
condition, (>= lower upper).
I thought for a minute or so, changed the condition
to (= lower (- upper 1)), and the
function passed all my tests.
In a sense, I cheated the intent of Bentley's
original challenge in another way. One of the
errors he found in many professional developers'
solution was an overflow when computing the midpoint
of the array's range. The solution that popped into
my mind immediately, (lower + upper)/2,
fails when lower + upper exceeds the
size of the variable used to store the intermediate
sum. I wrote my solution in Scheme, which handle
bignums transparently. My algorithm would fail in
any language that doesn't. And to be honest, I did
not even consider the overflow issue; having last
read Bentley's article many years ago, I had
forgotten about that problem altogether! This is
yet another good reason to re-read Bentley occasionally
-- and to use languages that do heavy lifting for you.
But.
One early commenter on Taylor's article said that the
no-tests rule took away some of my best tools and his
usual way of working. Even if he could go back to
basics, working in an unfamiliar probably made him
less comfortable and less likely to produce a good
solution. He concluded that, for this reason, a
challenge with a no-tests rule is not a good test of
whether someone is a good programmer.
As a programmer who prefers an agile style, I felt
the same way. Running that first test, chosen to
encounter a specific possibility, did exactly what I
had designed it to do: expose a flaw in my code. It
focused my attention on a problem area and caused me
to re-examine not only the stopping condition but
also the code that changed the values of
lower and upper.
After that test, I had better code and more confidence
that my code was correct. I ran more tests designed
to examine all of the cases I knew of at the time.
As someone who prides himself in his programming-fu,
though, I appreciated the challenge of trying to
design a perfect piece of code in one go: pass or
fail.
This is a conundrum to me. It is similar to a comment
that my students often make about the unrealistic
conditions of coding on an exam. For most exams,
students are away from their keyboards, their IDEs,
their testing tools. Those are big losses to them,
not only in the coding support they provide but also
in the psychological support they provide.
The instructor usually sees things differently. Under
such conditions, students are also away from Google
and from the buddies who may or may not be writing
most of their code in the lab. To the instructor,
This nakedness is a gain. "Show me what you can do."
Collaboration,
scrapheap programming,
and search engines are all wonderful things for
software developers and other creators. But at
some point, you gotta know stuff. You
want to know stuff. Otherwise you are doomed
to copy and paste, to having to look up the interface
to basic functions, and to being able to solve only
those problems Google has cached the answers to.
(The size of that set is growing at an alarming rate.)
So, I am of two minds. I agree with the commenter
who expressed concern about the challenge rules.
(He posted good code, if I recall correctly.) I also
think that it's useful to challenge ourselves regularly
to solve problems with nothing but our own two hands
and the cleverness we have developed through practice.
Resourcefulness is an important trait for a programmer
to possess, but so are cleverness and meticulousness.
Oh, and this was the favorite among the ones I read:
I fail. ... I bring shame to professional programmers
everywhere.
Fear not, fellow traveler. However well we delude
ourselves about living in a
Garrison Keillor world,
we are all in the same boat.
On a recent programming languages assignment, I
asked students to write a procedure named
if->boolean, whose spec was to
recognize certain undesirable if
expressions and return in their places equivalent
but simpler boolean expressions. This procedure
could be part of a simple refactoring engine for a
Scheme-like language, though I don't know that we
discussed it in such terms.
One student's procedure made me smile in a way only
a teacher can smile. As expected, his procedure was
a cond expression selecting among
the undesirable ifs. His procedure
began something like this:
The rest of the procedure was more of the same: comments
such as
; Has the form (if condition #t another)
followed by big and expressions to
recognize the noted undesirable if
and a call to a helper procedure that constructed
the preferred boolean expression. The code was long
and tedious, but the comments made its intent clear
enough.
Next to his code, I wrote a comment of my own:
Listen to your code. It is saying, "Write syntax
procedures!"
How much clearer this code would have been had it
read:
When I talked about this code in class (presented
anonymously in order to guard the student's privacy,
in case he desired it), I made it clear that I was
not being all that critical of the solution. It was
thorough and correct code. Indeed, I praised it for
the concise comments that made the intent of the code
clearer than it would have been without them.
Still, the code could have been better, and students
in the class -- many of whom had written code similar
but not always as good as this -- knew it. For
several weeks now we have been talking about
syntax procedures
as a way to define the interface of an ADT and as a
way to hide detail that complicates a piece of code.
Syntax Procedure is one pattern in a
family of patterns
we have learned in order to write structurally-recursive
code over an inductive data type. Syntax procedures
are, of course, much more broadly applicable than
their role in structural recursion, but they are
especially useful in helping us to isolate code for
manipulating a particular data representation from
the code that processes the data values and recurses
over their parts. That can be especially useful when
students are at the same time still getting used to a
language as unusual to them as Scheme.
The note I wrote on the student's printout was one
measure of chiding (Really, have you completely
forgotten about the syntax procs we've been writing
for weeks?) mixed with nine -- or ninety-nine
-- measures of stylistic encouragement:
Yes! You have written a good piece of code, but don't
stop here. The comment you wrote to help yourself
create this code, which you left in so that you
would be able to understand the code later, is a sign.
Recognize the sign, and use what it says to make
your code better.
Most experienced programmers can tell us about the
dangers of using comments to communicate a program's
intent. When a comment falls out of sync with the
code it decorates, woe to future readers trying to
understand and modify it. Sometimes, we need
a comment to explain a design decision that shapes
the code, which the code itself cannot tell us.
But most of the time, a comment is just that, a
decorator: something meant to spruce up the place
when the place doesn't look as good as we know it
should. If the lack of syntax procedures in my
student's code is a code smell, then his comment is
merely deodorant.
Listen to your code. This is one of my
favorite pieces of advice to students at all levels,
and to professional programmers as well. I even
wrote this advice up in a pattern of its own, called
Speak the Problem's Language.
I knew this pattern from many years writing Smalltalk
to build knowledge-based systems in domains from
accounting to enginnering. Then I read
Peter Norvig's
Paradigms of Artificial Intelligence Programming,
and his Chapter 2 expressed the wisdom so well that
I wanted to make it available as a core coding pattern
in all of the pattern languages I was writing at the
time. It is still one of my favorites. I hope my
student comes to grok it, too.
After class, one of the other students in the class
stopped to chat. She is a double major in CS and
graphic design, and she wanted to say how odd it was
to hear a computer science prof saying, "Listen to
your code." Her art professors tell her this sort
of thing all time. Let the painting tell you
where it wants to go. And, The sculpture
is already in the stone; your job is to set it
free.
Whatever we want to say about software 'engineering',
when we write a program to do something new, our
act of creation
is not all that different from the painter's, the
sculptor's, or the graphic designer's. We shape
the code, and it shapes us. Listen.
This was a pretty good way to spend an afternoon
talking to students.
Reflecting on your career choices is there anything
you would have done differently?
I'm pretty happy with my career, though I never did
enough calculus homework if I think how much calculus
has influenced how I think in terms of small units of
change.
Calculus came up in my programming languages course
today, while we were talking about maps, finite
functions, and discrete math. Our K-12 system aims
students toward calculus, and when they arrive at the
university they often end up taking a calculus course
if they haven't yet already. Many CS students struggle
in calc. They can't help but notice the dearth of
applications of calculus in most of their CS courses
and naturally ask, "Why are we required to take this
class?"
This is a common discussion even among faculty. I
can argue both sides of the case, though I admit to
believing that understanding the calculus at some level
is an essential part of being an educated person, just
as understanding the literary and historical context
in which one grows and lives is essential. The calculus
is one of the crowning achievements of the Enlightenment
and helped to usher in the scientific advances that
define in large part the world in which we all live
today. But Cunningham's reflection encourages us to
think about calculus in a different light.
Notice that Cunningham does not talk about direct
application of the calculus in any program he wrote.
The only program he mentions specifically is
WyCash,
a portfolio management system. Nor does he talk in
an abstract academic way about intellectual achievement
and the Age of Reason.
He says instead that the calculus's notion of small
units of change has affected the way he thinks.
I'm confident that he is thinking here not only of
agile software development, with its short iterations
and rapid feedback cycle, but also of test-driven
development, patterns, and wiki. One can accumulate
value in the smallest of the slices. If one accumulates
enough of them, then over time the value one amasses
can be the area under quite a large curve of action.
This is an indirect application of knowledge. Ward
either did enough calculus homework or paid enough
attention in class that he was able to understand one
of the central ideas underlying the discipline. That
understanding probably lay fallow in his mind until
he began to see how the idea was recurring in his
programming, in his community building, and in his
approach to software development. He was then able
to think about the implications of the idea in his
current work and learn from what we know about the
calculus.
I am a
fan of Ward's
in large part because of his wonderful ability to
make
such connections.
It is hard to anticipate this kind of connection
across domains. That's why it's so important to be
educated widely and to take seriously ideas from
all corners of human accomplishment. Even calc
class.
Today I ran across a recent article by Brian Hayes on
his
home-baked graphics.
Readers compliment him all the time on the great graphics
in his articles. How does he do it? they ask. The real
answer is that he cares what they look like and puts a
lot of time into them. But they want to know what tools
he uses. The answer to that question is simple: He
writes code!
His graphics code of choice is PostScript. But, while
PostScript is a full-featured postfix programming language,
it isn't the sort of language that many people want to
write general-purpose code in. So Hayes took the next
natural step for a programmer and built his own language
processor:
... I therefore adopted the modus operandi of writing
a program in my language of choice (usually some flavor
of Lisp) and having that program write a PostScript
program as its output. After doing this on an ad hoc
basis a few times, it became clear that I should abstract
out all the graphics-generating routines into a separate
module. The result was a program I named lips
(for Lisp-to-PostScript).
Most of what lips does is trivial syntactic
translation, converting the parenthesized prefix notation
of Lisp to the bracketless postfix of PostScript. Thus
when I write (lineto x y) in Lisp, it comes out
x y lineto in PostScript. The lips
routines also take care of chores such as opening and
closing files and writing the header and trailer lines
required of a well-formed PostScript program.
Programmers write code to solve problems. More often
than many people, including CS students, realize,
programmers write a language processor or even create
a little language of their own to make solving the
more convenient. We have been covering the idea of
syntactic abstractions in my programming languages
course for the last few weeks, and Hayes offers us
a wonderful example.
Hayes describes his process and programs in some detail,
both lips and his homegrown plotting program
plot. Still, he acknowledges that the world
has changed since the 1980s. Nowadays, we have more
and better graphics standards and more and better tools
available to the ordinary programmer -- many for free.
All of which raises the question of why I bother to roll
my own. I'll never keep up -- or even catch up -- with
the efforts of major software companies or the huge
community of open-source developers. In my own program,
if I want something new -- treemaps? vector fields? the
third dimension? -- nobody is going to code it for me.
And, conversely, anything useful I might come up with
will never benefit anyone but me.
Why, indeed? In my mind, it's enough simply to
want to
roll my own.
But I also live in the real world, where time is a scarce
resource and the list of things I want to do grows
seemingly unchecked by any natural force. Why then?
Hayes answers that question in a way that most every
programmer I know will understand:
The trouble is, every time I try working with an external
graphics package, I run into a terrible impedance mismatch
that gives me a headache. Getting what I want out of
other people's code turns out to be more work than writing
my own. No doubt this reveals a character flaw: Does not
play well with others.
That phrase stood me up in my seat when I read it. Does
not play well with others. Yep,
that's me.
Still again, Hayes recognizes that something will have to
give:
In any case, the time for change is coming. My way of
working is woefully out of date and out of fashion.
I don't doubt that Hayes will make a change. Programmers
eventually get the itch even with their homebrew code.
As technology shifts and the world changes, so do our
needs. I suspect, though, that his answer will not be
to start using someone else's tools. He is going to end
up modifying his existing code, or writing new programs
all together. After all, he is a programmer.
Early last year, I wrote a
blog entry
about using idea's from Al Aho's article,
Teaching the Compilers Course,
in the
most recent offering
of my course. When I saw that Aho was speaking at SIGCSE,
I knew I had to go. As
Rich Pattis
told me in the hallway after the talk, when you get a chance
to hear certain people speak, you do. Aho is one of those
guys. (For me, so is Pattis.)
The talk was originally scheduled for Thursday, but persistent
fog over southeast Wisconsin kept several people from arriving
at the conference on time, including Aho. So the talk was
rescheduled for Fri. I still had to see it, of course, so I
skipped the attention-grabbing "If you ___, you might be a
computational thinker".
Aho's talk covered much of the same ground as his inroads
paper, which gave me the luxury of being able to listen more
closely to his stories and elaborations than to the details.
The talk did a nice job of putting the compiler course into
its historical context and tried to explain why we might well
teach a course very different -- yet in many ways similar --
to the course we taught forty, twenty-five, or even ten years
ago.
He opened with lists of the top ten programming languages in
1970 and 2010. There was no overlap, which introduced Aho's
first big point: the landscape of programming languages has
changes in a big way since the beginning of our discipline,
and there have been corresponding changes in the landscape of
compilers. The dimensions of change are many: the number of
languages, the diversity of languages, the number and kinds
of applications we write. The growth in number and diversity
applies not only to the programming languages we use, which
are the source language to a compiler, but also to the target
machines and the target languages produced by compilers.
From Aho's perspective, one of the most consequential changes
in compiler construction has been the rise of massive compiler
collections such as
gcc
and
LLVM.
In most environments, writing a compiler is no longer a matter
of "writing a program" as much a software engineering exercise:
work with a large existing system, and add a new front end or
back end.
So, what should we teach? Syntax and semantics are fairly
well settled as matter of theory. We can thus devote time to
the less mathematical parts of the job, such as the art of
writing grammars. Aho noted that in the 2000s, parsing
natural languages is mostly a statistical process, not a
grammatical one, thanks to massive databases of text and easy
search. I wonder if parsing programming languages will ever
move in this direction... What would that mean in terms of
freer grammar, greater productivity, or confusion?
With the availability of modern tools, Aho advocates an agile
"grow a language" approach. Using lex and yacc, students can
quickly produce a compiler in approximately 20 lines of code.
Due to the nature of syntax-directed translation, which is
closely related to
structural recursion,
we can add new productions to a grammar with relative ease.
This enables us to start small, to experiment with different
ideas.
The
Dragon book
circa 2010 adds many new topics to its previous editions.
It just keeps getting thicker! It covers much more material,
both breadth and depth, than can be covered in the typical
course, even with graduate students. This gives instructors
lots of leeway in selecting a subset around which to build a
course. The second edition already covers too much material
for my undergrad course, and without enough of the examples
that many students need these day. We end up selecting such
a small subset of the material that the price of the book is
too high for the number of pages we actually used.
The meat of the talk matched the meat of his paper: the
compiler course he teaches these days. Here are a few
tidbits.
On the Design of the Course
Aho claims that, through all the years, every team
has delivered a working system. He attributes this
to experience teaching the course and the support they
provide students.
Each semester, he brings in at least one language
designer in as a guest speaker, someone like Stroustrup
or Gosling. I's love to do this but don't have quite
the pull, connections, or geographical advantage of Aho.
I'll have to be creative, as I was the last time I taught
agile software development and arranged a phone conference
with
Ken Auer.
Students in the course become experts in one language:
the one they create. They become much more knowledgable
in several others: the languages they to to write, build,
and test their compiler.
On System Development
Aho sizes each student project at 3,000-6,000 LOC. He
uses Boehm's model to derive a team size of 5, which fits
nicely with his belief that 5 is the ideal team size.
Every team member must produce at least 500 lines of code
on the project. I have never had an explicit rule about
this in the past, but experience in my last two courses
with team projects tells me that I should.
Aho lets teams choose their own technology, so that they
can in the way that makes them most comfortable. One
serendipitous side effect of this choice is that requires
him to stay current with what's going on in the world.
He also allows teams to build interpreters for complex
languages, rather than full-blown compilers. He feels that
the details of assembly language get in the way of other
important lessons. (I have not made that leap yet.)
On Language Design
One technique he uses to scope the project is to require
students to identify an essential core of their language
along with a list of extra features that they will implement
if time permits. In 15 years, he says, no team has ever
delivered an extra feature. That surprises me.
In order to get students past the utopian dream of a perfect
language, he requires each team to write two or three
programs in their language to solve representative problems
in the language's domain. This makes me think of test-first
design -- but of the language, not the program!
Aho believes that students come to appreciate our current
languages more after designing a language and grappling
with the friction between dreams and reality. I think this
lesson generalizes to most forms of design and creation.
I am still thinking about how to allow students to design their
own language and still have the time and energy to produce a
working system in one semester. Perhaps I could become more
involved early in the design process, something Aho and his suite
of teaching assistants can do, or even lead the design conversation.
On Project Management
"A little bit of process goes a long way" toward successful
delivery and robust software. The key is finding the proper
balance between too much process, which stifles developers,
and too little, which paralyzes them.
Aho has experimented with different mechanisms for organizing
teams and selecting team leaders. Over time, he has found it
best to let teams self-organize. This matches my experience
as well, as long as I keep an eye out for obviously bad
configurations.
Aho devotes one lecture to project management, which I need
to do again myself.
Covering more content
is a siren that scuttles more student learning than it buoys.
~~~~
Aho peppered his talk with several reminiscences. He told a short
story about lex and how it was extended with regular expressions
from egrep by Eric Schmidt, Google CEO. Schmidt worked for Aho as
a summer intern. "He was the best intern I ever had." Another
interesting tale recounted one of his doctoral student's effort
to build a compiler for a quantum computer. It was interesting,
yes, but I need to learn more about quantum computing to really
appreciate it!
My favorite story of the day was about
awk,
one of Unix's great little languages. Aho and his colleagues
Weinberger and Kernighan wrote awk for their own simple data
manipulation tasks. They figured they'd use it to write
throwaway programs of 2-5 lines each. In that context, you can
build a certain kind of language and be happy. But as Aho said,
"A lot of the world is data processing." One day, a
colleague came in to his office, quite perturbed at a bug he
had found. This colleague had written a 10,000-line
awk program to do computer-aided design. (If you have written
any awk, you know just how fantabulous this feat is.) In a
context where 10K-line programs are conceivable, you want a
very different sort of language!
The awk team fixed the bug, but this time they "did it right".
First, they built a regression test suite. (Agile Sighting 1:
continuous testing.) Second, they created a new rule. To
propose a new language feature for awk, you had to produce
regression tests for it first. (Agile Sighting 2: test-first
development.) Aho has built this lesson into his compiler
course. Students must write their compiler test-first and
instrument their build environments to ensure that the tests
are run "all of the time". (Agile Sighting 3: continuous
integration.)
An added feature of Aho's talk over his paper was three short
presentations from members of a student team that produced
PixelPower, a language which extends C to work with a
particular graphics library. They shared some of the valuable
insights from their project experience:
They designed their language to have big overlap with C.
This way, they had an existing compiler that they
understood well and could extend.
The team leader decided to focus the team, not try to make
everyone happy. This is a huge lesson to learn as soon as
you can, one the students in my last compiler course learned
perhaps a bit too late. "Getting things done," Aho's
students said, "is more important than getting along."
The team kept detailed notes of all their discussions and
all their decisions. Documentation of process is in many
ways much more important than documentation of code, which
should be able to speak for itself. My latest team used
a wiki for this purpose, which was a good idea they had
early in the semester. If anything, they learned that they
should have used it more frequently and more extensively.
One final note to close this long report. Aho had this to say
about the success of his course:
If you make something a little better each semester, after a
while it is pretty good. Through no fault of my own this course
is very good now.
I think Aho's course is good precisely because he adopted this
attitude about its design and implementation. This attitude
serves us well when designing and implementing software, too:
Many iterations. Lots of feedback. Collective ownership of
the work product.
The set of entries cataloged here records some of my
thoughts and experiences at
SIGCSE 2010,
in Milwaukee, Wisconsin, March 10-13. I'll update
it as I post new essays about the conference.
Today, a student told me that he doesn't copy and paste
code. If he wants to reuse code verbatim, he requires
himself to type it from scratch, character by character.
This way, he forces himself to confront the real cost
of duplication right away. This may motivate him to
refactor as soon as he can, or to reconsider copying
the code at all and write something new. In any case,
he has paid a price for copying and so has to take it
seriously.
The human mind is wonderfully creative! I'm not sure
I could make this my practice (I
use duplication tactically),
but it solves a very real problem and helps to make
him an even better programmer. When our tools make
it too easy to do something that can harm us -- such
as copy and paste with wild abandon, no thought of
the future pain it will cause us -- a different
process can restore some balance to the world.
The interplay between tools and process came to mind
as I read Clive Thompson's
Garry Kasparov, cyborg.
this afternoon. Last month, I read the same New
York Review of Books essay by chess grandmaster
Garry Kasparov,
The Chess Master and the Computer,
that prompted Thompson's essay. When I read
Kasparov, I was drawn in by his analysis of what it
takes for a human to succeed, as contrasted to what
makes computers good at chess:
The moment I became the youngest world chess champion
in history at the age of twenty-two in 1985, I began
receiving endless questions about the secret of my
success and the nature of my talent. ... I soon
realized that my answers were disappointing. I
didn't eat anything special. I worked hard because
my mother had taught me to. My memory was good, but
hardly photographic. ...
Kasparov understood that, talent or no talent,
success was a function of working and learning:
There is little doubt that different people are
blessed with different amounts of cognitive gifts
such as long-term memory and the visuospatial skills
chess players are said to employ. One of the
reasons chess is an "unparalleled laboratory" and a
"unique nexus" is that it demands high performance
from so many of the brain's functions. Where so
many of these investigations fail on a practical
level is by not recognizing the importance of the
process of learning and playing chess. The ability
to work hard for days on end without losing focus
is a talent. The ability to keep absorbing new
information after many hours of study is a talent.
Programming yourself by analyzing your decision-making
outcomes and processes can improve results much the
way that a smarter chess algorithm will play better
than another running on the same computer. We might
not be able to change our hardware, but we can
definitely upgrade our software.
"Programming yourself" and "upgrading our software"
-- what a great way to describe how it is that so
many people succeed by working hard to change what
they know and what they do.
While I focused on the individual element in Kasparov's
story, Thompson focused on the social side: how we can
"program" a system larger than a single player? He
relates one of Kasparov's stories, about a chess
competition in which humans were allowed to use
computers to augment their analysis. Several groups
of strong grandmasters entered the competition, some
using several computers at the same time. Thompson
then quotes this passage from Kasparov:
The surprise came at the conclusion of the event.
The winner was revealed to be not a grandmaster with
a state-of-the-art PC but a pair of amateur American
chess players using three computers at the same time.
Their skill at manipulating and "coaching" their
computers to look very deeply into positions
effectively counteracted the superior chess
understanding of their grandmaster opponents and the
greater computational power of other participants.
Weak human + machine + better process was superior
to a strong computer alone and, more remarkably,
superior to a strong human + machine + inferior process.
Thompson sees this "algorithm" as an insight into how
to succeed in a world that consists increasingly of
people and machines working together:
[S]erious rewards accrue to those who figure out the
best way to use thought-enhancing software.
... The process matters as much as the software
itself.
I see these two stories -- Kasparov the individual
laboring long and hard to become great, and "weak
human + machine + better process" conquering all --
as complements to one another, and related back to
my student's decision not to copy and paste code.
We succeed by mastering our tools and by caring
about our work processes enough to make them better
in whatever ways we can.
In a
recent entry,
I discussed how Kent Beck' design advice "Exploit Symmetries"
improves our ability to refactor code. When we take two
things that are similar and separate them into parts that
are either identical or different, we maximize the repetition
in our code. This enables us to factor the repetition in the
sharpest way.
Here is a simple example from Scheme. Suppose we are writing
a procedure to walk down a vector and count how many of items
satisfy a particular condition. Along the way, we might
produce code something like this:
(define count-occurrences-of-test-at
(lambda (test? von position)
(if (>= position (vector-length von))
0
(if (test? (vector-ref von position))
(+ 1 (count-occurrences-of-test-at test? von (+ position 1)))
(count-occurrences-of-test-at test? von (+ position 1))))))
Our procedure duplicates code, but it may not be obvious
at first how to factor it away. The problem is that the
duplication occurs nested in a larger expression at two
different levels: one is a consequent of the if
expression, and the other is part of the computation that
is the other consequent.
As a first step, we can increase the symmetry in our code
by rewriting the else clause as a similar
computation:
(define count-occurrences-of-test-at
(lambda (test? von position)
(if (>= position (vector-length von))
0
(if (test? (vector-ref von position))
(+ 1 (count-occurrences-of-test-at test? von (+ position 1)))
(+ 0 (count-occurrences-of-test-at test? von (+ position 1)))))))
Now we see that the duplicated code is always part of the
value of expression, and the if expression
itself is about choosing whether to add 1 or 0 to the
value of the recursive call. We can use one of the
distributive laws of code to factor out the
repetition:
(define count-occurrences-of-test-at
(lambda (test? von position)
(if (>= position (vector-length von))
0
(+ (if (test? (vector-ref von position)) 1 0)
(count-occurrences-of-test-at test? von (+ position 1))))))
Voilá! No more duplication. By increasing
the duplication in our code, we create a more symmetric
relation, and the symmetry enables us to eliminate
the duplication entirely. I have never thought of myself
as thinking in terms of symmetry when I write code, but I
do think in terms of regularity. My mind prefers
code with regular form, both on the surface and in the
programming structures I use. Often times, my thorniest
refactoring problems arise when I let irregular structure
sneak into my code. When some duplication or complexity
make me uneasy, I find that taking the preparatory step
of increasing regularity can help me see a way to simpler
code.
Of course, we might approach this problem differently
altogether, from a functional point of view, and write a
different sort of solution:
This eliminates another form of duplication that we find
across many procedures that operate on vectors: the common
structure of the code simulates a loop over a vector. That
is yet another form of regularity that we can exploit, once
we begin to recognize it. Then, when we write new code, we
can look for ways to express the solution in terms of the
functionally mapping pattern, so that we don't have to roll
our own loop by hand. When imperative programmers begin to
see this form of symmetry, they are on their way to
becoming functional programmers. (It is also the kind of
symmetry at the heart of
MapReduce.)
Smalltalk Best Practice Patterns is one of my
favorite programming books. In it, Kent Beck records
some of the design and implementation patterns that
he has observed in Smalltalk systems over the years.
What makes the book most valuable, though, is that
most of its patterns apply beyond Smalltalk, to other
object-oriented programming languages and even to
non-OO languages. That's because it is really about
how we think about and design our programs.
Kent's latest design endeavor is what he calls the
Responsive Design Project, and he reports some of this
thinking so far in a
recent blog entry.
The entry includes a number of short patterns of design.
These are not patterns that show up in designs,
but patterns of thinking that help give rise to designs.
Being hip deep in teaching functional design style to
students whose experience is imperative programming,
many of Kent's lessons hit home for me.
Inside or Outside. Change the interface or the
implementation but not both at the same time.
This is a classic that bears repeating. It's tempting
to start making big changes to even a small piece of
code, but whenever we conflate changes to interface and
implementation, we risk creating more complexity than
our small brains can manage.
Isolate Changes. Before making a change, isolate
the area to be changed from the rest of the system so
you can change an entire element at a time. For
example, before changing a part of a procedure, extract
the area to be changed into its own procedure. Make the
change, then inline the changed sub-procedure if
appropriate.
This one is beyond the ken of most intermediate-level
students, so it doesn't show up in my courses often.
When we confine a change to a small box, we control the
complexity of the change and the range of its effect.
This technique can even be used to control software
evolution at a
higher level.
Exploit Symmetries. Divide similar elements into
identical parts and different parts.
Many beginning programmers find it counter-intuitive that
the best way to eliminate duplicated code is to increase
the level of duplication, maximizing the repetition to
the point that it can be factored out in the cleanest and
sharpest way. I have come to know this pattern well but
sense that its value runs much deeper than the uses to
which I've put it thus far.
Then there is the seemingly contradictory pair
Cultivate Confidence. Master your tools. Your
feeling of mastery will improve your cognition.
and
Cultivate Humility. Try tools or techniques you
aren't comfortable with. Being aware of your limitations
will improve your effectiveness.
Of course, the practices themselves aren't contradictory
at all, though the notion that one can be confident and
humble at the same time might seem to be. But even that
holds no contradiction, because it's all about the edge
between mastery and learning. I often talk about these
patterns in my programming classes, if only hope that a
student who is already starting to sense the tension
between hubris and humility will know that it's okay to
walk the line.
Finally, my nominee for best new pattern name:
Both. Faced with design alternatives without a
clear winner, do it every way. Just coding each
alternative for an hour is more productive than arguing
for days about which is better in theory, and a lot more
satisfying.
You may have heard the adage, "Listen to your code",
which is often attributed to Kent or to Ward Cunningham.
This pattern goes one step beyond. Create the code that
can tell you what you need to hear. Time spent talking
about what code might do is often much less productive
than simply writing the code and finding out directly.
Early in his essay, Kent expresses the lesson that
summarizes much of what follows as
Our illusion of control over software design is a
dangerous conceit best abandoned.
He says this lesson "disturbs and excites me". I guess
I'm not too disturbed by this notion, because feeling
out of control when working in a new domain or style or
language has become routine for me. I often feel as if
I'm stumbling around in the dark while a program grows
into just what it needs to be, and then I see it.
Then I feel like I'm in control. I knew where
I was going all the time.
In my role as a teacher, this pattern holds great danger.
It is easy after the fact to walk into a classroom and
expound at length about a design or a program as if I
understood it all along. Students sometimes think that
they should feel in control all the time, too, and when
they don't they become discouraged or scared. But the
controlled re-telling of the story is a sham; I was
no more in control while writing my program than they
will be when they write theirs.
What excites me most about this pattern is that it lifts
a burden from our backs that we usually didn't know we
were carrying. Once we get it, we are able to move on
to the real business of writing and learning, confident
in the knowledge that we'll feel out of control much
of the time.
Being lucky is not generally a matter of luck
RT @gregyoung: http://is.gd/8qdIk
That shortened URL points to an article called,
Be Lucky: It's an Easy Skill to Learn.
The author, psychologist Richard Wiseman, reports some
of his findings after a decade studying people who
consider themselves lucky or unlucky. Not surprisingly,
one's state of mind has as much to do with perception
of luck as any events in the observable world. He has
identified three common threads that anyone can use to
become luckier:
Trust your intuition.
Use variety and pseudorandom behavior to create
opportunities for unexpected benefits.
See the positive in each event.
One of the things that struck me about this article was
the connection of unlucky people to tension.
... unlucky people are generally much more tense than
lucky people, and research has shown that anxiety
disrupts people's ability to notice the unexpected.
Tension relates directly to all three of the above
bullets. Tense people tend to overthink situations,
looking to optimize some metric, and thus quash
their gut instincts. They tend to seek routine as
a way to minimize distraction and uncertainty, which
cause them to miss opportunities. And their tension
tends to cause them to see the negative in any event
that does not match their desired optimum. Perhaps
the key to luck is nothing more than relaxation!
When I think of times I feel unlucky -- and I must
sheepishly admit that this happens all too often --
I can see the tension that underlies Wiseman's
results. But for me this usually manifests itself
as frustration. This thought, in turn, reminded me
of a blog entry I wrote a year ago on
embracing failure.
In it, I considered Rich Pattis observation about how
hard computer science must feel to beginners, because
it is a discipline learned almost wholly by failure.
Not just occasional failure, but a steady stream of
failures ranging from syntax errors to misunderstanding
complex abstractions. Succeeding in CS requires a
certain mindset in which embraces, fights through, or
otherwise copes with failure in a constructive way.
Some of us embrace it with gusto, seeing failure as
a challenge to surmount, not a comment on our value
or skills.
I wonder now if there might be a connection between
seeing oneself as lucky and embracing failure. Lucky
people find positive in the negative events; successful
programmers see valuable information in error messages
and are empowered to succeed. Lucky people seek out
variety and the opportunities it offers; successful
programmers try out new techniques, patterns, and
languages, not because they seek out failure but
because they seek opportunities to learn. Lucky
people respect their hunches; successful programmers
have the hubris to believe they can see their way to
a working program.
If relaxation is the key to removing tension, and
removing tension is the key to being lucky, and
being lucky is a lot like being a successful
programmer, then perhaps the key to succeeding as
a programmer is nothing more than relaxation! Yes,
that's a stretch, but there is something there.
One last connection. There have been a couple of
articles in the popular press recently about an
increase in the prevalence of cheating, especially
in CS courses. This has led to discussions of cheating
in a number of places CS faculty hang out. I imagine
there is a close connection between feeling frustrated
and tense and feeling like one needs to cheat to
succeed. If we can lower the level of tension in our
classrooms by lowering the level of frustration, there
may be a way for us to stem the growing tide of students
cheating. The broader the audience we have in any
given classroom, the harder this is to achieve. But
we do have tools available to us, including having our
students working in domains that give more feedback
more visibly, sooner, and more frequently.
About a decade ago I was chatting with some high school
teachers when my university hosted a programming contest
for high school kids. One teacher pointed out that her
best CS students were those that also played either music
or golf -- her theory was that they were used to tasks
where you are really bad at first, but you persevere and
overcome that. But you have to be able to accept that
you'll really stink at it for a good long while.
This struck me as a neat way to make a connection between
learning to program and learning music or sports. I had
forgotten about the discussion of "meaningful failure" in
my own entry... Tate explains the connection succinctly.
Whatever the connections among tension, fear of failure,
cheating, and luck, we need to find ways to help students
and novice developers learn how to take control of their
own destiny -- even if it is only in helping them
cultivate their own sense of good luck.
In my
previous entry
I mentioned colleague and graphic designer Roy Behrens.
My
first
blog
articles
featuring Behrens mentioned or centered on material from
Ballast Quarterly Review,
a quarterly commonplace book he began publishing in the
mid-1980s. I was excited to learn recently that Behrens
is beginning to reproduce material from BALLAST
on-line in his new blog,
The Poetry of Sight.
He has already posted both entries I've seen before and
entries new to me. This is a wonderful resource for
someone who likes to make connections between art,
design, psychology, literature, and just about any
other creative discipline.
All this is prelude to my recent reading of the entry
Art as Brain Surgery,
which recounts a passage from an interview with film
theorist Ray Carney that begins the idea behind the
entry's title:
The greatest works [of art] do brain surgery on their
viewers. They subtly reprogram our nervous systems.
They make us notice and feel things we wouldn't
otherwise.
I read this passage as a potential challenge to an
idea I had
explored previously:
programming is art. That article looked at the
metaphor from poet William Stafford's perspectives
on art. Carney looks at art from a different
position, one which places a different set of
demands on the metaphor. For example,
One of the principal ways [great works of art] do
this is through the strangeness of their styles.
Style creates special ways of knowing. ...
Artistic style induces unconventional states of
awareness and sensitivity.
This seems to contradict a connection to programming,
a creative discipline in which we seem to prefer --
at least in our code -- convention over individuality,
recognizability or novelty, and
the obvious over the subtle.
When we have to dig into an unfamiliar mass of legacy
code, the last thing we want are "unconventional
states of awareness and sensitivity". We want to
grok the code, and now, so that we can extend and
modify it effectively and confidently.
Yet I think we find beauty in programming styles that
extend our way of thinking about the world. Many OO
and procedural programmers encounter functional
programming and see it as beautiful, in part because
it does just what Carney says great art does:
It freshens and quickens our responses. It limbers
up our perceptions and teaches us new possibilities
of feeling and understanding.
The ambitious among us then try to take these new
possibilities back to their other programming styles
and imbue our code there with the new possibilities.
We turn our new perceptions into the conventions and
patterns that make our code recognizable and obvious.
But this also makes our code subtle in its own,
bearing a foreign beauty and sense of understanding
in the way it solves the work-a-day problems found
in the program's specs. The best software patterns
do this: they not only solve a problem but teach us
that it can be solved at all, often by bringing an
outside influence to our programs.
Perhaps it's just me, but there is something poetic
in how I experience the emotional peaks of writing
programs. I feel what Carney says:
The greatest works of art are not alternatives to or
escapes from life, but enactments of what it feels
like to live at the highest pitch of awareness -- at
a level of awareness most people seldom reach in
their ordinary lives.
The first Lisp interpreter, which taught us that
code is data.
VisiCalc, which brought program as spreading activation
to our desktops, building on AI work in the 1950s and
1960s. Smalltalk. Unix. Quicksort and mergesort,
implemented in thousands of programs in thousands of
ways, always different but always perceptibly the same.
Programmers experience these ideas and programs at the
highest pitch of awareness. I walk away from the
computer some days hoping that other people get to
feel the way I am feeling, alive with fire deep in my
bones.
The greatest works are inspired examples of some of
the most exciting, demanding routes that can be taken
through experience. They bring us back to life.
These days, more than ever, I relish the way even
reading a good program can bring me back to life.
That's to say nothing of
writing one.
Diverse Thinking, Narrative, Journalism, and Software
A friend sent me a link to a New York Times book
review,
Odysseus Engages in Spin, Heroically,
by Michiko Kakutani. My friend and I both enjoy
the intersection of different disciplines and
people who cross boundaries. The article reviews
"The Lost Books of the Odyssey", a recent novel
Kakutani calls "a series of jazzy, post-modernist
variations on 'The Odyssey'" and "an ingeniously
Borgesian novel that's witty, playful, moving and
tirelessly inventive". Were the book written by
a classicist, we might simply add the book to our
to-read list and move on, but it's not. Its author,
Zachary Mason is a computer scientist specializing
in artificial intelligence.
I'm always glad to see examples of fellow computer
scientists with interests and accomplishments in
the humanities. Just as humanists bring a fresh
perspective when they come to computer science, so
do computer scientists bring something different
when they work in the humanities. Mason's background
in AI could well contribute to how he approaches
Odysseus's narrative. Writing programs that make
it possible for computers to understand or tell
stories causes the programmer to think differently
about understanding and telling stories more
generally. Perhaps this experience is what
enabled Mason to "[pose] new questions to the
reader about art and originality and the nature of
storytelling".
Writing a program to do any task has the potential
to teach us about that task at a deeper level.
This is true of mundane tasks, for which we often
find our algorithmic description is unintentionally
ambiguous. (Over the last couple of weeks, I have
experienced this while working with a colleague in
California who is writing a program to implement a
tie-breaking procedure
for our university's basketball conference.) It
is all the more true for natural human behaviors
like telling stories.
In one of those unusual confluences of ideas, the
Times book review came to me the same week that I
read Peter Merholz's
Why Design Thinking Won't Save You,
which is about the value, even necessity, of
bringing different kinds of people and thinking
to bear on the tough problems we face. Merholz
is reacting to a trend in the business world to
turn to "design thinking" as an alternative to
the spreadsheet-driven analytical thinking that
has dominated the world for the last few decades.
He argues that "the supposed dichotomy between
'business thinking' and 'design thinking' is
foolish", that understanding real problems in
the world requires a diversity of perspectives.
I agree.
For me, Kakutani's and Merholz's articles intersected
in a second way as I applied what they might say
about how we build software. Kakutani explicitly
connects author Mason's CS background to his
consideration of narrative:
["Lost Books" is] a novel that makes us rethink the
oral tradition of entertainment that thrived in
Homer's day (and which, with its reliance upon
familiar formulas, combined with elaboration and
improvisation, could be said to resemble software
development) ...
When I read Merholz's argument, I was drawn to an
analogy with a different kind of writing, journalism:
Two of Adaptive Path's founders, Jesse James Garrett
and Jeffrey Veen, were trained in journalism. And
much of our company's success has been in utilizing
journalistic approaches to gathering information,
winnowing it down, finding the core narrative, and
telling it concisely. So business can definitely
benefit from such "journalism thinking."
So can software development. This passage reminded
of a panel I sat on at OOPSLA several years ago,
about the engineering metaphor in software development.
The moderator of the panel asked folks in the audience
to offer alternative metaphors for software, and Ward
Cunningham suggested journalism. I don't recall all
the connections he made, but they included working on
tight deadlines, having work product reviewed by an
editor, and highly stylized forms of writing. That
metaphor struck me as interesting then, and I have
since written about the relationship between software
development and writing, for example
here.
I have also expressed reservations about engineering
as a metaphor for building software, such as
here
and
here.
I have long been coming to believe that we can learn
a lot about how to build software better by studying
intensely almost every other discipline, especially
disciplines in which people make things -- even, say,
maps!
When students and their parents ask me to recommend
minors and double majors that go well with computer
science, I often mention the usual suspects but
always make a pitch for broadening how we think,
for studying something new, or studying intensely
an area that really interests the students. Good
will come from almost any discipline.
These days, I think that making software is
like so many things and unlike
them all. It's something new, and we are left
to find our own way home. That is indeed part of
the fun.
These days, I believe the key difference between practice,
value and principle (something much debated at one time
in the XP community and elsewhere) is simply how likely
we are to adjust them if things are going wrong for us
(i.e., practices change a lot, principles rarely). But
none should be immune from our consideration when our
actions result in negative outcomes.
To the list of practice, value, and principle, pragmatists
like Peirce, James, Dewey, and Meade would add
knowledge. When we focus on their instrumental
view of knowledge, it easy to forget one of the critical
implications of the view: that knowledge is contingent on
experience and context. What we call "knowledge" is not
unchanging truth about the universe; it is only less
likely to change in the face of new experience than other
elements of our belief system.
Last spring, a colleague commented that he didn't
think our department spent enough time trying to
be great. This made me sad, but it struck me as
true. At the time, I wasn't sure how to respond.
All groups have their internal politics. Some
political situations are short-lived; others are
persistent, endemic. We are no different, and
maybe even above average. (Someone has to be!)
Political struggles take time and energy. They
steal focus.
I think everyone in our group desires to be great.
Unfortunately, that's the easy part. For a group
to achieve greatness, individuals must work
together in a common direction. In our group, it
is hard to build consensus on a shared vision. I
don't pretend that once we share a vision that
greatness will come easily, but it's hard to get
anywhere unless everyone is trying to go to the
same place -- or at least is using the same criteria
for progress.
As for me, in my role as department head, I have
not always found -- or created -- the will, the
energy, or the tools I need to help us move
confidently in the direction of greatness. So,
at times, we seem to settle, working locally but
not globally.
This train of thought reminds me of a couple of
comments James Shore made about
stumbling through mediocrity
in the context of agile software development:
The emphasis [in the software world] has shifted
from "be great" to "be Agile." And that's too bad.
As much as I like it, there's really no point in
Agile for the sake of Agile.
The point is to be great, or perhaps more accurately,
to
do great things.
Agile approaches are a path, not a destination.
I want to work with people who want to be great.
People who aren't satisfied just fitting in.
People who are willing to take risks, rock the
boat, and change their environment to maximize
their productivity, throughput, and value.
One of the things that has surprised me so much
about group dynamics since I joined a faculty and
perhaps more so since I've been in the position
of head is the enormous role that fear plays in
how individuals work and interact with one another.
It takes courage to take risks,
to rock the boat, and to change the environment
in which we live and work. It takes courage to
be honest. It takes courage to take an action
that may make a colleague or supervisor unhappy.
Without courage, especially at key moments,
opportunities pass, sometimes before they are
even recognized.
I have experienced this in how I interact with
others, and occasionally I observe it how
colleagues interact with me and others. I never
thought that this would be a major obstacle on
my path to greatness, or my department's.
(For what it's worth, Shore's second passage also
describes the kind of students I like to work with,
too. If it is hard for experienced adults to have
this sort of gumption, imagine how much tougher
an expectation it is to have of young people who
are just learning how to step out into the world.
Fortunately, as teachers, we have an opportunity
to help students grow in this way.)
In Programming Style, as in Most Things, Moderation
As I prepare for a new semester of teaching programming
languages, I've been enjoying getting back into
functional programming. Over break, someone somewhere
pointed me toward a set of blog entries on why
functional programming doesn't work.
My first thought as I read the root entry was, "Just
use Scheme or Lisp", or for that matter any functional
language that supports mutation. But the author
explicitly disallows this, because he is talking about
the weakness of pure functional programming.
This is common but always seems odd to me. Many of
the arguments one sees against FP are against "pure"
functional programming: all FP, all the time. No one
ever seems to talk in the same way about stateful
imperative programming in, say, C. No one seems to
place a purity test on stateful programming: "Try
writing that without any functions!".
Instead, we use state and sequencing and mutation
throughout programs, and then selectively use
functional style in the parts of the program where
it makes sense. Why should FP be any different?
We can use functional style throughout, and then
selectively use state where it makes sense.
Mixing state and functions is the norm in imperative
programming. The same should be true when we
discuss functional programming. In the Lisp world,
it is. I have occasionally read Lispers say that
their big programs are about 90% functional and 10%
imperative. That ratio seems a reasonable estimate
for the large functional programs I have written,
give or take a few percent either way.
Once we get to the point of acknowledging the
desirability of mixing styles, the question becomes
which proportion will serve us best in a particular
environment. In game programming, the domain used
as an example in the set of blog entries I read,
perhaps statefulness plays a larger role than 10%.
My own experience tells me that whenever I can
emphasize functional style (or tightly-constrained
stateful style, a lá objects), I am usually
better off. If I have to choose, I'll take 90:10
functional over 90:10 imperative any day.
If we allow ourselves to mix styles, then solving the
author's opening problem -- making two completely
unrelated functions interdependent -- becomes
straightforward in a functional program: define the
functions (or doppelgangers for them) in a closure
and 'export' only the functions. To me, this is an
improvement over the "pure" stateful approach, as it
gives us state and dependent behavior without
global variables mucking up the namespace of the
program or the mindshare of the programmer.
Maybe part of the problem lies in how proponents of
functional programming pitch things. Some are surely
overzealous about the virtues of a pure style. But
I think as much of the problem lies in how limited
people with vast experience and deep understanding of
one way to think feel when they move outside their
preferred style. Many programmers still struggle
with object-oriented programming in much the same
way.
Long ago, I learned from
Ralph Johnson
to encourage people to think in terms of programming
style rather than programming paradigm.
Style implies choice and freedom of thought, whereas
paradigm implies rigidity and single-mindedness. I
like to encourage students to develop facility with
multiple styles, so that they will feel comfortable
moving seamlessly in and out of styles, across borders
whenever that suits the program they are writing.
It is better for what we build to be defined by what
we need, not our limitations.
(That last is a turn of phrase I learned from the book
Art and Fear,
which I have
referenced
a couple of times before.)
I do take to heart one piece of advice derived from
another article
in the the author's set of articles on FP. People who
would like to see functional programming adopted more
widely could help the cause by providing more guidance
to people who want to learn. What happens if we ask a
professional programmer to rewrite a video game (the
author's specialty) in pure FP, or
... just about any large, complex C++ program for that
matter[?] It's doable, but requires techniques that
aren't well documented, and it's not like there are
many large functional programs that can be used as
examples ...
First, both sides of the discussion should step away
from the call for pure FP and allow a suitable mix
of functional and stateful programming. Meeting in
the middle better reflects how real programmers
work. It also broadens considerably the set of
FP-style programs available as examples, as well as
the set of good instructional materials.
But let's also give credence to the author's plea.
We should provide better and more examples, and do
a better job of documenting the functional programming
patterns that professional programmer needs. How
to Design Programs is great, but it is written
for novices. Maybe Structure and Interpretation
of Computer Programs is part of the answer, and
I've been excited to see so many people in industry
turning to it as a source of professional development.
But I still think we can do better helping non-FP
software developers make the move toward a functional
style from what they do now. What we really need is
the functional programming equivalent of the Gang of
Four book.
And now
even the grading
is done. I enjoyed reading my students' answers to exam
questions about software engineering, especially agile
approaches. Their views were shaped in part by things
I said in class, in part by things I asked them to read,
and in part by their own experiences writing code. The
last of these included a small team project in class,
for which two teams adopted many XP practices.
Many people in the software industry have come to think
of agile development as implying an incomplete
specification. A couple of students inferred this as
well, and so came to view one of the weaknesses of agile
approaches as a high risk that the team will go in
circles or, worse yet, produce an incomplete or
otherwise unacceptable system because they did not spend
enough time analyzing the problem. Perhaps I can be
more careful in how I introduce requirements in the
context of agile development.
One exam question asked students to describe a key
relationship between refactoring and testing. Several
students responded with a variation of "Clean code is
easier to test." I am not sure whether this was simply
a guess, or this is what they think. It's certainly
true that clean code is easier to test, and for teams
practicing more traditional software engineering
techniques this may be an important reason to refactor.
For teams that are writing tests first or even using
tests to drive development, this is not quite as
important the answer I was hoping for: After you
refactor, you need to be able to run the test suite to
ensure that you have not broken any features.
Another person wrote an answer that was similar to the
one in the preceding paragraph, but I read it as
potentially more interesting: "Sometimes you need to
refactor in order to test a feature well." Perhaps
this answer was meant in the same way as "clean code
is easier to test". It could mean something else,
though, related to an idea I mentioned last week,
design for testability.
In XP, refactoring and test-first programming work
together to generate the system's design. The tests
drive additions to the design, and refactoring ensures
that the additions become part of a coherent whole.
Sometimes, you need to refactor in order to test well
a feature that you want to add in the next iteration.
If this is what the student meant, then I think he or
she picked up on something subtle that we didn't
discuss explicitly in class.
When asked what the hardest part of their project had
been and what the team had done in response to the
challenge, one student said, "We had difficulty writing
code, so we looked for ways to break the story into
parts." Hurray! I think this team got then idea.
A question near the end of the exam asked students
about Fred Brooks's
No Silver Bullet paper.
They read this paper early in the semester to get some
perspective on software engineering and wrote a short
essay about their thoughts on it. After having worked
on a team project for ten weeks, I asked them to revisit
the paper's themes in light of their experience. One
student wrote, "A good programmer is the best solution
to engineering software."
A lot of the teams seem to have come to a common
understanding that their design and programming skills
and those of their teammates were often the biggest
impediment to writing the software they envisioned.
If they take nothing from this course than the desire
and willingness to work hard to become better designers
and programmers, then we will have achieved an outcome
more important than anything try to measure with a
test.
I agree with Brooks and these students. Good programmers
are the best solution to engineering software. The trick
for us in computer science is how to grow, build, or find
great designers and programmers.
Today I was thinking retrospectively about themes as I
wrote the final exam for
my software engineering course.
It occurred to me that one essential theme of the course
needs to be design for testability. We talked about
issues such as coupling and cohesion, design heuristics
and patterns for making loosely connected, flexible code,
and Model-View-Controller as an architectural style.
Yet much of the code they wrote was coupled too tightly
to test conveniently and thoroughly. I need to help them
connect the dots from the sometimes abstract notions of
design to both maintenance and testing. This will help
me bring some coherence to the design unit of the course.
I am beginning to think that much of the value in this
course comes from helping students to see the relationships
among the so-called stages of the software life cycle:
design and testing, specification and testing, design
and maintenance, and so on. Each stage is straightforward
enough on its own. We can use our time to consider how
they interact in practice, how each helps and hinders
the others. Talking about relationships also provides a
natural way to discuss feedback in the life cycle and
to explore how the agile approaches capitalize on the
relationships. (Test-driven development is the ultimate
in design for testability, of course. Every bit of code
is provoked by a test!)
I realize that these aren't heady revelations. Most of
you probably already know this stuff. It's amazing that
I can teach a course on writing software for an entire
semester, after so many years of writing software myself,
and only come to see such a basic idea clearly after
having made a first pass. I guess I'm slow. Fortunately,
I do seem eventually to learn.
Last night I read a few words that I needed to see. They
come from Elizabeth Gilbert,
on writing:
Quit your complaining. It's not the world's fault that
you wanted to be an artist. It's not the world's job
to enjoy the films you make, and it's certainly not the
world's obligation to pay for your dreams. Nobody wants
to hear it. Steal a camera if you have to, but stop
whining and get back to work.
Plug 'programmer' or 'teacher' in for 'artist', and
'laptop' for 'camera', and this advice can help me out
on most days. Not because I feel unappreciated, but
because I feel pulled in so many directions away from
what I really want to do: prepare better courses and
-- on far, far too many days -- from writing code.
Like Gilbert, I need to repeat those words to myself
whenever I start to feel resentful of my other duties.
No one cares. I need to find ways to get back to work.
Gilbert closes her essay with more uplifting advice
that also feels right:
My suggestion is that you start with the love and then
work very hard and try to let go of the results.
If you love
to program,
or to teach, or
to run,
you do it. Remember the love that got you into the
game, and let it keep you there. The rest will follow.
Oh, and if you haven't seen Gilbert's TED talk, walk back
to her home page and watch. It's a good one.
We have entered finals week, which for me mean grading
team projects and writing and grading a final exam.
As I think back over the term, a few things stand out.
Analysis. This element of software engineering
was a challenge for me. The previous instructor was an
expert in gathering requirements and writing specs, but
I did not bring that expertise to the course. I need
to gather better material for these topics and think
about better ways to get help students experience them.
Design and implementation. The middle part of
my course disappointed me. These are my favorite parts
of making software and the areas about which I know the
most, both theoretically and practically. Unfortunately,
I never found a coherent approach for introducing the
key ideas or giving students deep experiences with them.
In the end, my coverage felt too clinical: software
architectures, design patterns, refactoring... just
ideas. I need to design more convincing exercises to
give students a feel for doing these; one big team
project isn't enough. Too much of the standard software
engineering material here boils down to "how to make UML
diagrams". Blech.
Testing. Somewhat to my surprise, I enjoyed
this material as much as anything in the course. I
think now that I should invert the usual order of the
course and teach testing first. This isn't all that
crazy, given the relationship between specs and tests,
and it would set us up to talk about test-driven design
and refactoring in much different ways. The funny
thing is that my recently-retired software engineering
colleague, who has taught this course for years, said
this idea out loud first, with no prompting from me!
More generally, I can think of two ways in which I
could improve the course. First, I sublimated my
desire to teach an agile-driven course far too much.
This being my first time to teach the course, I didn't
want to fall victim to my own biases too quickly. The
result was a course that felt too artificial at times.
With a semester under my belt, I'll be more comfortable
next time weaving agile threads throughout the course
more naturally.
Second, I really disappointed myself on the tool front.
One of my personal big goals for the course was to be
sure that students gained valuable experience with
build tools, version control, automated testing tools,
and a few other genres. Integrating tool usage into a
course like this takes either a fair amount of preparation
time up front, or a lot more time during the semester.
I don't have as much in-semester time as I'd like, and
in retrospect I don't think I banked enough up-front
time to make up for that. I will do better next time.
One thing I think would make the course work better is
to use an open-source software project or two as a
running example in class throughout the semester. An
existing project would provide a concrete way to
introduce both tools and metrics, and a new project
would provide a concrete way to talk about most of
the abstract concepts and the creative phases of
making software.
All this said, I do think that the current version of
the course gave students a chance to see what software
engineering is and what doing it entails. I hope we
did a good enough job to have made their time well-spent.
An undefined problem has an infinite number of solutions.
-- Robert A. Humphrey
It's always seemed to me that one of the best motivations
for writing tests first is to know when I'm done. I am
prone to wandering in the wilderness and to overthinking
what I do. Writing a test helps keep me close to task.
When I first heard Kent Beck ask, "How do you know when
you are done?", a little light went on for me. I felt
something similar when I first saw the above quote on the
old "Thinking Again!" blog. A test helps to define my
task, circumscribing the problem, taking me from what is
usually an incomplete statement in the specification or
in a list of requirements to a concrete answer to the
question, "Am I done?"
The idea behind test-driven development is that
well-written tests can do more. They also evoke a
particular design and implementation. This gives me
not only an idea of where I am going, but also an idea
of how to get there.
That said, an undefined problem may have zero
solutions, and executable code can help us avoid this
circumstance, too. Adam Bosworth makes this connection
in his blog entry on
creating healthcare XML standards.
He warns against writing standards in the abstract only:
5. Always have real implementations that are actually
being used as part of design of any standard. It is
hard to know whether something actually works or can
be engineered in a practical sense until you actually
do it.
Much like analysis and design done independent of any
code, a standard written independent of a reference
implementation may have big holes in it, not make
sense to potential implementors, or even be implementable
at all! This ought not be surprising. A standard is
a specification for a set of systems that we envision,
and our imaginations can outrun our ability to build
clear solutions. The best way not to get ahead of
ourselves is to build a clear solution as you go along.
The working system we build is a proof of concept for
the standard, a concrete implementation that helps us
to verify that we are on the right track agile. If
those who are intimately familiar with the standard
being written cannot implement it, then almost certainly
others will struggle more.
This implementation is different than a test in TDD, a
mirror image really. But it plays a similar role in
helping us to know if you are done. If our reference
implementation is unclear or are hard to build, we can
find weaknesses in the standard as it is written. If
we want to write a good standard, a usable standard,
then we are not done.
Bosworth's advice echoes the values that underlie
continuous testing in the agile approaches: a preference
for working code, a desire to test ideas against reality,
and a desire for continuous feedback that we can use to
make our product better.
Other advice in Bosworth's article embodies agile values,
too, especially a preference for people and simplicity.
Consider:
1. Keep the standard as simple and stupid as possible.
2. The data being exchanged should be human readable
and easy to understand.
After spending time with a person, do you usually
feel exhilarated or exhausted? If you always feel
tired, then you have been poisoned. Avoid people
who do this to you. I would add positive advice
in the same vein: Try to surround yourself with
people who give you energy, and try to be a person
who energizes those around you.
Less is not necessarily more. That's a lie we tell
ourselves too often when we face cuts. "Do less
with more." In the short term, this can be a way
to become more efficient. In the long term, it
starves us and our organizations. I like Glaser's
idea better: Just enough is more.
If you think you have achieved enlightenment, "then
you have merely arrived at your limitation". I see
this too often in academia and in industry. Glaser
uses this example of the lesson that doubt is better
than certainty, but it also relates to an earlier
lesson in the talk: Style is not to be trusted.
Styles come and go; integrity and substance remain
vital no matter what the fashion is for expressing
solutions.
This talk ends with a passage that brought to mind
discussion in recent months among agile software
developers and consultants about a the idea of
certifying agile practitioners:
Everyone interested in licensing our field might note
that the reason licensing has been invented is to
protect the public not designers or clients. "Do no
harm" is an admonition to doctors concerning their
relationship to their patients, not to their fellow
practitioners or the drug companies.
Much of the discussion in the agile community about
certification seems more about protecting the label
"agile" from desecration than about protecting our
clients. It may well be that some clients are being
harmed when unscrupulous practitioners do a lazy or
poor job of introducing agile methods, because they
are being denied the benefits of a more responsive
development process grounded in evidence gathered from
continuous feedback. A lot of the concern, though,
seems to be with the chilling effect that poorly-
executed agile efforts have on the ability of honest
and hard-working agile consultants and developers to
peddle our services under that banner.
I don't know what the right answer to any of this is,
but I like the last sentence of Glaser's talk:
If we were licensed, telling the truth might become
more central to what we do.
Whether we are licensed or not, I think the answer will
ultimately back to a culture of honesty and building
trust in relationships with our clients. So we can all
practice Glaser's tenth piece of advice: Tell the
truth.
Agile Themes: Organic Planning and the Cost of Change
My previous agile theme, on
organic planning,
has implications for how we design and implement
solutions -- for making decisions that "stick".
Derek Sivers recently used an apocryphal story about
walkways
to express a similar principle:
So when should you make business decisions?
When you have the most information, when you're at
your smartest: as late as possible.
My first thought was that this principle follows from
adaptive planning, but that confuses causal order with
temporal order. Sivers's conclusion assumes that we
are "at our dumbest at the beginning, and at our
smartest at the end". This is the same context in
which organic planning applies. It is not always the
context in which we work, but when it is, then late
binding -- lock-in -- is valuable.
One of the reasons I like to use dynamic programming
languages is because they give me late binding in two
dimensions: at programming time and at run time. When
I'm coding in a domain where I'm not very smart at the
outset and become smarter with experience, late binding
in programming time seems to make me more productive.
Allowing my programs to make decisions as late as
possible means that I can imbue my code with the same
sense of committing at the right time to an object or
function, not sooner.
Implicit in this notion is that our designs and programs
will change as we move forward, as we learn more. In
the domain of new business ideas, where Sivers works,
change and growth are almost unavoidable. Those of us
who program in interesting new domains experience a
similar pattern of learning and evolution. If change
is going to happen, the question becomes, should we
load our change into the beginning or end of our
development process? Seth Godin
knows the answer,
whether you work in software, business, or any other
creative endeavor:
You must thrash at the beginning,
because thrashing at the beginning is cheap.
Some people object to the notion of change as "thrashing",
because it sounds unskilled, unprofessional, even
undignified. Godin uses the term to indicate the kind
of frantic activity that some organizations undertake
as they near a deadline and are trying desperately to
finish a product that is worthy of delivery. In that
context, "thrashing" is a great term. That sort of
frantic activity is not wrong in and of itself -- it
reflects the group's attempt to incorporate all that
it has learned in the course of development. The
problem is in the timing: when too many sticky decisions
have been made, changing a product to incorporate what
we have learned is expensive.
Rather than try to fight against the thrashing, let's
instead move it to the beginning of the process, when
change is less expensive and when are still figuring
out which of our decisions will stick over the long-term.
This is how reactive planning, change, and late binding
can come together to make us more effective developers.
When I encounter people who are skeptical about agile
software development, one of the common concerns I
hear is about the lack of planning and design in
advance. How can we create software with a coherent
design when we don't "really" design? I commented on
this concern a while back when mused about
reactive planning
in AI and software.
Reading last week, I ran across a passage from Lewis
Mumford's book "The City in History" that brought to
mind a similar trade-off between planning upfront and
planning as a system evolves:
Organic planning does not begin with a preconceived
goal; it moves from need to need, from opportunity to
opportunity, in a series of adaptations that themselves
become increasingly coherent and purposeful, so that
they generate a complex final design, hardly less
unified than a pre-formed geometric pattern.
One thing I like about this passage is its recognition
that adaptive planning can produce something that is
coherent and purposeful. Indeed,
many of us prefer to live in places that have grown
organically, with a minimal amount of planning and
oversight to keep growth from going off-track. The
result can still feel whole in a way that other
city designs do not.
I know it is dangerous to extrapolate too casually
from other domains into software development, because
the analogy may not be a solid one. What this passage
offers is something of an existence proof that
adaptation through carefully reactive planning can
produce solid designs in a domain that people know
and understand. This may help us to overcome initial
resistance to the idea of agile planning of software
long enough that they will give it a try. The real
proof comes on software projects -- and many of us
have experienced that.
One of the fun parts of teaching software engineering
this semester has been revisiting some basic patterns
in the design part of the course, and now as we discuss
refactoring in the part of the course that deals with
implementation and maintenance. 2009 is the 15th
anniversary of the publication of Design Patterns,
the book that launched software patterns into the
consciousness of mainstream developers. Some folks
reminisced about the event at OOPSLA this year, but I
wasn't able to make it to Orlando. OOPSLA 2004 had a
great 10th-anniversary celebration, which I had the
good fortune to attend
and write about.
I wasn't present at OOPSLA in 1994, when the book
created an unprecedented spectacle in the exhibit
hall; that just predates my own debut at OOPSLA.
But wish I had been!
InformIT recently ran a series of interviews with OO
and patterns luminaries, sharing their thoughts on
the book and on how patterns have changed the
landscape of software development. The
interview with Brian Foote
had a passage that I really liked:
InformIT: How has Design Patterns changed your
impressions about the way software is built?
The vision of reuse that we had in the object-oriented
community in hindsight seems like a God that Failed. Just
as the Space Shuttle never lived up to its promised reuse
potential, libraries, frameworks, and components, while
effective in as far as they went, never became foundations
of routine software reuse that many had envisioned and
hoped.
Instead, designs themselves, design ideas, patterns
became the loci of reuse. We craft our ideas, by hand,
into each new artifact we build.
This insight gets to the heart of why patterns matter.
Other forms of reuse have their place and use, but they
operate at a code level that is ultimately fragile in
the face of the different contexts in which our programs
operate. So they are, by necessity, limited as vehicles
for reuse.
Design ideas are less specific, more malleable. They
apply in a million contexts, though never in quite the
same way. We mold them to the context of our program.
The patterns we see in our designs and tests and
implementations give us the abstract raw material out
of which to create our programs. We still strive for
reuse, but at a different level of thinking and working.
Read the full interview linked above. It is typical
Brian Foote: entertaining and full of ideas presented
slightly askew from the typical vantage point. That
twist helps me to think differently about things that
may have otherwise become commonplace. And as so often
happens, I had to
look a word up in the dictionary
before I reached the end. I always seem to learn
something from Brian!
Who would have thought that this would turn out
to be a major challenge to software developers,
software to improve on index cards?
Like a dog gnawing on a bone, I had planned to
write more about the topic of
software for XP planning.
The thread on the XP list just kept on going,
and I was sure that I needed to rebut some of
the attitude about index cards being the perfect
technology for executing XP. I'm not sure why
I felt this need. I mostly agree that small
cards and fat pens are the best way for us to
implement story planning and team communication
in XP. Maybe it's an academic's vice to drive
any topic into the ground on a technicality.
Fortunately, though, I came to realize that I
was punching a strawman. Most of the folks on
the list who are talking up the use of low-fi
technology don't take a hard stance on reality
versus simulation as discussed in my previous
post, even when it colors their rhetoric.
Most would simply say something like this:
"Index cards and felt-tip markers simply work
better for us right now than anything else.
If someone wants to claim that a software tool
can do as well or better, they'll have to show
us."
Skepticism and
asking for evidence
-- many of us all can do better with such an
attitude.
I also realized what has been the most interesting
result of this discussion thread for me: a chance
to see what XP practitioners consider to be the
essential features of a planning tool for agile
teams. Which characteristics of cards and markers
make them so useful? Which characteristics of
existing software tools get in the way of doing
the job as well as index cards? This includes
general-purpose software that we use for XP, say,
a spreadsheet, and software built explicitly for
P teams (there are many).
As a part of the XP list discussion, Ilja Preuss
posted a link to his blog entry on
criteria for XP team tools.
Here the start of a feature list for XP planning
software that I gleaned from that entry and from
a few of the articles in the thread:
easy to see all the stories at once
easy to move the stories around
easy to make notations of various sorts on
the stories
provides visual cues of the size of the
system and what stories are most important
makes all of the people related to the project
comfortable with making changes
The overarching themes in this discussion are high
visibility and strong collaboration. In
this context, good tools provide more than a one- or
even two-way communication medium. In addition to
what they communicate, they must communicate in a way
that is visible to as many team members as possible
at all times. This is the first step toward enabling
and encouraging interactivity. One of the most
powerful roles that cards play in software development
is that of tokens in a
cooperative game
-- several games, really -- that moves a project
forward. Without interactivity, the communication
that makes it possible for projects to succeed tends
to die off.
Some people are trying to build better tools, and I
applaud them. I hope they draw on their own experience
and on the experiences we find shared in forums such
as the XP list. One tool-in-progress that caught my
attention was
Taskboardy,
which builds on Google Wave. Kent Beck recently
tweeted and blogged that he had not yet grokked the
need to be satisfied by Wave. Without a killer itch
to be scratched, it is hard for a new technology,
especially a radically different one, to become
indispensable and displace other tools. Maybe the
high degree of communication and interactivity demanded
by agile software teams is just the sort of need that
Wave can satisfy? I don't know, but the best way to
find out is for someone to try.
A recent discussion on the XP mailing list discussed
the relative merits of using physical cards for story
planning versus a program, even something as simple
as a spreadsheet. Someone had asked, "why not use
a program?", and lots of XP aficionados explained
why not.
I mostly agree with the explanations, but one
undercurrent in the discussion bothered me. It is
best captured in this comment:
The software packages are simulations. The board
and cards are the real thing.
I was immediately transported twenty years back, to
a set of old arguments against artificial intelligence.
They went something like this... If we write a
program to simulate a rainstorm, we will not get wet;
it is just a simulation. By the same token, we can
write a program to simulate symbol processing the way
we think people do it, but it's not real symbol
processing; it is just a simulation. We can write a
program to simulate human thought, but it's not real;
it's just simulated thought. Just as a simulated
rainstorm will not make us wet, simulated thought
can't enlighten us. Only human thought is real.
That always raised my hackles. I understand the
difference between a physical phenomenon like rain
and a simulation of it. But symbol processing and
thought are something different. They are physical
in our brains, but they manifest themselves in our
interactions with the exterior world, including other
symbol processors and thinkers. Turing's insight in
his seminal paper
Computing Machinery and Intelligence
was to separate the physical instantiation of intelligent
behavior from the behavior itself. The essence of the
behavior is its ability to communicate ideas to other
agents. If a program can carry on such communication
in a way indistinguishable form how humans communicate,
then on what grounds are we to say that the simulation
is any less real than the real thing?
That seems like a long way to go back for a connection,
but when I read the above remark, from someone whose
work I greatly respect, it, too, raised my hackles.
Why would a software tool that supports an XP practice
be "only" a simulation and current practice be the real
thing?
The same person prefaced his conclusion above with
this, which explains the reasoning behind it:
Every software package out there has to "simulate" some
definite subset of these opportunities, and the more of
them the package chooses to support the more complex to
learn and operate it becomes. Whereas with a physical
board and cards, the opportunities to represent useful
information are just there, they don't need to be
simulated.
The current way of doing things -- index cards and
post-it notes on pegboards -- is a medium of expression.
It is an old medium, familiar, comfortable, and well
understood, but a medium nonetheless. So is a piece
of software. Maybe we can't express as much in our
program, or maybe it's not as convenient to say what
we want to say. This disadvantage is about what we
can say or say easily. It's not about reality.
The same person has the right idea elsewhere in his
post:
Physical boards and cards afford a much larger world
of opportunities for representing information about
the work as it is getting done.
Ah... The physical medium fits better into how we
work. It gives us the ability to easily represent
information as the work is being done. This is about
work flow, not reality.
Another poster gets it right, too:
It may seem counterintuitive for those of us who
work with technology, but the physical cards and
boards are simply more powerful, more expressive,
and more useful than electronic storage. Maybe
because it's not about storage but communication.
The physical medium is more expressive, which makes
it more powerful. More power combined with greater
convenience makes the physical medium more useful.
This conclusion is about communication. It doesn't
make the software tool less real, only less useful
or effective.
You will find that communication is often the bottom
line when we are talking about software development.
The agile approaches emphasize communication and so
occasionally reach what seems to be a counterintuitive
result for a technical profession.
I agree with the XP posters about the use of physical
cards and big, visible boards for displaying them.
This physical medium encourages and enhances human
communication in a way that most software does not
-- at least for now. Perhaps we could create better
software tools to support our work? Maybe computer
systems will evolve to the point that a live display
board will dynamically display our stories, tasks,
and status in a way that meshes as nicely with human
workflow and teamwork as physical displays do now.
Indeed, this is probably possible now, though not
as inexpensively or as conveniently as stash of index
cards, a cheap box of push pins, and some cork board.
I am open to a new possibility. Framing the issue
as one of reality versus simulation seems to imply
that it's not possible. I think that perspective
limits us more than it helps us.
In recent years, my favorite conference,
OOPSLA,
has been suffering a strange identity crisis. When
the conference began in the mid-1980s, object-oriented
programming was a relatively new idea, known to some
academics but unheard of by most in industry. By the
early 2000s, it had gone mainstream. Most developers
understands OOP now, or think they do. Our languages
and tools make it seem second nature. We teach it to
freshmen in many universities. Who needs a big conference
devoted to objects?
As I've written before, say,
here,
this reflects a fundamental misunderstanding about
OOPSLA has always been about. It's a natural
misunderstanding, given the name and the marketing
hype around it through the 1990s, but a misunderstanding
nonetheless. It's hard to unbrand a well-known
conference and re-brand it once its existing brand
loses its purpose or zip. So OOPSLA struggles a bit.
I hear that next year it will become one attraction
under the umbrella of a new event, "SPLASH". (More on
that later!)
In the last few years, people have begun to notice
something similar going on with a younger spinoff from
OOPSLA. Agile software development has started to
become mainstream. It is over the initial hump of
awareness and acceptance. Most everyone knows what
'agile' is, or thinks he does. Its practices have
begun to seep into a large number of software houses,
whether from Scrum or XP. Our languages and tools
now make it possible to work in shorter iterations
with continuous feedback and more confidence. We
teach it in universities, sometimes even to freshmen.
Agile has become old school.
Maybe I'm overstating things a bit, but the buzz has
certainly died off. Now we are more likely to hear
grumbling. I don't know that many people are asking
whether we need conferences devoted to agile approaches
yet. But I am starting to read articles that second
guess the "movement" and to see a lot of revisionist
history. Perhaps this is what happens when the
excitement of newness fades into the blandness of
same-old, same-old. The excitement passes, and people
begin to pay attention more to the chinks in the
armor than the strengths that gave the idea birth.
But why Agile sells isn't why I liked it. I liked
it *because* it put the programmer at the center
of the effort of programming (crazy notion that),
I didn't need the manifesto to tell me that I had
to find ways to make the person paying the money
delighted with my efforts, what I needed was a way
to tell them that I would gladly do so, if they
would just let me.
(The asterisks are his. The bold is mine.)
This is what made XP and the other agile approaches
so very important. Focusing on the buyers' needs
is easy to do. They pay for software and so have
an opportunity to affect strongly the nature of
software development. What was missing pre-agile
was attention to the developer. I still
prefer the term "programmer", with all it implies.
It was easy to find ways in which programmers were
marginalized, buried beneath processes, documentation,
and tools that seemed primarily to serve purposes
other than to trust and help programmers to make
great software.
The agile movement helped to change that, to shift
the perspective from inhuman processes that expected
the worst from programmers to practices that celebrate
programmers and their love for making software.
That some people are now even talking about restating
the Agile Manifesto's values toward maximizing
shareholder value is a tribute to agile's success at
changing the overarching story of the industry.
All this reminds me of an essay by Brian Marick on
ease and joy.
Agile is about joy at work. We programmers love to
make software -- software that improves the lives of
its users. Great software. Let us love writing
programs, and we can do great things for you.
I enjoyed Reg Braithwaite's talk
Ruby.rewrite(Ruby)
(slides
available on-line).
It gives a nice survey of some
metaprogramming hacks
related to Ruby's syntactic and semantic structure.
To me, one of the most thought-provoking things Reg
says is actually a rather small point in the overall
message of the talk. Object-oriented programming is,
he summarizes, basically a matter a matter of nouns
and verbs, objects and their behaviors. What about
other parts of speech? He gives a simple example of
an adverb:
blitz.not.blank?
In this expression, not
is an adverb that modifies the behavior of
blank?. At the
syntactic level, we are really telling
blitz to behave
differently in response to the next message, which
happens to be blank?,
but from the programmer's semantic level
not modifies the
predicate blank?.
It is an adverb!
Reg notes that some purists might flag this code as
a violation of the
Law of Demeter,
because it sends a message to an object received
from another message send. But it doesn't! It just
looks that way at the syntax level. We aren't
chaining two requests together; we are
modifying how one of the requests works, how
its result is to be interpreted. While this may
look like a violation of the Law of Demeter, it
isn't. Being able to talk about adverbs, and thus
to distinguish among different kinds of message,
helps to make this clear.
It also helps us to program better in at least two
ways. First, we are able to use our tools without
unnecessary guilt at breaking the letter of a law
that doesn't really apply. Second, we are freed
to think more creatively about how our programs can
say what we mean. I love that Ruby allows
me to create constructs such as
not and weave them
seamlessly into my code. Many of my favorite gems
and apps use this feature to create domain-specific
languages that look and feel like what they are and
look and feel like Ruby -- at the same time.
Treetop
is an example. I'd love to hear about your favorite
examples.
So, our OO programs have nouns and verbs and adverbs.
What about other parts of speech? I can think of
at least two from Java. One is pronouns. In English,
this is a
demonstrative pronoun. It is in Java, too. I think
that super is also
demonstrative pronoun, though it's not a word we use
similarly in English. As an object, I consist of
this part of me and
that (super) part
of me.
Another is adjectives. When I teach Java to students,
I usually make an analogy from access modifiers --
public,
private, and
protected -- to
adjectives. They modify the variables and methods
which they accompany. So do
synchronized and
volatile.
Once we free ourselves to think this way, though, I
think there is something more powerful afoot. We
can begin to think about creating and using our own
pronouns and adjectives in code. Do we need to say
something in which another part of speech helps us
to communicate better? If so, how can we make it
so? We shouldn't be limited to the keywords defined
for us five or fifteen or fifty years ago.
Thinking about adverbs in programming languages
reminds me of a wonderful
Onward! talk
I heard at the
OOPSLA 2003
conference.
Cristina Lopes
talked about
naturalistic programming.
She suggested that this was a natural step in the
evolution from aspect-oriented programming, which had
delocalized references within programs in a new way,
to code that is concise, effective, and understandable.
Naturalistic programming would seek to take advantage
of elements in natural language that humans have been
using to think about and describe complex systems for
thousand of years. I don't remember many of the details
of the talk, but I recall discussion of how we could
use anaphora (repetition for the sake of emphasis)
and temporal references in programs. Now that my mind
is tuned to this wavelength, I'll go back to read the
paper and see what other connections it might trigger.
What other parts of speech might we make a natural
part of our programs?
(While writing this essay, I have felt a strong sense
of deja vu. Have I written a previous blog
entry on this before? If so, I haven't found it yet.
I'll keep looking.)
One of my colleagues is an old-school C programmer.
He can make the machine dance using C. When C++
came along, he tried it for a while, but many of
the newly-available features seemed like overkill
to him. I think templates fell into that category.
Other features disturbed him. I remember him
reporting some particularly bad experiences with
operator overloading. They made code unreadable!
Unmaintainable! You could never be sure what
+ was doing, let
alone operators like ()
and casts. His verdict: Operator overloading and
its ilk are too powerful. They are fine in theory,
but real languages should not provide so much freedom.
Some people don't like languages with features that
allow them to reconfigure how the language looks and
works. I may have been in that group once, long ago,
but then I met Lisp and Smalltalk. What wonderful
friends they were. They opened themselves completely
to me; almost nothing was off limits. In Lisp, most
everything was open to inspection, code was data that
I could process, and macros let me define my own syntax.
In Smalltalk, everything was an object, including the
integers and the classes and the methods. Even better,
most of Smalltalk was implemented in Smalltalk, right
there for me to browse and mimic... and
change.
There is no such thing as metaprogramming.
It's all just programming.
(Note: "Colorful" is a euphemism for "not safe to read
aloud at work, nor to be read by those with tender
sensibilities".)
Ruby fits nicely with languages such as Common Lisp,
Scheme, and Smalltalk. It doesn't erect too many
boundaries around what you can do. The result can be
disorienting to someone coming from a more mainstream
language such as Java or C, where boundaries between
"my program" and "the language" are so much more common.
But to Lispers, Schemers, and Smalltalkers, the freedom
feels... free. It empowers them to express their ideas
in code that is direct, succinct, and powerful.
Actually, when you program in C, you learn the same
lesson, only in a different way. It's all just
programming. Good C programmers often implement their
own little interpreters and their own higher-order
procedures as a part of larger programs. To do so,
they simply create their own data structures and code
to manipulate them. This truth is the raw material out
of which
Greenspun's Tenth Rule of Programming
springs. And that's the point. In languages like C,
if you want to use more powerful features, and you
will, you have to roll them for yourself. My
friends who are "C weenies" -- including the
aforementioned colleague -- take great pride in their
ability to solve any problem with just a bit more
programming, and they love to tell us the stories
Metaprogramming is not magic. It is simply another tool
in the prepared programmer's toolbox. It's awfully nice
when that tool is also part of the programming language
we use. Otherwise, we are limited in what we can say
conveniently in our programs by the somewhat arbitrary
lines drawn between real and meta.
You know what? Almost everything in programming looks
like magic to me. That may seem like an overstatement,
but it's not. When I see a program of a few thousand
lines or more generate music, play chess, or even do
mundane tasks like display text, images, and video in
a web browser, I am amazed. When I see one program
convert another into the language of a particular
machine, I am amazed. When people show me shorter
programs that can do these things, I am even more
amazed.
The beauty of computer science is that we dig deeper
into these programs, learn their ideas, and come to
understand how they work. We also learn how to write
them ourselves.
It may still feel like magic to me, but in my mind I
know better.
Whenever I bump into a new bit of sorcery, a new
illusion or a new incantation, I know what I need to
do. I need to learn more about how to write programs.
I know all about the idea of "writing to learn". It
is one of the most valuable aspects of this blog for
me. When I first got into academia, though, I was
surprised to find how many books in the software
world are written by people who are far from experts
on the topic. Over the years, I have met several
serial authors who pick a topic in conjunction with
their publishers and go. Some of these folks write
books that are successful and useful to people.
Still the idea has always seemed odd.
In the last few months, I've seen several articles
in which authors talk about how they set out to write
a book on a topic they didn't know well or even much
at all. Last summer, Alex Payne wrote
this about writing the tapir book:
I took on the book in part to develop a mastery of Scala,
and I've looked forward to learning something new every
time I sit down to write, week after week. Though I
understand more of the language than I did when I started,
I still don't feel that I'm on the level of folks like
David Pollak, Jorge Ortiz, Daniel Spiewak, and the rest of
the Scala gurus who dove into the language well before Dean
or I. Still, it's been an incredible learning experience
...
I'm also completely confident in this statement -- if you
are willing to learn new things, and learn them quickly,
you don't need to be the lead maintainer and overlord to
write a good technical book on a topic. (Though it does
help tremendously to have a trusted super-expert as a
technical reference.)
Pick something that you are genuinely curious about and
that you want to understand really, really well. It's
painful to write even a chapter about something that
doesn't interest you.
This kind of writing to learn is still not a part of my
mentality. I've certainly chosen to teach courses in
order to learn -- to have to learn -- something I want
to know, or know better. For example, I didn't know any
PHP to speak of, so I gladly took on a
5-week course
introducing PHP as a scripting language. But I have a
respect for books, perhaps even a reverence, that makes
the idea of publishing one on a subject I am not expert
in unpalatable. I have to much respect for the people
who might read it to waste their time.
I'm coming to learn that this probably places an unnecessary
limit on myself. Articles like Payne's and Rappin's
remind me that I can study something and become expert
enough to write a book that is useful to others. Maybe
it's time to set out on that path.
Getting people to take this step is one good reason to
heed the call of
Pragmatic Programmers Writing Month
(PragProWriMo), which is patterned after the more generic
NaNoWriMo
(NaNoWriMo). Writing is like anything else: we can
develop a habit that helps us to produce material
regularly, which is a first and necessary step to ever
producing good material regularly. And if
research results on forming habits
is right, we probably need a couple of months of
daily repetitions to form a habit we can rely on.
So, whether it's a book or blog you have in mind, get
to writing.
(Oh, and you really should click through the link in
Rappin's essay to Merlin Mann's
Making the Clackity Noise
for a provocative -- if salty -- essay on why you should
write. From there, follow the link to Buffering, where
you will find a video of drummer Sonny Payne playing an
extended solo for Count Basie's orchestra. It is simply
remarkable.)
I was happy to come across Greg Wilson's talk,
Bits of Evidence,
on empirical data in software engineering. When I started
preparing to teach software engineering last summer, I
looked for empirical data to support some of the claims
that we make about building software. I wasn't all that
successful. I figured that either I wasn't looking hard
enough, or there wasn't much. The answer probably lies
somewhere in the middle.
Someone could do the SE world a great service by gathering,
organizing, and providing links to all the good work that
has been done. Wilson is one of the people I turn to for
pointers to empirical SE results.
I did have fun reading some classic old work in this area.
One is McCabe's
original article
on cyclomatic complexity. This is very cool and has a nice
tie to theory, but it simply describes a metric. It does
not gather present data from real programs against which
the metric has applied, and it doesn't provide any base
line for comparison. When he speaks of 10 as a reasonable
upper bound for a module's cyclomatic complexity, or of
code with cyclomatic complexity in the 3-7 range as "quite
well structured", I wonder "Why?" He drew these values
from experience looking at production code available to
him, but these numbers feel a bit unreliable.
I'm not a stickler who needs statistically significant
analysis of carefully collected data, though. I like
to learn from experience that is gathered and presented
qualitatively. I enjoyed reading about an informal
experiment into the
complexity of code developed test-first.
We need to be careful to take the results with a grain
of salt, given the informality of the definitions and
methodology used, but the experiment seems to say
something useful. I also liked Martin Fowler's
reflective analysis
of dynamic type checking in production Ruby code from
ThoughtWorks. He also wrote an interesting reflection
on
Ruby at ThoughtWorks
that I learned from.
Still, we need more of the sort of empirical evidence
that Wilson offers in his talk. As a discipline, we
can do a better job of paying attention to the validity
of our claims, and of more frequently asking, "Data,
please!"
I really enjoyed reading the text of William Cook's
banquet speech at ECOOP 2009.
When I served as tutorials chair for
OOPSLA 2006,
Cook was program chair, and that gave me a chance
to meet him and learn a bit about his background.
He has an interesting career story to tell. In
this talk, he tells us this story as a way to
compare and contrast computer science in academia
and in industry. It's well worth a read.
As a doctoral student, I thought my career path
might look similar to Cook's. I applied for
research positions in industry, with two of the
Big Six accounting firms and with an automobile
manufacturer, at the same time I applied for
academic positions. In the end, after years of
leaning toward industry, I decided to accept a
faculty position. As a result, my experience with
industrial CS research and development is limited
to summer positions and to interactions throughout
grad school.
Cook's talk needs no summary; you should read it
for yourself. Here are a few points that stood
out to me as I read:
Venture capitalists talk about pain killers versus
vitamins. A vitamin is a product that might make
you healthier over the long run, but it's hard to
tell. Pain killers are products where the customer
screams "give it to me now" and asks what it costs
later. Venture capitalists only want to fund pain
killers.
This is true not only of venture capitalists, but
of lots of people. As a professor, I recognize
this in myself and in my students all of the time.
Cook points out that most software development tools
are vitamins. So are many of the best development
practices. We need to learn tools and practices
that will make us most productive and powerful in
the long run, but without short-term pain we may
not generate the resolve to do so.
We read all the standard references on OO for
business applications. It didn't make sense to us.
We started investigating model-driven development
styles. We created modeling languages for data,
user interfaces, security and workflow. These four
aspects are the core of any enterprise application.
We created interpreters to run the languages, and
our interpreters did many powerful optimizations by
weaving together the different aspects.
To me, this part of the talk exemplifies best how
a computer scientist thinks differently than a
non-computer scientist, whether experienced in
software development or not. Languages are tools
we create to help us solve problems, not merely
someone else's solutions we pluck off the shelf.
Language processors are tools we create to make
our languages come to life in solving instances
of actual problems.
The way I see it is that industry generally has
more problems than they do solutions, but academia
often has more solutions than problems.
Cook makes a great case for a bidirectional flow
between industry, with its challenging problems in
context, and academia, with its solutions built of
theory, abstraction, and design. This transfer can
be mutually beneficial, but it is complicated by
context:
Industrial problems are often messy and tied to
specific technical situations or domains. It is
not easy to translate these complex problems into
something that can be worked on in academia. This
translation involves abstraction and selection.
The challenge is greatest when we then take
solutions to problems abstracted from real-world
details and selected for interestingness more than
business value and try to re-inject them into the
wild. Too often, these solutions fail to take hold,
not because people in industry are "stupid or timid"
but because the solution doesn't solve their
problem. It solves an ideal problem, not a
real one. The translation process from research to
development requires a finishing step that people
in the research lab often have little interest in
doing and that people in the development studio have
little time to implement. The result is a disconnect
that can sour the relationship unnecessarily.
Finally, the talk is full of pithy lines that I hope
to steal and use to good effect sometime soon. Here
is my favorite:
Simplicity is not where things start. ... It is
where they end.
Computer scientists seek simplicity, whether in
academia or in industry. Cook gives us some clues
in this talk about how people in these spheres can
understand one another better and, perhaps, work
better together toward their common goal.
I know that you are talking about visual design,
but I am struck by how this approach applies to
many other domains.
But I could have.
I started university life intending to become an architect,
and my interest in visual design has remained strong
through the years. I was delighted when I learned of
Christopher Alexander's influence on some in the software
world, because it gave me more opportunities to read and
think about architectural design -- and to think about
how its ideas relate to how we design software. I am
quite interested in the notion that there are universal
truths about design, and even if not what we can learn
from designers in other disciplines.
Garr Reynolds identifies seven principles of the Zen
aesthetic of harmony. Like the commenter, my thoughts
turned quickly from the visual world to another domain.
For me, the domain is software. How well do these
principles of harmony apply to software? Several are
staples of software design. Others require more
thought.
(1) Embrace economy of materials and means
(3) Keep things clean and clutter-free
These are no-brainers. Programmers want to keep their
code clean, and most prefer an economical style, even
when using a language that requires more overhead than
they would like.
(6) Think not only of yourself, but of the other (e.g., the viewer).
When we develop software, we have several kinds of
others to consider. The most obvious are our users.
We have disciplines, such as human-computer interaction,
and development styles, such as user-centered design,
focused squarely on the people who will use our programs.
We also need to think of other programmers. These are
the people who will read our code. Software usually
spends much more time in maintenance than in creation,
so readability pays off in a huge way over time. We
can help our readers by writing good documentation, an
essential complement to our programs. However, the
best way to help our readers is to write readable
code. In this we are more like Reynolds's presenters.
We need to focus on the clarity and beauty of our primary
product.
Finally, let's not forget our customers and our clients,
the people who pay us to write software. To me, one of
the most encouraging contributions of XP was its emphasis
on delivering tangible value to our customers every day.
(7) Remain humble and modest.
This is not technical advice. It is human advice. And I
think it is underrated in too many contexts.
I have worked with programmers who were not humble enough.
Sadly, I have been that programmer, too.
A lack of humility almost always hurts the project and
the team. Reynolds is right in saying that true confidence
follows from humility and modesty. Without humility,
a programmer is prone to drift into arrogance, and
arrogance is more dangerous than incompetence.
A programmer needs to balance humility against gumption,
the hubris that empowers us to tackle problems which seem
insurmountable. I have always found that humility is
a great asset when I have the gumption to tackle a big
problem. Humility keeps me alert to things I don't
understand or might not see otherwise, and it encourages
me to take care at each step.
... Now come a couple of principles that cause me to
thing harder.
(2) Repeat design elements.
Duplication is a bane to software developers. We long
ago recognized that repetition of the same code creates
so many problems for writing and modifying software that
we have coined maxims such as "Don't repeat yourself"
and "Say it one once and only once." We even create
acronyms such as DRY to get the idea across in three
spare letters.
However, at another level, repetition is unavoidable.
A stack is a powerful way to organize and manipulate
data, so we want to use one whenever it helps. Rather
than copy and paste the code, we create an abstract
data type or a class and reuse the component by
instantiating it.
Software reuse of this sort is how programmers repeat
design elements. Indeed, one of the most basic ideas
in all of programming is the procedure, an abstraction
of a repeated behavioral element. It is fundamental
to all programming, and one of the contributions that
computer science made as we moved away from our roots
in mathematics.
In the last two decades, programmers have begun to
embrace repeatable design units at higher levels.
Design patterns recur across contexts, and so now we
do our best to document them and share them with others.
Architectures and protocols and, yes, even our languages
are ways to reify recurring patterns in a way that makes
using them as convenient as possible.
(4) Avoid symmetry.
Some programmers may look at this principle and say,
"Huh? How can this apply? I'm not even sure what it
means in the context of software."
When linguistic structures and data structures repeat,
they repeat just as they are, bringing a natural
symmetry to the algorithms we use and the code we
write. But at the level of design patterns and
architectures, things are not so simple. Christopher
Alexander, the building architect who is the
intellectual forefather of the software patterns
community, famously said that a pattern appears a
million times, but never exactly the same. The pattern
is molded to fit the peculiar forces at play in each
system. This seems to me a form of breaking symmetry.
But we can take the idea of avoiding symmetry farther.
In the mathematical and scientific communities, there
has long been a technical definition of symmetry in
groups, as well as a corresponding definition of
breaking symmetry in patterns. Only a few people in
the software community have taken this formal step
with design patterns. Chief among them are Jim Coplien
and Liping Zhao. Check out their book chapter,
Symmetry Breaking in Software Patterns,
if you'd like to learn more.
A few years ago I was able to spend some time looking
at this paper and at some of the scientific literature
on patterns and symmetry breaking. Unfortunately, I
have not been able to return to it since. I don't yet
fully understand these ideas, but I think I understand
enough to see that there is something important here.
This glimmer convinces me that avoiding symmetry is
perhaps an important principle for us software designers,
one worthy of deeper investigation.
... This leaves us with one more principle from the
Presentation Zen article:
(5) Avoid the obvious in favor of the subtle
This is the one principle out of the seven that I think
does not apply to writing software. All other things
being equal, we should prefer the obvious to the
subtle. Doing something that isn't obvious is the
single best reason to write a comment in our code.
When we must do something unexpected by our readers, we
must tell them what we have done and why.
Subtlety is an impediment to understanding code.
Perhaps this is a way in which we who work in software
differ from creative artists. Subtlety can enhance a
work of art, by letting -- even requiring -- the mind
to sense, explore, and discover something beyond the
surface. As much art as there is in good code, code is
at its core a functional document. Requiring
maintenance programmers to mull over a procedure and to
explore its hidden treasures only slows them down and
increases the chances that they will make errors while
changing it.
I love subtlety in algorithms and designs, and I think
I've learned a lot from reading code that engages me
in a way I've not experienced before. But there is
something dangerous about code in which subtlety becomes
more important than what the program does.
But, it got me thinking about clever and production code.
In my opinion, clever is never good or wanted in production
code. It's great to learn and understand clever code,
though. It's a great mental workout to keep you sharp.
Maybe I am missing something subtle here; I've been
accused of not seeing nuance before. This may be like
the principle of avoiding symmetry, but I haven't
reached the glimmer of understanding yet. Certainly,
many people speak of Apple's great success with subtle
design that engages and appeals to users in a way that
other design companies do not. Others, though attribute
its success to creating products that are intuitive to
use. To me, intuitiveness points more to obviousness
and clarity than to subtlety. And besides, Apple's
user experience is at the level of design Reynolds is
talking about, not at the level of code.
I would love to hear examples, pro and con, of subtlety
in code. I'd love to learn something new!
If you're too old to remember DOS, this may not mean
much to you. Ironically, the article is about a
vestige of old Mac OS that is disappearing. It's an
interesting read, even for non-Mac guys, as an example
of software evolution.
Reader and occasional writer that I am, Michael
Nielsen's
Six Rules for Rewriting
seemed familiar in an instant. I recognize their
results in good writing, and even when I don't practice
them successfully in my own writing I know they would
often make it better.
Occasional programmer that I am, they immediately had
me thinking... How well do they apply to refactoring?
Programming is writing, and refactoring is one of our
common forms of rewriting... So let's see.
First of all, let's acknowledge up front that a
writer's rewriting is not identical to a programmer's
refactoring. First of all, the writer does not have
automated tests to help her ensure that the rewrite
doesn't break anything. It's not clear to me
exactly what not breaking anything means for a writer,
though I have a vague sense that it is meaningful for
most writing.
Also, the term "refactoring" does not refer to any
old rewrite of a code base. It has a technical
meaning: to modify code without changing its
essential functionality. There are rewrites of a
code base that are not refactoring. I think that's
true of writing in general, though, and I also think
that Nielsen is clearly talking about rewrites that
do not change the essential content or purpose of a
text. His rules are about how to say the same
things more effectively. That seems close enough
to our technical sense of refactoring to make this
exercise worth an effort.
Striking
Every sentence should grab the reader and propel
them forward.
Can we say that every line of code should grab
the reader and propel her forward?! I certainly prefer
to read programs in which every statement or expression
tells me something important about what the program is
and does. Some programming languages make this harder
to do, with boilerplate and often more noise than signal.
Perhaps we could say that every line of code should
propel the program forward, not get in the way of its
functionality? This says more about the conciseness
with which the programmer writes, and fits the spirit
of Nielsen's rule nicely.
Every paragraph should contain a striking idea,
originally expressed.
Can we say that every function or class
should contain a striking idea, originally expressed?
Functions and classes that do not usually get in the
reader's way. In programming, though, we often write
"helpers", auxiliary functions or classes that assist
another in expressing an essential, even striking,
idea. The best helpers capture an idea of deep value,
but it's may be the nature of decomposition that we
sometimes create ones that are striking only in the
context of the larger system.
The most significant ideas should be distilled into
the most potent sentences possible.
Yes! The most significant ideas in our programs
should be distilled into the most potent code
possible: expressions, statements,
functions, classes, whatever the
abstractions our language and style provide.
Style
Use the strongest appropriate verb.
Of course.
Names matter.
Use the strongest, most clearly named primitives and
library functions possible. When we create new
functions, give them strong, clear names. This rule
applies to our nouns, too. Our variables and classes
should carry strong names that clearly name their
concept. No more "manager" or "process" nouns. They
avoid naming the concept. What do those objects
do?
This rule also applies more broadly to coding style.
It seems to me that
Tell, Don't Ask
is about strength in our function calls.
Beware of nominalization.
In code, this guideline prescribes a straightforward
idea: Don't make a class when a function will do.
You Aren't Gonna Need It.
Meta
None of the above rules should be consciously applied
while drafting material.
Anyone who writes a lot knows how paralyzing it can be
to worry about writing good prose before getting words
down onto paper, or into an emacs buffer. Often we
don't know what to write until we write it;
why try to write that something perfect before we know
what it is?
This rule fits nicely with most lightweight approaches
to programming. I even encourage novice programmers
to write code this way, much to the chagrin of my more
engineering-oriented colleagues. Don't be paralyzed
by the blank screen. Write freely.
Make something work,
anything on the path to a solution, and only then
worry about making it right and fast.
Do the simplest thing
that will work. Only after your code works do you
rewrite to make it better.
Not all rewriting is refactoring, but all refactoring
is rewriting. Write. Pass the test.
Refactor.
Many people find that refactoring provides the most
valuable use of design patterns, as a target toward
which one moves the code. This is perhaps a more
important use of patterns than initial design, at
which time many of us tend to overdesign our programs.
Joshua Kerievsky's
Refactoring to Patterns
book makes shows programmers how to do this safely
and reliably. I wonder if there is any analogue to
this book in the writing world, or if there even
could be such a book?
I once wrote a post on
writing in an agile style,
and rewriting played a key role in that idea. Some
authors like rewriting more than writing, and I think
you can say the same thing of many, many programmers.
Refactoring brings a different kind of joy, at getting
something right that was before almost right
-- which is, of course, another way of saying not
yet right.
I recall once talking with a novelist over lunch about
tools for writers.
Yet even the most humble word processor has done so
much to change how authors write and rewrite. One of
the comments on Nielsen's entry asks whether new tools
for writing have changed the way writers think. We
might also ask whether new tools -- the ability to
edit and rewrite so much more easily and with so much
less= technical effort -- has changed the product
created by most writers. If not, could it?
New tools also change how we rewrite code. The
refactoring browser has escaped the confines of the
Smalltalk image and now graces IDEs for Java, C++,
and C## programmers; indeed, refactoring tools exist
for so many languages these days. Is that good or
bad? Many of my colleagues lament that the ease of
rewriting has led to an endemic sloppiness, to a
rash of random programming in which students keep
making seemingly random changes to their code until
something compiles. Back in the good old days, we
had to think hard about our code before we carved
it into clay tablets... It seems clear to me that
making rewriting and refactoring easier is a huge
win, even as it changes how we need to teach and
practice writing.
In retrospect, a lot of Nielsen's rules generalize
to dicta we programmers will accept eagerly.
Eliminate boilerplate. Write concise, focused code.
Use strong, direct, and clear language. Certainly
when we abstract the tasks to a certain level, writing
and rewriting really are much the same in text and
code.
Writing a test before writing code provides a wonderful
level of accountability to self and world. The test
helps me know what code to write and when we are done.
I am often weak and like being able to keep myself
honest. Tests also enable me to tell my colleagues and
my boss.
These days, I usually think in test-first terms whenever
I am creating something. More and more finding myself
wondering whether a test-driven approach might work even
better. In a recent blog entry, Ron Jeffries asked for
analogues of test-driven development
outside the software world. My first thought was, what
can't be done test-first or even test-driven?
Jeffries is, in many ways, better grounded than I am, so
rather than talk about accountability, he writes about
clarity and concreteness as virtues of TDD. Clarity,
concreteness, and accountability seem like good features
to build into most processes that create useful artifacts.
I once wrote about student outcomes assessment as a source
of
accountability and continuous feedback
in the university. I quoted Ward Cunningham at the top
of that entry, " It's all talk until the tests run.",
to suggest to myself a connection to test-first and
test-driven development.
Tests are often used to measure student outcomes from
courses that we teach at all levels of education. Many
people worry about placing too much emphasis on a specific
test as a way to evaluate student learning. Among other
things, they worry about "teaching to the test". The
implication is that we will focus all of our instruction
and learning efforts on that test and miss out
on genuine learning. Done poorly, teaching to the test
limits learning in the way people worry it will. But we
can make a similar mistake when using tests to drive our
programming, by never generalizing our code beyond a
specific set of input values. We don't want to do that
in TDD, and we don't want to do that when teaching. The
point of the test is to hold us accountable: Can our
students actually do what we claim to teach them?
Before the student learning outcomes craze, the common
syllabus was the closest thing most departments had to
a set of tests for a course. The department could
enumerate a set of topics and maybe even a set of skills
expected of the course. Faculty new to the course could
learn a lot about what to teach by studying the syllabus.
Many departments create common final exams for courses
with many students spread across many sections and many
instructors. The common final isn't exactly like our
software tests, though. An instructor may well have done
a great job teaching the course, but students have to
invest time and energy to pass the test. Conversely,
students may well work hard to make sense of what they
are taught in class, but the instructor may have done a
poor or incomplete job of covering the assigned topics.
I thought a lot about TDD as I was designing what is for
me a new course this semester, Software Engineering. My
department does not have common syllabi for courses (yet),
so I worked from a big binder of material given to me by
the person who has taught the course for the last few
years. The material was quite useful, but it stopped
short of enumerating the specific outcomes of the course
as it has been taught. Besides, I wanted to put my
stamp on the course, too... I thought about what the
outcomes should be and how I might help students reach
them. I didn't get much farther than identifying a set
of skills for students to begin learning and a set of
tools with which they should be familiar, if not facile.
Greg Wilson has done a very nice job of designing his
Software Carpentry course in the open
and using
user stories
and other target outcomes to drive his course design.
In modern parlance, my efforts in this regard can be
tagged #fail. I'm not too surprised, though.
For me, teaching a course the first time is more akin
to an
architectural spike
than a first iteration. I have to scope out the
neighborhood before I know how to build.
Ideally, perhaps I should have done the spike prior to
this semester, but neither the world nor I are ideal.
Doing the course this way doesn't work all that badly
for the students, and usually no worse than taking a
course that has been designed up front by someone who
hasn't benefitted from the feedback of teaching the
course. In the latter case, the expected outcomes
and tests to know they have been met will be imperfect.
I tend to be like other faculty in expecting too much
from a course the first few times I teach it. If I
design the new course all the way to the bottom, either
the course is painful for students in expecting too
much too fast, or the it is painful for me as I
un-design and re-design huge portions of the course.
Ultimately, writing and running tests come back to
accountability. Accountability is in short supply in
many circles, university curricula included, and tests
help us to have it. We owe it to our users, and we
owe it to ourselves.
The last two class days in my Software Engineering course,
I have introduced students to agile software development.
Here is a recent Twitter exchange between me and student
in the course:
Student: Agile development is the hippy approach
to programming.
Eugene: @student: "Agile development is the hippy
approach to programming." Perhaps... If valuing people
makes me a hippie, so be it.
Student: @wallingf I leave it up to the individual
whether they interpret that as good or bad. Personally, I
prefer agile, but am also a free spirit
Eugene: @student It's just rare that anyone would
mistake me for a hippie...
Student: @wallingf you do like the phrase "roll my
own" a lot
I guess I can never be sure what to expect when I tell
a story. I've been talking about agile approaches with
colleagues for a decade, and teaching them to students
off and on since 2002. No student has ever described
agile to me as hippie-style development development.
As I think about it from the newcomer's perspective,
though, it makes sense. Consider
Change, and keep changing,
a recent article by Liz Keogh:
Sometimes people ask me, "When we've gone Agile ... what
will it look like?" ...
Things will be changing. You'll be in a better place to
respond to change. Your people will have a culture of
courage and respect, and will seek continuous improvement,
feedback and learning. ...
I have no idea what skills your people will need. The
people you have are good people; start with them. ...
There is no end-state with Agile or Lean. You'll be
improving, and continue to improve, trying new things
out and discarding the ones which don't work. ...
I love Liz Keogh's stuff. Is this article representative
of the agile community? I think so, at least of a vibrant
part of it. Reading this article as I did right after
participating in the above exchange, I can see what the
student means.
I do not think there is a necessary connection between
hippie culture and a preference for agile development.
I am so not a hippie. Ask anyone who knows me.
I see agile ideas from a perspective of pragmatism.
Change happens. Responding to it, if possible, is
better than trying to ignore it while it happens before
my eyes.
Then again, a lot of my friends in the agile community
probably were hippies, or could have been. The Lisp
and Smalltalk worlds have long been sources of agile
practice, and I am willing to speculate that the
counterculture has long been over-represented there.
Certainly, those worlds are countercultural amid the
laced up corporate world of Cobol, PL/I, and Java.
I decided to google "agile hippie" to see who else
has talked about this connection. The
top hit
talks about common code ownership as "hippie socialism"
and highlights the need for a strong team leader to make
P work. Hmm. Then the
second hit
is an essay by Lisp guru and countercultural thinker
Richard Gabriel. It refers to agile methodologies as
rising from the world of paid consultants and open-source
software as the hippie thing.
One of Gabriel's points in this essay echoes something
I told my students today: the difference between
traditional and agile approaches to software is a matter
of degree and style, not a difference in kind. I told
my students that nearly all software development these
days is iterative development, more or less. The agile
community simply prefers and encourages an even tighter
spiral through the stages of development. Feedback is
good.
Folks may see a hippie connection in agile's emphasis
on conversation, working together, and close teamwork.
One thing I like about the Gabriel essay is its mention
of transparency -- being more open about the process
to the rest of the world, especially the client. I
need to bring this element out explicitly in my
presentation, too,
Maybe even the most straight-laced of agile developers
have a touch of hippie radical inside them.
Yesterday evening, in between volleyball games,
I had a chance to do some reading. I marked
several one-liners to blog on. I planned a
disconnected list of short notes, but after I
started writing I realized that they revolve
around a common theme: change.
Over the last few months, Kent Beck has been
blogging about his experiences creating a new
product and trying to promote a new way to think
about his design. In his most recent piece,
Turning Skills into Money,
he talks about how difficult it can be to create
change in software service companies, because the
economic model under which they operates actually
encourages them to have a large cohort of relatively
inexperienced and undertrained workers.
The best line on that page, though, is a much-tweeted
line from a
comment
by Niklas Bjørnerstedt:
A good team can learn a new domain much faster than
a bad one can learn good practices.
I can't help thinking about the change we would like
to create in our students through our
software engineering course.
Skills and good practices matter. We cannot
overemphasize the importance of proficiency, driven
by curiosity and a desire to get better.
Then I ran across Jason Fried's
The Next Generation Bends Over,
a salty and angry lament about the sale of Mint to
Intuit. My favorite line, with one symbolic editorial
substitution:
Is that the best the next generation can do? Become
part of the old generation? How about kicking the
$%^& out of the old guys? What ever happened to that?
I experimented with Mint and liked it, though I never
convinced myself to go all the way it. I have tried
Quicken, too. It seemed at the same time too little
and too much for me, so I've been
rolling my own.
But I love the idea of Mint and hope to see the
idea survive. As the industry leader, Intuit has the
leverage to accelerate the change in how people manage
their finances, compared to the smaller upstart it
purchased.
For those of us who use these products and services,
the nature of the risk has just changed. The risk
with the small guy is that it might fold up before it
spreads the change widely enough to take root. The
risk with the big power is that it doesn't really get
it and wastes an opportunity to create change (and
wealth). I suspect that Intuit gets it and so hold
out hope.
Still... I love the feistiness that Fried shows.
People with big ideas and need not settle. I've been
trying to encourage the young people with whom I work,
students and recent alumni, to shoot for the moon,
whether in business or in grad school.
This story meshed nicely with Paul Graham's
Post-Medium Publishing,
in which Graham joins in the discussion of what it
will be like for creators no longer constrained by
the printed page and the firms that have controlled
publication in the past. The money line was:
... the really interesting question is not what will
happen to existing forms, but what new forms will appear.
Change will happen. It is natural that we all want
to think about our esteemed institutions and what the
change means for them. But the real excitement lies
in what will grow up to replace them. That's where
the wealth lies, too. That's true for every discipline
that traffics in knowledge and ideas, including
our universities.
My first pass analysis suggests that, to make change
in CS, invent a language or tool at a well-known
institution. Textbooks or curricula rarely make
change, and it's really hard to get attention when
you're not at a "name" institution.
I think I'll have more to say about this article later,
but I certainly know what Mark must be feeling. In
addition to his analysis of tools and textbooks and
pedagogies, he has his own experience creating a new
way to teach computing to non-majors and major alike.
He and his team have developed a promising idea, built
the infrastructure to support it, and run experiments
to show how well it works. Yet... The CS ed world
looks much like it always has, as people keep doing
what they've always been doing, for as many reasons
as you can imagine. And inertia works against even
those with the advantages Mark enumerates. Education
is a remarkably conservative place,
even our universities.
There's been a long-running thread on the XP discussion
list about a variation of pair programming suggested by
a list member, on the basis of an experiment run in his
shop and documented in a simple research report. One
reader is skeptical; he characterized the research as
'only' an experience report and asked for more evidence.
Dave Nicolette
responded:
Point me to the study that proves...point me to
the study that proves...point me to the study
that proves...<yawn>
There is no answer that will satisfy the person
who demands studies as proof.
Studies aren't proof. Studies are analyses of
observed phenomena. The thing a study analyzes
has already happened before the study is
performed.
... The proof is in the doing.
This is one of those issues where each perspective
has value, and even dominates the other under
the right conditions.
Skepticism is good. Asking for data before changing
how you, your team, or your organization behaves
is reasonable. Change is hard enough on people when
it succeeds; when it fails, it wastes time and can
dispirit people. At times, skepticism is an
essential defense mechanism.
Besides, if you are happy with how things work now,
why change at all?
The bigger the changes, the more costly the change,
the more valuable is skepticism.
In the case of the XP list discussion, though, we
see a different set of conditions. The practice
being suggested has been tried at one company, so
its research report really is "just" an experience
report. But that's fine. We can't draw broadly
applicable conclusions from an experiment of one
anyway, at least not if we want the conclusions
to be reliable. This sort of suggestion is really
an invitation to experiment: We tried this, it
worked for us, and you might want to try it.
If you are dissatisfied with your current practice,
then you might try the idea as a way to break out
of a suboptimal situation. If you are satisfied
enough but have the freedom and inclination to
try to improve, then you might try the idea on a
lark. When the cost of giving the practice a test
drive is small enough, it doesn't take much of a
push to do so.
What a practice like this needs is to have a lot
of people try it out, under similar conditions
and different conditions, to find out if the first
trial's success indicates a practice that can be
useful generally or was a false positive. That's
where the data for a real study comes from!
This sort of practice is one that professional
software developers must try out. I could run
an experiment with my undergraduates, but they
are not (yet) like the people who will use the
practice in industry, and the conditions under
which they develop are rarely like the conditions
in industry. We could gain useful information
from such an experiment (especially about how
undergrads work and think), but the real proof
will come when teams in industry use the practice
and we see what happens.
Academics can add value after the fact, by
collecting information about the experiments,
analyzing the data, and reporting it to the
world. That is one of the things that academics
do well. I am reminded of Jim Coplien's
exhortations a decade and more ago for academic
computer scientists to study existing software
artifacts, in conjunction with practitioners,
to identify useful patterns and document the
pattern languages that give rise to good and
beautiful programs. While some CS academics
continue to do work of this sort -- the area of
parallel programming patterns is justifiably
hot right now -- I think we in academic CS have
missed an opportunity to contribute as much as we
might otherwise to software development.
We can't document a practice until it has been
tried. We can't document a pattern until it
recurs. First we do, then we document.
This reminds me of a
blog entry
written by Perryn Fowler about a similar relationship
between "best practices" and success:
Practices document success; they don't create it.
A tweet before its time...
As I have scanned through this thread on the discussion
list, I have found it interesting that some agile people
are as skeptical about new agile practices as non-agile
folks were (and still are) about agile practices. You
would think that we should be practicing XP as it was
writ nearly a decade ago. Even agile behavior tends
toward calcification if we don't remain aware of why
we do what we do.
Greg Wilson wrote a nice piece recently on the
big picture for his Software Carpentry course.
His first paragraph captures an idea that is key
to the notion of "programming for all" that I and
others have been talking about lately:
One of the lessons we learned ... is that most
scientists don't actually want to learn how to
program--they want solve scientific problems.
To many, programming is a tax they have to pay
in order to do their research. To the rest,
it's something they really would find interesting,
but they have a grant deadline coming up and
a paper to finish.
Most people don't care about programming. If they
do care, they don't like it, or think they don't.
They want to do something. Programming has to be
a compelling tool, something that makes their lives
better as they do the thing they like to do. If
it changes how they think about problems and solutions,
all the better. When we teach programming to people
who are non-CS types, we should present it as such:
a compelling tool that makes their lives better.
If we teach programming qua programming,
we will lose them before we have a chance to make
a difference for them.
It turns out that all this is true of CS students,
too. Most of them want to
do something.
And several of the lessons Wilson describes for
working with scientists learning to program apply to
CS students, such as:
When students have never experienced the pain
of working with big or long-lived programs that
benefit from good abstractions, effective
interfaces, and tools such as version control
systems, "no amount of handwaving is going to
get the idea across".
The best way to reach students is to give
them programming skills that will pay off for
them in the short term. This motivates better
than deferred benefit and encourages them to
dig in deeper on their own. That's where the
best learning happens anyway.
Students are often surprised when a course is
able to "convey the fundamental ideas needed
to make sensible decisions about software
without explicitly appearing to do so".
This issue is close to the surface for me as I work
on my
work on my software engineering course.
Undergraduate courses don't usually expose students
to the kind of software development projects that
are likely to give the right context for learning
many of the "big picture" ideas. An in-course
project can help, but contemporaneous experience
often runs out of sync with the software engineering
content of the course. Next semester, they will
take a project course in which they can apply what
they learn in this course, but little good that does
us now!
(Idea for later: Why not teach the project course
first and follow with course that teaches
techniques that depend on the experience?)
Fortunately, most students trust their professors
and give them some leeway when learning skills
that are beyond their experience to really grok
-- especially when the skills and ideas are a
known part of the milieu in which they will work.
Software Engineering this semester offers another
complication. There is a wide spread in the level
of software and programming experience between the
most and least experienced students in the course.
What appeals to students at one end of the spectrum
often won't appeal students on the other. More fun
for the professor...
In closing, I note that many of specific ideas from
Wilson's course and Udell's conception of
computational thinking apply to a good Software
Engineering course for majors. (Several of Wilson's
extensions to the body of CT apply less well, in
part because they are part of other courses in the
CS curriculum and in part because they go beyond
the CT that every person probably needs.) I should
not be surprised that these basic ideas apply.
Wilson is teaching a form of software engineering
aimed at a specific audience of developers, and
computational thinking is really just a distillation
of what all CS students should be learning throughout
their undergraduate careers!
Mark Guzdial
blogged this morning
about a bug slipped through into the latest release
of JES, the Jython IDE that his group has created to
support courses and workshops in media computation.
The bug was the result of a simple variable renaming
in which n-1 of the uses was changed. (That
nth always comes back to haunt us.) Mark uses
this bug as an opportunity to discuss some bigger
issues involving process, language, and the nature of
CS1. He is taking some heat from a couple of pro-Python
commenters, but I'm glad he wrote the article. People
too rarely share mistakes when they are made, and
besides Mark offers some interesting ideas both in his
post and in his responses to comments.
Should we use a different kind of language when we
program for others than when we program for ourselves?
A compiler would have found this simple error at the
time JES was built and saved everyone the grief of
a new release. But so would running the test suite
that the JES team has built. The difference is that
developers have a choice of running the test suite
or not, whether they use a compiled language or an
interpreted one, but they have to compile
their program when they use a compiled language.
People make mistakes. I am certainly not in a position
to look down on the poor developer who opted not to
run the unit tests after making what seemed like a
trivial change. I have made similar mistakes before,
and I'm sure I'll make another like it soon. And
at least one thing is true about teaching university
courses: students will find my mistakes!
I like it when a compiler catches errors like this for
me, but... Still, I'm uneasy to give up the freedom
that a language like Smalltalk, Scheme, or Ruby gives
me when I am writing code. Even when the value of
Mark's f() rises. What is someone like me
to do?
The compiler is a tool that helps me find a certain
kind of error. But there are other tools that help
me find this and other kinds of error. The unit
tests are one. A refactoring browser is another.
If the JES developer had had at his or her disposal
a refactoring browser for Python, it would have at
least been able to point out possible effects of
renaming the variable behind this bug. Dynamic
languages pose a particular challenge for building
really useful static analysis tools, but we can still
build tools to help.
But the developer might not use the refactoring
browser. The change is so simple, a quick romp in
emacs or vi is all we need, right?
The compiler is a build tool; the programmer has to
run it to create the executable. One approach that
developers using dynamic languages can take is to use
a build system that always runs the test suite.
Another is to tool the version control system to
run the tests before accepting the code at check-in.
These tools more closely fulfill the role played by
the compiler.
In response to another comment on his entry, Mark
mentions a trade-off between process and language,
a lá the familiar space-time trade-off among
algorithms and data structures. This, I think, is
the most interesting implication of his post. But
the language in which we write code is just one tool
that we use in building software. The compiler is
another. So are editors, browsers, version control
systems, build systems, and testing frameworks.
The trade-off is between processes and
tools.
This trade-off is one that seems to fly under most
people's radar. The authors of the
Agile Manifesto
wrestle with the trade-off between caring for
"individuals and interactions" and caring for
"processes and tools". They come down on the side
of individuals and interactions. But as I
wrote a
few weeks ago,
valuing people over tools makes having the right
tools even more important. I should probably have
said "the right tools and process", because the
process by which one works is just as important
a part of the infrastructure that any programmer
or creator needs. The question then becomes: In
supporting individuals and interactions, how do
we find the right balance between tools and
process?
People characterize the different kinds of process
available to programmers in a number of ways:
high ceremony versus low ceremony
heavy versus lightweight
sturdy versus agile
Some people assume that the righthand side of these
choices require more discipline than the left, because
the lefthand-style processes provide more rules to
follow. That's not right. Discipline is, at best,
orthogonal to this distinction. I think that the
agile, lightweight, and low-ceremony approaches usually
require more discipline, not less. In XP, you have
to code in pairs, even if you think you don't need to.
You have to run the tests. You have to refactor
frequently and, on occasion, vigorously. You have
to integrate code frequently. You have to take what
you learn from all the practices and feed that back
into the code. Easy? Not at all. Undisciplined?
Not if you are practicing what you preach.
This sort of disciplined approach only works when the
practices are at the level of granularity where they
can become habit, part of one's muscle memory. It also
works well only when supported by tools that make the
process comfortable, almost disappear from conscious
thought. Good tools shift as much of the burden of
details and administrivia off of the programmer's
mind and onto the tools that we use to write, build,
test, share, and deliver our code.
I understand why many people want to use a compiler
to support their process. But I still prefer to use
languages that give me other kinds of freedom --
along with other tools that support my creative
process.
I've been thinking a lot about the Software Engineering
course I'm teaching this fall, which commences a week
from Tuesday. Along the way, I have been looking at a
lot of books and articles with "software engineering"
in the title. It's surprising how few of them get any
where near code. I know I shouldn't be surprised. I
remember taking courses on software engineering, and
I've stayed close enough to the area all these years
to know what matters. There are issues other than
programming that we need to think about while building
big systems. And there is plenty of material out there
about programming and programming tools and the nuts
and bolts of programming.
Still, I think it is important when talking about
software engineering to keep in mind what the goal is:
a working program, or collection of programs. When we
forget that, it's too easy to spin off into a land of
un-reality. It's also important to keep in mind that
someone has to actually write code, or no software will
ever be engineered. I hope that the course I teach
can strike a good balance.
In the interest of keeping code in mind, I share with
you an assortment of programming news. Good, bad,
ugly, or fun? You decide.
Hiding the Rainforest. Mark Guzdial reports
that Georgia Tech is
eliminating yet another language
from its computing curriculum. Sigh.
Thought experiments
notwithstanding, variety in language and style is
good for programmers. On a pragmatic note, someone
might want to tell the GT folks that programming for
the JVM may soon
look more like Lisp
and
feel more like ML
than Java or C++.
Programming meets the Age of Twitter. A
Processing programming contest
with a twist: all programs must be 200-characters or
less. I'll give extra credit for any program that is
a legal tweet.
Power to the Programmer! Phil Windley enjoys
saving $60 by
writing his own QIF->CSV converter.
But the real hero is the person who wrote
Finance::QIF.
Why Johnny Can't Read Perl. Courtesy of
Lambda the Ultimate
comes news we all figured had to be true: a formal
proof that
Perl cannot be parsed.
Who said the Halting Theorem wasn't useful? I guess
I'll stop working on my refactoring browser for Perl.
Via Jason Yip,
this dandy story
from a hospital president who favors process improvement
Lean-style. It features Hideshi Yokoi, who is president
of a Toyota production system support center in Kentucky:
... At one point, we pointed out a new information
system that we were thinking of putting into place
to monitor and control the flow of certain inventory.
Mr. Yokoi's wise response, suggesting otherwise, was:
"When you put problem in computer, box hide answer.
Problem must be visible!"
I have had many experiences, both personal and professional,
in which putting something in a computer hides the problem
from view and complicates finding the answer. Too often,
when I decide to improve my process by putting data into
my computer, I get so caught up in the rest of my tasks that
I forget all about the problem. Tasks to do get lost in an
ever-growing text file. Concerns about how we allocate
merit pay get lost behind complex formulas in a spreadsheet
that implement our current method. Scheduling and budget
issues are lost in the last-minute details of readying
this semester's spreadsheet for the next step in a
university we don't control.
When you lose sight of a problem, it's hard to solve it.
Moving things out of the daily clutter too easily becomes
moving them out of our attention altogether.
I agree with Mr. Yokoi. A problem must be visible! But
that cannot mean not using technology to automate and
improve a process. Instead it means that we have to
find ways to make the problem visible. JUnit
was, for me, a great model. We needed to improve how
we tested our programs, so we make the tests code.
Rather than leave that code sitting lonely on disk, no
better than textual documentation, we use a tool that
runs the tests for us and tells what passes and what
fails. Rather than leave that tool sitting lonely on
disk, gathering dust because we forget to run the tests,
we build running the tool into our development tools,
where the tests can be run every time we save our changes
or build our program. Make things visible.
We can avoid much of Mr. Yokoi's valid concern by
changing our tools and our practices to ensure that
problems don't disappear when we automate processes.
That allows us to use computers to make us better.
Last month, in honor of the Apollo 11 mission's
fortieth anniversary,
Google Code announced
the open-sourcing of code for the mission's command
and lunar modules. Very cool indeed. This project
creates opportunities for many people. CS historians
can add this code to their record of computing and
can now study computing at NASA in a new way. Grady
Booch will be proud. He has been working for many
years on the task of preserving code and other
historic artifacts of our discipline that revolve
around software.
Software archeologists can study the code to find
patterns and architectural decisions that will help
us understand the design of software better. What
we learn can help us do more, just as the Apollo 11
mission prepared the way for future visitors to the
moon, such as Charles Duke of Apollo 16 (pictured here).
This code could help CS educators convince a few students
to assembly language programming seriously. This code
isn't Java or even C, folks. Surely some young people
are still mesmerized enough by space travel that they
would want to dig in to this code?
As a person who appreciates assembly-level programming
but prefers working at a higher level, I can't help
but think that it would be fun to reverse-engineer
these programs to code at a more abstract level and
then write compilers that could produce equivalent
assembly that runs on the simulator. The higher-level
programs created in this way would be a great way for
us to record the architecture and patterns we find in
the raw source.
Reading this code and about the project that surrounds
it, I am in awe of the scale of the programming
achievement. For a computer scientist, this
achievement is beautiful. I'd love to use this code
to share the excitement of computing with non-computer
scientists, but I don't know how. It's assembly, after
all. I'm afraid that most people would look at this
code and say, "Um, wow, very impressive" while thinking,
"Yet another example of how computer science is beyond
me."
If only those people knew that many computer scientists
feel the same way. We are in awe. At one level, we
feel like this is way over our heads, too. How could
these programmers done so much with so little? Wow.
But then we take a breath and realize that we have the
tools we need to dig in and understand how this stuff
works. Having some training and experience, we can
step back from our awe and approach the code in a
different way. Like a scientist. And anyone can have
the outlook of a scientist.
When I wonder how could the programmers of the 1960s
could have done so much with so little, I feel another
emotion, too: sheepishness. How far have we as a
discipline progressed in forty years? Stepping back
from the sheepishness, I can see that since that time
programmers have created some astoundingly complex
systems in environments that are as harsh or harsher
than the Apollo programmers faced. It's not fair to
glorify the past more than it deserves.
But still... Wow. Revisiting this project forty
years later ought to motivate all of us involved
with computer science in 2009 -- software professionals,
academics, and students -- to dream bigger dreams
and tackle more challenging projects.
The software engineering tip
Every line of code is a user interface
expresses several important ideas. Design matters.
Names matter. Separating business logic from system
wiring matters. Programs are read by people, so the
code you write matters.
As I think about it, though, it embodies another
important idea that is right up agile development's
alley. We all know that programs tend to evolve over
time, as user's needs and wants change. As developers,
we also know that, as we build more systems in the
same domain, we can evolve one-off programs toward
a common framework. The framework generalizes over
the separate programs, pulling the wiring out for
maintenance in one place and for use in creating new
programs in the same domain later.
What's interesting to me about the police database
system described in that article is that it needed
to evolve away from its built-in wiring and toward
a more generic framework created in the outside
world:
Specifically it wasn't Microsoft Access we had to
worry about, but Ruby on Rails that provided 99%
of all the infrastructure we'd built ourselves for
an HTML-fronted database application.
It didn't have to be Rails, because web frameworks
in other languages would probably have done as
well for their shop. The point is, when the
frameworks came along, their code was too tangled
to easily take advantage of them. On the business
side, another company could come along, replicate
the business logic on top of one of the frameworks
that provided the 99% infrastructure, and compete
right away.
Is your design clean enough?
Time
I mentioned David Ogilvy's Confessions of an
Advertising Man in a
recent entry.
Another passage from the book set of the alarm in
my brain that watches for examples of shorter-than-usual
iterations and continuous feedback:
Most young men in big corporations behave as
if profit were not a function of time. When
Jerry Lambert scored his first breakthrough
with Listerine, he speeded up the whole process
of marketing by dividing time into months.
Instead of locking himself into annual
plans, Lambert reviewed his advertising
and his profits every month.
I guess that Lambert wasn't satisfied with
halving his project length;
he went straight to a factor of twelve. Feedback
matters in the advertising game. In the same
chapter of Confessions, Ogilvy talks about
the importance of testing campaigns in front of
real users. He claims that 24 out of 25 ideas will
fail, so it's better to find out in testing than in
production -- which both costs more and exposes the
company to public failure. (Reputation matters a
lot in the advertising game.)
Lambert's approach went further by monitoring
projects that had already been deployed on a much
shorter cycle and making decisions based on more
frequent feedback about the projects. This reminded
me of the approach suggested by Ricardo Semler in
his talk
Leading by Omission.
Semler says that long-term plans, even yearly plans,
are simply too large-grained to be useful. He
advocates continuous feedback and monitoring.
Time is related to evolution, of course. When we
operate at smaller units of time, we can evolve --
through both failure and success -- that much
faster.
You don't need (or have to be) a special kind of
leader, which Lambert and Semler seem to be, to
benefit from this style. A disciplined process
such as XP can guide you, and a team of developers
operating from a set of agile principles can work
to achieve similar goals.
Thanks to
John Cook,
I came across the blog of Dan Meyers, a high school
math teacher. Cook pointed to an
entry with a video
of Meyer speaking
pecha kucha-style
at OSCON. One of the important messages for teachers
conveyed in this five minutes is Be less
helpful. Learning happens more often when people
think and do than when they follow orders in a
well-defined script.
While browsing his archive I came across this
personal revelation
about the value of the time he was spending on his
class outside of the business day:
I realize now that the return on that investment of
thirty minutes of my personal time isn't the promise
of more personal time later. ... Rather it's the
promise of easier and more satisfying work time
now.
Time saved later is a bonus. If you depend on that
return, you will often be disappointed, and that
feeds the emotional grind that is teaching. Kinda
like
running in the middle.
I think it also applies more than we first realize to
reuse and development speed in software.
Learning and Doing
One of the underlying themes in Meyers's writing seems
to be the same idea in this line from Gerd Binnig, which
I found at
Physics Quote of Day:
Doing physics is much more enjoyable than just learning
it. Maybe 'doing it' is the right way of learning ....
Programming can be a lot more fun than learning to
program, at least the way we often try to teach it. I'm
glad that so many people are working on ways to teach it
better. In one sense, the path to better seems clear.
Knowing and Doing
One of the reasons I named by blog "Knowing and Doing"
was that I wanted to explore the connection between
learning, knowing, and doing. Having committed to that
name so many years ago, I decided to
stake its claim
at Posterous, which I learned about via
Jake Good.
Given some technical issues with using NanoBlogger, at
least an old version of it, I've again been giving some
thought to upgrading or changing platforms. Like Jake,
I'm always tempted to roll my own, but...
I don't know if I'll do much or anything more with Knowing
and Doing at Posterous, but it's there if I decide that
it looks promising.
A Poignant Convergence
Finally, a little levity laced with truth. Several people
have written to say they liked the name of my recent entry,
Sometimes, Students Have an Itch to Scratch.
On a whim, I typed it into
Translation Party,
which alternately translates a phrase from English into
Japanese and back until it reaches equilibrium. In only
six steps, my catchphrase settles onto:
Sometimes I fear for the students.
Knowing how few students will try to scratch their own
itches with their new-found power as a programmer, and
how few of them will be given a chance to do so in their
courses on the way to learning something valuable, I
chuckled. Then I took a few moments to mourn.
Some days, the work is tedious, labour-intensive and as
repetitive as a production line in a factory. ... The
key is having a good infrastructure. ...
But none of it works without discipline. Early on in my
career, I was told that success demanded one thing above
all others: turning up. Turning up every bloody day,
regardless of everything.
This was said by artist Hazel Dooney, but it could just
as well been said by a programmer -- or a university
professor. One thing I love about the agile software
world is its willingness to build new kinds of tools
to support the work of programmers. Isn't it ironic?
Valuing people over tools makes having the right tools
even more important.
Advice on my Advice to a Prospective Web Developers
Thanks to everyone who responded to my
call for advice
on what advice I should give to a student interested
in studying at the university with a goal of becoming
a web developer. People interpreted the article in
lots of different ways and so were able to offer
suggestions in many different ways.
In general, most confirmed the gist of my advice.
Learn a broad set of technical skills from the
spectrum of computer science, because that prepares
one to contribute to the biggest part of the web
space, or study design, because that's they part the
techies tend to do poorly. A couple of readers
filled me in on the many different kinds of web
development programs being offered by community
colleges and technical institutes. We at the
university could never compete in this market, at
least not as a university.
Mike Holmes
wrote a bit about the confusion people have about
computer science, with a tip of the hat to
Douglas Adams.
This confusion does play a role in prospective
students' indecision about pursuing CS in college.
People go through phases where they think of the
computer as replacing an existing technology or
medium: calculator, typewriter and printing press,
sketchpad, stereo, television. Most of us in
computer science seem to do one of two things:
latch onto the current craze, or stand aloof from
the latest trend and stick with theory. The
former underestimates what computing can be and
do, while the latter is so general that we appear
not to care about what people want or need. It
is tough to balance these forces.
In some twittering around my request,
Wade Arnold tweeted
about the technical side of the issue:
@wallingf Learn Java for 4 years to really know one
language well. Then they will pick up php, ruby, or
python for domain specific speed
The claim is that by learning a single language
really well, a person really learns how to program.
After that, she can learn other languages and fill in
the gaps, both language-wise and domain-wise. This
advice runs counter to what many, many people say,
myself included: students should learn lots of
different languages and programming styles in order
to really learn how to program. I think
Wade agrees with that over the long term of a
programmer's career. What's unusual in his advice
is the idea that a student could or should spend
all four years of undergrad study mastering one
language before branching out.
A lot of CS profs will dismiss this idea out of
hand; indeed, one of the constant complaints one
hears in certain CS ed circles is that too many
schools have "gone Java" to the exclusion of all
other languages and to the lasting detriment of
their students. My department's curriculum
has, since before I arrived, required students to
study a single language for their entire first
year, in an effort to help students learn one
language well enough that they learn how to
program before moving on to new languages and
styles. When that language was, say, Pascal,
students could pretty well learn the whole language
and get a lot of practice using it. C is simple
enough for that purpose, I suppose, but C++, Ada,
and Java aren't. If we want students to master
those languages at a comparable level, we might
well need four years. I think that says more
about the languages we use than about students
learning enough programming in a year to be
ready to generalize and fill in gaps with new
languages and styles.
This entry has gotten longer than I expected,
yet I have more to say. I'll write more in
the days to come.
For the last couple of days, I've been speaking
with a prospective non-traditional student who
is seeking advice about what to study for a
second bachelor's degree. His indecision about
careers and school is worthy of its own post;
I've seen it in so many other 20- and 30-somethings
who are unhappy with their first careers and
not sure of where to go next.
He wants to get into web development. What
should he study? Well, he thinks he wants to
get into web development, but he isn't sure
exactly what it is. This is a common issue for
prospective CS majors coming out of high school;
they rarely know just what computer science is.
It is apparently also an issue with the more
visible discipline of web development. People
see the products, but they are not sure at all
how they are created. Is this a problem for
budding electrical engineers or civil engineers?
This young man asked me for precise definitions
of the terms "web design" and "web development",
especially clear distinctions between the two,
and a map from the terms onto specific undergrad
majors. I explained that these are fuzzy terms,
like so many of our best words and phrases.
That didn't satisfy him much, because the
fuzziness won't easily wipe away his indecision.
He is asking the head of the Computer Science
department for advice, so I tell him what I
think about web development, as fairly as I
can, but with an unmistakeable fondness for
my discipline. On the one hand, there is
presentation, the web pages themselves
and how they appear to users within a browser.
On the other, there is the technology
that underlies the web, the code and data that
make it all work. To be versatile in the web
game, and ultimately great, a person should
learn both.
We do not offer a program in web development
at my university, so a student must go to
departments that teach the ideas and tools
behind these facets of the web. I suggested
graphic design with a little psychology for
the presentation side, and computer science
for the technology side. We have a
excellent graphic design program
here, and our CS program introduces students
to programming and to the ideas of data
structures, databases, algorithms, and
information storage and retrieval that drive
the web. We even teach an undergrad course
in user interface design, which is the closest
our major courses gets to presentation.
A freshman coming out of high school would do
well to double-major in CS and graphic design.
We have at least one such double-major now --
a dynamite student -- and a few others are
thinking about taking this route. Majoring
in both is a challenge, because it requires
skills that are, on the surface, so unlike
one another. I think the styles of thinking
at the heart of these two disciplines are
not so different after all. Besides, these
majors don't just require skills; they help
to develop them. It is a great double major.
However, most nontraditional students coming
back to school are not interested in re-living
the four- or five-year undergrad experience.
They have lives to support, and often families,
so they are usually focused on making a career
change and getting on with it. As a result,
one of these majors will have to do.
It seems to me that if you want to make a dent
in the web world, you really want to know the
technology and the ideas that make them work.
Philip Greenspun teaches a
software engineering course
at MIT with web programming as its centerpiece,
based in large part on the premise that this
particular technology is so central to the
experience of current CS grads when they get
out in the world.
(I wonder what it would be like if I tried to
teach Greenspun's course as
my SE course?!
My guess is that a lot of students would love
it, a few would hate it, and the respective
ratios for the faculty would be swapped.)
Not all students want to do the technology.
I would rather students make this decision
from a position of power -- knowing something
about the technology -- than from a position
of ignorance, but that's not always how the
world works. Fine. Then the student can
study graphic design and psychology and apply
that knowledge to learning how to make web
sites whose appearances sizzle. There is a
shortage of great web sites out there, which
tells me there may be a shortage of great web
designers. Go for it.
I had to be honest. You can learn a lot about
how to make websites at the tool level
without giving any university a lot of money.
With a high school degree and a few books on
HTML, CSS, Javascript (three topics we teach
in a
course for non-majors),
and maybe Flash (which we currently teach in
an
experimental course,
also for non-majors), any reasonably intelligent
person can become a competent web developer.
This student already has a college degree, so
with discipline and perseverance he could
probably make this career shift on his own.
There may be practical limitations on the career
potential for some people who choose this path,
but it's viable.
In at least two of my exchanges with this young
man, I ran into a concern that I expected to
encounter. It is the fear that rises to the
top of almost every neophyte's mind whenever
he or she is confronted with the words
"computer science": Will I have to do much
programming? I think he was asking as
much about the jobs he would get in web
development as about the CS courses he would
have to take to get a major here.
My part of these conversations can be summed
up in a mantra I now keep close to my heart:
You don't have to program; you get
to program.
We need to do something to change the default
expectation young people have about programming.
Seriously.
This particular student is a reasonable young
man. He is college-educated and earnest about
finding a good career. He is also a little
afraid. In my recent experience, I have
encountered many like him, and I'd like to
help them as best I can. So, let's get back
to the original question, "What should a
person study in college if she wants to get
into web development?" Faithful readers:
What should I tell them? What am I missing?
I often find myself at meetings with administrator types,
where I am the only person who has spent much time in a
classroom teaching university students, at least recently.
When talk turns
to teaching, I sometimes feel like a pregnant woman at an
ob-gyn convention. They may be part of a university and
may even have taught a workshop or specialty course, but
they don't usually know what it's like to design and teach
several courses at a time, over many semesters in a row.
That doesn't always stop them from having deeply-held and
strong opinions about how to teach. Having been a student
once isn't enough to know what it's like to teach.
I have had similar experiences as a university professor
among professional software developers. All have been
students and have learned something about teaching and
learning from their time in school. But their lessons
are usually biased by their own experiences. I was a
student once, too, but that prepared me only a bit for
being a teacher... There are so many different kinds of
people in a classroom, so many different kinds of student.
Not very many are just like me. (Thank goodness!)
Some software developers have taught. Many give half-
or full-day tutorials at conferences. Others teach
week-long courses on specific topics. A few have even
taught a university course. Even still, I often don't
feel like we are talking about the same animal when we
talk about teaching. Teaching a training course for
professional developers is not the same as teaching a
university course to freshmen or even seniors. Teaching
an upper-division or graduate seminar bears little
resemblance to an elective course for juniors, let
alone a class of non-majors. Even teaching such a
course as an adjunct can't deliver quite the same
experience as teaching a full load of courses across
the spectrum of our discipline, day in and day out for
a few years in a row. The principle of sustainable
pace pops up in a new context.
As with administrators, lack of direct experience
doesn't always stop developers from having deeply-held
and strong opinions about what we instructors should
be doing in the classroom. It creates an interesting
dialectic.
That said, I try to learn whatever I can from the
developers with whom I'm able to discuss teaching,
courses, content, and curricula. One of the reasons
I so enjoy PLoP, ChiliPLoP, and OOPSLA is having an
opportunity to meet reflective individuals who have
thought deeply about their own experiences as students
and who are willing to offer advice on how I can do
better. But I do try to step back from their advice
and put it into the context of what it's like to teach
in a real university, not one we've invented. Some
ideas sound marvelous in the abstract but die a grisly
death on the banks of daily university life. Revolution
is easy when the battlefield is in our heads.
When it comes to working with software developers, I
am more concerned that they will feel like
the pregnant woman when they discuss their area of
expertise with me and my university colleagues. One
of my goals is not to be "that guy" when talking about
software development with developers. I hope and
prefer to speak out of personal and professional
experience, rather than a theory I read in a book or
a blog, or something another professor told me.
What we teach needs to have some connection to what
developers do and what our students will need to do
when they graduate. There is a lot more to a CS
degree than just cutting code, but when we do talk
about building software, we should be as accurate
and as useful as we can be. This makes teaching a
course like
software engineering
a bigger challenge for most CS profs than the more
theoretical or foundational material such as algorithms
or even programming languages.
One prescription is the same as above: I listen and
try to learn whatever I can from developers when we
talk about building software. Conferences like PLoP,
ChiliPLoP, and OOPSLA give me opportunities I would
not have otherwise, and I listen to alumni tell me
about what they do -- and how -- whenever I can. I
still have to sift what I learn into the context of
the university, but it makes for great raw material.
Another prescription is to write code and use the
tools and practices the people in industry use.
Staying on top
of that fast-moving game gets harder all the time.
The world software is alive and changing. We professors
have to keep at it. Mostly, it's a matter of us
staying alive, too.
Weak developers will move heaven and earth to do the
wrong thing. You can't limit the damage they do by
giving them less powerful tools. They'll just swing
the blunt tools harder.
I still agree with the sentiment, as well as the bigger
point: Give people powerful tools, teach them what you
can, and let them create. The best programmers will do
amazing things; the rest will be none the worse off.
If you help to create a culture that values learning
and encourages responsibility for others, you may even
find some of the weak growing into amazing programmers,
too.
In trying to understand the role patterns and pattern
languages play both in developing software and in
learning to develop software, I often look for
different angles from which to look at patterns.
I've written the idea of
patterns as descriptive grammar
and the idea of
patterns as a source of freedom
in design. Both still seem useful to me as perspectives
on patterns, and the latter is among the most-read
articles on my blog. The notion of patterns-as-grammar
also relates closely to one of the most commonly-cited
roles that patterns play for the developer or learner,
that of vocabulary for describing the meaningful
components of a program.
This weekend, I read Brian Hayes's instructive article
on compressive sensing,
The Best Bits.
Hayes talks about how it is becoming possible to imagine
that digital cameras and audio recorders could record
compressed streams -- say, a 10-megapixel camera storing
a 3MB photo directly rather than recording 30MB and then
compressing it after the fact. The technique he calls
compressive sensing is a beautiful application of some
straightforward mathematics and a touch of algorithmic
thinking. I highly recommend it.
While reading this article, though, the idea of patterns
as vocabulary came to mind in a new way, triggered
initially by this passage:
... every kind of signal that people find meaningful
has a sparse representation in some domain.
This is really just another way of saying that a
meaningful signal must have some structure or
regularity; it's not a mere jumble of random bits.
Programs are meaningful signals and have structure and
regularity beyond the jumble of seemingly random
characters at the level of the programming level.
The chasm between random language stuff and high-level
structure is most obvious when working with beginners.
They have to learn that structure can exist and that
there are tools for creating it. But I think developers
face this chasm all the time, too, whenever they dive
into a new language, a new library, or a new framework.
Where is the structure? Knowing it is there and seeing
it are too different matters.
The idea of a sparse representation is fundamental to
compression. We have to find the domain in which a
signal, whether image or sound, can be represented in
as few bits as possible while losing little or even
none of the signal's information. A pattern language
of programs does the same thing for a family of programs.
It operates at a level (in Hayes' terms, in a domain)
at which the signal of the program can be represented
sparsely. By describing Java's I/O stream library as
a set of decorators on a set of concrete streams, we
convey a huge amount of information in very few words.
That's compression. If we say nothing else, we have a
lossy compression, in that we won't be able to reconstruct
the library accurately from the sparse representation.
But if we use more patterns to describe the library
(such as Abstract Class and "Throw, Don't Catch"), we
get a representation that pretty accurately captures
the structure of the library, if not the bit-by-bit
code that implements it.
This struck me as a useful way to think about what
patterns do for us. If you've seen other descriptions
of patterns as a means for compression, I'd love to
hear from you.
Agile Moments: TDD and the Affordances of Programming
I recently ran across a link to a Dan Bricklin article
from a few years ago,
Why Johnny can't program.
(I love the web!) Bricklin discusses some of the
practical reasons why more people don't program.
As he points out, it's not so much that people
can't program as that they won't
or choose not to program. Why? Because
the task of writing code in a textual language
isn't fun for everyone. What Bricklin calls "typed
statement" programming fails all of Don Norman's
principles of good design: visibility, good
conceptual model, good mappings, and full and
continuous feedback. Other programming models do
better on these counts -- spreadsheets, rule-based
expert system shells, WYSIWYG editors in which users
generate HTML through direct manipulation -- and
reach a wider audience. Martin Fowler recently
talked about this style, calling it
illustrative programming.
I had an agile moment as I read this paragraph from
Bricklin about why debugging is hard:
One of the problems with "typed-statement" systems
is that even though each statement has an effect,
you only see the final result. It is often unclear
which statement (or interaction of statements) caused
a particular problem. With a "Forms" or direct
manipulation system, the granularity is often such
that each input change has a corresponding result
change.
When we write unit tests for our code at about the
same time we write the code, we improve our programming
experience by creating intermediate results that help
us to debug. But there's more. Writing tests helps
us to construct a conceptual model of the program we
are writing. They make visible the intended state of
the program, and help us to map objects and functions
in the code onto the behavior of the program at run-time.
When we take small steps and run our tests frequently,
they give us full and continuous feedback about the
state of our program. Best of all, this understanding
is recorded in the tests, which are themselves code!
In some ways, test-driven programming may
improve on styles where we don't type statements.
By writing tests, we participate actively in creating
the model of our program. We are not simply passive
users of someone else's constraint engine or inference
engine. We construct our understanding as we construct
our program.
Then again, some people don't need or want to write the
reasoning component, so we need to provide access to
tools they can use to be productive. Spreadsheets did
that for regular folks. Scripting languages do it for
programmers. Some people complain about scripting
languages because they lack type safety, hide details,
and are too slow. But the fact is that programmers are
people, too, and they want tools that put them into a
flow. They want languages that hit them in their
sweet spot.
Bricklin concludes:
From all this you can see that the way a system requires
an author to enter instructions into the computer affects
the likelihood of acceptance by regular people. The more
constrained the instructions the better. The more the
instructions are clearly tied to various results the
better. The more obvious and quickly the results may
be examined the better.
TDD does all this, and more. It makes professional
programmers more productive by providing better cognitive
support for mental tasks we have to perform anyway.
If we use TDD properly as we teach people to program,
perhaps it can help us hit the sweet spot for more
people, even in a "typed statement" environment.
I've been buried in a big project on campus for the
last few months. Yesterday, we delivered our report
to the president. Ah, time to breathe, heading into
a holiday weekend! Of course, next week I'll get
back to my regular work. Department stuff. Cleaning
my desk. And thinking about
teaching software engineering
this fall.
A bit of side reading found via my Twitter friends
has me thinking about testing, and the role it will
play in the course. In the old-style software
engineering course, testing is a "stage" in the
"process", which betrays a waterfall view of the
world even when the instructor and textbook say that
they encourage iterative development. But testing
usually doesn't get much attention in such courses,
maybe one chapter that describes the theory of
testing and a few of the kinds of testing we need
to do.
It seems to me that testing can take a bigger place
in the course, if only because it exemplifies the
sort of empiricism that we should all engage in as
software developers. When we test, we run experiments
to gather evidence that our program works as
specified. We should adopt a similar mindset about
how we build our programs. How do we know that
our design is a good one? Or that our team is
functioning well? Or that we are investing enough
time and energy in writing tests and refactoring
our code?
That's one reason I like Joakim Karlsson's post
about the
principle of locality in code changes.
There may be ways that he can improve his analysis,
but the most important thing about this post is that
he analyzed code at all. He had a question about
how code edits work, so he wrote a program to ask
subversion repositories for the answer. That's so
much better than assuming that his own hypothesis
was correct, or that conventional wisdom was.
In regard to the testing process itself, Michael
Feathers wrote a piece on
"canalizing" design
that points out a flaw in how we usually test our
code. We write tests that are independent of one
another in principle but that our test engines
always run in the same order. This inadvertent
weakness of sequential code creates an opportunity
for programmers to write code that takes advantage
of the implicit relationship between tests. But
it's not really an advantage at all, because we
then have dependencies in our code that we may not
be aware of and which should not exist at all.
Feathers suggests putting the tests in a set data
structure and executing them them from there. At
least then the code makes explicit that there is
no implied order to the tests, which reminds the
programmers who modify the code later that they
should not depend on the order of test execution.
(I also like this idea for its suggestion that
programs can and other should be dynamic structures,
not dead sequences of text. Using a set of tests
also moves us a step closer to making our code
work well in a parallel environment. Explicit
and implicit sequencing in programs makes it hard
to employ the full power of multicore systems,
and we need to re-think how we structure our
programs if we want to break away from purely
sequential machines. The languages guy in me sees
some interesting applications of this idea in how
write our compilers.)
Finally, I enjoyed reading
Gojko Adzic's description
of
Keith Braithwaite's
"TDD as if you mean it" exercise. Like the
programming challenges
I have described, it asks developers to take an
idea to its extreme to break out of habits and
to learn just how the idea feels and what it can
give. Using tests to drive how the writing of
code is more different from what most of us do
than we usually realize. This exercise can help
you to see just how different -- if you have an
exercise leader like Keith to keep you honest.
However, I disagree with something Keith said
in response to a comment about the relationship
between TDD and functional programming:
I'm firmly convinced that sincere TDD leads one
towards a functional style.
TDD will drive you to the style whose language
you think.
There will be functional components to your solution
to support the tests, and some good OOP has a
functional feel. But in my experience you can end
up with very nice objects in an object-oriented
program as a result of faithfully-executed TDD.
Another of Braithwaite's comments saved the day,
though. He credits Allan Watts for this line
that captures his intent in designing exercises
like this:
I came not as a salesman but as an entertainer.
I want you to enjoy these ideas because I enjoy them.
Love this! He has a scholar's heart.
There is a lot more to testing that unit tests or
regression testing. Finding ways to introduce
students to the full set of ideas while also
giving them a visceral sense of testing in the
trenches is a challenge. I have to teach enough
to prepare a general audience and also prepare
students who will go on to take our follow-up
course,
Software Testing.
That's a course that undergraduates at most schools
don't have the opportunity to take, a strong point
of our program. But that course can't be an
excuse not to do testing well in the software
engineering course. It's not a backstop; it's
new ballgame.
Poor programmers will move heaven and earth to do
the wrong thing. Weak tools can't limit the damage
they'll do.
Vanderburg is likely talking about professional
programmers. I have experienced this truth when
working with students. At first, it surprised me
when students learning OOP would contort their code
into the strangest configurations not to use
the OO techniques they were learning. Why use a class?
A fifty- or hundred-line method will do nicely.
Then, students learning functional programming would
seek out arcane language features and workarounds
found on the Internet to avoid trying out the
functional patterns they had used in class. What could
have been ten lines of transparent Scheme code in two
mutually recursive functions became fifteen or more of
the most painfully tortured C code wrapped in a thin
veil of Scheme.
I've seen this phenomenon in other contexts, too, like
when students take an elective course called Agile
Software Development and go out of their way to do
"the wrong thing". Why bother with those unit tests?
We don't really need to try pair programming, so we?
Refactor -- what's that?
This feature of programmers and learners has made me
think harder trying to help them see the value in just
trying the techniques they are supposed to learn. I
don't succeed as often as I'd like.
While reading about the fate of newspapers prior to
writing my recent entry on
whether universities are next,
I ran across a blog entry by Dave Winer called
If you don't like the news....
Winer had attended a panel discussion at the
UC-Berkeley school of journalism. After hearing what
he considered the standard "blanket condemnation of
the web" by the journalists there, he was thinking
about all the blogs he would love to have shown them
-- examples of experts and citizens alike writing
about economics, politics, and the world; examples of
a new sort of journalism, made possible by the web,
which give him hope for the future of ideas on the
internet.
Here is the money quote for me:
I would also say to the assembled educators -- you
owe it to the next generations, who you serve, to
prepare them for the world they will live in as adults,
not the world we grew up in. Teach all of them
the basics of journalism, no matter what they came to
Cal to study. Everyone is now a journalist. You'll
see an explosion in your craft, but it will cease to
be a profession.
Replace "journalism" with "computer science", and
"journalist" with "programmer", and this statement
fits perfectly with the theme of much of this blog
for the past couple of years. I would be happy to
say this to my fellow computer science educators:
Everyone should now be a programmer. We'll see an
explosion in our craft.
Will programming cease to be a profession? I don't
think so, because there is still a kind and level
of programming that goes beyond what most people
will want to do. Some of us will remain the
implementors of certain tools for others to use,
but more and more we will empower others to make
the tools they need to think, do, and maybe even
play.
Are academic computer scientists ready to make this
shift in mindset? No more so than academic
journalists, I suspect. Are practicing programmers?
No more so than practicing journalists, I suspect.
Purely by happenstance, I ran across another quote
from Winer this week, one that expresses something
about programming from the heart of a programmer:
i wasn't born a programmer.
i became one because i was impatient.
-- @davewiner
I suspect that a lot of you know just what he means.
How do we cultivate the right sort of impatience in
our students?
The first: Our local paper carries a parenting advice
column by
John Rosemond,
an advocate of traditional parenting. In Wednesday's
column, a parent asked how to handle a child who refuses
to eat his dinner. Rosemond responded that the parents
should calmly, firmly, and persistently expect the child
to eat the meal -- even if it meant that the child went
hungry that night by refusing.
[Little Johnny] will survive this ordeal -- it may take
several weeks from start to finish -- with significantly
lower self-esteem and a significantly more liberal
palette, meaning that he will be a much happier child.
If you know Rosemond, you'll recognize this advice.
I couldn't help thinking about what happens when we
adults learn a new programming style (object-oriented
or functional programming), a new programming technique
(test-driven development, pair programming), or even a
new tool that changes our work flow (say, SVN or JUnit).
Calm, firm, persistent self-discipline or coaching are
often the path to success. In many ways, Rosemond's
advice works more easily with 3- or 5-year-olds than
college students or adults, because the adults have
the option of leaving the room. Then again, the coach
or teacher has less motivation to ensure the change
sticks -- that's up to the learner.
I also couldn't help thinking how often college students
and adults behave like 3- and 5-year-olds.
The second: Our paper also carries a medical advice
column by a Dr. Gott, an older doctor who harkens back
to an older day of doctor-patient relations. (There
is a pattern here.) In Wednesday's column, the good
doctor said about a particular diagnosis:
There is no laboratory or X-ray test to confirm or rule
out the condition.
My first thought was, well, then how do we know it
exists at all? This a natural reaction for a scientist
-- or pragmatist -- to have. I think this means that we
don't currently have a laboratory or X-ray test for the
presence or absence of this condition. Or there may be
another kind of test that will tell us whether the
condition exists, such as a stress tests or an MRIs.
Without any test, how can we know that something is?
We may find out after it kills the host -- but then we
would need a post-mortem test. While the patient lives,
there could be a treatment regimen that works reliably
in face of the symptoms. This could provide the evidence
we need to say that a particular something was present.
But if the treatment fails, can we rule out the condition?
Not usually, because there are other reasons that the
treatment fails.
We face a similar situation in software with bugs. When
we can't reproduce a bug, at least not reliably, we have
a hard time fixing it. Whether we know the problem
exists depends on which side of the software we live...
If I am the user who encounters the problem, I know it
exists. If I'm the developer, then maybe I don't. It's
easy for me as developer to assume that there is something
wrong with the user, not my lovingly handcrafted code.
When the program involves threading or a complex web of
interactions among several systems, we are more inclined
to recognize that a problem exists -- but which problem?
And where? Oh, to have a test... I can only think of
two software examples of reliable treatment regimens that
may tell us something was wrong: rebooting the machine
and reinstalling the program. (Hey to Microsoft.). But
those are such heavy-handed treatments that they can't
give us much evidence about a specific bug.
There is, of course, the old saying of TDD wags: Code
without a test doesn't exist. Scoff at that if you want,
but it is a very nice guideline to live by.
To close, here are my favorite new phrases from stuff
I've been reading:
from the Xark article quoted in my
previous article:
forward into the now
from the David Allen book quoted in
How To Be Invincible:
creative discomfort for progress
Expect to see these jewels used in an article sometime
soon.
Brian Marick tweeted about his mini-blog post
Pay me until you're done,
which got me to thinking. The idea is something
like this: Many agile consultants work in an
agile way, attacking the highest-value issue
they can in a given situation. If the value of
the issues to work on decreases with time, there
will come a point at which the consultant's
weekly stipend exceeds the value of the work he
is doing. Maybe the client should stop buying
services at that point.
My first thought was, "Yes, but." (I am far too
prone to that!)
First, the "yes": In the general case of consulting,
as opposed to contract work, the consultant's
run will end as his marginal effect on the company
approaches 0. Marick is being honest about his
value. At some point, the value of his marginal
contribution will fall below the price he is
charging that week. Why not have the client end
the arrangement at that point, or at least have
the option to? This is a nice twist on our usual
thinking.
Now for the "but". As I tweeted back this feels
a bit like
Zeno's Paradox.
Marick the consultant covers not half the distance
from start to finish each week, but the most
valuable piece of ground remaining. With each
week, he covers increasingly less valuable
distance. So our consultant, cast in the role of
Achilles, concedes the race and says, okay, so
stop paying me.
This sounds noble, but remember: Achilles would
win the race. We unwind Zeno's Paradox when we
realize that the sum of an infinite series can
be a finite number -- and that number may be
just small enough for Achilles to catch the
tortoise. This works only for infinite series
that behave in a particular way.
Crazy, I know, but this is how the qualification
of the "yes" arose in my mind. Maybe, the
consultant helps to create a change in his client
that changes the nature of the series of tasks
he is working on. New ideas might create new
or qualitatively different tasks to do. The
change created may change the value of an
existing task, or reorder the priorities of
the remaining tasks. If the nature of the
series changes, it may cause the value of the
series to change, too. If so, then the client
may well want to keep the consultant around,
but doing something different than the original
set of issues would have called for.
Another thought: Assume that the conditions
that Marick described do hold. Should the
compensation model be revised? He seems to be
assuming that the consultant charges the same
amount for each week of work, with the value
of the tasks performed early being greater than
that amount and the value of the tasks performed
later being less than that amount. If that is
true,then early on the consultant is bringing
in substantially more value than he costs. If
the client pulls the plug as soon as the value
proposition turns in its favor, then the
consultant ends up receiving less than the
original contract called for yet providing more
than average value for the time period. If the
consultant thinks that is fair, great. What if
not? Perhaps the consultant should charge more
in the early weeks, when he is providing more
value, than in later week? Or maybe the client
could pay a fee to "buy out" the rest of the
contract? (I'm not a professional consultant,
so take that into account when evaluating my
ideas about consultant compensation...)
And another thought: Does this apply to what
happens when a professor teaches a class? In
a way, I think it does. When I introduce a new
area to students, it may well be the case that
the biggest return on the time we spend (and
the biggest bang for the students' tuition
dollars) happens in the first weeks. If the
course is successful, then most students will
become increasingly self-sufficient in the area
as the semester goes on. This is more likely
the case for upper-division courses than for
freshmen. What would it be like for a student
to decide to opt out of the course at the point
where she feels like she has stopped receiving
fair value for the time being spent? Learning
isn't the same as a business transaction, but
this does have an appealing feel to it.
The university model for courses doesn't
support Marick's opt-out well. The best students
in a course often reach a point where they are
self-sufficient or nearly so, and they are
"stuck". The "but" in our teaching model is
that we teach an audience larger than one, and
the students can be at quite different levels
in background and understanding. Only the best
students reach a point where opting out would
make sense; the rest need more (and a few need a
lot more -- more than one semester can offer!).
The good news is that the unevenness imposed by
our course model doesn't hurt most of those
best students. They are usually the ones who
are able to make value out of their time in the
class and with the professor regardless of what
is happening in the classroom. They not only
survive the latency, but thrive by veering off in
their own direction, asking good questions and
doing their own programming, reading, thinking
outside of class. This way of thinking about
the learning "transaction" of a course may help
to explain another class of students. We all
know students who are quite bright but end up
struggling through academic courses and programs.
Perhaps these students, despite their intelligence
and aptitude for the discipline, don't have the
skills or aptitude to make value out of the latency
between the point they stop receiving net value
and the end of the course. This inability creates
a problem for them (among them, boredom and low
grades). Some instructors are better able to
recognize this situation and address it through
one-on-one engagement. Some would like to help
but are in a context that limits them. It's
hard to find time for a lot of one-on-one
instruction when you teach three large sections
and are trying to do research and are expected
to meet all of the other expectations of a
university prof.
Sorry for the digression from Marick's thought
experiment, which is intriguing in its own
setting. But I have learned a lot from applying
agile development ideas to my running. I have
found places where the new twist helps me and
others where the analogy fails. I'm can't shake
the urge to do the same on occasion with how we
teach.
One of the challenges every beginner faces is learning
the subtle judgments they must make. How much time
will it take for us to implement this story? Should
I create a new kind of object here? Estimation and
other judgments are a challenge because the beginner
lacks the "instinct" for making them, and the
environment often does provide enough data to make
a clear-cut decision.
I've been living with such a beginner's mind this
week on my morning runs. Tuesday morning I started
with a feeling of torpor and was sure I'd end with
a slow time. When I finished, I was surprised to
have run an average time. On Wednesday morning,
I felt good yet came in with one of my slowest
times for the distance ever. This morning, my legs
were stiff, making steps seem a chore. I finished
in one of my better times at this distance since
working my mileage back up.
My inaccurate judgments flow out of bad instincts.
Sometimes, legs feel slow and steps a challenge
because I am pushing. Sometimes, I run with ease
because I'm not running very hard at all!
At this stage in my running, bad instincts are not
a major problem. I'm mostly just trying to run
enough miles to build my aerobic base. Guessing
my pace wrong has little tangible effect. It's
mostly just frustrating not to know. Occasionally,
though, the result is as bad as the judgment.
Last week,
I ran too fast on Wednesday after running faster
than planned on Tuesday. I ended up sick for the
rest of the week and missed out on 8-10 miles I
need to build my base. Other times, the result
goes the other way, as when I turned in a
best-case scenario half-marathon
in Indianapolis. Who knew? Certainly not me.
So, inaccurate instincts can give good or bad
results. The common factor is unpredictability.
That may be okay when running, or not; in any
case, it can be a part of the continuous change
I seek. But unpredictability in process is not
so okay when I am developing software. Continuous
learning is still good, but being wrong can wreak
havoc on a timeline, and it can cause problems for
your customer.
Bad instincts when estimating my pace wasn't a
problem two years, though it has been in my deeper
past. When I started running, I often felt like
an outsider. Runners knew things that I didn't,
which made me feel like a pretender. They had
instincts about training, eating, racing, and
resting that I lacked. But over time I began to
feel like I knew more, and soon -- imperceptibly
I began to feel like a runner after all. A lot
-- all? -- of what we call "instinct" is developed,
not inborn. Practice, repetition, time -- they
added up to my instincts as a runner.
Time can also erode instinct. A lack of practice,
a lack of repetition, and now I am back to where
I was several years ago, instinct-wise. This is,
I think, a big part of what makes learning to run
again uncomfortable, much as
beginners are uncomfortable
learning the first time.
One of the things I like about agile approaches to
software development is their emphasis on the
conscious attention to practice. They encourage
us to reflect about our practice and look for ways
to improve that are supported by experience. The
practices we focus on help us to develop good
instincts: how much time it will take for us to
implement a story, when to write --
and not write
-- tests, how far to refactor a system to prepare
for the next story. Developing accurate and
effective instinct is one way we get better, and
that is
more important than being agile.
The traditional software engineering community
thinks about this challenge,
too. Watts Humphrey created the Personal Software
Process to help developers get a better sense of
how they use their time and to use this sense to
get better. But, typically, the result feels so
heavy, so onerous on the developers it aims to
help, that few people are likely to stick with it
when they get into the trenches with their code.
An aside: This reminds me of conversations I had with
students in my AI courses back in the day. I asked
them to read Alan Turing's classic
Computing Machinery and Intelligence,
and in class we discussed the Turing Test and the
many objections Turing rebuts. Many students clung
to the notion that a computer program could never
exhibit human-like intelligence because humans lacked
"gut instinct" -- instinct. Many students played
right into Turing's rebuttal yet remained firm; they
felt deeply that to be human was different. Now, I
am not at ease with scientific materialism's claim
that humans are purely deterministic beings, but the
scientist in me tells me to strive for natural
explanations of as much of every phenomenon as
possible. Why couldn't a program develop a "gut
feeling"? To the extent that at least some of our
instincts are learned responses, developed through
repetition and time, why couldn't a program learn
the same instincts? I had fun playing devil's
advocate, as I always do, even when I was certain
that I was making little progress in opening some
students' minds.
In your work and in your play, be aware of the role
that practice, repetition, and time play in developing
your instincts. Do not despair that you don't have
good instincts. Work to develop them. The word
missing from your thought is "yet". A little
attention to your work, and a lot of practice, will
go a long way. Once you have good instincts, cherish
them. They give us comfort and confidence. They make
us feel powerful. But don't settle. The same attention
and practice will help you get better, to grow as a
developer or runner or whatever your task.
As for my running, I am certainly glad to be getting
stronger and to be able to run faster than I expect.
Still, I look forward to the feeling of control I have
when my instincts are more reliable. Unpredictable
effort leads to unpredictable days.
Sometimes it pays to keep reading.
Last time, I commented on
breaking rules
and mentioned a thread on the XP mailing list. I
figured that I had seen all I needed there and was
on the verge of skipping the rest. Then I saw a
message from Laurent Bossavit
and decided to read. I'm not surprised to learn
something from Laurent; I have
learned
from
him
before.
Laurent's note introduced me to the legal term
bright line.
In the law, a bright-line rule is...
... a clearly defined rule or standard, composed of
objective factors, which leaves little or no room for
varying interpretation. The purpose of a bright-line
rule is to produce predictable and consistent results
in its application.
As Laurent says, Bright lines are important in
situations where temptations are strong and the slope
particularly steep, a well-known example is alcoholics'
high vulnerability to even small exceptions.
Test-driven development, or even writing tests soon
after code and thus maintaining a complete suite of
automated tests, requires a bright line for many
developers. It's too easy to slide back into old
habits, which for most developers are much older and
stronger. Staying on the right side of the line may
be the only practical way to Live Right.
This provides a useful name for what teachers often
do in class: create bright lines for students. When
students are first learning a new concept, they need
to develop a new habit. A bright-line rule -- "Thou
shalt always write a test first." or "Thou shalt
write no line of code outside of a pair." -- removes
from the students' minds the need to make a judgment
that they are almost always not prepared to make
yet: "Is this case an exception?" While learning,
it's often better to play
Three Bears
and overdo it. This gives your mind a chance to
develop good judgment through experience.
(For some reason, I am reminded of one way that I
used to learn to play a new chess opening. I'd play
a bazillion games of speed chess using it. This
didn't train my mind to think deeply about the
positions the opening created, but it gave me a
bazillion repetitions. I soon learned a lot of
patterns that allowed me to dismiss many bad
alternatives and focus my attention on the more
interesting positions.)
I often ask students to start with a bright line,
and only later take on the challenge of a
balancing test.
It's better to evolve toward such complexity, not
try to start there.
The psychological benefits of a bright-line test
are not limited to beginners. Just as alcoholics
have to hold a hard line and consider every choice
consciously every day, some of us need a good
"Thou shalt.." or "Thou shalt not..." in certain
cases. As much as I like to run, I sometimes have
to force myself out of bed at 5:00 AM or earlier
to do my morning work-out. Why not just skip one?
I am a creature of habit, and skipping even one
day makes it even harder to get up the next, and
the difficulty grows until I have a new habit.
(This has been one of the most challenging parts
of trying to get back up to my old mileage after
several extended breaks last year. I am proud
finally to have done all five of my morning runs
last week -- no days off, no PM make-ups. A new
habit is in formation.)
If you know you have a particular weakness, draw
a bright line for yourself. There is no shame in
that; indeed, I'd say that it shows professional
maturity to recognize the need and address it.
If you need a bright line for everything,
that may be a problem...
Sometimes, I adopt a bright line for myself because
I want everyone on the team to follow a practice.
I may feel comfortable exercising judgment in the
gray area but not feel the rest of the team is ready.
So we all play by the rules rather than discuss
every possible judgment call. As the team develops,
we can begin having those discussions. This is
similar to how I teach many practices.
This may sound too controlling to you, and occasionally
a student will say as much. But nearly everyone in
class benefits from taking the more patient road
to expertise. Again, from Laurent:
Rules which are more ambiguous and subtle leave more
room for various fudge factors, and that of course
can turn into an encouragement to fudge, the top of
a slippery slope.
Once learners have formed their judgment, they are
ready to balance forces. Until then, most are more
likely to backslide out of habit than to make an
appropriate choice to break the rule. And time
spent arguing every case before they are ready is
time not spent learning.
When I am writing a program, I will on occasion
add a new piece of functionality without writing a
test.
I am whispering because I have seen the reaction
on the XP mailing list and on a number of blogs
that Kent Beck received to his recent article,
To Test or Not to Test?
That's a Good Question.
In this short piece, Kent describes his current
thinking that, like golf, software development may
have "long game" and "short game", which call for
different tools and especially mentalities. One
of the differences might be whether one is willing
to trade automated testing for some other value,
such as delivering a piece of software sooner.
Note that Kent did not say that in the
long game he chooses not to test his code; he
simply tested manually. He also didn't say that
he plans never to write the automated tests he
needs later; he said he would write them later,
either when he has more time or, perhaps, when he
has learned enough to turn 8 hours of writing a
test into something much shorter.
Many peoples' public reactions to Kent's admission
have been along these lines: "We test you to make
this decision, Kent, but we don't trust everyone
else. And by saying this is okay, you will
contribute to the delinquency of many programmers."
Now you know why I need to whisper... I am
certainly not in the handful of programmers so
good that these folks would be willing to excuse
my apostasy. Kent himself is taking a lot of
abuse for it.
I have to admit that Kent's argument doesn't seem
that big a deal to me. I may not agree with
everything he says in his article, but at its core
he is claiming only that there is a particular
context in which programmers might choose to use
their judgment and not write tests before or
immediately after writing some code. Shocking:
A programmer should use his or her judgment in
the course of acting professionally. Where is
the surprise?
One of the things I like about Kent's piece is
that he helps us to think about when it might be
useful to break a particular rule. I know that
I'll be breaking rules occasionally, but I often
worry that I am surrendering to laziness or
sloppiness. Kent is describing a candidate
pattern: In this context, with these goals, you
are justified in breaking this rule consciously.
We are balancing forces, as we do all the time
when building anything. We might disagree with
the pattern he proposes, but I don't understand
why developers would attack the very notion of
making a trade-off that results in breaking a
rule.
In practice, I often play a little loose with
the rules of XP. There are a variety of reasons
that lead me to do so. Sometimes I pay for not
writing a test, and when I do I reflect on what
about the situation made the omission so dangerous.
If the only answer I can offer is "You must
write the test, always.", then I worry that I have
moved from behaving like a professional to
behaving like a zealot. I suspect that a lot of
developers make similar trade-offs.
I do appreciate the difficulty this raises for
those of us who teach XP, whether at universities
or in industry. If we teach a set of principles
as valuable, what happens to our students'
confidence in the principles when we admit that
we don't follow the rules slavishly? Well, I
hope that my students are learning to think, and
that they realize any principle or rule is
subject to our professional judgment in any given
circumstance.
Of course, in the context of a course, I often
ask students to follow the rules "slavishly",
especially when the principles in question require
a substantial change in how they think and behave.
TDD is an example, as is pair programming. More
broadly, this idea applies when we teach OOP or
functional programming or any other new practice.
(No assignment statements or sequences until Week
10 of Programming Languages!) Often, the best way
to learn a new practice is to live it for a while.
You understand it better then than you can from
any description, especially how it can transform
the way you think. You can use this understanding
later when it comes to apply your judgment about
potential trade-offs.
Even still, I know that, no matter how much an
instructor encourages a new practice and strives
to get students to live inside it for a while,
some students simply won't do it. Some want to
but struggle changing their habits. I feel for
them. Others willfully choose not to try the
something new and deny themselves the opportunity
to grow. I feel for them, too, but in a different
way.
Once students have had a chance to learn a set of
principles and to practice them for a while, I
love to talk with them about choices, judgment,
and trade-offs. They are capable of having a
meaningful discussion then.
It's important to remember that Kent is not teaching
novices. His primary audience is professional
programmers, with whom he ought to be able to
have a coherent conversation about choices, judgment,
and trade-offs. Fortunately, a few folks on the
P list have entertained the "long game versus
short game" claim and related their own experiences
making these kind of decisions on a daily basis.
If we in the agile world rely on unthinking
adherence to rules, then we are guilty of
proselytizing, not educating. Lots of folks who
don't buy the agile approaches love when they see
examples of this rigidity. It gives them evidence
to support their tenuous position about the whole
community. From all of my full-time years in the
classroom, I have learned that perhaps the most
valuable asset I can possess is my students'
trust in my goals and attitudes. Without that,
little I do is likely to have any positive effect
on them.
Kent's article has brought to the surfaced another
choice agilistas face most every day: the choice
between dogma and judgment. We tend to lose people
when we opt for unthinking adherence to a rule or
a practice. Besides, dogmatic adherence is rarely
the best path to getting better every day at what
we do, which is, I think one of the principles
that motivate the agile methods.
I am coming to a newfound respect for
Robert's Rules of Order
these days. I've usually shied away from that level
of formality whenever chairing a committee, but I've
experienced the forces that can drive a group in that
direction.
For the last year, I have been chairing a campus-wide
task force. Our topic is one on which there are many
views on campus and for which there is not currently
a shared vision. As a result, we all realized that
our first priority was communication: discussing key
issues, sharing ideas, and learning what others thought.
I'll also say that I have learned a lot about what I
think from these discussions. I've learned a lot
about the world that lies outside of my corner of
campus.
With sharing ideas and building trust as our first
goals, I kept our meetings as unstructured as possible,
even allowing conversations to drift off topic at times.
That turned out well sometimes, when we came to a new
question or a new answer unexpectedly.
We are nearing the end of our work, trying to reach
closure on our descriptions and recommendations.
This is when I see forces pushing us toward more
structure. It is easy to keep talking, to talk
around a decision so much that we find ourselves
doubting a well-considered result, or even
contradicting the it. At this point, we are usually
cover well-trod ground. A little formality -- motion,
second, discussion, vote, repeat -- may help. At
least I now have some first hand experience of what
might have led Mr. Robert to define his formal set
of rules.
It occurs to me that Robert's Rules are a little
like the heavyweight methodologies we often see in
the software development world. We agile types
are sometimes prone to look down on big formal
methodologies as obviously wrong: too rigid, too
limiting, too unrealistic. But, like the
Big Ball of Mud,
these methodologies came into being for a reason.
Most large organizations would like to ensure
some level of consistency and repeatability in
their development process over time. That's hard
to do when you have a 100 or a 1000 architects,
designers, programmers, and testers. A natural
tendency is to formalize the process in order
more closely to control it. If you think you
value safety more than discovery, or if you think
you can control the rate of change in requirements,
then a big process looks pretty attractive.
Robert's Rules looks like a solution to a similar
problem. In a large group, the growth in
communication overhead can outpace the value gained
by lots of free-form discussion. As a group grows
larger, the likelihood of contention grows as well,
and that can derail any value the group might gain
from free-form discussion. As a group reaches the
end of its time together, free-form discussion can
diverge from consensus. Robert's Rules seek to
ensure that everyone has a chance to talk, but that
the discussion more reliably reach a closing point.
They opt for safety and lowering the risk of
unpredictability, in lieu of discovery.
Smaller teams can manage communication overhead
better than large ones. This is one of the key
ideas behind agile approaches to software development:
keep teams small so that they can learn at the
same time they are making steady process toward
a goal. Agile approaches can work in large
organizations, too, but developers need to take
into account the forces at play in larger and
perhaps more risk-averse groups. That's where
the sort of expertise we find in Jutta Eckstein's
Agile Software Development in the Large
comes in so handy.
While I sense the value of running a more structured
meeting now, I don't intend to run any of my task
force or faculty meetings using Robert's Rules any
time soon. But I will keep in mind the motivation
behind them and try to act in the spirit of a more
directed discussion when necessary. I would rather
still value people and communication over rules
and formalisms, to the greatest extent possible.
If I ask you whether you like variety, you'll say
yes. Baloney. You like surprises you want. The
others, you call problems.
Some people are better than others at accepting the
surprises that they don't want. Perhaps that is why
Robbins's anecdote reminded me of a story I read last
summer in a book by John G. Miller called
QBQ! The Question Behind the Question.
The story, perhaps fictional, tells of a father
and young daughter out for a fun plane ride one day,
with dad behind the controls. When the plane's
engine dies unexpectedly, dad turns to his daughter
and says, calmly, I'm going to need to fly
the plane differently.
I don't make generally New Year's resolutions, but
when I am next tempted, I'll probably think again
of this story. I want to be that guy, and I'm not.
----
(Quick book review: QBQ! is pretty
standard for this genre of business self-help lit.
It says a lot of things we all should already know,
and probably do. But there are days when some of
us need a reminder or a little pep talk. This book
is full of short pep talks. It's a quick read and
good enough at its task, as long as you remember
that unless you change your behavior books like
these are nothing but empty calories. A bit like
software design methodologies.)
Though final grades are not all yet submitted,
the semester is over. We made
adjustments to the specification
in my compilers course, and the students were
able to produce a compiler that produced compilable,
executable Java code for a variety of source
programs. For the most part, the issues we
discussed most at their finals week demo dealt
with quality control. We found some programs
that confounded their parser or code generator,
which were evidence of bits of complexity they
had not yet mastered. There is a lesson to be
learned: theory and testing often take a back
seat to team dynamics and practices. Given the
complexity of their source language, I was not
too disappointed with their software, though I
think this team fell short of its promise. I
have been part of teams that have fallen similarly
short and so can empathize.
So, what is the verdict on a couple of
new ideas we tried this semester:
letting the team design its own source language
and working in a large team, of six? After their
demo, we debriefed the project as a group, and
then I asked them to evaluate the project and
course in writing. So I have some student data
on which to draw as well as my own thoughts.
On designing their own language: yes, but.
Most everyone enjoyed that part of the project,
and for some it was their favorite activity.
But the students found themselves still churning
on syntax and semantics relatively late into the
project, which affected the quality and stability
of their parser. We left open the possibility of
small changes to the grammar as they learned more
about the language by implementing it, but this
element of reality complicated their jobs. I did
not lock down the language soon enough and left
them making decisions too late in the process.
One thing I can do the next time we try this is
to put a firmer deadline on language design.
One thing thing that the students and I both
found helpful was writing programs in the proposed
language and discussing syntactic and semantic
language issues grounded in real code. I think
I'll build a session or two of this into the
course early, before the drop-dead date for the
grammar, so that we can all learn as much as we
can about the language before we proceed on to
implementing it.
We also discussed the idea of developing the
compiler in a more agile way, implementing
beginning-to-end programs for increasing subsets
of the language features until we are done.
This may well help us get better feedback about
language design earlier, but I'm not sure that
it addresses the big risks inherent in letting
the students design their own language. I'll
have to think more on this.
On working is a team of size six: no.
The team members and I were unanimous that a
team of size six created more problems than it
solved. My original thinking was that a larger
team would be better equipped to do the extra
work introduced by designing their own language,
which almost necessarily delayed the start of
the compiler implementation. But I think we
were bitten by a preemptive variation of
Brooks's Law
-- more manpower slowed them down. Communication
overhead goes up pretty quickly when you move
from a team of three to a team of six, and it
was much harder for the team to handle all of
its members' ideas effectively. This might well
be true for a team of experienced developers,
but for a team of undergrads working on their
first collaborative project of this scale, it
was an occasional show-stopper. I'll know
better next time.
As an aside, one feature the students included
in the language they designed was first-class
functions. This clearly complicated their
syntax and their implementation. I was pleased
that they took the shot. Even after the project
was over and they realized just how much extra
work first-class functions turned out to be,
the team was nearly unanimous in saying that,
if they could start over, they would retain
that feature. I admire their spunk and their
understanding of the programming power this
feature gave to their language.
When I teach programming languages, we discuss the
concepts of static and dynamic scoping. Scheme,
like most languages these days, is statically scoped.
This means that a variable refers to the binding that
existed when the variable was created. For example,
> (define f
(let ((i 100))
(lambda (x)
(+ x i))))
> (define i 1)
> (f 1)
101
This displays 101, not 2, because the reference to
i in the body of function f is
to the local variable i that exists when
the function was created, not to the i
that exists when the function is called. If the
interpreter looked to the calling context to find
its binding for i, that would be an example
of dynamic scope, and the interpreter would display
2 instead.
Most languages use static typic these days for a
variety of reasons, not the least of which is that
it is easier for programmers to reason about code
that is statically scoped. It is also easier to
decompose programs and create modules that
programmers can understand easily and use reliably.
In my course, when looking for an example of a
dynamically-scoped language, I usually refer to
Common Lisp. Many old Lisps were scoped dynamically,
and Common Lisp gives the programmer the ability
to define individual variables as dynamically-scoped.
Lisp does not mean much to students these days,
though. If I were more of a Perl programmer, I
would have known that Perl offers the same ability
to choose dynamic scope for a particular variable.
But I'm not, so I didn't know about this feature
of the language until writing this entry. Besides,
Perl itself is beginning to fade from the forefront
of students' attention these days, too. I could
use an example closer to my students' experience.
A recent post on
why Python does not optimize tail calls
brought this topic to mind. I've often heard it
said that in Python closures are "broken", which is
to say that they are not closures at all. Consider
this example drawn from the linked article:
IDLE 1.2.1
>>> def f(x):
if x > 0:
return f(x-1)
return 0;
>>> g = f
>>> def f(x):
return x
>>> g(5)
4
g is a function defined in terms of
f. By the time we call g,
f refers to a different function at the
top level. The result is something that looks a
lot like dynamic scope.
I don't know enough about the history of Python
to know whether such dynamic scoping is the result
of a conscious decision of the language designer
or not. Reading over the
Python history blog,
I get the impression that it was less a conscious
choice and more a side effect of having adopted
specific semantics for other parts of the language.
Opting for simplicity and transparency as an
overarching sometimes means accepting their effects
downstream. As my programming languages students
learn, it's actually easier to implement dynamic
scope in an interpreter, because you get it "for
free". To implement static scope, the interpreter
must go to the effort of storing the data
environment that exists at the time a block,
function, or other closure is created. This leads
to a trade-off: a simpler interpreter supports
programs that can be harder to understand, and a
more complex interpreter supports programs that
are easier to understand.
So for now I will say that dynamic scope is a feature
of Python, not a bug, though it may not have been
one of the intended features at the time of the
language's design.
If any of your current favorite languages use or
allow dynamic scope, I'd love to
hear about it
-- and especially whether and how you ever put that
feature to use.
Slipping Schedules and Changing Scope in the Compiler Course
We have fallen behind in my compilers course. You may
recall that before the semester I
contemplated some changes
in the course, including letting letting the students
design their own language. My group of six chose that
route, and as a part of that choice decided to work as
a team of six, rather than in pairs or threes. This
was the first time for me to have either of these
situations in class, and I was curious to see how it
would turn out.
Designing a language is tough, and even having lots of
examples to work from, both languages and documents
describing languages, is not enough to make it easy.
We took a little longer than I expected. Actually,
the team met its design deadline (with no time to
spare, but...), but then followed a period of thinking
more about the language. We both needed to come to a
better understanding of the implications of some of
their design decisions. Over time they changed their
definition, sometimes refining and sometimes simply
making the language different. This slowed the process
of starting to implement the language and caused a few
false starts in the scanner and parser.
Such bumps are a natural part of taking on the tougher
problem of creating the language, so I don't mind that
we are behind. I have learned a few things to do
differently the next time a compiler class chooses
this route. Working as a team of six increases the
communication overhead they face, so I need to do a
better job preparing them for the management component
of such a large development project. It's hard for a
team to manage itself, either through specific roles
that include a nominal team leader or through town-hall
style democracy. As the instructor, I need to watch
for moments when the team needs me to take the rudder
and guide things a bit more closely. Still, I think
that this has been a valuable experience for the students.
When they get out into industry, they will see successes
and failures of the sort they've created for themselves
this semester.
Still, things have gone reasonably well. It's almost
inevitable that occasional disagreements about technical
detail or team management will arise. People are people,
and we are all hard to work with sometimes. But I've
been happy with the attitude that all have brought to the
project. I think all have shown a reasonable degree of
commitment to the project, too, though they may not
realize yet just what sort of commitment getting a big
project like this done can require.
I have resisted the urge to tell (or re-tell?) the story
of my senior team project: a self-selected team of good
programmers and students who nonetheless found ways to
fall way behind their development schedule. We had
no way to change the scope of the system, struggled
mightily in the last weeks of the two-term project,
and watched our system crash on the day of the acceptance
test. The average number of hours I spent on this project
during its second term? 62 hours. And that was while
taking another CS course, two accounting courses, and
a numerical analysis course -- the final exam for which
I have literally no recollection of at all, because by
that time I was functioning on nearly zero sleep for
days on end. This story probably makes me sound crazy
-- not committed, but in need of being committed.
Sometimes, that's what a project takes.
On the technical side, I will do more next time to
accelerate our understanding of the new language and
our fixing of the definition. One approach I'm
considering is early homework assignments writing programs
in the new language, even before we have a scanner or
parser. This causes us all to get concrete sooner.
Maybe I will offer extra-credit points to students who
catch errors in the spec or in others students' programs.
I'll definitely give extra-credit for catching errors in
my programs. That's always fun, and I make a perfect
foil for the class. I am sure both to make mistakes and
to find holes in their design or their understanding of
it.
But what about this semester? We are behind, with three
weeks to D-Day. What is the best solution?
The first thing to recognize is that sometimes this sort
of thing happens. I do not have the authority to
implement a death march, short of becoming an ineffective
martinet. While I could try telling students that they
will receive incompletes until the project is finished,
I don't really have the authority to push the deadline of
the project beyond the end of our semester.
The better option is one not made available to my project
team in school, but which we in the software world now
recognize as an essential option: reduce the scope of
the project. The team and I discussed this early in
the week. We can't do much to make the language smaller,
because it is already rather sparse in data types,
primitive operators, and control structure. The one
thing we could drop is higher-order procedures, but I
was so please when they included this feature that I
would feel bad watching it drop out now. But that would
not really solve our problem. I am not sure they could
complete a compiler for the rest of the language in
time anyway.
We decided instead to change the target language from
JVM bytecodes to Java itself. This simplifies what
remains for them quite a bit, but not so much that it
makes the job easy. The big things we lose are
designing and implementing a low-level run-time system
and emitting machine-level code. The flip side is that
we decided to retain the language's support for
higher-order procedures, which is not trivial to
implement in generated Java code. They'll still get
to think about and implement closures, perhaps using
anonymous inner classes to implement function arguments
and results.
This results in a different challenge, and a change in
the experience the students will have. The object
lesson is a good one. We have made a trade-off, and
that is the nature of life for programmers. Change
happens, and things don't always proceed according to
plan. So we adapt and do the best we can. We might
even spend 60 hours one week working on our project!
For me, the biggest effect of the change is on our
last two and a half weeks of lecture. Given where we
are and what they will be doing, what do they most
need to learn? What ideas and techniques should they
see even if they won't use them in their compilers?
I get to have some fun right up to the end, too.
Last evening, Mike Feathers
tweeted a provocative idea:
The world might be better if all code
disappeared at a fix age and we had to constantly
rewrite it. Heck, he could even
write a tool to seek and destroy
all code as it reaches the age of three
months. Crazy, huh?
Maybe this idea is not so crazy. At my university
and most other places, hardware is on a 3- or
4-year "replacement cycle". Whether we need new
computers in our student labs, we replace them
on a schedule. Why? Because we recognize that
hardware reaches a natural "end of life". Using
it beyond that time means that we carry an
ever-increasing risk that it will fail. Rather
than let it fail and be caught without for a short
while, we accept the upfront cost of replacing it
with newer, more reliable, better equipment. The
benefit is piece of mind, and more reliable
performance.
Maybe we should recognize that software can be
like hardware. It reaches a natural "end of life"
-- not because physical components wear out, but
because the weight of changing requirements and
growing desires push it farther out of compliance
with reality. (This is like when we replace a
computer because its processor speed and RAM size
fall out of compliance with reality: the demands
of new operating systems and application software.)
Using software beyond its natural end of life
means that we carry an ever-increasing risk of
failure -- when it actually breaks, or when we
"suddenly" need to spend major time and money to
"maintain" it. Rather than risk letting our
software fail out from under us, we could accept
the cost of replacing it with newer, more reliable,
better software.
One of the goals of the agile software development
community is to reduce the cost of changing our
code. If agile approaches are successful, then
we might be more willing to bear the risk of our
code falling away from reality, because we are
not afraid of changing it. (Agile approaches also
value continuous feedback, which allows us to
recognize the need for change early, perhaps before
it becomes too costly.) But there may be times or
environments in which these techniques don't work
as well as we like.
Suppose that we committed to rewriting 1/4 of every
system every year. This would allow graceful,
gradual migration to new technologies. A possible
cost of this strategy is increasing complexity,
because our systems would come to be amalgams of
two, three, or even four technologies and programming
languages interoperating in one system. But is this
all that much different from life now? How many of
our systems already consist of modules in several
languages, several technologies, several styles?
Another side of me is skeptical. Shouldn't our
programs just keep working? Why not take care to
design them really well? Why not change small parts
of the system as needed, rather than take on
wholesale changes we don't need yet? Doesn't this
approach violate the principle of
YAGNI?
Another advantage of the approach: It gives us a
built-in path to continuous learning. Rewriting
part of a system means digging into the code,
learning or re-learning what it's made of and how
it works. With pair programming, we could bring
new people into a deeper understanding of the code.
This would help us to increase the feeling of
collective code ownership, as well as preserving
and replenishing corporate memory.
Another disadvantage of the approach: It is hard
to maintain this sort of discipline in hard
financial times. We see this with hardware, too.
When money is short, we often decide to lengthen
or eliminate the replacement cycle. In such
times, my colleagues who traffic in computer labs
and faculty desktop computers are a little more
worried than usual; what happens if... Software
development seems always to be under financial
pressure, because user demands grow to outpace
our capacity to produce meet them. Even if we
decided to try this out for software, administration
might immediately declare exigency and fall back
into the old ways: build new systems, now, now,
now.
Even after thinking about the idea for a while
now, it still sounds a little crazy. Then again,
sometimes crazy ideas have something to teach us.
It is not so crazy that I will dismiss it out of
hand. Maybe I will try it some time just see
how it works. If it does, I'll give Mike the
credit!
... for a definition of "the day" that includes
when I read them, not when the authors posted
them.
Tweet of the Day
Marick's Law: In software, anything of the form
"X's Law" is better understood by replacing the
word "Law" with "Fervent Desire".
-- Brian Marick
I love definitions that apply to themselves.
They are the next best thing to recursion. I
will have plenty of opportunities to put Brian's
fervent desire into practice while preparing to
teach software engineering
this fall.
Non-Tech Blog of the Day
I don't usually quote former graffiti vandals
or tattoo artists here. But I am an open-minded
guy, and this says something that many people
prefer not to hear. Courtesy of
Michael Berman:
"Am I gifted or especially talented?" Cartoon said.
"No. I got all this through hard work. Through
respecting my old man. From taking direction from
people. From painting when everyone else was asleep.
I just found something I really love and practiced
at it my whole life."
-- Mister Cartoon
Okay, so I am tickled to have quoted a guy named
Mister Cartoon. His work isn't my style, but
his attitude is. Work. Respect. Deference.
Practice. Most days of the week, I would be
well-served by setting aside my hubris and
following Mister Cartoon's example.
William Stafford's Writing the Australian
Crawl includes several essays on language,
words, and diction in poetry. Words and language
-- he and others say -- are co-authors of poems.
Their shapes and sounds drive the writer in
unexpected ways and give rise to unexpected
results, which are the poems that they needed to
write, whatever they had in mind when they started.
This idea seems fundamental to the process of
creation for most poets.
We in CS think a lot about language. It is part
of the fabric of our discipline, even when we don't
deal in software. Some of us in CS education think
and talk way too much about programming languages:
Pascal! Java! Ada! Scheme!
But even if we grant that there is
art in programming and programs,
can we say that language drives us as we build
our software? That language is the co-author of
our programs? That its words and shapes (and
sounds?) drive the programmer in unexpected ways
and gives rise to unexpected results, which are
the programs we need to write, whatever we have
in mind when we start? Can the programmer's
experience resemble in any way the poet's
experience that Stafford describes?
[Language] begins to distort, by congealing parts
of the total experience into successive, partially
relevant signals.... [It] begins to enhance the
experience because of a weird quality of language:
the successive distortions of language have their
own cumulative potential, and under certain
conditions the distortions of language can
reverberate into new experiences more various,
more powerful, and more revealing than the
experiences that set off language in the first
place.
Successive distortions with cumulative potential...
Programmers tend not to like it when the language
they use, or must use, distorts what they want to
say, and the cumulative effects of such distortions
in a program that can give us something that feels
cumbersome, feels wrong, is wrong.
Still... I think of my experiences coding in
Smalltalk and Scheme, and recall hearing others
tell similar tales. I have felt Smalltalk push me
towards objects I wasn't planning to write, even
to objects of a kind I had previously been unaware.
Null objects, and numbers as control structures;
objects as streams of behavior. Patterns of
object-oriented programs often give rise to
mythical objects that don't exist in the world,
which belies OOP's oft-stated intention to build
accurate models of the world. I have felt Scheme
push me toward abstractions I did not know existed
until just that moment, abstractions so abstract
that they make me -- and many a programmer already
fearful of functional style -- uncomfortable. Yet
it is simply the correct code to write.
For me: Smalltalk and Lisp and Scheme, yes.
Maybe Ruby. Not Java. C?
Is my question even meaningful? Or am I drowning
in my own inability to maintain suitable boundaries
between things that don't belong together?
My in-flight and bedtime reading for my
ChiliPLoP trip
was
William Stafford's
Writing the Australian Crawl, a book on reading
and especially writing poetry, and how these relate
to Life. Stafford's musings are crashing into my
professional work on the trip, about solving problems
and writing programs. The collisions give birth to
disjointed thoughts about software, programming, and
art. Let's see what putting them into words does to
them, and to me.
Intention endangers creation.
An intentional person is too effective to be a good
guide in the tentative act of creating.
I often think of programming as art. I've certainly
read code that felt poetic to me, such as McCarthy's
formulation of Lisp in Lisp (which I discussed way
back in an entry on the
unity of data and program.
But most of the programs we write are intentional:
we desire to implement a specific functionality.
That isn't the sort of creation that most artists
do, or strive to do. If we have a particular
artifact in mind, are we really "creating"?
Stafford might think not, and many software people
would say "No! We are an engineering discipline,
not an artistic one." Thinking as "artists", we are
undisciplined; we create bad software: software that
breaks, software that doesn't serve its intended
purpose, software that is bad internally, software
that is hard to maintain and modify.
Yet many people I know who program know... They
feel something akin to artistry and creation.
How can we impress both sides of this vision on
people, especially students who are just starting
out? When we tell only one side of the story, we
mislead.
Art is an interaction between object and beholder.
Can programs be art? Can a computer system be art?
Yes. Even many people inclined to say 'no' will
admit, perhaps grudgingly, that the iPod and the
iPhone are objects of art, or at least have elements
of artistry in them. I began writing some of these
notes on the plane, and all around me I see iPods
and iPhones serving people's needs, improving their
lives. They have changed us. Who would ever have
thought that people would be willing to watch
full-length cinematic films on a 2" screen? Our
youth, whose experiences are most shaped by the new
world of media and technology, take for granted this
limitation, as a natural side effect of experiencing
music and film and cartoons everywhere.
Yet iPods aren't only about delivering music, and
iPhones aren't just ways to talk to our friends.
People who own them love the feel of these devices
in their hands, and in our lives. They are not just
engineered artifacts, created only to meet a purely
functional need. They do more, and they are more.
Intention endangers creation.
Art reflects and amplifies experience. We programmers
often look for inspirations to write programs by being
alert to our personal experience and by recognizing
disconnects, things that interrupt our wholeness.
Robert Schumann said, To send light into the
darkness of men's hearts -- such is the duty of the
artist. Artists deal in truth, though not in
the direct, assertional sense we often associate with
mathematical or scientific truth. But they must deal
in truth if they are to shine light into the darkness
of our hearts.
Engineering is sometimes defined as using scientific
knowledge and physical resources to create artifacts
that achieve a goal or meet a need. Poets use words,
not "physical resources", but also shapes and sounds.
Their poems meet a need, though perhaps not a narrowly
defined one, or even one we realize we had until it
was met in the poem. Generously, we might think of
poets as playing a role somewhat akin to the engineer.
How about engineers playing a role somewhat akin to
the artist? Do engineers and programmers "send light
into the darkness of men's hearts"? I've read a lot
of Smalltalk code in my life that seemed to fill a
dark place in my mind, and my soul, and perhaps even
my heart. And some engineered artifacts do, indeed,
satisfy a need that we didn't even know we had
until we experienced them. And in such cases it is
usually experience in the broadest sense, not the
mechanics of saving a file or deleting our e-mail.
Design, well done, satisfies needs users didn't know
they had. This applies as well to the programs we
write as to any other artifact that we design with
intention.
I have more to write about this, but at this time I
feel a strong urge to say "Yes".
Well, Carefree. But it plays the Western theme to the
hilt.
This was a shorter conference visit than usual. Due to bad
weather on the way here, I arrived on the last flight in on
Sunday. Due to work constraints of my workshop colleagues,
I am heading out before the Wednesday morning session. Yet
it was a productive trip -- like
last year,
but this time on our own work, as originally planned. We
produced
the beginnings of a catalog of data-driven real-world
problems used in CS1 courses across the country, and
half of a grant proposal to NSF's CPATH program, to
fund some of our more ambitious ideas about programming
for everyone, including CS majors.
A good trip.
Yesterday over our late afternoon break, we joined with the
other workshop group and had an animated discussion started
by a guy who has been involved with the agile community.
He claimed that XP and other agile approaches tell us that
"thinking is not allowed", that
no design is allowed.
A straw man can be fun and useful for exploring the boundaries
of a metaphor. But believing it for real? Sigh.
A passing thought: Will professionals in other disciplines
really benefit from knowing how to program? Why can't they
"just" use a spreadsheet or a modeling tool like
Shazam?
This question didn't come to mind as a doubt, but as a
realization that I need a variety of compelling stories to
tell when I talk about this with people who don't already
believe my claim.
While speaking of spreadsheets... My co-conspirator
Robert Duvall
was poking around
Swivel,
a web site that collects and shares open data sets, and
read about the founders' inspiration. They cited something
Dan Bricklin said about his own inspiration for inventing
the spreadsheet:
I wanted to create a word processor for data.
Very nice. Notice that Bricklin's word processor for data
exposes a powerful form of end-user programming.
When I go to conferences, I usually feel as if the friends
and colleagues I meet are doing more, and more interesting,
things than I -- in research, in class, in life. It turns
out that a lot of my friends and colleagues seem to think
the same thing about their friends and colleagues,
including me. Huh.
I write this in the air. I was booked on a 100% full 6:50
AM PHX-MSP flight. We arrive at the airport a few minutes
later than planned. Rats, I have been assigned a window
seat by the airline. Okay, so I get on the plane and take
my seat. A family of three gets on and asks me hopefully
whether there is any chance I'd like an aisle seat. Sure,
I can help. (!) I trade out to the aisle seat across the
aisle so that they can sit together. Then the guy booked
into the middle seat next to me doesn't show. Surprise:
room for my Macbook Pro and my elbows. Some days, the
smile on me in small and unexpected ways.
I learned a long time ago that the two best debugging
tools I own are a nice piece of paper, and a good
pencil.
Writing something down is a great way to "think out
loud". My
Ghostbusters-loving
colleague, Mark Jacobson, calls this biction.
He doesn't define the term on
his web page,
though he does have this poetic sequence:
That sounds fanciful, but biction is a nuts-and-bolts
idea. The friction of that Bic pen on the paper is
when ideas that are floating fuzzily through the mind
confront reality.
Mark and I taught a data structures course together
back in the 1990s, and we had a rule: if students
wanted to ask one of us a question, they had to
show us a picture they had drawn that illustrated
their problem: the data structure, pointers, a bit
of code, ... If nothing else, this picture helped
us to understand their problem better. But it
usually offered more. In the process of showing
us the problem using their picture, students often
figured out the problem in front of our eyes. Other
students commented that, while drawing a picture in
preparing to ask a question, they saw the answer
for themselves. Biction.
Of course, one can also "think out loud" out loud.
In response to my post on
teaching software engineering,
a former student suggested that I should expose my
students to pair programming, which he found "hugely
beneficial" in another course's major project, or
at least to
rubber duck debugging.
That's biction with your tongue.
It may be that the most important activity happens
inside our heads. We just need to create some
friction for our thoughts.
We offer a lot of our upper-division courses
on a three-semester rotation. For the last
few years, I have been teaching Programming
Languages and our compilers course as a part
of our rotation. Before I became department
head, I taught Algorithms -- a course I love
-- in the third slot. I passed the course on
to someone else my first semester as head, and
I've never gotten it back. The person who
teaches it now is really good, and this leaves
me to be a utility infielder, covering whatever
most needs to be covered that semester. I've
taught our intro course in this slot, as well
as a set of 1-credit courses on individual
programming languages.
This fall, I will teach a course I have never
taught before: software engineering. This is
a traditional introduction to the discipline
for juniors and seniors:
Study of software life cycle models and their
phases -- planning, requirements, specifications,
design, implementation, testing, and maintenance.
Emphasis on tools, documentation, and applications.
I have taught non- traditional software
engineering before, in the form of two offerings
of a course on agile software development. In
fact, I taught that course during my first full
semester after starting this blog, and it --
along with and sometimes in tandem with training
for my second marathon -- provided a wealth of
inspiration for my writing.
Long-term readers of this blog know that I have
expressed skepticism about the software engineering
metaphor, both
in general
and in some of the specifics, such as
gathering requirements.
Still, I respect the goals of the discipline and
the effort and earnestness of its proponents. I
also am able to put aside philosophical concerns
in the
interest of department concerns.
We all agree that developing software, especially
in the large, is a challenging endeavor that
requires knowledge and skill. That is the goal
of our course, and it will be the goal of my
offering this fall.
The course I teach needs to stay pretty close to
the traditional notion of software engineering,
because that's what our curriculum calls for.
By most accounts, employers who hire our students
are pretty happy with what we teach in the course,
in particular the breadth of exposure we give them.
This is one of the constraints I face as I plan.
That said, I will certainly teach my own course.
I will make sure that students are exposed to the
agile approaches. Many of our alumni have told
me that their employers are introducing elements
of XP or Scrum into their software development
processes, and that they wish they had learned a
bit about them during their undergraduate studies.
This is the right place for them to encounter agile
principles and practices, as a different perspective
on the phases of the software lifecycle.
I also tend more toward the working-code end of
the spectrum, whereas this course has historically
tended toward the modeling-and-abstraction end.
I'd like to find a way to ensure that students
see and experience both. Models are nothing more
than pictures on a whiteboard or in a CASE tool
until we can implement them in code. Besides, our
students seem to graduate with an alarming lack
of exposure to modern tools for version control,
build management, and testing. I'd like to find
a way for them to learn not only what the stages
of software development are but also tools and
practices for effectively evolving programs through
those stages.
I'm looking for papers and ideas that can help
me design a good course that balances several
of these forces. Karen Reid's and Greg Wilson's
Learning by doing
is a great exemplar; it talks about how to introduce
version control by using a tool like CVS or SVN to
deliver, manage, and collect student assignments.
In the end, I want this course to serve well
students wherever they end up after graduation,
whether at a big-process company such as Rockwell
Collins or a mostly-agile shop consisting of a
few developers. Most of our graduates will end
up working in several different development
environments within a few years, regardless of
where they land, so broad principles and
understanding trump mastery of any particular skill
set. But I also know that mastery plays a big role
in how they will come to understand the principles.
Whatever I do, I want the course to be real,
not merely an academic exercise.
My daily bleg:
please send me
any thoughts you have on this course, ways to
organize it, or tools to use. As always, I value
your suggestions and will gladly share the credit!
Adele Goldberg, Computer Scientist and Entrepreneur
My slogan is:
computing is too important to be left to men.
-- Karen Sparck-Jones, 1935-2007
We talk a lot about the state of women in computing.
Girls have deserted computer science as an academic
major in recent years, and female undergrad
enrollment is at a historic low relative to boys.
Some people say, "Girls don't like to program," but
I don't think that explains all of the problem. At
least a few women agree with me... During a session
of the
Rebooting Computing Summit
in January, one of the men asserted that girls don't
like to program, and one of the women -- Fran Allen,
I think -- asked, "Says who?" From the back of the
room, a woman's voice called out, "Men!"
A lot of people outside of computer science do not
know how much pioneering work in our discipline was
done by women. Allen
won a Turing Award
for her work on languages and compilers, and the
most recent Turing Award was given to
Barbara Liskov,
also for work in programming languages. Karen
Sparck-Jones, quoted above, discovered the idea
of inverse document frequency, laying the
foundation for a generation of advances in
information retrieval. And these are just the
ones ready at hand; there many more.
When people assert that women don't like (just) to
program, they usually mean that women prefer to do
computer science in context, where they can see
and influence more directly the effects that their
creations will have in the world. One of my heroes
in computing,
Adele Goldberg,
has demonstrated that women can like -- and excel --
on both sides of the great divide.
(Note: I am not speaking of
this Adele Goldberg,
who is, I'm sure, a fine computer scientist in her
own right!)
Goldberg is perhaps best known as co-author of several
books on Smalltalk. Many of us fortunate enough to
come into contact with Smalltalk back in the 1980s
cut our teeth on the fabulous "blue book",
Smalltalk-80: The Language and Its
Implementation. You can check out a portion
of the blue book
on-line.
This book taught many a programmer how to implement
a language like Smalltalk. It is still one of the
great books about a language implementation, and it
still has a lot to teach us a lot about object-oriented
languages.
But Goldberg didn't just write about
Smalltalk; she was in the lab doing the work that
created it. During the 1970s, she was one of the
principal researchers at Xerox PARC. The team at
PARC not only developed Smalltalk but also created
and experimented with graphical user interfaces and
other features of the personal computing experience
that we all now take for granted.
Goldberg's legacy extends beyond the technical side
of Smalltalk. She worked with Alan Kay to develop
an idea of computing as a medium for everyone and
a new way for young people to learn, using the
computer as a dynamic medium. They described their
vision in
Personal Dynamic Media,
a paper that appeared in the March 1977 issue of
IEEE Computer. This was a vision that most
people did not really grasp until the 1990s, and it
inspired many people to consider a world far beyond
what existed at the time. But this paper did not
just talk about vision; it also showed their ideas
implemented in hardware and software, tools that
children were already using to create ideas. When
I look back at this paper, it reminds me of one
reason I admire Goldberg's work: it addresses both
the technical and the social, the abstract and the
concrete, idea and implementation. She and Kay
were thinking Big Thoughts and also then testing
them in the world.
(A PDF of this paper is currently available on-line
as part of the
New Media Reader.
Read it!)
After leaving PARC, Goldberg helped found ParcPlace,
a company that produced a very nice Smalltalk product
suitable for corporate applications and CS research
alike. The Intelligent Systems Lab I worked in as
a grad student at Michigan State was one of ParcPlace's
first clients, and we built all of our lab's software
infrastructure on top of its ObjectWorks platform.
I still have ObjectWorks on 3.5" floppies, as well
as some of the original documentation. (I may want
to
use it again some day...)
Some academics view founding a business as
antithetical to the academic enterprise, or at least
as not very interesting, but Goldberg sees it as
a natural extension of what computer science is:
The theoretical and practical knowledge embodied in
CS is interesting as standalone study. But the real
opportunity lies in equipping oneself to partner with
scientists or business experts, to learn what they
know and, together, to change how research or business
is conducted.
(I found this quote as a sidebar in
Women in Computing -- Take 2,
an article in a recent issue of Communications
of the ACM.)
I suppose that the women-don't-like-to-program
crowd might point to Goldberg's career in industry
as evidence that she prefers computing in its
applied context to the hard-core technical work
of computer science, but I don't think that is
true. Her work on Smalltalk and real tools at
PARC was hard-core technical, and her work at
ParcPlace on Smalltalk environments was hard-core
technical, too. And she has the mentality of
a researcher:
Don't ask whether you can do something, but how
to do it.
When no one knows the answer, you figure it out
for yourself. That's what Goldberg has done
throughout her career. And once she knows how,
she does it -- both to test the idea and make it
better, and to get the idea out into the world
where people can benefit from it. She seems to
like working on both sides of the divide. No,
she would probably tell us that the divide is
an artificial barrier of our own making, and
that more of us should be doing both kinds of
work.
When we are looking for examples of women who
have helped invent computer science, we find
researchers and practitioners. We
find women working in academia and in
industry, working in technical laboratories
and in social settings where applications
dominate theory. We don't have to limit our
vision of what women can do in computing to
any one kind of work or work place. We can
encourage young women who want to be programmers
and researchers, working on the most technical
of advances. We can encourage young women who
want to work out in the world, changing how
people do what they do via the dynamic power of
software. If you are ever looking for one person
to serve as an example of all these possibilities,
Adele Goldberg may be the person you seek.
Quoting from About Photography (1949)
by American photographer Will Connell (hat tip
Brendan MacRae): "Every medium suffers from its
own particular handicap. Photography's greatest
handicap is the ease with which the medium as
such can be learned. As a result, too many
budding neophytes learn to speak the language
too long before they have anything to say."
Programming doesn't seem to suffer from this
problem! Comments to Bray's entry about books
like "C for Dummies" notwithstanding, there are
not many people walking around who think
programming is too easy. Mark Guzdial
has described the reaction
of students taking a non-majors course with a
computational economics theme when they found
out they would have to do a little scripting in
Python. Most people who do not already have an
interest in CS express disdain for programming's
complexity, or fear of it. No one likes to feel
stupid. Perhaps worst of all, even students who
do want to major in CS
don't want to program.
We in the business seem almost to have gone out
of our way to make programming hard. I am not
saying that programming is or can be "easy", but
we should stop erecting artificial barriers that
make it harder than it needs to be -- or that
create an impression that only really smart
people can write code. People who have ideas
can write. We need to extend that idea to the
realm of code. We cannot make professional
programmers out of everyone, any more than piano
and violin lessons can make professional musicians
out of everyone. But we ought to be able to do
what music teachers can do: help anyone become
a competent, if limited, practitioner -- and
come to appreciate the art of programming
along the way.
The good news is that we can solve this
"problem", such as it is. As Guzdial wrote in
another fine piece:
An amazing thing about computing is that there
are virtually no ground rules. If we don't
like what the activity of programming is like,
we can change it.
We need to create tools that expose powerful
constructs to novices and hide the details until
later, if they ever need to be exposed. Scratch
and Alice are currently popular platforms in
this vein, but we need more. We also need to
connect the ability to program with people's
desires and interests. Scripting Facebook seems
like the opportunity du jour that is
begging to be grasped.
I'm happy to run across good news about
programming, even if it is only the backhanded
notion that programming is not too easy. Now
we need to keep on with the business of making
certain that programming is not too hard.
On Learning Curves, I read a
lament
about calculus students having a hard time putting
their skills into practice on some basic word
problems. This line stood out:
They can do the calculus. The algebra slays them.
Of late, our CS faculty have been discussing a
programming corollary. Students have passed their
intro programming course and a data structures
course. They get to an intermediate programming
course, or a programming languages course, or an
AI course, where they learn some more advanced
design idea or algorithm. They answer conceptual
courses about the material on exams and do well.
Then they try to write code... and hit a wall.
Sometimes a new programming language gets in the
way, but sometimes not -- students are using a
language they used for a year in the intro
sequence. And whether it's a new language or
an old one, the problems seem ticky-tack:
semicolons, declarations, function calls.
They can talk about the advanced concepts, but
simple programming tasks to implement the ideas
slays them. The programming part looks like
attention to detail to me, or effort spent to
internalize basic grammar and vocabulary. One
prof half-jokingly says his students have gone
out of their way to forget what they already
knew.
You don't really know programming unless you
can write a program from a real problem, and
not just a tightly-specified exercise designed
by the instructor. And I'm not sure you can
really know a concept -- not in the way that
a computer scientist needs to know it -- unless
you can write a program using it for a real
problem. If syntax is in the way, you simply
need to buckle down and learn the syntax.
I don't have any answers on this but thought
it was interesting that a calculus prof is
running into the same kind of problem.
My compiler students are getting to the point where
they should be deep in writing a parser for their
language. Walking back from lunch, I was thinking
about some very simple things they could do to make
their lives -- and project -- better.
1. Start.
Yes, start. If you read the literature of the agile
software development world or even of the life hacker
world, people talk about the great power that comes
just from taking the first step. I've always loved
the old Goethe quote about the power of committing
to a course of action. But isn't this all
cliché?
It is so easy to put off tracing your language
grammar, or building those FIRST and FOLLOW sets,
or attacking what you know will be a massive parsing
table. It is so easy to be afraid of writing the
first line of code because you aren't sure what the
whole app will look like.
Take the first step, however small and however scary.
I'm always amazed how much more motivated I feel once
I break the seal on a big task and have some real
feedback from my client or my compiler.
2. Always have live code.
Live code is always better than ideas in your head.
Brian Marick
tells us so.
One of the Gmail guys
tells us so:
We did a lot of things wrong during the 2.5 years
of pre-launch Gmail development, but one thing we
did very right was to always have live code. ...
Of course none of the code from my prototype
ever made it near the real product (thankfully),
but that code did something that fancy arguments
couldn't do (at least not my fancy arguments), it
showed that the idea and product had real potential.
Your code can tell which ideas are good ones and
which are bad ones. It can teach you about the
app you are building. It can help you learn what
your user wants.
I hear this all the time from students: "We have
a pretty good handle on this, but no code yet."
Sounds good, but... Live code can convince your
professor that you really have done
something. It can also help you ask questions
and be submitted on the due date. Don't
underestimate the value in that.
As Buchheit says from the Gmail experience, spend
less time talking and more time prototyping. You
may not be Google, but you can realize the same
benefits as those guys. And with version control
you don't have to worry about taking the wrong
step; you can always back up.
3. Don't forget what you know.
Okay, I have to admit that this did not occur to
me on my walk home form lunch. This afternoon,
a
former student
and
local entrepreneur
gave a
department seminar
on web app security. He twice mentioned that
many of the people he hires have learned many
useful skills in object-oriented design and
software engineering, using system languages
such as Java and Ada. When they get to his
shop, they are programming in a scripting
language such as PHP. "And they throw away
all they know!" They stop using the OOP
principles and patterns they have learned.
They stop documenting code and testing.
It's as if scripting occurs in a different
universe.
As he pointed out after the talk, all of
those skills and techniques and practices
matter just as much -- no, more -- when
using a language with many power tools, few
boundaries, and access to all of his and his
clients' data and filesystem.
When building a compiler in class, or any
other large-scale team project in a capstone
course, all of those skills and techniques
and practices matter, too, and sometimes for
the first time in student's career. This is
likely the largest and most sophisticated
program they have ever written. It is the
first time they have ever had to depend on
one or two or five other students to get
done, to understand and work with others'
code, to turn their own code other for the
understanding and use of their teammates.
There is a reason that you are learning all
this stuff. It's for the project you are
working on right now.
Through the years, despite our best efforts to
articulate that CS is more than "just programming,"
the misconception that the two are equivalent
remains. This equation continues to project a
narrow and misleading image of our discipline --
and directly impacts the character and number of
students we attract.
I remain sympathetic to this concern. Many people,
including lost potential majors, think that CS ==
programming. I don't know any computer scientists
who think that is true. I'd like for people to
understand what CS is and for potential majors who
end up not wanting to program for a living to know
that there is room for them in our discipline. But
pitching programming to the aside altogether is the
wrong way to do that, and will do more harm than
good -- even for non-computer scientists.
It seems to me that the authors of this column
conflate CS with programming at some level, because
they equate writing a program with "scholarly work"
in computer science:
While being educated implies proficiency in basic
language and quantitative skills, it does not imply
knowledge of or the ability to carry out scholarly
English and mathematics. Indeed, for those students
interested in pursuing higher-level English and
mathematics, there exist milestone courses to help
make the critical intellectual leaps necessary to
shift from the development of useful skills to the
academic study of these subjects. Analogously, we
believe the same dichotomy exists between CT, as a
skill, and computer science as an academic subject.
Our thesis is this: Programming is to CS what
proof construction is to mathematics and what
literary analysis is to English.
In my mind, it is a big -- and invalid -- step from
saying "CT and CS are different" to saying that
programming is fundamentally the domain of CS
scholars. I doubt that many professional software
developers will agree with a claim that they are
academic computer scientists!
I am familiar with Peter Naur's
Programming as Theory Building,
which Alistair Cockburn brought to the attention
of the software development world in his book,
Agile Software Development.
I'm a big fan of this article and am receptive to
the analogy; I think it gives us an interesting
way to look at professional software development.
But I think there is more to it than what Naur
has to say. Programming is writing.
Back to the ACM column. It's certainly true that,
at least for many areas of CS, "The shift to the
study of CS as an academic subject cannot .. be
achieved without intense immersion in crafting
programs." In that sense, Naur's thesis is a
good fit. But consider the analogy to English.
We all write in a less formal, less intense way
long before we enter linguistic analysis or even
intense immersion in composition courses. We do
so as a means of communicating our ideas, and
most of us succeed quite well doing so without
advanced formal training in composition.
How do we reach that level? We start young and
build our skills slowly through our K-12 education.
We write every year in school, starting with
sentences and growing into larger and larger
works as we go.
I recall that in my junior year English class we
focused on the paragraph, a small unit of writing.
We had written our first term papers the year
before, in our sophomore English course. At the
time, this seemed to me like a huge step backward,
but I now recognize this as part of the
Spiral pattern.
The previous year, we had written larger works, and
now we stepped back to develop further our skills
in the small after seeing how important they were
in the large.
This is part of what we miss in computing: the K-8
or K-12 preparation (and practice) that we all get
as writers, done in the small and across many other
learning contexts.
Likewise, I disagree that proof is solely the province
of mathematics scholars:
Just as math students come to proofs after 12 or
more years of experience with basic math, ...
In my education, we wrote our first proofs in
geometry -- as sophomores, the same year we wrote
our first term papers.
I do think one idea from the article and from
the CT movement merits more thought:
... programming should begin for all
students only after they have had substantial
practice acting and thinking as computational
agents.
Practice is good! Over the years, I have learned
from CS colleagues encountered many effective ways
to introduce students, whether at the university
or earlier, to ideas such as sorting algorithms,
parallelism, and object-oriented programming by
role play and other active techniques -- through
the learner acting as a computational agent. This
is an area in which the Computational Thinking
community can contribute real value. Projects
such as
CS Unplugged
have already developed some wonderful ways to
introduce CT to young people.
Just as we grow into more mature writers and
mathematical problem solvers throughout our school
years, we should grow into more mature computational
thinkers as we develop. I just don't want us to
hold programming out of the mix artificially.
Instead, let's look for ways to introduce
programming naturally where it
helps students understand ideas better.
Let's create languages and build tools to make
this work for students.
As I write this, I am struck by the different
nouns phrases we are using in this conversation.
We speak of "writers", not "linguistic thinkers".
People learn to speak and write, to communicate
their ideas. What is it that we are learning to
do when we become "computational
thinkers"? Astrachan's plea for "computational
doing" takes on an even more XXXXX tone.
Alan Kay's dream for Smalltalk has always been
the children could learn to program and grow
smoothly into great ideas, just as children
learn to read and write English and grow smoothly
into the language and great ideas of, say,
Shakespeare. This is a critical need in computer
science. The
How to Design Programs crowd
have shown us some of the things we might do to
accomplish this: language levels, tool support,
thinking support, and pedagogical methods.
Deep knowledge of programming is not essential to
understand all basic computer science, some
knowledge of programming adds so very much even
to our basic ideas.
A while back, I clipped this quote from a university
publication, figuring it would decorate a blog entry
some day:
The thing about a liberal arts education ... is it
prepares you to fail successfully and learn from that
failure. ... You will all fail. That's OK.
-- Jim Linahon
Linahon is an alumnus of our school who works in the
music industry.
He gave a talk on campus for students aspiring to
careers in the industry, the theme of which was,
"Learn to fail. It happens"
More recently, I ran across this as the solution
to a word puzzle in our local paper:
You've got to jump off cliffs all the time and
build your wings on the way down.
-- Ray Bradbury
Bradbury was one of my favorite authors when I was
growing up (The Martian Chronicles mesmerized
me!) This quote goes farther than Linahon's: what
other people call failure is learning to fly. Do
not fear.
A comment made at the
Rebooting Computing summit
about "embracing failure" brought these quotes back
to mind, along with an e-mail message Rich Pattis
wrote sometime last year. Rich talked about how
hard our discipline must feel to beginners, because
it is a discipline learned almost wholly by failure.
Learning to program can seem like nothing more than
an uninterrupted sequence failures: syntax errors,
logic errors, boundary cases, ugly interface, ....
I'm not a novice any more, but I still feel the
constant drip of failure whenever I work on a piece
of code I don't already understand well.
The thing is, I kinda like that feeling -- the
challenge of scaling a mountain of code. My friends
who program can at least say that they don't mind it,
and the best among them seem to thrive in such an
environment. I think that's part of what separates
programmers from less disturbed people.
Then again, repeated failure is a part of learning
many things. Learning to play a musical instrument
or a sport require repeated failure for most people.
Hitting a serve in tennis, or a free throw on the
hardcourt, or a curve ball in baseball -- the only
way to learn is by doing it over and over, failing
over and over, until the mind and body come together
in a memory that make success a repeatable process.
This seems to be an accepted part of athletics, even
among the duffers who only play for fun. How many
people in America are on a golf course this day,
playing the game poorly but hoping -- and working
-- to get better?
Why don't we feel the same way about academics, and
about computer programming in particular? Some
small number seem to, maybe the 2% that Knuth said
are capable of getting it.
I have heard some people say that in sports we have
created mechanisms for "meaningful failure", though
I'm not sure exactly what that means, but I suspect
that if we could build tools for students and set
problems before them that give them a sense of
meaningful failure, we'd probably not scare off so
many people from our early courses. I suspect that
this is part of what some people mean when they say
we should make our courses more fun, though thinking
in terms of meaningful failures might give us a
better start on the issue than simply mantras about
games and robots.
I don't think just equating programming to sports
is enough. Mitch Wand sent a message to the PLT
Scheme mailing list this weekend on a metaphor he
has been using to help students want to stick to
the design recipes of How to Design Programs:
In martial arts, the first thing you learn is to
do simple motions very precisely. Ditto for ballet,
where the first thing you learn is the five positions.
Once those are committed to muscle memory, you
can go on to combinations and variations.
Same deal for programming via HtDP: first
practice using the templates until you can do it
without thinking. Then you can go on to combinations
and variations.
I like the analogy and have used a similar idea with
students in the past. But my experience is that this
only works for students who want to learn to programming
-- or martial arts or ballet, for that matter. If
you start with people who want to go through the process
of learning, then lots of things can work. The teacher
just needs to motivate the student every once in a while
to stick with the dream. But it's already their
dream.
Maybe the problem is that people want
to play golf and the martial arts -- for whatever
social, business, or masochistic reasons -- but that
most people don't want to learn to program? Then our
problem comes back to a constant theme on this blog:
putting a feeling of power in peoples' hands when we
show them programming, so they want
to endure the pain.
One last quote, in case you ever are looking for a
literary way to motivate students to take on tough
challenges rather than little ones that acquiesce
easily and making us feel good sooner:
What we choose to fight is so tiny!
What fights us is so great!
...
When we win it's with small things,
and the triumph itself makes us small.
...
Winning does not tempt that man.
This is how he grows: by being defeated, decisively,
by constantly greater beings.
This comes from Rainer Maria Rilke's
The Man Watching.
What a marvelous image, growing strong by being
beaten -- decisively, less -- by ever greater
opponents. I'm sure you professional programmers
who have been tackling functional programming,
continuations, Scheme, Haskell, and Erlang these
last few years know just the feeling Rilke
describes, deep in the marrow of your bones.
I recently read an early version of a paper by a
colleague in the agile world that talks about several
different ways he approaches design problems. I
like that he is writing about design. After all
these years, I still encounter many people who think
this statement is an axiom:
agile development → no design
In those situations, I try to share (gently) my
experience as developer and occasional consultant,
but the notion is pretty well ingrained. As I
wrote last month,
it's hard a slog.
As I read the preprint, I thought more about doing
design in a reactive way, responding to new features
as we add them to our code. My skeptical colleagues
think that the sort of design so many of us do in
agile settings is not design at all. But I think
they are wrong, and the word "reactive" brought to
mind a similar notion from my days in AI:
reactive planning.
When I first heard that term in a graduate readings
course, it sounded like an oxymoron to me. Planning
is the opposite of reaction, right? If an agent
does not construct a plan, then how is it planning?
Reactive planning contrasts with what then came to
be known as
classical planning.
An agile wag wag might coin the term "BPUF" -- big
planning up-front.
But I learned about the idea and found it wasn't an
oxymoron at all, that reactive planning was a real
and valuable way for an agent to prepare its actions.
I have learned the same is true of "reactive" design.
We folks in the agile world probably haven't done
enough to teach agile novices to design in this way,
which is one reason I'm hoping to see more papers like
the draft I just read.
The latest edition of inroads, the quarterly
publication of SIGCSE, arrived in my mailbox yesterday.
The invited editorial was timely for me, as I finally
begin to think about teaching this spring. Alfred Aho,
co-author of the
dragon book
and creator of several influential languages and
programming tools, wrote about
Teaching the Compilers Course.
He didn't write a theoretical article or a solely
historical one, either; he's been teaching compilers
every semester for the last many years at Columbia.
As always, I enjoyed reading what an observant mind
has to say about his own work. It's comforting to
know that he and his students face many of the same
challenges with this course as my students and I do,
from the proliferation of powerful, practical tools
to the broad range of languages and target machines
available. (He also faces a challenge I do not --
teaching his course to 50-100 students every term.
Let's just say that my section this spring offers
ample opportunity for familiarity and one-on-one
interaction!)
Two of Aho's ideas are now germinating in my mind as
I settle on my course. The first is something that
has long been a feature of my senior project courses
other than compilers: an explicit focus on the
software engineering side of the project. Back when
I taught our Knowledge-Based Systems course (now
called Intelligent Systems) every year, we paid a
lot of attention to the process of writing a large
program as a team, from gathering requirements and
modeling knowledge to testing and deploying the
final system. We often used a
supplementary text
on managing the process of building KBS. Students
produced documents as well as code and evaluated
team members on their contributions and efforts.
When I moved to compilers five or six years ago
after a year on sabbatical, I de-emphasized the
software engineering process. First of all, I
had smaller classes and so no teams of three, four,
or five. Instead, I had pairs or even individuals
flying solo. Managing team interactions became
less important, especially when compared to the
more intellectually daunting content of the compiler
course. Second, the compiler students tended to
skew a little higher academically, and they seemed
to be able to handle more effectively the challenge
of writing a big program. Third, maybe I got a
little lazy and threw myself into the fun content
of the course, where my own natural inclinations
lie.
Aho has his students work in teams of five and, in
addition to writing a compiler and demoing at the
end of the semester:
write a white paper on their source language,
write a tutorial on using it, and
close with a substantial project report written
by every member of the team.
This short article has reawakened my interest in
having my students -- many of whom will graduate into
professional careers developing software and managing
its development -- attend more to process. I'll keep
it light, but these three documents (white paper,
tutorial, and project report) will provide structure
to tasks the students already have to do, such as to
understand their source language well and to explore
the nooks and crannies of its use.
The second idea from Aho's article is to have students
design their own language to compile. This is something
I have never done. It is also a feature that brings
more value to the writing of a white paper and a
tutorial for the language. I've always given students
a language loosely of my own design, adapted from the
many source languages I've encountered in colleagues'
courses and professional experience. When I design
the language, I have to write specs and clarifications;
I have to code sample programs to demonstrate the
semantics of the language and to test the students'
compilers at the end of the semester.
I like the potential benefits of having students design
their own language. They will encounter some of the
issues that the designers of the languages they use,
such as Java, C++, and Ada faced. They can focus their
language in a domain or a technology niche of interest
to them, such as music and gaming or targeting a
multi-core machine. They may even care more about
their project if they are implementing an engine that
makes their own creation come to life.
If I adopt these course features, they will shift the
burden between instructor and student in some unusual
ways. Students will have to exert more energy into the
languages of the course and write more documentation.
I will have to learn about their languages and follow
their projects much more intimately as the semester
proceeds in order to be able to provide the right kind
of guidance at the right moments. But this shift,
while demanding different kinds of work on both our
parts, should benefit both of us. When I design more
of the course upfront, I have greater control over
how the projects proceed. This gives me a sense of
comfort but deprives the students of experiences with
language design and evolution that will serve them
well in their careers. The sense of comfort also
deprives me of something: the opportunity to step
into the unknown in real-time and learn. Besides,
my students often surprise me with what they have
to teach me.
As I said, I'm just now starting to think about my
course in earnest after letting Christmas break be
a break. And I'm starting none to soon -- classes
begin Monday. Our first session will not be until
Thursday, however, as I'll begin the week at the
Rebooting Computing summit.
This is not the best timing for a workshop, but it
does offer me the prospect of a couple of travel
days away from the office to think more about my
course!
An acquaintance of mine sent a link to James Shore's
The Decline and Fall of Agile
to a mailing list with a warning: "You probably don't
want to read it if you're a follower of the religion."
His use of the pejorative reveals that he's not a fan.
He is a strong believer in design -- if not BDUF, at
least more than he perceives agile methods to encourage.
I read Shore's articles anyway, so I was happy to now.
I don't think of myself as religious on this matter, but
I often speak positively about agile approaches (I might
say "fairly") when a colleague expresses what I think
os a misconception, so here goes...
Shore is right. He also echoes something that comes up
every so often when I am discussing agile approaches with
folks who have had a bad experience: When a company does
something it calls "agile" but which is unsound (perhaps
because they leave something important out), things
usually do not go well. But that's because they've done
something unsound, not because they call what they did
"agile".
I really try not to be a knee-jerk apologist for agile
methods. They don't solve every problem in the world;
nothing does. So when someone tells me that agile has
failed them, I try to listen carefully to what they've
been doing. Otherwise, it's too easy to say, "Oh, you
did it wrong." That's the sort of behavior that leads
people to talk about religion. And it's intellectually
sloppy, which bothers me more.
But sometimes people do have a misconception, or do leave
out an essential practice, or do something else that
counters the desired benefit. When someone tells me,
[Extreme Programming] says you should spend no more
than 10 minutes on design during a three-week sprint.
10 minutes!
... I have to say something. Maybe some agile evangelists
have said this; maybe not. But it's wrong, and someone
has to say so.
For what it's worth, my understanding of XP goes back
to the original spirit: If doing something is valuable,
then why not do it all the time? As a result, I encourage
the teams I work with at the university and in industry
to think about design all the time. But I also encourage
them not to design too far ahead of their code base,
because that is too often untested thought. Refactoring,
a practice that some design-oriented people like to
deride as "not doing it right the first time", is a key
part of the design process. (Teams that don't refactor
all the time are usually in big trouble -- and then unhappy
with the other agile practices they have adopted.)
As with any idea that becomes more buzzword than idea,
there is always a huge risk that the energy of the
"movement" will flame out early when things don't go as
predicted by eager creators and early adopters. We see
the same thing happen in educational settings all the
time. Many of you have lived through
objects-first in the CS curriculum.
Software patterns encountered the same fate. Hype
outran practice. When this happens, it is usually best
to let the fad die out. The good news is that some
people will persevere with the good part of the idea
and do wonderful things. The most recent patterns
example I know of is the resurgence of interest in
patterns in the parallel programming community, which
faces many of the same challenges that faced a world
moving to object-oriented programming faced fifteen
years ago. The
Parallel Computing Laboratory
at Cal-Berkeley is undertaking an
ambitious pattern language project
in this area.
Echoing Shore:
What frustrates me the most is that this situation
is entirely avoidable. In a green-field environment,
the solid agile engineering practices included in
Extreme Programming pay for themselves within the
first few months.
When this passage leads the person with whom you are
speaking to say,
I didn't know anyone used XP anymore.
I feel sorry for them.
... you'll know it's time to stop talking. The religion
that is getting in the way of developing software better
may not be on the agile side of the conversation.
Today, I was asked the best question ever by a
high-school student.
During the fall, we host weekly campus visits by
prospective students who are interested in majoring
in CS. Most are accompanied by their parents, and
most of the dialogue in the sessions is driven by
the parents. Today's visitors were buddies from
school who attended sans parents. As a part
of our talking about careers open to CS grads, I
mentioned that some grads like to move into positions
where they don't deal much with code. I told them
that two of the things I don't like about my
current position is that I only get to teach one
course each semester and that I don't have much time
to cut code. Off-handedly, I said, "I'm a programmer."
Without missing a beat, one the students asked me,
"What hobby projects are you working on?"
Score! I talked about a couple of things I work on
whenever I can, little utilities I'm growing for
myself in Ruby and Scheme, and some refactoring
support for myself in Scheme. But the question was
much more important than the answer.
Some people
like to program.
Sometimes we discover the passion in unexpected ways,
as we saw in the article I referred to in
my recent entry:
[Leah] Culver started out as an art major at the
University of Minnesota, but found her calling
in a required programming class. "Before that
I didn't even know what programming was," she
admits. ... She built
Pownce
from scratch using a programming language called
Python.
Programmers find a way to program, just as
runners find a way to run.
I must admit, though, that I am in awe of the
numbers Steve Yegge uses when talking about
all the code he has written
when you take into account his professional and
personal projects:
I've now written at least 30,000 lines of serious
code in both Emacs Lisp and JavaScript, which pales
next to the 750,000 or so lines of Java I've [spit]
out, and doesn't even compare to the amount of C,
Python, assembly language or other stuff I've written.
Wow. I'll have to do a back-of-the-envelope estimate
of my total output sometime... In any case, I am
willing to stipulate to his claim that:
... 30,000 lines is a pretty good hunk of code for
getting to know a language. Especially if you're
writing an interpreter for one language in another
language: you wind up knowing both better than you
ever wanted to know them.
The students in our compiler course will get a small
taste of this next semester, though even I -- with
the reputation of a slave driver -- can't expect
them to produce 30 KLOC in a single project! I can
assure them that they will make a non-trivial dent
in the 10,000 hours of practice they need to master
their discipline. And most will be glad for it.
Humans plus running code are smarter than humans plus time.
We can sit around all day thinking, and we may come up
with something good. But if we turn our thoughts into
code and execute it, we will probably get there faster.
Running a piece of code gives us information, and we can
use that feedback to work smarter. Besides, the act of
writing the code itself tends to make us smarter, because
writing code forces us to be honest with ourselves in
places where abstract thought can get away with being
sloppy.
Brian offers this assertion as an assumption that underlies
the agile software value of working software, and specifically
as assumption that underlies a guideline he learned from
Kent Beck:
No design discussion should last more than 15 minutes
without someone turning to a computer to do an experiment.
An experiment gives us facts, and facts have a way of
shutting down the paths to fruitless (and often strenuous)
argument we all love to follow whenever we don't have
facts.
I love Kent Beck. He has a way of capturing great ideas
in simple aphorisms that focus my mind. Don't make the
mistake that some people make, trying to turn one of his
aphorisms into more than it is. This isn't a hard and
fast rule, and it probably does not apply in every
context. But it does capture an idea that many of us
in software development share: execucting a real program
usually gives us answers faster and more reliably than
a bunch of software developers sitting around
pontificating about a theoretical program.
As Brian says:
Rather than spending too much time predicting the future,
you take a stab at it and react to what you learn from
writing and running code...
This makes for a nice play on Alan Kay's most famous
bon mot, "The best way to predict the future is
to invent it." The best way to predict the future of
a program is to invent it: to write the program, and
to see how it works. Agile software development depends
on the fact that software is -- or should be -- soft,
malleable, workable in our hands. Invent the future
of your program, knowing full well that you will get
some things wrong, and use what you learn from writing
and running the program to make it better. Pretty
soon, you will know what the program should look like,
because you will have it in hand.
To me, this is one of the best lessons from Brian's
keynote, and well worth an Agile Thought.
Just this weekend I learned about
Ashleigh Brilliant,
a cartoonist and epigrammist. From little I've seen
in a couple of days, his cartoons remind me of
Hugh MacLeod's
business-card doodles
Gaping Void
-- only with a 1930s graphic style and language that
is more likely SFW.
This Brilliant cartoon, #3053, made it into my Agile
Development Hall of Fame on first sight:
This lesson was fresh in my mind over the weekend from
a small dose of programming. I was working on the
financial software
I've
decided to write for myself,
which has me exploring a few corners of PLT Scheme that
I don't use daily. As a result, I've been failing more
frequently than usual. The best failures come rat-a-tat-tat,
because they are often followed closely by an a-ha!
Sunday, just before I learned of Brilliant's work, I
felt one of those great releases when, for the first
time, my code gave me an answer I did not already know
and had not wanted to compute by hand: our family net
worth. At that moment I was excited to verify the
result manually (I'll need that test later!) and enjoy
all the wrong wrong work that had brought me to this
point. Brilliant has something.
In recent weeks, the financial markets of the world have
entered "interesting times". There is a great story to
tell here about the role that computational models have
played in the financial situation we face, but I have
been more intrigued by another connection to computing,
more specifically to software development. It turns
out that these bad times for the economy are a good time
to "be agile".
Paul Graham writes that this is a
good time to start a start-up,
in part because a start-up can be more nimble and consume
fewer resources than a big software shop. A new product
can grow in small steps in a market where resources are
limited. Tim Bray expands on that idea in his post,
A Good Time for Agility.
It may be difficult to get major projects and corresponding
big budgets approved in tough times, because most execs
will be focused on cost containment and surviving to the
quarterly report. But...
The classic Agile approach, where you pick two or three
key features, spec'em out with test suites that involve
the business side, build'em and test'em, and then think
about maybe going back for the next two or three, well,
that's starting to look awfully attractive.
Small steps and small up-front expense draw less attention
than BDUF and multi-month budgets. And if they lead to
concrete, measurable improvements, they have a greater
chance of sticking. They might even lead to important
new software.
The third example I read recently came in a posting to
the XP mailing list, the link to which I seem to have
lost. The gist was straightforward: The writer worked
in the software arm of a major financial institution.
Having previously adopted agile practices enabled his
shop to shift direction on short notice in response to
the market crash. They were not in the middle of a
major project with a specific market but in the middle
of ongoing creation of loan products. The market for
their usual products deteriorated and were able to
begin delivering software to a new market relatively
quickly. This did not require a new major project, but
a twist on their current trajectory.
This shouldn't surprise us. Agile approaches allow us
to manage risk and change at finer levels of granularity,
and in a time of major change the massive dinosaurs will
be at a disadvantage against more nimble species.
Not all news is so rosy. Bureaucracy can still dominate
an environment. Last Friday, an alumnus of our department
gave a talk for our current students on how not to stink
in industry. His advice was uniformly practical, with
many of his technical points reminiscent of The
Practical Programmer. But in response to a question
about XP and agile practices, his comments were not so
positive. He and his team have not yet figured out how
to do planning for XP projects, so they are left with
tool-specific XP practices such as pair programming and
testing early and often. I think that I can help him
get a grip on XP-style planning, and offered to do so,
but I think his problem goes deeper, to something he has
little control over: his team's customers expect big
project plans and fixed-price "contracts".
This is not a new problem. I was fortunate to visit
RoleModel Software
back when Ken Auer was first building it, and one topic
of discussion within the company was how to educate
clients about a new way of planning and budgeting for
projects and how to shift the culture when all of its
competitors was doing the same old thing. His potential
customers had one way of managing the risk they faced,
and that was do to things the usual way, even if that
led to software that was off target, over budget, and
over time. I don't know much more about the issue than
this and need to see if anyone has written of positive
experiences with it in industry.
My former student works for a government agency, which
perhaps makes the bureaucracy hard to move by law or
administrative rule, rather than by market forces. I
feel for him as my department continues to work on
outcomes assessment.
University mandates are my job's version of "the customer
demands a big project plan". (Outcomes assessment is
an academic form of unit testing for its curriculum.)
As we try to enact an outcomes assessment plan in small
steps, we face a requirement to produce a BDUF plan by
the end of this year. It's hard to figure out what will
work best for us if we have to predict what is best up
front. Some will tell us that the academic world
understands outcomes assessment well enough to design a
suitable plan from scratch, but many of us in the trenches
will disagree. It's certainly possible to design from
scratch a plan that looks familiar to other people, but
who knows if that is what will help this department and
this faculty steer its programs most effectively?
Complete operational plans of this sort often end up
being as useful as many of their software design
counterparts. Worse, mandates for such also tend to
counterproductive, because when the last big plan fails,
and when administration doesn't follow through by holding
departments accountable for fixing the plans, faculty
learn to mistrust both the mandates and the plans. That
is how the link in the previous paragraph can be to a
post nearly two years old, yet my department still not
have an effective assessment plan in place: the faculty
have a hard time justifying spending the time and energy
to take on such a big project if it is likely to fail
or if not developing a plan has no consequences.
I am hoping that we can use the most recent mandate as
an opportunity to begin growing an assessment regimen that
will serve us well over time. I believe in units tests
and continuous feedback. I'm also willing to argue to
the administration that an "incomplete" but implementable
plan is better than a complete plan with no follow-through.
As the software guys are saying, this is a good time to
be agile.
I had one of those agile moments on Wednesday. A colleague
stopped by my office to share his good feeling. He had
just come from a CS 2 lab. "I love it whenever I design
a lab in which students work in pairs. There is such life
in the lab!" He went on to explain the interactions within
pairs but also across pairs; one group would hear what
another was thinking or doing, and would ask about it. So
much learning was in the air.
This reminded me of the old joke... Patient: "Doctor, it
hurts when I do this." (Demonstrates.) "Can you help me?"
Doctor: "Sure. Don't do that."
Of course, it reminded of the
negative space
around the joke. Patient: "Doctor, life is great when I
do this." (Demonstrates.) "Can you help me?" Doctor:
"Sure. Do more of that."
"But..." But. We faculty are creatures of habit, both
in knowing and in doing. We just know we can't teach all
of our material with students working in pairs, so we
don't. I think we can, even when I don't follow my own
advice. (Doctor, heal thyself!) We design the labs, so
if we want students to work in pairs, we can have them
work in pairs.
I've had one or two successful experiences with all pair
programming all the time in closed labs. Back when we
taught CS1 and CS2 in C++, in the mid-1990s, and I was
doing our first-year courses a lot, I designed all of my
labs for students working in pairs. I wish I could say
I had bee visionary, but my motivation was extrinsic:
I had 25-30 students in class and 15 computers in the
lab. Students worked with different students every week,
in pseudo-random assignments of my device.
My C++-based courses probably weren't very good -- I
was relatively new to teaching, and we were using C++
after all -- and the paired programming in our lab
sessions may have been one of the saving graces:
students shared their perplexity and helped each other
learn. When they worked on outside programming assignments
for the course, they could call on a sturdy network
of friends they had built in lab sessions. Without
the pairs, I fear that our course would have worked
well for very few students.
If something works well, let's try to understand the
context in which it works, and then do it more often
in those contexts. That's an agile sentiment, whether
we apply it to pair programming or not. Whether we
apply it at the university or in industry. Whether
we apply it to software development or any other
practice in which we find ourselves engaged.
When I first came to UNI, a colleague and I talked a lot
about programming by novices, graphical programming,
programming by example, declarative programming, and the
like. Many people saw ideas such as these as a way to
broaden participation by making it possible for people
to program without "programming". Anyone can draw a
flowchart, right? Or program by dragging and dropping
widgets, right?
No, said my colleague. He was fond of saying that all
of those solutions were really just new kinds of programming
language in disguise; ultimately, you had to know how
to write a program. That may not be an insanely difficult
task, but it is not a trivial task, either -- even if
pictures were the lingua franca.
Yet the world goes on, looking for its next way to bypass
the hard work of programming and make it disappear with
pretty pictures. So I'm glad when people say out loud
in public what my colleague has always said in-house.
Here is
Uncle Bob Martin
sounding in on the latest,
model-driven architecture:
Some folks have put a great deal of hope in technologies
like MDA. I don't. The reason is that I don't see MDA as
anything more than a different kind of computer language.
To be effective it will still need 'if' and 'for' statements
of some kind. And 'programmers' will still need to write
programs in that language, because details will still need
to be managed. There is no language that can eliminate
the programming step, because the programming step is the
translation from requirements to systems irrespective of
language. MDA does not change this.
Programming is the translation from requirements to systems,
whether we write it down in C, Java, or Ruby -- or an MDA
model. There will be always be a program, and so there will
be always be programmers. Making better programming tools
helps, but as Bob says we also need thinkers, practitioners
and academics alike, to figure out better what it means "to
program" and to help others learn how to do it.
A couple of weeks ago, I mentioned that I might have my
students
create their own examples
for a homework assignment. Among the possible benefits
of this were:
helping the programmers to write down their understanding
of the problem in a concrete way early in the process
giving the programmers a way of to ask concrete questions
early in the process -- and reason to ask the questions
helping the programmers know how much code to write and
when to stop
I tried this and, as usual, learned as much or more than my
students.
Getting students to think concretely about their tasks is
tough, but asking them to write examples seemed to help.
Most of them made a pretty good effort and so fleshed out
what the one- or two-line text description I gave them
meant. I saw lots of the normal cases for each task but
also examples at the boundaries of the spec (What if the
list is empty?) and on the types of arguments (What if the
user passes an integer when the procedure asks for a list?
What if the user passes -1 when the procedure expects a
non-negative integer?) In class, before the assignment
was due, we were able to discuss how much type checking
we want our procedures to do, if any, in a language like
Scheme without
manifest types.
Similarly, should we write examples with the wrong number
of arguments, which result in an error?
I noticed that most students' examples contrasted cases
with different inputs to a procedure, but that few thought
about different kinds of output from the procedure.
Can filter return an empty list? Well, sure;
can you show me an example? I'll know next time to talk
to students about this and have them think more broadly
about their specs.
Requiring examples part-way through the assignment did
motivate questions earlier than usual. On previous
assignments, if I received any questions at all, they
tended to arrive in my mailbox the night before the
programs were due. That was still the case, but now
the deadline was halfway through the assignment period,
before they had written any code. And most of the
class seemed happy to comply with my request that they
write their examples before they wrote their code.
(They are rarely in a hurry to write their code!)
Did having their own examples in hand help the students
know how much code to write and when to stop? Would
examples provided by me have helped as much? I don't
know, but I guess 'yes' to both. Hmm. I didn't ask
students about this! Next time...
Seeing their examples early helped me
as much writing their examples early helped them. They
got valuable feedback, yes, but so did I. I learned a
bit of what they were thinking about the specific problems
at hand, but I also learned a bit of what they think
about more generally when faced with a programming
task.
My first attempt at this also gave me some insight about
how to describe the idea of writing examples better, and
why it's worth the effort. The examples should clarify
the textual description of the problem. They aren't
about testing. They may be useful as tests later, but
they probably aren't sufficient. (They approximate
are a form of
black box testing,
but not
white box testing.)
As clarifiers, one might take an extreme position: If
the textual description of the problem were missing,
would the examples be enough for us to know what
procedure to write? At this extreme, examples with the
wrong number and type of arguments might be essential;
in the more conventional role of clarifying the spec,
those examples are unnecessary.
One thing that intrigued me after I made this assignment
is that students might use their examples as the source
material for test-driven development. (There's that word
again.) I doubt many students consider this on their
own; a few have an inclination to write and test code in
close temporal proximity, but TDD isn't a natural outgrowth
of that for most of them. In any case, we are currently
learning a
pattern-driven style of programming,
so they have a pretty good idea of what their simplest
piece of code will look like. There is a nice connection,
though. Structural recursion relies on mimicking the
structure of the input data, and that data definition
also gives the programmer an idea about the kinds of
input for which she should have examples. That s-list
is either an empty list or a pair...
I'm probably reinventing a lot of wheels that the crew
behind How to Design Programs smoothed out long
ago. But I feel like I'm learning something useful along
the way.
I'm a big tennis fan. I like to play and would love to
play more, though I've never played well. But I also
like to watch tennis -- it is a game of athleticism
and strategy. The players are often colorful, yet many
of the greatest have been quiet, classy, and respectful
of the game. I confess a penchant for the colorful
players; Jimmy Connors is my favorite player of all
time, and in the 1990s my favorite was Andre Agassi.
Agassi's chief rival throughout his career was one of
the game's all-time greats, Pete Sampras. Sampras won
a record fourteen Grand Slam titles (a record under
assault by the remarkable Roger Federer) and finished
six consecutive years as the top-ranked player in the
world (a record that no one is likely to break any time
soon). He was also one of the quiet, respectful players,
much more like me than the loud Agassi, who early in his
career seemed to thrive on challenging authority and
crossing boundaries just for the attention.
Sampras recently published a tennis memoir, A
Champion's Mind, which I gladly read -- a rare
treat these days, reading a book purely for pleasure.
But even while reading for pleasure I could not help
noticing parallels to my professional interest in
software development and teaching. I saw in Sampras's
experience some lessons that that we in CS have also
learned. Here are a few.
Teaching and Humility
After Sampras had made his mark as a great player,
one of his first coaches liked to be known as one of
the coaches who helped make Sampras the player he was.
Sampras gave that coach his due, and gave the two men
who coached him for most of his pro career a huge
amount of credit for honing specific elements of his
game and strategy. But without sounding arrogant, he
also was clear that no coach "made" him. He had a
certain amount of native talent, and he was also born
with the kind of personality that drove him to excel.
Sampras would likely have been one of the all-time
greats even if he had had different coaches in his
youth, and even as a pro.
Great performers have what it takes to succeed. It is
rare for a teacher to help create greatness in a student.
What made Sampras's pro coaches so great themselves is
not that they built Sampras but that they were able to
identify the one or two things that he needed at that
point in his career and helped him work on those parts
of his game -- or his mind. Otherwise, they let the
drive within him push him forward.
As a teacher, I try figure out what students need and
help them find that. It's tough to do when teaching a
class of twenty-five students, because so much of the
teaching is done with the group and so cannot be
tailored to the individual as much as I might like and
as much as each might need. But when mentoring students,
whether grad students or undergrads, a dose of humility
is in order. As I think back to the very best of my
past students, I realize that I was most successful
when I helped them get past roadblocks or to remove
some source of friction in their thinking or their
doing. Their energy often energized me, and I fed off
of the relationship as much as they did.
Agile Moments
The secret of greatness is working hard day in and day
out. Sampras grew as a player because he had to in
order to achieve his goal of finishing six straight
years as #1. And the only way to do that was to add
value to his game every day. This seems consistent
with agile developers' emphasis on adding value to
their programs every day, through small steps and
daily builds. Being out there every day also makes
it possible to get feedback more frequently and so
make the next day's work potentially more valuable.
For some reason, Sampras's comments on a commitment
to being in the arena day in and day out reminded me
of one of Kent Beck's early bits of writing on XP,
in which he proclaimed that, and the end of the day,
if you hadn't produced some code, you probably had
not given your customer any value. I think Sampras
felt similarly.
Finally, this paragraph from a man who never changed
the model of racket he used throughout his career,
even as technology made it possible for lesser players
to serve bigger and hit more powerful ground strokes.
Here he speaks of the court on which his legend grew
beyond ordinary proportion, Centre Court at the All
England Club:
I enjoyed the relative "softness" of the court; it
was terrific to feel the sod give gently beneath my
feet with every step. I felt catlike out there,
like I was on a soft play mat where I could do as I
pleased without worry, fear, or excessive wear and
tear. Centre Court always made me feel connected
to my craft, and the sophisticated British crowd
enhanced that feeling. It was a pleasure to play
before them, and they inspired me to play my best.
Wimbledon is a shrine, and it was always a joy to
perform there.
Whatever else the agile crowd is about, feeling
connected to the craft of making software is at
its heart. I like to use tools that give gently
beneath my feet, that let me make progress without
worry and fear. Even ordinary craftsmen such as
I appreciate these feelings.
The latest issue of ACM's on-line pub Ubiquity consists of
Chauncey Bell's
My Problem with Design,
an article that first
appeared on his blog
a year ago. I almost stopped reading it early on, distracted
by other things and not enamored with its wordiness. (I'm
one to talk about another writer's wordiness!) I'm glad I
read the whole article, because Bell has an inspiring take
on design for a world that has redefined the word from its
classic sense. He echoes a common theme of the software
patterns and software craftsmanship crowd, that in separating
design from the other tasks involved in making an artifact
we diminish the concept of design, and ultimately we diminish
the quality of the artifact thus made.
But I was especially struck by these words:
The distinctive character of the designer shapes each design
that affects us, and at the same time the designer is shaped
by his/her inventions. Successful designs shape those for
whom they are designed. The designs alter people's worlds,
how they understand those worlds, and the character and
possibilities of inhabiting those worlds. ...
Most of our contemporaries tell a different story about
designing, in which designers fashion or craft artifacts
(including "information") that others "use." One reason that
we talk about it this way, I think, is that it can be
frightening to contemplate the actual consequences of our
actions. Do we dare speak a story in which, in the process
of designing structures in which others live, we are designing
them, their possibilities, what they attend to, the choices
they will make, and so forth?
(The passage I clipped gives the networked computer as the
signature example of our era.)
Successful designs shape those for whom they are designed.
In designing structures for people, we design them,
their possibilities.
I wonder how often we who make software think this sobering
thought. How often do we simply string characters together
without considering that our product might -- should?! --
change the lives of its users? My experience with software
written by small, independent developers for the Mac leads
me to think that at least a few programmers believe they
are doing something more than "just" cutting code to make
a buck.
I have had similar feelings about tools built for the agile
world. Even if Ward and Kent were only scratching their
own itches when they built their first unit-testing
framework in Smalltalk, something tells me they knew they
were doing more than "making a tool"; they were changing
how they could write Smalltalk. And I believe that Kent
and Erich knew that JUnit would redefine the world of
the developers who adopted it.
What about educators? I wonder how often we who "design
curriculum" think this sobering thought. Our students
should become new people after taking even one of our
courses. If they don't, then the course wasn't part of
their education; it's just a line on their transcripts.
How sad. After four years in a degree programs, our
students should see and want possibilities that
were beyond their ken at the start.
I've been fortunate in my years to come to know many CS
educators for whom designing curriculum is more than
writing a syllabus and showing up 40 times in a semester.
Most educators care much more than that, of course, or
they would probably be in industry. (Just showing up
out there pays better than just showing up around here,
if you can hold the gig.) But even if we care, do we
really think all the time about how our courses are
creating people, not just degree programs? And even if
we think this way in some abstract way, how often do we
let it seep down into our daily actions. That's tough.
A lot of us are trying.
I know there's nothing new here. Way back, I wrote
another entry
on the riff that "design, well done, satisfies needs
users didn't know they had". Yet it's probably worth
reminding ourselves about this every so often, and to
keep in mind that what we are doing
today, right now, is probably a form of design. Whose
world and possibilities are we defining?
This thought fits nicely with another theme among some
CS educators these days, context. We should design in
context: in the context of implementation and the other
acts inherent in making something, yes, but also in the
context of our ultimate community of users. Educators
such as
Owen Astrachan
are trying help us think about our computing in the
context of problems that matter to people outside of the
CS building. Others, such as
Mark Guzdial,
have been preaching computing in context for a while
now. I write occasionally on this topic here. If
we think about the context of our students, as we
will if we think of design as shaping people, then
putting our courses and curricula into context becomes
the natural next step.
On the PLT Scheme mailing list, someone asked why
the authors of How to Design Programs do
not provide unit tests for their exercises. The
questioner could understand not giving solutions,
but why not give the examples that the students
could use to guide their thinking. A list member
who is not an HtDP c-author speculated that if
the authors provided unit tests then students
would not bother to implement their own.
Co-author Matthias Felleisen responded "Yes" and
added this stronger assertion:
I have come to believe that being able to make up
your own examples (inputs, outputs) is
the critical step in solving most
problems.
Writing examples is one of the essential elements
of the "design recipe" approach on which Felleisen
et al. base How to Design Programs.
The idea itself isn't new, as I'm sure the book's
authors will tell you. Some CS teachers have been
requiring students to write test cases or test plans
for many years, and the practice is similar to what
some engineers learn to do from the start of their
education. Heck, test-driven design has gone from
being the latest rage in agile development to an
accepted (if too infrequently practiced) part of
creating software.
What HtDP and TDD do is to remind us all of the
importance of the practice and to make it an essential
step in the student's or developer's programming
process.
What struck me by Matthias's response is that making
up examples is the critical step in
writing code. It is certainly reasonable, for so
many reasons, among them:
It forces the programmer to write down her
understanding of the problem in a concrete
way early in the process. Concrete
understanding is always preferable to the
fuzzy-minded understanding that follows
reading a problem statement. Besides,
writing a program requires that level of
understanding.
Having examples in hand gives the programmer a
way of talking to the client or teacher to see
if her understanding matches that of the person
who "owns" the problem.
It gives the programmer a way of knowing how
much code to write and so when to stop. Most
students can use that guidance.
I usually give my students several examples as a
part of specifying problems and ask them to write a
few of their own. Most don't do much on their own
and, uncharacteristically, I don't hold them accountable
often enough. My next programming assignment may
look different from the previous ones; I have an idea
of how to sneak this little bit of design recipe
thinking into the process.
When I was in grad school, my advisor sent me to a series
of swank conferences on expert systems in business, finance,
and accounting. Among the things these conferences did
for me was to give a chance to stay at Ritz Carlton hotels.
This Midwestern boy had never been treated so well.
At the 1990 conference, I heard a talk by Gary Ribar from
KPMG Peat Marwick, one of the Big Six accounting consulting
firms of the time. Ribar described LoanProbe, a program
that evaluated the collectibility of commercial loans.
LoanProbe was a rule-based system organized in a peculiar
way, with its 9000 rules separated into thirty-three separate
"knowledge bases". It was a significant application that
interacted with sixty external programs and two large data
bases. Peat Marwick took LoanProbe a step further and used
its organizational technique to build a knowledge acquisition
program that enabled non-programmers to create systems with
a similar structure.
I was so excited. I recognized this technique as what we
in our lab called
structured matching,
a remarkably common and versatile pattern in knowledge-based
systems. LoanProbe looked to me like the largest documented
application of structured matching, which I was working on
as a part of my research. Naturally, I wanted to make a
connection to this work and share experiences with the
speaker.
After the talk, I waited in line to speak with him. When
my turn came, I gushed that their generic architecture was
very cool and that "we do something just like that in our
lab!". I expected camaraderie, but all I received back
was an icy stare, a curt response, and an end to the
conversation.
I didn't understand. Call me naive. For a while, I
wondered if Mr. Ribar was simply an unfriendly guy. Then
I realized that he probably took my comment not as a
compliment -- We do that, too! -- but as a claim that
the work he described was less valuable because it was
not novel. I realized that I had violated one of the
basic courtesies of research by telling him that his work
was known already.
These days, I think fondly of Ribar, that talk, and that
conference. He was behaving perfectly reasonably, given
the culture in which he worked. Novelty is prized.
A few years after that conference, I came across
PLoP
and the software patterns community. This group of people
valued discovering, documenting, and sharing common
solutions, the patterns that make our software and our
programming lives better. Structured Matcher did that,
and it appeared in programs from all sorts of domain.
If you tell someone a great idea, and they say "Yes, we
do something like that too!", that's
a pattern.
Documenting and sharing old, proven solutions that
expert practitioners use may not get you a publication
in the best research journal (though it might, if you
are persistent and fortunate), but it will make the
world better for programmers and software users. That
is valuable, too.
Fall semester is just around the corner. Students will begin
to arrive on campus next week, and classes start a week from
Monday. I haven't been able to spend much time on my class
yet and am looking forward to next week, when I can.
What I have been doing is clearing a backlog of to-dos from
the summer and handling standing tasks that come with the
start of a new semester and especially a new academic year.
This means managing several different to-do lists, crossing
priorities, and generally trying to
get things done.
As I look at this mound of things to do I can't help being
reminded of something
Jeff Patton blogged
a month or so ago: two secrets of success in software
development, courtesy of agile methods pioneer
Jim Highsmith:
start sooner, and do less.
Time ain't some magical quantity that I can conjure out of
the air. It is finite, fixed, and flowing relentlessly by.
If I can't seem to get done on time, I need to start sooner.
If I can't seem to get it all done, I need to do less.
Nifty procedures and good tools can help only so much.
I need to keep this in mind every day of the year.
Oh, and to you students out there: You may not be able
to do less work in my class, but you can start sooner.
You may have said so yourself
at the end of last semester.
Heck, you may even want to do more, like read the book...
I once wrote that
extreme programming is a self-help system.
This generalizes pretty well to other software methodologies,
too. As we step away from developing software to personal
hygiene, there is an entire ecosystem around the notion of
life hacks,
self-help for managing information and combatting data
overload. Programmers and techies are active players in
the lifehacking community because, well, we love to make
tools to solve our problems and we love self-help systems.
In the end, sometimes, we spend more time making tools and
playing with them than actually solving our problems.
One of the popular lifehacking systems among techies is
David Allen's
Getting Things Done,
or GTD. I've
never read the book
or adopted the system, but I've read about it and borrowed
some of its practices in trying to treat my own case of
information overload. The practices I have borrowed feel
a lot like XP and especially test-driven development. Maybe
that's why they appeal to me.
Consider
this post
on the basic concepts of GTD. Here is why GTD makes me
think of TDD:
think in terms of outcomes: write a test
take the next action: take a simple action
review your circumstances regularly: refactor
This is not a perfect match. In GTD, a goal from Step 1
may require many next actions, executed in sequence. In
TDD, we decompose such big goals into smaller steps so that
we can define a very clear next action to perform. And in
GTD, Step 3 isn't really refactoring of a system. It's
more a global check of where you are and how your lists
of projects and next actions need to be revised or pruned.
What resonates, though, is its discipline of regular review
of where you are headed and how well your current 'design'
can get you there.
It's not a perfect match, but then no metaphor is. Yet
the vibe feels undeniably similar to me. Each has a mindset
of short-term accountability through tests, small steps to
achieve simple, clear goals, and regular review and clean-up
of the system. The lifehackers who play with GTD even like
to build tools to automate as much as they can so that they
stay in the flow of getting things done as much as possible
and trust their tools to help them manage performance and
progress.
Successful patterns recur. I shouldn't be surprised to
find these similarities.
Greg Wilson
relates an observation by Michael Feathers:
"refactoring pure functional code is a lot easier than
refactoring imperative code". In one sense, this ought
not to surprise us. When we eliminate side effects from
our code, dependencies among functions flow through
parameters, which make individual functions more
predictably independent of one another. Without side
effects, we don't have sequences of statements, which
encourages smaller functions, which also makes it easier
to understand the functions.
(A function call does involve sequencing, because
arguments are evaluated before the function is invoked.
But this encourages small functions, too: Deeply-nested
expressions can be quite hard to read.)
There is another force counteracting this one, though.
Feathers has been playing a lot with Haskell, which is
strongly-typed through manifest types and type inferencing.
Many functional languages are dynamically-typed, and
dynamic typing makes it harder to refactor functional
programs -- at least to guarantee that a particular
refactoring does not change the program's behavior.
I'm a Scheme programmer when I use a functional language,
so I encounter the conflict between these two forces.
My suspicion from personal experience is that functional
programmers need less support, or at least different
kinds of support, when it comes to refactoring tools.
The first key step is to
identify refactorings from FP practice.
From there, we can find ways to automate support for
these refactorings. This is a
longstanding interest of mine.
One downside to my current position is a lack of time
to devote to this research project...
Ralph Johnson
pointed me to a design idea for very large databases
called a
shard.
This is a neat little essay for several reasons. First,
its author, Todd Hoff, explains an architecture for massive,
distributed databases that has grown up in support of
several well-known, high-performance web sites, including
Flickr, Google, and LiveJournal. Second, Hoff also wrote
articles that
describe the architectures of
Flickr,
Google,
and
LiveJournal.
Third, all four pages point to external articles that are
the source of the information summarized. Collectively,
these pages make a wonderful text on building scalable
data-based web systems.
I've posted this entry in my
Patterns
category because this recurring architecture has all the
hallmarks of a design pattern. It even has great name and
satisfies
Rule Of Three,
something I've
mentioned before
-- and what a fine three it is. Each implementation uses
the idea of a shard slightly differently, in fitting with
the particular forces at play in the three companies'
systems.
Buried near the bullet list on the Google page was an item
worth repeating:
Don't ignore the Academy. Academia has a lot of good ideas
that don't get translated into production environments.
Most of what Google has done has prior art, just not prior
large scale deployment.
This advice is a bit different from some advice I once shared
for entrepreneurs,
looking for Unix commands
that haven't been implemented on the web yet, but the spirit
is similar. Sometimes I hear envious people remark that
Google hasn't done anything special; they just used a bunch
of ideas others created to build a big system. Now, I don't
think that is strictly true, but I do think that many of the
ideas they used existed before in the database and networking
worlds. And to the extent that is true, good for them! They
paid attention in school, read beyond their assignments, and
found some cool ideas that they could try in practice. Isn't
that the right thing to do?
In any case, I recommend this article and encourage others
to write more like it.
A
recent entry
mentioned that one advantage of short source code for
beginners is a smaller space for errors. If a student
writes only three lines of code, then any error in the
program is probably on one of those three lines. That's
better than looking for errors in a 100-line program, at
least when the programmer is learning.
This assertion may seem like an oversimplification. What
if the students writes a bunch of three-line procedures
that call one another? Couldn't an error arise out of the
interaction of multiple procedures, and thus lie far from
the point at which it is discovered? Sure, but that is
usually only a problem if the student doesn't know that
each three-line procedure works. If we develop the habit
of testing each small piece of code well, or even reasoning
formally about its behavior, then we can have confidence
in the individual pieces, which focuses the search for an
error in the short piece of code that calls them.
This is, of course, one of the motivations behind the
agile practices of taking small steps and creating tests
for each piece of code as we go along. It is also why
programming in a scripting language can help novices.
The language provides powerful constructs, which allow
the novice programmer to say a lot in a small amount of
code. We can trust the language constructs to work
correctly, and so focus our search for errors in the
small bit of code.
Even still, it's not always as simple as it sounds. I
am reminded of an
article on a new course
proposed by Matthias Felleisen, in which he argues for
the use of a limited proof language. Even when we think
that a 'real' language is small enough to limit the
scope of errors students can make, we are usually
surprised. Felleisen comments on the Teach Scheme!
experience:
... we used to give students the "simple language of
first-order Lisp" and the code we saw was brutal.
Students come up with the worst possible solution that
you can imagine, even if you take this sentence into
account in your predictions.
This led the Teach Scheme! team to create a sequence
of language levels that expose students to
increasingly richer sets of ideas and primitives,
culminating in the complete language. This idea has
also been in the Java world, via
Dr. Java.
Another benefit of using limited teaching languages is
that the interpreter or compiler can provide much more
specific feedback to students at each level because it,
too, can take advantage of the smaller space of possible
errors.
Felleisen does not limit the idea of limited language
to the programming language. He writes of carefully
introducing students to the vocabulary we use to talk
about programming:
Freshmen are extremely limited in their vocabulary and
"big words" (such as 'specification' and 'implementation')
seem to intimidate them. We introduce them slowly and
back off often.
When I read this a
couple of weeks ago,
it troubled me a bit. Not because I disagree with what
Felleisen says, but because it seems to conflict with
something else I believe and blogged about
couple of weeks ago:
speak to students in real language, and help the students
grow into the language. I have had good experience with
children, including my own, when talking about the world
in natural language. What makes the experience of our
students different.
As I write this, I am less concerned that these conflict.
First, Felleisen mentions one feature of the CS1 experience
that distinguishes it from my kids' experience growing
up: fear. Children don't spend a lot of their time afraid
of the world; they are curious and want to know more.
They are knowledge sponges. CS1 students come out of a
school system that tends to inculcate fear and dampen
curiosity, and they tend to think computer science is a
little scary -- despite wanting to major in it.
Second, when I speak to children in my usual vocabulary,
I take the time to explain what words mean. Sometimes they
ask, and sometimes I notice a quizzical curious look on
their faces. Elaboration of ideas and words gives us more
to talk about (a good thing) and connects to other parts
of their knowledge (also good). And I'm sure that I don't
speak to kids using only thirteen-letter words; that's not
the nature of regular life, at least in my house. In
computing jargon words of excessive length are the norm.
So I don't think there's a contradiction in these two ideas.
Felleisen is reminding us to speak to students as if they
are learners, which they are, and to use language carefully,
not simplistically.
Even if there is a contradiction, I don't mind. It would
not be the only contradiction I bear. Strange as it may
sound, I try to be true to both of these ideas in my teaching.
I try not to talk down to my students, instead talking to
them about real problems and real solutions and cool ideas.
My goal is to help students reach up to the vocabulary and
ideas as they need, offering scaffolding in language and
tools when they are helpful.
Yesterday, I wrote
a bit about scripting languages.
It seems odd to have to talk about the value of
scripting languages in 2008, as Ronald Loui does in
his recent IEEE Computer article,
but despite their omnipresence in industry, the academic
world largely continues to prefer traditional systems
languages. Some of us would like to see this change.
First, let's consider the case of novice programmers.
Most scripting languages lack some of the features
of systems languages that are considered important
for learners, such as static typing. Yet these
"safer" languages also get in the way of learning,
as Loui writes, by imposing "enterprise-sized
correctness" on the beginner.
Early programmers must learn to be creative and
inventive, and they need programming tools that
support exploration rather than production.
This kind of claim has been made for years by
advocates of languages such as Scheme for CS1, but
those languages were always dismissed by "practical"
academics as toy languages or niche languages. Those
people can't dismiss scripting languages so easily.
You can call Python and Perl toy languages, but they
are used widely in industry for significant tasks.
The new ploy of these skeptics is to speak of the
"scripting language du jour" and to dismiss
them as fads that will disappear while real languages
(read: C) remain.
What scripting language would be the best vehicle for
CS1? Python
has had the buzz
in the CS ed community for a while. After having
taught
a little PHP
las semester, I would deem it too haphazard for CS1.
Sure, students should be able to do powerful things,
but the pocket-protected academic in me prefers a
language that at least pretends to embody good
design principles, and the pragmatist in me prefers
a language that offers a smoother transition into
languages beyond scripting. JavaScript is an idea
I've seen proposed more frequently of late, and it
is a choice with some surprising positives. I don't
have enough experience with it to say much, but I
am a little concerned about the model that programming
in a browser creates for beginning students.
Python and Ruby do seem like the best choices among
the scripting languages with the widest and deepest
reach. As Loui notes, few people dislike either, and
most people respect both, to some level. Both have
been designed carefully enough to be learned by
beginners and and support a reasonable transition as
students move to the next level of the curriculum.
Having used both, I prefer Ruby, not only for its
OO-ness but also for how free I feel when coding in
it. But I certainly respect the attraction many people
have to Python, especially for its better developed
graphics support.
Some faculty ask whether scripting languages scale to
enterprise-level software. My first reaction is: For
teaching CS1, why should we care? Really? Students
don't write enterprise-level software in CS1; they learn
to program. Enabling creativity and supporting exploration
are more important than the speed of the interpreter.
If students are motivated, they will write code -- a
lot of it.
Practice
makes perfect, not optimized loop unrolling and type
hygiene.
My second reaction is that these languages scale quite
nicely to real problems in industry. That is why they
have been adopted so widely. If you need to process a
large web access log, you really don't want to
use Java, C, or Ada. You want Perl, Python, or Ruby.
This level of scale gives us access to real problems
in CS1, and for these tasks scripting languages do more
than well enough. Add to that their simplicity and the
ability to do a lot with a little code, and student
learning is enhanced.
Loui writes, "Indeed, scripting languages are not the
answer for long-lasting, CPU-intensive nested loops."
But then, Java and C++ and Ada aren't the answer for all
the code we write, either. Many of the daily tasks that
programmers perform lie in the space better covered by
scripting languages. After learning a simpler language
that is useful for these daily tasks, students can move
on to larger-scale problems and learn the role of a
larger-scale language in solving them. That seems more
natural to me than going in the other direction.
Now let's consider the case of academic programming
languages research. A lot of interesting work is being
done in industry on the design and implementation of
scripting language, but Loui laments that academic
PL research still focus on syntactic and semantic
issues of more traditional languages.
Actually, I see a lot of academic work on DSLs --
domain-specific languages -- that is of value. One
problem is this research is so theoretical that it is
beyond the interest of programmers in the trenches.
Then again, it's beyond the mathematical ability and
interest of many CS academics, too. (I recently had
to comfort a tech entrepreneur friend of mine who was
distraught that he couldn't understand even the titles
of some PL theory papers on the resume of a programmer
he was thinking of hiring. I told him that the lambda
calculus does that to people!)
Loui suggest that PL language research might profitably
move in a direction taken by linguistics and consider
pragmatics rather than syntax and semantics. Instead
of proving something more about type systems, perhaps
a languages researcher might consider "the disruptive
influence that Ruby on Rails might have on web programming".
Studying how well "convention over configuration" works
in practice might be of as much use as incrementally
extending a compiler optimization technique. The effect
of pragmatics research would further blur the line
between programming languages and software engineering,
a line we have seen crossed by some academics from the
PLT Scheme community. This has turned out to be practical
for PL academics who are interested in tools that support
the programming process.
Loui's discussion of programming pragmatics reminds me
of my time in studying knowledge-based systems. Our work
was pragmatic, in the sense that we sought to model the
algorithms and data organization that expert problem
solvers used, which we found to be tailored to specific
problem types. Other researchers working on such
task-specific architectures arrived at models consistent
with ours. One particular group went beyond modeling
cognitive structures to the sociology of problem solving,
John McDermott's lab at Carnegie Mellon. I was
impressed by McDermott's focus on understanding problem
solvers in an almost anthropological way, but at the
time I was hopelessly in love with the algorithm and
language side of things to incorporate this kind of
observation into my own work. Now, I recognize it as
the pragmatics side of knowledge-based systems.
(McDermott was well known in the expert systems community
for his work on the pioneering programs R1 and XCON.
I googled him to find out what he was up to these days
but didn't find much, but through some
publications,
I infer that he must now be with the
Center for High Assurance Computer Systems
at the Naval Research Laboratory. I guess that accounts
for the sparse web presence.)
Reading Loui's article was an enjoyable repast, though
even he admits that much of the piece reflects old
arguments from proponents of dynamic languages. It did
have, I think, at least one fact off track. He asserts
that Java displaced Scheme as the primary language used
in CS1. If that is true, it is so only for a slender
subset of more elite schools, or perhaps that Scheme
made inroads during a brief interregnum between Java
and ... Pascal, a traditional procedural language that
was small and simple enough to mostly stay out of the
way of programmers and learners.
As with so many current papers, one of the best results
of reading it is a reminder of a piece of classic
literature, in this case
Ousterhout's 1998 essay.
I usually read this paper again each time I teach programming
languages, and with my next offering of that course to
begin in three weeks, the timing is perfect to read it
again.
Scripting Languages, Software Development, and Novice Programmers
Colleague and reader
Michael Berman
pointed me to the July 2008 issue of IEEE Computer,
which includes an article on the virtues of scripting
languages, Ronald Loui's
In Praise of Scripting: Real Programming Pragmatism.
Loui's inspiration is an even more important article in
praise of scripting, John Ousterhout's classic
Scripting: Higher Level Programming for the 21st Century.
Both papers tell us that scripting deserves more respect
in the hierarchy of programming and that scripting languages
deserve more consideration in the programming language and
CS education communities.
New programming languages come from many sources, but most
are created to fill some niche. Sometimes the niche is
theoretical, but more often the creators want to be able
to do something more easily than they can with existing
languages. Scripting languages in particular tend to
originate in practice, to fill a niche in the trenches,
and grow from there. Sometimes, they come to be used
just like a so-called general-purpose programming language.
When programmers have a problem that they need solve
repeatedly, they want a language that gives them tools
that are "ready at hand". For these programming tasks,
power comes from the level of abstraction provided by
built-in tools. Usually these tools are chosen to fill
the needs of a specific niche, but they almost always
include the ability to process text conveniently, quickly,
and succinctly.
Succinctness is a special virtue of scripting languages.
Loui mentions the virtue of short source code, and I'm
surprised that more people don't talk about the value
of small programs. Loui suggests one advantage that
I rarely see discussed: languages that allow and even
encourage short programs enable programmers to get done
with a task before losing motivation or concentration.
I don't know how important this advantage is for professional
programmers; perhaps some of my readers who work in the
real world can tell me what they think. I can say, though,
that, when working with university students, and especially
novice programmers, motivation or concentration are huge
factors. I sometimes hear colleagues say that students
who can't stay motivated and concentrate long enough to
solve an assignment in C++, Ada, or Java probably should
not be CS majors. This seems to ignore reality, both of
human psychology and of past experience with students.
Not to mention the fact that
teach non-majors,
too.
Another advantage of succinctness Loui proposes relates
to programmer error. System-level languages include
features intended to help programmers make fewer errors,
such as static typing, naming schemes, and verbosity.
But they also require programmers to spend more time
writing code and to write more code, and in that time
programmers find other ways to err. This is, too, is
an interesting claim if applied to professional software
development. One standard answer is that software
development is not "just" programming and that such errors
would disappear if we simply spent more time up-front in
analysis, modeling, and design. Of course, these activities
add even more time and more product to the lifecycle, and
create more space for error. They also put farther in
the future the developers' opportunity to get feedback
from customers and users, which in many domains is the
best way to eliminate the most important errors that
can arise when making software.
Again, my experience is that students, especially CS1
students, find ways to make mistakes, regardless of how
safe their language is.
One way to minimize errors and their effects is to shrink
the universe of possible errors. Smaller programs --
less code -- is one way to do that. It's harder to make
as many or even the same kind of errors in a small piece
of code. It's also easier to find and fix errors in a
small piece of code. There are exceptions to both of
these assertions, but I think that they hold in most
circumstances.
Students also have to be able to understand the problem
they are trying to solve and the tools they are using to
solve it. This places an upper bound on the abstraction
level we can allow in the languages we give our novice
students and the techniques we teach them. (This has long
been an argument made by people who think we should not
teach OO techniques in the first year, that they are too
abstract for the minds of our typical first-year students.)
All other things equal, concrete is good for beginning
programmers -- and for learners of all kinds. The fact
that scripting languages were designed for concrete
tasks means that we are often able to make the connection
for students between the languages abstractions and tasks
they can appreciate, such as manipulating images, sound,
and text.
My biases resonate with this claim in favor of scripting
languages:
Students should learn to love their own possibilities
before they learn to loathe other people's restrictions.
I've always applied this sentiment to languages such as
Smalltalk and Scheme which, while not generally considered
scripting languages, share many of the features that make
scripting languages attractive.
In this regard, Java and Ada are the poster children in
my department's early courses. Students in the C++ track
don't suffer from this particular failing as much because
they tend not to learn C++ anyway, but a more hygienic C.
These students are more likely to lose motivation and
concentration while drowning in an ocean of machine details.
When we consider the problem of teaching programming to
beginners, this statement by Loui stands out as well:
Students who learn to script early are empowered throughout
their college years, especially in the crucial Unix and Web
environments.
Non-majors who want to learn a little programming to become
more productive in their disciplines of choice don't get
much value at all from one semester learning Java, Ada, or
C++. (The one exception might be the physics majors, who
do use C/C++ later.) But even majors benefit from learning
a language that they might use sooner, say, in a summer job.
A language like PHP, JavaScript, or even Perl is probably
the most valuable in this regard. Java is the one
"enterprise" language that many of our students can use
in the summer jobs they tend to find, but unfortunately
one or two semesters are not enough for most of them to
master enough of the language to be able to contribute much
in a professional environment.
Over the years, I have come to think that even more important
than usefulness for summer jobs is the usefulness a language
brings to students in their daily lives, and the mindset
it fosters. I want CS students to customize their
environments. I want them to automate the tasks they do
every day when compiling programs and managing their files.
I want them to automate their software testing.
When students learns a big, verbose, picky language, they
come to think of writing a program as a major production,
one that may well cause more pain in the short term than
it relieves in the long term. Even if that is not true,
the student looks at the near-term pain and may think,
"No, thanks." When students learn a scripting language,
they can see that writing a program should be as easy as
having a good idea -- "I don't need to keep typing these
same three commands over and over", or "A program can
reorganize this data file for me." -- and writing it down.
A program is an idea,
made manifest in an executable form. They can make our
lives better. Of all people, computer scientists should
be able to harness their power -- even CS students.
This post has grown to cover much more than I had originally
planned, and taken more time to write. I'll stop here for
now and pick up this thread of thought in my next entry.
... for months, in an operation one army officer likened to
a "broken telephone," military intelligence had been able to
convince Ms. Betancourt's captor, Gerardo Aguilar, a guerrilla
known as "Cesar," that he was communicating with his top
bosses in the guerrillas' seven-man secretariat. Army
intelligence convinced top guerrilla leaders that they were
talking to Cesar. In reality, both were talking to army
intelligence.
As Bruce Schneier reports
in Wired magazine,
this strategy is well-known on the internet, both to would-be
system crackers and to security experts. The risk of
man-in-the-middle attacks is heightened on-line because the
primary safeguard against them -- shared social context -- is
so often lacking. Schneier describes some of the technical
methods available for reducing the risk of such attacks, but
his tone is subdued... Even when people have a protection
mechanism available, as they do in SSL, they usually don't
take advantage of it. Why? Using the mechanism requires
work, and most of us are just too lazy.
Then again, the probability of being victimized by a
man-in-the-middle attack may be small enough that many of us
can rationalize that the cost is greater than the benefit.
That is a convenient thought, until we are victimized!
The problem feature that makes man-in-the-middle attacks
possible is unjustified trust. This is not
a feature of particular technical systems, but of any social
system that relies on mediated communication. One of the neat
things about the Colombian hostage story it that shows that
some of the problems we study in computer science are relevant
in a wider context, and that some of our technical solutions
can be relevant, too. A little computer science can amplify
the problem solving of almost anyone who deals with "systems",
whatever their components.
This story shows a potential influence from computing on the
wider world. Just so that you know the relationship runs both
ways, I point you to Joshua Kerievsky's announcement of
"Programming with the Stars", one of the events on the
Developer Jam stage
at the upcoming Agile 2008 conference. Programming with the
Stars adapts the successful formula of
Dancing with the Stars,
a hit television show, to the world of programming. On
the TV show, non-dancers of renown from other popular
disciplines pair with professional dancers for a weekly
dance competitions. Programming with the Stars will work
similarly, only with (pair) programming plugged in for
dancing. Rather than competitions involving samba or tango,
the competitions will be in categories such as test-driven
development of new code and refactoring a code base.
As in the show, each pair will include an expert and a
non-expert, and there will be a panel of three judges:
I've already
mentioned Uncle Bob in this blog,
even in a humorous vein, and I envision him playing the
role of Simon Cowell from "American Idol". How Davies
and Hill compare to Paula Abdul and Randy Jackson, I
don't know. But I expect plenty of sarcasm, gushing
praise, and hip lingo from the panel, dog.
Computer scientists and software developers can draw
inspiration from pop culture
and have a little fun along the way. Just don't forget
that the ideas we play with are real and serious. Ask
those rescued hostages.
Most papers presented at SIGCSE and the OOPSLA Educators'
Symposium are about teaching methods, not computational
methods. When the papers do contain new technical content,
it's usually content that isn't really new, just new to
the audience or to mainstream use in the classroom.
The most prominent example of the latter that comes to
mind immediately is the series of papers by
Zung Nguyen
and
Stephen Wong
at SIGCSE on design patterns for data structures. Those
papers were valuable in principle because they showed
that how one conceives of containers changes when one is
working with objects. In practice, they sometimes missed
their mark because they were so complex that many teachers
in the audience said, "Cool! But I can't do that in class."
However, the OOPSLA Educators' Symposium this year received
a submission with a cool object-oriented implementation
of a common introductory programming topic. Unfortunately,
it may not have made the cut for inclusion based on some
technical concerns of the committee. Even so, I was so
happy to see this paper and to play with the implementation
a little on the side! It reminded me of one of the first
efforts I saw in a mainstream CS book to show how we think
differently about a problem we all know and love when
working with objects. That was Tim Budd's implementation
of the venerable
eight queens problem
in
An Introduction to Object-Oriented Programming.
Rather than implement the typical procedural algorithm
in an object-oriented language, Budd created a solution
that allowed each queen to solve the problem for herself
by doing some local computation and communicating with
the queen to her right. I remember first studying his
code to understand how it worked and then showing it to
colleagues. Most of them just said, "Huh?" Changing
how we think is hard, especially when we already have a
perfectly satisfactory solution for the problem in mind.
You have to want to get it, and then work until you do.
You can still find Budd's code from the "download area"
link on the textbook's page, though you might find a
more palatable version in the download area for the
book's
second edition.
I just spent a few minutes creating a
Ruby version,
which you are welcome to. It is slightly Ruby-ized but
mostly follows Budd's solution for now. (Note to self:
have fun this weekend refactoring that code!)
Another thing I liked about "An Introduction to
Object-Oriented Programming" was its linguistic ecumenism.
All examples were given in four languages: Object Pascal,
C++, Objective C, and Smalltalk. The reader could learn
OOP without tying it to a single language, and Budd could
point out subtle differences in how the languages worked.
I was already a Smalltalk programmer and used this book
as a way to learn some Objective C, a skill which has
been useful again this decade.
(Budd's second edition was a step forward in one respect,
by adding Java to the roster of languages. But it was
also the beginning of the end. Java soon became so
popular that the next version of his book used Java only.
It was still a good book for its time, but it lost some
of its value when it became monolingual.)
In March I talked about a
couple of OOPSLA submissions
written by our merged ChiliPLoP groups. In May
I wrote about the
verdict on one
but forgot to mention the other. Maybe because the
rejection was so much more interesting!
Anyone, our second submission was accepted into the
Educators' Symposium.
It is not a paper, really, but an extended abstract
for an activity we will run: a code review recast as
it might happen in a software studio. We hope to give
participants a snapshot of what a studio-based course
looks, feels, and works like. This is something
instructors can try on a small scale in class and, if
it works for them, expand throughout their course.
Even if code reviews is all the farther they go, we
co-authors think that this will be a useful step for
many instructors. It draws on experiences in the
writers' workshops
of
PLoP
helps students to think about the many design choices
they make when writing software, and to make them
reflectively rather than subconsciously.
The real trick to this activity will be the homework
we give before the symposium:
Before coming to OOPSLA, Educators' Symposium participants
will be asked to submit a program, in a language of their
choice (though using only standard libraries), which
implements the core of a program to generate Tag Clouds
from a data set. ...
My experience with many workshops in the past and especially
with the Educators' Symposium is that participants never do
this kind of homework. Some are well-intentioned but never
make time for it, while others figure they can skate by
without having written the code. (Sounds as if professors
are a lot like their students, huh?) Without code to review,
a code review doesn't get very far. We hope that we can
find a way to encourage symposium attendees to overcome
history and come with some code to workshop.
[Attention] is the taking possession by the mind, in clear and
vivid form, of one out of what seem several simultaneously possible
objects or trains of thought. ... It implies withdrawal from some
things in order to deal effectively with others....
Prone
as
I am
to
agile moments,
this message from James struck me in an interesting way.
First of all, I occasionally battle the issue that Stone
writes about, the to-do list that grows no matter productive
I seem to be on a given day. (And on lazy summer June
days, well, all bets are off.) James tells me that part
of my problem isn't a shortage of time, but a lack of will
to focus. I need to make better, more conscious choices
about what tasks to add to the list. Kent Beck is fond of
saying something to the effect that you may have too many
things to do and too little time, but you ultimately have
control over only one side of the equation. James would
tell us the same thing.
My mind also made a connection from this quote to the agile
software and test-driven development practice of working on
small stories, on taking small steps. If I pick up a card
with a single, atomic, well-defined feature to be added to
my program, I am able to focus. What is the shortest step
I can take and make this feature part of my code? No
distractions, no Zerstreutheit. Though I have an idea in
mind toward where my program is evolving, for this moment
I attend to one small feature and make it work. Focus.
James would be proud.
I think it's ironic in a way that one of the more effective
ways to reach the state of
flow
is to decompose a task into the smallest of tasks and focus
on them one at a time. The mind gets into a rhythm of
red bar-green bar: select task, write code, refactor, and
soon it is deep in its own world. I would like to be more
effective at doing this in my non-programming duties.
Perhaps if I keep James and his quote in mind, I can be.
This idea applies for me in other areas, in particular in
running and training for particular events. Focusing each
day on a particular goal -- intervals, Long Slow Distance,
hill strength, and so on -- helps the mind to push aside
its concerns with other parts of the game and attend to a
particular kind of improvement. There is a great sense of
relaxation in running super-hard repeats when the problem
I've been having is, say, picking up pace late in a run.
(I'd love to run super-hard repeats again some day soon,
but I'm
not there yet.)
I ran across a pattern today that reminded of another
I encountered
while at ChiliPLoP.
Both help developers deal with side effects,
changes to a program's state. Let me share these
patterns with you all, with a common explanation of
their value.
Most programs written these days are in a style where
setting and changing the values of one or more variables,
via a sequence of imperative statements. Side effects
are a common source of programmers' misunderstanding
when reading code. A program can change a variable's
state almost anywhere, and that makes reading any bit
of code uneasy: "Do I really know what this variable
means right now?" Using only local variables only in
the context of a small procedure is one way to localize
effects. Even still, problems can arise.
I won't try write full patterns for these. I'll write
short patlets and give you links to the articles I read,
which do a good job talking about the ideas.
Mutual Recursion with Side Effects
In
Solving Every Sudoku Puzzle,
Peter Norvig builds a Python program for the title task.
About 40% of the way in, he says:
If you have two mutually-recursive functions that both
alter the state of an object, try to move almost all
the functionality into just one of the functions.
Otherwise you will probably end up duplicating code.
Duplicate code is usually a bad thing, because it creates
a problem for programmers keeping the copies in sync.
Duplicate code that modifies state is especially bad,
because it brings in the extra complication of making
another procedure harder to understand.
Side Effects and Python's Default Parameters
Coincidentally, the second pattern involves Python, too.
This time the pattern is Python-specific, addressing
an issue with a language feature.
Context: You are writing a procedure with a
default parameter.
Problem: The procedure needs to modify the
default parameter. Python evaluates a default parameter's
initial value only on the first call to the procedure.
Solution: Whenever the parameter is missing,
initialize it within the method.
def function( item, stuff=None ):
stuff = stuff or []
# ... modify stuff, etc.
This pattern allows the user to take advantage of the
default parameter when he has no collection to send.
It does so by following a principle laid out in the
article Ottinger references:
In Python, "don't use mutable objects as function defaults."
This pattern may not be Python-specific, because there
may be other languages with this initialize-once behavior.
It seems like a bug to me, not a feature, but I'm not a
Python programmer and so can't speak authoritatively.
But I am glad that
Ruby doesn't do this.
~~~~~
Postscript: While preparing this article, I learned
something new about Ruby, unrelated to this issue.
It is possible to extract from a class a new class that
has a
subset of the original class's protocol.
Very nice indeed!)
The verdict is in on the paper we
wrote at ChiliPLoP
and submitted to
Onward!:
rejected. (We are still waiting to hear back on our
Educators' Symposium
submission.) The reviews of our Onward! paper were mostly
on mark, both on surface features (e.g., our list of references
was weak) and on the deeper ideas we offer (e.g., questions
about the history of studio approaches, and questions about
how the costs will scale). We knew that this submission was
risky; our time was simply too short to afford enough
iterations and legwork to produce a good enough paper for
Onward!.
I found it interesting that the most negative reviewer
recommended the paper for acceptance. This reviewer was
clearly engaged by the idea of our paper and ended up writing
the most thorough, thoughtful review, challenging many of our
assumptions along the way. I'd love to have the chance to
engage this person in conversation at the conference. For
now, I'll have to settle for pointing out some of the more
colorful and interesting bits of the review.
In at least one regard, this reviewer holds the traditional
view about university education. When it comes to the
"significant body of knowledge that is more or less standard
and that everyone in the field should acquire at some point
in time", "the current lecture plus problem sets approach is
a substantially more efficient and thorough way to do this."
Agreed. But isn't it more efficient to give the students
a book to read? A full prof or even a TA standing in a
big room is an expensive way to demonstrate standard
bodies of knowledge. Lecture made more sense when books
and other written material were scarce and expensive.
Most evidence on learning is that lecture is actually much
less effective than we professors (and the students who do
well in lecture courses) tend to think.
The reviewer does offer one alternative to lecture:
"setting up a competition based on mastery of these skills".
Actually, this approach is consistent with the spirit of
our paper's studio-based, apprenticeship-based, and
project-based. Small teams working to improve their skills
in order to win a competition could well inhabit the studio.
Our paper tended to overemphasize the softer collaboration
of an idyllic large-scale team.
This comment fascinated me:
Another issue is that this approach, in comparison with
standard approaches, emphasizes work over thinking. In
comparison with doing, for example, graph theory or
computational complexity proofs, software development has
a much lower ratio of thought to work. An undergraduate
education should maximize this ratio.
Because I write a blog called
Knowing and Doing,
you might imagine that I think highly of the interplay
between working and thinking. The reviewer has a point:
an education centered on projects in a studio must be
certain to engage students with the deep theoretical
material of the discipline, because it is that material
which provides the foundation for everything we do and
which enables us to do and create new things. I am
skeptical of the notion that an undergrad education
should maximize the ratio of thinking to doing, because
thinking unfettered by doing tends to drift off into an
ether of unreality. However, I do agree that we must
try to achieve an appropriate balance between thinking
and doing, and that a project-based approach will tend
to list toward doing.
One comment by the reviewer reveals that he or she is
a researcher, not a practitioner:
In my undergraduate education I tried to avoid any course
that involved significant software development (once I
had obtained a basic mastery of programming). I believe
this is generally appropriate for undergraduates.
Imagine the product of an English department saying, "In
my undergraduate education I tried to avoid any course
that involved significant composition (once I had obtained
a basic mastery of grammar and syntax). I believe this
is generally appropriate for undergraduates." I doubt
this person would make much of a writer. He or she might
be well prepared, though, to teach lit-crit theory at a
university.
Most of my students go into industry, and I encourage them
to take as many courses as they can in which they will
build serious pieces of software with intellectual content.
The mixture of thinking and doing stretches them and keeps
them honest.
An education system that produces both practitioners and
theoreticians must walk a strange line. One of the goals
of our paper was to argue that a studio approach could do
a better job of producing both researchers
and practitioners than our current system, which often
seems to do only a middling job by trying to cater to both
audiences.
I agree wholeheartedly, though, with this observation:
A great strength of the American system is that it keeps
people's options open until very late, maximizing the
ability of society to recognize and obtain the benefits
of placing able people in positions where they can be
maximally productive. In my view this is worth the lack
of focus.
My colleagues and I need to sharpen our focus so
that we can communicate more effectively the notion that
a system based on apprenticeship and projects in a studio
can, in fact, help learners develop as researchers and as
practitioners better than a traditional classroom approach.
The reviewer's closing comment expresses rather starkly
the challenge we face in advocating a new approach to
undergraduate education:
In summary, the paper advocates a return to an archaic
system that was abandoned in the sciences for good
reason, namely the inefficiency and ineffectiveness of
the advocated system in transmitting the required basic
foundational information to people entering the field.
The write-up itself reflects naive assumptions about the
group and individual dynamics that are required to make
the approach succeed. I would support some of the
proposed activities as part of an undergraduate education,
but not as the primary approach.
The fact that so many university educators and graduates
believe our current system exists in its current form
because it is more efficient and effective than the
alternatives -- and that it was designed intentionally
for these reasons -- is a substantial cultural obstacle
to any reform. Such is the challenge. We owe this
reviewer our gratitude for laying out the issues so well.
In closing, I can't resist quoting one last passage from
this review, for my friends in the other sciences:
The problem with putting students with no mastery of the
basics into an apprenticeship position is that, at least
in computer science, they are largely useless. (This is
less true in sciences such as biology and chemistry, which
involve shallower ideas and more menial activities. But
even in these sciences, it is more efficient to teach
students the basics outside of an apprenticeship situation.)
The serious truth behind this comment is the one that
explains why building an effective computer science
research program around undergraduates can be so difficult.
The jocular truth behind it is that, well, CS is just plain
deeper and harder! (I'll duck now.)
I've tried to explain the idea of software patterns in a lot
of different ways, to a lot of different kinds of people.
Reading James Tauber's
Grammar Rules
reminds me of one of my favorites: a pattern language is a
descriptive grammar. Patterns describe how (good)
programmers "really speak" when they are working in the
trenches.
Talking about patterns as grammar creates the potential for
the sort of misunderstanding that Tauber discusses in his
entry. Many people, including many linguists, think of
grammar rules as, well, rules. I was taught to "follow the
rules" in school and came to think of the rules as beyond
human control. Linguists know that the rules of grammar
are man-made, yet some still seem to view them as
prescriptive:
It is as if these people are viewing rules of grammar like
they would road rules--human inventions that one may disagree
with, but which are still, in some sense, what is "correct"...
Software patterns are rarely prescriptive in this sense.
They describe a construct that programmers use in a particular
context to balance the forces at play in the problem. Over
time, they have been found useful and so recur in similar
contexts. But if a programmer decides not to use a pattern
in a situation where it seems to apply, the programmer isn't
"wrong" in any absolute sense. But he'll have to resolve the
competing forces in some other way.
While the programmer isn't wrong, other programmers might
look at him (or, more accurately, his program) funny. They
will probably ask "why did you do it that way?", hoping to
learn something knew, or at least confirm that the programmer
has done something oddly.
This is similar to how human grammar works. If I say, "Me
wrote this blog", you would be justified in looking at me
funny. You'd probably think that what I speaking incorrectly.
Tauber points out that, while I might be violating the
accepted rules of grammar, I'm not wrong in any absolute sense:
... most linguists focus on modeling the tacit intuitions
native speakers have about their language, which are very
often at odds with the "rules of grammar" learnt at school.
He gives a couple of examples of rules that we hear broken all
of the time. For example, native speakers of English almost
always say "It's me", not "It's I", though that violates the
rules of nominative and accusative case. Are we all wrong?
In Sr. Jeanne's 7th-grade English class, perhaps. But English
grammar didn't fall from the heavens as incontrovertible rules;
it was created by humans as a description of accepted forms
of speech.
When a programmer chooses not to use a pattern, other programmers
are justified in taking a second look at the program and asking
"why?", but they can't really say he's guilty of anything more
than doing things differently.
Like grammar rules, some patterns are more "right" than others,
in the sense that it's less acceptable to break some than others.
I can get away with "It's me", even in more formal settings,
but I cannot get away with "Me wrote this blog", even in the
most informal settings. An OO programmer might be able get
away with not using the Chain of Responsibility pattern in
a context where it applies, but not using Strategy or Composite
in appropriate contexts just makes him look uninformed, or
uneducated.
A few more thoughts:
So, patterns are not like a grammar for programming language,
which is prescriptive. To speak Java at all, you have to
follow the rules. They are like the grammar of a human
language, which model observations about how people speak
in the wild.
As a tool for teaching and learning, patterns are so useful
precisely because they give us a way to learn accepted usages
that go beyond the surface syntactic rules of a language.
Even better, the pattern form emphasizes documenting
when a construct works and why. Patterns
are better than English grammar in this regard, at least
better than the way English grammar is typically taught
to us as schoolchildren.
There are certainly programmers, software engineers, and
programming language theorists who want to tell us how to
program, to define prescriptive rules. There can be value
in this approach. We can often learn something from a model
that has been designed based on theory and experience. But
to me prescriptive models for programming are most useful
when we don't feel like we have to follow them to the
letter! I want to be able to learn something new and then
figure out how I can use it to become a better programmer,
not a programmer of the model's kind.
But there is also a huge, untapped resource in writing the
descriptive grammar of how software is built in practice.
It is awfully useful to know what real people do -- smart,
creative people; programmers solving real problems under
real constraints. We don't understand programming or
software development well enough yet not to seek out the
lessons learned by folks working in the trenches.
This brings to mind a colorful image, of software linguists
venturing into the thick rain forest of a programming
ecosystem, uncovering heretofore unexplored grammars and
cultures. This may not seem as exotic as
studying the Pirahã,
but we never know when some remote programming tribe might
upend our understanding of programming...
Update: Added a known use contributed by Joe Bergin. -- 05/19/08.
Also Known AsFrequent Releases
From Pattern Language Graduate Student
You are writing a large document that one or more other people
must read and provide feedback on before it is distributed
externally.
The archetype is a master's thesis or doctoral dissertation,
which must be approved by a faculty committee.
You want to give your reviewers the best document possible.
You want them to give you feedback and feel good about
approving the document for external distribution.
You want to publish high-quality work. You would also like
to have your reviewers see only your best work, for a variety
of reasons. First, you respect them and are thankful for
their willingness to help you. Second, they often have the
ability to help you further in the future, in the form of
jobs or recommendations. Good work will impress your reviewers
more than weaker work. A more complete and mature document
is more likely to resemble the final result than a rougher,
earlier version.
In order to produce a document of the highest quality, you
need time -- time to research, write, and revise. This delays
your opportunity to distribute it to your reviewers. It also
delays their opportunity to give you feedback.
Your reviewers are busy. They have their own work to do and
are often volunteering their time to serve you.
Big tasks require a lot of time. If a task takes a lot of
time to do, some people face a psychological barrier to
starting the task.
A big task decomposed into several smaller tasks may take as
much time as the big task, or more, but each task takes a
smaller time. It is often easier to find time in small chunks,
which makes it easier to start on the task in the first place.
The sooner your reviewers are able to read parts of the
document, the sooner they will be able to give you feedback.
This feedback helps you to improve the document, both in the
large (topic, organization) and the small (examples, voice,
illustrations, and so on).
Therefore:
Distribute your document to reviewers periodically over a
relatively drawn out period. Early versions can be complete
parts of the document, or rough versions of the entire document.
In the archetypal thesis, you might give the reviewers one
chapter per week, or you might give a whole thesis in which
each part is in various stages of completeness.
There is certainly a trade-off between the quality of a
document and the timeliness of delivery. Don't worry; this
is just a draft. You are always free to improve and extend
your work. Keep in mind that there is also a trade-off between
the quality of a document and the amount of useful feedback
you are able to incorporate.
There is value in distributing even a very rough or incomplete
document at regular intervals. If reviewers read the relatively
weak version and make suggestions, they will feel valuable.
If they don't read it, they won't know or mind that you have
made changes in later versions. Furthermore, they may feel
wise for not having wasted their time on the earlier draft!
With the widespread availability of networks, we can give
our reviewers real-time access to an evolving document in
the form of an-line repository. In such a case, Small
Doses may take the form of comments recorded as each
change is committed to the repository. It is often better
for your reviewers if you give them periodic descriptions
of changes made to the document, so that they don't have to
wade through minutiae and can focus on discrete meaningful
jumps in the document.
I have seen Small Doses work effectively in a variety
of academic contexts, from graduate students writing theses
to instructors writing lecture notes and textbooks for
students. I've seen it work for master's students and
doctoral students, for text and code and web sites.
Joe Bergin
says that this pattern is an essential feature of the
Doctor of Professional Studies
program at Pace University. Joe has documented
patterns
for succeeding in the DPS program.
(If you know of particularly salient examples of Small
Doses, I'd love to hear them.)
Often times, the value of Small Doses is demonstrated
best in the results of its applying its antipattern,
Avalanche. Suppose you are nearing a landmark date,
say, the deadline for graduation or the end of spring semester,
when faculty will scatter for the summer. You dump a 50-, 70-,
or 100+-page document on your thesis committee. In the busy
time before the magic date, committee members have a difficulty
finding time to read the whole document. Naturally, they put
off reading it. Soon they fall way behind and have a hard time
meeting the deadline -- and they blame you for the predicament,
for unrealistic expectations. Of course, had you given the
committee a chapter at a time for 5 or 6 weeks leading up to
the magic date, some committee members would still have fallen
behind reading it, because they are distracted with their own
work. But then you could blame the them for not getting done!
Related Patterns
Extreme Programming
and other agile software methodologies encourage Short
Iterations and Frequent Releases. Such
frequent releases are the Small Doses of the
software development world. They enable more continuous
feedback and allow the programmers to improve the quality of
the code based on what they learn. The Avalanche
antipattern is the source of many woes in the world of software,
in large part due to the lack of feedback they afford from
users and clients.
I learned the Small Doses pattern from
Carl Page,
my Artificial Intelligence II professor at Michigan State
University in 1987. Professor Page was a bright guy and very
good computer scientist, with an often dark sense of humor.
He mentored his students and advisees with sardonic stories
like Small Doses. He was also father to another
famous Page,
Larry.
Yesterday I was listening to comedian
Rodney Laney
do a bit called "Old Jobs". He explained that the best kind
of job to have is a one-word job that everyone understands.
Manager, accountant, lawyer -- that's good. But if you have
to explain what you do, then you don't have a good job.
"You know the inside of the pin has these springs? I put
the springs on the inside of the pins." And then you have
to explain why you matter... "Without me, the pins wouldn't
go click." Bad job.
Okay, computer scientists and software developers, raise
your hands if you've had to explain what you do to a new
acquaintance at a party. To a curious relative? I should
say "tried to explain", because my own attempts come up
short far too often.
I think good Rodney has nailed a major flaw in being a
computer scientist.
Sadly, going with the one-word job title of "programmer"
doesn't help, and the people who think know what
a programmer is often don't really know.
Even still, I like what I do and know why it's a great job.
(Thanks to the wonders of the web, you can watch another
version of Laney's routine,
Good Jobs,
on-line at Comedy Central. I offer no assurance that
you'll like it, but I did.)
Owen is reputed to have said something like "Don't give as a
programming assignment something the student could just as
easily do by hand." (I am still
doing penance,
even though Lent ended two weeks ago.) This has been dubbed
Astrachan's Law,
perhaps by Nick Parlante. In the linked paper, Parlante says
that showmanship is the key to the Law, that
A trivial bit of code is fine for the introductory in-lecture
example, but such simplicity can take the fun out of an
assignment. As jaded old programmers, it's too easy to
forget the magical quality that software can have, especially
when it's churning out an unimaginable result. Astrachan's
Law reminds us to do a little showing off with our computation.
A program with impressive output is more fun to work on.
I think of this Astrachan's Law in a particular way. First,
I think that it reaches beyond showmanship: Not only do
students have less fun working on trivial programs, they
don't think that trivial programs are worth doing at all --
which means they may not practice enough or at all. Second,
I most often think of Astrachan's Law as talking about data.
When we ask students to convert Fahrenheit to Celsius, or to
sum ten numbers entered at the keyboard, we waste the value
of a program on something that can be done faster with a
calculator or -- gasp! -- a pencil and paper. Even if
students want to know the answer to our trivial assignment,
they won't see a need to master Java syntax to find it. You
don't have to go all the way to
data-intensive computing,
but we really should use data sets that matter.
Yesterday, I encountered what might be a variant or extension
of Astrachan's Law.
John Zelle
of Wartburg College gave a seminar for our department on how
to do virtual reality "on a shoestring" -- for $2000 or less.
He demonstrated some of his equipment, some of the software
he and his students have written, and some of the programs
written by students in his classes. His presentation impressed
me immensely. The quality of the experience produced by a
couple of standard projects, a couple of polarizing filters,
and a dollar pair of paper 3D glasses was remarkable. On top
of that, John and his students wrote much of the code driving
the VR, including the VR-savvy presentation software.
Toward the end of his talk, John was saying something about
the quality of the VR and student motivation. He commented
that it was hard to motivate many students when it came to
3D animation and filmmaking these days because (I paraphrase)
"they grow up accustomed to Pixar, and nothing we do can
approach that quality". In response to another question, he
said that a particular something they had done in class had
been quite successful, at least in part because it was something
students could not have done with off-the-shelf software.
These comments made me think about how, in the typical media
computation programming course, students spend a lot of time
writing code to imitate what programs such as Photoshop and
Audacity do. To me, this seems empowering: the idea that a
freshman can write code for a common Photoshop filter in a few
lines of Java or Python, at passable quality, tells me how
powerful being able to write programs makes us.
But maybe to my students, Photoshop filters have been done,
so that problem is solved and not worthy of being done again.
Like so much of computing, such programs are so much a part
of the background noise of their lives that learning how to
make them work is as appealing to them as making a ball-point
pen is to people of my age. I'd hope that some CS-leaning
students do want to learn such trivialities, on the
way to learning more and pushing the boundaries, but there
may not be enough folks of that bent any more.
On only one day's thought, this is merely a conjecture in
search of supporting evidence. I'd love to here what you
think, whether pro, con, or other.
I do have some anecdotal experience that is consistent in part
with my conjecture, in the world of 2D graphics. When we
first started teaching Java in a third-semester object-oriented
programming course, some of the faculty were excited by what
we could do graphically in that course. It was so much more
interesting than some of our other courses! But many students
yawned. Even back in 1997 or 1998, college students came to
us having experienced graphics much cooler than what they could
do in a first Java course. Over time, fewer and fewer students
found the examples knock-out compelling; the graphics became
just another example.
If this holds, I suppose that we might view it as a new law,
but it seems to me a natural extension of Astrachan's Law,
a corollary, if you will, that applies the basic idea into the
realm of application, rather than data.
My working title for this conjecture is the Pixar Effect, from
the Zelle comment that crystallized it in my mind. However, I
am open to someone else dubbing it the Wallingford Conjecture
or the Wallingford Corollary. My humility is at battle with
my ego.
Is anybody home? After a flurry of writing from SIGCSE, I
returned home to family time and plenty of work at the
office. The result has been one entry in ten days. I look
forward to finishing up my
SIGCSE reports,
but they appear to lie forward a bit, as the next week or
so are busy. I have a few new topics in the hopper waiting
for a few minutes to write as well.
One bit of good news is that part of my busy-ness this week
and next is launching the third iteration of my
language topics course.
We've done bash and PHP and are now moving on to Ruby, one
of my favorite languages. Shell scripting is great, but its
tools are too limited to make writing bigger programs fun.
PHP was better than I expected, but in the end it is really
about building web sites, not writing more general programs.
(And after a few weeks of using the language, PHP's warts
started to grate on me.)
Ruby is... sublime. It isn't perfect, of course, but even
its idiosyncrasies seem to get out of my way when I am deep
in code. I looked up the
definition of 'sublime',
as I sometimes do when I use a word which is outside my daily
working vocabulary or is misused enough in conversation that
I worry about misusing it myself. The first set of definitions
have a subtlety reminiscent of Ruby. To "vaporize and then
condense right back again" sounds just like Ruby getting out
of my way, only for me to find that I've just written a
substantial program in a few lines. (My favorite, though, is
"well-meaning ineptitude that rises to empyreal absurdity"!)
This is my first time to teach Ruby formally in a course.
I hope to use this new course beginning as a prompt to write
a few entries on Ruby and what teaching it is like.
There are many wonderful resources for learning about and
programming in Ruby. I've suggested that my students use the
pickaxe book
as a primary reference, even if they use the first edition,
a complete version of which is available
on-line.
In today's class, though, I used a simple evolutionary example
from
Brian Marick's
book
Everyday Scripting with Ruby.
I hesitated to use this book as the student's primary source
because it was originally written for tester's without any
programming background, and my course is for upper-division
CS majors with several languages under their belts. But
Brian works through several examples in a way that I find
compelling, and I think I can base a few solid sessions on
one or two of them.
This book makes me wonder how easy it would be to re-target
a book from an audience like non-programming testers to an
audience of scripting-savvy programmers who want to learn
Ruby's particular yumminess. I know that in the course of
writing the book Brian generalized his target audience from
testers to the union of three different audiences (testers,
business analysts, and programmers). Maybe after I've lived
with the book and an audience of student programmers I'll
have a better sense of how well the re-targeting worked. If
it works for my class, then I'll be inclined to adopt it for
the next offering of this course.
Anyway, today we evolved a script for diffing to directories
of files for a tester. I liked the flow of development and
the simple script that resulted. Now we will move on to
explore language features and their use in greater depth.
One example I hope to work through soon, perhaps in conjunction
with Ruby's regular expressions, is "Finding Things", Tim Bray's
chapter in
Beautiful Code.
Oh, and I must say that this is the first time that one of
my courses has a
theme song
-- and a fine theme song, indeed. Now, if only someone would
create a new programming language called "Angie", I would be
in heaven.
The second day of the conference opened with the keynote
address by Google's VP of Search Products and User
Experience, Marissa Mayer. She was one of the early
hires as the company expanded beyond the founders, and
from her talk it's clear that she has been involved with
a lot of different products in her time there. She is
also something the discipline of computer science could
use more of, a young woman in a highly-visible technical
and leadership and roles. Mayer is a great ambassador
for CS as it seeks to expand the number of female
high-school and college students.
This talk was called
Innovation, Design, and Simplicity at Google
and illustrated some of the ways that Google encourages
creativity in its employees and gets leverage from their
ideas and energy. I'll drop some of her themes into this
report, though I imagine that the stories I relate in
between may not always sync up. Such is the price of
a fast-moving talk and five days of receding memory.
Creativity loves constraint.
I have written on this topic a few times, notably in the
context of patterns,
and it is a mantra for Google, whose home page remains
among the least adorned on the web. Mayer said that she
likes to protect its minimalist feel even when others
would like to jazz it up. The constraints of a simple
page force the company to be more creative in how it
presents results. I suspect it also played a role in
Google developing its cute practice of customizing the
company logo in honor of holidays and other special
events. Mayer said that minimalism may be a guide now,
but it was not necessarily a reason for simplicity in
the beginning. Co-founder Sergey Brin created the first
Google home page, and he famously said, "I don't do HTML."
Mayer has a strong background both in CS and in CS
education, having worked with the undergrad education
folks at Stanford as a TA while an undergrad. (She said
that it was Eric Roberts who first recommended Google
to her, though at the time he could not remember the
company's name!) One of her first acts as an employee
was to run a user study on doing search from the Google
homepage. She said that when users first sat down and
brought up the page, they just sat there. And sat there.
They were "waiting for the rest of it"! Already, users
of the web were already accustomed to fancy pages and
lots of graphics and text. She said Google added its
copyright tag line at the bottom of the page to serve
as punctutation, to tell the user that that's all there
was.
Search is a fixed focus at Google, not a fancy user
interface. Having a simple UI helps to harness the
company's creativity.
Work on big problems, things users do every day.
Work on things that are easy to explain and understand.
Mayer described in some detail the path that a user's
query follows from her browser to Google and back again
with search results. Much of that story was as expected,
though I was surprised by the fact that there are load
balancers to balance the load on the load balancers that
hand off queries to processors! Though I might have
thought that another level of indirection would slow the
process it down, indeed it is necessary in order to ensure
that the system doesn't slow down. Even with the web
server and the ad server and the mixers, users generally
see their results in about 0.2 seconds. How is that for
a real-time constraint to encourage technical creativity?
Search is the #2 task performed on the web. E-mail is
(still) #1. Though some talking heads have begun to
say that search is a mature business in need of
consolidation, Google believes that search is just getting
started. We know so little about how to do it well, how
to meet the user's needs, and how to uncover untapped
needs. Mayer mentioned a problem familiar to this old
AI guy: determining the meaning of the words
used in a query so that they can serve pages that match
the user's conceptual intent. She used a nice example
that I'll probably borrow the next time I teach AI. When
a user asks for an "overhead view", he almost always
wants to see a picture!
This points in the direction of another open research
area, universal search. The age in which users want to
search for text pages, images, videos, etc., as separate
entities has likely passed. That partitioning is a
technical issue, not a user's issue. The search companies
will have to find a way to mix in links to all kinds of
media when they serve results. For Google, this also
means figuring out how to maintain or boost ad revenue
when doing so.
Ideas come from everywhere.
Mayer gave a few examples. One possible source is office
hours, which are usually thought of as an academic
concept but which she has found useful in the corporate
world. She said that the idea for Froogle walked through
her office door one day with the scientist who had it.
Another source is experiments. Mayer told a longer story
about Gmail. The company was testing it in-house and
began to discuss how they could make many from it. She
suggested the industry-standard model of giving a small
amount of storage for free and then charging for more.
This might well have worked, because Google's cost
structure would allow it to offer much larger amounts
at both pricing levels. But a guy named Paul -- he may
be famous, but I don't know his last name -- suggested
advertising. Mayer pulled back much as she expected
users to do; do people really want Google to read their
e-mail and serve ads? Won't that creep them out?
She left the office late that night believing that the
discussion was on hold. She came back to work the next
morning to find that Paul had implemented an experimental
version in a few hours. She was skeptical, but the idea
won her over when the system began to serve ads that
were perfectly on-spot. Some folks still prefer to read
e-mail without ads, but the history of Gmail has shown
just how successful the ad model can be.
The insight here goes beyond e-mail. The search ad data
base can be used on any paged on the
web. This is huge... Search pages account for about
5% of the pages served on the web. Now Google knew that
they could reach the other 95%. How's that for a business
model?
To me, the intellectual lesson is this:
If you have an idea, try it out.
This is a power that computer programmers have. It is
one of the reasons that I want everyone to be able to
program, if only a little bit. If you have an idea, you
ought to be able to try it out.
Not every idea will lead to a Google, but you never
know which ones will.
Google Books started as a simple idea, too. A person,
a scanner, and a book. Oh, and a metronome -- Mayer
said that when she was scanning pages she would get out
of rhythm with the scanner and end up photocopying her
thumbs. Adding a metronome to the system smoothed the
process out.
... "You're smart. We're hiring." worked remarkably
well attracting job candidates. We programmers have
big egos! Google is one of the companies that has
made it okay again to talk about hiring smart people,
not just an army of competent folks armed with a
software development process, and giving them the
resources they need to do big things.
Innovation, not instant perfection.
Google is also famous for not buying into the hype of
agile software development. But that doesn't mean that
Google doesn't encourage a lot of agile practices. For
example, at the product level, it has long practiced a
"start simple, then grow" philosophy.
Mayer contrasted two kinds of programmers, castle builders
and nightly builders. Companies are like that, too.
Apple -- at least to outside appearances -- is a
castle-building company. Every once in a while, Steve
Jobs et al. go off for a few years, and then come back
with an
iPod
or an iPhone. This is great if you can do it, but only
a few companies can make it work. Google is more of a
nightly builder. Mayer offered Google News as a prime
example -- it went through 64 iterations before it
reached its current state. Building nightly and
learning from each iteration is often a safer approach,
and even companies that are "only good" can make it work.
Sometimes, great companies are the result.
Data is a-political.
Mayer didn't mean Republican versus Democrat here, rather
that well-collected data provide a more objective basis
for making decisions than the preferences of a manager
or the guesses of a designer or programmer. Designing an
experiment that will distinguish the characteristics you
are in interested, running it, and analyzing the data
dispassionately are a reliable way to make good decisions.
Especially when a leader's intuition is wrong, such as
Mayer's was on Gmail advertising.
She gave a small plug for using Google Trends as a way
to observe patterns in search behavior when they might
give an idea about a question of interest. Query volume
may not not change much, but the content of the queries
does.
Users, users, users.
What if some users want more than the minimalist white
front page offered by Google? In response to requests
from a relatively small minority of users -- and the
insistent voices of a few Google designers -- iGoogle
is an experiment in offering a more feature-filled
portal experience. How well will it play? As is often
the case, the data will tell the story.
Give license to dream.
Mayer spent some time talking about the fruits of
Google's well-known policy of 20% Time, whereby every
employee is expected to spend 1/5 of his or her time
working on projects of personal interest. While
Google is most famous for this policy these days, like
most other ideas it isn't new. At ChiliPLoP this week,
Richard Gabriel reported that Eric Schmidt took this
idea to Google with him when he left Sun, and Pam Rostal
reported that 3M had a similar policy many years ago.
But Google has rightly earned its reputation for the
fruits of 20% Time. Google News. Google Scholar.
Google Alerts. Orkut. Froogle Wireless. Much of
Google Labs. Mayer said that 50% of Google's new
products come from these projects, which sounds like
a big gain in productivity, not the loss of
productivity that skeptics expect.
I have to think that the success Google has had with
this policy is tied pretty strongly with the quality
of its employees, though. This is not meant to diss
the rest of us regular guys, but you have to have good
ideas and the talent to carry them out in order for this
to work well. That said, these projects all resulted
from the passions of individual developers, and we
all have passions. We just need the confidence to
believe in our passions, and a willingness to do the
work necessary to implement them.
Most of the rest of Mayer's talk was a litany of these
projects, which one wag in the audience called a long
ad for the goodness of Google. I wasn't so cynical,
but I did eventually tire of the list. One fact that
stuck with me was the description of just how physical
the bits of Google Earth are. She described how each
image of the Earth's surface needs to be photographed
at three or four different elevations, which requires
three or four planes passing over every region. Then
there are the cars driving around taking surface-level
shots, and cameras mounted to take fixed-location shots.
A lot of physical equipment is at work -- and a lot of
money.
Share the data.
This was the last thematic slogan Mayer showed, though
based on the rest of the talk I might rephrase it as
the less pithy "Share everything you can, especially
the data." Much of Google's success seems based in a
pervasive corporate culture of sharing. This extends
beyond data to ideas. It also extends beyond Google
campus walls to include users.
The data-sharing talk led Mayer to an Easter Egg she
could leave us. If you check Google's
Language Tools
page, you will see Bork, Bork, Bork, a language spoken
(only?) by the Swedish chef on the Muppets. Nonetheless,
the Bork, Bork, Bork page gets a million hits a year
(or was it a day?). Google programmers aren't the only
ones having fun, I guess.
Mayer closed with suggestions for computer science
educators. How might we prepare students better to
work in the current world of computing? Most of her
recommendations are things we have heard before:
build and use applications, work on large projects
and in teams, work with legacy code, understand and
test at a large scale, and finally pay more attention
to reliability and robustness. Two of her suggestions,
though, are ones we don't hear as often and link back
to key points in her talk: work with and understand
messy data, and understand how to
use statistics to analyze the data
you collect.
After the talk, folks in the audience asked a few
questions. One asked how Google conducts user studies.
Mayer described how they can analyze data of live users
by modding the key in user cookies to select 1/10 or
1/1000 of the user population, give those users a
different experience, and then look at characteristics
such as click rate and time spent on page by these
users compared to the control group.
The best question was in fact a suggestion for Google.
Throughout her talk, Mayer referred repeatedly to
"Google engineers", the folks who come up with neat
ideas, implement them in code, test them, and then
play a big role in selling them to the public. The
questioner pointed out that most of those "engineers"
are graduates of computer science programs,
including herself, Sergey Brin, and Larry Page. He
then offered that Google could do a lot to improve the
public perception of our discipline if it referred to
its employees as computer scientists.
I think this suggestion caught Mayer a little off-guard,
which surprised me. But I hope that she and the rest
of Google's leadership will take it to heart. In a time
when it is true both that we need more computer science
students and that public perception of CS as a discipline
is down, we should be trumpeting the very cool stuff that
computer scientists are doing at places like
Google.
All in all, I enjoyed Mayer's talk quite a bit. We should
try to create a similarly creativity-friendly environment
for our students and ourselves. (And maybe work at a place
like Google every so often!)
As I mentioned in my
last SIGCSE entry,
I have moved from carefree Portland to Carefree, Arizona,
for ChiliPLoP 2008. The elementary patterns group spent
yesterday, its first, working on the idea of integrating
large datasets into the CS curriculum. After a few years
of working on specific examples, both stand-alone and
running, we started this year thinking about how CS students
can work on real problems from many different domains.
In the sciences, that often means larger data sets, but
more important it means authentic data sets, and data sets
that inspire students to go deeper. On the pedagogical
side of the ledger, much of the challenge lies in finding
and configuring data sets so that they can used reliably
and without unnecessary overhead placed on the adopting
instructor.
This morning, we volunteered to listen to a presentation
by the other hot topic group on its work from yesterday:
a "green field" thought experiment designing an undergrad
CS program outside of any constraints from the existing
university structure. This group consists of Dave West
and Pam Rostal, who presented an earlier version of this
work at the
OOPSLA 2005 Educators' Symposium,
and
Richard Gabriel,
who brings to the discussion not only an academic background
in CS and a career in computer science research and industry
but also an MFA in poetry. Perhaps the key motivation for
their hot topic is that most CS grads go on to be professional
software developers or CS researchers, and that our current
way of educating them doesn't do an ideal job of preparing
grads for either career path.
Their proposal is much bigger than I can report here. They
started by describing a three-dimensional characterization of
different kinds of CS professionals, including provocative and
non-traditional labels as "creative builder", "imaginative
researcher", and "ordinologist". The core of the proposal is
the sort of competency-based curriculum that West and Rostal
talked about at OOPSLA, but I might also describe it as
studio-based, apprenticeship-based, and project-based. One
of their more novel ideas is that students would learn
everything they need for a liberal arts, undergraduate
computer science education through their software projects
-- including history, English, writing, math, and social
science. For example, students might study the mathematics
underlying a theorem prover while building a inference
engine, study a period of history in order to build a
zoomable timeline on the web for an instructional web site,
or build a Second Life for a whole world in ancient Rome.
In the course of our discussion, the devil's advocates in
the room raised several challenging issues, most of which
the presenters had anticipated. For example, how do the
instructors (or mentors, as they called them) balance the
busy work involved in, say, the students implementing some
Second Life chunk with the content the students need to
learn? Or how does the instructional environment ensure
that students learn the intellectual process of, say,
history, and not just impose a computer scientist's
worldview on history? Anticipating these concerns does
not mean that they have answers, only that they know the
issues exist and will have to be addressed at some point.
But this isn't the time for self-censorship... When trying
to create something unlike anything we see around us, the
bigger challenge is trying to let the mind imagine the
new thing without prior restraint from the imperfect
implementations we already know.
We all thought that this thought experiment was worth
carrying forward, which is where the change of direction
comes in. While our group will continue to work on the
dataset idea from yesterday, we decided in the short term
to throw our energies into the wild idea for reinventing
CS education. The result will be two proposals to OOPSLA
2008: one an activity at the
Educators' Symposium,
and the other an
Onward! paper.
This will be my first time as part of a proposal to the
Onward! track, which is both a cool feeling and an
intimidating prospect. We'll see what happens.
This set of entries records my experiences at
SIGCSE 2008,
in Portland, Oregon, March 12-16. I'll update it as I post
new pieces about the conference. One of those entries will
explain why my posts on SIGCSE may come more slowly than
they might.
The
Prometheus Awards
are the Iowa tech industry equivalent of the Academy Awards.
At last night's 2008 award ceremony, CS alumni from my
school made a good showing.
T8Design
won Software Company of the Year in the Small Company
Division. Alumnus
Wade Arnold
is one of T8's co-founders, its former CTO, and its current
CEO. Wade accepted the statuette and gave a fine acceptance
speech. At least two other alumni were there in the T8
delegation, and it was good to be able to congratulate them
all in person.
Alliance Technologies
won the award for IT Service Provider of the Year. Alumnus
and UNI CS advisory board member
Mike Lang,
CEO and President of Alliance, represented the company on
the dais.
There were two other software connections to our program
among the winners. Alumnus
Tony Bibbs
was part of the team that wrote one of the pieces of software
nominated for Best Innovation in Government, which was won by
ABC Virtual. And the most distant connection involved Express
Auto, which won Top Growth Company of the Year in the Under
$25M Division. One of the first programs that got Express
Auto off the ground back in the mid-1990s was written by a
UNI alumnus and CS advisory board member Fred Zelhart.
It was a good evening for UNI Computer Science alumni, and
a good night for this CS prof. With the exception of Mike,
who graduated the year before I came here, I had all of these
entrepreneurs and developers as students in class, and now
I work with Mike, Fred, and Wade on an ongoing basis. I
feel a little paternal -- now fraternal -- pride!
All I know is that if there is a place for post-modernist,
lit-crit, social constructivist thinking in the modern
world, it's nowhere near the field of computing.
Robert Biddle and James Noble may have a duel
on their hands
(PDF)! I think that we have the makings of an outstanding
OOPSLA 2008 panel.
I'd certainly like to hear more from Perera if he has more
ideas of this sort:
... emergent behaviours are in a sense dual to the
requirements on a solution. Requirements are
known and obligate the system in certain
ways, whereas emergent behaviours ("emergents", one could
call them) are those which are permitted
by the system, but which were not known a priori.
This is an interesting analogy, one I'd like to think more
about. For some reason, it reminds of Jon Postel's dictum
about protocol design, "Be liberal in what you accept, and
conservative in what you send" and Bertrand Meyer's ideas
about design by contract.
This week I ran across Jonathan Edwards's
review
of
Gregor Kiczales's
OOPSLA 2007 keynote address, "Context, Perspective and
Programs" (which is available from the
conference podcast page).
Having recently
commented on
Peter Turchi's keynote, I figured this was a good time
to go back and listen to all of Gregor's again. I first
listened to part of it back when I posted it to the page,
but I have to admit that I didn't understand it all that
well then. So a second listen was warranted. This time
I had access to his
slides,
which made a huge difference.
In his talk, Kiczales tries to bring together ideas from
philosophy, language, and our collective experience writing
software to tackle a problem that he has been working
around his whole career: programs are abstractions, and
any abstraction represents a particular point of view.
Over time, the point of view changes, which means that
the program is out of sync. Software folks have been
thinking about ways to make programs capable of responding
naturally as their contexts evolve. Biological systems
have offered some inspiration in the last decade or so.
Kiczales suggests that computer science's focus on
formality gets in the way of us finding a good answer
to our problem.
Some folks took this suggestion as meaning that we would
surrender all formalism and take up models of social
negotiation as our foundation. Roly Perera wrote a
detailed and pointed review
of this sort. While I think Perera does a nice job of
placing Kiczales's issues in their philosophical context,
I do not think Kiczales was saying that we should go from
being formal to being informal. He was suggesting that
we shouldn't have to go from being completely
formal to being completely informal; there should be a
middle ground.
Our way of thinking about formality is binary -- is that
any surprise? -- but perhaps we can define a continuum
between the two. If so, we could write our program at
an equilibrium point for the particular context it is in
and then, as the context shifts, allow the program to
move along the continuum in response.
Now that I understand a little better what Kiczales is
saying, his message resonates well with me. It sounds
a lot like the way a pattern balances the forces that
affect a system. As the forces change, a new structure
may need to emerge to keep the code in balance. We
programmers refactor our code in response to such
changes. What would it be like for the system to
recognize changes in context and evolve? That's how
natural systems work.
As usual, Kiczales is thinking thoughts worth thinking.
While catching up on some work at the office yesterday --
a rare Saturday indeed -- I listened to
Peter Turchi's
OOPSLA 2007 keynote address, available from the conference
podcast page.
Turchi is a writer with whom conference chair
Richard Gabriel
studied while pursuing his MFA at
Warren Wilson College.
I would not put this talk in the same class as Robert Hass's
OOPSLA 2005 keynote,
but perhaps that has more to do with my listening to an audio
recording of it and not being there in the moment. Still,
I found it to be worth listening as Turchi encouraged us to
"get lost" when we want to create. We usually think of
getting lost as something that happens to us when we are
trying to get somewhere else. That makes getting lost
something we wish wouldn't happen at all. But when we get
lost in a new land inside our minds, we discover something
new that we could not have seen before, at least not in the
same way.
As I listened, I heard three ideas that captured much of the
essence of Turchi's keynote. First was that we should strive
to avoid preconception. This can be tough
to do, because ultimately it means that we must work without
knowing what is good or bad! The notions of good and bad are
themselves preconceptions. They are valuable to scientists
and engineers as they polish up a solution, but they often
are impediments to discovering or creating a solution in the
first place.
Second was the warning that a failure to get lost is
a failure of imagination. Often, when we work deeply
in an area for a while, we sometimes feel as if we can't see
anything new and creative because we know and understand the
landscape so well. We have become "experts", which isn't
always as dandy a status as it may seem. It limits what we
see. In such times, we need to step off the easy path and
exercise our imaginations in a new way. What must I do in
order to see something new?
This leads to the third theme I pulled from Turchi's talk:
getting lost takes work and preparation.
When we get stuck, we have to work to imagine our way out
of the rut. For the creative person, though, it's about more
about getting out of a rut. The creative person needs to get
lost in a new place all the time, in order to see something
new. For many of us, getting lost may seem like as something
that just happens, but the person who wants to be lost has
to prepare to start.
Turchi mentioned Robert Louis Stevenson as someone with a
particular appreciation for "the happy accident that planning
can produce". But artists are not the only folks who benefit
from these happy accidents or who should work to produce the
conditions in which they can occur. Scientific research
operates on a similar plane. I am reminded again of
Robert Root-Bernstein's ideas
for actively engaging the unexpected. Writers can't leave
getting lost to chance, and neither can scientists.
Turchi comes from the world of writing, not the world of
science. Do his ideas apply to the computer scientist's
form of writing, programming? I think so. A couple of years
ago, I described a structured form of getting lost called
air-drop programming,
which adventurous programmers use to learn a legacy code base.
One can use the same idea to learn a new framework or API,
or even to learn a new programming language. Cut all ties to
the familiar, jump right in, and see what you learn!
What about teaching? Yes. A colleague stopped by my office
late last week to describe a great day of class in which he
had covered almost none of what he had planned. A student
had asked a question whose answer led to another, and then
another, and pretty soon the class was deep in a discussion
that was as valuable, or more, than the planned activities.
My colleague couldn't have planned this unexpectedly good
discussion, but his and the class's work put them in a
position where it could happen. Of course, unexpected
exploration takes time... When will they cover all the
material of the course? I suspect the students will be just
fine as they make adjustments downstream this semester.
What about running? Well, of course. The topic of air-drop
programming came up during a conversation about a general
tourist pattern for learning a new town. Running in a new
town is a great way to learn the lay of the land. Sometimes
I have to work not to remember landmarks along the
way, so that I can see new things on my way back to the hotel.
As I wrote
after a glorious morning run
at ChiliPLoP three years ago, sometimes you run to get from
Point A to Point B; sometimes, you should just run. That
applies to your hometown, too. I once read about an elite
women's runner who recommended being dropped off far from
your usual running routes and working your way back home
through unfamiliar streets and terrain. I've done something
like this myself, though not often enough, and it is a
great way to revitalize my running whenever the trails start
look like the same old same old.
It seems that getting lost is a universal pattern, which made
it a perfect topic for an OOPSLA keynote talk.
... though I can't in good conscience say, "for I know not what
I do."
1. Write a script named simple-interest.php
that defines a function to compute the simple interest on an
amount, given the amount, annual interest rate, and number of
months. Your script should apply the function to its command-line
arguments, which are those same values.
The rest of my PHP class's first homework is more reasonable,
with a couple of problems repeated from the bash class's first
assignment as a way for students to get a sense of trade-offs
between shell programming and scripting in a more general-purpose
language.
Still, I had to squeeze my eyes shut tight to hit the key that
published this assignment. I keep telling myself that this is
just an ice-breaking assignment for students who have never
written any PHP before, or learned how to access command-line
arguments, or convert strings to integers. That such a simple,
context-free task is a nice way for them to succeed on their
first effort. That our future assignments will be engaging,
challenging, worthwhile. But... Ick.
The first time I teach a course, there always seem to be clunkers
like this. Starting from scratch, relying on textbooks for
inspiration, and working under time pressure all work against
my goal of making everything students do in the class worth their
time and energy. I suppose that problems such as this one are
my opportunities to improve next time out.
My despair notwithstanding, I suspect that many students are
happy enough to have at least one problem that is a gift,
however uninteresting it may be. Maybe I can find solace in
that while I'm working on exercises for my next problem set.
Are all the open jobs in computing that we keep hearing
about going unfilled?
Actually -- they're not. Companies do fill those jobs.
They fill them with less expensive workers, without
computing degrees, and then train them to program.
Mark Guzdial
is concerned
that some American CEOs and legislators are unconcerned
-- "So? Where's the problem?" -- and wonders how we
make the case that degrees in CS matter.
I wonder if the US would be better off if we addressed
a shortage of medical doctors by starting with less
expensive workers, without medical degrees, and then
trained them to practice medicine? We currently do face
a shortage of medical professionals willing to practice
in rural and underprivileged areas.
The analogy is not a perfect one, of course. A fair
amount of the software we produce in the world is
life-critical, but a lot is not. But I'm not sure whether
we want to live in a world where our financial, commercial,
communication, educational, and entertainment systems
depend on software to run, and that software is written
by folks with a shallow understanding of software and
computing more generally.
Maybe an analogy to the law or education is more on-point.
For example, would the US would be better off if we
addressed a shortage of lawyers or teachers by starting
with less expensive workers, without degrees in those
areas, and then trained them? A shortage of lawyers --
ha! But there is indeed a critical shortage of teachers
in many disciplines looming in the near future, especially
in math and science. This might lead to an interesting
conversation, because many folks advocate loosening the
restrictions on professional training for folks who teach
in our K-12 classrooms.
I do not mean to say that folks who are trained "on the job"
to write software necessarily have a shallow understanding
of software or programming. Much valuable learning occurs
on the job, and there are many folks who believe strongly
in a
craftsmanship approach
to developing developers. My friend and colleague Ken Auer
built
his company
on the model of
software apprenticeship.
I think that our university system should adopt more of a
project-based
and
apprenticeship-based
approach to educating software developers. But I wonder
about the practicality of a system that develops all of its
programmers on the job. Maybe my view is colored by
self-preservation, but I think there is an important role
for university computing education.
Speaking of practicality, perhaps the best way to speak to
the CEOs and legislators who doubt the value of academic
CS degrees is in their language of supply and productivity.
First, decentralized apprenticeship programs are probably
how people really became programmers, but they
operate on a small scale. A university program is able to
operate on a slightly larger scale, producing more folks
who are ready for apprenticeship in industry sooner than
industry can grow them from scratch. Second, the
best-prepared folks coming out of university programs are
much more productive than the folks being retrained, at
least while the brightest trainees catch. That lack of
productivity is at best an opportunity cost, and at worst
an invitation for another company to eat your lunch.
Of course, I also think that in the future more and more
programmers will be
scientists
and
engineers
who have learned how to program. I'm inclined to think
that these folks and the software world will be better
off being educated by folks with a deep understanding of
computing.
Artists,
too. And not only for immediately obvious economic reasons.
I don't usually play meme games in my web, but as I am
winding down for the week I ran across this one on
Brian Marick's blog:
grab the nearest book, open it to page 123, go to the
5th sentence, and type up the three sentences beginning
there.
With my mind worn out from a week in which I caught
something worse than a meme, I fell prey and swung my
arm around. The nearest book was Beautiful Code.
Technically, I suppose that a stack of PHP textbooks is
a couple of inches closer to me, but does anyone really
want to know what is on Page 123 of any of them?
Here is the output:
The resultant index (which was called iSrc in
FilterMethodCS) might be outside the bounds of
the array. The following code loads an integer 0 on the
stack and branches if iSrc is less than 0,
effectively popping both operands from the stack. This
is a partial equivalent of the if statement
conditional in line 19 of Example 8-2:
Okay, that may not be much more interesting than what a
PHP book might have to say, at least out of context.
I'm a compiler junkie, though, and I was happy to find
a compiler-style chapter in the book. So I turned to
the beginning of the chapter, which turns out to be
"On-the-Fly Code Generation for Image Processing" by
Charles Petzold. I must admit that this sounds pretty
interesting to me. The chapter opens with something
that may be of interest to others, too:
Among the pearls of wisdom and wackiness chronicled in
Steve Levy's classic "Hackers: Heroes of the Computer
Revolution" (Doubleday), my favorite is this one by
Bill Gosper,
who once said, "Data is just a dumb kind of programming."
Petzold then goes on to discuss the interplay between
code and data, which is something I've
written about
as one of the big ideas computer science has taught the
world.
What a nice way for me to end the week. Now I have a new
something to read over the weekend. Of course, I should
probably spend most of my time with those PHP textbooks;
that language is iteration 2 in my
course this semester.
But I've avoided "real work" for a lot less in the past.
That is the title of a blog post that I planned to write
five or six weeks ago. Here it is over a month later,
and the course just ended. Well, it ended, and it begins
again on Tuesday. So now I am thinking agile thoughts as
I think back over my course, and still thinking agile
thoughts as I prepare for the course. Let me explain.
810:151 is a different sort of course for us. We try to
expose students to several different programming languages
in the course of their undergraduate study. Even so, it
is common for students to graduate thinking, "I wish I'd
learned X." Sometimes X is a relatively
new language, such as Scala or Groovy. Sometimes it's a
language that is now more mainstream but has not yet made
it into one of our courses, such as Ruby. Sometimes it is
even a language we do emphasize in a course, such as
Scheme, but in a course they didn't have an opportunity
to take. We always have told students who express this
wish that they should be well-equipped to learn a new
language on their own, and they are. But...
While taking a full load of courses and working part-time
(or taking a part-time load of courses and working full-time),
it is often hard for students to set aside time to learn
completely optional. People talk about "the real world"
as if it is tougher than being in school, but students face
a lot of competing demands for their time. Besides, isn't
it often more fun to learn something from an expert who
can help you learn the tricks of the trade faster and miss
a few of the potholes that lie along the way?
I sometimes think of this course, which we call "Topics
in Programming Languages", as a "make time" course for
students who want to learn a new language, or perhaps a
broader topic related to language, but who want or need
the incentive that a regular course, assigned readings, and
graded work provides. The support provided by the prof's
guidance also is a good safety net for the less seasoned
and less confident. For these folks, one of the desired
outcomes is for them to realize, hey, I really can learn
a language on my own.
We usually offer each section of 810:151 as a 1-credit
course. The content reason is that the course has the
relatively straightforward purpose of teaching a single
language, without a lot of fluff. The practical purpose
is that we can offer three 1-credit courses in place of
a single 3-credit course. Rather than meet one hour per
week for the entire semester, the course can meet 3 hours
per week for 5 weeks. This works nicely for students who
want to take all three, as they look and feel like a
regular course. It also works nicely for students who
choose to take only one or two of the courses, as they
need not commit an entire semester's worth of attention
to them.
This is my first semester assigned (by me) to teach this
odd three-headed course. The topics this semester are
Unix shell programming in bash, PHP, and Ruby.
I've been thinking of the three courses as three 5-week
iterations. Though the topics of the three courses
are different, they share a lot in terms of being focused
on learning a language in five weeks. How much material
can I cover in a course? How can students best use their
time? How can I best evaluate their work and provide
feedback? Teaching three iterations of a similar course
in one semester is so much better for me when it comes to
taking what I learn and trying to improve the next offering.
With an ordinary course taught every semester, I would have
to wait until next fall to begin implementing improvements;
with an ordinary course three-course rotation, I would have
to wait until Fall 2009!
I opted to dispense with all examinations and evaluate
students solely in terms of the bash scripts they wrote. The
goal of the course is for students to learn how to program in
bash, so that is where I wanted the students' attention to be.
One side effect of this decision is that the course is not
really over yet; students will work on their final problem
set in the coming week, and I'll have to grade it next Friday.
The problem sets have consisted mostly in small-ish scripts
that exercise the features of bash as we encounter them.
We did have one larger task that students solved in three
parts over the course of the semester, a processor for a
Markdown-like
mark-up language that produces HTML. This project scratched
one of my own itches, as I like to use simple text-based,
e-mail-friendly mark-up, and now I have a simple bash script
that does the job!
One thing I did not do this semester that I thought I might,
and which perhaps I should, is to work with them through
a non-trivial shell script or two. I had thought that the
fifth week would be devoted to examining and extending
larger scripts, but I kept uncovering more techniques and
ideas that I wanted them to see. Perhaps I could use a
real script as a primary source for learning the many
features of bash, instead of building their skills from
the bottom up. That is how many of them have to come to
know what little they know about shell scripting, by
confronting a non-trivial script for building or
configuring an open-source application that interests them.
To be honest, though, I think that the bottom-up style that
we used this semester may prepare them better for digging
into a more complex script than starting with a large
program first. This is one of the issues I hope to gain
some insight into from student feedback on the course.
Making this "short iterations" more interesting is the fact
that some students will be in all three of the iterations,
but there will be a significant turnover in the class rosters.
The client base evolves, but there should be enough overlap
that I can get some comparative feedback as I try to implement
improvements.
I tried to follow a few other agile principles as I started
teaching this new prep. I tend to start each new course with
a template from my past courses, from the way I organize
sessions and lecture notes to the look-and-feel of the web
site. This semester, I tried to maintain a
YAGNI
mindset: start as simple as I can, and add new elements only
as I use them -- not when I think I need them tomorrow. By
and large I have succeeded in this regard. My web site is
bare-bones in comparison to my past sites, and lecture notes
are plain text records of in-class activities and short
messages to remind me and the students of what we discussed.
I saved a lot of time not trying to produce attractive and
complete lecture notes in HTML. Maybe some day, but this
time around I just didn't need them.
One agile practice that I didn't think to encourage soon
enough was unit testing. Shame on me. Some
students suffered far more than I from this oversight.
Many did a substandard job of testing their scripts, in part
I think because they were biting off too much of a task to
start. Unix pipelines are almost perfectly suited to unit
testing, as one can test the heck out of each stage in
isolation, growing the pipeline one stage at a time until
the task is solved. The fact that each component is reading
from stdin and writing to stdout means that later stages can
be tested independent of the stages that precede it before
we add it to the end.
For whatever reason, it didn't occur to me that there would
exist an
shUnit.
It's too late for me to use it this semester, but I'll be
sure to put
phpUnit
to good use in the next five weeks. And I've always known
that I would use a unit testing framework such as
this one
for Ruby. Heck, we may even roll our own as we learn the
language!
I've really enjoyed teaching a course with the
Unix philosophy
at the forefront of our minds. Simple components, the
universal interface of plain text streams, and a mandate to
make tools to work together -- the result is an amazingly
"agile" programming environment. The best way to help
students see the value of agile practices is to let them
live in an environment where that is natural, and let them
feel the difference from the programming environments in
which they other times find themselves. I just hope that
my course did the mindset justice.
The tool-builder philosophy that pervaded this course
reminded me of this passage from Jason Marshall's
Something to Say:
There's an old saying, "A good craftsman never blames his
tools." Many people take this to mean "Don't make excuses,"
or even, "Real men don't whine when their tools break."
But I take it to mean, "A good craftsperson does not abide
inferior tools."
A good craftsman never blames his tools, because if his
tools are blameworthy, he finds better tools. I associate
this idea more directly with the
pragmatic programmers
than with the agile community, but it seems woven into the
fabric of the agile approaches. The
Agile Manifesto
declares that we value "individuals and interactions over
processes and tools", but I do not take this to mean that
tools don't matter. I think it means that we should use
tools (and processes) that empower us to focus our energy
on people and interactions. We should let programs do what
they do best so that we programmers can do what we do best.
That's why we have unit testing frameworks, refactoring
tools, automatic build tools, and the like. It's also
why Unix is far more human-affirming than it is sometimes
given credit for.
As I told students to close the lecture notes for this
course: Don't settle for inferior tools. You are a
computer programmer. Make the tools that make you better.
I recently came across a SIGCSE paper from 1991 called
Integrating Writing into Computer Science Courses,
by Linda Hutz Pesante, who at the time was affiliated
with the Software Engineering Institute at Carnegie
Mellon. This paper describes both content and technique
for teaching writing within a CS program, a topic that
cycles back into the CS education community's radar every
few years. (CS academics know that it is important even
during trough periods, but their attention is on some
other, also often cyclic, attention-getter.)
What caught my attention about Pesante's paper is that
she tries help software engineers to use their engineering
expertise to the task of writing technical prose. One
of her other publications, a video, even has the enticing
title,
Applying Software Engineering Skills to Writing.
I so often think about applying ideas from other disciplines
to programming, the thought of applying ideas from software
development to another discipline sounded like a new twist.
Pesante's advice on how to teach writing reflects common
practice in teaching software development:
Attend to the writing process, as well as the final
product.
Use analogies to programming, such as debugging and
code reviews.
Have students practice, and give them feedback.
Given Pesante's affiliation with the SEI, her suggestions
for what to teach about writing made a bigger impression
on me. The software engineering community certainly
embraces a broad range of development "methodologies"
and styles but, underlying its acceptance even of
iterative methods, there seems to be a strong emphasis
on planning and "getting things right" the first time.
Her content advice relies on the notion that "writing
and software development have something in common", from
user analysis through the writing itself to evaluation.
As such, a novice writer can probably learn a lot from
how programmers write code. Programmers like to be
creative and explore when they write, too, but they also
know that thinking about the development process can add
structure to a potentially unbounded activity. They use
tools to help them manage their growing base of documents
and to track revisions over time. That part of the
engineer's mindset can come in handy for writers. For
the programmer who already has that mindset, applying
it to the perhaps scary of writing prose can put the
inexperienced writer at ease.
Pesante enumerates a few other key content points:
The writing process is neither linear nor algorithmic.
The writing process is iterative.
Correct is not the same as effective.
The middle two of these especially feel more agile than the
typical software engineering discussion. I think that the
agile software community's emphasis on short iterations with
frequent releases of working software to the client also
matches quite nicely the last of the bullets. It's all too
easy to do a good job of analysis and planning, produce a
piece of software that is correct by the standards of the
analysis and plan, and find that it does not meet the user's
needs effectively. With user feedback every few weeks,
the development team has many more opportunities to ensure
that software stays on a trajectory toward effectiveness.
Most people readily accept the idea that creative writing
is iterative, non-linear, and exploratory. But I have
heard many technical writers and other writers of
non-creative prose say that their writing also has these
features -- that they often do not know what they had to
say, or what their ultimate product would be, until they
wrote it. My experience as a writer, however limited,
supports the notion that almost all writing is exploratory,
even when writing something so pedestrian as a help sheet
for students using an IDE or other piece of software.
As a result, I am quite open to the notion that
programming -- what many view as the creating of an
"engineered" artifact -- also iterative, non-linear, and
exploratory. This is true, I think, not only for what we
actually call "exploratory programming" but also for more
ordinary programming tasks, where both the client and I
think we have a pretty good handle on what the resulting
programming should do and look like. Often, over the
course of writing an ever-larger program, our individual
and shared understanding of the program evolves. Certainly
my idea of the internal shape of the program -- the
structure, the components, the code itself -- changes as
the program grows. So I think that there is a lot to be
learned going both directions in the writing:programming
metaphor.
... about teaching, and about software development.
The February 2008 issue of Smithsonian Magazine
contains an article called
Being Funny,
by comedian, writer, and actor
Steve Martin,
that has received a fair amount of discussion on-line
already. When I read it this weekend, I was surprised
by how similar some of the lessons Martin learned as he
grew into a professional comedian are to lessons that
software developers and teachers learn. I enjoyed
being reminded of them.
I gave myself a rule [for dealing with the audience].
Never let them know I was bombing: this is funny,
you just haven't gotten it yet.
This is about not showing doubt. Now, I think it's
essential for an instructor to be honest -- something
I wrote about a while back,
in the context of comedy
as well. So I don't mean that I as teacher should try to
bluff my way through something I don't know or know but
have botched. Martin is talking about the audience getting
it, and the doubt that enters my mind when a classroom of
students seem not to. I experience this occasionally when
I teach a course like Programming Languages to a new group
of students. Some classes don't warm to me or the material
in quite the same way as others, but I know that the material
I'm teaching and the basic approach I am using are sound.
When this semester's crowd takes a while to catch on --
or if they are openly skeptical of the material or approach
-- it's essential that I remain confident. Sure, I'll make
adjustments to the presentation to account for my current
students' needs, but I should remain steadfast: This is
good stuff; they'll get it soon.
I'm not sure this applies as well for software developers.
Often, when my users don't get it yet and I feel compelled
to bull on through, I have gone beyond the requirements, at
least as my users understand them. In those cases, it's
usually better to say to myself "You aren't gonna need it"
and simplify.
Everything was learned in practice, and the lonely road, with
no critical eyes watching, was the place to dig up my boldest,
or dumbest, ideas and put them onstage.
This is hard to do as a teacher. I don't get to go on the
road to a hundred musty nightclubs and try out my new lecture
on continuation-passing style, as Martin did with his bits.
He was practicing on small stages in order to prepare for
the big ones, such as The Tonight Show. It's
next to impossible for me to try a lecture out on a
representative audience that isn't my regular audience: my
students. I can practice my research talks before a small
local audience before taking them to a conference, but the
number of repetitions available to me is rather small even
in that scenario. For class sessions, I pretty much have
to try them out live, see what happens, and feed the results
back into my next performance.
Fortunately, I'm not often trying radically new ideas out
in a lecture, so fewer and live repetitions may suffice.
I have tried teaching methods that quite different than
the norm for me and for my students, such as a Software
Systems course or gen-ed capstone course with no lecture
and all in-class exercises. In those scenarios, I had to
follow the advice discussed above: This is going
to work; they just haven't gotten it yet...
This piece of advice applies perfectly to programming.
The lonely road is my office or my room at home, where I
can try out every new idea that occurs to me by writing
a program (or ten) and seeing how it works. No critical
eyes but my eye, which I turn off. Bold ideas, dumb ideas
-- I find out which are which through practice.
The consistent work enhanced my act. I learned a lesson:
it was easy to be great. Every entertainer has a night
when everything is clicking. These nights are accidental
and statistical: like lucky cards in poker, you can count
on them occurring over time. What was hard was to be
good, consistently good, night after
night, no matter what the circumstances.
This is so true of teaching that I have nothing more to
say. Read Martin's line again.
I think this is also true of programming, and writing more
generally. Every so often, a great idea comes to mind; a
great turn of phrase; a cool little hack that solves the
problem at hand. To be a good programmer, you need to
practice, so that each time you sit down to code you can
produce something of value. That kind of skill is earned
by practice, and, I think, attainable by everyone.
On one of my appearances [on The Tonight Show,
after [Johnny Carson] had done a solid impression of Goofy
the cartoon dog, he leaned over to me during a commercial
and whispered prophetically, "You'll use everything
you ever knew."
When working with students, I find myself borrowing from
every good teacher I've ever had, and drawing on any
experience I can recall. I've borrowed standards and
attitudes from one of my favorite undergrad profs, who
taught me the value of meeting deadlines. I've used
phrases and jokes spoken by my high school chemistry
teacher, who showed us that studying a difficult subject
could be fun, with the right mindset and a supportive
group of classmates. Whatever works, works. Use it.
Adapt it.
Likewise, this advice is true when programming. In the
last few years, the notion of
scrapheap programming
has become quite popular. In this style, a programmer
looks for old pieces of code that do part of the job at
hand, adapts them, and glues them together to get the job
done. But this is how all writers and programmers work,
drawing on all of the old bits of code rolling around their
heads. In addition to practice, you can improve as a
programmer by exposing yourself to as many different
programs as possible. That way, you will see the data
structures, the idioms, the design patterns, and, yes,
the snippets of code that you will use twenty years from
now when the circumstance is right. That may seem goofy,
but it's not.
Finally:
I believed it was important to be funny now, while the
audience was watching, but it was also important to be funny
later, when the audience was home and thinking about it.
As a teacher, I would like for what my students see, hear,
and do in class today to make an impression today. That is
what makes the material memorable and, besides, it's a lot
more fun for both of us that way than the alternative. But
perhaps more important, I would like for the ideas to make
a lasting impression. When the student is home thinking
about the course, or an assignment, or computer science in
general, I want them to realize how much depth the idea or
technique has, or breadth. Today's memorability can be
ephemeral. When the idea sticks later, it can affect how
the student programs forever.
The hard part is trusting when I don't see students getting
it in real-time. Martin says that he learned not to worry
if a gag got no response from his audience, "as long as I
believed it had enough strangeness to linger". Strangeness
may not be what I hope for in my class sessions, but I know
what he means.
As a programmer, I think this advice applies, too. When I
was an undergrad, I was once on a team building a large
system as part of our senior project course. One of our
teammates loved to write code that was clever, that would
catch our eye on first read and recognize his creativity
and skill. But we soon learned that much of this code was
inscrutable in a day or two, which made modifying and
maintaining his modules impossible. Design and code that
makes a module easy to read and understand in a few weeks
are what the team needed. Sometimes, the cleverness of a
solution shone through then, too, but it impressed us all
the more when it had "staying power".
Steve Martin is wacky comedian, not a programmer or teacher
per se. Does his advice apply only in that context?
I don't think so. Comedians are writers and creators, and
many of the traits that make them successful apply to other
tasks that require creating and communicating.
Readers of this blog know that programming is one of the
topics I most like to write about. In recent months I've
had something of a "programming for everyone" theme, with
programming as a medium of expression, as a way to create
new forms, ideas, and solutions. But programming is also
for computer scientists, being the primary mode for
communicating their ideas.
To the non-CS folks reading this, that may seem odd. Isn't
CS about programming? Most non-CS folks seem to take as
a given that computer science is, but these days
it is de rigeur for us in the discipline to talk
about "computing" and how much bigger it is than "just
programming".
Too some extent, I am guilty of this myself. I often use
the term "computing" generically in this blog to refer to
the fuzzy union of computer science, software engineering,
applications, and related disciplines. This term allows
me to talk about issues in their broadest context without
limiting my focus to any one sub-discipline. But it also
lets me be fuzzy in my writing, by not requiring that I
commit.
Sometimes, that breadth can give the impression that I
think programming is but a small part of the discipline.
But most of my writing comes back to programming, and
when I teach a CS course, programming is always central.
When I teach introductory computer science, programming
is a way for us to explore ideas. When I teach compilers,
it all comes down to the project. My students learn
Programming Languages and Paradigms by writing code in
a new style and then using what they learn to explore
basic ideas about language in code. When I taught AI
for eight or ten straight years, as many of the big
ideas as possible found their way into lab exercises.
Even when I taught one course that had no programming
component -- an amalgam of design, HCI, and professional
responsibility called Software Systems -- I had students
read code: simple implementations of
model-view-controller, written in Java, C++, Common Lisp,
or Ada!
I
love to program,
and I hope students leave my courses seeing that programming
is medium for expressing and creating ideas -- as well as
creating "business solutions", which will be the professional
focus for most of them. Then again, the best business
solutions are themselves ideas that need to be discovered,
explored, and evolved. Programming is the perfect medium
to do that.
So when I ran across
The Nerd Factor is Huge,
via Chuck Hoffman at
Nothing Happens,
I found myself to be part of the choir, shouting out "Amen,
brother!" every so often. The article is a paean to
programming, in a blog "dedicated to the glory of software
programming". It claims that programming needs an academic
home, a discipline focused on understanding it better and
teaching people how to do it. (And that discipline should
have its own conference!)
In Yegge-like fashion, the author uses expressive prose to
makes big claims, controversial claims. I agree with many
of them, and feel a little in harmony even with the ones
I wouldn't likely stake my professional reputation on.
The shortage of women in computer science hurts our
discipline, and it limits the opportunities available
to the women, both intellectual and economic. I
would broaden this statement to include other
underrepresented groups.
Trying to interest girls and other underrepresented
groups by "expanding the non-programming ghettos of
computer science" is misguided and insults these
people. We can certainly do more to communicate
how becoming a computer scientist or programmer
empowers a person to effect change and produce ideas
that help people, but we should not remove from the
equation the skill that makes all that possible.
Human-computer interaction doesn't belong in computer
science. Doing so "is as insulting to the study of
interaction design ... as it is to computer science".
This is perhaps the most controversial claim in this
paper, but the authors makes clear that he is not
showing to disrespect to HCI. Instead, he wants due
respect shown to it -- and programming, which tends
to get lost in a computer science that seeks to be
too many things.
I agree with the central thesis of this article. However,
separating programming as a discipline from HCI and some
of the other "non-programming ghettos" of CS creates a
challenge for university educators. Most students come
to us not only for enlightenment and great ideas but
also for professional preparation. With several distinct
disciplines involved, we need to help students put them
all together to prepare them to be well-rounded pros.
How should we encourage more kids -- girls and boys alike
-- to study computer science? "Nerd Factor" is right:
don't shy away from programming; teach it, and sooner
rather than later. Show them "how easy it is to create
something. Because that is what programming is all about:
making things." And making things is the key. Being able
to program gives anyone the power to turn
ideas into reality.
One of my early memories of OOPSLA comes from a panel
discussion. I don't recall the reason for the panel, but
several big names were talking about what we should call
people who create software. There were probably some folks
who supported the term "software engineer", because there
always are. Kent Beck spoke heresy: "I'm just a programmer."
I hope I muttered a little "Amen, brother" under my breath
that day, too.
I wasn't expecting to hear
John Maeda's
name during the
What is a Tree?
talk, because I didn't know that researchers in Maeda's
lab had created the language
Processing.
But hearing his name brought to mind something that has
been in the back of my mind for a couple of months, since
the close of my
first theater experience.
I had blogged about a few observations my mind had made
about the processes of acting in and directing a play.
The former were mostly introspective, and the latter
were mostly external, as I watched our director coalesce
what seemed like a mess into a half-way decent show.
Some of these connections involved similarities I noticed
between producing a play and creating software.
I made notes of a few more ideas that I hadn't mentioned
yet, including:
"Release time" is chaos. Even with all of the practice
and rehearsal, the hours before the show on opening
night were a hectic time, worrisome for a few and
distracting for others.
You hope for perfection, but there will mistakes.
Just do it.
No matter what happens on stage or off, when you are
on stage, you must stay in character. You are not
yourself playing a character; you are the character.
As a novice player, I struggled throughout, even to
the last call of the final show, with self-consciousness
on stage. I think that unself-consciousness --
detachment -- is a skill that can be developed with
practice. I need more.
I'm still wondering if those last two have any useful
analogue in software development...
Since the show ended, I have occasionally tried to discern
the value in the analogy between producing a play and
creating software -- indeed, if there is any. That's
where the connection to Maeda comes in. Last summer, I
read the slender
Laws of Simplicity,
a collection of essays from Maeda's
blog of the same name.
The book suggest ten ways that we can design simpler
systems and products. I must not have been in the
right place to read the book just then, because I didn't
get as much out of it as I had hoped. But one part of
the book stuck with me.
For a metaphor to engage us deeply, Maeda wrote, it is
essential that it relate,
translate, and surprise.
As I recall now, this means that the metaphor must relate
the elements of the two things, that it must translate
foreign elements from one of the things to the other,
and that the result of this translation should surprise
-- it should make us see or understand the other thing
in a new way, give us insight.
There is a danger in finding analogies everywhere we look
by making superficial connections. I am perhaps more prone
to this risk than many other folks. That may be why I liked
Maeda's relate/translate/surprise triad so much. Since
reading it, I have used it as an external checkpoint for
any new analogy that I want to make. If I can explain how
the metaphor relates the two things, translates disparate
elements, and surprises me, then I have some reason to think
that the metaphor offers value -- at least more reason than
just saying, "Hey, look at this cool new thing I noticed!"
To this point, I have not found the "surprise" in the
theater experience that teaches me something new about
how to think about making software. This doesn't mean that
there is no value in the analogy, only that I haven't found
it yet. By remaining skeptical a little while longer, I
decrease the probability that I try to draw an inappropriate
conclusion from the relationship.
Of course, just because I haven't yet found the surprise
in the analogy doesn't mean that I did not find value in
the experience that led me to it. A rich web of experiences
is valuable in its own right, and enjoyable. It also
provides the source material for learning.
Last night I attended a meeting with several CS colleagues,
colleagues from Physics and Industrial Technology,
representatives from the local company
DISTek Integration,
and representatives from
National Instruments,
which produces the programming environment
LabVIEW.
Part of the meeting was about LabVIEW and how students and
faculty at my school use it. Our CS department does not
use it at all, which is typical; the physicists and
technologists use it to create apps for data acquisition
and machine control.
Most of the meeting was much more interesting than tool
talk and sales pitch, because it was about how to excite
more kids and university students about IT careers and
programming, and about how LabVIEW users work. Most of
the folks who program in LabVIEW at DISTek are test
engineers, not trained software developers. But the
programming environment makes it possible for them to
build surprisingly complex applications. As they grow
their apps, and attack bigger problems because they can,
the programs become unwieldy and become increasingly
difficult to maintain and extend.
It turns out that program design matters. It turns out
that software architecture matters. But these programmers
aren't trained in the writing software, and so they do
much of their work with little or no understanding of
how to structure their code, or refactor it into something
more manageable.
These folks are engineers, not scientists, but I felt
a deep sense of deja vu. Our conversations
sounded a lot like what we discussed
with physicists
at the SECANT workshop to which I keep referring.
I think we have a great opportunity to work with the folks
at DISTek to help their domain-specific programmers learn
the software development skills they need to become more
effective programmers. Working with them will require us
to think about how to teach a focused software development
curriculum for non-programmers. I think that this will be
work worth doing as we encounter more and more folks, in
more and diverse domains, who need that sort of software
development education -- not a major or maybe even minor
in CS -- in order to do what they do.
I enjoyed a brisk 5-mile run outdoors yesterday morning.
That isn't much to write about, except that yesterday
morning the temperature dipped to an all-time record
low for January 24 here, bottoming out at -29°
Fahrenheit. (All together now:
Here's your sign.)
At least the wind didn't make it feel much colder
than that.
The thing is, I did enjoy the run. I stayed plenty warm,
thanks to my clothing and the physical act of running.
First, I threw on a layer or two more than usual. Second,
my wife gave me a couple of pieces of new gear for Christmas:
a pair of fleece running mittens with a second, wind-resistant
outer layer, and an ultra-warm headband that I wore under
my usual thermal hat. My fingers and toes have always
been my weak spot in the cold, and for the first time ever
in very cold weather, my fingers didn't get cold at all.
My attire did the job, and the new gear worked just as I
had hoped.
In running, as in programming, good tools make all the
difference. I really liked Jason Marshall's take on this
in a recent
Something to Say:
There's an old saying, "A good craftsman never blames his
tools." Many people take this to mean "Don't make excuses,"
or even, "Real men don't whine when their tools break."
But I take it to mean, "A good craftsperson does not abide
inferior tools."
I'm teaching a course on Unix shell scripting the first five
weeks of this semester, and tool-building is central to the
Unix philosophy. I hope that students see that they never
have to abide inferior tools, or even okay tools that do not
meet their needs. With primitive Unix commands, pipelines,
I/O redirection, a little sed and awk, and the more general
programming language of bash, they can do so much to
customize their environment so that it meets their needs.
If the shell isn't enough, they can use a general-purpose
programming language.
Progress depends on the creation of better tools.
I like to build software tools for myself. I'm not equipped
to make my own running gear, though, and being, um, careful
with my money means that I am sometimes slow to buy the
more expensive item. But after running 7500 miles over the
last four years, I've slowly realized that I'm enough of a
runner to use better gear. A few experiences like
yesterday morning's make it easier to purchase the right
equipment for the job. Learning shell scripting, or a better
programming language, can have the same effect on a programmer.
More on Computational Simulation, Programming, and the Scientific Method
As I was running through some very cold, snow-covered streets,
it occurred to me that
my recent post
on James Quirk's AMRITA system neglected to highlight one of
the more interesting elements of Quirk's discussion:
Computational scientists have little or no incentive to become
better programmers, because research papers are the currency
of their disciplines. Publications earn tenure and promotion,
not to mention street cred in the profession. Code is viewed
by most as merely a means to an end, an ephemeral product on
the way to a citation.
What I take from Quirk's paper is that code isn't -- or shouldn't
be -- ephemeral, or only a means to an end. It is the experiment
and the source of data on which scientific claims rest. As I
thought more about the paper I began to wonder, can computational
scientists do better science if they become better programmers?
Even more to the point, will it become essential for a
computational scientist to be a good programmer just to do the
science of the future? That's certainly what I heard some of
the scientists at the
SECANT workshop
saying.
While googling to find a link to Quirk's article for my entry
(Google is the new
grep.TM),
I found the paper
Computational Simulations and the Scientific Method
(pdf), by
Bil Kleb
and Bill Wood. They take the programming-and-science angle
in a neat software direction, suggesting that
the creators of a new simulation technique should
publish unit tests that specify the technique's
intended behavior, and
the developers of scientific simulation code for a
given technique use its unit tests to demonstrate that
their component correctly implements the technique.
Publishing a test fixture offers several potential benefits,
including:
a way to communicate a technique or algorithm better
a way to share the required functionality and performance
features of an implementation
a way to improve repeatability of computational
experiments, by ensuring that scientists using the
same technique are actually getting the same output
from their component modules
a way to improve comparison of different experiments
a way to improve verification and validation of
experiments
These are not about programming or software development; they
are about a way to do science.
This is a really neat connection between (agile) software
development and doing science. The idea is not necessarily
new to folks in the agile software community. Some of these
folks speak of test-driven development in terms of being a
"more scientific" way to write code, and agile developers of
all flavors believe deeply in the observation/feedback cycle.
But I didn't know that computational scientists were talking
this way, too.
After reading the Kleb and Wood paper, I was not surprised
to learn that Bil has been involved in the Agile 200?
conferences over the years. I somehow missed the 2003
IEEE Software article that he and Wood co-wrote on
P and scientific research and so now have something new
to read.
I really like the way that Quirk and Kleb & Wood talk
about communication and its role in the practice of science.
It's refreshing and heartening.
Some days, I want to write but don't have anything to say.
The start of the semester often finds me too busy doing
things to do anything else. Plowing through the arcane
details of Unix basic regular expressions that I tend
not to use very often is perhaps the most interesting
thing I've been doing.
Over the weekend, I did have a chance to read
this paper
by James Quirk, a computational scientist who has built
a sophisticated simulation-and-documentation system called
AMRITA. (You can download the paper as a PDF from his
web site,
by following About AMRITA and clinking on the link
"Computational Science: Same Old Silence, Same Old
Mistakes".) Quirk's system supports a writing style that
interleaves code and commentary in the spirit of
literate programming
using the concept of a program fold, which at one
level is a way to specify a different processor for each
item in a tree of structured text items. The AMRITA
project is an ambitious mixture of (1) demonstrating a new
way to communicate computational science results and (2)
arguing for software standards that make it possible for
computational scientists to examine one another's work
effectively. The latter point is essential if computational
science is to behave like science, yet the complexity of
most simulation programs almost precludes examination,
replication, and experimentation with the ideas they
implement.
Much of what Quirk says about scientists as programmers
meshes with what I wrote in my reports on November's
SECANT workshop.
The paragraph that made me sit up, though, was this lead-in
to his argument:
The AMR simulation shown in Figure 1 was computed July 1990....
It took just over 12 hours to run on a Sun SPARCstation 1.
In 2003 it can be run on an IBM T30 laptop in a shade over
two minutes.
It is sobering occasionally to see the advances in processors
and other hardware presented in such concrete terms. I
remember programming on a Sun SPARCstation 1 back in the
early '90s, and how fast it seemed! By 2003 a laptop could
perform more than 300 times faster on a data-intensive
numeric simulation. How much faster still by 2008?
Quirk is interested in what this means for the conduct of
computational science. "What should the computational science
community be doing over and above scaling up the sizes of the
problems it computes?" That is the heart of his paper, and
much of the motivation behind AMRITA.
I don't write many entries for the purpose of passing on
a link, but I am making an exception for the
Repository for Open Software Education
(ROSE), being hosted by a group at North Carolina State
University that includes
Laurie Williams.
You know I am a big fan of project-based courses, and
one of the major impediments to faculty teaching courses
this way is creating suitable projects. For example,
every time I teach compilers, I face the task of choosing
or creating a programming language for students to use as
their source. I like to use a language that is at least
a little different than languages I've used in the past,
for a couple of reasons, and that is hard work.
For more generic project courses in software engineering,
the problem is compounded by the fact that you may want
your students to work on an existing system, so that they
can encounter issues raised by a larger system than they
might write from scratch themselves. But where will
such large software come from? Sites like SourceForge
offer plenty of systems, but they come at so many levels
of completeness, complexity, documentation, and accessibility.
Finding projects suitable for a one-semester undergraduate
course in the morass is daunting.
ROSE aims to host open-source projects that are of suitable
scope and can grow slowly as different project teams extend
them. Being targeted at educators, the repository aims to
record information about requirements, design, and testing
that are often missing or inscrutable in other open-source
projects. At this point, ROSE contains only one project
larger than 5K lines of code, but that will change as
others contribute their projects to the repository.
As Laurie noted in her announcement of ROSE, for a few years
now the CS education community has had a
Nifty Assignments
repository, which offers instructors a set of fun,
challenging, and battle-tested programming assignments
to use in lower-division courses. ROSE will host larger
open-source projects for use in a variety of ways. It
is a welcome addition.
After "worrying out loud" in a
recent entry,
I suppose I should report that our faculty retreat went well.
We talked about several different across over the course of
the day, especially long-term goals, outcomes assessment,
and tactics for the next few months. The biggest part of
our goals discussion related to broadening our reach to
more students who are not and may never want to be CS majors.
That includes
science majors
but also social science, business, humanities, and education
students.
While discussing how to determine whether or not our courses
and programs of study were accomplishing what we want them
to accomplish, we had what was in many ways the most
interesting discussion of the day. It dealt with our
"capstone" project course.
In all of the CS majors we offer, each student is required to
complete a "project course" in one of the areas of study we
offer. This will be the third course the student takes in
that area, which is one way that we try to require students
to gain some depth in at least one area of computing. When
we added this requirement to our programs, the primary goal
was to give students a chance to work in teams on a large
piece of software, something bigger than they'd worked on in
previous courses and bigger than one person could complete
alone.
Some of our project courses are "content-heavy", in that they
introduce new topical content while students are working on
the project. The
compilers course
is an example of such a course; "Real-Time Embedded Systems"
is another. Others do not introduce much new content and
focus on the team project experience. "Projects in Systems"
(for the OS/networking crowd) and "Projects in Information
Science" (for the database/IR crowd) are examples. Over the
years, as we've broadened our faculty and the areas we teach,
we've added new project courses to the broaden the type of
experience offered as well. In some of these courses, code
is not the primary deliverable. For example, in "Software
Testing", students might develop a testing environment, a
suite of test plans, and documentation; in "User Interface
Design", students focus on developing a front end to an
existing system or to a lighter proof-of-concept back end
that they write. Some of these courses implement looser
versions of the original idea in other ways, too. My compiler
students usually work in pairs or threes, rather than the
four or five that we imagined we designed this part of the
curriculum over a decade ago.
Our outcomes assessment discussion turned quickly to the
nature of a project course and in particular the diversity
we now offer under this banner. We can't write outcomes
for the project requirement that refer to code as a primary
deliverable if, in fact, several courses do not require that
of students. Well, we could, but then we would have to
change how we teach the courses -- perhaps drastically.
The question was, is code an essential outcome of this
part of our curriculum?
We faced similar questions as we explored the other elements
of diversity. How much new content should a project
introduce? Must students write prose, in the form of
documentation, etc.? Should they give oral presentations?
If so, should these be public, or is an internal presentation
to the class or instructor sufficient? What about the
structured demos that our interface design students give as
a part of an end-of-the-term open house?
I enjoyed listening to all of my colleagues describe their
courses in more detail than I had heard in a while. After
our discussion, we decided for the most part to preserve the
rich ecology of our project course landscape. Test plans
and UIs are okay in place of code in certain courses; the
essential outcome is that students be expected to produce
multiple deliverables across the life of the project. We
also found some common themes that we could agree on, even
if it meant tweaking our courses. For example, whatever
kind of presentation our students give at the end of the
project, it should be open to the public and allow public
questioning. We will be writing these outcomes up more
formally as we proceed this semester and use them as we
evaluate the efficacy of our curriculum.
I was impressed with the diversity of ideas in practice in
our project courses. Perhaps the results of this discussion
were interesting mostly because we have had this sort of
conversation in a long time, at least not as a whole faculty.
It's funny, but "shared knowledge" isn't always what we think
it is. Sometimes we don't share as much as we think we do,
at least of the surface. When we dig deeper, we can find
common themes and also fundamental differences, which we
can then explore explicitly and in the context of the shared
knowledge. It was neat to see how each of us learned a little
something new about the goals of the project course and left
the conversation with an idea for improving our own courses.
My compiler students certainly don't write enough technical
prose in my course, certainly not as much or as structured
as students in some of the other project courses. I can make
my course stronger, and more consistent with the other options,
by changing how I teach the course next time, and what I
require of the class.
Our retreat didn't answer all my questions about the direction
of the department or our strategic and tactical plans. Only
in the fantasy of a manager could it! My job now is to take
what we learned and decided about ourselves that day, help
craft from that a coherent plan of action for the department,
and begin to take concrete actions to move us in the direction
we want to go. I hope that, as in most other endeavors, we
will do some things, learn from the feedback, and adjust
course as we go.
Second, I am looking forward to my spring teaching assignment.
Rather than teaching one 3-credit course, I will be teaching
three 1-credit courses. Our 810:151 course introduces our
upper-division students to languages that they may not encounter
in their other courses. In some departments, students see a
smorgasbord of languages in the Programming Languages course,
but we use an interpreter-building approach to teach language
principles in that course. (We do expose them in that course
to functional programming in Scheme, but more deeply.)
I like what that way of teaching Programming Languages, but I
also miss the experience of exposing students to the beauty of
several different languages. In the spring, I'll be teaching
five-week modules on Unix shell programming, PHP, and Ruby.
Shell scripting and especially Ruby are favorites of mine,
but I've never had a chance to teach them. PHP was thrown in
because we thought students interested in web development
might be interested. These courses will be built around
small and medium-sized projects that explore the power and
shortcomings of each language. This will be fun for me!
As a result, I've been looking through a lot of books, both
to recommend to students and to find good examples. I even
did something I don't do often enough... I bought
a book, Brian Marick's
Everyday Scripting with Ruby.
Publishers send exam copies to instructors who use a text
in a course, and I'm sent many, many others to examine for
course adoption. In this case, though, I really wanted the
book for myself, irrespective of using it in a course, so
I decided to support the author and publisher with my own
dollars.
Steve Yegge got me to thinking about languages, too, in one
of his recent articles. The
article
is about the pitfalls of large code bases but, while I may
have something to say about that topic in the future, what
jumped out to me while reading this week were two passages
on programming languages. One mentioned Ruby:
Java programmers often wonder why Martin Fowler "left" Java to
go to Ruby. Although I don't know Martin, I think it's safe to
speculate that "something bad" happened to him while using Java.
Amusingly (for everyone except perhaps Martin himself), I think
that his "something bad" may well have been the act of creating
the book Refactoring, which showed Java programmers how to make
their closets bigger and more organized, while showing Martin
that he really wanted more stuff in a nice, comfortable,
closet-sized closet.
For all I know, Yegge's speculation is spot on, but I think it's
safe to speculate that he is one of the better fantasy writers
in the technical world these days. His fantasies usually have
a point worth thinking about, though, even when they are wrong.
This is actually the best piece of language advice in the
article, taken at its most general level and not a slam at
Java in particular:
But you should take anything a "Java programmer" tells you with
a hefty grain of salt, because an "X programmer", for any value
of X, is a weak player. You have to cross-train to be a decent
athlete these days. Programmers need to be fluent in multiple
languages with fundamentally different "character" before they
can make truly informed design decisions.
We tell our students that all the time, and it's one of the
reasons I'm looking forward to three 5-week courses in the
spring. I get to help a small group of our undergrads
crosstrain, to stretch their language and project muscles
in new directions. That one of the courses helps them to
master a basic tool
and another exposes then to one of the more expressive and
powerful languages in current use is almost a bonus for me.
Finally, I'm feeling the itch -- sometimes felt as a need,
other times purely as desire -- to upgrade the tool I use
to do my blogging. Should I really upgrade, to a newer
version of
my current software?
(v3.3 >> v2.8...) Should I hack my own upgrade? (It
is 100% shell script...) Should I roll my own, just for the
fun of it? (Ruby would be perfect...) Language choices
abound.
Agile processes promote sustainable development. The
sponsors, developers, and users should be able to maintain
a constant pace indefinitely.
When I hear people talk about sustainable pace, they are
usually discussing time -- how many hours per week a
healthy developer and a healthy team can produce value
in their software. The human mind and body can work so
hard for only so long, and trying to work hard for longer
leads to problems, as well as decline in productivity.
The first edition of XP had a practice called 40-hour
work week that embodied this notion. The practice was
later renamed sustainable pace to reflect that 40 hours is
an arbitrary and often unrealistic limit. (Most university
faculty certainly don't stop at 40 hours. By self-report
at my school, the average work week is in the low-50s.)
But the principle is the same.
Does this mean that we cannot become more productive?
Recall that pace -- rate -- is a function of two variables:
rate = distance / time
Productivity is like distance. One way to cover more
distance is to put in more time. Another is to increase
the amount of work you can do in a given period of time.
This is an idea close to the heart of runners. While I
have written against running
all out, all the time,
I know that the motivation found in that mantra is to
get faster. Interval training, fartleks, hill work,
and sustained fast pace on long runs are all intended to
help a runner get stronger and faster.
How can software developers "get faster"? I think that
one answer lies in the tools they use.
When I use a testing framework and automate my tests, I am
able to work faster, because I am not spending time running
tests by hand. When I use a build tool, I am able to work
faster, because I am not spending time recompiling files
and managing build dependencies. When I use a powerful --
and programmable -- editing tool, whether it is Eclipse or
Emacs,
I am able to work faster, because I am not spending time
putzing around for the sake of the tool.
And, yes, when I use a more powerful programming language,
I am able to work faster, because I am not spending time
expressing thoughts in the low-level terms of a language
that limits my code.
So, programmers can increase their sustainable pace by
learning tools that make them more productive. They can
learn more about the tools they already use. They can
extend their tools to do more. And they can write new
tools when existing tools aren't good enough.
Perhaps it is not surprising that I had this thought
while running a pace that I can't sustain for more
than a few miles right now. But I hope in a few months
that a half marathon at this pace will be comfortable!
My first run as an
actor
has ended without a Broadway call. Nonetheless I consider it
to have been successful enough. My character didn't cause any
major interruptions in the flow of our three performances, and
I even got us back on track a time or two. Performing in front
of a crowd -- especially a crowd that contained personal friends
-- was enough different from giving a lecture or speaking in
public that it wracked a few nerves. But getting a laugh from
a real audience was also enough different from a laugh in a
lecture, too, and the buzz could feed the rest of the performance.
My first post on this topic recorded dome thoughts I had had on
the relationship between developing software and directing a
play. In those thoughts, the director or producer is cast as
the software developer, or vice versa. In the last couple of
weeks, my thoughts turned more often to my role as performer.
Here are a few:
Before each rehearsal and performance, I found myself
spending important minutes setting up my environment:
making sure props were in place, adjusting positions based
on any results from the last time, and finding a place
backstage for my time between scenes. This felt a lot
like how I set up for time writing code, getting my tools
in place.
I wonder if there is any analogue in software development
the self-consciousness I felt as I began to perform on
stage? Over time, the director helped me to morph some
of the self-consciousness into a sensitivity to the scene
and my fellow players.
After a while, experience helps push self-consciousness
into the background. It was even possible to get into a
flow
where the self disappeared for a moment. I think I need
more experience in character to have more experiences like
that! But those moments were special.
Once we got into performances, I noticed a need for the
same almost contradictory combination of hubris and humility
that a programmer needs. At some point, I had to know my
lines and scenes so well that I could nail them blind.
That drove a form of confidence that let me "own" my
character in a scene. Yet I had to be careful not to
become too cocky, because suddenly something would go wrong
and I'd find myself exposed and not at all in control. So
I spent a few minutes before every scene preparing, just
refreshing my memory of cues and placements and notes the
director had given. That bit of humility gave me more
confidence than I otherwise could have had.
Most of the relationships I noticed between acting in the play
and building software were really patterns of good teams. In
every scene I depended upon the presence and performance of
others -- and they depended on me. Being a good teammate
mattered both on stage (while performing) and off (when
preparing and when taking and giving feedback). "The key to
acting," said our director, "is listening to other people."
Funny how that is the key to so many things.
As I look back on this (first?) experience being a player in
a stage production, I think that there is a lot to this notion
that developing software is like producing a play -- and that
producing a play is like developing software. The two media
are so different, but they are both malleable, and both
ultimately depend on their audiences (users).
Over the course of two weeks or so, the director did a lot
of what I call refactoring. For example, he found the
equivalent of duplicated code -- lines and even larger parts
of scenes that don't move the story forward, given how the
rest of the play is being staged. Removing duplicated stuff
frees up stage real estate and time for making other additions
and changes. He also aggressively sought and deleted dead
space -- moments when no one was on stage (say, in the transition
between scenes) or no active was taking place (say, when
lighting changed). Dead space kills the energy of the show
and distracts the viewer. Dead space is a little like dead
code and over-designed code -- code that isn't contributing
to the application. Cut it.
Every night after rehearsal and even shows, the director "ran
notes" with us. This was a time after each "iteration"
dedicated to debugging and refactoring. That's good practice
in software.
One other connection jumped out to me yesterday. After we
closed the show, I was chatting with
Scott Smith,
a local filmmaker whose is real-life husband to the woman who
played my wife in the show. We were discussing how filmmaking
has changed in the last decade or so. In the not-so-old days
folks in video were strongly encouraged to become specialists
in one of the stages: writing, directing, shooting, editing,
and so on. Now, with the wide availability of relatively
inexpensive equipment and digital tools, and economic pressures
to deliver more complete services, even veterans such as Smith
find themselves developing skills across the board, becoming
not a jack-of-all-trades but master of none, but rather strong
in all phases of the game.
I immediately thought of extreme programming's rapid development
cycle that requires programmers to be not only writers of code
but also writers of stories and tests, to be able to interact
with clients and to grow designs and architectures. It's hard
to be a master of all trades, but the sort of move we have seen
in software and in filmmaking from specialist to generalist
encourages a deep competence in all areas. Too often I have
heard folks say "I am a generalist" as way to explain their
lack of expertise in any one area. But the new generalist is
competent across the board, perhaps expert in multiple areas,
and able to contribute meaningful to the whole lifecycle.
One last idea. Just before our final show, the director gave
us our daily pep talk. He said that come performers view the
last show as occasion to do something wacky -- to misplace
someone's prop, or deliver a crazy line not from the script,
or to affect some voice or mannerism on stage. That sounds
like fun, he said, but remember: For the audience out in
the seats today, this is the first show. They deserve
to see the best version of the show that we can give. For
some reason, I thought of software developers and users. Maybe
my mind was just hyperactive at that moment when we were about
to create our illusion. Maybe not.
I recently wrote that I will be
in a play
this Christmas season. I'm also excited to have been asked by
Brian Marick
to serve on a committee for the
Agile2008
conference, which takes me in another direction with the
performance metaphor. As much as I write about agile methods
in my
software development
entries, I have never been to one of the agile conferences.
Well, at least not since they split off from OOPSLA and
took on their own identity.
Rather than using the traditional and rather tired notion of
"tracks", Agile2008 is organized around the idea of
stages,
using the metaphor of a music festival. Each stage is designed
and organized by a stage producer, a passionate expert, to attract
an audience with some common interest. In the track-based metaphor
-- a railroad? -- such stages are imposed over the tracks in much
the way that aspects cut across the classes in an object-oriented
program.
(At a big conference like OOPSLA, defining and promoting the
crosscutting themes is always a tough chore. Now that I have made
this analogy, I wonder if we could use ideas from aspect-oriented
programming to do the job better? Think, think.)
I look forward to seeing how this new metaphor plays out. In many
important ways, the typical conference tracks (technical papers,
tutorials, workshops, etc.) are implementation details that help
the conference organizers do their job but that interfere
with the conference participants' ability to access
events that interest them. Why not turn the process inside out
and focus on our users for a change? Good question!
(Stray connection: This reminds of an interview I heard recently
with comedian Steve Martin, who has written a biography of himself.
He described how he developed his own style as a stand-up comedian.
Most comedians in that era were driven by the punch line -- tell
a joke that gets you to a punch line, and then move on to the next.
While taking a philosophy course, he learned that one should
question even the things that no one ever questioned, what was
taken for granted. What would be comedy be like without a punch
line? Good question!)
Of course, this changes how the conference organizers work. First
of all, it seems that for a given stage the form of activity being
proposed could be almost anything: a presentation, a small workshop,
a demonstration, a longer tutorial, a roundtable, ... That could
be fun for the producers and their minions, and give them some
much needed flexibility that is often missing. (Several times
in the past I have had to be part of rejecting, say, a tutorial
when we might gladly have accepted the submission if reformulated
as a workshop -- but we were the tutorials committee!)
Brian tells me that Agile 2008 will try a different sort of
submission/review/acceptance process. Submissions will be posted
on the open web, and anyone will be able to comment on them. The
review period will last several months, during which time submitters
can revise their submissions. If the producer and the assistant
producers participate actively in reviewing submissions over the
whole period, they well put in more work than in a traditional
review process (and certainly over a longer period of time.) But
the result should be better submissions, shaped by ideas from all
comers -- including potential members of the audience that the stage
hopes to attract! -- and so better events and a better conference.
It will be cool to be part of this experiment.
As you can see from the Agile 2008 web site, its stages correspond
to themes, not event formats. Brian is producing a stage called
"Designing, Testing, and Thinking with Examples", the logo for
which you see here. This is an interesting theme that goes beyond
particular behaviors such as designing, testing, and teaching to
the heart of a way to think about all of them, in terms of concrete
examples. The stage will not only accept examples for
presentation, demonstration, or discussion, but glory
in them. That word conveys the passion that Brian and his
assistant producer Adam Geras bring to this theme.
I think Brian asked me to help them select the acts for this stage
because I have exhibited some strong opinions about the role of
examples and problems in teaching students to program and to learn
the rest of computer science. I'm pretty laid back by nature, and
so don't often think of myself in terms of passion, but I guess I
do share some of the passion for examples that Brian and Adam bring
to the stage. This is a great opportunity for me to broaden my
thinking about examples and to see what they means for the role
they play in my usual arenas.
In a stroke of wisdom, no one has asked me yet to be on
the stage, unlike my local director friend. Whatever practice I
get channeling
Jackson Davies,
I am not sure I will be ready for prime time on the bright lights
of an Agile stage...
It occurs to me that, following this metaphor one more step, I
am not playing the role of a contestant on, say, American Idol,
but the role of talent judge. Shall I play
Simon
or
Paula?
(Straight up!)
Learning About Software from The Theater, and Vice Versa
Last Sunday was my fourth rehearsal as a
newly-minted actor.
It was our first run-through of the entire play on stage,
and the first time the director had a chance to give notes
to the entire cast. The whole afternoon, my mind was
making connections
between plays and programs -- and I don't mean the playbill.
These thoughts follow from my experiences in the play and
my experiences as a software developer. Here are a few.
Scenes and Modularity Each
scene is a like a module that the director debugs. In some
plays, the boundaries between scenes are quite clean, with
a nice discrete break from one to the next. With a play
on stage, the boundaries between scenes may be less clear.
In our play, scenes often blend together. Lights go down
on one part of the stage and up on another, shifting the
audience's attention, while the actors in the first scene
remain in place. Soon, the lights shift back to the first
and the action picks up where it left off. Plays work this
way in part because they operate in limited real estate,
and changing scenery can be time-consuming. But this also
It is easier to debug scenes that are discrete modules.
Debugging scenes that run together is difficult for the same
reasons that debugging code modules with leaky boundaries is.
A change in one scene (say, repositioning the players) can
affect the linked scene (say, by changing when and where a
player enters).
Actors and Code If the director
debugs a scene, then maybe the actors, their lines, and the
props are like the code. That just occurred to me while
typing the last section!
Time Constraints It is hard to
get things right in a rush. Based on what he sees as the
play executes, the director makes changes to the content of
the show. He also refactors: rearranging the location of
a prop or a player, either to "clean things up" or to
facilitate some change he has in mind. It takes time to
clean things up, and we only know that something needs to
be changed as we watch the play run, and think about it.
Mock Objects and Stand-Ins When
rehearsing a scene, if you don't have the prop that you will
use in the play itself, then use something to stand in its
place. It helps you get used to the the fact that something
will be there when you perform, and it helps the director
remember to take into account its use and placement. You
have to remember to have it at the right time in the right
place, and return it to the prop table when it's not in use.
A good mock prop just needs to have some of the essential
features of the actual prop. When rehearsing a scene in
which I will be carrying some groceries to the car, I grabbed
a box full of odds and ends out of some office. It was big
enough and unwieldy enough to help me "get into the part".
Conclusion for Now The
relationship between software and plays or movies is not a
new idea, of course. I seem to recall a blog entry a couple
of years ago that explored the analogy of developing software
as producing a film, though I can't find a link to it just
now. Googling for it led me to a page on
Ward's wiki
and to
two
entries
on the Confused of Calcutta blog. More reading for me...
And of course there is Brenda Laurel's seminal
Computers As Theatre.
You really should read that!
Reading is a great way to learn, but there is nothing quite
like living a metaphor to bring it home.
The value that comes from making analogies and metaphors
comes in what we can we learn from them. I'm looking forward
to a couple of weeks more of learning from this one -- in
both directions.
Several folks have sent interesting comments on recent
posts, especially
A Program is an Idea.
A couple of comments on that post, in particular, are
worth following up on here.
Bill Tozier
wrote that learning to program -- just program -- is insufficient.
I'd argue that it's not enough to "learn" how to program, until
you've learned a rigorous approach like test-driven development
or behavior-driven development. Many academic and scientific
colleagues seem to conflate software development with "programming",
and as a result they live their lives in slapdash Dilbertesque
pointy-haired boss territory.
This is a good point, and goes beyond software development.
Many, many folks, and especially university students, conflate
programming with computer science, which disturbs
academic CS folks to no end, and for good reason. Whatever
we teach scientists about programming, we must teach it in
a broader context, as a new way of thinking about science.
This should help ameliorate some of the issues with conflating
programming and computer science. The need for this perspective
is also one of the reasons that the typical CS1 course isn't
suitable for teaching scientists, since its goals relative
to programming and computer science are so different.
I hadn't thought as much about Bill's point of conflating
programming with software development. This creates yet
another reason not to use CS1 as the primary vehicle for
teaching scientists to ("program" | "develop software"),
because even more so in this regard are the goals of CS1 for
computer science majors very different from the goals of a
course for scientists.
Indeed, there is already a strong tension between the goals of
academic computer science and the goals of professional
software development that makes the introductory CS curriculum
hard to design and implement. We don't want to drag that mess
into the design of a programming course for scientists, or
economists, or other non-majors. We need to think about how
best to help the folks who will not be computer scientists
learn to use computation as a tool for thinking about, and
doing work in, their own discipline.
And keep in mind that most of these folks will also not
be professional software developers. I suspect that folks who
are not professional software developers -- folks using
programs to build models in their own discipline -- probably
need to learn a different set of skills to get started using
programming as a tool than professional software developers do.
Should they ever want to graduate beyond a few dozen lines of
code, they will need more and should then study more about
developing larger and longer-lived programs.
All that said, I think that that scientists as a group might
well be more amenable than many others to learning test-driven
development. It is quite scientific in spirit! Like the
scientific method, it creates a framework for thinking and
doing that can be molded to the circumstances at hand.
The other comment that I must respond to came from Mike McMillan.
He recalled having run across a video of Gerald Sussman giving a
talk
on the occasion of
Daniel Friedman's 60th birthday,
and hearing Sussman comment on expressing scientific ideas in
in Scheme. This brought to his mind Minsky's classic paper "Why
Programming Is a Good Medium for Expressing Poorly-Understood
and Sloppily-Formulated Ideas", which is now
available on-line
in a slightly revised form.
This paper is the source of the oft-quoted passage that appears
in the
preface
of Structure and Interpretation of Computer Programs:
A computer is like a violin. You can imagine a novice trying
first a phonograph and then a violin. The latter, he says,
sounds terrible. That is the argument we have heard from our
humanists and most of our computer scientists. Computer programs
are good, they say, for particular purposes, but they aren't
flexible. Neither is a violin, or a typewriter, until you learn
how to use it.
(Perhaps Minsky's paper is where Alan Kay picked up his violin
metaphor and some of his ideas on computation-as-medium.)
Minsky's paper is a great one, worthy of its own essay sometime.
I should certainly have mentioned it in my essay on scientists
learning to program. Thanks to Mike for the reminder! I am
glad to have had reason to track down links to the video and
the PDF version of the paper, which until now I've only had
in hardcopy.
Earlier this week, I read The Geomblog's
A day in the life...,
in which Suresh listed what he did on Monday. Research did
not appear on the list.
I felt immediate and intense empathy. On Monday, I had spent
all morning on our college's Preview Day, on which high school
students who are considering studying CS at my university visit
campus with their parents. It is a major recruiting effort in
our college. I spent the early morning preparing my discussion
with them and the rest of the morning visiting with them. The
afternoon was full of administrative details, computer labs and
registration and prospective grad students. On Tuesday, when
I read the blog entry, I had taught compilers -- an oasis of
CS in the midst of my weeks -- and done more administration:
graduate assistantships, advising, equipment purchases, and
a backlog of correspondence. Precious little CS in two days,
and no research or other scholarly activity.
Alas, that is all too typical. Attending an NSF workshop this
week is a wonderful chance to think about computer science, its
application in the sciences, and how to teach it. Not research,
but computer science. I only wish I had a week or five after
it ends to carry to fruition some of the ideas swirling around
my mind! I will have an opportuniy to work more on some of these
ideas when I return to the office, as a part of my department's
curricular efforts, but that work will be spread over many weeks
and months.
That is not the sort of intense, concentrated work that I and
many other academics prefer to do. Academics are bred for
their ability to focus on a single problem and work intensely
on it for long periods of time. Then comes academic positions
that can spread us quite then. An administrative position
takes that to another level.
Today at the workshop, I felt a desire to bow down before an
academic who understands all this and is ready to take matters
into his own hands. Some folks were discussing the shortcomings
of the current Mac OS X version of
VPython,
the installation of which requires X11, Xcode, and Fink. Bruce
Sherwood is one of the folks in charge of VPython. He apologized
for the state of the Mac port and explained that the team needs
a Mac guru to build a native port. They are looking for one,
but such folks are scarce. Never fear, though... If they can't
find someone soon, Sherwood said,
I'm retiring so that I can work on this.
Now that is commitment to a project. We should
all have as much moxie! What do you say, Suresh?
Weinberg often describes exercises that writers can use to
free their minds and words. It doesn't surprise me that
"freeing" exercises are
built on constraints.
In one post, Weinberg describes
The Missing Letter,
in which the writer writes (or rewrites) a passage without
using a randomly chosen letter. The most famous example of
this form, known as a lipogram, is La disparition,
a novel written by Georges Perec without an using the letter
'e' -- except to spell the author's name on the cover.
When I read that post months ago, I immediately thought of
creating programming exercises of a similar sort. As I quoted
someone in a
post on a book about Open Court Publishing,
"Teaching any skill requires repetition, and few great works
of literature concentrate on long 'e'." We can design a set
of exercises in which the programmer surrenders one of her
standard tools. For instance, we could ask her to write a
program to solve a given problem, but...
with no if statements. This is
exactly the idea embodied in the
Polymorphism Challenge
that my friend
Joe Bergin
and I used to teach a workshop at SIGCSE a couple of years
ago and which I often find useful in helping programmers
new to OOP see what is possible.
with no for statements. I took
a big step in understanding how objects worked when I
realized how the internal iterators in Smalltalk's collection
classes let me solve repetition tasks with a single message
-- and a description of the action I wanted to take. It
was only many years later that I learned the term "internal
iterator" or even just "iterator", but by then the idea was
deeply ingrained in how I programmed.
Recursion is the usual path for students to learn how to
repeat actions without a for statement, but I
don't think most students get recursion the way most folks
teach it. Learning it with a rich data type makes a lot
more sense.
with no assignment statements.
This exercise is a double-whammy. Without assignment
statements, there is no call explicit sequences of
statements, either. This is, of course, what pure
functional programming asks of us. Writing a big app in
Java or C using a pure functional style is wonderful
practice.
with no base types. I nearly wrote about
this sort of exercise a couple of years ago when discussing
the OOP anti-pattern
Primitive Obsession.
If you can't use base types, all you have left are instances
of classes. What objects can do the job for you? In most
practical applications, this exercise ultimately bottoms out
in a domain-specific class that wraps the base types required
to make most programming languages run. But it is a worthwhile
practice exercise to see how long one can put off referring
to a base type and still make sense. The overkill can be
enlightening.
Of course, one can start with an language that provides only
the most meager set of base types, thus forcing one to build
up nearly all the abstractions demanded by a problem. Scheme
feels like that to most students, but only a few of mine seem
to grok how much they can learn about programming by working
in such a language. (And it's of no comfort to them that
Church built everything out of functions in his lambda calculus!)
This list operates at the level of programming construct. It is
just the beginning of the possibilities. Another approach would
be to forbid the use of a data structure, a particularly useful
class, or an individual base type. One could even turn this idea
into a naming challenge by hewing close to Weinberg's exercise
and forbidding the use of a selected letter in identifiers.
As an instructor, I can design an exercise targeted at the needs
of a particular student or class. As a programmer, I can design
an exercise targeted at my own blocks and weaknesses. Sometimes,
it's worth dusting off an old challenge and doing it for it's
own sake, just to stay sharp or shake off some rust.
Lest you all think I have strayed so far from software and
computer science with
my last note
that I've fallen off the appropriate path for this blog,
let me reassure you. I have not. But there is even a
connection between my last post and the world of software,
though it is sideways.
Richard Bach, the writer whom I quoted last time, is best
known for his bestselling Jonathan Livingston Seagull.
I read a lot of his stuff back in high school and college.
It is breezy pop philosophy wrapped around thin plots, which
offers some deep truths that one finds in Hinduism and other
Eastern philosophies. I enjoyed his books, including his
more straightforward books on flying small planes.
But one of Richard Bach's sons is
James,
a software tester with whose work I came into contact via
Brian Marick's.
James is a good writer, and I enjoy both his blog and his
other writings about software, development methods, and
testing. Another of Richard Bach's son,
Jon,
is also a software guy, though I don't know about his work.
I think that James and Jon have published together.
Illusions offers a book nested inside another book
-- a magic book, no less. All we see of it are the snippets
that our protagonist needs to read each moment he opens it.
One of the snippets from this book-within-a-book might be
saying something important about an
ongoing theme
here:
There is no such thing as a problem without a gift for you
in its hands. You seek problems because you need their gifts.
Here is the magic page that grabbed me most as I thumbed
through the book again this morning:
Live never to be ashamed if anything you do or say is published
around the world -- even if what is published is not true.
Now that is detachment.
How about one last connection? This one is not to software.
It is an unexpected connection I discovered between Bach's
work and my life after I moved to Iowa. The title character
in Bach's most famous book was named for a real person, John
Livingston, a
world-famous pilot
circa 1930. He was born in Cedar Falls, Iowa, my adopted
hometown, and once even taught flying at my university, back
when it was a teachers' college. The terminal of the
local airport,
which he once managed, is named for Livingston. I have spent
many minutes waiting to catch a plane there, browsing pictures
and memorabilia from his career.
Over on one of the mailing lists I browse --
maverick software development
-- there has been a lot of talk about how a lack of trust is
one of the primary dysfunctions of teams. The discussion
started as a discussion of Patrick Lencioni's
The Five Dysfunctions of a Team
but has taken on its own life based on the experiences of the
members of the list.
One writer there made the bold claim that all team
dysfunctions are rooted in a lack of trust. Others, such as
fear of conflict and lack of commitment to shared goals, grow
solely from a lack of trust among team members and leaders.
This is, in fact, what Lencioni claims in his book, that a
lack of trust creates an environment in which people fear
conflict, which ensures a lack of commitment and ultimately
an avoidance of accountability, ending in an inattention to
the results produced by the team.
The writer who made this claim asked list members for
specific counterexamples. I don't know if I can do that,
but I will say that it's amazing what a lack of
confidence can do to an individual's outlook and
performance, and ultimately on his or her ability to contribute
positively as a team member.
When a person lacks confidence in his ability, he will be
inclined to interpret every contingent signal in a different
way than it was intended. This interpretation is often extreme,
and very often wrong. This creates an impediment to performance
and to interaction.
I see it in students all the time. A lack of confidence makes
it hard to learn! If I don't trust what I know or can do, then
every new idea looks scary. How can I understand this if I
don't understand the more fundamental material? I don't want
to ask this question, because the teacher, or my classmates,
will see how little I know. There's no sense in trying this;
I'll just fail.
This is, I think a problem in CS classes between female and
male students. Male students seem more likely than females
to bluff their way through a course, pretending they understand
something more deeply than they do. This gives everyone a
distorted image of the overall understanding of the class, and
leaves many female students thinking that they are alone in
not "getting it". One of the best benefits of teaching a CS
class via discussion rather than lecture is that over time
the bluffers are eventually outed by the facts. I still
recall one of our female students telling me in the middle
of one of my courses taught in this way that she finally saw
that no one else had any better grasp on the material than
she did and that, all things considered, she was doing pretty
well. Yes!
I see the effects of lack of confidence in my faculty colleagues,
too. This usually shows up in a narrow context, where the
person doesn't know a particular area of computing very well,
or lacks experience in a certain forum, and as a result shies
away from interacting in venues that rely on this topic.
I also see this spill over into other interactions, where a
lack of confidence in one area sets the tone for fear of
conflict (which might expose an ignorance) and disengagement
from the team.
I see it in myself, as instructor on some occasions and as a
faculty member on others. Whenever possible I use a lack of
confidence in my understanding of a topic as a spur to learn
more and get better. But in the rush of days this ideal
outlook often falls victim to rapidly receding minutes.
A personal lack of confidence has been most salient to me in
my role as a department head. This was a position for which
I had received no direct training, and grousing about the
performance of other heads offers only the flimsiest foundation
for doing a better job. I've been sensitized to nearly every
interaction I have. Was that a slight, or standard operating
procedure? Should I worry that my colleague is displeased
with something I've done, or was that just healthy feedback?
Am I doing a good enough job, or are the faculty simply
tolerating me? As in so many other contexts, these thoughts
snowball until they are large enough to blot everything else
out of one's sight.
The claimant on the mailing list might say that trust is the
real issue here. If the student trusts his teacher, or the
faculty member trusts his teammates, or the department head
trusts his faculty, either they would not lack confidence or
would not let it affect their reactions. But that is precisely
the point: they are reactions, from deep within. I think we
feel our lack of confidence prior to processing the emotion
and acting on trust. Lack of confidence is probably not more
fundamental than lack of trust, but I think they are often
orthogonal to one another.
How does one get over a lack of confidence? The simplest way
is to learn what we need to know, to improve our skills. In
the mean time, a positive attitude -- perhaps enabled by a
sense of trust in our teammates and situation -- can do wonders.
Institutionally, we can have, or work to get, support from above.
A faculty member who trusts that she has room to grow in the
presence of her colleagues and head, or a new department who
trusts that he has room to grow in the presence of his dean,
will be able to survive a lack of confidence while in the process
of learning. I've seen new deans and heads cultivate that sort
of trust by acting cautiously at the outset of their tenure, so
as not to lose trust before the relationship is on firm ground.
In the context of software development, the set of tasks for
which someone is responsible is often more crisply delineated
than the set of tasks for a student or manager. In one way,
that is good news. If your lack of confidence stems from not
knowing how
Spring
or
continuation passing style
works, you can learn it! But it's not too simple, as there are
time constraints and team relationships to navigate along the
way.
Ultimately, a mindset of detachment is perhaps the best tool
a person who lacks confidence can have. Unfortunately, I do
not think that detachment and lack of confidence are as common
a package as we might hope. Fortunately, one can cultivate a
sense of detachment over time, which makes dealing with recurring
doubts about one's capabilities easier to manage over time.
If only it were as easy to do these things as it is to say them!
Back in 2002, I had a sabbatical (which are, for political
reasons, called "professional development assignments" here)
to document some of the patterns of
programs that are written in a functional style. So much
good work had been done by then on object-oriented patterns,
and a few people had begun to describe OO patterns that
were motivated by functional programming techniques. But
few people had begun to document functional programming
patterns. I had a feeling that something useful could come
from moving into that space. In the end I didn't make the
sort of progress I had hoped, but I did learn a lot that has
continued to influence my teaching and research.
One of the areas explored as a part of that project was
refactoring functional programs. I believe that refactorings
are the behavioral side of patterns, and by looking at work
on existing work on functional refactorings I hoped to speed
my search for patterns. There hadn't been much work done on
refactoring functional programs at that time, but I wasn't
alone in thinking of it -- Simon Thompson and Claus Reinke
were just beginning their quite productive
research program
on the same topic. That work, like most of the work that
deals with patterns and refactoring in functional programming,
focused more on the language-processing side of the topic,
considering refactorings as program transformation in the
vein of compiler optimizations. What seems to me still to
be missing is a look at refactoring of functional programs
from the software developer's perspective: I have a piece
of code that I want to restructure in order to improve its
design, or in order to facilitate the next addition to the
program. What do I do next?
Noel Welsh recently wrote a blog entry called
Refactoring Functional Programs
that makes a very nice contribution in the space. Noel is
just the sort of person who should be documenting FP patterns
and refactorings, a practicing developer who works primarily
in a functional or mostly functional language and who is
growing a significant software system over time. His essay
talks about a sequence of refactorings that he applied to his
system, a web application framework, which moved one of its
modules from a long-ish, overly complex, repetitive piece of
code to something shorter, simpler, and well-factored. You
will enjoy reading the article even if you don't program in
Scheme, because Noel explains the thinking he did as he
attacked this piece of code, including an alternative step
that he considered but rejected due to the forces that affect
his system.
For the record, his three refactorings were these. The names
are part mine, part his:
convert mutually tail-recursive state machine to
continuation-passing style
separate computational abstraction from control abstraction
convert continuation-passing style to direct style
One of the things I like about this story is how it makes a
"round-trip" to CPS and back, using the trip to change the
program's design in a way that might have been inaccessible
otherwise. I teach my students a similar "refactoring pattern"
when teaching them functional programming, make a round-trip
through
Mutual Recursion,
by way of
Program Derivation,
to convert a messy one-procedure solution into a clean and
one-elegant one-procedure solution.
I hope that other developers using functional programming in
the trenches will follow Noel's lead and document some of the
patterns and refactorings that they discover in their code and
process. More than anything else, this sort of pragmatic,
nuts-and-bolts writing will help to increase the accessibility
of functional programming style to a wider audience of
programmers.
I am sad this week to be missing
OOPSLA 2007.
You might guess from my
recent positive words
that missing the conference would make me really
sad, and you'd be right. But demands of work and family
made traveling to Montreal a work infeasible. After
attending eleven straight OOPSLAs, my fall schedule has
a whole in it. My blog might, too; OOPSLA has been the
source of many, many writing inspirations in the three
years since I began blogging.
One piece of good news for me -- and for you, too -- is
that we are podcasting all of OOPSLA's keynote talks this
year. That would be a bonus for any conference, but with
OOPSLA it is an almost sinfully delicious treat. I was
reading someone else's blog recently, and the writer --
a functional programming guy, as I recall -- went down
the roster of OOPSLA keynote speakers:
Peter Turchi
Kathy Sierra
Jim Purbrick & Mark Lentczner
Guy Steele & Richard Gabriel
Fred Brooks
John McCarthy
David Parnas
Gregor Kiczales
Pattie Maes
... and wondered if this was perhaps the strongest lineup
of speakers ever assembled for a CS conference. It is
an impressive list!
If you are interested in listening in on what these deep
thinkers and contributors to computing are telling the
OOPSLA crowd this week, checkout the
conference podcast
page. We have all of Tuesday's keynotes (through Steele
& Gabriel in the above list) available now, and we
hope to post today's and tomorrow's audio in the next day
or so. Enjoy!
[Update: I found the link to Michael
Mitzenmacher's blog post on programming in theory courses
and added it below.]
A couple of days ago, a student in my compilers course was
in my office discussing his team's parser project. He was
clearly engaged in the challenges that they had faced, and
he explained a few of the design decisions they had made,
some of which he was proud of and some of which he was less
thrilled with. In the course of conversation, he said that
he prefers project courses because he learns best when he
gets into the trenches and builds a system. He contrasted
this to his algorithms course, which he enjoyed but which
left him with a nagging sense of incompleteness -- because
they never wrote programs.
(One can, of course, ask students to program in an algorithms
course. In my undergraduate algorithms, usually half of the
homework involves programming. My recent favorite has been a
Bloom filters
project. Michael Mitzenmacher has written about programming
in algorithms courses in his blog
My Biased Coin.)
I have long been a fan of "big project" courses, and have
taught several different ones, among them intelligent systems,
agile software development, and recently compilers. So it
was with great interest I read (finally) Philip Greenspun's
notes on
improving undergraduate computer science education.
Greenspun has always espoused a pragmatic and irreverent
view of university education, and this piece is no different.
With an eye to the fact that a great many (most?) of our
students get jobs as professional software developers, he
sums up one of traditional CS education's biggest weaknesses
in a single thought: We tend to give our students
a tiny piece of a big problem, not a small problem to solve
by themselves.
This is one of the things that makes most courses on compilers
-- one of the classic courses in the CS curriculum -- so
wonderful. We usually give students a whole problem, albeit a
small problem, not part of a big one.
Whatever order
we present the phases of the compiler, we present them all,
and students build them all. And they build them as part
of a single system, capable of compiling a complete language.
We simplify the problem by choosing (or designing) a smallish
source language, and sometimes by selecting a smallish target
machine. But if we choose the right source and target
languages, students must still grapple with ambiguity in the
grammar. They must still grapple with design choices for
which there is no clear answer. And they have to
produce a system that satisfies a need.
Greenspun makes several claims with which I largely agree.
One is this:
Engineers learn by doing progressively larger projects,
not by doing what they're told in one-week homework assignments
or doing small pieces of a big project.
Assigning lots of well-defined homework problems is a good
way to graduate students who are really good at solving
well-defined homework problems. The ones who can't learn
this skill change majors -- even if they would make good
software developers.
Here is another Greenspun claim. I think that it is likely
even more controversial among CS faculty.
Everything that is part of a bachelor's in CS can be taught
as part of a project that has all phases of the engineering
cycle, e.g., teach physics and calculus by assigning students
to build a flight simulator.
Many will disagree. I agree with Greenspun, but to act on
this idea would, as Greenspun knows, require a massive change
in how most university CS departments -- and faculty -- operate.
This idea of building all courses around projects is similar
to an idea I have written about many times here, the value of
teaching CS in the context of
problems that matter,
both to students and to the world. One could teach in the
context of a problem domain that requires computing without
designing either the course or the entire curriculum around
a sequence of increasingly larger projects. But I think the
two ideas have more in common than they differ, and problem-based
instruction will probably benefit from considering projects
as the centerpiece of its courses. I look forward to
following the progress of Owen Astrachan's
Problem Based Learning in Computer Science
initiative to see what role projects will play in its results.
Owen is a pragmatic guy, so I expect that some valuable
pragmatic ideas will come out of it.
Finally, I think students and employers alike will agree with
Greenspun's final conclusion:
A student who graduates with a portfolio of 10 systems, each
of which he or she understands completely and can show off
the documentation as well as the function (on the Web or on
the student's laptop), is a student who will get a software
development job.
Again, a curriculum that requires students to build such a
portfolio will look quite different from most CS curricula
these days. It will also require big changes in how CS
faculty teach almost every topic.
Do read Greenspun's article. He is thought-provoking, as
always. And read the comments; they contain some interesting
claims, too, including the suggestion that we redesign CS
education as professional graduate degree program along the
lines of medicine.
Remember this as a reader--whatever you are reading
is only a snapshot of an ongoing process of learning
on the part of the author.
-- Kent Beck
Sometimes, learning opportunities on a particular topic seem
to come in bunches. I wrote recently about
revisiting Forth
and then this week ran across an article on Lambda the
Ultimate called
Minimal FORTH compiler and tutorial.
The referenced compiler and tutorial are an unusually nice
resource: a "literate code" file that teaches you as it
builds. But then you also get the discussion that follows,
which points out what makes Forth special, some implementation
tricks, and links to several other implementations and articles
that will likely keep me busy for a while.
Perhaps because I am teaching a compilers course right now,
the idea that most grabbed my attention came in a discussion
near the end of the thread (as of yesterday) on teaching
language.
Dave Herman
wrote:
This also makes me think of how compilers are traditionally
taught: lexing → parsing → type checking →
intermediate language → register allocation →
codegen. I've known some teachers to have success in going
the other way around: start at the back end and move your
way forward. This avoids giving the students the impression
that software engineering involves building a product,
waterfall-style, that you hope will actually do something at
the very, *very* end -- and in my experience, most courses
don't even get there by the end of the semester.
I have similar concerns. My students will be submitting
their parsers on Monday, and we are just past the midpoint
of our semester. Fortunately, type checking won't take long,
and we'll be on to the run-time system and target code soon.
I think students do feel satisfaction at having accomplished
something along the way at the end of the early phases. The
parser even give two points of satisfaction: when it can
recognize a legal program (and reject an illegal on), and then
when it produces an abstract syntax tree for a legal program.
But those aren't the feeling of having compiled a program
from end to end.
The last time I
debriefed teaching this course,
I toyed with the idea making several end-to-end passes
through compilation process, inspired by a paper on
15 compilers in 15 weeks.
I've been a little reluctant to mess with the traditional
structure of this course, which has so much great history.
While I don't want to be one of those professors who teaches
a course "the way it's always been done" just for that sake,
I also would like to have a strong sense that my different
approach will give students a full experience. Teaching
compilers only every third semester makes each course
offering a scarce and thus valuable opportunity.
I suppose that there are lots of options... With a
solid framework and reference implementation, we could
cover the phases of the compiler in any order we like,
working on each module independently and plugging them
into the system as we go. But I think that there needs
to be some unifying theme to the course's approach to
the overall system, and I also think that students learn
something valuable about the next phase in the pipeline
when we build them in sequence. For instance, seeing the
limitations of the scanner helps to motivate a different
approach to the parser, and learning how to construct
the abstract syntax tree sets students up well for type
checking and conversion to an intermediate rep. I
imagine that similar benefits might accrue when going
backwards.
I think I'll ask Dave for some pointers and see what a
backwards compiler course might look like. And I'd still
like to play more with the agile idea of growing a working
compiler via several short iterations. (That sounds like
an excellent research project for a student.)
Oh, and the quote at the top of this entry is from Kent's
addendum
to his forthcoming book,
Implementation Patterns.
I expect that this book will be part of my ongoing process
of learning, too.
Browsing through several overflowing mailboxes from various
agile software development lists -- thank the mail gods for
procmail
-- I ran across three messages that made save them for later
reflection or use in a class.
> How do you deal with [a change breaks lots of tests]?
See it as an opportunity. A single change breaking a lot of tests
means that your design has excessive coupling, *or* that your unit
tests are written at too low a level of abstraction. This is an
important and valuable thing to have learned about your code and
tests.
Most of the time, we treat unexpected obstacles as problems --
either problems to solve, or problems to avoid. When
we operate under time pressure, we usually try to avoid such
obstacles. Students often find themselves in a bind for time
and so seek to avoid problems, rather using them as an opportunity
to make their programs better. This is another reason to start
assignments early: to have time to be opportunistic on unexpected
chances to learn!
Time pressure isn't the only reason students avoid problems.
Some are driven by grades, in order to impress potential
employers. (Maybe this
will change
in a world not driven by "getting a job".) Others are simply
afraid to take the risk. Our school system does a pretty
good job of beating risk-taking behavior out of students by
the time they reach the university, and universities often
don't do enough to undo this before they graduate into
professional careers.
On the agile content of Laurent's comment, he is spot-on, of
course. All those broken tests are excellent feedback on a
weakness in either the system or the tests. Listen to the code.
On the
Crystal Clear mailing list
(dedicated to discussing "the ultralight Crystal Clear software
development methodology"), methodology creator Alistair Cockburn
wrote:
"Deciding what to build" is my new replacement phrase for
"requirements". The word "requirements" tends to imply
that [someone can] correctly locate and pluck them,
that they are "true"
None of those are correct. They don't already pre-exist so they
can't be "plucked", [no one is] in that unique position [to locate
and pluck them], and they aren't "true".
which is why I nowadays prefer to talk about "deciding what to build".
I wish that more people -- software engineers, programmers, and
consumers of software and software development services alike --
would think like this! "Gathering requirements" is a metaphor
that goes wrong both on 'gathering' and on 'requirements'.
"Deciding what to build" creates a completely different mental
image and sets up a completely different set of performance
expectations. As Alistair tells it, "deciding what to build"
is a negotiation, not an exam question about
Platonic ideals that has a correct answer. A negotiation can
take into account many factors, including benefits, costs,
preferences, and time.
The developer and customer can then record the results of their
negotiation in a "contract" of whatever form they prefer. If
they are so inclined, the contract can take the form of a set of
tests that captures what the developer will deliver, say,
FIT tests.
When one side needs to "break the contract", the negotiation
should have specified relative preferences that enable the
parties to arrive at a new understanding of the system to be
built. More negotiation -- not "adding a requirement" or
"not delivering a requirement".
Finally, for a touch of humor, I give you this passage from
a message to the
refactoring mailing list
from Buddha Buck:
Our team is considering implementing the refactoring "Replace
C++ With Language With Good Refactoring Tool Support". It's
a major refactoring, and full implementation might take months,
if we decide to do it.
There have to be some pleasant steps to execute in this
refactoring, and some even more pleasant milestones. That
last rm *.cpphas to feel good.
More seriously, I think there is a great opportunity to write
refactorings that aren't about software architecture and code.
The
patterns of Christopher Alexander
begat the
software patterns world,
which caused many of us to write the patterns of other kinds
of systems, including music, management, and
pedagogy.
In many software circles, refactorings are behavior-preserving
modifications that target the patterns of the domain. If we
write patterns of management or pedagogy, then why not write
refactorings that help people prepare their environments for
disruptive change? An interesting question comes to mind: what
does it mean for a change to a management system to "preserve
behavior"? This seems like a very cool avenue for some thought,
even if it hits a dead end.
It is easy to forget how diverse the ecosphere of programming
languages is. Even most of the new languages we see these
days look and feel like the same old thing. But not all
languages look and feel the same. If you haven't read about
the
Forth
programming language, you should. It will remind you just how
different a language can be. Forth is a stack-based language
that uses postfix notation and the most unusual operator set
this side of
APL.
I've been fond of stack-based languages since spending a few
months playing with the functional language
Joy
and writing an interpreter for it while on sabbatical many years
ago. Forth is a more of a systems language than Joy, but the
programming style is the same.
I recently ran across a link to creator Chuck Moore's
Forth -- The Early Years,
and it offered a great opportunity to reacquaint myself with
the language. This paper is an early version of the paper
that became the
HOPL-2 paper
on Forth, but it reads more like the notes of a talk -- an
informal voice, plenty of sentence fragments, and short
paragraphs that give the impression of stream of consciousness.
This "autobiography of Forth" is a great example of how a
program evolves into a language. Forth started as
a program to compute a least-squares fitting of satellite
tracking data to determine orbits, and it grew into an
interpreter as Moore bumped up against the limitations of the
programming environment on the IBM mainframes of the day.
Over time, it grew into a full-fledged language as Moore took
it with him from job to job, porting it to new environments
and extending it to meet the demands of new projects. He did
not settle for the limitations of the tools available to him;
instead, he thought "There must be a better way" -- and made
it so.
As someone teaching a compilers course right now, I smiled
at the many ways that Forth exemplified the kind of thinking
we try to encourage in students learning to write a compiler.
Moore ported Forth to Fortran and back. He implemented
cross-assemblers and code generators. When speed mattered,
he wrote native implementations. All the while, he kept the
core of the language small, adding new features primarily as
definitions of new "words" to be processed within the core
language architecture.
My favorite quotes from the paper appear at the beginning and
the end. To open, Moore reports that he experienced what is
in many ways the Holy Grail for a programmer. As an
undergraduate, he took a part-time job with the Smithsonian
Astrophysical Observatory at MIT, and...
My first program, Ephemeris 4, eliminated my job.
To close, Moore summarizes the birth and growth of Forth as
having "the making of a morality play":
Persistent young programmer struggles against indifference to
discover Truth and save his suffering comrades.
This is a fine goal for any computer programmer, who should
be open to the opportunity to become a language designer
when the moment comes. Not everyone will create a language
that lasts for 50 years, like Forth, but that's not the point.
Today I wrote a program, just for fun. I wrote a solution
to the classic
WordLadder
game, which is a common
nifty assignment
used in the introductory Data Structures course. I had
never assigned it in one of my courses and had never had
any other reason to solve it. But my daughter came home
yesterday with a math assignment that included a few of
these problems, such as converting "heart" to "spade",
and in the course of talking with her I ended up doing a
few of the WordLadder problems on my own. I'm a hopeless
puzzle junkie.
Some days, an almost irrational desire to write a program
comes over me, and last night's fun made me think, "I
wonder how I might do this in code?" So I used a few
spare minutes throughout today to implement one of my
ideas from last night -- a simple breadth-first search
that finds all of the shortest solutions in a particular
dictionary.
A few of those spare minutes came at the public library,
while the same daughter was participating in a writers'
workshop for youth. As I listened to their discussion
of a couple of poems written by kids in the workshop in
the background, I thought to myself, "I'm writing here,
too." But then it occurred to me that the kids in the
workshop wouldn't call what I was doing "writing". Nor
would their workshop leader or most people that we call
"writers". Nor would most computer scientists, not
without the rest of the phrase: "writing a program".
Granted, I wasn't writing a poem. But I was exploring an
idea that had come into my mind, one that drove forward.
I wasn't sure what sort of program I would end up, and
arrived at the answer only after having gone down a couple
of expected paths and found them wanting. My stanzas, er,
subprocedures, developed over time. One grew and shrank,
changed name, and ultimately became much simpler and clearer
than what I had in mind when I started.
I was telling a story as much as I was solving a problem.
When I finished, I had a program that communicates to my
daughter an idea I described only sketchily last night.
The names of my variables and procedures tell the story,
even without looking at too much of their detail. I was
writing as a way to think, to find out what I really
thought last night.
I occasionally write about how students these days don't
want to program. Not only don't they want to do it for
a living, they don't even want to learn how. I have seen
this manifested in a virtual disappearance of non-majors
from our intro courses, and I have heard it expressed by
many prospective CS majors, especially students interested
in our networking and system administration majors.
First of all, let me clarify something. When I say talk
about students not wanting to program, one of my colleagues
chafes, because he thinks I mean that this is an unchangeable
condition of the universe. I don't. I think that the world
could change in a way that kids grow up wanting to program
again, the way some kids in my generation did. Furthermore,
I think that we in computer science can and should help try
to create this change. But the simple fact is that nearly
all the students who come to the university these days do
not want to write programs, or learn how
to do so.
If you are interested in this issue, you should definitely
read
Mark Guzdial's blog.
Actually, you should read it in any case -- it's quite
good. But he has written passionately about this
particular phenomenon on several occasions. I first read
his ideas on this topic in last year's entry
Students find programming distasteful,
which described experiences with non-majors working in
disciplines where computational modeling are essential to
future advances.
This isn't about not liking programming as a job choice --
this isn't about avoiding facing a cubicle engaged in long,
asocial hours hacking. This is about using programming as a
useful tool in a non-CS course. It's unlikely that most of
the students in the Physics class have even had any programming,
and yet they're willing to drop a required course to avoid it.
In two recent posts [
1
|
2 ],
Mark speculates that the part of the problem involving
CS majors may derive from our emphasis on software
engineering principles, even early in the curriculum.
One result is an impression that computer science is
"serious":
We lead students to being able to create well-engineered
code, not necessarily particularly
interesting code.
One result of that result is that students speak of becoming
a programmer as if this noble profession has its own chamber
in one of the middle circles in Dante's hell.
I understand the need for treating software development
seriously. We want the people who write the software we
use and depend upon every day to work. We want much of it
to work all the time. That sounds serious. Companies will
hire our graduates, and they want the software that our
graduates write to work -- all the time, or at least better
than the software of their competitors. That sounds serious,
too.
Mark points out that, while this requirement on our majors
calls for students to master engineering practice, it does
"not necessarily mesh with good science practice".
In general, code that is about great ideas is not typically
neat and clean. Instead, the code for the great programs
and for solving scientific problems is brilliant.
And -- here is the key -- our students want to be
creative, not mundane.
Don't get me wrong here. I recently wrote on the
software engineering metaphor as mythology,
and now I am taking a position that could be viewed as
blaming software engineering for the decline of computer
science. I'm not. I do understand the realities of the
world our grads will live in, and I do understand the need
for serious software developers. I have supported our
software engineering faculty and their curriculum proposals,
including a new program in software testing. I even went
to the wall for an
unsuccessful curriculum proposal
that created some bad political feelings with a sister
institution.
I just don't want us to close the door to our students'
desire to be brilliant. I don't want to close the door on
what excites me about programming. And I don't want to
present a face of computing that turns off students --
whether they might want to be computer scientists, or
whether they will be the future scientists, economists,
and humanists who use our medium to change the world in
the ways of those disciplines.
Thinking cool ideas -- ideas that are cool to the thinker
-- and making them happen is intellectually rewarding.
Computer programming is a new medium that empowers people
to realize their ideas in a way that has never been
available to humankind before.
As Mark notes in his most recent article on this topic,
realizing one's own designs also motivates students to want
to learn, and to work to do it. We can use the power of
our own discipline to motivate people to sample it, either
taking what they need with them to other pastures or
staying and helping us advance the discipline. But in
so many ways we shoot ourselves in the foot:
Spending more time on comments, assertions, preconditions,
and postconditions than on the code itself
is an embarrassment to our field.
Amen, Brother Mark.
I need to do more to advance this vision. I'm moving slowly,
but I'm on the track. And I'm following good leaders.
I have like to write programs since I first learned Basic
in high school. When I discovered
OOPSLA
back in 1996, I felt as if I had found a home. I had been
programming in Smalltalk for nearly a decade. At the time,
OOP was just reaching down into the university curriculum,
and the OOPSLA
Educators' Symposium
introduced me to a lot of smart, interesting people who were
wrestling with some of the questions we were wrestling with
her.
But the conference was about more than objects. It had
patterns, and agile software development, and aspect-oriented
programming, and language processing, and software design more
generally. It was about programs. The
people at OOPSLA liked to write programs. They liked to
look at programs, discuss, and explore new ways of writing
them. I was hooked.
When objects were in ascendancy in industry, OOPSLA had the
perfect connection to academia and industry. That was
useful. But now that OOP has become so mainstream as to
lose its sense of urgency, the value of having "OO" in the
conference name has declined. Now, the "OO" part of the
name is more misleading than helpful. In some ways, it was
an accident of history that this community grew up around
object-oriented programming. Its real raison d'etre is
programming.
The conference cognoscenti have been bandying about the idea
of changing the name of the conference for a few years now,
to communicate better why someone should come to the
conference. This is a risky proposition, as the OOPSLA name
is a brand that has value in its own right.
You can see one small step toward the possibility of a new
name in how we have been "branding" the conference this year.
On the 2007 web site, instead of saying "OOPSLA" we have
been saying ooPSLA. There are a
couple of graphical meanings one can impose on this spelling,
but it is a change that signals the possibility of more.
It has been fun hearing the discussions of a possible name
change. You can see glimpses of the "OOPSLA as programming"
theme, and some of the interesting ideas driving thoughts
of change, in this year's conference program. General chair
Richard Gabriel
writes:
I used to go to OOPSLA for the objects -- back in the 1980s
when there was lots to find/figure out about objects and how
that approach -- oop -- related to programming in general.
Nowadays objects are mainstream and I go for the programming.
I love programs and programming. I laugh when people try to
compare programming to something else, such as: "programming
is like building a bridge" or "programming is like following
a recipe to bake a soufflé." I laugh because programming
is the more fundamental activity -- people should be comparing
other things to it: "writing a poem is like programming an
algorithm" or "painting a mural is like patching an OS while
it's running." I write programs for fun the way some people
play sudoku or masyu, and so I love to hear and learn about
programs and programming.
Programming is the more fundamental activity...
Very few people in the world realize this -- including a great
many computer scientists. We need to communicate this better
to everyone, lest we fail to excite the great minds of the
future to help us build this body of knowledge.
OOPSLA has an
Essays
track that distinguishes it from other academic conferences.
An OOPSLA essay enables an author to reflect ...
... upon technology, its relation to human endeavors, or its
philosophical, sociological, psychological, historical, or
anthropological underpinnings. An essay can be an exploration
of technology, its impacts, or the circumstances of its
creation; it can present a personal view of what is, explore
a terrain, or lead the reader in an act of discovery; it can
be a philosophical digression or a deep analysis. At its
best, an essay is a clear and compelling piece of writing that
enacts or reveals the process of understanding or exploring
a topic important to the OOPSLA community. It shows a keen
mind coming to grips with a tough or intriguing problem and
leaves the reader with a feeling that the journey was worthwhile.
As 2007 Essays chair Guy Steele writes in his welcome,
Perhaps we may fairly say that while Research Papers focus
on 'what' and 'how' (aided and abetted by 'who' and 'when'
and 'where'), Essays take the time to contemplate 'why' (and
Onward! papers perhaps brashly cry 'why not?').
This ain't your typical research paper, folks. Writers are
encouraged to think big thoughts about programs and programming,
and then share those thoughts with an audience that cares.
Steele refers to
Onward!,
and if you've never been to OOPSLA you may not be able to
what he means. In many ways, Onward! is the archetypal example
of how OOPSLA is about programs and all the issues related to
them. A few years ago, many conference folks were frustrated
that the technical track at OOPSLA made no allowance for papers
that really push the bounds of our understanding,
because they didn't fit neatly into the mold of conventional
programming languages research. Rather than just bemoan the
fact, these folks -- led by Gabriel -- created the
conference-within-a-conference that is Onward!. Crista
Lopes's Onward! welcome leaves no doubt that the program is
the primary focus of the Onward! and, more generally, the
conference:
Objects have grown up, software is everywhere, and we are now
facing a consequence of this success: the perception that we
know what programming is all about and that building software
systems is, therefore, just a simple matter of programming ...
with better or worse languages, tools, and processes. But we
know better. Programming technology may have matured,
programming languages, tools, and processes may have
proliferated, but fundamental issues pertaining to computer
Programming, Systems,
Languages, and Applications
are still as untamed, as new, and as exciting as they ever were.
Lopes also wrote a marvelous message on the conference mailing
list last October that elaborates on these ideas. She argued
that we should rename OOPSLA simply the ACM Conference on
Programming. I'll quote only this portion:
Over the past couple of decades, the words "programming" and
"programmer" fell out of favor, and were replaced by several
other expressions such as "software engineer(ing)", "software
design(er)", "software architect(ure)", "software practice",
etc. A "programmer" is seen in some circles as an inferior
worker to a "software engineer" or, pardon the comparison!, a
"software architect". There are now endless, more fashionable
terms that try to hide, or subsume, the fact that, when the
rubber hits the road, this is all about developing systems
whose basic elements are computer programs, and the processes
and tools that surround their creation and composition.
...
While I have nothing against the new, more fashionable terms,
and even understand their need and specificity, I think it's
a big mistake that the CS research community follows the
trend of forgetting what this is all about. The word
"programming" is absolutely right on the mark!, and CS needs
a research community focusing on it.
On this view, we need to rename OOPSLA not for OOPSLA's sake,
but for the discipline's. Lopes's "Conference on Programming"
sounds to bland to those with a marketing bent and too
pedestrian for those who with academic pretension. But I'm
not sure that it isn't the most accurate name.
What are the options? For many, then default is to drop the
"oo" altogether, but that leaves PSLA -- which breaks whatever
rule there is against creating acronyms that sound unappealing
when said out loud. So I guess the
ooPSLA crowd should just keep
looking.
There is a great scene toward the end of one of my favorite
movies,
An Officer and a Gentleman.
The self-centered and childlike protagonist,
Zach Mayo,
has been broken down by
Drill Instructor Foley.
He is now maturing under the Foley's tough hand. The basic
training cohort is running the obstacle course for its last
time. Mayo is en route to a course record, and
his classmates are urging him on. But as his passes one
of his classmates on the course, he suddenly stops.
Casey Seeger
has been struggling with wall for the movie, and it looks
like she still isn't going to make it. But if she doesn't,
she won't graduate. Mayo sets aside his record and stands
with Seeger, cheering her and coaching her over the wall.
Ultimately, she makes it over -- barely -- and the whole
class gathers to cheer as Mayo and Seeger finish the run
together. This is one of the triumphant scenes of the film.
I thought of this scene while running mile repeats on the
track this morning. Three young women in the ROTC program
were on the track, with two helping the third run sprints.
The two ran alongside their friend, coaxing her and helping
her continue when she clearly wanted to stop. If I recall
correctly from my sister's time in ROTC, morning PT (physical
training) is a big challenge for many student candidates
and, as in An Officer and a Gentleman, they must
meet certain fitness thresholds in order to proceed with
the program -- even if they are in non-combat roles, such
as nurses.
It was refreshing to see that sort of teamwork, and friendship,
among students on the track.
It is great when this happens in one our classes. But when it
does, it is generally an informal process that grows among
students who were already friends when they came to class. It
is not a part of our school culture, especially in computer
science.
Some places, it is part of the culture. A professor here
recently related a story from his time teaching in Taiwan. In
his courses there, the students in the class identified a leader,
and then they worked together to make sure that everyone in the
class succeeded. This was something that students expected of
themselves, not something the faculty required.
I have seen this sort of collectivism imposed from above by
CS professors, particularly in project courses that require
teamwork. In my experience, it rarely works well when foisted
on students. The better students resent having their grade
tied to a weaker student's, or a lazier one's. (Hey, it's all
about the grade, right?) The weaker students resent being made
someone else's burden. Maybe this is a symptom of the Rugged
Individualism that defines the West, but working collectively
is generally just not part of our culture.
And I understand how the students feel. When I found myself
in situations like this as a student, I played along, because I
did what my instructors asked me to do. And I could be helpful.
But I don't think it ever felt natural to me; it was an
external requirement.
Recently I found myself discussing pair programming in CS1 with
a former student who now teaches for us. He is considering
pairing students in the lab portion of his non-majors course.
Even after a decade, he remembers (fondly, I think) working
with a different student each week in my CS1 lab. But the
lab constituted only a quarter of the course grade, and the
lab exercises did not require long-term commitment to helping
the weakest members of the class succeed. Even still, I had
students express dissatisfaction at "wasting their time".
This is one of the things that I like about the agile software
methods: it promotes a culture of unity and of teamwork. Pair
programming is one practice that supports this culture, but so
are collective ownership, continuous integration, and coding
standard. Some students and programmers, including some of the
best, balk at being forced into "team". Whatever the psychological,
social, and political issues, and whatever my personal preferences
as a programmer, there seems something attractive about a team
working together to get better, both as a team and as
individuals.
I wish the young women I saw this morning well. I hope they
succeed, as a team and as individuals. They can make it over
the wall.
... the kind of laziness that makes you want to minimize
future effort but investing effort today, to maximize your
productivity and performance over the long haul, not the
kind that leads you to avoid essential work or makes you
want to cut corners.
... the kind of impatience that encourages you to work
harder, not the kind of impatience that steals your spirit
when you hit a wall or makes you want to cut corners.
... the kind of hubris that makes you think that you can
do it, to trust yourself, not the kind of hubris that makes
you think you don't have to listen to the problem, your code,
or other people -- or the kind that makes you want to cut
corners.
I love to hear from readers who have enjoyed an article.
Often, folks have links or passages to share from their
own study of the same issue. Sometimes, I feel a need
to share those links with everyone. Here are three, in
blog-like reverse chronological order:
Geoff Wozniak
pointed me in the direction of
Gilad Bracha's
work on
pluggable type systems.
I had heard of this idea but not read much about it.
Bracha argues that a type system should be a wrapper
around the dynamically typed core of a program. This
makes it possible to expose different views of a
program to different readers, based on their needs and
preferences. More thinking to do...
Chris Johnson,
a former student of mine, is also a fan of Bob Lucky's.
As a graduate student in CS at Tennessee, though, he
qualifies for a relatively inexpensive IEEE student
membership and so can get his fix of Lucky each month
in Spectrum. Chris took pity on his old prof and
sent me a link to
Lucky's Reflections
on-line. Thank you, thank you! More reading to do...
Seth Godin's thesis is that all good marketers "lie" because
they tell a story tailored to their audience -- not "the
truth, the whole truth, and "nothing but the truth".
I applied his thesis to CS professors and found it fitting.
As old OOSPLA friend and colleague
Michael Berman
reminds us, this is not a new idea:
Another noteworthy characteristic of this manual is that it
doesn't always tell the truth.... The author feels that this
technique of deliberate lying will actually make it easier
for you to learn the ideas.
That passage was written by Donald Knuth in the preface to
The TEXbook,
pages vi-vii. Pretty good company to be in, I'd say, even
if he is an admitted liar.
In a recent blog entry,
JRuby
developer
Charles Nutter
claimed that, in general, "[g]ood authors do not have time to
be good developers". This post has engendered a fair amount
of discussion, but I'm not sure why. It shouldn't surprise
anyone that staying on top of your game in one time-consuming
discipline makes it hard, if not impossible to stay on top of
your game in a second time-consuming discipline. There are so
many hours in a day, and only so many brain cycles to spend
learning and doing.
I face this trade-off, but between trying to be a good teacher
and trying to be a good developer. Like authors, teachers
are in a bind: To teach a topic well, we should do it well.
To do it well takes time. But the time we spend learning and
doing it well is time that we can't spend teaching well. The
only chance we have to do both well is to spend most of our
time doing only these two activities, but that can mean living
a life out of balance.
If I had not run for 3-1/2 hours
last Sunday,
I suppose that I could have developed another example for my
class or written some Ruby. But would I have been better off?
Would my students? I don't know.
While I have considered the
prospect of writing a textbook,
I've not yet found a project that made me want to give up
time from my teaching, my programming, my running, and my
family. Like Nutter,
I like to write code.
This blog gives me an opportunity to write prose and to reach
readers with my ideas, while leaving me the rest of the day
to teach, to perhaps to help others learn to like to write
code by my example.
A couple of my recent entries
(here
and
here)
have questioned the value of data types, at least in relation
to a corresponding set of unit tests. While running this
weekend, I played devil's advocate with myself a bit, thinking,
"But what would a person who prefers programming with manifest
types say?"
One thing that types provide that tests do not is a sense of
universality. I can write a test for one case, or two,
or ten, but at the end of the day I will have only a finite
number of test cases. A type checker can make a more general
statement, of a more limited scope. The type checker can say,
"I don't know the values of all possible inputs, but I do know
that all of the values are integers." That information can be
quite useful. A compiler can use it to generate more efficient
target code. A programmer can use it to generalize more
confidently from a small set of tests to the much larger set
of all possible tests.
In the terms of unit testing, types give us a remarkable level
of test coverage for a particular kind of
test case.
This is a really useful feature of types. I'd like to take
advantage of it, even if I don't want my language to get in my
way very much while I'm writing code. One way I can have both
is to use
type inference
-- to let my compiler, or more generally my development environment,
glean type information from my code and use that in ways that
help me.
There is another sense in which we object-oriented programmers
use types without thinking about them: we create objects! When
I write a class, I define a set of objects as an abstraction.
Such an object is specified in terms of its behavioral
interface, which is public, and its internal state, which is
private. This creates a kind of encapsulation that is just like
what a data type provides. In fact, we often do think of classes
as abstract data types, but with the twist that we focus on an
object's behavioral responsibility, rather than manipulating its
state.
That said, newcomers to my code benefit from manifest types
because the types point them to the public interface expected
of the objects that appear in the various contexts of my program.
I think this gets to the heart of the issue. Type information
is incredibly useful, and helps the reader of a program in ways
that a set of tests does not. When I write a programs with a
data-centric view of my abstractions, specifying types up
front seems not only reasonable but almost a no-brainer. But
when I move away from a data-centric view to a behavioral
perspective, tests seem to offer a more flexible, comfortable
way to indicate the requirements I place on my objects.
This is largely perception, of course, as a Java-style interface
allows me to walk a middle road. Why not just define an
interface for everything and have the benefits of both worlds?
When I am programming bottom-up, as I often do, I think the
answer comes down to the fact that I don't know what the
interfaces should look like until I am done, and fiddling with
manifest types along the way slows me down at best and distracts
me from what is important at worst. By the time I know what my
types should look like, they are are of little use to me as a
programmer; I'm on to the next discovery task.
I didn't realize that my mind would turn to type inference when
I started this line of questioning. (Thinking and writing can
be like that!) But now I am wondering how we can use type
inference to figure out and display type information for readers
of code when it will be useful to them.
The software world always seems to have a bandwagon du
jour, which people are either riding or rebelling against.
When extreme programming became the rage a while back, all
I seemed to hear from some folks was that "agile" was a
buzzword, a fad, all hype and no horse. Object-oriented
programming went through its bandwagon phase, and Java had
its turn. Lately it seems Ruby is the target of knowing
whispers, that its popularity is only the result of good
marketing, and it's not really all that different.
But what's the alternative? Let's see what Turing Award winner
Niklaus Wirth
has to say:
Why, then, did Pascal capture all the attention, and Modula
and Oberon got so little? Again I quote Franz: "This was, of
course, partially of Wirth's own making". He continues: "He
refrained from ... names such as Pascal-2, Pascal+, Pascal 2000,
but instead opted for Modula and Oberon". Again Franz is right.
To my defense I can plead that Pascal-2 and Pascal+ had already
been taken by others for their own extensions of Pascal, and that
I felt that these names would have been misleading for languages
that were, although similar, syntactically distinct from Pascal.
I emphasized progress rather than continuity, evidently a poor
marketing strategy.
But of course the naming is by far not the whole story. For one
thing, we were not sufficiently active -- today we would say
aggressive -- in making our developments widely known.
Good names and aggressive dissemination of ideas. (Today, many
would call that "marketing".)
Wirth views Pascal, Modula, and Oberon as an ongoing development
of 25 years that resulted in a mature, elegant, and powerful
language, a language who couldn't even imagine back in 1969.
Yet for many software folks, Modula was a blip on the scene, or
maybe just a footnote, and Oberon was, well, most people just
say "Huh?" And that's a shame, because even if we choose not to
program in Oberon, we lose something by not understanding what
it accomplished as a language capable of supporting teams and
structured design across the full array of system programming.
I never faulted Kent Beck for aggressively spreading XP and the
ideas it embodied. Whatever hype machine grew up around XP was
mostly a natural result of people becoming excited by something
that could so improve their professional practice. Yes, I know
that some people unscrupulously played off the hype, but the
alternative to risking hype is anonymity. That's no way to
change the world.
I also applaud Kent for growing as he watched the results of XP
out in the wild and for folding that growth back into his vision
of XP. I wonder, though, if the original version of XP will be
Pascal to XP2e's Modula.
By the way, the Wirth quote above comes from his 2002 paper
Pascal and Its Successors.
I enjoy hearing scientists and engineers tell the stories of their
developments, and Wirth does a nice job conveying the context in
which he developed Pascal, which had a great many effects in
industry but more so in the academic world, and its progeny. As
I read, I reacted to several of his remarks:
On Structured Programming:
Its foundations reached far deeper than simply "programming
without go to statements" as some people believed. It is
more closely related to the top-down approach to problem
solving.
Yes, and in this sense we can more clearly see the different
mindset between the Structured Programming crowd and the
bottom-up Lisp and Smalltalk crowd.
On static type checking:
Data typing introduces redundancy, and this redundancy can
be used to detect inconsistencies, that is, errors. If the
type of all objects can be determined by merely reading the
program text, that is, without executing the program, then
the type is called static, and checking can be performed by
the compiler. Surely errors detected by the compiler are
harmless and cheap compared to those detected during program
execution in the field, by the customer.
Well, yeah, but what if I
write tests
that let me detect the errors in house -- and tell more about
my program and intentions than manifest types can?
On loopholes in a language:
The goal of making the language powerful enough to describe
entire systems was achieved by introducing certain low-level
features.... Such facilities ... are inherently contrary to
the notion of abstraction by high-level language, and should
be avoided. They were called loopholes, because they allow
to break the rules imposed by the abstraction. But sometimes
these rules appear as too rigid, and use of a loophole becomes
unavoidable. The dilemma was resolved through the module
facility which would allow to confine the use of such "naughty"
tricks to specific, low-level server modules. It turned out
that this was a naive view of the nature of programmers. The
lesson: If you introduce a feature that can be abused, then
it will be abused, and frequently so!
This is, I think, a fundamental paradox. Some rules, especially
in small, elegant languages, don't just appear too rigid; they
are. So we add accommodations to give the programmer a way to
breach the limitation. But then programmers use these features
in ways that circumvent the elegant theory. So we take them out.
But then...
The absence of loopholes is the acid test for the quality of
a language. After all, a language constitutes an abstraction,
a formal system, determined by a set of consistent rules and
axioms. Loopholes serve to break these rules and can be
understood only in terms of another, underlying system, an
implementation.
Programming languages are not (just) formal systems. They are
tools used by people. An occasional
leak in the abstraction
is a small price to pay for making programmers' lives better.
As Spolsky says, "So the abstractions save us time working,
but they don't save us time learning."
A strong culture is a better way to ensure that programmers
don't abuse a feature to their detriment than a crippled
language.
All that said, we owe a lot to Wirth's work on Pascal, Modula,
and Oberon. It's worth learning.
A good friend sent me a note today that ended like this:
I feel like this has opened up a whole new world, a whole new
way of thinking about programming. In fact, I haven't had such
a feeling ... since my early days of first learning Pascal and
the days of discovering data structures, for loops, recursion,
etc...
I know this sensation and hope every person -- student and
professional -- gets to feel it every so often. Students,
seek it out by taking courses that promise more than just
more of the same. Professionals, seek it out by learning a
new kind of language, a new kind of web framework, a new kind
of programming. This feeling is worth the effort, and makes
your life better as a result.
In an XP mailing list thread "Are current "popular" programming
languages enterprise grade?", someone raised a concern that some
languages result in "buggier" code. William Pietri
responded
to a more general concern:
From the "enterprise" perspective, I think there's some legitimate
worry about more flexible languages.
If I have to inherit a great code base, I'm sure I'd be happy if
it were in Ruby. But if I have to inherit a bad one, I'd rather
it be in Java. Its surly and restrictive nature makes some sorts
of archeology easier, partly because it prevents some of Ruby's
beautiful magic.
Now personally, I'd solve this problem by making sure all code
bases are great ones. But if one already has a culture of
tolerance for mediocrity and/or building one's house on sand,
then restricting people to "safe" tool choices isn't crazed.
Maybe I haven't been paying attention, but this is the first
time I recall seeing someone say in quite this way why "better"
languages are risky for general use. A more powerful language
enables beautiful magic that makes digging into a new
codebase more difficult. The claim seems to be that it
is easier to understand bad code written in a less powerful
language.
I'm not sure how I feel about this claim just yet. Is it
really easier for a Scheme programming expert to
understand bad Scheme code than bad Java code? Is difficulty
more a function of the beautiful magic a language allows, or
more a function of the programmer's skill. William speaks of
his inheriting someone else's bad code, but maybe our concern
should be a weak programmer inheriting someone else's bad code?
This is the heart of many people's concerns with using powerful
but non-mainstream languages in production systems, that there
just aren't enough good programmers prepared to work in those
languages.
But William's answer has me thinking. It provoked another
interesting message,
Phlip's response
that took the claim in a different direction:
That's just a way to say this
...static typing is a form of unit tests
...Java enforces static typing viciously
...I'd rather inherit a project with any unit tests.
This is a great way to think about
manifest typing:
Types are a degenerate form of unit test, and languages that
enforce manifest types require programmers to write degenerate
tests. In Phlip's idea, William is happy to receive a bad Java
codebase because at least it has types as tests. But if the
Ruby codebase you inherit comes with unit tests...
Many agile developers extol the virtue of programming in more
flexible -- and powerful -- languages, and most know that by
writing tests they mitigate the loss of manifest typing and
end up with a net win: code whose tests tell us much more than
the manifest types would have anyway, and they benefited from
using a more powerful language. I'd argue that for a large
many programmers, using a more powerful language can be a lot
more fun, too.
Ultimately, the issue comes back to an old question: Can we
prepare the majority of programmers to use Scheme, Ruby,
Smalltalk, or Haskell effectively enough to make them suitable
for the mainstream. I still think yes, and believe that the
drifting of powerful concepts into popular languages such as
Ruby is a sign of gradual gains. Whether this pans out in the
long run, we'll have to see.
Software Engineering Metaphor, Mythology, and Truth
We often speak of metaphors for software development, but
what we are really talking about is a mythology. Until
this morning, I forgot that I had already written about
this topic back in September 2004, when I wrote
Myth and Patterns
about a session led by Norm Kerth at PLoP that year. I
just re-read that piece and had two thoughts. One, what
a great day that was! And two, I don't have much new to
say on this topic after all. I was jazzed this morning
to talk about the fact that software engineering is more
a mythology of software development than a meaningful
metaphor for doing it.
Why jazzed? Recently I ran across a satirical fable entitled
Masterpiece Engineering
by Thomas Simpson, which appears as an appendix in
Brian Randell's reminiscence
of having edited the reports of the 1968-196969 NATO Software
Engineering conferences. Simpson's satire made light of the
software engineering metaphor by comparing it the engineering
of artistic masterpieces. He wrote it in response to the
unexpected tone of the second NATO conference, held in 1969.
The first conference is famous for being where the term
"software engineering" was coined, more as a thought experiment
about software developers might strive for than anything else.
But, as Randell writes, the second conference took some
participants by surprise:
Unlike the first conference, at which it was fully accepted
that the term software engineering expressed a need rather
than a reality, in Rome there was already a slight tendency
to talk as if the subject already existed. And it became
clear during the conference that the organizers had a hidden
agenda, namely that of persuading NATO to fund the setting
up of an International Software Engineering Institute.
Show me the money. Some things never change.
However things did not go according to their plan. The
discussion sessions which were meant to provide evidence of
strong and extensive support for this proposal were instead
marked by considerable scepticism...
I'm glad that I found Simpson's satire and Randell's report.
I enjoyed both, and they caused me to look back to my blog
on Kerth's PLoP session. Reading it again caused me to think
again about what I had planned to write this morning. That
old piece reminded me of something I've forgotten: myths
embody truth. I was set to diss the engineering metaphor as
"nothing but a story", but I had forgotten that we create
myths to help us explain the ways of the universe. They
contain some truths, sometimes filled out with fanciful
details whose primary purpose are to make us want to hear
the story -- and tell it to others. "Deep truths often lie
inside stories that are themselves not strictly factual."
So rather than to speak ill of software engineering, the
worst I can say this morning that we became too self-important
in the software engineering myth too soon. We came to believe
that all the filler -- all of the details we borrowed from
engineering to make the story more complete -- were true,
too. We created an orthodoxy out of what was really just
a great source of inspiration to find our own way in the
challenging world of creating software.
Maybe we have learned enough in the last forty years to know
that much of the software engineering myth no longer matches
our understanding of the world, but we aren't willing to give
up the comfort of the story.
What we need to do is to identify the deep truths that lie
at the heart of our myth, and use them to help us move on
to something better. I think Ward and Kent did that when
they created XP. But it, too, has now reached an age at which
we should deconstruct it, identify its essential truths, and
create something better. Fortunately, the culture of XP and
other agile approaches not only allows this growth; it
encourages it. The agile myth is meant "to be shaped to its
environment, retold in as many different forms as there are
tellers, as we all work together to find deeper truths about
how to build better software better."
I'm still learning from a conference I attended three years
ago this weekend.
This week I ran across a link to an old essay called
Good Writing,
by Marc Raibert. By now I shouldn't be so happy to be
reminded how much good programming practice is similar to
good writing in general. But I usually am. The details
of Raibert's essay are less important to me than some of
his big themes.
Raibert starts with something that people often forget.
To write well, one must ordinarily want to write
well and believe that one can. Anyone who teaches
introductory computer science knows how critical motivation
and confidence are. Many innovations in CS1 instruction
over the years have been aimed at helping students to
develop confidence in the face of what appear to be
daunting obstacles, such as syntax, rigor, and formalism.
Much wailing and gnashing of teeth has followed the slowly
dawning realization that students these days are much
less motivated to write computer programs than they have
been over most of the last thirty years. Again, many
innovations and proposals in recent years have aimed at
motivating students -- more engaging problems, media
computation, context in the sciences and social sciences,
and so on. These efforts to increase motivation and
confidence are corporate efforts, but Raibert reminds us
that, ultimately, the individual who would be a writer
must hold these beliefs.
After stating these preconditions, Raibert offers several
pieces of advice that apply directly to computing. Not
surprisingly, my favorite was his first: Good
writing is bad writing that was rewritten. This
fits nicely in the agile developer's playbook. I think
that few developers or CS teachers are willing to say that
it's okay to write bad code and then rewrite. Usually,
when folks speak in terms of do the simplest thing that
will work and refactor mercilessly, they do
not usually mean to imply that the initial code was bad,
only that it doesn't worry inordinately about the future.
But one of the primary triggers for refactoring is the
sort of duplication that occurs when we do the simplest
thing that will work without regard for the big picture
of the program. Most will agree that most such duplication
is a bad thing. In these cases, refactoring takes a
worse program and creates a better one.
Allowing ourselves to write bad code empowers us, just as
it empowers writers of text. We need not worry about
writing the perfect program, which frees us to write code
that just works. Then, after it does, we can worry about
making the program better, both structurally and stylistically.
But we can do so with the confidence that comes from knowing
that the substance of our program is on track.
Of course, starting out with the freedom to write bad code
obligates us to re-write, to refactor, just
as it obligates writers of text to re-write. Take the time!
That's how we produce good code reliably: write and re-write.
I wish more of my freshmen would heed this advice:
The first implication is that when you start a new [program],
there is nothing wrong with using bad writing. Your goal
when you start is to get your ideas down on paper in any
form you can.
For the novice programmer, I do not recommend
writing ungrammatical or "stream of consciousness" code, but
I do encourage them to take the ideas they have after having
thought about the problem and expressing them in code. The
best way to find out if an idea is a good one is to see it
run in code.
Raibert's other advice also applies. When I read Spill
the beans fast, I think of making my code transparent.
Don't hide its essence in subterfuge that makes me seem
clever; push its essence out where all can see it and understand
the code. Many of the programmers whose code I respect most,
such as
Ward Cunningham,
write code that is clear, concise, and not at all clever.
That's part of what makes it beautiful.
Don't get attached to your prose is essential when
writing prose, and I think it applies to code as well.
Just because you wrote a great little method or class
yesterday doesn't mean that it should survive in your
program of tomorrow. While programming, you
discover more
about your problem and solution than you knew yesterday.
I love Raibert's idea of a PRIZE_WINNING_STUFF.TXT
file. I have a directory labeled playground/
where I place all the little snippets I've built as simple
learning experiments, and now I think I need to create a
winners/ directory right next to it!
Raibert closes with the advice to get feedback
and then to trust your readers. A couple of months
back I had a couple of entries on
learning from critics,
with different perspectives from Jerry Weinberg and Alistair
Cockburn. That discussion was about text, not code (at least
on the surface). But one thing that we in computer science
need to do is to develop a stronger culture of peer review
of our code. The lack of one is one of the things that most
differentiates us from other engineering disciplines, to
which many in computing look for inspiration. I myself look
more to the creative disciplines for inspiration than to
engineering, but on this the creative and engineering
disciplines agree: getting feedback, using it to improve
the work, and using it to improve the person who made the
work are essential. I think that finding ways to work the
evaluation of code into computer science courses, from intro
courses to senior project courses, is a path to improving
CS education.
This last bit of advice from Raibert is also timely, if
bittersweet for me... In just a few days,
PLoP 2007
begins. I am quite bummed that I won't be able to attend
this year, due to work and teaching obligations. PLoP is
still one of my favorite conferences. Patterns and writers'
workshops are both close to my heart and my professional mind.
If you have never written a software pattern or been to PLoP,
you really should try both. You'll grow, if only when you
learn how a culture of review and trust can change how you
think about writing.
The good news for me is that
OOPSLA 2007,
which I will be attending, features a Mini-PLoP. This track
consists of a
pattern writing bootcamp,
a
writers' workshop for papers in software development,
and a follow-up poster. I hope to attend the writers' workshop
session on Monday, even if only as a non-author who pledges to
read papers and provide feedback to authors. It's no substitute
for PLoP, but it's one way to get the feeling.
Today I "refactored" the web page for a class session,
along with files that support it. I used scare quotes
there, but my process really was affected by the
refactoring
that we do to our code. I can probably describe it
in terms of code refactorings.
Here is what I started with: a web page that loads
thirteen images from a subdirectory named
session02/, and a web page that loads two images
from a subdirectory named session03/.
Due to changes in the timing of presentation, I needed
to move a big chunk of HTML text from Session 3 to
Session 2, including the text that loads the images
from session03/.
In the old days, I would have cut the text from Session 3,
pasted it into Session 2, renamed the images in
session03/ so that they did not clash with files
in session02/, moved them to session03/,
and deleted session03/.
Along the way, there are a number of mistakes I could make,
from inadvertently overwriting a file to losing text in
transit by bungling a few keystrokes in emacs. I have
done that before, and ended up spending precious time
trying to recover the text and files I had lost.
I did something different this time. I didn't move and
delete files or text. First, I copied text from one page
to the other, allowing Session 2 to load images from the
existing session03/ directory. I tested this
change by loading the page to see that all the images
still loaded in the right places. Only then did I delete
the text from Session 2. Next, I copied the images from
session03/ to session02/, using new names,
and modified the web page to load the new images. I tested
this change by re-loading the web page to verify the lecture.
Only then did I delete session03/ and the images
it contained.
Everything went smoothly. I felt so good that I even made
a subdirectory named sample-compiler/ in the
session02/ directory and moved the images in
session02/ associated with the sample compiler --
one of the original session02/ images plus the
two originally in session03/ -- down into the
new subdirectory. I made this change in a similarly
deliberate and safe way, making copies and running tests
before removing any existing functionality.
When I got done, I felt as if I had applied to common
code refactorings:
Move Method
and
Extract Subclass.
The steps were remarkably similar.
My description may sound as if this set of changes took
me a long time to effect, but it didn't. Perhaps it
took a few seconds longer than if I had executed a more
direct path without error, but... I moved much more
confidently in this approach, and I did not make any
errors. The trade-off of deliberate action as insurance
against the cost of recovering from errors was a net
gain.
I refactored my document -- really, a complex of HTML
files, subdirectories, and images -- using the steps
like those we learn in
Fowler
and
Kerievsky:
small, seemingly too small in places, but guaranteed to
work while "passing tests" along the way. My test,
reloading the web page and examining the result after
each small change, would be better if automated, but
frankly the task here is simple enough the simple
"inspect the output" method works just fine.
The ideas we discover in developing software often apply
outside the world of software. I'm not sure this is an
example of what people
computational thinking,
except in the broadest sense, but it is an example of
how an idea we use in designing and implementing programs
applies to the design and implementation of other
artifacts. The ideas we discover in developing software
often apply outside the world of software. We really
should think about how to communicate them to the other
folks who can use them.
Running on the university track late last week, I saw this
slogan on the back of a student's T-shirt:
All out. All the time.
Such slogans are de rigeur for high school sports teams
these days. They serve as mantras for the team, used to motivate
the individual athlete but even more so to build team identity
and spirit. I don't remember when I saw the first of these, but
these days every team has one.
The folks at
Despair.com
have profited from pointing out how shallow and lame such slogans
and motivational tools are. But I cut most of these T-shirts
some slack, because they are aimed at kids, who are not perhaps
at a deep level when it comes to motivation. I do hope that the
involved coaches help their student-athletes move on to a deeper
understanding of teams and motivation, both individual and group,
than the slogans give.
But more importantly, I hope that these young athletes know that
-- taken literally -- these slogans are usually wrong.
"All out. All the time." Any runner knows that this can't be
true. If you run all out for any length of time, your body will
let you know that won't be doing it all the time. Sprint 200
meters all out, and you'll need to recover. (Most coaches
recommend at least 100m of recovery, or the same amount of time
it took you to run the 200.) If you try to sprint 400 meters at
the same pace that you can sprint 200 meters, then you'll usually
fade fast at the end. Move all the way up to a marathon, and you
have to make serious changes in your expected pace. That's just
the our bodies work.
The same is true in any sport, along some dimension of exertion.
The same is also true in creative work. And in software development.
One of the great elements of Extreme Programming is the practice
originally dubbed
40-hour work week
and later renamed
sustainable pace.
Kent and Ward recognized that developers can't produce good code
if they work beyond the pace that their minds and bodies allow.
Ignoring those natural bounds is no different than trying to run
your 200m pace for 400 or 800 or 1600 meters -- or for a marathon.
If you try to go too fast for too long, you'll fade. That's not
good for your client, and it's not good for developers.
There is a time for sprinting, surely, but software development
and good relationships with customers are more of a long-term
affair. Sprint in short bursts where that adds value for the
customer and doesn't hurt the developers. But back off the
throttle as a long-range plan.
The runners wearing slogans such as "All Out. All the Time."
must know that they can't actually go all
out all of the time. If they could, then I would never be able
to pass them on the track with my tired old body, which most
surely cannot go all out all of the time. But like them, I
do like to go all out some of the time -- it feels good! And
sometimes I myself will use even shallow, emotional sentiments
to push myself when I am at the boundaries of what I think I
can accomplish.
Helping Developers Feel the Win of Agile Practices
Sometimes the best way to help someone learn a new habit
is to let him or her feel the action happening, or not
happening, in a new way. Sometimes, the action seems
more natural when this feeling strikes a new chord.
I proposed an example of this approach many posts ago, in
an entry called
I Feel Good. I Feel Great. I Feel Wonderful.
It reported an agile development fantasy I had after
watching the Bill Murray flick
What About Bob?.
In my fantasy, I might use Dr. Leo Marvin's "Death Therapy"
in an agile development scenario: Walk in one morning
unannounced, and pull the plug on the project. An agile
team should have something pretty reasonable to deliver.
But would my students stone me before I could exit the
room?
I managed to catch the beginning of a thread on the XP
mailing list for once, a thread titled
Your favorite teaching tricks?,
launched by William Pietri. Unfortunately, this thread
lasted only two messages, but both were valuable.
Pietri tells a story that displays one of his tricks
for getting developers to write tests:
Friday night, I hung out with a pal who has been learning
TDD. He is naturally full of questions, and one exchange
went like this:
"If I have tested all the low-level methods, I don't need
to test the components together, do I?"
"Did you run it to see if it worked?"
"Sure! I tried a few different options, and carefully
looked at the output to be sure it was ok."
"If you had to check it, then you weren't sure it worked.
Ergo, you should have written a test."
"Doh!"
Most developers already test in this way, writing simple
little main programs that exercise their code.
(Heaven help those who don't do at least this much -- and
the people who use their code!) Why not automate that test?
It's a small step from a handcrafted main to an
xUnit test. And in my experience, that little main
grows into an unmanageable mess. The xUnit test can grow
gracefully into a suite of tests. (That doesn't mean you
can't create an unmanageable mess, but at least we have a
good book
to help us get things right.) And from writing our
post facto tests in xUnit, it's a somewhat larger
but still small step to writing the test first.
J. B. Rainsberger
followed up
with a trick of his own, for working with customers:
I have one to help customers describe customer tests. If
they seem not to want to do it, or have trouble, then when
they ask me to build the feature, I immediately say "Done!"
They look puzzled. "You are not."
"Sure I am. Done!"
"You haven't done anything!"
"How do you know?"
The next thing out of their mouth is usually something we
can easily turn into a customer test.
Very nice. I can't wait for one of my students to pull
this on me for one of my underspecified assignments!
Rainsberger does warn that this trick works best "only if
you have a good personal relationship with the person
acting as customer". So perhaps only those students who
have developed a relationship of trust with me will want
to venture this.
Of all the runaway threads on the XP list, this is one that
I would like to have seen run longer. I'd love to hear
others share some of their tricks at helping developers
become more agile, whether in testing, pairing, refactoring,
or any other practice.
My last post looked at the relationship between
honesty and blocking,
motivated by a recent thread on the XP discussion
list. In another thread, I encountered
Dale Emery's message
on The Prime Directive, and that got me to thinking
about being honest with myself about my own behavior,
and how to get better.
If you read much in the agile world, you'll run across the
phrase "Prime Directive" a lot. I'm not a Trekkie, though
I have enjoyed the several movies and TV series, but the
first thing I think of when I hear the phrase is
James T. Kirk. That's not what the agile folks are
talking about... even if that directive raises interesting
questions for a software person introducing agile methods
to an organization!
If you google "prime directive agile", the first link is to
Bob Martin's
The Prime Directive of Agile Development,
which is: Never be blocked. This is an ironic choice
of words, given what I discussed in my
previous post,
but Martin is using an analogy from billiards, not football:
An agile developer "makes sure that the shot he is taking
sets up the next shot he expects to take.... A good agile
developer never takes a step that stops his progress, or
the progress of others." This is a useful notion, I think,
but again not what most agilists mean when they speak of
the Prime Directive.
They are referring instead to Norm Kerth's use of the phrase
in the realm of
project retrospectives,
in which teams learn from the results of a recently-completed
project in order to become a better team for future projects.
Here is the
Prime Directive
for retrospectives, according to Norm:
The prime directive says:
Regardless of what we discover, we understand and truly believe
that everyone did the best job they could, given what they knew
at the time, their skills and abilities, the resources available,
and the situation at hand.
At the end of a project everyone knows so much more. Naturally
we will discover decisions and actions we wish we could do over.
This is wisdom to be celebrated, not judgement used to embarrass.
This directive creates an environment in which people can
examine past actions and results without fear of blame or
reprisal. Instead the whole team can find ways to improve.
When we look back at behavior and results in this context,
we can be honest -- with our teammates and with ourselves.
It's hard to improve oneself without facing the
brutal facts
that define our world and our person.
Emery's article focuses on the power of the phrase "given
what they knew at the time". He does not view it as a
built-in excuse -- well, I didn't know any better, so...
-- rather as a challenge to identify and
adjust the givens that limit us.
I apply The Prime Directive to my personal work by saying,
"I did the best I could, given..." then fill in the givens.
Then I set to work removing or relaxing the limiting
conditions so that I perform better in the future. Usually,
the most important conditions are the conditions within me,
the conditions that I created.... If I created those conditions
(and I did), then they are the conditions I can most directly
improve.
Well said. Being honest with myself isn't easy, nor is
following through on what I learn when I am. I take this
as a personal challenge for the upcoming year.
(By the way, I strongly recommend Norm Kerth's
book on retrospectives,
as well as his pattern language on the transition from
software analysis to design,
Caterpillar's Fate.
Norm is an engaging speaker and doer who celebrates the
human element in whatever he touches. I reported on a
talk he gave at PLoP 2004 on
myth and patterns
back in the early days of this blog.)
I recently wrote about a long-running thread on the XP
discussion list about
defining 'agile'.
Another theme I've noticed across several threads is
honesty. This entry and the one that follows look at
two facets of the theme.
In one thread that seems to be dying down, the list has
discussed the ethics of "blocking", a term that Scott
Ambler borrowed from (American) football to describe
teams that create the facade of following the official
software development methodology while behind the scenes
doing what they think is best to deliver the software.
Scott wrote about this behavior, in which some members
of the team protect the agile process by
Running Interference
for the rest of the team, in a 2003 Software Development
article.
Is it right to do this? As developers, do we want to
live our lives doing one thing and saying that we do
another? I'm leery of any prescription that requires me
to lie, yet I see
shades of gray
here. I don't think that my employer or our client are
better served by actually following a process that is
likely to fail to deliver the software as promised. Or,
if my team is capable of delivering the software reasonably
using the official methodology, then why do I need to lie
in order to use an agile process? For me, programming in
an agile way is a lot more fun, so there is that, but then
maybe I need to find a place that will let me do that -- or
start my own.
As I mentioned last time, I have not been able to follow the
list discussion 100%, and I can't recall if Kent Beck ever
chimed in. But I can imagine what he might say, given the
substance and tone of his postings the last few years. If
you have to lie -- even if we give it an innocuous name like
"blocking"; even if we view it as a last resort -- then
something is wrong, and you should think long and hard about
how to make it right. Agile developers value people over
processes, and honesty is one way we demonstrate that we
value people.
George Dinwiddie has a
blog entry
that considered a more pragmatic potential problem with
blocking. We may be getting the job done in the short term,
but blocking is shortsighted and may hurt the agile cause in
the long run. If we give the appearance of succeeding via
the official route, our employer and customer are likely to
conclude that the official route is a good one -- and that
will make it even harder to introduce agile practices into
the workplace. There is a practical value in telling the
truth, even it requires us to take small steps. After all,
agile developers ought to appreciate the power of small steps.
Every so often the
XP discussion list
takes off in a frenzy of activity. The last few weeks have
seen such a frenzy, which makes it difficult for readers
like me to keep up. Fortunately, I am often able to find
some nuggets of value with a two-pronged heuristic approach
to reading: I usually home in on messages from a few folks
whose posts I have found valuable in the past and scan the
sub-threads that follow, and I occasionally select messages
pseudo-randomly based on subject lines that tickle my fancy.
I'm sure that I miss out on some valuable conversations
along the way, but I do find enough to keep my wheels moving.
One long-running recent thread has focused on "defining agile"
-- that is, being able to tell when an organization is using
agile methods or not. If the list were made up solely of
academics, this thread would be a natural. Academics love
to put things into categories and name them. But this list
is made up mostly of practitioners, and there interest in
defining agile comes from many different directions, not
the least of which is dispelling hype and distinguishing
practices that help folks succeed.
I used to be much more dogmatic about naming things and
separating methods and approaches and people into categories.
A prime example was "real" object-oriented programming from
the charade that some people display in a language that
supports objects. Over time, I have soured of the battles
and am more likely to espouse the point of view expressed
by Andy Hunt somewhere back in the thread:
Instead of a test for agile, how about a test for "was your
project a success or was it horked?" If it was a success,
call it anything you want. If not, don't dare call it agile. :-)
This sort of pragmatism is reminiscent of Alan Turing's
sidestepping of the question "what is intelligence?" in his
seminal
Computing Machinery and Intelligence.
Such a definition makes it hard for agilists to defend their
turf, but it lets folks who want to build systems get down
to busy, rather than argue.
That said, I think that George Dinwiddie has done a nice job
of capturing the essence of defining agile methods in a
blog entry
responding to the thread: using feedback that is frequent,
timely, aligned with our desired goals, and pervasive. If
you have read much of this blog, especially back in the first
couple of years, you know that I have written frequently of
the value of using feedback in many different circumstances,
from developing software to teaching a class to training for
and running a marathon. My appreciation of Dinwiddie's
characterization is unsurprising.
Tim Haughton created a branch off this thread with a post that
defines the
Three Colours of Agile.
Haughton reminds us that we need to tell different stories
when we are dealing with the different parties involved in
software projects. In particular, the customer who will use
our software and the manager who oversees the development
team have much different views on software development than
the developers themselves have. Most of our discussion about
agile methods focuses on the practices of developers and only
peripherally with our interface to the rest of the world, if
at all. Telling the right story at the right time can make
a huge difference in whether another person buys into a new
method proposed by developers. When we communicate the value
of agile methods to the customer and manager from their
perspective, the approach looks so much more palatable
than a laundry list of developer practices they don't understand.
Again, frequent readers of this blog will recognize a recurring
theme of story telling.
I haven't written much in anticipation of
OOPSLA 2007,
but not because I haven't been thinking about it. In
years when I have had a role in content, such as the
2004
and
2005
Educators' Symposia or even the
2006
tutorials track, I have been excited to be deep in the
ideas of a particular part of OOPSLA. This year I have
blogged just once, about the
December planning meeting.
(I did write once from the spring planning meeting, but
about a movies.)
My work this year for the conference has been in an
administrative role, as communications chair, which has
focused on sessions and schedules and some web content.
Too be honest, I haven't done a very good job so far,
but that is a subject for another post. For now, let's
just say that I have not been a very good
Mediator
nor a good
Facade.
I am excited about some of the new things we are doing
this year to get the word out about the conference. At
the top of this list is a podcast. Now, podcasts have
been around for a while now, but they are just now becoming
a part of the promotional engine for many organizations.
We figured that hearing about some of the cool stuff that
will happen at OOPSLA this year would complement what you
can read on the web. So we arranged to have two outfits,
Software Engineering Radio
and
DimSumThinking,
co-produce a series of episodes on some of the hot topics
covered at this year's conference.
Our first episode, on a workshop titled No Silver Bullet:
A Retrospective on the Essence and Accidents of Software
Engineering, organized by Dennis Mancl, Steven Fraser,
and Bill Opdyke, is on-line at the
OOPSLA 2007 Podcast
page. Stop by, give it a listen, and
subscribe
to the podcast's feed so that you don't miss any of the
upcoming episodes. (We are available in iTunes, too.) We
plan to role new interviews out every 7-10 for the next few
months. Next up is a discussion of a Scala tutorial with
Martin Odersky, due out on July 16.
If you would like to read a bit more about the conference,
check out conference chair Richard Gabriel's
The (Unofficial) How To Get Around OOPSLA Guide,
and especially his
ooPSLA Impressions.
As I've written a few times, there really isn't another
conference like OOPSLA. Richard's impressions page does
a good job communicating just how, mostly in the words of
people who've been to OOPSLA and seen it.
While putting together some of his podcast episodes, Daniel
Steinberg of
DimSumThinking
ran into something different than usual: fun.
I've done three interviews for the oopsla podcast -- every
interviewee has used the same word to describe OOPSLA: fun.
I just thought that was notable -- I do a lot of this sort
of thing and that's not generally a word that comes up to
describe conferences.
And that fun comes on top of the ideas and the people you
will encounter, that will stretch you. We can't offer a
Turing Award winner
every year, but you may not notice with all the intellectual
foment. (And this year, we can offer
John McCarthy
as an invited speaker...)
Summer is more than half over. I had planned by now to be
deep in planning for my fall compilers course, but the
other work has kept me busy. I have to admit also to
suffering from a bout of intellectual hooky. Summer is a
good time for a little of that.
Compilers is a great course, in so many ways. It is one
of the few courses of an undergraduate's curriculum in
which students live long enough with code that is big
enough
to come face-to-face with technical debt.
Design matters, implementation matters, efficiency matters.
Refactoring matters. The course brings together all of
the strands of the curriculum into a real project that
requires knowledge from the metal up to the abstraction of
language.
In the last few weeks I've run across several comments
from professional developers extolling the virtues of
taking a compilers course, and often lamenting that too
many schools no longer require compilers for graduation.
We are one such school; compilers is a project option
competing with several others. Most of the others are
perceived to be easier, and they probably are. But few
of the others offer anything close to the sort of capstone
experience that compilers does.
Building OSes and building compilers are the two ends of
the spectrum of applied CS. Learn about both, and you'll
be able to solve most problems coming your way.
I agree, but a compilers course can also illuminate theoretical
CS in ways that other courses don't. Many of the neat ideas
that undergrads learn in an intro theory course show up in the
first half of compilers, where we examine grammars and build
scanners and parsers.
My favorite recent piece on compilers is ultra-cool Steve
Yegge's
Rich Programmer Food.
You have to read this one -- promise me! -- but I will tease
you with Yegge's own precis:
Gentle, yet insistent executive summary: If you don't know
how compilers work, then you don't know how computers work.
If you're not 100% sure whether you know how compilers work,
then you don't know how they work.
Yegge's article is long but well worth the read.
As for my particular course, I face many of the same issues
I faced
the last time I taught it:
choosing a good textbook, choosing a good source language,
and deciding whether to use a parser generator for the main
project are three big ones. If you have any suggestions,
I'd love to
hear from you.
I'd like to build a larger, more complete compiler for my
students to have as a reading example, and writing one
would be the most fun I could have getting ready for the
course.
I do think that I'll pay more explicit attention in class
to refactoring and other practical ideas for writing a big
program this semester. The extreme-agile idea of
15 compilers in 15 days,
or something similar, still holds me in fascination, but at
this point I'm in love more with the idea than with the
execution, because I'm not sure I'm ready to do it well.
And if I can't do it well, I don't want to do it at all.
This course is too valuable -- and too much fun -- to
risk on an experiment in whose outcome I don't have enough
confidence.
I'm also as excited about teaching the course as
the last time I taught it. On a real project of this
depth and breadth, students have a chance to take what
they have learned to a new level:
How lasts about five years, but why is forever.
(I first saw that line in Jeff Atwood's article
Why Is Forever.
I'm not sure I believe that understanding why is a right-brain
attribute, but I do believe in the spirit of this assertion.)
Don't believe me about
computational processes occurring in nature?
Check out
Clocking In And Out Of Gene Expression,
via
The Geomblog.
Some genes turn other genes on and off. To mark time, they
maintain a clock by adding ubiquitin molecules to a chain;
when the chain reaches a length of five, the protein is
destroyed. That sounds a lot like a Turing machine using a
separate tape as a counter...
Becky Hirta learned something that should make all of us
feel either better or worse:
basic math skills are weak everywhere.
We can feel better because it's not just our students, or
we can feel worse because almost no one can do basic math.
One need not be able to solve solve linear equations to
learn how to write most software, but an inability to
learn how to solve solve linear equations doesn't bode
well.
Hey, I made the
latest Carnival of the Agilists.
The Carnival dubs itself "the bi-weekly blogroll that takes
a sideways slice through the agile blogosphere". It's a
nice way for me to find links to articles on agile software
development that I might otherwise have missed.
Several folks have already recommended
Gerard Meszaros's
new book,
xUnit Test Patterns.
I was fortunate to have a chance to review early drafts of
Gerard's pattern language on the web and then at
PLoP 2004,
where Gerard and I were in a writers' workshop together.
By that time I felt I knew a little about writing tests
and using JUnit, but reading Gerard's papers that fall
taught me just how much more there was for me to learn.
I learned a lot that month and can only hope that my
participation in the workshop helped Gerard a small fraction
as much as his book has helped me. I strongly echo
Michael Feathers's recommendation:
"XUnit Patterns is a great all around reference." (The
same can be said for
Michael's book,
though my involvement reviewing early versions of it was
not nearly as deep.)
As I grow older, I have a growing preference for short books.
Maybe I am getting lazy, or maybe I've come to realize that
most of the reasons for which I read don't require 400 or
600 hundred words. Gerard's book weighs in at a hefty
883 pages -- what gives? Well, as Martin Fowler
writes in his post
Duplex Book,
XUnit Test Patterns is really more than one book.
Martin says two, but I think of it as really three:
a 181-page narrative that teaches us
about automated tests, how to write them, and how to
refactor them,
a 91-page catalog of smells you will
find in test code, and
an approximately 500-page catalog of
the patterns of test automation. These patterns
reference one another in a tight network, and so might
be considered a pattern language.
So in a book like this, I have the best of two worlds: a
relatively short, concise, well-written story that shows me
the landscape of automated unit testing and gets me started
writing tests, plus a complete reference book to which I can
turn as I need to learn a particular technique in greater
detail. I can read the story straight through and then jump
into and out of the catalogs as needed. The only downside
is the actual weight of the book... It's no pocket reference!
But that's a price I am happy to pay.
One of my longstanding goals has been to write an introductory
programming textbook, say for CS1, in the duplex style. I'm
thinking something like the dual The Timeless Way of
Building/A Pattern Language, only shorter and
less mystical. I had always hoped to be the first to do this,
to demonstrate what I think is a better future for instructional
books. But at this increasingly late date, I'd be happy if
anyone could succeed with the idea.
Tim Ottinger recently posted a
blog entry
on a problem that we all face: how to know what the
simplest thing is when tying to do the simplest thing.
Tim points out that what he finds simple may not match
at all what others find simple, and vice versa. This
is a problem whenever we are working collaboratively,
because our decision becomes part of the common code
base that everyone works with. But I think it's also
a problem for solo programmers who want to remain true
to the spirit of
YAGNI
and reap the benefits offered by growing a program
organically in small steps.
When I face this decision in my individual programming,
I try to make the choice between two potential implementations
based on the sheer effort I have to make today
to make my program run with the new feature in it. This
means ignoring the voice in my head that says, "But you
know that later you'll have to change that." Well, okay
then, I'll change it later. The funny thing is that
sometimes, I don't have to change it later, at least not
in the way I thought back then.
Below a certain threshold of time and energy, I treat
all effort as roughly the same. Often, one approach uses
a base data type and the other uses a simple object that
hides the base data type. I can often implement the
former a small bit faster, but I can usually implement
both quickly enough to have my feature running now. In
such cases, I will usually opt for the object. Maybe
this violates the spirit of doing the simplest thing that
could possibly work, but I don't find that to be the case
in practice. Even when I am wrong and make a change later,
it is almost never to retract my object but to change the
object's implementation. I almost always want my program
to speak in the language of the problem domain, not the
underlying programming language, and the object enables my
program to do that. In this sense, my experience gibes
with that of Kevin Lawrence, who
coined an eponymous maxim
to address a similar case:
If you ever feel yourself drawn toward writing a static method,
obey Kevin's Maxim: "in an object-oriented language the simplest
thing that could possibly work is an object."
The key is that we seek to defer non-trivial programming
effort until the time spent making it will prove valuable
in today's version of the system.
Whenever pair programming is involved, the desire to do the
simplest thing becomes the subject of a pairwise conversation.
And as pairs form and dissolve over time, the group's
collective wisdom can become part of the decision-making
process. The goal of focusing the time spent of delivering
value today remains the same, but now we can draw
on more experience in making the decision.
Ultimately, I think the value in having YAGNI and
Do the Simplest Thing that Could Possibly Work
as goals comes back to something that came up in my
last post.
The value of these guidelines comes not from the specific
answers we come up with but from the fact that we are asking
the questions at all. At least we are thinking about giving
our customer fair value for the work we are doing today, and
trying to keep our program simple enough that we can grow
them honestly over time. With those goals in mind, we will
usually be doing right by our customers and ourselves. We
will grow wiser over time as to what is simplest in our
problem domain, in our programming milieu, and for us as
developers. As a result, we ought to be able to give even
better answers in the future.
I don't run into Basic and Cobol all that often these days,
but lately they seem to pop up all over. Once recently I
even ran into them together in an
article by Tim Bray
on trends in programming language publishing:
Are there any here that might go away? The only one that
feels threatened at all is VB, wounded perhaps fatally in
the ungraceful transition to .NET. I suppose it's unlikely
that many people would pick VB for significant new applications.
Perhaps it's the closest to being this millennium's COBOL;
still being used a whole lot, but not creatively.
Those are harsh words, but I suppose it's true that Cobol is
no longer used "creatively". But we still receive huge call
for Cobol instruction from industry, both companies that
typically recruit our students and companies in the larger
region -- Minneapolis, Kansas City, etc. -- who have learned
that we have a Cobol course
on the books.
Even with industry involvement, there is effectively no student
demand for the course. Whether VB is traveling the same path,
I don't know. Right now, there is still decent demand for VB
from students and industry.
Yesterday, I ran into both languages again, in a cool way...
A reader and former student pointed out that I had "hit the
big leagues" when my
recent post on Alan Kay
started scoring points at
programming.reddit.com.
When I went there for a vanity stroke, I ran into something
even better, a
Sudoku solver written in Cobol!
Programmers are a rare and wonderful breed. Thanks to Bill
Price for sharing it with us. [1]
While looking for a Cobol compiler for my Intel Mac [2], I
ran instead into
Chipmunk Basic,
"an old-fashioned Basic interpreter" for Mac OS. This brings
back great memories, especially in light of my upcoming 25th
high school reunion. (I learned Basic as a junior, in the
fall of 1980.) Chipmunk Basic doesn't seem to handle my old
graphics-enabled programs, but it runs most of the programs my
students wrote back in the early 1990s. Nice.
I've been considering a Basic-like language as a possible
source language for my compiler students this fall. I first
began having such thoughts when I read a special section on
lightweight languages in a 2005 issue of
Dr. Dobbs' Journal
and found Tom Pitman's article
The Return of Tiny Basic.
Basic has certain limitations for teaching compilers, but
it would be simple enough to tackle in full within a semester.
It might also be nice for historical reasons, to expose
today's students to something that opened the door to so many
CS students for so many years.
----
[1] I spent a few minutes poking around Mr. Price's website.
In some sort of cosmic coincidence, it seems that Mr. Price is
took his undergraduate degree at the university where I teach
(he's an Iowa native), and is an avid chessplayer -- not to
mention a computer programmer! That's a lot of intersection
with my life.
[2] I couldn't find a binary for a Mac OS X Cobol, only sources
for
OpenCOBOL.
Building this requires building some extension packages that
don't compile without a bunch of tinkering, and I ran out of
time. If anyone knows of a decent binary package somewhere,
please
drop me a line.
Without having comments enabled on my blog, I miss out on
most of the feedback that readers might like to give. It
seems like a bigger deal to send an e-mail message with comments.
Fortunately for me, a few readers go out of their way to
send me comments. Unfortunately for the rest of my readers,
those comments don't make it back into the blog the way
on-line comments do, and so we all miss out on the sort of
conversation that a blog can generate. I think it's time
to upgrade my blogging software, I think...
Contrary to Weinberg, I use the exact opposite evaluation of
a critic's comments: I assume that anybody, however naive and
unschooled, has a valid opinion. No matter what they say, how
outrageous, how seemingly ill-founded, someone thought it true,
and therefore it is my job to examine it from every
presupposition, to discover how to improve the <whatever it
is>. I couldn't imagine reducing valid criticism to only
those who have what I choose to call
"credentials". Just among other things, the <whatever it
is> improves a lot faster using my test for validity.
This raises an important point. I suspect that Weinberg
developed his advice while thinking about one's inner
critics, that four-year-old inside our heads. When he
expressed it as applying to outer critics, he may well
still have been in the mode of protecting the writer from
prior censorship. But that's not what he said.
I agree with Alistair's idea that we should be open
to learning from everyone, which was part of the reason I
suggested that students not use this as an opportunity to
dismiss critique from professors. When students are receiving
more criticism than they are used to, it's too easy to fall
into the trap of blaming the messenger rather than considering
how to improve. I think that most of us, in most situations,
are much better served by adopting the stance, "What can I
learn from this?" Alistair said it better.
But in the border cases I think that Alistair's position
places a heavy and probably unreasonable burden on the writer:
"... my job to examine it from every presupposition,
to discover how to improve the <whatever it is>." That
is a big order. Some criticism is ill-founded, or
given with ill will. When it is, the writer is better off
to turn her attention to more constructive pursuits. The
goal is to make the work better and to become a better writer.
Critics who don't start in good faith or who lie too far from
the target audience in level of understanding may not be able
to help much.
Last week I somehow came across a pointer to Matthias
Müller-Prove's excerpt of
"The Reactive Engine",
Alan Kay's 1969 Ph.D. thesis at the University of Utah.
What a neat find! The page lists the full table of
contents and gives then gives the abstract and a few short
passages from the first section on FLEX, his
hardware-interpreted interactive language that foreshadows
Smalltalk.
Those of you who have read here for a while know that
I am a big fan of Kay's work and often cite his ideas
about programming as a medium for expressing and creating
thought. One of my most popular entries is a summary of
his
Turing Award talks
at the 2004 OOSPLA Educators' Symposium. It is neat to
see the roots of his recent work in a thesis he wrote
nearly forty years ago, a work whose ambition, breadth,
and depth seem shocking in a day where advances in computing
tend toward the narrow and the technical. Even then,
though, he observed this phenomenon: "Machines which do
one thing only are boring, yet exert a terrible fascination."
His goal was to construct a system that would serve as a
medium for expression, not just be a special-purpose
calculator of sorts.
The excerpt that jarred me most when I read it was this
statement of the basic principles of his thesis:
Probably the two greatest discoveries to be made [by
pre-literate man] were the importance of position in a
series of grunts, and that one grunt could abbreviate a
series of grunts. Those two principles, called syntax (or
form) and abstraction, are the essence of this work.
In this passage Kay ties the essential nature of computing
back to its source in man's discovery of language.
In these short excerpts, one sees the Alan Kay whose
manner of talking about computing is delightfully his own.
For example, on the need for structure in language:
The initial delights of the strongly interactive languages
JOSS and CAL have hidden edges to them. Any problem not
involving reasonably simple arithmetic calculations quickly
developed unlimited amounts of "hair".
I think we all know just what he means by this colorful
phrase! Or consider his comments on LISP and TRAC. These
languages were notable exceptions to the sort of interactive
language in existence at the time, which left the user
fundamentally outside of the models they expressed. LISP
and TRAC were "'homoiconic', in that their internal and
external representations are essentially the same". (*)
Yet these languages were not sufficient for Kay's goal of
making programming acceptable to any person interested in
entering a dialog with his system:
Their only great drawback is that programs written in them
look like King Burniburiach's letter to the Sumerians done
in Babylonian cun[e]iform!
Near the end of his introduction to FLEX Kay describes the
goals for the work documented in the thesis (bolded text is
my emphasis):
The summer of 1969 sees another FLEX (and another machine).
The goals have not changed. The desire is still to
design an interactive tool which can aid in the
visualization and realization of provocative
notions. It must be simple enough so that one does
not have to become a systems programmer (one who understands
the arcane rites) to use it. ... It must do more than just
be able to realize computable functions; it has to be able
to form the abstractions in which the user deals.
The "visualization and realization of provocative notions"...
not just by those of us who have been admitted to the guild
of programmers, but everyone. That is the ultimate promise
-- and responsibility -- of computing.
Kay reported then that "These goals have not been reached."
Sadly, forty years later, we still haven't reached them,
though he and his team continue to work in this vein. His
lament back in 2004 was that too few of us had joined in
the search, settling instead to focus on what will in a
few decades -- or maybe even five years -- be forgotten as
minutiae. Even folks who thought they were on the path had
succumbed to locking in to vision of Smalltalk that is now
over twenty-five years old, and which Kay himself knows to
be just a stepping stone early on the journey.
In some ways, this web page is only a tease. I really should
obtain a copy of his full thesis and read it. But Matthias
has done a nice job pulling out some of the highlights of
the thesis and giving us a glimpse of what Alan Kay was
thinking back before our computers could implement even a
small bit of his vision. Reading the excerpt was at once a
history lesson and a motivating experience.
----
(*) Ah, that's where I ran across the link to this thesis,
in a mailing-list message that used the term "homoiconic"
and linked to the excerpt.
In what serious discipline is "It's too hard" a legitimate
excuse? I have never seen a bank that eschews multiplication:
"We use repeated addition here--multiplication was too hard for our
junior staffers." And I would be uncomfortable if my surgeon said,
"I refuse to perform procedures developed in the last 10 years--it
is just too hard for me to learn new techniques."
Priceless. This retort applies to many of our great high-level
languages, such as Scheme or Haskell, as anyone who has taught
these languages will attest.
The problem we in software have is this conundrum: The level of
hardness -- usually, abstraction -- we find in some programming
languages narrows our target population much more than the level
of hardness that we find in multiplication. At the same time,
our demand for software developers far outstrips our demand for
surgeons. Finding ways to counteract these competing forces is
a major challenge for the software industry and for computing
programs.
For what it's worth, I strongly second Stuart's comments in
Ruby vs. Java Myth #1,
on big and small projects. This is a case where conventional
wisdom gets things backwards, at a great cost to many teams.
A Programmer's Programmer
I recently ran across a link to this
interview with Don Knuth
from last year. It's worth a read. You gotta love Knuth as
much as you respect his work:
In retirement, he still writes several programs a week.
Programmers
love to program
and just have to do it. But even with 40+ years of experience,
Knuth admits a weakness:
"If I had been good at making estimates of how long something
was going to take, I never would have started."
If you've studied AI or search algorithms, you from
A*
that underestimates are better than overestimates, for almost
exactly the reason that they helped Knuth. There are
computational reasons this is true for A*, but with people it
is mostly a matter of psychology -- humans are more likely to
begin a big job if they start with a cocky underestimate.
"Sure, no problem!"
If you are an agile developer, Knuth's admission should help
you feel free not to be perfect with your estimates; even the
best programmers are often wrong. But do stay agile and work
on small, frequent releases... The agile approach requires
short-term estimates, which can be only so far off and which
allow you to learn about your current project more frequently.
I do not recommend underestimates as drastic as the ones Knuth
made on his typesetting project (which ballooned to ten years)
or his Art of Computing Programming series (at nearly forty
years and counting!) A great one like Knuth may be creating
value all the long while, but I don't trust myself to be
correspondingly productive for my clients.
[ UPDATE: I have corrected the quote of
Alistair Cockburn
that leads below. I'm sure Kent gave the right quote in
his talk, and my notes were in error. The correct quote
makes more sense in context. Thanks, Alistair. ]
Back in March 2006, I posted notes on an OOPSLA 2003
invited talk by
David Ungar.
While plowing through some old files last week, I found
notes from another old OOPSLA invited talk, this from
2002: Kent Beck's "The Metaphor Metaphor". I've always
appreciated Kent's person-centered view of software
development, and I remember enjoying this talk. These
notes are really a collection of snippets that deal with
how language matters in how we think about our projects.
The Metaphor Metaphor, by Kent Beck
November 6, 2002
"Embellishment is the pitfall of the methodologist." (Alistair Cockburn)
You gain experience. You are asked for advice. You give advice. They
ask for more. Eventually, you reach the end of your experience. You
run out of advice to give. But you don't run out of people asking you
for advice. So, you reach...
Stupid ideas are important. How else will you know that the clever ideas
are clever? Don't be afraid of stupid ideas.
A trope is an expression whose meaning is not intended
to be derived from the literal interpretation of its words. There are
many kinds of trope:
irony: spoken such that the opposite is true
paralipsis: speaking to a subject by saying that you won't
hyperbole: excessive exaggeration
pun: using word sounds to create ambiguity
metonymy: refer to the whole by referring to a part or a role
simile: explicit comparison
analogy: simile with connections among the parts
metaphor: the linkages plus the concomitant understanding that results
Think about how much of our communication is tropic. Is this a sign that
our words and tools are insufficient for communication, or a sign that
communication is really hard? (Kent thinks both.)
A key to the value of metaphor is the play between is
and is not. How a metaphor holds and how it doesn't
both tell us something valuable.
Metaphors run deep in computing. An example: "This is a memorycellcontaininga 1 or a 0." All four underlined
phrases are metaphorical!
Kent's college roommate used to say, "Everything is an interpreter."
Some metaphors mislead. "war on terrorism" is a bad metaphor. "war
on disease (e.g., cancer)" is a bad metaphor. Perhaps "terrorism is
a disease" is a better metaphor!?
Lakoff's Grounding Hypothesis states: All metaphors ground in physical
reality and experience. [Kent gave an example using arithmetic and
number lines, relating to an experiment with children, but my notes
are incomplete.]
We made Hot Draw "before there were computers". This meant that doing
graphics "took forever". Boy was that fun! One cool thing about graphics
programming: your mistakes look so interesting!
Hot Draw's metaphors: DRAWING +
FIGURE
TOOL
HANDLE
A lot of good design is waiting productively.
Regarding this quote, Kent told a story about duplicating code --
copy-and-paste with changes to two lines -- and not removing it.
That's completely different from copying and pasting code with
changes to two lines and not removing. [This is, I think, a nod
to the old AI koan (listed first
here)
about toggling the on/off switch of a hung computer to make it
work...]
Kent's final recommendations:
Be aware of computing's metaphors -- and your own!
If the Grounding Hypothesis is correct,
then more physical activity makes better programmers.
(Or at least ones with more interesting things to talk about.)
[end of excerpt]
That last recommendation reflects a truth that people often
forget: Well-rounded people bring all sorts of positives,
obvious and less so, to programming. And I love the quote
about design as "productive waiting".
As with any of my conference reports, the ideas presented belong
to Kent unless stated otherwise, but any mistakes are mine. With
a five-year-old memory of the talk, mistakes in the details are
probably unavoidable...
Here's an excellent test to perform before listening to
any critic, inside or outside:
What have they written that shows they have the
credentials to justify the worth of their criticism?
This test excludes most high-school and college teachers
of English, most of your friends, lots of editors and
agents, and your mother.
It also excludes your [inner] four-year-old, who's never
written anything.
Computer science students should show due respect to their
professors (please!), but they might take this advice to
heart when deciding how deeply to take criticism of their
writing -- their programs. Your goal in a course is to
learn something, and the professor's job is to help you.
But ultimately you are responsible for what you learn, and
it's important to realize that the prof's evaluation is
just one -- often very good -- source. Listen, try to
decide what is most valuable, learn, and move on. You'll
start to develop your own tastes and skills that are
independent of your the instructors criticism.
Weinberg's advice is more specific. If the critic has
never written anything that justifies the worth of their
criticism, then the criticism may not be all that valuable.
I've written before about the
relevance of a CS Ph.D.
to teaching software development. Most CS professors have
written a fair amount of code in their days, and some have
substantial industry experience. A few continue to program
whenever they can.
But frankly some CS profs don't write much code in their
current jobs, and a small group have never written any
substantial program. As sad as it is for me to say, those
are the folks whose criticism you sometimes simply have to
take with a grain of salt when you are learning from them.
The problem for students is that they are not ideally situated
to decide whose criticism is worth acting on. Looking for
evidence is a good first step. Students are also not ideally
situated to evaluate the quality of the evidence, so some
caution is in order.
Weinberg's advice reminds me of something Brian Marick said,
on a panel at the
OOPSLA'05 Educators' Symposium.
He suggested that no one be allowed to teach university
computer science (or was it software development?) unless
said person had been a significant contributor to an
open-source software project. I think his motivation
is similar to what Weinberg suggests, only broader. Not
only should we consider someone's experience when assessing
the value of that person's criticism, we should also consider
the person's experience when assessing the value of what they
are able to teach us.
Of course, you should temper this advice as well with a
little caution.
Even when you don't have handy evidence, that doesn't mean
the evidence doesn't exist. Even if no evidence exists, that
doesn't mean you have nothing to learn from the person. The
most productive learners find ways to learn whatever their
circumstances. Don't close the door on a chance to learn just
because of some good advice.
So, I've managed to bring earlier threads together involving
Brian Marick
and
Gerald Weinberg,
with a passing reference to
Elvis Costello
to boot. That will have to do for closure. (It may also
boost Brian's ego a bit.)
I don't have to be good at <fill in the blank>.
I'll be working on a team.
The implication is that the student can be good enough at
one something and thus not have to get good at some other
part of the discipline. Usually the skill they want to
depend is a softer skill, such as communication or analysis,
The skill they want to avoid mastering is something they
find harder, usually a technical skill and -- all too often
-- programming.
First, let me stipulate that not everyone master every part
of computer science of software development. But this
attitude usually makes some big assumptions about whether
a company should want to entrust systems analysis or even
"just" interacting with clients. I always tell students
that many people probably won't want them on their teams
if they aren't at least competent at all phases of the job.
You don't have to great at <fill in the blank>,
or everything, but you do have to be competent.
What should teams do with the time they're not spending going
too fast? They should invest in one of the four values I want
to talk about: skill. As someone who wants to
remain anonymous said to me:
I've also been tired for years of software people who seem
embarrassed to admit that, at some point in the proceedings,
someone competent has to write some damn code.
He's a programmer.
This doesn't preclude specialization. Maybe each team has
one someone competent has to write some damn code. But most
programmers who have been in the trenches are skeptical of
working with teammates who don't understand what it's like
to deliver code. Those teammates can make promises to
customers that can't be met, and "design system architectures"
that are goofy at best and unimplementable at worst.
One of the things I like about the agile methods is that
they try to keep all of the phases of software development
in focus at once, on roughly an even keel. That's not how
some people paint Agile when they talk it down, but it is
one of the critical features I've always appreciated. And
I like how everyone is supposed to be able to contribute
in all phases -- not as masters, necessatily, but as competent
members of the team.
This is one of the ideas that Brian addresses in the linked-to
article, which talks about the challenge facing proponents
of so-called agile software development in an age when
execution is more important than adoption. As always, Brian
writes a compelling story. Read it. And if you aren't
already following his blog
in its new location,
you should be.
In my experience and that of others I've read, the technical
debt metaphor works well with businesspeople. It fits well
into their world view and uses the language that they use to
understand their business situation. But
as I wrote earlier,
I don't find that this works all that well with students.
They don't live in the same linguistic and experiential
framework as businesspeople, and the way people typically
perceive risk biases them against being persuaded.
A few years ago Owen Astrachan, Robert Duvall, and I wrote
a paper called
Bringing Extreme Programming to the Classroom
that originally appeared at
XP Universe 2001
and was revised for inclusion in
Extreme Programming Perspectives.
In that paper, we described some of the micro-examples
we used at that time to introduce refactoring to novice
students. My experience up to then and since has been
that students get the idea and love the "a-a-a-ahhh" that
comes from a well-timed refactor, but that most students
do not adopt the new practice as a matter of course. When
they get into the heat of a large project, they either
try to design everything up front (and usually guess wrong,
of course) or figure they can always make do with whatever
design they currently have, whether designed or accreted.
Students simply don't live with most code long enough,
even on a semester-long project, to come face-to-face with
technical bankruptcy. When they, they declare it and make
do. I think in my compilers course this fall I'm going to
try to watch for the first opportunity to help one of the
student groups regain control of their project through
refactoring, perhaps even as a demonstration for the whole
class. Maybe that will work better.
That said, I think that Ray's steering wheel analogy may
well work better for students than the debt metaphor.
Driving is an integral part of most students' lives, and
maybe we can connect to their
ongoing narratives
in this way. But the metaphor will still have to be
backed up with a lot of concrete practice that helps them
make recognizable progress. So watching for an opportunity
to do some macro-level refactoring is still a good idea.
Another spoke in this wheel is helping students adopt the
other agile practices that integrate so nicely with
refactoring. As Brian Marick said recently in pointing out
values missing from the Agile Manifesto,
Maybe the key driver of discipline is the
practice of creating working software --
running, tested features
-- at frequent intervals. If you're doing that, you just
don't have time for sloppiness. You have
to execute well.
But discipline -- especially discipline that conflicts with
one's natural, internal, subconscious biases -- is hard to
sell. In a semester-long course, by the time students realize
they really did need that discipline, time is too short to
recover properly. They need time to ingrain new practice as
habit. For me as instructor, the key is "small", simple
practices that people can do without high discipline, perhaps
with some external guidance until their new habit forms.
Short iterations are something I can implement as an
instructor, and with enough attention paid throughout the
term and enough effort exerted at just the right moments,
I think I can make some headway.
Of course, as Keith reminds us and as we should always
remember when trafficking in metaphor: "Like all analogies,
there's a nugget of truth here, but don't take the analogy
too far."
Recently I wrote about
persuasion and teaching,
in light of what we know about how humans perceive and react
to risk and new information. But isn't marketing inherently
evil, in being motivated by the seller's self-interest and
not the buyer's, and thus incompatible with a teacher/student
relationship? No.
First of all, we can use an idea associated with a "bad" use
to achieve something good. Brian Marick points out that the
motivating forces of XP are built in large part on peer
pressure:
Some of XP's practices help with discipline. Pair programming
turns what could be a solitary vice into a social act: you and
your pair have to look at each other and acknowledge that you're
about to cheat. Peer pressure comes into play, as it does
because of collective code ownership. Someone will notice the
missing tests someday, and they might know it was your fault.
This isn't unusual. A lot of social organizations provide a
former of positive peer pressure to help individuals become
better, and to create a group that adds value to the world.
Alcoholics Anonymous is an example for people tempted to do
something they know will hurt them; groups of runners training
for a marathon rely on one another for the push they need to
train on days they feel like not and to exert the extra effort
they need to improve. Peer pressure isn't a bad thing; it's
just depends on who you choose for your peers.
Returning to the marketing world, reader Kevin Greer sent me
a short story on something he learned from an IBM sales trainee:
The best sales guy that I ever worked with once told me that
when he received sales training from IBM, he was told to make
sure that he always repeated the key points six times. I
always thought that six times was overkill but I guess IBM
must know what they're talking about. A salesman is someone
whose income is directly tied to their ability to effectively
"educate" their audience.
What we learn here is not anything to do with the salesman's
motive, but with the technique. It is grounded in experience.
Teachers have heard this advice in a different adage about
how to structure a talk: "Tell them what you are about to tell
them. Then tell them. Then tell them what you have just told
them." Like Kevin, I felt this was overkill when I first
heard it, and I still rarely follow the advice. But I do
know from experience how valuable it can be me, and in the
meantime I've learned that how the brain works makes it
almost necessary.
While I'm still not a salesman at heart, I've come to see
how "selling" an idea in class isn't a bad idea. Steve
Pavlina describes what he calls
marketing from your conscience.
His point ought not seem radical: "marketing can be done
much more effectively when it's fully aligned (i.e., congruent)
with one's conscience."
Good teaching is not about delusion but about conscience. It
is sad that we are all supposed to believe the cynical
interpretation of selling, advertising, and marketing. Even
in the tech world we certainly have plenty of salient reasons
to be cynical. We've all observed near-religious zealotry in
promoting a particular programming language, or a programming
style, or a development methodology. When we see folks
shamelessly shilling the latest silver bullet as a way to
boost their consulting income, they stand out in our minds and
give us a bad taste for promotion. (Do you recognize this as
a form of the
availability heuristic?)
But.
I have to overcome my confirmation bias, other heuristic
biases that limit my thinking, and my own self-interest
in order to get students and customers to gain the knowledge
that will help them; to try new languages, programming
styles, and development practices that can improve their
lives. What they do with these is up to them, but I have
a responsibility to expose them to these
ideas, to help them appreciate them, to empower them to
make informed choices in their professional (and personal!)
lives. I can't control how people will use the new ideas
they learn with me, or if they will use them at all, but
if help them also to learn how to make informed choices
later, then I've done about the best I can do. And not
teaching them anything isn't a better alternative.
I became a researcher and scholar because I love knowledge
and what it means for people and the world. How could I
not want to use my understanding of how people learn and
think to help them learn and think better, more satisfyingly?
Over the last couple of months, I've been collecting some
good lines and links to the articles that contain them.
Some of these may show up someday in something I write,
but it seems a shame to have them lie fallow in a text
file until then. Besides, my blog often serves as my
commonplace book
these days. All of these pieces are worth reading for more
than the quote.
If the code cannot express itself, then
a comment might be acceptable. If the code does
not express itself, the code should be fixed.
-- Tim Ottinger,
Comments Again
In a concurrent world, imperative is the wrong default!
-- Tim Sweeney of Epic Games,
The Next Mainstream Programming Language:
A Game Developer's Perspective, an invited talk at ACM POPL'06
(full slides in
PDF)
When you are tempted to encode data structure in a variable
name (e.g. Hungarian notation), you need to create an object
that hides that structure and exposes behavior.
-- Uncle Bob Martin
The Hungarian Abhorrence Principle
Lisp... if you don't like the syntax, write your own.
-- Gordon Weakliem,
Hashed Thoughts,
on simple syntax for complex data structures
Pairing is a practice that has (IIRC) at least five
different benefits. If you can't pair, then you need to find
somewhere else in the process to put those benefits.
-- John Roth, on the XP mailing list
Fumbling with the gear is the telltale sign that I'm out
of practice with my craft. ... And day by day, the enjoyment
of the craft is replaced by the tedium of work.
-- Mike Clark,
Practice
So when you get rejected by investors, don't think "we
suck," but instead ask "do we suck?" Rejection is a question,
not an answer.
-- Paul Graham,
The Hacker's Guide to Investors
I find it interesting that part of what I learned again
from
Schneier's psych of risk paper
leads to stories. But biases in how we think, such as
availability
and
framing,
make the stories we tell important -- if we want them to
reach our audience as intended. Then again, perhaps my
direction in this series follows from a bias in my own mind:
I had been intending to blog about a confluence of stories
about stories for a few weeks.
First, I was sitting in on lectures by untenured and adjunct
faculty this semester, doing year-end evaluations. In the
middle of one lecture, it occurred to me: The story matters.
A good lecture is a cross product of story and facts (or data,
or knowledge).
What if a lecture is only good as a story? It is like empty
calories from sugar. We feel good for a while, but pretty soon
we feel an emptiness. Nothing of value remains.
What if a lecture is only good for its facts? I see this often,
and probably do this all too often. Good slides, but no story
to make the audience care. The result is no interest. We may
gain something, but we don't enjoy it much. And Schneier tells
us that we might not even gain that much -- without a story that
makes the information available to us, we may well forget it.
Soon after that, I ran across
Ira Glass: Tips on storytelling
at Presentation Zen. Glass says that the basic building
blocks of a good story are the anecdote itself, which
raises an implicit question, and moments of reflection.
which let the user soak in the meaning.
Soon after that, I was at Iowa State's
HCI forum
and saw a research poster on the role of narrative in games
and other virtual realities. It referred to the
Narrative Paradigm
of
Walter Fisher
(unexpected Iowa connection!),
which holds that "All meaningful communication is a form of
storytelling." And: "People experience and comprehend their lives
as a series of ongoing narratives." (emphasis added)
Then, a couple of weeks later, I read the Schneier paper. So
maybe I was predisposed to make connections to stories.
Our audiences -- software developers, students, business
people -- are all engaged in their own ongoing narratives.
How do we connect what we are teaching with one of their
narratives? When we communicate Big Ideas, we might even strive
to create a new thread for them, a new ongoing narrative that will
define parts of their lives. I know that OOP, functional programming,
and agile techniques do that for developers and students. The
stories we tell help them move in that direction.
Some faculty seem to make connections, or create new threads.
Some "just" lecture. Others do something more interactive.
These are the faculty whom students want to take for class.
Others don't seem to make the connections. The good news for
them -- for me -- is that one can learn how to tell stories
better. The first step is simply to be aware that I am telling
a story, and so to seek the hook that will make an idea
memorable, worthwhile, and valuable. A lot of the motivation
lies with the audience, but I have to hold up my end of the
bargain.
Not just any story will do. People want a story that helps
them do something. I usually know when my
story isn't hitting the mark; if not before telling it, then
after. The remedy usually lies in one of two directions:
finding a story that is about my audience and not (just) me,
or making my story real by living it first. Real problems and
real solutions mean more than an concocted stories about
abstract ideas of what might be.
I have written three posts recently
[
1 |
2 |
3
] on various applications of Bruce Schneier's
The Psychology of Security
to software development and student learning. Here's
another quote:
The moral here is that people will be persuaded more by
a vivid, personal story than they will by bland statistics
and facts, possibly solely due to the fact that they remember
vivid arguments better.
I think that this is something that many of us know
intuitively from experience both as learners and as teachers.
But the psychological evidence that Schneier cites give us
all the more reason to think carefully about many of the
things we do. Consider how it applies to...
... "selling" agile ideas, to encouraging adoption among the
developers who make software. The business people who make
decisions about the making of software. The students who
learn how to make software from us.
... "marketing" CS as a rewarding, worthwhile, challenging
major and career path.
... "framing" ideas and practices for students whom we hope
to help grow in some discipline.
Each of these audiences responds to vivid examples, but the
examples that persuade best will be stories that speak to
the particular desires and fears of each. Telling personal
stories -- stories from our own personal experiences -- seem
especially persuasive, because they seem more real to the
listener. The listener probably hasn't had the experience
we relate, but real stories have a depth to them that often
can't be faked.
I think my best blogging fits this bill.
As noted in one of the earlier entries, prospect theory tells
us that "People make very different trades-offs if something
is presented as a gain than if something is presented as a loss."
I think this suggests that we must frame arguments carefully
and explicitly if we hope to maximize our effect. How can we
frame stories most beneficially for student learning? Or to
maximize the chance that developers adopt, or clients accept,
new agile practices?
I put the words "selling", "marketing", and "framing" in scare
quotes above for a reason. These are words that often cause
academics great pause, or even lead academics to dismiss an
idea as intellectually dishonest. But that attitude seems
counter to what we know about how the human brain works. We
can use this knowledge positively -- use our newfound powers
for good -- or negatively -- for evil. It is our choice.
Schneier began his research with the hope of using what he
learned for good, to help humans understand their own behavior
better and so to overcome their default behavior. But he soon
learned that this isn't all that likely; our risk-intuitive
behaviors are automatic, too deeply-ingrained. Instead he
hopes to pursue a middle road -- bringing our feelings
of security into congruence with the reality of security.
(For example, he now admits that palliatives -- measures that
make users feel better without actually improving their
security -- may be acceptable, if they result in closer
congruence between feeling and reality.)
This all reminded me of Kathy Sierra's entry
What Marketers Could Do For Teachers.
There, she spoke the academically incorrect notion that
teachers could learn from marketers because they:
"know what turns the brain on"
"know how to motivate someone almost instantly"
"know how to get--and keep--attention"
"spend piles of money on improving retention and
recall"
"know how to manipulate someone's thoughts and
feelings about a topic"
"Manipulate someone's thoughts and feelings about a topic."
Sounds evil, or at least laden with evil potential. Sierra
acknowledges the concern right up front...
[Yes, I'm aware how horrifying this notion sound -- that
we take teachers and make them as evil as marketers? Take
a breath. You know that's not what I'm advocating, so keep
reading.]
Kathy meant just what Schneier is trying to do, that we can
learn not the motivations of marketing but their understanding
of the human mind, the human behavior that makes possible the
practices of marketing. Our motivations are already good
enough.
While at workshop
a couple of weeks ago,
I had the pleasure of visiting my Duke friends and colleagues
Robert Duvall
and
Owen Astrachan.
In Owen's office was a copy of the book
Fish Is Fish,
by well-known children's book author
Leo Lionni.
Owen and Robert recommended the simple message of this
picture book, and you know me, so... When I got back to town,
I checked it out.
The book's web site summarizes the book as:
A tadpole and a minnow are underwater friends, but the tadpole
grows legs and explores the world beyond the pond and then
returns to tell his fish friend about the new creatures he
sees. The fish imagines these creatures as bird-fish and
people-fish and cow-fish and is eager to join them.
The story probably reaches young children in many ways, but
the first impression it left on me was, "You can't imagine
what you can't experience." Then I realized that this was
both an overstatement of the story and probably wrong, so
I now phrase my impression as, "How we imagine the the rest
of the world is strongly limited by who we are and the world
in which we live." And this theme matters to grown-ups as
much as children.
Consider the programmer who knows C or Java really well, but
only those languages. He is then asked to learn functional
programming in, say, Scheme. His instructor describes
higher-order procedures and currying, accumulator passing
and tail-recursion elimination, continuations and call/cc.
The programmer sees all these ideas in his mind's eye as C or
Java constructs, strange beasts with legs and fins.
Or consider the developer steeped in the virtues and practices
of traditional software engineering. She is then asked to "go
agile", to use test-first development and refactoring browsers,
pair programming and continuous integration, the planning game
and YAGNI. The developer is aghast, seeing these practices in
her mind's eye from the perspective of traditional software
development, horrific beasts with index cards and lack of
discipline.
When we encounter ideas that are really new to us, they seem
so... foreign. We imagine them in our own jargon, our own
programming language, our own development style. They look
funny, and feel unnecessary or clunky or uncomfortable or
wrong.
But they're just different.
Unlike the little fish in Lionni's story, we can climb out
of the water that is our world and on to the beach of a new
world. We can step outside of our experiences with C or
procedural programming or traditional software engineering
and learn to live in a different
world. Smalltalk. Scheme. Ruby. Or Erlang, which seems
to have a lot of buzz these days. If we are willing to do
the work necessary to learn something new, we don't flounder
in a foreign land; we make our universe bigger.
Computing fish don't have to be (just) fish.
----
(Ten years ago, I would have used OOP and Java as the strange
new world. OO is mainstream now, but -- so sadly -- I'm not
sure that real OO isn't still a strange new world to most
developers.)
Maybe I am making too much of
this
and
this.
Reader
Chris Turner
wrote to comment that not internalizing is natural:
The things that I internalize are things I personally use. ...
"Use" != "Have to know for a quiz". The reason I internalize
them is because it's faster to remember than to look it up. If
I hardly ever use it, though, the time spent learning it is
wasted time. YAGNI as applied to knowledge, I suppose. ...
[E]specially in the software development field, that this is
not only acceptable, but encouraged. I simply don't have
enough time to learn all I can about every design pattern out
there. I have, however, internalized several that have been
useful to me in particular.
I agree that one will -- and needs to -- internalize only
what one uses on a regular basis. So as an instructor I need
to be sure to give students opportunities to use the ideas
that I hope for them to internalize. However, I am often
disappointed that, even in the face of these opportunities,
students seem to choose other activities (or no programming
activities at all) and thus miss the chance to internalize
an important idea. I guess I'm relying on the notion that
students can trust that the ideas I choose for them are
worth learning. People who bothered to master a theoretical
construct like call/cc were able to create the idea
of a continuation-based web server, rather than having to
wait to be a third-generation adopter of a technology
created, pre-processed, and commoditized by others.
But there's more. As one of my colleagues said yesterday,
part of becoming educated is learning how to
internalize, through conscious work. Perhaps we need to do
a better job helping students to understand that this is
one of the goals we have for them.
This leads me to think about another human bias documented
in Schneier's article psychology article. I think that student
behavior is also predicted by time discounting,
the practice of valuing a unit of resource today more than the
same unit of resource at a future date. In the financial
world, this makes great sense, because a dollar today can be
invested and earn interest, thus becoming more than $1 at the
future date. The choice we face in valuing future resources
is in predicting the interest rate.
I think that many of us, especially when we are first learning
to learn, underestimate the "interest rate", the rate
of return on time spent studying and learning-by-programming.
Investment in a course early in the semester, especially when
learning a new language or programming style, is worth much more
than an equivalent amount of time spent later preparing for
assignments and exams. And just as in the financial world,
investing more time later often cannot make up for the ground
lost to the early, patient investor. A particularly self-aware
student once told me that he had used what seemed to be the
easy first few weeks of my Programming Languages course to
dive deep into Scheme and functional programming on his own.
Later, when the course material got tougher, he was ready.
Other students weren't so lucky, as they were still getting
comfortable with syntax and idiom when they had to confront
new content such as lexical addressing.
I like the prospect of thinking about the choice between
internalizing and relying on external cues in terms innate
biases on risk and uncertainty. This seems to give me a
concrete way to state and respond to the issue -- to make
changes in how I present my classes that can help students
by recognizing their subconscious tendencies.
You ever notice
how anyone driving slower than you is an idiot,
and anyone driving faster than you is a maniac?
-- George Carlin
I spent my time flying back from Montreal reading
Bruce Schneier's
popular article
The Psychology of Security
and had a wonderful time. Schneier is doing want any good
technologist should do: try to understand how the humans
who use their systems tick. The paper made me harken back
to my days studying AI and reasoning under uncertainty.
One of the things we learned then is that humans are not
very good at reasoning in the face of uncertainty. and most
don't realize just how bad they are. Schneier studies the
psychology of risk and probabilistic reasoning with the
intention of understanding how and why humans so often
misjudge values and trade-offs in his realm of system
security. As a software guy, my thoughts turned in different
directions. The result will be a series of posts.
To lead off, Schneier describes a couple of different models
for how humans deal with risk. Here's the standard story he
uses to ground his explanation:
Here's an experiment .... Subjects were divided into two
groups. One group was given the choice of these two alternatives:
Alternative A: A sure gain of $500.
Alternative B: A 50% chance of gaining $1,000.
The other group was given the choice of:
Alternative C: A sure loss of $500.
Alternative D: A 50% chance of losing $1,000.
The expected values of A and B are the same, likewise C and D.
So we might expect people in the first group to choose A 50%
of the time and B 50% of the time, likewise C and D. But some
people prefer "sure things", while others prefer to gamble.
According to traditional utility theory from
economics, we would expect people to choose A and C (the sure
things) at roughly the same rate, and B and D (the gambles)
at roughly the same rate. But they don't...
But experimental results contradict this. When faced with a
gain, most people (84%) chose Alternative A (the sure gain)
of $500 over Alternative B (the risky gain). But when faced
with a loss, most people (70%) chose Alternative D (the risky
loss) over Alternative C (the sure loss).
This gave rise to something called prospect theory,
which "recognizes that people have subjective values for gains
and losses". People have evolved to prefer sure gains to
potential gains, and potential losses to sure losses. If you
live in a world where survival is questionable and resources
are scarce, this makes a lot of sense. But it also leads to
interesting inconsistencies that depend on our initial outlook.
Consider:
In this experiment, subjects were asked to imagine a disease
outbreak that is expected to kill 600 people, and then to
choose between two alternative treatment programs. Then, the
subjects were divided into two groups. One group was asked
to choose between these two programs for the 600 people:
Program A: "200 people will be saved."
Program B: "There is a one-third probability that 600
people will be saved, and a two-thirds probability that
no people will be saved."
The second group of subjects were asked to choose
between these two programs:
Program C: "400 people will die."
Program D: "There is a one-third probability that
nobody will die, and a two-thirds probability that
600 people will die."
As before, the expected values of A and B are the same,
likewise C and D. But in this experiment A==C and B==D
-- they are just worded differently. Yet human bias
toward sure gains to and potential losses holds true, and
we reach an incongruous result: People overwhelmingly
prefer Program A and Program D in their respective
choices!
While Schneier looks at how these biases apply to the
trade-offs we make in the world of security, I immediately
began thinking of software development, and especially
the so-called agile methods.
First let's think about gains. If we think not in terms
of dollars but in terms of story points, we are
in a scenario where gain -- an additive improvement to our
situation -- is operative. It would seem that people out
to prefer small, frequent releases of software to longer-term
horizons. "In our plan, we can guarantee delivery of 5
story points each week, determined weekly as we go along,
or we can offer an offer a 60% chance of delivering an
average of 5 story points a week over the next 12 months."
Of course, "guaranteeing" a certain number of points a
week isn't the right thing to do, but we can drive our
percentage up much closer to 100% the shorter the release
cycle, and that begins to look like a guarantee. Phrased
properly, I think managers and developers ought to be
predisposed by their psychology to prefer smaller cycles.
That is the good bet, evolutionarily, in the software world;
we all know what
vaporware
is.
What about losses? For some reason, my mind turned to
refactoring here. Now, most agile developers know that
refactoring is a net gain, but it is phrased in terms of
risk and loss (of immediate development time). Phrased as
"Refactor now, or maybe pay the price later," this choice
falls prey to human bias preference for potential losses
over sure losses. No wonder selling refactoring in these
terms is difficult! People are willing to risk carrying
design debt, even if they have misjudged the probability
of paying a big future cost. Maybe design debt and the
prospect of future cost is the wrong metaphor for helping
people see the value of refactoring.
But there is one more problem: optimism bias.
It turns out that people tend to believe that they will
outperform other people engaged in the same activity, and we
tend to believe that more good will happen to us than bad.
Why pay off design debt now? I'll manage the future trajectory
of the system well enough to overcome the potential loss.
We tend to underestimate both the magnitude of coming loss
and the probability of incurring a loss at all. I see this
in myself, in many of my students, and in many professional
developers. We all think we can deliver n LOC this
week even though other teams can deliver only n/2
LOC a week -- and maybe even if we delivered n/2
LOC last week. Ri-i-i-i-ight.
There is a lot of cool stuff in Schneier's paper. It offers
a great tutorial on the fundamentals of human behavior and
biases when reacting to and reasoning about risk and probability.
It is well worth a read for how these findings apply in other
areas. I plan a few more posts looking at applications in
software development and CS education.
I don't have time to keep up with the
XP mailing list
these days, especially when it spins off into a deep
conversation on a single topic. But while browsing quickly
last week before doing an rm on my mailbox, I ran
across a couple of posts that deserved some thought.
Discipline in Practice
In a thread that began life as "!PP == Hacking?", discussion
turned to how much discipline various XP practices demand,
especially pair programming and writing tests (first). Along
the way, Ron Jeffries volunteered that he is not always able
to maintain discipline without exception: "I am the least
disciplined person you know ..."
Robert Biddle followed:
I was pleased to read this. I'm always puzzled when people
talk about discipline as a good thing in itself. I would
consider it a positive attribute of a process that it required
less, rather than more, discipline.
One of the things I've learned over the years is that, while
habit is a powerful mechanism, processes that require people
to pay close attention to details and to do everything just
so are almost always destined to fail for the majority of us.
It doesn't matter if the process is a diet, a fitness regimen,
or a software methodology. People eventually stop doing them.
They may say that they are still following the process,
but they aren't, and that may be worse than just stopping.
Folks often start the new discipline with great energy,
psyched to turn over a new leaf. But unless they can adapt
their thinking and lifestyle, they eventually tire of having
to follow the rules and backslide. Alistair Cockburn has
written a
good agile software book
that starts with the premise that any process must build on
the way that human minds really work.
Later in the thread, Robert notes that -- contrary to what many
folks who haven't tried XP for very long think -- XP tolerates
a lower level of discipline than other methodologies:
For example, as a developer, I like talking to the customer
lots; and as a customer I like talking to developers. That
takes way less discipline for me than working with complex specs.
My general point is that it makes sense for processes and
tools to work with human behaviour, supporting and protecting us
where we are weak, and empowering us where we are strong.
He also points out that the boundary between high discipline
and low discipline probably varies from person to person. A
methodology (or diet, or training regimen) capable of succeeding
within a varied population must hit close to the population's
typical threshold and be flexible enough that folks who lie
away from that threshold have a chance find a personal fit.
As methodology, XP requires us to change how we think, but it
places remarkably few picayune demands on our behavior. A
supportive culture can go a long toward helping well-intended
newbies give it a fair shake. And I don't think it is as
fragile in its demands as the Atkins Diet or many detailed
running plans for beginners.
Accelerating Experience
In a different thread, folks were discussing how much experience
one needs in order to evaluate a new methodology fairly, which
turned to the bigger question of how much project experience one
can realistically obtain. Projects that last 6 months or 2 years
place something of an upper bound on our experience. I like
Laurent Bossavit's
response:
> It takes a lot of time to get experienced.
> How many software development projects can you
> experience in a life-time? How many can you
> experience with three years of work experience?
Quite a lot, provided they're small enough.
Short cycles let you make mistakes faster, more often. They
let us succeed faster. They let us learn faster.
A post later in this thread by someone else pointed out that
P and other agile approaches change the definition of a
software project. Rather than thinking in terms of a big
many-month or multi-year project, we think in terms of 2- or
3-week releases. These releases embody a full cycle from
requirements through delivery, which means that we might
think of each release as a "whole" project. We can do short
retrospectives, we can adapt our practices, we can shift
direction in response to feedback.
Connections... This reminds me of an
old post from Laurent's blog
that I cited in an
old post of my own.
If you want to increase your success rate, double your failure
rate; if you want to double your failure rate, all you have to
do is halve your project length. Ideas keep swirling around.
It occurred to me recently one thing that makes administrative
work different from my previous kinds of work, something that
accounts for an occasional dissatisfaction that I never used
to feel as a matter of course.
In my administrative role, I can often work long and hard without
producing anything.
It's not that I don't do anything as department head. It's just
that the work doesn't always result in a product, something
tangible, something complete that one can look to and say, "I
made that." Much of a head's work is about relationships,
interaction, and one-one interaction. These are all valuable
outcomes, and they may result in something tangible down the
road. Meeting with students, parents of prospective students,
industry partners, or prospective donors all may result in
something tangible -- eventually. And the payoff -- say, from
a donor -- can be quite tangible, quite sizable! But in the
meantime, I sometimes feel like, "What did I accomplish today?"
This realization struck me a week or so back when I finished
producing the inaugural issue of my department's new newsletter.
I wrote nearly all of the content, arranged the rest, and did
all of the image preparation and document layout. When I got
done, I felt that sense one gets from making something.
I get that feeling when I write software. I think that one of
the big wins from small, frequent releases is the shot of
adrenaline that it gives the developers. We rarely talk about
this advantage, instead speaking of the value of the releases
in terms of customer feedback and quality. But the buzz that
we developers feel in producing a whole something, even if it's
a small whole, probably contributes more than we realize to
motivation and enjoyment. That's good for the developers, and
for the customer, too.
I get that feeling when I write code and a lesson for teaching
a class, too. The face-to-face delivery creates its own buzz.
This makes me wonder how students feel about frequent release
dates, or small, frequent homework assignments. I often use
this approach in my courses, but again more for "customer-side"
and quality reasons. Maybe students feel good producing something,
making tangible progress, every week or so? Or does the competing
stress of several other courses, work, and life create an
overload? Even if students prefer this style, it does create
a new force to be addressed: small frequent failures must be
horribly disheartening. I need to be sure that students feel
challenge and success.
Sheepishly, I must admit that I've never asked my students how
they feel about this. I will next week. If you want to share
your thoughts,
please do.
Today I am reminded to put a variant of this pattern into
practice:
The old-fashioned idea (my door is always open; when you want
to talk, c'mon in) was supposed to give people down the line
access to you and your ears. The idea was that folks from
layers below you would come and clue you in on what was really
happening.
I don't think that ever worked for most of us. Most folks
didn't have the courage to come in, so we only learned what was
on the minds of the plucky few. We were in our environment,
not theirs. We couldn't verify what we were hearing by looking,
touching, and listening in the first person. And we got fat
from all that sitting.
I ran into this quote in Jason Yip's post
Instead of opening the door, walk through it.
Jason is seconding an important idea: that an open door policy
isn't enough, because it leaves the burden for engaging
in communication on others -- and there are reasons that these
other folks may not engage, or want to.
This idea applies in the working-world relationship between
supervisors and their employees, but it also applies to the
relationship between a service provider and its customers.
This includes software developers and their customers. If we
as software developers sit in a lab, even with our door open,
our customer may never come in to tell us what they need. They
may be afraid to bother us; they may not know what they need.
Agile approaches seek to reduce the communication gap between
developers and customers, sometimes to the point of putting
them together in a big room. And these approaches encourage
developers to engage the customer in frequent communication
in a variety of ways, from working together on requirements
and acceptance to releasing working software for customer use
as often as possible.
As someone who is sitting in a classroom with another professor
and a group of grad students just now, I can tell you that this
idea applies to teachers and students. Two years ago tomorrow,
I wrote about
my open office hours
-- they usually leave me lonely like the
Maytag Repairman.
Learning works best when the instructor engages the student --
in the classroom and in the hallway, in the student union, on
the sidewalk, and at the ballgame. Often, students yearn to
be engaged, and learning is waiting to happen. It may not happen
today, in small talk about the game, but at some later time. But
that later time may well depend on the relationship built up by
lots of small talk before. And sometimes the learning happens
right there on the sidewalk, when the students feel able to ask
their data structures question out among the trees!
But above, I said that today reminded me of a variant of this
pattern... Beginning Monday and culminating today, I was
fortunate to have a member of my department engage me in
conversation, to question a decision I had made. Hurray! The
open door (and open e-mail box) worked. We have had a very
good discussion by e-mail today, reaching a resolution. But I
cannot leave our resolution sitting in my mail archive. I have
to get up off my seat, walk through the door, and ensure that
the discussion has left my colleague satisfied, in good standing
with me. I'm almost certain it has, as I have a long history
with this person as well as a lot of history doing e-mail.
But I have two reasons to walk through the door and engage now.
First, my experience with e-mail tells me that sometimes I am
wrong, and it is almost always worth confirming conclusions
face-to-face. If I were "just" faculty, I might be willing to
wait until my next encounter with this colleague to do the
face-to-face. My second reason is that I am department head
these days. This places a burden on communication, due to the
real and perceived differences in power that permeate my
relationships with colleagues. The power differential means
that I have to take extra care to ensure that interactions,
whether face to face or by e-mail, are building our relationship
and not eroding it. Still being relatively new to this
management business, it still feels odd that I have to be
careful in this way. These folks are my colleagues, my friends!
But as I
came to realize pretty quickly,
moving into the Big Office Downstairs changes things, whatever
we may hope. The best way to inoculate ourselves from the bad
effects of the new distance? Opening the door and walking
through it.
Oh, and this applies to the relationship between teachers and
students, too. I understand that as an advisor to my grad
students, having been a grad student whose advisor encouraged
healthy and direct communication. But I see it in my relationship
with undergraduates, too, even in the classroom. A little care
tending one-on-one and one-on-many relationships goes a long
way.
(And looking back at that old post about the
Friends
connection, I sometimes wonder if any of my colleagues has a
good Boss Man Wallingford impression yet. More likely, one
of my students does!)
Over at
Lambda the Ultimate,
I ran into a minimal Lisp system named PicoLisp. Actually,
I ran into a
paper
that describes PicoLisp as a "radical approach to application
development", and from this paper I found my way to the
software system
itself.
PicoLisp is radical in eschewing conventional wisdom about
programming languages and application environments. The
Common Lisp community has accepted much of this conventional
wisdom, it would seem, in reaction to criticism of some of
Lisp's original tenets: the need for a compiler to achieve
acceptable speed, static typing within an abundant set of
specific types, and the rejection of pervasive, shallow
dynamic binding. PicoLisp rejects these ideas, and takes
Lisp's most hallowed feature, the program as s-expression,
to its extreme: a tree of executable nodes, each of which...
... is typically written in optimized C or assembly, so the
task of the interpreter is simply to pass control from one
node to the other. Because many of those built-in Lisp functions
are very powerful and do a lot of processing, most of the time
is spent in the nodes. The tree itself functions as a kind of
glue.
In this way an "interpreter" that walks the tree can produce
rather efficient behavior, at least relative to what many
people think an interpreter can do.
As a developer, the thing I notice most in writing PicoLisp
code is its paucity of built-in data types. It supports but
three, numbers, symbols, and lists. No floats; no strings or
vectors. This simplifies the interpreter in several ways, as
it now need to make run-time checks on fewer different types.
The price is paid by the programmer in two ways. First, at
programming time, the developer must create the higher-order
data types as ADTs -- but just once. This is a price that any
user of a small language must pay and was one of the main
trade-offs that Guy Steele discussed in his well-known OOPSLA
talk
Growing a Language.
Second, at run time, the program will use more space and time
than if the those types were primitive in the compiler. But
space is nearly free these days, and the run-time disadvantage
turns out to be smaller than one might imagine. The authors
of PicoLisp point out that the freedom their system gives them
saves them a much more expensive sort of time -- developer time
in an iterative process that they liken to XP.
Can this approach work at all in the modern world? PicoLisp's
creators say yes. They have implemented in PicoLisp a full
application development environment that provides a database
engine, a GUI, and the generation of Java applets. Do they
have the sort of competitive advantage that Paul Graham's writes
about having had at the dawn of ViaWeb? Maybe so.
As a fan of languages and language processors, I always enjoy
reading about how someone can be productive working in an
environment that stands against conventional wisdom. Less may
be more, but not just because it is less (say, fewer types
and no compiler). It is usually more because it is also
different (s-expressions as powerful nodes glued together with
simple control).
Agile Moments: Accountability and Continuous Feedback in Higher Ed
It's all talk until the tests run.
-- Ward Cunningham
A couple of years ago, I wrote about what I call my
Agile Moments,
and soon after wrote about
another.
If I were teaching an agile software development course, or
some other course with an agile development bent, I'd probably
have more such posts. (I teach a compiler development course
this fall...) But I had an Agile Moment yesterday afternoon in
an un-software-like place: a talk on program assessment at
universities.
Student outcomes assessment
is one of those trendy educational movements that comes and go
like the seasons or the weather. Most faculty in the trenches
view it with unrelenting cynicism, because they've been there
before. Some legislative body or accrediting agency or
university administrator decides that assessment is essential,
and they deem it Our Highest Priority. The result is an
unfunded mandate on departments and faculty to create an assessment
plan and implement the plan. The content and structure of the
plans are defined from above, and these are almost always
onerous -- they look good from above but they look like unhelpful
busy work to professors and students who just want to do
computer science, or history, or accounting.
But as a software developer, and especially as someone with an
agile bent, I see the idea of outcomes assessment as a no-brainer.
It's all about continuous feedback and accountability.
Let's start with accountability. We don't set out to write
software without a specification or a set of stories that tell
us what our goal is. Why do we think we should start to teach
a course -- or a four-year computer science degree program! --
without having a spec in hand? Without some public document
that details what we are trying to achieve, we probably won't
know if we are delivering value. And even if we
know, we will probably have a hard time convincing anyone
else.
The trouble is, most university educators think that they know
what an education looks like, and they expect the rest of the
world to trust them. For most of the history of universities,
that's how things worked. Within the university, faculty shared
a common vision of what to do when, and outside the students
and the funders trusted them. The relationship worked out fine
on both ends, and everyone was mostly happy.
Someone at the talk commented that the call for student and program
outcomes assessment "break the social contract" between a university
and its "users". I disagree and think that the call merely
recognizes that the social contract is already broken. For whatever
reason, students and parents and state governments now want the
university to demonstrate its accountable.
While this may be unsettling, it really shouldn't surprise us.
In the software world, most anyone would find it strange if the
developers were not held accountable to deliver a particular
product. (That is even more true in the rest of the economy, and
this difference is the source of much consternation among folks
outside the software world -- or the university.) One of the
things I love about what Kent Beck has been teaching for the last
few years is the notion of accountability, and the sort of honest
communication that aims at working fairly with the people who hire
us to build software. I don't expect less of my university.
In the agile software world, we often think about to whom they
are accountable, and even focus on the best word to use, to send
the right message: client, customer, user, stakeholder, ....
Who is my client when I teach a CS course? My customer? My
stakeholders? These are complex question, with many answers
depending on the type of school and the level at which we ask
them. Certainly students, parents, the companies who hire our
graduates, the local community, the state government, and the
citizens of the state are all partial stakeholders and thus
potential answers as client or customer.
Outcomes assessment forces an academic department to specify
what it intends to deliver, in a way that communicate the
end product more effectively to others. This offers better
accountability. It also opens the door to feedback and
improvement.
When most people talk about outcomes assessment, they are
thinking of the feedback component. As an agile software
developer, I know that continuous feedback is essential to
keeping me on track and to helping me improve as a developer.
Yet we teach courses at universities and offer degrees to
graduates while collecting little or no data as we go along.
This is the data that we might use to improve our course or
our degree programs.
The speaker yesterday quoted someone as saying that universities
"systematically deprive themselves" of input from their
customers. We sometimes collect data, but usually at the end of
the semester, when we ask students to evaluate the course and the
instructor using a form that often doesn't tell us what we need to
know. Besides, the end of the semester is too late to improve the
course while teaching the students giving the feedback!
From whom should I as instructor collect data? How do I use that
data to improve a course? How do I use that data to improve my
teaching more generally? To whom must I provide an accounting of
my performance?
We should do assessment because we want to know something --
because we want to learn how to do our jobs better. External
mandates to do outcomes assessment demotivate, not motivate.
Does this sound anything like the world of software development?
Ultimately, outcomes assessment comes down to assessing student
learning. We need to know whether students are learning what
we want them to learn. This is one of those issues that goes
back to the old social contract and common understanding of
the university's goal. Many faculty define what they want
students to know simply as "what our program expects of them"
and whether they have learned it as "have they passed our
courses?" But such circular definitions offer no room for
accountability and no systematic way for departments t get
better at what they do.
The part of assessment everyone seems to understand is grading,
the assessment of students. Grades are offered by many professors
as the primary indicator that we are meeting our curricular
goals: students who pass my course have learned the requisite
content. Yet even in this area most of us do an insufficient
job. What does an A in a course mean? Or an 87%?
When a student moves on to the next course in the program with
a 72% (a C in most of my courses) in the prerequisite course,
does that mean the student knows 72% of the material 100% of the
way, 100% of the material 72% of the way, some mixture of the two,
or something altogether different? And do we want to such a
student writing the software on which we will depend tomorrow?
Grades are of little use to students except perhaps as carrots
and sticks. What students really need is feedback that helps them
improve. They need feedback that places the content and process
they are learning into the context of doing something.
More and more I am convinced that we need to think about how to
use the idea of course competencies that
West and Rostal
implemented in their apprenticeship-based CS curriculum as a way
to define for students and instructors alike what success in a
course or curriculum mean.
My mind made what it thinks is one last connection to agile
software development. One author suggests that we think of
"assessment as narrative", as a way of telling our story.
Collecting the right data at the right times can help us to
improve. But it can also help us tell our story better. I think
a bit part of agile development is telling our story: to other
developers on the team, to new people we hire, to our clients
and customers and stakeholders, and to our potential future clients
and customers. The continuous feedback and integration that we do
-- both on our software and on our teams -- is an essential cog in
defining and telling that story. But maybe my mind was simply
in overdrive when it made this connection.
It was the at end of this talk that I read the quote which led
me to think of Kurt Vonnegut, coincidental to his passing
yesterday, and which led me to write
this entry.
So it goes.
I'm not entirely sure why, but I searched ACM and IEEE for all
papers with "Considered Harmful" in the title. The length of
this list should substantiate my claim that that phrase should
be banned from the literature.
And he lists them all. The diversity of areas in computing
where people have off Dijkstra's famous
screed on go-to statements
is pretty broad. The papers range from computer graphics
(Bishop et al.) to software engineering (de Champeaux), from
the use of comments (Beckman) to web services (Khare et al.)
and human-centered design (Donald Norman!). Guy Steele has
two entries on the list, one from his classic
lambda series
of papers and the other on arithmetic shifting, of all things.
A lot of the "considered harmful" papers deal with low-level
programming constructs, like go-to, =, if-then-else,
and the like. People doing deep and abstract work in computing
and software development can still have deeply-held opinions
about the lowest-level issues in programming -- and hold them
so strongly that feel obligated to make their case publicly.
There is even a paper on the list that uses the device in a
circular reference: "'Cloning Considered Harmful' Considered
Harmful", by Kapser and Godfrey. This idea is taken to its
natural endpoint by
Eric Meyer
in his probably-should-be-a-classic essay
"Considered Harmful" Essays Considered Harmful.
While Meyer deserves credit for the accuracy his title, I
can't help but thinking he'd have score more style points
from the judges for the pithier "Considered Harmful"
Considered Harmful.
Of course, that would invite the obvious rejoinder
"'Considered Harmful' Considered Harmful" Considered
Harmful, and where would that leave us?
Meyer's essay makes a reasonable point:
It is not uncommon, in the context of academic debates over
computer science and Web standards topics, to see the publication
of one or more "considered harmful" essays. These essays have
existed in some form for more than three decades now, and it
has become obvious that their time has passed. Because
"considered harmful" essays are, by their nature, so incendiary,
they are counter-productive both in terms of encouraging open
and intelligent debate, and in gathering support for the view
they promote. In other words, "considered harmful" essays cause
more harm than they do good.
I think that many authors adopt the naming device as an attempt
to use humor to take the sharp edge off what is intended as an
incendiary argument, or at least a direct challenge to what is
perceived as an orthodoxy that no one thinks to challenge any
more.
Apparently, the CS education community is more prone than most
to making this sort of challenge. CS educators are indeed
almost religious in their zeal for particular approaches, and
the
conservatism of academic CS
is deeply entrenched. Looking at Overbey's list, I identify
at least nine "considered harmful" papers on CS education
topics, especially on the teaching of intro CS courses:
Westfall, "'Hello, World' Considered Harmful"
Rosenberg and Koelling, "I/O Considered Harmful..."
Martin, "Toy Projects Considered Harmful"
Johnson, "C in the First Course Considered Harmful"
Schneider, "Compiler Textbook Bibliographies Considered Harmful"
Hitchner et al., "Programming Early Considered Harmful"
Buck and Stucki, "Design Early Considered Harmful"
Kay, "Bandwagons Considered Harmful..." (in curriculum development)
Hu, "Dataless Objects Considered Harmful"
I've read far too many of these... And there may well be
other intro CS papers on the list that I don't recognize
just from their names.
Some of the papers on the CS ed list are even in direct
opposition to one another! Consider "Programming Early
Considered Harmful" and "Design Early Considered Harmful". If
we can't do programming early, and we can't do design early,
what can we do? Certainly not structured programming; that's on
the bigger list twice.
This tells you something about the differences that arise in
CS education, as well as the community's sense of humor. It
may also say something about our level of creativity! (Just
joking... I know some of these folks and know them to be
quite creative.)
Yesterday I went to a talk by
Roy Behrens,
an
earlier talk of whose
I enjoyed very much and blogged about. That time he talked
about teaching as a "subversive inactivity", and this time
he spoke more on the topic of his scholarly interest, in
creativity and design, ideas and metaphors, similarities
and differences, even
camouflage!
Given that these are his scholarly interests, I wasn't
surprised that this talk touched on some of the same concepts
as his teaching talk. There are natural connection between
how ideas are formed at the nexus os similarity and difference
and how one can best help people to learn. I found this talk
energizing and challenging in a different sort of way.
In the preceding paragraph, I first wrote that Roy "spoke
directly on the topic of his scholarly interest",
but there was little direct about this talk. Instead, Roy
gave us parallel streams of written passages and images from
a variety of sources. This talk felt much like an issue of
his commonplace book/journal
Ballast Quarterly Review,
which I have
blogged about
before. The effect was mesmerizing, and it had its intended
effect in illustrating his point: that the human mind is a
connection-making machine, an almost unwilling creator of
ideas that grow out of the stimuli it encounters. We all
left the talk with new ideas forming.
I don't have a coherent, focused essay on this talk yet, but
I do have a collection of thoughts that are in various stages
of forming. I'll share what I have now, as much for my own
benefit as for what value that may have to you.
Similarity and difference, the keys to metaphor, matter in
the creation of software.
James Coplien
has written an important
book
that explicates the roles of commonality analysis
and variability analysis in the design of software
that can separate domain concerns into appropriate modules
and evolve gracefully as domain requirements change.
Commonality and variability; similarity and difference. As
one of Roy's texts pointed out, the ability to recognize
similarity and difference is common to all practical arts
-- and to scientists, creators, and inventors.
The idea of metaphor in software isn't entirely metaphorical.
See
this paper
by Noble, Biddle, and Tempero that considers how metaphor and
metonymy relate to object-oriented design patterns. These
creative fellows have explored the application of several
ideas from the creative arts to computing, including
deconstruction
and
postmodernism.
To close, Roy showed us the 1952 short film
Blacktop:
A Story of the Washing of a School Play Yard. And that's
the story it told, "with beautiful slow camera strides, the
washing of a blacktop with water and soap as it moves across
the asphalt's painted lines". This film is an example of
how to make something fabulous out of... nothing. I think
the more usual term he used was "making the familiar strange".
Earlier in his talk he had read the last sentence of this
passage from Maslow (emphasis added):
For instance, one woman, uneducated, poor, a full-time housewife
and mother, did none of these conventionally creative things and
yet was a marvelous cook, mother, wife, and home-maker. With
little money, her home was somehow always beautiful. She was a
perfect hostess. Her meals were banquets, her taste in linens,
silver, glass crockery and furniture was impeccable. She was in
all these areas original, novel, ingenious, unexpected, inventive.
I learned from her and others like her that a first-rate
soup is more creative than a second-rate painting, and that,
generally, (un)cooking or parenthood or making a home could be
creative while poetry need not be; it cold be uncreative.
Humble acts and humble materials can give birth to unimagined
creativity. This is something of a theme for me in the design
patterns world, where I tell people that even novices engage
in creative design when they write the simplest of programs
and where so-called
elementary patterns
are just as likely to give rise to creative programs as
Factory or Decorator.
Behrens's talk touched on two other themes that run through
my daily thoughts about software, design, and teaching.
One dealt with tool-making, and the other with craft and
limitations.
At one point during the Q-n-A after the talk, he reminisced
about
Let's Pretend,
a radio show from his youth which told stories. The value to
him as a young listener lay in forcing -- no,
allowing -- him to create the world of the
story in his own mind. Most of us these days are conditioned
to approach an entertainment venue looking for something that
has already been assembled for us, for the express purpose of
entertaining ourselves. Creativity is lost when our minds
never have the opportunity to create, and when our minds'
ability to create atrophies from disuse. One of Roy's goals
in teaching graphic design students is to help students see
that they have the tools they need to create, to entertain.
This is true for artists, but in a very important sense it is
true for computer science students, too. We can create. We
can build our own tools--our own compilers, our own IDEs, our
own applications, our own languages... anything we
need! That is one of the great powers of learning computer
science. We are in a new and powerful way masters of our own
universe. That's one of the reasons I so enjoy teaching
Programming Languages
and compilers: because they confront CS students directly
with the notion that their tools are programs just like any
other. You never have to settle for less.
Finally, may favorite passage from Roy's talk plays right
into my weakness for the relationship between writing and
programming, and for the indispensable role of limitation
in creativity and in learning how to create. From Anthony
Burgess:
Art begins with craft, and there is no art until craft has
been mastered. You can't create until you're willing to
subordinate the creative impulses to the constriction of a
form. But the learning of craft takes a long time, and we
all think we're entitled to shortcuts.... Art is rare and
sacred and hard work, and there ought to be a wall of fire
around it.
One of my favorite of my blog posts is from March 2005, when
I wrote a piece called
Patterns as a Source of Freedom.
Only in looking back now do I realize that I quoted Burgess
there, too -- but only the sentence about willing subordination!
I'm glad that Roy gave the context around that sentence
yesterday, because it takes the quote beyond constriction of
form to the notion of art growing out of craft. It then closes
with that soaring allusion. Anyone who has felt even the
slightest sense of creating something knows what Burgess means.
We computer scientists may not like to admit that what we do
is sometimes art, and that said art is rare and sacred, but
that doesn't change reality.
Good talk -- worth much more in associations and ideas than
the lunch hour it cost. My university is lucky to have Roy
Behrens, and other thinkers like him, on our faculty.
A couple of nights I was able to see a performance by the
Merce Cunningham Dance Company
here on campus. This was my first exposure to Cunningham,
who is known for his exploration of patterns in space and
sound. My knowledge of the dance world is limited, but I
would call this "abstract dance". My wife, who has some
background in dance, might call it something else, but not
"classical"!
The company performed two pieces for us. The first was
called eyeSpace, and it seemed the more avant
garde of the two. The second, called
Split Sides,
exemplifies Cunningham's experimental mindset quite well.
From the company's
web site:
Split Sides is a work for the full company of fourteen dancers.
Each design element was made in two parts, by one or two artists,
or, in the case of the music, by two bands. The order in which
each element is presented is determined by chance procedure at
the time of the performance. Mathematically, there are thirty-two
different possible versions of Split Sides.
And a mathematical chance it was. At intermission, the performing
arts center's director came out on stage with five people, most
local dancers, and a stand on which to roll a die. Each of the
five assistants in turn rolled the die, to select the order of
the five design elements in question: the pieces, the music,
the costumes, the backgrounds, and a fifth element that I've
forgotten. This ritual heightened the suspense for the audience,
even though most of us probably had never seen Split Sides before,
and must have added a little spice for the dancers, who do this
piece on tour over and over.
In the end, I preferred the second dance and the second piece of
music (by Radiohead), but I don't know to what extent this
enjoyment derived from one of the elements or the two together.
Overall, I enjoyed the whole show quite a bit.
Not being educated in dance, my take on this sort of performance
is often different from the take of someone who is. In practice,
I find that I enjoy abstract dance even more than classical.
Perhaps this comes down to me being a computer scientist, an
abstract thinker who enjoys getting lost in the patterns I see
and hear on stage. A lot of fun comes in watching the symmetries
being broken as the dance progresses and new patterns emerge.
Folks trained in music may sometimes feel differently, if only
because the patterns we see in abstract dance are not the
patterns they might expect to see!
Seeing the Merce company perform reminded of a quote about
musician Philip Glass, which I ran across in the newspaper
while in Carefree for
ChiliPLoP:
... repetition makes the music difficult to play.
"As a musician, you look at a Philip Glass score and it
looks like absolutely nothing," says Mark Dix, violist with the
Phoenix Symphony, who has played Glass music, including his
Third String Quartet.
"It looks like it requires no technique, nothing demanding.
However, in rehearsal, we immediately discovered the difficulty
of playing something so repetitive over so long a time. There
is a lot of room for error, just in counting. It's very easy to
get lost, so your concentration level has to be very high to
perform his music."
When we work in the common patterns of our discipline -- whether
in dance, music, or software -- we free our attention to focus
on the rest of the details of our task. When we work outside
those patterns, we are forced to attend to details that we have
likely forgotten even existed. That may make us uncomfortable,
enough so that we return to the structure of the pattern language
we know. That's not necessarily a bad thing, for it allows us
to be productive in our work.
But there can be good in the discomfort of the broken pattern.
One certainly learns to appreciate the patterns when they are
gone. The experience can remind us why they are useful, and
worth whatever effort they may require. The experience can
also help us to see the boundaries of their usefulness, and
maybe consider a combination, or see a new pattern.
Another possible benefit working without the usual patterns is
hidden in Dix's comments above. Without the patterns, we have
to concentrate. This provides a mechanism whereby we
attend to details and hone our concentration, our attention to
detail. I think it also allows us to focus on a new technique.
Programming
at the extremes,
without an if-statement, say, forces you to exercise the
other techniques you know. The result may be that you are a
better user of polymorphism even after you return to the familiar
patterns that include imperative selection.
And I can still enjoy abstract dance and music as an outsider.
There is another, more direct connection between Cunningham's
appearance and software. He has worked with developers to
create a new kind of choreography software called
DanceForms 1.0.
While his troupe was in town, they asked the university to try
to arrange visits with computer science classes to discuss
their work. We had originally planned for them to visit our
User Interface Design course and our CS I course (which has a
media computation theme), but schedule changes on our end
prevented that. I had looked forward to hearing Cunningham
discuss what makes his product special, and to see how they
had created "palettes of dance movement" that could be composed
into dances. That sounds like a language, even if it doesn't
have any curly braces.
What prompted me to finally
write about
Frances Allen winning the Turing Award was a bit of
sad news.
One of the pioneers of computing, John Backus,
has died.
Like Allen, Backus also worked in the area of programming
languages. He is most famous as the creator of Fortran,
as reported in the Times piece:
Fortran changed the terms of communication between humans and
computers, moving up a level to a language that was more
comprehensible by humans. So Fortran, in computing vernacular,
is considered the first successful higher-level language."
I most often think of Backus's contribution in terms of the
compiler for Fortran. His motivation to write the compiler
and design the language was that shared by many computer
scientists through history: laziness. Here is my favorite
quote from the CNN piece:
"Much of my work has come from being lazy," Backus told Think,
the IBM employee magazine, in 1979. "I didn't like writing
programs, and so, when I was working on the IBM 701 (an early
computer), writing programs for computing missile trajectories,
I started work on a programming system to make it easier to
write programs."
Work on a programming system to make it easier to write
programs... This is the beginning of computer science as we
know it!
Backus's work laid the foundation for Fran Allen's work; in
fact, her last big project was called PTRAN, an homage to
Fortran that stands for Parallel TRANslation.
One of my favorite Backus papers is his Turing Award essay,
Can Programming Be Liberated from the von Neumann Style?
(subtitled: A Functional Style and its Algebra of Programs).
After all his years working on language for programmers and
translators for machines, he had reached a conclusion that
the mainstream computing world is still catching up to, that
a functional programming style may serve us best. Every
computer scientist should read it.
This isn't the first time I've written of the passing of a
Turing Award winner. A couple of years ago, I commented on
Kenneth Iverson,
also closely associated with his own programming language,
APL. Ironically, APL offers a most extreme form of liberation
from the von Neumann machine. Thinking of Iverson and Backus
together at this time seems especially fitting.
The Fortran programmers among us know what the title means.
RIP.
Last week I ran across this quote by noted rocker Elvis
Costello:
Writing about music is like dancing about architecture --
it's really a stupid thing to want to do.
My immediate reaction was an intense no.
I'm not a dancer, so my reaction was almost exclusively
to the idea of writing about music or, by extension, other
creative activities. Writing is the residue of thinking,
an outward manifestation of the mind exploring the world.
It is also, we hope, occasionally a sign of the mind growing,
and those who read can share in the growth.
I don't imagine that dancing is at all like writing in this
respect.
Perhaps Costello meant specifically writing about music and
other pure arts. But I did
study architecture
for a while, and so I know that architecture is not a pure
art. It blends the artistic and purely creative with an
unrelenting practical element: human livability. People
have to be able to use the spaces that architects create.
This duality means that there are two levels at which one
can comment on architecture, the artistic and the functional.
Costello might not think much of people writing about the
former, but he may allow for the value in people writing
about the latter.
I may be overthinking this short quote, but I think it might
have made more sense for Costello to have made this analogy:
"Writing about music is like designing a house about dancing
...". But that doesn't have any of the zip of his original!
I can think of one way in which Costello's original makes
some sense. Perhaps it is taken out of context, and implicit
in the context is the notion of only writing about
music. When someone is only a critic of an art form, and
not a doer of the art form, there is a real danger of becoming
disconnected from what practitioners think, feel, and do.
When the critic is disconnected from the reality of the domain,
the writing loses some or all of its value. I still think it
is possible for an especially able mind to write about without
doing, but that is a rare mind indeed.
What does all this have to do with a blog about software and
teaching? I find great value in many people's writing about
software and about teaching. I've learned a lot about how to
build more expressive, more concise, and more powerful software
from people who have shared their experiences writing such
software. The whole
software patterns
movement is founded upon the idea that we should share our
experiences of what works, when and why. The
pedagogical patterns
community and the SIGCSE community do the same for teachers.
Patterns really do have to be founded in experience, so "only"
writing patterns without practicing the craft turns out to be
a hollow exercise for both the reader and the writer, but
writing about the craft is an essential way for us to share
knowledge. I think we can share knowledge both of the practical,
functional parts of software and teaching and of the artistic
element -- what it is to make software that people want
to read and reuse, to make courses that people want to take.
In these arts, beauty affects functionality in a way that we
often forget.
I don't yet have an appetite for dancing about software,
but my mind is open on the subject.
I'm communications chair for
OOPSLA 2007
and was this morning updating the CFP for the research papers
track, adding URLs to each member of the program committee.
Chair David Bacon has assembled quite a diverse committee,
in terms of affiliation, continent, gender, and research
background. While verifying the URLs by hand, I visited
Yannis Smaragdakis's
home page and ran across his self-proclaimed
Yannis's Law.
This law complements Moore's Law in the world of software:
Programmer productivity doubles every 6 years.
I have long been skeptical of claims that there is a "software
crisis", that as hardware advances give us incredibly more
computing power our ability to create software grows slowly,
or even stagnates. When I look at the tools that programmers
have today, and at what students graduate college knowing, I
can't take seriously the notion that programmers today are
less productive than those who worked twenty or more years ago.
We have made steady advances in the tools available to mainstream
programmers over the last thirty years, from frameworks and
libraries, to patterns, to integrated environments such as
.NET and Eclipse, down to the languages we use, like Perl,
Ruby, and Python. All help us to produce more and better code
in less time than we could manage even back when I graduated
college in the mid-1980s.
Certainly, we produced far fewer CS graduates and and employed
far fewer programmers thirty years ago, and so we should not be
surprised that that cohort was -- on average -- perhaps stronger
than the group we produce today. But we have widened the channel
of students who study CS in recent decades, and these kids do
all right in industry. When you take this democratization of
the pool of programmers into account, I think we have done all
right in terms of increasing productivity of programmers.
I agree with Smaragdakis's claim that a decent programmer working
with standard tools of the day should be able to produce Parnas's
KWIC index system in a couple of hours. I suspect that a decent
undergrad could do so as well.
Building large software systems is clearly a difficult task, one
usually dominated by human issues and communication issues. But
we do our industry a disservice when we fail to see how far we
have come.
SIGCSE Day 2: Read'n', Writ'n', 'Rithmetic ... and Cod'n'
Back in 2005, Grady Booch gave a
masterful invited talk
to close OOPSLA 2005, on his project to preserve software
architectures. Since then, he has undergone open-heart
surgery to repair a congenital defect, and it was good to
see him back in hale condition. He's still working on his
software architecture project, but he came to SIGCSE to
speak to us as CS educators. If you read
Grady's blog,
you'll know that he blogged about speaking to us back on
March 5. (Does his blog have permalinks to sessions that
I am missing?) There, he said:
My next event is
SIGCSE
in Kentucky, where I'll be giving a keynote titled Read'n,
Writ'n, 'Rithmetic...and Code'n. The gap between the
technological haves and have-nots is growing and the gap
between academia and the industries that create these
software-intensive systems continues to be much lamented.
The ACM has pioneered
recommendations for curricula,
and while there is much to praise about these recommendations,
that academia/industry gap remains. I'll be offering some
observations from industry why that is so (and what might be
done about it).
And that's what he did.
A whole generation of kids has grown up not knowing a time
without the Internet. Between the net, the web, iPods,
cell phones, video games with AI characters... they think
they know computing. But there is so much more!
Grady recently spent some time working with grade-school
students on computing. He did a lot of the usual things,
such as robots, but he also took a step that "walked the
walk" from his
OOPSLA talk --
he showed his students the code for Quake. Their
eyes got big. There is real depth to this
video game thing!
Grady is a voracious reader, "especially in spaces outside
our discipline". He is a deep believer in broadening the
mind by reading. This advice doesn't end with classic
literature and seminal scientific works; it extends to the
importance of reading code. Software is everywhere. Why
shouldn't read it to learn to understand our discipline? Our
CS students will spend far more of their lives reading code
than writing it, so why don't we ask them to read it? It is
a great way to learn from the masters.
While there may be part of computer science
that is science,
that is not what Booch sees on a daily basis. In industry,
computing is an engineering problem, the resolution of forces
in constructing an artifact. Some of the forces are static,
but most are dynamic.
What sort of curriculum might we develop to assist with this
industrial engineering problem? Booch referred to the IEEE
Computer Society's Software Engineering Body of Knowledge
(SWEBOK)
project in light of his own software architecture effort. He
termed SWEBOK "noble but failed", because the software
engineering community was unable to reach a consensus on the
essential topics -- even on the glossary of terms! If we
cannot identify the essential knowledge, we cannot create a
curriculum to help our students learn it.
He then moved on to curriculum design. As a classical guy, he
turned to the historical record, the
ACM 1968 curriculum recommendations.
Where were we then?
Very different from now. A primary emphasis in the '68
curriculum was on mathematical and physical scientific computing
-- applications. We hadn't laid much of the foundation of
computer science at that time, and the limitations of both
the theoretical foundations and physical hardware shaped the
needs of the discipline and thus the curriculum. Today,
Grady asserts that the real problems of our discipline are
more about people than physical limits. Hardware is cheap.
Every programmer can buy all the computing power she needs.
The programmer's time, on the other hand, is still quite
expensive.
What about
ACM 2005?
As an outsider, Grady says, good work! He likes the way
the problem has been decomposed into categories, and the
systematic way it covers the space. But he also asks about
the reality of university curricula; are we really teaching
this material in this way?
But he sees room for improvement and so offered some
constructive suggestions for different ways to look at the
problem. For example, the topical categories seem limited.
The real world of computing is much more diverse than our
curriculum. Consider...
Grady has worked with
SkyTV.
Most of their software, built in web-centric world, is less
than 90 days old. Their software is disposable! Most of
their people are young, perhaps averaging 28 years old or so.
He has also worked with people at the London Underground.
Their software is old, and their programmers are old (er,
older). They face a legacy problem like no other, both in
their software and in their physical systems. I'm am
reminded of my interactions with colleagues from Lucent, who
work with massive, old physical switching systems driven by
massive, old programs that no one person can understand.
What common theme do SkyTV and London Underground folks
share? Building software is a team sport.
Finally, Grady looked at the ACM K-12 curriculum guidelines.
He was so glad to see it, so glad to that see we are teaching
the ubiquitous presence of computing in contemporary life to
our young! But we are showing them only the fringes of the
discipline -- the applications and the details of the OS
du jour. Where do we teach them our deep ideas,
the beauty and nobility of our discipline?
As he shifted into the home stretch of the talk, Grady
pointed us all to a blog posting he'd come across called
The Missing Curriculum for Programmers and High Tech
Workers,
written by a relatively recent Canadian CS grad working in
software. He liked this developers list and highlighted
for us many of the points that caught his fancy as potential
modifications to our curricula, such as:
Sometimes, worker harder or longer won't get the job done.
Learn a scripting language!
Documentation is essential, but it must be tied to code.
Learn the patterns of organization behavior.
Learn about many other distinctly human elements of the
profession, like meetings (how to stay awake, how to
avoid them), hygiene (friend or foe?), and planning for
the future.
One last suggestion for our consideration involved his
Handbook of Software Architecture.
There, he has created categories of architectures that he
considers the genres of our discipline. Are these genres
that our students should know about? Here is a challenging
thought experiment: what if these genres were the categories
of our curriculum guidelines? I think this is a fascinating
idea, even if it ultimately failed. How would a CS curriculum
change if it were organized exclusively around the types of
systems we build, rather than mostly on the abstractions of
our discipline? Perhaps that would misrepresent CS as
science, but what would it mean for those programs that are
really about software development, the sort of engineering
that dominates industry?
Grady said that he learned a few lessons from his excursion
into the land of computing curriculum about what (else) we
need to teach. Nearly all of his lessons are the sort of
things non-educators seem always to say to us: Teach
"essential skills" like abstraction and teamwork, and teach
"metaskills" like the ability to learn. I don't diminish
these remarks as not valuable, but I don't think these folks
realize that we do actually try to teach these, but
they are hard to learn, especially in the typical
school setting, and so hard to teach. We can address the
need to teach a scripting language by, well, adding a
scripting language to the curriculum in place of something
less relevant these days. But newbies in industry don't
abstract well because they haven't gotten it yet, not
because we aren't trying.
The one metaskill on his list that we really shouldn't forget,
but sometimes do, is "passion, beauty, joy, and awe". This
is what I love about Grady -- he considers these metaskills,
not squishy non-technical effluvium. I do, too.
During his talk, Grady frequently used the phrase "right and
noble" to describe the efforts he sees folks in our industry
making, including in CS education. You might think that this
would grow tiresome, but it didn't. It was uplifting.
It is both a privilege and a responsibility, says Grady, to
be a software developer. It is a privilege because we are
able to change the world in so many, so pervasive, so
fundamental ways. It is a responsibility for exactly the
same reason. We should keep this mind, and be sure that our
students know this, too.
At the end of his talk, he made one final plug that I must
relay. He says that patterns are the coolest, most important
thing that have happened in the software world over the
last decade. You should be teaching them. (I do!)
And I can't help passing on one last comment of my own.
Just as he did
at OOPSLA 2005,
before giving his talk he passed by my table and said hello.
When he saw my iBook, he said almost exactly the same thing
he said back then: "Hey, another Apple guy! Cool."
I thought about calling this piece "The Case Against C"
but figured that this legal expression in the language
makes a reasonably good case on its own. Besides, that
is the name of a old paper by P.J. Moylan from which I
grabbed the expression.
(
PDF
|
HTML, minus footers with quotes)
When I first ran across a reference to this paper, I
thought it might make a good post for my attempt at the
Week of Science,
but by the author's own admission this is more diatribe
than science.
C is a medium-level language combining
the power of assembly language with
the readability of assembly language.
I finally finished reading the paper on my
way home from ChiliPLoP,
and it presented a well-reasoned argument that computer
scientists and programmers consider using languages that
incorporate advances in programming languages since the
creation of C. He doesn't diss C, and even professes an
admiration for it; rather he speaks to specific features
about which we know much more now than we did in the early
1970s. I ended up collecting a few good quotes, like the
one above, and a few good facts, trivia, and guidelines.
I'll share some of the more notable with you.
Facts, Trivia, and Guidelines
One of the features of C that is behind the times is
its weak support for modular code. C supports separate
compilation of modules, but Moylan reminds us that
modularity is really about information hiding and abstraction.
In this regard, C's system is lacking. Moylan gives a very
nice description of ten practices that one can adopt in
order to build effective modular programs in C, ranging
from technical advice such as "Exactly one header file per
module.", "Every module must import its own header file,
as a consistency check.", and "The compiler warning 'function
call without prototype" should be enabled, and any warning
should be treated as an error." to team practices such as
"Ideally, programmers working in a team should not have
access to one another's source files. They should share
only object modules and header files." He is not optimistic
about the consistent use of these rules, though:
Now, the obvious difficulty with these rules is that few
people will stick to them, because the compiler does not
enforce them. ... And, what is worse, it takes only one
programmer in a team to break the modularity of a project,
and to force the rest of the team to waste time with grep
and with mysterious errors caused by unexpected side-effects.
Moylan gives a simple example that as concisely as
possible how C's #include directive can lead to
a program that is in an inconsistent state because some
modules which should have been re-compiled were not. The
remedy of always recompiling everything is obviously
unattractive to anyone working on a large system.
Conventional wisdom says that C compilers produce
faster code than compilers for other things. Moylan
objects on several grounds, including the lack of any
substantial recent evidence for the conventional wisdom.
He closes with my favorite piece of trivia from the
paper:
It is true that C compilers produced
better code, in many cases, than the Fortran compilers of
the early 1970s. This was because of the very close
relationship between the C language and PDP-11 assembly
language. (Constructs like *p++ in C have the
same justification as the three-way IF of Fortran II:
they exploit a special feature of the instruction set
architecture of one particular processor.) If your
processor is not a PDP-11, this advantage is lost.
I learned my assembly language and JCL on an IBM mainframe
and so never had the pleasure of writing assembly for a
PDP-11. (I did learn Lisp on a PDP-8, though...) Now
I want to go learn about the
PDP-11's assembly language
so that I can use this example at greater depth in my
compilers course next semester.
Favorite Quotes
You've already seen one above. My other favorite is:
Much of the power of C comes from having a powerful
preprocessor. The preprocessor is called a programmer.
There were other good ones, but they lack the technical
cleanness of the best because they could well be said of
other languages. Examples from this category include
"By analysis of usenet source, the hardest part of C to
use is the comment." and "Real programmers can write C
in any language." (My younger readers may not know what
Moylan means by "usenet", which makes me feel old. But
they can learn more about it
here.)
----
As readers here probably know from earlier posts such as
this one,
I'm as tempted by a guilty language pleasure as anyone,
so I enjoyed Moylan's article. But even if we discount
the paper's value for its unabashed advocacy on language
matters, we can also learn from his motivation:
I am not so naive as to expect that diatribes such as
this will cause the language to die out. Loyalty to a
language is very largely an emotional issue which is
not subject to rational debate. I would hope, however,
that I can convince at least some people to re-think
their positions.
I recognise, too, that factors other than the inherent
quality of a language can be important. Compiler
availability is one such factor. Re-use of existing
software is another; it can dictate the continued use
of a language even when it is clearly not the best choice
on other grounds. (Indeed, I continue to use the language
myself for some projects, mainly for this reason.) What
we need to guard against, however, is making
inappropriate choices through simple inertia.
Just to keep in mind that we have a choice of
language each time we start a new project is a worthwhile
lesson to learn.
Our working group had its most productive ChiliPLoP in recent
memory this year. The work we did isn't ready for public
consumption yet, so I can't post a link just yet, but I am
hopeful that we will be able to share our results with
interested educators soon enough. For now, a summary.
This year, we made substantial progress toward producing a
well-documented resource for instructors who want to teach
Java and OOP. As our working paper begins:
The following set of exercises builds up a simple application
over a number of iterations. The purpose is to demonstrate,
in a small program, most of the key features of object-oriented
programming in Java within a period of two to three weeks. The
course can then delve more deeply into each of the topics introduced,
in whatever order the instructor deems appropriate.
An instructor can use this example to lay a thin but complete
foundation in object-oriented Java for an intro course within the
first few weeks of the semester. By introducing many different
ideas in a simple way early, the later elements of the course
can be ordered at the instructor's discretion. So many other
approaches to teaching CS 1 create strict dependencies between
topics and language constructs, which limits the instructor's
approach over the course of the whole semester. The result is
that most instructors won't adopt a new approach, because they
either cannot or do not want to be tied down for the whole
semester. We hope that our example enables instructors to do
OO early while freeing them to build the rest of their course
in a way that fits their style, their strengths and interests,
and their institution's curriculum.
Our longer-term goal is that this resource serve as a good example
for ourselves and for others who would like to document teaching
modules and share them with others. By reducing external
dependencies to a minimum, such modules should assist instructors
in assembling courses that use good exercises, code, and OO
programming practice.
... but where are the patterns? Isn't a
PLoP conference
about patterns? Yes, indeed, and that is one reason that I'm more
excited about the work we did this week than I have been in a while.
By starting with a very simple little exercise, growing progressively
into an interesting simulation via short, simple steps, we have
assembled both a paradigmatic OO CS 1 program and
the sequence of changes necessary to grow it. To me, this is an
essential step in identifying the pattern language that generates
the program. I may be a bit premature, but I feel as if we are
very close to having documented a pattern sequence in the
Alexandrian sense.
Such a pattern sequence is an essential part of a pattern-oriented
approach to design, and one that only a few people -- Neil Harrison
and
Jim Coplien
-- have written much about. And, like Alexander's idea of pattern
diagnosis, pattern sequences will, I think, play a valuable role in
how we teach pattern-directed design.
My self-assigned task is to explore this extension of our ChiliPLoP
work while the group works on filling in some details and completing
our public presentation.
One interesting socio-technical experiment we ran this week was
to write collaboratively using a
Google doc.
I'm still not much a fan of browser-based apps, especially word
processors, but this worked out reasonably well for us. It was
fast, performed autosaves in small increments, and did a great
job handling the few edit conflicts we caused in two-plus days.
We'll probably continue to work in this doc for a few more weeks,
before we consider migrating the document to a web page that we
can edit and style directly.
Two weeks from today, the whole crew of us will be off to SIGCSE
2007, which is an unusual opportunity for us to follow up our
ChiliPLoP and hold ourselves accountable for not losing momentum.
Of course, two weeks back home
like this
would certainly wipe my mind clear of any personal momentum I
have built up, so I will need to be on guard!
Programming Patterns and "The Conciseness Conjecture"
For most of my research career, I have been studying patterns in
software. In the beginning didn't think of it in these terms.
I was a graduate student in AI doing work in knowledge-based
systems, and our lab worked on so-called
generic tasks,
little molecules of task-specific design that composed into
systems with expert behavior. My first uses of the term
"pattern" were home-grown, motivated by an interest to help
novice programmers recognize and implement the basic structures
that made up their Pascal, Basic, and C programs. In the mid-1990s
I came into contact with the work of
Christopher Alexander
and the
software patterns community,
and I began to write up patterns of both sorts, including
Sponsor-Selector,
loops,
Structured Matcher,
and even
elementary patterns
of Scheme programming for
recursion.
My interest turned to the patterns at the interface between
different programming styles, such as object-oriented and
functional programming. It seemed to me that many object-oriented
design patterns implemented constructs that were available
more immediately in functional languages, and I wondered
whether it were true that patterns in any one style would
reflect the linguistic shortcomings of the style, implementing
ideas available directly in another style.
My work in this area has always been more phenomenological
than mathematical, despite occasional short side excursions
into promising mathematics like group and category theory.
I recall a 6- to 9-month period five or six years ago when
a graduate student and I looked group theory and symmetries
as a possible theoretical foundation for characterizing
relationships among patterns. I think that this work still
holds promise, but I have not had a chance to take it any
further.
Only recently did I finally read
Matthias Felleisen's
1991 paper
On the Expressive Power of Programming Languages.
I should have read it sooner! This paper develops a framework
for comparing languages on the basis of their expressiveness
powers and then applies it to many of the issues relevant to
language research of the day. One section in particular speaks
to my interest in programming patterns and shows how Felleisen's
framework can help us to discern the relative merits of more
expressive languages and the patterns that they embody. This
section is called "The Conciseness Conjecture". Here is the
conjecture itself:
Programs in more expressive programming languages that use
the additional features in a sensible manner contain fewer
programming patterns than equivalent programs in less
expressive languages.
Felleisen gives a couple of examples to illustrate his
conjecture, including one in which Scheme with assignment
statements realizes the implementation of an stateful object
more concisely, more clearly, and with less convention than
a purely functional subset of Scheme. This is just the sort
of example that led me to wonder whether functional programming's
patterns, like OOP's patterns, embodied ideas that were
directly expressible in another style's languages -- a Scheme
extended with a simple object-oriented facility would make
implementation of Felleisen's transaction manager even
clearer than the stateful lambda expression that
switches on transaction types.
Stated as starkly as it is, I am not certain I believe the
conjecture. Well, that's not quite true, because in one sense
it is obviously true. A more expressive language allows us to
write more concise code, and less code almost always means
fewer patterns. This is true, of course, because the patterns
reside in the code. I say "almost always" because there is
an alternative to fewer patterns in smaller code: the same
number of patterns, or more, in denser
code!
If we qualify "fewer programming patterns" as "fewer
lower-level programming patterns", then I most
certainly believe Felleisen's conjecture. I think that this
paper makes important contribution to the study of software
patterns by giving us a vocabulary and mechanism for talking
about languages in terms of the trade-off between expressiveness
and patterns. I doubt that Felleisen intended this, because
his section on the Conciseness Conjecture confirms his
uneasiness with pattern-driven programming. "The most
disturbing consequence," he writes, of programming patterns
is that they are an obstacle to understanding of programs for
both human readers and program-processing programs." For
him, an important result of his paper is to formalize "how
the use of expressive languages seems to be the ability to
abstract from programming patterns with simple statements and
to state the purpose of a program in the concisest possible
manner."
This brings me back to the notions of "concise" and "dense".
I appreciate the goal of using the most abstract language
possible to write programs, in order to state as unambiguously
and with as little text as possible the purpose and behavior
of a program. I love to show my students how, after learning
the basics of recursive programming. they can implement a
higher-order operation such as fold to eliminate the
explicit recursion from their programs entirely. What power!
all because they are using a language expressive enough to
allow higher-order procedure. Once you understand the
abstraction of folding, you can write much more concise code.
Where is the down side? Increasing concision ultimately leads
to a trade-off on understandability. Felleisen points to the
danger that dispersion poses for code readers: in the worst
case, it requires a global understanding of the program to
understand how the program embodies a pattern. But at the
other end of the spectrum is the danger posed by concision:
density. In the worst, the code is so dense as to overwhelm
the reader's sense. If density were an unadulterated good,
we would all be programming in a descendant of
APL!
The density of abstraction is often the reason "practical"
programmers cite for not embracing functional programming
is the density of the abstractions one finds in the code.
It is an arrogance for us to imply that those who do not
embrace Scheme and Haskell are simply not bright enough to
be programmers. Our first responsibility is to develop
means for teaching programmers these skills better, a
challenge that Felleisen and his
Teach Scheme!
brigade have accepted with great energy. The second is to
consider the trade-off between concision and dispersion in
a program's understandability.
Until we reach the purest sense of declarative programming,
all programs will have patterns. These patterns are the
recurring structures that programmers build within their
chosen style and language to implement behaviors not
directly supported by the language. The patterns literature
describes what to build, in a given set of circumstances,
along with some idea of how to build the what in a way that
makes the most of the circumstances.
I will be studying "On the Expressive Power of Programming
Languages" again in the next few months. I think it has a
lot more to teach me.
Between meetings today, I was able to sneak in some reading.
A number of science bloggers have begun to write a series
of "basic concepts" entries, and one of the math bloggers
wrote a piece on the basics of
recursion and induction.
This is, of course, a topic well on my mind this semester
as I teach functional programming in my Programming
Languages course. Indeed, I just gave my first lecture on
data-driven recursion in class last Thursday, after having
given an introduction to induction on Tuesday. I don't spend
a lot of time on the mathematical sort of recursion in this
course because it's not all that relevant to to the processing
of computer programs. (Besides, it's not nearly as fun!)
This would would probably make a great "basic concepts in
CS" post sometime, but I don't have time to write it today.
But if you are interested, you can browse my
lecture notes
from the first day of recursive programming techniques in
class.
(And, yes, Schemers among you, I know that my placement of
parentheses in some of my procedures is non-standard. I do
that in this first session or so so that students can see the
if-expression that mimics our data type stand out.
I promise not to warp their Scheme style with this convention
much longer.)
People you've got the power over what we do
You can sit there and wait
Or you can pull us through
Come along, sing the song
You know you can't go wrong
-- Jackson Browne, "The Load-Out"
Every group of students is unique. This is evident every time
I teach a course. I think I notice these differences most when
I teach a course Programming Languages, the course I'm teaching
this semester.
In this course, our students learn to program in a functional
style, using Scheme, and then use their new skills to build small
language interpreters that help them to understand the principles
of programming languages. Because we ask students to learn a new
programming style and a language very different from any they
know when the enter the course, this course depends more than
most on the class's willingness to change their minds. This
willingness is really attribute of each of the individuals in the
class, but groups tend to develop a personality that grows out of
the individual personalities which make it up.
The last time I taught this course, I had a group that was eager
to try new ideas. These folks were game from Day 1 to try
something like functional programming. Many of them had studied
a language called
Mumps
in another course, which had shown them the power that can be
had in a small language that does one or two things well.
Many of them were Linux hackers who appreciated the power of
Unix and its many little languages. Scheme immediately appealed
to these students, and they dove right in. Not all of them ended
up mastering the language or style, but all made a good faith
effort. The result was an uplifting experience both for them and
for me. Each class session seemed to have a positive energy that
drove us all forward.
But I recall a semester that went much differently. That class
of students was very pragmatic, focused on immediate skills and
professional goals. While that's not always my orientation (I
love many ideas for their own sake, and look for ways to improve
myself by studying them), I no longer fault students who feel
this way. They usually have good reasons for having developed
such a mindset. But that mindset usually doesn't make for a very
interesting semester studying techniques for recursive programming,
higher-order procedures, syntactic abstractions, and the like.
Sure, these ideas show up -- increasingly often -- in the languages
that they will use professionally, and we can make all sorts of
connections between the ideas they learn and the skills they will
need writing code in the future. It's just that without a playful
orientation toward new ideas, a course that reaches beyond the
here-and-now feels irrelevant enough to many students to be seem
an unpleasant burden.
That semester, almost every day was a chore for me. I could feel
the energy drain from my body as I entered the room each Tuesday
and Thursday and encountered students who were ready to leave
before we started. Eventually we got through the course, and the
students may even have learned some things that they have since
found useful. But at the time the course was like a twice-weekly
visit to the dentist to have a tooth pulled.
In neither of these classes was there only the one kind of
student. The personality of the class was an amalgam, driven by
the more talkative members or by the natural leaders among the
students. In one class, I would walk into the room and find a
few of them discussing some cool new thing they had tried since
the last time we met; in the other, they would be discussing the
pain of the current assignment, or a topic from some other course
they were enjoying. These attitudes pervaded the rest of the
students and, at least to some extent, me. As the instructor, I
do have some influence over the class's emotional state of mind.
If I walk into the room with excitement and energy, my students
will feel that. But the students can have the same effect. The
result is a symbiotic process that requires a boost of energy from
both sides every class period.
We are now two weeks into the new semester, and I am trying to get
a feel for my current class. The vocal element of the class has
been skeptical, asking lots of "why?" questions about functional
programming and Scheme alike. So far, it hasn't been the negative
sort of skepticism that leads to a negative class, and some of the
discussion so far has had the potential to provoke their curiosity.
As we get deeper into the meat of the course, and students have a
chance to write code and see its magic, we could harness their
skepticism into a healthy desire to learn more.
Over the years, I've learned how better to respond to the sort
of questions students ask at the outset of the semester in this
course. My goal is to lead the discussion in a way that is at
the same time intellectually challenging and pragmatic.
I learned long ago that appealing only to the students' innate
desire to learn abstract ideas such as continuations doesn't
work for the students in my courses. In most practical ways,
the course is about what they need to learn, not about what I
want blather on about. And as much as we academics like papers
such as
Why Functional Programming Matters
-- and I do like this paper a lot! -- it is only persuasive to
programmers who are open to being persuaded.
But I've also found that pandering to students by telling them
that the skills they are learning can have an immediate effect
on their professional goals does not work in this sort of course.
Students are smart enough to see that even if Paul Graham got rich
writing ViaWeb in Lisp,
most of them aren't going to be starting their own companies,
and they are not likely to get a job where Scheme or functional
programming will matter in any direct way. I could walk into
class each day with a different example of a company that has
done something "in the real world" with Scheme or Haskell, and at
the end of the term most students would have perceived only thirty
isolated and largely irrelevant examples.
This sort of course requires balancing these two sets of forces.
Students want practical ideas, ideas that can change how they do
their work. But we sell students short when we act as if they
want to learn only practical job skills. By and large they do
want ideas, ideas that can change how they think. I'm
better at balancing these forces with examples, stories, and
subtle direction of classroom discussion than I was ten or fifteen
years ago, but I don't pretend to be able to predict where we'll
all end up.
Today we begin a week studying Scheme procedures and some of the
features that make functional programming different from what they
are used to, such as first-class procedures, variable arity,
higher-order procedures, and currying. These are ideas with the
potential to capture the students' imagination -- or to make them
think to themselves, "Huh?" I'm hopeful that we'll start to build
a positive energy that pulls us forward into a semester of discovery.
I don't imagine that they'll be just like my last class; I do hope
that we can be a class which wants to come together a couple of
times every week until May, exploring something new and wonderful.
Tiger Woods recently won the PGA's
Player of the Year
for the eighth time in his ten-year professional
career. Since 1990, no other player has won the award more
than twice. He is widely considered the most dominant athlete
in any sport in the world -- which is saying a lot when you
consider the amazing runs that tennis's Roger Federer and
cycling's Lance Armstrong have had during Tiger's own run.
Woods is great, but he also stands out for something else:
his remarkable efforts to get better. Now, most
pros are continually working on the games, trying to improve
their skills. Woods has taken this effort to a new level,
by completely rebuilding his swing twice during his professional
career. Sportswriter Leonard Shapiro
describes Woods's most recent reconstruction,
back in 2004 and early 2005. In 2004, a lot of commentators
thought that Tiger had perhaps peaked, as other players on
the Tour had been winning the majors and left him as just
another competition. Tiger wasn't striking the ball as well,
and his tee shots were errant. He seemed to have gotten
worse. But suddenly in 2005, he returned to the top of the
leaderboard with a vengeance and had one of the all-time
great years in PGA history.
You see, while Tiger was seemingly getting worse, he was
actually getting better.
A golf swing is complex mechanical act. There is very little
margin of error between a great shot and a merely good shot.
At the top level of golf, the standard deviation is even
smaller. When Tiger decided that he had reached a plateau
in his game with his current swing, he knew that he had to
develop an entirely new swing. And while he was building
that new swing, using it on every shot for nearly eighteen
months, he performed worse than he had with the old swing.
Only after all that repetition, feedback, and adjustment
did he have the swing he needed to regain his peak. And his
new peak was even higher than the old one.
This progression from plateau to valley to new peak is not
unique to Tiger or to golf swings. Any complex skill that
depends on muscle memory requires the sort of repetition
and feedback that usually results in degraded performance
during the learning phase. The key to improvement in this
phase is patience. Learning a new skill takes time, while
we train our brains and bodies to execute their tasks in an
accurate, repeatable way.
Mental skills, even ones that we carry out with more conscious
attention, have this feature. Sometimes, we can make only
small incremental improvements from our current skill base,
but an effort to learn something radically different can
alter our skill base in a qualitative way -- and result in
radical improvements in our performance.
Many programmers know this. The last couple of years, a
common new year meme among bloggers has been to learn a new
language. Often the language is something very different
from their daily tools of Java and XML and C. Haskell, Ruby,
Scheme, and Smalltalk seem to show up on peoples' lists
frequently precisely because they are so different. They
offer the promise of a radical improvement in skill because
to master them requires looking at problems and solutions in
a radically different. You can't speak fluid Haskell or
Scheme without coming to grips with a functional mindset.
Even if list comprehensions, continuations, and tail recursion
are not part of the programming language you use in your day
job, understanding them can help you use that language in a
new way. And who knows, those features may ultimately make
their way into your day job's language -- either this one,
or the next one.
Martin Fowler writes about his own experience crossing the
improvement ravine
on the way to new mastery. He even quotes Gerald Weinberg,
whom I've mentioned occasionally since I
first began blogging.
Martin points out a couple of key insights. One is that
sometimes the new thing doesn't work, at least for you.
Worse, there is a
Halting Problem
complicating matters: you can't be sure if the technique has
failed for you or if you just need to stick with it a little
longer. The best hope for circumventing this problem is to
have a good teacher working with you, whether in a classroom
or one one one. Tiger had his coach, Hank Haney, to help him
assess the state of his swing and decide to keep going, even
during the darkest days of 2004. Working with colleagues or
a trusted friend can also serve this purpose.
I think another key to this process is a sort of courage.
It's hard to be patient while you're failing, or while you're
struggling with a new idea. In this context, your teacher
coach, or friend plays the important role of support system,
encouraging you to stick with the process. As with almost
anything, doing it over and over helps us to have the courage
we need. Tiger's 2004 rebuild was the second such publicized
episode of his career, and I'm guessing that having succeeded
in the first helped him to remain steadfast during the second.
One requires less courage as one feels less fear. But I think
that I will always feel a real fear anytime I step way outside
my expertise in an effort to get better. Maybe even a great
one such as Tiger does, too. Courage will always play a role.
This notion of getting worse for a while in order to get better
is on my mind right now because I have just begun a new semester
in which I will try to teach Scheme and functional programming
to a bunch of students who probably feel pretty comfortable
in their imperative programming skills with Java, C++, and Ada.
I have to help them see that mastering such a different new
language, and especially style of programming, will require
that they feel awkward for a while. The tried-and-true syntax,
operators, idioms, and patterns no longer seem to work. That
is scary. But it's worth going through this scary
phase, practicing "the real thing" as much as they can. With
practice and time, they will soon learn the new syntax, master
the new operators, appreciate the new idioms and develop some
of their own, and finally discover the new patterns that will
make them better programmers than they were before.
My memory is always drawn back to two former students in particular
who approached this in a Tiger-like fashion. They went home
every night for three weeks or so and just tried to write good
functional programs in Scheme. They read my examples and those
from the textbook; they experimented with small modifications
and then large ones, eventually trying to write whole programs.
For a while this was painful, because their programs broke and
my evaluation of their homework didn't result in the easy As to
which they had become accustomed. But suddenly -- or so it
seemed -- they got it. They were excellent functional
programmers. The rest of their Programming Languages course
went smoothly, as they could focus on the language concepts
without having to worry about whether they could make Scheme
work for them.
If the greatest golfer in the world, the most dominant athlete
of a generation, can take the time to get worse for a while in
order to get better, I think we all can. But do we have the
patience and courage to take the chance and stay the course?
And do we have the teachers and coaches who can help us along
the way?
Yesterday while clearing out some of the paper that has
built up in my office over the course of the semester,
I was reading through the conference copy of several
sets of OOPSLA tutorial notes. One that grabbed by
interest was from a tutorial that we had to cancel for
lack of registration, on how to write user guides and
tutorial documents. OOPSLA caters to software developers,
and we knew at the time we accepted this one that the
audience might be slim. But as I thought about the
notes I was sad that we didn't attract more of an audience
for this tutorial. It would have been useful to a lot
of folks.
I was struck by the fact that writers of documentation for
users face many of the same issues that teachers face.
The first part of the tutorial dealt with users and
learning: what they need to learn, and how they can learn
it. The writer needs to remember that the user doesn't
see the system in the same way as the developer, and may
in fact be a different sort of person entirely. This echoes
the recent "our students aren't like us" theme in several
of my posts. The tutorial then proceeds to give concrete
advice on the such topics as:
the differences between learning by reading and
learning by doing
the cognitive burden shouldered by learners
the distinction between dedicates learners and
midtask learners
I think that I sometimes assume that my students will be
dedicated learners, focused on the ideas that I am trying
to convey, rather than midtask learners, focused on
getting something done. But I suspect that many students
do a lot of their learning just-in-time, while attempting
a programming assignment or homework problem. Midtask
learners approach the learning task differently than the
dedicated learner. In particular, they tend to look for
what they need right now and stop reading as soon as they
find it -- or realize that they won't! This makes brevity
and specificity important elements of user documentation.
They are just as important when writing instructions and
tutorials for students.
The tutorial goes on to give concrete advice and examples
on how to write instructions, how to induce rehearsal in
the learner, and how to organize presentation to avoid
overloading the learner. Almost every page of the notes
has something to use as I think about refining my spring
Programming Languages and Paradigms course. I've written
extensive lecture notes for this course, of which I'm
proud. But I think I'll use some of my prep time in the
coming term to apply the ideas from this tutorial to my
lectures. I can think of a couple ways to improve them:
varying the strategies I use to invoke rehearsal
(zooming and out, changing modes of presentation,
and supporting a new assertion with what we just
learned)
making sure that my instructions clearly communicate
their intention, endpoint, time frame, and possible
signs o success and failure.
I guess I am not surprised by the similarities among writing
user doc and writing for students (and teaching from that
writing), but it never occurred to me to mine the former
to help me improve the latter.
These tutorial notes were fun to read even without having
the presenter in the room. They were written well, spare
but engaging. That said, as with most printouts from
slide presentations, I would have learned a lot more by
having the writer tell the stories that were abstracted
into her slides. And I definitely would like to see the
examples that she had planned to distribute to illustrate
the ideas in the tutorial.
User documentation is certainly not the only other writing
form from which instructors can draw ideas and inspiration.
Nat Pryce recently wrote about the idea of using
the comic book as a form for end-user documentation,
and there may be something we instructors could learn from
comic book writers. Before you scoff, recall that the
U.S. 9/11 Commission Report
The Path to 9/11
was adapted into a highly-acclaimed
comic book.
(If I recall correctly, either artist Ernie Colon or writer
Sid Jacobson is from my adopted state of Iowa.)
I think the OOPSLA crowd missed a good opportunity to learn
from this tutorial. But there is one consolation... I believe
that the tutorial presenter is currently writing a book on this
topic. I'll definitely pick up a copy, and not because I plan
to write a lot of user documentation.
Almost every day I am reminded of how the way the world
works is changing all around us. For example, Philip
Windley writes of the day, coming soon, when
MP3 player are like pens
-- "everywhere, given away, easily abandoned, even disposable".
(I almost wrote "ballpoint pens", but that would betray
my ever more apparent state of being a dinosaur.)
Then I learned about
My Dream App,
which lies at the convergence of American Idol, the
web, and the independent software world:
My Dream App is a grand experiment to see what happens
when you combine the expertise of some of the best
talents in the software and tech world with great ideas
and feedback from everyone else.
Like Idol, My Dream App had open tryouts to get into the
pool of contestants and then judging by a panel of experts
as the apps were winnowed through a series of rounds.
However, My Dream App's panel of experts puts Idol's to
shame! At the end, the viewing public selected winners
by voting on-line. At stake was not a recording contract
but a contract to have the idea implemented by a crack
team of Mac developers, with royalties for life. The
coding team has some great developers, including one of
the guys behind
SubEthaEdit.
While I'm not all that enamored by most of the apps that
finished at the top of the pile, with perhaps
one exception,
I think that this is a great idea. It exploits the power
of a large number of people to brainstorm ideas and then
allows them to participate in a selection process that is
guided by informed folks who can provide a more focused
perspective. And the allure of having Woz act as Simon
Cowell must surely have attracted a few people to take
their shot at submitting an idea. "That's the most
pathetic feature I've seen since Bill Atkinson
wanted to
prevent users from specifying their own desktop patterns
on the original Mac."
This is a new variation in the space of idea generation
that I
have written about before.
On one end of a continuum is the great solo creator like
Steve Jobs, who seems to have an innate sense of what of
is good; at the other end is Howard Moskowitz, who
produces an insanely large set of possibilities, including
strange ones that we think no one might like, and then lets
people discover what they like. My Dream App is more in
the Moskowitz vein, but with a twist -- let everyone with
an internet connection build your set of possibilities for
you, and then let the crowd work with informed guides to
winnow the set. The ubiquity of the web makes possible a
collaborative process that would have been unwieldy at best
in earlier times.
I wonder long it will be before a mainstream producer --
say, an automobile manufacturer -- uses this sort of approach
to design a mainstream product. Just imagine... the 2009
Long Tail coupe, original idea by a insurance executive in
Hawarden, Iowa, refined by the masses under the watchful
eye of Lee Iacocca. Many auto manufacturers do worse on
their own. When harnessed in the right sort of process,
the wisdom of the crowd is a powerful force.
I like to write code that most people take for granted.
I like to write code to solve hard problems. I like
to write simple programs. I like to solve the programming
assignments that I set before my students. I like to
discover problems to solve and then solve them with code.
Sometimes, I like to make up problems just so I can write
code to solve them.
A colleague of mine is fond of reminding university
professors that they are not like most of our students.
He means that in the sense that we professors were
usually good students, or at least students who liked
school, and that we can't expect our students to think
the way we do or to like school the way we did. This
can be useful as we design our courses and plan our
day-to-day interactions with students. It's wise for
me to remember that I am probably not like all of my
students in another way: I just love to write code.
One of my great joys as an instructor is to come across
a student, or even a class full of students, who love to
write code. I enjoy working with them in class, and on
independent projects, and on undergraduate research. I
learn from them, and I hope they learn a little from me
along the way:
Ultimately we learn best by placing our confidence
in men and women whose examples invite us
to love what they love.
-- Robert Wilken
One of my colleagues occasionally comments that many of the
folks in our department don't often practice in the rest of
our professional lives what we preach in our areas of technical
expertise. For example, in software engineering we often speak
of the importance of gathering requirements, writing a complete
specification, and then later testing our product to ensure
that it meets the spec. But CS faculty are often reluctant
to practice these ideas in the context of curriculum and
departmental mission, which leads to a lack of motivation for
tasks such as
academic program review
both on the side of specifying concrete department goals and
concrete course competencies and on the side of measuring
outcomes.
My colleague's observation is usually true. Expertise doesn't
transfer very well across domains of practice; and, even when
the mindset transfers, the practices and habits don't. It takes
a lot of work to translate the mindset into the new habits we
need in the new domain, and we have to watch out for pitfalls
that let us convince ourselves that the new domain is so different
that we can't practice what we preach.
Though my colleague has never made his observation to me when
commenting on my performance, I know well that I am guilty.
I strongly encourage the use of agile methods in software
development, and I've even written in this space on how I have
intended to "be agile" in how I approach my administrative
duties. But as I look back over my first fifteen months as
a department head, I see a path littered with good intentions
leading to a very different place than I wanted to be.
I had hoped to write a retrospective of my first year in the
Big Office by now, but I haven't yet -- in part because I
don't feel I have synthesized much of an understanding of
what I do yet, but also in part, I think, because I feel a
bit ashamed of my weaknesses. I haven fallen woefully
behind on several major projects, including ones that were
centerpieces of my desire to become head. As I look back,
I see many of the signature problems of big software projects
falling behind. As Fred Brooks tells us in The Mythical
Man-Month, how do disastrously late projects get that way?
"One day at a time." When I fall farther behind, it is rarely
because a
major task
preempts my time; most of the slippage in my schedule
results from "termites" -- little interruptions, small
distractions, and bad decisions made in the small.
I am agile in mindset, but not in practice. How can I change
that? Go back to the basics: Define small tasks. Define
"tests" that will help me know that I have made concrete progress.
Release small deliverables frequently to the folks who depend
on my work, especially the faculty.
I know what to do. Now it is time to get serious about new
practices for the new tasks I tackle.
In addition to the several OOPSLA sessions I've already blogged
about, there were a number of other fun or educational moments
at the conference. Here are a few...
Elisa Baniassad
presented an intriguing Onward! talk called
The Geography of Programming.
She suggested that we might learn something about programming
language design by considering the differences between Western
and Eastern thought. Her motivation came from Richard Nisbett's
The Geography of Thought: How Asians and Westerners Think
Differently--And Why. One more book added to my must-read
list...
Partly in honor of OOPSLA stalwart John Vlissides, who
passed away since OOPSLA'05,
and partly in honor of Vlissides et al.'s seminal book
Design Patterns,
there was a GoF retrospective panel. I learned two bits of
trivia... John's favorite patterns were flyweight (which made
it into the book) and solitaire (which didn't). The oldest
instance of a GoF pattern they found in a real system?
Observer -- in Ivan Sutherland's
SketchPad!
Is anyone surprised that this pattern has been around that long,
or that Sutherland discovered its use over 40 years ago? I'm not.
On the last morning of the conference, there was scheduled
a panel on the marriage of XP and Scrum in industry. Apparently,
though, before I arrived on the scene it had morphed into
something more generally agile. While discussing agile
practices, "Object Dave" Thomas admitted he believes that,
contrary to what many agilists seem to imply, comments in code
are useful. After all, "not all code can be read, being
encrypted in Java or C++ as it is". But he then absolved his
sin a bit by noting that the comment should be "structurally
attached" to the code with which it belongs; that is a tool
issue.
Then, on the last afternoon of the conference, I
listened in on the Young Guns panel, in which nearly a dozen
computer scientists under the age of 0x0020 commented on the
past, present, and future of objects and computing. One of
these young researchers commented that scientists tend to
make their great discoveries while still very young, because
they don't yet know what's impossible. To popularize this
wisdom, gadfly and moderator
Brian Foote
suggested a new motto for our community: "Embrace ignorance."
During this session, it occurred to me that I am no
longer a "young gun" myself, spending the six last days of my
0x0029th year at OOPSLA. This is part of how I try to stay
"busy being born", and I look forward to it every year. I
certainly don't feel like an old fogie, at least not often.
Finally, as we were wrapping up the conference in the
committee room after the annual ice cream social, I told
Dick Gabriel that I would walk across the street to hear
Guy Steele read a restaurant menu aloud. Maybe there is a
little bit of
hero worship
going on here, but I always seem to learn something when Steele
shares his thoughts on computing.
----
Another fine OOPSLA is in the books. The 2007 conference
committee is already at work putting together next year's
event, to be held in Montreal during the same week. Wish
us wisdom and good fortune!
OOPSLA Day 3: Philip Wadler on Faith, Evolution, and Programming Languages
"Of course, the design should be object-oriented." Um. "Of
course not. The design should be functional". Day 3's
invited speaker,
Philip Wadler,
is a functional programming guy who might well hear the first
statement here at OOPSLA, or almost anywhere out in a world
where Java and OO have seeped through the software development
culture, and almost as often he reacts with the second statement
(if only in his mind). He has come to recognize that these
aren't scientific statements or reactions; they are matters of
faith. But faith and science as talking about different things.
Shouldn't we make language and design choices on the basis of
science? Perhaps, but we have a problem: we have not yet put
our discipline on a solid enough scientific footing.
The conflict between faith and science in modern culture, such
as on the issue of evolution, reminds Wadler of what he sees
in the computing world. Programming language design over the
last fifty years has been on an evolutionary roller coaster,
with occasional advances injected into path of languages
growing out of the dominant languages of the previous generation.
He came to OOPSLA in a spirit of multiculturalism, to be a
member of a "broad church", hoping to help us see the source
of his faith and to realize that we often have alternatives
available when we face language and design decisions.
The prototypical faith choice that faces every programmer is
static typing versus dynamic typing. In the current ecosystem,
typing seems to have won out versus no typing, static typing
has usually had a strong upper hand over dynamic typing. Wadler
reminded us that this choice goes back to the origins of our
discipline, between the untyped lambda calculus of Alonzo Church
and the typed calculus of Haskell Curry. (Church probably did
not know he had a choice; I wonder how he would have decided
if he had?)
Wadler then walked us through his evolution as a programming
languages researcher, and taught us a little history on the
way.
Church: The Origins of Faith
Symbolic logic was largely the product of the 19th century
mathematician Gottlob Frege. But Wadler traces the source
of his programming faith to the German logician Gerhard
Gentzen (1909-1945). Gentzen followed in footsteps of Frege,
both as a philosopher of symbolic logic and as an anti-Semite.
Wadler must look past Gentzen's personal shortcomings to
appreciate his intellectual contribution. Gentzen developed
the idea of natural deduction and proof rules.
(Wadler showed us page of inference rules using the notation
o mathematical logic, and then asked for a show of hands to
see if we understood the ideas and the notation on his slides.
On his second question, enough of the audience indicated
uncertainty that he slowed down to explain more. He said that
he didn't mind the diversion: "It's a lovely story.")
Next he showed the basics of simplifying proofs -- "great
stuff", he old us, "at least as important as the calculus",
something man had searched for thousands of years. Wadler's
love for his faith was evident in the words he chose and the
conviction with which he said them.
Next came Alonzo Church, who did his work after Gentzen but
still in the first half of the 20th century. Church gave us
the lambda calculus, from which the typed lambda calculus was
"completely obvious" -- in hindsight. The typed lambda
calculus was all we needed to make the connection between
logic and programming: a program is a proof, and a type is a
proof term. This equivalence is demonstrated in the
Curry-Howard isomorphism,
named for the logician and computer scientist, respectively,
who made the the connection explicit. In Wadler's view, this
isomorphism predicts that logicians and computer scientists
will develop many of the same ideas independently, discovered
from opposite sides of the divide.
This idea, that logic and programming are equivalent, is
universal. In the movie,
Independence Day,
the good guys defeat the alien invaders by injecting a virus
written in C into its computer system. The aliens might not
have known the C programming language, and thus been vulnerable
on that front, but they would have to have
known the lambda calculus!
Haskell: Type Classes
The
Hindley-Milner algorithm
is named for another logician/computer scientist pair that made
the next advance in this domain. They showed that even without
type annotations an automated system can deduce the most general
data types that make the program execute. The algorithm is
both correct and complete. Wadler wanted to show us that this
idea is so important, so beautiful, that he took a step to the
side of his podium and jumped up and down!
Much of Wadler's renown in the programming language derives from
his seminal contributions to
Haskell,
a pure functional language based on Curry-Howard isomorphism and
the Hindley-Milner algorithm. Haskell implements these ideas in
the form of type classes. Wadler introduced this idea into the
development of Haskell, but he humbly credited others for doing
the hard work to make things work.
Java: Adding Generics
Java 1.4 was in many ways too simple. We had to use a List
of some sort for almost everything, in order to have polymorphic
structures. Trying to add C-style templates threatened to make
things only worse. What the Java team needed was... the lambda
calculus!
(At this moment, Wadler stopped his talk Superman-style and took
off his business suit to reveal his Lambda-man outfit. The crowd
responded with hearty applause!)
Java generics
have the same syntax as C++, but different semantics.
(He added parenthetically that Java generics "have semantics".)
The templates are merely syntactic sugar, rewritten into older
Java in a technique called "erasure". The rewrite produces
identical byte codes that a programmer's own Java might. Much was
written about this language addition both before and after he it
was made to the Java specification, and I don't want to get into
that discussion. But, as Wadler notes, this approaches supports
the evolution of the language in a smooth way, consistent with
existing Java practice. Java generics also bear more than a
passing resemblance to type classes, which means that it could
evolve into something more different -- and more.
Links: Reconciliation
Web applications typically consist in three tiers: the browser,
the server, and the database. All are typically programmed in
different languages, such as HTML, CSS, JavaScript, Perl, and
SQL. Wadler's newest language,
Links,
is intended to be one language used for all three tiers. It
compiles to SQL for running directly against a database. Links
is similar to the similar-sounding
LINQ,
a dynamic query language developed at Microsoft. The similarity
is no coincidence -- one of its architects,
Erik Meijer,
came from Haskell community. Again, type classes figure
prominently in Links. Programmers in the OO community can think
of them in an OO way with no loss of understanding. But they may
want to broaden their faith to include something more.
Wadler closed his talk by returning to the themes with which he
began: faith, evolution, and multiculturalism. He viewed the
OOPSLA conference committee's inviting him to speak as a strong
ecumenical step. "Faith is well and good", but he would like
for computer science to make inroads helping us to make better
decisions about language design and use. Languages like Links,
implemented with different features and used in experiments,
might help.
Last year, OOPSLA introduced another new track called Essays.
This track shared a motivation from another recent introduction,
Onward!, in providing an avenue for people to write and present
important ideas that cannot find a home in the research-oriented
technical program of the usual academic conference. But not all
advances are in the form of novelty, of results from
narrowly-defined scientific experiments. Some empirical results
are the fruit of experience, reflection, and writing. The Essays
track offers an avenue for sharing this sort of learning. The
author writes an essay in the spirit of
Montaigne
and
Bacon,
using the writing to work out an understanding of his experience.
He then presents the essay to the OOPSLA audience, followed by a
thoughtful response from a knowledge person who has read the
essay and thought about the ideas. (Essays crossed my path in
a different arena last week, when I blogged a bit on the idea of
blog as essay.)
Jim Waldo, a distinguished engineer at Sun, presented the first
essay of OOPSLA 2006, titled "On System Design". He reflected
on his many years as a software developer and lead, trying to
get a handle on what he now believes about the design of software.
What is a "system"? To Waldo, it is not "just a program" in the
sense he thinks meant by the
postmodern programming
crowd, but a collection of programs. It exists at many levels
of scale that must be created and related; hence the need for us
to define and manage abstractions.
Software design is a craft, in the classical sense. Many of
Waldo's engineer friends are appalled at what software engineers
think of as engineering (essentially the application of patterns
to roll out product in a reliable, replicable way) because what
engineers really do involves a lot of intuition and craft.
Software design is about technique, not facts. Learning technique
takes time, because it requires trial and error
and criticism. It requires patience -- and faith.
Waldo paraphrase Grady Booch as having said that the best benefit
of the Rational toolset was that it gives developers "a way to look
like they were doing something while they had time to think".
The traditional way to learn system design is via apprenticeship.
Waldo usually asks designers he respects who they apprenticed
with. At first he feared that at least a few would look at him
oddly, not understanding the question. But he was surprised to
find that every person answered without batting an eye. They
all not only understood the question but had an immediate
answer. He was also surprised to hear the same few names over
and over. This may reflect Waldo moving in particular circles,
or only a small set of master software developers out there!
In recent years, Waldo has despaired of the lack of time,
patience, and faith shown in industry for developing developers.
Is all lost? No. In reflecting on this topic and discussing
with readers of his early drafts, Waldo sees hope in two parts
of the software world: open source and extreme programming.
Consider open source. It has a built-in meritocracy, with
masters at the top of the pyramid, controlling the growth and
design of their systems. New developers learn from example --
the full source of the system being built. Developers face
real criticism and have the time and opportunity to learn and
improve.
Consider extreme programming. Waldo is not a fan of the agile
approaches and doesn't think that the features on which they
are sold are where they offer most. It isn't the illusion of
short-term cycles or of the incrementalism that grows a big
ball of mud which give him hope. In reality, the agile
approaches are based in a communal process that builds systems
over time, giving people the time to think and share, mentor
and learn. Criticism is built into the process. The system
is an open, growing example.
Waldo concludes that we can't teach system design in a class.
As an adjunct professor, he believes that system design skills
aren't a curriculum component but a curricular
outcome. Brian Marick, the discussant on
Waldo's took a cynical turn: No one should be allowed to
teach students system design if they haven't been a committer
to a large open-source project. (Presumably, having had
experience building "real" big systems in another context
would suffice.) More seriously, Marick suggested that it is
only for recent historical reasons that we would turn to
academia to solve the problem of producing software designers.
I've long been a proponent of apprenticeship as a way of
learning to program, but Waldo is right that doing this as
a part of the typical university structure is hard, if not
impossible. We heard about a
short-lived attempt to do this
at last year's OOPSLA, but a lot of work remains. Perhaps
if more people like Waldo, not just the more provocative folks
at OOPSLA, start talking openly about this we might be able to
make some progress.
Bonus reading reference: Waldo is trained more broadly as a
philosopher, and made perhaps a surprising recommendation for
a great document on the act of designing a new sort of large
system:
The Federalist Papers.
This recommendation is a beautiful example of the value in
a broad education. The Federalist Papers are often taught
in American political science courses, but from a different
perspective. A computer scientist or other thinker about the
design of systems can open a whole new vista on this sort of
document. Here's a neat idea: a system design course team
taught by a computer scientist and a political scientist,
with The Federalist Papers as a major reading!
Now, how to make system design as a skill an inextricable
element of all our courses, so that an outcome of our major
is that students know the technique? ("Know how", not "know
that".)
The first two sentences of
Guy Steele's
OOPSLA 2006 keynote this morning were eerily reminiscent of
his describes the application of the principles from his
justly famous OOPSLA 1998 invited talk
Growing a Language.
I'm pretty sure that, for that few seconds, he used only
one-syllable words!
This talk,
A Growable Language,
was related to that talk, but in a more practical sense. It
applied the spirit and ideas expressed in that talk to a new
language. His team at Sun is designing
Fortress,
a "growable language" with the motto "To Do for Fortran What
Java Did for C".
The aim of Fortress is to support high-performance scientific
and engineering programming without carrying forward the
historical accidents of Fortran. Among the additions to
Fortran will be extensive libraries, including for networking,
a security model, type safety, dynamic compilation (to enable
the optimization of running program), multithreading, and
platform independence. The project is being funded by DARPA
with the goal of improving programmer productivity for writing
scientific and engineering applications -- to reduce the time
between when a programmer receives a problem and when the
programmer delivers the answer, rather than focus solely on
the speed of the compiler or executable. Those are important,
too, but we are shortsighted in thinking that they are the
only formsof speed that matter. (Other DARPA projects in this
vein are the Extend language from IBM[?] and the Chapel language
from Cray.)
Given that even desktop computers are moving toward multicore
chips, this sort of project offers potential value beyond the
scientific programming community.
The key ideas behind the Fortress project are threefold:
Don't build a language; grow it piecemeal.
Create a programming notation that is more like the
mathematical notation that this programmer community
uses.
Make parallelism the default way of thinking.
Steele reminded his audience of the motivation for growing
a language from his first talk: If you plan for a language,
and then design it, then build it, you will probably miss
the optimal window of opportunity for language. One of
the guiding questions of the Fortress project is, Will
designing for the growth of a language and its user community
change the technical decisions the team makes or, more
importantly, the way it makes them?
One of the first technical questions the team faced was what
set of primitive data types to build into the language. Integer
and float -- but what sizes? Data aggregates? Quaternions,
octonions? Physical units such as meter and kilogram?? He
"might say 'yes' to all of them, but he must say no to some
of them." Which ones -- and why?
The strategy of the team is to, wherever possible, add a
desired feature via a library -- and to give library designers
substantial control over both the semantics and the
syntax of the library. The result is a two-level language
design: a set of features to support library designers and
a set of features to support application programmers. The
former have turned out to be quite obbject-oriented, while
the latter is not obbject-oriented at all -- something of a
surprise to the team.
At this time, the language defines some very cool types in
libraries: lists, vectors, sets, maps (with better, more
math-like notion), matrices and multidimensional vectors,
and units of measurement. The language also offers as a
feature mathematical typography, using a wiki-style mark-up
to denote Unicode characters beyond what's available on the
ASCII keyboard.
In the old model for designing a language, the designers
study applications
add language features to support application developers
In the new model, though, designers
study applications
add language features to support library
designers in creating the desired features
let library designers create a library that supports
application developers
At a strategic level, the Fortress team wants to avoid
creating a monolithic "standard library", even when taking
into account the user-defined libraries created by a single
team or by many. Their idea is instead to treat libraries as
replaceable components, perhaps with different versions.
Steele says that Fortress effectively has make and
svn built into its toolset!
I can just hear some of my old-school colleagues decrying this
"obvious bloat", which must surely degrade the language's
performance. Steele and his colleagues have worked hard to
make abstraction efficient in a way that surpasses
many of today's languages, via aggressive static and dynamic
optimization. We OO programmers have come to accept that our
environments can offer decent efficiency while still having
features that make us more productive. The challenge facing
Fortress is to sell this mindset to C and Fortran programmers
with habits of 10, 20, even 40 years thinking that you have
to avoid procedure calls and abstract data types in order to
ensure optimal performance.
The first category of features in Fortress intend to support
library developers. The list is an impressive integration of
ideas from many corners of the programming language community,
including first-class types, traits and trait descriptors
(where, comprise, exclude), multiple
inheritance of code but not fields, and type contracts.
In this part of the language definition, knowledge that used to
be buried in the compiler is brought out explicitly into code
where it can be examined by programmers, reasoned over by the
type inference system, and used by library designers. But these
features are not intended for use by application programmers.
In order to support application developers, Steele and his team
watched (scientific) programmers scribble on their white boards
and then tried to convert as much of what they say as possible
into their language. For example, Fortress takes advantage of
subtle whitespace cues, as in phrases such as
{ |x| | x ← S, 3 | x }
Note the four different uses of the vertical bar, disambiguated
in part by the whitespace in the expression.
The wired-in syntax of Fortress consists of some standard
notation from programming and math:
() for grouping
, for separating values in a tuple
; for separating statements on a line
. for selecting fields and methods
conservative, traditional rules of precedence
Any other operator can be defined as infix, prefix, or postfix.
For example, ! is defined as a postfix for factorial.
Similarly, juxtaposition is a binary operator, one which can be
defined by the library designer for her own types. Even nicer
for the cientific programmer, the compiler knows that the
juxtaposition of functions is itself a function (composition!).
The syntax of Fortress is rich and consistent with how scientific
programmers think. But they don't think much about "data types",
and Fortress supports that, too. The goal is for library
designers to think about types a lot, but application
programmers should be able to do their thing with type inference
filling in most of the type information.
Finally, scientists, engineers, and mathematicians use particular
textual conventions -- fonts, characters, layout -- to communicate.
Fortress allows programmers to post-process their code into a
beautiful mathematical presentation. Of course, this idea and even
its implementation are not new, but the question for the Fortress
team was what it would be like if a language were designed
with this downstream presentation as the primary mode o presentation?
The last section of Steele's talk looked a bit more like a POPL
or ICFP paper, as he explained the theoretical foundations
underlying Fortress's biggest challenge: mediating the language's
abstractions down to efficient executable code for parallel
scientific computation. Steele asserted that parallel programming
is not a feature but rather a pragmatic compromise. Programmers
do not think naturally in parallel and sop need language support.
Fortress is an experiment in making parallelism the default mode
of computation.
Steele's example focused on the loop, which in most languages
conflates two ideas: "do this statement (or block) multiple times"
and "do things in this order". In Fortress, the loop itself
means only the former; by default its iterations can be
parallelized. In order to force sequencing, the programmer
modifies the interval of the loop (the range of values that
"counts" the loop) with the seqoperator. So, rather
than annotate code to get parallel compilation, we must annotate
to get sequential compilation.
Fortress uses the idea of generators and reducers -- functions
that produce and manipulate, respectively, data structures like
sequences and trees -- as the basis of the program transformations
from Fortress source code down to executablecode. There are many
implementations for these generators and reducers, some that are
sequential and some that are not.
From here Steele made a "deep dive" into how generators and
reducers are used to implement parallelism efficiently. That
discussion is way behind what I can write here. Besides, I
will have to study the transformations more closely before I
can explain them well.
As Steele wrapped up, he reiterated The Big Idea that guides
the Fortress team: to expose algorithm and design decisions
in libraries rather than bury them in the compiler -- but to
bury them in the libraries rather than expose them in
application code. It's an experiment that many of us
are eager to see run.
One question from the crowd zeroed in on the danger of dialect.
When library designers are able to create such powerful extensions,
with different syntactic notations, isn't there a danger that
different libraries will implement similar ideas (or different
ideas) incompatibly? Yes, Steele acknolwedge, that is a real
danger. He hopes that the Fortress community will grow with
library designers thinking of themselves as language designers
and so exercise restraint in the the extensions they make, and
work together to create community standards.
I also learned about a new idea that I need to read about...
the BOOM hierarchy. My memory is vagues, but the discussion
involved considering whether a particular operation -- which,
I can't remember -- is associative, commutative, and idempotent.
There are, of course, eight possible combinations of these
features, four of which are meaningful (tree, list, bag/multiset,
and set). One corresponds to an idea that Steele termed a
"mobile", and the rest are, in his terms, "weird". I gotta
read more!
OOPSLA Day 1: Gabriel and Goldman on Conscientious Software
The first episode of
Onward!
was a tag team presentation by
Ron Goldman
and
Dick Gabriel
of their paper
Conscientious Software.
The paper is, of course, in the proceedings and so the ACM Digital
Library, but the presentation itself was performance art. Ron gave
his part of the talk in a traditional academic style, dressed as
casually as most of the folks in the audience. Dick presented an
outrageous bit of theater, backed by a suitable rock soundtrack,
and so dressed outrageously (for him) in a suit.
In the "serious" part of the talk, Ron spoke about complexity and
scale, particularly in biology. His discussion of protein, DNA,
and replication soon turned to how biological systems suffer damage
daily to their DNA as a natural part of their lifecycle. They also
manage to repair themselves, to return to equilibrium. These systems,
Ron said, "pay their dues" for self-repair. Later he discussed
chemotaxis
in E.Coli, wherein "organisms direct their movements according to
certain chemicals in their environment". This sort of coordinated
but decentralized action occurs not among a bacterium's flagella
but also among termites as they build a system, and elephants as
they vocalize across miles of open space, and among chimpanzees
as they pass emotional state via facial expression.
We have a lot to learn from living things as we write our programs.
What about the un-"serious" part of the talk? Dick acted out a
set of vignettes under title slides such as "Thirteen on Visibility",
"Continuous (Re)Design", "Requisite Variety", and "What We Can
Build".
His first act constructed a syllogism, drawing on the theme that
the impossible is famously difficult. Perfect understanding
requires abstraction, which is the ability to see the simple truth.
Abstraction ignores the irrelevant. Hence abstraction requires
ignorance. Therefore, perfect understanding requires ignorance.
In later acts, Dick ended up sitting for a while, first listening
to his own address was part of the recorded soundtrack and then
carrying on a dialogue with his alter ego, which spoke in a
somewhat ominous Darth Vader-ized voice in counterpoint. The
alter ego espoused a standard technological view of design and
modularity, of reusable components with function and interface.
This left Gabriel himself to embody a view centered on organic
growth and complexity -- of constant repair and construction.
Dick's talk considered Levittown and the intention of "designed
unpredictability", even if inconvenient, such as the placement
of the bathroom far from the master bedroom. In Levittown, the
'formal cause' (see my notes on
Brenda Laurel's keynote
from the preceding session) lay far outside the "users", in
Levitt's vision of what suburban life should be. But today
Levittown is much different than designed; it is lived-in,
a multi-class, multi-ethnic community that bears "the complexity
of age".
On requisite variety, Dick started with a list of ideas (including
CLOS, Smalltalk, Self, Oaklisp, ...) disappearing one by one to
the background music of Fort Minor's
Where'd You Go.
The centerpiece of Gabriel's part of the talk followed a slide
that read
Ghazal
(google it)
on
"Unconventional Design"
He described an experiment in the artificial evolution of electronic
circuits. The results were inefficient to our eyes, but they were
correct and carried certain advantages we might not expect from a
human-designed solution. The result was labeled "... magical ...
unexpected ...". This sort system building is reminiscent of
what neural networks promise in the world of AI, an ability to
create (intelligent) systems without having to understand the
solution at all scales of abstraction. For his parallel, Dick
didn't refer to neural nets but to cities -- they are sometimes
designed; their growth is usually governed; and they are built
(and grow) from modules: a network of streets, subways, sewers.
Dick closed his talk with a vignette whose opening slide read
"Can We Get There From Here" (with a graphical flourish I
can't replicate here). The coming together of Ron's and Dick's
threads suggest one way to try: find inspiration in biology.
Brenda Laurel
is well known in computing, especially the computer-human interaction
computing, for her books
The Art of Human-Computer Interface Design
and the iconic
Computers as Theatre.
I have felt a personal connection to her for a few years, since an
OOPSLA a few years ago when I bought Brenda's
Utopian Entrepreneur,
which describes her part in starting Purple Moon, a software company
to produce empowering computer games for young girls. That sense of
connection grew this morning as I prepared this article, when I
learned that Brenda's mom is from
Middletown, Indiana,
less than an hour from my birthplace, and just off the road I drove
so many times between my last Hoosier hometown and my university.
Laurel opened this year's OOPSLA as the
Onward!
keynote speaker, with a talk titled, "designed animism: poetics for
a new world". Like many OOPSLA keynotes, this one covered a lot of
ground that was new to me, and I can remember only a a bit -- plus
what I wrote down in real time.
These days, Laurel's interests lie in pervasive, ambient computing.
(She recently gave a talk much like this one at
UbiComp 2006.)
Unlike most folks in that community, her goal is not ubiquitous
computing as primarily utilitarian, with its issues of centralized
control, privacy, and trust. Her interest is in pleasure.
She self-effacingly attributed this move to the design tactic of
"finding the void", the less populated portion of the design space,
but she need not apologize; creating artifacts and spaces for human
enjoyment is a noble goal -- a necessary part of of our charter --
in its own right. In particular, Brenda is interested in the design
of games in which real people are characters at play.
(Aside: One of Brenda's earliest slides showed this painting, "Dutch
Windmill Near Amsterdam" by
Owen Merton
(1919). In finding the image I learned that Merton was the father of
Thomas Merton, the Buddhist-inspired Catholic monk whom I have
quoted here before.
Small world!)
Laurel has long considered how we might extend Aristotle's
poetics to understand and create interactive form. In the
Poetics, Aristotle "set down ... an understanding
of narrative forms, based upon notions of the nature and
intricate relations of various elements of structure and
causation. Drama relied upon performance to represent
action." Interactive systems complicate matters relative
to Greek drama, and ubiquitous computing "for pleasure"
is yet another matter altogether.
To start, drawing on Aristotle, I think, Brenda listed the
four kinds of cause of a created thing (at this
point, we were thinking drama):
the end cause
-- its intended purpose
the formal cause
-- the platonic ideal in the mind of the creator that
shaped the creation
the efficient cause
-- the designer herself
the material cause
-- the stuff out of which it is made,
which constrains and defines the thing
In an important sense, the material and formal causes work
in opposite directions with respect to dramatic design. The
effects of the material cause work bottom-up from material to
pattern on up to the abstract sense of the thing, while the
effects of the formal cause work top-down from the ideal to
components on to the materials we use.
Next, Brenda talked about plot structure and the "shape of
experience". The typical shape is a triangle, a sequence of
complications that build tension followed by a sequence of
resolutions that return us to our balance point. But if we
look at the plots of most interesting stories at a finer
resolution, we see local structures and local subplots,
other little triangles of complication and resolution.
(This part of the talk reminded of a talk I saw
Kurt Vonnegut
give at UNI almost a decade or so ago,in which he talked about
some work he had done as a master's student in sociology at
the University of Chicago, playfully documenting the small
number of patterns that account for almost all of stories we
tell. I don't recall Vonnegut speaking of Aristotle, but I
do recall the humor in is own story. Laurel's presentation
blended bits of humor with two disparate elements: an academic's
analysis and attention to detail, and a child's excitement at
something that clearly still lights up her days.)
One of the big lessons that Laurel ultimately reaches is this:
There is pleasure in the pattern of action.
Finding these parts is essential to telling stories that give
pleasure. Another was that by using natural materials (the
material causality in our creation), we get pleasing patterns
for free, because these patterns grow organically
in the world.
I learned something from one of her examples, Johannes Kepler's
Harmonices Mundi,
an attempt to "explain the harmony of the world" by finding rules
common to music and planetary motion within the solar system.
As Kepler wrote, he hoped "to erect the magnificent edifice of
the harmonic system of the musical scale ... as God, the Creator
Himself, has expressed it in harmonizing the heavenly motions."
In more recent times, composers such as Stravinsky, deBussy, and
Ravel have tried to capture patterns from the visual world in
their music, seeking more universal patterns of pleasure.
This led to another of Laurel's key lessons, that throughout
history artists have often captured patterns in the world on
the basis of purely phenomenological evidence, which were
later reified by science. Impressionism was one example; the
discovery of fractal patterns in Jackson Pollock's drip
projectories were another.
The last part of Laurel's talk moved on to current research
with sensors in the ubiquitous computing community, the idea
of distributed sensor networks that help us to do a new sort
of science. As this science exposes new kinds of patterns in
the about the world, Laurel hopes for us to capitalize on the
flip side of the art examples before: to be able to move from
science, to math, and then on to intuition. She would like
to use what we learn to inform the creation of new dramatic
structures, of interactive drama and computer games that
improve the human condition -- and give us pleasure.
The question-and-answer session offered a couple of fun moments.
Guy Steele asked Brenda to react to Marvin Minsky's claim that
happiness is bad for you, because once you experience it you
don't want to work any more. Brenda laughed and said, "Marvin
is a performance artist." She said that he was posing with
this claim, and told some stories of her own experiences with
Marvin and Timothy Leary (!). And she is even declared a verdict
in my old discipline of AI: Rod Brooks and his subsumption
architecture are right, and Minsky and the rest of symbolic AI
are wrong. Given her views and interests in computing, I was
not surprised by her verdict.
Another question asked whether she had seen the tape of Christopher
Alexander's OOPSLA keynote in San Jose. She hadn't, but she
expressed a kinship in his mission and message. She, too, is a
utopian and admitted to trying to affect our values with her talk.
She said that her research through the 1980s especially had taught
her how she could sell cosmetics right into the insecurities of
teenage girls -- but instead she chose to create an "emotional
rehearsal space" for them to grow and overcome those insecurities.
That is what Purple Moon was all about!
As usual, the opening keynote was well worth our time and energy.
As a big vision for the future, as a reminder of our moral center,
it hit the spot. I'm still left to think how these ideas might
affect my daily work as teacher and department leader.
(I'm also left to track down Ted Nelson's
Computer Lib/Dream Machines,
a visionary, perhaps revolutionary book-pair that Laurel mentioned.
I may need the librarian's help for this one.)
Unlike
last year,
the first day of OOPSLA was not an intellectual charge
for me. As tutorials chair, I spent the day keeping tabs
on the sessions, putting out small fires involving notes
and rooms and A/V, and just hanging out. I had thought
I might sneak into the back of a
technical workshop
or a
educational workshop,
but my time and energy were low.
Today was the
Educators' Symposium,
my first since chairing in
2004
and
2005.
I enjoyed not having to worry about the schedule or making
introductions. The day held a couple of moments of inspiration
for me, and I'll write about at least one -- on
teaching novices to design programs
-- later.
The day's endpoint was an invited talk by Robert
Uncle Bob
Martin. In a twist, Bob let us choose the talk we wanted to
hear: either his classic "Advanced Principles of
Object-Oriented Class Design" or his newer and much more
detailed "Clean Code".
While we thought over our options, Martin started with a
little astronomy lesson that involved
Henrietta Levitt,
globular clusters, distance calculations, and the width of
our galaxy. Was this just filler? Was there a point related
to software? I don't know. Maybe Bob just likes telescopes.
The vote of the group was for Principles. Sigh. I wanted
Clean Code. I've read all of Bob's papers that underlie
this talk, and I was in the mood for digging into code.
(Too many hours pushing papers and attending meetings will
do that to a guy who is Just a Programmer at heart.)
But this was good. With some of the best teachers, reading
a paper is no substitute for the
performance art
of a good presentation. This blog can't recreate the talk,
so if you already know Martin's five principles of OO design,
you may want to move on to his
latest ruminations
on naming.
At its core, object-oriented design is about managing
dependencies in source code. It aims to circumvent
the problems inherent in software with too many dependencies:
rigidity, fragility, non-reusability, and high viscosity.
Bob opened with a simple but convincing example of a copy
routine, a method that echoes keyboard input to a printer,
to one of his five principles, the Dependency Inversion
Principle. In procedural code, dependency flows from the top
down in a set of modules. In OO code, there a point where
top-down dependencies end at an abstraction like an interface,
and the dependencies begin to flow up from the details to the
same abstractions. My favorite detail in this example was
his pointing out that getch() is polymorphic method,
programmed to the abstractions of standard input and standard
output. ("Who needs all that polymorphism nonsense," say my
C-speaking colleagues. "Let's teach students the fundamentals
from the bottom up." Hah!)
Martin then went through each of his five principles, including
DIP, with examples and a theatrical interaction with his
audience. Here are the highlights to me:
In the Single Responsibility Principle, a class
should have one and only one reason to change.
Side lesson: There is no perfect way to write code.
There are always competing forces. There is a conflict
between the design principle encapsulation and the SRP.
To ensure the SRP, we may need to relax encapsulation;
to ensure encapsulation, we may need to relax the SRP.
How to choose? All other things equal, we should prefer
the SRP, as it protects us from a
clear and present danger,
rather than from potential bad behavior of programmers
working with our code in the future. A mini-sermon on
overprotective languages and practices followed. The
Smalltalk programmers in the audience surely recognized
the theme.
The Open/Closed Principle states that a class
should be open for extension and closed for modification.
The idea is that any change to behavior should be
implemented in new code, not in changes to existing code.
Side lesson: OO design works best if you can predict
the future, so that you can select the abstractions which
are likely to change. We can predict the future (or try)
either by thinking hard or by letting customers use early
versions of the code and reacting to the actual changes
they cause. Ceteris paribus, OO design may be better than
the alternatives, but it still requires work to get right.
The Liskov Substitution Principle is the formal
name for one of the central principles of my second-course
OO programming course over the last decade, which I have
usually called "substitutability". We should be able to
drop an instance of a subclass into a variable typed to a
superclass -- and not have the client know the difference.
In practice, we recognize violations of the LSP when we
see limitations in subclasses such as overriding methods
throwing exceptions.
Of all Martin's principles, the one I tend to teach and
consider consciously least often is the Integration
Segregation Principle. Rather than writing classes
that depend on a "fat" class that offers many services,
we should segregate clients into sets according to their
thinner needs by means of interfaces.
Finally, we return to the Dependency Inversion
Principle. In some ways, this is the most basic
of the design ideas in Martin's cadre, and it is the
one by which we can often recognize OO pretenders from
those who really get it. Details in our programs should
depend on abstractions, not the other way around. If you
call a method, create a subclass, override a method ...
you wish the depended-on method or class to be abstract.
Abstractions hide the client code from changes that
almost necessarily follow concrete implementations.
Side lesson: Another conflict we face when we program
is that between flexibility and type safety. As with the
SRP and encapsulation, to achieve one of flexibility and
type safety in practice, we often have to relax the other.
Martin described how the trend toward test-driven design
and full-coverage unit testing eliminates many of the
compelling reasons for us to seek type safety in a language.
The result is that in this competition between forces we
can favor flexibility as our preferred goal -- and choose
the languages we use differently! Ruby, Python, duck
typing... these trends signal our ability to choose
empowering, freeing languages as long as we are willing
to achieve the value of type safety through the alternate
means of tests.
The talk just ended with no summary or conclusion, probably
due to us being short on time. Martin had been generous with
his audience interaction throughout, asking and answering
questions and playfully enjoying all comments. The talk
really was quite good, and I can see how he has become one
of the top draws on the OO speaking circuit. At times he
sounded like a preacher, moving and intoning in the rhythms
of a revival minister. Still, one of his key points was
that OO as religion isn't nearly as compelling as OO as
proven technique for building better software.
The teacher in me left the symposium feeling a little bit
second-best. How might I speak and teach classes in a way
that draws such rapt interest from my audience? Could I
teach more effectively if I did? The easy answer is that
this is just not my style, but that may be an excuse.
Can I -- should I -- try to change? Or should I just try
to maximize what I do well? (And just what is that?)
Technology doesn't lead change.
Need leads change.
-- Dennis Clark, O&P1
This morning I am hanging out at a campus conference on
Commercializing Creative Endeavors. It deals with
entrepreneurship, but from the perspective of faculty.
As a comprehensive university, not an R-1 institution,
we tend to generate less of the sort of research that
generates start-ups. But we do have those opportunities,
and even more so the opportunity to work with local and
regional industry.
The conference's keynote speaker is Dennis Clark, the
president of
O&P1,
an local orthotics and prosthetics company that is doing
amazing work developing more realistic prosthetics. His
talk focused on his collaboration with
Walter Reed Army Medical Center
to augment amputees from the wars in Afghanistan and Iraq.
It is an unfortunate truth that war causes his industry to
advance, in both research and development.
O&P1's innovations include new fabrication
techniques, new kinds of liners and sensors, and shortened
turnaround times in the design, customization, fabrication,
and fitting prosthetics for specific patients.
Dennis has actively sought collaborations with UNI faculty.
A few years ago he met with a few of us in computer science
to explore some project ideas he had. Ultimately, he ended
up working closely with two professors in physics and physical
education on a particular prosthetics project, specifically
work with the human gait lab at UNI, which he termed
"world-class". That we have a world-class gait lab here at
UNI was news to me! I have never worked on human gait
research myself, though I was immediately reminded of some
work on modeling gait by folks in Ohio State's
Laboratory for AI Research,
which was the intellectual progenitor of the work we did
in our intelligent systems lab at
Michigan State.
This is an area rich in interesting applications for
building computer models that support analysis o gait and
the design of products.
As I listened to Dennis's talk this morning, two connections
to the world of computing came to mind. The first was to
understand the remarkable amount of information technology
involved in his company's work, including CAD, data
interchange, and information storage and retrieval. As in
most industries these days, computer science forms the
foundation on which these folks do their work, and speed
of communication and collaboration are a limiting factor.
Second, Dennis's description of their development process
sounded very much like a
scrapheap challenge
a lá the
OOPSLA 2005 workshop
of the same name.
Creating a solution that works now for a specific individual,
whose physical condition is unique, requires blending
"space-age technology" with "stone-age technology". They
put together whatever artifacts they have available to
make what they need, and then they can step back and figure
out how to increase their technical understanding for solving
similar problems in the future.
The Paul Graham article I
discussed yesterday
emphasized that students who think they might want to start
their own companies should devote serious attention to finding
potential partners, if only by surrounding themselves with
as many bright, ambitious people as possible. But often just
as important is considering potential partnerships with folks
in industry. This is different than networking to build a
potential client base, because the industrial folks are more
partners in the development of a business. And these real
companies are a powerful source of problems that need to be
solved.
My advice to students and anyone, really, is to be curious.
If you are a CS major, pick up a minor or a second major
that helps you develop expertise in another area -- and the
ability to develop expertise in another area. Oh,
and learn science and math! These are the fundamental tools
you'll need to work in so many areas.
Great talk. The sad thing is that none of our students heard
it, and too few UNI faculty and staff are here as well. They
missed out on a chance to be inspired by a guy in the trenches
doing amazing work, and helping people as the real product of
his company.
I enjoy following
Paul Graham's
writings about start-up companies and how to build
one. One of my goals the last few years, and
especially now as a department head, is to encourage
our students to consider
entrepreneurship as a career choice.
Some students will be much better served, both
intellectually and financially, by starting their own
companies, and the resulting culture will benefit other
students and our local and state business ecosystem.
Graham's
latest essay
suggests that even undergraduate students might consider
creating a start-up, and examines the trade-offs among
undergrads, grad students, and experiences folks already
in the working world. He has a lot more experience with
start-ups than I, so I figure his suggestions are at
least worth thinking about.
Some of his advice is counterintuitive to most undergrads,
especially to the undergrads in the more traditional
Midwest. At one point, Graham tells students who may want
to start their own companies that they probably should not
take jobs at places where they will be treated well --
even Google.
I realize this seems odd advice. If they make your life so
good that you don't want to leave, why not work there?
Because, in effect, you're probably getting a local maximum.
You need a certain activation energy to start a startup. So
an employer who's fairly pleasant to work for can lull you
into staying indefinitely, even if it would be a net win for
you to leave.
It's hard for the typical 22-year-old to pass up a comfortable
position at a top-notch but staid corporation. Why not enjoy
your corporate work until you are ready to start your own
company? You can make connections, build experience, learn
some patterns and anti-patterns, and save up capital. The
reason is that in short order you can create an incredible
inertia against moving on -- not the least of which is the
habit of receiving a comfortable paycheck each week. Going
back to ramen noodles thrice daily is tough after you've
had three squares paid for by your boss. I give similar
advice to undergrads who say, "I plan to go to graduate
school in a few years, after I work for a while." Some
folks manage this, but it's harder than it looks to most
students.
I also give my students a piece of advice similar to
another of Graham's suggestions:
Most people look at a company like Apple and think, how could
I ever make such a thing? Apple is an institution, and I'm
just a person. But every institution was at one point just a
handful of people in a room deciding to start something.
Institutions are made up, and made up by people no different
from you.
The moral is: Don't be intimidated by a great company. Once
it was just a few people mostly like us who had an idea and
a willingness to make their idea work. I give similar advice
about programs that intimidate my students, language
interpreters and compilers. One of the morals of my
programming languages and compilers courses is that each of
these tools is "Just Another Program". Written by a
knucklehead just like me. Learn some basic techniques,
apply your knowledge of programming and data structures to
the various sub-problems faced when building a language
processor, and you can write one, too.
This reference to professors raises another connection to
Graham's advice, regarding how many students who want to
create a start-up mistake the implementation of their idea
as a commercial product with just a big class project:
That leads to our second difference [between a start-up's
product and a class project]: the way class projects are
measured. Professors will tend to judge you by the distance
between the starting point and where you are now. If someone
has achieved a lot, they should get a good grade. But customers
will judge you from the other direction: the distance remaining
between where you are now and the features they need. The market
doesn't give a shit how hard you worked. Users just want your
software to do what they need, and you get a zero otherwise.
That is one of the most distinctive differences between school
and the real world: there is no reward for putting in a good
effort. In fact, the whole concept of a "good effort" is a fake
idea adults invented to encourage kids. It is not found in nature.
The connection between effort, grade, and learning is not nearly
as clean as most students think. Some courses require a lot of
effort and require little learning; those are the courses that
most of us hate. Sometimes one student has to exert much more
effort than another to learn the concepts of a course, or to earn
an equivalent grade. Every student starts in a different place,
and courses exert different forces on different students. The
key is to figure out which courses will best reward hard work
-- preferably with maximum learning -- and then focus more of
our attention there. Time and energy are scarce quantities,
so we usually have to ration them.
If an undergraduate knows that she wants to start her own
company, she has a head start in making this sort of decision
about where to exert their learning efforts:
Another thing you can do [as an undergrad, to prepare to start
your own company] is learn skills that will be useful to you
in a startup. These may be different from the skills you'd
learn to get a job. For example, thinking about getting a job
will make you want to learn programming languages you think
employers want, like Java and C++. Whereas if you start a
startup, you get to pick the language, so you have to think
about which will actually let you get the most done. If you
use that test you might end up learning Ruby or Python instead.
... or Scheme! (These days, I think I'd go with Ruby.)
As in anything else, having some idea about what you want
from your future can help you make better decisions about
waht you want to do now. I admire young people have a big
dream even as undergrads; sometimes they create
cool companies.
They also make interesting students to have in class,
because their goals have a groundedness to them. They
ask interesting questions, and sometimes doze off after
a long night trying something new out. And even with
this lead in making choices, they usually get out into
the world and end up thinking, "Boy, I wish I had paid
more attention in [some course]." Life is usually more
complicated than we expect, even when we try to think
ahead.
Steve Yegge's
entertaining fantasy on developing programmers
contains a respectful but pointed critique of the relevance
of a Ph.D. in computer science to contemporary software
development, including:
You hire a Ph.D., it's hit-or-miss. Some of them are brilliant.
But then some subset of virtually every educated group is brilliant.
The problem is that the notion of a Ph.D. has gradually been watered
down for the last century. It used to mean something to be a Doctor
of Philosophy: it meant you had materially advanced your discipline
for everyone. Von Neumann, Nash, Turing -- people like
that, with world-changing dissertations, ....
... These kids have to work hard for their Ph.D., and a lot of them
never quite finish. But too often they finish without having written
more than a few hundred lines of code in the past five years. Or
they've over-specialized to the point where they now think Big-O is
a tire company; they have no idea how computers or computation actually
work anymore. They can tell you just about everything there is to
know about SVM kernels and neural-net back propagation, or about
photorealistic radiosity algorithms that make your apartment look
fake by comparison. But if you want a website thrown together, or
a scalable service written, or for that matter a graphics or
machine-learning system, you're usually better off hiring a
high-school kid, because the kid might actually know how to program.
Some Ph.D.s can, but how many of them is it, really? From an
industry perspective, an alarming number of them are no-ops.
Ouch. I'm sure Steve is exaggerating for dramatic effect, but
there is a kernel of truth in there. People who study for a
Ph.D. in computer science are often optimizing on skills that
are not central to the industrial experience of building software.
Even those who work on software tend to focus on a narrow slice
of some problem, which means not studying broadly in all of
the elements of modern software development.
So, if you want to apprentice with one person
in an effort to learn the software industry, you can often
find a better "master" than by selecting randomly among the
run-of-the-mill CS professors at your university. But then,
where will you connect with this person, and how will you
convince him or her to carry you while you slog through
learning the basics? Maybe when Wizard Schools are up and
running everywhere, and the Ward Cunninghams and Ralph Johnsons
of the world are their faculty, you'll have a shot. Until
then, a CS education is still the most widely available and
trustworthy path to mastery of software development available.
You will, of course, have to take your destiny into your own
hands by seeking opportunities to learn and master as many
different skills as you can along the way. Steve Yegge reminds
his readers of this all the time.
In this regard, I was fortunate in my graduate studies to work
on AI, in particular intelligent systems. You might not think
highly of the work done by the many, many AI students of the
1980s. Paul Graham had this to say in a
recent essay:
In grad school I was still wasting time imitating the wrong
things. There was then a fashionable type of program called
an expert system, at the core of which was something called
an inference engine. I looked at what these things did and
thought "I could write that in a thousand lines of code."
And yet eminent professors were writing books about them,
and startups were selling them for a year's salary a copy.
What an opportunity, I thought; these impressive things seem
easy to me; I must be pretty sharp. Wrong. It was simply a
fad.
But whatever else you say, you have to admit that most of us
AI weenies produced a lot of code. The AI and KBS research
groups at most schools I knew sported the longest average
time-to-graduate of all the CS areas, in large part because
we had to write huge systems, including a lot of infrastructure
that was needed in order to do the highly-specialized whatever
we were doing. And many of us wrote our code in one of those
"super-succinct 'folding languages'" developed by academics,
like Lisp. I had the great good fortune of schlocking a
non-trivial amount of code in both Lisp and Smalltalk. I
should send my advisor a thank-you note, but at the time we
felt the burden of all the code we had to produce to get to
the place where we could test our cool ideas.
I do agree with Yegge that progressive CS departments need
to work on how better to prepare CS graduates and other
students to participate in the development of software.
But we also have to wrestle with the differences between
computer science and software development, because we need
to educate students in both areas. It's good to know that
at least a few of the CS professors know how to build software.
Not very many of us know when to set the fourth preference
on the third tab of the latest .NET development wizard, but
we do have some idea about what it's like to build a large
software system and how students might develop the right
set of skills to do the same.
As I've mentioned a few times in recent months that I am
teaching our intro course this semester for the first time
in a decade or so. After only two weeks, I have realized
this: Teaching CS1 every so often is a very good idea
for a computer science professor!
With students who have no programming background, I cannot
take anything for granted: values, types, variables, ...
expressions, statements, functions/methods ... reference,
binding ... so many fundamental concepts to build! In one
sense, we have to build them from scratch, because students
have no programming knowledge to which we can connect.
But they do have a lot of knowledge of the world, and they
know something about computers and files as users, and we
can sometimes get leverage from this understanding. So far,
I remain of the view that we can build the concepts in many
different orders. The context in which students learn guides
the ordering of concepts, by making some concepts relatively
more or less "fundamental". The media computation approach
of Guzdial and Ericson has been a refreshing change for me
-- the idea of a method "happened" naturally quite early, as
a group of operations that we have applied repeatedly from
Dr. Java's interactions pane. Growing ideas and programs
this way lets students learn bottom-up but see useful ideas
as soon as they become useful.
I've spent a lot of time so far talking about the many
different kind of names that we use and define when
thinking computationally. So much of what we do in computing
is combining parts, abstracting from them an idea, and then
giving the idea a name. We name values (constant),
arbitrary or changing values (variable), kinds of values
(type, class), processes (function, method)... Then we
have arguments and parameters, which are special kinds of
arbitrary values, and even files -- whose names are, in an
important way, outside of our programs. I hope that my
students are appreciating this Big Idea already.
And then there is all of the jargon that we computer folks
use. I have to assume that my students don't know what
any of that jargon means, which means that (1) I can't use
much, for fear of making the class sound like a sea of
Babel, and (2) I have to define what I use. Today, for
example, I found myself wanting to say "hard-coded", as
such as a constant hard-coded into a method. I caught
myself and tried to relate it to what we were doing, so
that students would know what I meant, both now and later.
I often speak with friends and colleagues who teach a lot
of CS as trainers in industry. I wonder if they ever get
a chance to teach a CS1 course or something like it. The
experience is quite different for me from teaching even
a new programming style to sophomores and juniors. There,
I can take so much for granted, and focus on differences.
But for my intro student the difference isn't between two
somethings, but something and nothing.
However, I also think that we have overglamorized how
difficult it is to learn to program. I am not saying that
learning to program is easy; it is tough,
with ideas and abstractions that go beyond what many
students encounter. But I think that sometimes lure
ourselves into something of a
Zeno's paradox:
"This concept is so difficult to learn; let's break it down
into parts..." Well, then that part is so difficult to learn
that we break it down into parts. Do this recursively,
ad infinitum, and soon we have made things more difficult than
they really are -- and worse, we've made them incredibly boring
and devoid of context. If we just work from a simple context,
such as media computation, we can use the environment to guide
us a bit, and when we reach a short leap, we make it, and trust
our students to follow. Answer questions and provide support,
but don't shy away from the idea.
That's what I'm thinking this afternoon at least. Then again,
it's only the end of our second week of classes!
If you've read many of my entries on agile software
development, you know that I run the risk of being
one of those guys who see agile principles everywhere
I look in the world. I've certainly explored the
relationship between agile approaches and my
running.
I've even seen agile truths a
Bill Murray film.
One way to do an analogy, and the people who use it, a
disservice is take it too far, to go beyond where it
adds value to where it misleads. But sometimes when we
see something everywhere it's because it is everywhere,
in some form. What's the pattern?
I was again struck by the similarities between agile
software development and teaching techniques while reading
an article recently. Another department head in my college
shared some of the papers she has been reading on how to
improve the way we teach large, general-education courses.
One of these papers is a product of the
National Center for Academic Transformation,
a project based on two ideas:
using scientific evidence from cognitive psychology
and learning research to design instruction more
effectively, and then
using information technology to implement instructional
designs more efficiently and cost-effectively.
One of the papers,
Improving Quality and Reducing Cost:
Designs for Effective Learning by Carol Twigg, motivated the
ideas behind the project and described some of the hallmarks
of courses redesigned according to them.
The project currently focuses on the largest of courses in
order to maximize its effect. According to Twigg, "just 25
courses generate about half of all student enrollments in
community colleges and about a third of all enrollments in
four-year institutions". This had never occurred to me but
isn't too surprising, given that nearly all colleges students
at every school take a common set of introductory courses in
English, mathematics, science, and business. What did
surprise me was the typical failure rates in these courses:
15% at research universities, 30-40% at comprehensive
universities, and 50-60% at community colleges. Some of these
failures are certainly the result of filtering out students
who shouldn't be in college, but I have to think that a
significant percentage of the failures are by people who
have been poorly served by a lecture-only section of 100s
of people.
What does agile software development have to do with all
this? In order to improve the quality of instruction
(including the failure rates in these large and common
courses) and reduce the cost of teaching them (in a
climate of declining funding and rising expenses), this
paper recommends that universities change the way they
design and teach university courses -- in ways that echo
how agile developers work, and using information technology
to automate whatever automation can improve.
One of the fundamental principles of this transformation
is continuous assessment and feedback.
Rather than testing students only with a midterm and a
final, an instructor should keep in continuous touch with
how students are comprehending the material. The traditional
way to do this is to administer frequent quizzes, but that
approach has as many minuses as plusses. Grading all those
quizzes is a pain no sane instructor relishes, and you end
up using a lot of class time taking quizzes.
Technology can help here, if we think about automating
continuous assessment and feedback. On-line quizzes can
give students an opportunity to test their understanding
frequently and receive feedback about what they know and
don't know, and they can provide the instructor with feedback
about both individuals and the group. Other technology
can be more continuous yet, allowing instructors to quiz
students "on the fly" and receive aggregated results
immediately, a la
Who Wants to be a Millionaire?
Folks at my university have begun to use interactive
feedback tools of this sort, but they haven't made their
way into my department yet. Our most common immediate
assessment-and-feedback tool is still the compiler.
But the agile programmers -- and agile-thinking instructors
-- among us know all about automating continuous assessment
and feedback, and use more tools: IDEs that provide
immediate compilation of code ... unit testing frameworks.
Red bar, green bar! These tools help students know right
where they are all the time, getting past some of the
ticky-tack syntax issue that unnecessarily interfere with
new students' progress. I think it's a huge win to let
the IDE point out "you forgot a semicolon..." and "your
code doesn't pass this test...".
There is a risk in allowing students to develop a "do it 'til
you get it right" mindset, but CS folks have already had to
deal with this with the easy availability of compilers. Two
years ago -- almost exactly! -- I wrote about this issue of
multiple iterations and care for programs.
Many professors still don't like that students can and do
go through many compile iterations. Since that time, I've
become even further convinced that students should do this,
but learn how to do it right. People master skills
by careful repetition, so we need to let them use repetition
-- carefully, thoughtfully. In some ays, this seems like
a statistical problem. To succeed by making random tries but
never learning, they need to have time for a lot of tries.
If they have that much time, then they have too little to do!
The rest of the paper outlines other agile-sounding techniques:
increased student interaction (pair programming), continuous
support (the coach, and access to the working system), and
sharing resources (collective ownership). But the key is
feedback, and the use of automation to do this as cleanly
and painlessly as possible.
Ultimately, I just like the mentality these folks have about
teaching. Twigg quotes a math prof involved with the project
as saying, "Students learn math by doing math, not by listening
to somebody talking about doing math." Of course! But you'd
never know it by looking at most university courses.
This sort of re-design requires a big change in how instructors
behave, too, and that change is harder to effect than the one
in students. Instructors are no longer primarily responsible
for introducing basic material. (Isn't that what reading is
for?) Instead, they need to be able to review what students have
done and expand on it in real-time, extending what students do
and leading them to new ideas and to integration of ideas.
That's intimidating to most of us and so requires a whole new
brain.
The next book on my nightstand is
Talking About Leaving:
Why Undergraduates Leave the Sciences,
by Elaine Seymour and Nancy Hewitt. The dean and department
heads in my college have had an ongoing discussion of national
trends in university enrollment in mathematics and the sciences,
because all of our departments with the exception of biology
have seen their number of majors drop in recent years. If we
can understand the issue better, perhaps we can address it.
Are students losing interest in the sciences in college? In
high school? In grade school? Why? One of the common themes
on this blog for the last year or so has been apparent declining
interest in CS among students both at the university and in the
K-12 system. At this point, all I know is that this is a
complex problem with a lot of different components. Figuring
out which components play the largest role, and which ones we
as university faculty and as citizens can affect, is the
challenge.
My net acquaintance Chad Orzel, a physicist, recently commented
on
why they're leaving,
drawing his inspiration from an
Inside Higher Ed piece
of the same name. That article offers four explanations for why
students leave the physical sciences and engineering disciplines:
lower GPAs, weed-out courses, large and impersonal sections, and
"vertical curricula". The last of these refers to the fact that
students in our disciplines often have to "slog" through a bunch
of introductory skills courses before they are ready to do the
intersting work of science.
While Chad teaches at a small private college, my experience here
at a mid-size public university seems to match with his. We don't
have many large sections in computer science at UNI. For a couple
of years, my department experimented with 100-person CS1 sections
as a way to leverage faculty expertise in a particular language
against our large enrollments. (Irony!) But for the most part
our sections have always been 35 or less. I once taught a 53-person
section of our third course (at that time, object-oriented
programming), but that was an aberration. Our students generally
have small sections with plenty of chance to work closely with
the tenure-track faculty who teach them.
We've never had a weed-out course, at least not intentionally.
Many of our students take Calculus and may view that as a weeder,
but my impression from talking to our students is that this is
nothing like the brutal weed-out courses used in many programs
to get enrollments down to a manageable size of sufficient
quality. These days, the closest thing we have to a weed-out
course is our current third course, Data Structures. It certainly
acts as a gatekeeper, but it's mostly a matter of programming
practice; students who apply themselves to the expectations of
the instructor ought to be able to succeed.
The other two issues are problems for us. The average GPA of
a computer science student is almost surely well below the
university average. I haven't seen a list of average GPAs
sorted by department in many years, but the last few times I did
CS and economics seemed to be jostling for the bottom. These
are not disciplines that attract lots and lots of weak students,
so grading practices in the departments must play a big role.
As the Inside Higher Ed article points out, This culture of
grading is common in the natural sciences and the more
quantitative social sciences at most universities. I don't
doubt that many students are dissuaded from pursuing a CS
major by even a B in an intro course. Heck, they get As in
their other courses, so maybe they are better suited for those
majors? And even the ones who realize that this is an illogical
deduction may figure that their lives will simply be easier with
a different major.
I won't speak much of the other problem area for us, because I've
written about it a lot recently. I've never used the word
"vertical" to describe our problem of boring intro courses that
hide or kill the joy of doing computing before students ever get
to see it, but I've certainly written about the issue. Any student
who graduates high school with the ability to read is ready for
a major in history or communication; the same student probably
needs to learn a programming language, learn how to write code,
and figure out a lot of new terminology before being ready to
"go deep" in CS. I think we can do better, but
figuring out how
is a challenge.
I must point out, though, that the sciences are not alone in the
problem of a vertical curriculum. As an undergraduate, I
double-majored in CS and accounting. When I switched from
architecture to CS, I knew that CS was what I wanted to do, but
my parents encouraged me to take a "practical" second major as
insurance. I actually liked accounting just fine, but only
because I saw past all of the bookkeeping. It wasn't until I
got to managerial accounting as a junior and auditing as a
senior that I got to the intellectually interesting part of
accounting, how one models an organization in terms of its
financial system in order to understand how to make it
stronger. Before that came two years of what was, to me,
rather dull bookkeeping -- learning the "basics" so that we
could get to the professional activities. I often tell
students today that accounting is more interesting than it
probably seems for the first one, two, or three years.
Computer science may not have moved much faster back then.
I took a one-quarter CS 1 to learn how to program (in Fortran),
a one-quarter data structures course, and a couple of courses
in assembly language, job control language, and systems
programming, but within three or four quarters I was taking
courses in upper-division content such as databases, operating
systems, and programming languages -- all of which seemed like
the Real Thing.
One final note. I actually read the articles mentioned at the
beginning of this essay after following a link from another piece
by Chad, called
Science Is Not a Path to Riches.
In it, Chad says:
A career in research science is not a path to riches, or even
stable employment. Anyone who thinks so is sadly deluded, and
if sure promotion and a fat paycheck are your primary goal (and
you're good at math), you should become an actuary or an accountant
or something in that vein. A career in research science can be
very rewarding, but the rewards are not necessarily financial
(though I hasten to add, I'm not making a bad living, either).
This is one place where we differ from physicists and chemists.
By and large, CS graduates do get good jobs. Even in times of
economic downturn, most of our grads do pretty well finding and
keeping jobs that pay above average for where they live. Our
department is willing to
advertise this
when we can. We don't want interested kids to turn away because
they think they can't get a job, because all the good jobs are
going to India.
Even still, I am reluctant to over-emphasize the prospect of
financial reward. For one thing, as the mutual fund companies all
have to tell us, "past performance is no guarantee of future results".
But more importantly, intrinsic interest matters a lot, too, perhaps
more so than extrinsic financial reward, when it comes to finding a
major and career path that works. I'd also like to attract kids
because CS is
fun, exciting, and worth doing.
That's where the real problem of 'verticality' comes in. We don't
want kids who might be interested to turn away because the discipline
looks like a boring grind.
I hope to learn more about this systemic problem from the empirical
data presented in Talking About Leaving, and use that to
figure out how we can do better.
Now that the issue has been resolved, I can finally write
on a topic I mentioned
three weeks ago,
my department's proposal to create a new major in Software
Engineering. This is one of those persistent "interruptions"
this summer that really was an important task in its own right.
It also reminds us all that academic politics are a non-trivial
exercise.
A couple of years ago, the faculty in my department decided
to propose three new majors. One, bioinformatics, targeted
an area of growing importance in which computing is an
essential component. Graduate programs in bioinformatics
were becoming common at this time, but few or no undergraduate
programs existed. We figured that this major would attract a
new audience of potential students and capitalize on the strong
math and biology departments here. The other two proposals were
extensions of the standard B.S. in Computer Science program we
already offered: Software Engineering, and Networking and System
Administration. These proposals targeted particular professional
areas that our students pursue within our existing majors, giving
them a little extra heft and their own identity. We figured that
these majors would allow current CS students to choose a major
that more directly matched their professional careers and hoped
that they would attract students interested in these areas who
might otherwise not attend our university.
Such "targeted majors" are becoming more common throughout
the country, and we hoped to be in the vanguard. Personally,
I'm not a big fan of "superset majors" like Software
Engineering and Networking, because I think even our most
professionally-oriented students are best served with a broad
CS major that prepares them for a diverse and dynamic discipline.
But I do understand their appeal to students and thus their
utility as marketing tools. Add to this reports such as Iowa's
Information Technology Strategic Roadmap,
which recommends focused majors as tools for developing the
state's base of IT workers, and such majors become even more
attractive to the university. At a time when our discipline
is changing, such majors represent a reasonable effort to
broaden and focus our reach at the same time.
In order to create a new major at one of Iowa's three public
universities, you must have it approved by the system-wide
Board of Regents. Before a proposal reaches the Board level,
though, it first must receive approval from the provosts at
the three institutions. This is a reasonable mechanism which
generally ensures that all of the universities know what
the others are doing, helps identify opportunities for
collaboration, and prevents unnecessary duplication in
programs.
Our bioinformatics and NaSA proposals were approved in the initial
proposal cycle, but software engineering was not. One of our
sister institutions raised objections to all three proposals, but
the other gave us its blessing. As part of a compromise to overcome
the objections, our administration withdrew the Software Engineering
proposal from the table. This succeeded because, while the objecting
school would have preferred that we not offer any of the new majors,
its greatest objection was to the Software Engineering proposal.
This objection ultimately came down to our use of the word 'engineering'
in the title of a degree program. The other schools have Colleges of
Engineering, but we do not.
Engineers take use of the word 'engineering' quite seriously as a
matter of professional honor. To them, engineering means something
specific, and engineering education requires a specific set of
courses in mathematics and the physical sciences, as well as specific
experiences rooted in how professional engineers craft their trade.
My university does not offer a traditional engineering program, so
our engineering colleagues do not consider us capable of
offering an engineering major.
So we passed on our Software Engineering proposal and put our
energies into launching the other two new majors. They've now been
on the books for a year and have begun to attract majors. We've
also experimented with
professional marketing techniques
to introducing bioinformatics to our target audiences.
By the time I became department head, we had a new dean and a new
provost, and our faculty really wanted to re-propose the Software
Engineering major. The faculty did not feel that the original
proposal had been dismissed on its merits, but rather for political
reasons, and they wanted the chance to make their case that we be
allowed to offer this new major, which so closely aligns with the
professional goals of many of our students.
So we set out to educate our new administration on the discipline and
why our university should be offering degrees in software engineering.
Once they were convinced, we took our case back to the council of
provosts. Not too surprisingly, we encountered the same objection.
Actually, we encountered several objections. Since the time of our
initial proposal, the objecting school had proposed its own
Software Engineering degree program. So now there were concerns
about duplication of effort and resources. Those of you on
university faculties surely know that duplication among state
schools is a big issue these days. State funding isn't as plentiful
as it used to be, and so unnecessary duplication is viewed as an
unacceptable financial luxury.
Another objection involved the fact that we did not intend to seek
accreditation of our program by
ABET,
the standard accrediting agency for engineering programs. As
a matter of professional standards, nearly all traditional
engineering programs are accredited by ABET. Software engineering
programs are a relatively recent phenomenon, as is their accreditation.
Programs started within colleges of engineering do tend to seek
accreditation, but not all do. A considerable number of
undergraduate software engineering programs -- about a quarter
of the thirty programs currently being offered in the U.S. --
lie outside of an engineering college and are much less likely
ever to seek accreditation.
This might be a concern for the established engineering disciplines,
but I think it is less of an issue for software engineering. I'm
not sure we know how to "engineer" large software all that reliably
yet, and I'm not sure that we have a good sense of what all software
engineers should know or be able to do. Projects such as
SWEBOK
are valuable efforts to catalog our current understanding, but what
we really need is many more years building big systems and examining
our practices along the way.
This brings us back to the semantic issue that lies at the heart of
the objections to our program proposal. Our engineering colleagues
consider software engineering to be an engineering discipline like
mechanical or electrical or civil engineering, and as such they think
it should be treated like the traditional engineering programs.
Whatever the professional assessment of engineering colleges regarding
the use of the word "engineering", the term "software engineering"
is widely used throughout the U.S. and the world in a broad sense,
to describe the disciplined construction of software systems. Courses
in software engineering are offered by many different academic
institutions, including the majority of Computer Science departments
these days. Graduates of computer science and information systems
programs move immediately into positions with the title "software
engineer" in many different kinds of companies. For our students,
these employers ranges from traditional engineering companies to
financial services companies such as insurance companies and banks.
Many small, independent software developers consider themselves to
be software engineers, though they would never consider becoming a
licensed professional engineer. Standard use of the term "software
engineering" does not indicate "engineering" in the sense understood
by the engineering profession.
Perhaps it should. Our colleges of engineering would prefer to
define the term prescriptively, setting standards and ensuring
that anyone who bears the title of engineer meet a set of common
standards first. This is a noble aspiration. But my definition of
the term is descriptive, in the sense of describing how it is used by
people out in the world. In this descriptive sense, I think it is
perfectly reasonable for my university to offer a Software Engineering
degree.
Alas, I am not the one to make this decision. Our sister institutions
persisted in their objections to our proposal, and so again it
failed. Had we changed the name of our program to Software
Development or almost anything else without the word 'engineering'
in it, we would probably have succeeded in having our program
approved. Our faculty decided that to change the name of our
program to something non-standard would defeat the purpose of
offering a specialized degree in the discipline; it wouldn't
match up with the expectations of students or the companies that
hire them. Besides, the non-standard name feels distinctly
sub-standard, as if we aren't capable of offering
a degree in the discipline that folks have come to regard as
standard in industry.
Sadly, I fear that there may have been an element of this thinking
in our sister institution's objection to our proposal. They think
us worthy of offering an "applied computer science" program in
something called software development, but not worthy of
awarding degrees in Software Engineering.
I work at a so-called teaching university. While most of our
faculty is engaged in research and other scholarly activity,
basic research is not our mission; producing well-educated
citizens is. A computer science program at a school such as
mine blends a solid core of empirical CS with what amounts to
professional education, not all that different from the
pre-professional programs we offer students interested in
pursuing law degrees and medical degrees. For most of our CS
students, computer science is a professional degree, and software
engineering is one of their professions of choice. One of our
goals is to produce broadly educated practitioners in a discipline
that changes rapidly, while at the same time changing the world
in which the practitioners practice.
Ultimately, I think that our position on who should be teaching
software engineering will be proven right by history. While
I am not a big fan of the metaphor, software engineering as a
discipline is much bigger than colleges of engineering conceive
it, and more and more schools will teach it. In the meantime,
we will continue on with what we have -- a B.S. program in Computer
Science, with a Software Engineering emphasis -- and prepare
students to enter the world ready to develop software, including
the largest of systems, whatever that activity may be like in the
future.
I sit hear now wondering what software engineering programs in
colleges of engineering and think about agile approaches to
software development. Maybe we are lucky not to be constrained
by the straightjacket of expectations that accompany the programs
in established engineering disciplines. We are still learning how
to build software, and we can fold our learning into our courses
and curricula much faster when we don't have to worry about a set
of restrictions based in other engineering disciplines.
Anyway, for those of you who think that "office politics" in the
"real world" make life worse than it is in the ivory tower, this
little story only scratches the surface of what university politics
are like. That's a whole other story...
You always have to design something before you build it. The
question is: "How much do I have to design before I build?"
... the act of building is *part* of the act of design....
To many people, this sense of design is heresy. They prefer
a more formal definition, one that makes clear a distinction
between between design and implementation, and analysis and
design. Even in a day where iterative models of software
development have replaced the waterfall model in the minds of
even the most traditional software engineers, many people still
think of the phases of development as very different.
Agile software developers seek to iterate more quickly through
the phases of software development, in large part because of
what Martin reminds us: we learn too much about our design
from writing code to wait very long to begin writing code.
Likewise, we learn too much from our design and coding about
how well we understand our problem to wait very long to begin
designing and writing code.
So, what is the best definition of design for us to use in
our work, and with our students and new hires? Folks who see
the phases of software development as Major Events to be seen
as separate activities are most likely to give Major Definitions
to the phases. But I've learned a lot about design from folks
who have more pragmatic takes on software development.
Sometime last year, the members of a mailing list I'm on
discussed the definition of design. Jim Coplien and Grady Booch
gave very thorough definitions of design, both the verb (the act
of designing) and the noun (the artifact produced). Both of their
definitions incorporated the idea of a system and its behavior,
related to the forces that exist in the system's intended
environment. The thing I liked best about Booch's definition
was how it managed to account for the scientific side of design,
where empiricism and experiment help us to make optimal decisions
in a large search space, as well as the artistic side, where
science leaves enough degrees of freedom to enable clever and
elegant decisions.
Whatever else design is, it is about the choices
we make while building things. Some of the features of a system
are required by the customer, and others are driven by the
technologies that we use, including the programming language.
The rest of the system is determined by the developer. This is
how James Noble characterized design in our e-mail discussion:
the decisions we make that determine the rest of the system.
By the way, Noble's definition reminds us just how important it
is not to use an overly restrictive programming language when we
build systems. Such a language makes too many decisions for us
upfront, without regard the problem we are solving or the environment
in which the system will live. Choosing such a language surrenders
too much freedom, too much possibility, too soon.
Once we get to the point of seeing design as being about choices,
and without any predisposition to create a complex definition in
order to distinguish design in some formal way, we can get to my
all-time favorite one-line definition of design. This definition
is courtesy of Ward Cunningham, whose gift for simplicity I have
extolled before:
Design is your choices that stick.
This brings us back to the fundamental truth in the agile approach
captured by Robert Martin in the passage above: Not all of our
choices will stick, and we need to learn which will and which
won't as quickly as possible, from whatever sources we have
available. And that includes the program itself.
That was my standard answer to a particular family of questions
for many years. The prototypical question in this family was,
"Do you think you'll ever want to be a department head?" And
I always said, "July 27 at 2:00 PM".
If you are a faculty member or even a graduate student, you probably
know just what I meant. Summer is a great time to be a faculty
member. We get to read, write code, play with new ideas -- all
without having to worry about preparing for and meeting classes,
attending department meetings, or otherwise doing much with the
day-to-day business of the university. Even better, we can read,
write, and play most anywhere we want, most anytime we want. We
can become absorbed in a program and work all day, and never have
to worry about a meeting or a class interrupting the flow. We can
work from home or from the road, but we don't have to work at our
offices unless we want to. No one expects us to be there much.
Department heads, though, are administrators. The daily business of the university goes on, and the heads have to keep tabs on it. There are salary letters to be written, budgets to be closed, memos to write for the dean and provost, and inquiries to be answered. The university pays their salary during the summer, and the university expects a return on its investment.
So, there we are, 2:00 PM on a beautiful Thursday, July 27th. As a faculty member, I could be almost anywhere, doing almost anything, learning something new. As a department head, I would be in the office, dressed well enough to meet the public if necessary, "working".
"July 27 at 2:00 PM" meant "I don't think so, and here's why...".
The great irony is that I am now finishing up my first year as department head now, and it is nearly 2:00 PM on Thursday, July 27. It's overcast outside, not sunny, and frightfully muggy. Where am I? In my home study. What am I doing? Reading from the stack of papers that has built up over the last few months, and writing a quick entry for this blog. Not much different than any other summer in the past 15 years.
However, I stand by metaphorical answer. All other things being equal, summer life as a faculty member is freer and open to more possibilities than summer life as a department head. It requires some adjustment.
My reading today has been from an old-fashioned pile of stuff, the papers and journal articles that I run into during busy days and set aside for later. I don't know about you, but my eyes are always bigger than my stomach when it comes to the list of things I want to read. So I print them out and wait for a free moment. Eventually the pile of papers exceeds any realistic amount of time I have to read and the amount of space I have to store them. Today, I made a few free moments to do triage, tossing papers that I know I'll never get to and, every so often, stopping to read something that sounds good right now. A very few papers earn a spot in the new, streamlined pile of stuff, in an almost certainly fantastic hope that some day I'll get to them.
Here are two passages I read today that made the effort worthwhile. First, a quote from
Uncle Bob Martin,
from a 2004 message to the extreme programming mailing list, in the thread "Designing before doing":
> "But how can you do anything without designing it first?!" ...
You can't. You always have to design something before you build it.
The question is: "How much do I have to design before I build?"
The answer is: "Just enough so that what I build gives me better insight into the design of the next step."
Seen this way, the act of building is *part* of the act of design, and the original question inverts itself: "How can you design something without verifying your design decisions by implementing them?"
Summer is a great time to read old papers, though this
summer has been too light on free reading time for my
tastes. This morning, I read
David Gries's
1974 SIGCSE paper
What Should We Teach in an Introductory Programming Course?,
which came up in a SIGCSE mailing list discussion
earlier this year. Gries has long been involved in the
effort to improve computer science instruction, from at
least his 1973 PL/I-based intro text with Conway,
An Introduction to Programming
up to his recent multimedia effort
Program Live!,
with his son, Paul. In part because his work tends to
be more formalist than my own, I usually learn a lot from
his writing.
This paper focuses on two of what Gries thinks are the
three essential aspects of an intro course: how to solve
problems and how to describe solutions algorithmically.
His discussion of general problem solving was the reason
the paper came up in the SIGCSE discussion, which
considered how best to teach students "general
problem-solving skills". Gries notes that in disciplines
such as philosophy one studies problem-solving methods
as philosophical stances, but not as processes to try in
practice, and that in subjects such as mathematics one
learns how to solve specific classes of problems by dint
of repetition. By exposing students to several classes
of problem, teachers hope that they generalize their
learning into higher-order skills. This is true in many
disciplines.
But we in computer science face a more challenging
problem. We strive to teach our students how to write
programs that solve any sort of problem, whether from
business or science or education. In order to program
well across all the disciplines, our students
must learn more general problem-solving
skills.
That said, I do not think that we can teach general
problem-solving skills in our intro course, because I do
not think the brain works that way. A lot of evidence
from cognitive psychology shows that humans learn and tend
to operate in specific contexts, and expertise transfers
across boundaries only with great attention and effort.
The the real question is not how we can teach general
problem-solving skills in our intro course, but rather
how can we help students develop general problem-solving
skills over the course of our curriculum. My current
belief is that we should teach
programming in context,
while opportunistically pointing out the patterns that
students see and will see again later. Pick a context
that students care about, so that they will have plenty
of their own motivation to succeed. Then do it again, and
again. By making explicit the more general patterns that
students see, I think that we can do better than most CS
and math curricula currently do. We would not be teaching
general problem-solving skills in any course so much as
creating an environment in which students can maximize
their likelihood of "getting it". Our courses should not
be weed-out courses, because I think most students can get
it -- and we need them to, whether as CS majors or as
non-majors prepared to participate in a technological
society.
When Gries looked at what people were teaching in intro
CS courses back then, he found them doing what many of
our courses do now: describing a set of tools available
in a programming language, showing students a few examples,
and then sending them off to write programs. Not much
different than our math brethren teaching differentiation
or integration. Gries exposes the folly in this approach
with a little analogy:
Suppose you attend a course in cabinet making. The
instructor briefly shows you a saw, a plane, a hammer,
and a few other tools,letting you use each one for a few
minutes. He next shows you a beautifully-finished cabinet.
Finally, he tells you to design and build your own cabinet
and bring him the finished product in a few weeks.
You would think he was crazy!
(For some reason, this passage reminded me of a witty
student evaluation that Rich Pattis shared in his
SIGCSE keynote address.)
Gries offers a few general principles from the likes of
Descartes,
Polya, and Dijkstra and suggests that we might teach them
to students, that they might use the principles to help
themselves organize their thoughts in the midst of writing
a complex program. I suspect that their greatest value is
in helping instructors organize their thoughts and keep the
ultimate goal of the course in mind. For example, while
reading this section, I was struck by Polya's fourth phase
of solving problems: "Look back". We instructors must
remember to give our students both the opportunity
to look back at what they've done and think about their
process and product, and the time to consolidate
their learning. So often, we are driven by the need to
cover more, more, more material, and the result is a
treadmill from which students fall at the end of the
course, exhausted and not quite sure what all just happened.
Gries then offers a language for describing algorithms,
very much in sync with the Structured Programming movement
of the 1970s. My primary reaction to this discussion was
"where are the higher-level patterns?" If all we teach
students are basic statements, procedure definitions and
calls, and control structures, we are operating only barely
above the level of the programming language -- and thus
leaving students to discover on their own fundamental
patterns like Guarded Linear Search.
What language should we teach in the intro course? Gries
attacks this question with gusto. As I've written before,
language sniping is a
guilty pleasure
of mine, and Gries's comments are delightful. Indeed, this
whole paper is written in a saucy style not often seen in
academic papers, then and especially now. I wonder if most
SIGCSE referees would let such style pass these days?
First, Gries reminds us that in an intro the programming
language is only a vehicle for teaching the ideas we think
are important. It should be as close as possible to the
way we want students to think about programs, but also
"simple, elegant, and modular, so that features and
concepts not yet taught won't get in the way." (As a
smug language weenie, I am already thinking Smalltalk
or Scheme...) But we usually teach the wrong language:
The language taught is often influenced by people outside
the computer science profession, even though their
opinions are not educated enough to deserve recognition.
At the time he wrote the paper, Gries would like to have
taught Pascal, BLISS, or a variant of Algol, but found
that most departments taught Fortran, BASIC, or PL/I.
Gries minces no words. On Fortran:
Fortran is out of date and shouldn't be used unless there
is absolutely nothing else available. If this is the
case, use it under protest and constantly bombard the
manufacturers or other authorities with complaints,
suggesting the make available a more contemporary.
I learned Fortran in my CS 1 course back in 1983!
On Basic:
[It] should never have come into existence. When it was
contemplated, its designers should have done their
research to see what programming and programming languages
are all about before plunging in.
I learned Basic as my first programming language in high
school, in 1980!
But then Gries expresses one of the tenets of his approach
that I disagree with:
I have doubts about teaching students to think "on-line";
algorithms should be designed and written slowly and
quietly at one's desk. Only when assured of correctness
is it time to go to the computer and test the algorithm
on-line.
First, notice the older sense of "on-line". And then ask
yourself: Is this how you program, or how you want to
program? I know I'm not smart enough to get any but the
most trivial programs correct without testing them on-line.
Of the choices realistically available, Gries decided that
PL/I was the best alternative and so wrote his text with
with Conway. I used the 1979 version of this text as the
PL/I reference in my data structures course back in 1983.
(It was the language companion to the language-independent
Standish text
I so loved.)
Even though Gries grudgingly adopted PL/I, he wasn't
happy:
What's wrong with PL/I? Its syntax is enough to offend
anyone who has studied English grammar; its data structure
facilities ... could have been less clumsy ...; it is not
modular ...; its astonishment factor is much too high
(e.g., what is 25 + 1/3 ?); ... and so on.
But with the right subset of the language, Gries felt he
could teach structured programming effectively. That is
just the sort of compromise that C++ advocates made in
the 1990s. I willingly accepted C++ as a CS 1 language
myself, though it didn't take long for me to realize
that this was a mistake. By comparison, PL/I was a
relatively nice language for novices.
The last section of Gries's paper turns to the topic of
program documentation. His central tenet will sound
familiar to agile programmers of the new century:
Program documentation should be written while
the program is being written, if not before,
and should be used by the programmer in proving correctness
and in checking his program out.
This is a fine argument for test-driven development! This
is a common theme among formalist computer scientists, and
one I've written about with regard to
Edsger Dijkstra.
The place where the agile folks diverge from folks like
Gries and Dijkstra is in their strong conviction that we
should use code -- executable tests -- to document the
intended behavior of the system. If the documentation is
so valuable, why not write it in a form that supports
automated application and continuous feedback? Sitting
quietly at one's desk and writing an outline of the
intended algorithm by candlelight seems not only quaint
but also sub-optimal.
The outline form that Gries recommends is certainly more
palatable than other alternatives, such as flowcharts.
I think that the modern rendition of this approach is
Matthias Felleisen's
design recipe approach, described most completely in
How to Design Programs.
I have great respect for this work and am always looking
for ways to use its ideas to improve how I teach.
Gries concludes his paper with good advice on "practicing
what you teach" for any instructor:
The students will easily sense whether you
believe in what you tell them, and whether you yourself
practice what you teach.
He wrote this at a time when many CS instructors needed
to be retrained to teach the new orthodoxy of structured
programming. It has been equally true over the last
ten years or so, with the move to object-oriented programming
and then agile approaches. One of the reasons I
dislike textbooks these days
is that too often I get the sense that the authors don't
really believe what they are saying or, if they
do, that the belief is more a skin they've put on than a
deep grokking of the ideas. Gries advises ways in which
to deepen one's understand, including the surprisingly
surprising "write several programs, both large and small,
using the tools and techniques advocated". Why should this
be surprising to anyone? I don't know, but I wonder how
many folks who now teach an OO intro course have ever
written and lived inside a large object-oriented program.
The end of this paper supports a claim I made about
academic conservatism
a couple of years ago, and brings us back to Dijkstra
again. First he expresses hope:
You would think that the University, where one searches
for truth and knowledge, would be the place for
innovative thinking, for people are tuned to new and
better ideas.
... and then he quotes Dan McCracken, who had surveyed
academics about their intro courses:
"Nobody
would claim that Fortran is ideal for
anything, from teachability, to
understandability of finished programs, to extensibility.
Yet it is being used by a whopping 70% of the students
covered by the survey, and the consensus among the
university people is that nothing is going to change much
anytime soon."
Does this sound like educators who are committed to
teaching concepts, to teaching people what they need to
know to prepare for the future?
As noted above, my alma mater was still teaching Fortran
in CS 1 into the 1980s. Gries is hard on his colleagues,
as I have been at times, but the truth is that changing
how one programs and teaches is hard to do. And he and I
have been guilty of making PL/I-like compromises, too, as
we try to introduce our own ideas. The lesson here is
not one of blame but one of continually reminding ourselves
of what matters and trying to make those things happen in
our courses.
Reading this paper was a nice diversion from the other
duties I've been facing lately, and a nice way to start
preparing more for my fall CS 1 course.
One of the enjoyable outreach activities I've been
involved with as department head this year has
been the state of Iowa's Information Technology
Council. A few years back, the
Iowa Department of Economic Development
commissioned the Battelle corporation to study
the prospects for growing the state's economy in
the 21st century. They focused on three areas:
bioscience, advanced manufacturing, and information
technology. The first probably sounds reasonable
to most people, given Iowa's reputation as an
agriculture state, but what of the other two? It
turns out that Iowa is much more of a manufacturing
state than many people realize. Part of this relates
back to agriculture. While John Deere is headquartered
in Moline, Illinois, most of its factories are in
Iowa. We also have manufacturers such as Rockwell
Collins and Maytag (though that company has been
purchased by Whirlpool and will close most or all of
its Iowa locations soon).
But information technology? Des Moines is home to
several major financial services companies or their
regional centers, such as Principal Financial Group
and Wells Fargo. Cedar Rapids has a few such firms
as well, as well as other companies with a computing
focus such as NCR Pearson and ACT.
IDED created the IT Council to guide the state in
implementing the Information Technology Strategic
Roadmap developed by Battelle as a result of its
studies. (You can see the report at this
IDED web page.)
The council consists of representatives from most of
Iowa's big IT firms and many of the medium-sized and
small IT firms that have grown up throughout the state.
Each of the three state universities has a representative
on the council, as does the community college system and
the consortium of Iowa's many, many private colleges and
universities. I am UNI's representative.
The council has been meeting for only one year, and we
have spent most of our time really understanding the
report and mapping out some ideas to act on in the
coming year. One of the big issues is, of course,
how Iowa can encourage IT professionals to make the
state their home, to work at existing companies and
to create innovative start-ups that will fuel economic
growth in the sector. Another part of the challenge
is to encourage Iowa students to study computer science,
math, and other science and engineering disciplines --
and then to stay in Iowa, rather than taking attractive
job offers from the Twin Cities, Chicago, Kansas City,
and many other places with already-burgeoning IT
sectors.
To hear
Paul Graham tell it,
we are running a fool's errand. Iowa doesn't seem
to be a place where nerds and the exceedingly rich want
to live. Indeed, Iowa is one of those red states that
he dismisses out of hand:
Conversely, a town that gets praised for being "solid"
or representing "traditional values" may be a fine place
to live, but it's never going to succeed as a startup hub.
The 2004 presidential election ... conveniently supplied
us with a county-by-county
map
of such places.
[6]
Actually, as I look at this map, Iowa is much more people
than red, so maybe we have a chance! I do think that a
resourceful people that is willing to look forward can
guide its destiny. And the homes of our three state
universities -- Iowa City, Ames, and Cedar Falls -- bear
the hallmark of most university towns: attracting and
accepting more odd ideas than the surrounding environment
tends to accept. But Iowans are definitely stolid
Midwestern US stock, and it's not a state with grand
variation in geography or history or culture. We have
to bank on solidity as a strength and hope that some
nerds might like to raise their families in a place
with nice bike trails and parks, a place where you
can let your kids play in the neighborhood with fearing
the worst.
We also don't have a truly great university, certainly
not of the caliber Graham expects. Iowa and Iowa State
are solid universities, with very strong programs in
some areas. UNI is routinely praised for its efficiency
and for its ability to deliver a solid education to its
students. (Solid -- there's that word again!) But none
of the schools has a top-ten CS program, and UNI has not
historically been a center of research.
I've sometimes wondered why Urbana-Champaign in Illinois
hasn't developed a higher-profile tech center. UIUC has
a top-notch CS program and produces a lot of Ph.D., M.S.,
and B.S. graduates every year.
Eric Sink
has blogged for a few years about the joys of starting
an independent software company amid the farmland
of eastern Illinois. But then there is that solid,
traditional-values, boring reputation to overcome.
Chicago is only a few hours' drive away, but Chicago
just isn't a place nerds want to be near.
So Iowa is fighting an uphill battle, at least by most
people's reckoning. I think that's okay, because I
think the battle is still winnable -- perhaps not on the
level of the original Silicon Valley but at least on the
scale needed to invigorate Iowa's economy. And while
reputation can be an obstacle, it also means that
competitors may not be paying enough attention. The
first step is to produce more tech-savvy graduates,
especially ones with an entrepreneurial bent, and then
convince them to stay home. Those are steps we can
take.
One thing that has surprised me about my work with
the IT Council is that Iowa is much better off on another
of Graham's measures than I ever realized, or than most
people in this state know. We have a fair amount of
venture capital and angel funding waiting for the right
projects to fund. This is a mixture of old money derived
from stodgy old companies like Deere and new money from
the 1990s. We need to find a way to connect this money
to entrepreneurs who are ready to launch start-ups, and
to educate folks with commercializable ideas on how to
make their ideas attractive to the folks with the money.
Here at UNI, we are blessed to have an existence proof
that it is possible to grow a tech start-up right here
in my own backyard:
TEAM Technologies,
which among its many endeavors operates the premier
data center in the middle part of the USA. A boring,
solid location with few people, little crime, and no
coastal weather turns out to be a good thing when you
want to store and serve data safely! TEAM is headed
up by a UNI alumnus -- another great strength for our
department as we look for ways to expand our role in
the economic development of the state.
I finally got around to reading Glenn Vanderburg's
Buried Treasure.
The theme of his article is "our present is our past,
and there's more past in our future". Among his
conclusions, Glenn offers some wisdom about programming
languages and software education that we all should
keep in mind:
What I've concluded is that you can't keep a weak
team out of trouble by limiting the power of their
tools. The way forward is not figuring out how to
achieve acceptable results with weak teams; rather,
it's understanding how to build strong teams and
how to train programmers to be part of such teams.
Let's stop telling ourselves that potential software
developers can't learn to use powerful tools and instead
work to figure out how to help them learn. Besides,
there is a lot more fun in using powerful tools.
Glenn closes his article with a nascent thought of his,
an example of how knowing the breadth of our discipline
and its history might help a programmer solve a thorny
problem. His current thorny problem involves database
migration in Rails, and how that interacts with version
control. We usually think of version control as tracking
static snapshots of a system, but a database migration
subsystem is itself a tracking of snapshots of an evolving
database schema -- so your version control system ends up
tracking snapshots of what is in effect a little version
control system! Glenn figures that maybe he can learn
something about solving this problem from Smalltalkers,
who deal with this sort of this thing all the time --
because their programs are themselves persistent objects
in an evolving image. If he didn't know anything about
Smalltalk or the history of programming languages, he
might have missed a useful connection.
Speaking of Smalltalk, veteran Smalltalker Blaine Buxton
wrote recently
on a theme you've
seen here:
better examples. All I can say is what Blaine himself
might say, Rock on, Blaine! I think I've
found a textbook
for my CS 1 course this fall that will help my students
see lots of more interesting examples than "Hello, world!"
and Fibonacci numbers.
That said, my Inner Geek thoroughly enjoyed a little
Scheme programming episode motivated by
one of the comments
on this article, which taught me about a cool feature of
Fibonacci numbers:
Fib(2k) = Fib(k) * (Fib(k+1) + Fib(k-1))
This property lends itself to computing Fib very efficiently
using binary decomposition and memoizing (caching perviously
computed values). Great fun to watch an interminably slow
function become a brisk sprinter!
As the commenter writes, simple problems often hide gems of
this sort. The example is still artificial, but it gives
us a cool way to learn some neat ideas. When used tactically
and sparingly, toy examples open interesting doors.
Short answer: Because sometimes I am too cocky
for my own good.
If you read the
recent entry
on my latest half marathon, you may have noticed
that my mile 3 time stands out as slower than the
rest. What happened? After running two comfortable
miles at exactly 7:32, about a half minute faster
than planned, I started daydreaming about what a
great race I would soon have run. "Let's see,
that's 91... plus six-and-a half, which is...
Wow!" While patting myself on the back in advance,
I forgot to keep running. Too cocky.
Last summer, when I took on the
responsibilities of department head,
I managed to convince myself that I was the best
person for the job. Maybe even the only person.
With this attitude, it is all too easy to fall
into habits of thought and action where I forget
that I have to do the hard work of the job. Why
aren't things coming more easily? Too cocky.
So it is with programming. It's quite easy to
attack a problem before we fully understand our
customer's needs, to start pumping out code before
we know where we are going. Get cocky, and pretty
soon the problem and the program step up to humble
me. Unfortunately, by then, I too often have a
big mess on my hands.
I work better when I'm a little nervous, when I'm
a bit unsure of whether I can do what I'm trying
to do. Maybe that's a trait peculiar to me, but
I think not. I've had good friends who thrived on
an element of tension, where just enough uncertainty
heightens their senses. I am more aware then.
When I get cocky, I stop paying attention.
One reason that I like agile approaches to software
development is that they encourage me not to get
cocky. They tell me to take small steps, so I can't
run ahead of my understanding. They tell me to find
simple solutions, so that I have a better chance of
succeeding (and, when I don't, I won't have erred
too badly). They tell me to seek continuous feedback,
so that I can't fool myself into thinking that all
is going smoothly. The red bar cannot be denied!
They tell me to integrate my work continuously, so
that I can't fool myself about the system at large.
They tell me to interact with other developers and
with my customer as frequently as I can, so that
others can help me, and keep me honest. The whole
culture is one of humility and honesty.
I see that Ralph Johnson is giving the Friday
keynote talk at
ECOOP 2006
this year. His talk is called "The Closing of the Frontier",
and the
abstract
shows that it will relate to an idea that Ralph has
blogged about before:
software development is program transformation.
This is a powerful idea that has emerged in our industry
over the last decade or so, and I think that there are
a lot of computer scientists who have to learn it yet.
I have CS colleagues who argue that most programs are
developed essentially from scratch, or at least that the
skills our students most need to learn most closely
relate to the ability to develop from scratch.
I'm a big believer in learning "basic" programming
skills (most recently discussed
here),
but I'd like for my students to learn many different
ways to think about problems and solutions. It's
essential they learn that, in a great many contexts,
"Although user requirements are important, version N+1
depends more on version N than it does on the latest
requests from the users."
Seeing Ralph's abstract brought to mind a paper I
read and
blogged about
a few months back, Rich Pattis's "A Philosophy and
Example of CS-1 Programming Projects". That paper
suggested that we teach students to reduce program specs
to a minimum and then evolve successive versions of a
program which converges on the program that satisfies
all of the requirements. Agile programming for CS1
back in 1990 -- and a great implementation of the
notion that software development is program transformation.
I hope to make this idea a cornerstone of my CS1 course
this fall, with as little jargon and philosophizing as
possible. If I can help students to develop good habits
of programming, then their thoughts and minds will
follow. And this mindset helps prepare students for a
host of powerful ideas that they will encounter in later
courses, including programming languages, compilers,
theory, and software verification and validation.
I've come to realize something while preparing for my
fall CS1 course.
I don't like textbooks.
That's what some people call a "sweeping generalization",
but the exceptions are so few that I'm happy to make one.
For one thing, textbooks these days are expensive.
I sympathize with the plight of authors, most of whom put
in many more hours than book sales will ever pay them for.
I even sympathize with the publishers and bookstores, who
find themselves living in a world with an increasingly
frictionless used-book market, low-cost Internet-based
dealers, and overseas sellers such as Amazon India. But
none of this sympathy changes the fact that $100 or more
for a one-semester textbook -- one that was written
specifically not to serve as a useful reference book for
later -- is a lot. Textbook prices probably have not
risen any faster than the rate of tuition and room and
board, but still.
Price isn't my real problem. My real problem is that I
do not like the books themselves. I want to teach
my course, and more and more the books
just seem to get in the way. I don't like the style of the
code shown to students. I don't like many of the design
ideas they show students. I don't like all the extra words.
I suppose that some may say these complaints say more about
me than about the books, and that would be partly true. I
have some specific ideas about how students should learn
to program and think like a computer scientist, and it's
not surprising that there aren't many books that fit my
idiosyncrasy.
Sticking to the textbook may have its value, but
it is hard to do when I am unhappy at the thought turning
another page.
But this is not just me. By and large,
these books aren't about anything.
They are about Java or C++ or Ada. Sure, they may be about
how to develop software, too, but that's an inward-looking
something. It's only interesting if you are already
interested in the technical trivia of our discipline.
This issue seems more acute for CS 1, for a couple of reasons.
First, one of the goals of that course is to teach students
how to program so that they can use that skill in later
courses, and so they tend toward teaching language. More
important is the demand side of the equation, where
the stakes are so high.
I can usually live with one of the standard algorithms books
or compilers books , if it gives students a reasonable point
of view and me the freedom to do my own thing. In those cases,
the book is almost a bonus for the students. (Of course, then
the price of the book becomes more distasteful to students!)
Why use a text at all? For some courses, I reach a point of
not requiring a book. Over the last decade or more, I have
evolved a way of teaching Programming Languages that no longer
requires the
textbook
with which I started. (The textbook also evolved away from
our course.) Now, I require only
The Little Schemer,
which makes a fun, small, relatively inexpensive contribution
to how my students learn functional programming. After a few
times teaching Algorithms, I am getting close to not needing
a textbook in that course, either.
I haven't taught CS 1 in a decade, so the support of a strong
text would be useful. Besides, I think that most beginning
students find comfort at least occasionally in a text, as
something to read when today's lecture just didn't click,
something to define vocabulary and give examples.
So, what was the verdict? After repressing my true desires
for a few months in the putative interest of political harmony
within the department, yesterday I finally threw off my
shackles and chose Guzdial and Ericson's
Introduction to Computing and Programming with Java:
A Multimedia Approach.
It is relatively small and straightforward, though a still
a bit expensive -- ~ $90. But I think it will "stay out of
my way" in the best sense, teaching programming and computing
through concrete tasks that give students a chance to see and
learn abstractions. Perhaps most important, it is
about something,
a something that students may actually care about. Students
may even want to program. This book passes what I
call the Mark Jacobson Test, after a
colleague
who is a big believer in motivation and fun in learning:
a student's roommate might look over her shoulder one night
while she's doing some programming and say, "Hey, that looks
cool. Whatcha doing?"
I've been meaning to write all week, but it turned
out to be busy. First, my wife and daughters
returned from Italy,
which meant plenty of opportunity for family time.
Then, I spent much of my office week writing content
for our new
department website.
We were due for a change after many years of the same
look, and we'd like to use the web as a part of
attracting new students
and faculty. The new site is very much an early first
release, in the agile development sense, because I
still have a lot of work to do. But it fills some of
our needs well enough now, and I can use bits and pieces
of time this summer to augment the site. My blogging
urge was most satisfied this week by the material I
assembled and wrote for the
prospective students section
of the site. (Thanks to the
Lord of the Webs
for his design efforts on the system.)
I did get a chance to thumb through the May issue of
ACM Queue
magazine, where I read with some interest the
interview with Werner Vogels,
CTO of Amazon. Only recently I had been discussing
Vogels as a potential speaker for OOPSLA this or some
year soon. I've read enough of Vogels's blog to know
that he has interesting things to say.
At the
end of the interview,
Vogels comments on recruiting students and more generally
on the relationship of today's frontier IT firm to academia.
First, on what kind of person Amazon seeks:
The Amazon development environment requires engineers and
architects to be very independent creative thinkers. We
are building things that nobody else has done before, so
you need to be able to think outside the box. You need
to have a strong sense of ownership, because in the small
teams in which you will work at Amazon, your colleagues
will count on you to pull your weight -- especially when
it comes to operating the service that you have built.
Can you take responsibility for making this the best it
can be?
Many students these days hear so much about teamwork and
"people" skills that they sometimes forget that every
team member has to be able to contribute.
No one wants a teammate who can't produce. Vogels stresses
this upfront. To be able to contribute effectively, each
of us needs to develop a set of skills that we can use
right now, as well as the ability to pick up new skills
with some facility.
I'd apply the same advice to another part of Vogels's
answer. In order to "think outside the box",
you have to start with a box.
Vogels then goes on to emphasize how important it is for
candidates to "think the right way about customers and
technology. Technology is useless if not used for the
greater good of serving the customer." Sometimes, I
think that cutting edge companies have an easier time
cultivating this mindset than more mundane IT companies.
A company selling a new kind of technology or lifestyle
has to develop its customer base, and so thinks a lot
about customers. It will be interesting to see how
companies like Yahoo!, Amazon, and Google change as they
make the transition into the established, mainstream
companies of 2020.
On the relationship between academia and industry, Vogels
says that faculty and Ph.D. students need to get out into
industry in order to come into contact with "the very
exciting decentralized computing work that has rocked the
operating systems and distributed systems world in the past
few years". Academics have always sought access to data
sets large enough for them to test their theories. This
era of open source and open APIs has created a lot of new
opportunities for research, but open data would do even
more. Of course, the data is the real asset that the big
internet companies hold, so it won't be open in the same
way for a while. Internships and sabbaticals are the best
avenue open for academics interested in this kind of research
these days.
Yesterday evening, I was thinking about map-making,
which I had discussed briefly in my blog on
Programming as Discovery and Expression.
Dick Gabriel discussed map-making as an activity like
writing and programming, an act blending discovery and
expression. I've long considered the analogy between
programming and writing, but the analogy between
programming and map-making was new to me. It jumped
back into the forefront of mind while walking.
Programming is a lot like map-making. Cartographers
start with the layout of the physical world, the earth
and its features, and produce a model for a specific
purpose. We programmers start with a snapshot of some
part of the world, too, and produce a model for a
specific purpose. Like map-makers, we leave out some
details, the ones that don't serve our purpose. When
we write business software, we create little models of
people as objects or entries in a database table, but
we leave out all sorts of features. I rarely see a
"hair color" attribute on my business objects. Like
map-makers, we accentuate other details of interest,
such as wage rate and years of service.
Is there anything
for us to learn
about programming from this analogy? Have you ever
heard of this metaphor before, or seen it discussed
somewhere? I'm not thinking of conceptual analogs
like "mind maps" and generic modeling, but
honest-to-goodness maps, with mercator projections
and isobars and roads. I think I'll have to read
a bit on the act of cartography to see what value
there might be in the analogy.
Recently
I pointed you to Dick Gabriel's
The Art of Lisp & Writing,
which I found when I looked for a Gabriel essay that
discussed triggers and Richard Hugo. I must confess
that I recommended Dick's essay despite never having
read it; then again, I've never been disappointed by
one of his essays and figured you wouldn't be, either.
I read the essay over tortellini last night, and I
wasn't disappointed. I learned from his discussion
of the inextricable partners in creation, discovery
and presentation. I learned about mapmakers and how
their job is a lot like an engineer -- and a lot like
a writer.
Most of exploration is in the nature of the locally
expected: What is on the other side of that hill is
likely to be a lot like what's on this side. Only
occasionally is the explorer taken totally by surprise,
and it is for these times that many explorers live.
Similarly for writers: What a writer thinks up in the
next minute is likely to be a lot like what is being
thought this minute -- but not always: Sometimes an
idea so initially apparently unrelated pops up that
the writer is as surprised as anyone. And that's why
writers write.
As anyone who has ever written a program worth writing
will tell you, that is also why programmers program.
But then that is Dick's point. Further, he reminds us
why languages such as Lisp and Smalltalk never seem to
die: because programmers want them, need them.
Gabriel has been writing about programming-and-writing
for many years now, and I think that his metaphor can
help us to understand our discipline better. For example,
by explaining writing as "two acts put together: the act
of discovery and the act of perfecting the presentation",
the boundaries of which blur for each writer and for each
work, we see in relief one way in which "software
engineering" and the methodologists who drive it have
gone astray. I love how Dick disdains terms such as
"software developer", "software design and implementation".
For him, it's all programming, and to call it something
else simply obscures a lot of what makes programming
programming in the first place.
Reading this essay crystallized in mind another reason
that I think Java, Ada, and C++ are not the best (or even
okay) choices for CS 1: They are not languages for discovery.
They are not languages that encourage play, trying to solve
a hard problem and coming to understand the problem in the
process of writing the program that solves it. That's the
great of of programming, and it is exactly what novice
programmers need to experience. To do so, they need a
language that lets them -- helps them? -- both to discover
and to express. Java, Ada, and C++ are Serious Languages
that optimize on presentation. That's not what novice
programmers need, and probably not the pros need, either.
This essay also may explain the recent rise of Ruby as a
Programmer's Programming Language. It is a language for
both to discovery and expression.
As usual, Gabriel has explored a new bit of landscape for
me, discovered something of value, and given us a map of
the land.
As a part of seeing my wife and daughters
off to Italy,
I cooked a few special meals for them on Sunday and
Monday. One friend suggested that I needn't have
bothered, because they will encounter much better
food in Italy, but I think that an unusual meal
prepared by Dad is still a nice treat -- and my wife
loved not having to think about any meals for the last
couple of days of packing and preparing. Besides,
I'm not too shabby in the kitchen.
I like to cook. I'm not an accomplished chef, or
anything of the sort, just an amateur who like to work
in the kitchen and try new things.
While blanching asparagus for my last and finest effort
of the weekend, I remembered an article that ran in our
local paper last March under the headline
Cookbooks simplify terms as kitchen skills dwindle.
It discusses the dumbing down of cookbooks over the last
couple of decades because Americans no longer know the
common vocabulary of the kitchen. These days, recipes
tend not to use words like "blanch", "dredge", or even
"saute", "fold", and "braise", for fear that the casual
reader won't have any idea what they mean. Cookbooks
that buck the trend must provide detailed glossaries that
explain what used to be standard techniques.
In some ways, this is merely a cultural change. People
generally don't spend as much time cooking full meals or
from scratch these days, and women in particular are less
likely than their mothers to carry forward the previous
generation's traditional culinary knowledge. That may
not be a good or bad thing, just a difference borne out
of technology and society. The article even implicates
the digital computer, claiming that because kids grow up
with computers these days they expect everything, even
their cooking, to be fast. Who knew that our computers
were partly responsible for the dumbing down of America's
kitchen?
I sometimes think about connections between cooking and
programming, and between recipes and programs. Most
folks execute recipes, not create them, so we
may not be able to learn much about how learning to
programming from learning to cook. But the dumbing down
of cooking vocabulary is a neat example for how programs
work. When a recipe says to "fold" an ingredient into
a mixture, it's similar to making a procedure call.
Describing this process using different terms does not
change the process, only the primitives used to describe
the process. This focus on process, description, and
abstraction is something that we computer scientists
know and think a lot about.
In a more general teaching vein, I chuckled in my
empathy for this cookbook editor:
"Thirty years ago, a recipe would say, 'Add two eggs,'"
said Bonnie Slotnick, a longtime cookbook editor and
owner of a rare-cookbook shop in New York's Greenwich
Village. "In the '80s, that was changed to 'beat two
eggs until lightly mixed.' By the '90s, you had to
write, 'In a small bowl, using a fork, beat two eggs,'"
she said. "We joke that the next step will be, 'Using
your right hand, pick up a fork and...' "
Students probably feel that way about programming,
but I sometimes feel that way about my students...
... which bring me back to my day job. I have reason
to think about such issues as I prepare to teach CS 1
for the first time in a decade or so. Selecting a
textbook is a particular challenge. How much will
students read? What kinds of things will they read.
How well can they read? That seems like an
odd question to ask of college freshmen, but I do
wonder about the technical reading ability of the
average student who has questionable background in
math and science but wants to "program computer games"
or "work with computers". Colleagues complain about
what they see as a dumbing down of textbooks, which
grow in size, with more and more elaborate examples,
while in many ways expecting less. Is this sort of
text what students really need? In the end, what I
think they really need are a good language reference
and lots of good examples to follow, both in the
practice of programming and in the programs themselves.
It's our job to teach them how to read a language
reference and programs.
My selection of a CS 1 textbook is complicated by the
particular politics of the first year curriculum in my
department. I need something that feels traditional
enough not to alienate faculty who are skeptical of
OO, but true enough to OO that Java doesn't feel like
an unnecessary burden to students.
Postscript: Many recipes require that vegetables be
blanched -- scalded in boiling water a short time --
before being added to a dish. Blanching stops the enzyme
action, which allows them to stay crisp and retain their
color and flavor. Here is a
simple how-to
for blanching. I didn't lear this from my mom or any
of the cooks in my family (including my dad); I learned
it the old-fashioned way: I ran into the term in a recipe,
I wanted to know what it meant, so I looked it up in the
cookbook. If we could give our programming students the
right sort of reference for looking up the terms and ideas
they encounter, we would be doing well. Of course, some
students of programming will be like some students of
cooking and try to fake it. I don't recommend faking
the blanching of asparagus -- it's a temperamental
vegetable!
It seems that folks have been discussing a flap
between Google and Yahoo about choice in the
search engine market. "Choice" has become a
loaded term in several political contexts over
the last couple of decades, and I suppose that
this context is political in its own way.
I don't have much to say today about the Google,
Yahoo, Microsoft situation, but something
Jeremy Zawodny said
recently struck a chord:
First off, I agree that companies should compete
based on quality. But Microsoft and McDonald's are
both shining examples of how that's not necessarily
the way it works when "the market" is involved in
the decision making. Price and convenience tend
to trump quality.
Far be it from me to defend Microsoft and McDonald's,
neither of whose products I use with any frequency.
But... it seems Jeremy is saying that companies
compete based only on quality, whereas the
market introduces unfortunate forces such as price
and convenience into the mix.
Why should companies compete based only on quality?
Quality is only one good. Other features have value,
too. I don't think the market introduces issues such
as price and convenience into the equation so much
as expose what people really value.
I think that I value quality, but I also value other
things in this world. In particular, I am often a
price-sensitive consumer. With two daughters to
raise, I sometimes have to make choices based on both
quality and price, if I want to save money for other
purchases I want to make.
In the search arena, if Yahoo! or some other company
creates the absolute best, highest-quality search
engine, but it costs a pretty penny, I may choose a
"lower-quality" provider simply to conserve my scarce
resources for something else that I value. And I may
not suffer at all for my choice; good enough is often
good enough.
We face this kind of choice in software development, of
course, and folks like Richard Gabriel have
written about
the phenomenon's effect in the software world. Agile
methodologies encourage us not to build the Perfect
Solution if we
aren't gonna need it.
I suppose that the choice between "do the right thing"
and "do the simplest thing" is still an open question
in the software world, with many folks not enamored
with the agile approach to things, but I think in the
long run "do the simplest thing" will win out -- and
produce both the most software and the best software.
This is all basic economics: we have to make choices in
a world of scarce resources and conflicting values.
As something of a disclaimer, while I can pinch pennies
with the best of them, I'm not a "least common denominator"
kind of guy. I don't eat a lot of fast food, at McDonald's
or elsewhere, because I value some things more than the
convenience and immediate price savings over some of the
alternatives. I'm writing this blog entry on a computer
made by a
company
that has built its reputation on the idea that it makes
better products. Users of these products seem prouder
than most to be using the better tools. And those of us
who use these products pay a small premium to do so.
When I buy a new computer, I take quality and price into
account, along with a whole host of other factors, including
convenience and the intangibles of my experience using
the product.
I value quality, but I value many other things, too.
(Oh, and if Jeremy didn't mean what I thought he meant,
I apologize for dragging him into this. His blog entry
was simply the trigger for this piece. For more on
triggers in writing, start with this
piece by Richard Gabriel.
I also recommend the Hugo book that Richard cites.)
Our semester ended a couple of weeks ago. It was busier
than usual, for a variety of reasons, but my compiler
course was one of the enjoyable experiences. Of course,
my students will say that my compiler course was one of
the major reasons that their semester was busier
than usual.
A compiler is usually the largest piece of software an
undergraduate CS student will write. Some of my students
may have written other large programs, in other senior
project courses, but I doubt they've written larger, and
certainly not in smaller teams. (Most worked in pairs.)
Several commented that they learned more just trying to
write such a large program than they had in any of my
courses. That doesn't surprise... It's one of the main
reasons that I think it's essential for every undergrad
to take a project course of this sort. There is no
substitute.
After watching my students struggle to meet deadlines
and to deliver assigned functionality, I've been thinking
about using agile methods to write a compiler. Even with
occasional suggestions from me for how to manage their
projects, students fell behind. It is just too easy for
students to fill their time with other, more immediate
demands and watch project deadlines such as "table-driven
parser, due in three weeks" get closer and closer.
Then there were times when students made a good-faith
effort to estimate how long a task would take them, only
to be off by an order of magnitude. The code for the
table-driven parser isn't so bad, but, boy, does that
table take a long time to build!!
Throughout the semester, I made several common suggestions,
ones that will sound familiar: take small steps through
the spec; have unit tests for each element you build, so
that you won't be so afraid to make changes. But next
time, I think I may go one step farther and make two other
agile practices cornerstones of the course: short
iterations and small releases. How about
a deliverable every week!?
Figuring out how best to define the stories and then
order them for implementation will be the challenge. In
my mind's eye, I'd like for each release to create a
complete compiler, for some linguistically meaningful
definition of "complete". Start with such a subset of
the language that we can build a compiler for it with
little or no overhead. Then, add to the language grammar
bit by bit in ways that slowly introduce the ideas we
want to study and implement. Eventually we need a more
principled form of scanning; eventually, we need a parser
that implements a derivation explicitly. The issues
would not have to arise in the traditional front-to-back
order of a compiler course; why do we necessarily have to
build a fancy parser before implementing a rudimentary
run-time system?
Can this work for something like the parsing table? Adding
grammar elements to the language piecemeal can have odd
effects on the parsing rules. But I think it's possible.
And if I seem stuck on the table-driven parser in all of
my examples, this may be a result of the fact that I still
like for students to implement their parsers by hand. I
know that we could go a lot farther, and do a lot more
with code generation and optimization, if we built our
parsers using a tool such as
Yacc,
JavaCC,
or
SableCC.
But I can't shake the feeling of the value that comes
from implementing a non-trivial parser by hand. Maybe
I'm a dinosaur; maybe my feelings will change in the
next eighteen months before I teach the course again.
Though I've been thinking some of these thoughts since
last summer, I have to give credit to Jeremy Frens and
Andrew Meneely of Calvin College, who presented a paper
at this year's SIGCSE called
Fifteen Compilers in Fifteen Days
(also available from the
ACM Digital Library).
I'm not sure I'd want to follow their course outline
very closely, but they do have some experience in
sequencing the stories for the project in a way that
introduces complexities in an interesting way. And the
idea is just what I think we need: fifteen compilers in
fifteen weeks.
Sometime in the last month, I came across a link to an
article that is a couple of years old,
Why Good Programmers Are Lazy and Dumb.
I like to read that kind of article every once in a while,
even if I've seen the general ideas before. Usually, such
an article hits me in a particular way according to my
current frame of mind. Here are the ideas that stood out
for me this weekend:
Balance. Without it, we usually go astray.
Lazy? "... because only lazy programmers will want to
write the kind of tools that might replace them in the
end."
But you can't be so lazy that you are unwilling to
write those tools, or to refactor your code, to save
time in the future. You have to be forward-thinking
lazy.
You Aren't Gonna Need It
is an admonition against doing work too soon. But sometimes,
you do need it.
Dumb? "The less you know, the more radical will your
approaches become...." You know,
beginner's mind
and all that.
But you can't be so dumb that you don't have the raw
material out of which to propose a radical solution.
You can only think outside the box when
you start with a box.
Just as it's true that if you can't handle the
right kind of pain
you'll have a hard time getting better at much of anything,
it's true that if you can't find the balance between the
rights kind of lazy and dumb, you'll have a hard time
taking your skills to the next level.
My family and I watched the Tim Rice/Andrew Lloyd Webber
rock opera "Jesus Christ Superstar" this weekend. Both
of my daughters are into the theater, having performed
a few times and seen most of the local children's theater's
productions over the last many years. My older daughter
vaguely remembers a stage production we saw a few years
ago at an excellent
local playhouse
and wanted to see the show again. Our local library
had two versions, the
original 1973 movie
and a 2000
London theatrical performance
staged for television. Fortunately, we all like the
music, so watching the same show on back-to-back nights
was just fine.
Watching two versions so close in time really made the
differences in tone, characterization, and staging stand
out in great relief. The newer version took a European
viewpoint, with the Romans as fascist/Nazi-like overlords
and the common people seeking a revolution. The older
version focused more on the personal struggles of the
main characters -- Jesus, Mary, and especially Judas --
as they tried to come to grips with all that was happening
around them.
For some reason, this brought to mind a short blog entry
called
Process as theatre
written by Laurent Bossavit nearly two years ago. Laurent
considers the differences between Extreme Programming as
described in Kent Beck's original book and as practiced by
Kent and others since, and compares them to the script of
a play like "Hamlet". The script stays the same, but each
staging makes its own work of art. The two videos I watched
this weekend were at the same time both the same play and
very different plays. (I was proud when my younger daughter
recognized this and was able to express the two sides.)
Folks who feel compelled to follow every letter of every
rule of a methodology often find themselves burning out and
becoming disillusioned. Or, even when they are able to
keep the faith, they find it difficult to bring others into
the process, because those folks don't feel any need to be
so limited.
On the other hand, we've all seen performances that take
too many liberties with a script or story -- and instinctively
feel that something is wrong. Similarly, we can't take too
many liberties with XP or other methodologies before we are
no longer working within their spirit. In XP, if we give
up too many restrictions, we find that some of the remaining
practices lose their effectiveness without the balancing
effects of what we've removed.
As in so many things, striking the right balance between all
or nothing is the key. But we start from a healthier place
when we realize that a development process consists of both
script and production, fixed and dynamic elements working
together to create a whole.
I had forgotten that Laurent's blog entry refers to the book
Artful Making.
In an interesting confluence, I just this week asked our
library to purchase a copy of this book so that I can read
it over the summer. Now I'm even more eager.
Oh, and on the two versions of "Superstar": call me an
old fogey,
but I still love the 1973 movie.
Larry Marshall
as Simon Zealotes gives an awesome performance in his
highlighted scene, and
Josh Mostel
delivers one of the all-time great comedic song-and-dance
performances as King Herod. "Get out of my life!"
While doing a little reading to end what has been
a long week at the office, I ran across a pointer to
Steve Yegge's
old piece,
Tour de Babel,
which has recently been touched up. This is the third
time now that Yegge's writing has come recommended to
me, and I've enjoyed the recommended article each time.
That means I need to add his blog to my newsreader.
This was my favorite quote from the article, a perfect
thought with which to end the week:
Familiarity breeds contempt in most cases, but not with
computer languages. You have to become an expert with
a better language before you can start to have
contempt for the one you are most familiar with.
So if you don't like what I am saying about C++, go
become an expert at a better language (I recommend
Lisp), and then you'll be armed to disagree with me.
You won't, though. I'll have tricked you. You won't
like C++ anymore...
I know that this is the sort of inflammatory, holier-than-thou
pronouncement that
smug Lisp weenies
make all the time, and that it doesn't do anything
to move a language discussion forward. But from all
I've read by Steve, he isn't a language bigot at all
but someone who seems to like lots of languages for
different virtues. He even speaks kindly of C++ and
Java when they are discussed in certain contexts.
Even though I know I shouldn't like these sorts of
statements, or give them the bully pulpit of my
ever-so-popular blog, I give in to the urge. They
make me smile.
I myself am not a smug Lisp weenie. However, if you
replaced "Lisp" with "Smalltalk" or "Scheme" in the
quoted paragraph, I would be smiling even wider. (And
if you don't know why replacing "Lisp" with "Scheme"
in that sentence would be a huge deal to a
large number of Lisp devotees, well, then you just don't
understand anything at all about smug Lisp weenies!)
The
SIGCSE
mailing list has been alive this week with a thread that
started with pseudocode, moved to flowcharts, and eventually
saddened a lot of readers. At the center of the thread is
the age-old tension among CS educators that conflates debates
between bottom-up and top-down, low-level and high-level,
machine versus abstraction, and "the fundamentals" with
"the latest trends". I don't mean to rehash the whole
thread here, but I do want to share my favorite line in
the discussion.
Suffice to say: Someone announced an interest in introducing
programming via a few weeks of working in pseudocode, which
would allow students to focus on algorithms without the
distraction of compilers. He asked for advice on tools
and resources. A group of folks reported having had success
with a similar idea, only using flowchart tools. Others
reported the advantages of lightweight assembly-language
style simulators. The discussion became a lovefest for
the lowest-level details in CS1.
My friend and colleague
Joe Bergin,
occasionally quoted here, saw where this was going. He
eventually sent an impassioned and respectful message to
the SIGCSE list, imploring folks to look forward and not
backwards. In a message sent to a few of us who are
preparing for next week's
ChiliPLoP 2006
conference, he wrote what became the closing salvo in
his response.
The pseudocode thread on the SIGCSE list is incredibly
depressing. ... Why not plugboards early? Why not
electromechanical relays early? Why not abacus early?
An "abacus-early" curriculum. Now, there's the
fundamentals of computing! Who needs "objects first",
"objects early", "procedures early", "structured programming",
...? Assignment statements and for-loops are
johnny-come-latelys to the game. Code? Pshaw. Let's
get back to the real basics.
Joe, you are my hero.
(Of course, I am being facetious. We all know that
computing reached its zenith when C sprang forth as whole
cloth from Bell Labs.)
Am I too young to be an old fogey tired of the same old
discussions? Am I too young to be a guy who likes to
learn new things and help students do the same?
I can say that I was happy to see that Joe's message
pulled a couple of folks out of the shadows to say
what really matters: that we need to share with students
the awesome beauty and power of computing, to help them
master this new way of thinking that is changing the
world as we live. All the rest is details.
The other night at dinner, I was telling my family about
the state of my legs after my most recent run, and I said,
"My legs don't hurt, but my hamstrings are sore." My
younger daughter, Ellen, responded, "Um, Dad, your
hamstring is part of your leg." And I was caught. Fun
was had by all at my expense.
Of course, I was talking about different kinds of pain.
I've been thinking about different kinds of pain a lot
lately. As I mentioned in my
last post,
I have been having trouble with my hamstrings. I have
not suffered from a running injury in the three-plus
years since I developed a larger commitment to running,
but I've felt plenty of pain. Whenever we push our
bodies farther than they are used to going, they tend
to talk back to us in the form of muscle soreness and
maybe even a little joint soreness. That pain is a
natural part of the growth process, and if we can't
handle that sort of pain then we can't get better --
more speed, more stamina. Oh, I suppose that we might
be able to get better slowly, but so slowly
that it wouldn't be any fun. Even still, we runners
have to listen to their bodies and let them tell us
when to lighten up. I live with this sort of pain
periodically, as it is a part of the fun.
This is a different sort of pain than the pain we feel
when something is wrong with the body. Last week, my
hamstrings hurt. Walking was painful
at times, and going upstairs was torturous. This is
the kind of pain that evolved to tell us our bodies
are broken in a way that wasn't helping. Listening to
this kind of pain is crucial, because unheeded the
underlying cause can debilitate us. When we feel this
kind of pain, we need to "get better", not get "better".
This week I have been talking with students in my
compilers class. They are feeling a kind of pain --
the pain of a large project, larger than they've ever
worked on, that involves real content. If they design
the parsing table incorrectly, or implement the table-driven
parsing algorithm incorrectly, then their programs
won't work. To their credit, they all see this sort of
pain as useful, the sort of pain you feel when you are
getting better. "I've learned more about Java programming
and object-oriented design than I've ever learned
before." They realize that, in this case, less pain would
be worse, not better. Still, I feel for them,
because I recall what those first few experiences with
non-trivial programs felt like.
For my agile software development readers: I know that
I haven't written much about agile in a while, but I can
say that many of my students are also experiencing the
pain that comes from not using the agile practices that
they know about. Taking small steps, using unit tests,
and getting as much feedback from their code as often as
possible -- all would make their lives better. There is
nothing like trying to debug several hundred lines of
tightly-coupled code for the first time and needing to
track down why Rule 42 of 200 doesn't seem to be firing
at the right time!
This is also advising time, as students begin to register
for fall courses. Sometimes, the best course for a
student will be painful, because it will stretch him or
her in a way that the mind is not used to. But that may
be just what the student needs to get over the hump and
become a top-notch computer scientist!
These encounters with various kinds of pain remind me of an
essay by Kathy Sierra
from a month or so ago. One of her central points is that,
to become really good at a task, you must practice the parts
that you are weakest at -- you have to choose pain.
Most of us prefer to practice that with which we are already
comfortable, but then we don't stretch our (programming,
piano-playing, golfing, running) muscles enough to grow.
I suspect that it's even worse than that, that by repeatedly
practicing skills we are already good at we drive our
muscles into a rut that leaves us worse, not better. I see
that happen in my running every so often, and it probably
happens to my programming, too.
But is all the psychic pain we feel when taking a compilers
course or learning to program a good sign? Probably not.
We do need to choose tasks to master for which we are
well suited, that we like enough to work on at all. If
you really have no affinity for abstraction and problem
solving, then computer science probably isn't for you.
You'll not like doing it, no matter how expert you become.
But after selecting a task that you can be good at or
otherwise interested in, you after to be ready to take
on the growing pains that come with mastering it. Indeed,
you have to seek out the things you aren't good at and
whip them. (*)
I hope you have the chance to feel the right kind of pain
soon. But not for long -- be sure to move on to the fun
of getting better as soon as possible.
~~~~~
(*) I do offer one caveat, though. It is too easy to
tell ourselves, "Oh, I don't like that" as a way to avoid
finding out whether we might like something enough in
practice. I don't know how many times people have said,
upon hearing that I ran 20 miles that morning, "Oh, I
can't run long distances" or "I don't like to run at all".
I usually smile politely, but sometimes I'll let them
know that I didn't know I liked it until I had done it
for a while. I used to make jovial fun of my friends
who ran. Then I did a little for ulterior reasons
and thought, "Hmmm...", and then I did more and more.
Sometimes we need to try something out for a while just
to know it well enough to judge it.
A couple of days ago I was tracking down an article
that had been mentioned in a thread on the
SIGCSE
mailing list and ran across
Rich Pattis's
paper, "A Philosophy and Example of CS-1 Programming
Projects"
(pdf),
from the February 1990 issue of the ACM SIGCSE
Bulletin. Having recently
written about Rich's work,
I couldn't resist taking it home for a weekend read.
Not surprisingly, I am glad I did.
On its face, this paper is relatively unassuming.
It describes a project that he assigns to his CS 1
students as an example of how he thinks about projects.
Reading it reminded me of the sort of simplicity I
associate with
Ward Cunningham.
But I was amazed to see Rich talk about two ideas
that have been discussed everywhere in CS education
for the last few years.
Section 2 is titled "Using Packages in Projects".
It lays out Rich's philosophy of projects, which
consists of at least two key ideas:
Students "are more motivated and enthusiastic
about writing programs whose significance and
usefulness they can plainly understand."
Long-time Knowing and Doing readers know that
this topic is
often on my mind.
Real problems are complex and may require code
and ideas that are beyond the students' current
level of understanding. But "one way to simplify
a programming project is to provide students with
packages that contain useful operations that are
beyond their ability to write."
Anyone who has been trying to teach OOP faithfully
in the first year recognizes this as a central
theme.
Then, Section 5 describes the software "methodology"
that Rich taught his students, which he called Stepwise
Enhancement. If you read this paper today, you'll
say to yourself, wait a minute, that's XP! Consider
these fragments:
... students first must reduce the program specifications
to a minimum, concentrating on their main structural
features and ignoring all the complicated details that
will make the program difficult to write. Then they
design, implement, and test ... a complete version of
the program that meets these simplest specifications.
The students continue repeating this process - at each
stage enhancing the specifications and writing an enhanced
program that meets these new specifications - until they
have solved the complete problem described in the original
specifications.
At every stage they are making small additions or
modifications to an already correct (for the simplified
specifications) program.
Fundamentally the stepwise-enhancement technique is
useful because it is easier to design, implement, and
test a series of increasingly more sophisticated complete
programs than it is to attempt writing one large program
that solves the original problem specifications at the
outset...
This technique also allows students to test their original
ideas on how to solve the main features of the problem
in a simple program first. They receive feedback, at very
short intervals, that tells them whether or not they are
on the correct path to a solution program. ... such
feedback is critical for students who are learning in
parallel the language features and how to use these
features when writing programs.
As students gain more programming experience, it will
become more obvious to them what are the important
structural features in specifications and what are
the complicated details....
At the end of each stage, students should have a working
program that they can test on the computer to ensure that
it correctly solves the problem at that stage.... If
they do not finish a program, they still should have a
running program that solves a simpler problem.
I could quote more, but there is something known as
"fair use". Besides, you should just go read the paper,
which you can find in the ACM Digital Library. Bonus
points to the reader who finds the most XP values
and practices in this three quarters of a page of text!
Plus, you get a sense of the practical experience Rich
had gained while teaching this style of development.
I haven't even mentioned the sample project, a simple
cardioverter-defibrillator. Now that I am on deck to
teach our CS1 course, I have a great place to adapt
and use this project when teaching about selection and
repetition. After reading this paper, I realize how
much fun I will have going back to my old CS1 notes,
ten years old and older, and recalling how I was
teaching elementary patterns and little bits of agile
methods back then. I hope that I do an even better
job of teaching CS1 after my experiences from the last
decade.
Rich wrote this paper almost 17 years ago -- which
should remind all of us who are trying to do new things
that there isn't much that is all that new. We have
a lot to learn from what folks were doing before our
new ideas came along. You just have to know where to
look. Considering that guys like Rich and the folks
he hangs out with are usually thinking about big ideas
and how they might help us improve CS education before
anyone else, any CS educator would do well to keep an
eye on what they were doing a few years ago. And
whatever they are doing right now, well, we'll probably
all be doing that in a few years.
To soothe my
bruised ego,
yesterday evening I did a little light blog reading.
Among the articles that caught my attention was
Philip Greenspun's
Why I love teaching flying more than software engineering.
People learning to fly want to get better;
I'm guessing that most of them want to become as good
as they possibly can. (Just like
this guy
wanted to make as good a product as possible.) Philip
enjoys teaching these folks, more so than teaching
students in the area of his greatest expertise,
computing, because the math and computing students
don't seem to care if they learn or not.
I see students who will work day and night until they
become really good software developers or really good
computer scientists, and the common thread through their
stories is an internal curiosity that we can't teach.
But maybe we can expose them to enough cool problems
and questions that one will kick their curiosity into
overdrive. The ones who still have that gear will do
the rest. Philip worries that most students these days
"are satisfied with mediocrity, a warm cubicle, and a
steady salary." I worry about this, too, but sometimes
wonder if I am just imagining some idyllic world that
never has existed. But computer science is so much fun
for me that I'm sad that more of our students don't feel
the same joy.
While reading, I listened to Olin Shivers's talk at
Startup School
2005, "A Random Walk Through Startup Space"
(mp3).
It had been in my audio folder for a while, and I'm
glad I finally cued it up. Olin gives lots of pithy
advice to the start-up students. Three quotes stood
out for me yesterday:
At one point, Olin was talking about how you have
to be courageous to start a company. He quoted
Paul Dirac,
who did "physics so beautiful it will bring tears
to your eyes", as saying
Scientific progress advances in units of courage,
not intelligence.
Throughout his talk, Olin spoke about how failure
is unavoidable for those who ultimately succeed.
... to start a business, you've got to have a high
tolerance for feeling like a moron all the time.
And how should you greet failure when you're staring
it in the face?
Thank you for what you have taught me.
Next, I plan to listen to Steve Wozniak's much-blogged talk
(mp3).
If I enjoy that one as much as I enjoyed Shivers's,
I may check out the
rest of them.
If you've read my blog for long, you know that I like
a good metaphor. We can often learn something useful
about one system by considering it as another kind of
system and seeing what kind of questions this new
conception leads us to ask.
"Software engineering" is a metaphor, even if many folks
take it for granted as reality. I've never been all that
fond of the metaphor, though we certainly can learn
something about how to develop software by considering
how engineers make things. But my experience with
commercial engineering projects on university campuses
has never felt like how I do or might build software.
My latest experience -- with the renovation of an old
building on campus as a new home for my department --
has illustrated yet again why we should not limit
ourselves to engineering as the model for how we make
software.
This building project is now over six months late. Each
time the schedule is adjusted, it seems to fall behind
again within the month. Communication among the various
units responsible for, and affected by, project has been
abysmal. Changes were made to plans, but these changes
did not propagate to everyone who needed to know and as
a result work plans were often out of sync. Sometimes,
folks knew about a change but had no incentive to find
out how the change affected what they should be doing
-- so they didn't.
My favorite example of this was when a service closet
was converted to a server room for my department. The
change was made in conjunction with building architects,
and the updated drawings for the building now showed a
"server room". At least some of folks responsible for
building infrastructure were aware of the change, but
they either assumed that the change didn't affect them
or figured they didn't want to know how it would. Plans
proceeded as they were, with no provision made for the
necessary cooling or power to the room. As the time
came for us to move in, we increasingly pressed for these
changes to the room, which would now be costlier to
implement, both in time and money.
I know, this is only an anecdote, one experience by one
person with one project. It hardly serves as a suitable
logical basis for arguing that a seemingly useful idea
should be discarded. But this experience is representative
others I have had, and also representative of experiences
had by many others on this and other campuses with building
construction and renovation. It is a now banal joke on
campus that we should add months to each target date we are
given for the completion of projects.
Don't get me wrong. These are not bad people. I think all
are trying to do their jobs well under demanding circumstances.
But as Mary Poppendieck reported in a
widely read paper on lean construction,
the system doesn't work in a way that makes smooth, timely
projects all that likely. Projects are complicated, plans
are tightly coupled, and pipelines are sensitive to small
changes in expectation. That's just how the world really
is.
This is one of the dangers inherent in metaphor: unreality.
It is easy for us in software to idealize other
disciplines and how they work. One result is that we beat
ourselves up for how we could do better is only we were more
like "them", for some broad spectrum of thems. Architecture
-- isn't it just dreamy? Engineering -- tough, rigid, clean,
controlled. But we need to make metaphors with our eyes
carefully tuned to how the world really is in those other
disciplines, not only the ideas but the daily practices
and experiences. Otherwise, we are bound to create
unrealistic expectations for how we do what we do, and how
well we do it.
And ultimately we lose out on the learning to be had from
the metaphor, because we will miss the opportunity to ask
ourselves the questions that will help us to understand
better what we do.
Education is an admirable thing,
but it is well to remember from time to time
that nothing worth knowing can be taught.
-- Oscar Wilde
Recently I have been having an ongoing conversation with one
of my colleagues, a senior faculty member, about teaching
methods. This conversation is part of a larger discussion
of the quality of our programs and the attractiveness of our
majors to students.
In one episode, we were discussing the frequency with which
one quizzes and exams the class. Some of our math professors
quiz almost daily, and even some CS professors give substantial
quizzes every week. My colleague thinks is a waste of valuable
class time and a disservice to students. I tend to agree, at
least for most of our CS courses. When we assess students so
frequently for the purposes of grading, the students become
focused on assessment and not on the course material. They
also tend not to think much about the fun they could be having
writing programs and understanding new ideas. They are too
worried about the next quiz.
My colleague made a much stronger statement:
Students are paying for content.
In an interesting coincidence, when he said this I was preparing
a class session in which my students would do several exercises
that would culminate in a table-driven parser for a small language.
We had studied the essential content over the previous two weeks:
first and follow sets, LL(1) grammars, semantic actions, and so on.
I don't think I was wasting my students time or tuition money.
I do owe them content about compilers and how to build them.
But they have to learn how to build a compiler, and they
can't learn that by listening to me drone on about it at the
front of the classroom; they have to do it.
My colleague agrees with me on this point, though I don't think
he ever teaches in the way I do. He prefers to use programming
projects as the only avenue for practice. Where I diverge is
in trying to help students gain experience doing in a tightly
controlled environment where I can give almost immediate
feedback. My hope is that this sort of scaffolded experience
will help them learn and internalize technique more readily.
(And don't worry that my students lack for practical project
experience. Just ask my compiler students, who had to submit
a full parser for a variant of Wirth's Oberon-0 language at
4 PM today.)
I think that our students are paying for more than just content.
If all they need is "dead" content, I can give them a book.
Lecture made a lot of sense as the primary mode of instruction
back when books were rare or unavailable. But we can do better
now. We can give students access to data in a lot of forms,
but as expert practitioners we can help them learn how to
do things by working with them in the process of doing things.
I am sympathetic to my colleague's claims, though. Many folks
these days spend far too much time worrying about teaching
methodology than about the course material. The content of
the course is paramount; how we teach it is done in service
of helping students learn the material. But we can't fall
into the trap of thinking that we can lecture content and
magically put it into our students' heads, or that they can
magically put it there by doing homework.
This conversation reminded me of a
post on learning styles
at Tall, Dark, and Mysterious. Here is an excerpt she
quotes from a cognitive scientist:
What cognitive science has taught us is that children do differ
in their abilities with different modalities, but teaching the
child in his best modality doesn't affect his educational
achievement. What does matter is whether the child is taught
in the content's best modality. All students learn more when
content drives the choice of modality.
The issue isn't that teaching a subject, say, kinesthetically,
doesn't help a kinesthetic learner understand the material
better; the issue is that teaching material kinesthetically
may compromise the content.
Knowledge of how to do something sometimes requires an approach
different from lecture. Studio work, apprenticeship, and other
forms of coached exercise may be the best way to teach some
material.
Finally, that post quotes someone who sees the key point:
Perhaps it's more important for a student to know their learning
style than for a teacher to teach to it. Then the student can
make whatever adjustments are needed in their classroom and
study habits (as well as out of classroom time with the instructor).
In any case, a scientist or a programmer needs to possess
both a lot of declarative knowledge and a lot of procedural
knowledge. We should use teaching methods that best help
them learn.
Pascal Van Cauwenberghe writes a bit about agile
development, lean production, and other views
of software engineering. He recently quoted
the Toyota Way Fieldbook as inspiration
for how to
introduce lean manufacturing as change.
I think that educators can learn from Pascal's
excerpt, too.
... we're more likely to change what people
think by changing what they do, rather
than changing what people do by changing what they
think.
I can teach students about object-oriented
programming, functional programming, or agile
software development. I can teach vocabulary,
definitions, and even practices and methodologies.
But this content does not change learners "deeply
held values and assumptions". When they get back
into the trenches, under the pressure of new problems
and time, old habits of thought take over. No one
should be surprised that this is true for people who
are not looking to change, and that is most people.
But even when programmers want to practice the new
skill, their old habits kick in with regularity and
unconscious force.
The Toyota Way folks use this truth as motivation to
"remake the structure and processes of organizations",
with changes in thought becoming a result, not a cause.
This can work in a software development firm, and
maybe across a CS department's curriculum, but within
a single classroom this truth tells us something more:
how to orient our instruction. As an
old pragmatist,
I believe that knowledge is habit of thought, and
that the best way to create new knowledge is to
create new habits. This means that we need to
construct learning environments in which people
change what they do in practical,
repeatable ways. Once students develop habits of
practice, they have at their disposal experiences
that enable them to think differently about problems.
The ideas are no longer abstract and demanded by an
outside agent; they are real, grounded in concrete
experiences. People are more open to change when
it is driven from within than from without, so this
model increases the chance that the learner entertain
seriously the new ideas that we would like them to
learn.
In my experience, folks who try XP practices -- writing
and running tests all the time, refactoring, sharing
code, all supported by pair programming and a shared
culture of tools and communication -- are more likely
to "get" the agile methods than are folks to whom the
wonderfulness of agile methods is explained. In the
end, I think that this is true for nearly all learning.
Eric Sink tells
one of the best stories ever to illustrate the idea of
eating your own dog food.
Go read the whole paper and story, but I can set up
the punchline pretty quickly: Table saws are powerful,
dangerous tools. Many woodworkers lose fingers every
year using table saws. But...
A guy named Stephen Gass has come up with an amazing
solution to this problem. He is a woodworker, but he
also has a PhD in physics. His technology is called
Sawstop. It consists of two basic inventions:
He has a sensor which can detect the difference in
capacitance between a finger and a piece of wood.
He has a way to stop a spinning table saw blade
within 1/100 of a second, less than a quarter turn
of rotation.
The videos of this product are amazing. Slide a piece
of wood into the spinning blade, and it cuts the board
just like it should. Slide a hot dog into the spinning
blade, and it stops instantly, leaving the frankfurter
with nothing more than a nick.
Here's the spooky part: Stephen Gass tested his product
on his own finger! This is a guy who really wanted to
close the distance between him and his customers.
Kinda takes the swagger out of your step for using your
own blogging tool.
Eric's paper is really about software developers and
their distance from users. His title,
Yours, Mine and Ours,
identifies three relationships developers can have
with the software they write vis-á-vis the
other users of the product. Many of his best points
come in the section on UsWare, which is software
intended for use by both end users and the developers
themselves. Eric is well-positioned to comment on
this class of programs, as his company develops a
version control tool used by his own developers.
It's easy for developers to forget that they are
not like other users. I know this danger well;
as a university faculty need to remind myself daily
that I am not like my students, either in profile or
in my daily engagement with the course material.
I like his final paragraph, which summarizes his only
advice for solving the ThemWare/UsWare problems:
Your users have things to say. Stop telling them
how great your software is and listen to them tell
you how to make it better.
We all have to remind ourselves of this every once
in a while. Sadly, some folks never seem to. Many
faculty assume that they have nothing to learn from
what their students are saying, but that is almost
always because they aren't really listening. Many
universities spend so much time telling students
why they should come there that they don't have the
time or inclination to listen to students say what
would make come.
I also learned an interesting factoid about State
Farm Insurance, the corporate headquarters for
which are located down I-74 from Eric's home base of
Urbana, Illinois. State Farm is also a major corporate
partner of the IT-related departments at my university,
including the CS department. They work hard to
recruit our students, and they've been working hard
to help us with resources when possible. The factoid:
State Farm is Microsoft's largest non-government
customer. [In my best Johnny Carson imitation:]
I did not know that. As a result of this fact,
Microsoft has an office in the unlikely location of
Bloomington, Illinois.
Despite an obvious interest in hiring folks with
experience using Microsoft tools, State Farm has never
pressured us to teach .NET or C# or VisualStudio or
any particular technology. I'm sure they would be
happy if we addressed their more immediate needs,
but I am glad to know that they have left decisions
about curriculum to us.
That said, we are beginning to hear buzz from other
insurance companies and banks, most located in Des
Moines, about the need for student exposure to .NET.
We probably need to find a way to give our students
an opportunity to get experience here beyond VB.NET
and Office. Where is that link to
Mono...
I've been having a few Functional Programming Moments
lately. In my Translation of Programming Languages
course, over half of the students have chosen to write
their compiler programs in Scheme. This brought back
fond memories
of a previous course in which one group chose to build
a content management system in Scheme, rather than one
of the languages they study and use more in their other
courses. I've also been buoyed by reports from professors
in courses such as Operating Systems that some students
are opting to do their assignments in Scheme. These
students seem to have really latched onto the simplicity
of a powerful language.
I've also run across a couple of web articles worth noting.
Shannon Behrens wrote the provocatively titled
Everything Your Professor Failed to Tell You
About Functional Programming.
I plead guilty on only one of the two charges. This
paper starts off talking about the seemingly inscrutable
concept of monads, but ultimately turns to the question
of why anyone should bother learning such unusual ideas
and, by extension, functional programming itself. I'm
guilty on the count of not teaching monads well, because
I've never taught them at all. But I do attempt to make
a reasonable case for the value of learning functional
programming.
His discussion of monads is quite nice, using an analogy
that folks in his reading audience can appreciate:
Somewhere, somebody is going to hate me for saying this,
but if I were to try to explain monads to a Java programmer
unfamiliar with functional programming, I would say: "Monad
is a design pattern that is useful in purely functional
languages such as Haskell.
I'm sure that some folks in the functional programming
community will object to this characterization, in ways
that Behrens anticipates. To some, "design patterns"
are a lame crutch object-oriented programmers who use
weak languages; functional programming doesn't need
them. I like Behrens's response to such a charge
(emphasis added):
I've occasionally heard Lisp programmers such as Paul
Graham bash the concept of design patterns. To
such readers I'd like to suggest that the concept
of designing a domain-specific language to solve
a problem and then solving that problem in that
domain-specific language is itself a design pattern
that makes a lot of sense in languages such as Lisp.
Just because design patterns that make sense
in Java don't often make sense in Lisp doesn't detract
from the utility of giving certain patterns names
and documenting them for the benefit of ... less
experienced programmers.
His discussion of why anyone should bother to do the
sometimes hard work needed to learn functional
programming is pretty good, too. My favorite part
addressed the common question of why someone should
willingly take on the constraints of programming
without side effects when the freedom to compute
both ways seems preferable. I have written on this
topic before, in an entry titled
Patterns as a Source of Freedom.
Behrens gives some examples of self-imposed cosntraints,
such as encapsulation, and how breaking the rules
ultimately makes your life harder. You soon realize:
What seemed like freedom is really slavery.
Throw off the shackles of deceptive freedom! Use Scheme.
The second article turns the seductiveness angle upside
down.
Lisp is Sin,
by Sriram Krishnan, tells a tale being drawn to Lisp the
siren, only to have his boat dashed on the rocks of
complexity and non-standard libraries again and again.
But in all he speaks favorably of ideas from functional
programming and how they enter his own professional
work.
I took advantage of a long weekend to curl up
with a book which has been called the best book
on programming ever -- Peter Norvig's Paradigms
of Artificial Intelligence Programming: Case Studies
in Common Lisp. I have read SICP but
the 300 or so pages I've read of Norvig's book have
left a greater impression on me than SICP. Norvig's
book is definitely one of those 'stay awake all night
thinking about it' books.
I have never heard anyone call Norvig's book the best
of all programming books, but I have heard many folks
say that about SICP --
Structure and Interpretation of Computer Programs,
by Abelson and Sussman. I myself have
praised Norvig's book
as "one of my favorite books on programming", and it
teaches a whole lot more than just AI programming or
just Lisp programming. If you haven't studied, put
it at or near the top of your list, and do so soon.
You'll be glad you did.
In speaking of his growth as a Lisp programmer,
Krishnan repeats an old saw about the progression
of a Lisp programmer that captures some of the
magic of functional programming:
... the newbie realizes that the difference between
code and data is trivial. The expert realizes that
all code is data. And the true master realizes that
all data is code.
I'm always heartened when a student takes that last
step, or show that they've already been there. One
example comes to mind immediately: The last time I
taught compilers, students built the parsing tables
for the compiler by hand. One student looked at the
table, thought about the effort involved in translating
the table into C, and chose instead to write a program
that could interpret the table directly. Very nice.
Krishnan's article closes with some discussion of how
Lisp doesn't -- can't? -- appeal to all programmers.
I found his take interesting enough, especially the
Microsoft-y characterization of programmers as one of
"Mort, Elvis, and Einstein". I am still undecided just
where I stand on claims of the sort that Lisp and its
ilk are too difficult for "average programmers" and thus
will never be adoptable by a large population. Clearly,
not every person on this planet is bright enough to do
everything that everyone else does. I've learned that
about myself many, many times over the years! But I am
left wondering how much of this is a matter of ability
and how much is a matter of needing different and better
ways to teach? The monad article I discuss above is a
great example. Monads have been busting the chops of
programmers for a long time now, but I'm betting that
Behrens has explained it in a way that "the average
Java programmer" can understand it and maybe even have
a chance of mastering Haskell. I've long been told by
colleagues that Scheme was too abstract, too different,
to become a staple of our students, but some are now
choosing to use it in their courses.
Dick Gabriel once said that talent does not determine
how good you can get, only how fast you get there.
Maybe when it comes to functional programming, most of
us just take too long to get there. Then again, maybe
we teachers of FP can find ways to help accelerate the
students who want to get good.
Finally, Krishnan closes with a cute but "politically
incorrect analogy" that plays off his title:
Lisp is like the
villainesses
present in the Bond movies. It seduces you with its
sheer beauty and its allure is irresistible. A fleeting
encounter plays on your mind for a long, long time.
However, it may not be the best choice if you're looking
for a long term commitment. But in the short term, it
sure is fun! In that way, Lisp is...sin."
Everyone is talking about Web 2.0 these days. This
isn't the sort of buzzword that tends to absorb me,
as patterns and refactoring and agile methods did,
but as
tutorials chair
for
OOPSLA 2006,
I am keen to get a sense of what developers are talking
about and interested in learning about these days.
Web 2.0 is everywhere, and so I've been reading a bit
deeper to see what we should offer, technology-wise,
at the conference. But the sociology of the term and
its penumbra has been as much intriguing as its
technology.
Christian Sepulveda
gave thought to why Web 2.0 had captured mindshare now
and how it was different from what we've been doing.
His answer to "why now?" centered on the convergence of
intellectual supply and demand: "The demand for a user
centric web, where sharing, communication and a rich
experience is the norm, is intersecting the availability
of technology, such as RSS and AJAX, to make it happen."
How is Web 2.0 different from Web 1.x? It is driven by
the demands and needs of real users with real problems.
So much of the previous web boom, he feels, was driven
by a "build it and they will come" mentality.
Of course, that mentality worked for a lot of ideas that
took root back in the old days -- even the 20th century!
-- and now have matured. Wikis and blogs are only two
such ideas.
Paul Graham took a
somewhat more dispassionate position
on Web 2.0, which isn't surprising given his general
outlook on the world and, more relevant here, his own
experiences doing cool web stuff back before
the "availability of technology, such as RSS and AJAX,
to make it happen." Here's my precis of his article,
consisting of its first and last paragraphs:
Does "Web 2.0" mean anything? Till recently I thought
it didn't, but the truth turns out to be more complicated.
Originally, yes, it was meaningless. Now it seems to
have acquired a meaning. And yet those who dislike the
term are probably right, because if it means what I think
it does, we don't need it.
The fact that Google is a "Web 2.0" company shows that,
while meaningful, the term is also rather bogus. It's
like the word "allopathic." It just means doing things
right, and it's a bad sign when you have a special word
for that.
Graham applauds the fact that Ajax now brings the
ability to develop sites that take advantage of the
web's possibilities to everyday developers. I found
his discussion of democracy on the web, exemplified by
sites such as del.icio.us, Wikipedia, Reddit, and Digg,
to be right on the mark. The original promise of the
web was how it could help us share information, but
that promise was only the beginning of something bigger.
It took guys like
Ward Cunningham
to show us the way. This sense of democracy extends
beyond participants in social conversation to those
folks we in software have always called
users.
It turns out that users get to participate in the
conversation, too!
In the March 2006 issue of Dr Dobb's Journal, editor
at large
Michael Swaine
expressed a more cynical version of Graham's take:
Web 2.0 is a commemorative coin minted in celebration
of the end of the dot-com crash. Like all commemorative
coins, it has no actual value.
So, we should focus our attention on the technologies
that buttress the term, but as Graham points out the
ideas behind the technologies aren't new; they are
just in a new syntax, a new framework, a new language.
The software world creates its own troubles when it
recycles old ideas in new form, and then complains
that the world is changing all the time.
The fascinating thing about Ajax is that it is an
amalgam of existing technologies that all date back
to the twentieth century. It's what the Web 2.0
crowd might call a mash-up. Only the name is new.
Of course, all this cynicism doesn't change the fact
that today's developers need to learn the current
technologies and how to make them play with the rest
of their software. So we'll certainly offer the best
tutorials we can for the folks who come to OOPSLA'06.
And, as always, we should be careful not to let our
nostalgia for our old tools blind us. For a sanity
check on a slightly different topic (though perhaps
more similar than the subject indicates), check out
this article by Adam Connor.
After chairing the OOPSLA Educators' Symposium in
2004
and
2005,
I've been entrusted with chairing the tutorials track at
OOPSLA 2006.
While this may not seem to have the intellectual cachét
of the Educators' Symposium, it carries the responsibility of
a major financial effect on the conference. If I had screwed
an educators' event, I would have made a few dozen people unhappy.
If I screw up the tutorials track, I could cost the conference
tens of thousands of dollars!
The
call for tutorial proposals
is out, with a deadline of March 18. My committee and I will
also be soliciting a few tutorials on topics we really want to
see covered and from folks we especially want to present. We'd
like to put together a tutorial track that does a great job of
helping software practitioners and academics get a handle on
the most important topics in software development these days,
with an emphasis on OO and related technologies. In marketing
terms, I think of it as exciting the folks who already know that
OOPSLA is a must-attend conference and attracting new folks who
should be attending.
I'd love to hear what you think we should be thinking about.
What are the hottest topics out there, the ones we should all
be learning about? Is there something on the horizon that
everyone will be talking about in October? I'm thinking not
only of the buzzwords that define the industry these days,
but also of topics that developers really need to take their
work to another level.
Who are the best presenters out there, the ones we should be
inviting to present? I'm thinking not only of the Big Names
but also of those folks who simply do an outstanding job teaching
technical content to professionals. We've all probably
attended tutorials where we left room thinking, "Wow, that
was good. Who was that guy?"
One idea we are considering this year is to offer tutorials
that help people prepare for certifications in areas such as
Java and MSCD. Do you think that folks could benefit from
tutorials of this sort, or is it an example trying to do too
much?
Trying to keep a great conference fresh and exciting requires
a mix of old ideas and new. It's a lot like revising a good
course... only in front of many more eyes!
I've noticed an interesting disconnect between student
behavior when in the role of student and when in the
role of software developer.
When they are in the role of developer, students often
fight the idea of XP's small steps: breaking tasks
into small, estimable steps, writing a test for each
small step, and then making sure the code passes the
test before thinking about the next step. They want
to think ahead, trust their experience and "intuition",
write a lot of code -- and only then compile, run, and
test the code. The testing is usually sloppy or, more
charitably, incomplete -- at least in part because they
are champing at the bit to move on to more code.
Is this merely a matter of habit they have developed
in past CS courses? Or have their years in the K-12
educational system encouraged them to rush headlong
into every problem? Perhaps it is our natural human
state.
... but when in the role of student, students
tend behave much differently. They want feedback --
now. When they turn in an assignment, they want the
graded result as soon as possible.
I used to have a serious Grading Avoidance Problem,
and all my students disliked it. Students who were
otherwise quite happy with my course became cranky
when I fell behind in returning assignments. Students
who were unhappy with the course for other reasons,
well, they became downright hostile.
I'm mostly over this problem now, though I have to
be alert not to backslide. Like a recovering addict,
I have to face each day anew with resolve and humility.
But I have a colleague for whom this issue is still a
major problem, and it creates difficulties for him with
his students.
I can't blame students for wanting graded items back
quickly. Those grades are the most reliable way they
have of knowing where they stand in the course. Students
can use this feedback to make all sorts of decisions
about how and how much to study. (I do wish that more
students paid more attention to the substantive feedback
on their assignments and tried to use that information
to improve their technique, to guide decisions about
what to study.)
So: students like frequent feedback to guide their
studies.
Many students also seem to prefer small, discrete, and
detailed tasks to work on. This is especially true of
students who are just learning to program, but I also
see it in juniors or seniors. Many of these upper-division
students do not seem to have developed confidence in
their ability to solve even medium-sized problems. But
when they are given a set of steps that has already been
decomposed and ordered, they feel confidence enough to
get the job done. They are industrious workers.
Confessions of a Community College Dean captured my
feeling about this feature of today's students when
it said,
"As a student, I would have been insulted by this
approach. But they aren't me." I myself enjoy
tackling big problems, bringing order to an unruly
mass of competing concerns. Had I always been
spoon-fed toy problems already broken into nearly
trivial pieces, I wonder if I would have enjoyed
computer science as much. I suspect I might have
because, like many people who are attracted to CS,
I like to
create my own problems!
So: students like to work on small, well-developed
tasks whose boundaries they understand well. This,
too, helps students focus their study.
My net acquaintance Chad Orzel, a physicist at Union
College,
speculates on why
students prefer to work in this way. The conventional
wisdom is that working on many small, discrete tasks
encourages them to keep up with their reading. But
I think he is right when he takes this diagnosis one
step further: This style of course helps students
to compensate for poor time management skills. Larger,
less well-defined units require students to figure
out what the subtasks are, estimate how long each will
take, and then actually do them all in a timely fashion.
By structuring our courses as a set of smaller, discrete
tasks, we do much of the preparatory work for our students.
When students are first learning, this is good, but as
they grow (or should be growing) we are merely reinforcing
bad habits.
It seems that we professors are enablers in a system of
codependency. :-)
Even in this regard, the relationship between student as
software developer and student as student holds. As I have
written before,
software methodologies are self-help systems. Perhaps
so are the ways we structure problems and lectures for
our students.
Once again, I can't blame students for preferring to
work on small, discrete, well-defined tasks. Most
people work better under these circumstances. Even
those of us who love the challenge of tackling big
problems usually succeed by taming the problem's
complexity, reducing it to a system of smaller,
independent, interacting components. That's what
design is.
Students need to learn how to design, too. When
students are getting started, professors need to
scaffold their work by doing much of the design for
them. Then, as students increase in knowledge and
skill, we need to pull the scaffolding away slowly
and let students do more and more of their own design.
It's easy for professors to fall into the habit of
finely specifying student tasks. But in doing this
thinking for them, we deny them the essential experience
of decomposing tasks for themselves.
Maybe we can leverage the agile-facing side of student
behavior in helping them to develop agile habits as
software developers. People aren't always able to
change their behavior in one arena when they come to
see that it is inconsistent with their behavior in
another; we aren't wired that way. But knowing ourselves
a little better is a good thing, and creates one more
opportunity for our mind to grow.
(I doubt going the other way would work very well. But
it might take away some of the pressure to grade work
quickly!)
Electron Blue
recently wrote about some of her
experiments in art.
As an amateur student of physics, she knows that these
experiments are different the experiments that scientists
most often perform. She doesn't always start with a
"hypothesis", and when she gets done it can be difficult
to tell if the experiment was a "success" or not. Her
experiments are opportunities to try ideas, to see whether
a new technique works out. Sometimes, that's easy to
see, as when the paint of a base image dries with a grainy
texture that doesn't fit the image or her next stage.
Other times, it comes down to her judgment about balance
or harmony.
This is quite unlike many science experiments, but I think
it has more in common with science than may at first appear.
And I think it is very much like what programmers and
software developers do all the time.
Many scientific advances have resulted from what amounts
to "trying things out", even without a fixed goal in
mind. On my office wall, I have a wonderful little news
brief called "Don't leave research to chance", taken from
some Michigan State publication in the early 1990s. The
article is about some work by
Robert Root-Bernstein,
an MSU science professor who in the 1980s spent time as
a MacArthur Prize fellow studying creativity in the
sciences. In particular, it lists ten ways to increase
one's chances of serendipitously encountering valuable
new ideas. Many of these are strict matters of technique,
such as removing background "noise" that everyone else
accepts or varying experimental conditions or control
groups more widely than usual. But others fit the art
experiment mold, such as running a reaction backward,
amplifying a side reaction, or doing something else
"unthinkable" just to see what happens. The
world of science isn't always as neat as it appears
from the outside.
And certainly we software developers explore and play
in a way that an artist would recognize -- at least
we do when we have the time and freedom to do so.
When I am learning a new technique or language or
framework, I frequently invoke the
Three Bears Pattern
that I first learned from Kent Beck via one of the
earliest
pedagogical patterns
workshops. One of the instantiations of this pattern
is to use the new idea everywhere, as often and as
much as you can. By ignoring boundaries, conventional
wisdom, and pat textbook descriptions of when the
technique is useful, the developer really
learns the technique's strengths and weaknesses.
I have a directory called software/playground/
where I visit when I just want to try something out.
This folder is a living museum of some of the
experiments I've tried. Some are as mundane as
learning some hidden feature of Java interfaces,
while others are more ambitious attempts to see
just how far I can take the Model-View-Controller
pattern before the resulting pain exceeds the benefits.
Just opportunities to try an idea, to see how a new
technique works out.
My own experience is filled with many other examples.
A grad student and I learned pair programming by giving
it a whirl for a while to see how it felt. And just
a couple of weeks ago, on the plane to Portland for the
OOPSLA 2006 fall planning meeting, I whipped
up a native
Ook!
interpreter in Scheme -- just because. (There is still
a bug in it somewhere... )
Finally, I suspect that web designers experiment in
much the way that artists do when they have ideas
about layout, design, and usability. The best way
to evaluate the idea is often to implement it and
see what real users think! This even fits Electron
Blue's ultimate test of her experiments: How do
people react to the work? Do they like it enough to
buy it? Software developers know all about this,
or should.
One of the things I love most about programming is
that I have the power to write the code -- to make
my ideas come alive, to watch them in animated bits
on the screen, to watch them interacting with other
people's data and ideas.
As different as artists and scientists and software
developers are, we all have some things in common,
and playful experimentation is one.
I teach at a "comprehensive university", one of those
primarily undergraduate institutions that falls outside
of the Research I classification whose schools dominate
the mind share of the computer science world. After
graduation, most of our students become software
practitioners at companies in Iowa and the midwestern
U.S.
Last spring, I was excited when one of my M.S. students
became the first student at our university to receive
a job offer from Google. I may not have been more
excited than he was, but then again maybe I was... His
thesis presented some novel work on algorithms for
automatic route planning of snow removal operations,
an important topic for road departments in my part of
the world, and Google found him a promising developer
for Google Maps. As an advisor and faculty member,
I was filled with pride -- perhaps a false pride.
Look at this validation of my work!
Imagine my disappointment when, for a variety of
personal and pragmatic reasons, my student turned
Google down. I sympathized with his difficult
choice, but where's the caché for me in
"I was the advisor of a student who almost
worked for Google"? What about my needs?
Today my excitement was renewed when I found that
a former undergraduate student
of mine has accepted an offer from ThoughtWorks.
In the software world, ThoughtWorks is known as
one of the cooler consulting firms out there.
Like Google, it seems to hire up lots of the
interesting folks, especially in the OO and agile
circles I frequent.
Chris approached Thoughtworks through its
ThoughtWorks University
program, aimed at attracting promising recent
graduates. He is just the sort of student that
programs like this seek: a guy who has demonstrated
potential in classwork and research, even though
he doesn't come from a Big-Name Institution. His
undergraduate research project on the construction
of
zoomable user interfaces
won the award for undergraduate scientific research
at our university, an award that usually goes to a
student in the hard sciences.
Universities like ours are a relatively untapped
resource for advanced technology companies. Our
best students are as strong as the best students
anywhere. The only problem is that many of them
don't have a big enough vision of what they can
accomplish in the world. Turning their vision
outward, toward
entrepreneurial opportunities
whether in start-ups or established firms, is
the key. It's one of my major goals for our
department over the next three years.
I can take some pride in knowing that my courses
in object-oriented programming and agile software
development probably helped this student attract
some attention from the folks at ThoughtWorks, but
I know that it's these students themselves who make
opportunities for themselves. As an educator, my
job is to help them to see just how big the world
of ideas and opportunities really is.
My friend Kris Anderson sent e-mail in response
to my entry on
I = k|P|.
Here's part of what he said:
So then, I got to thinking about the variable "|P|"
in your equation. Absolute value? As I thought about
it, Aerosmith's "Dream On" started playing in my head...
"Live and learn from fools and from sages..." 'Fools'
represent negative values and 'Sages' represent positive
values. And since the lesson one can learn from either
is of equal value, that's why 'P' must be '|P|'. Very
cool.
As I told him, Now that is cool. When I wrote
my message, by |P| I meant the cardinality of the set P.
Kris took P to mean not a set but the value of some
interaction, either positive or negative. The ambiguous
|P| then can indicate that we learn something of value
from both positive influences and negative influences,
like positive and negative examples in induction. I
think that I'll stick with my original intention and
leave credit for this re-interpretation to Kris.
And who knew that anyone would read my entry and make
a connection to
Aerosmith?
Different people, different familiar ideas, different
connections. That reminds of something
Ward Cunningham said
at OOPSLA 2005.
I learn so much from other folks reading what I write
-- yet another example of the point of the article.
It occurred to me today that my intelligence on any
given day is roughly proportional to the number of
people I talk to that day:
I = k|P|
This is true when I do department head stuff. The
more people I get information from, the more people
I share ideas with and get feedback from... the
more I know, and the better I can do my job.
It is true when I teach. When I talk to other
instructors, I learn from them, both by hearing their
ideas and by expressing my ideas verbally to them.
When I talk to students about our classes, whether
they are in my class or not, I learn a little bit
about what works, what doesn't, and what makes students
tick.
It is true when I program. The agile software methods
institutionalized this in the form of high degree of
interaction among developers. XP raises it to the
level of Standard Practice in the form of pair
programming. Programmers who refuse to try pairing
rarely understand what they are missing.
The value of k depends on a lot of factors,
some of which are within my daily control and some of
which are in my control only over longer time horizons.
On a daily basis, I can seek out the best folks possible
on campus and in my circle of professional colleagues
available only by e-mail. Over longer time periods,
I can choose the conferences I should attend, the academic
communities I can participate in, and even where I want
to be employed.
We all know the adages about hiring the smartest employees
one can, about being the least accomplished person on the
team, and so on. This is why: it increases the value of
your k!
The daily grind of the department office has descended
upon me the last couple of weeks, which with the
exception of two enjoyable talks (described
here
and
here)
have left me with little time to think in the way that
academics are sometimes privileged. Now comes a short
break full of time at home with family.
Here are a few things that have crossed my path of late:
Belated "Happy Birthday" to
GIMP,
which turned 10 on Monday, November 21, 2005.
There is a lot of great open-source software out
there, much of which is older than GIMP, but there's
something special to me about this open-source
program for image manipulation. Most of the pros
use
Photoshop,
but GIMP is an outstanding program for a non-trivial
task that shows how far an open-source community can
take us. Check out the
original GIMP announcement
over at Google Groups.
Then there is this recently renamed
oldie but goodie
on grounded proofs. My daughters are at the ages
where they can appreciate the beauty of math, but
their grade-school courses can do only so much.
Teaching them bits and pieces of math and science
at home, on top of their regular work, is fun but
challenging.
The great thing about explaining something to a
non-expert is that you have to actually understand
the topic.
Content and method both matter. Don't let either
the education college folks or the "cover all the
material" lecturers from the disciplines tell you
otherwise.
Finally, something my students can appreciate
as well as I:
If schedule is more important than accuracy, then
I can always be on time.
Courtesy of
Uncle Bob,
though I disagree with his assumption that
double-entry bookkeeping is an essential practice
of modern accounting. (I do not disagree with the
point he makes about test-driven development!)
Then again, most accountants hold double-entry
bookkeeping in nearly religious esteem, and I've
had to disagree with them, too. But one of my
closest advisors as a graduate student,
Bill McCarthy,
is an accountant with whom I can agree on this issue!
I have an interest in writing, both in general as
a means for communication and in particular as it
relates to the process of programming. So I headed
over to the
Earth Science department
yesterday for a talk on popular science writing
called "Words, Maps, Rocks: One Geologist's Path".
The speaker was
Marcia Bjornerud
of
Lawrence University,
who recently published the popular geology book
Reading the Rocks: The Autobiography of the Earth.
The Earth Science faculty is using Reading the
Rocks as reader in one of their courses, and
they asked Dr. Bjornerud to speak on how she came
to be a geologist and a popularizer of science.
Bjornerud took a roundabout way into science. As a
child, she had no desire to be a scientist. Her
first loves were words and maps. She loved the history
of words, tracing the etymology of cool words back to
their origin in European languages, then Latin or Greek,
and ultimately back to the source of their roots. The
history of a word was like a map through time, and the
word itself was this rich structure of now and then.
She also loved real maps and delighted in the political,
geographical, and temporal markings that populated them.
Bjornerud told an engaging story about a day in grade
school when snow created a vacation day. She remembers
studying the time zones on the map and learning that at
least two places had no official time zone: Antarctica
and Svalborg, Norway.
These reminiscences probably strike a chord in many
scientists. I know that I have spent many hours poring
over maps, just looking at cities and open spaces and
geopolitical divisions, populations and latitudes and
relative sizes. I remember passing time in an undergraduate
marketing class by studying a large wall map of the US
and first realizing just how much bigger Iowa (a state
I had never visited but would one day call home) was
than my home state of Indiana (the smallest state west
of the Appalachian Mountains!) I especially love looking
at maps of the same place over time, say, a map of the
US in 1500, 1650, 1750, 1800, and so on. Cities grow
and die; population moves inexorably into the available
space, occasionally slowing at natural impediments but
eventually triumphing. And words -- well, words were
why I was at this talk in the first place.
Bjornerud loved math in high school and took physics
at the suggestion of friends who pointed out that the
calculus had been invented in large part in order to
create modern physics. She loved the math but hated
the physics course; it was taught by someone with no
training in the area who acknowledged his own inability
to teach the course well.
It wasn't until she took an introductory college geology
course that science clicked for her. At first she was
drawn to the words: esker, alluvium,
pahoehoe, ... But soon she felt drawn to what
the words name. Those concepts were interesting in their
own right, and told their own story of the earth. She
was hooked.
We scientists can often relate to this story. It may
apply to us; some of us were drawn to scientific ideas
young. But we certainly see it in our friends and
family members and people we meet. They are interested
in nature, in how the world works, but they "don't like
science". Why? Where do our schools go wrong? Where
do we as scientists go wrong? The schools are a big
issue, but I will claim that we as scientists contribute
to the problem by not doing a good job at all of communicating
to the public why we are in science. We don't
share the thrill
of doing science.
A few years ago, Bjornerud decided to devote some of
her professional energy to systematic public outreach,
from teaching Elderhostel classes to working with grade
schoolers, from writing short essays for consumption by
the lay public to her book, which tells the story of
the earth through its geological record.
To write for the public, scientists usually have to
choose a plot device to make technical ideas accessible
to non-scientists. (We agile software developers might
think of this as the much-maligned
metaphor
from XP.)
Bjornerud used two themes to organize her book. The
central theme is "rocks as text", reading rocks like
manuscripts to reveal the hidden history of the earth.
More specifically, she treats a rock as a
palimpsest,
a parchment on which a text was written and then scraped
off, to be written on again. What a wonderful literary
metaphor! It can captivate readers in a day when the
intrigue of forensic science permeates popular culture.
Her second theme, polarities, aims more at the
micro-structure of her presentation. She had as an
ulterior motive, to challenge the modern tendency to
see dichotomy everywhere. The world is really a tangled
mix of competing concepts in tension. Among the
polarities Bjornerud explores are innovation versus
conservation
(sound familiar?)
and strength versus weakness.
Related to this motive is a desire -- a need -- to instill
in the media and the public at larger an appetite
for subtlety. People need to know that they can and
sometimes must hold two competing ideas in their minds
simultaneously. Science is a halting journey toward
always-tentative conclusions.
These themes transfer well to the world of software.
The tension between competing forces is a central theme
driving the literature of software patterns. Focusing
on a dichotomy usually leads to a sub-optimal program;
a pattern that resolves the dichotomy can improve it.
And the notion of "program as text" is a recurring idea.
I've written occasionally about the value in having
students read programs as they learn to write them,
and I'm certainly not the first person to suggest this.
For example, Owen Astrachan once wrote quite a bit on
apprenticeship learning through reading master code
(see, for example, this
SIGCSE paper).
Recently, Grady Booch blogged
On Writing,
in which he suggested "a technical course in selected
readings of software source code".
Bjornerud talked a bit about the process of writing,
revising, finding a publisher, and marketing a book.
Only one idea stood out for me here... Her publisher
proposed a book cover that used a photo of the Grand
Canyon. But Bjornerud didn't want Grand Canyon on
her cover; the Grand Canyon is a visual cliche,
particularly in the world of rocks. And a visual
cliche detracts from the wonder of doing geology;
readers tune out when they see yet another picture
of the Canyon. We are all taught to avoid linguistic
cliches like the plague, but how many of us think
about cliches in our other media? This seemed like
an important insight.
Which programs are the cliches of software education?
"Hello, World", certainly, but it is so
cliche that it has crossed over into the realm of
essential kitsch. Even folks pitching über-modern
Ruby show us puts "Hello, World."
Bank account. Sigh, but it's so convenient; I used
it today in a lecture on closures in Scheme. In the
intro Java world,
Ball World
is the new cliche. These trite examples provide a
comfortable way to share a new idea, but they also
risk losing readers whose minds switch off when they
see yet another boring example they've seen before.
In the question-and-answer session that followed the
talk, Bjornerud offered some partial explanations
for where we go wrong teaching science in school.
Many of us start with the premise that science is
inherently interesting, so what's the problem?
Many science teachers don't like or even know
science. They have never really done
science and felt its beauty in their bones.
This is one reason that, all other things
being equal, an active scholar in a discipline
will make a better teacher than someone else.
It's also one of the reasons I favor schools
of education that require majors in the content
area to be taught (Michigan State) or that at
least teach the science education program out
of the content discipline's college (math and
science education at UNI).
We tend explain the magic away in a pedantic
way. We should let students discover ideas!
If we tell students "this is all there is to
it", we hide the beauty we ourselves see.
Bjornerud stressed the need for us to help students
make a personal connection between science and
their lives. She even admitted that we might help
our students make a spiritual connection
to science.
Finally, she suggested that we consider the
"aesthetic" of our classrooms. A science room
should be a good place to be, a fun place to
engage ideas. I think we can take this one step
further, to the aesthetic of our instructional
materials -- our code, our lecture notes, our
handouts and slides.
The thought I had as I left the lecture is that too
often we don't teach science; we teach about
science. At that point, science becomes a list of
facts and names, not the ideas that underlie them.
(We can probably say the same thing about history and
literature in school, too.)
Finally, we talked a bit about learning. Can children
learn about science? Certainly! Children learn by
repetition, by seeing ideas over and over again at
increasing degrees of subtlety as their cognitive
maturity and knowledge level grow. Alan Kay has often
said the same thing about children and language. He
uses this idea as a motivation for a programming
language like Smalltalk, which enables the learner to
work in the same language as masters and grow in
understanding while unfolding more of the language as
she goes. His groups work on
eToys
seeks to extend the analogy to even younger children.
Most college students and professionals learn in this
way, too. See the
Spiral
pedagogical pattern for an example of this idea.
Bjornerud tentatively offered that any topic -- even
string theory!?,
can be learned at almost any level. There may be some
limits to what we can teach young children, and even
college students, based on their level of cognitive
development, their ability to handle abstractions. But
for most topics most of the time -- and certainly for
the basic ideas of science and math -- we can introduce
even children to the topic in a way they can appreciate.
We just have to find the right way to pitch the idea.
This reminds me, too, of Owen Astrachan and his work on
apprenticeship mentioned above. Owen has since backed
off a bit from his claim that students should read master
code, but not from the idea of reading code itself.
When he tried his apprenticeship through reading master
code, he found that students generally didn't "get it".
The problem was that they didn't yet have the tools to
appreciate the code's structures, its conventions and
its exceptions, its patterns. They need to read code
that is closer to their own level of programming.
Students need to grow into an appreciation of master
code.
Talks like this end up touching on many disparate
issues. But a common thread runs through Bjornerud's
message. Science is exciting, and we scientists have
a responsibility to share this with the world. We
must do so in how we teach our students, and in how
we teach the teachers of our children. We must do so
by writing for the public, engaging current issues
and helping the citizenry to understand how science
and technology are changing the world in which we
live, and by helping others who write for the public
to appreciate the subtleties of science and to share
the same through their writing.
I concur. But it's a tall order for a busy scientist
and academic. We have to choose to make time to meet
this responsibility, or we won't. For me, one of my
primary distractions is my own curiosity -- that which
makes us a scientist in the first place drives us to
push farther and deeper, to devote our energies to the
science and not to the popularizing of it. Perhaps
we are doomed to the G. H. Hardy's conclusion in his
wonderful yet sad
A Mathematician's Apology:
Only after a great mind has outlived its ability to
contribute to the state of our collective knowledge
can -- should? will? -- it turn to explaining. (If
you haven't read this book, do so soon! It's a quick
read, small and compact, and it really is both
wonderful and sad.)
But I do not think we are so doomed. Good scientists
can do both. It's a matter of priorities and choice.
And, as in all things, writing matters. Writing well
can succeed where other writing fails.
Last week, I was contacted by a gentleman named
Alex Gofman, who is CTO for
Moskowitz Jacobs Inc.
and is writing a book on the marketing techniques
of his company's founder, Howard Moskowitz. If
you have been reading this blog for long, you may
remember a nearly year-old article I wrote entitled
What Does the iPod have in Common
with Prego Spaghetti Sauce?,
in which I discussed some ideas on design, style,
and creativity. My thoughts there were launched
by articles I'd read from Paul Graham and Malcolm
Gladwell. The Gladwell piece had quoted Moskowitz,
and I quoted Gladwell quoting Moskowitz.
Mr. Gofman apparently had googled on Moskowitz's
name and come across my blog as a result. He was
intrigued by the connections I made between the
technique used to revive Prego and the design ideas
of Steve Jobs, Paul Graham, agile software methods,
and
Art and Fear.
He contacted me by e-mail to see if I was willing
to chat with him at greater depth on these ideas,
and we had a nice 45-minute conversation this morning.
It was an interesting experience talking about an
essay I wrote a year ago. First of all, I had to go
back and read the piece myself. The ideas I wrote
about then have been internalized, but I couldn't
remember anything particular I'd said then. Then,
during the interview, Mr. Gofman asked me about an
earlier blog entry I'd written on the rooster story
from Art and Fear, and I had to scroll down
to remember
that piece!
Our conversation explored the edges of my thoughts,
where one can find seeming inconsistencies. For
example, the artist in the rooster story did many
iterations but showed only his final product. That
differs from what Graham and XP suggest; is it an
improvement or a step backward? Can a great designer
like Jobs create a new and masterful design out of
whole cloth, or does he need to go through a phase
of generating prototyping to develop the idea?
In the years since the Prego experience reported by
Gladwell, Moskowitz has apparently gone away from
using trained testers and toward many iterations
with real folks. He still believes strongly in
generating many ideas -- 50, not 5 -- as a means to
explore the search space of possible products. Mr.
Gofman referred to their technique as "adaptive
experimentation". In spirit, it still sounds a lot
like what XP and other agile methods encourages.
I am reluctant to say that something can't happen.
I can imagine a visionary in the mold of Jobs whose
sense of style, taste, and the market enable him to
see new ideas for products that help people to feel
desires they didn't know they had. (And not in the
superficial impulse sense that folks associate with
modern marketing.) But I wouldn't want to stake my
future or my company on me or most anyone I know
being able to do that.
The advantage of the agile methods, of the techniques
promoted in Art and Fear, is that they give
mere mortals such as me a chance to create good products.
Small steps, continuous feedback from the user, and
constant refactoring make it possible for me to try
working software out and learn from my customers what
they really want. I may not be able to conceive the
iPod, but I can try 45 kinds of sauce to see which one
strikes the subconscious fancy of a spaghetti eater.
This approach to creating has at least two other benefits.
First, it allows me to get better at what I do. Through
practice, I hone my skills and learn my tools. Though
sheer dent of repetition and coming into contact with
many, many creations, I develop a sense of what is good,
good enough, and bad. Second, just by volume I increase
my chances of creating a masterpiece every now and then.
No one may have seen all of my scratch work, but you can
be sure that I will show off my occasional masterpiece.
(I'm still waiting to create one...)
We should keep in mind that even visionary designers like
Jobs fail, too -- whether by creating a product ahead of
its time, market- or technology-wise too soon, or by
simply being wrong. They key to a guy like Jobs is that
he keeps coming back, having learned from his experience
and trying again.
I see this mentality as essential to my work as a programmer,
as a teacher, and now as an administrator. My best bet
is to try many things, trust my "customer" (whether user,
student, or faculty colleague) enough to let them see my
work, and try to get better as I go on.
In part as a result of our conversation this morning,
Mr. Gofman -- who is a software developer trained as a
computer engineer -- decided to proposing adding a chapter
to his book dealing with software development as a domain
for adaptive experimentation. I learned that he is an XP
aficionado who understands it well enough to know that it
has limits. This chapter could be an interesting short
work on agile methods from a different angle. I look
forward to seeing what may result.
As Mr. Gofman and I chatted this morning, I kept thinking
about how fear and creativity had come up a few times at
OOPSLA this year, for example,
here
and
here.
But I didn't have a good enough reason to tell him, "You
should read every article on my blog." :-) In any case,
I wish him luck. If you happen to read the book, be on
the look out for a quote from yours truly.
I have now published the last of my entries intended
to describe the goings-on at
OOPSLA 2005.
As you can see from both the number and the length of
entries I wrote, the conference provided a lot of
worthwhile events and stimulated a fair amount of
thinking. Given the number of entries I wrote, and
the fact that I wrote about single days over several
different entries and perhaps several weeks, I thought
that some readers might appreciate a better-organized
index into my notes. Here it is.
Of course, many other folks have blogged on the
OOPSLA'05 experience, and my own notes are necessarily
limited by my ability to be in only one place at a
time and my own limited insight. I suggest that you
read far and wide to get a more complete picture.
First stop is the
OOPSLA 2005 wiki.
Follow the link to "Blogs following OOPSLA" and
the conference broadsheet, the Post-Obvious Double
Dispatch. In particular, be sure to check out
Brian Foote's
excellent color commentary, especially his insightful
take on the
software devolution
in evidence at this year's conference.
OOPSLA Day 2: A Panel of the Direction of CS Education
The final item on the
Educators Symposium
program this year was a panel discussion on the
future of computer science education. It was
called
Are We Doomed? Reframing the Discussion,
in partial gest following last SIGCSE's panel debate
Resolved: "Objects Early" Has Failed.
After that session,
Owen Astrachan
commented, "We're doomed." What did he mean by this?
Despite our own declarations that this is The Age of
Information and that computer science is a fundamental
discipline for helping the world to navigate and use
the massive amount of information now being collected,
we still teach CS courses in essentially the same way
we always have. We still use toy examples in toy
domains that don't really matter to anyone, least of
all of students. We still teach our introductory
courses as 100% old-style programming, with barely a
nod to users, let alone to the fact that sophisticated
consumers of computing grow increasingly independent
of us and our inward focus.
This summer, Owen said it this way:
We have the human genome project, we have Google, we
have social networks, we have contributions to many
disciplines, and our own discipline, but we argue
amongst ourselves about whether emacs is better than
vi, Eclipse better than IDEA, C++ better than Java or
Scheme, or what objects-first really means.
I'm sorry, but if we don't change what we talk
about amongst ourselves, we are doomed to a niche
market while the biologists, the economists, the
political scientists, etc., start teaching there own
computational/modeling/programming/informatics courses.
Nearly everyone turns to math for calculus, nearly
everyone turns to math/stats for statistics. These are
nearly universally acknowledged as basic and foundational
for *lots* of disciplines. In the age of information
nearly no discipline at a large scale requires computer
science, certainly not programming as we teach it.
Owen isn't as pessimistic as the provocative "We're
doomed" sounds; he simply wants to cause us to think about
this sea change and begin to make a change ourselves.
I decided that this would make a great closing for my
second Educators Symposium. Last year, my first
symposium opened with Alan Kay challenging us all to
set a higher bar for ourselves -- in computer science,
and in computer science education. This year, my second
symposium would close with a challenge to reinvent what
we do as a discipline.
As in so many things, the panel did not turn out quite
the way I had planned. First of all, Owen wasn't able
to be at OOPSLA after all, so we were without our
intellectual driving force. Then, when the panel went
live, discussion on the panel went in a different direction
than I had planned. But it had its good points nonetheless.
The panel consisted of
Robert Biddle,
Alistair Cockburn,
Brian Marick,
and
Alan O'Callaghan.
I owe special thanks to Alistair and Alan, who joined
us on relatively short notice.
As moderator, I had hoped to pen a wonderfully humorous
introduction for for each of the panelists, to loosen
things up before we dropped the gloves and got serious
about changing the face of computer science. Perhaps
I should have commissioned a
master
to ghostwrite, for in my own merely mortal hands my
dream went unfulfilled. I did have a couple of good
lines to use. I planned to introduce Robert as the
post-modern conscience of the Educators Symposium,
maybe with a visual bow to one of his previous Onward!
presentations. For Brian, my tag line was to be "the
panelist most likely to quote Heidegger -- and make you
love him anyway". But I came up short for Alistair and
Alan. Alistair's paper on software development as
cooperative game playing was one possible source of
inspiration. For Alan, all I could think was, "This
guy has a higher depth/words ratio than most everyone
I know". In the end, I played it straight and we got
down to business rather quickly.
I won't try to report the whole panel discussion, as
I got sucked into it and didn't take elaborate notes.
In general, rather than focusing on how CS is being
reinvented and how CS education ought to be reinvented,
it took a turn toward metaphors for CS education.
I will describe what was for me the highlight of the
session and then add a couple of key points I remember.
The highlight for me was Robert's presentation, titled
"Deprogramming Programming". It drew heavily on the
themes that he and
James Noble
have been pitching at recent Onward! performances, in
particular that much of what we take as accepted wisdom
in software development these days is created by us and
is, all too often, just wrong.
He started with a quote from Rem Koolhaus and Bruce Mau's
"S, M, L, XL":
Sous le pavé, la plage.
(Under the paving stone, the beach.)
There is something beneath what we have built as a
discipline. We do not program only our computers...
We've programmed ourselves, in many wrong
ways, and it's time to undo the program.
The idea that there is a software crisis is a fraud.
There isn't one now, and there wasn't one when the
term 'software engineering' was coined and became a
seemingly unavoidable part of our collective psyche.
Robert pointed out that in Greek mythology
Narcissus
fell in love not with himself but with his reflection.
He believes that the field of software engineering has
done the same, fallen in love with an image of itself
that it has created. We in CS education are often guilty
of the same offense.
Robert then boldly asserted that he loves his job as
a teacher of computing and software development. If we
look under the pavement, we will see that we developed
a lot of useful, effective techniques for teaching
students to build software: study groups, role play,
and especially case studios and studios. I have written
before about my own strong belief in the value of case
studios and software studios, so at this point I nearly
applauded.
Finally:
The ultimate goal of computer science is the
program.
This quote is in someways antithetical to the idea
Owen and I were basing the panel on (which is one
reason I wanted Robert to be on the panel!), but it
also captures what many folks believe about computing.
I am one of them.
That certainly doesn't do justice to the stark imagery
and text that constituted Robert's slides, nor to the
distinctive verbal oratory that Robert delivers. But
it does capture some of the ideas that stuck with me.
The rest of the panel presentations were good, and the
discussion afterward ranged far and wide, with a
recurring them of how we might adopt a different model
for teaching software development. Here are a few points
that stood out:
Brian offered two of ideas of interest: demonstration
a lá the
famed on-line demo
of using
Ruby on Rails
to build a blog engine fifteen minutes, and education
patterned on that his wife received and dishes out as
a doctor of veterinary medicine.
Alan said that we in CS tend to teach the
anatomy of a language, not how to use a
language. He and I have discussed this idea before,
and we both believe that patterns -- elementary or
otherwise -- are a key to changing this tendency.
Dave West chimed in from the audience with a new
statement of computer science's effect on the world
reminiscent of his
morning presentation:
"We are redefining the world in which all of us
work and live."
Two ideas that should be a bigger part of how we
teach software development are a focus on useful
things and study of existing work.
Various people have been using these ideas in various
forms for a while now, and we have uncovered some of
the problems hidden behind their promise. For example,
students aren't often ready to read programs that are
*too* good very quickly; they simply don't appreciate
their goodness until they have developed a better sense
of taste. But if we framed more of our teaching efforts
around these ideas and worked to compensate for their
shortcomings, we would probably be better off than
doing The Same Old Thing.
All in all, the panel did not go where I had intended for
it to go. Of course, Big Design Up Front can be that way.
Sometimes you have to take into account what your
stakeholders want. In my case, the stakeholders were the
panelists and the audience, with the audience playing the
role of pseudo-customer. Judging from the symposium
evaluations, many folks enjoyed the panel, so maybe it
worked out all right after all.
Of course, what I had hoped for the panel was to challenge
folks in the audience to feel uneasy about the direction
of the discipline, to dare to think Big Thoughts about our
discipline. I don't think we accomplished that. There
will be more opportunities in the future.
As
PragDave recently wrote,
the
Ruby Extensions Project
contains a "absolutely wonderful hack". This
hack brought back memories and also reminded me
of a similar but more ambitious project going on
in the Ruby world.
First of all, here's the hack... One of Ruby's
nice features is its collections' internal
iterators. Instead of writing a for-loop
to process every item in a collection, you send the
collection a map message with a one-argument
block as its argument. PragDave's example is to
convert all the strings in an array uppercase, and
the standard Ruby code is
names.map { |name| name.upcase }
The map method applies the block -- effectively
a nameless method -- to every item in names.
This is a very nice feature, but after you program in
Ruby you want more... Isn't writing that block more
work than I should have to do? Why can't I just pass
upcase, which is a one-argument method, as the
argument to map? Because upcase isn't
a method or a procedure; it's a symbol that names
a method.
As PragDave reports, the Ruby Extensions hack adds a
method to the Symbol class that allows
Symbols to be coerced to a procedure object
at run-time. The result is that we can now write the
following:
names.map(&:upcase)
That's more succinct and avoids the need to create a
new procedure object on the fly.
Now the memory... I distinctly remember the afternoon
I learned the same hack in Smalltalk, back in the
summer of 1988. You see, Smalltalk's collections also
offer an array of internal iterators that eliminates
the need to write most for-loops, and these
iterators take blocks as arguments.
I was just learning Smalltalk and loved this idea --
it was my first exposure to object-oriented programming
and the power of blocks, which are like functional
programming's higher-order procedures. I was working
on some code to sort a collection. In Smalltalk,
collections also respond to a sort: message,
whose argument is a two-argument block for comparing
the values. So, to sort a collection of strings in
ascending order, I could write:
names sort: [ x y | x < y ]
But soon I wanted more... Why can't I just pass
< to sort:? The same reason I
can't do it in Ruby: < isn't a block or
a method; it is a symbol that names a method.
While figuring this out, I learned how sort:
works. It turns around and sends the block a
value:value: message with pairs of values
from the collection as the two arguments. Hmm, what
if a Symbol could respond to value:value:
and do the right thing? I added a one-line method to
the Symbol class, and they could:
(perform: behaves something like Scheme's
eval procedure.)
And now I could write the wonderfully compact
names sort: <
I soon added the one-argument form to Symbol,
too, and began to write new code with abandon.
I felt pretty smug at the time, for having created
something so beautiful. But I soon learned that I
had merely rediscovered a hack that every Smalltalk
programmer either reinvents or sees in someone else's
code. That didn't diminish the beauty of my idea,
but it did extinguish my smugness.
It turns out that this new hack is not only more
compact and more convenient to write, but it runs
faster than the block alternative, too. The callback
on the symbol doesn't require the creation of a
block on the fly, which requires memory allocation
and the whole bit.
Finally, for the more ambitious project... This
cool hack points out that Ruby and Smalltalk method
names are symbols, and without some coercion they
are not evaluated to their method values in ordinary
use. What if messages were first-order objects in
these languages? If so, then I can writing message
sends that take other messages as arguments, thus
creating higher-order messages. If you are
interested in this idea, check out Nat Pryce's
recent efforts
to add higher-order messaging to Ruby, if you haven't
already seen it. Nat gives a link to the paper that
laid the foundation for this idea and steps you
through the value of higher-order messages and their
implementation in Ruby. It's another absolutely
wonderful hack.
Two of Paul Graham's latest essays,
Ideas for Startups
and
What I Did This Summer,
echo ideas about simplicity, exploration, and
conventional wisdom that Ward Cunningham talked
about in his
Educators' Symposium keynote address.
Of course, Graham speaks in the context of
launching a start-up company, but I don't think
he sees all that much difference between that
and other forms of exploration and creation.
Ideas for Startups focuses first on a problem
that many people face when trying to come up
with a Big Idea: they try to come up with a
Big Idea. Instead, Graham suggests asking a
question...
Treating a startup idea as a question changes
what you're looking for. If an idea is a
blueprint, it has to be right. But if it's a
question, it can be wrong, so long as it's wrong
in a way that leads to more ideas.
Humility. Simplicity. Learn something along
the way. This is just the message that Ward
shared.
Later, he speaks of how to "do" simplicity...
Simplicity takes effort -- genius, even. ...
It seems that, for the average engineer, more
options just means more rope to hang yourself.
In this regard, Ward offers more hope to the
rest of us. Generating a truly great something
may require genius; maybe not. But in any case,
ordinary people can act in a way that biases
their own choices toward simplicity and humility,
and in doing so learn a lot and create good
programs (or whatever). That's what things like
CRC cards, patterns, and XP are all about. I know
a lot of people think that XP requires Superhero
programmers to succeed, but I know lots of ordinary
folks who benefit from the agile mindset. Take
small steps, make simple choices where possible,
and get better as you go.
I am not sure whether of how pessimistic Graham
really is here about achieving simplicity, but his
writing often leaves us thinking he is. But I
prefer to read his stuff as "Yeah, I can do that.
How can I do that?" and take good lessons from
what he writes.
Then, in "What I Did This Summer", Graham relates
his first experience with the Summer Founders
Program, bankrolling a bunch of bright, high-energy,
ambitious your developers. Some of the lessons his
proteges learned this summer are examples of what
Ward told us. For example, on learning by doing:
Another group was worried when they realized they
had to rewrite their software from scratch. I told
them it would be a bad sign if they didn't. The
main function of your initial version is to be
rewritten.
This is an old saw, one I'm surprised that the SFP
needed to learn. Then again, we often know something
intellectually but, until we experience it, it's
not our own yet.
But I really liked the paragraphs that came next:
That's why we advise groups to ignore issues like
scalability, internationalization, and heavy-duty
security at first. I can imagine an advocate of
"best practices" saying these ought to be considered
from the start. And he'd be right, except that they
interfere with the primary function of software in a
startup: to be a vehicle for experimenting with its
own design. Having to retrofit internationalization
or scalability is a pain, certainly. The only bigger
pain is not needing to, because your initial version
was too big and rigid to evolve into something users
wanted.
I suspect this is another reason startups beat
big companies. Startups can be irresponsible and
release version 1s that are light enough to evolve.
In big companies, all the pressure is in the direction
of over-engineering.
Ward spoke with great feeling about being willing
to settle for the incomplete, about ignoring some
things you probably shouldn't ignore, about disobeying
conventional wisdom -- all in the service of keeping
things simple and being able to see patterns and ideas
that are obscured by the rules. We are conditioned to
think of these behaviors as irresponsible, but they
may in fact point us in the most likely direction of
success.
----
I also found one really neat idea to think about from
reading these papers that is independent of Ward's
Cunningham. Graham was talking about doodling and
what the intellectual equivalent is, because doodling
is such a productive way for visual artists to let
their minds wonder. Technical innovators need to
let their minds wander so that they can stumble upon
newly synthesized ideas, where a common frame of
reference is applied to some inappropriate data.
This can be the source of analogies that help us to
see newly.
Out of this discussion, his programmer's mind created
a programming analogy:
That's what a metaphor is: a function applied to an
argument of the wrong type.
What a neat idea, both as a general characterization
of metaphor and also as a potential source of ideas
for programming languages. What might a program gain
from the ability to reason about a function applied
to invalid arguments? On its face, that's an almost
meaningless question, but that's part of Graham's --
and Ward's -- point. What may come from such a thought?
I want to think more.
I don't know that I have any more time than Graham
to spend on this particular daydream...
OOPSLA Day 2: Ward Cunningham on Seeking and Exploiting Simplicity
The keynote address for this year's
Educators' Symposium
was given by
Ward Cunningham,
one of the software folks I admire most. Of course, he's
admired by many folks, including not surprisingly by the
folks who organized the
Wiki Symposium
launched by and collocated with OOPSLA this year. As a
result, Ward's keynote to our group had to be moved from
its traditional first slot of the day to the slot immediately
after lunch. This gave the keynote a different feel, because
we all had a
morning's worth of activities
in which to hear Ward's words. (You can read a
summary
of Ward's Wiki Symposium keynote, titled "The Crucible of
Creativity".)
I introduced Ward by telling the audience how I first
encountered his work. At AAAI 1995 in Montreal, I was
discussing some of my ideas on teaching elementary patterns
with a colleague from Wales. He said, "I have a book for
you to review..." You see, he was one of the editors of
the journal
Expert Systems,
and he had received a book for review that he didn't know
what to do with. It was about software patterns, and he
figured that I'd be an okay reviewer. He was probably
encouraged to think this by the fact that none of his other
AI friends seemed to be interested.
The book was
Pattern Languages of Program Design,
and it changed my life. I had never been exposed to the
nascent software patterns community, and this book
introduced me to a lot of ideas and, ultimately, people
who have played an important role in my academic work since.
One of the papers in PLoPD-1 affected me immediately. It
was about the
CHECKS pattern language,
and it was written by Ward Cunningham. These patterns were
so simple, so obvious, yet as I read them I learned something
about maintaining the integrity of the data in my programs.
As I looked for more of Ward's work, I soon learned that
what attracted me to CHECKS was a hallmark of Ward's: the
ability to recognize simple ideas that offered unexpected
depth and to explore that depth, patiently and humbly. So
many of Ward's contributions to standard practice have been
the result of a similar process: CRC cards, patterns, wiki,
extreme programming, test-first design, and FIT among them.
I asked Ward to keynote the Educators Symposium because I
admired his work but because I hoped that he could teach
us educators -- especially me -- a little bit of his secret
gift. Maybe I could nurture the gift in myself, and maybe
even pass on something to my students.
Ward opened his talk with a reminiscence, too. As an
electrical engineering major in college, he learned about
Maxwell's equations from a Professor Simpson. The professor
taught the equations with passion, and he expected his
students to appreciate their beauty. Much of their beauty
lay in their simplicity, in how that brought so many important
facets together into such a small number of straightforward
equations. Professor Simpson also loved the work of Richard
Feynman, who himself appreciated simplicity and wrote with
humanity about what he learned.
One of Ward's first slides was The Big Slide, the take-home
point of his talk. He characterized his way of working as:
Immerse yourself in a pool of ideas. Come to know them.
Make them your own. Then look for some humble idea lying
around, something that we all understand or might. Play
with this idea to see whether it gives rise to something
unexpected, some new ability that changes how we see or
work with the pool of familiar ideas you are swimming in.
I have experienced the dangers inherent in looking for a
breakthrough idea in the usual ways. When we look for Big
Ideas, too often we look for Big Ideas. But they are hard
to find. Maybe we can't recognize them from our current
vantage point; maybe they are out of scale with the ideas
we have right now.
Ward pointed out another danger: Too often, we look for
complete ideas when a simple but incomplete idea
will be useful enough. (Sounds like
You Aren't Gonna Need It!)
Sometimes, we reach a useful destination by ignoring
things we aren't supposed to ignore. Don't worry about
all the things you are supposed to do, like taking your
idea through to its logical conclusion right away, or
polishing it up so that everyone can see how smart you
are. Keep the ideas simple, and develop just what you
need to move forward.
Ward pointed out that one thing we educators do is the
antithesis of his approach: the project due date. It
forces students to "get done", to polish up the "final
version", and to miss opportunities to explore. This
is one of the good things behind longer-term projects
and undergraduate research -- they allow students more
time to explore before packaging everything up in a
neat little box.
How can we honor the simple in what we do? How can we
develop patience? How can we develop the ability to
recognize the simple idea that offers more?
Ward mentioned Kary Mullis's
Dancing Naked in the Mind Field
as a nice description of the mindset that he tries to
cultivate. (You may recall
my discussion of Mullis's book
last year.) Mullis was passionate, and he had an
immediate drive to solve a problem that no one thought
mattered much. When he showed his idea to his colleagues,
they all said, "Yeah, that'd work, but so what?". So
Mullis gave in to the prevailing view and put his idea
on the shelf for a few months. But he couldn't shake
the thought that his simple little not-much of an idea
could lead to big things, and eventually he returned
to the idea and tinkered a little more... and won a
Nobel Prize.
Extreme Programming grew out of the humble practices
of programmers who were trying to learn how to work in
the brave new image of Smalltalk. Ward is happy that
P creates a work environment that is safe for the kind
of exploration he advocates. You explore. When you
learn something, you refactor. XP says to
do the simplest thing that could possibly work,
because
you aren't gonna need it.
Many people have misunderstood this advice to mean do
something simplistic, something stupid. But it really
means that you don't have to wait until you understand
everything before you do anything.
You can do useful work by taking small steps. These
principles encourage programmers to seriously consider
just what is the simplest thing that could
possibly work. If you don't understand everything about
your domain and your task, at least you can do this
simplest thing now, to move forward. When you learn
more later, you won't have over-invested in ideas you
have to undo. But you will have been making progress
in the meantime.
(I don't think that Ward actually said all of these words.
They are my reconstruction of what he taught me during
his talk. If I have misrepresented his ideas in any
way, the fault is mine.)
Ward recalled first getting Smalltalk, which he viewed
as a "sketchpad for the thinking person to write spike
solutions". Have an idea? Try to program it! Everything
you need or could want to change is there before you,
written in the same language you are using. He and Kent
realized that they now had a powerful machine and that
they should "program in a powerful way". Whenever in
the midst of programming they slowed down, he would
ask Kent, "What is the simplest thing that could possibly
work?", and they would do that. It got them over the
hump, let them regain their power and keep on learning.
This practice specializes his Big Slide from above to the
task of programming:
Remember: You can't do it all at once.
Ride small steps forward.
This approach to programming did not always follow the
most efficient path to a solution, but it always made
progress -- and that's more than they could say by trying
to stay on the perfect path. The surprise was that the
simple thing usually turned out to be all they needed.
Ward then outlined a few more tips for nurturing simple
ideas and practices:
Practice that which is hard.
... rather than avoiding it. Do it every day,
not just once. An example from software development
is schema evolution. It's too hard to design perfect
schema up front, so design them all the time.
Hang around after the fact.
After other people have explored an area heavily
and the conventional wisdom is that all of the
interesting stuff has been done, hang around. Tread
in well-worn tracks, looking for opportunities to
make easier what is hard. He felt that his work on
objects was a good example.
Connect with lower level abstractions.
That's the beauty of Smalltalk -- so many levels
of abstraction, all written in the same language, all
connected in a common way.
Seek a compact expression.
In the design of programming languages, we often
resist math's greatest strength -- the ability to
create compact expressions -- in favor of uniformity.
Smalltalk is two to four times more compact than
Java, and Ward likes that -- yet he knows that it
could be more compact. What would Smalltalk with
fewer tokens feel like?
Reverse prevailing wisdom.
Think the opposite of what everyone says is the
right way, or the only way. You may not completely
reverse how you do what you do, but you will be
able to think different thoughts. (Deconstruction
reaches the technical world!)
From the audience,
Joe Bergin
pointed out his personal favorite variant of this
wisdom (which, I think, ironically turns Ward's
advice back on itself): Take a good idea and do
it to the hilt. This is, of course, how Kent Beck
initially described XP -- "Turn the knobs up to
10."
Simplicity is not universal but personal, because it
builds upon a person's own pool of familiar ideas.
For example, if you don't know mathematics, then you
won't be able to avail yourself of the simplicities
it offers. (Or want, or know to want to.)
At this point, Ward ended his formal talk and spent
almost an hour demonstrating some of these ideas in
the testbed of his current hobby project, the building
of simple computers to drive an equally simple little
CRT. I can't do justice to all he showed us during
this phase of his keynote, but it was remarkable...
He created his own assembly language and then built a
little simulator for it in Java. He created macros.
He played with simple patterns on the screen, and
simple patterns in the wiring of his little computer
board. He hasn't done anything to completion -- his
language and simulator enable him to do only what he
has done so far. But that has been good enough to
learn some neat ideas about the machines themselves
and about the programs he's written.
While I'm not sure anything concrete came out of this
portion of his talk, I could see Ward's joy for
exploration and his fondness for simple questions
and just-good-enough solutions while playing.
We probably should all have paid close attention to
what Ward was doing because, if the recent past has
taught us anything, it is that in five years we will
all be doing what Ward is playing with today.
A work of art is a machine with an aesthetic
purpose.
(I am uncomfortable with the impression these quotes
give, that artistic expression is mechanistic, though
I believe that artistic work depends deeply on craft
skills and unromantic practice.)
Thanks to the wonders of the web, James came across
my post and responded with to my parenthetical:
You may be amused to learn that fear of such comments
is the reason I never said this to anyone except my
wife, until I said it to Gerry! Nevertheless, my
remark is true. It's just that word "machine" that
rings dissonant bells for many people.
I was amused... I mean, I am a computer
scientist and an old AI researcher. The idea of a
program, a machine, being beautiful or even creating
beauty has been one of the key ideas running through
my entire professional life. Yet even for me the
word "machine" conjured up a sense that devalued
art. This was only my initial reaction to Sussman's
sentiment, though. I also felt an almost immediate
need to mince my discomfort with a disclaimer about
the less romantic side of creation, in craft and
repetition. I must be conflicted.
James then explained the intention underlying his use
of the mechanistic reference in way that struck close
to home for me:
I find the "machine" idea useful because it leads the
musician to look for, and expect to find, understandable
structures and processes in works of music. This is
productive in itself, and at the same time, it highlights
the existence and importance of those elements of the
music that are beyond this kind of understanding.
This is an excellent point, and it sheds light on other
domains of creation, including software development.
Knowing and applying programming patterns helps
programmers both to seek and recognize understandable
structures in large programs and to recognize the
presence and importance of the code that lies outside
of the patterns. This is true even -- especially!?
-- for novice programmers, who are just beginning to
understand programs and their structure, and the process
of reading and writing them. Much of the motivation for
work on the use of elementary patterns in instruction,
as we try to help learn to comprehend masses of code that
at first glance may seem but a jumble but which in fact
bear a lot of structure within them. Recognizing code
that is and isn't part of recurring structure, and
understanding the role both play, is an essential skill
for the novice programmer to learn.
Folks like Gerry Sussman and Dick Gabriel do us all a
service by helping us to overcome our discomfort when
thinking of machines and beauty. We can learn something
about science and about art.
Thanks to James for following up on my post with his
underlying insight!
OOPSLA Day 5: Grady Booch on Software Architecture Preservation
Grady Booch refers to himself as an "IBM fellow and
free radical". I don't know if 'free radical' part
of his job description or only self-appellation, but
it certainly fits his roving personality. He is a
guy with many deep interests and a passion for
exploring new lands.
His latest passion is
Handbook of Software Architecture,
a project that many folks thinks is among the most
important strategic efforts for the history and
future of software development.
Booch opened his invited talk at OOPSLA by reminding
everyone that "classical science advances via the
dance between quantitative observation and theoretical
construction." The former is deliberate and intentional;
the latter is creative and testable. Computer science
is full of empirical observation and the construction
of theories, but in the world of software we often
spend all of time building artifacts and not enough
time doing science. We have our share of theories,
about process and tools, but much of that work is
based on anecdote and personal experience, not the
hard, dispassionate data that reflects good empirical
work.
Booch reminisced about a discussion he had with
Ralph Johnson
at the
Computer Museum
a few years ago. They did a
back-of-envelope calculation
that estimated the software industry had produces
approximately 1 trillion lines of code in high-level
languages since the 1950s -- yet little systematic
empirical study had been done of this work. What
might we learn from digging through all that code?
One thing I feel pretty confident of: we'd find
surprises.
In discussing the legacy of OOPSLA, Booch mentioned
one element of the software world launched at OOPSLA
that has taken seriously the attempt to
understand real systems: the
software patterns community,
of which Booch was a founding father. He hailed patterns
as "the most important contribution of the last 10-12
years" in the software world, and I imagine that his fond
evaluation rests largely on patterns community's empirical
contribution -- a fundamental concern for the structure
of real software in the face of real constraints, not
the cleaned up structures and constraints of traditional
computer science.
We have done relatively little introspection into the
architecture of large software systems. We have no common
language for describing architectures, no discipline that
studies software in a historical sense. Occasionally,
people publish papers that advance the area -- one that
comes to mind immediately is Butler Lampson's
Hints for Computer System Design
-- but these are individual efforts, or ad hoc group
efforts.
The other thing this brought to my mind was my time in
an undergraduate
architecture program.
After the first-year course, every archie took courses
in the History of Housing, in which students learned
about existing architecture, both as historical matter
and to inform current practice. My friends became
immersed in what had been done, and that certainly gave
them a context in which to develop their own outlook on
design. (As I look at the program's
current curriculum,
I see that the courses have been renamed History of
Architecture, which to me replaces the rich flavor of
houses for the more generic 'architecture',
even if it more accurately reflects the breadth of the
courses.)
Booch spent a next part of his talk comparing software
architecture to civil architecture. I can't do justice
to this part of his talk; you should read the growing
volume of content on his
web site.
One of his primary distinctions, though, involved the
different levels of understanding we have about the
materials we use. The transformation from vision to
execution in civil systems is not different in principle
from that in software, but we understand more about the
physical materials that a civil architect uses than we
do about a software developer's raw material. Hence
the need to study existing software systems more deeply.
Civil architecture has made tremendous progress over the
years in its understanding of materials, but the scale
of its creations has not grown commensurately other what
the ancients built. But the discipline has a legacy of
studying the works of the masters.
Finally he listed a number of books that document patterns
in physical and civil systems, including
The Elements of Style
-- not the
Strunk and White
version -- and the books of
Christopher Alexander,
the godfather of the software patterns movement.
Booch's goal is for the software community to document
software architectures in as great detail, both for
history's sake and for the patterns that will help us
create more and more beautiful systems. His project
is one man's beginning, and an inspirational one at
that. In addition to documenting classic systems such
as MacPaint, he aims to preserve our classic software
as well. That will enable us to study and appreciate
it in new ways as our understanding of computing and
software grow.
He closed his talk with inspiration but also a note
of warning... He told the story of contacting
Edsger Dijkstra
to tell him about the handbook project and seek his
aid in the form of code and papers and other materials
from Dijkstra's personal collection. Dijkstra supported
the project enthusiastically and pledged materials from
his personal library -- only to die before the details
had been formalized. Now, Booch must work through the
Dijkstra estate in hopes of collecting any of the
material pledged.
We are a young discipline, relatively speaking, but time
is not on our side.
Get a bunch of technology folks together for any time
and they are bound to coin some interesting words, or
use ones they've coined previously, either out of habit
or to impress their friends. The
Extravagaria gang
was no exception.
Example 1: When someone asked how many of us were
left-handed, Dick Gabriel said that he was partially
ambidextrous, to which Guy Steele volunteered that he
was ambimoustrous. I like.
Example 2: At lunch, Guy Steele asked us if we ever
intentionally got lost in a town, perhaps a town new
to us, so that we had to learn the place in order to get
back to a place we knew. Several people nodded vigorous
agreement, and
John Dougan
noted that he and his colleagues use a similar
technique to learn a new legacy code base. They call this
air-drop programming. This is a colorful
analogy for a common pattern among software developers.
Sometimes the best way to learn a new framework or
programming language is to parachute behind enemy lines,
surrender connection to any safety nets outside, and
fight our way out. Or better, not fight, but methodically
conquer the new terrain.
But the biggest source of neologisms at the workshop was
our speaking stick. At a previous Extravagaria workshop,
Dick used a moose as the communal speaking stick, in
honor of Vancouver as the host city. (Of course, there
are probably as many moose in San Diego as in Vancouver,
but you know, the Great White North and all.) He had
planned to bring the moose to this workshop but left it
at home accidentally. So he went to a gift shop and
bought a San Diego-themed palm tree to use in its place.
The veterans of the workshop dubbed it "the moose" out
of one year's worth of tradition, and from there we
milked the moose terminology with abandon.
Some of my favorites from the day:
on the moose -- back in session; on the clock
moose cycles -- a measure of the speed of
communication around the group, signified in the
passing of the moose
virtual moose -- speaking without the moose,
but with implicit group permission (We didn't always
follow our own rules!)
"Moose! Moose!" -- "Me next!"
Even computer professionals, even distinguished computing
academics, surrender to the silliness of a good game.
Perhaps we take joy in binding objects to names and
growing systems of names more than most.
I suppose that I should be careful reporting this, because
my students will surely hold it over my head at just the
right -- or wrong -- moment!
OOPSLA Day 3: Sussman on Expressing Poorly-Understood Ideas in Programs
Gerald Sussman
is renown as one of the great teachers of computing. He
co-authored the seminal text
Structure and Interpretation of Computer Programs,
which many folks -- me included -- think is the best book
ever written about computer science. Along with Guy Steele,
he wrote an
amazing series of papers,
collectively called the "Lambda papers", that taught me
as much as any other source about programming and machines.
It also documented the process that created Scheme, one
of my favorite languages.
Richard Gabriel introduced on Sussman before
his talk
with an unambiguous statement of his own respect for
the presenter, saying that when Sussman speaks, "... record
it at 78 and play it back at 33." In inimitable Gabriel
fashion, he summarized his career as, "He makes things.
He thinks things up. He teaches things."
Sussman opened by asserting that programming is, at its
foundation, a linguistic phenomenon. It is a way
in which we express ourselves. As a result, computer
programs can be both prose and poetry.
In programs, we can express different kinds of "information":
knowledge of world as we know it
models of possible worlds
structures of beauty
emotional content
The practical value that we express in programs sometimes
leads to the construction of intellectual ideas, which
ultimately makes us all smarter.
Sussman didn't say anything particular about why we should
seek to express beauty and emotional content in programs,
but I can offer a couple of suggestions. We are more likely
to work harder and deeper when we work on ideas that compel
us emotionally. This is an essential piece of advice for
graduate students in search of thesis topics, and even
undergrads beginning research. More importantly, I think
that great truths possess a deep beauty. When we work on
ideas that we think are beautiful, we are working on ideas
that may ultimately pay off with deeper intellectual content.
Sussman then showed a series of small programs, working
his way up the continuum from the prosaic to the beautiful.
His first example was a program he called "useful only",
written in the "ugliest language I have ever used, C".
He claimed that C is ugly because it is not expressive
enough (there are ideas we want to express that we cannot
express easily or cleanly) and because "any error that can
be made can be made in C".
His next example was in a "slightly nicer language",
Fortran. Why is Fortran less prosaic than C? It doesn't
pretend to be anything more than it is. (Sussman's
repeated use of C as inelegant and inexpressive got a
rise out of at least one audience member, who pointed out
afterwards that many intelligent folks like C and find it
both expressive and elegant. Sussman agreed that many
intelligent folks do, and acknowledged that there is room
for taste in such matters. But I suspect that he believes
that folks who believe such things are misguided or in
need of enlightenment. :-)
Finally Sussman showed a program in a language we all knew
was coming, Scheme. This Scheme program was beautiful
because it allows us to express the truth of the domain,
that states and differential states are computed by
functions that can be abstracted away, that states are
added and subtracted just like numbers. So, the operators
+ and — must be
generic across whatever value set we wish to compute over
at the time.
In Scheme, there is nothing special about +
or —. We can define them to mean what
they mean in the domain where we work. Some people don't
like this, because they fear that in redefining fundamental
operations we will make errors. And they are right! But
addition can be a fundamental operation in many domains with
many different meanings; why limit ourselves? Remember what
John Gribble
and
Robert Hass
told us: you have to take risks to create something beautiful.
This point expresses what seemed to be a fulcrum point
in Sussman's argument: Mathematics is a language,
not a set of tools. It is useful to us to the extent we
we can express the ideas that matter to us.
Then Sussman showed what many folks consider to be among
the most beautiful pieces of code ever written, if not the
most beautiful: Lisp's eval procedure written in
Lisp. This may be as close to
Maxwell's equations
in computer science as possible.
This is where Sussman got to the key insight of his talk,
the insight that has underlay much of his intellectual
contribution to our world:
There are some things we could not express until we invented
programming.
Here Sussman distinguished two kinds of knowledge about the
world, declarative knowledge and imperative knowledge.
Imperative knowledge is difficult to express clearly in an
ambiguous language, which all natural languages are. A
programming language lets us express such knowledge in a
fundamentally new way.
In particular, computer programs improve our ability to
teach students about procedural knowledge. Most every
computer science student has had the experience of getting
some tough idea only after successfully programming it.
Sussman went further to state baldly, "Research that doesn't
connect with students is a waste." To the extent that we
seek new knowledge to improve the world around us, we must
teach it to others, so I suppose that Sussman is correct.
Then Sussman clarified his key insight, distinguishing
computer programs from traditional mathematics. "Programming
forces one to be precise and formal, without being excessively
rigorous." I was glad that he then said more specifically
what he means here by 'formal' and 'rigorous'. Formality
refers to lack of ambiguity, while rigor referd to what a
particular expression entails. When we write a program, we
must be unambiguous, but we do not yet have to understand
the full implication of what we have written.
When we teach students a programming language, we are able
to have a conversation with them of the sort we couldn't
have before -- about any topic in which procedural knowledge
plays a central role. Instead of trying to teach students
to abstract general principles from the behavior of the
teacher, a form of induction, we can now give them a
discursive text that expresses the knowledge directly.
In order to participate in such a conversation, we need only
know a few computational ideas. One is the lambda calculus.
All that matters is that you have a uniform system for naming
things. "As anyone who has studied spirituality knows, if you
give a name to a spirit, you have power over it." So perhaps
the most powerful tool we can offer in computing is the ability
to construct languages quickly. (Use that to evaluate your
favorite programming language...)
Sussman liked the Hass lecture, too. "Mr. Hass thinks very
clearly. One thing I've learned is that all people, if they
are good at what they do, whatever their area -- they all
think alike." I suspect that this accounts for why many of
the OOPSLA crowd enjoyed the Hass lecture, even if they do
not think of themselves as literary or poetic; Hass was
speaking truths about creativity and beauty that computer
scientists know and live.
Sussman quoted two artists whose comments echoed his own
sentiment. First, Edgar Allan Poe from his 1846
The Philosophy of Composition:
... it will not be regarded as a breach of decorum on my
part to show the modus operandi by which some one of my
own works was put together. I select "The Raven" as most
generally known. It is my design to render it manifest
that no one point in its composition is referable either
to accident or intuition -- that the work proceeded step
by step, to its completion with the precision and rigid
consequence of a mathematical problem.
And then concert pianist James Boyk:
A work of art is a machine with an aesthetic purpose.
(I am uncomfortable with the impression these quotes
give, that artistic expression is mechanistic, though
I believe that artistic work depends deeply on craft
skills and unromantic practice.)
Sussman considers himself an engineer, not a scientist.
Science believes in a "talent theory" of knowledge, in
part because the sciences grew out of the upper classes,
which passed on a hereditary view of the world. On the
other hand, engineering favors a "skill theory" of knowledge;
knowledge and skill can be taught. Engineering derived
from craftsmen, who had to teach their apprentices in
order to construct major artifacts like cathedrals; if the
product won't be done in your lifetime, you need to pass
on the skills needed for others to complete the job!
The talk went on for a while thereafter, with Sussman
giving more examples of using programs as linguistic
expressions in electricity and mechanics and mathematics,
showing how a programming language enables us --
forces us -- to express a truth more formally
and more precisely than what our old mathematical and
natural languages did.
Just as most programmers have experienced the a-ha!
moment of understanding after having written a program
in an area we were struggling to learning, nearly every
teacher has had an experience with a student who has
unwittingly bumped into the wall at which computer
programming forces us to express an idea more precisely
than our muddled brain allows. Just today, one of my
harder-working students wrote me in an e-mail message,
"I'm pretty sure I understand what I want to do, but
I can't quite translate it into a program." I empathize
with his struggles, but the answer is: You probably
don't understand, or you would be able to write the
program. In this case, examination of the student's
code revealed the lack of understanding that manifests
itself in a program far more complex than the idea itself.
This was a good talk, one which went a long way toward
helping folks see just how important computer programming
is as an intellectual discipline, not just as a technology.
I think that one of the people who made a comment after the
talk said it well. Though the title of this talk was
"Why Programming is a Good Medium for Expressing Poorly
Understood and Sloppily Formulated Ideas", the point of
this talk is that, in expressing poorly-understood and
sloppily-formulated ideas in a computer program, we
come to understand them better. In expressing them,
we must eliminate our sloppiness and really understand
what we are doing. The heart of computing lies in the
computer program, and it embodies a new form of epistemology.
As always, OOPSLA has been a constant font of ideas.
But this year's OOPSLA seems to have triggered even
more than its usual share. I think that is a direct
result of the leadership of Dick Gabriel and Ralph
Johnson, who have been working for eighteen months
to create a coherent and focused program. As much as
I have already written this week -- and I know that
some of my articles have been quite long; sorry for
getting carried away... -- I have plenty of raw material
to keep me busy for a while, including the rest of the
Educators Symposium, Gerald Sussman's invited talk, my
favorite neologism of the week, and the event starting
as I type this: Grady Booch's conference-closing talk
on his ambitious project to build a handbook of
software architecture.
For now, I'd like to share just a few ideas from the
two panels I attended in the middle part of this fine
last day of OOPSLA.
The Echoes panel was aimed at exploring the echoes of
the structured design movement of the late 1970s. It
wasn't as entertaining or as earth-shaking as it might
have been given its
line-up of panelists,
but I took away two key points:
Kent Beck said that he recently re-read
Structured Design
and was amazed how much of the stuff we talk about
today is explained in that book. I remember reading
that book for the first time back in 1985, after
reading
Structured Analysis and System Specification
in my software engineering senior sequence. They
shaped how I thought about software construction.
I plan to re-read both books in the next year.
Grady Booch said that no one reads code, not like
folks in other disciplines read the literature of
their disciplines. And code is in many ways the
real literature that we are creating. I agree with
Grady and have long thought about how the CS courses
we teach could encourage students to read real
programs -- say, in operating systems, where students
can read Linux line by line if they want. Certainly,
I do this my compilers course, but not with a
non-trivial program. (Well, my programming languages
students usually read a non-trivial interpreter, a
Scheme interpreter written in Scheme modeled on
McCarthy's original Lisp interpreter. That program
is small but not trivial. It is the
Maxwell equations
of computing.)
I am going to think about how to work this idea
more concretely into the courses I teach in the next
year.
Like Echoes, the
Yoshimi Battles the Pink Robots
panel -- on the culture war between programmers and users
-- didn't knock my socks off, but Brian Foote was in
classic form. I don't think that he was cast in the
role of Yoshimi, but he defended the role of the
programmer qua programmer.
His position statement quoted Howard Roark, the
architect in Ayn Rand's
The Fountainhead:
"I don't build in order to have clients.
I have clients in order to build."
I immediately thought of a couple of plays
on the theme of this quote:
I don't teach to have students. I have students to teach.
I don't blog to have readers. I have readers to blog.
Brian played on words, too, but not Howard Roark's.
He read, in his best upper-crust British voice,
the lyrics of "I Write the Code", with no apologies
at all to
Barry Manilow.
I am hacker, and I write the code.
And this one was Just Plain Brian:
You know the thing that is most annoying about users
is that they have no appreciation for the glory, the
grandeur, or the majesty of living inside the code.
It is my cathedral.
Oh: on his way into the lecture to give his big talk,
Grady Booch
walked by, glanced at my iBook, and said, "Hey,
another Apple guy. Cool."
OOPSLA Day 5: Martin Fowler on Finding Good Design
Sadly... The last day of OOPSLA is here. It will be
a good day, including
Onward! Films
(or
Echoes
-- could I possibly skip a panel with Kent and so many
Big Names?) (later note: I didn't),
Lightning Talks
(or the
Programmers versus Users
panel) (later note: I am at this panel now), and finally,
of course,
Grady Booch.
But then it's over. And I'll be sad.
On to Martin or, as he would say, Mah-tin. Ralph Johnson
quoted
Brian Foote's
epigrammatic characterization of Martin: an intellectual
jackal with good taste in carrion. Soon, Ralph began
to read his official introduction of Martin, written by
... Brian. It was a play on the location of conference,
in Fashion Valley. In the fashion world, good design is
essential, and we know our favorite designers by one name:
Versace, Halston, Kent, Ward -- and Mah-tin. Martin lives
a life full of beautiful models, and he is "a pretty good
writer, for an Englishman".
On came Martin. He roamed the full stage, and then sat down
in a cushy chair.
When asked to keynote at a conference like OOPSLA, one is
flush with pride. Then you say 'yes', which is your first
mistake. What can you say? Keynoters are folks who make
great ideas, who invent important stuff. Guy's talks was
the best. But I'm not a creator or deep thinker, says...
I'm that guy who goes to a fashion show, steals the ideas
he sees, knocks off the clothing, and then mass-markets
them at the mall. I just want to know where we are, says
Martin; predicting the future is beyond me.
To shake things up, he called on
George Platts
to the stage. Those of you who have attended a
PLoP
conference know George as a "lateral thinking consultant"
and games leader. Earlier, Martin had asked him to
create a game for the whole crowd, designed to turn us
into intellectual jackals. For this game, George drew
his inspiration from the magnificent book
Life of Pi.
(Eugene says: If you have not read this book, do it.
Now.) George read a list of animal sounds from one page
in the book and told each of us to choose one. He then
told each of us to warm up by saying our own name in
that fashion. (I grunted "Eugene"). He then asked
everyone whose first name started with A to stand and
do it for the crowd. Then I and R; D, M, V; G, P, Y;
... and finally E, N, and W. Finally, the whole room
stood and hissed, grunted, growled "OOPSLA".
Back came Martin to the forefront, for the talk itself.
Martin's career is aimed at answering the question,
"What is good design?" He seeks an answer that is
more than just fuzzy words and fuzzy ideas.
At the beginning of his career, Martin was an EE. In
that discipline, designers drawing a diagram that
delineate a product and then passes it on to the
person who constructs the thing. So when Martin moved
on to software engineering, which had adopted this
approach. But soon he came to reject this approach.
Coding as construction fails. He found that designs
-- other people's design and his own -- always turned
out to be wrong. Eventually, he met folks he recognized
as good designers who design and code at the same
time. Martin came to see that the only way to
design well is to program at the same time, and the
only way to program well is to design at the same time.
That's the philosophy underlying all of Martin's work.
How do we characterize good designs? A set of principles.
One principle central to all good designs is to eliminate
duplication. He remembers when Kent told him this, but
at the time Martin dismissed it as not very deep. But
then he saw that there is much more to this than he first\
thought. It turns out that when you eliminate duplication,
your designs end up good, almost irrespective of anything
else. He noted that this has been pattern in his life:
see an important idea, dismiss it, and eventually come
around. (And then write a book about it. :-)
Another principle: orthogonality, the notion that different
parts of a system should do different kinds of things.
Another principle: separate the user interface from the
guts of the program. One way to approach this is to
imagine you have to add a new UI to your system. Any code
you would have to duplicate is in the wrong place.
Philosophy. Principles. What is the next P?
Patterns -- the finding of recurring structures. Martin
turned to Ralph Johnson, who has likened pattern authors
to Victorian biologists, who went off to investigate a
single something in great detail -- cataloging and
identifying and dissecting and classifying. You learn
a lot about the one thing, but you also learn something
bigger. Consider Darwin, who ultimately created the
theory of natural selection.
The patterns community is about finding that core
something which keeps popping in a slightly different
way all over the place. Martin does this in his work.
He then did a cool little human demonstration of one
of the patterns from his
Patterns of Enterprise Application Architecture,
an event queue. In identifying and naming the pattern,
he found so many nice results, including some unexpected
ones, like the ability to rewind and reply transactions.
Patterns people "surface" core ideas, chunk them up into
the right scale, and identify when and when not to use
them.
Why isn't the patterns community bigger? Martin thinks
it should be bigger, and in particular should be a
standard part of every academic's life! We academics
should go out, look at big old systems for a couple of
months, and try to make sense of them.
At the end of the session,
James Noble
pointed out two reasons why academic programmers don't
do this: they do not receive academic credit for such
activity, and they do not have access to the large
commercial systems that they really need to study. On
the first point, Martin agreed. This requires a shift
in the academic culture, which is hard to do. (This
issue of academic culture, publishing, and so on came
up again at the
Echoes panel
later in the morning.)
Martin volunteered to bellow in that direction whenever
and wherever asked. On the second point, he answered
with an emphatic 'yes!' Open source software opens a
new avenue for this sort of work...
Philosophy. Principles. Patterns. What is the last P?
Practices. His favorite is, of course, refactoring. He
remembers watching Kent Beck editing a piece of code of
Martin Fowler code. Kent kept making these small, trivial
changes to the code, but after each step Martin found
himself saying, "Hmm, that is better." The
lightbulb went off again.
He thanked John Brant and Don Roberts, Bill Opdyke and
Ralph Johnson, and Ward and Kent. It's easy to write
good books when other people have done the deep thinking.
He then pointed to
Mary Beth Rosson's
project that asks students to fixing code as a way to
learn. (Eugene thinks: But that's not refactoring,
right?) Refactoring is a good practice for students
as they learn. "Here is some code. Smell it. Come
back when it's better."
My students had better get ready...
Another practice that Martin lives and loves is test-driven
design. Of course,it embodies the philosophy he began
this talk with: You design and program at the same time.
And thus endeth the lesson.
In addition to the comment on academics and patterns,
James Noble asked another question. (Martin lamented,
"First I was Footed, and now I am Nobled." If you know
Foote and Noble, you can imagine why this prospect would
have a speaker a bit on edge.) James played it straight,
except for a bit of camera play with the mic and stage,
and pointed out that separating the UI ought causes an
increase in the total amount of code -- he claimed
50%. How is that better? Martin: I don't know. Folks
have certainly questioned this principle. But then, we
often increase duplication in order to make it go away;
maybe there is a similarity here?
Or, as Martin closed, maybe he is just wrong. If so, he'll
learn that soon enough.
In my entry on
Robert Hass's keynote address,
I discussed the juxtaposition of 'conservative' and
'creative', the tension between the desire to be safe
and the desire to be free, between memory and change.
Hass warned us against the danger inherent in seeking
safety, in preserving memory, to an extreme:
blindness to current reality. But he never
addressed the danger inherent in seeking freedom and
change to the exclusion of all else. I wrote:
There is a danger in safety, as it can blind us
to the value of change, can make us fear change.
This was one of the moments in which Hass surrendered
to a cheap political point, but I began to think
about the dangers inherent in the other side of the
equation, freedom. What sort of blindness does
freedom lead us to?
During a conversation about the talk with
Ryan Dixon,
it hit me. The danger inherent in seeking freedom and
change to an extreme untethered idealism.
Instead of "Ah, the good old days!", we have, "The world
would be great if only...". When we don't show proper
respect to memory and safety, we become blind in a
different way -- to the fact that the world can't be the
way it is in our dreams, that reality precludes somehow
our vision.
That doesn't sound so bad, but people sometimes forget
not to include other people in their ideal view. We
sometimes become so convinced by our own idealism that
we feel a need to project it onto others, regardless of
their own desires. This sort of blindness begins to
look in practice an awful lot like the blindness of
overemphasizing safety and memory.
Of course, when discussing creative habits, we need to
be careful not to censor ourselves prematurely. As we
discussed at
Extravagaria,
most people tend toward one extreme. They need
encouragement to overcome their fears of failure and
inadequacy. But that doesn't mean that we can divorce
ourselves from reality, from human nature, from the
limits of the world. Creativity, as Hass himself told
us, thrives when it bumps into boundaries.
Being creative means balancing our desire for safety
and freedom. Straying too far in either way may work
in the short term, but after too long in either land we
lose something essential to the creative process.
OOPSLA Day 4: Mary Beth Rosson on the End of Users
As you've read here in the past, I am one of a growing
number of CS folks who believe that we must expand the
purview of computer science education far beyond the
education of computer scientists and software developers.
Indeed, our most important task may well lie in the
education of the rest of the educated world -- the
biologists and sociologists, the economists and physicists,
the artists and chemists and political scientists whose
mode of work has been fundamentally altered by the
aggregation of huge stores of data and the creation of
tools for exploring data and building models. The
future of greatest interest belongs not to software
development shops but to the folks doing real work in
real domains.
So you won't be surprised to know how excited I was to come
to Mary Beth Rosson's
Onward! keynote address
called "The End of Users".
Mary Beth
has been an influential researcher across a broad spectrum
of problems in OOP, HCI, software design, and end-user
programming, all of which have had prominent places at
OOPSLA over the years. The common theme to her work is
how people relate to technology, and her methodology has
always had a strong empirical flavor -- watching "users"
of various stripes and learning from their practice how
to better support them.
In today's talk, Mary Beth argued that the relationship
between software developers and software users is changing.
In the old days, we talked about "end-user programming",
those programming-like activities done by those without
formal training in programming. In this paradigm, end
users identify requirements on programs and then developers
produce software to meet the need. This cycle occurs at
a relatively large granularity, over a relatively long
time line.
But the world is changing. We now find users operating in
increasingly complex contexts. In the course of doing their
work, they frequently run into ad hoc problems for their
software to solve. They want to integrate pieces of solution
across multiple tools, customize their applications for
specific scenarios, and appropriate data and techniques
from other tools. In this new world, developers must produce
components that can be used in an ad hoc fashion, integrated
across apps. Software developers must create knowledge bases
and construction kits that support an interconnected body of
problems. (Maybe the developers even strive to respond on
demand...)
These are not users in the traditional sense. We might call
them "power users", but that phrase is already shop-worn.
Mary Beth is trying out a new label: use developers.
She isn't sure whether this label is the long-term solution,
but at least this name recognizes that users are playing an
increasingly sophisticated role that looks more and more like
programming.
What sorts of non-trivial tasks do use developers do?
An example scenario: a Word user redefining the 'normal'
document style. This is a powerful tool with big potential
costs if done wrong.
Another scenario: an Excel user creates a large spreadsheet
that embodies -- hides! -- a massive amount of computation.
(Mary Beth's specific example was a grades spreadsheet.
She is a CS professor after all!)
Yet another: an SPSS defines new variables and toggles
between textual programming and graphical programming.
And yet another: a FrontPage user does visual programming
of a web page, with full access to an Access database --
and designs a database!
Mary Beth summarized the characteristics of use developers as:
comfortable with a diverse array of software apps
and data sources
work with them multiple apps in parallel and so want to
pick and choose among functionality at any time, hooking
components up and configuring custom solutions on demand.
working collaboratively, with group behaviors emerging
see the computer as a tool, not an end; it should not get
in their way
Creating use developers has potential economic benefits (more
and quicker cycles getting work done) and personal benefits
(more power, more versatility, higher degree of satisfaction).
But is the idea of a use developer good?
Mary Beth quoted an IEEE Software editor whose was
quite dismissive of end users. He warned that they do not
systematically test their work, that they don't know to think
about data security and maintainability, and -- when they do
know to think about these issues -- they don't know *how* to
think about them. Mary Beth thinks these concerns are
representative of what folks in the software world and that
we need to be attentive to them.
(Personally, I think that, while we certainly should be
concerned about the quality of the software produced by end
users, we also must keep in mind that software engineers have
a vested interested in protecting the notion that only
Software Engineers, properly trained and using Methods
Anointed From On High are capable of delivering software
of value. We all know of complaints from the traditional
software engineering community about agile software
development methods, even when the folks implementing and
using agile methods are trained in computing and are,
presumably, qualified to make important decisions about the
environment in which we make software.)
Mary Beth gave an example to illustrate the potential cost
inherent in the lack of dependability -- a Fannie Mae
spreadsheet that contained a $1.2B error.
As the base of potential use developers grows so do the
potential problems. Consider just the spreadsheet and
database markets... By 2012, the US Department of Labor
estimates that there will be 55M end users. 90% of all
spreadsheets contain errors. (Yes, but is that worse or
better than in programs written by professional
software developments?) The potential costs are not just
monetary; they can be related to the quality of life we
all experience. Such problems can be annoying and ubiquitous:
web input forms with browser incompatibilities; overactive
spam filters that lose our mail; Word styles that break
the other formatting in user documents; and policy decisions
based on research findings that themselves are based on
faulty analysis due to errors in spreadsheets and small
databases.
Who is responsible for addressing these issues? Both!
Certainly, end users must take on the responsibility of
developing new habits and learning the skills they need
to use their tools effectively and safely. But we in the
software world need to recognize our responsibilities:
to build better tools, to build the scaffolding users
need to be effective and safe users. The
tools we build should offer the right amount of help
to users who are in the moment of doing their jobs.
to promote a "quality assurance" culture among users.
We need to develop and implement new standards for
computing literacy courses.
How do we build better tools?
Mary Beth called them smarter tools and pointed
to a couple of the challenges we must address. First,
much of the computation being done in tools is invisible,
that is, hidden by the user interface. Second, people do
not want to be interrupted while doing their work! (We
programmers don't want that; why should our users have
to put up with it?)
Two approaches that offer promise are interactive
visualization of data and minimalism. By minimalism, she
means not expanding the set of issues that the user has
concern herself with by, say, integrating testing and
debugging into the standard usage model.
The NSF is supporting a five-school consortium called
EUSES,
End Users Shaping Effective Software,
who are trying these ideas out in tool and experiment.
Some examples of their work:
CLICKS is a drag-and-drop, design-oriented web
development environment.
Whyline
is a help system integrated directly into Alice's user
environment. The help system monitors the state of the
user's program and maintains a dynamic menu of problems
they may run into.
WYSIWYT
is a JUnit-style interface for debugging spreadsheets,
in which the system keeps an eye on what cells have and
have not been verified with tests.
How can we promote a culture of quality assurance? What is
the cost-benefit trade-off involved for the users? For
society?
Mary Beth indicated three broad themes we can build on:
K-12 education: making quality a part of schoolchildren's
culture of computer use
universal access: creating tools aimed at specific
populations of users
communities of practice: evolving reflective practices
within the social networks of users
Some specific examples:
Youngsters who learn by debugging in Alice. This is
ongoing work by Mary Beth's group. Children play in
3D worlds that are broken, and as they play the child
users are invited to fix the system as they play. You
may recognize this as the
Fixer Upper
pedagogical pattern, but in a "non-programming"
programming context.
Debugging tools that appeal to women. Research shows
that women take debugging seriously, but they tend to
use strategies in their heads more than the tools
available in the typical spreadsheet and word
processing systems. How do we invite women with lower
self-confidence to avail themselves of system tools?
One experimental tool does this by letting users
indicate "not sure" when evaluating correctness of a
spreadsheet cell formula.
Pair programming community simulations. One group has
has a Sim City-like world in which a senior citizen
"pair programs" with a child. Leaving the users
unconstrained led to degeneration, but casting the
elders as object designers and the children as builders
led to coherent creations.
Sharing and reuse in a teacher community. The Teacher
Bridge project has created a collaborative software
construction tool to support an existing teacher
community. The tool has been used by several groups,
including the one that created
PandapasPond.org.
This tool combines a wiki model for its dynamic "web
editor" and more traditional model for its static design
tool (the "folder editor"). Underneath the service,
the system can track user activity in a variety of ways,
which allows us to explore the social connections that
develop within the user community over time.
The talk closed with a reminder that we are just beginning
the transition from thinking of "end users" to thinking of
"use developers", and one of our explicit goals should be
to try to maximize the upside, and minimize the downside,
of the world that will result.
For the first time in a long time, I got up to ask a
question after one of the big talks. Getting up to stand
in line at an aisle mic in a large lecture hall, to ask a
question in front of several hundred folks, seems a rather
presumptuous act. But my interest in this issue is growing
rapidly, and Mary Beth has struck on several issues close
to my current thinking.
My question was this: What should university
educators be thinking about with regard to this transition?
Mary Beth's answer went in a way I didn't anticipate: We
should be thinking about how to help users develop the
metacognitive skills that software developers learn within
our culture of practice. We should extend cultural literacy
curricula to focus on the sort of reflective habits and skills
that users need to have when building models. "Do I know
what's going on? What could be going wrong? What kinds of
errors should I be watching for? How can I squeeze errors
out of my program?"
After the talk, I spent a few minutes discussing curricula
issues more specifically. I told her about our interest
in reaching out to new populations of students, with the
particular example of a testing certificate that folks in
my department are beginning to work on. This certificate
will target non-CS students, the idea being that many non-CS
students end up working as testers in software development for
their domain, yet they don't understand software or testing
or much anything about computing very deeply. This certificate
is still aimed at traditional software development houses,
though I think it will bear the seeds of teaching non-programmers
to think about testing and software quality. If these folks
ever end up making a spreadsheet or customizing Word, the
skills they learn here will transfer directly.
Ultimately, I see some CS departments expanding their computer
literacy courses, and general education courses, to aim at
use developers. Our courses should treat them with the same
care and respect as we treat Programmers and Computer Scientists.
The tasks users do are important, and these folks deserve tools
of comparable quality.
Three major talks, three home runs. OOPSLA 2005 is hot.
I am nobody:
A red sinking autumn sun
Took my name away.
-- Richard Wright
As I
noted before,
I nearly blew off Sunday, after a long and tiring two days
before. As you might have gathered from that same entry,
I am happy that I did not. The reasons should be obvious
enough: cool ideas happen for me only when I am engaged
with ideas, and the people and interactions at
Extravagaria
were a source of inspiration that has remained alive with
me throughout the rest of the conference.
In the afternoon of the workshop, we did two group exercises
to explore issues in creativity -- one in the realm of
writing poetry, and one in the realm of software design.
Gang-Writing Haiku
Haiku
is a simple poetic form that most of us learn as schoolchildren.
It is generally more involved than we learn in school, with
specific expectations on the content of the poems, but at its
simplest it is a form of three lines, consisting of 5, 7, and
5 syllables, respectively.
If I understood correctly, a
tonka
is a poem constructed by following a haiku with a couplet
in which line is 7 syllables. We can go a step further yet,
by connecting a sequence of tonkas into a
renga.
John called the renga the "stretch limo" of haiku. Apparently,
the Japanese have a traditional drinking game that requires
each person to write a verse of a growing renga in turn,
taking a drink with each verse. The poems may degenerate,
but the evening is probably not a complete loss...
Our first exercise after lunch was a variation of this
drinking game, only without the drinking. We replaced the
adult beverages with two features intended to encourage
and test our creativity. First, we were given one minute
or less to write each verse. Second, when we passed the
growing poem on to the next writer, we folded it over so
that the person could see only the verse we had just written.
Rather than start with scratch, John seeded our efforts with
haiku written by the accomplished American novelist Richard
Wright. In the last eighteen months of his life, Wright
became obsessed with haiku, writing dozens a day. Many of
these works were published in a collection after his death.
John gave each of person a haiku from this collection. One
of them, my favorite, appears at the top of this essay.
Then we were off, gang-writing poetry. My group consisted
of Brian Foote, Joe Yoder, Danny Dig, Guy Steele, and me.
Each of us started with a Wright haiku, wrote a couplet in
response to it, folded Wright's stanza under, and passed the
extended poem on to continue the cycle. After a few minutes,
we had five renga. (And yet we were sober, though the quality
of the poetry may not have reflected that. :-)
The second step of the exercise was to select our favorite,
the one we thought had the highest quality. My group opted
for a two-pass process. Each of us cast a vote for our two
favorites, and the group then deliberated over the the top
two vote-getters. We then had the opportunity to revise
our selection before sharing it with the larger group. (We
didn't.) Then each of the groups read its best product to
the whole group.
My group selected the near-renga we called
Syzygy Matters
(link to follow)
as our best. This was not one of my two favorites, but it
was certainly in line with my choices. One poem I voted
for received only my vote, but I won't concede that it
wasn't one of our best. I call it
Seasons Cease.
Afterwards, we discussed the process and the role creativity
played.
Most of us tried to build on the preceding stanza,
rather than undo it.
This exercise resembles a common technique in
improvisational theater. There, the group goes through
rounds of one sentence per person, building on the
preceding sentences. Sometimes, the participants
cycle through these conjunctions in order: "Yes, and...",
"No, and...", "Yes, but...", and "No, but...".
Time pressure matters.
Personally, I noticed that by moving so fast that I
had no chance to clear my mind completely, a theme
developed in my mind that carried over from renga to
renga. So my stanzas were shaped both by the stanza
I was handed and by the stanza I wrote in the previous
round.
Guy was optimistic about the process but pessimistic
about the products. The experience lowered his
expectations for the prospects for groups writing
software by global emergence from local rules.
We all had a reluctance to revise our selected poems.
The group censored itself, perhaps out of fear of
offending whoever had written the lines. (So much
for Common Code Ownership.) Someone suggested that
we might try some similar ideas for the revision
process. Pass all the poems we generated to another
group, which would choose the best of the litter.
Then we pass the poem on to a third group, which is
charged with revising the poem to make it better.
This would eliminate the group censorship effect
mentioned above, and it would also eliminate the
possibility that our selection process was biased
by personal triggers and fondness.
Someone joked that we should cut the first stanza,
the one written by Wright!, because it didn't fit
the style of the rest of the stanzas. Joke aside,
this is often a good idea. Often, we need to let
go of the triggers that initially caused us to write.
That can be true in our code, as well. Sometimes
a class that appears early in a program ultimately
outlives its utility, its responsibilities distributed
across other more vital objects. We shouldn't be
afraid of cutting the class,but sometimes we hold
an inordinate attachment to the idea of the class.
To some, this exercise felt more like a white-board
design session than a coding exercise. We placed
a high threshold on revisions, as we often do for
group brainstorm designs.
Someone else compared this to design by committee,
and to the strategy of separating the coding team
from the QA team.
Later, we discussed how, in technical writing and other
non-fiction, our goal is to make the words we use match
the truth as much as possible, but sometimes an exaggeration
can convey truth even better. Is such an exaggeration
"more true" than the reality, by conveying better the
feel of a situation than pure facts would have? Dick
used the re-entry season from
Apollo 13
as an example.
(Aside: This led to a side discussion of how
watching a movie without listening to its soundtrack
is usually avery different experience. Indeed, most
directors these days use the music as an essential
story-telling device. What if life were like that?
Dick offered that perhaps we are embarking on a new
era in which the personal MP3 player does just that,
adding a soundtrack to our lives for our own personal
consumption.)
A good story tells the truth better than the truth
itself. This is true in mathematical proofs, where
the proof tells a story quite different from the actual
process by which a new finding is reached. It is true
of papers on software system designs, of software
patterns. this is yet another way in which software
and computer science are like poetry and Mark Twain.
A Team Experiment with Software Design
The second exercise of the afternoon asked four "teams"
-- three of size four, and the fourth being Guy Steele
alone -- to design a program that could generate
interesting Sudoku puzzles. Half way through our hour,
two teams cross-pollinated in a Gabriel-driven episode
of crossover.
I don't have quite as much to save about this exercise.
It was fun thinking about Sudoku, a puzzle I've started
playing a bit in the last few weeks. It was fun watching
working with Sudoku naifs wrap their games around the
possibilities of the game. It was especially fun to watch
a truly keen mind describe how he attacked and solved
a tough problem. (I saved Guy's handwritten draft of his
algorithm. I may try to implement it later. I feel like
a rock star groupie...)
The debrief of this exercise focused on whether this
process felt creative in the sense that writing haiku
did, or was it more like the algorithm design exercise
one might solve on a grad school exam, taken from Knuth.
Guy pointed out that these are not disjoint propositions.
What feels creative is solving something we don't yet
understand -- creativity lies in exploring what do not
understand, yet. For example, writing a Sudoku solver
would have involved little or no creativity for most of
us, because it would be so similar to backtracking
programs we have written before, say, to solve the
8-queens puzzle.
In many ways, these exercises aren't representative of
literary creativity, in several significant ways. Most
writers work solo, rather than in groups. Creators may
work under pressure, but not often in 1-minute compressions.
But sprints of this sort can help jolt creativity, and
they can expose us to models of work,models we can adopt
and adapt.
One thing seems certain: Change begets creativity.
Robert Hass
spoke of the constant and the variable, and how -- while
both are essential to creativity -- it is change and
difficulty that are usually the proximate causes of
the creative act. That's why cross-pollination of teams
(e.g., pair programmers) works, and why we should switch
tools and environments every so often, to jog the mind
to open itself to creating something new.
With
Dick Gabriel
and
Ralph Johnson
leading OOPSLA this year, none of us were that the themes
of the conference were creativity and discovery. This
theme presented itself immediately in the conference's
opening keynote speaker, former poet laureate
Robert Hass.
He gave a marvelous talk on creativity.
Hass began his presentation by reading a poem (whose name
I missed) from Dick's new chapbook,
Drive On.
Bob was one of Dick's early teachers, and he clearly reveled
in the lyricism, the rhythm of the poem. Teachers often form
close bonds with their students, however long or short the
teaching relationship. I know the feeling from both sides
of the phenomenon.
He then described his initial panic at thought of introducing
the topic of creativity to a thousand people who develop
software -- who create, but in a domain so far from his
expertise. But a scholar can find ways to understand and
transmit ideas of value wherever they live, and Hass is
not only a poet but a first-rate scholar.
Charles Dickens burst on scene with publication of
The Pickwick Papers.
With this novel, Dickens essentially invented the genre of
the magazine-serialized novel. When asked how he created
a new genre of literature, he said simply, "I thought of
Pickwick."
I was immediately reminded of something John Gribble said
in his talk at
Extravagaria
on Sunday: Inspiration comes to those already involved
in the work.
Creativity seems to happen almost with cause. Hass consulted
with friends who have created interesting results. One solved
a math problem thought unsolvable by reading the literature
and "seeing" the answer. Another claimed to have resolved
the two toughest puzzles in his professional career by going
to sleep and waking up with the answer.
So Hass offered his first suggestion for how to be creative:
Go to sleep.
Human beings were the first animals to trade instinct for
learning. The first major product of our learning was our
tools. We made tools that reflected what we learned about
solving immediate problems we faced in life. These tools
embodied the patterns we observed in our universe.
We then moved on to broader forms of patterns: story, song,
and dance. These were,according to Hass, the original forms
of information storage and retrieval, the first memory
technologies. Eventually, though, we created a new tool,
the printing press, that made these fundamentally less
essential -- less important!? And now the folks in this room
contribute to the ultimate tool, the computer, that in many
ways obsoletes human memory technology. As a result, advances
in human memory tech have slowed, nearly ceased.
The bulk of Hass's presentation explored the interplay between
the conservative in us (to desire to preserve in memory) and the
creative in us (the desire to create anew). This juxtaposition
of 'conservative' and 'creative' begets a temptation for cheap
political shots, to which even Hass himself surrendered at
least twice. But the juxtaposition is essential, and Hass's
presentation repeatedly showed the value and human imperative
for both.
Evolutionary creativity depends on the presence having a
constant part and a variable part, for example, the mix of
same and different in an animal's body, in the environment.
The simultaneous presence of constant and variable is the basis
of man's physical life. It is also the basis of our psychic
life. We all want security and freedom, in an unending cycle
Indeed, I believe that most of us want both all the time,
at the same time. Conservative and creative, constant and
variable -- we want and need both.
Humans have a fundamental desire for individuation, even while
still feeling a oneness with our mothers, our mentors, the
sources of our lives. Inspiration, in a way, is how a person
comes to be herself -- is in part a process of separation.
"Once upon a time" is linguistic symbol, the first step of
the our separation from the immediate action of reading into
a created world.
At the same time, we want to be safe and close to, free and
faraway. Union and individuation. Remembering and changing.
Most of us think that most everyone else is more creative than
we are. This is a form of the fear John Gribble spoke about
on Sunday, one of the blocks we must learn to eliminate from
our minds -- or at least fool ourselves into ignoring. (I
am reminded of John Nash choosing to ignore the people his
mind fabricates around him in
A Beautiful Mind.)
Hass then told a story about the siren song from
The Odyssey.
It turns out that most of the stories in Homer's epics are
based in "bear stories" much older than Homer. Anyway,
Odysseus's encounter with the sirens is part of a story
of innovation and return, freedom on the journey followed
by a return to restore safety at home. Odysseus exhibits
the creativity of an epic hero: he ties himself to the mast
so that he can hear the sirens' song without having to take
ship so close to the rocks.
According to Hass, in some versions of the siren story, the
sirens couldn't sing -- the song was only a sailors' legend.
But they desire to hear the beautiful song, if it exists.
Odysseus took a path that allowed him both safety and freedom,
without giving up his desire.
In preparing for this talk,hass asked himself, "Why should
I talk to you about creativity? Why think about it all?"
He identified at least four very good reasons, the desire
to answer these questions:
How can we cultivate creativity in ourselves?
How can we cultivate creativity in our children?
How can we identify creative people?
How can we create environments that foster creativity?
So he went off to study what we know about creativity.
A scholar does research.
Creativity research in the US began when academic psychologists
began trying to measure mental characteristics. Much of this
work was done at the request of the military. As time went
by, the number of characteristics, perhaps in correlation of
research grants awarded by the government. Creativity is,
perhaps, correlated with salesmanship. :-) Eventually, we
had found several important characteristics, including that
there is little or no correlation between IQ and creativity.
Creativity is not a province of the intellectually gifted.
Hass cited the research of Howard Gardner and Mihaly
Csikszentmihalyi
(remember him?),
both of whom worked to identify key features of the moment
of a creative change, say, when Dickens thought to publish
a novel in serial form. The key seems to be immersion in a
domain, a fascination with domain and its problem and
possibilities. The creative person learns the language
of the domain and sees something new. Creative
people are not problems solvers but problem
finders.
I am not surprised to find language at the center of creativity!
I am also not surprised to know that creative people find
problems. I think we can save something even stronger, that
creative people often create their own problems to
solve. This is one of the characteristics that biases me
away from creativity: I am a solver more than a finder. But
thinking explicitly about this may enable me to seek ways to
find and create problems.
That is, as Hass pointed out earlier, one of the reasons for
thinking about creativity: ways to make ourselves more
creative. But we can use the same ideas to help our children
learn the
creative habit,
and to help create institutions that foster the creative act.
He mentioned OOPSLA as a social construct in the domain of
software that excels at fostering creative. It's why we all
keep coming back. How can we repeat the process?
Hass spoke more about important features of domains. For
instance, it seems matter how clear the rules of the domain
are at the point that a person enters it. Darwin is a great
example. He embarked on his studies at a time when the rules
of his domain had just become fuzzy again. Geology had recently
expanded European science's understanding of the timeline of
the earth;
Linnaeus
had recently invented his taxonomy of organisms. So, some of
the knowledge Darwin needed was in place, but other parts of
the domain were wide open.
The technology of memory is a technology of safety. What are
the technologies of freedom?
Hass read us a funny poem on story telling. The story teller
was relating a myth of his people. When his listener questioned
an inconsistency in his story, the story teller says, "You know,
when I was a child, I used to wonder that..." Later, the
listener asked the same question again, and again, and each
time the story teller says, "You know, when I was a child, I
used to wonder that..." When he was a child, he questioned the
stories, but as he grew older -- and presumably wiser -- he
came to accept the stories as they were, to retell them
without question.
We continue to tell our stories for their comfort. They make
us feel safe.
They is a danger in safety, as it can blind us to the value of
change, can make us fear change. This was one of the
moments in which Hass surrendered to a cheap political point,
but I began to think about the dangers inherent in the other
side of the equation, freedom. What sort of blindness does
freedom lead us to?
Software people and poets have something in common, in the
realm of creativity: We both fall in love with patterns,
with the interplay between the constant and the variable,
with infinite permutation. In computing, we have the variable
and the value, the function and the parameter, the framework
and the plug-in. We extend and refactor, exposing the constant
and the variable in our problem domains.
Hass repeated an old joke, "Spit straight up and learn something."
We laugh, a mockery of people stuck in same old patterns. This
hit me right where I live. Yesterday at the
closing panel
of the Educators' Symposium,
Joe Bergin
said something that I
wrote about
a while back: CS educators are an extremely conservative
lot. I have something to say about that panel, soon...
First safety, then freedom -- and with it the power to innovate.
Of course, extreme danger, pressure, insecurity can also be
the necessity that leads to the creative act. As is often
the case, opposites turn out to be true. As Thomas Mann said,
A great truth is a truth whose opposite is also a great truth.
Hass reminds us that there is agony in creativity -- a pain
at stuckness, found in engagement with the world. Pain is
unlike pleasure, which is homeostatic ("a beer and ballgame").
Agony is dynamic, ceasing to cling to safe position. There
is always an element of anxiety, consciousness heightened at
the moment of insight, gestalt in face of incomplete pattern.
The audience asked a couple of questions:
Did he consult only men in his study of creativity?
Yes, all but his wife, who is also a poet. She said,
"Tell them to have their own strangest thoughts."
What a great line.
Is creativity unlimited? Limitation is essential to
creativity. If our work never hits an obstacle, then
we don't know when it's over. (Sounds like test-driven
development.) Creativity is always bouncing up against
a limit.
I'll close my report with how Hass closed the main part of
his talk. He reached "the whole point of his talk" -- a
sonnet by Michelangelo -- and he didn't have it in his notes!!
So Hass told us the story in paraphrase:
The pain is unbearable, paint dripping in my face, I climb
down to look at it, and it's horrible, I hate it, I am no
painter...
It was the ceiling of the Sistine Chapel.
~~~~~
UPDATE (10/20/05):
Thanks again
to Google, I have tracked down the
sonnet
that Hass wanted to read. I especially love the ending:
Defend my labor's cause,
good Giovanni, from all strictures:
I live in hell and paint its pictures.
-- Michelangelo Buonarroti
I have felt this way about a program before. Many times.
This was my
second consecutive year
to chair the OOPSLA
Educators' Symposium,
and my goal was something more down to earth yet similar
in flavor: encouraging educators to consider Big Change.
Most of our discussions in CS education are about how
to do the Same Old Thing better, but I think that we
have run the course with incremental improvements to our
traditional approaches.
We opened the day with a demonstration called Agile
Apprenticeship in Academia, wherein two professors
and several students used a theatrical performance to
illustrate a week in a curriculum built almost entirely
on software apprenticeship. Dave West and Pam Rostal
wanted to have a program for developing software developers,
and they didn't think that the traditional CS curriculum
could do the job. So they made a Big Change: they tossed
the old curriculum and created a four-year studio program
in which students, mentors, and faculty work together to
create software and, in the process, students learn how
to do create software.
West and Rostal defined a set of 360 competencies that
students could satisfy at five different levels. Students
qualify to graduate from the program by satisfying each
competency at at least the third level (the ability to
apply the concept in a novel situation) and some number
at higher levels. Students also have to complete the
standard general education curriculum of the university.
Thinking back to yesterday's
morning session at Extravagaria,
we talked the role of fear and pressure in creativity.
West and Rostal put any fear behind them and acted on
their dream. Whatever difficulties they face in making
this idea work over the long run in a broader setting --
and I believe that the approach faces serious challenges
-- at least they have taken a big step forward could
make something work. Those of us who don't take any
big steps forward are doomed to remain close to where
we are.
I don't have much to say about the paper sessions of
the day except that I noticed a recurring theme:
New ideas are hard on instructors. I agree, but I
do not think that they are hard in the NP-hard sense
but rather in the "we've never done it that way before"
sense. Unfamiliarity makes things seem hard at first.
For example, I think that the biggest adjustment most
professors need to make in order to move to the sort
of studio approach advocated by West and ROstal is
from highly-scripted lectures and controlled instructional
episodes to extemporaneous lecturing in response to
student needs in real-time. The real hardness in this
is that faculty must have a deep, deep understanding
of the material they teach -- which requires a level
of experience doing that many faculty don't
yet have.
This idea of professors as practitioners, as professionals
practiced in the art and science we teach, will return
in later entries from this conference...
Like yesterday's entry, I'll have more to say about
today's Educators' Symposium in upcoming entries. I
need some time to collect my thoughts and to write.
In particular, I'd like to tell you about
Ward Cunningham's keynote address
and our
closing panel
on the future of CS education. The panel was especially
energizing but troubling at the same time, and I hope
to share a sense of both my optimism and my misgivings.
But with the symposium over, I can now take the rest of
the evening to relax, then sleep, have a nice longer
run, and return to the first day of OOPSLA proper
free to engage ideas with no outside encumbrances.
OOPSLA
has arrived, or perhaps I have arrived at OOPSLA.
I almost blew today off, for rest and a run and work
in my room. Some wouldn't have blamed me after
yesterday, which began at 4:42 AM with a call from
Northwest Airlines that my 7:05 AM flight had been
cancelled, included my airline pilot missing the
runway on his first pass at the San Diego airport,
and ended standing in line for two hours to register
at my hotel. But I dragged myself out of my room --
in part out of a sense of obligation to having been
invited to participate, and in part out of a schoolboy
sense of propriety that I really ought to go
to the events at my conferences and make good use of
my travels.
My event for the day was an
all-day workshop
called
Extravagaria III: Hunting Creativity.
As its title reveals, this workshop was the third
in a series of workshops initiated by
Richard Gabriel
a few years ago. Richard is motivated by the belief
that computer science is in the doldrums, that what
we are doing now is mostly routine and boring, and that
we need a jolt of creativity to take the next Big Step.
We need to learn how to write "very large-scale programs",
but the way we train computer scientists, especially
Ph.D. students and faculty, enforce a remarkable
conservatism in problem selection and approach.
The Extravagaria workshops aim to explore creativity
in the arts and sciences, in an effort to understand
better what we mean by creativity and perhaps better
"do it" in computer science.
The workshop started with introductions, as so many do,
but I liked the twist that Richard tossed in: each of
us was to tell what was the first program we ever
wrote out of passion. This would reveal
something about each of us to one another, and also
perhaps recall the same passion within each storyteller.
My first thought was of a program I wrote as a high school
junior, in a BASIC programming course that was my first
exposure to computers and programs. We wrote all the
standard introductory programs of the day, but I was
enraptured with the idea of writing a program to compute
ratings for chessplayers following the
Elo system
used for chessplayers. This was much more complex than
the toy problems I solved in class, requiring input in
the form of player ratings and a crosstable showing results
of games among the players and output in the form of
updated ratings for each player. It also introduced new
sorts of issues, such as using text files to save state
between runs and -- even more interesting to me -- the
generation of an initial set of ratings through a mechanism
of successive approximations, process that may never quite
converge unless we specified an epsilon larger than 0.
I ultimately wrote a program of several hundred lines,
a couple of orders of magnitude larger than anything I
had written before. And I cared deeply about my program,
the problem it solved, and its usefulness to real people.
I enjoyed everyone else's stories, too. They reminded us
all about the varied sources of passion, and how a solving
a problem can open our eyes to a new world for us to
explore. I was pleased by the diversity of our lot, which
included workshop co-organizer John Gribble, a poet friend
of Richard's who has never written a program;
Rebecca Rikner,
the graphic artist who designed the wonderful motif for
Richard's book
Writers' Workshops and the Work of Making Things,
and Guy Steele, one of the best computer scientists
around. The rest of us were computer science and software
types, including one of my favorite bloggers,
Nat Pryce.
Richard's first passionate program was perhaps a program
to generate "made-up words" from some simple rules, to use
in naming his rock-and-roll-band. Guy offered three
representative, if not first, programs: a Lisp interpreter
written in assembly language, a free verse generator
written in APL, and low chart generator written in RPG.
This wasn't the last mention of APL today, which is often
the sign of a good day.
Our morning was built around an essay written by John
Gribble for the occasion, called "Permission, Pressure,
and the Creative Process". John read his essay, while
occasionally allowing us in the audience to comment on
his remarks or previous comments. John offered as axioms
two beliefs that I share with him:
that all people are creative, that is, possess the
potential to act creatively, and
that there is no difference of kind between creativity
in the arts and creativity in the sciences.
What the arts perhaps offer scientists is the history and
culture of examining the creative process. We scientists
and other analytical folks tend to focus on product,
often to the detriment of how well we understand how we
create them.
John quoted Stephen King from his book
On Writing,
that the creator's job is not to find good ideas
but to recognize them when they come along.
For me, this idea foreshadows
Ward Cunningham's keynote address
at tomorrow's
Educators' Symposium.
Ward will speak on "nurturing the feeble simplicity",
on recognizing the seeds of great ideas despite their
humility and nurturing them into greatness. As Brian
Foote pointed out later in the morning, this sort of
connection is what makes conferences like OOPSLA so
valuable and fun -- plunk yourself down into an idea-rich
environment, soak in good ideas from good minds, and your
own mind has the raw material it needs to make connections.
That's a big part of creativity!
John went on to assert that creativity isn't rare, but
rather so common that we are oblivious to it. What is
rare is for people to act on their inspirations.
Why do we not act? We have so low an opinion of our
selves that we figure the inspiration isn't good enough
or that we can't do it justice in our execution. Another
reason: We fear to fail, or to look bad in front of
our friends and colleagues. We are self-conscious,
and the self gets in the way of the creative act.
Most people, John believes, needpermission to act creatively. Most of us
need external permission and approval to act, from friends
or colleagues, peers or mentors. This struck an immediate
chord with me in three different relationships: student
and teacher, child and parent, and spouse and spouse.
The discussion in our workshop focused on the need to
receive permission, but my immediate thought was
of my role as potential giver of permission. My
students are creative, but most of them need me to give
them permission to create. They are afraid of bad grades
and of disappointing me as their instructor; they are
self-conscious, as going through adolescence and our
school systems tend to make them. My young daughters
began life unself-conscious, but so much of their lives
are about bumping into boundaries and being told "Don't
do that." I suspect that children grow up most creative
in an environment where they have permission to create.
(Note that this is orthogonal to the issue of discipline
or structure; more on that later.) Finally, just as I
find myself needing my wife's permission to do and act
-- not in the henpecked husband caricature, but in the
sense of really caring about what she thinks -- she
almost certainly feels the need for *my* permission.
I don't know why this sense that I need to be a better
giver of permission grew up so strong so quickly today,
but it seemed like a revelation. Perhaps I can change
my own behavior to help those around me feel like they
can create what they want and need to create. I suspect
that, in loosing the restrictions I project onto others,
I will probably free myself to create, too.
When author Donald Ritchie is asked how to start writing,
he says, "First, pick up your pencil..." He's not being
facetious. If you wait for inspiration to begin, then
you'll never begin. Inspiration comes to those already
involved in the work.
Creativity can be shaped by constraints. I wrote about
this idea six months or so ago in an entry named
Patterns as a Source of Freedom.
Rebecca suggested that for her at least constraints are
essential to creativity, that this is why she opted to
be a graphic designer instead of a "fine artist". The
framework we operate in can change, across projects or
even within a project, but the framework can free us to
create. Brian recalled a song by the '80s punk-pop band
Devo called
Freedom Of Choice:
freedom of choice is what you got
then if you got it you don't want it
seems to be the rule of thumb
don't be tricked by what you see
you got two ways to go
freedom from choice is what you want
Richard then gave a couple of examples of how some
artists don't exercise their choice at the level of
creating a product but rather at the level of selecting
from lots of products generated less self-consciously.
In one, a photographer for
National Geographic,
put together a pictorial article containing 22 pictures
selected from 40,000 photos he snapped. In
another, Francis Ford Coppolla shot 250 hours of film in
order to create the 2-1/2 hour film
Apocalypse Now.
John then told a wonderful little story about an
etymological expedition he took along the trail of ideas
from the word "chutzpah", which he adores, to "effrontery",
"presumptuous", and finally "presumption" -- to act
as if something were true. This is a great way to
free oneself to create -- to presume that one can, that
one will, that one should. Chutzpah.
Author William Stafford had a particular angle he took on
this idea, what he termed the "path of stealth". He
refused to believe in writer's block. He simply lowered
his standards. This freed him to write something and,
besides, there's always tomorrow to write something
better. But as I noted earlier, inspiration comes to
those already involved in the work, so writing anything
is better than writing nothing.
As editor John Gould once told Stephen King, "Write with
the door closed. Revise with the door open." Write for
yourself, with no one looking over your shoulder. Revise
for readers, with their understanding in mind.
Just as permission is crucial to creativity, so is time.
We have to "make time", to "find time". But sometimes
the work is on its own time, and will come when and at
the rate it wants. Creativity demands that we allow enough
time for that to happen! (That's true even for the
perhaps relatively uncreative act of writing programs
for a CS course... You need time, for understanding to
happen and take form in code.)
Just as permission and time are crucial to creativity,
John said, so is pressure. I think we all have experienced
times when a deadline hanging over our heads seemed to
give us the power to create something we would otherwise
have procrastinated away. Maybe we need pressure
to provide the energy to drive the creative act. This
pressure can be external, in the form of a client, boss,
or teacher, or internal.
This is one of the reasons I do not accept late work for a
grade in my courses; I believe that most students benefit
from that external impetus to act, to stop "thinking about
it" and commit to code. Some students wait too long and
reach a crossover point: the pressure grows quite high, but
time is too short. Life is a series of balancing acts.
The play between pressure and time is, I think, fundamental.
We need pressure to produce, but we need time to
revise. The first draft of a paper, talk, or
lecture is rarely as good as it can be. Either I need to
give myself to create more and better drafts, or -- which
works better for me -- I need to find many opportunities
to deliver the work, to create multiple opportunities to
create in the small through revision, variation, and
natural selection. This is, I think, one of the deep and
beautiful truths embedded in extreme programming's cycle
"write a test, write code, and refactor".
Ultimately, a professional learns to rely more on internal
pressure, pressure applied by the self for the self, to
create. I'm not talking about the censoriousness of
self-consciousness, discussed earlier, which tells us
that what we produce isn't good enough -- that we should
not act, at least in the current product. I'm talking about
internal demands that we act, in a particular way or time.
Accepting the constraints of a form -- say, the line and
syllable restrictions of haiku, or the "no side effects"
convention of functional programming style -- puts pressure
on us to act in a way, whether it's good or bad. John
gave us two other kinds of internal pressure, ones he applies
to himself: the need to produce work to share at his two
weekly writers' workshops, and the self-discipline of
submitting work for publication every month. These pressures
involve outside agents, but they are self-imposed, and require
us do something we might otherwise not.
John closed with a short inspiration. Pay attention to your
wishes and dreams. They are your mind's way of telling you
to do something.
We spent the rest of the morning chatting as a group on
whatever we were thinking after John's talk. Several
folks related an experience well-known to any teacher:
someone comes to us asking for help with a problem and,
in the act of explaining the problem to us they discover
the answer for themselves. Students do this with me
often. Is the listener essential to this experience, or
could we just ask if we were speaking to someone? I
suspect that another person is essential for this to
work for the learner, both because having a real person
to talk to makes us explain things (pressure!) and
because the listener can force us to explain the problem
more clearly ("I don't understand this yet...")
A recurring theme of the morning was the essential
interactivity of creativity, even when the creator works
fundamentally alone. Poets need readers. Programmers
need other folks to bounce ideas off of. Learners need
someone to talk to, if only to figure things out for
themselves. People can be sources of ideas. They can
also be reflectors, bouncing our own ideas back at us,
perhaps in a different form or perhaps the same, but with
permission to act on them. Creativity usually comes in
the novel combination of old ideas, not truly novel ideas.
This morning session was quite rewarding. My notes on
the whole workshop are, fittingly, about half over now,
but this article has already gotten quite long. So I
think I'll save the afternoon sessions for entries to
come. These sessions were quite different from the
morning, as we created things together and then examined
our processes and experiences. They will make fine
stand-alone articles that I can write later -- after
I break away for a bite at the IBM Eclipse Technology
Exchange reception and for some time to create a bit
on my own for what should take over my mind for a few
hours: tomorrow's
Educators' Symposium,
which is only twelve hours and one eight- to ten-mile
San Diego run away!
I'm not a Way Old-Timer, but I have been teaching
at my current university for thirteen years. In
that time, I have seen a lot of odd student programs:
wacky bugs, quirky algorithms, outlandish hacks, and
just plain funny code. But today I saw a new one...
One of my colleagues is teaching our intro majors
course. In the lab today, he asked students to write
some code, including a three-argument Java method to
return the minimum of the three. The goal of this
exercise was presumably to test the students' ability
to consider multiple decisions, to write compound
boolean expressions, and most probably to write nested
if statements.
Here is my rendition of one student's extraordinary
solution:
public int min( int x, int y, int z )
{
for (int i = Integer.MIN_VALUE; i <= Integer.MAX_VALUE; i++)
if ( i == x )
return x;
else if ( i == y )
return y;
else if ( i == z )
return z;
}
Sadly, the student didn't do this quite right, as
right would be for this approach. The program did
not use Integer.MIN_VALUE and Integer.MAX_VALUE
to control its loop; it used hardcoded negative
and positive 2,000,000,000. As a result, it had to
throw in a back-up return statement after
the for-loop to handle cases where the
absolute of all three numbers were greater than
2,000,000,000. So, the solution loses points for
correctness, and a bit of luster on style.
But still -- wow. No matter what instructors think
their students will think, the students can come up
with something out of left field.
I have to admit... In a certain way, I admire this
solution. It demonstrates creativity, and even applies
a pattern that works well in other contexts. If the
student had been asked to write a method to find the
smallest value in a three-element unsorted array, then
brute force would not only have seemed like a reasonable
thing to do; it would have been the only option. Why
not try it for ints? (For us XP mavens: Is
this algorithm the simplest thing that will work?)
One answer to the "Why not?" question comes at run time.
This method uses 12 seconds or so on average to find its
answer. That's almost 12 seconds more than an
if-based solution uses. :-)
Students can bring a smile to an instructors face
most every day.
When I started writing my recent piece on
math requirements for CS degrees,
I had intended to go in a different direction than
the piece ultimately went. My original plan was to
discuss how it is that students who do
take courses like algebra in high school still seem
so uncomfortable or ill-prepared to do basic arithmetic
in their CS courses. But a related thread on the
SIGCSE mailing list took my mind, and so the piece,
elsewhere. You know what they say... You never know
what you will write until you write.
So I figured I would try to write an article on my
original topic next. Again before I could write it,
another math coincidence occurred, only this time
nearer to my intended topic. I read Tall, Dark, and
Mysterious's
detailed exploration
of the same problem. She starts by citing a survey
that found 40% of university professors believe
that *most* of their students lack "the basic skills
for university-level work", explores several possible
causes of the problem, and then discusses in some
detail what she believes the problem to be: an
emphasis in education these days on content over
skill. I think that this accounts for at least part
of the problem.
Whether we overemphasize content at the expense of
skill, though, I think that there is another problem
at play. Even when we emphasize skill, we don't always
require that students master the skills that
they learn.
For many years, I had a short article hanging on my
office wall that asked the question: What is the
difference between a grade of C and a grade of A
in a course? Does it mean that a C student has
learned less content than the A student? The same
content, but not as deeply? Something else?
Several popular jokes play off this open question.
Do you want your medical doctor to have been a C
student? Your lawyer? The general leading your
army into battle?
In my experience as a student and educator, the
difference between a C and an A indicates different
things depending on the teacher involved and, to a
lesser extent, the school involved. But it's not
clear to me that even for these teachers and schools
the distinction is an intentional one, or that the
assigned grades always reflect what is intended.
Learning theory gives us some idea of how we might
assign grades that reflect meaningful distinctions
between different levels of student performance.
For example,
Bloom's taxonomy
of educational objectives includes six levels of
of learning: knowledge, comprehension, application,
analysis, synthesis, and evaluation. These levels
give us a way to talk about increasingly more masterful
understanding and ability. Folks in education have
written a lot in this sphere of discussion which,
sadly, I don't know as well as I probably should.
Fortunately, some CS educators have begun to write
articles applying the idea to computer science curricula.
We are certainly better off if we are thinking explicitly
about what satisfactory and unsatisfactory performance
means in our courses, and in our curricula overall.
I heard about an interesting approach to this issue
this morning at a meeting of my college's department
heads. We were discussing the shortcomings of a
course-by-course approach to assessing the learning
outcomes of our university's liberal arts core, which
purports by cumulative effect to create well-rounded,
well-educated thinkers. One head described an
assessment method she had read about in which the
burden was shifted to the student. In this
method, each student was asked to offer evidence that
they had achieved the goal of being a well-rounded
thinker. In effect, the student was required to
"prove" that there were, in fact, educated. If we
think in terms of the Bloom taxonomy discussed above,
each student would have to offer evidence of that
they had reached each of the six cognitive levels of
maturity. Demonstrating knowledge might be straightforward,
but what of comprehension, application, analysis,
synthesis, and evaluation? Students could assemble
a portfolio of projects, the development of which
required them to comprehend, apply, analyze, synthesize,
and evaluate.
This reminded me very much of how my architecture friends
had to demonstrate their readiness to proceed to the
next level of the program, and ultimately to graduate:
through a series of juried competitions. These projects
and their juried evaluation fell outside the confines
of any particular course. I think that this would be
a marvelous way for computer science students, at least
the ones focused on software development as a career
path, to demonstrate their proficiency. I have been
able to implement the idea only in individual courses,
senior-level project courses required of all our majors.
The result has been some spectacular projects in the
intelligent systems area, including
one I've written about before.
I've also seen evidence that some of our seniors
manage to graduate without having achieved a level
of proficiency I consider appropriate. As one of
their instructors, I'm at least partly responsible
for that.
This explains why I am so excited about one of the
sessions to be offered as a part of the upcoming
Educators Symposium
at
OOPSLA 2005.
The session is called
Apprenticeship Agility in Academia.
Dave West and Pam Rostal, formerly of New Mexico Highlands
University, will demonstrate "a typical development
iteration as practiced by the apprentices of the NMHU
Software Development Apprenticeship Program". This
apprenticeship program was an attempt to build a
whole software development curriculum on the idea that
students advance through successive levels of knowledge
and skill mastery. Students were able to join projects
based on competencies already achieved and the desire
to achieve further competencies offered by the projects.
Dave and his folks enumerated all of the competencies
that students must achieve prior to graduation, and
students were then advanced in the program as they
achieved them at successive levels of mastery. It
solves the whole "C grade versus A grade" problem by
ignoring it, focusing instead on what they really wanted
students to achieve.
Unfortunately, I have to use the past tense when
describing this program, because NMHU canceled the
program -- apparently for reasons extraneous to the
quality or performance of the program. But I am
excited that someone had the gumption and an opportunity
to try this approach in practice. I'd love to see
more schools and more CS educators try to integrate
such ideas into their programs and courses. (That's
one of the advantages of chairing an event like the
OOPSLA Educators Symposium...
I have some ability to shape or direct the discussion
that educators have at the conference.)
For you students out there: To what extent do you
strive for mastery of the skills you learn in
your courses? When do you settle for less, and why?
What can you do differently to help yourselves become
effective thinkers and practitioners?
For you faculty out there: To what extent do you
focus your teaching and grading efforts on student
mastery of skills? What techniques work best, and
why? When doyou settle for less, and why?
I myself know that I settle for less all too often,
sometimes due to the impediments placed in my way
by our curriculum and university structure, but
sometimes due to my own lack of understanding or
even laziness. Staying in an intellectual arena
in which I can learn from others such as West and
Rostal is one way I encourage myself to think Big
Thoughts and try to do better.
Every once in a while, someone says something that just
makes me say, "Oh, yeah" -- even if I've
already written a similar piece
myself. From The Fishbowl:
Programming is looking at a feature request in the
morning, thinking, "I can do that in one line of code",
and then six hours later having refactored the rest of
the codebase sufficiently that you can implement the
feature...
...in one line of code.
That makes a nice complement to the quote from Jason
Marshall and the epigram from Brian Foote quoted in
my earlier post. It may have to go on to my office
door.
An interesting coincidence... Soon after I post my
spiel on
preparing to study computer science,
especially the role played by mathematics courses,
the folks on the
SIGCSE
mailing list have started a busy thread on the place
of required math courses in the CS curriculum. The
thread began with a discussion of differential equations,
which some schools apparently still require for a CS
degree. The folks defending such math requirements
have relied on two kinds of argument.
One is to assert that math courses teach discipline and
problem-solving skills, which all CS students need. I
discussed this idea in my previous article. I don't
think there is much evidence that taking math courses
teaches students problem-solving skills or
discipline, at least not as most courses are taught.
They do tend to select for problem-solving
skills and discipline, though, which makes them handy
as a filter -- if that's what you want. But they are
not always helpful as learning experiences for students.
The other is to argue that students may find themselves
working on scientific or engineering projects that require
solving differential equations, so the course is valuable
for its content. My favorite rebuttal to this argument
came from a poster who listed a dozen or so projects
that he had worked on in industry over the years. Each
required specific skills from a domain outside computing.
Should we then require one or more courses from each of
those domains, on the chance that our students work on
projects in them? Could we?
Of course we couldn't. Computing is a universal tool,
so it can and usually will be applied everywhere. It
is something of a chameleon, quickly adaptable to the
information-processing needs of a new discipline. We
cannot anticipate all the possible applications of
computing that our students might encounter any more
than we can anticipate all the possible applications
of mathematics they might encounter.
The key is to return to the idea that underlies the
first defense of math courses, that they teach skills
for solving problems. Our students do need to develop
such skills. But even if students could develop such
skills in math courses, why shouldn't we teach them in
computing courses? Our discipline requires a particular
blend of analysis and synthesis and offers a particular
medium for expressing and experimenting with ideas.
Computer science is all about describing what can be
systematically described and how to do so in the face
of competing forces. The whole point of an education
in computing should be to help people learn how to use
the medium effectively.
Finally,
Lynn Andrea Stein
pointed out an important consideration in deciding
what courses to require. Most of my discussion and
the discussion on the SIGCSE mailing list has focused
on the benefits of requiring, say, a differential
equations course. But we need also to consider the
cost of such a requirement. We have already
encountered one: an opportunity cost in the form of
people. Certain courses filter out students who are
unable to succeed in that course, and we need to be
sure that we are not missing out on students who would
make good computer science student. For example, I do
not think that a student's inability to succeed in
differential equations means that the student cannot
succeed in computer science. A second opportunity
cost comes in the form of instructional time. Our
programs can require only so many courses, so many
hours of instruction. Could we better spend a course's
worth of time in computing on a topic other than
differential equations? I think so.
I remember learning about opportunity cost, in an
economics course I took as an undergrad. Taking a
broad set of courses outside of computing really
can be useful.
Yesterday, our department hosted a "preview day" for
high school seniors who are considering majoring in
computer science here at UNI. During the
question-and-answer portion of one session, a student
asked, "What courses should we take in our senior year
to best prepare to study CS?" That's a good question,
and one that resulted in a discussion among the CS
faculty present.
For most computer science faculty, the almost reflexive
answer to this question is math and science.
Mathematics courses encourage abstract thinking, attention
to detail, and precision. Science courses help think
like an empiricist: formulating hypotheses, designing
experiments, making and recording observations, and
drawing inferences. A computer science student will
use all of these skills throughout her career.
I began my answer with math and science, but the other
faculty in the room reacted in a way that let me know
they had something to say, too. So I let them take the
reins. All three downplayed the popular notion that
math, at least advanced math, is an essential element
of the CS student's background.
One faculty member pointed out the students with
backgrounds in music often do very well in
CS. This follows closely with the
commonly-held view
that music helps children to develop skill at spatial
and symbolic reasoning tasks. Much of computing deals
not with arithmetic reasoning but with symbolic reasoning.
As an old AI guy, I know this all too well. In much
the same way that music might help CS students, studying
language may help students to develop facility
manipulating ideas and symbolic representations, skills
that are invaluable to the software developer and the
computing researcher alike.
We ended up closing our answer to the group by saying
that studying whatever interests you deeply -- and
really learning that discipline -- will help you prepare
to study computer science more than following any blanket
prescription to study a particular discipline.
(In retrospect, I wish I had thought to tack on one
suggestion to our conclusion: There can be great value
in choosing to study something that challenges you, that
doesn't interest you as much as everything else, precisely
because it forces you to grow. And besides, you may find
that you come to understand the something well enough to
appreciate it, maybe even like it!)
I certainly can't quibble with the direction our answer
went. I have long enjoyed
learning from writers,
and I believe that my study of language and literature,
however narrow, has made me a better computer scientist.
I have had many CS students with strong backgrounds in
art and music, including one
wrote about last year.
Studying disciplines other than math and science can
lay a suitable foundation for studying computer science.
I was surprised by the strength of the other faculty's
reaction to the notion that studying math is among the
best ways to prepare for CS. One of these folks was once
a high school math teacher, and he has always expressed
dissatisfaction with mathematics pedagogy in the US at
both the K-12 and university levels. To him, math teaching
is mostly memorize-and-drill, with little or no explicit
effort put into developing higher-order thinking skills
for doing math. Students develop these skills implicitly,
if at all, through sheer dint of repetition. In his mind,
the best that math courses can do for CS is to filter out
folks who have not yet developed higher-order thinking
skills; it won't help students develop them.
That may well be true, though I know that many math
teachers and math education researchers are trying to do
more. But, while students may not need advanced math
courses to succeed in CS -- at least not in many areas of
software development -- they do need to master some
basic arithmetical skills. I keep thinking back to
a relatively straightforward programming assignment
I've given in my CS II course, to implement
Nick Parlante's
NameSurfer nifty assignment
in Java. A typical NameSurfer display looks like this
image, from Nick's web page:
As the user resizes the window, the program should grow
or shrink its graph accordingly. To draw this image,
the student must do some basic arithmetic to lay out the
decade lines and to place the points on the lines and the
names in the background. To scale the image, the student
must do this arithmetic relative to window size, not with
fixed values.
Easy, right? When I assigned this program, many students
reacted as if I had cut off one of their fingers. Others
seemed incapable of constructing the equations needed to
do scaling correctly. (And you should have the reaction
students had when once, many years ago, I asked students
to write a graphical Java version of
Mike Clancy's
delicious
Cat And Mouse nifty assignment.
Horror of horror -- polar coordinates!)
This isn't advanced math. This is algebra. All students
in our program were required to pass second-year algebra
before being admitted to our university. But passing a
course does not require mastery, and students find themselves
with a course on their transcript but not the skills
that the course entails.
Clearly, mastery of basic arithmetic skills is essential
to most of computer science, even if more advanced math,
even calculus, are not essential. Especially when I think
of algebraic reasoning more abstractly, I have hard time
imagining how students can go very far in CS without
mastering algebraic reasoning. Whatever its other strengths
or weaknesses the
How to Design Programs
approach to teaching programming does one thing well, and
that is to make an explicit connection between algebraic
reasoning and programs. The result is something in the
spirit of
Polya's How to Solve It.
This brings us back to what is the weakest part of the
"math and science" answer to our brave high school
student's question. So much of computing is not theory
or analysis but design -- the act of
working out the form of a program, interface, or system.
While we may talk about the "design" of a proof or
scientific experiment, we mean something more complex
when we talk about the design of software. As a result,
math and science do relatively little to help students
develop the design skills which will be so essential
to succeeding in the software side of CS.
Studying other disciplines can help, though.
Art, music, and writing all involve the students in
creating things, making them think about how to make.
And courses in those disciplines are more likely to
talk explicitly about structure, form, and design
than are math and science.
So, we have quite defensible reasons to tell students
to study disciplines other than science and math. I
would still temper my advice by suggesting that students
study both math and science and
literature, music, art, and other creative disciplines.
While this may not be what our student was looking for,
perhaps the best answer is all of the above.
Then again, maybe success in computing is
controlled by aptitude,
than by learning. If that is the case, then many of us,
students and faculty alike, are wasting a lot of time.
But I don't think that's true for most folks. Like
Alan Kay, I think we just need to understand better
this new medium that is computing so that we can find
the right ways to empower as many people as possible
to create new kinds of artifact.
I have written about Scheme my last two times out,
so I figured I should give some love to another
of my favorite languages.
Like many folks these days, I am a big fan of Ruby.
I took a Ruby tutorial at OOPSLA several years ago
from Dave Thomas and Andy Hunt, author of the
already-classic
Programming Ruby.
At the time, the only Ruby interpreter I could find
for Mac OS 9 was a port written by a Japanese
programmer, almost of whose documentation was written
in, you guessed, Japanese. But I made it run and
learned how to be functional in Ruby within a few hours.
That told me something about the language.
(Recalling these tutorial reminds me of two things.
One, Dave and Andy give a great tutorial. If you
get the chance, learn from them in person. The same
can be sai for many
OOPSLA tutorials.
Two, thank you, Apple, for OS X as a Unix -- and for
shipping it with such a nice collction of programming
tools.)
If you want to augment the Pragmatic Programmers'
guide to Ruby, check out
Why's (Poignant) Guide to Ruby.
You can learn Ruby there, plus quite a bit on
programming more generally. You could have some fun,
too.
Unlike many dynamic language fans, I like Java
just fine. I can enjoy programming in Java, but there
is no question that it gets in my way more than a
language like Scheme or Ruby.
Still, I feel compelled to share this opportunity to
improve your geekware collection:
Thanks to the magic of CafePress.com, you can buy
a variety of merchandise in the
Java Rehab
line. But why?
Java coding need not be a life-long debilitation.
With the proper treatment, and a copy of Programming
Ruby, you can return to a life of happy, productive
software development.
So, give yourself over to a higher power! Learn
Ruby...
Just imagine how much more fun Java would be if it
gave itself over to the higher power of higher-order
procedures...
Finally, a little Ruby on Ruby. Check out Sam
Ruby's talk,
The Case for Dynamic Languages.
Sam uses Ruby to illustrate his argument that the
distinction between system languages and scripting
languages is slowly shrinking, as the languages we
use everyday become more dynamic. Along the way,
he shows the power of several ideas that have
entered mainstream programming parlance only in the
last decade, among them closures and higher-order
procedures in the form of blocks.
But my favorite part of Sam's talk is his sub-title:
Reinventing Smalltalk, one decade at a time
Paul Graham
says that we are reinventing Lisp, and he has a strong
case. With either language as a target, the lives of
programmers can only get better. The real question
is whether objects as abstractions ultimately displace
functions as the starting level of abstraction for the
program. Another question, perhaps more important,
is whether the language-as-environment can ever displace
the minimalism of the scripting language as the programmer's
preferred habitat. I have a hunch that the answer to
both questions will be the same.
But after your lecture on mutual recursion yesterday,
[another student] commented to me, "Is it wrong to
think code is beautiful? Because that's beautiful."
It certainly isn't wrong to think code is beautiful.
Code can be beautiful. Read
McCarthy's original Lisp interpreter,
written in Lisp itself. Study Knuth's TeX program,
or Wirth's Pascal compiler. Live inside a Smalltalk
image for a while.
I love to discover beautiful code. It can be
professional code or amateur, open source or
closed. I've even seen many beautiful programs
written by students, including my own. Sometimes
a strong student delivers something beautiful as
expected. Sometimes, a student surprises me by
writing a beautiful program seemingly beyond his
or her means.
The best programmers strive to write beautiful code.
Don't settle for less.
(What is mutual recursion, you ask? It is a technique
used to process mutually-inductive data types. See
my paper
Roundabout
if you'd like to read more.)
The student who told me the quote above followed
with:
That says something about the kind of students I'm
associating with.
... and about the kind of students I have in class.
Working as an academic has its advantages.
Second... While catching up on
some blog reading this afternoon, I spent some
time at Pragmatic Andy's blog. One of his essays
was called
What happens when t approaches 0?,
where t is the time it takes to write
a new application. Andy claims that this is the
inevitable trend of our discipline and wonders how
it will change the craft of writing software.
I immediately thought of one answer, one of those
unforgettable Kent Beck one-liners. On a panel at
OOPSLA 1997 in Atlanta, Kent said:
As speed of development approaches infinity,
reusability becomes irrelevant.
If you can create a new application in no time flat,
you would never worry about reusing yesterday's
code!
----
Is there a connection between these two snippets?
Because I am teaching a course in programming
languages course this semester, and particularly
a unit on functional programming right now, these
snippets both call to mind the beauty in Scheme.
You may not be able to write networking software
or graphical user interfaces using standard Scheme
"out of the box", but you can capture some elegant
patterns in only a few lines of Scheme code. And,
because you can express rather complex computations
in only a few lines of code, the speed of development
in Scheme or any similarly powerful language approaches
infinity much faster than does development in Java
or C or Ada.
I do enjoy being able to surround myself with the
possibility of beauty and infinity each day.
Technology based on the digital computer and networking
has radically changed the world. In fact, it has changed
what is possible in such a way that how we do business
and entertain ourselves in the future may bear little
resemblance to what we do today.
This will surely come as no surprise to those of you
reading this blog. Blogging itself is one manifestation
of this radical change, and many bloggers devote much of
their blogging to discussing how blogging has changed the
world (ad nauseam, it sometimes seems). But even without
blogs, we all know that computing has redefined the
parameters within each information is created and shared,
and defined a new medium of expression that we and the
computer-using world have only begun to understand.
Two caveats up front. The first is simple enough: I
have not read the book The The World Is Flat
yet, so my comments here will refer only to the talk
Friedman delivered here last night. I am excited by
the ideas and would like to think and write about them
while they are fresh in my mind.
The second caveat is a bit touchier. I know that
Friedman is a political writer and, as such carries
with him the baggage that comes from at least occasionally
advocating a political position in his writing. I
have friends who are big fans of his work, and I have
friends who are not fans at all. To be honest, I don't
know much about his political stance beyond my friends'
gross characterizations of him. I do know that he has
engendered strong feelings on both sides of the political
spectrum. (At least one of his detractors has taken the
time to create the
Anti-Thomas Friedman Page
-- more on that later.) I have steadfastly avoided
discussing political issues in this blog, preferring to
focus on technical issues, with occasional drift into
the cultural effects of technology. This entry will
not be an exception. Here, I will limit my comments
to the story behind the writing of the book and to
the technological arguments made by Friedman.
On a personal note, I learned that, like me, Friedman
is from the American Midwest. He was born in Minneapolis,
married a girl from Marshalltown, Iowa, and wrote his
first op-ed piece for the
Des Moines Register.
The idea to write The The World Is Flat
resulted as a side effect of research Friedman was
doing on another project, a documentary on off-shoring.
He was interviewing
Narayana Murthy,
chairman of the board at Infosys, "the Microsoft
of India", when Murthy said, "The global economic
playing field is being leveled -- and you Americans
are not ready for it." Friedman felt as if he had
been sideswiped, because he considers himself
well-studied in modern economics and politics, and
he didn't know what Murthy meant by "the global
economic playing field is being leveled" or how we
Americans were so glaringly unprepared.
As writers often do, Friedman set out to write a
book on the topic in order to learn it. He studied
Bangalore, the renown center of the off-shored
American computing industry. Then he studies
Dalien, China,
the Bangalore of Japan.
Until last night, I didn't even know such a place
existed. Dalyen plays the familiar role. It is a
city of over a million people, many of whom speak
Japanese and whose children are now required to
learn Japanese in school. They operate call centers,
manage supply chains, and write software for
japanese companies -- all jobs that used to be done
in Japan by Japanese.
Clearly the phenomenon of off-shoring is not US-centric.
Other economies are vulnerable. What is the dynamic
at play?
Friedman argues that we are in a third era of
globalization. The first, which he kitschily calls
Globalization 1.0, ran from roughly 1492, roughly
when Europe began its imperial expansion across the
globe, to the early 1800s. In this era, the agent
of globalization was the country. Countries
expanded their land holdings and grew their economies
by reaching overseas. The second era ran from the
early 1800s until roughly 2000. (Friedman chose this
number as a literary device, I think... 1989 or 1995
would have made better symbolic endpoints.) In this
era, the corporation was the primary agent
of globalization. Companies such as the
British East India Company
reached around the globe to do commerce, carrying with
them culture and politics and customs.
We are now in Friedman's third era, Globalization 3.0.
Now, the agent of change is the individual.
Technology has empowered individual persons to reach
across national and continental boundaries, to interact
with people of other nationalities, cultures, and
faiths, and to perform commercial, cultural, and
creative transactions independent of their employers
or nations.
Blogging is, again, a great example of this phenomenon.
My blog offers me a way to create a "brand identity"
independent of any organization. (Hosting it at
www.eugenewallingford.com would sharpen
the distinction!) I am able to engage in intellectual
and even commercial discourse with folks around the
world in much the same way I do with my colleagues
here at the university. In the last hour, my blog
has been accessed by readers in Europe, Australia,
South America, Canada, and in all corners of the
United States. Writers have always had this
opportunity, but at glacial rates of exchange. Now,
anyone with a public library card can blog to the
world.
Technology -- specifically networking and the digital
computer -- has made Globalization 3.0 possible.
Friedman breaks our current era into a sequence of
phases characterized by particular advances or
realizations. The specifics of his history of
technology are sometimes arbitrary, but at the
coarsest level he is mostly on the mark:
11/09/89 - The Berlin Wall falls, symbolically
opening the the door for the East and West to
communicate. Within a few months, Windows 3.0
ships, and the new accessibility of the personal
computer made it possible for all of us to be
"digital authors".
08/09/95 - Netscape went public. The investment
craze of its IPO presaged the dot-com boom, and
the resultant investment in network technology
companies supplied the capital that wired the
world, connecting everyone to everyone else.
mid 1990s - The technology world began to move
toward standards for data interchange and
software connectivity. This standards movement
resulted in what Friedman calls a "collaboration
platform", on which new ways of working together
can be built.
These three phases have been followed in rapid
succession by a number of faster-moving realizations
on top of the collaboration platform:
outsourcing tasks from one company to another
offshoring tasks from one country to another
uploading of digital content by individuals
supply chaining to maximize the value of offshoring
and outsourcing by carefully managing the flow of goods
and services at the unit level
insourcing of other companies into public
interface of a company's commercial transactions
informing oneself via search of global networks
mobility (my term) of data and means of communication
Uploading is the phase where blogs entered the picture.
But there is so much more. Before blogs came open source
software, in which individual programmers can change their
software platform -- and share their advances with others
but uploading code into a common repository. And before
open source became popular we had the web itself. If
Mark Rupert
objects to what he considers Thomas Friedman's "repeated
ridicule" of those opposed to globalization, then he can
create a
web page
to make his case. Early on, academics had an edge in
creating web content, but the advance of computing
hardware and now software has made it possible for
anyone to publish content. The blogging culture has
even increased the opportunity to participate in
wider debate more easily (though, as discussions of
the "long tail" have shown, that effect may be dying
off as the space of blogs grows beyond what is
manageable by a single person).
Friedman's description of insourcing sounded a lot
like outsourcing to me, so I may need to read his
book to fully get it. He used UPS and FedEx as
examples of companies that do outsourced work for
other corporations, but whose reach extends deeper
into the core functions of the outsourcing company,
intermingling in a way that sometimes makes the
two companies' identities indistinguishable to
the outside viewer.
The quintessential example of informing is, of
course,
Google,
which has made more information more immediately
accessible to more people than any entity in
history. It seems inevitable that, with time,
more and more content will become available on-line.
The interesting technical question is how to
search effectively in databases that are so large
and heterogeneous. Friedman explains well to his
mostly non-technical audience that we are at just
the beginning of our understanding of search.
Google isn't the only player in this field,
obviously, as
Yahoo!,
Microsoft,
and a host of other research groups are exploring
this problem space. I hold out belief that
techniques from artificial intelligence will
play an increasing role in this domain. If
you are interested in Internet search, I suggest
that you read
Jeremy Zawodny's blog.
Friedman did not have a good name for the most
recent realization atop his collaboration
platform, referring to it as all of the above
"on steroids". To me, we are in the stage of
realizing the mobility and pervasiveness of
digital data and devices. Cell phones are
everywhere, and usually in use by the holder.
Do university students ever hang up?
(What a quaint anachronism that is...) Add
to this numerous other technologies such as
wireless networks, voice over internet,
bluetooth devices, ... and you have a time in
which people are never without access to their
data or their collaborators. Cyberspace isn't
"out there" any more. It is wherever you are.
These seven stages of collaboration have, in
Friedman's view, engendered a global communication
convergence, at the nexus of which commerce,
economics, education, and governance have been
revolutionized. This convergence is really an
ongoing conversion of an old paradigm into a
new one. Equally important are two other
convergences in process. One he calls "horizontaling
ourselves", in which individuals stop thinking
in terms of what they create and start thinking
in terms of who they collaborate with, of what
ideas they connect to. The other is the one
that ought to scare us Westerners who have grown
comfortable in our economic hegemony: the opening
of India, China, and the former Soviet Union,
and 3 billion new players walking onto a level
economic playing field.
Even if we adapt to all of the changes wrought
by our own technologies and become well-suited
to compete in the new marketplace, the shear
numbers of our competitors will increase so
significantly that the market will be a much
starker place.
Friedman told a little story later in the evening
that illustrates this point quite nicely. I
think he attributed the anecdote to Bill Gates.
Thirty years ago, would you prefer to have been
born a B student in Poughkeepsie, or a genius
in Beijing or Bangalore? Easy: a B student in
Poughkeepsie. Your opportunities were immensely
wider and more promising. Today? Forget it.
The soft B student from Poughkeepsie will be
eaten alive by a bright and industrious Indian
or Chinese entrepreneur.
Or, in other words from Friedman, remember: In
China, if you are "1 in a million", then
there are 1300 people just like
you.
All of these changes will take time, as we build
the physical and human infrastructure we need
to capitalize fully on new opportunities. The
same thing happened when we discovered electricity.
The same thing happened when Gutenberg invented
the printing press. But change will happen
faster now, in large part due to the power of the
very technology we are harnessing, computing.
Gutenberg and the printing press. Compared to
the computing revolution. Where have we heard
this before?
Alan Kay
has been saying much the same thing, though
mostly to a technical audience, for over 30
years! I was saddened to think that nearly
everyone in the audience last night thinks that
Friedman is the first person to tell this story,
but gladdened that maybe now more people will
understand the momentous weight of the change
that the world is undergoing as we live.
Intellectual middlemen such as Friedman still
have a valuable role to play in this world.
As Carly Fiorina (who was recently Alan's boss
at Hewlett-Packard before both were let go in
a mind-numbing purge) said, "The 'IT revolution'
was only a warm-up act." Who was it that said,
"The computer revolution hasn't happened yet."?
The question-and-answer session that followed
Friedman's talk produced a couple of good stories,
most of which strayed into policy and politics.
One dealt with a topic close to this blog's
purpose, teaching and learning. As you might
imagine, Friedman strongly suggests education
as an essential part of preparing to compete
in a flat world, in particular the ability to
"learn how to learn" He told us of a recent
speaking engagement at which an ambitious 9th
grader asked him, "Okay, great. What class do
I take to learn how to learn?" His answer may
be incomplete, but it was very good advice
indeed: Ask all your friends who the best
teachers are, and then take their courses --
whatever they teach. It really doesn't matter
the content of the course; what matters is to
work with teachers who love their material, who
love to teach, who themselves love to learn.
As a teacher, I think one of the highest forms
of praise I can get from a student is to be told
that they want to take whatever course I am
teaching the next semester. It may not be in
their area of concentration, or in the hot topic
du jour, but they want to learn with me. When a
student tells me this -- however rare that may be
-- I know that I have communicated something of
my love for knowledge and learning and mastery
to at least one student. And I know that the
student will gain just as much in my course as
they would have in Buzzword 401.
We in science, engineering, and technology may
benefit from Friedman's book reaching such a
wide audience. He encourages a focus not merely
on education but specifically on education in
engineering and the sciences. Any American who
has done a Ph.D. in computer science knows that
CS graduate students in this country are largely
from India and the Far East. These folks are
bright, industrious, interesting people, many
of whom are now choosing to return to their
home countries upon completion of their degrees.
They become part of the technical cadre that
helps to develop competitors in the flat world.
As I listened last night,
Chad Fowler's
new book
My Job Went to India
came to mind. This is another book I haven't read
yet, but I've read a lot about it on the web. My
impression is that Chad looks at off-shoring not
as a reason to whine about bad fortune but as an
opportunity to recognize our need to improve our
skills for participating in today's marketplace.
We need to sharpen our technical skills but also
develop our communication skills, the soft skills
that enable and facilitate collaboration at a level
higher than uploading a patch to our favorite
open source project. Friedman, too, looks at the
other side of off-shoring, to the folks in Bangalore
who are working hard to become valuable contributors
in a world redefined by technology. It may be easy
to blame American CEOs for greed, but that ignores
the fact that the world is changing right before us.
It also does nothing to solve the problem.
All in all, I found Friedman to be an engaging speaker
who gave a well-crafted talk full of entertaining
stories but with substance throughout. I can't
recommend his book yet, but I can recommend that
you go to hear him speak if you have the opportunity.
This being Friday, September 9, I have to come to
grips with the fact that I won't be participating in
PLoP 2005.
This is the 12th
PLoP,
and it would have been my 10th, all consecutively.
PLoP has long been one of my favorite conferences,
both for how much it helps me to improve my papers
and my writing and for how many neat ideas and people
I encounter there. Last year's PLoP led directly
to four blog entries, on
patterns as autopsy,
patterns and change,
patterns and myth, and
the wiki of the future,
not to mention a few others indirectly later.
Of course, I also wrote about the wonderful
running
in and around
Allerton Park,
the pastoral setting of PLoP. I will dearly
miss doing my 20-miler there this weekend...
Sadly, events conspired against me going to PLoP
this year. The deadline for submissions fell at
about the same time as the deadline for applications
for the chair of my department, both of which fell
around when I was in San Diego for the
spring planning meeting
for
OOPSLA 2005.
Even had I submitted, I would have had a hard time
doing justice to paper revisions through the summer,
as I learned the ropes of my new job. And now, new
job duties make this a rather bad time to hop into
the car and drive to Illinois for a few days. (Not
that I wasn't tempted early in the week to drive
down this morning to join in for a day!)
I am not certain if other academics feel about some
of the conferences they attend the way I feel about
PLoP, OOPSLA, and
ChiliPLoP,
but I do know that I don't feel the same way about
other conferences that I attend, even ones I enjoy.
The PLoPs offer something that no other conference
does: a profound concern for the quality of technical
writing and communication more generally. PLoP Classic,
in particular, has a right-brain feel unlike any
conference I've attended. But don't think that this
is a result of being overrun by a bunch of non-techies;
the conference roster is usually dominated by very
good minds from some of the best technical outfits
in the world. But these folks are more than just
techies.
Unfortunately I'm not the only regular who is missing
PLoP this year. The attendee list for 2005 is smaller
than in recent years, as was the number of submissions
and accepted papers. The
Hillside Group
is considering the future of PLoP and ChiliPLoP in
light of the more mainstream role of patterns in
the software world and the loss of cache that comes
when one software buzzword is replaced with another.
Patterns are no longer the hot buzzword -- they are
a couple of generations of buzzwords beyond that --
which changes how conferences in the area need to be
run. I think, though, that it is essential for us
to maintain a way for new pattern writers to enter
the community and be nurtured by pattern experts.
It is also essential that we continue to provide a
place where we care not only about the quality of
technical content but also about the quality of
technical writing.
In the patterns movement, there was the notion of
"forces". The idea of applying a pattern or pattern
language was to "balance" the forces.
I hope Ron's use of past tense was historical, in the
sense that the patterns movement first emphasized the
notion of forces "back then", rather than a comment
that the patterns movement is over. The heyday is over,
but I think we software folks still have a lot to learn
about design from patterns.
I am missing PLoP 2005. Sigh. I guess there's always
ChiliPLoP 2006. Maybe I can even swing
EuroPLoP
next year.
Earlier this week, I learned a bit about how to
use my university's financial information system.
It is an application built almost entirely out
of the box using
Oracle E-Business Suite
tools. By the time I left the room, I was
embarrassed for my discipline.
My college secretary gave an informal tutorial
to me, another new head, and our acting dean.
We learned that it is not straightforward to
do most of the tasks that we might want to do.
What was worst, from most point of view as a
software developer, is that the complexity of
the interface matched or exceeded the complexity
of the underlying data.
The primary users of this system -- secretaries
and office personnel -- seem to be good troopers.
They acknowledge the complexity of the system with
mostly good cheer and seem intent on mastering
the complexity of the interface. Then again,
perhaps they are just being kind when they speak
to me, a "computer person", and are burning their
mousepads -- and me in effigy -- when I'm not around.
I wouldn't blame them.
The administrators I've talked to, who have to use
the system to manage their budgets and personnel,
openly grumble about the system.
To be fair, this software solves a very large
problem in our medium-sized institution. As an
undergraduate, I worked as a programmer in
administrative computing at my alma mater.
The database with which we worked seemed uncommonly
complex at the time. Of course, it wasn't; I was
just inexperienced in the ways of computing.
Financial information systems these days are even
more complex, managing the interactions among
several classes of employees and supervisors,
payroll and grants and foundation accounts,
departments and units and colleges, .... On top
of that are issues of security and responsiveness.
I don't doubt that our financial information system
is more complex than any IS with which I have worked.
But users shouldn't have to see any more of this
complexity than necessary. Users of our system
seem to see nothing but complexity. Layers of
jargon-laden links that serve as menus. Several
cryptic codes that must be entered before you can
reach data on any form. Few, if any, defaults.
Few, if any, shortcuts.
The giveaway that the system is too complex for
its own good? Regular users have asked system
administrators to create a "cheat sheet", a page
containing advice of the sort, "If you want to
see data on x, do the following..."
Why can't frequent, knowledgeable users find their
way to commonly-needed data already?
The good news for users here is that the team
that administers our system has produced good
on-line training material. (Someone at
OracleAppsBlog
thinks so, too.) Good. But why should the
main focus of a software unit be to produce
good documentation? As we in the agile community
know, the need to write better comments usually
indicates the need to write better code. The need
for excellent training materials implies a need
for a better interface.
I don't want to be too hard on Oracle. I know that
the task is complex, and I know that Oracle isn't
the only computing company producing software that
users can't use, at least comfortably. This system
is just one example, albeit a very good one, of a
general problem in our industry. But I guess I do
expect more from
"the world's largest enterprise software company"
...
And I'm certainly not complaining about the UNI folks
who have assembled our information system. They built
the system on a relatively small budget using standard
Oracle code, interface components, and style sheets.
But, as a user, I wish that we could do better.
Even sadder in these days of budget cuts in higher
education, my university has almost certainly sunk
in excess of $100,000 into this system and thus are
committed to the long-term costs of keeping it
functional. When I add in training costs, the
total cost probably goes up significantly. When I
add in the cost of the time lost battling the system
... I don't want to think about it.
We in software development do a disservice to users
when we tell them, explicitly or implicitly, that
things have to be complex, hard to use, uncomfortable,
painful. We tell them that they don't
understand. We tell them that they must just not
be smart enough to use technology. We are wrong, and
they should be told that.
In thinking about concrete, relatively low cost
steps we would take to improve the quality of user
experience, a friend and I focused on the fact that
most accesses into the system recurring. While I
was being "trained", I repeatedly heard "you don't
need to worry about these options. You'll never use
them. Focus on this subset of options...." How about
something simple, which Mac OS has had forever: an
easily-accessible recent items menu? Or a
"most-frequently accessed reports" menu? I am guessing
that, within a few uses, most administrators would
never have to venture outside one of these lists.
More frequent users might need a longer list, but
that's no problem.
Upon further inspection, it seems that users of our
system can build their own shortcuts lists,
by "customizing" their own "portlets". (Portlet?)
But I am not yet certain how to use this interface
feature properly. I must not be smart enough to use
this system. Maybe I don't understand. Sorry, I
don't believe that -- about me or about any of the
regular users of this system.
After a week impersonating one of the
Two Men and a Truck
guys, I'm finally back to reading a bit.
Brian Marick wrote several articles in the
last week that caught my attention, and I'd
like to comment on two now.
The
first
talked about why Brian thinks the agile movement
in software development is akin to the British
cybernetics movement that began in the late 1940's.
He points out three key similarities in the two:
a preference for performance (e.g., writing
software) over representation (e.g., writing
requirements documents)
constant adaptation to the environment as a
means for achieving whole function
a fondness for surprises that arise when we
build and play with complex artifacts
I don't know much about British cybernetics, but
I'm intrigued by the connections that Brian has
drawn, especially when he says, "What I wanted
to talk about is the fact that cybernetics fizzled.
If we share its approaches, might we also share
its fatal flaws?"
My interest in this seemingly abstract connection
would not surprise my
Ph.D. advisor
or any of the folks who knew me back in my grad
school days -- especially my
favorite philosophy professor.
My research was in the area of knowledge-based
systems, which naturally took me into the related
areas of cognitive psychology and epistemology.
My work with Dr. Hall led me to the American
pragmatists -- primarily
C. S. Peirce,
William James,
and
John Dewey.
I argued that the epistemology of the pragmatists,
driven as it was by the instrumental value of
knowledge for changing how we behave in particular
contexts, was the most appropriate model for AI
scientists to build upon, rather than the mathematical
logic that dominates most of AI. My doctoral work
on reasoning about legal arguments drew heavily on
the pragmatic logic of
Stephen Toulmin
(whose book The Uses of Argument I strongly
recommend, by the way).
My interest in the connection between AI and pragmatic
epistemology grew from a class paper into a proposed
chapter in my dissertation. For a variety of reasons
the chapter never made it into my dissertation, but
my interest remains strong. While going through files
as a part of my move last week, I came across my folder
of drafts and notes on this. I would love to make time
to write this up in a more complete form...
Brian's
second
article gave up -- only temporarily, I hope -- on
discussing how flaws in the agile movement threaten
its advancement, but he did offer two suggestions
for how agile folks might better ensure the long-term
survival and effect o their work: produce a seminal
undergraduate-level textbook and "take over a computer
science department". Just how would these accomplish
the goal?
It's hard to overestimate the value of a great textbook,
especially the one that reshapes how folks think about
an area. I've written often about the ebbs and flows
of the first course in CS and, while much of the history
of CS1 can be told by tracing the changes in programming
language used, perhaps more can be told by tracing the
textbooks that changed CS1. I can think of several
off-hand, most notably Dan McCracken's Fortran IV text
and Nell Dale's Pascal text. The C++ hegemony in CS 1
didn't last long, and that may be due to the fact that
no C++-based book ever caught fire with everyone. I
think Rick Mercer's Computing Fundamentals with C++
made it possible for a lot of instructors and schools
to teach a "soft" object-oriented form of OOP in C++.
Personally, I don't think we have seen the great
Java-in-CS1 book yet, though I'm sure that the small
army of authors who have written Java-in-CS1 books
may think differently.
Even for languages and approaches that will never
dominate CS1, a great textbook can be a defining
landmark. As far as OOP in CS1 goes,
I think that
Conner, Nigidula, and van Dam's Object-Oriented
Programming in Pascal is still the benchmark.
More recently, Felleisen et al.'s
How to Design Programs
stakes a major claim for how to teach introductory
programming in a new way. Its approach is very
different from traditional CS1 pedagogy, though,
and it hasn't had a galvanizing effect on the world
yet.
An agile software engineering text could allow us
agile folks to teach software engineering in a new
and provocative way. Many of us are teaching such
courses already when we can, often in the face of
opposition from the "traditional" software engineers
in our departments. (When I taught my course last
fall, the software engineering faculty argued strongly
that the course should not count as a software
engineering course at all!) I know of only agile
software engineering text out there -- Steinberg
and Palmer's Extreme Software Engineering
-- but it is not positioned as the SE-complete
text that Brian envisions.
Closer to my own world, of course, is the need for
a great patterns-oriented CS1 book of the sort some
of us have been
working on for a while.
Such a text would almost certainly be more agile
than the traditional CS1 text and so could provide
a nice entry point for students to experience the
benefits of an agile approach. We just haven't yet
been able to put our money where our mouth is -- yet.
On Brian's three notes:
Using Refactoring and Test-Driven
Development and various other readings can
work well enough for an agile development course,
but the need for a single text is still evident.
First, having scattered materials is too much
work for the more casual instructor charged with
teaching "the agile course". Second, even together
they do not provide the holistic view of software
engineering required if this text is to convince
CS faculty that it is sufficient for an introductory
SE course.
Yes and yes. Alternative forms of education such
as apprenticeship may well change how we do some
of our undergraduate curriculum, but no one should
bet the survival of agile methods on the broad
adoption of radically different teaching methods
or curricula in the university. We are, as a whole,
a conservative lot.
That doesn't mean that some of us aren't trying.
I'm chairing
OOPSLA's
Educators' Symposium
again this year, and we are leading off our day
Dave West and Pam Rostal's
Apprenticeship Agility in Academia,
which promises a firestorm of thinking about how to
teach CS -- and software development and agility and
... -- differently.
I have used
Bill Wake's
Refactoring Workbook as a source of lab
exercises for my students. It is a great resource,
as is Bill's website. But it isn't a software
engineering textbook.
Why "take over a computer science department"? To
create a critical mass of agile-leaning faculty who
can support one another in restructuring curricula,
developing courses, writing textbook, experimenting
with teaching methods, and thinking Big Thoughts.
Being one among nine or 15 or 25 on a faculty means
a lot of hard work selling a new idea and a lot of
time isolated from the daily conversations that help
new ideas to form and grow.
OOPSLA
and
Agile 200x
and
SIGCSE
only come once a year, after all. And Cedar Falls,
Iowa, is far from everywhere when I need to have a
conversation on agile software development right
now. So is Raleigh, North Carolina, for that matter,
when
Laurie Williams
could really use the sort of interaction that the
MIT AI Lab
has been offering AI scientists for 40 years.
Accomplishing this takeover is an exercise left
to the reader. It is a slow process, if even
possible. But it can be done, when strong leaders
of departments and colleges set their minds and
resources to doing the job. It also requires a
dose of
luck.
I've recently run across in several different places
recommendations for Leonard Koren's Wabi-Sabi:
for Artists, Designers, Poets & Philosophers, so I
thought I'd give it a read. My local libraries don't
have it, so I'm still waiting. While looking, though,
I saw another book by Koren, called 13 Books : (Notes
on the Design, Construction & Marketing of my Last...).
The title was intriguing, so I looked for it in the stacks.
The back cover kept my attention, so I decided to read it
this weekend. It contained the opening sentences of the
book:
Authorship unavoidably implies a certain degree of expertise
about the subject you are writing on. This has always troubled
me because, although I have written numerous books on various
subjects, I've never really considered myself an expert about
anything. Recently, however, I had an encouraging realization.
Surely I must know more about the making of the 13 books
... that he has written than anyone else! So he wrote this
book, which consists of a discussion of each of his previous
works, including his source of inspiration for the work, the
greatest difficulty he faced in producing it, and one enduring
lesson he learned from the experience.
(This book ties back nicely to two previous entries here.
First, it adds to my
league-leading total
for being the first reader of a book in my university library.
Second, it was a gift to the library by Roy Behrens, a design
professor here whose Ballast Quarterly Review
I mentioned a few months ago.)
13 Books is clearly the product of a graphic designer
who likes to explore the interplay between text and graphic
elements and who likes to make atypical books. It's laid out
in a style that may distract some readers. But, within the
self-referential narrative, I found some of Koren's insights
to be valuable beyond his experience, in terms of software,
creativity, and writing.
On software
Projects ultimately develop their own identity, at which
point the creator has a limited role in determining its
shape. Koren learned this when he felt compelled to include
a person in one of his books, despite the fact that he didn't
like the guy, because it was essential to the integrity of
the project. I feel something similar when writing programs
in a test-code-refactor rhythm. Whether I like a particular
class or construct, sometimes I'm compelled to create or
retain it. The code is telling me something about its own
identity.
Just from its brief appearance in this book, I can see how
the idea of wabi-sabi found an eager audience with software
developers and especially XPers. Koren defines wabi-sabi as
"a beauty of things imperfect, impermanent, and incomplete...
a beauty of things modest and humble..." In the face of changing
requirements and user preferences, we must recognize that our
software is ever-changing. If our sense of beauty is bound up
in its final state, then we are destined to design software in
a way that aims at a perfect end -- only to see the code break
down when the world around it changes. We need a more dynamic
sense of beauty, one that recognizes beauty in the work-in-progress,
in the system that needs a few more features to be truly useful,
in the program whose refactoring is part of its essence.
Later in the book, Koren laments that making paper books is
"retrograde" to his tech friends. He then says, "And the concept
of wabi-sabi, the stated antithesis of digital this and digital
that, was, by extrapolation, of negligible cultural relevance."
I see no reason that wabi-sabi stands in opposition to digital
creations. I sense it my programs.
Finally, here is my favorite quote from the book that is
unwittingly about software:
The problem with bad craftsmanship is that it needlessly
distracts from the purity of your communication; it draws
away energy and attention; it raises questions in the reader's
mind that shouldn't be there.
Koren writes of font, layout, covers, and bindings. But
he could just as easily be writing of variable names, the
indentation of code, comments, ...
On creativity and learning
At least one of the thirteen books was inspired by Koren's
rummaging through his old files, aimlessly looking at photos.
We've seen this advice before, even more compellingly, in
Twyla Tharp's "start with a box".
(That reminds me: I've been meaning to write up a more
complete essay on that book...)
Taking on projects for reasons of perceived marketability
or laziness may sometimes make sense, but not if your
goal is to learn:
The ideas for both books came too quickly and easily, and
there was no subsequent concept of development. In my
future books I would need to challenge myself more.
In building software systems, in learning new languages,
in adopting new techniques -- the challenge is where you
grow.
In retrospect, Koren categorized his sources of inspiration
for his books. The split is instructive: 40% were the next
obvious step in a process, 30% came from hard work, and 30%
were the result of "epiphanies from out of the blue". This
means that fully two-thirds of his books resulted from the
work of of being a creator, not from a lightning bolt.
Relying on
flashes of inspiration
is a recipe for slow progress -- probably no progress at
all, because I believe that those flashes ultimately flow
from the mind made ready by work.
On writing and publishing
Koren is a graphic designer for whom books are the preferred
medium. Throughout his career, he has often been dissatisfied
with power imbalance between creators and publishers. He is
constantly on the look-out for a new way to publish. For many,
the web has opened new avenues for publishing books, articles,
and software with little or no interference from a publisher.
The real-time connectedness of the web has even made possible
new modes of publication such as the blog, with conversations
as a medium for creating and sharing ideas in a way. Blogs
are often characterized as being ephemeral and light, but I
think that we'll all be referring to Martin Fowler's essays
and the Pragmatic Programmers' articles on their blogs for
years to come.
While Koren may remain a bookmaker, and despite his comments
against digital technology as creative medium, I think his
jangling, cross-linked, quick-hit style would play well in a
web site. It might be interesting to see him produce an
on-line work that marries the two. Heck, it's been
been done with PowerPoint.
As someone who has been reflecting a year writing this blog,
I certainly recognize the truth in this statement:
A book need be grand neither in scale nor subject matter
to find an audience.
Waiting until I have something grand to say is a sure
way to paralyze myself.
Finally, Koren offered this as the enduring lesson he
learned in producing his book Useful Ideas from
Japan:
Reducing topical information to abbreviated humorous
tidbits is a road to popular cultural resonance.
It seems that Koren has the spirit of a blogger after all.
While out running today, I had one of those flashes of
inspiration -- a crystal-clear, wholly-formed thought --
for how I might introduce agile software development in
an undergraduate course. In this image, we begin the
first day of a course with a software project to implement.
The first thing we do is work as a group to decompose the
into chunks that the students believe they can implement
in one day. No
Planning Game
jargon; just a bunch of students working with me to design
the course project and the programming assignments they
will have to do. On another day, we could work on one of
the day-long projects, breaking it down further and writing
a test for each small piece before we write any code. No
TDD
or
JUnit
jargon; just a bunch of folks writing short test programs
for code they think they understand how to write.
I'm not sure why this flash happened today. I'm not slated
to teach agile software development per se for a
while. The last time I taught the offers some reason that
my mind would seek a new way to open the course. Then, I
*talked about* agile development first, and we began to work
on agile practices with test-first development first. At
the end of the course, I felt as if too few of the students
had grokked the idea, at least in part before they never
felt motivated to give it a reasonable shot. I don't mean
that the students necessarily started with a desire not to
get it; rather, they never felt a strong internal desire to
endure the pain of changing their habits for building software.
And old habits die hard, if at all.
People don't choose rationally to listen to your message
and then have a feeling about it. They choose to listen
to your message because they have a feeling about it.
University instructors and industrial trainers should
keep this thought close to their minds. The folks at
Creating Passionate Users
know that it is hard to spark passion in readers or product
users when they have no particular feeling for the work.
The same is true for many students in a course. I may be
able to draw in a few students slowly over time, as things
click in their minds, but for most I need to help them want
to learn and know and do. This is especially true of helping
people to change deeply ingrained habits,such as how they
develop software.
Then what should I read today but this quote from Malcolm
Gladwell's The Tipping Point, over at
Agile Advice,
presented in just the context of my inspirational
moment:
...the content of the message matters, too. And the
specific quality that a message needs to be successful
is the quality of "stickiness." Is the message - or
the food, or the movie, or the product - memorable?
Is it so memorable, in fact, that it can create change,
that it can spur someone to action?
I need to find and communicate better the stickiness of
agile development. My running thought seems closer to
agile development's stickiness than what I've done before.
If my thoughts were controlled more by my rational side,
I would be having flashes of inspiration for teaching
my programming languages course this fall. What is the
stickiness of functional programming, of Scheme? How
can I shape a mindset in my students whereby they feel
passion to learn these new ideas and change how they
think about programs?
Maybe I need to go for another run and cross my fingers.
One of the things I miss being at a smaller school in
a less densely populated part of the country is the
ability to go to stimulating research talks on a
regular basis. When I was at
Michigan State,
I could go to a good talk in computer science or a
closely related discipline
frequently, if I had the time and inclination. It's
hard to create that sort of environment at a school
the size of UNI. One of my goals for the department
this fall is to create a seminar series that draws on
the research our faculty is doing, as well as research
and scholarship being done at the many other schools in
Northeast Iowa. I don't know if we have a critical mass
of audience to sustain such a series, but I think that
it's worth finding out.
In the meantime, following other people's involvement in
research talks is one solace. Andrew Birkett recently
wrote about
attending the Scottish Programming Languages Seminar
held last month. Just reading his summary stimulated my
mind a bit...
One talk described an attempt to measure the productivity
difference between static and dynamic languages, toward
which Andrew was skeptical. I am, too. The difference
between static and dynamic languages is at least as much
one of culture and habit of thought as it is of language
and tools.
When you use a dynamic language, it's not because you have
a masochistic enjoyment of finding statically-findable bugs
by hand. It's because you enjoy a much more flexible overall
programming experience - different toolset, and better support
for "exploratory programming" as you learn about the problem
domain.
Measuring differences in productivity across cultures is
tricky. In my experience, folks just end up scratching
their heads at the other camp and thinking, "But that's not
even a part of my universe." That said, I would be interested
in evaluating an attempt to tackle this hard problem.
Another talk centered on the notion that the purpose of
type checking is, at one level, to distinguish 'good'
programs from 'bad' ones, for a particular definition of
those evaluative terms. In the usual sense of static
typing, good programs pass the type checker, and bad
programs do not. The presumption of strongly, statically
typed languages is that the first step toward being a good
program is passing the type checker. This presumption
can get in the way sometimes. I remember my frustration
when learning Haskell: I would write a mutually recursive
function that executed correctly for all inputs, but the
Haskell type inference system refused to accept the definition
because it could not infer the types of the inductive data
elements. Writing those type definitions by hand proved
difficult or impossible.
(Don't take this remark about Haskell out of context,
though. It is a very cool language that can change how
you think about programs -- definitely worth the energy
to
go learn it!)
Defining 'good' and 'bad' programs in terms of passing
a type checker is potentially a very fine thing to do,
but it has important implications for how programmers
think about programs and programming. What if we decided
that the first step toward being a good program was something
else and then designed a tool to enforce that notion?
Programming might be quite different! In a sense, I think
that test-driven development is an example of just this sort
of thing. Passing a test is more important than making the
type checker happy. Working in dynamic languages such as
Scheme can feel that way, too -- the emphasis is not on
types but on passing test cases.
The talk that raised this idea about type systems went on
to describe an interesting idea: creating a type checker
that blends static and dynamic checks. The checker infers
as much as it can statically and then leaves the rest of
the type checks for run time.
And then you can either go back and tweak your source code
to provide more information, or you can go ahead and run
your program, knowing that some properties have been checked
statically (i.e., they are true for all possible runs of the
program) and some will be checked dynamically (i.e., the
program will terminate if a properties is discovered to be
false).
If Haskell had this sort of flexibility in its typing system,
then I would have been more inclined to use the language as
more than a learning and research vehicle.
Now that I have mentioned Haskell a couple of times, I will
close with one last comment from Andrew, about another of
the talks at the seminar:
The formal side of this talk was a little bit beyond me.
I have to concentrate when people discuss Monads formally.
I have to admit, with some sheepishness, that reading papers
and listening to talks about monads have always made
my head hurt. I don't know if this situation can be remedied
by the right sort of practice, or if it is merely a sign of
my fundamental cognitive limitations. In either case, I'm
content with my state for now.
Do you remember
this old Billy Crystal/Christopher Guest skit
from
Saturday Night Live?
The guys were janitors. When they ran into one
another, they would take turns describing to one
another accidents that had happened to them. The
first incidents in the exchange were the sort that
could happen to a working guy, such as "You know
when you're working in the shop and you hit your
thumb with a hammer?" But as the skit progresses,
the accidents become incidents of strange, self-inflicted
pain that could never happen accidentally, such as
"You know when stick your inside your car door and
just slam the door right on your head? That really
hurts." The unforgettable catch phrase of the skit
was this classic: "I *hate* when that happens."
Interval training
on a track can be like that. I imagine most non-runners
listening to me tell tales of my track work-outs and
thinking of me the way we all thought of Guest and
Crystal at the end of their skits. "I *hate* when that
happens." Well, duh. It's all quite funny, unless
your the guy with his head crushed by the car door.
When I run intervals, or repeats, I am trying to work
my body at the edge of its capabilities. As a result,
there is little margin for error or unexpectedness.
When things don't go as well as expected, the workout
can feel something like slamming a car door on my head
-- voluntarily, at 5:30 or 6:00 in the morning. I hate
when that happens.
Doing my 6x1200m workout this morning, I re-learned
what all good experimental scientists know: too many
free variables make it difficult to know why what happened
happened when what happened isn't what you expected.
What happened? I came up way short today. I was trying
to run each repeat in 4:52 or less. The first was tough
but right on mark. The second slowed down by 3 seconds
and felt bad enough that I decided to jog lightly through
the third. When I ran the fourth, I slowed down another
2 seconds and realized that I was going to be able to
meet my goal for the day. In place of the fifth and sixth
repeats, I chose to alternate faster laps with slower
ones, in hopes of not turning the day into just another
slow jog.
But why did this happen? Here are some possibilities:
I tried to do too many repeats.
I tried to run each repeat too fast.
I ran too short a recovery period in between repeats.
I wasn't ready to run my repeats outdoors on the
400m track just yet.
My repeats were too long because I was not running
the inside lane of the track.
I am still feeling lingering effects of my
recent half marathon,
two hard workouts last week too soon after the half,
and a moderately fast 14-miler on Sunday?
Running outside itself wasn't likely the problem, though
the nature of the feedback is different. Attempting six
repeats wasn't likely the problem, either, because the
problem wasn't with Repeat 6; it was Repeat 3, or even #2.
I think the most likely explanation is the combination
of three variables. First, my legs are still tired
from last week. Second, I tried running 400m recoveries
instead of the more ordinary 600m (50% of the repeat
distance). I will try to remedy those next week.
Finally, and perhaps most important, I now realize that
I was running repeats longer than 1200m. Last week's
4:53 repeats were right at my target distance, because
I was running to lane markers on the indoor track. This
morning, I was running three laps in Lane 4 of the 400m
outdoor track. Four laps in Lane 4 is actually about
1.05 miles, so my three laps work out as a little over
1266m. That extra 66m is enormous when it comes
to running at my limits. To do my target 1200m pace, I
should have allowed myself an extra 16 seconds on each
repeat!
The idea that my laps were longer than planned didn't
occur to me at all until I was out on the track, slogging
through laps, asking myself, "But why?" I *hate* when
that happens.
I should have taken the feedback from my body at face
value and adapted my pace. Whatever the reason, I was
not going to be able to do 1:37 laps, so I should have
eased off to a pace that I could sustain. Instead, I
despaired a bit and gave up on a couple of the repeats.
Note to self: Feedback is good; use it to get better.
Multiply these three factors together, and you get a
workout that does not go as planned.
Then again, in retrospect, maybe my times weren't so
bad after all. After crunching the numbers, I think
that I can safely conclude that I was simply trying to
run too fast.
Unfortunately, things don't usually turn out so tidily.
Ordinarily, I wouldn't know for certain the reason that
the workout that did not go as planned, because I put
too many variables into play. What I don't want to do
is use my good fortune this week as rationalization for
making the same mistake next week.
My excuse, er, reason, for changing so many things at
once is that training time is precious. From last
Sunday, I had exactly 13 weeks until the
Twin Cities Marathon.
If I hope to meet my race goals, I need to make steady
and rapid progress in my workouts.
That is just the sort of reason that we software
developers use to convince ourselves and our clients
that we need to shove more and more features into the
next release. It's the same excuse that teachers tell
themselves and their students when they try to squeeze
just one more topic into the already crowded
syllabus of a course. The results are similar, too.
The developers and instructors often fail to achieve
their goals; software clients and students are left
holding the bag. And then in the end, we are left
asking ourselves why.
Of course, this morning's experience also taught me
another lesson: do my homework better when it comes to
computing repeat distances on the track. "Do your
homework" is, of course, also a fine piece of advice
for software developers, software clients, teachers,
and students alike. :-)
A week or so ago, I ran across Adam Connor's blog entry
What do we know about teaching programming skills?.
I wanted to respond immediately, either in a comment
there or in a more complete essay here. But then I
realized: I don't have anything succinct to say. As
much as I think about teaching programming, and discuss
it with friends, and write about facets of it here,
I don't have a broadside that I can offer to folks
like Adam who seek a concise, straightforward introduction
to what we know about teaching programming. This
realization disappointed me.
For now, I can offer only a few points that seem to
be recurring themes in how I understand how to teach
programming. Later I will write up something that
Adam and people in his position can use right away.
Whether that will be in time to help Adam much, I
don't know...
In no particular order:
Concrete examples matter.
Practice, practice, practice!
Reading code helps us to write better code.
Expert programmers work top-down and bottom-up,
but novices seem to learn best when working
bottom-up first.
Students learn patterns of programs, whether or
not you think about them or teach them explicitly.
You are better suited to design your examples
and instruction around the patterns you want
them to learn, and then help them to name the
patterns. A side benefit: you and your students
will share a growing design vocabulary!
Read what you can by folks like Eliot Soloway
and Robert Rist to learn about the educational
psychology of programming.
That's a start. You know what they say: start small,
then grow.
This spring I was asked to participate on a panel at
XP2005,
which recently wrapped up in the UK. This
panel
was on agile practices in education, and as you may
guess I would have enjoyed sharing some of my ideas
and learning from the other panelists and from the
audience. Besides, I've not yet been to any of the
agile software development conferences, and this seemed
like a great opportunity. Unfortunately, work and
family duties kept me home for what is turning out to
be a mostly at-home summer.
In lieu of attending XP2005, I've enjoyed reading blog
reports of the goings-on. One of the highlights seems
to have been Laurent Bossavit's
Coding Dojo workshop.
I can't say that I'm surprised. I've been reading
Laurent's blog,
Incipient(thoughts),
for a while and exchanging occasional e-mail messages
with him about software development, teaching, and
learning. He has some neat ideas about learning how
to develop software through communal practice and
reflection, and he is putting those ideas into practice
with his dojo.
The Coding Dojo workshop inspired Uncle Bob to write
about the notion of
repeated practice
of simple exercises. Practice has long been a theme
of my blog, going back to
one of my earliest posts.
In particular, I have written several times about
relatively small exercises that Joe Bergin and I call
etudes,
after the compositions that musicians practice for
their own sake, to develop technical skills. The
same idea shows up in an even more obviously physical
metaphor in Pragmatic Dave's programming
katas.
The kata metaphor reminds us of the importance of
repetition. As Dave wrote in
another essay,
students of the martial arts repeat basic sequences
of moves for hours on end. After mastering these
artificial sequences, the students move on to "kumite",
or organized sparring under the supervision of a master.
Kumite gives the student an opportunity to assemble
sequences of basic moves into sequences that are
meaningful in combat.
Repeating programming etudes can offer a similar
experience to the student programmer. My re-reading
of Dave's article has me thinking about the value
of creating programming etudes at two levels, one
that exercises "basic moves" and one that gives the
student an opportunity to assemble sequences of
basic moves in the context of a more open-ended
problem.
But the pearl in my post-XP2005 reading hasn't been
so much the katas or etudes themselves, but one of
the ideas embedded in their practice: the act of
emulating a master. The martial
arts student imitates a master in the kata sequences;
the piano student imitates a master in playing
Chopin's etudes. The practice of emulating a master
as a means to developing technical proficiency is
ubiquitous in the art world. Renaissance painters
learned their skills by emulating the masters to
whom they were apprenticed. Writers often advise
novices to imitate the voice or style of a writer
they admire as a way to ingrain how to have a voice
or follow a style. Rather than creating a mindless
copycat, this practice allows the student to develop
her own voice, to find or develop a style that suits
their unique talents. Emulating the master
constrains the student, which frees her
to focus on the elements of the craft without the
burden of speaking her own voice or being labeled as
"derivative".
Uncle Bob writes
of how this idea means just as much in the abstract
world of software design:
Michael Feathers has long pondered the concept of
"Design Sense". Good designers have a "sense" for
design. They can convert a set of requirements into
a design with little or not effort. It's as though
their minds were wired to translate requirements to
design. They can "feel" when a design is good or
bad. They somehow intrinsically know which design
alternatives to take at which point.
Perhaps the best way to acquire "Design Sense" is
to find someone who has it, put your fingers on top
of theirs, put your eyeballs right behind theirs,
and follow along as they design something. Learning
a kata may be one way of accomplishing this.
Watching someone solve a kata in a workshop can give
you this sense.
Participating in a workshop
with a master, perhaps as programming partner, perhaps
as supervisor, can, too.
The idea isn't limited to software design. Emulating
a master is a great way to learn a new programming
language. About a month ago, someone on the
domain-driven design mailing list
asked about learning a new language:
So assuming someone did want to want to learn to think
differently what would you go with? Ruby, Python,
Smalltalk?
Ralph Johnson's
answer echoed the importance of working with a master:
I prefer Smalltalk. But it doesn't matter what I prefer.
You should choose a language based on who is around you.
Do you know somebody who is a fan of one of these languages?
Could you talk regularly with this person? Better yet,
could you do a project with this person?
By far the best way to learn a language is to work with
an expert in it. You should pick a language based on
people who you know. One expert is all it takes, but
you need one.
The best situation is where you work regularly with the
expert on a project using the language, even if it is only
every Thursday night. It would be almost as good if you
would work on the project on your own but bring code
samples to the expert when you have lunch twice a week.
It is possible to learn a language on your own, but it
takes a long time to learn the spirit of a language unless
you interact with experts.
Smalltalk or Scheme may be the best in some objective
(or entirely subjective!) sense, but unless you can work
with an expert... it may not the right language for you,
at least right now.
As a student programmer -- and aren't we all? -- find
a person to whom you can "apprentice" yourself. Work
on projects with your "master", and emulate his style.
Imitate not only high-level design style but also those
little habits that seem idiosyncratic and unimportant:
name your files and variables in the same way; start
your programming sessions with the same rituals. You
don't have to retain all of these habits forever, and
you almost certainly won't. But in emulating the master
you will learn and internalize patterns of practice,
patterns of thinking, and, yes, patterns of design and
programming. You'll internalize them through repetition
in the context of real problems and real programs, which
give the patterns the richness and connectedness that
make them valuable.
After lots of practice, you can begin to reflect on
what you've learned and to create your own style and
habits. In emulating a master first, though, you will
have a chance to see deeper into the mind and actions
of someone who understands and use what you see to
begin to understand better yourself, without the
pressure of needing to have a style on your own yet.
If you are a computer scientist rather than a programmer,
you can do much the same thing. Grad students have been
doing this as long as there have been grad students.
But in these days of the open-source software revolution,
any programmer with a desire to learn has ample opportunity
to go beyond the Powerbook on his desk. Join an
open-source project and interact with a community of
experts and learners -- and their code.
And we still have open to us an a more traditional avenue,
in even greater abundance, literature. Seek out a writer
whose books and articles can serve in an expert's stead.
Knuth, Floyd, Beck, Fowler... the list goes on and on.
All can teach you through their prose and their code.
Knowing and doing go hand in hand. Emulating the masters
is an essential part of the path.
One thing I have noticed in my last few weeks preparing
to
move into the Big Office Downstairs:
I view the actions of the administrators around me in a
different light. Where I might have reacted immediately
to some behavior, often negatively, I now am a bit more
circumspect. What could make that seem the right thing
to do? If nothing else, I am aware that I will soon be
in the position of having to make such decisions, and
it probably looks easier to do than it is. Kind of like
playing
Jeopardy!
from the comfort of your own home... even
Ken Jennings
is an easy mark when you're sitting on your sofa.
Swapping roles is a great way to develop empathy for
others. This is certainly true for students and teachers.
I do't know how many students who, after having to teach
a short course at work or having to lecture in place of
a traveling advisor, have told me, "I never knew how hard
your job was!" Those students tend to treat their own
instructors differently thereafter.
Playing many different roles on a software team can serve
a similar purpose. Developers who have tested or documented
software often appreciate the difficulties of those jobs
more than "pure" developers. Of course, playing different
roles can help software people do more than develop empathy
for their teammates; it can help them build skills that help
them do all the jobs better. Writing and testing code come
to my mind first in this regard.
Empathy is a good trait to have. I hope to have more of it
-- and put it to good use -- as a result of my new experience.
Friday was my wife's and my 16th wedding anniversary.
To celebrate, we went out for lunch prepared by a
well-known local chef, put on at the
Waterloo Center for the Arts.
We had the pleasure of dining with Cedar Falls author
Nancy Price,
her daughter, and her son-in-law. Ms. Price is most
famous for her novel Sleeping with the Enemy,
which was made into a
major motion picture
starring Julia Roberts. Her father, Malcolm Price,
was president of my university back in the 1940s.
As is often the case, when these folks found out that
I am a computer scientist, they eagerly shared their
views on how programs help and hinder them in their
jobs. All three have plenty of experience with
computers, though as relatively non-technical users.
The daughter and son-in-law hold Ph.D.s and write
as a part of their jobs. The son-in-law, a botanist,
claims to have been the first person in his department
at Cal-Berkeley to produce his dissertation using a
word processor.
Ms. Price herself writes, and so her computer is a big
part of her professional life. She wasn't shy in telling
me that, in her experience, software still doesn't support
her work very well. "Available programs just don't do
a very good job helping an author work with a four- or
five-hundred page document."
The ensuing conversation led me to several questions.
What programs do authors use these days? Microsoft
Word is the de facto standard, I suppose, as it seems
to be the de facto word-processing standard everywhere
these days. As a faculty member, I have long tilted at
windmills in an attempt to eliminate the Word .doc as the
standard interchange format. I have heard from colleagues
who've written books using Word, and they tell stories of
annoying little quirks. But these days many publishers
seem to be using Word, at least as the interface with
their authors.
I wasn't much help to my lunch partners in this regard,
as I hang with a technical crowd that likes to get their
hands dirty when writing. I wrote my dissertation using
WordPerfect, and I did have to fight the system on issues
such as pagination and figure placement. Some still use
Framemaker, though that seems to be losing mindshare. The
academic standard has long been LaTex, which has the author
write at the lowest level in plain text. These days,
software folks are as likely to roll their own authoring
systems,
writing with XML
and creating custom solutions to their own problems,
such as
writing source code in text.
But that isn't an option for most writers, who just want
a program that lets them do what comes naturally.
What should a novelist's workbench look like? What should
it do? Googling on
novelists software
brings up lots and lots of tools, mostly for Windows.
I don't have any good sense for what, if anything, these
programs offer an author that a standard word processor
doesn't have. When I examine my own writing needs, I
usually end up thinking about technical problems such
as source code in text that have no meaning to a poet
or novelist. I guess I should find a project working
with a writer to produce such a program -- that's always
the best way for me to learn about the needs of a domain,
by writing programs for the experts.
Who would produce such a product? Ms. Price offered an
answer, based only on an anecdote from a writing colleague.
She said that he had spent some time working with a
software company in an effort to find out why there
weren't better programs for writers out there. He had
reported back, she related with a playful smile, that the
programs were only mediocre because there was no money to
be made -- authors simply weren't a big enough or rich
enough market to drive a software niche.
This is the sort of cynical attitude that we software
folks often encounter when we talk to users out in the
world. I think it should bother us more than it sometimes
does. Why are we willing, if not content, to let people
think that we are unwilling or incapable of meeting the
needs of users?
Actually, a program for writers seems like the perfect
sort of task for a small, specialty software house. My
Google link earlier certainly indicates that a lot of
small developers are in play. I doubt that the market
could support an expensive program, but the right product
might be able to attract enough volume to be lucrative
enough. I don't imagine that this program would be a
huge technical challenge to a software developer, which
would leave plenty of energy for adapting the program and
creating a wonderful interface.
One last note from lunch. Our dining partners expressed
great surprise that I, a computer scientist, am a Mac user.
"I didn't figure they'd let you use a Mac in a CS department,"
the botanist said. I explained that I've been a Mac man
since graduate school in the 1980s, though I've also been
a Unix user for just as long. Now that Mac OS is a Unix,
I explained, my tools are quite in vogue. "Even the Linux
geeks will talk to me now!" If I'd had more time and an
inclination to ramble on, I'd've told them how so many
high profile folks in the software world use Macs these
days. But they didn't seem to be sold on the virtues of
a Mac, and lunch time was winding down.
I enjoyed our lunch and conversation and was reminded
that we computer scientists and software developers
can find interesting questions almost everywhere we
go, just by talking to users of the programs we write.
This isn't (just) a running post, though it starts
with a running story.
This morning, I did my last speed workout before the
half marathon
I will run in 11 days. I have not yet started back
to real interval training since
my marathon last October,
Instead, I have been focusing on sustaining speed over
longer distances. I would ordinarily have run 8 miles
today at something just under 7:00/mile. With the
half-marathon looming, I decided to test myself a bit
and try to run 10 miles at 7:00/mile. In an ideal
world, I would run that pace in my race. For my
workout, I'd be slowing down a bit to target race pace
but sustaining the pace for a longer stretch. It's
good to train the body and mind to recognize and hold
your target pace, so I was hoping to run all of my
miles this morning in about the same time, between
6:50-6:54/mile.
Going from 8 miles to 10 at a challenging pace may not
seem like all that much, but it is a challenge. Usually,
I finish my 8-mile workout pretty well spent, often
having to work hard over the last three miles to keep
the pace up. Where would I get the extra energy, both
physical and mental, to go as fast for longer?
In some ways, the physical part is the easier of the
two. You can usually do more physically than you think.
When a person tells me, "I can't even jog a block", I
usually think they could. It might well hurt a bit,
but they could do it. There muscles are more powerful
than they realize. Since getting into better shape, I
have often been surprised that my body could do more
than I expected of it.
The mental energy is another story. Even if my body can
handle 10 miles at race pace, it will beginning feeling
the stress much sooner. I knew that my body would be
talking back to me this morning -- "Why? Why?" -- by
the six or seventh mile. Being able to keep the faith
and keep the pace becomes a mental challenge, answering
the calls of fatigue and pain with energy found elsewhere.
How did I manage? I think that the key was having a
fixed and realistic target for the run. 10 miles isn't
that much more than 8, so I know that my body
can do it. Knowing that I only had to put together two
more miles allowed my mind to adjust to the small increment
before the run began. When I started to feel the workout
in its seventh mile, my mind was ready... "Just a couple
of more miles. Focus on the pace of individual laps.
It's only two miles beyond what you usually do." Then,
when I reached the 8-mile mark and my body mostly felt
like stopping, I could say to myself, "Just a couple
of more miles. You just did two tough ones. Will these
really be any harder?" They weren't. My body could do it.
I don't actually conduct this internal dialogue all that
much as I run, only in the moments when my focus shifts
away from the lap I'm running to the seemingly vast number
of laps that remain. I can't run those laps yet; all I
have is this one.
I think it's a game of expectations.
With reasonable expectations, the mind can help you do
more than otherwise would be comfortable. An important
part of reasonableness is duration--this only works well
in the short term. Had I tried to run a full 13 miles
this morning at race pace, my mind may have failed me.
My body is still recovering from
recent 5K
and a 12-mile weekend run, and so it would begin to
complain with increasing fervor as the miles added up.
And I doubt that my spirit would have been strong enough
to win the battle, because doing a 13 miles at race pace
isn't reasonable for this day. But with a reasonable
short-term expectation, I was able to handle crunch time
with that short-term horizon in mind.
I've written about sustainable pace before, including
about what happens when I
try to go faster than a sustainable pace
for too long and how software developers might
train for speed.
(I've even referenced sustainable pace in the context
of a
Bill Murray film.)
But the idea has been on mind again lately in a
different way. The pace that is sustainable is
closely tied to one's expectations about its endurance.
This mental expectations game applies in running, but
it also applies in other human endeavors, including
software development.
A recent thread on the XP mailing list considered the
proposition that
"crunch mode" doesn't work.
There didn't seem to be many folks defending the side
that crunch mode can work. That's because
most people were thinking about sustainable pace over
the long run, which is what agile folks tend to mean
when they talk about pace. They do so for good reason,
because the danger in software development has usually
been for companies to try to overdo it, to push developers
too far and too fast, with the result being a decrease
in software quality and ultimately the burn-out of the
developers.
At least one person, though,
argued that crunch mode can work.
The gist of SirGilligan's claim is that a software team
can go faster and still do quality work -- but only for
a well-defined short term. He even used a running metaphor
in defining such a crunch time: We are not 1/3 along
the way, we are in the straight-a-way and heading for the
finish line. How can developers win the expectations
game in such a scenario? The end is clearly in sight:
Pending features are well defined. Order of feature
implementation is defined. Team is excited for the
chance to deliver. It is the team's choice and idea
to crunch, not some manager's idea. We enter crunch
mode! After we deliver everyone gets the following
Friday and Monday off for a four-day weekend!
That sounds an awful lot like what a runner does when
she races a marathon or half-marathon faster than she
thinks otherwise possible. The pending goal is
well-defined. The runner is excited to deliver. She
chooses to push faster. And, after the race, you take
a few days off for rest. A party, of course, is always
in order!
I think the great ones are able to manage their
expectations in a way that allows them to do more than
usual for a short while. The good news for the rest of
us is that we can learn to do the same, which gives us
the ability to succeed in a wider variety of circumstances.
Just always keep in mind: You can't keep going faster
indefinitely.
As I think I've mentioned here before, I am a big fan of
Electron Blue,
a blog written by a professional artist who has taken up
the study of physics in middle age. Her essays offer
insights into the mind of an artist as it comes into
contact with the abstractions of physics and math.
Sometimes, the two mindsets are quite different, and
others they are surprisingly in tune.
I just loved this line, taken from
an essay
on some of the similarities between a creator's mind and
a theoretical scientists:
When I read stuff about dark energy and string theory and
other theoretical explorations, I sometimes have to laugh,
and then I say, "And you scientists think that we artists
make things up!"
Anyone who has done graduate research in the sciences
knows how much of theory making is really story telling.
We in computer science, despite working with ethereal
computation as our reality, are perhaps not quite so
make-believe as our friends in physics, whose efforts
to explain the workings of the physical world long ago
escaped the range of our senses.
Then again, I'm sure some people look at XP and think,
"It's better to program in pairs? It's better
to write code with duplication and then 'refactor'?
Ri-i-i-i-ght." What a story!
Last week, I posted a note on a cool consequence
of Smalltalk being written in Smalltalk, the
ability to change the compiler
to handle new kinds of numeric literals. Here
is another neat little feature of Smalltalk:
You can quit the interpreter in the middle
of executing code, and when you start back up the
interpreter will finish executing the code!
Consider this snippet of code:
Smalltalk snapshot: true andQuit: true. ... code to execute at next start-up, such as:
PWS serveOnPort: 80 loggingTo: 'log.txt'
If you execute this piece of code, whether as a
method body or as stand-alone code in a workspace,
it will execute the first statement -- which
saves the image and quits. But in saving the
image, you save the state of the execution, which
is precisely this point in the code being executed.
When you next start up the system, it will resume
write where it left off, in this case with the
message to start up a web server.
How I wish my Java environments did this...
This is another one of those things that you want
Java, Perl, Python, and Ruby programmers to know
about Smalltalk: it isn't just a language; it is
a living system of objects. When you program in
Smalltalk, you don't think of building a new program
from scratch; you think of molding and growing the
initial system to meet your needs.
This example is from
Squeak,
the open-source Smalltalk I use when I have the
chance to use Smalltalk. I ran across the idea
at
Blaine Buxton's blog,
and he found the idea in a Squeak Swiki entry for
running a Squeak image headless.
(A "headless image" is one that doesn't come up
interactively with a user. That is especially
useful for running the system in the background
to drive some application, say a web server.)
Modern invention has been a great leveler.
A machine may operate far more quickly
than a political or economic measure to
abolish privilege and wipe out the distinctions
of class or finance.
-- Ivor Brown, The Heart of England
I finally read Paul Graham's newest essay,
Hiring is Obsolete,
this weekend. I've been thinking about the place
of entrepreneurship in my students' plans recently
myself. When I gave my interview presentation to
our faculty when applying to be department head,
I talked about how -- contrary to enrollment trends
and popular perception -- this is the best
time ever to go into computer science. One of the
biggest reasons is the opportunity for ambitious
students to start their own companies.
The engineering staff at Google threw a big party
for Silicon Valley nerds last Thursday night [May 5],
...
Larry Page, one of the founders, gave an inspiring talk
about what a great time this is to be an engineer. He
recalled how at one point Google had five employees and
two million customers. Outside of Internet applications
it is tough to imagine where that would be possible.
Page also talked about the enjoyment of launching something,
getting feedback from users, and refining the service on
the fly. ...
This sounds like the same sort of experience that Graham
touts from ViaWeb.
Admittedly, not every start-up will be a
ViaWeb
or a
Google,
but that's not the point. The ecosphere is rife with
opportunities for small companies to fill niches not
currently being served by larger companies. Not all
such companies are doing work specifically for the
web, but the web makes it possible for them to make
their products visible and available. The web
reduces a company's need for some of the traditional
trappings of a business, such as a large, dedicated
sales staff.
The sort of entrepreneurship Graham touts is more
common in
Silicon Valley and the Route 128 corridor,
and more generally in large metropolitan areas, but
Grahams's advice applies even here in the
Great Midwest
-- no, not "even here", but especially here.
The whole point of the web's effect on business is
that almost anyone almost anywhere can now create a
business that does something no one else is doing,
or does something others are doing but better, make
a lot of money. Ideas and hard work are now more
important than location or who you know.
UNI students have had a few successes in this regard.
I keep in close touch with one successful entrepreneur
who is former student of ours. When he was a student
here, he already exhibited the ambition that would
lead to his business success. He read broadly on the
web and software and technology. He asked questions
all the time. By the time he left UNI, he had already
started a web hosting company with a vision to do things
differently and better. I love to visit his place
company, give whatever advice I can still give, and
learn from him and what he is doing.
Back in the old days, most people would have moved to
New York or San Francisco in order to start his first
company -- because that's "where the action was". I'm
sure that some people told him that he should move to
Chicago or at least Minneapolis to have a chance to
succeed. But he started his company right here in
little ol' Cedar Falls, Iowa, and did just fine. He
can enjoy the life available in a small city in a
relatively rural part of America. His company's
building is ten feet from a paved bike trail that
circles a small lake and connects into a system of
miles and miles of trails. His margins can be lower
because his costs of doing business are lower. And
working with the growing tech community here he can
dream as big as he likes and is willing to work.
This guy hasn't made it big like Graham or Page or
Gates, but he is one example of the bountiful
opportunities available to students studying at
schools like UNI throughout the world. And he could
never have learned as much or done as much if he had
followed the steady flow of our students to the big-box
insurance companies and service businesses that hire
most of our students.
How can we -- instructors and the world at large --
help students appreciate that the "cage is open",
as Graham describes the Brave New World of business?
The tendency of most university professors is to offer
another course :-). When I was a grad student at
Michigan State,
I sat in on a course during my last quarter that was
being offered jointly by the Colleges of Engineering
and Business to teach some essential skills of the
entrepreneurial engineer. I wish that it had come
earlier in my studies because by then my mind was
set on either going corporate (AI research with a
big company like Ford or Price Waterhouse) or going
academic.
There is certainly some value in incorporating this
kind of material into our curricula and maybe even
offering stand-alone courses with an entrepreneurial
bent. But this transition in how the world works is
more about attitude and awareness than the classroom.
Students have to think of starting a company in the
same they think of going to work for IBM or going to
grad school, as a natural option open to everyone.
Universities will serve students better by making
starting their own companies a standard part of how
we talk about their futures and of the futures we
expose them to.
There are some particular skills that universities
need to help students develop, beyond what we teach
now. First and foremost is the ability to identify
problems with economic potential. We are pretty
good at helping students learn to identify cool problems
with academic potential, because that's what we do when
we do our own research. But a problem of basic academic
interest rarely results in a program or service that
someone would pay for, at least not enough someones to
make it reasonable as the basis for a commercial venture.
Graham gives some advice in his various essays on this
topic, and the key almost always comes down to "Know
users." Only by observing carefully people who are doing
real work are we likely to stumble upon those inefficiencies
that they would be willing to pay to make go away.
Eric Sink
has also written some articles useful to folks who are
thinking about starting their own software house.
The other things we teach students are still important,
too. A start-up company needs programmers, people who
know how to develop software well and who have strong
analytic skills. "The basics" such as data structures,
algorithms, and programming languages are still the
basics. Students just need to have a mindset in which
they look for ways to use these skills to solve real
problems that real users have -- problems that no one
else is solving for them yet.
Hiring is Obsolete
has more to say than just that students should consider
being entrepreneurs. In particular, Graham talks about
the opportunities available to large companies in an
ecosphere in which start-ups do initial R&D and identify
the most capable software developers. But I think that
these big companies will take care of themselves. My
interest is more in what we can do better in the university,
including what we can do to get folks to see what a
wonderful time this is to study computer science.
I think I should take my next sabbatical working for one
of my former students...
I recently made a bittersweet decision: I am
not going to renew my membership in
AAAI.
The AAAI is the American Association for Artificial
Intelligence, and I have been a member since 1987,
when I joined as a graduate student.
Like many computer scientists who grew up in the '70s
and '80s, AI was the siren that lured me to computing.
Programs that could play chess, speak and understand
English sentences, create a piece of music; programs
that could learn from experience... so many
tantalizing ideas that all lay in the sphere of AI.
I wanted to understand how the mind works, and how I
could make one, if only a pretend one in the silicon
of the rather inelegant machines of the day.
I remember when I first discovered
Gödel, Escher, Bach
and was enchanted even further by the idea of
self-reference, by the intertwining worlds of music,
art, mathematics, and computers that bespoke a
truth much deeper than I had ever understood before.
The book took me a whole summer to read, because every
few pages set my mind whirling with possibilities that
I had to think through before moving on.
I did my doctoral work in AI, at the intersection of
knowledge-based systems and memory-based systems, and
reveled in my years as a graduate student, during which
the
Turing Test
and
Herb Simon's
sciences of the artificial and cognitive science were
constant topics of discussion and debate. These ideas
and their implications for the world mattered so much
to us. Even more, AI led me to study psychology and
philosophy, where I encountered worlds of new and
challenging ideas that made me a better and more
well-rounded thinker.
My AI research continued in my early years as an
assistant professor, but soon my interests and the
needs of my institution pulled me in other directions.
These days, I think more about programming support
tools and programming languages than I do AI. I
still love the AI Enterprise but find myself on the
outside looking in more often than not. I still love
the idea of machine learning, but the details of modern
machine learning research no longer enthrall me. Maybe
the field matured, or I changed. The AI that most
interests me now is whatever technique I need to build
a better tool to support programmers in their task.
Still, a good game-playing program still draws my
attention, at least for a little while...
In any case, the idea of paying $95 a year to receive
another set of printed magazines that I don't have time
to study in depth seems wasteful of paper and money
both. I read some AI stuff on the web when I need or
want, and I keep up with what my students are doing
with AI. But I have to admit that I'm not an AI
scientist anymore.
For some reason, that is easier to be than to say.
I have had
this link
and quote in my "to blog" folder for a long time:
... the one thing that a Ruby (or Python) programmer should
know about Smalltalk is, it's all written in Smalltalk.
But I wanted to have a good reason to write about
it. Why does it matter to a Smalltalker that his
language and environment are implemented in Smalltalk
itself?
Today, I ran across a
dynamite example
that brings the point home. David Buck
... was working for a company once that did a lot
of work with large numbers. It's hard, though,
to write 45 billion as 45000000000. It's very
hard to read. Let's change the compiler to accept
the syntax 45b as 45 billion.
And he did it -- by adding six
lines of code to his standard working environment
and saving the changes. This is the sort of openness
that makes working in Java or most any other ordinary
language feel like pushing rocks up a mountain.
Lisp and Scheme read macros give you a similar
sort of power, and you can use regular macros to
create many kinds of new syntax. But for me,
Smalltalk stands above the crowd in its pliability.
If you want to make the language you want to use,
start with Smalltalk as your raw material.
Customers have a tendency to become like
the kind of customers you treat them.
Ben related the quote as a commentary on trust in commerce.
(Trust and social relationships are ongoing themes of his
blog.) He notes that he has observed this truth in many
situations. I have, too. Indeed, I think this truth
applies in almost all human relationships.
(Like all generalizations, this one isn't foolproof, so
feel free to prefix each of the following claims with
"by and large" or your favorite waffle words.)
Parents and Children
Children grow into the people you expect them to be.
The best sort of discipline for most children is to
create an environment in which children know what your
expectations are, and then live consistently in that
way. Nagging youngsters doesn't work; they come to
expect you to nag before they know you care about
something. Yelling and screaming don't work, either;
they come to think that you don't believe they can
behave without being verbally assaulted. If you simply
set a standard and then live as if you expect them to
meet the standard, they will. When they don't, don't
resort to needy negative reinforcement. Usually they
know they've fallen short and strive to do better the
next time.
Teachers and Students
Students become what their teachers expect of them,
too. If you act as if they are not trustworthy, say,
by creating elaborate rules for late work, cheating,
and grading, they will soon look for ways to game the
system. If you act as if they don't respect class
time, say, by wasting it yourself through lack of
preparation or rambling digression, they will soon
come not to value their time in class.
If you set a high standard and expect them to learn
and achieve, they usually will. If you
trust them with masterpieces,
they will come to value masterpieces.
Developers and Users
The quote applies to all sorts of developer/user
relationships. If software developers don't trust
their clients, then their clients will start to
look out for themselves at the developer's expense.
If an API designer acts as if programmers are not
smart or reasonable enough to use the API wisely,
and so creates elaborate rituals to be followed to
ensure that programmers are doing the right thing,
then programmers will look for ways to game the
API. The result is hacks that confirm the API
designer's expectations.
Agile methods place a high premium on developing a
mutually beneficial relationship between the client
and the programmer. The result is that programmers
and clients feel free to be what they should be to
one another: partners in creating something valuable.
Managers and Team Members
This truth is a good thing to keep in mind for someone
embarking on an administrative or managerial position.
When "bosses" treat their "employees" as adversaries
in a competition, the employees soon become adversaries.
They do so almost out of necessity, given the power
imbalance that exists between the parties. But if
a manager approaches the rest of the team with
openness, transparency, and respect,
I think that most members of the team will also
respond in kind.
Husbands and Wives
All of the relationships considered above are
hierarchical or otherwise imbalanced. What about
peer relationships? I think the assertion still
holds. In my many years of marriage, I've noticed
that my wife and I often come to behave in the way
we think our spouse expects. When one of us acts
as if the other is untrustworthy, the other comes
to protect his or her own interest. When one of us
acts as if the other is incapable of contributing
to a particular part of our lives together, the
other stops caring to contribute. But when we act
as if we are both intelligent, trustworthy, caring,
and respectful, we receive that back from each other.
----
Given its wide range of applicability, I think that
the truism needs to be restated more generally.
Perhaps:
People tend to become like the kind of people
you treat them to be.
Or maybe we can restate it as a new sort of Golden
Rule:
Treat people like the kind of people you want --
or expect -- them to be.
Or perhaps "Do unto others as you expect them to be."
Leave it to the guys from Google to offer the
Summer of Code
program for students. Complete an open-source
project through one of Google's collaborators,
and Google will give you a $4500 award. The
collaborators range from relatively large groups
such as Apache and FreeBSD, through medium-sized
projects such as Subversion and Mono, down to
specific software tools such as Jabber and Blender.
Of course, the Perl Foundation, the Python Software
Foundation, and Google itself are supporting projects.
You can even work on open-source projects in Lisp for
LispNYC,
a Lisp advocacy group!
The program bears a strong resemblance to the Paul
Graham-led
Summer Founders Program.
But the Summer of Code is much less ambitious --
you don't need to launch a tech start-up; you only
have to hack some code -- and so is likely to have
a broader and more immediate effect on the tech
world. Of course, if one of the SFP start-ups
take off like Google or even ViaWeb, then the
effects of the SFP could be much deeper and longer
lasting.
This is another slick move from the Google image
machine. A bunch of $4500 awards are pocket change
to Google, and in exchange they generate great PR
and establish hefty goodwill with the open-source
organizations participating.
From my perspective, the best part of the Summer of
Code is stated right on its web page: "This Summer,
don't let your programming skills lie fallow...".
I give this advice to students all the time, though
they don't often appreciate its importance until the
fall semester starts and they feel the rust in their
programming joints. "Use it, or lose it" is trite
but true, especially for nascent skills that are not
yet fully developed or internalized.
Practice, practice, practice.
The Summer of Code is a great chance for ambitious
and relatively advance students to use this summer for
their own good, by digging deep into a real project and
becoming better programmers. If you feel up to it,
give it a try. But even if you don't, find some project
to work on, even if it's just one for your amusement.
Perhaps I should say especially if it's just
one for your amusement -- most of the great software
in this world was originally written by people who
wanted the end result for themselves. Choose a project
that will stretch your skills a bit; that will force
you to improve in the process. Don't worry about getting
stuck... This isn't for class credit, so you can take
the time you need to solve problems. And, if you
really get stuck, you can always e-mail your favorite
professor with a question. :-)
Oh, if you do want to take Google up on its offer, you
will want to hurry. Applications are due on June 14.
A couple of days ago, blog reader Mike McMillan sent
me a link to
Stanley Fish's
New York Times op-ed piece,
Devoid of Content.
Since then, several of my CS colleagues have recommended
this article. Why all the interest in an opinion piece
written by an English professor?
The composition courses that most university students
take these days emphasize writing about something:
current events, everyday life, or literature. But
Fish's freshman composition class does something much
different. He asks students to create a new language,
"complete with a syntax, a lexicon, a text, rules for
translating the text and strategies for teaching your
language to fellow students". He argues that the best
way to learn how to write is to have a deep understanding
of "a single proposition: A sentence is a structure of
logical relationships." His students achieve this
understanding by having to design the mechanisms by
which sentences represent relationships, such as
tense, number, manner, mood, and agency.
Fish stakes out a position that is out of step with
contemporary academia: Learning to write is about
form, not content. Content is not
only the not the point; it is a dangerous
delusion that prevents students from learning what
they most need.
Content is a lure and a delusion, and it should be
banished from the classroom. Form is the way.
Fish doesn't say that content isn't important, only
that it's should not be the focus of learning to
write. Students learn content in their science
courses, their social science courses, and their
humanities courses -- yes, even in their literature
courses.
(I, for one, am pleased to see Fish distinguish the
goals of the composition courses taught in English
departments from the goals of the literature courses
taught there. Too many students lose interest in
their comp courses when they are forced to write
about, oh, a
poem by Edna St. Vincent Millay.
Just because a student doesn't connect with
twentieth-century lyric poetry doesn't mean that he
shouldn't or can't learn to write well.)
So, how is Fish's argument relevant to a technical
audience? If you have read my blog much, you can
probably see my interest in the article. I like to
read books about writing,
to explore ways of writing better programs.
I've also written a little about the role form
plays in
evaluating technical papers
and
unleashing creativity.
On the other side of the issue, though, I have
several times recently about the role of
real problems
and
compelling examples
in learning to program. My time at ChiliPLoP 2005
was spent working with friends to explore some
compelling examples for CS1.
In the context of this ongoing discussion among
CS educators, one of my friends sloganized Fish's
position as "It's not the application, stupid;
it's the BNF."
So, could I teach my freshman computer programming
class after Fish's style? Probably not by mimicking
his approach note for note, but perhaps by adopting
the spirit of his approach.
We first must recognize that freshman CS students
are usually in a different intellectual state from
freshman comp students. When students reach the
university, they may not have studied tense and
mood and number in much detail, but they do have
an implicit understanding of language on which the
instructor can draw. Students at my university
already know English in a couple of ways. First,
they speak the language well enough to participate
in everyday oral discourse. Second, they know enough
at least to string together words in a written form,
though perhaps not well enough to please Fish or me.
My first-year programming students usually know
little or nothing about a programming language,
either as a tool for simple communication or in
terms of its underlying syntactic structures. When
Fish's students walk into his classroom, he can
immediately
start a conversation with them,
in a rich language they share. He can offer endless
example sentences for his students to dissect, to
rearrange, to understand in a new way. These sentences
may be context-free, but they are sentences.
In a first-year programming course, instructors
typically have to
spiral
our dissection of programs with the learning of
new language features and syntax. The more complex
the language, the wider and longer the spiral must
be.
Using a simple computer language might make an
approach like Fish's work in a CS1 course. I think
of the
How to Design Programs
project in these terms. Scheme is simple enough
syntactically that the authors can rather quickly
focus on the structure of programs, much as Fish
focuses on the structure of sentences. The HtDP
approach emphasizes form through its use of BNF
definitions and "design recipes". However, I
don't get the sense that HtDP removes content from
the classroom so much as it removes it from the
center of attention. Felleisen et al. still try
to engage their students with examples that might
interest someone.
So, I think that we may well be able to teach
introductory programming in the spirit of Fish's
approach. But is it a good idea? How much of the
motivation to learn how to program springs from the
desire to do something particular? I do
not know the answer to this question, but it lies
at the center of the real problems/compelling
examples discussion.
In an unexpected twist of fate, I was thumbing
through
Mark Guzdial's
new book, Introduction to Computing and
Programming with Python: A Multimedia Approach,
and read the opening sentences of its preface:
Research on computing education clearly demonstrates
that one doesn't just "learn to program." One learns
to program something [5,20], and the
motivation to do that something can make the difference
between learning and not learning to program [7].
(The references are to papers on situated learning
of the sort Seymour Papert has long advocated.)
I certainly find myself in the compelling problems
camp these days and so am heartened by Guzdial's
quote, and the idea embodied in his text. But I
also feel a strong pull to find ways to emphasize
the forms that will help students become solid
programmers. That pull is the essence of my interest
in documenting elementary programming patterns and
using them to gain leverage in the classroom.
Regardless of how directly we might use Fish's
approach to teach first-year courses in programming,
I am intrigued by what seems to me to be a much cleaner
connection between his ideas and the CS curriculum, the
traditional Programming Languages course! I'll be
teaching our junior/senior level course in languages
this fall, and it seems that I could adopt Fish's course
outline almost intact. I could walk in on Day 1 and
announce that, by the end of the semester, each group of
students will have created a new programming language,
complete with a syntax, a set of primitive expressions,
rules for translating programs, and the whole bit.
Their evolving language designs would serve as the
impetus for exploring the elements of language at a
deeper level, touching all the traditional topics
such as bindings, types, scope, control structures,
subprograms, and so on. We could even implement our
growing understanding in a series of increasingly
complex interpreters that extract behavior from
syntactic expressions.
Actually, this isn't too far from the approach that
I have
used in the past,
based on the textbook
Essentials of Programming Languages.
I'll need to teach the students some functional
programming in Scheme first, but I could then
turn students loose to design and implement
their own languages. I could still use the
EOPL-based language that I call Babel as my
demonstration language in class.
School's barely out for the summer, and I'm already
jazzed by a new idea for my fall class. I hope
I don't peak too soon. :-)
As you can see, there are lots of reasons that
Fish's op-ed piece has attracted the attention
of CS folks. It's about language and learning
to use it, which is ultimately what much of computer
science and software development are about.
Have you heard of Stanley Fish before? I first
ran into him and his work when I read a
blog entry by Brian Marick
on the role the reader plays in how we write
code and comments. Brian cited Fish's work
on reader-response criticism and hypothesized
an application of it to programming. You may have
encountered Fish through Brian's article, too, if
you've read
one of my oldest blog entries.
I finally checked the book by Fish that Brian
recommended so long ago out of the library today
-- along with another Fish book, The Trouble
with Principle, which pads my
league-leading millions total.
(This book is just for kicks.)
I ran across a neat little example of reflective
practice on the major league baseball diamond in
The Scholarly Rigor of Carlos Delgado.
Carlos is the first baseman for the Florida Marlins
in U.S. baseball's National League. He apparently
has the agile habit of recording detailed information
about every one of his at-bats in a notebook he keeps
with him in the dugout. By collecting this data, he
is able to derive feedback from his results and use
that to improve his future at-bats.
As the article points out, most professional sports
teams -- at least in America -- record all of their
performances these days and then mine the film for
information they can use to do better next time out.
Delgado, "like a medieval Benedictine at Monte Cassino",
is one of the few major leaguers who still use the
ancient technologies of pencil and paper to personally
track his own performances. The act of writing is
valuable on its own, but I think that as important is
the fact that Delgado reflects on his performance
immediately after the event, when the physical sensations
of the performance are still fresh and accessible to
his conscious mind.
How is this related to my previous post? I think that
we programmers can benefit from such a habit. If we
recorded the smells that underlay our refactorings for
a month or even a week, we would all probably have a
much better sense of our own tendencies as programmers,
which we could then feed back into our next code. And,
if we shared our experiences, we might develop an even
more comprehensive catalog of smells and refactorings
as a community. If it's
good enough for Donald Knuth,
it ought to work for me, too.
Agility works for Delgado, one of the better offensive
players in all of baseball. Knowing about his habit,
I'm even happier to have him as a member of my
rotisserie baseball team, the Ice Nine. :-)
Intentional Duplication
The
Zen Refactoring thread
on the XP mailing list eventually came around to the
idea deliberately creating code duplication. The
idea is this: It is easier first to write code that
duplicates other code and then to factor the duplication
out later than it is to write clean code first or to
refactor first and then add the new code.
I operate in this way most of the time. It allows me
to add a new feature to my code immediately, with as
little work as possible, without speculating about
duplication that might occur in the future.
Once I see the actual duplication, I make it go away.
Copy-and-paste can be my friend.
This technique is one way that you can refactor your
code toward suitable domain abstractions away from
primitive data. When you run into a situation where
you find yourself handling a tolerance in multiple
places,
Extract Class
does the trick. This isn't a foolproof approach,
though, as Chris Wheeler pointed out in
his article.
What happens when you have references to
mass-as-an-int in zillions of places and
only then does the client say, "Um, we allow
tolerances of 0.1g"? Good design and good refactoring
tools are your friend then.
> I have also sometimes created the duplication, and then
> worked to make the duplicated code as similar as possible
> before removing the duplication. Does anyone else do this?
I once saw Kent Beck do that in a most amazing way, but I haven't
learned the trick of making code look similar prior to removing
duplication; would love to see an example.
Now I have fodder for a new blog entry: to write up
a simple example of this technique that I use in my
freshman-level OOP programming course. It's a wonderful
example of how a little refactoring can make a nice
design fall out naturally.
How is this related to my previous post? Duplication is
one of my pet code smells, though I often create it
willingly, with the intention of immediately factoring
it out. Like Primitive Obsession, though you have to
learn to strike a proper balance between too little
and too much. Just right is hard to find sometimes.
Recently, Chris Wheeler posted a thoughtful blog
entry called
My Favourite Smells,
which described only one smell, but one every
OOP programmer knows deep in his soul: using
a primitive data type instead of a domain-specific
type. James Shore calls this smell
Primitive Obsession,
and Kevin Rutherford calls it
Primitive Feature Envy.
Chris has been justifiably lauded for starting a
conversation on this topic. I find this smell in my
programs and even in many of the programs I read from
good OOP programmers. When programmers are first learning
to write object-oriented programs, the tendency to write
code in terms only of the primitive data types is hard
to shake. Who needs that Piece class, when a
simple integer flag taking values from 1 to 4 will do
just fine? (Heck, we can always
use Hungarian Notation
to make the semantics clear. :-) When students come
to see the value of that Piece class, they
begin to see the value of OOP.
That said, we have to be careful to remember that this
smell is not an absolute indicator. There is an inherent
tension between the desire to create classes to model the
domain more closely and the desire to
do the simplest thing that could possibly work.
If I try to wrap every piece of primitive data in its
own class, I can very quickly create a lot of unnecessary
code that makes my program worse, not better. My program
looks like it has levels of abstraction that simply aren't
there.
That's not the sort of thing that Chris, James, and Kevin
are advocating, of course. But we need to learn how to
strike the proper balance between Primitive Obsession
and Class Obsession, to find the abstractions that
make up our domain and implement them as such. I think
that this is one of the reasons that Eric Evans' book
Domain-Driven Design
is so important: it goes a long way toward teaching us
how to make these choices. Ultimately,
though, you can only grok this idea through experience,
which usually means doing it wrong many times in both
directions so that your mind learns the patterns of
good designs. As Chris', James', and Kevin's articles
all point out, most of us start with a predilection to
err on the side of primitives.
One way to push yourself to learn this balance is to
use the
Three Bears pattern
first described by Kent Beck to create situations in
which you confront the consequences of going too far
one way or the other. I think that this can be another
one of those programming etudes that help you become a
better programmer, a lá the
Polymorphism Challenge
that Joe Bergin and I used at
SIGCSE 2005,
in which we had folks rewrite some standard programs
using few or zero if statements.
In order to feel the kind of effects that Chris describes
in his article, you have to live with your code for a
while, until the specification changes and you need that
tolerance around your masses. I think that the folks
running the
ICFP 2005 programming contest
are using a wonderful mechanism to gauge a program's
ability to respond to change. They plan to collect the
contestants' submissions and then, a couple of weeks
later, introduce a change in the spec and require the
contestants to adapt their programs on an even shorter
deadline. What a wonderful idea! This might be a nice
way to help students learn the value of adaptable code.
Certainly, Primitive Obsession is not much of a problem
if you never encounter the need for an abstraction.
Ron Jeffries posted a message to the XP discussion list
earlier today confessing that one of his weaknesses as a
programmer is a tendency to create small classes too
quickly. As an old Smalltalker, he may be on the
opposite end of the continuum from most folks. But we
need a good name for the smell that permeates his code,
too. My "Class Obsession" from above is rather pedestrian.
Do you have better name?
Please share...
Whatever the name, I suspect that Ron's recognition of
his tendency makes it easier for him to combat. At least
he knows to pay attention.
Chris's article starts with the idea of favorite smells
but then settles on one. It occurs to me that I should
tell you my personal favorite smell. I suspect that it
relates to duplication; my students certainly hear that
mantra from me all the time. I will have to think a bit...
Last weekend, while my daughter was doing a final
practice for her Suzuki Book I recital, I picked
Vaclav Havel's The Art of the Impossible:
Politics as Morality in Practice off the piano
teacher's bookshelf for a little reading. This
is a collection of speeches and short essays that
Havel in the first half of the 1990s about his role
as dissident, reformer, and president of the Czech
Republic. He is, of course, famous as a poet, and
his writing and speaking style have a poet's flare.
I ended up spending most of my time with Havel's
speech to the Academy of Humanities and Political
Sciences in Paris on October 27, 1992. (I just
noticed the date -- that's my birthday!) This
speech discussed the different forms of waiting.
The first kind is sometimes characterized as
waiting for Godot, after the absurdist
play by Samuel Beckett. In this form, people
wait for some sort of universal salvation. They
have no real hope that life will get better, so
they hold tightly to an irrational illusion of
hope. Havel says that, for much of the 20th
century, residents of the former communist world
waited for Godot.
At the opposite end of the waiting spectrum lies
patience. Havel describes patience as
waiting out of principle -- doing the right thing
because it is right, not out of any expectation of
immediate satisfaction. In this sense, patience
is "waiting as a state of hope, not as an expression
of hopelessness". Havel believes that the dissidents
who ultimately toppled the communist regimes behind
the Iron Curtain practiced this sort of waiting.
When the curtain fell and the people of, say,
Czechoslovakia took their first unsteady steps into
the light of the western world, folks practicing the
different forms of waiting encountered distinctive
problems. Those who had been waiting for Godot
felt adrift in a complex world unlike anything they
had known or expected. They had to learn how to
hope and to be free again.
You might think that the patient dissidents would
have adjusted better, but they faced an unexpected
problem. They had hoped for and imagined
a free world around them, but when they became free
things didn't change fast enough. Havel relates
his own struggles at being too idealistic and now
impatient with the rate at which the Czech and
Slovak republics assumed the mantel of democratic
responsibility. Like many revolutionaries, he was
criticized as out of his element in the new world,
that he was most effective in the role of dissident
but ineffective in the role of democratic leader.
What struck me most about this essay came next.
Havel recognized the problem: He had waited
patiently as a dissident because he had no control
over how anyone but himself behaved. Now that the
huge impediment of an authoritarian regime had
been surmounted, he found that he had become impatient
for all the details of a democratic system to fall
into place. He no longer waited well.
In short, I thought time belonged to me. ...
The world, Being, and history have their own time.
We can, of course, enter that time in a creative
way, but none of us has it entirely in his hands.
The world and Being do heed the commands of the
technologist or the technocrat....
In his own transition from dissident to democratic
leader, Havel learned again that he had to wait
patiently as the world takes its "own meandering
course". He asserts that the "postmodern politician"
must learn waiting as patience -- a waiting founded
on a deep respect for the world and its sense of
time. Read:
His actions cannot derive from impersonal analysis;
they must come out of a personal point of view,
which cannot be based on a sense of superiority
but must spring from humility.
When the world changed, even in the way for which
he had been working, Havel had to learn again how
to be patient.
I think that the art of waiting is something that
has to be learned. We must patiently
plant the seeds and water the ground well, and
give the plants exactly the amount of time they
need to mature.
Just as we cannot fool a plant, we cannot fool history.
I think that 'waiting patiently as the world takes
its own meandering course' translates into showing
respect for people and the rate at which they can
assimilate new ideas and change their behavior.
Perhaps this speech affected me as it did because
I am now thinking about leading my department. I
certainly do not face a situation quite as extreme
as Havel did when the communist regime fell in
Czechoslovakia, yet I am in a situation where people
do not trust the future as much as I'd like, and
I need to find a way to help my department move in
that direction. As Havel reminds me, I cannot move
the department myself; I can only patiently plant
the seeds of trust, water the ground well, and
give the plants the time they need to grow.
The value of this sort of waiting is not limited
to the world of administration. Good instructors
need to wait patiently, working with students to
create the atmosphere in which they can grow and
then giving them time and opportunity to do so.
I also think that this sort of waiting holds great
value in the world of software development. Agile
methods are often characterized by folks in the
traditional software engineering world as impatient
in their desire to get to code sooner. But I think
the opposite is true -- the agile methods are all
about patience: waiting to write a piece
of code until you really know what it should do,
and waiting to design the whole program until you
understand the world well enough to do it right.
In this sense, traditional software engineering is
the impatient approach, telling us to presumptuously
design grand solutions to force the world to follow
our senses of direction and time. The worlds in
which most programs live are too complex for such
hubris.
I cannot resist closing with one last quote from the
rich language of Havel himself:
If we are certain that the planting was good and that
we are watering regularly, we have no reason to be
impatient. It is enough to realize that our waiting
has meaning.
Waiting that has meaning because it grows out of hope
and not hopelessness, from faith and not despair, from
humility toward the time of the world and not out of
fear of its sublime tranquility, is accompanied not by
boredom but by suspense. This kind of waiting is more
than just waiting.
It is life. Life as the joyous involvement in the
miracle of Being.
That sounds like a poet speaking, but it could be a
programmer. And maybe the world would be a better
place if all administrators thought this way. :-)
I've been thinking a bit about how much the agile
software development mindset affected my application
for department head. When I first starting making
notes for my statement of administrative philosophy,
I jotted down some agile ideas: communication, people
over processes, trust. Later, as I made notes for my
presentation to the search committee, I again had a
bullet for agile ideas, with feedback and continuous
improvement appearing.
In the end, many of these ideas played important
roles in my application. Open communication and
building trust became cornerstones of my philosophy.
Feedback and continuous improvement became cornerstones
of my plan for doing the job. I never got around to
using the term "agility" in any of my materials, but
its footprint was everywhere.
My administrative philosophy rested on three points:
open communication
transparent decision making
respect for individuals
These principles are essential to any healthy organization.
They are perhaps even more important in an academic department,
which consists of individuals who are both highly autonomous
but also interdependent. They are especially important in
a department fraught with lack of trust and persistent
interpersonal conflict.
These principles are also very much a part of the agile
software movement. Communication fosters trust and
enables feedback, which is how we learn to do our jobs
better. People matter. What about transparent decision
making? Only decisions are made openly can everyone
involve contribute to the process. I believe that, in
most situations, more ideas lead to better results.
Furthermore, when someone disagrees with the decision
that is made, at least the person can trust that the
decision was made fairly and on principle.
Some folks think that preferring people to processes
means having little or no process. Others think
that not tying themselves down with process (in
administrative parlance "procedures and policies")
frees them to adapt better to changing circumstances.
Though I value adaptability, and people over process,
I believe that appropriate process is essential to
effective operation. XP isn't just a set of values
or a set of principles; it is also a set of
practices. These practices support
the values and principles, make it possible for the
team to live its values and embody its principles.
I hope to help my department develop an appropriate
set of procedures and policies. This will involve
streamlining some of our existing procedures and
implementing some new ones.
Soon after I submitted my application materials,
a related discussion developed on the
XP discussion list.
It started with a request for advice for navigating
the waters of corporate politics and soon turned into
a discussion of how the principles and practices of
P can help us to create a good corporate environment.
Along the way, someone said,
Ok, those are good suggestions for navigating oneself
through everyday relationships, in and out of work.
But they are not techniques that are specific to XP.
The answer to this assertion is both yes and no. Certainly,
communication, feedback, continuous improvement, and the
like are not specific to XP or any other agile methodology.
But they are fundamental to the agile methods, and by making
them explicit the agile methods help us to reflect and act
on them more readily.
As I told my colleagues and the other members of the search
committee, I harbor no illusions that I will do this job
perfectly. But I hope that, by making explicit the values
that I hold and the principles that I think should guide our
department, I hope to do a good job -- and to get better as
I go along. This will depend in great part on the level
of trust and communication that we are able to develop.
I just read Joel Spolsky's latest essay,
Making Wrong Code Look Wrong.
I'm all for Joel's goal of writing code that reveals
the writer's intention, of making code transparent to
the reader. And I'm sympathetic to his concerns about
operator overloading in C++ and
leaky abstractions.
But the following paragraph exemplifies why I find his
C-at-all-costs mentality somewhat uncomfortable:
If you read Simonyi's paper closely, what he was
getting at was the same kind of naming convention
as I used in my example above where we decided that
us meant "unsafe string" and s
meant "safe string". They're both of type string.
The compiler won't help you if you assign one to the
other and Intellisense won't tell you bupkis. But
they are semantically different; they need to be
interpreted differently and treated differently and
some kind of conversion function will need to be
called if you assign one to the other or you will have
a runtime bug. If
you're lucky.
Does anyone else think that Joel needs a really
good abstraction here? If my program deals with
two different kinds of string -- objects that are
semantically different -- then I'd like to
reflect that in more than a cryptic two-letter
prefix. Classes may seem like overkill for these
kinds of thing, but enums and
Ada subtypes
can be wonderful aids. Then, instead of relying
solely on the programmer to read and interpret
the prefixes, we could let our compilers and
refactoring tools help us.
Intention-revealing names
are an important part of transparent code, but we
should use languages and techniques that support
our efforts, too.
before you can think out of the box,
you have to start with a box
-- Twyla Tharp
I've been reading Twyla Tharp's The Creative
Habit, and that quote is the title of Chapter
5. As soon as I read it, I scribbled it down
immediately on the note card I had tucked in the
back of the book for just such occasions. The
idea of "starting with a box" struck me in a
particular way, and as I read the chapter I went
through a journey from thinking that Tharp meant
something else to thinking that, ultimately, we
were onto the same idea. For Tharp, "the box" is
as organizational system, a way of storing and
managing her memory as she works on a new creative
project. But the box is more than that -- it is
really about preparation.
Bobby Knight, the famous US college basketball
coach, once said something along the lines, "The
will to win is the most overrated desire in all
of sports. Everybody has the will to win. What
separates those who succeed is the will to
prepare to win."
I often encounter students who say that they can
be successful contributors in the software industry
despite their unwillingness to work hard to become
really good programmers -- because they will be
part of a team in industry. I guess they figure
that some other member of the team is going to do
the heavy lifting. My response to them is always
the same: Why would a team want you as a member
if you can't help with the most important product
it produces? That's awfully presumptuous of you.
For some folks, the desire not to program is borne
out of a lack of interest in programming. But for
many it grows out of a lack of success, and a consequent
unwillingness to do the hard work needed to prepare
for programming tasks.
Most people can tell when they are unprepared for a
job, though our egos sometimes hide the truth from us.
Introductory students often come to my office with
questions about a programming assignment, saying,
"I know just what I want to do, but when I try to
write the program I just can't say it in Java."
(In earlier years, it was C++, or Pascal.) Again,
my response is often the same: You don't really
know what you want to say, or the program would come
more easily. Tharp says so, too, using a journalist
as her example:
If his reporting is good, the writing will reflect
that. It will come out quickly and clearly. If
the reporting is shoddy, the writing will be, too.
It will be torture to get the words out.
Some may think that this all sounds bad for agile
methodologies, which de-emphasize months of on-project
preparation of requirements and design. But I think
that this line of thought betrays a misunderstanding
of agile methods, one reflected in the idea that
they are reckless. Unprepared developers cannot
write good software using an agile method. Agility
doesn't mean not being prepared; it means letting
your preparation work in concert with concrete steps
forward to prepare you even better for what comes
next.
One thing I like about Tharp's chapter is that she
doesn't stop at "be prepared". She reminds us that
preparation is only preparation.
The box is not a substitute for creating. The
box doesn't compose or write a poem or create
a dance step. The box is the raw index of your
preparation. It is the repository of your creative
potential, but it is not that potential realized.
You still have to create! You have to write code.
You have to pull your head out of design-land, out
of the code library, out of the archives and
actually begin writing code.
Sadly, some people never get beyond the box stage
in their creative life. We all know people who have
announced that they've started work on a project ...
but some time passes, and when you politely ask how
it's going, they tell you that they're still researching.
... Maybe they like the comfort zone of research as
opposed to the hard work of writing. ... All I know
for sure is that they are trapped in the box.
Some students do this, too. They work hard -- they
really do -- but when the assignment comes due, there
is no program to turn in; they never got around to
actually producing something. And the
program is the whole point of the assignment. Okay,
okay, learning is probably the real
point of the assignment, but you can't learn what
you really need to learn until you write the program!
This is where we can see a strong connection to the
agile methods. They encourage us to be in a continuous
state of writing small bits of code, testing and designing,
cycling quickly between planning and producing.
Tharp ends her chapters with exercises for the reader,
activities that can help readers work on the idea
they've just read about. The section at the end of
"start with a box" consists of a single exercise,
and it's not especially concrete,. But it does have
an agile feel to it. When you are having a hard time
getting out of the box, take a big leap somewhere in
the project. Don't worry about the beginning or the
end; just pick something, an especially salient point
(or user story) and get to work. You never know
where it will take you.
"Getting out of the box" was one of the primary
motivations for me starting my blog. I had boxes
and boxes of stuff (metaphorical boxes, of course
-- mine were either computer files or file folders
stuffed with hastily written notes). But I had
stopped taking the risk of putting my thoughts out
in the public space. In that regard, this blog has
been a huge success for me.
(I wrote a complete essay on this topic over the
course of several hours on Monday and then, in a
few swift seconds of haste, I did the unthinkable:
I rmed it. Sigh. I don't know if I can
reproduce that wondrous work of art, but I still
have something I want to say, so here goes.)
Last time,
I wrote about how having a standard literary form
can ease the task faced by writers and readers,
including reviewers. I found this to be true of
submissions to the OOPSLA
Educators Symposium,
and my colleague
Robert Biddle
found it to be true of submissions to the conference's
practitioner reports
track. From this starting point, Robert and I
moved onto an ambitious idea.
I closed my last entry with a cliffhanger: The
unsupported claim that "the lack of a standard
form is especially acute in the area of practitioner
reports, which have the potential to be one most
important contributions OOPSLA makes in the software
world." This time, I'd like to talk about both
parts of this claim.
First, why is the lack of a standard literary
form especially acute in the area of practitioner
reports?
Keep in mind that the authors of practitioner
reports are software practitioners, folks in the
trenches solving real problems. Most of these
folks are not in the habit of writing expository
prose to teach others or to share experiences --
their jobs are primarily to create software.
Unlike most submitters to the Educators Symposium,
the authors of practitioner reports are usually
not academics, who typically have experience with
expository writing and and can at least fall back
on the literary forms they learned in publishing
academic papers. (Sadly, those forms tend not
to work all that well for sharing pedagogical
experience.)
Not having a standard literary form makes writing
and reading practitioner reports that much harder.
How can authors best communicate what they learned
while building a software project? What ideas do
readers expect to find in the paper? What's worse,
because many software developers don't have much
experience writing for a broad audience, not knowing
how to go about writing a paper can create a
considerable amount of fear -- and the result is
that many practitioners won't even try to write a
paper in the first place. It turns out that a
standard literary form has another benefit: it
provides comfort to potential authors, lowering
the entry barrier to new writers.
A great example of this effect is the software
patterns community. Its popularization of a
common and powerful literary form made it both
possible and attractive to many practicing
software developers to record and disseminate
what they had learned writing programs. The
software community as a whole owes an extraordinary
debt for this contribution.
So, I contend that the practitioner's track would
benefit even more than the educators' track from
the creation and widespread adoption of a standard
literary form. (But I still hope that we educators
will take steps to improve our lot in this regard.)
Second, how do practitioner reports have the
potential to be one most important contributions
that OOPSLA or any other conference makes in the
software world?
Keep in mind that the authors of practitioner
reports are software practitioners, folks in the
trenches solving real problems. Researchers
and methodologists can propose ideas that sound
great in theory, but practitioners find out how
well they work in the real world, where academic
abstractions take a back seat to the messiness
of real businesses and real people and real
hardware. Even when researchers and methodologists
make a good-faith effort to vette their ideas
outside of their labs, it is difficult to
recreate all the complexities that can arise
when new adopters try implement the ideas in
their organizations.
The result is, we don't really know how well
ideas work until they have been tried in the
trenches. And practitioner reports can tell
us.
Sharing knowledge of a practical sort used to
lie outside the domain of computer science and
even software engineering, but the software
patterns movement showed us that it could be
done, that it should be done, and gave us some
hints for how to do it. The potential benefit
to practitioners is immeasurable. Before
trying out XP, or migrating from Visual Basic
to VB.Net, or integrating automated acceptance
tests into the build cycle, a practitioner can
read about what happened when other folks in
the trenches tried it out. Usually, we expect
that the ideas worked out okay in practice,
but a good report can point out potential
pitfalls in implementation and describe
opportunities to streamline the process.
Of course, academics can benefit from good
practitioner reports, too, because they close
the loop between theory and practice and point
out new questions to be answered and new
opportunities to exploit.
Robert and I didn't talk much about what I've
written so far in this entry, because we rather
quickly moved on to Robert's bigger vision of
what practitioner reports can be, one that
presupposes the untapped value buried in this
resource: the software case study.
As Robert pitched it, consider
NCSA Mosaic.
Here is a program that changed the world. How
was it built? What technical and non-technical
problems arose while it was being written, and
how did the development team solve them? Did
serendipity ever strike, and how did they gain
leverage? We can find the answers to all of
these questions and more -- the creators are
still around to tell the story!
Case studies are a standard part of many disciplines.
In business schools, students learn the how companies
work by reading case studies. I remember well a
management course I took as an undergraduate in
which we studied the development of particular
companies and industries through case studies.
(Most of what I know about the soft drink industry
came from that case book!) Of course, the law
itself is structured around cases and webs of
facts and relationships.
We are fortunate to have some very nice case studies
in computing. Knuth has written widely about his
own programs such as Tex and his literate programming
tools. Because Smalltalk is as much system as
language, Alan Kay's
The Early History of Smalltalk
from History of Programming Languages II
qualifies as a software case study. Other papers
in the HOPL volumes probably do, too. I have read
some good papers on Unix that qualify as case studies,
too.
Two of my favorite textbooks, Peter Norvig's
Paradigms of AI Programming
and Clancy and Linn's
Designing Pascal Solutions,
are built around sets of case studies. In the
latter, the cases were constructed for the book;
in the former, Norvig analyzes programs from the
history of AI and reimplements them in Common
Lisp. (You really *must* study this book.) I
even used a case study book as a CS undergrad:
Case Studies in Business Data Bases, by
James Bradley. It's still on my bookshelf. More
recently, the College Board's
Marine Biology Case Study
has received considerable attention in the AP
and CS1 communities.
So, if we believe that software case studies have
merit, we find ourselves back in the trenches...
How do we write them? Using an excellent case
study as an exemplar would be a start. I suggest
that any case study of value probably must tell
us at least three things:
In what context did we operate?
What did we do?
What did we learn?
These elements apply to case studies of whole
systems as well as to case studies of incremental
changes to systems or process improvements. They
are almost certainly part of the better practitioner
reports presented at OOPSLA.
Robert and I will likely work on this idea further.
If you have any ideas, please
share them.
In particular, I am interested in hearing about
existing and potential software case studies.
Which of the case studies you've read do you
think are the best exemplars of the genre?
Which programs would you like to see written up
in case studies?
The Value of Standard Form in Evaluating Technical Papers
Over lunch today, Robert Biddle and I discussed some
thoughts we had after reviewing submissions to the
OOPSLA
Educators Symposium
and practitioners reports track this year. Both of
these tracks suffer from a problem that had never
really occurred to me before this year: not having
an accepted form for telling stories.
If you read the proceedings of most computer science
conferences, you will recognize that all the papers
have a similar look and feel. This is the way that
scientists in the domain communicate with one another.
One function of a common form is to ensure an efficient
exchange of information; having a common style means
that readers immediately feel at home when they come
to a paper. But there is a subtle secondary function,
too. When you see a paper, you can tell whether the
author is a part of the community or not.
One of the the things that makes reviewing papers for
the Educators Symposium tough is the variety of papers.
With no standard, authors are left to mimic other
papers or invent new forms that fit the story they
want to tell. But every new form makes the program
committee's job harder, too. How do we evaluate the
contribution of a paper that looks and sounds different
than any we've seen? What role should experimental
validation of a teaching technique play? What role
should an explanation of lessons learned, or a
discussion of how to implement the technique at a
different institution?
Most frustrating for me as program chair were situations
in which two reviewers evaluated the same paper in
essentially complementary ways. This isn't a fault of
the reviewers, because the community as a whole has not
reached a consensus for what papers should be like. I
suppose that one of my jobs as program chair is to guide
this process closely, working with the program committee
to give authors and reviewers alike a better sense of
what we are looking for in submissions. The nifty
assignment track that I introduced to the symposium last
year was an attempt in this direction. I borrowed from
a
successful form
used at recent SIGCSEs to encourage OO educators to
tell the stories of their coolest and most engaging
programming assignments. Having an expectation of what
a nifty assignment should look like has led, I think,
to a more satisfying evaluation process for these
submissions.
Maybe we as a community of educators need to work
together to develop a standard way to tell teaching
stories. Perhaps the greatest contribution of the
software patterns community was to standardize the
way practitioners and academics discuss the elements
of program design and construction at a level above
algorithms and data structures. As linguistic form,
it enables communication in a way that was heretofore
impossible.
Notice here that a common literary form is
more than a literary format. The patterns community
is a good example of this. Even after a decade there
are a number of accepted formats for writing patterns,
some favored by one group of writers, some viewed as
especially effective for patterns of a particular sort.
The key to the pattern community's contribution is
that it establishes expectations for the
content of software patterns. I can
comfortably read a pattern in almost any format, but
if I can't find the context, the problem, the forces,
and the solution, then I know the pattern has problems.
The PLoP conferences play the role of enculturating
pattern writers by helping them to learn the standard
form and how to use it.
The lack of a standard form is especially acute in the
area of practitioners reports, which have the potential
to be one most important contributions OOPSLA makes in
the software world. I'll have more to say about this
tomorrow.
Today and tomorrow, I am in San Diego for the
OOPSLA 2005
spring planning meeting. I have the honor of chairing
the
Educators Symposium
again this year and so am on the conference committee
that makes OOPSLA happen. As usual, I'm impressed by
the energy and talent of the people behind the scenes
of OOPSLA. These folks are in the trenches scheduling
talks and panels, tutorials and workshops, while
simultaneously thinking about the future of software
and where the conference can and should go in the future.
San Diego will be a great location for OOPSLA. We are
at the
Town and Country Resort,
about 15 miles from downtown. The resort is more than
just a hotel; the property includes several buildings
of convention space, meeting rooms, and restaurants,
not too mention the pools and outdoor gathering spaces.
San Diego's temperate weather makes outdoor gatherings
a real possibility. On our site tour earlier, a couple
of us joked about holding software demonstrations
poolside -- or even on the water, the "floating demo".
We may as well surrender to the inevitable temptations
that accompany meeting space adjacent to an outdoor
pool.
Last night, I had the pleasure of catching up with a
current friend, a former student who now calls San Diego
home. Kris picked me up, gave me a short driving tour
of the area, and then took me off for dinner with another
former UNI student, a former Waterloo native, and another
Iowan. We talked sports, much to the chagrin of the
ladies, and current campus goings-on. Dinner was at
Quiigs Bar and Grill (5091 Santa Monica Ave) -- I had
a wonderful grilled prawns dish.
This morning, I checked out the running options from
the hotel. I did an easy 10+-miler, heading west
along Friars Road toward the beach. I never reached
the beach but I did find an unexpected bonus: down
near a marina off Sea World Drive, I came upon the
start location for the
Spring Sprint Triathlon and Biathlon.
This is a little tri, a ¼-mile swim, a 9-mile
bike, and a 3-mile run -- just within my reach.
One of these days...
Dick Gabriel and Ralph Johnson have a lot of
neat ideas in the works
for OOPSLA this year, including a track for
essays,
collocated symposia on wiki and Dylan, and the
evolving Onward! track, which will debut a
film festival.
If you want to know what software people will be
talking about in earnest three or four years from
now, make sure to attend OOPSLA this year!
While doing some link surfing yesterday, I ran
across an
old blog entry
that has a neat programming languages idea in it:
Wouldn't it be nice if we could encapsulate
language features.
The essay considers the difference between two kinds
of complexity we encounter in programs. One is
complexity in the language features themselves.
First-class closures or call-with-current-continuation
are examples. Just having them in a language seems
to complicate matters, because then we feel a need
to teach people to use them. Even if we don't, some
programmer may stumble across them, try to use them,
and shoot himself in the foot. Such abstractions
are sometimes more than the so-called ordinary
programmer needs.
Another kind of complexity comes from the code we
write. We build a library of functions, a package
of classes, or a framework. These abstractions can
also be difficult to use, or it may be difficult to
understand their inner workings. Yet far fewer people
complain about a language having too many libraries. (*)
Why? Because we can hide details in libraries,
in two ways. First, in order to use Java's HashMap
class, I must import java.util.HashMap explicitly.
Second, once I have imported the class, I don't really
need to know anything about the inner workings of the
class or its package. The class exposes only a set of
public methods for my use. I can write some
pretty sophisticated code before I need to delve into
the details of the class.
Alexander asks the natural question: Why can't we
encapsulate language features in a similar way?
Following his example, suppose that Sun adds operator
overloading to Java but doesn't want every programmer
to have to deal with it. I could write a package that
uses it and then add a new sort of directive at the
top of my source file:
exposeFeature operatorOverloading;
Then, if other programmers wanted to use my package,
they would have to import that feature into their
programs:
importFeature operatorOverloading;
Such an information-hiding mechanism might make adding
more powerful features to a language less onerous on
everyday programmers, and thus more attractive to
language designers. We might even so languages grow
in different and more interesting ways.
Allowing us to reveal complex language features
incrementally would also change the way we teach
and write about programming. I am reminded of the
concept of "language levels" found in
Dr. Scheme
(and now in
Dr. Java).
But the idea of the programmer controlling the
exposure of his code to individual language
features seems to add a new dimension of power --
and fun -- to the mix.
More grist for my Programming Languages and
Compilers courses next year...
I sometimes like to think about ways in which
learning to program is like learning to speak
a foreign language. Usually, I focus on
similarities between the two, to see whether
I can use a correspondence to improve how I
present an idea. In the middle of class this
morning, a difference between the two occurred
to me, and now I wonder how I can use this idea
to improve my courses on a daily basis.
The difference: Students of foreign language
are more easily, more obviously, and more
naturally held accountable for their
level of preparation and their current state
of proficiency than are students of computer
programming.
There has been a lot of discussion recently on
the
XP discussion list
about the idea of accountability. Apparently,
this concept is a driving force behind the "new
P" described in Kent Beck's second edition of
XP Explained. (I haven't had a chance
to read it yet.) Much of the discussion concerns
just what the word means. For me,
Merriam-Webster's definition
seems clear enough:
... an obligation or willingness to accept
responsibility or to account for one's actions
Am I obliged to account for my actions
and take responsibility for them? Then I am
being held accountable. Am I
willing to account for my actions and
take responsibility for them? Then I am being
accountable. (*)
My compiler holds me accountable for the correctness
of the code I write. Each time I compile, I find
out if my program is syntactically correct. My
unit tests hold me accountable for the correctness
of the code I write. Each time I run my tests,
the green bar tells me that my program is
functionally correct -- or the red bar tells me
otherwise.
Of course, I have to compile my program (at least
once :-), but I am not obliged to write and run
tests. One of the beauties of the agile programming
practices is their demonstration of programmers'
willingness to be held accountable for their time
and their efforts. Obligation is supplanted by
willingness, which opens the programmer to a new
level of growth and performance.
The compiler holds students accountable, too.
As they learn and use new ideas, the compiler
and their testing give them a measure of their
accomplishments. So, the more practice they get
-- the more code they write, the more projects
they do -- the more feedback they get about their
level of proficiency.
In a typical computer science course, the instructor
has only a small number of opportunities to gauge
each student's development. In my most
programming-intensive courses, I ask students to
write only 12 programs for evaluation. That is
quite a lot in a fifteen-week semester, but it's
not enough. I wish that I could interact with
each student every day, gauging
preparation and proficiency, folding what I learn
back into my instruction.
What do I do now? I give students in-class
exercises and discuss solutions every day. But
some students work on the exercises only
half-heartedly, if only because the absence of a
keyboard and a compiler makes writing much code
tedious. The discussion usually goes pretty well,
but only a small subset of the students tend to
participate actively. In class this morning, the
inadequacy of my seemed especially obvious.
So, my mind wanders... How would a course in
spoken German or French differ? My in-class
exercises and discussions pale in comparison to
what a foreign language teacher can do so naturally:
start a conversation with a student! A classroom
discussion can grow quite easily to include many
students, because each interaction with a student
exposes the student's level of preparation and
proficiency. Human conversation works that way.
I can draw students into classroom discussions,
but there is a big difference between writing
code and talking about code, even
talking about writing code. Someone can talk
about code, or the ideas underlying code, even
if they have difficulty writing the same.
Students who are willing to account for their
work sometimes find that they are not asked to.
Students who need to be obliged to account for
their work -- who would benefit greatly from
being held more accountable -- come to count on
not being so held.
This line of thought was triggered today by my
recognition that a couple of students came to
class unprepared this morning. A couple said
so, honest that they hadn't studied the reading
assignment yet wanting to ask questions. A
couple tried to blend in, relying on the fact
that they would probably manage to get by. I
wasn't in the mood to call them to account,
but I was in the mood to think about the
attitude itself.
Owen Astrachan
uses a great strategy for driving classroom
interaction that has a side effect of holding
students accountable for the time they spend in
class on exercises. He passes blank transparencies
out to groups of students working together on
an exercise. They write their code on the
transparencies. Finally Owen collects them and
puts them on the projector for everyone to see
and discuss. I don't know how often he makes
the authors of a slide known to the class, or
if he ever does In either case, I think that
this strategy creates an environment in which
students feel accountable.
Some students are intrinsically motivated to learn.
They hold themselves accountable no matter what
the instructor or other students do. But some
university students are not quite ready for this
level of autonomy. Some instructors and universities
seem to adopt an attitude of sink-or-swim, leaving
it to students to figure out that they have to take
control of their own learning. In some contexts,
this is the right thing to do. Ultimately, each
student is responsible for his or her own learning,
accountable only to themselves.
The role of a teacher, though, is more I think.
Especially when working with children and even
university freshmen, a teacher should help students
learn to hold themselves accountable. I'd like to
be able to readily recognize students who are struggling
with material or not doing the work so that I can
intervene. My German teachers could readily assess
my level of preparation and proficiency by walking
into the room, saying, "Guten Tag, Eugen! Wie
geht's?" -- and then simply listening. Strategies
like Owen's may be the best we can do in computer
science, so we need to share them when we have them.
When you have to write your code on a slide and
give it to the professor for possible display in
front of the whole class, you have a built-in
accountability partner.
The success of groups such as
Alcoholics Anonymous
is founded in large part on relationships in which
one person helps another to hold himself accountable.
Sometimes, just telling someone else that you are
quitting smoking or trying to curb your profanity
can be enough external support to do a better job.
Who wants to disappoint a friend, or look weak?
You might even
tell the Internet.
When a student signs up for a formal course in
a topic, one element of the action is to put
themselves in a formal accountability relationship.
The teacher and the classmates act as accountability
partners. Obviously, this isn't the only responsibility
of a teacher, nor even the most important, but
it is a good part of the deal for the learner.
This is wandered a bit from thought that triggered
all this, which was something like, "If a student
went to a French class as unprepared as some students
come to their programming classes, they would be
found out quickly. That would straighten them up!"
(In moments of weakness, I sometimes surrender to
temptation.) But ultimately I am motivated by a
desire to do a better job as a teacher.
(*) I've not gotten into the mailing list discussion
much, but this seems to be what Kent asks of himself
and other programmers. It seems pretty reasonable
to me, and at the heart of many agile development
practices.
Agile methods aren't just for managing individual
projects. They may be an essential component in
a start-up company's long-term strategy.
In his recent essay,
How to Start a Startup,
Paul Graham talks about how important the choice
of type of software to write is for the success
of a start-up. He suggests that a start-up
write software for smaller companies, where the
competition and sums of money are smaller. But
then he says:
They're the more strategically valuable part
of the market anyway. In technology, the low end
always eats the high end. It's easier to make an
inexpensive product more powerful than to make a
powerful product cheaper. So the products that
start as cheap, simple options tend to gradually
grow more powerful till, like water rising in a
room, they squash the "high-end" products against
the ceiling.
He cites several examples from the recent history
of technology, from digital cameras to desktop
publishing to Henry Ford and the automobile. In
any case, this sounds like a harnessing of
simplicity-first and piecemeal growth as a
business strategy for product and market selection.
Once you know the kind of product you want to
sell, you have to find out what customers want.
How best to do that?
... get a version 1 out as soon as you can.
... The only way to make something customers want
is to get a prototype in front of them and refine
it based on their reactions.
Graham calls the alternative a "Hail Mary" strategy:
do a lot of planning, generate a
big design up front,
develop a finished working product -- and then
pray that enough customers will pay you for it.
Graham's own start-up benefited greatly from its
agility. ViaWeb's initial target market consisted
of web consultants, but it soon learned that its
software made the consultants disposable which,
needless to say, didn't endear the idea to the
consultants. As a result of early experience with
customers, the company shifted its market focus to
small merchants and its software focus to ease of
use: making a product that users could actually
use to do their job better. The customer played
a central role in defining and refining the
requirements of the project.
Graham is not an "agile guy", and from my reading
of him I'd guess he's a bit suspicious of all the
hype around agile methods. Lisp hackers and
Smalltalk hackers have long had the patterns that
make up the agile development methods. It seems
that an agile mindset on the technology side of
things is compatible with an agile mindset on the
business side of things -- and perhaps crucial to
the viability of new companies.
While I'm on the topic of Graham's essays, if
you are a student, you should definitely read
his recent articles
Undergraduation
and
What You'll Wish You'd Known.
They give an interesting perspective on how to
approach your high school and college years.
Heck, even if you aren't a student you might
well enjoy them.
After teaching Agile Software Development to
university juniors and seniors last semester for
the second time, and introducing test-driven
design early in CS II this semester, I am coming
to a deeper appreciation for how much agile
methods require a change in deeply-rooted habits.
It is easy for a person who have already developed
a new habit (read: me) to walk into classroom and
make assumptions about what will motivate students
to change their habits. It doesn't take long before
new practices become uncomfortable enough that a
learner prefers to drop back to what she knows best.
In CS II, students soon bump into objects that are
hard for them to test, file processors and GUIs
among them. And, as
Bill Caputo points out,
the benefits of TDD don't just happen, "you have to
want to find a way to structure the code so that it
can be tested without resorting to resources beyond
the test." That can be hard for any programmer
learning to do TDD, and it's harder for students
who are still learning how to program at all.
I've been thinking been thinking about how to
introduce these new ideas more effectively in the
classroom. We university educators have something
to learn from industry trainers who introduce
agile methods to their clients. Brian Marick's
recent article
describes advice he gives to clients who ask him
for help. Some of the details don't apply to my
usual situation, such as "read Michael Feathers'
wonderful
Working Effectively with Legacy Code".
Not that the book isn't wonderful -- it is! It's
just that my students aren't usually ready for
this book yet. But the more general advice --
work on developing habits deliberately, focus
on test writing before refactoring, encourage
collective learning and sharing -- can help me.
I need to find ways to implement this advice in
my context.
I suppose that my experience as an
agile methods actor
tells me that I have something to learn from
this book,
too. But my students aren't always fearless,
and neither am I.
I started college as an architecture major. In the
first year, architecture students took two courses
each semester: Studio and Design
Communications Media. The latter had a lofty
title, but it focused on the most basic drawing
skills needed in order to communicate ideas visually
in architecture. At the time, we all considered it
a freehand art class, and on the surface it was.
But even then I realized that I was learning more.
The textbook for DCM was Betty Edwards's
Drawing on the Right Side of the Brain.
It is about more than drawing as a skill; it is
also about drawing out one's creativity. Studying
this book, for the first time I realized that what
we do in life depends intimately on what we see.
Often, when people try to draw a common object,
such as a chair, they don't really draw the chair
in front of them but rather some idealized form,
a Chair, seen in their mind's eye. This chair
is like a Platonic ideal, an exemplar, that
represents the idea of a chair but is like no
chair in particular. When the mind focuses on
this ideal chair, it stops seeing the real chair
in front of it, and the hands go onto cruise
control drawing the ideal.
The great wonder in Edwards's book was that I
could learn to see the objects in front
of me. And, in doing so, I could learn to see
things differently.
Drawing on the Right Side of the Brain
introduces a number of techniques for seeing an
object, for the first time or in a new way, with
exercises aimed at translating this new vision
into more realistic depictions of those items on
paper or canvas.
I recently found myself thinking again about one
of the techniques that Edwards taught me, in the
realm of software. Alan Kay has often said that
we computer computer scientists focus so intently
on the objects in our object-oriented programming
that we miss something much more important: the
space between the objects. He speaks of the
Japanese word ma, which can refer to the
"interstitial tissue" in the web of relationships
that make up a complex system. On this view, the
greater value in creating software lies in getting
the ma right.
This reminds me of the idea of negative
space discussed in Edwards's book. One
of her exercises asked the student to draw a chair.
But, rather than trying to draw the chair itself,
the student is to draw the space around the chair.
You know, that little area hemmed in between the
legs of the chair and the floor; the space between
the bottom of the chair's back and its seat; and
the space that is the rest of the room around the
chair. In focusing on these spaces, I had to
actually look at the space, because I don't have
an image in my brain of an idealized space between
the bottom of the chair's back and its seat. I
had to look at the angles, and the shading, and
that flaw in the seat fabric that makes the space
seem a little ragged.
In a sense, the negative space technique is merely
a way to trick one's mind into paying attention
to the world in a situation when it would prefer
to lazily haul out a stock "kitchen chair" image
from its vault and send it to the fingers for
drawing. But the trick works! I found myself
able to draw much more convincing likenesses than
I ever could before. And, if we trick ourselves
repeatedly, we soon form a new habit for paying
attention to the world.
This technique applies beyond the task of drawing,
though. For example, it proves quite useful in
communicating more effectively. Often, what
isn't said is more important than what
is said. The communication lies in the idea-space
around the words spoken, its meaning borne out
in the phrasing and intonation.
The trigger for this line of thought was my
reading an
entry
in Brad Appleton's blog:
... the biggest thing [about software design] that
I learned from [my undergraduate experience] was the
importance of what I believe Christopher Alexander
calls "negative space", only for software architecture.
I glibly summarized it as
There is no CODE that is more flexible than NO Code!
The "secret" to good software design wasn't in
knowing what to put into the code; it was in knowing
what to leave OUT! It was in recognizing where the
hard-spots and soft-spots were, and knowing where to
leave space/room rather than trying to cram in more
design.
Software designers could use this idea in different
ways. Brad looks at the level of design and code:
Leave room in a design, rather than overspecifying
every behavior and entity that a program may need.
But this sense of negative space is about what to
leave out, not what to put in. The big
surprise I had when using Edwards's negative space
technique was that it helped me put the right things
into my drawings -- by focusing on their complement.
I often think that the Decorator design pattern
embodies negative space: Rather than designing
new classes for each orthogonal behavior, define
objects as behaviors with receptacles into which we
can plug other objects. The negative space in a
Decorator is what makes the Decorator powerful; it
leaves as many details uncommitted as possible while
still defining a meaningful behavior. I suppose
that the Strategy pattern does the same sort of
thing, turned inside out.
Maybe we can take this idea farther. What would
it be like to design a program not as a set of
objects, or a set of functions, but as Kay's
ma? Rather than design actors, design
the spaces in between them. Interfaces are a
simple form of this, but I think that there is
something deeper here. What if all we defined
were an amorphous network of messages which some
nebulous agents were able to snatch and answer?
Blackboard architectures, once quite common in
artificial intelligence, work something like this,
but the focus there is still on creating knowledge
sources, not their interactions. (Indeed, that
was the whole point!)
Even crazier: what it would be like to design software
not by focusing on the requirements that our users
give us, but on the "negative space" around them?
Instead of adding stuff to a concoction that we
build, we could carve away the unwanted stuff from
a block of software, the way a sculptor creates a
statue. What would be our initial block of granite
or marble? What would the carving feel like?
Whether any of these farfetched ideas bears fruit,
thinking about them might be worthwhile. If Alan
Kay is right, then we need to think about them.
Edwards's negative space technique makes for a
powerful thinking strategy. Like any good metaphor,
it helps us to ask different questions, ones that
can help us to expose our preconceptions and
subconscious biases.
And it could be of practical value to software
designers, too. The next time you are stumped
by a design problem, focus on the negative space
around the thing you are building. What do you
see?
The notion that practices from agile software
development work outside of software should
not surprise us too much. Agile practices
emphasize individuals and interactions, doing
things rather than talking about things,
collaboration and communication, and openness
to change. They reflect patterns of organization
and interaction that are much bigger than the
software world. (This reminds me of an idea
that was hot a few years ago: design patterns
occur in the real world, too.)
Oh, and good luck, Brian! I know the feeling.
Two years ago, I had broken the 190-pound barrier
and, despite recreational jogging, felt soft
and out of shape. By exercising more and eating
less (okay, exercising a lot more and eating
a lot less), I returned to the healthier and
happier 160-pound range. I'll keep an eye on
your big visible chart.
Yesterday morning, one of my students told me that
he was thinking of changing his major. It turns
out that he was English major before switching to
CS, and he is thinking about switching back. We
got to talking about the similarities and differences
between the majors and how much fun it would be to
major in English or literature.
Some salesman I am! We need more CS majors, so
I should probably have tried to convince to stay
with us. Discussing the relative value in the
two majors was beyond the scope of our short
discussion, though, and that's not really what
I want to write about.
The student mentioned that he knew of other folks
who have bounced between CS and English in school,
or who have studied in one field and ended up
working in the other. I wasn't too surprised,
as I know of several strong students in both
disciplines who have performed well in the other
and, more importantly, have deep interests in
both. Writing and programming have a lot more
in common than most people realize, and people
who love to communicate in written form may
well enjoy programming.
I myself love to read books by artists about their
crafts. The "recommended reading list" that I give
to students who ask includes two books on writing:
William Zinsser's On Writing Well and
Joseph Williams's Style. But I've enjoyed
many wonderful books on writing over the years,
often on recommendation from other software
developers...
several of Zinsser's other books,
Natalie Goldberg's Writing Down the Bones
Richard Hugo's The Triggering Town
Scott Russell Sanders's Writing From The Center
Anne Lamott's Bird by Bird
Annie Dillard's The Writing Life
E.L. Doctorow's Reporting the Universe
Each has taught me something about how to write.
They have helped me write better technical papers
and better instructional material. But I have to
admit that I don't usually read these books for
such practical reasons. I just like to feel what
it's like to be a writer: the need to have a voice,
the passion for craft. These books keep me motivated
as a computer scientist, and they have indirectly
helped me to write better programs.
Writers aren't the only artists whose introspective
writing I like to read. The next book to read on
my nightstand is Twyla Tharp's The Creative
Habit. Dance is much different than fiction,
but it, too, has something to teach us software
folks. (I seem to recall a dinner at
PLoP
many years ago at which
Brad Appleton
suggested dance as a
metaphor for software development.)
When I started writing this essay, I thought
that it would be about my recommended reading
list. That's not how it turned out. Writing
is like that. So is software development
sometimes.
'Men are wise in proportion, not to their experience,
but to their capacity for experience.
-- George Bernard Shaw
Yesterday in my CS II course, my students and I
discussed some of the possible designs for their
current assignment and how the decisions each
programmer makes will change the nature of the
program each writes. Later in the day, I received
an e-mail message from one of the students. It
ended:
P.S. Got home today, and started lab over, got
to the same spot as before in under 2 hours, code
is much easier to read and look at! Thanks.
My immediate thought was, "This guy has what it
takes."
When I encounter such students, I don't need to see
their code to know that they will eventually
become good software developers, if their interest
in computing stays strong. They have the most
important characteristic of any learner: the
capacity for experience.
This idea seems to be a theme running through many
of my own experiences and reading lately. First,
I remember reading
this piece
by Johanna Rothman. It distinguishes "several years
of experience" from "the same year of experience
several times". Johanna's blog focuses on hiring
technical people, and she suggests questions you can
ask job applicants in order to decide which kind
of person they are. A candidate question is "Tell
me about the first time you did that kind of work."
People who know the difference between the same
year of experience multiple times and multiple years
of experience have answers to these questions. People
who do the same thing year-in, year-out don't have
good answers.
I see the same thing in college students. Some
students would use Johanna's question as a springboard
into an engaging conversation about what they learned
in the process of that first time. We end up talking
not only about the first time but many times since.
Even in the conversation we both may end up learning
something, as we complement one another's experiences
with our own.
Other students look at me unknowingly. They are often
the ones who are still hitting the delete key 67 times
instead of having taken the time to learn dd
in vi (ctrl-k or something similar
for emacs devotees :-).
Then I re-read Malcolm Gladwell's
The Physical Genius
after running into Pragmatic Dave's
short note on making mistakes.
I first read Gladwell's article a few years ago
when someone first introduced me to his writing,
but this time time it struck me in my experiential
theme. Not only do these physical geniuses prepare
obsessively, they also share a deep capacity for
recognizing their own mistakes and learning
from them. Rather than hide their errors
behind a wall of pride, they almost revel in having
recognized them and overcome them. They use their
experiences to create experience.
Dave quotes Gladwell quoting Charles Bosk, who
had tried to find a way to distinguish good
surgeons from the not so good:
In my interviewing, I began to develop what I
thought was an indicator of whether someone was
going to be a good surgeon or not. It was a couple
of simple questions: Have you ever made a mistake?
And, if so, what was your worst mistake? The people
who said, 'Gee, I haven't really had one,' or, 'I've
had a couple of bad outcomes but they were due to
things outside my control' - invariably those were
the worst candidates. And the residents who said,
'I make mistakes all the time. There was this horrible
thing that happened just yesterday and here's what
it was.' They were the best. They had the ability
to rethink everything that they'd done and imagine
how they might have done it differently."
Johanna Rothman would probably agree with Bosk's
approach.
Some folks don't seem to have the mindset of Bosk's
successful surgeons, at least by the time they reach
my classroom, or even when they reach the workplace.
In that same CS II class yesterday, I sensed that
a few of the students were uncomfortable with the
notion that they themselves had to make these design
decisions. What if they made the wrong choice? I
suggested to them that none of the choices was really
wrong, and that each would make some things easier
and other things harder. Then I told them that,
even if they came to rue their choice of an
Object[] over a Vector, that's
okay! They can rest assured that the alternative
would have been rueful in another way, and besides
they will have learned something quite useful along
the way. That was no comfort at all to the students
who aren't uncomfortable.
So much of what students learn in college courses
isn't listed in the course catalog description.
I hope I can help some of my students to learn new
habits of mind in this regard. Developing a
capacity for experience is more important than
learning the habit of TDD.
Then again, software people with a capacity for
experience seem to gather in places where practices
like TDD become a focal point. Patterns.
Pragmatic programming. XP. Agile software
development. All grew out of folks reflecting
on their successes and failures with humility
and asking, "How can we do better?" The student
who sent me that e-mail message will fit in
quite nicely.
When I
first learned
that
Mihaly Csikszentmihalyi
(whose name is pronounced 'me-HI chick-SENT-me-hi')
would be speaking here, I hoped that he might be able
to help me to understand better the role of
flow in learning
and programming. These ideas have been on mind
occasionally through experience with the Suzuki
method of piano instruction and Alan Kay's comments
on the same in his
talks at OOPSLA.
When I left the lecture room last night, I was a
bit disappointed with the talk, but as time passes
I find that its ideas have me thinking...
Csikszentmihalyi opened by explaining that his
interest creativity began as a child in Hungary.
Many of his family members were artists and lived
rich lives, but most people he knew lived "fragile
lives", all too sensitive to the vagaries of war
and economy. He chose to study creative people
to see how everyone can live a better life, a less
fragile life, a beautiful life.
Through his studies, he came to distinguish "small
c" creativity and "big C" Creativity. To some
degree, we all are creative in the small-c way,
doing things that enrich our own lives but do not
receive recognition from the outside world. Big-c
creativity is different -- it produces ideas that
"push our species ahead". At first, the use of
recognition to distinguish quality of creativity
seemed incongruent, but I soon realized that
creative ideas take on a different form when they
move out into the world and mingle with the rest
of a domain's knowledge and culture. Csikszentmihalyi
came back to this nugget later in his talk.
Big-C creativity is rare. Defining it is impossible,
because every definition seems to over- or
underconstrain something essential to creativity
from our own experience. But Csikszentmihalyi
asserted that society values Creativity for its
ability to transform people and cultures, and
that it drives creative people to "pursue to completion"
the creative act.
To support his claim of scarcity and to begin to
expose the culture's role in recognizing creativity,
Csikszentmihalyi presented some empirical studies
on the relationship between individuals' contributions
and their disciplines. The first was the so-called
Lotka Curve.
Alfred Lotka
was an eminent biophysicist of the early 1900s. In
the mid-1920s, he identified a pattern of publication
in scientific journals. Roughly 60% of all people
who publish publish only one journal article. The
percentage of people who publish two articles is much
smaller, and the percentage of people who publish
more articles falls rapidly as the number of articles
increases. This creates an L-shaped graph of the
function mapping number of publications onto the
percentage of contributors at that level.
The second was Price's Law. He referred not to
the law from physics, which describes a model of
gravitational collapse and the "strong cosmic
censorship conjecture" (a great name!), but to
another model of contribution: one-half of all
contributions in any domain are made by the
square root of all potential contributors.
According to Csikszentmihalyi, Price derived
his law from data in a large variety of domains.
I do not have citations to refereed publications
on either of these models, so I'm at the speaker's
mercy as to their accuracy. The implication is
substantial: in any group, most people contribute
little or nothing to the group. Perhaps that is
stated too strongly as a generalization, because
a single publication or a single piece of art
can make a major contribution to the world, belying
the creator's point on the Lotka Curve. But if
these models mean what Csikszentmihalyi claims,
culture and even narrower domains of discourse
are driven forward by the work of only a few.
I don't think that this will alarm too many people.
It sounds just like the
long tail
and
power law
that dominates discussion of the web and social
networks these days.
Finally Csikszentmihalyi got around to describing
his own results. Foremost was this model of how
creativity and ideas affect the world:
The culture transmits information to people. Some
people are happy to keep it at that, to absorb knowledge
and use it in their lives. These folks accept the
status quo.
The creative person, though, has the idea that he
can change the world. He produces a novelty and
pushes it out for others see. Only a small percentage
of folks do this, but the number is large enough
that society can't pay attention to all of the
novelties produce.
A field of discourse, such as an academic discipline
or "the art world", selects some of the novelties as
valuable and passes them onto the culture at large
with a seal of approval. Thus the field acts as a
gatekeeper. It consists of the critics and powerbrokers
esteemed by the society.
When there doesn't seem to be enough creativity for
rapid change in a domain, the problem is rarely with
the production of sufficient ideas but in
the field's narrow channel for recognizing enough
important novelties. I suppose that it could also
come back to a field's inability to accurately evaluate
what is good and what isn't. The art world seems to
go through phases of this sort with some regularity.
How about the sciences?
Csikszentmihalyi has devoted much of his effort
to identifying common characteristics in the
personalities of creative individuals. The list
of ten characteristics he shared with his audience
had some predictable entries and some surprises
to me:
suffering, vulnerable, insecure
(not particularly joyful, strong, or self-confident)
I'm not surprised to see high energy, openness to new
experience, ambition, passion, ... on the list. They
are just what I expect in someone who changes the
world. But Numbers 7, 8, and 10 seemed counterintuitive
to me. But some reflection and further explanation
made sense of them. For example, #7 is a simplification,
on the notion that historically many of the biggest
contributors of ideas and works of art to society
have been men. And these creative men tend to have
personality traits that society usually associates
with women. This element works the other way, too.
Major female contributors tend to have personality
traits that society usually associates with men.
So this element might more accurately be labeled
outside society's gender expectations or
somesuch.
(And before anyone feels the needs to rain flame
down on me a lá the recent Larry Summers
fiasco, please note that I recognize fully the
role that socialization and and other social
factors play in the documented history of male
and female contributions to the world. I also
know that it's just a generalization!)
Convergent thinking and conservatism also seemed
out of place on the list, but they make sense when
I consider Csikszentmihalyi's systemic model of
the flow of contributions. In order to affect the
world, one must ordinarily have one's idea vetted
by the field's powerbrokers. Rebelliousness isn't
usually the best means to that end. The creative
person has to balance rule breaking with rule
following. And convergence of thought with ideas
in the broader culture increases the likelihood
of new ideas being noticed and finding a natural
home in others' minds. Ideas that are too novel
or too different from what is expected are easy
to admire and dismiss as unworkable.
This talk didn't deal all that much with
Csikszentmihalyi's signature issue, flow, but
he did close with a few remarks from folks he
had studied. Creators seem to share a predilection
to deep attention to their work and play. In such
moments, the ordinary world drops beyond the scope
of their awareness. He displayed a representative
quote from poet
Mark Strand:
The idea is to be so ... so saturated with it that
there's no future or past, it's just an extended
present in which you're, uh, making meaning. And
dismantling meaning, and remaking it.
I'm guessing that every programmer hears that quote
and smiles. We know the feeling--saturation, making
meaning.
Csikszentmihalyi closed his talk with a couple of
short remarks. The most interesting was to refute
the common perception that Creative people are
prone to living dissolute lives. On the contrary,
the majority of the folks he has studied and
interviewed have been married for all of their
adult lives, have families, participate at their
churches in in civic organizations. They have
somehow come to balance "real life" with sustained
episodes of flow. But, true to Personality Trait
#10 on the list above, they all feel guilty about
not having spent more time with their spouses and
children!
(At this point, I had to leave the talk just as the
question-and-answer session was beginning. I had
to pick my daughters up from play rehearsal. :-)
This talk has led me to a few thoughts...
If the world is changed by a rather small number
of contributors, where does that leave the rest
of us? Certainly, we can be creative and improve
our own lives as a result. But we can also improve
the lives of those around us. And we shouldn't
think that we will never have effects beyond our
local world. Contributions of the small sort can
sometimes lead to effects we never anticipated.
Csikszentmihalyi mentioned the significant role
that luck plays in both the creative act and its
entry into the culture. I liken this to making
money in the stock market. Most of the growth
in the market occurs on a few days of extreme
growth; if you want to make money, you have to
be in the market when those unpredictable days
pass by. You can try to time the market, but the
risk of being out of the market for a few days
is much higher than the marginal increase you
may achieve. Likewise, moments of inspiration
happens sometimes when you least expect them.
The key is to be active, engaged, and
aware. If you are doing when inspiration
comes, you will be able to capitalize. If you
are dawdling or wasting time on the web, then
you'll miss it.
And, to the extent that we can stimulate an
environment in which the creative moment can
occur, you need to active, engaged,
and aware. That is a major component of the
success that we see in highly productive people.
I believe that a person can cultivate the
personality traits shared by creative people.
Some are easier to practice than others, and
what's toughest to cultivate differs from person
to person. I'm sociable but not extroverted,
so I have to work at engaging people more than
some other folks. And, while I think I'm
relatively insecure compared to other academics,
I don't naturally expose myself as vulnerable.
But these are habits as much as anything, and
they can be unlearned. Some folks may have
gifts that give them a head start to being
creative and productive, we all can be, if we
choose to work hard to change.
What about the agile software community? The
agile approaches encourage "small" practices,
the sort of small-c creativity that can improve
the developer's life and the developer's company.
But they can also improve the lives of clients.
And I believe that the cumulative effect of simple
practices, can be a qualitative difference in
how we behave -- from which large-c Creativity
can emerge. If a person has the right mindset,
they can sometimes make great leaps in understanding.
Many people have engaged in practices we now call
agile for decades. But a select few decided to
"go public", to try to change how software is
built in the world. They sought to bring social
attention to these ideas and to build a new
community of discourse. The folks who started
the
Agile Alliance,
the folks who have tried to take these ideas
into the testing community... they are engaging
in big-c Creativity, even as it emerged from
lots of little acts -- and even if they hadn't
planned to.
I suspect some of the leaders of the agile
movement did start out with the intention of
changing the world. Guys like Kent Beck, Ward
Cunningham, and Alistair Cockburn have a vision
that they want to bring to the community as a
whole. I admire them for their ambition and
energy. I also admire that they are willing to
learn in the public and adapt. For example, Kent
learned a lot in writing and promoting XP
Explained, and now he has written a second
edition that embodies what he has learned --
and he tells readers upfront that it's different,
and that he has learned.
With so many great books to read, now that I have seen
Csikszentmihalyi speak, I doubt that I'll read "Flow"
any time soon. But I think its ideas will continue
to percolate in mind.
When I taught a course on Agile Software Development
last semester, I fell into a habit of beginning the
first class each week with a segment called "Agile
Moments". Think of Saturday Night Live's old
Deep Thoughts, by Jack Handy,
only on a more serious plane. I'd gather up one or
two interesting ideas I'd encountered in the previous
week from posts to the XP mailing list, blogs I'd
read, or projects I was working on. Then I'd pull
out a provocative or entertaining quote and use
that to launch into a discussion of the idea with
my students. This seemed like a good way to share
topical information with my students while showing
them that they could enter into real conversations
about how to write programs. It also reminded my
students that I am always reading what others are
writing about agile software, and that they could,
too.
Anyway, I've been so busy planning for
ChiliPLoP 2005,
for which I am program chair and a Hot Topic
leader, and
SIGCSE 2005,
at which I am
co-leading a workshop with Joe Bergin,
that I haven't been writing a lot here. But I
do find myself having Agile Moments, so let me
share them with you.
Programming and Testing
Patrick Logan has a nice article on
speaking in objects,
which suggests that programming is best thought
of as a dialog with the computer. The pithy quote
that stands out in this article is one he
attributes to Ward Cunningham:
It's all talk until the tests run.
We all know that's true.
Simple Design
Grady Booch is spending a lot of time in his
considerable library as hew works on his
Handbook of Software Architecture.
Yesterday he wrote about
one of his favorite books,
John Gall's Systemantics. Based on Grady's
recommendation, I just picked this book up from our
library. Among other things, Gall argues that
successful large systems invariably come from
successful small systems. This reminds me of agile
development's emphasis on piecemeal growth and
evolutionary design through tests and refactoring.
One of Gall's quotes captures one of the primary
motivations of the agile approaches:
Bad design can rarely be overcome by more design,
whether good or bad.
This points out the big risk of
Big Design Up Front:
If we get it wrong, we likely have sunk our project.
It is hard to recover from a bad design.
Of course, in true Agile Moments fashion, I also
encountered a cautionary tale about evolutionary
design. Martin Fowler warns of the risks of
Abundant Mutation,
which can occur with large teams when many sub-teams
attack a common issue in different ways, or with
smaller teams when a stream of newcomers continually
join a project in mid-stream and take unfinished
code in different directions. Martin reminds us
that "evolutionary design requires attention, skill,
and leadership".
Continuous Refactoring
Blaine Buxton recently posted a
quote
worthy of being an agile slogan:
Code removed is code earned.
Refactoring may end up shrinking the size of your
system, but it is a net addition in the
quality of your system. You earn the ability to
add the next requirement more easily, as well as
the ability to understand the program more easily.
Blaine's quote reminded me of my favorite quote
about the joys of refactoring, which showed up
in a
blog entry
I wrote long ago:
The only thing better than a 1000-line of code
weekend is a minus 1000-line of code weekend.
-- Brian Foote
Brian could make a fine living as a writer of
slogans and jingles!
One of my favorite TV shows back when I was little
guy in the 1970s was
The Paper Chase.
It was a show about a group of law students,
well, being law students. It was based on a
1973 movie
of the same name. It's not the sort of show that
tends to hang around the TV schedule very long;
it lasted only a year or two on network television.
Even still, I fell in love with the quiet drama
of university life while watching this show.
Whether you remember the show or not, you may
well know its most famous character, Professor
Charles W. Kingsfield, Jr., played with panache
by the eminent
John Houseman.
Professor Kingsfield was in many ways the
archetype for the brilliant scholar and demanding
yet effective university teacher that one so often
sees on film. Growing up, I always hoped that I
might encounter such a professor in my studies,
certain that he would mold me into the great
thinker I thought I should be. In all my years
of study, I came across only one teacher who could
remind me of Kingsfield: William Brown, an old
IBM guy who was on the faculty at
Ball State University
until his retirement. Many professors demanded
much of us, and some were brilliant scholars, but
only Dr. Brown had the style that made you feel
honor in the fear that you might not meet his
standard. I had plenty of great professors at
Ball State, but none like Dr. Brown.
Why this reminiscence on a Friday afternoon 20
or 25 years later? I thought of
John Houseman
and a particular episode of
The Paper Chase
yesterday afternoon. The episode revolved
around a particularly laborious assignment that
Kingsfield had given his Contracts class.
(Kingsfield made contract law seem like the
most lively intellectual topic of all!) The
assignment required students to answer one
hundred questions about the law of contracts.
Some of these questions were relatively routine,
while others demanded research into hard-to-find
articles and journals from way back. Of course,
students worked together in study groups and so
shared the load across four or five people, but
even so the assignment was essentially impossible
to complete in the time allotted.
While sharing their despair, our protagonists --
Mr. Ha-a-a-rt
and his study group -- stumbled upon a plan:
why not share the load with other
study groups, too? Soon, all the study groups
were working out trades. They couldn't trade
answers one for one, because some groups
had worked on the hardest questions first,
so the answers they offered were more valuable
than those of a group that had cherry-picked
the easy ones first. By the end of the episode,
the groups had drawn up contracts to guide
the exchange of information, executed the
deals, and submitted a complete set of answers
to Kingsfield.
As the students submittted the assignments,
some worried that they had violated the spirit
of individual work expected of them in the
classroom. But Hart realized that they had,
in fact, fulfilled Kingsfield's plan for them.
Only by negotiating contracts and exchanging
information could they conceivably complete
the assignment. In the process, they learned
a lot about the law of contracts from the
questions they answered, but they had learned
even more about the law of contracts by
living it. Kingsfield, the master,
had done it again.
So, why this episode? Yesterday I received
an e-mail message from one of our grad students,
who has read some of my recent entries about
helping students to learn new practices.
(The most recent strand of this conversation
started with
this entry.)
He proposed:
... I wonder if you have considered approaches
to teaching that might include assigning projects
or problems that are darned-near unsolvable using
the methods you see the students using that you
wish to change? ... you can't really force anyone
to open up or see change if they don't feel there
is anything fundamentally wrong with what they are
doing now.
This is an important observation. A big part of
how I try to design homework assignments involves
finding problems that maximize the value of the
skills students have learned in class. Not all
assignments, of course; some assignments should
offer students an opportunity to practice new
ideas in a relatively stress-free context, and
others should give them a chance to apply their
new knowledge to problems that excite them and
are methodology-neutral.
But assigning problems where new practices
really shine through is essential, too.
Kingsfield's approach is a form of Extreme
Exercise, where students can succeed only
if they follow the program laid out in class.
In university courses on programming and software
development, this is a bigger challenge than in
a law school. It is Conventional Wisdom that
the best programmers are ten or more times more
productive than their weakest colleagues. This
disparity is perhaps nowhere wider than in the
first-year CS classroom, where we have students
everywhere along the continuum from extensive
extracurricular experience and understanding to
just-barely-hanging-on in a major that is more
abstract and demanding than previously realized.
Kingsfield's approach works better with a more
homogeneous student body -- and in an academic
environment where the mentality is "sink or
swim", and students who fail to get it are
encouraged to pursue another profession.
I still like the idea behind the idea, though,
and think I should try to find an exercise that
makes, say, test-driven design and refactoring
the only real way to proceed. I've certainly
done a lot of thinking along these lines in
trying to teach functional programming in my
Programming Languages course!
Practical matters of educational psychology
confound even our best efforts, though. For
example, my reader went on to say:
If a teacher can come up with scenarios that
actually ... require the benefits of one approach
over the other, I suspect that all but the most
stubborn would be quick to convert.
In my years as a teacher, I've been repeatedly
surprised by the fact that no, they won't.
Some will change their majors. Others will cling
to old ways at the cost of precious grade points,
even in the face of repeated lack of success as
a programmer. And, of course, those very best
students will find a way to make it work using
their existing skills, even at the cost of precious
grade points. Really, though, why we penalize
students very much for succeeding in a way we
didn't anticipate?
With the image of Professor Kingsfield firmly
planted in my mind, I will think more about
how the right project could help students by
making change the only reasonable option. I
could do worse than to be loved for having the
wisdom of Kingsfield.
And, as always, thanks to readers for their
e-mail comments. They are an invaluable part
of this blog for me!
I recently saw a statement somewhere, maybe on the XP
mailing list, to the effect that XP doesn't prevent
people who will fail from failing; it helps people
who will succeed to succeed more comfortably or more
efficiently.
I think that, in one sense, this is true. No software
methodology can do magic. People who for whatever
reason are unprepared to succeed are unlikely to
succeed. And I believe that good developers can do
even better when they work in an agile fashion.
But in another sense I think that XP and the other
agile methods can help developers get better at what
they do. If a person makes a commitment to improve,
then adopting XP's disciplines can become a better
developer.
This all came to the front of my mind yesterday as
I read a short essay over at
43 Folders
on
systems for improving oneself.
Merlin's comments on self-improvement systems caused
a light bulb to go off: XP is a self-help system!
Consider...
Successful self-help systems help a person to
become more self-aware and to use what they
observe to effect a more favorable solution.
Successful systems encourage simplicity and
communication.
Agile software methods draw on a desire to get better
by paying attention to what the process and
code tell us and then feeding that back into the
system -- using what we learn to change how we
do what we do.
Practices such as continuous unit testing provide the
feedback. The rhythm of the test-code-refactor cycle
accentuates the salience of feedback, making it possible
for the developer to make small improvements to the
program over and over and over again. The agile
methods also encourage using feedback from the process
to fine-tune the process to the needs of the team,
the client, and the project.
Improvement doesn't happen by magic. The practices
support acquiring information and
feeding it back into the code.
A person is more likely to stick with a system
if it is simple enough to perform regularly and
encourages small corrections.
Merlin proposes that all successful self-improvement
systems embody...
... a few basic and seemingly immutable principles:
action almost always trumps inaction
planning is crucial; even if you don't follow
a given plan
things are easier to do when you understand
why you're doing them
your brain likes it when you make things as
simple as possible
That sure sounds like an agile approach to software
development. How about this:
... the idea basically stays the same: listen
critically, reflect honestly, and be circumspect
about choosing the parts that comport with your
needs, values, and personal history. Above all,
remember that the secret code isn't hiding ...
-- the secret is to watch your progress and just
keep putting one foot in front of the other.
Keep remembering to think, and
stay focused on achieving modest improvements in
whatever you want to change. Small
changes stick.
Any software developer who wants to get better
could do much worse than to adopt this mindset.
I've been so busy that writing for the blog has taken a
back seat lately. But I have run across plenty of cool
quotes and links recently, and some are begging to be
shared.
Why Be a Scientist?
Jules Henri Poincare said...
The scientist does not study nature because it is
useful. He studies it because he delights in it, and
he delights in it because it is beautiful.
... as quoted by Arthur Evans and Charles Bellamy
in their book An Inordinate Fondness for Beetles.
How to Get Better
When asked what advice he would give young musicians,
Pat Metheny said:
I have one kind of stock response that I use, which
I feel is really good. And it's "always be the worst guy
in every band you're in." If you're the best guy there,
you need to be in a different band. And I think that works
for almost everything that's out there as well.
I remember when I first learned this lesson as a high
school chessplayer. Hang out with the best players
you can find, and learn from them.
(I ran across this at Chris Morris's
cLabs wiki,
which has some interesting stuff on software development.
I'll have to read more!)
All change is stressful - even if we know it's good change. ...
Those of us who attempt to act as agents of change, whether
within other organisations or within our own, could do well
to remember it.
Perryn writes in the context of introducing agile software
methods into organizations, but every educator should keep
this in mind, too. We are also
agents of change.
While reading about the
muddled state of Groovy,
I ran across a blog post on the topic of trying to
get students to adopt new practices. Greg Wilson
writes on his blog
Pyre:
It's easy to make students jump through hoops in a course.
What's hard is convincing them that jumping through those
hoops after the course is over really will make their
lives better. The best way I've found so far is to bring
in experienced programmers who are doing exciting things,
and have them say, "Comments, version control, test-driven
development..."
Earlier in the same entry, he suggests that XP succeeds
not because of its particular practices, but rather...
... that what really matters is deciding that you
want to be a better programmer. If you make a
sincere commitment to that, then exactly how you get
there is a detail.
That's spot on with what I said in my
last message.
Learning happens when a person opens himself to
change. That openness makes it possible for the
learner to make the commitment to a new behavior.
With that commitment,
even small changes in practice can grow
to large changes in capability.
And I certainly concur with Gregg's advice to
bring in outsiders who are doing cool things.
Some students reach a level of internal motivation
in that way that they will never reach through
being asked to change on their own.
The temperature here has risen to unseasonably high
levels the last week or so. That means that I am
able to run outdoors again. And I love it -- fresh
air and open space are where the great running is.
I live where the American Midwest meets its Great
Plains, so by most folks' standard the land here
is flat. But I live near a river, and we do have
gently rising and falling terrain, which makes
every run more interesting and more challenging than
any track can offer.
One thing I notice whenever I am able to break away
from track running is an increase in the variability
of my pace. When I run on a short indoor track,
I usually find myself running relatively steady lap
times, drawn into a rhythm by the short, repetitive
environment.
Another thing I notice is that tend to run faster
than I'd like, even on days I'd rather take it
easy. One good result of this is that
I get faster,
but the negative side effect is that I end up more
tired all week long. That affects the other parts
of my life, like my teaching and my time with my
family.
You might think that a couple of seconds per lap
-- say, 52 second laps instead of 54 -- wouldn't make
that much difference. That's less than 4%, right?
But a small difference in effort can have a big
effect of the body. That small difference compounds
at every lap, much like interest in a bank account.
What feels comfortable in the moment can be less
so far after the fact, when that compounded difference
makes itself apparent. There can value be in such
stresses ("the only way to get faster is to run
faster"), but there are also risks: a depressed
immune system, increased susceptibility to injury,
and the tiredness I mentioned earlier.
Most runners learn early to respect small changes
and to use them wisely. They learn to mix relatively
easy runs and even off days in with their harder
runs as a way to protect the body from overuse.
Folks who train for a marathon are usually told
never to increase their weekly mileage by more
than 10% in a given week, and to drop back every
second or third week in order to let the body
adjust to endurance stress.
At first, the 10% Rule seems like an inordinate
restriction. "At this rate, it will take me
forever to get ready for the marathon!"
Well, not forever, but it will take a while.
Most people don't have any real choice, though.
The human body isn't tuned to accepting huge
changes in endurance very quickly.
But their is hope, in the bank account analogy
above. You may have heard of the
Rule of 72,
an old heuristic from accounting that tells us
roughly how quickly a balance can double. If
a bank account draws 5% interest a year, then
the balance will double in roughly 72/5 ~~
14 years. At 10% interest, it will double in
about seven. This is only a heuristic, but the
estimates are pretty close to the real numbers.
Applied to our running, the Rule of 72 reminds
us that if we increase our mileage 10% a week,
then we can double our mileage in only seven
weeks! Throw in a couple of adjustment weeks,
and still we can double in 10 weeks or less.
And that's at a safe rate of increase that will
feel comfortable to most people and protect their
bodies from undue risks at the same time. Think
about it: Even if you can only jog three miles
at a time right now, you could be ready to finish
a marathon in roughly 30 weeks! (Most training
plans for beginners can get you there faster,
so this is really just an upper bound...)
What does this all have to do with software
development? Well, I have been thinking about
how to encourage students, especially those in
my first-year course, to adopt new habits, such
as test-driven design and refactoring. I had
hoped that, by introducing these ideas early in
their curriculum, they wouldn't be too set in their
ways yet, with old habits too deeply ingrained yet.
But even as second-semester programmers, many of
them seem deeply wedded to how they program now.
Of course, programmers and students are people, too,
so they bring with them cognitive habits from other
courses and other subjects, and these habits interact
with new habits we'd like them to learn. (Think
deeply about the problem. Write the entire program
from scratch. Type it in. Compile it. Run it.
Submit it. Repeat.)
How can I help them adopt new practices? The XP
mailing list discusses this problem all the time,
with occasional new ideas and frequent reminders
that people don't change easily. Keith Ray
recently posted a
short essay
with links to some experience reports on incremental
versus wholesale adoption of XP. I've been focusing
on incremental change for the most part, due to the
limits of my control over students' motivation and
behavior.
The 10% Rule is an incremental strategy. The Rule
of 72 shows that such small changes can add up to
large effects quickly.
If students spends 10 minutes refactoring on the
first day, and then add 10% each subsequent day,
they could double their refactoring time in a week!
Pretty soon, refactoring will feel natural, a part
of the test-code-refactor rhythm, and they won't
need to watch the clock any more.
I'm not sure how to use this approach with testing.
So far, I've just started with small exercises and
made them a bit larger as time passed, so that the
number of tests needed has grown slowly. But I know
that many still write their tests after they think
they are done with the assignment. I shouldn't
complain -- at least they have tests now, whereas
before they had none. And the tests support refactoring.
But I'd like to help them see the value in writing
the tests sooner, even first.
Together, the 10% Rule and the Rule of 72 can result
in big gains when the developer commits to a new
practice in a disciplined way. Without commitment,
change may well never happen. A runner who doesn't
run enough miles, somehow increasing stamina and
strength, isn't likely to make to the level of a
marathon. That discipline is essential. The 10%
Rule offers a safe and steady path forward, counting
on the Rule of 72 to accumulate effects quicker than
you might realize.
So off I trudge to the Java Language Reference,
where on Page 27 I find:
Java performs all integer arithmetic using
int or long operations. A value
that is of type byte, short, or
char is widened to an int or a
long before the arithmetic operation is
performed.
So your RHS value are upcast to ints for
the subtraction, resulting in a downcast on assignment.
But why does Java work this way? Any ideas?
Second: I'm teaching an undergraduate algorithms
course this year for the first time in a long while,
and I often find myself whipping up a quick program
in Scheme or Java to demonstrate some algorithms we've
designed in class. This afternoon I was implementing
a brute-force algorithm for the old Gas Station Problem:
A cyclic road contains n gas stations placed at
various points along the route. Each station has some
number of gallons of gas available. Some stations have
more gas than necessary to get to the next station, but
other stations do not have enough gas to get to the next
station. However, the total amount of gas at the
n stations is exactly enough to carry a car
around the route exactly once.
Your task: Find a station at which a driver can
begin with an empty tank and drive all the way around
the road without ever running out of gas.
The input to your algorithm is a
list of n integers, one for each station. The
ith integer indicates the number of miles a car
can travel on the gas available at the ith station.
For simplicity, let's assume that stations are 10
miles apart. This means that the sum of the n
integers will be exactly 10n.
The output of your algorithm should
be the index of the station at which the driver should begin.
Our algorithm looked like this:
for i ← 1 to n do
tank ← 0
for j ← i to ((i + n) mod n) do
tank := tank + gas[j] - 10
if tank < 0 then next i
return i
How to do that next i thing? I don't
know. So off again I go to the language reference
to learn about labels and the continue
statement. Now, to be honest, I knew about both
of these, but I had never used them together or
even thought to do so. But it works:
outer:
for ( int i = 0; i < gas.length; i++ )
{
tank = 0;
for ( int j = i; j < i + gas.length; j++ )
{
tank = tank + gas[j % gas.length] - 10;
if ( tank < 0 )
continue outer;
}
return i;
}
Some days I have major epiphanies, but more often
I learn some little nugget that fills an unexpected
hole in the web of my knowledge. The Java gurus
among you are probably thinking, "He really didn't
know that? Sheesh..."
Neither one of these Java nuggets is earth-shaking,
just the sort of details I only learn when I need
to use them in program for the first time. I suppose
I could study the Java Language Reference in my free
time, but I don't have the sort of job for which that
sounds attractive. (Is there such a job?)
I've been following the development of Laurent Bossavit's
software development dojo. He wrote about the idea in
his blog a few times last year and then created a separate
blog for it at this month at
http://bossavit.com/dojo/.
The most recent article there speculates about programming
as a
performance art.
It seems that the guys in the dojo have been presenting
their code to one another and doing some of the programming
live in front of the group. The experience has caused the
author to re-think his artistic sense of programming:
Had I to choose earlier an art form which I felt connected
to the act of programming, I would have picked book writing
without hesitation. Something static, written at some time,
read at another. Few dojo sessions later, I am not so
positive anymore. I speculate the act of programming is
also about the here and the now: how you currently live
through the problem up to a satisfying conclusion, and how
I feel engaged, watching your sharing techniques and insights.
No cathartic experience so far -- hold your horses, this is
sill embryonic stage -- although this could become a personal
quest.
I feel a kinship here after the first three week of my CS
II class, in which my students and I have been "gang
programming" Ron Jeffries's bowling game using TDD. I've
spent very little time expounding ex cathedra;
most of my remarks have been made in the flow of programming,
with only an occasional impromptu mini-lecture of a few
minutes. If you know me, you probably don't think of me
as a natural performer, but I've felt myself slipping into
the gentle drama of programming. New requirements puzzle
us, then worry us. A test fails. Programming ideas
compete for attention. Code grows and shrinks. Green
bar. Relief.
I hope that most of the students in the class are getting
a sense of what it's like to make software. I also hope
that they are enjoying the low drama of course.
My recent experience has brought to mind my favorite article
on this topic, Bill Wake's
Programming as Performance Art.
He tells of seeing a particularly stirring performance
by Kent Beck and Jim Newkirk:
They tackled the chestnut "Sieve of Eratosthenes." The
4-hand arrangement worked well, and let us see not only
"programmer against complexity" but also "programmer
against self" (when they started to make mistakes) and
"programmer against programmer" (when they resolved their
differences). The audience appreciated the show, but we
should have applauded more enthusiastically.
I don't know what I'd do if my students ever applauded.
But even if they never do, I like the feel of our live
programming sessions. We'll see how effective they are
as learning episodes as the semester progresses.
Brian Button recently posted a long blog entry on his
extreme refactoring
of the video store class from
Martin Fowler'sRefactoring. Brian "turned [his] refactoring
knob up to about 12" to see what would happen. The result
was extreme, indeed: no duplication, even in loops, and
methods of one line only. He concluded, "I'm not sure
that I would ever go this far in real life, but it is
nice to know that I could."
Turning the knobs up in this way is a great way to learn
something new or to plumb for deeper understanding of
something you already know. A few months ago, I wrote
of a similar approach to
deepening one's understanding off polymorphism
and dynamic dispatch via a simple etude: Write a
particular program with a budget of n if-statements
or less, for some small value of n. As n approaches 0,
most programmers -- especially folks for whom procedural
thinking is still the first line of attack -- find this
exercise increasingly challenging.
Back at
ChiliPLoP 2003,
we had a neat discussion along these lines. We were
working with some ideas from Karel the Robot, and
someone suggested that certain if-statements
are next to impossible to get rid of. For example,
How can we avoid thisif?
public class RedFollowingRobot
{
public void move()
{
if (nextSquare().isRed())
super.move();
}
}
public class Square
{
public boolean isRed()
{
...
}
}
But it's possible...
Joe Bergin
suggested a solution using the Strategy pattern, and
I offered a solution using simple dynamic dispatch.
You can see our solutions at
this wiki page.
Like Brian said in his article, I'm not sure that
I would ever go this far in real life, but it is
nice to know that I could. This is the essence of
the powerful
Three Bears pattern:
Often, in taking an idea too far, we learn best the
bounds of its application.
Joe and I like this idea so much that we are teaching
a workshop based on it, called
The Polymorphism Challenge
(see #33 there) at
SIGCSE
next month. We hope that spending a few hours doing
"extreme polymorphism" will help some CS educators
solidify their OO thinking skills and get away from
the procedural way of thinking that is for many of
them the way they see all computational problems.
If you have any procedural code that you think
simply must use a bunch of if-statements,
send it to me, and Joe and I will see if it makes a
good exercise for our workshop!
Back in October, I signed on for a second year as program
chair for the
OOPSLA
Educators Symposium. Last year's symposium
went well,
with
Alan Kay's keynote
setting an inspirational mood for the symposium and
conference, and I welcomed the chance to help put
together another useful symposium for OO eductaors.
Besides, the chance to work with
Ralph Johnson
and
Dick Gabriel
on their vision for an evolving OOPSLA was too much
to pass up.
The
calls for submissions
to OOPSLA 2005 are available on-line now. All of
the traditional options are available again, but
what's really exciting are the new tracks: Essays,
Lightning Talks, Software Studies, and FilmFest.
Essays and Lightning Talks provide a new way to
start serious conversations about programming,
languages, systems, and applications, short of the
academic research papers found in the usual technical
program. I think the Software Studies track will
open a new avenue in the empirical study of programs
and their design. Check these CFPs out.
Of course, I strongly encourage all of you folks who
teach OOP to consider submitting a paper, panel
proposal, or nifty assignment to the
Educators Symposium.
As much as software development, teaching well depends
on folks sharing successful techniques, results of
experiments, and patterns of instructional materials.
This year, the symposium is honored to have
Ward Cunningham
as our keynote speaker. As
reported here,
Ward spoke at last year's OOPSLA. I love Ward's
approach to programming, people, and tools. "OOPSLA
is about programming on the edge, doing practical
things better than most." "Be receptive to discovery."
The symposium's program committee is looking forward
to Ward sharing his perspective with educators.
If you've been to OOPSLA before, you know how valuable
this conference can be to your professinal development.
If not, ask someone who has been, or trust me and try
it yourself. You won't be disappointed.
I recently learned that
Mihaly Csikszentmihalyi
will be visit my campus for several talks in early
March. Csikszentmihalyi (whose name is pronounced
'me-HI chick-SENT-me-hi') is well known for his theory
of flow and its role in creativity and learning.
Long ago I read some of Csikszentmihalyi's work, though
I've never read the bestseller that made his name,
Flow: The Psychology of Optimal Experience.
Maybe now is the time.
Throughout his career, Csikszentmihalyi has studied
the psychology of the creative individual: What
characteristics are common to creative individual?
How do creative people create? His talks here, though,
will focus on the context in which creative
individuals thrive. His main talk will describe how
to create the sort of environment that must exist in
order for a creative individual to contribute most
effectively. His other talks will focus on specific
contexts: How can educators "design curricula that
capitalize on the human need to experience flow?"
How work can contribute to well-being, and how can
managers and employees create the right sort of
workplace?
We agile folks often speak of "rhythm" and how TDD
and refactoring can create a highly productive
flow. And, while I've often heard critics say that
P limits the individuality of developers, I've always
thought that agile methods can unleash creativity.
I'm curious to hear what Csikszentmihalyi has to say
about flow and how we can create environments that
support and nurture it, both for software development
and for learning. You may recall an
earlier discussion here
about flow in learning, inspired by the Suzuki
method of instruction and by
Alan Kay's talks at OOPSLA.
I think Csikszentmihalyi can help me to understand
these ideas better.
I teach our second course, CS II. It comes between an
intro course in which students learn a little bit about
Java and a little bit about objects, and a traditional
data structures course using Ada95. The purpose of CS
II is to give students a deeper grounding in Java and
object-oriented programming.
The first thing I did on our first day of class was to
write code. The first line of code I wrote was a test.
The next thing I did was try to compile it, which failed,
so I wrote the code to make it compile. Then I ran the
test in
JUnit
and watched it fail. Then we wrote the code to make
it pass.
And then we did it again, and again, and again.
I've long emphasized various agile practices in my
courses, even as early as CS II, especially short
iterations and refactoring. In recent semesters I've
encouraged it more and more. Soon after fall semester
ended, I decided to cross the rubicon, so to speak.
Let tests drive all of our code. Let students feel
agile development from all class and lab work.
Day 1 went well. We "gang-programmed", with students
helping me to order requirements, write tests, find
typos, and think through application logic. The
students responded well to the unexpected overhead of
JUnit. Coming out of the first course, they aren't
used to non-java.* or extra "stuff".
In our second session, a lab class, students installed
JUnit in their own accounts and wrote their first
Java code of the semester: a JUnit test against the
app we built in Day 1.
Oh, the app? Ron Jeffries'
BowlingGame
etude. It had just enough complexity to challenge students
but not enough to pull too much of their attention away
from the strange and wonderful new way we were building
the program.
Next time, we'll add a couple of requirements that lead us
to factor out a Frame, allowing us to see refactoring
and how tests support changing their code.
I'm excited even as I'm a little on edge. New things in
the classroom do that to me.
Brian Marick
just blogged
on Joel Spolsky's
Advice for Computer Science College Students.
I had the beginnings of an entry on Joel's stuff sitting
in my "to blog" folder, but was planning to put it off
until another day. (Hey, this is the last Thursday
I'll be able to go home early for sixteen weeks...)
But now I feel like saying something.
Brian's entry points that Joel's advice reflects a change
in the world of programming from back when we old fogies
studied computer science in school: C now counts as close
enough to the hardware to be where students should learn
how to write efficient programs. (Brian has more to say.
Read it.)
I began to think again about Joel's advice when I read the
article linked above, but it wasn't the first time I'd
thought about it. In fact, I had a strong sense of deja
vu. I looked back and found another article by Joel,
on
leaky abstractions,
and then another, called
Back to Basics.
There is is a long-term theme running through Joel's articles,
that programmers must understand both the abstractions they
deal in and how these abstractions are implemented.
In some ways, his repeated references to C are mostly pragmatic;
C is the lingua franca at the lowest level of software
development, even -- Brian mentions -- for those of us who prefer
to traffic in Ruby, Smalltalk, Perl or Python. But C isn't
the key idea Joel is making. I think that this, from the
leaky abstractions,
article, is [emphasis added]:
The law of leaky abstractions means that whenever somebody comes
up with a wizzy new ... tool that is supposed to make us all
ever-so-efficient, you hear a lot of people saying "learn how to do
it manually first, then use the wizzy tool to save time." [...]
tools which pretend to abstract out something, like all abstractions,
leak, and the only way to deal with the leaks competently is to
learn about how the abstractions work and what they are abstracting.
So the abstractions save us time working, but they don't
save us time learning.
And all this means that paradoxically, even as we have higher and
higher level programming tools with better and better abstractions,
becoming a proficient programmer is getting harder and harder.
Programming has always been hard, but it gets harder when we move
up a level in abstraction, because now we have to worry about the
interactions between the levels. Joel's article argues us that
it's impossible to create an abstraction that doesn't leak. I'm
not sure I willing to believe it's impossible just yet, but I do
believe that it's close enough for us to act as if it is.
That said, Brian's history lesson offers some hope that that the
difficulty of programming isn't growing harder at an increasing
rate, because sometimes what counts as the lowest level rises.
C compilers really are good enough these days that we don't have
to learn assembly in order to appreciate what's happening at the
machine level. Or do we?
Oh, and I second Brian's recommendation to read Joel's
Advice for Computer Science College Students.
He may just be one of those old fogies "apt to say goofy,
antediluvian things", but I think he's spot on with his
seven suggestions (even though I think a few of his reasons
are goofy). And that includes the one about microeconomics!
When I'm out shopping for any big-ticket item, such as a car,
I am notoriously slow to pull the trigger. I can be just as
slow on even relatively inexpensive items like stereos, or
snack food. My wife long ago learned to give me time, to
walk off and let me stew a bit, before putting any pressure
on me to make a decision. But she also learned that without
such pressure I may never decide to buy or not. Talk about
the Halting Problem.
What's the cause of my shopping behavior? Perhaps I'm prone
to regret and am trying to protect myself from that gnawing
feeling that I've made the wrong choice. Having even a few
alternatives makes my choice difficult. (To be honest, I
think I worry about feeling regret at having spent the money
at all, which just makes me cheap. :-)
Difficulty making choices has been a thread over on the
XP discussion list
recently.
Jason Yip
read Barry Schwartz's April 2004 Scientific American article
The Tyranny of Choice,
which is based on his popular book
The Paradox of Choice.
Schwartz argues that there exists something of a
Laffer curve
at work when it comes to the psychology of decision making.
Having few or no choices gives people little opportunity
to control their destinies, which often results in being
disappointed with how things turn out. Having many choices
gives people a feeling of control but increases the probability
of making the wrong choice, which leads to regret. Schwartz
points out that regret tends to make people more unhappy than
disappointment. From this, he concludes that having too many
alternatives is actually worse for people than having too few.
Jason raised Schwartz's thesis in the context of customer choice
in XP, brought on by an earlier thread about optional scope
contracts. He asked if anyone had observed the "tyranny of
choice" phenomenon manifest itself as resistance to more flexible
approaches to defining project scope. We can frame the question
even more broadly, as XP offers many choices in the release and
iteration planning phases of a project that customers may not
be used to. The resulting thread of discussion offered several
interesting takes on this idea. Check it out.
When I'm doing XP, my customers face a somewhat different situation
than I do when I'm buying a car. Customers tend to make their
choices as part of a longer-term relationship, and the new choices
P gives them are more about ordering the steps of the project than
selecting only one from a set of alternatives. If they make a choice
they regret, they will have a chance to re-prioritize requirements
when helping to plan the next release. As a result, their regret
will tend to be short-lived and more about short-term opportunity
cost.
(Mike Feathers
made a similar argument on the discussion list.)
Of course, when developing software in a more traditional way,
someone is making all these choices, though often it
is the technical team. You'd think that customers would be no
worse off making their own choices, even if they come to regret
them, than by having some programmer make the decision in his
cubicle one night. But that's the vexing part of Schwartz's
thesis: They feel worse off in regret at their
decision than they do in disappointment at the programmer's.
Knowing this, agile developers can play a valid role in helping
their customers make choices. When they see a customer having
difficulty setting priorities, they can inject some of their
professional experience into the mix. Telling customers how
past projects have gone may help them set a priority for the
current release. Reminding them that they will have a chance
to guide the project's course again at the next release or
iteration may help them avoid paralysis motivated by fear of
regret.
Some folks on the XP list offered some fun little strategies
for helping break a deadlock in decision making. For example,
if the customer says that all features are equally important,
try selecting what seems to you to be the least valuable feature
as the first one to implement. Sometimes, that's enough of
a push to get the customer to think he can do a better job
than you and so choose. I'm guessing that it's especially
important to manage expectations in this scenario -- you don't
want the customer to think you tricked him into making
a choice he ultimately regrets, because then he'll be saddled
not only with regret but also a distrust of you. And trust
is essential to a good working relationship, especially in an
agile approach.
For me, this brings to mind my younger daughter. Since she
was a toddler, she has generally had trouble deciding, whether
the choice is among alternatives for dessert, or outfits to
where, or whether to ride home in the car with mommy or
daddy. (Like many other families, we often end up in the
same with both cars!) Instinctively, I've always tried to
reassure her that her decision isn't the Final Answer, that
if she later wishes she'd chosen ice cream for dessert, well
then, we can just have ice cream tomorrow. That hasn't always
seemed to help, at least not with the choice at hand. But
I think that it's a good way to approach the situation: don't
put undue pressure on her, and help calm her fears -- whether
of regret or of disappointing me, which sometimes seems to
be a factor in her decisions that I didn't expect. Building
a relationship in which she can trust me is the best I can
hope for in helping her learn to choose. And, as she's gotten
older, she has become a more confident decision maker.
Back to software: Ultimately, I think that the "paradox of
choice" phenomenon is more a case for agile methods
than a case against them. It underscores one of the great
strengths of the agile approaches: an attitude
toward job and customer based in respect, trust, and communication.
When we value these ahead of hard-and-fast rules and ahead of
"the process", we are able to adjust our approach to the
particulars of the customer and the current project.
Owen Astrachan
pointed me in the direction of Jonathan Edward's
new blog.
I first encountered Edwards's work at
OOPSLA 2004,
where he gave a talk in the Onward! track on his
example-driven programming tool.
In his initial blog entries, Edwards introduces readers
to the programming revolution in which he would like to
participate, away from more powerful and more elegant
languages and toward a programming for the Everyman,
where we build tools and models that fit the way the
real programmer's mind works. His Onward! talk demoed
a initial attempt at a tool of the sort, in which the
programmer gives examples of the desired computation
and the examples become the program.
Edwards's current position stands in stark contrast to
his earlier views as a more traditional researcher in
programming languages. As many of us are coming to see,
though, "programming is about learning to work effectively
in the face of overwhelming complexity" than it is about
ever more clever programming languages and compiler tricks.
When it comes to taming the complexity inherent in large
software, "simplicity, flexibility, and usability are more
effective than cleverness and elegance."
The recent trend toward agile development methodologies
and programming support tools such as
JUnit
and
Eclipse
also draw their inspiration from a desire for simpler
and more flexible programs. Most programmers -- and
for Edwards, this includes even the brightest -- don't
work very well with abstractions. We have to spend a
lot of brain power managing the models we have of our
software, models that range from execution on a standard
von Neumann architecture up to the most abstract
designs our languages will allow. Agile methods such
as XP aim to keep programmers' minds on the concrete
embodiment of a program, with a focus on building
supple code that adapts to changes in our understanding
of the problem as we code. Edwards even uses one of
Kent Beck's old metaphors that is now fundamental to
the agile mindset: Listen carefully to what our code
is telling us.
But agile methods don't go quite as far as Edwards seems
to encourage. They don't preclude the use of abstract
language mechanisms such as closures or higher-order
procedures, or the use of a language such as Haskell,
with its "excessive mathematical abstraction". I can
certainly use agile methods when programming in Lisp or
Smalltalk or
even Haskell,
and in those languages closures and higher-order procedures
and type inference would be natural linguistic constructs
to use. I don't think that Edwards is saying such things
are in and of themselves bad, but only that they are a
symptom of a mindset prone to drowning programmers in
the sort of abstractions that distract them from what they
really need in order to address complexity. Abstraction
is a siren to programmers, especially to us academic types,
and one that is ultimately ill-suited as a universal tool
for tackling complexity. Richard Gabriel told us that
years ago in Patterns of Software
(pdf).
I am sympathetic to Edwards's goals and rationale. And,
while I may well be the sort of person he could recruit
into the revolution, I'm still in the midst of my own
evolution from language maven to tool maven. Oliver
Steele coined those terms, as near as a I can tell, in
his article
The IDE Divide.
Like many academics, I've always been prone to learn
yet another cool language rather than "go deep" with a
tool like emacs or Eclipse. But then it's been a long
time since slogging code was my full-time job, when
using a relatively fixed base of language to construct
a large body of software was my primary concern. I
still love to learn a Scheme or a Haskell or a Ruby or
a Groovy (or maybe Steele's own Laszlo) to see what new
elegant ideas I can find there. Usually I then look
to see how those ideas can inform my programming in the
language where I do most of my work, these days Java, or
in the courses where I do most of my work.
I don't know where I'll ultimately end up on the continuum
between language and tool mavens, though I think the shift
I've been undergoing for the last few years has taken me
to an interesting place and I don't think I'm done yet.
A year spent in the trenches might have a big effect on me.
As I read Edwards's stuff, and re-read Steele's, a few
other thoughts struck me:
I retain a romantic belief in the potential of scientific
revolution ... that there is a "Calculus of Programming"
waiting to be discovered, which will ... revolutionize the
way we program....
(The analogy is to the invention of the calculus,
which revolutionized the discipline of physics.) I
share this romantic view, though my thoughts have been
with the idea of a pattern language of programs. This
is a different sort of 'language' than Edwards means
when he speaks of a calculus of programs, but both
types of language would provide a new vocabulary for
talking about -- and building -- software.
Later in the same piece, Edwards says,
Copy & paste is ubiquitous, despite universal
condemnation. ... I propose to decriminalize copy &
paste, and even to elevate it into the central mechanism
of programming.
Contrary to standard pedagogy, I tell my students that
it's okay to copy and paste. Indeed, I encourage it --
so long as they take the time after "making it
work" to make it right. This means refactoring to
eliminate duplication, among other things. Some students
find this to be heresy, or nearly so, which speaks to
how well some of their previous programming instructors
have drilled this wonderful little practice out of them.
Others take to the notion quite nicely but, under the
time pressures that school creates for them and that
their own programming practices exacerbate, have a hard
time devoting sufficient energy to the refactoring
part of the process. The result is just what makes
copy and paste so dangerous: a big ball of mud with
all sorts of duplicated code.
Certainly, copy and paste is a central mechanism
of doing the simplest thing that could possibly work.
The agile methods generally suggest that we then look for
ways to eliminate duplication. Perhaps Edwards would
suggest that we look for ways to leave the new code as
our next example.
At the end of the same piece, Edwards proposes an idea
I've never seen before: the establishment of "something
like a teaching hospital" in which to develop this new
way of programming. What a marvelous analogy!
Back when I was a freshman architecture major, I saw
more advanced students go out on charrette. This
exercise had the class go on site, say, a road trip
to a small town, to work as a group to design a solution
to a problem facing the folks there, say, a new public
activity center, under the supervision of their instructors,
who were themselves licensed architects. Charrette was
a way for students to gain experience working on a real
problem for real clients, who might then use the solution
in lieu of paying a professional firm for a solution
that wasn't likely to be a whole lot better.
Software engineering courses often play a similar role
in undergraduate computer science programs. But they
usually miss out on a couple of features of a charrette,
not the least of which is the context provided
by going to the client site and immersing the team in
the problem.
A software institute that worked like a teaching hospital
could provide a more authentic experience for students
and researchers exploring new ways to build software.
Clients would come to the institute, rather than instructors
drumming up projects that are often created (or simplified)
for students. Clients would pay for the software and use
it, meaning that the product would actually have to work
and be usable by real people. Students would work with
researchers and teachers -- who should be the same people!
-- in a model more like apprenticeship than anything our
typical courses can offer.
The
Software Engineering Institute
at Carnegie Mellon may have some programs that work like
this, but it's an idea that is broader than the SEI's
view of software engineering, one that could put our CS
programs in much closer touch with the world of software
than many are right now.
There seems to be a wealth of revolutionary projects swirling
in the computer science world these days: test-driven
development, agile software methods,
Croquet
and
eToys
.... That's not all that unusual, but perhaps unique to
our time is the confluence of so many of these movements in
the notion of simplicity, of pulling back from abstraction
toward the more concrete expression of computational ideas.
This more general trend is perhaps a clue for us all, and
especially for educators. One irony of this "back to
simplicity" trend is that it is predicated on increasingly
complex tools such as Eclipse and Croquet, tools that
manage complexity for us so that we can focus our limited
powers on the things that matter most to us.
In two recent articles
(here
and
here),
I participated in a conversation with
John Mitchell
and
Erik Meade
about the role of speed in developing software
development skills. While the three of us
agreed and disagreed in some measure, we all
seemed to agree that "getting faster" is a
valuable part of the early learning process.
Now comes an article from cognitive psychologists
that may help us understand better the role of
pressure. My old cognitive psychology professor,
Tom Carr,
and one of his students,
Sian Bielock,
have written an article, "Why High Powered People
Fail: Working Memory and 'Choking Under Pressure'
in Math", to appear in the journal
Psychological Science.
This article reports that strong students may
respond worse under the pressure of hard exams than
less gifted students. This form of choking seems to
result from pressure-induced impairment of working
memory, which is one of the primary advantages that
stronger students have over others. You can read a
short article from the NY Times
on the study, or a
pre-print of the journal article
for full details.
The new study is a continuation of Beilock's doctoral
research, which seems to have drawn a lot of interest
in the sports psychology world. An earlier study by
Beilock and Carr,
On the Fragility of Skilled Performance:
What Governs Choking Under Pressure?
from the Journal of Experimental Psychology:
General supports the popular notion that
conscious attention to internalized skills hurts
performance. Apparently, putting pressure on a
strong student increases their self-consciousness
about their performance, thus leading to what
we armchair quarterbacks call choking.
I'm going to study these articles to see what
they might teach me about how not to
evaluate students. I am somewhat notorious
among my students for having difficult tests,
in both content and length. I've always thought
that the challenge of a tough exam was a good
way for students to find out how far they've
advanced their understanding -- especially
the stronger students. But I s I need to be
careful that my exams not become tests primarily
of handling pressure well and only secondarily
about understanding course content.
By the way, Tom Carr was one of my all-time
favorite profs. I enjoyed his graduate course
in cognitive psychology as much as any course
I ever took. He taught me a lot about the
human mind, but more importantly about how
a scientist goes about the business of trying
to understand it better. I still have the
short papers I wrote for that course on disk
(the virtues of plaintext and nroff!). I
was glad to see some of his new work.
Martin Fowler has a dandy
blog entry
on the good and the bad of playing the "metaphor game"
with software development. This was the take-home
point for me:
... it all comes down to how you use the metaphor.
Comparing to another activity is useful if it helps
you formulate questions; it's dangerous when you
use it to justify answers.
I've always had an
uneasy relationship
with metaphors for software development, though I'm
a sucker for the
new ones
I run across. But what do I gain from the metaphors,
and how do I avoid being burned by them? Martin's
article captures it.
Maybe this is something I should have known along.
But I didn't. Thanks, Martin.
While my students are taking their object-oriented
programming final exam, I'm listening to Kent Beck's
talk on developer testing
at the recent Developer Testing Forum held at PARC.
The big theme of the talk is that developer testing
is a way that an individual programmer can take
control of his own accountability -- whether or not
he adopts other agile practices, whether or not anyone
else in his organization goes agile. Kent's been talking
a lot about accountability lately, and I think it captures
one of those very human values that underlie the agile
methods, one of the non-techie reasons that I am drawn to
the agile community.
My favorite idea in the talk is one that Kent introduces
right away: the distinction between quality (an
instantaneous measure of a system's goodness) and
health (a measure over time). I'm not sure I like
the use of "quality" to mean an instantaneous measure,
but I love the distinction. Many developers, including
students, mistake "there are no bugs in my code" with
"this is good code". In one sense, I suppose this is
true. The code runs. It performs as desired. That is
a Good Thing.
But in another sense the implication is just wrong.
Can people extend the program? Change it? Use it?
Port it? Kent's turns to his health metaphor to explain.
In my words: A person may have a good heart rate and
normal blood pressure, but if he can't walk around the
block without keeling over then he's probably not all
that healthy.
Refactoring mercilessly is a practice that recognizes the
importance of the distinction between quality and health.
Just because my code passes all the tests does not
mean that the code is healthy. At least it's not as
healthy as it can be. Refactoring is an exercise
regimen for my system. It seeks to improve the
long-term health of my program by drawing on its strength
at the moment.
Rigorous developer testing also recognizes the importance
of this distinction. Having tests means that I can extend
and change my code -- work akin to walking around the block
-- with some confidence that I won't break the system. And,
if I do, the system helps me recover from any errors
I introduce. The tests are the immune system of my
program!
I really like this "system health" metaphor and think it
extends quite nicely to many of the principles and practices
of the agile methods. Continuous feedback and
sustainable pace
spring to mind immediately. Others, such as continuous
integration and pair programming, require some thought.
That will make for a future blog entry!
Oh, and one other thing I liked from the talk... In the
Q-n-A session after the talk, someone asked Kent how we
know that our tests are correct. They are, after all,
software, too. Kent said that you can't ever know for
certain, but you can be more or less confident, depending
on how thoroughly you test and refactor. It's like
cross-checking sums in arithmetic or accounting. Over
the long run, the chance that you make the offsetting
mistakes in the code and the tests He made an
analogy to mathematical proof, saying something to this
effect:
There's no such thing as proof in software. Proof of
correctness isn't proof of correctness; it's proof of
equivalence. "Here is one expression of what
I'm trying to compute, and here's another expression
of what I'm trying to compute, and they match." That's
what you do with a proof of correctness. Tests and
code are the same way. You're saying these two
expressions are equivalent in some sense. ... That
means my confidence in the answer is much, much
higher.
Well said. Scientific reasoning, even in the artificial
world of mathematics, is about confidence, not
certainty; evidence, not proof. We should not
expect more of the messy, human enterprise of building
software.
As I write final exams and begin to think ahead to
next semester, I've been thinking about how I teach
programming and software development. Sometimes,
I get so busy with all of the extras that can make
programming interesting and challenging and more
"real-world" -- objects and design and refactoring
and GUIs and unit tests and frameworks and ... --
that I lose sight of the fact that my students are
just trying to learn to write programs. When the
abstractions and extra practices get in the way of
learning, they have become counterproductive.
I'd like to streamline my approach to programming
courses a bit. First, I'll make some choices about
which extras are more distraction than contribution,
and eliminate them. Second, I'll make a conscious
effort to introduce abstractions when students
can best appreciate them: after having concrete
experience with problems and techniques for solving
them.
My colleagues and students need not fear that I am
going back to the Dark Ages with my teaching style.
My friend
Stuart Reges
(more information at his
old web page)
isn't going quite that far, but he is in the process
of redesigning his introductory courses on the model
of his mid-1980s approach. He seems to be motivated
by similar feelings, that many of the ideas we've
added to our intro courses in the last 20 years have
gotten in the way of teaching programming. Where
Stuart and I differ is that I don't think there is
anything more "fundamental" about what we did in
Pascal in the '80s than what we should do with
objects and messages in, say, Java. The vocabulary
and mindset are simply different. We just haven't
quite figured out the best way to teach programming
in the new mindset.
I wish Stuart well in his course design and hope
to learn again from what he does. But I want to
find the right balance between the old stuff --
what my colleagues call "just writing programs"
-- and the important new ideas that can make us
better programmers. For me, the first step
is a renewed commitment to having students write
programs to solve problems before having them
talking about writing programs.
This train of thought was set off by a
quote I read
over at
43 Folders.
The article is about "hacking your way out of
writer's block" but, as with much advice about
writing, it applies at some level to programming.
After offering a few gimmicks, the writer says:
On the other hand, remember Laurence Olivier.
One day on the set of
Marathon Man,
Dustin Hoffman showed up looking like shit. Totally
exhausted and practically delirious. Asked what the
problem was, Hoffman said that at this point in the
movie, his character will have been awake for 24 hours,
so he wanted to make sure that he had been, too.
Laurence Olivier shook his head and said, "Oh, Dusty,
why don't you just try acting?"
I don't want all the extras that I care about --
and that I want students to care about -- to be
affectations. I don't want to be
Dustin Hoffman
to Stuart's
Olivier.
Actually that's not quite true... I admire
Hoffman's work, have always thought him to be
among the handful of best actors in Hollywood.
I just don't want my ideas to become merely
affectations, to be distractions to students
as they learn the challenging and wonderful skill
of programming. If I am to be a method teacher,
I want the method to contribute to the goal.
Ultimately, I want to be as comfortable in what
I'm doing in the classroom as Hoffman is with
his approach to acting. (Though who could blame
him if he felt a little less cocksure when chided
by the great Olivier that day?)
The bottom line for now is that there are times
when my students and I should just write programs.
Programs that solve real problems. Programs that
work. We can worry about the abstract stuff after.
Yesterday, someone reminded me of my friend Rich Pattis's
Quotations for Learning Programming.
I jumped, randomly as near as I can tell, to the Os and
had not scanned too far down the page when I saw this quote:
As a rule, software systems do not work well until
they have been used, and have failed repeatedly, in
real applications.
- D. Parnas
Of course, David Parnas is a famous computer scientist,
well known for his work on modularity and software design.
Many give him credit for best explaining encapsulation as
a design technique. He is revered as an icon of traditional
software engineering.
Yet, when I read this quote, I could help but think, "Maybe
Parnas is a closet agile developer." :-) Frequent readers
may recall that I do this occasionally... See my discussion
of
Dijkstra as a test-driven developer.
Whether Parnas is sympathetic to the methodological side
of agile software development or not, this quote points
out a truth of software development that is central
to agile approaches: There is benefit in getting to
working code sooner. The motive usually given for this
is so that developers can learn about the problem and
the domain from writing the code. But perhaps a secondary
value is that it can begin to fail sooner -- but
in the lab, under test-driven conditions, where developers
can learn from those *failures* and begin to fix them sooner.
I have to be careful not to misinterpret a person's position
by projecting my own views onto a single quote taken out
of context. For example, I can surely find a Parnas quote
that could easily be interpreted as condemning
agile software methodologies (in particular, I'm
guessing, their emphasis on not doing
big design up front).
I don't worry about such contradictions; I prefer to use
them as learning opportunities. When I see a quote like
the one above, I like to take a moment to think... Under
what conditions can this be right? When does it fail,
or not hold? What can I learn from this idea that will
make me a better programmer or developer? I don't think
I'd ever consciously considered the idea that continuous
feedback in XP might be consist of the same sort of
failure that occurs when we deploy a live system.
Parnas quote has me thinking about it now, and I think
that I may learn something as a result.
More subconsciously agile quotes?
As I scanned Rich's list in my agile state of mind,
a few others caught my eye...
Blaise Pascal, proponent of refactoring?
I have made this letter longer than usual, only because
I have not had the time to make it shorter.
An anonymous cautionary tale about agile methods
-- but also about traditional software engineering?
The fast approach to software development:
Ready, fire, aim (the fast approach to software development).
The slow approach to software development:
Ready, aim, aim, aim, aim ...
Maybe those guys in Redmond know something about
agility after all...
Microsoft, where quality is job 1.1.
Finally, this quote has long been a favorite of mine.
I have it hanging on the wall in my home office:
We are what we repeatedly do.
Excellence, then, is not an act, but a habit.
- Aristotle
This quote isn't a statement about agile practice, or
even more generally about pragmatic practice. It is
a hallmark of the reflective professional. It's also
a pretty good guide for living life.
Last evening, I commented on the idea of
speed training for software developers,
raised in
Erik Meade's blog.
John Mitchell also
commented on this idea.
Check out what John has to say. I think he makes a useful
distinction between pace and rhythm. You'll
hear lots of folks these days talk about rhythm in software
development; much of the value of test-driven development
and refactoring lie in the productive rhythm they support.
John points out that speed work isn't a good idea for
developers, because that sort of stress doesn't work in the
same way that physical stress works on the muscles. He
leaves open the value of intensity in learning situations,
more like speed play, which I think is where the
idea of software fartleks can be most valuable.
Be sure to check out the comments to John's article, too.
There, he and Erik hash out the differences between their
positions. Seeing that comment thread make me again want
to add comments to my blog again!
In making analogies between software development and running,
I've occasionally commented on sustainable pace, the notion
from XP that teams should work at a pace they can sustain
over time rather than at breakneck paces that lead to bad
software and burn-out. In
one entry,
I discuss the value of continuous feedback in monitoring
pace. In
another,
I describe what can happen when one doesn't maintain a
sustainable pace, in the short tem and over the longer term.
Not unexpectedly, I'm not alone in this analogy. Erik Meade
recently
blogged
on sustainable pace and business practice. I was initially
drawn to his article by its title reference to
increasing your sustainable pace via the fartlek.
While I liked his use of the analogy to comment on standard
business practice, I was surprised that he didn't delve
deeper into the title's idea.
Fartlek
is Swedish for "speed play" and refers to an unstructured
way for increasing one's speed while running: occasionally
speed up and run faster for a while, then slow down and
recover. We can contrast this approach to more structured
speed work-outs such as
Yasso 800s,
which specify speeds and durations for fast intervals
and recoveries. In a fartlek, one simply has fun speeding
up and slowing down. This works especially well when working
out with a friend or friends, because partners can take turns
choosing distances and speeds and rewards. In the case of
both fartleks and structured interval training, though, the
idea is the same: By running faster, you can train your body
to run faster better.
Can this work for software development? Can we train
ourselves to develop software faster better?
It is certainly the case that we can learn to work faster
with practice when at the stage of internalizing knowledge.
I encourage students to work on their speed in in-class
exercises, as a way to prepare for the time constraints
of exams. If you are in the habit of working leisurely
on every programming task you face, then an exam of ten
problems in seventy-five minutes can seem like a marathon.
By practicing -- solving lots of problems, and trying to
solve them quickly -- students can improve their speed.
This works because the practice helps them to internalize
facts and skills. You don't want forever to be in the
position of having to look up in the Java documentation
whether
Vectors
respond to length() or
size().
I sometimes wonder whether working faster actually helps
students get faster or not, but even if it doesn't I am
certain that it helps them assess how well they've internalized
basic facts and standard tasks.
But fartleks for a software development team? Again, working
on speed may well help teams that are at the beginning of
their learning curves: learning to pair program, learning
to program test-first, learning to use
JUnit,
... All benefit from lots of practice, and I do believe
that trying to work efficiently, rather than lollygagging
as if time were free, is a great way to internalize knowledge
and practice. I see the results in the teams that make up
my agile software development course this semester. The teams
that worked with the intention of getting better, of attempting
to master agile practices in good faith, became more skilled
developers. The teams that treated project assignments as
mostly a hurdle to surmount still struggle with tools and
practices. But how much could speed work have helped them?
The bigger question in my mind involves mature
development teams. Will occasional speed workouts, whether
from deadline pressure on live jobs or on contrived
exercises in the studio, help a team perform faster the
next time they face time pressure? I'm unsure. I'd love to
hear what you think.
If it does work, we agile developers have a not-so-secret
advantage... Pair programming is like always training with
a friend!
When a runner prefers to run alone rather than with others,
she can still do a structured work-out (your stopwatch is
your friend) or even run fartleks. Running alone leaves
the whole motivational burden on the solo runner's shoulders,
but the self-motivated can succeed. I have run nearly
every training run the last two years alone, more out of
circumstance than preference. (I run early in the morning
and, at least when beginning, was unsuitable as a training
partner for just about any runner I knew.) I can remember
only two group runs: a 7-miler with two faster friends about
two weeks before my
first marathon
last fall, and an 8-mile track workout the day before
Thanksgiving two weeks ago. As for the latter, I *know* that
I trained better and harder with a friend at my side, because
I lacked the mental drive to go all out alone that morning.
Now I'm wondering about how pair programming might play this
motivational role sometimes when writing software. But that
blog entry will have to wait until another day.
This is why I love the blogosphere so much. Somehow,
I stumble across a link to
Leonardo,
an open-source blogging and wiki engine written in
Python.
I follow the link and start reading the blog of
Leonardo's author,
James Tauber.
It's a well-written and thoughtful set of articles
on an interesting mix of topics, including Python,
extreme programming, mathematics, linguistics, New
Testament Greek, music theory and composition, record
producing and engineering, filmmaking, and general
relativity. For example, my reading there has taught
me some of the mathematics that underlie recent work
on proving the
Poincare Conjecture.
But the topic that attracted my greatest attention
is the confluence of personal information management,
digital lifestyle aggregation, wiki, blogging, comments
and trackbacks, and information hosting. I've only
recently begun to learn more deeply about the issue
of aggregation and its role in information sharing.
This blog argues for an especially tight intellectual
connection among all of these technologies and cultures.
For example, Tauber argues that wiki entries are essentially
the same as blog trackbacks, and that trackbacks could
be used to
share information about software projects
among bosses and teammates, using RSS feeds, and
to integrate requests with one's PIM. But I'm not
limited to reading Tauber's ideas, as he links to
other blogs and web pages that present alternative
viewpoints on this topic.
Following all these threads will take time, but that
I can at all is a tribute to the blogosphere. Certainly,
all of this could have been done in the olden days of
the web, and indeed many people were publishing there
diverse ideas about diverse topics back then. But the
advent of RSS feeds and blogging software and wikis has
made the conversation much richer, with more power in
the hands of both readers and writers. Furthermore,
the blogging culture encourages folks to prepare their
ideas sooner for public consumption, to link ideas in
a way that enables scientific inquiry, to begin a
conversation rather than just publish a tract.
Recently, I ran across an interesting article by David
Roundy called
The Theory of Patches,
which is actually part of the manual for Darcs, a
version-control alternative to CVS and the like. Darcs
uses an inductive definition to define the state of a
software artifact in the repository:
So how does one define a tree, or the context of a patch?
The simplest way to define a tree is as the result of
a series of patches applied to the empty tree. Thus,
the context of a patch consists of the set of patches
that precede it.
Starting with this definition, Roundy goes on to develop
a set of light theorems about patches, their composition,
and their merging. Apparently these theorems guide the
design and implementation of Darcs. (I haven't read that
far.)
The reason I found this interesting was the parallel
between repeated application of patches to an empty
tree and
the repeated application of patterns to a design,
leading to piecemeal growth of a system, and
the agile methods' cyclic process of extension
and refactoring.
This led me to think about how an IDE such as Eclipse
might have version control build right into it. Each
time the programmer adds new behavior or applies a
refactoring, the change can be recorded as a patch,
a diff to the previous system. The theory of patches
needed for a version control system like Darcs would
be directly useful in implementing such a system.
I used to program a lot in Smalltalk, and Smalltalk's
.changes file served as a lightweight, if
incomplete, version control system. I suppose that
a Smalltalker could implement something more complete
rather easily. Someone probably already has!
November 2004 will enter the books as my least-blogged month
since starting
Knowing and Doing
back in July. I'm not all that surprised, given that:
it is the last full month of my semester,
it follows a month in which I was on the road every
weekend and for a full week at OOPSLA, and
it contains a 5-day week for Thanksgiving.
Each of these would cut into my time for blogging on its
own, and together they are a death knell to any free moments.
When I
started Knowing and Doing,
I knew that regular blogging would require strict discipline
and a little luck. Nothing much has changed since then. I
still find the act of writing these articles of great value
to me personally, whether anyone reads them or not. That
some folks do find them useful has been both gratifying and
educational for me. I learn a lot from the e-mails I receive
from Faithful Readers.
I reached the 100-post plateau ten days ago with this
puff piece.
I hope that most of my posts are of more valuable than that!
In any case, reaching 1000 entries will be a real
accomplishment. At my current pace, that will take me three
more years...
While on this nostalgic kick, I offer these links as
some obligatory content for you. Both harken back to
yesteryear:
Brian Foote waxes poetic in his inimitable way
about watching undergrads partake in the
rite of initiation
that is a major operating systems project. He
points out that one thing has changed this experience
significantly since he and I went through it thirty
and (can it be?) twenty years ago, respectively: unit
tests.
John O'Conner has a
nice little piece
on generalizing the lesson we all learned -- some of
us long ago, it seems -- about magic numbers in our
code. Now if only we turned all those constants into
methods a lá the
Default Value Method
pattern...
On Saturday,
Jason Yip
started a conversation about the
danger of accepting blame reflexively.
He fears that accepting the blame preemptively "reinforc[es]
the mistaken belief that having someone take blame is somehow
important." Fixing the problem is what matters.
This is, of course, true. As
Jerry Weinberg
says in The Secrets of Consulting:
The chances of solving a problem decline the closer you
get to finding out who was the cause of the problem.
(You may recall that some of my earliest blog entries
here
and
here
referred to this gem of a book.)
When people focus on whose fault it is, they tend to become
defensive, to guard their egos, even at the expense of
fixing the problem. This is a very human response, and one
that is hard to control intellectually. The result is both
that the problem remains and its systematic cause
remains, pretty much guaranteeing more problems in the future.
If we can depersonalize the problem, focusing on what is
wrong and how we can fix it, then there is hope of both
solving the problem and learning how not to cause similar
problems in the future.
I think Jason is right on that people can use "It's my fault"
as a way to avoid discussion and thus be as much of an
obstacle to growth and improvement as focusing on placing
blame. And someone who *always* says this is either trying
to avoid confrontation or making way too many mistakes. :-)
But as one commenter posted on his site, saying "I made a
mistake. Let's fix it, and let's find a way to avoid such
problems in the future" is a welcome behavour, one that
can help individuals and teams grow. The real problem is
saying "I made a mistake." when you didn't make a mistake
or don't want to discuss what you did.
I have been fortunate never to have worked at a place where
people played The Blame Game, at least not too destructively.
Walking on eggshells all day is no way to live one's life,
and not the sort of environment in which a person can learn.
These days, I don't have much trouble in professional settings
acknowledging my mistakes, though I probably wasn't always
as easy-going. I give a lot of credit for my growth in this
regard to having papers I've written
workshopped
at
PLoP conferences.
At PLoP, I learned how better to separate my self from my
product. The practices of writers workshops aim to create a
safe environment,
where authors can learn about how well their papers work.
As much as the practices of the patterns community help,
it probably takes going through the workshop process a
few times to wear away the protective shell that most of
use use to protect ourselves from criticism. Being with
the right sort of people helps.
All that said, I had to chuckle at
It's Chet's Fault,
a fun little community practice of the famed
C3 project
that gave rise to XP as a phenomenon. On a team of folks
working together to get better, I think that this sort of
levity can help people remember to keep their eyes on what
really matters. On the other hand, lots of things can work
with a team of folks striving to get better. Being with
the right sort of people helps.
What Does the iPod have in Common with Prego Spaghetti Sauce?
While waiting for the UNI's
first men's basketball game
of the year to begin yesterday, I read a couple of articles
I'd found while surfing the blogosphere. I was surprised
to run across the same Big Idea in both papers, albeit it
in different forms:
Design, well done, satisfies needs users didn't know they had.
I found it first in Paul Graham's new essay,
Made in USA.
Graham relates how he felt after buying an iPod:
I just got an iPod, and it's not just nice. It's
surprisingly nice. For it to surprise me, it must
be satisfying expectations I didn't know I had. No focus
group is going to discover those. Only a great designer can.
The essay itself is about why the US is good at designing
some things, like software, and bad at others, like cars.
Graham's diagnosis: Americans don't care much for taste
or quality. Instead of relying on a sense of good
design, American auto manufacturers rely on focus groups
to tell them "what people want".
So why is the US good at designing other products, such as
software? Americans are driven by speed, and some products
are done better when done quickly without undue emphasis on
getting it "right". Indeed, when I read the essay, the
quote that most struck me wasn't the one about the iPod,
but this one:
In software, paradoxical as it sounds, good craftsmanship
means working fast. If you work slowly and meticulously,
you merely end up with a very fine implementation of your
initial, mistaken idea. Working slowly and meticulously
is premature optimization. Better to get a prototype done
fast, and see what new ideas it gives you.
What a nice crystallization of the spirit of agile
development: If you work slowly and meticulously,
you merely end up with a very fine implementation of your
initial, mistaken idea. Working slowly and meticulously
is premature optimization.
Graham points to Steve Jobs as an exception to this general
rule about technological fields and offers hope that
American designers who care about quality and craftsmanship
can succeed. Of course, Apple, has never been more than
a niche player in the market for computer software and
hardware (a niche in which I proudly reside).
Next, I found myself reading Malcolm Gladwell's recent
The Ketchup Conundrum.
Yes, an article about ketchup. Actually, it's about mustard,
too, and Prego spaghetti sauce. When Campbell's Soup was
trying to reinvigorate its Prego-brand sauce in the late
1980s, they brought in an unconventional market researcher
named Howard Moskowitz to inject some new ideas in their
approach. This quote caught my eye (emphasis added):
Standard practice in the food industry would have been to
convene a focus group and ask spaghetti eaters what they
wanted. But Moskowitz does not believe that consumers --
even spaghetti lovers -- know what they desire if what
they desire does not yet exist. "The mind," as Moskowitz
is fond of saying, "knows not what the tongue wants."
Moskowitz uses focus groups -- Graham's bane -- but with
a twist. Rather than have the Prego folks create what
they think people want and then taste-test it against
standard sauces, Moskowitz had the Prego folks create
forty-five varieties of Prego, in all the different
combinations they could think of. Then ran these varieties
against a panel of trained food tasters before taking
the options to the people.
In many ways, this is exactly the opposite of the Jobs
approach, which relies on a genius designer to assess
the state of the world and create a product that scratches
an itch no one quite knew they had. The Moskowitz
approach is more in the
Art and Fear
philosophy, to produce a lot of artifacts. Many will
have no shelf life, but in the volume you are more likely
to create something of value. Not stated in the Gladwell
article is another potential benefit of Moskowitz's
approach: in producing lots of stuff, designers overcome
the fear of creating, especially things that are different
from what already exists. Even better, such designers
can begin to develop a sense of what works and what
doesn't through voluminous experience.
Design, well done, satisfies needs users didn't know they had.
And you can do it well in different ways.
This morning I went out for a 12-mile run. That's my usual
Sunday morning run when I'm not training for a marathon,
part of my "maintenance mileage" year 'round. But before
today I had run this far only once since
running the Des Moines Marathon,
plus I've been dragging a bit from running faster the last
couple of weeks. So this morning I planned for a little
LSD. That's
long slow distance,
not the
psychotropic drug,
though both can lead to out-of-body experiences.
Forty-eight minutes into the run, I felt a little discouraged.
I still had a little over an hour to go! But then I thought,
you run almost 48 minutes even on your shortest days; what's
the big deal? The big deal was that that second thing: I
still had a little over an hour to go. The psychology of a
long run is much different than the psychology of a short run.
That's what makes marathons so challenging.
Then I got to thinking about the psychology of long and
short runs in software development. I wonder if the short
iterations encouraged by agile methodologies help to buttress
the morale of developers on those days and projects that
leave them feeling down? I've certainly worked on traditional
software projects where the thought of another six months
before a release seemed quite daunting. Working from a state
of relative uncertainty is no fun. On agile projects, we
at least get to issue releases more frequently and incorporate
feedback from the customer into the next iterations.
Sometimes, running requires endurance. If you want to run
a marathon, then you had better get ready to run for 3, 4,
or 5 hours. I suppose that big software projects require
stamina, too. A year-long project will take a year whether
done in many short releases or in one big one. But the
closer horizon of short iterations can be comforting,
even without considering the value of continuous feedback.
With my mind occupied thinking about software and psychology,
pretty soon my run was over. I was tired, as expected, and
a little stiff. But I felt good for having done 12. My
next 45-minute iteration happens on Tuesday.
In talking about how hard artists work, I am reminded of the
story about the man who asked a Chinese artist to draw a rooster
for him and was told to come back in a month. When he returned,
the artist drew a fabulous rooster in a few minutes. The man
objected to paying a large sum of money for something that took
so little time, whereupon the artist opened the door to the next
room in which there were hundreds of drawings of roosters.
Sometimes folks, non-runners and runners alike, comment on how
they can't run as far or as fast (hah!) as I do. There are
days when I wish that I could open a door to let the person
see a room full of runs like the one I had this morning: hard
work, pushing at my limits, finishing with nothing left, but
still short of the goal I've been working toward.
Folks who make this sort of comment almost always mean well,
intending a compliment. Often, though, I think that the
unstated implication is that they couldn't do what I do even
if they tried, that runners have some innate ability that
sets them apart from everyone else. Now, I don't doubt at
all that some people have innate physical abilities that give
them some advantage at running. The very best -- the guys
who run 9.9s in the 100m, or 2:10 marathons -- almost certainly
have gifts. But I am not a gifted runner, other than having
the good fortune to not injure easily or get sick very often.
And let's not forget how hard those 9.9s sprinters and 2:10
marathoners have to work in order to reach and maintain their
level of excellence.
Richard Gabriel
often says that "talent determines only how fast you get good,
not how good you get". Good poems, good art, and good runs
are made by ordinary people. Art and Fear says this:
"Even talent is rarely distinguishable, over the long run,
from perseverance and lots of hard work."
That is good news for runners like me. Maybe, if I keep working,
I'll reach my speed goal next week, or the week after that.
It's also good news for programmers like me.
Computer science students should take this idea to heart,
especially when they are struggling. Just keep working at
it. Write programs every day. Learn a new something every
day. You'll get there.
On
Wednesday
I blogged about helping students succeed more by cutting
their projects in half. I haven't tried that yet, but I
did take a small step in that spirit, toward helping students
learn in a different way than usual.
In my agile development course, we've been reading
The Pragmatic Programmer,
and recently discussed the idea that professionals are
masters of their tools. I've been encouraging students
in the course to broaden their skill sets, including both
tools specific to the agile arena, such as
JUnit,
and tools more general to their professional needs, such
as a command shell, an editor, and a couple of programming
languages. But I find that most students (have to) focus
so much on the content of their programming assignments
that they don't attend much to their practices.
So, I made their latest assignment be specifically to
focus on skills. They will use a new tool (a testing
framework other than
JUnit)
to work with a program they've already written and to
write a very simple program. At the same time, they
are to choose a particular skill they want to develop
-- say, to learn emacs or to finally learn how
to use a Linux command line -- and do it. With almost
no content to the assignment, at least not new content,
I hope that students will feel they have the time and
permission to focus on developing their skills.
I am reminded of one of my favorite piano books, Playing
the Piano for Pleasure, by Charles Cooke (Simon and
Schuster, 1941). Cooke was a writer by trade but an
ardent amateur pianist, and he used his writing skills
to share some of his secrets for studying and practicing
piano. Among other things, Cooke suggested a technique
in which he would choose his weakest part of a piece,
what he calls a 'fracture', and then practice it with
such intensity and repetition that it becomes one of his
strongest. He likened this to a bone healing after a
fracture, when the newly knitted bone exceeds the strength
of the bone around it.
I try to have this mindset when working on my professional
skill set. And I'd certainly like my students to grow
toward such a mentality as they develop into software
professionals and happy adults.
I hope that some of the students working on my new
assignment will attack their own weakest areas and turn
them into strengths or, at the least, grow to the point
that they no longer have to fear the weakness. Overcoming
even a little fear can help a student move a long way
toward being a confident and successful programmer.
If you want to increase your success rate,
double your failure rate.
... to which he adds a second part:
If you want to double your failure rate,
all you have to do is halve your project length.
Then, winking, he points out that the second step may fail,
because shorter projects may actually succeed more often!
I think this is wonderful software development advice.
As a teacher, I have been thinking about how to bring
this idea to my courses and to my students.
I always encourage my students to approach their course
projects in this way: take lots of small steps doing the
simplest thing possible, writing test code to verify
success at each step, and refactoring frequently to
improve their design. By taking small steps, they should
feel confident that whatever they've done so far actually
works. And, when it doesn't, they haven't gone too far
astray, because they only worked on a little bit of
specification. Debugging can often be localized to the
most recently added code.
Breaking a complex but unitary spec ("implement a program
to play MasterMind") down into smaller stories is hard,
especially for freshmen and sophomores. Even my upper
division students sometimes have difficulty breaking
requirements that are smaller but still too big into even
smaller steps.
In recent semesters, I've tried to help by writing my
assignments as a list of small requirements or user stories.
My second-semester students are currently implementing a
simple text-based voice mail system, which I specified
as a sequence of individual requirements. Sometimes, I
even specify that we will grade assignments story-by-story
and stop as soon as the program "fails" a story.
This approach sounds great, but it is out of step with the
student culture these days. Taking small steps, and
especially refactoring, requires having a certain amount
of time to go through the process, with some reflection
at each step. Most students are inclined to start every
project a few days or less before it's due, at which point
they feel a need to "just do it". I've tried to encourage
them not to postpone starting -- don't all professors face
this problem? -- mostly to no avail.
In my Agile Software Development course, we've been doing
2- and 3-week releases, and I think we've had some success
with doing 3 week-long iterations, with full submission of
the project, within each release. Even still, word in the
class is that many folks start each iteration on a day or
two or three before it's due.
Maybe I should take the "recipe for project success"
advice for them... I could assign two half-week assignments
instead of a one-week assignment! Students would have twice
as many opportunities to succeed, or to fail and learn.
One of the downsides of this idea for me is grading. I don't
like to grade and, while am usually (but not always!) timely
in getting assignments back to students, I use enough mental
energy grading for three courses as it is. I could automate
more of the grading, using JUnit, say, to run tests against
the code. But to the extent that I need to look at their code,
this approach requires some new thinking about grading.
One of the downsides of this idea for my students is the
old time issue. With 15 hours of class and 30 hours at work
and whatever time they spend in the rest of their lives,
students have a tough time working steadily on each course
throughout each week. Throw in exams and projects and
presentations during special times in the semester, and the
problem gets worse.
But I can't shake the feeling that there is something deeply
right about halving the size of every project. I may have
to "just do it" myself and face whatever difficulties arise
as they do.
Alan Kay gave two talks at OOPSLA last week, the keynote address
at the
Educators Symposium
and, of course, his
Turing Award lecture.
The former was longer and included most of the material from
the Turing lecture, especially when you consider his generous
question-and-answer session afterwards, so I'll just comment
on the talks as a single presentation. That works because
they argued for a common thesis: introductions to computing
should use simple yet powerful computational ideas that
empower the learner explore the larger world of ideas.
Kay opened by decrying the premature academization of computing.
He pointed out that Alan Perlis coined the term "computer science"
as a goal to pursue, not as a label for existing practice, and
that the term "software engineering" came with a similar motivation.
But CS quickly ossified into a discipline with practices and
standards that limit intellectual and technical discovery.
Computing as science is still an infant. Mathematicians work
in a well-defined space, creating small proofs about infinite
things. Computing doesn't work that way: our proofs are programs,
and they are large, sometimes exceedingly so. Kay gave a delightful
quote from Donald Knuth, circa 1977:
Beware of bugs in the above code; I have only proved it
correct, not tried it.
The proof of our programs lies in what they do.
As engineering, computing is similarly young. Kay contrasted
the construction of the Great Pyramid by 200,000 workers over
20 years with the construction of the Empire State Building
by fewer than 3,000 people in less than 11 months. He asserts
that we are somewhere in the early Middle Ages on that metaphorical
timeline. What should we be doing to advance? Well, consider
that the builders of the Pyramid used hand tools and relatively
weak ideas about building, whereas the engineers who made the
Empire State Building used power tools and even more powerful
ideas. So we should be creating better tools and ideas. (He
then made a thinly veiled reference to VisualStudio.NET 2005,
announced at OOPSLA, as just another set of hand tools.)
So, as a science and professional discipline in its youth,
what should computing be to people who learn it? The worst
thing we can do is to teach computer science as if it already
exists. We can afford to be humble. Teach students
that much remains to be done, that they have to help us
invent CS, that we expect them to do it!
Kay reminded us that what students learn first will have a
huge effect on what they think, on how they think
about computing. He likened the effect to that of
duck imprinting,
the process in which ducklings latch onto whatever object
interacts with them in the first two days of their lives
-- even if the object is a human. Teaching university
students as we do today, we imprint in them that computing
is about arcane syntax, data types, tricky little algorithms,
and endless hours spent in front of a text editor and
compiler. It's a wonder that anyone wants to learn computing.
So what can we do instead? I ran into some interesting
ideas on this topic at OOPSLA even before the Educators'
Symposium and had a few of my own during the week. I'll
be blogging on this soon.
Alan has an idea of the general direction in which we should
aim, too. This direction requires new tools and curricula
designed specifically to introduce novices to the beauty
of computing.
He held up as a model for us Frank Oppenheimer's
Exploratorium,
"a collage of over 650 science, art, and human perception exhibits."
These "exhibits" aren't the dead sort we find in most museums,
where passive patrons merely view an artifact, though. They are
stations with projects and activities where children can come
face to face with the first simple idea of science: The world
is not always as it seems. Why are there so many different
exhibits? Kay quoted Oppenheimer to the effect that, if only
we can bring each student into contact with that one project or
idea that speaks directly to her heart, then we will have succeeded.
Notice that, with that many projects available, a teacher does
not have to "assign" particular projects to students at a
particular point in time. Students can choose to do something
that motivates them. Kay likened this to reading the classics.
He acknowledged that he has read most of the classics now, but
he didn't read them in school when they were assigned to him.
Then he read other stuff, if only because the he had chosen
for himself. One advantage of students reading what they want
is that a classroom will be filled with people who have read
different things, which allows you to have an interesting
conversation about ideas, rather than about "the book".
What are the 650 examples or projects that we need to light a
fire in every college student's heart? Every high schooler?
Every elementary school child?
Kay went on to say that we should not teach dumbed-down
versions of what experts know. That material is unnecessarily
abstract, refined, and distant from human experience. Our goal
shouldn't be to train a future professional computer scientist
(whatever that is!) anyway. Those folks will follow naturally
from a population that has a deep literacy in the ideas of
science and math, computing and communication.
Here, he pointed to the typical first course in the English
department at most universities. They do not set out to
create professional writers or even professional readers.
Instead, they focus on "big ideas" and how we can represent
and think about them using language. Alan thinks introductory
computer science should be like this, too, about big ideas
and how to represent and think about them in language.
Instead, our courses are "driver's ed", with no big ideas
and no excitement. They are simply a bastardization of
academic computer science.
What are the big ideas we should introduce to students?
What should we teach them about language in order that they
might represent ideas, think about them, and even have ideas
of their own?
Alan spent quite a few minutes talking about his first big
inspiration in the world of computing. Ivan Sutherland's
Sketchpad.
It was in Sketchpad that Kay first realized that computing
was fundamentally a dynamic medium for expressing new ideas.
He hailed Sutherland's work "the greatest
Ph.D. dissertation
in computer science of all time", and delighted in pointing
out Sketchpad's two-handed user interface ("the way all UIs
should be"). In an oft-told but deservedly repeated anecdote,
Kay related how he once asked Sutherland how he could have
created so many new things -- the first raster graphics system,
the first object-oriented system, the first drawing program,
and more -- in a single year, working alone, in machine language.
Sutherland replied, "... because I didn't know it was hard".
One lesson I take from this example is that we should take
care in what we show students while they are learning. If
the see examples that are so complex that they can't conceive
of building them, then they lose interest -- and we lose a
powerful motivator.
Sutherland's dissertation includes the line, "It is to be hoped
that future work will far surpass this effort". Alan says we
haven't.
Eventually, Kay's talk got around to showing off some of the
work he and his crew have been doing at
Squeakland,
a science, math, and computing curriculum project built on
top of the modern, open source version of Smalltalk,
Squeak.
One of the key messages running through all of this work can
be found in a story he told about how, in his youth, he used
to take apart an old Model T Ford on the weekend so that he
could figure out how it worked. By the end of the weekend,
he could put it back together in running condition. We
should strive to give our students the same experience in the
computing environments they use: Even if there's a Ferrari
down there, the first thing you see when you open the hood
is the Model T version -- first-order theories that, even if
they throw some advanced ideas away, expose the central ideas
that students need to know.
Alan demoed a sequence of increasingly sophisticated examples
implemented and extended by the 5th- and 6th-grade students
in B.J. Conn's charter school classes. The demos in the
Educators' Symposium keynote were incredible in their depth.
I can't do them justice here. The best you can do is to check
out the film
Squeakers,
and even that has only a small subset of what we saw in
Vancouver. We were truly blessed that day!
The theme running through the demos was how students
can explore the world in their own experience, and learn
powerful ideas at the "hot spot" where math and science
intersect. Students can get the idea behind
tensor calculus long before they can appreciate the
abstractions we usually think of as tensor calculus.
In the course of writing increasingly complex scripts
to drive simulations of things they see in the world,
students come to understand the ideas of the variable,
feedback, choice, repetition, .... They do so by exposing
them in action, not in the abstract.
The key is that students learn because they are having fun
exploring questions that matter to them. Sometime along
in here, Kay uttered what was for me the Quote of the Day,
no, the Quote of OOPSLA 2004:
If you don't read for for fun, you won't be fluent enough
to read for purpose.
I experience this every day when interacting with university
students. Substitute 'compute' or 'program' for 'read',
and you will have stated a central truth of undergraduate
CS education.
As noted above, Kay has a strong preference for simple,
powerful ideas over complex ideas. He devoted a part of
his talk to the Hubris of Complexity, which he
believes long ago seduced most folks in computing.
Software people tend to favor the joy of complexity,
yet we should strive for the joy of simplicity.
Kay gave several examples of small "kernels" that have
changed the world, which all people should know and
appreciate. Maxwell's equations were one. Perhaps in
honor of the upcoming U.S. elections, he spent some time
talking about the U.S. Constitution as one such kernel.
You can hold it in the palm of your hand, yet it thrives
still after 225 years. It is an example of great system
design -- it's not law-based or case-based, but
principle-based. The Founding Fathers created
a kernel of ideas that remains not only relevant but
also effective.
I learned a lot hearing Alan tell some of the history of
objects and OOP. In the 1960s, an "object" was simply a
data structure, especially one containing pointers. This
usage predates object-oriented programming. Alan said
that his key insight was that an object could act as a
miniature software computer -- not just a data structure,
not just a procedure -- and that software scales to any
level of expression.
He also reminded us of something he has said repeatedly
in recent years: Object-oriented programming is about
messages, not the objects. We worry about
the objects, but it's the messages that matter.
How do we make messages the centerpiece of our
introductory courses in computing?
Periodically throughout the talk, Alan dropped in small
hints about programming languages and features. He
said that programming language design has a large UI
component that we technical folks sometimes forget.
A particular example he mentioned was inheritance. While
inheritance is an essential part of most OOP, Alan said
that students should not encounter it very soon in their
education, because it "doesn't pay for the complexity it
creates".
As we design languages and environments for beginners, we
can apply lessons from Mihaly Csikszentmihalyi's idea of
"flow". Our goal should be to widen the path of flow for
learners. One way to do that is to add safety to
the language so that learners do not become anxious.
Another is to create attention centers to push away
potential boredom.
Kay's talks were full of little nuggets that I jotted down and
wanted to share:
He thanked many people for participating in the creation
of his body of work, sharing with them his honors. Most
notably, he thanked
Dan Ingalls
"for creating Smalltalk; I only did the math". I have often
heard Alan single out Ingalls for his seminal contributions.
That makes a powerful statement about the
power of teams.
Throughout the talk, Alan acknowledged many books and ideas
that affected him. I couldn't get down all of the recommended
reading, but I did record a few:
Bruce Alberts, "Molecular Biology of the Cell"
Lewis Carroll Epstein, "Relativity Visualized"
James D. Watson, "Molecular Biology of the Gene"
Clifford Shaw's
JOSS
was the most beautiful programming language ever created.
I've heard of JOSS but now have to go learn more.
Whatever you do, ask yourself, "What's the science
of it?" You can replace 'science' with many other
words to create other important questions: art, math,
computing, civilization.
"In every class of thirty 11-year-olds, there's usually
one Galileo kid." What can we do to give him or her
the tools needed to redefine the world?
Alan closed both talks on an inspirational note, to wrap up
the inspiration of what he had already said and shown us.
He told us that Xerox PARC was so successful not because
the people were smart, but because they had big ideas and
had the inclination to pursue them. They pursued their
ideas simple-mindedly. Each time they built something
new, they asked themselves, "What does the complexity in
our system buy us?" If it didn't buy enough, they strove
to make the thing simpler.
People love to quote Alan's most famous line, "The best way
to predict the future is to invent it." I leave you today
with the lines that follow this adage in Alan's paper
"Inventing the Future" (which appears in The AI Business:
The Commercial Uses of Artificial Intelligence, edited
by Patrick Henry Winston and Karen Prendergast). They tell
us what Alan wants us all to remember: that the future is
in our hands.
The future is not laid out on a track. It is something that
we can decide, and to the extent that we do not violate any
known laws of the universe, we can probably make it work the
way that we want to.
-- Alan Kay, 1984
Guys like Alan set a high bar for us. But as I noted
last time,
we have something of a responsibility to set high goals
when it comes to computing. We are creating the medium
that people of the future -- and today? -- will use to
create the next Renaissance.
Some other folks have blogged on their experiences at
OOPSLA
last week. These two caught my attention, for different
reasons.
The trade-off between power and complexity in language
Nat Pryce writes
about stopping on the
SeaSide
BoF. SeaSide is a web app framework written in Smalltalk.
Nat marvels at its elegance and points out:
SeaSide is able to present such a simple API because it takes
advantage of "esoteric" features of its implementation
language/platform, Smalltalk, such as continuations and closures.
Java, in comparison to Smalltalk, is designed on the assumption
that programmers using the Java language are not skilled enough
use such language features without making a mess of things, and
so the language should only contain simple features to avoid
confusing our poor little heads. Paradoxically, the result is
that Java APIs are overly complex, and our poor little heads get
confused anyway. SeaSide is a good demonstration that powerful,
if complex, language features make the job of everyday programming
easier, not harder, by letting API designers create elegant
abstractions that hide the complexity of the problem domain and
technical solution.
There is indeed great irony in how choosing the wrong kind
of simplicity in a language leads to unnecessary complexity
in the APIs and systems written in the language. I don't
have an opportunity to teach students Smalltalk much these
days, but I always hope that they will experience a similar
epiphany when programming in Scheme.
Not surprisingly, Alan Kay has a lot to say on this topic
of simplicity, complexity, and thinking computationally, too.
I hope to post my take on Alan's two OOPSLA talks later this
week.
Brian Marick writes
about three talks that he heard on the first day at OOPSLA.
He concludes wistfully:
I wish the genial humanists like Ward [Cunningham] and the obsessive
visionaries like Alan Kay had more influence [in the computing world].
I worry that the adolescence of computers is almost over, and that
we're settling into that stagnant adulthood where you just plod on
in the world as others made it, occasionally wistfully remembering
the time when you thought endless possibility was all around you.
In the world where Ward and Alan live, people use computing to
make lives better. People don't just consume ideas; they also
produce them. Ward's talk described how programmers can change
their world and the world of their colleagues by looking for
opportunities to learn from experience and creating tools that
empower programmers and users. Alan's talk urged us to take
that vision out into the everyone's world, where computers can
serve as a new kind of medium for expressing new kinds of ideas
-- for everyone, not just software folks.
This are high goals to which we can aspire. And if we don't
then who else will be able to?
Don't worry. This entry is rated G, for general audiences.
The last session of the Onward! track at OOPSLA was a
panel-turned-open-mike called Breakthrough Ideas. The
idea was simple: Anyone could take the mike for four
minutes or less and propose something that would, if
true or made so by future development, fundamentally
alter the way we use computers, program them, or view
computation. The four-minute limit was strictly enforced
in order to cycle through as many ideas as possible in
the ninety minute session, and to prevent the inevitable
rambling that ensues when some of us start talking about
some idea yet ill-formed in our minds. The format can't
eliminate rambling, only cut it off.
A few of the proposed ideas made me smile and want
to think about them further:
programmed program death: build into each piece
of code an expiration date or a dying process so
that, at the appointed time, the code goes away.
(So much for the Y2K problem!)
a Pulitzer Prize for wonderful code, code that
is elegant, understated, understandable, beautiful.
The genre categories might be application areas
or, more likely, languages. In order to appreciate
the beauty of most code, you have to speak the
language.
program our computer tools to ask us questions,
rather than waiting for us to fill in every details
and, in the process, make mistakes.
programming on the model of a research professor:
when you need a program, you delegate to a graduate
student. What would that be like between me and my
computer?
an oldie but a goodie: the whiteboard compiler.
But maybe we are getting closer on this one...
A poster on the Squeak list recently said that he now
uses Squeak for much of his creative work. He can't
throw his pencils and paper out quite yet, but he feels
like he's getting closer. Alan Kay's talks certainly
encouraged us to think about how we can make progress
toward this goal.
Some other ideas immediately became questions in my mind,
either because I didn't understand the proposal or because
the proposal really was a question.
What would it be like to write software on the model of
living organisms? Software these days has hard edges --
rigid interfaces -- that delineate the boundaries of each
functional component, which does its job and nothing else.
But biological systems have soft edges and seem to operate
on the premise that components fail all the time. (See
Brian Marick's
body-as-kludge article.)
Their components also differ from software in that, say,
a liver consists of oodles of liver cells, none of which
are a liver but which in concert act as a liver -- with
primary and secondary and tertiary functions intermingled.
Finally, what would you do if you knew that one billion
people would use your software? For starters, you would
probably have to make the program multilingual down to its
foundations... Or would you?
I think it's neat that some people think thoughts like these,
and that at least a few of them are even actively pursuing
answers...
Brian Marick's
talk on
methodology work as ontology work
sounds more forbidding than it is. His central point
is this: whenever adopt a particular software development
approach, or create a new one (that's the methodology
part), we implicitly take on, or promote, a particular
way of seeing the world (that's the ontology part).
One implication of this is that communication between
folks in different methodology camps -- say, XPers and
more traditional software engineers -- is often difficult
precisely because these folks see the world differently.
They can look at the same project or team or testing
scenario and see different things. To help such
folks communicate better, you must often help them to
build a common vocabulary, or at least recognize the
names collisions in their individual vocabularies.
Coming to know is to change how we perceive the world.
Those of us in AI community came to learn this up close
and personal through the 1970s, '80s, and early '90s.
While many of us built useful and usable knowledge-based
systems using techniques that codify knowledge in the
form of rules or other explicit structures, we soon
learned the limits of these approaches. Experts don't
have rules for doing their job; they just do it.
The same is true for everyday knowledge. You don't have
an algorithm for determining whether you are tired.
You merely know it.
Merely. In learning, you lose the rules and learn to
see something new.
Another implication of this view is that we can often
use perception to drive behavior better than rule-based
prescriptions. Brian gave two examples:
Big Visible Charts
are a better way for a team to know the bugs that
need to be fixed than annotations in code like
"TODO" comments.
JUnit's
red bar/green bar metaphor is better than just
a numeric output on a list.
As always, I liked Brian's talk for his broad scholarship
and skills making connections. For example, I learned
that scientists like research programs:
that have a "hard core", a small, tightly
connected set of assumptions. This point
echoed Alan Kay's love of "kernels" such as
Maxwell's equations.
that work out consequences of their theories
and 'ignore' counterexamples as potential
refutation. That sounds counter to what we
often learn about the falsifiability of
scientific theories, but it is really a sign
of a deep commitment to the simple idea that
underlies a theory.
that make novel or surprising predictions which
are subsequently confirmed. One such confirmation
can often trump dozens of little counterexamples
based on the details of a theory's explication.
We have a lot to learn from the philosophy of science.
an Onward! session on changing the experience of programming.
Jonathan Edwards talked about example-centric programming,
and in particular two tools he has built: EG, an Eclipse
plug-in for integrating examples directly into code and the
IDE, and subtext,
a language for programming in an example-centric way. The
neat idea here is one I've seen elsewhere, that text strings
are not the right way to represent programs. A structured
format offers some interesting possibilities for writing code.
David Hovemeyer spoke about
FindBugs,
a static analyzer of Java programs that finds common bugs
based on common bug patterns the authors have identified.
an Onward! panel on transforming the software lifecycle.
It was entertaining in a way, but I have nothing to say
about it.
a panel on whether software development is (math and science)
or (arts and crafts). Engineering wasn't in the title, which
upset a few folks. The panel was high-powered --
Robert Biddle,
Martin Fowler,
Dick Gabriel,
Ralph Johnson,
and
Steve McConnell
-- and there was some interesting stuff said, especially
by Biddle on English literature -- but mostly it didn't
give insights that haven't been given before at many
events of this sort. The key lesson is something I
blogged a couple of weeks ago:
Metaphors can both help and limit us in our discovery.
Use with care.
The evening has been BoFs. The first was for the
Domain Driven Design
community. Eric Evans published the marvelous book of this title
last year (read it!), and he has cultivated an on-line community
around the idea. I have volunteered to help out by serving as
an editor and light writer for the FAQ on the web site's wiki.
I have so much free time... but this is an idea and a community
I want to support.
The second -- going now -- is for planning the OOPSLA 2005
conference. I agreed to chair the Educators Symposium again.
Giddy-up!
Up next is a fun event at the Vancouver Aquarium, of which I've
heard many good things. I'm ready for a break.
Steve McConnell on the Realities of Software Construction
Let's try this blogging thing in real time. Steve McConnell,
author of the recent bestseller
Code Complete 2,
is giving the opening talk for Day 2 of OOPSLA. The first
edition of Code Complete is a classic in the field,
still cited by software engineers and practitioners.
McConnell opened with some humor on the hazards of renaming
a book called 'complete'. The best ones played off cultural
icons: Davinci Code Complete and Code Complete:
This Time It's Personal.
The first part of the talk gave several lists summarizing
the software world since Code Complete, the prequel,
came out. A lot of the humor and insight in these lists
lay in how some items showed up multiple times, or in how
opposites showed up.
The worst construction ideas of the 1990s
code and fix
Big Design Up Front (Back then, it was *all* design up
front.)
designing programs based on speculative requirements
the belief that components will solve all our problems
(Just as Biddle and Noble's
postmodernism theme
tells us, there is no one story that can account for all
we can or should do.)
automatic programming
calling everything "object-oriented"
The worst construction ideas of the 2000s, so far
code and fix
no design up front
planning to refactor, usually meant as fixing code
the belief that offshore outsourcing will solve all of our
problems
automatic programming
uninformed use of extreme programming (An informed use
of the waterfall approach is likely better uninformed use
of extreme programming.)
calling everything "agile"
But not everything in the software world is bad...
A decade of advances in software development
With the theatrical release of The Lord of the Rings,
all companies now have servers named 'gandalf' and 'frodo'.
We now do design at a higher level. Indeed, this may be
the ultimate legacy of OO: we design our systems in terms
of larger aggregations or abstractions.
The daily build and smoke test minimizes integration
problems and institutionalizes incremental development.
There is now accepted, widespread use of standard libraries.
The creation of VisualBasic has brought several advances to
common use in the public: visual programming, widespread
use of COTS components, and improved control constructs
that learned from Ada language design principles.
open source software
the web as a research tool
the widespread use of incremental development
Test-first design shortens time to defect detection
and increases personal discipline.
Refactoring as a discipline, not as a cop-out, improves
the design of software.
Faster computers have radically changed how we have to
think about software development. Computers are so much
faster than they used to be (McConnell spoke of having to
perform test code 5 million times just to get measurable
results!) that we should no longer think about optimization
at the code level. It is almost never worth the effort.
We can now pay attention to optimization primarily at the
design level. Machine speed also means that we can
use languages that we like, that make us more productive,
without having to worry about the speed of interpreters,
compilers, and compiled code.
I'm not going to report all of McConnell's ten realities of
modern software construction, but I will summarize some of
the points that struck me:
Construction is a legitimate topic of discussion as an
activity, a set of practices, separate from the other
parts of software development.
Personal discipline matters -- in the form of making
realistic predictions, refactoring code, and creating
simple designs. McConnell didn't mention writing tests,
but I think it belongs here, too. He did point out
that, while many folks think of Ward Humphrey and
Kent Beck as representing very different sorts of
software methodology, perhaps at opposite ends of
a continuum, the discipline of Humphrey's PSP and the
courage of Kent's XP are in much the same spirit. I
think that this is a great insight. XP is not high
ceremony, but it is high discipline. I once asked
Kent what one new practice I should introduce into my
first-year courses, and he said, "Have your students
keep a project notebook", so that students could record
their behaviors and be able to examine and improve
them. Not so much different than PSP.
The fundamental tension in software is between simplicity
and complexity. In the trade-off between write-time
convenience and read-time convenience, the former is worth
essentially nothing, given how much more code is read
than written.
The toolbox metaphor gives us great power. We should
keep that in mind when thinking about our development
methodologies.
Talk Complete. (That was McConnell's joke, not mine. :-)
Earlier this week, my students and I discussed a chapter from
The Pragmatic Programmer.
A few students wrinkled their noses at Dave and Andy's use of
gardening as a metaphor for software development. I know lots
of folks who don't like this and other "soft" metaphors for
making software. For most folks, engineering and architecture
still make the most sense.
At one level, of course, software development is like
engineering.
Software developers design and build artifacts in response
to human needs. They base their designs on a scientific and
mathematical understanding of the world. They strive for
processes that are verifiable and repeatable, so that they
can reliably build artifacts that meet their specifications.
But, as I admitted to my students almost in a whisper, I like
the gardening metaphor. Design, programming, refactoring, and
debugging all have reasonable analogs in gardening, and even
better is the mindset of "cultivating" a system over time.
It's an organic metaphor, and that feels right to me.
We do make software, but software isn't really like
a bridge or an auto. The abstractness of software makes it
more like a legal argument or a scientific theory. As a
graduate student, I built models of arguments and theories
and tried to understand how people create them. There's a
lot of value in taking an engineering viewpoint on these tasks,
but it doesn't always seem much like how people do them.
Of course, the relationship between art, science, and engineering
is a popular topic among reflective practitioners of all three.
In just the last week I ran across an article by a physicist
talking about
superstition in scientific method
and an article by an artist talking about
the mundaneness of artistic craft.
It seems that many seemingly different activities are less different
in the doing than they seem at first glance.
While I appreciate the gardening metaphor and think that it
can help us understand something about what we do, I don't
think it suffices as a model for how we make software. None
of the metaphors I've heard of do. That's why I really like
this quote from
Richard Gabriel:
Over the years I've tried to make the point that programming
(even in its "hacking" form) is not precisely like anything
else that people do, but is like everything that people do
all at once: Programming is not engineering, but programmers
do engineering, programming is not art, but programmers need
to be artists, etc. The totality of the activity of programming
is not like any one thing people do, but because people are
people, we bring to bear all our ways of doing things - alone,
in groups.
We are just beginning to understand what it is to build software.
Metaphors can both help and limit us in our discovery.
Every once in a while I run across an article in a journal or trade
magazine that reflects some misunderstandings about agile methods.
Last July, I
blogged about an article
from a CS education magazine which asserted that using agile methods
was unprofessional. (Presumably, then, so is teaching them as a viable
alternative to traditional methods.)
Yesterday,
Steve Berczuk
pointed the members of the XP discussion list to an article in the
October issue of IEEE Computer called "Do Agile Methods
Marginalize Problem Solvers?", by Victor Skowronski. (The article is
available on-line
to IEEE-CS members.) As Steve said, this column "sounds like it was
written by someone who has read about agile methods but not used them."
Skowronski's argument seems to be this:
Excellent problem solvers often have personalities ill-suited
for teamwork and, further, must often work in ways that do not
match well with teamwork.
Agile methodologies favor people with lesser technical skills
and strong "people skills" over excellent problem solvers and
others with technical skills whose people skills are subpar.
Thus, agile methodologies are unsuitable for environments that
require excellent problem solving skills and thus must attract
people who have them.
This, of course, means that agile methodologies are unsuitable for
many (most?) software projects.
The article uses two of history's great thinkers as examples: Isaac
Newton and St. Thomas Aquinas. Apparently, Newton wasn't much of a
team player, feuding with rivals, guarding his advances until
publication, and preferring to work in isolation. Aquinas, though,
was just quiet, a man living the life of the mind irrespective of
his social circumstances.
Would I really want a Newton on my team? Most software developers
aren't writing software that will change the intellectual foundation
of a discipline or even a company. They don't need to create new
ideas of the depth and complexity of Newton's advances.
Most software developers also don't get jobs for being pains in the
behind.
Would I want Aquinas on my team? Maybe. I can imagine having
an excellent programmer be a valuable contributor to my team even
though he is unable to pair effectively. I've never worked in
such an environment, as my agile background is limited to teams
that chose to use agile methods on their own, but I can imagine
it. Maybe over time the loner becomes an effective pair; maybe
instead the team adapts to the loner. It could work.
Like so many articles of this sort, this one projects a lot of
details into the description of agile methods that aren't really
there. Perhaps this projection follows from never having tried
agile methods, or maybe from an ideological bias. In any case,
this article makes assumptions that demean agile proponents'
professionalism and ethics.
Forcing programmers into a communal workspace with no opportunity
for either personal or professional privacy in the work place?
Discouraging the writing of all documentation? Building software
without adequate knowledge of one's task, tools, and domain?
Please. Those aren't agile practices. They are just bad ones.
A big part of the article discusses how the phases of problem
solving fit with an agile approach, but it is largely beside the
point. When an agile team needs to solve a thorny problem, agile
developers can read books and seek other sources of information.
They can take time away from the active production of code, if
that's what's needed. The team can make reasonable decisions
about how to advance its work.
I did have some good thoughts as I read this piece, reminders
to be agile:
Adapt to your personnel. Certainly. Agile processes
aren't just about software; they also encourage us to be
agile in how they work with people.
That said, you should take care in assembling any software
team, and an agile team is no exception. You may choose not
to have a Newton or Aquinas on your team, if they don't fit.
You might choose not to have lots of different kinds of people
on my team.
Don't overlook developers who can contribute value but don't
fit your stereotypes. This is a variant of the previous
point. The article reminds us that a good problem solver who
lacks people skills may seem less competent than a person who
fits the agile mold. We certainly don't want to overlook
potential contributors. We need to watch for opportunities
to bring potential contributors onto the team and help them
to contribute. They might even grow in the process, too.
Use methods appropriate to your project and environment.
Well, certainly. Agile is as agile does. We need to mold
our approach to the task at hand. But that doesn't mean
throwing out things that we value as essential, like
communication.
Throughout this article, the author seems to imply that you can't
find good problem solvers who are capable of working on an agile
project. Hogwash. Not every person who excels at problem solving
behaves as badly as Newton. I know a lot of smart people with
great technical and problem-solving skills who use agile methods
and like them. They wouldn't choose to develop software any other
way. Furthermore, not all software teams need a problem
solver as singular as Newton. Writing software is hard, but it
is rarely as hard as inventing the calculus.
One other claim caught my eye. This article defines the "best
programmer" as the one with the most advanced problem solving
skills. This is almost certainly the wrong answer. The best
programmers are those people able to deliver high value to their
customers for suitable cost. Problem solving is certainly an
important component in being able to do that. It is essential
that software developers be able to think deeply and to find
solutions to thorny problems. But problem solving is not the
only requirement for a good programmer; indeed, often
it's not even the most important one.
I know that this article is presented as an opinion piece, in a
column that the editors of IEEE Computer hope will stir
up foment. In that regard, I suppose, this piece succeeds. But
still I wonder about the disinformation and misunderstanding of
agile methods that cause people to write such stuff. I hope
that Mr. Skowronski does better research before diving into one
of those really hard problems that he needs to solve.
In a
recent post,
I mentioned that a group of my students is doing an XP-style project
in Scheme. They have available a nice
Scheme unit testing framework,
equivalent to
JUnit
and tools available in many languages. Teams working in Java also
have tool support for refactoring, particularly the open-source
Eclipse
and the academically-inexpensive
IntelliJ IDEA.
But googling and checking the
refactoring tools page
reveal no refactoring browser or IDE for Scheme. There are plenty
of tools for Java, an increasing number for C#, and even one for
Python... but none for Scheme. I am aware of a project by Simon
Thompson and Claus Reinke on
refactoring functional programs,
but they are targeting the pure, statically-typed functional language
Haskell.
I think that the Scheme group most likely to produce a wonderful
refactoring browser soon is the
Dr. Scheme group,
but I don't think they have done anything in this direction yet.
They do have a unit testing framework integrated right into their
IDE, though.
One of my current R&D goals is to create a simple refactoring
browser for Scheme. I started a project on Scheme-processing tools
last spring, and refactoring is the first big tool I want to
produce. Right now, I'm working in Java, because of its
platform-independent support for GUI code and because it is
most accessible to my students at the university. Eventually,
I could see migrating to Dr. Scheme, and writing the tools and
browser in Scheme itself.
If you are a a student who is interested in working on this project,
let me know.
If you know of any other projects targeting refactoring support
for Scheme programmers,
let me know.
I just received my copy of Jutta Eckstein's new book,
Agile Software Development in the Large: Diving into the Deep
in the mail yesterday. (Thanks, Jutta!) This book addresses one of
the persistent myths about agile methodologies: that they only work
for small teams. Jutta is a consultant with many years' experience
in software development, and she has written this book to document
practices that have worked for large teams building software in an
agile way. And when she says 'large', she means 'large', projects
with up to a 1,000 developers.
Most books on agile software development either theorize or talk
about the use of agile methods on a smaller scale. That is natural,
as many of the pioneers are writing about their experiences using
agile ideas in their own smaller organizations. Unfortunately,
this has left the agile folks at a disadvantage when asked, "But
does it scale?" My answer to this question has always had to be
"I don't know for certain", because I've never seen agile methods
applied in large, traditional software houses. (I always follow
up with theorizing about how it could or should scale, but such
theories don't encourage much confidence in a person who has to
bear the risk of potential failure if it doesn't.)
Just from my first skim of the book, I see many things that I
like. Perhaps best is that this book presents practical guidelines
we can all follow. It illustrates the guidelines with stories of
real projects, but Jutta has done some serious thinking to distill
wisdom from her decade of experience with the agile methods. I
also like that the book isn't specific to XP or Scrum or any other
particular agile approach. It deals instead with the values and
principles that are common to all of these. As a result, the advice
we receive here should be useful no matter how we tailor a particular
approach to our organizations.
So, I am quite excited to read Jutta's book this weekend. She
can teach me something about agile software development that lies
outside my experience. I know of Jutta's work in the OOP and
patterns communities, and I have come to respect her insight and
pragmatism. This book should become a staple on my agile
bookshelf.
My Agile Software Development class is doing a big course project.
The students are creating the beginnings of a content management
system for me, with an initial eye toward me writing content for
a book and their program generating a web site for the content.
I don't know how far we will get this semester, but that is part
of the fun of the project.
Most of our students have spent a year learning Java and a semester
learning Ada, so those tend to be the languages in which they
want to program. I expected most folks to want to work in Java,
given all of the tools that support agile development in that
language, starting with
JUnit
but extending to
Eclipse,
Ant,
and others. (Actually, I knew that a few would probably want to
program in C, but tool support for agile approaches in C is still
weak.
Go, Ale, go!)
Imagine my surprise when a four-person team asked me if they
could use Scheme. They had all learned Scheme in my Programming
Languages course, so this wasn't an impossible request. But
only rarely does Scheme attract a student's fancy in my course...
The language is just so different from what they know that, even
if they come to appreciate its power, they usually don't grok how
they might use it as a development language on a "real" project.
These students had all done well in the Scheme part of Programming
Languages, but they hadn't expressed any deep love for the language
at the time.
So my initial reaction was, "Are you jerking my chain?" But they
insisted they weren't, that Scheme seemed like the right tool for
the job at hand: transforming data from one form to another, with
flexible parsing underneath. So I let out a little bit more
chain and said, "Well, you'll have to get a unit testing framework
so that you can write your tests first..." I had mentioned
SchemeUnit
in passing earlier in the course but hadn't told them just how
nice unit testing can be in a dynamically typed and highly flexible
language like Scheme. They said, "No problem."
They did it. The team submitted the build of its first iteration
last Friday. They have three dozen or so tests and three of four
domain modules. The code looks good. We'll see what happens by
the end of the first "official" release of their code -- two more
iterations to go -- but I've graduated from cynical skepticism to
guarded optimism.
This is enough to restore my faith in humanity. To quote ranch owner
Clay Stone
from one of my favorite movies,
City Slickers,
I'm as happy as a puppy with two peters.
We all know that, all other things being equal, duplication in a program
is bad.
The Pragmatic Programmer
uses the phrase DRY -- "Don't Repeat Yourself" -- to capture the essence
of this idea. Unchecked, duplication creates a maintenance nightmare,
because changes to the system may be needed in several, hard to find
places.
When programming test-first, duplication is a natural part of the
development process. First, we craft a test for a requirement, and
then we do the simplest thing possible to make the test pass. That
simplest thing often involves duplicating some other piece of code,
with perhaps a few tweaks that distinguish the new case from the
existing one. Test-first development doesn't leave the duplication
unchecked, though, because it calls for us to refactor our code as
soon as the code for a test passes.
What sort of duplication should we look for when refactoring code,
whether as a part of TDD, as part of taming a legacy system, or as
part of improving our non-TDD system?
Duplication can occur in many guises, not all of which are immediately
obvious when examining a body of code.
The simplest form of duplication is when two pieces of code look the
same. Such textual duplication results from copy and paste,
but it can also occur when solving related problems independently.
When we duplicate text via copy and paste, we usually know to eliminate
the duplication in the upcoming refactoring phase. Even when we
generate it independently, it's easy enough to recognize as we move
around our code base. Common refactorings such as factoring out a
method or superclass address textual duplication.
A particular sort of textual duplication arises in how we sometimes
name things. Consider this piece of Java code, based on a thread
on the refactoring discussion list:
sendMessageToServer( Message m, Server s )
There's a not-so-subtle duplication in the name of the method and
its arguments. I like explicit names, to the point of using longer
names than most folks like to type or read, but this example repeats
the intent of the method in the method name sendMessageToServer
and the argument types Message and Server. The duplication
rises to another level when used in this too-common way:
Message message = ...;
Server server = ...;
...
sendMessageToServer( message, server );
That's triplication, not duplication! Let your language do some
work for you. And you don't need to work in a statically-typed
language to see how good names can eliminate such repetition. A
typical Smalltalk method signature for the above would probably
read:
send: aMessage to: aServer
We can eliminate this sort of name duplication by choosing better
names. :-) Name methods for their actions, and let the names of
argument objects participate in the readability of an statement.
A related form of duplication occurs when two pieces of code behave
alike. We can call this functional duplication. Sometimes
functional duplication begins as textual duplication, but it can
happen quite innocently as programmers working on different parts
of a system reinvent one another's solutions to common problems.
When two methods or two classes do the same thing, we run into
the same maintenance problem as in textual duplication. When
requirements change, one of the methods or classes may be modified
or enhanced, leaving some part of the system using an older version.
Functional duplication is hard to find, because the code may not
jump out at you. One of the less-mentioned benefits of small
methods and small classes is that it's harder for functional
duplication to hide in complex code. If you see code that does
the same thing as another piece of code, you're more likely to
see it in simpler code. XP's encouragement that all programmers
work on all parts of the system over time, through promiscuous
pairing and non-exclusive attachment to particular sub-systems
also helps us avoid this problem, as we are more likely to come
into contact with all of the system's functionality sooner or
later. Once identified, we can eliminate functional duplication
using many of the same factoring techniques as we use on textual
duplication. But we may also need to redesign some of our
interfaces when different functionality goes by different names
in the system.
Dave Astels points out another kind of duplication in his article on
bad code:
temporal duplication, when work is repeated unnecessarily
in a program. I see this sort of duplication when both client
code and server code perform safety checks on the values of variables,
say, to verify a pre- or post-condition. But it can happen in other
ways, too. For example, student code often asks a collection if
it contains an entry with a particular key, and when the collection
says 'yes' it asks for the entry. This may involve searching the
underlying collection instance variable twice. Temporal duplication
is harder to find, because it requires a deeper feel for what the
code is doing.
One way to eliminate temporal duplication is to decide who is responsible
for an invariant condition and then having only that object enforce
it. Another is to rethink the interface of an object -- why ask the
collection if it contains the key; why not just ask for the desired
entry and behave appropriately when it can't find it? A third way
is to cache the result of the first effort and then return the value
immediately upon future requests. Choosing which of these techniques
to use is a matter of balancing different forces. Someone should
write some patterns...
There are some other forms of duplication that show up as a result
of how we design our code. Kevin Rutherford wrote an
article
or two on how many if statements duplicate knowledge
held elsewhere in the system. This is a sort of epistemological
duplication that lies at the heart of good system design. In
object-oriented programming, we don't need to use an if
statement to recover what the system knows or used to know. At the
moment the system knows something about its future behavior, it can
create an object that has that behavior.
Joe Bergin
and I have been encouraging this as a way for students and instructors
to design programs that make better use of polymorphic dispatch than
explicit selection. The advantage of polymorphic dispatch over
if statements is, of course, that we can customize
a program's behavior by plugging a new kind of object into the
system, rather than editing the program code to address another
case in the if statement. And, where there is one
such if, there tends to be more than one, and we
end up with a form of textual duplication if only in the structure
of the choices being made!
I like this quote from the Rutherford article mentioned above as
a concrete criterion for recognizing epistemological duplication
in choices:
Therefore it seems to me that there are two kinds of conditional
statement in a code base: The first kind tests an aspect of the
running system's external environment (did the user push that button?
does the database hold that value? does that file exist?). And the
second kind tests something that some other part of the system
already knows. Let's ban the second kind...
Duplication in all its forms can come back to hurt a programmer
in the long run. I think that one of reasons we feel so good
when we read the code of the masters is that even the less obvious
forms of duplication are nowhere to be found. We may not recognize
this reason, but it's there. Look for these kinds of duplication
the next time a piece of code makes you say "Ahh!" or "Ugh."
You may be surprised by what you find -- and what you don't.
Then think about these kinds of duplication the next time you are
refactoring your code. You will surprise yourself by the opportunities
you have to improve your program.
"If you can't write a test for the code you are about to write,
then you shouldn't even be thinking about writing the code."
And if you can, why not write it now? Then you will know for
certain that you can, and that you aren't just fooling yourself.
Good programmers sometimes ask me why they should bother. They
already write good code. Do such programmers really need the
extra discipline of TDD? Perhaps not. But good programmers
are people, too, and so are subject to the same tendencies as
anyone else. When the pressure is on, or when they are surprised
by a new requirement, they are all too prone to tell themselves
that they really do understand.
There is another, perhaps better, reason for good programmers to
practice TDD: good programmers often work as part of a team. And
as a member of a team, they depend on the quality of the code
produced by the entire team, not just themselves. A good programmer
can benefit from having his teammates practice the discipline.
In this way, even weaker members of the team will develop better
code, which benefits everyone. The good programmers will want
test-first to be a team discipline, so everyone practices it.
If writing tests first is something you can do anyway, the real
question becomes: Why not?
I just read a long rant by a student who is studying Paul Graham's
ANSI Common Lisp.
He was trying to understand an especially Lispy piece of code
and having troubles. At the top of the code file he submitted,
he included a comment over a page long talking about code
readability, comments, and mental sanity. I enjoyed it very
much.
Many folks who have studied "advanced" Scheme or Lisp code know
what he is talking about. I use the scare quotes because, while
students often characterize the code this way, the code doesn't
really have to be all that advanced to create this kind of
disorientation. It doesn't have to be Scheme or Lisp, for that
matter; I had a similar experience when I studied Haskell
programs. It's more about programming style and familiarity
than language. (Perl may be an exception. Does anyone really
understand that stuff? :-)
Functional languages tend to cause the kind of disorientation
that my student felt, because we don't teach or learn functional
programming very much or very well at most schools. Almost
everyone who comes into contact with functional programming
does so from a position of weakness. That's too bad, because
functional programming can be powerful and beautiful, and as
time passes we see more and more elements from functional
languages migrating into popular languages like Java, C##,
and Python. I'm glad that the
TeachScheme!
folks are building tools and developing techniques for teaching
this stuff better.
That's really just a prelude to what triggered my writing on
this topic, which was the part of the student's rant that
dealt with comments. He felt that, if Graham had commented
the function in question, understanding it would have been
easier. But as I read further into the rant, I found that
much of the student's misunderstanding arose from his not
understanding graphs and graph search as well as he might.
Graham could certainly have explained more about graphs and
breadth-first search, but his function isn't a textbook; it's
a Lisp function. He could have added a comment with a
pointer to explanatory material, but I suspect that Graham
assumed his readers would already know certain CS basics.
He is trying to teach a certain audience how to program in
Lisp effectively, and perhaps something more general about
programming. But teaching data structures and algorithms
isn't one of his goals.
Commenting code is a perennial topic of debate among programmers,
students, and instructors. How much is too little, enough, too
much? Brian Marick wrote a
nice little piece
that points out something folks seem to forget occasionally:
But code can only ever be self-explanatory with respect to
an expected reader.
When writing code, you have to know your expected audience, but
you also have to know something about other potential readers.
Then you have to make some hard decisions about how to write
your code and comments in light of all that.
I don't expect that my students put a lot of comments in the
code they write for class. Their expected audience consists
of primarily me, with themselves and their fellow students as
other potential readers. I don't need them to explain to me
how a for loop works, or what an assignment
statement does. I much prefer that they choose
variable names and organize their code in ways that make their
intention clear than that they add gratuitous comments to the
code.
On the other hand, I sometimes put comments in my code that
reflect the fact that I am teaching students about some idea.
If my code example is for CS I, then I may well comment a
for loop with explanatory material. For CS II,
I may add comments that explain the role played by a class
in the Decorator pattern. Even so, I sometimes don't add
comments of this sort, because the code is read as a part of
lecture notes that explain the ideas behind the code. Maybe
I should be more conscientious of the fact that many students
will read the code of the context of the lecture -- or not
even read the lecture at all!
As I responded to some of my student's rant, my mind shifted
to the old questions: Just when are comments most useful?
When should programmers comment their code, and with what sort
of comment? Let's assume that the programmer is writing for
readers of roughly her own level of skill and understanding.
I surfed on over to a wiki page I first read long ago and have
always loved,
Method Commenting.
Ward Cunningham started that page with some patterns of code
and comments to summarize a discussion of the topic. These
patterns resonate with me. The basic theme is that people
read code, and you should write for them.
Code should reveal the intentions of the programmer, using
names and method decomposition that communicate purpose. For
example, one of the things my student disliked in the function
he was studying was its lack of data abstraction -- the function
uses cars and cars all over the place,
which are implementation details. The code would read better with
Syntax Procedures
for the abstract path operations they implement.
That said, programmers have to learn how to think like the
machine. Programs aren't novels; they aren't even how-to
manuals. A reader can't expect to have normal computational
behavior explained in comments. What counts as normal depends
on many things, including at least the programming style and
language.
Here is a situation that calls for a comment: Sometimes, you
have to write code for the machine, for example, when an
optimization is required. This code may mislead the reader.
So, give the reader a clear warning in order to avert
a misunderstanding.
Here's another: Sometimes, you can take advantage of a given
specification, say, a limit on the size of a collection, and
implement an especially efficient algorithm. But the spec may
change, and the code may then become a liability. So, fence
off your code by documenting in a comment the constraint and
its role on your implementation. (These days, I find that my
unit tests serve this purpose better, and they are code!)
There are some other situations where I use a comment, but they
usually involve process. Sometimes, I have to leave a piece of
code undone. A comment can help me know what is left to be done.
Other times, I have a great idea that I don't have time to
explore at the moment, and a comment can help me remember the
idea. But I worry about both of these kinds of comments, because
they tend to have a short lifespan of utility. If I don't get
back to the same code soon, the comment on my great idea may
not mean much to me when I get back to it. Or, worse, I don't
see the comment until after it's too late. I usually prefer
to make a note to myself in some other form for such things.
Mark Jacobson, a colleague of mine, is a big fan of the movie
Ghostbusters.
Now, I like that movie, too... I remember the first time I saw
it, when my brother and I came home and replayed the whole movie
all afternoon, and I've seen it many times since. But Mark is
a big fan. He believes that Ghostbusters can help students
learn to be better students. You can see his many
Ghostbusters-related links on his
homepage.
I am a huge Bill Murray fan. Last night, I watched one of
my other favorites from his filmography,
What About Bob?
This movie is pure goofiness, unlike the high art of Ghostbusters,
but I enjoy it. I must have been in a goofy mood this weekend,
because I began to notice all the things that What About Bob?
can teach us about agile software development. Humor me.
First, a little about the movie. Bob Wiley
(Murray)
is a mess, a multiphobic who can barely even leave his apartment.
He's also so obsessive about his therapists that they keep passing
him on. At the beginning of the movie, Bob's current therapist
leaves his practice in order to get away from. Bob is referred
to Dr. Leo Marvin, a successful and self-absorbed psychiatrist
played to perfection by
Richard Dreyfuss.
Leo is about to go on vacation after the publication of his
blockbuster self-help book Baby Steps. Bob manages to
wheedle an appointment on that fateful last morning, making his
first sparks with Leo and receiving a retail-price copy of
Baby Steps.
It took me a long time to realize that Bob is a software developer.
He's paralyzed by change, fears interacting with people (clients),
and can't make progress toward his goals. He also isn't good at
pairing.
He was married once, but that ended quickly because, as he tells
Leo in their first session together, there are two kinds of people
in the world: people who like Neil Diamond, and those who don't.
And people of different kinds can't work together.
The first thing he learns from Leo is take baby steps. Trying to
take on all of the world's pressures at once would paralyze anyone.
Set a small goal, take the actions that achieve just that goal,
and then reassess the situation. (That's
test-first development,
Do the Simplest Thing,
and
small releases.)
One thing that Bob already seems to understand is the need for
continuous feedback. That's what he seeks from his therapists
-- and also what keeps driving them away. He needs too much attention,
because he is caught up the backwards pathology of modern business.
He seeks feedback not from the world, which is where he takes his
actions, but from his therapist, who represents his manager. He
wants someone else to tell him what to do, and how to feel, and how
to live. A professional must take responsibility for his own actions
and feelings and life. That's one of the things that folks like
Jerry Weinberg and
Pragmatic Programmers
have emphasized so often to software people for so many years.
We also see that Leo needs feedback, too. When planning for
his live interview on Good Morning, America, he asks
his family to help him choose what to wear and where to stand,
but they are so busy with Bob that they don't pay him enough
attention. "I need feedback, people!" he screams in a moment
of raw emotion. And he does. The ever presence of the dysfunctional
Bob accentuates Leo's own egotistic tendencies and pushes him
to cry out for help.
Another lesson Bob learns from Leo comes in the form of a
prescription -- not for more medication, with which Bob seems
to have far too much experience, but to "Take a Vacation".
This is a veiled reference to the agile principle of
sustainable pace.
In addition to taking steps that are too big, Bob spends every
waking moment, and apparently many of his sleeping ones, focused
on his problems. Such obsession will burn a person out, and
only taking regular breaks can cure the obsession. Bob isn't
cured when he decides to take a literal vacation from his
problems, but his vacation is another step on the road to
recovery. Unfortunately for Leo, Bob decides to vacation
in Lake Winnipisaukee along with the Marvin family, which
is another step for Leo toward collapse.
I'm still working on the role played by Leo's family in our
little morality play. Leo's wife, Fay, and children Anna
and Siggy take to Bob quickly, finding his attempts to put
a happy face on the world refreshing after all the years of
seriousness and isolation from Leo. It is in his interactions
with these gentle, loving people that Bob begins to grow out
of his sarcophagus, putting the lessons of baby steps and
vacations into practice. Perhaps they somehow symbolize
clients, though most software developers wouldn't characterize
all of their clients as gentle and loving. However, it is
in interaction with these folks that Bob learns that he does
not have to shoulder all of his burdens alone. (As an aside,
Anna's
Kathryn Erbe
can have a role in my stories any day!)
This leads us to the central question remaining: Who is
Dr. Leo Marvin? The agile coach, of course. He teaches Bob
to overcome his fears, to accept the world as it is, and to
embrace change. Unlike with Bob, I felt an overwhelming urge
to identify Leo with a real person in the community. Kent
Beck?
Uncle Bob
Martin? Finally, near the end of the movie, we have our answer.
Bob Wiley is ultimately cured by Leo's latest invention, the
not-so-tongue-in-cheek Death Therapy. Through a single attempt
at Death Therapy, Bob learns to untie the self-made knots that
bind him and to take command of his life. He even becomes able
to
pair again,
marrying Leo's sister, Leo.
And so we learn that
the model for Leo must be
Ron Jeffries,
who recently so eloquently described the role that
Death Therapy
might play in reversing the fortunes of a software industry that
so often binds itself up with long-range plans, unnecessary
separation of tasks, and fear of change.
Shh. Don't tell Ron any of this, though. Leo goes crazy at the
end of What About Bob?, unable to shake Bob's obsessions.
But Bob is cured!
That's all the
Metaphor
I can manage today. Thankyouverymuch.
Oh, and if you are one of my students, don't expect this to show
up in one of my classes. As much as I'd love to watch What
About Bob? again with you all in class, I don't quite have
the personality to carry this sort of thing off live. Then again,
you never know...
At PLoP last week Gerard Meszaros said something that caught my ear:
risk = probability X consequence
Why waste energy minimizing a risk whose consequence is too low
to be worth the effort?
This idea came up later at the conference when Ward talked
about the
convention-busting assumption of wiki,
but it is of course a central tenet in the agile methods. Too
often, when faced with an undesirable potential result, we focus
too quickly on the event's likelihood, or on its effects. But
risk arises in the interplay between the two, not in either
factor alone. If an event is likely to happen but has only a
small negative effect, or if it has a major effect but is unlikely
to occur, then our risk is mitigated by the second factor.
Recognizing this can help us avoid the pitfall of running from
a potential event for the wrong reasons.
Recognizing this relationship can also help us to take control
of the problem. In XP and the other agile methods, we accept
that change is highly likely, so we work to minimize the consequence
of change. We do that by maintaining a comprehensive suite of
tests to help us verify that changes to the system don't break
something unexpectedly; and, when they do, we use the tests to
find and fix the problem spots. We minimize the consequence of
change by using refactoring tools that help us to change the
structure of our programs when design requirements call for something
different. We minimize the consequence of change by working on
short iterations, continuously integrating our code, and releasing
versions frequently, because these disciplines ensure that we
get feedback from our tools and client frequently.
Learning to pay attention to all the variables in a situation
is more general than just assessing risk. In a
recent message
to the XP mailing list, Kent Beck said that he tries to help his
customers to think in terms of return, not just value or cost:
I have another goal for early estimation, which is to encourage the
business-decision-makers to focus on return instead of just value.
If the choice is between the Yugo and the Ferrari, I'll take the
Ferrari every time. If I have $6000 and I know the price of the
two cars, my thinking is more realistic.
A system's value is a function of many variables, including its
features, its cost, and the environment in which it must operate.
We can become more accurate, more efficient decision makers by
paying attention to what really matters, and not being distracted
by our biases and initial reactions. Often, these biases were
learned in other times, other environments. Fortunately, I think
that this is something that we can learn to do, by consciously
developing new habits of thought. It takes discipline and patience
to form new habits, but the payoff is often worth the effort.
Yesterday was an unusual day for
PLoP:
we didn't have any writers workshops. This year, we squeezed all of
the paper sessions into the first two days of the conference, setting
aside Saturday for two extended sessions by Norm Kerth and Ward Cunningham.
Among their many accomplishments, Norm and Ward are two of the founding
fathers of the software patterns community, and their talks commemorated
the first PLoP conference ten years ago.
Norm led a discussion on myths. I like two of the definitions offered.
One person defined a myth as "a story that is so true you can't use the
facts to explain it."
Richard Gabriel's
definition turned on a myth's effects: A myth is "a story capable of
generating stories in every person who hears it."
Many folks might think that a discussion of myth is out of place at a
conference on software development, but this session was spot on at
PLoP for two reasons. First, this session celebrated the conference's
tenth anniversary, and so stories about its founders and founding were
on everyone's mind. The conference's
opening session
focused on the Genesis Myth of the patterns community, sprinkling facts
among the essential truths. Norm's session this morning was more about
the Hero's Journey myth, told in various forms by all cultures.
More important is the second reason. Science is itself a myth. It
is a set of stories that purport to explain how and why the world is.
We hold some of these stories true (the Greek theory of atoms) until a
better story comes along (Newtonian physics, relativity, quantum mechanics,
string theory...).
Software folks have their myths, too. Software engineering is a
comprehensive one. Extreme programming is a myth, one of a complex
set of myths that we call agile software development.
Patterns are themselves myths. They are stories we tell about the
successful systems we see around us in the world. They have a
narrative form and expected components. We use them to help others
understand what we think we understand, and we write them to help
ourselves understand.
I don't worry that these ideas are "just" stories that we tell. They
embody our current understanding of the world. We try to use more
scientific methods than our forbears in constructing and refining our
stories, but we must always keep in mind that they are just that --
stories -- and that we can them. One of the beauties of XP
is that Kent Beck and his colleagues chose to create a story with
such a challenging premise and the promise of something different.
Because it is agile, it is made to be shaped to its environment,
retold in as many different forms as there are tellers, as we all
work together to find deeper truths about how to build better software
better.
Deep truths often lie inside stories that are themselves not strictly
factual. A classicist who now does software at IBM reminded us of
this during the session. I love PLoP.
"... as we all work together to find deeper truths ..." is a great
segue to Ward's afternoon session, but because I didn't post this
last night I will have to wait to tell that story after I get home
from the conference.
Conventional wisdom is that many software projects are completed late
and over budget. I don't know whether this is true, or to what extent,
but few dispute the claim. Within the software engineering community,
this assertion is used as motivation to develop more rigorous methods
for building software and managing the process. In the popular press,
it is viewed with much head shaking and a bit of disdain. Yet people
must continue to buy software.
We face a similar issue in academia. Many professors accept late work
for a few days after an assignment is due. Sometimes they assess a
penalty, such as 10% of the available points per day. But compassion
usually dictates some degree of flexibility with our young charges.
My grading policy has always been not to accept late work.
I tell students to submit their best available work at the time the
assignment is due. I also place a lower bound on the acceptable
quality of a submission: If a program doesn't compile, or compiles
but blows up horribly when run, then the resulting grade will be
quite low. I tell students that, all other things being equal, a
compilable, runnable, yet incomplete program is more valuable than
a program that doesn't compile or run. It's hard for me to have much
confidence in what a student knows or has created when even the
compiler balks.
I'm reasonable enough to make exceptions when events warrant them.
Sometimes, extenuating circumstances interfere with a student's
opportunity to do the assigned work in a timely fashion. Sometimes
a reasonably good, nearly complete program causes an exception in an
unusual situation that the student doesn't yet understand. But for
the most part, the policy stands. Students long ago stopped questioning
this rule of mine, perhaps accepting it as one of my personal quirks.
But when deadlines approach, someone will usually ask for a break
because with just a little more time...
Of course, I also encourage students to do short iterations and
generate many "small releases" as they write programs. If they
work systematically, then they can always be in the position of
having a compilable, runnable -- if incomplete -- program to submit
at every point in a project. I demonstrate this behavior in class,
both in project retrospectives and in my own work at the computer.
I don't know how many actually program this way themselves.
These thoughts came to mind earlier this week when I saw a message
from Ron Jeffries to the XP mailing list, which appeared in expanded
form in his blog as
Good Day to Die.
Ron considers the problem of late software delivery in industry and
wonders,
What if the rule was this?
On the day and dollar specified in the plan, the project will
terminate. Whatever it has most recently shipped, if it has shipped
anything, will be assessed to decide whether the project was successful
or not.
Does that sound familiar? His answer sounds familiar, too. If you
program in the way that the so-called agile methods people suggest,
this won't be a problem. You will always have a working
deliverable to ship. And, because you will have worked with your
client to choose which requirements to implement first, the system
you ship should be the best you could offer the client on that day.
That is fair value for the time spent on the project.
Maybe my grading policy can help students learn to produce software
that achieves this much, whatever its lifespan turns out to be.
Everyone knows that using good names in code is essential. What more
is there to say? Apparently, plenty. I've encountered discussions
of good and bad names several times in the last few weeks.
Not too surprisingly, the topic of names came up during the first week
of my introductory OOP course. I gave my students a program to read,
one that is larger than they've read in preceding courses and that
uses Java classes they've never used. We talked about how good names
can make a program understandable even to readers who don't know the
details of how an object works. The method names in a class such as
java.util.Hashtable are clear enough that, along with the
context in which they were used, students could understand the class
that uses them.
Often, issues that involve names are really about something bigger.
Consider these:
Jason Marshall writes about a design anti-pattern that he calls
Implied Structure.
Sometimes, developers need to create an object with a descriptive
name in order to communicate knowledge they possess but that their
program doesn't express. The new object, even if it is light on
behavior, captures a valuable domain abstraction. The name
communicates the abstraction to readers of the code, and it also
allows the compiler to enforce meaningful values for variables.
When a client passes false as the second argument
with this message, the result is that the button is disabled.
Such code is almost impossible to follow, because you have to pay
attention to the guilty argument in order to get even a high-level
understanding of the code.
Avoiding this situation is relatively easy. Create a second
method with a name that says what the method means:
Not only is Nat spot on with his analysis, but he has come
up with a wonderfully evocative name for this anti-pattern, at
least for those of us of a certain age: the Wayne's World Method.
This name may be too specific in time and culture to have a long
life, but I just love it.
Finally,
OOPSLA 2004
has been much on my mind lately, with all my work on the
Educators Symposium.
I always look forward to OOPSLA's invited talks and keynote addresses,
and this year one in particular has caught my eye, Ward Cunningham's
Objects, Patterns, Wiki and XP: All Systems of Names.
I am a
big fan
of Ward and his work. He seems always to be in the vanguard of
what everyone will thinking about in a few years. According to
the promotional buzz, Ward's talk will "unravel" his experience
"building tools for the not quite tangible".
I'm not sure exactly what Ward will talk about, and I can't
wait to find out. But the title hints that he will follow the
thread of names through several of his contributions to our
industry. Just think about the role names play in connecting the
tissue of a pattern language, the fabric of ideas that is a wiki
-- and the domain model that comprises an object-oriented program.
And perhaps names play a more central role? I look forward to
Vancouver.
Important ideas have a depth that we can explore in thousands of ways,
never quite the same. Names are one of them.
Ryan Dixon
pointed out an interesting connection between technology, speed, and
language in response to one of my recent posts. Recall that Clive
Stephenson had blogged on
how typing changes how we write,
because it lets us put more material on the page faster than writing
by hand. In
my recent entry,
I talked about how a similar 'speed-up' technology -- agile development --
affects how we write programs and how this perhaps should affect
how we teach programming.
In response, Ryan sent me this quote by Paul Graham, from his wonderful
On Lisp:
Imagine the kind of conversation you would have with someone so far away
that there was a transmission delay of one minute. Now imagine speaking
to someone in the next room. You wouldn't just have the same conversation
faster, you would have a different kind of conversation. In Lisp,
developing software is like speaking face-to-face. You can test code as
you're writing it. And instant turnaround has just as dramatic an effect
on development as it does on conversation. You don't just write the same
program faster; you write a different kind of program.
This is an important insight: you would have a different kind of
conversation. Notice the how the ideas of testing and continuous
feedback play into Graham's comment. And notice that the synergy
between the two leads not just to a difference in degree but a
difference in kind. Graham obviously thinks that the change is an
improvement. I do, too.
I think this notion underlies the benefits of having empowering
technology in your hands. It's why writers are usually better
off by getting lots of material down on paper quickly: the act
of making thoughts concrete in words changes the act of writing,
and it gives the writer something real with which to work. It's
why an agile development style can lead to good programs -- better
programs!? -- even without big design upfront: the act of writing
small tests and small functional bits of code change the act of
programming. They also give programmers something concrete with
which to work, rather than fuzzy requirements and the design
abstractions they build in their head. Programmers learn from
the growing program, and they can feed this learning back into
the next code they write.
Graham speaks specifically of Lisp, but I think he'd agree that
other languages offer a similar experience. Smalltalk is one.
Interactivity plays a big part in the experience, though there's
also something about the kind of language one programs in buried
in there, too. Some languages facilitate this style of programming
more than others. Lisp and Smalltalk, with their "everything
is customizable" designs, do just that.
I love how seemingly little ideas can flow together to create
something much bigger...
Fall semester is in the air. The students are beginning to arrive.
As I prepare for my courses, I've been thinking about some issues
at the intersection of agile development, programming style, thinking
ahead, cognitive styles, and technology.
Many computer science faculty pine for the good old days when students
had to plan their programs with greater care. To this way of thinking,
when students had to punch programs on cards and submit them for batch
processing at the computer center, they had to really care about
the quality of their code -- think through their approach ahead of time,
write the code out by hand, and carefully desk-check it for correctness
and typos. Then came the era of interactive computing at the university
-- when I was an undergrad at
Ball State,
this era began with the wide availability of DEC Vax terminals -- and
students no longer had to be careful. Professors love to tell stories
from those Vax days of receiving student submissions that were Version
132 of the program. This meant that the student had saved the program
132 times and presumably compiled and run the program that many times
as well, or close to it. What could be a worse sign of student attention
to planning ahead, to getting their programs right before typing?
I've never held this view in the extreme, but I used to lament the general
phenomenon. But my view is now mixed, at best, and moving toward
a more agile perspective. Under what conditions would I want
my students to save, compile, and run a program 142 times?
In agile development, we encourage taking small steps, getting frequent
feedback from the program itself, and letting a program evolve in
response to the requirements we implement. In test-driven development,
we explicitly call for compiling and running a program even when we
expect a failure -- and then adding functionality to the program to
make the test pass.
If my students program this way, then they will necessarily end up with
many, many saves and compiles. But that would be a good thing, and at
every step along the way they would have a program that deserves partial
credit for a correct but incomplete solution.
In order for this approach to be desirable, though, students need to
do more than just code, compile, and run. They will need to add
individual features to their programs in a thoughtful, disciplined way.
They will need to do some testing at each step, to ensure that the new
feature works and that all older features still work. They will need
to continuously re-work the design of their program -- refactor! -- as
the design of the program evolves. And all of these take time.
Not the frenzied iterations of a student whose program is due tomorrow
morning, but the intentional iterations of a programmer in control.
To me, this is the biggest difficulty in getting students to program
in an agile style. Students are so used to procrastinating, to
doing triage on their to-do lists in order to get the most urgent
project done first. Unfortunately, many also give higher priority
to non-school activities all too often. I am always on the look-out
for new ways to help students see how important time is in creating
good programs, whether by planning carefully ahead or by going through
many planned iterations. Please
share any ideas
you have.
So, many iterations isn't a problem in itself, but rather a style
in which those iterations are the result of the seemingly random
modify-and-compile approach that many students seem to fall into
when a program gets tough. Part of our job as teachers is helping
students learn discipline in attacking a problem -- more so than
teaching them any particular discipline itself.
Why the mention of cognitive styles above? A
blog entry
by Clive Stephenson brought this topic to the front of my mind a few
weeks ago, and it wasn't about programming at all, but about writing
more generally:
... Is there any difference between our cognitive styles when we write
longhand, versus typing on a keyboard?
Since I type about 70 words per minute, I can type practically as fast
as I can compose sentences in my head. So does the much-slower pace
of handwriting actually create a different way not just of writing,
but of thinking? Does the buffer buildup between my brain and my arm
affect things?
What I mean is this: When I'm typing, because I can generate text
so fast, I'll toss lots of stuff out on the page -- and then quickly
edit or change it. But when I'm writing by hand, because it's so much
slower I'll try to compose the sentence in my head before trying to
write it. With a keyboard, I sort of offload some of my mental-sorting
onto the page, where I can look at the words I've written, meditate on
them, and manipulate them. With writing, that manipulation happens before
the output. Clearly this would lead to some cognitive difference
between the two modes ... but I can't quite figure out what it would be.
Changes in technology have made it easier for us to get ideas out of our
heads and onto paper, or into a computer file. That's true of good ideas
and bad, well-formed and inchoate. For many writers, this is a *good*
thing, because it allows them to get over the fear of writing by getting
something down. That's one of the things I like about having my students
use more agile techniques to program: Many students in introductory
courses are intimidated by the problems they face, are afraid of not
being able to get the Right Answer. But if they approach the problem
with a series of small steps, perhaps each small step will seem
doable. After a few small steps, they will find themselves well on the
way to creating a complete program. (This was also one of my early
motivations for structuring my courses around patterns -- reducing
fear.)
Used inappropriately, the technology is simply a way to do a poor job
faster. For people whose cognitive style is more attuned to up-front
planning, newer technologies can be a trap that draws them away from
the way they work best.
In retrospect, a large number of compiles may be a bad sign, if they
were done for the wrong reason. Multiple iterations is not the issue;
the process that leads to them is. With a disciplined approach, 142
compiles is the agile way!
On the last day of SugarLoafPLoP 2004, I gave my
test-driven development tutorial
as the last event on the main program, just before the closing
ceremony. I was pretty tired but brought as much energy as I
could to it. The audience was tired, too, and it showed on their
faces, but most folks were attentive and a couple asked interesting
questions.
One person asked about the role of traditional testing skills, such
as finding equivalence classes on inputs, in TDD. These skills are
still essential to writing a complete set of tests.
Brian Marick
and his colleagues in "agile testing" have written a lot about how
testers work with agile projects. One of the great values of agile
software development is that most everyone on your team can develop
some level of expertise at writing tests, and can use whatever
knowledge they learn about testing.
Someone in industry asked whether TDD increases the quality of code
but at the cost of longer development times. I answered that many
believe TDD doesn't increase net development time, because this
approach includes some testing time and because the increase in
code quality means many fewer bugs to fix downstream. I could not
point to any controlled experiments that confirm this, such as the
ones
Laurie Williams
has condcuted on pair programming. If you know of any such studies,
I would love to
hear from you.
I think this is an area ripe with possibilities.
All in all, folks were skeptical, which is no surprise from an
audience with a serious bent toward traditional software engineering
practice. TDD and other agile practices are as disorienting to many
folks as finding myself in the Sao Paulo airport was to me. Perhaps
I helped them to see at least that TDD isn't irresponsible, that it
can be a foundation for sound software development.
This day turned into one like last Sunday -- after a half day of
conference, Rossana Andrade took me and Paulo Masiero on a short
sightseeing and souvenir-shopping trip around Fortaleza. Then she
and her husband Richard took me to a cool Brazilian pizza place
for dinner, and finally they took me to the airport a few hours
before my 11:10 PM flight to Rio de Janeiro, the first leg
of my journey home. The day became Saturday with no fanfare, just
a long flight with a layover in Recife to exchange passengers and
arrival in an empty and quite English-free Rio de Janeiro airport.
I must say thanks to my hosts in Brazil, Paulo and Rossana. They
took wonderful care of me, fed me lots of authentic food, told me
all about their cities and country, chauffered me around, and translated
everything from pizza menus to billboards for me. Indeed, all the
folks at the conference were wonderful hosts and colleagues. I can
heartily recommend SugarLoafPLoP to anyone interested in participating
in a patterns conference.
I finally gave my talk on
writing patterns and pattern languages
this morning. It went well enough, I suppose, but I broke many of
the suggestions I made in the paper: too few examples, too abstract.
Sigh. How can I manage so often often to know what to do yet not
do it? This talk will be better the next time I give it.
The best question at this session was about trying to write patterns
that "live forever". I used Alexander's "Light on Two Sides of Every
Room" as an example, and this prompted someone to point out that even
the best patterns seem to become stale after a certain period of time.
People wouldn't want to have two windows on two sides of their rooms
if they lived in a dirty part of Sao Paulo, so Alexander's pattern is
already dated; and, if Alexander's patterns suffer this fate, how can
we mortals hope to write software patterns that live forever?
My answer was two-fold:
The reason why "Light on Two Sides of Every Room" doesn't
work in certain parts of big cities is that it is out of
contex there -- the patterns that must be present before
"Light" applies aren't there. If we wish to apply
Alexander's pattern language in a form of diagnosis, a la
The Oregon Experiment, we would have to start with
patterns far upstream of this one. Indeed, Alexander would
probably urge us to start from scratch somewhere else and
make a more livable space to begin with!
In a discipline as young as building software, we can't
expect that we will always understand things as well as
we may in the future. So we should write patterns that
document what works according to our current understanding
of the world and, if we come to understand more or better
five years hence, then update the language. Our pattern
languages are always works in progress, as the software
community discovers its communal knowledge of what gives
software the Quality.
That's my understanding today. If I learn something to make me
change my mind tomorrow, I'll post an update. :-)
Well, I made it to Brazil. Yesterday was a day that came and went
with no end. I ran 18 miles in Bradenton before the sun rose, visited
with parents until after lunch, and then went to the airport for an
overnight flight that brought me to Recife at lunch time Monday.
The change from English to Portugese on theb plane from Miami to
Sao Paulo made the newness of my surroundings obvious. In Sao
Paulo, I went through the dreaded American immigration line.
The Brazilian government strives to treat each nation's citizens
as that nation treats Brazilian citizens and, with the procedures
in place here since 9/11, that means long lines, fewer handling
stations, photographs, and fingerprints for Americans entering
Brazil. I spent over two and half hours of a three-hour layover
in Sao Paulo going through the immigration line. And by I use
the word "line" with some hesitation. The South Americans and
Europeans in the crowd certainly didn't feel limited by any idea
of the linear.
My first stop was the Federal University of Pernambuco (UFPE),
in Recife. My
SugarLoafPLoP
co-program chair, Paulo Borba, teaches there, and he asked me
to give a talk to his department. I debuted the
test-driven development talk
that I planned to give at the conference. It went well, despite
my not having slept more than an hour since 34 hours earlier and
our running so late after lunch that on arrival I walked straight
into the classroom and gave my talk. The audience was mostly
graduate students, many of whom write software in industry. I'd
forgotten what it felt like to be in a room with a bunch of grad
students trying fit whatever talk they here into the context of
their own research. I spent considerable time discussing the
relation of TDD and refactoring to aspect-oriented programming,
JML,
and code coverage tools such as
Clover.
This dry run led me to make a couple of improvements to the talk
before delivering it on Friday to the conference audience.
I was energized by the foment! But then I was ready to crash.
Does test-driven development help us to build software with a higher
degree of encapsulation? I feel like it does when I write code.
But this is the sort of claim that, when made in front of students,
can be exposed as either wrong or more complex than it first appears.
That's because it depends on assumptions and skills that not all
programmers hold.
How might test-driven development help us to build
better-encapsulated software? When we write tests first, we have an
opportunity to think about our code in terms solely of its interface
because we haven't written the implementation yet! In an object-oriented
program, the test involves sending a message to an object in order to
see whether the object behaves as expected. The object's class may
may be partially implemented, but not the behavior we are testing.
And we are supposed to be thinking about just the requirement at
hand, not anything else.
But how can we go wrong? If we become sloppy, we can fall into the
trap of writing a test that causes a change in the object's state
and then verifies that the expected change has occurred. This often
requires adding a public accessor to the object's interface that is
otherwise unnecessary. Even you don't intend for client programmers
to use the method, it's now there. One of the lessons of interface
design is that, if it's there, clients will use it.
It's more than just sloppiness that can lead us astray, though.
Testing some behaviors is not straightforward because they involve
outside resources (say, a web connection) or non-trivial collaborations
(say, a network error). Often it's easier to write a state-based
test than a behavior-based test. But those kinds of tests usually
leave me feeling unfulfilled. That feeling is my test telling me to
do better.
The idea of
mock objects
developed in the XP community as a way to support behavior-driven testing
in the face of such difficulties. But even mock objects aren't a guarantee
that we will write well-encapsulated code. Martin Fowler wrote a recent
article discussing the common confusion of
mocks
with stubs.
I do think that TDD encourages and supports well-encapsulated code --
but only if the programmer understands the
Tell,
Don't Ask
principle for designing objects. And practices it faithfully. And uses
mock objects (or their equivalent in your programming style) for the
tough cases. That's a lot of assumptions built into a simple claim.
But most knowledge works that way.
How can you support yourself in those assumptions? Pair programming!
Those XP practices really do add up to something more than their parts.
Last week, I had a celebratory dinner with a group of folks who've
been involved in developing a program that is now ready for prime
time. It was a nice to recall the trajectory of a project that has
been useful to me in several ways.
The dinner was called by the leader of the project, Ed, a mathematics
professor who specializes in early elementary education. Several
years ago, he and I hooked up over his desire to have a computer
program for assessing the performance of students who have been
taught to basic arithmetic facts in a particular way. His research
has identified a set of strategies for doing simple addition,
subtraction, multiplication, and division, and a set of strategies
for teaching students. What he needed was a way to tell
whether and how well students were using the basic facts strategies.
He needed the answer to these questions in order to demonstrate
that his approach was working. More practically for teachers, answers
to these questions could serve as diagnostic information, helping
them know which students need more work with which strategies.
Such data can make the dream of individualized instruction more
of a reality.
I did some initial design work with the math professor and then
turned the bulk of the code writing over to Masa Noborikawa, an
M.S. student in search of a master's project. Masa's interest
lay in the role of design patterns as targets for refactoring
during the evolution of a large project, and this project gave
him something large enough to grow over many months, refactoring
and introducing many of the design patterns he'd learned about
"in the small" in his courses. The result for the larger project
was a first version of an assessment tool, written in Java.
Our first version had a couple of weaknesses that we needed to
address. The first involved portability. Now, Java is characterized
as "write once, run anywhere". But when anywhere includes old Macs
running various versions of older Mac OS, Java -- especially its
graphics library -- doesn't run as cleanly everywhere as we had hoped.
The second involved networkability. As written the program was
a single-user, single-machine tool. But teachers needed to be able
to amalgamate data across machines and classrooms, and school
districts wanted to be able to the same across different schools.
The program needed to be networked with a central server and
database.
We went through an uncomfortable hiatus in the project. One of the
risks for long-term projects at a school with only a small master's
program is the the unreliable flow of manpower and skills. When
I was a graduate student, we seemed to have an endless supply of
new students looking for projects and ready to work. As a researcher
at UNI, I often hit dry spots when suitable students are sparse.
It's one of the downsides of a program like ours.
Eventually I found the perfect person for the job,
Ryan Dixon,
an undergraduate with a lot of experience programming on Macs.
Not only did Ryan have the right experience for the job, he is a
good software designer, user interface designer, and programmer.
He took control of the software and produced a Version 2 that
addressed the above weaknesses and more. In particular, he created
a parallel UI that depended on Java 1.1.8 or less, so that the
program would run the same on all platforms, even the abandoned
Mac OS.
Since then, Ryan has gone off to graduate school, returning to do
some work for us this summer. We also have a local consultant
who has added some of the networking capability and other extensions.
Anyway, as the project reaches the point of being marketed as
a part of a mathematics curriculum for use in schools, the lead
math professor brought us all together, with our families, to
celebrate the achievements of the last few years. We all enjoyed
a nice meal and the good company. Of course, there is always more
to be done...
This is my first experience as an academic working with internal client
who is taking a project "commercial". You get to learn more from
working on real projects than you can ever learn just by reading
and hearing about others' experiences. I have along track record
working on real projects with real clients, but this is the first
on which the resulting program will be used by a mass audience
outside of the client's office. In this case, our client isn't
even the user -- just someone who has lots of ideas about the project
and who works with the real users.
Much of my job on this project is listening to the client figure out
what he wants, listening to him talk out loud and asking questions,
sometimes rhetorical. When Ed says, "Do you have two minutes?",
I know two things:
that I'm in for a conversation longer than two minutes :-), and
that I have a chance to learn something more about where our
project can go -- and that he may be about to learn something,
too.
As with most clients, he often doesn't really know what he wants.
As with most non-software people, he often doesn't even know what
is possible in a program. As a result, he asks for too much or for
not enough, sometimes at the same time. By participating in the
conversation, I help him find the boundaries of the technology
while he thinks through the boundaries of his project. Magically,
sometimes it all comes together.
Version 3 of the program could be awesome, but how we'll get there
is yet unknown.
It's hard to get rich writing programs for educational markets, but
there is a chance that this could take off. This curriculum shows
promise, and the assessment program opens doors to possibilities
that are unavailable to most elementary curricula. But even if we
never make more than a token royalty check, the project will have
been worth the time and energy.
As I prepare my
upcoming tutorial on test-driven development
for
SugarLoafPLoP 2004,
I find myself frequently coming back to the idea of refactoring and
its synergy with TDD. Fortunately, there will also be a tutorial
on refactoring at SugarLoafPLoP, by Joe Yoder. I think that our
tutorials will be able to work together, too, to help folks see
that, to get full benefit of either, one really ought to practice both!
That isn't to say that one can't do test-driven development alone.
My coding practice in interactive languages like Scheme and Smalltalk
have always been test-driven, because it's so easy to build a test
suite and the desired code in parallel. On the other hand, in a
language like Java, it's so easy to get caught up in the details of
a big class and lose sight of the tests. This is where I find that
having cultivated TDD as a practice has has made me a better
programmer.
... on my most productive day of coding ever, I had written negative
500 lines of code. On my longest sustained 'productive' cycle, on
the first project I mentioned, I averaged negative 200 lines of code
for four weeks ...
This reminded me of one of Brian Foote's wonderful aphorisms: "The
only thing better than a 1000-line of code weekend is a minus
1000-line of code weekend." Of course, it's sometimes hard to
convince anyone still living in a LOC world to appreciate the value
in your accomplishment!
Anyone who has had to live with an out-of-control code base understands.
Jason's article explains well the value of refactoring even in the
absence of any other agile practices: Repetition, especially the
mindless sort, ultimately makes the code too big and too hard to
understand. That makes it hard for anyone to add to the program.
Today I am working on an invited tutorial that I will be giving at the
Fourth Latin American
Conference on the Pattern Languages of Programs, affectionately
known as SugarLoafPLoP 2004. The conference is August 10 through 13
in Porto das Dunas, a resort town in the north of Brazil.
I am also serving as program co-chair for the conference. Being a program
chair for a PLoP conference can be quite time consuming, but this has not
been too bad. My Brazilian co-chair,
Paulo Borba,
has done a lot of work, especially with submissions written in Portugese,
and the conference chair,
Rossana Andrade,
has shouldered most of the responsibility for the conference schedule.
This has left me to focus on the writers workshop program for authors
working in English and with handling basic inquiries from authors and
presenters.
My tutorial is on test-driven development (TDD). I plan first to give
some background on
extreme programming
(XP) and TDD's place in it, and then to introduce the practices,
supporting tools, and "theory" of TDD through a pair programming
demonstration. Lecturing on how to do something always seems like
a bad idea when you can do it and talk about it at the same
time. One of the things I've been thinking a lot about is how
practicing TDD can both help and hinder the evolution of good design,
and how other practices such as refactoring work with TDD to even
better effect. I hope for my talk to convey the "rhythm" of TDD and
how it changes one's mindset about writing programs.
On my way to SugarLoafPLoP, I am giving a talk to the
Centro de Informática
at the
Universidade Federal de Pernambuco
in Recifé. I think that this talk will also be on TDD, with
a focus on interaction-based testing with mock objects. I've been
learning about this idea from a
recent
article by Martin Fowler. I could always still talk on elementary
patterns, which is the work closest to my heart, but it seems more
convenient to mine the same thread of material that's occupying my mind
most deeply right now.
This is my first trip outside of North America, so I'm looking forward
several new experiences! Now, back to those talks...
I don't usually think of Edsger Dijkstra as an "agile methods" kind of
guy, but yesterday as I re-read "The Humble Programmer", his 1972 Turing
Award lecture, an interesting connection formed in my mind. (I ran
across this paper again at
Malcolm Davis's blog.)
As a part of Dijkstra's argument that it is possible for computer
scientists to develop large programs at reasonable cost, he considers
the problem of correctness. The value of testing as traditionally
practiced is limited:
... program testing can be a very effective way to show the presence
of bugs, but it is hopelessly inadequate for showing their absence.
So, rather than write code then test it, or even write code then prove
it correct,
... the programmer should let correctness proof and program grow hand
in hand. ... If one first asks oneself what the structure of a
convincing proof would be and, having found this, the constructs a
program satisfying this proof's requirements then these correctness
concerns turn out to be a very effective heuristic guidance.
This sounds a lot like test-driven development to me. The tests
in TDD are really more about specification than testing, and
as such act as assertions, or delimiters of correctness. Each test
is a claim about what the code should do. A test guides the development
of a part of the code, and the body of tests and the program grow
hand in hand.
Dijkstra would certainly argue for a systematic and sound development
of tests that define the system, but I do think he would appreciate
TDD's emphasis on writing tests first.
This lecture has so many neat ideas that resonate today, from the
value of patterns to language design to the conservatism of the
academic computer science community. I will save some of those ideas
for other days.
However, I can't resist quoting Dijkstra on the importance of
computing. The conclusion of the paper is worthy of a Turing Award
lecture and offers a deeply inspirational message. Two quotes stand
out for me. First,
[Computers] have had a great impact on our society in their capacity
of tools, but in that capacity their influence will be but a ripple
on the surface of our culture, compared with the much more profound
influence they will have in their capacity of intellectual challenge
without precedent in the cultural history of mankind.
And then later,
This challenge, viz. the confrontation with the programming task, is
so unique that this novel experience can teach us a lot about
ourselves. It should deepen our understanding of the processes of
design and creation, it should give us better control over the task
of organizing our thoughts. If it did not do so, to my taste we
should not deserve the computer at all!
The desire to understand creation and design better is exactly what drew
me to computer science in my undergraduate days, what led me to study AI
as a graduate student, and what continues to drive me today. Dijkstra's
position also reminds me of Alan Kay's forty-year advocacy that we can
-- must -- do so much more with computers than we currently do, that the
digital computer can fundamentally alter how we create and communicate
ideas. We are lucky to be guided by such visionaries.
Don Gotterbarn, writes
the "Thinking Professionally" column in the SIGCSE Bulletin. His most
recent column (Volume 36, Number 2, June 2004) suggests that agile
development methods are unprofessional. Here are some of his assertions:
They "do not take a systems or engineering view of development".
Customers are "the only stakeholders identified in system
development models like agile methods...".
"... they quite specifically narrow our focus in dangerous ways."
He includes RUP in those admonitions, but he reserves some of his
harsher words for agile methods. He speaks dismissively of "designing
a web page while agilely chatting with the customer". Later, he says,
"Agile methods' emphasis on a 'people-centric view of software development'
is about supporting the individual developer's needs to feel free to be
creative and not about a concern for people affected by the system."
These words sound rather disparaging, but I think they reflect a common
misconception of agile methods by some in the software engineering
community. Such folks often see the agile methods' emphasis on
different elements of the development process as a rebuke of their
own professional concerns. The result is often an overreaction to
the agile methods. (Some of the hype that ushered in XP probably
didn't help this situation, either.)
In particular, I think Gotterbarn's article reflects two misconceptions.
First, it assumes that agile methods do pay not adequate attention to
gathering requirements. While some in the agile community have written
a bit loosely of unit tests almost as a replacement for requirements,
that's not what the agile methods actually call for. (Brian Marick makes
the
distinction quite nicely.) For example, XP's "planning game"
prioritizes and selects from product requirements that were developed
in consultation with the client. The key point XP makes about requirements
is that the client should be responsible for business decisions, and
the developers should be responsible for technical decisions.
Second, the article assumes that developers using agile methods are not
allowed to use their professional judgment. I don't think that any
proponent of the agile methods thinks that or wants practitioners to
behave this way. A professional can explore the context of a project
with the client. A professional can use his or her domain knowledge
when choosing stories to implement and when implementing them. A
professional can acknowledge a lack of knowledge about a task. For
example, several of Gotterbarn's examples are based in poor user interface
design. Designing a user interface without knowledge of the intended
user audience is unprofessional regardless of the development method
used. Likewise for designing a user interface without knowledge of
usability design.
Perhaps both of these misconceptions ultimately come back to the agile
methods' emphasis on the separation of responsibilities between the
client and the developer. Certainly, agile methods depend in large part
on the client specifying an appropriate system, in collaboration with
the developer. That won't be different under any other software
development method. Gathering requirements is still essential to
building good software, and it is still difficult to do well. One
of the things I like about the agile methods is their emphasis
on communication, on close interaction with the client, precisely because
they give the developer an opportunity to be a more active part of the
conversation that defines the project.
Agile methods don't tell us to turn our professional judgment off,
or to ignore what we know about the domains in which we work. They
do encourage us not to substitute our expertise for the client's in
relation to the client's domain and needs. They do encourage us not
to run too far head of the client's needs, not to build a system that
is bigger, more complex, more costly, and more error-prone than the
client needs. I don't think that any software professional or educator
can disagree with these goals.
Over the last couple of months, I've been following the discussion on
the
Extravagaria
wiki. Extravagaria is a workshop organized by
Richard Gabriel and Janet Holmes
at OOPSLA 2004. It aims to explore
how software people can use techniques of the arts "to explore research
questions and explain results".
I am a "Suzuki dad" to my daughter as she learns to play the piano. For
the last few weeks, I've been picking up "Zen and the Art of Motorcycle
Maintenance" during her lesson and reading a section while she works with
her teacher. Yesterday, something I read brought Extravagaria to mind.
I was reading Chapter 25, in which Pirsig talks about the synthesis of
classical and romantic thought. He argues that adding the romantic as
a veneer over the classical almost always results in "stylish" but
unsatisfying -- even ugly -- results, both the product itself and the
experience of users and designers. Instead, the classical and romantic
must be united at a more fundamental level, in his notion of Quality.
Pirsig then says:
At present we're snowed under with an irrational expansion of blind
data-gathering in the sciences because there's no rational format for
any understanding of scientific creativity. At present we are also
snowed under with lots of stylishness in the arts -- thin art --
because there's very little assimilation or extension into underlying
form. We have artists with no scientific knowledge and scientists
with no artistic knowledge and both with no spiritual sense of gravity
at all, and the result is not just bad, it is ghastly. The time for
real reunification of art and technology is long overdue.
How much artistic knowledge do scientists require in order to avoid
producing ghastly results? Can we just put a "stylish" veneer on our
work, or must we study art -- do art -- so that the process is
a part of us?
I sometimes feel as though I am affecting an artistic stance when
the substance of my work is little different.
That isn't to say that I have not benefited from adopting practices
from the arts. I learned a lot from Natalie Goldberg's Writing Down
the Bones. Since reading it, I have always tried to write a little
every day (code and text) as a way to keep my ideas, and my ability to
write them down, flowing. One of the reasons that I started this blog
was, in part, as an external encouragement to write something of value
every day, and not just the surface of an interesting but inchoate
thought. Gabriel has been something of an inspiration in this regard,
with his "one poem a day" habit.
I have also certainly benefited from learning to play the piano (well,
beginning to learn) as an adult. The acts of learning an obviously
artistic skill, talking about it with my teacher, and reading about it
have all changed my brain in subtle but useful ways. The change affects
how I teach computer science and how I read its literature; I suspect that
it has begun to change how I do computer science, too.
How easily can scientists adopt practices from the arts without
'grokking' them in the artistic sense? I suppose that this is one
of the points of Extravagaria.
If you are interested in this topic, be sure to check out the
Extravagaria
wiki.
While out on a run recently, I realized that I was practicing the agile
software development principle of getting continuous feedback --
without even trying.
Most mornings, I want to control the pace I am running. Maybe I am doing
a tempo run, on which I want to average my 10K pace for a few miles.
Maybe I'm doing a speed work-out and need to run several repetitions of
a particular shorter distance at a faster pace. I have to be careful when
trying to run fast, because it's easy for me to overdo it. Then I run out
of gas and can't finish comfortably, or at all. And it's even easier to
run too slowly and not get the full benefit of the workout.
Or maybe I *want* to run slower than usual, as a way to recover from faster
work-outs or as a way bump my mileage up. On days like this, I have to be
careful not to run too fast, because my body needs the break.
So I need a way to pace myself. I'm not very good at doing that naturally,
so I like to use landmarks to monitor my pace.
One place I can do that is on a recreation trail near my home. This trail
contains a 6.2-mile loop and has four 1-mile segments labeled. When I try
to run a steady pace on this route, I used to find that my miles varied
by anywhere between 10 and 20 seconds. These days I do better, but sometimes
I can't seem to get into a groove that keeps me steady enough.
I do my weekly speed workouts on the indoor track at my university's
wellness center. This track requires me to do 9 laps per mile, and
it has signs marking 200m, 400m, 800m, and 1200m splits. Running on
this track I get feedback every 1/9th of a mile, and I can synchronize
myself at the longer splits, too. Not too surprisingly, I pace myself
much better on the track than on the trail. And more frequent
feedback is the reason. When I get off by a second or two for a lap,
I make can make a small adjustment to get back on pace -- and I can
tell if the adjustment was successful within a 1/9th of a mile.
Doing my Yasso
800s on the small track has been invaluable in helping me get faster.
Even better, they have helped me learn to pace myself naturally. Now
when I run mile repeats on the trail, I find that my pace rarely varies
more than 10 seconds per mile, and sometimes I can clip off several miles
in a row all within 3-7 seconds of each other. Getting continuous feedback
as I've learned has helped me to develop better "instincts".
I recently took my speed workouts outside to the university's 1/4-mile
track, to enjoy the summer weather more and to
lengthen
my repeats. Running consistent 1200m repeats on the longer track is
tougher, because I don't yet have the instincts for racing fast at a
desired pace and because the track gives me feedback less frequently.
But I hope that a few weeks of practice will remedy that...
My goal is eventually to be able to find a groove where my pace is steady,
comfortable, and right on the mark for a particular marathon time.
Continuous feedback plays an important role in training by body and mind
to do that.
I think that this story may be a good way to illustrate and motivate the
idea of continuous feedback in my Agile Software Development course this
fall.
Some of my colleagues become uncomfortable when I teach our students agile
software development methods. "That's just trendy hogwash," they want to
say. (They mostly don't, because they are too polite.) Of course, folks
from the Smalltalk and Lisp communities say just the opposite -- many of
the ideas and practices of the agile software movement have their roots in
ideas and practices found in those communities back in the 1980s and even
earlier.
I was reminded of just how fundamental some of these ideas are when I read
one of the early chapters in Gerald Weinberg's The Secrets of
Consulting, which I first blogged on yesterday. Weinberg talks about
the necessity of recognizing trade-offs and making them explicit in the
projects one does. Whenever the client asks for some optimal something --
the minimum cost solution, the shortest possible time, the best possible
way -- the wise consultant asks, "What are you willing to sacrifice?"
This sounds an awful lot like what Extreme Programming says about The Four
Variables: cost, time, scope, and quality. To maximize or minimize one
of these fundamental variables, you have to give up something for at least
one of the others, maybe all. Trade-offs of this sort aren't a new idea
at all, even in the world of software development punditry. Weinberg
wrote his book in 1985.
I especially like one of the examples Weinberg uses to make his case, the
Trade-off Chart. Here is such a chart, updated to 2004:
This chart shows the trade-off between speed and distance in the product
category "world's fastest runner". If you want a runner to maintain a
faster speed, then you will have to give up distance. If you want a
runner to maintain a speed for a particular distance, then you will have
to accept a slower speed. This is true of the world's fastest runners
-- the upper bounds on expected performance for most -- and so it is
generally true for other runners, too.
As an erstwhile runner, I understand just what Weinberg is saying. And
I am nowhere near the upper bound at any distance! Yet, like many people,
I sometime forget about the fundamental trade-offs I face when working on
a software project. I sometimes forget when I'm running, too, and pay the
price later, in the form of fatigue or injury.
Weinberg goes on to show how a developer or consultant can use such a
chart to begin asking the right questions about the requirements for
a project, and how these questions can help both consultant and client
follow a reasonable path toward a working system.
I wonder what a four-dimensional trade-off chart for XP's four variables
looks like for typical kinds of software? Even two-dimensional chart
showing pairwise trade-offs among the variables would be useful in
understanding the forces at play when building software. These are the
sort of pictures that Kent Beck draws with words in his book Extreme
Programming Explained.
So, no, dear colleagues, I'm not teaching only the latest fads in my
Agile Software Development course. We are learning the basics.






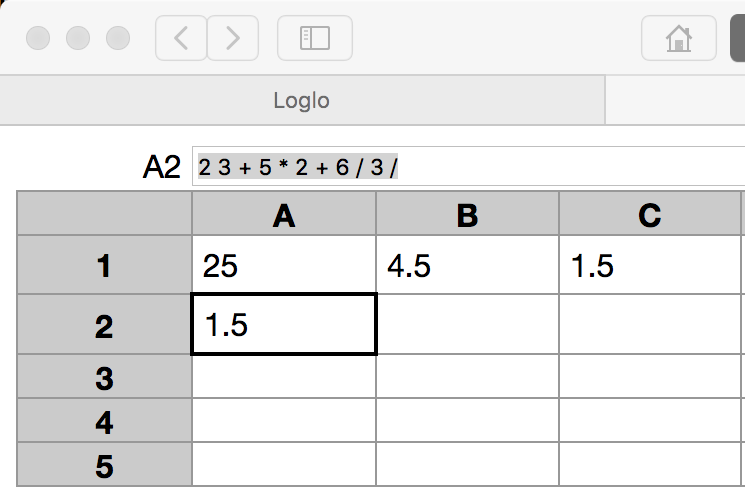
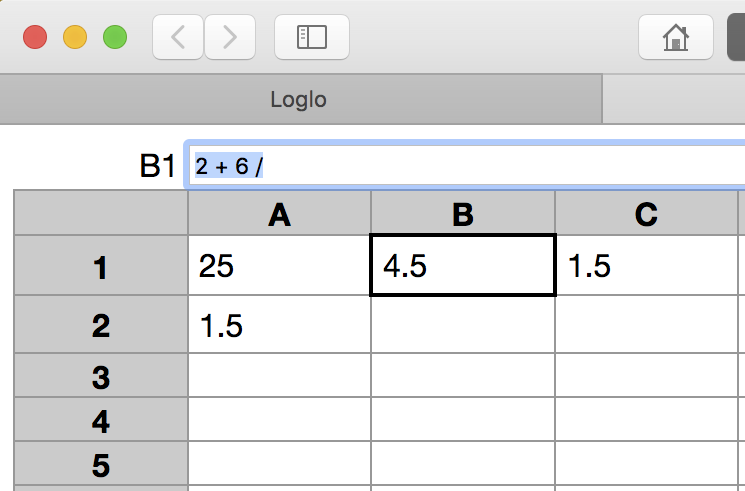
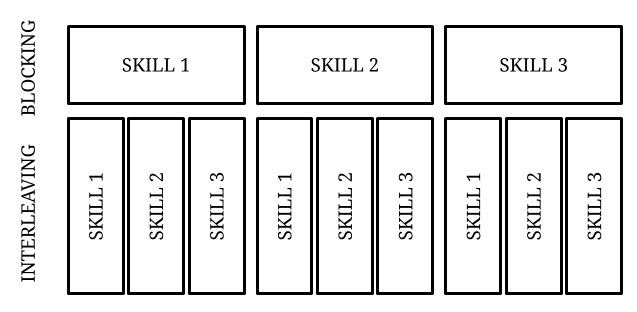
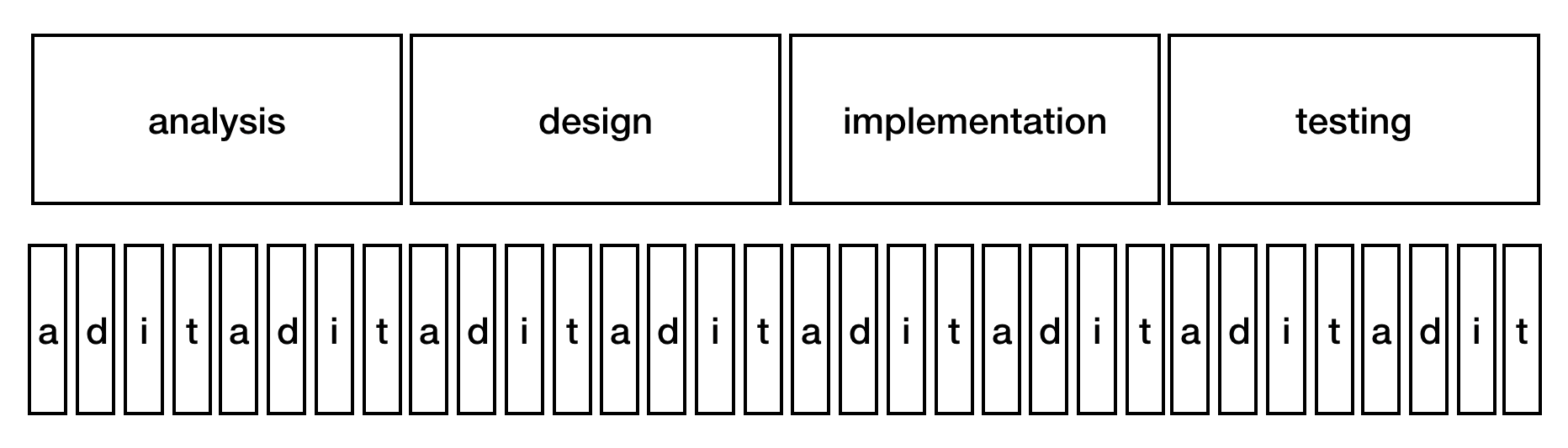


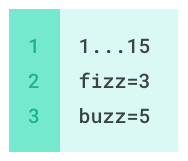




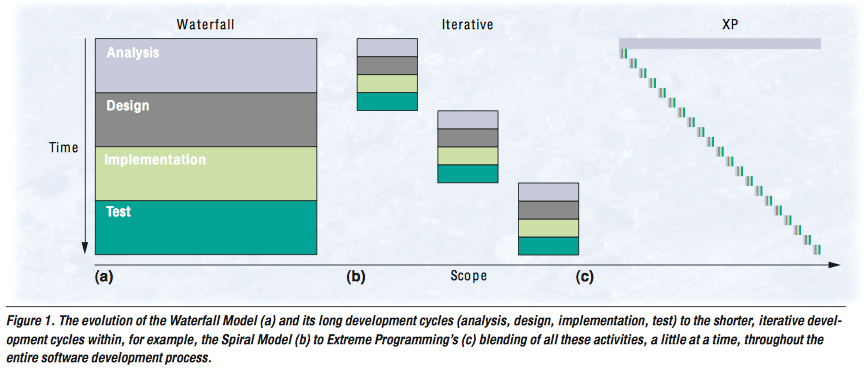












































































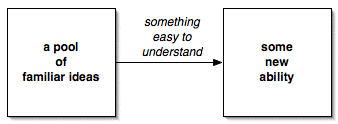






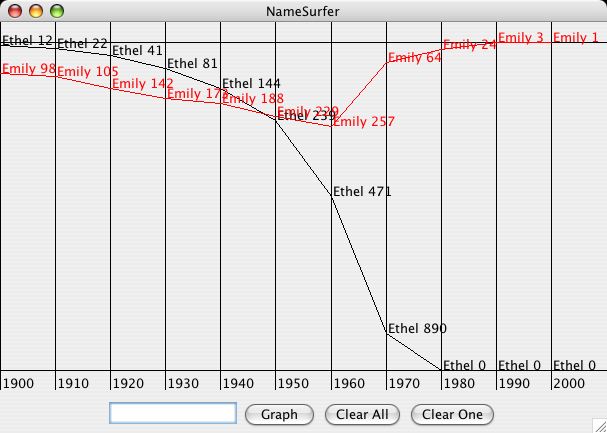












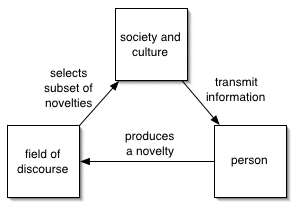



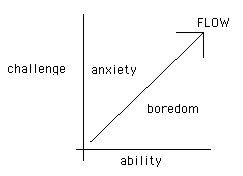


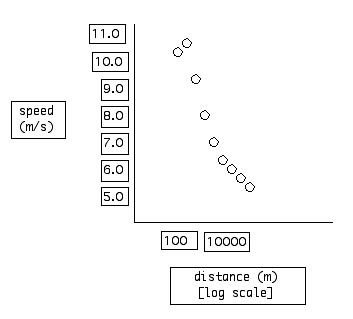







.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}